Embed Size (px)
Citation preview

Lecture 8: Informed Search
Dr John Levine
52236 Algorithms and ComplexityFebruary 27th 2006
Notes on Practical 1
• For Q1, try using System.nanoTime() instead of System.currentTimeMillis()
• For Q2, for the cubic algorithm, use the code provided (see next slide)
• For Q2, you are asked to find an O(n2) algorithm by cutting out repeated computation
• For Q2, the best algorithm is O(n): I don’t expect you to find this, but if you do, extra credit will be given!
• Deadline: 5pm, Friday March 17th 2006
• Please hand in a printed copy to my office (L13.21)

Code for Practical 1, Q2
public static int maxSubsequenceSumCubic( int [ ] a ) {
int maxSum = 0;
for( int i = 0; i < a.length; i++ )
for( int j = i; j < a.length; j++ ) {
int thisSum = 0;
for( int k = i; k <= j; k++ )
thisSum += a[ k ];
if( thisSum > maxSum ) {
maxSum = thisSum;
seqStart = i;
seqEnd = j; } }
return maxSum; }
O(n3)

Assignment 2 (from last week)
• This is a pen-and-paper exercise, done in the same groups as for Practical 1
• Your answer can be typeset or hand-written
• There are three questions on searching, covering material from Lectures 6, 7 and 8 (search)
• Deadline: 5pm, Monday 20th March 2006
• Please hand in a printed or hand-written copy to my office (L13.21)
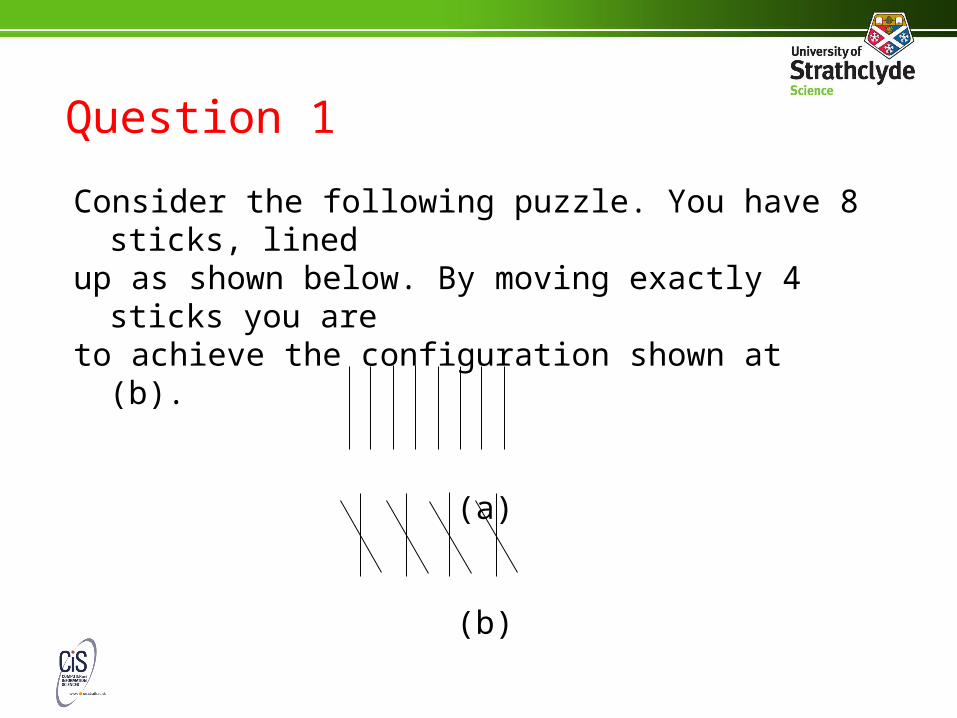
Question 1
Consider the following puzzle. You have 8 sticks, linedup as shown below. By moving exactly 4 sticks you areto achieve the configuration shown at (b).
(a)
(b)

Question 1
Each move consists of picking up a stick, jumping overexactly two other sticks, and then putting it down onto a fourth stick. In the figure below, stick e could be movedonto stick b or h, whereas stick f cannot move at all:
a b c d e f g h
Question 1
a. Decide on a notation for representing states which you could use in state space search.
b. Using this notation, map out the search space (states which are essentially identical due to symmetry need not be included).
c. Apply the uninformed search algorithms (depth-first and breadth-first search) to the search tree. How many nodes do they search? How large does the agenda grow for each form of search?
d. Why is the problem solved so much more easily if you search backwards from the goal state?
Question 2
A farmer needs to get a fox, a chicken and some cornacross a river using a boat. The boat is small and leakyand can only take the farmer and one item of cargo.
If the farmer leaves the fox and the chicken together, thefox will eat the chicken. If the farmer leaves the chickenand corn together, the chicken will eat the corn. Leavingthe fox and corn together is fine.
How can the farmer get all three items across the river?

Question 2
a. Decide on a notation for representing states which you could use in state space search.
b. Give details of all the move operators for the search. Make sure that the operators only allow legal moves (i.e. ones which are physically possible and result in states in which no item of cargo gets eaten).
c. Using your representation and operators, map out the search space for this problem. Is there more than one possible solution to this problem?

Question 3
Consider the following game for two players:
• There are 8 sticks on the table
• Players take turns at removing 1, 2 or 3 sticks
• The aim is to make your opponent take the last stick
• Example:

Question 3
a. Draw out the game tree for 8 sticks. Is this a win for the first player or the second player?
b. If the first player’s first move is to take 2 sticks, what move should the second player make?
c. What should the first player’s strategy be in the case where there are N sticks in the start state? For what values of N can the second player achieve a win?

The story so far
• Lecture 1: Why algorithms are so important
• Lecture 2: Big-Oh notation, a first look at different complexity classes (log, linear, log-linear, quadratic, polynomial, exponential, factorial)
• Lecture 3: simple search in a list of items is O(n) with unordered data but O(log n) with ordered data, and can be even faster with a good indexing scheme and parallel processors
• Lecture 4: sorting: random sort O(n!), naïve sort is O(n2), bubblesort is O(n2), quicksort is O(n log n)

The story so far
• Lecture 5: more on sorting: why comparison sort is O(n log n), doing better than O(n log n) by not doing comparisons (e.g. bucket sort)
• Lecture 6: harder search: how to represent a problem in terms of states and moves
• Lecture 7: uninformed search through states using an agenda: depth-first search and breadth-first search
• Lecture 8: making it smart: informed search using heuristics; how to use heuristic search without losing optimality – the A* algorithm

The story so far
• Lecture 5: more on sorting: why comparison sort is O(n log n), doing better than O(n log n) by not doing comparisons (e.g. bucket sort)
• Lecture 6: harder search: how to represent a problem in terms of states and moves
• Lecture 7: uninformed search through states using an agenda: depth-first search and breadth-first search
• Lecture 8: making it smart: informed search using heuristics; how to use heuristic search without losing optimality – the A* algorithm

State Space Search
Problem solving using state space search consists ofthe following four steps:
1. Design a representation for states (including the initial state and the goal state)
2. Characterise the operators in terms of when they apply (preconditions) and the states they generate (effects)
3. Build a goal state recogniser
4. Search through the state space somehow by considering (in some or other order) the states reachable from the initial and goal states
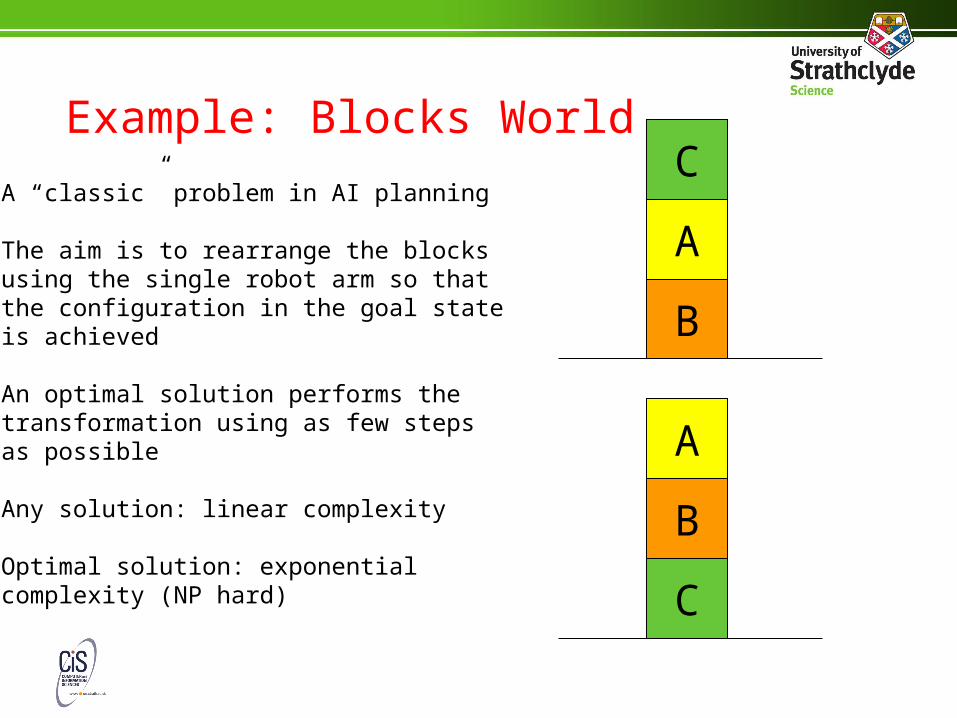
Example: Blocks World
A “classic” problem in AI planning
The aim is to rearrange the blocksusing the single robot arm so thatthe configuration in the goal stateis achieved
An optimal solution performs thetransformation using as few stepsas possible
Any solution: linear complexity
Optimal solution: exponentialcomplexity (NP hard)
C
A
B
B
A
C
Search Spaces
• The search space of a problem is implicit in its formulation– You search the space of your representations
• We generate the space dynamically during search (including loops, dead ends, branches
• Operators are move generators
• We can represent the search space with trees
• Each node in the tree is a state
• When we call NextStates(S0) [S1,S2,S3], then we say we have expanded S0
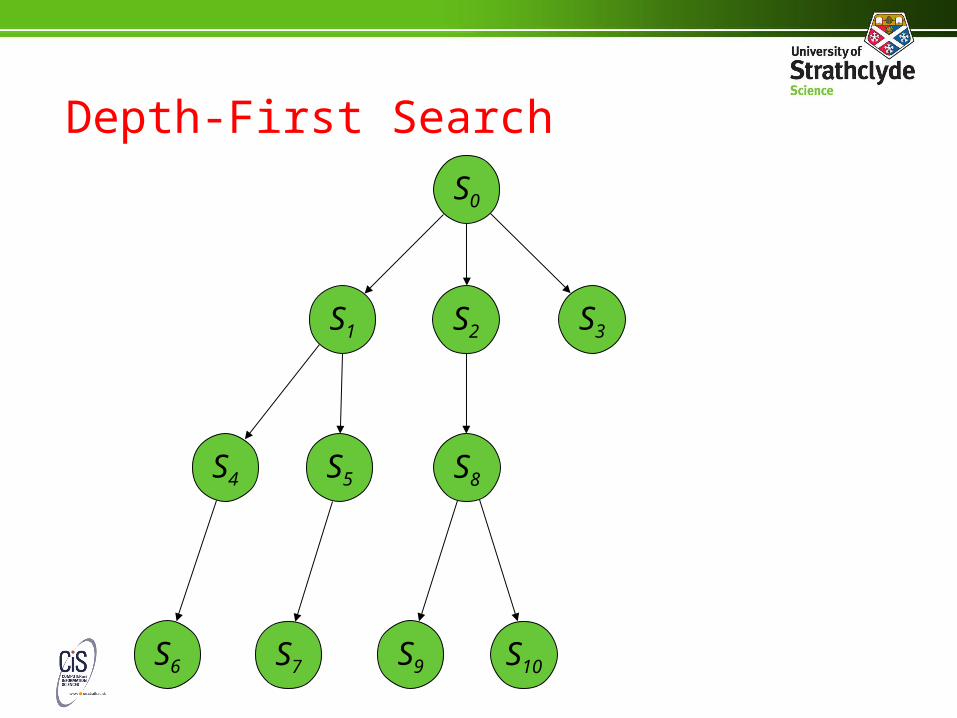
Depth-First Search
S0
S3S2S1
S8S5S4
S9S7S6 S10
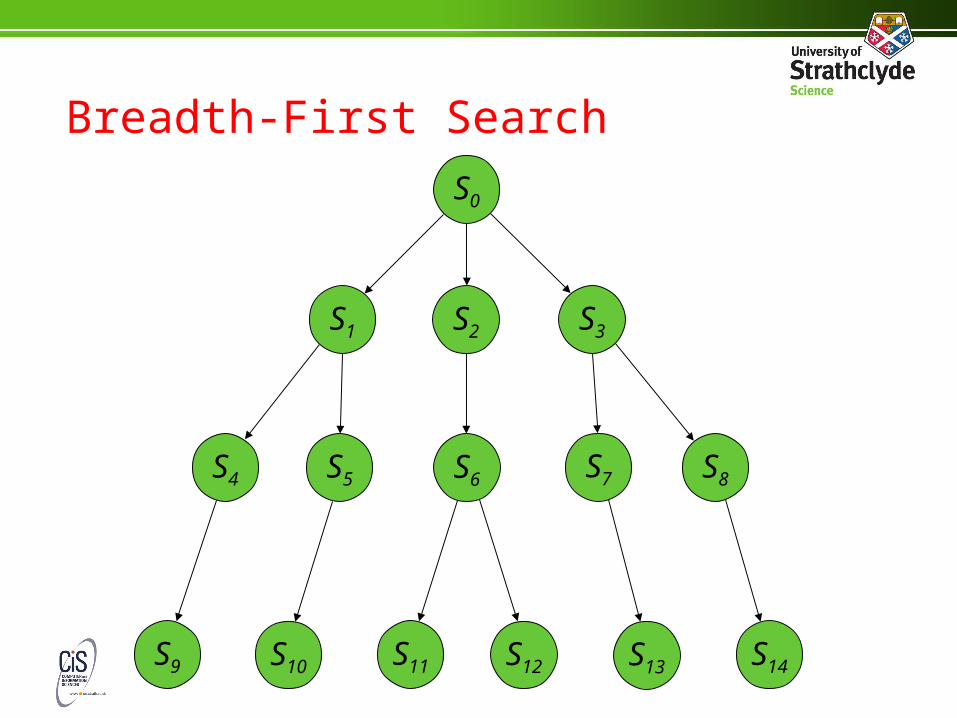
Breadth-First Search
S0
S3S2S1
S7S6S5S4 S8
S11S10S9 S12 S13 S14

Searching Using an Agenda
• When we expand a node we get multiple new nodes to expand, but we can only expand one at a time
• We keep track of the nodes still to be expanded using a data structure called an agenda
• When it is time to expand a new node, we choose the first node from the agenda
• As new states are discovered, we add them to the agenda somehow
• We can get different styles of search by altering how the states get added

Depth-First Search
• To get depth-first search, add the new nodes onto the start of the agenda (treat the agenda as a stack):
let Agenda = [S0 ]
while Agenda ≠ [ ] do
let Current = First (Agenda)
let Agenda = Rest (Agenda)
if Goal (Current) then return (“Found it!”)
let Next = NextStates (Current)
let Agenda = Next + Agenda

Breadth-First Search
• To get depth-first search, add the new nodes onto the end of the agenda (treat the agenda as a queue):
let Agenda = [S0 ]
while Agenda ≠ [ ] do
let Current = First (Agenda)
let Agenda = Rest (Agenda)
if Goal (Current) then return (“Found it!”)
let Next = NextStates (Current)
let Agenda = Agenda + Next
Heuristic Search
• DFS and BFS are both searching blind – they search all possibilities in an order dictated by NextStates(Si)
• When people search, we look in the most promising places first – try { [a], [b], [c] } { [a, b, c] }
• There are six possible moves, but somehow it seems like the best move is move(b,c) giving { [a], [b, c] }
• The most promising states are often those which are closest to the goal state, G
• But how can we know how close we are to the goal state?
Heuristic Search
• We can often estimate the distance from Si to G by using a heuristic function, f(Si,G)
• The function efficiently compares the two states and tries to get an estimate of how many moves remain without doing any searching
• For example, in the blocks world, all blocks that are stacked up in the correct place never have to move again; all blocks that need to move that are on the table only need to move once; and all other blocks only need to move at most twice:
f(Si,G) = 2*Bbad + 1*Btable + 0*Bgood

Heuristic Function Exercise
Consider a simple transportation problem:
• There are cities {a, b, c,…}, packages {p1, p2, p3,…}, and a truck (called tr1).
• Example state: { at(p1,a), at(p2,a), at(p3,c), at(tr1,b) }
• The operators are load(p), unload(p), and drive(x,y)
• Try to invent a heuristic function for estimating the distance between any two states
• Try it out on the above state and the goal state { at(p1,b), at(p2,b), at(p3,b) }

Best-First Search
• If we have a decent heuristic function, we should use it to direct the search somehow
• We still need to keep track of the nodes we haven’t yet expanded, using the agenda
• As new states are discovered, we add them to the agenda and record the value of the heuristic function
• When we pick the next node to explore, we choose the one which has the lowest value for the heuristic function (i.e. the one that looks nearest to the goal)
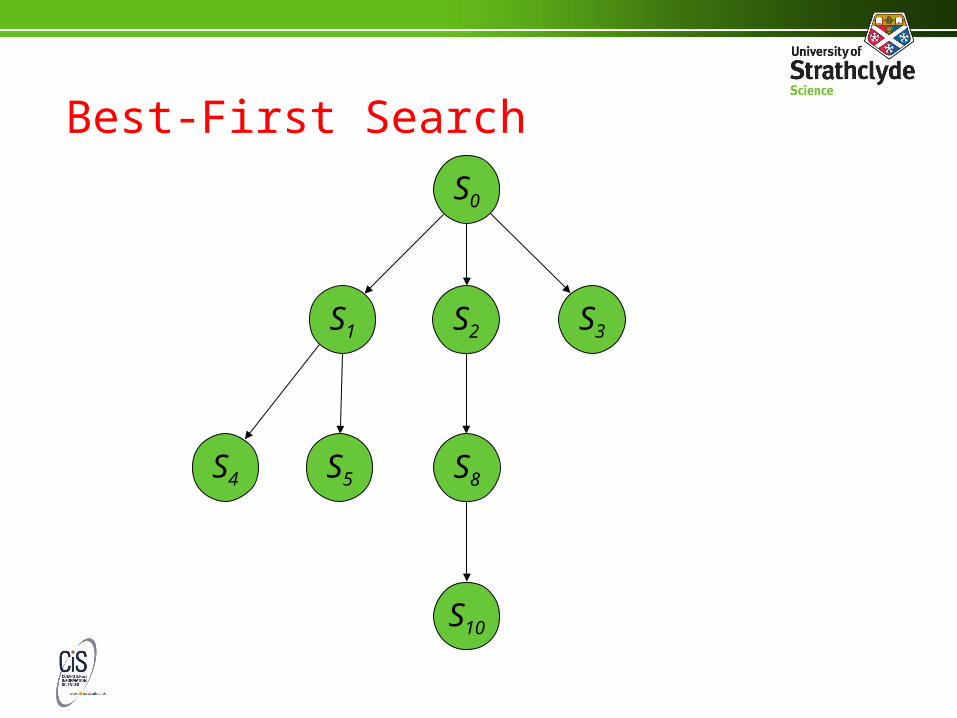
Best-First Search
S0
S3S2S1
S8S5S4
S10

Best-First Search
• To get best-first search, pick the best node on the agenda as the one to be explored next:
let Agenda = [S0 ]
while Agenda ≠ [ ] do
let Current = Best (Agenda)
let Agenda = Rest (Agenda)
if Goal (Current) then return (“Found it!”)
let Next = NextStates (Current)
let Agenda = Agenda + Next

Best-First Search and Algorithm A
• Best-first search can speed up the search by a very large factor, but can it isn’t guaranteed to return the shortest solution
• When deciding to expand a node, we need to take account of how long the path is so far, and add that on to the heuristic value:
h(Si ,G) = g(S0 ,Si ) + f(Si ,G)
• This will give a search which has elements of both breadth-first search and best-first search
• This type of search is called “Algorithm A”

Algorithm A*
• If f(Si,G) always underestimates the distance from Si to the goal, it is called an admissible heuristic
• If f(Si,G) is admissible, then Algorithm A will always return the shortest path (like breadth-first search) but will omit much of the work if the heuristic function is informative
• The use of an admissible heuristic turns Algorithm A into Algorithm A*
• Uses: problem solving, route finding, path planning in robotics, computer games, etc.



















![Levine Complaint [1]](https://img.pdfslide.us/doc/110x75/55cf9026550346703ba353fe/levine-complaint-1.jpg)









