Embed Size (px)
Citation preview

CS4/MSc Parallel Architectures - 2012-2013
Lect. 10: Chip-Multiprocessors (CMP) Main driving forces:
– Complexity of design and verification of wider-issue superscalar processor – Performance gains of either wider issue width or deeper pipelines would be
only marginal Limited ILP in applications Wire delays and longer access times of larger structures
– Power consumption of the large centralized structures necessary in wider-issue superscalar processors would be unmanageable
– Increased relative importance of throughput oriented computing as compared to latency oriented computing
– Continuation of Moore’s law so that more transistors fit in a chip
1

CS4/MSc Parallel Architectures - 2012-2013
Early (ca. 2006) CMP’s
2
Example: Intel Core Duo – 2 cores
12-stage pipeline 2-way simultaneous
multithreading (HT) Up to 2.33GHz P6 (Pentium M)
microarchitecture – 2MB shared L2 cache – 151M transistors in 65nm
technology – Power consumption between
9W and 30W
CS4/MSc Parallel Architectures - 2012-2013
A different design for CMP
3
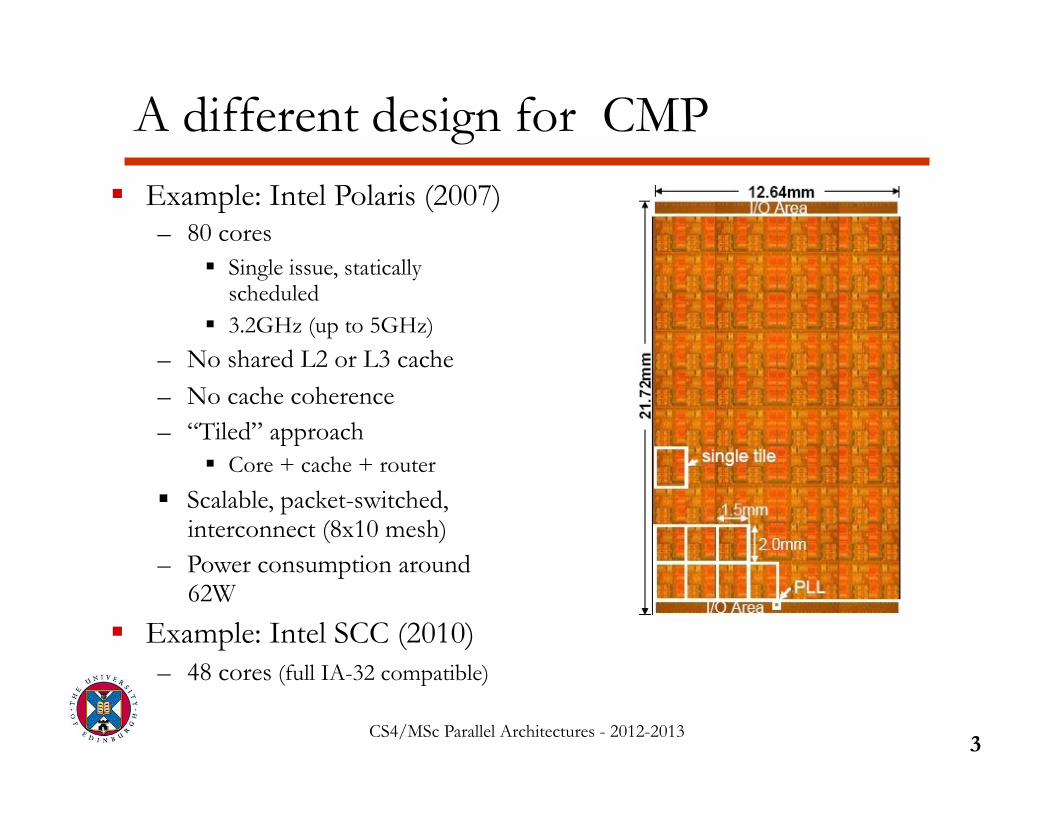
Example: Intel Polaris (2007) – 80 cores
Single issue, statically scheduled
3.2GHz (up to 5GHz) – No shared L2 or L3 cache – No cache coherence – “Tiled” approach
Core + cache + router
Scalable, packet-switched, interconnect (8x10 mesh)
– Power consumption around 62W
Example: Intel SCC (2010) – 48 cores (full IA-32 compatible)
CS4/MSc Parallel Architectures - 2012-2013
Now (2012)
4
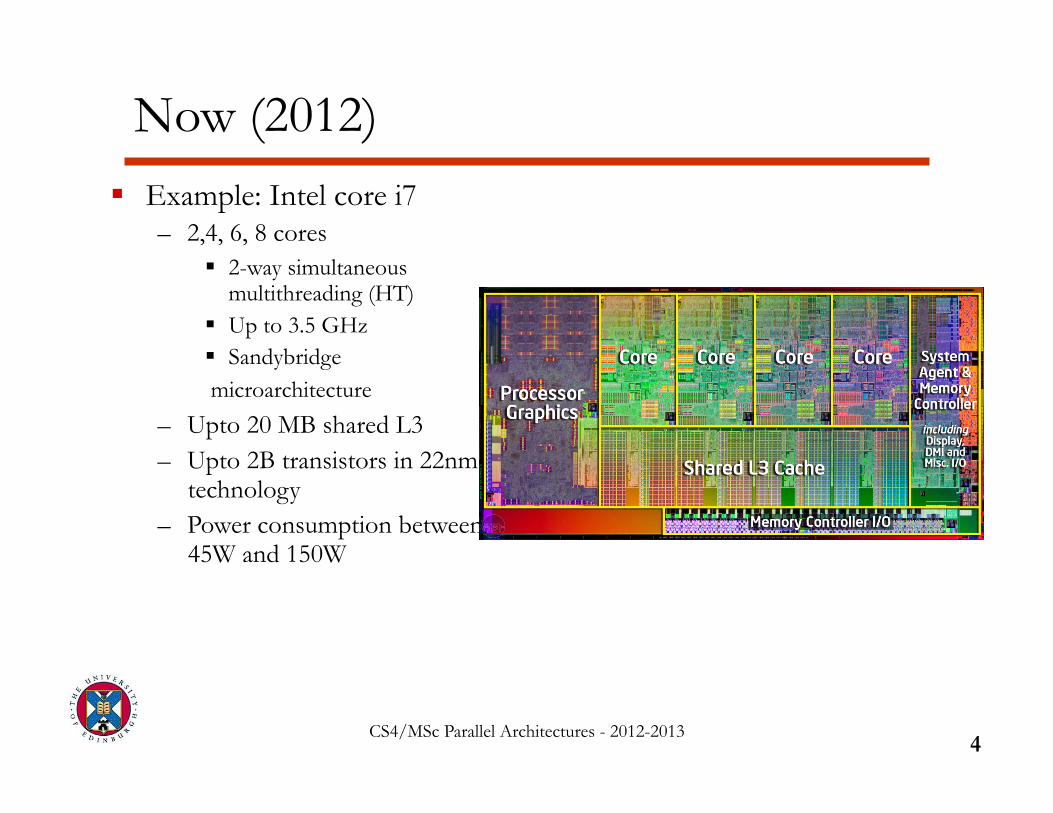
Example: Intel core i7 – 2,4, 6, 8 cores
2-way simultaneous multithreading (HT)
Up to 3.5 GHz Sandybridge microarchitecture
– Upto 20 MB shared L3 – Upto 2B transistors in 22nm
technology – Power consumption between
45W and 150W

CS4/MSc Parallel Architectures - 2012-2013
CMP’s vs. Multi-chip Multiprocessors
5
While conceptually similar to traditional multiprocessors, CMP’s have specific issues: – Off-chip memory bandwidth: number of pins per package does not
increase much – On-chip interconnection network: wires and metal layers are a very scarce
resource – Shared memory hierarchy: processors must share some lower level cache
LLC (e.g., L2 or L3) and the on-chip links between these – Wire delays: actual physical distances to be crossed for communication
affect the latency of the communication – Power consumption and heat dissipation: both are much harder to fit
within the limitations of a single chip package – Dark Silicon

CS4/MSc Parallel Architectures - 2012-2013
Shared vs. Private L2 Caches
6
Private caches: + Less chance of negative interference between processors + Simpler interconnections – Possibly wasted storage in less loaded parts of the chip – Must enforce coherence across L2’s
Shared caches: – More chance for negative interference between processors + Possible positive interference between processors + Better utilization of storage + Single/few threads have access to all resources when cores are idle + No need enforce coherence (but still must enforce coherence across L1’s)
and L2 can act as a coherence point (i.e., directory) – All-to-one interconnect takes up large area and may become a bottleneck

CS4/MSc Parallel Architectures - 2012-2013
Shared vs. Private L2 Caches
6
Note: L1 caches are tightly integrated into the pipeline and are an inseparable part of the core
Note: Processor nowadays have private L2 caches and shared L3 caches

CS4/MSc Parallel Architectures - 2012-2013
Priority inversion
7
– In uniprocessors and multi-chip multiprocessors: processes with higher priority are given more resources (e.g., more processors, larger scheduling quanta, more memory/caches, etc) → faster execution
– In CMP’s with shared resources (e.g., LLC caches, off-chip memory bandwidth, issue slots with multithreading) Dynamic allocation of resources to threads/processes is oblivious to OS (e.g.,
LRU replacement policy in caches) Hardware policies attempt to maximize utilization across the board Hardware treats all threads/processes equally and threads/processes compete
dynamically for resources
– Thus, at run time, a lower priority thread/process may grab a larger share of resources and may execute relatively faster than a higher thread/process
– In more general terms, overall quality of service should be directly proportional to priority
CS4/MSc Parallel Architectures - 2012-2013
Fair Cache Sharing
8
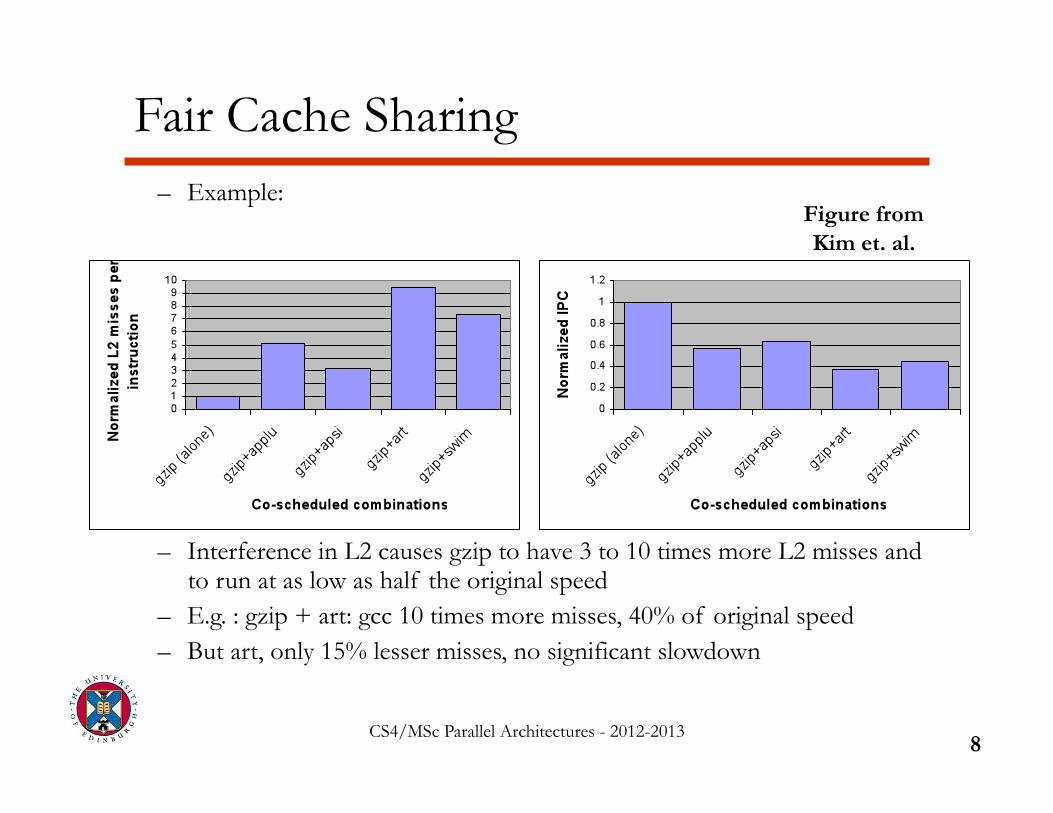
– Example:
– Interference in L2 causes gzip to have 3 to 10 times more L2 misses and to run at as low as half the original speed
– E.g. : gzip + art: gcc 10 times more misses, 40% of original speed – But art, only 15% lesser misses, no significant slowdown
Figure from Kim et. al.

CS4/MSc Parallel Architectures - 2012-2013
Fair Cache Sharing
9
Fair Sharing – Condition for fair sharing:
Where Tdedi is the execution time of thread i when executed alone in the CMP with a dedicated LLC cache and Tshri is its execution time when sharing LLC with the other n-1 threads
– To maximize fair sharing, minimize:
where
– Possible solution: partition caches in different sized portions either statically or at run time
Tshr1
Tded1
= Tshr2
Tded2
= … = Tshrn
Tdedn
Mij = Xi - Xj
Xi = Tshri
Tdedj

Partitioning Caches
HW Support for partitioning – Constraining cache placement – Constraining cache replacement
How to partition – Static fair caching – Dynamic fair caching
CS4/MSc Parallel Architectures - 2012-2013

CS4/MSc Parallel Architectures - 2012-2013
NUCA LLC Caches
10
On-chip LLC caches are expected to continue increasing in size Such caches are logically divided in a few (2 to 8) logical banks
with independent access Banks are physically divided into small (128KB to 512KB) sub-
banks L3 caches will likely have 32 or more sub-banks Increasing wire delays mean that sub-banks closer to a given
processor could be accessed quicker than sub-banks further away Also, some sub-banks will invariably be closer to one processor
and far from another, and some sub-banks will be at similar distances from a few processors
Bottom-line: Access times will be increasingly inefficient

CS4/MSc Parallel Architectures - 2012-2013
NUCA LLC Caches
11
Key ideas: – Allow and exploit the fact that different sub-banks have different access
times
– Dynamically map and migrate the most heavily used lines to the banks closer to the processor
– By tweaking the dynamic mapping and migration mechanisms such NUCA caches can adapt from shared to private caches
– Obviously, with such dynamic mapping and migration, searching the cache and performing replacements becomes more expensive
CS4/MSc Parallel Architectures - 2012-2013
Directory Coherence On-Chip?
12
Mem. Dir.
CPU
L2 Cache
Mem. Dir.
CPU
L2 Cache
L2 Cache Dir.
CPU
L1 Cache
L2 Cache Dir.
CPU
L1 Cache
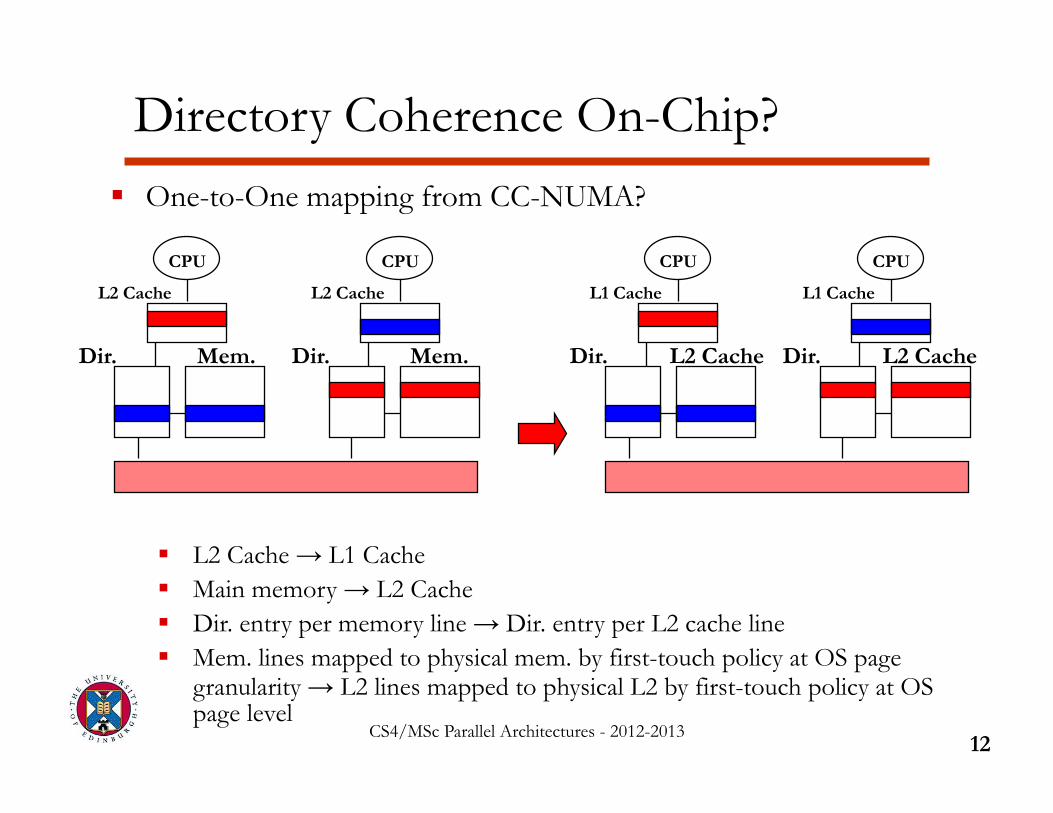
One-to-One mapping from CC-NUMA?
L2 Cache → L1 Cache Main memory → L2 Cache Dir. entry per memory line → Dir. entry per L2 cache line Mem. lines mapped to physical mem. by first-touch policy at OS page
granularity → L2 lines mapped to physical L2 by first-touch policy at OS page level

CS4/MSc Parallel Architectures - 2012-2013
Directory Coherence On-Chip
13
The mapping problem (home node) OS page granularity is too coarse, may lead to imbalance in mapping Line granularity with first-touch needs a hardware/OS mapping of every
individual cache line to a physical L2 (too expensive) Solution: map at line granularity but circularly based on physical address
(mem. line 0 maps to L2 #0, mem. line 1 maps to L2 #1, etc) The problem with this solution is that locality of use is lost!
The eviction problem Upon eviction of an L2 (mem.) line the corresponding dir. entry is lost
and all L1 cached copies must be invalidated (ok for rare paging case in CC-NUMA, but not ok for small L2)
Solution: associate dir. entries not with L2 cache lines, but with cached L1 lines (replicated tags and exclusive L1-Home L2)

CS4/MSc Parallel Architectures - 2012-2013
Exclusivity with Replicated Tags
12
Dir. contains copy of the L1 tags of lines mapped to the home L2, but L2 does not have to keep the L1 data itself Good: lines can be evicted from L2 silently (by exclusivity, they are not
cached in any L1) and Dir. does not change Bad: replicated tags (i.e., the Dir. information) increases with number of
L1 caches E.g., for 8 cores with 32KB L1 with 32B lines (i.e., 1024 lines) and
fully associative → 8x1024 = 8,192 entries per Dir.
L2 Cache
CPU
L1 Cache
L2 Cache Dir.
CPU
L1 Cache
Dir.

CS4/MSc Parallel Architectures - 2012-2013
References and Further Reading
14
Early study of chip-multiprocessors “The Case for a Single-Chip Multiprocessor”, K. Olukotun, B. Nayfeh, L.
Hammond, K. Wilson, and K. Chang, Intl. Conf. on Architectural Support for Programming Languages and Operating Systems, October 1996.
More recent study of chip-multiprocessors (throughput-oriented) “Maximizing CMP Throughput with Mediocre Cores”, J. Davis, J. Laudon,
and K. Olukotun, Intl. Conf. on Parallel Architecture and Compilation Techniques, September 2005.
First NUCA caches proposal (for uniprocessor) “An Adaptive, Non-uniform Cache Structure for Wire-delay Dominated On-
chip Caches”, C. Kim, D. Burger, and S. Keckler, Intl. Conf. on Architectural Support for Programming Languages and Operating Systems, October 2002.

CS4/MSc Parallel Architectures - 2012-2013
References and Further Reading
15
NUCA cache study for CMP “Managing Wire Delay in Large Chip-Multiprocessor Caches”, B. Beckmann
and D. Wood, Intl. Symp. on Microarchitecture, December 2004.
Fair cache sharing studies “Fair Cache Sharing and Partitioning in a Chip Multiprocessor Architecture”,
S. Kim, D. Chandra, and Y. Solihin, Intl. Conf. on Parallel Architecture and Compilation Techniques, October 2004.
“CQoS: A Framework for Enabling QoS in Shared Caches of CMP Platforms”, R. Iyer, Intl. Conf. on Supercomputing, June 2004.
Other studies on priorities and quality of service in CMP/SMT “Symbiotic Job-Scheduling with Priorities for Simultaneous Multithreading
Processors”, A. Snavely, D. Tullsen, and G. Voelker, Intl. Conf. on Measurement and Modeling of Computer Systems, June 2002.





























