Embed Size (px)
Citation preview

Kunstmatige Intelligentie / RuG
KI2 - 11
Reinforcement Learning
Sander van Dijk

What is Learning ?
Percepts received by an agent should be used not only for acting, but also for improving the agent’s ability to behave optimally in the future to achieve its goal.
Interaction between an agent and the world

Learning Types
Supervised learning: Input, output) pairs of the function to be
learned can be perceived or are given.Back-propagation
Unsupervised Learning: No information at all about given output
SOM
Reinforcement learning: Agent receives no examples and starts with
no model of the environment and no utility function. Agent gets feedback through rewards, or reinforcement.

Reinforcement Learning
Task Learn how to behave successfully to achieve a
goal while interacting with an external environmentLearn through experience from trial and error
Examples Game playing: The agent knows it has won or
lost, but it doesn’t know the appropriate action in each state
Control: a traffic system can measure the delay of cars, but not know how to decrease it.
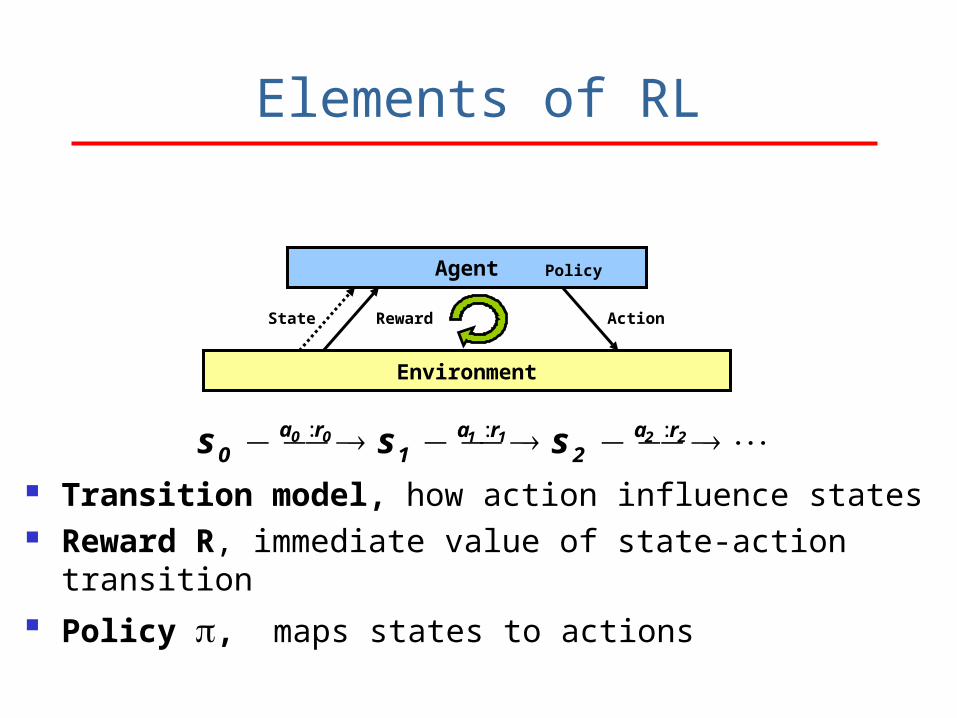
Elements of RL
Transition model, how action influence states Reward R, immediate value of state-action transition Policy , maps states to actions
Agent
Environment
State Reward Action
Policy
sss 221100 r a2
r a1
r a0 :::
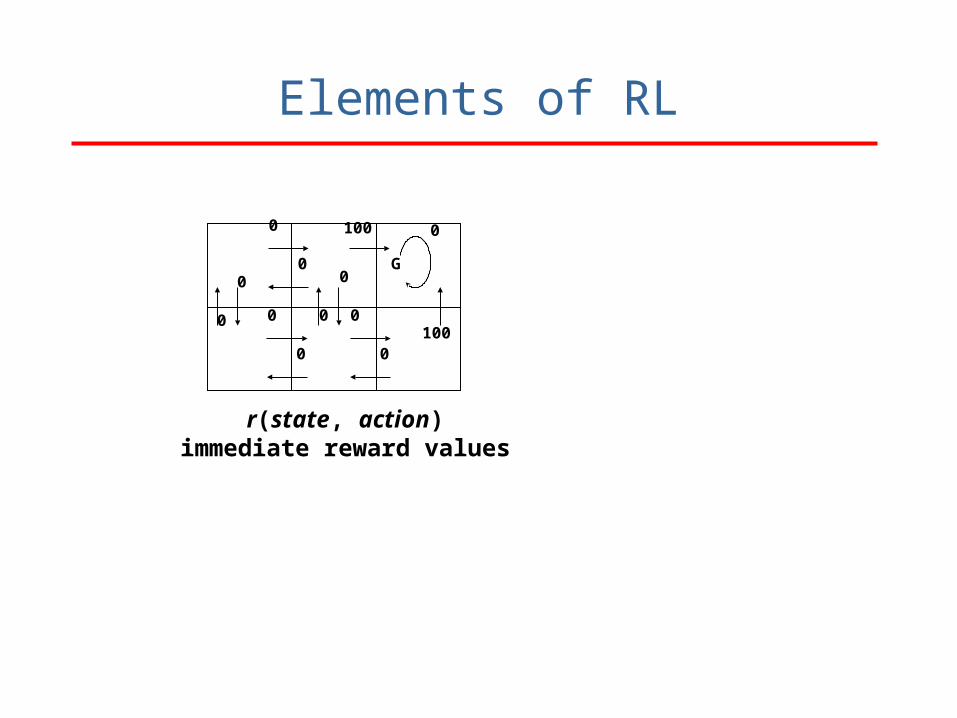
Elements of RL
r(state, action)immediate reward values
100
0
0
100
G
0
0
0
0
0
0
0
0
0

Elements of RL
Value function: maps states to state values
Discount factor [0, 1) (here 0.9)
V*(state) valuesr(state, action)immediate reward values
100
0
0
100
G
0
0
0
0
0
0
0
0
0 G
90 100 0
81 90 100
2 11π trγtγrtrsV ...
G 90 100 0
81 90 100
G 90 100 0
81 90 100

RL task (restated)
Execute actions in environment,
observe results.
Learn action policy : state action
that maximizes expected discounted
reward
E [r(t) + r(t + 1) + 2r(t + 2) + …]
from any starting state in S

Reinforcement Learning
Target function is : state action
However… We have no training examples of form
<state, action>
Training examples are of form
<<state, action>, reward>

Utility-based agents
Try to learn V * (abbreviated V*) Perform look ahead search to choose best action
from any state s
Works well if agent knows
: state action state
r : state action R
When agent doesn’t know and r, cannot choose
actions this way
a s,δ*Va s,rmaxargsπ*a

Q-values
Q-values
Define new function very similar to V*
If agent learns Q, it can choose optimal
action even without knowing or R
Using Q
a s,δ*Va s,ra s,Q
a s,Q maxargsπ*a

Learning the Q-value
Note: Q and V* closely related
Allows us to write Q recursively as
Temporal Difference learning
a' s,Q maxargs*Va'
a' ,tsQmax γta ,tsr
ta ,tsδγVta ,tsr ta ,tsQ
a'1

Learning the Q-value
FOR each <s, a> DO
Initialize table entry:
Observe current state s
WHILE (true) DO
Select action a and execute it
Receive immediate reward r
Observe new state s’
Update table entry for as follows
Move: record transition from s to s’
0 a s,Q̂
a s,Q̂
a' ,s'Q max γa s,r a s,Q a'
ˆˆ
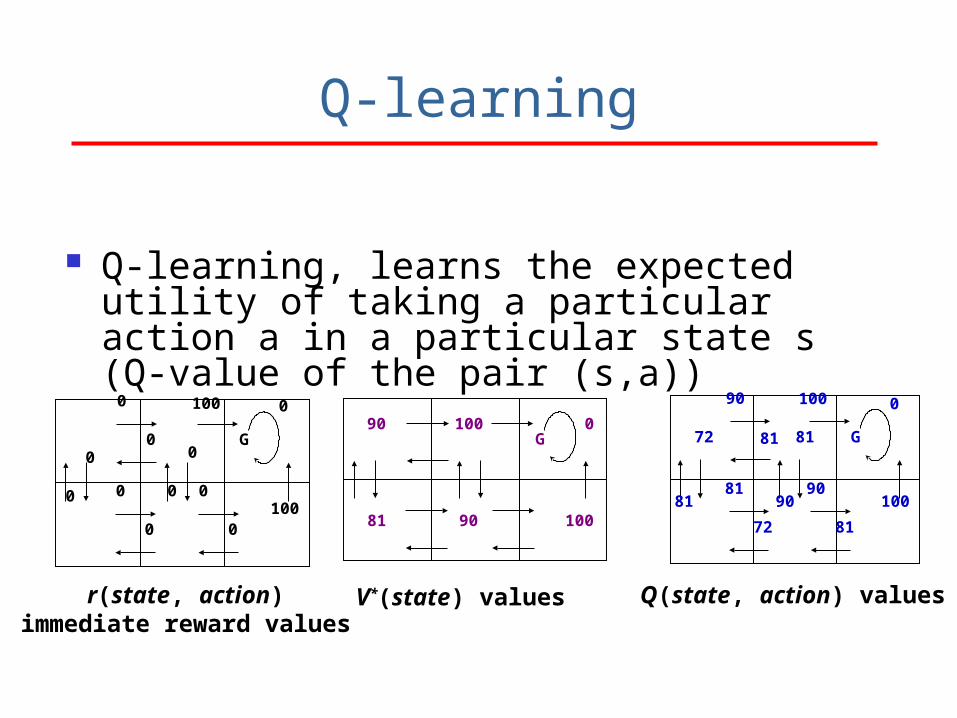
r(state, action)immediate reward values
Q(state, action) valuesV*(state) values
100
0
0
100
G
0
0
0
0
0
0
0
0
0
90
81
100
G
0
81
72
90
81 81
72
90
81
100
G 90 100 0
81 90 100
Q-learning
Q-learning, learns the expected utility of taking a particular action a in a particular state s (Q-value of the pair (s,a))

Representation
Explicit
Implicit Weighted linear function/neural network
Classical weight updating
State Action Q(s, a)
2 MoveLeft 81
2 MoveRight 100
... ... ...

Exploration
Agent follows policy deduced from learned Q-values
Agent always performs same action in certain state, but perhaps there is an even better action?
Exploration: Be safe <-> learn more, greed <-> curiosity.
Extremely hard, if not impossible, to obtain optimal exploration policy.
Randomly try actions that have not been tried often before but avoid actions that are believed to be of low utility

Q-learning estimates one time step difference
Why not for n steps?
a ,tsQ max γ tr ta ,tsQ a
11 ˆ
a ,ntsQ maxγntrγ tγr tr ta ,tsQ a
nnn ˆ11 1
Enhancement: Q()

Q() formula
Intuitive idea: use constant 0 1 to combine estimates from various look ahead distances (note normalization factor (1- ))
ta ,tsQλta ,tsλQta ,tsQ λ ta ,tsQ λ 32211
Enhancement: Q()

Enhancement: Eligibility Traces
Look backward instead of forward. Weigh updates by eligibility trace e(s,
a). On each step, decay all traces by and
increment the trace for the current state-action pair by 1.
Update all state-action pairs in proportion to their eligibility.

Genetic algorithms
Imagine the individuals as agent functions
Fitness function as performance measure or reward function
No attempt made to learn the relationship between the rewards and actions taken by an agent
Simply searches directly in the individual space to find one that maximizes the fitness functions
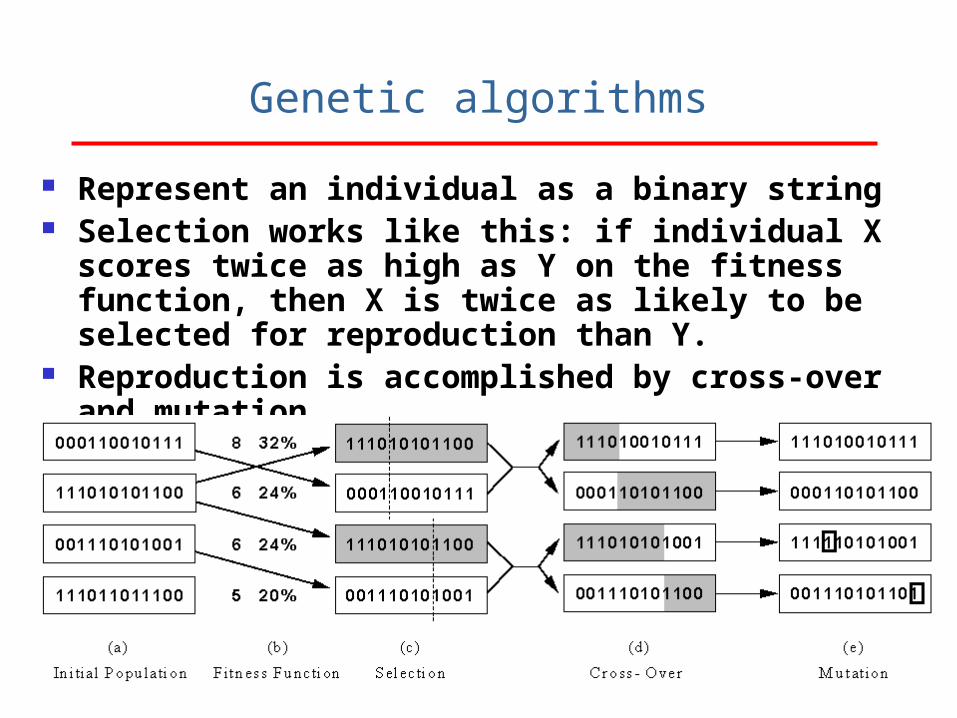
Genetic algorithms
Represent an individual as a binary string Selection works like this: if individual X scores
twice as high as Y on the fitness function, then X is twice as likely to be selected for reproduction than Y.
Reproduction is accomplished by cross-over and mutation

Cart – Pole balancing
Demonstration
http://www.bovine.net/~jlawson/hmc/pole/sane.html

Summary
RL addresses the problem of learning control strategies for autonomous agents
TD-algorithms learn by iteratively reducing the differences between the estimates produced by the agent at different times
In Q-learning an evaluation function over states and actions is learned
In the genetic approach, the relation between rewards and actions is not learned. You simply search the fitness function space.





























