Embed Size (px)
Citation preview

Learning Hand-Eye Coordination for Robotic Grasping with Deep Learningand Large-Scale Data Collection
Sergey Levine [email protected] Pastor [email protected] Krizhevsky [email protected] Quillen [email protected]
AbstractWe describe a learning-based approach to hand-eye coordination for robotic grasping frommonocular images. To learn hand-eye coordi-nation for grasping, we trained a large convo-lutional neural network to predict the probabil-ity that task-space motion of the gripper will re-sult in successful grasps, using only monocularcamera images and independently of camera cal-ibration or the current robot pose. This requiresthe network to observe the spatial relationshipbetween the gripper and objects in the scene,thus learning hand-eye coordination. We thenuse this network to servo the gripper in real timeto achieve successful grasps. To train our net-work, we collected over 800,000 grasp attemptsover the course of two months, using between 6and 14 robotic manipulators at any given time,with differences in camera placement and hard-ware. Our experimental evaluation demonstratesthat our method achieves effective real-time con-trol, can successfully grasp novel objects, andcorrects mistakes by continuous servoing.
1. IntroductionWhen humans and animals engage in object manipulationbehaviors, the interaction inherently involves a fast feed-back loop between perception and action. Even complexmanipulation tasks, such as extracting a single object froma cluttered bin, can be performed with hardly any advanceplanning, relying instead on feedback from touch and vi-sion. In contrast, robotic manipulation often (though notalways) relies more heavily on advance planning and anal-ysis, with relatively simple feedback, such as trajectoryfollowing, to ensure stability during execution (Srinivasaet al., 2012). Part of the reason for this is that incorpo-rating complex sensory inputs such as vision directly into
Figure 1. Our large-scale data collection setup, consisting of 14robotic manipulators. We collected over 800,000 grasp attemptsto train the CNN grasp prediction model.
a feedback controller is exceedingly challenging. Tech-niques such as visual servoing (Siciliano & Khatib, 2007)perform continuous feedback on visual features, but typi-cally require the features to be specified by hand, and bothopen loop perception and feedback (e.g. via visual servo-ing) requires manual or automatic calibration to determinethe precise geometric relationship between the camera andthe robot’s end-effector.
In this paper, we propose a learning-based approach tohand-eye coordination, which we demonstrate on a roboticgrasping task. Our approach is data-driven and goal-centric: our method learns to servo a robotic gripper to
arX
iv:1
603.
0219
9v1
[cs
.LG
] 7
Mar
201
6

Learning Hand-Eye Coordination for Robotic Grasping with Deep Learning and Large-Scale Data Collection
poses that are likely to produce successful grasps, with end-to-end training directly from image pixels to task-spacegripper motion. By continuously recomputing the mostpromising motor commands, our method continuously in-tegrates sensory cues from the environment, allowing it toreact to perturbations and adjust the grasp to maximize theprobability of success. Furthermore, the motor commandsare issued in the frame of the robot, which is not known tothe model at test time. This means that the model does notrequire the camera to be precisely calibrated with respect tothe end-effector, but instead uses visual cues to determinethe spatial relationship between the gripper and graspableobjects in the scene.
Our method consists of two components: a grasp successpredictor, which uses a deep convolutional neural network(CNN) to determine how likely a given motion is to pro-duce a successful grasp, and a continuous servoing mecha-nism that uses the CNN to continuously update the robot’smotor commands. By continuously choosing the best pre-dicted path to a successful grasp, the servoing mechanismprovides the robot with fast feedback to perturbations andobject motion, as well as robustness to inaccurate actuation.
The grasp prediction CNN was trained using a dataset ofover 800,000 grasp attempts, collected using a cluster ofsimilar (but not identical) robotic manipulators, shown inFigure 1, over the course of several months. Although thehardware parameters of each robot were initially identi-cal, each unit experienced different wear and tear over thecourse of data collection, interacted with different objects,and used a slightly different camera pose relative to therobot base. These differences provided a diverse dataset forlearning continuous hand-eye coordination for grasping.
The main contributions of this work are a method for learn-ing continuous visual servoing for robotic grasping frommonocular cameras, a novel convolutional neural networkarchitecture for learning to predict the outcome of a graspattempt, and a large-scale data collection framework forrobotic grasps. Our experimental evaluation demonstratesthat our convolutional neural network grasping controllerachieves a high success rate when grasping in clutter ona wide range of objects, including objects that are large,small, hard, soft, deformable, and translucent. Supplemen-tal videos of our grasping system show that the robot em-ploys continuous feedback to constantly adjust its grasp,accounting for motion of the objects and inaccurate actu-ation commands. We also compare our approach to open-loop alternative designs to demonstrate the importance ofcontinuous feedback, as well as a hand-engineering grasp-ing baseline that uses manual hand-to-eye calibration anddepth sensing. Our method achieves the highest successrates in our experiments.
2. Related WorkRobotic grasping is one of the most widely explored areasof manipulation. While a complete survey of grasping isoutside the scope of this work, we refer the reader to stan-dard surveys on the subject for a more complete treatment(Bohg et al., 2014). Broadly, grasping methods can be cat-egorized as geometrically driven and data-driven. Geomet-ric methods analyze the shape of a target object and plan asuitable grasp pose, based on criteria such as force closure(Weisz & Allen, 2012) or caging (Rodriguez et al., 2012).These methods typically need to understand the geometryof the scene, using depth or stereo sensors and matchingof previously scanned models to observations (Goldfederet al., 2009b). Data-driven methods take a variety of dif-ferent forms, including purely human-supervised methodsthat predict grasp configurations (Herzog et al., 2014; Lenzet al., 2015) and methods that predict finger placementfrom geometric criteria computed offline (Goldfeder et al.,2009a). Both types of data-driven grasp selection haverecently incorporated deep learning (Kappler et al., 2015;Lenz et al., 2015; Redmon & Angelova, 2015). Feedbackhas been incorporated into grasping primarily as a way toachieve the desired forces for force closure and other dy-namic grasping criteria (Hudson et al., 2012), as well as inthe form of standard servoing mechanisms, including vi-sual servoing (described below) to servo the gripper to apre-planned grasp pose (Kragic & Christensen, 2002). Themethod proposed in this work is entirely data-driven, anddoes not rely on any human annotation either at trainingor test time, in contrast to prior methods based on grasppoints. Furthermore, our approach continuously adjuststhe motor commands to maximize grasp success, provid-ing continuous feedback. Comparatively little prior workhas addressed direct visual feedback for grasping, most ofwhich requires manually designed features to track the en-deffector (Vahrenkamp et al., 2008; Hebert et al., 2012).
Our approach is most closely related to recent work onself-supervised learning of grasp poses by Pinto & Gupta(2015). This prior work proposed to learn a network to pre-dict the optimal grasp orientation for a given image patch,trained with self-supervised data collected using a heuris-tic grasping system based on object proposals. In contrastto this prior work, our approach achieves continuous hand-eye coordination by observing the gripper and choosing thebest motor command to move the gripper toward a suc-cessful grasp, rather than making open-loop predictions.Furthermore, our approach does not require proposals orcrops of image patches and, most importantly, does not re-quire calibration between the robot and the camera, sincethe closed-loop servoing mechanism can compensate foroffsets due to differences in camera pose by continuouslyadjusting the motor commands. We trained our method us-ing over 800,000 grasp attempts on a very large variety of

Learning Hand-Eye Coordination for Robotic Grasping with Deep Learning and Large-Scale Data Collection
objects, which is more than an order of magnitude largerthan prior methods based on direct self-supervision (Pinto& Gupta, 2015) and more than double the dataset size ofprior methods based on synthetic grasps from 3D scans(Kappler et al., 2015).
Another related area to our method is visual servoing,which addresses moving a camera or end-effector to a de-sired pose using visual feedback (Kragic & Christensen,2002). In contrast to our approach, visual servoing meth-ods are typically concerned with reaching a target poserelative to objects in the scene, and often (though not al-ways) rely on manually designed or specified features forfeedback control (Espiau et al., 1992; Wilson et al., 1996;Vahrenkamp et al., 2008; Hebert et al., 2012; Mohta et al.,2014). Photometric visual servoing uses a target imagerather than features (Caron et al., 2013), and several vi-sual servoing methods have been proposed that do not di-rectly require prior calibration between the robot and cam-era (Yoshimi & Allen, 1994; Jagersand et al., 1997; Kragic& Christensen, 2002). To the best of our knowledge, noprior learning-based method has been proposed that usesvisual servoing to directly move into a pose that maximizesthe probability of success on a given task (such as grasp-ing).
In order to predict the optimal motor commands to maxi-mize grasp success, we use convolutional neural networks(CNNs) trained on grasp success prediction. Althoughthe technology behind CNNs has been known for decades(LeCun & Bengio, 1995), they have achieved remarkablesuccess in recent years on a wide range of challengingcomputer vision benchmarks (Krizhevsky et al., 2012), be-coming the de facto standard for computer vision systems.However, applications of CNNs to robotic control problemshas been less prevalent, compared to applications to passiveperception tasks such as object recognition (Krizhevskyet al., 2012; Wohlhart & Lepetit, 2015), localization (Gir-shick et al., 2014), and segmentation (Chen et al., 2014).Several works have proposed to use CNNs for deep rein-forcement learning applications, including playing videogames (Mnih et al., 2015), executing simple task-spacemotions for visual servoing (Lampe & Riedmiller, 2013),controlling simple simulated robotic systems (Watter et al.,2015; Lillicrap et al., 2016), and performing a variety ofrobotic manipulation tasks (Levine et al., 2015). Manyof these applications have been in simple or synthetic do-mains, and all of them have focused on relatively con-strained environments with small datasets.
3. OverviewOur approach to learning hand-eye coordination for grasp-ing consists of two parts. The first part is a prediction net-work g(It,vt) that accepts visual input It and a task-space
motion command vt, and outputs the predicted probabil-ity that executing the command vt will produce a success-ful grasp. The second part is a servoing function f(It)that uses the prediction network to continuously controlthe robot to servo the gripper to a success grasp. We de-scribe each of these components below: Section 4.1 for-mally defines the task solved by the prediction network anddescribes the network architecture, Section 4.2 describeshow the servoing function can use the prediction networkto perform continuous control.
By breaking up the hand-eye coordination system intocomponents, we can train the CNN grasp predictor using astandard supervised learning objective, and design the ser-voing mechanism to utilize this predictor to optimize graspperformance. The resulting method can be interpreted asa type of reinforcement learning, and we discuss this in-terpretation, together with the underlying assumptions, inSection 4.3.
In order to train our prediction network, we collected over800,000 grasp attempts using a set of similar (but not iden-tical) robotic manipulators, shown in Figure 1. We discussthe details of our hardware setup in Section 5.1, and discussthe data collection process in Section 5.2. To ensure gener-alization of the learned prediction network, the specific pa-rameters of each robot varied in terms of the camera poserelative to the robot, providing independence to camera cal-ibration. Furthermore, uneven wear and tear on each robotresulted in differences in the shape of the gripper fingers.Although accurately predicting optimal motion vectors inopen-loop is not possible with this degree of variation, asdemonstrated in our experiments, our continuous servoingmethod can correct mistakes by observing the outcomes ofits past actions, achieving a high success rate even withoutknowledge of the precise camera calibration.
4. Grasping with Convolutional Networks andContinuous Servoing
In this section, we discuss each component of our ap-proach, including a description of the neural network ar-chitecture and the servoing mechanism, and conclude withan interpretation of the method as a form of reinforcementlearning, including the corresponding assumptions on thestructure of the decision problem.
4.1. Grasp Success Prediction with ConvolutionalNeural Networks
The grasp prediction network g(It,vt) is trained to pre-dict whether a given task-space motion vt will result in asuccessful grasp, based on the current camera observationIt. In order to make accurate predictions, g(It,vt) mustbe able to parse the current camera image, locate the grip-

Learning Hand-Eye Coordination for Robotic Grasping with Deep Learning and Large-Scale Data Collection
I0 It
Figure 2. Example input image pair provided to the network,overlaid with lines to indicate sampled target grasp positions. Col-ors indicate their probabilities of success: green is 1.0 and red is0.0. The grasp positions are projected onto the image using aknown calibration only for visualization. The network does notreceive the projections of these poses onto the image, only offsetsfrom the current gripper position in the frame of the robot.
per, and determine whether moving the gripper accordingto vt will put it in a position where closing the fingers willpick up an object. This is a complex spatial reasononingtask that requires not only the ability to parse the geometryof the scene from monocular images, but also the abilityto interpret material properties and spatial relationships be-tween objects, which strongly affect the success of a givengrasp. A pair of example input images for the network isshown in Figure 2, overlaid with lines colored accordinglyto the inferred grasp success probabilities. Importantly, themovement vectors provided to the network are not trans-formed into the frame of the camera, which means that themethod does not require hand-to-eye camera calibration.However, this also means that the network must itself inferthe outcome of a task-space motor command by detemrin-ing the orientation and position of the robot and gripper.
Data for training the CNN grasp predictor is obtained byattempting grasps using real physical robots. Each graspconsists of T time steps. At each time step, the robotrecords the current image Ii
t and the current pose pit, and
then chooses a direction along which to move the gripper.At the final time step T , the robot closes the gripper andevaluates the success of the grasp, producing a label `i.Each grasp attempt results in T training samples, given by(Ii
t ,piT − pi
t, `i). That is, each sample includes the imageobserved at that time step, the vector from the current poseto the one that is eventually reached, and the success of theentire grasp. This process is illustrated in Figure 3. Thisprocedure trains the network to predict whether moving agripper along a given vector and then grasping will producea successful grasp. Note that this differs from the stan-dard reinforcement-learning setting, where the predictionis based on the current state and motor command, whichin this case is given by pt+1 − pt. We discuss the inter-
I it
pit piT
pitpiTvit
Figure 3. Diagram of the grasp sample setup. Each grasp i con-sists of T time steps, with each time step corresponding toan image Ii
t and pose pit. The final dataset contains samples
(Iit ,p
iT − pi
t, `i) that consist of the image, a vector from the cur-rent pose to the final pose, and the grasp success label.
pretation of this approach in the context of reinforcementlearning in Section 4.3.
The architecture of our grasp prediction CNN is shown inFigure 4. The network takes the current image It as input,as well as an additional image I0 that is recorded beforethe grasp begins, and does not contain the gripper. This ad-ditional image provides an unoccluded view of the scene.The two input images are concatenated and processed by5 convolutional layers with batch normalization (Ioffe &Szegedy, 2015), following by max pooling. After the 5th
layer, we provide the vector vt as input to the network.The vector is represent by 5 values: a 3D translation vector,and a sine-cosine encoding of the change in orientation ofthe gripper about the vertical axis.1 To provide this vec-tor to the convolutional network, we pass it through onefully connected layer and replicate it over the spatial di-mensions of the response map after layer 5, concatenatingit with the output of the pooling layer. After this concate-nation, further convolution and pooling operations are ap-plied, as described in Figure 4, followed by a set of smallfully connected layers that output the probability of graspsuccess, trained with a cross-entropy loss to match `i, caus-ing the network to output p(`i = 1). The input matches are512 × 512 pixels, and we randomly crop the images to a472× 472 region during training to provide for translationinvariance.
Once trained the network g(It,vt) can predict the proba-
1In this work, we only consider vertical pinch grasps, thoughextensions to other grasp parameterizations would be straightfor-ward.

Learning Hand-Eye Coordination for Robotic Grasping with Deep Learning and Large-Scale Data Collection
3 channels 64 filters
conv1
image inputs
6x6
conv
+ R
eLU
strid
e 2
472472
3 channels
472472
3x3
max
poo
l
64 filters
pool1
64 filters
conv2
5x5
conv
+ R
eLU
64 filters
conv7
3x3
max
poo
l
64 filters
pool2
3x3
conv
+ R
eLU
64 filters
conv8
64 filters
conv13
2x2
max
poo
l
64 filters
pool3
3x3
conv
+ R
eLU
64 filters
conv14
64 filters
conv16
64 u
nits
64 u
nits
graspsuccess
probability
+
64
tiledvector
spat
ial
tilin
g
64 u
nits
fully
con
n. +
ReL
U
fully
con
n. +
ReL
U
fully
con
n.R
eLU
motor command
repe
ated
5x5
conv
+ R
eLU
repe
ated
3x3
conv
+ R
eLU
repe
ated
3x3
conv
+ R
eLU
motor commandvt
It
I0
Figure 4. The architecture of our CNN grasp predictor. The input image It, as well as the pregrasp image I0, are fed into a 6 × 6convolution with stride 2, followed by 3× 3 max-pooling and 6 5× 5 convolutions. This is followed by a 3× 3 max-pooling layer. Themotor command vt is processed by one fully connected layer, which is then pointwise added to each point in the response map of pool2by tiling the output over the special dimensions. The result is then processed by 6 3× 3 convolutions, 2× 2 max-pooling, 3 more 3× 3convolutions, and two fully connected layers with 64 units, after which the network outputs the probability of a successful grasp througha sigmoid. Each convolution is followed by batch normalization.
bility of success of a given motor command, independentlyof the exact camera pose. In the next section, we discusshow this grasp success predictor can be used to continuousservo the gripper to a graspable object.
4.2. Continuous Servoing
In this section, we describe the servoing mechanism f(It)that uses the grasp prediction network to choose the motorcommands for the robot that will maximize the probabil-ity of a success grasp. The most basic operation for theservoing mechanism is to perform inference in the grasppredictor, in order to determine the motor command vt
given an image It. The simplest way of doing this is torandomly sample a set of candidate motor commands vt
and then evaluate g(It,vt), taking the command with thehighest probability of success. However, we can obtain bet-ter results by running a small optimization on vt, whichwe perform using the cross-entropy method (CEM) (Ru-binstein & Kroese, 2004). CEM is a simple derivative-freeoptimization algorithm that samples a batch of N valuesat each iteration, fits a Gaussian distribution to M < N ofthese samples, and then samples a new batch ofN from thisGaussian. We use N = 64 and M = 6 in our implementa-tion, and perform three iterations of CEM to determine thebest available command v?
t and thus evaluate f(It). Newmotor commands are issued as soon as the CEM optimiza-tion completes, and the controller runs at around 2 to 5 Hz.
One appealing property of this sampling-based approach isthat we can easily impose constraints on the types of graspsthat are sampled. This can be used, for example, to incor-porate user commands that require the robot to grasp in aparticular location, keep the robot from grasping outside of
the workspace, and obey joint limits. It also allows the ser-voing mechanism to control the height of the gripper duringeach move. It is often desirable to raise the gripper abovethe objects in the scene to reposition it to a new location,for example when the objects move (due to contacts) or iferrors due to lack of camera calibration produce motionsthat do not position the gripper in a favorable configurationfor grasping.
We can use the predicted grasp success p(` = 1) producedby the network to inform a heuristic for raising and lower-ing the gripper, as well as to choose when to stop movingand attempt a grasp. We use two heuristics in particular:first, we close the gripper whenever the network predictsthat (It, ∅), where ∅ corresponds to no motion, will succeedwith a probability that is at least 90% of the best inferredmotion v?
t . The rationale behind this is to stop the graspearly if closing the gripper is nearly as likely to produce asuccessful grasp as moving it. The second heuristic is toraise the gripper off the table when (It, ∅) has a probabil-ity of success that is less than 50% of v?
t . The rationalebehind this choice is that, if closing the gripper now is sub-stantially worse than moving it, the gripper is most likelynot positioned in a good configuration, and a large motionwill be required. Therefore, raising the gripper off the ta-ble minimizes the chance of hitting other objects that arein the way. While these heuristics are somewhat ad-hoc,we found that they were effective for successfully graspinga wide range of objects in highly cluttered situations, asdiscussed in Section 6. Pseudocode for the servoing mech-anism f(It) is presented in Algorithm 1. Further details onthe servoing mechanism are presented in Appendix A.

Learning Hand-Eye Coordination for Robotic Grasping with Deep Learning and Large-Scale Data Collection
Algorithm 1 Servoing mechanism f(It)
1: Given current image It and network g.2: Infer v?
t using g and CEM.3: Evaluate p = g(It, ∅)/g(It,v?
t ).4: if p = 0.9 then5: Output ∅, close gripper.6: else if p ≤ 0.5 then7: Modify v?
t to raise gripper height and execute v?t .
8: else9: Execute v?
t .10: end if
4.3. Interpretation as Reinforcement Learning
One interesting conceptual question raised by our approachis the relationship between training the grasp predictionnetwork and reinforcement learning. In the case whereT = 2, and only one decision is made by the servoingmechanism, the grasp network can be regarded as approxi-mating the Q-function for the policy defined by the servo-ing mechanism f(It) and a reward function that is 1 whenthe grasp succeeds and 0 otherwise. Repeatedly deploy-ing the latest grasp network g(It,vt), collecting additionaldata, and refitting g(It,vt) can then be regarded as fitted Qiteration (Antos et al., 2008). However, what happens whenT > 2? In that case, fitted Q iteration would correspondto learning to predict the final probability of success fromtuples of the form (It,pt+1 − pt), which is substantiallyharder, since pt+1 − pt doesn’t tell us where the gripperwill end up at the end, before closing (which is pT ).
Using pT −pt as the action representation in fitted Q itera-tion therefore implies an additional assumption on the formof the dynamics. The assumption is that the actions inducea transitive relation between states: that is, that movingfrom p1 to p2 and then to p3 is equivalent to moving fromp1 to p3 directly. This assumption does not always holdin the case of grasping, since an intermediate motion mightmove objects in the scene, but it is a reasonable approxima-tion that we found works quite well in practice. The majoradvantage of this approximation is that fitting the Q func-tion reduces to a prediction problem, and avoids the usualinstabilities associated with Q iteration, since the previousQ function does not appear in the regression. An interest-ing and promising direction for future work is to combineour approach with more standard reinforcement learningformulations that do consider the effects of intermediateactions. This could enable the robot, for example, to per-form nonprehensile manipulations to intentionally reorientand reposition objects prior to grasping.
5. Large-Scale Data CollectionIn order to collect training data to train the prediction net-work g(It,vt), we used between 6 and 14 robotic manipu-
monocular RGBcamera
7 DoF roboticmanipulator
2-fingergripper
objectbin
Figure 5. Diagram of a single robotic manipulator used in our datacollection process. Each unit consisted of a 7 degree of freedomarm with a 2-finger gripper, and a camera mounted over the shoul-der of the robot. The camera recorded monocular RGB and depthimages, though only the monocular RGB images were used forgrasp success prediction.
lators at any given time. An illustration of our data collec-tion setup is shown in Figure 1. This section describes therobots used in our data collection process, as well as detailsof the data collection procedure.
5.1. Hardware Setup
Our robotic manipulator platform consists of a lightweight7 degree of freedom arm, a compliant, underactuated, two-finger gripper, and a camera mounted behind the arm look-ing over the shoulder. An illustration of a single robot isshown in Figure 5. The underactuated gripper providessome degree of compliance for oddly shaped objects, atthe cost of producing a loose grip that is prone to slipping.An interesting property of this gripper was uneven wareand tear over the course of data collection, which lastedseveral months. Images of the grippers of various robotsare shown in Figure 7, illustrating the range of variation ingripper wear and geometry. Furthermore, the cameras weremounted at slightly varying angles, providing a differentviewpoint for each robot. The views from the cameras ofall 14 robots during data collection are shown in Figure 6.
5.2. Data Collection
We collected about 800,000 grasp attempts over the courseof two months, using between 6 and 14 robots at any givenpoint in time, without any manual annotation or supervi-sion. The only human intervention into the data collectionprocess was to replace the object in the bins in front of therobots and turn on the system. The data collection process

Learning Hand-Eye Coordination for Robotic Grasping with Deep Learning and Large-Scale Data Collection
Figure 6. Images from the cameras of each of the robots during training, with each robot holding the same joint configuration. Notethe variation in the bin location, the difference in lighting conditions, the difference in pose of the camera relative to the robot, and thevariety of training objects.
Figure 7. The grippers of the robots used for data collection at theend of our experiments. Different robots experienced different de-grees of wear and tear, resulting in significant variation in gripperappearance and geometry.
started with random motor command selection and T = 3.2
When executing completely random motor commands, therobots were successful on 10% - 30% of the grasp attempts,depending on the particular objects in front of them. Abouthalf of the dataset was collected using random grasps, andthe rest used the latest network fitted to all of the data col-lected so far. Over the course of data collection, we up-dated the network 4 times, and increased the number ofsteps from T = 3 at the beginning to T = 10 at the end.
The objects for grasping were chosen among commonhousehold and office items, and ranged from a 4 to 20 cmin length along the longest axis. Some of these objects areshown in Figure 6. The objects were placed in front ofthe robots into metal bins with sloped sides to prevent the
2The last command is always vT = ∅ and corresponds to clos-ing the gripper without moving.
Figure 8. Previously unseen objects used for testing (left) and thesetup for grasping without replacement (right). The test set in-cluded heavy, light, flat, large, small, rigid, soft, and translucentobjects.
objects from becoming wedged into corners. The objectswere periodically swapped out to increase the diversity ofthe training data.
Grasp success was evaluated using two methods: first, wemarked a grasp as successful if the position reading on thegripper was greater than 1 cm, indicating that the fingershad not closed fully. However, this method often missedthin objects, and we also included a drop test, where therobot picked up the object, recorded an image of the bin,and then dropped any object that was in the gripper. Bycomparing the image before and after the drop, we coulddetermine whether any object had been picked up.
6. ExperimentsTo evaluate our continuous grasping system, we conducteda series of quantitative experiments with novel objects thatwere not seen during training. The particular objects usedin our evaluation are shown in Figure 8. This set of objectspresents a challenging cross section of common office andhousehold items, including objects that are heavy, such asstaplers and tape dispensers, objects that are flat, such as
Learning Hand-Eye Coordination for Robotic Grasping with Deep Learning and Large-Scale Data Collection
post-it notes, as well as objects that are small, large, rigid,soft, and translucent.
The goal of our evaluation was to answer the followingquestions: (1) does continuous servoing significantly im-prove grasping accuracy and success rate? (2) how welldoes our learning-based system perform when comparedto alternative approaches? To answer question (1), wecompared our approach to an open-loop method that ob-serves the scene prior to the grasp, extracts image patches,chooses the patch with the highest probability of a suc-cessful grasp, and then uses a known camera calibration tomove the gripper to that location. This method is analogousto the approach proposed by Pinto & Gupta (2015), but usesthe same network architecture as our method and the sametraining set. We refer to this approach as “open loop,” sinceit does not make use of continuous visual feedback. To an-swer question (2), we also compared our approach to a ran-dom baseline method, as well as a hand-engineered grasp-ing system that uses depth images and heuristic positioningof the fingers. This hand-engineered system is describedin Appendix B. Note that our method requires fewer as-sumptions than either of the two alternative methods: un-like Pinto & Gupta (2015), we do not require knowledgeof the camera to hand calibration, and unlike the hand-engineered system, we do not require either the calibrationor depth images.
We evaluated the methods using two experimental proto-cols. In the first protocol, the objects were placed into a binin front of the robot, and it was allowed to grasp objectsfor 100 attempts, placing any grasped object back into thebin after each attempt. Grasping with replacement tests theability of the system to pick up objects in cluttered settings,but it also allows the robot to repeatedly pick up easy ob-jects. To address this shortcoming of the replacement con-dition, we also tested each system without replacement, asshown in Figure 8, by having it remove objects from a bin.For this condition, which we refer to as “without replace-ment,” we repeated each experiment 4 times, and we reportsuccess rates on the first 10, 20, and 30 grasp attempts.
The results are presented in Table 1. The success rate ofour continuous servoing method exceeded the baseline andprior methods in all cases. For the evaluation without re-placement, our method cleared the bin completely after 30grasps on one of the 4 attempts, and had only one objectleft in the other 3 attempts (which was picked up on the 31st
grasp attempt in 2 of the three cases, thus clearing the bin).The hand-engineered baseline struggled to accurately re-solve graspable objects in clutter, since the camera was po-sitioned about a meter away from the table, and its perfor-mance also dropped in the non-replacement case as the binwas emptied, leaving only small, flat objects that could notbe resolved by the depth camera. Many practical grasping
withoutreplacement
first 10(N = 40)
first 20(N = 80)
first 30(N = 120)
random 67.5% 70.0% 72.5%hand-designed 32.5% 35.0% 50.8%open loop 27.5% 38.7% 33.7%our method 10.0% 17.5% 17.5%
withreplacement failure rate (N = 100)
random 69%hand-designed 35%open loop 43%our method 20%
Table 1. Failure rates of each method for each evaluation condi-tion. When evaluating without replacement, we report the failurerate on the first 10, 20, and 30 grasp attempts, averaged over 4repetitions of the experiment.
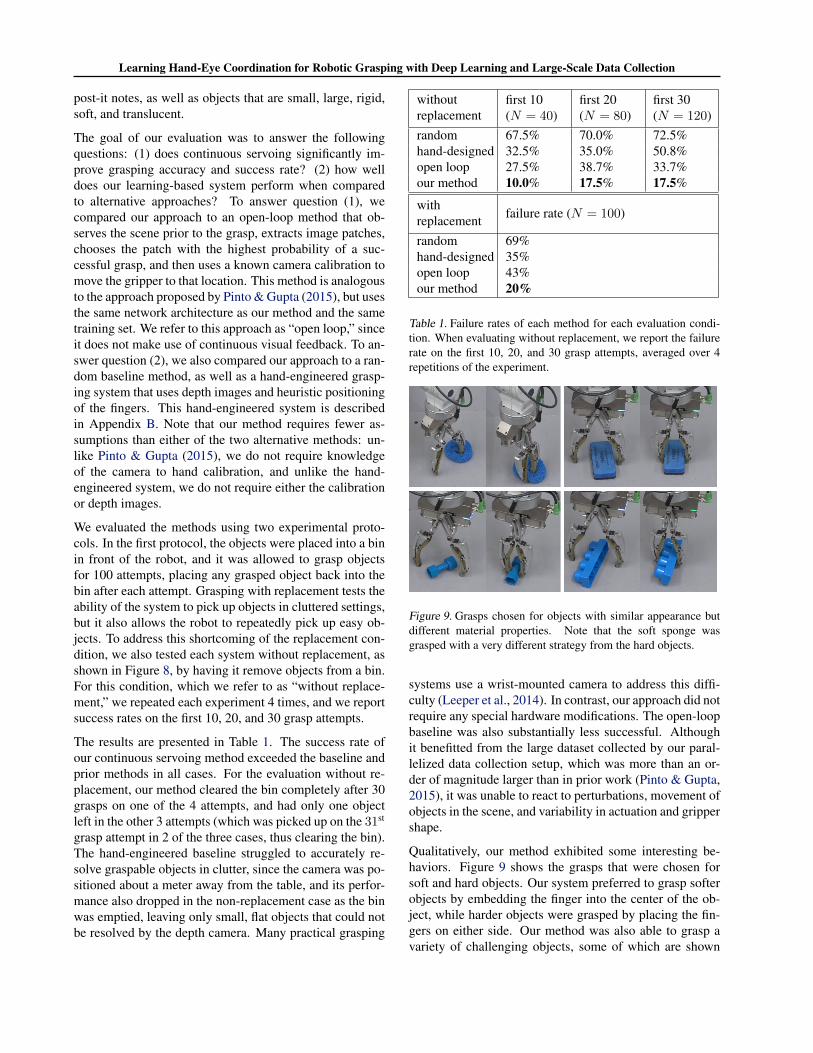
Figure 9. Grasps chosen for objects with similar appearance butdifferent material properties. Note that the soft sponge wasgrasped with a very different strategy from the hard objects.
systems use a wrist-mounted camera to address this diffi-culty (Leeper et al., 2014). In contrast, our approach did notrequire any special hardware modifications. The open-loopbaseline was also substantially less successful. Althoughit benefitted from the large dataset collected by our paral-lelized data collection setup, which was more than an or-der of magnitude larger than in prior work (Pinto & Gupta,2015), it was unable to react to perturbations, movement ofobjects in the scene, and variability in actuation and grippershape.
Qualitatively, our method exhibited some interesting be-haviors. Figure 9 shows the grasps that were chosen forsoft and hard objects. Our system preferred to grasp softerobjects by embedding the finger into the center of the ob-ject, while harder objects were grasped by placing the fin-gers on either side. Our method was also able to grasp avariety of challenging objects, some of which are shown

Learning Hand-Eye Coordination for Robotic Grasping with Deep Learning and Large-Scale Data Collection
Figure 10. Examples of difficult objects grasped by our algo-rithm, including objects that are translucent, awkardly shaped,and heavy.
in Figure 10. Other interesting grasp strategies, correc-tions, and mistakes can be seen in our supplementary video:https://youtu.be/cXaic_k80uM
7. Discussion and Future WorkWe presented a method for learning hand-eye coordina-tion for robotic grasping, using deep learning to build agrasp success prediction network, and a continuous servo-ing mechanism to use this network to continuously controla robotic manipulator. By training on over 800,000 graspattempts from 14 distinct robotic manipulators with varia-tion in camera pose, we can achieve invariance to cameracalibration and small variations in the hardware. Unlikemost grasping and visual servoing methods, our approachdoes not require calibration of the camera to the robot, in-stead using continuous feedback to correct any errors re-sulting from discrepancies in calibration. Our experimentalresults demonstrate that our method can effectively grasp awide range of different objects, including novel objects notseen during training. Our results also show that our methodcan use continuous feedback to correct mistakes and repo-sition the gripper in response to perturbation and movementof objects in the scene.
As with all learning-based methods, our approach assumesthat the data distribution during training resembles the dis-tribution at test-time. While this assumption is reason-able for a large and diverse training set, such as the oneused in this work, structural regularities during data collec-tion can limit generalization at test time. For example, al-though our method exhibits some robustness to small vari-ations in gripper shape, it would not readily generalize tonew robotic platforms that differ substantially from thoseused during training. Furthermore, since all of our train-ing grasp attempts were executed on flat surfaces, the pro-posed method is unlikely to generalize well to grasping onshelves, narrow cubbies, or other drastically different set-tings. These issues can be mitigated by increasing the di-versity of the training setup, which we plan to explore as
future work.
One of the most exciting aspects of the proposed graspingmethod is the ability of the learning algorithm to discoverunconvential and nonobvious grasping strategies. We ob-served, for example, that the system tended to adopt a dif-ferent approach for grasping soft objects, as opposed tohard ones. For hard objects, the fingers must be placedon either side of the object for a successful grasp. How-ever, soft objects can be grasped simply by pinching intothe object, which is most easily accomplised by placingone finger into the middle, and the other to the side. Weobserved this strategy for objects such as paper tissues andsponges. In future work, we plan to further explore the re-lationship between our self-supervised continuous graspingapproach and reinforcement learning, in order to allow themethods to learn a wider variety of grasp strategies fromlarge datasets of robotic experience.
At a more general level, our work explores the implicationsof large-scale data collection across multiple robotic plat-forms, demonstrating the value of this type of automaticlarge dataset construction for real-world robotic tasks. Al-though all of the robots in our experiments were locatedin a controlled laboratory environment, in the long term,this class of methods is particularly compelling for roboticsystems that are deployed in the real world, and there-fore are naturally exposed to a wide variety of environ-ments, objects, lighting conditions, and wear and tear. Forself-supervised tasks such as grasping, data collected andshared by robots in the real world would be the most rep-resentative of test-time inputs, and would therefore be thebest possible training data for improving the real-world per-formance of the system. So a particularly exciting avenuefor future work is to explore how our method would needto change to apply it to large-scale data collection acrossa large number of deployed robots engaged in real worldtasks, including grasping and other manipulation skills.
Acknowledgements
We would like to thank Kurt Konolige and Mrinal Kalakr-ishnan for additional engineering and insightful discus-sions, Jed Hewitt, Don Jordan, and Aaron Weiss for helpwith maintaining the robots, Max Bajracharya and Nico-las Hudson for providing us with a baseline perceptionpipeline, and Vincent Vanhoucke and Jeff Dean for supportand organization.
ReferencesAntos, A., Szepesvari, C., and Munos, R. Fitted Q-Iteration
in Continuous Action-Space MDPs. In Advances in Neu-ral Information Processing Systems, 2008.
Bohg, J., Morales, A., Asfour, T., and Kragic, D. Data-

Learning Hand-Eye Coordination for Robotic Grasping with Deep Learning and Large-Scale Data Collection
Driven Grasp Synthesis A Survey. IEEE Transactionson Robotics, 30(2):289–309, 2014.
Caron, G., Marchand, E., and Mouaddib, E. Photometricvisual servoing for omnidirectional cameras. Autonou-mous Robots, 35(2):177–193, October 2013.
Chen, L., Papandreou, G., Kokkinos, I., Murphy, K., andYuille, A.L. Semantic Image Segmentation with DeepConvolutional Nets and Fully Connected CRFs. arXivpreprint arXiv:1412.7062, 2014.
Espiau, B., Chaumette, F., and Rives, P. A New Approachto Visual Servoing in Robotics. IEEE Transactions onRobotics and Automation, 8(3), 1992.
Girshick, R., Donahue, J., Darrell, T., and Malik, J. Richfeature hierarchies for accurate object detection and se-mantic segmentation. In IEEE Conference on ComputerVision and Pattern Recognition, 2014.
Goldfeder, C., Ciocarlie, M., Dang, H., and Allen, P.K. TheColumbia Grasp Database. In IEEE International Con-ference on Robotics and Automation, pp. 1710–1716,2009a.
Goldfeder, C., Ciocarlie, M., Peretzman, J., Dang, H., andAllen, P. K. Data-Driven Grasping with Partial SensorData. In IEEE/RSJ International Conference on Intelli-gent Robots and Systems, pp. 1278–1283, 2009b.
Hebert, P., Hudson, N., Ma, J., Howard, T., Fuchs, T., Ba-jracharya, M., and Burdick, J. Combined Shape, Appear-ance and Silhouette for Simultaneous Manipulator andObject Tracking. In IEEE International Conference onRobotics and Automation, pp. 2405–2412. IEEE, 2012.
Herzog, A., Pastor, P., Kalakrishnan, M., Righetti, L.,Bohg, J., Asfour, T., and Schaal, S. Learning ofGrasp Selection based on Shape-Templates. AutonomousRobots, 36(1-2):51–65, 2014.
Hudson, N., Howard, T., Ma, J., Jain, A., Bajracharya, M.,Myint, S., Kuo, C., Matthies, L., Backes, P., and Hebert,P. End-to-End Dexterous Manipulation with DeliberateInteractive Estimation. In IEEE International Confer-ence on Robotics and Automation, pp. 2371–2378, 2012.
Ioffe, S. and Szegedy, C. Batch Normalization: Acceler-ating Deep Network Training by Reducing Internal Co-variate Shift. In International Conference on MachineLearning, 2015.
Jagersand, M., Fuentes, O., and Nelson, R. C. Experimen-tal Evaluation of Uncalibrated Visual Servoing for Pre-cision Manipulation. In IEEE International Conferenceon Robotics and Automation, 1997.
Kappler, D., Bohg, B., and Schaal, S. Leveraging Big Datafor Grasp Planning. In IEEE International Conferenceon Robotics and Automation, 2015.
Kragic, D. and Christensen, H. I. Survey on Visual Servo-ing for Manipulation. Computational Vision and ActivePerception Laboratory, 15, 2002.
Krizhevsky, A., Sutskever, I., and Hinton, G. E. Im-ageNet Classification with Deep Convolutional NeuralNetworks. In Advances in Neural Information Process-ing Systems, pp. 1097–1105, 2012.
Lampe, T. and Riedmiller, M. Acquiring Visual ServoingReaching and Grasping Skills using Neural Reinforce-ment Learning. In International Joint Conference onNeural Networks, pp. 1–8. IEEE, 2013.
LeCun, Y. and Bengio, Y. Convolutional networks for im-ages, speech, and time series. The Handbook of BrainTheory and Neural Networks, 3361(10), 1995.
Leeper, A., Hsiao, K., Chu, E., and Salisbury, J.K. UsingNear-Field Stereo Vision for Robotic Grasping in Clut-tered Environments. In Experimental Robotics, pp. 253–267. Springer Berlin Heidelberg, 2014.
Lenz, I., Lee, H., and Saxena, A. Deep Learning for De-tecting Robotic Grasps. The International Journal ofRobotics Research, 34(4-5):705–724, 2015.
Levine, S., Finn, C., Darrell, T., and Abbeel, P. End-to-endTraining of Deep Visuomotor Policies. arXiv preprintarXiv:1504.00702, 2015.
Lillicrap, T., Hunt, J., Pritzel, A., Heess, N., Erez, T., Tassa,Y., Silver, D., and Wierstra, D. Continuous control withdeep reinforcement learning. In International Confer-ence on Learning Representations, 2016.
Mnih, V. et al. Human-level control through deep rein-forcement learning. Nature, 518(7540):529–533, 2015.
Mohta, K., Kumar, V., and Daniilidis, K. Vision BasedControl of a Quadrotor for Perching on Planes and Lines.In IEEE International Conference on Robotics and Au-tomation, 2014.
Pinto, L. and Gupta, A. Supersizing self-supervision:Learning to grasp from 50k tries and 700 robot hours.CoRR, abs/1509.06825, 2015. URL http://arxiv.org/abs/1509.06825.
Redmon, J. and Angelova, A. Real-time grasp detectionusing convolutional neural networks. In IEEE Inter-national Conference on Robotics and Automation, pp.1316–1322, 2015.

Learning Hand-Eye Coordination for Robotic Grasping with Deep Learning and Large-Scale Data Collection
Rodriguez, A., Mason, M. T., and Ferry, S. From Cagingto Grasping. The International Journal of Robotics Re-search, 31(7):886–900, June 2012.
Rubinstein, R. and Kroese, D. The Cross-EntropyMethod: A Unified Approach to Combinatorial Opti-mization, Monte-Carlo Simulation, and Machine Learn-ing. Springer-Verlag, 2004.
Siciliano, B. and Khatib, O. Springer Handbook ofRobotics. Springer-Verlag New York, Inc., Secaucus,NJ, USA, 2007.
Srinivasa, S., Berenson, D., Cakmak, M., Romea, A. C.,Dogar, M., Dragan, A., Knepper, R. A., Niemueller,T. D., Strabala, K., Vandeweghe, J. M., and Ziegler, J.HERB 2.0: Lessons Learned from Developing a MobileManipulator for the Home. Proceedings of the IEEE,100(8):1–19, July 2012.
Vahrenkamp, N., Wieland, S., Azad, P., Gonzalez, D., As-four, T., and Dillmann, R. Visual Servoing for HumanoidGrasping and Manipulation Tasks. In 8th IEEE-RAS In-ternational Conference on Humanoid Robots, pp. 406–412, 2008.
Watter, M., Springenberg, J., Boedecker, J., and Riedmiller,M. Embed to Control: A Locally Linear Latent Dynam-ics Model for Control from Raw Images. In Advances inNeural Information Processing Systems, 2015.
Weisz, J. and Allen, P. K. Pose Error Robust Grasping fromContact Wrench Space Metrics. In IEEE InternationalConference on Robotics and Automation, pp. 557–562,2012.
Wilson, W. J., Hulls, C. W. Williams, and Bell, G. S.Relative End-Effector Control Using Cartesian PositionBased Visual Servoing. IEEE Transactions on Roboticsand Automation, 12(5), 1996.
Wohlhart, P. and Lepetit, V. Learning Descriptors for Ob-ject Recognition and 3D Pose Estimation. In Proceed-ings of the IEEE Conference on Computer Vision andPattern Recognition, pp. 3109–3118, 2015.
Yoshimi, B. H. and Allen, P. K. Active, uncalibrated visualservoing. In IEEE International Conference on Roboticsand Automation, 1994.
A. Servoing Implementation DetailsIn this appendix, we discuss the details of the inferenceprocedure we use to infer the motor command vt with thehighest probability of success, as well as additional detailsof the servoing mechanism.
In our implementation, we performed inference using threeiterations of cross-entropy method (CEM). Each iterationof CEM consists of sampling 64 sample grasp directionsvt from a Gaussian distribution with mean µ and covari-ance Σ, selecting the 6 best grasp directions (i.e. the 90th
percentile), and refitting µ and Σ to these 6 best grasps.The first iteration samples from a zero-mean Gaussian cen-tered on the current pose of the gripper. All samples areconstrained (via rejection sampling) to keep the final poseof the gripper within the workspace, and to avoid rotationsof more than 180◦ about the vertical axis. In general, theseconstraints could be used to control where in the scene therobot attempts to grasp, for example to impose user con-straints and command grasps at particular locations.
Since the CNN g(It,vt) was trained to predict the suc-cess of grasps on sequences that always terminated with thegripper on the table surface, we project all grasp directionsvt to the table height (which we assume is known) beforepassing them into the network, although the actual grasp di-rection that is executed may move the gripper above the ta-ble, as shown in Algorithm 1. When the servoing algorithmcommands a gripper motion above the table, we choose theheight uniformly at random between 4 and 10 cm.
B. Details of Hand-Engineered GraspingSystem Baseline
The hand-engineered grasping system baseline results re-ported in Table 1 were obtained using perception pipelinethat made use of the depth sensor instead of the monocu-lar camera, and required extrinsic calibration of the camerawith respect to the base of the arm. The grasp configura-tions were computed as follows: First, the point clouds ob-tained from the depth sensor were accumulated into a voxelmap. Second, the voxel map was turned into a 3D graphand segmented using standard graph based segmentation;individual clusters were then further segmented from topto bottom into “graspable objects” based on the width andheight of the region. Finally, a best grasp was computedthat aligns the fingers centrally along the longer edges ofthe bounding box that represents the object. This graspconfiguration was then used as the target pose for a task-space controller, which was identical to the controller usedfor the open-loop baseline.





























