Embed Size (px)
DESCRIPTION
Â
Citation preview
Let me start with a disclaimer, the title
is inspired by a presentation given by FTC chairwoman Edith Ramirez at an Aspen Summit last month, where she lauded BD, but also pointed at regulatory challenges caused by BD.
Although with far less standing, I aim to do the same
today (with a different speech BTW).
I will pick out some of the BD issues that interest me.I will use
examples from medical domain

official statistics
and behavioural targeting to illustrate things.
First let’s set the
stage, and get to the
the basics.
What is Big Data
As the name

implies, it is about data, large amounts of data. Think peta and zeta bytes
BD is driven by society and facilitated by technology
on the societal side we have lots of developments, including commerce with a belief that if you can sell more stuff to consumers if you know them.But there is also the risk society
with paranoid NSA as a clear element. the more they know the safer we are presumably.
on the technology side, it is a rapidly declining cost of processing and storage power,
Moore's law is the observation that over the history of computing hardware, the number of transistors on integrated circuits doubles approximately every two
allowing infinite retention of data rather than selecting what is stored and what deleted.
Big data is about Vs, not this one, I will get to this
not, or not only, talking about neat structured tables with know attributes in columns, and individuals or cases in the rows, but instead

about unstructured data like written text,
such as Tweets.
both online.
Think of the already
mentioned social media, where we actively disclose information, but

also unintentionally
give off behavioural data that reveals information about what we do.But also what we think and how we feel.
Many of these sources
are open, in the sense of easily available
, basically to everyone.
under the hood everything changes, but moreimportantly, the data is processed and analysed in a different way
well known statistical techniques are employed, but also
data mining and artificial Intelligence techniques such as machine learning.
These techniques facilitate
trawling through the data to find new information, new

patterns and previously unknown correlations.
Well known is US retail chain Target,
which discovered that women on the baby registry were buying larger quantities of unscented lotion around the beginning of their second trimester.
And
that pregnant women, in the first 20 weeks, loaded up on supplements like calcium, magnesium and zinc. probably
any doctor could have told you to get more zinc,
Anyway, typically, in BD

it is about correlation, rather than theory and
causation.
In many cases correlation is the only thing that matters. In online business an increase in clickthru rate of 0.01 percent can mean a large amount of money.
A master in BD is the Google we all learned to love
Google show that throwing lots of data against the proper algorithms, sort of works. Now that we’re on the same page regarding BD in general, I
would like to briefly look at apportunities provided by DB
An obvious one is that the costs of collecting data goes down which has an effect on organisational practices and their costs
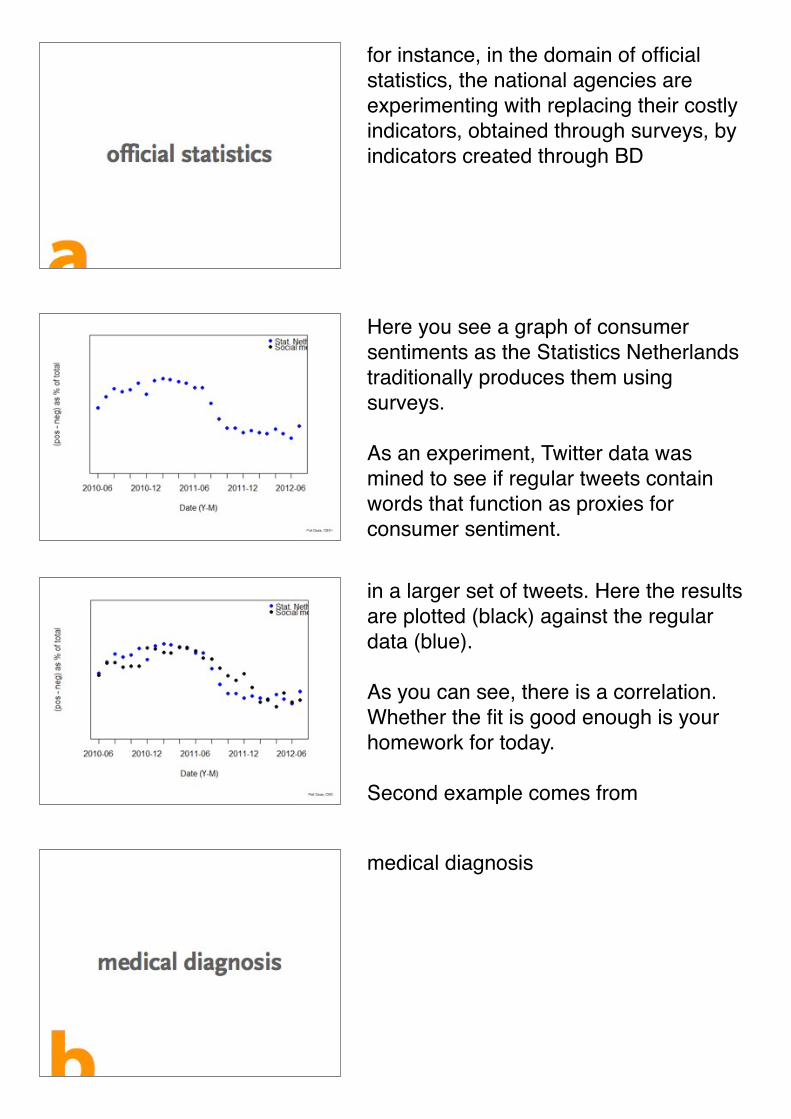
for instance, in the domain of official statistics, the national agencies are experimenting with replacing their costly indicators, obtained through surveys, by indicators created through BD
Here you see a graph of consumer sentiments as the Statistics Netherlands traditionally produces them using surveys.
As an experiment, Twitter data was mined to see if regular tweets contain words that function as proxies for consumer sentiment.
in a larger set of tweets. Here the results are plotted (black) against the regular data (blue).
As you can see, there is a correlation. Whether the fit is good enough is your homework for today.
Second example comes from
medical diagnosis

there is a lot of biomedical research. So much
that it doubles every 7 yearsThere is no way practitioners can keep up with development and growth in knowledge
And then
there is trend of digitising invidiual patient records and medical histories
Big Data already has shown
capable of making medical predictions. Google flu trend, based on flu and its symptoms related queries has shown accurate in predicting flu outbreaks often up to two weeks before the US centers for disease control detects them.
more impressive or more potential has

IBM’s Watson
February 2011 IBM’s Watson competed with the 2 best US Jeopardy players
and beat them in answering questions likeg trivia in history, literature, the arts, pop culture, science, sports, geography, wordplay, and other topics. The show has a unique answer-and-question format in which contestants are presented with clues in the form of answers, and must phrase their responses in question form.
which question has 5280 as its answer
Dutch Google
does not know, by the way, although
has some suggestions.
It is quick though
And no
the question is not suggestsion 4
What is the most awful item in the Playmobil catalgue
Anyway, Watson did provide
provide the correct answer
Watson was not wired to the internet, but

kept all knowledge it could bring to bear
15 Petabytes of it, stored locally.
Watson uses
Now IBM is
IBM is taking Watson to the next level

to your home, the legal environment in which you operate.
As you know,
on the one hand there is the promise of basing results on ones own personality, identity and behaviour.
Not really my thing. So maybe it’s time to switch perspective
it is not only gold at the end of the rainbow.

there are challenges
and issues, and hence the lifeguard should pay attention.
Especially because some of
of the issues are new and potentially big.
I will briefly tour the grounds and provide you with some food for thought
The issues I am most interested in relate to human rights, such as privacy, autonomy, non discrimination
Let me start close to home,

privacy and data protection.
Some, or even many data, we discuss today are personal data.
The data
protection Directive defines personal data as
… any information relating to an identified or identifiable natural person.
Thre are two elements to note: identifiable and any information.
Individuals can not only be identified by
their name, but also through

identity numbers,
car license plates
and be recognized in images.
This means that
Tweets oftentimes are personal data. They allow identification of the sender (at least to some people). Me here.
And the may contain information about the sender or others, such as Sir Berners-Lee in this example.
This means that when mining tweets,
the DPD applies.
This raises interesting issues.
As an aside
, just because the data is freely available out there does not mean you just can take it and do anything you want.
If you want to play the game, you will have
to play by today’s rules, which is the DPD.
I won’t bore you with the details, but only point out some highlights.
Personal data may only be processed for specified purposes.
In case of analysis by entity Y, let’s say Statistics Netherlands of data collected by others, such as in the Twitter case, the secondary use differs (significantly) from the use for which the data where collected, which may be problematic.

for statistical processing.
However, whether the existing safeguards are appropriate for Big Data analytics may be an open question.
Second, personal data may only be processed when the processing is covered by one
of these justifications.
Legal obligation and/or public interest are the ones that apply to official statistics, but they don’t seem very applicable for the kind of secondary use for new kinds of indicators.
Hence, legitimate interest of the controller is the one to aim for. This requires some challenges, because it does not go very well with the principle that the individuals concerned need to be informed.
More profound concerns
regarding secondary use also exist.
We have recently learned that not every organization is exactly open open about their

use of personal dat,
After what we’ve learned from the Snowden
revelations, I’m not so sure everybody plays by the rules.
and we can be sure that the NSA uses BD techniques
As many of you know, the
Directive will be replaced in due course by a regulation, which should harmonise the patchwork of national data protection regimes across Europe, update the data protection framework and align it with technologies such as BDA.
do we stand
Commission proposal Jan 2012Albrecht report (rapporteur), Jan 2013committee input
Now hold on to your seats,

There are almost 4000 amendments to the Commission proposal (3133 Civil Liberties committee, 417 industry committee, 266 internal market committee, 27 employment committee, 196 legal affairs committee)
And then in parallel, the
Council is working on their proposal. Some parts of he council version are public, some are unfinished.
the Libe commission has voted on a compromise package. Whether this will be the final text is uncertain and hence how
\data protection regulation is aligned with BDA in the future is unclear as well
Big data is not only used for trends, but also for deciding about individuals. Here there are plenty of issues

inferences are being made and conclusions drawn, but
on what data and how.
transparency, accountability, due process

are the big issues here.
For instance,
first off, let’s look!
at IBM’s Watson
Watson operates in two modes

research mode in which the aim to to generate general knowledge, and treatment mode, in which it brings its knowledge to bear on a single case
what is the status of the output
watson named after Thomas Watson jr., Watson decision maker over important decisions, business developments etc
John Watson Sherlock Holmes’ somewhat dumb sidekick with the medical practitioner as the person in charge.

so what does Watson produce when it looks at a patient record.
IBM
is very clear, Watson as in John Watson
I understand this from a liability perspective, but there reasons to suspect this is not the end of it.
two comments/remarks
1.medical domain has been evidence-based for a long time.medical trials, longitudinal studies, medical literature, etc.
So, observing Watson’s performancebringing to bear best available information
2 but what about the wider circle?not only in the confines of hospital or treatment room,
also others, insurance companies, Rmode or Tmode?Will these offer due process
incidently

sounds plausible.
But how does this work in a medical domain
Experts often are bad at explaining their results, and if they provideexplanation , do we understand.
We use external indicators
dr Gregory House, best doctor in town, but would you trust him

or rather trust this confindently well groowed 50ish guy?
what about
computers providing explanations.Given that this is MacOS 9, it must be 90s
Is Watson an oracle
examples I’ve seen look promising,

but the topic needs to be taken seriously
stereotyping and discrimination
I have already said that on the one hand there is the promise of basing results on ones own personality, identity and behaviour,

yet on the other hand BD results show clear signs of sterotyping and disrimination.
weblining, de digitale variant van redlining (POSTCODEDISCRIMINATIE)
Is There a Two-tiered Mortgage Market Based on Race?Posted on July 25, 2012 by Tim O'ConnellRed-lining has long been a topic of concern in the housing industry. I have known people who actually saw the maps in bank offices, with the big red line surrounding minority neighborhoods on it, or the predominantly minority Census Tracts colored red.
price discrimination or
no fly lists that prevent people from flying can be based on biased and false inferences, actually just like non BD practices.
Note that the biker playmobil is not the only horrible Playmobil

The third effect that interests me is the effect of BDA/profiling on autonomy.
One documented form in which this takes place is known as the
“my TiVo thinks I’m gay” phenomenon. TiVo a smart videorecorder scheme makes inferences on the behaviour of a user and all others, and apparently some of these inferences are false.
It is a case of what Eli
Paliser has termed the filter bubble.
You get information presented on inferences about you and more and more presented information fits within this frame (or bubble), thus reinforcing the bubble.
Should you have thought Google presents the same results to everyone, think again.

but personalised information.
This affects our the space in which we make decisions and hence touches upon our autonomy.
whose data is used in all these BD processes
Take Twitter for example. I’ve talked about how Stat Netherlands is using Twitter to measure consumer confidence.
Who is on Twitter?
A quick search revealed these data derived from analysing 36 million profiles (a lot, but still not a lot).
Gender distribution, not even bad, but
self reported age distribution, totally skewed.
Geographical spread,

again skewed.
Then, what about the people
who are not on social media, don’t have credit cards, mobile phones etc. How are these represented in the BD data sources?
Proxies

Some lessons to conclude.
The techniques are changing, as is the amounts of data becoming available.Data sources change: combining existing registries, incorporating ‘open’ sources.The tools change the inferences that can be made from the datadata can be processed in (almost) real time.
With that, my time is up. I thank you for your attention.














![19.4ÊQ020.3Ê Discover your Tochigi 4B c126ô 21 [B] 12 161±] 4B … · 2019-11-12 · r Sl-#-z-- JR ržd< —EM—JD](https://img.pdfslide.us/doc/110x75/5f981e110cb87e0cbb62f4d2/194q0203-discover-your-tochigi-4b-c126-21-b-12-161-4b-2019-11-12.jpg)















