Embed Size (px)
Citation preview

Math Camp
Justin Grimmer
Associate ProfessorDepartment of Political Science
Stanford University
September 7th, 2016
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 1 / 1

Optimization
Political scientists are often concerned with finding extrema: maxima orminima
- Given data, most likely value of a parameter
- Game theory: given other player’s strategy, action that maximizesutility
- Across substantive areas: what is the optimal action, strategy,prediction?
How to Optimize
- When functions are well behaved and known analytic solutions
- Differentiate, set equal to zero, solve- Check end points and use second derivative test
- More difficult problems computational solutions
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 2 / 1

Optimization
Political scientists are often concerned with finding extrema: maxima orminima
- Given data, most likely value of a parameter
- Game theory: given other player’s strategy, action that maximizesutility
- Across substantive areas: what is the optimal action, strategy,prediction?
How to Optimize
- When functions are well behaved and known analytic solutions
- Differentiate, set equal to zero, solve- Check end points and use second derivative test
- More difficult problems computational solutions
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 2 / 1

Optimization
Political scientists are often concerned with finding extrema: maxima orminima
- Given data, most likely value of a parameter
- Game theory: given other player’s strategy, action that maximizesutility
- Across substantive areas: what is the optimal action, strategy,prediction?
How to Optimize
- When functions are well behaved and known analytic solutions
- Differentiate, set equal to zero, solve- Check end points and use second derivative test
- More difficult problems computational solutions
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 2 / 1

Optimization
Political scientists are often concerned with finding extrema: maxima orminima
- Given data, most likely value of a parameter
- Game theory: given other player’s strategy, action that maximizesutility
- Across substantive areas: what is the optimal action, strategy,prediction?
How to Optimize
- When functions are well behaved and known analytic solutions
- Differentiate, set equal to zero, solve- Check end points and use second derivative test
- More difficult problems computational solutions
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 2 / 1

Optimization
Political scientists are often concerned with finding extrema: maxima orminima
- Given data, most likely value of a parameter
- Game theory: given other player’s strategy, action that maximizesutility
- Across substantive areas: what is the optimal action, strategy,prediction?
How to Optimize
- When functions are well behaved and known analytic solutions
- Differentiate, set equal to zero, solve- Check end points and use second derivative test
- More difficult problems computational solutions
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 2 / 1

Optimization
Political scientists are often concerned with finding extrema: maxima orminima
- Given data, most likely value of a parameter
- Game theory: given other player’s strategy, action that maximizesutility
- Across substantive areas: what is the optimal action, strategy,prediction?
How to Optimize
- When functions are well behaved and known analytic solutions
- Differentiate, set equal to zero, solve- Check end points and use second derivative test
- More difficult problems computational solutions
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 2 / 1

Optimization
Political scientists are often concerned with finding extrema: maxima orminima
- Given data, most likely value of a parameter
- Game theory: given other player’s strategy, action that maximizesutility
- Across substantive areas: what is the optimal action, strategy,prediction?
How to Optimize
- When functions are well behaved and known analytic solutions
- Differentiate, set equal to zero, solve
- Check end points and use second derivative test
- More difficult problems computational solutions
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 2 / 1

Optimization
Political scientists are often concerned with finding extrema: maxima orminima
- Given data, most likely value of a parameter
- Game theory: given other player’s strategy, action that maximizesutility
- Across substantive areas: what is the optimal action, strategy,prediction?
How to Optimize
- When functions are well behaved and known analytic solutions
- Differentiate, set equal to zero, solve- Check end points and use second derivative test
- More difficult problems computational solutions
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 2 / 1

Optimization
Political scientists are often concerned with finding extrema: maxima orminima
- Given data, most likely value of a parameter
- Game theory: given other player’s strategy, action that maximizesutility
- Across substantive areas: what is the optimal action, strategy,prediction?
How to Optimize
- When functions are well behaved and known analytic solutions
- Differentiate, set equal to zero, solve- Check end points and use second derivative test
- More difficult problems computational solutions
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 2 / 1

Optimization
Political scientists are often concerned with finding extrema: maxima orminima
- Given data, most likely value of a parameter
- Game theory: given other player’s strategy, action that maximizesutility
- Across substantive areas: what is the optimal action, strategy,prediction?
How to Optimize
- When functions are well behaved and known analytic solutions
- Differentiate, set equal to zero, solve- Check end points and use second derivative test
- More difficult problems computational solutions
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 2 / 1

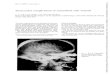
Intuition: Optimization with Derivatives, Known wellbehaved functions
−3 −2 −1 0 1 2 3
−4
−2
02
46
Rolle's Theorem
x
f(x)
f'(x) = 0
- Rolle’s theoremguarantee’s that, atsome point, f
′(x) = 0
- Intuition fromproof—what happens aswe approach from theleft?
- Intuition fromproof—what happens aswe approach from theright?
- critical intuition first,second derivatives
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 3 / 1

Intuition: Optimization with Derivatives, Known wellbehaved functions
−3 −2 −1 0 1 2 3
−4
−2
02
46
Rolle's Theorem
x
f(x)
f'(x) = 0
- Rolle’s theoremguarantee’s that, atsome point, f
′(x) = 0
- Intuition fromproof—what happens aswe approach from theleft?
- Intuition fromproof—what happens aswe approach from theright?
- critical intuition first,second derivatives
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 3 / 1

Intuition: Optimization with Derivatives, Known wellbehaved functions
−3 −2 −1 0 1 2 3
−4
−2
02
46
Rolle's Theorem
x
f(x)
f'(x) = 0
- Rolle’s theoremguarantee’s that, atsome point, f
′(x) = 0
- Intuition fromproof—what happens aswe approach from theleft?
- Intuition fromproof—what happens aswe approach from theright?
- critical intuition first,second derivatives
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 3 / 1

Intuition: Optimization with Derivatives, Known wellbehaved functions
−3 −2 −1 0 1 2 3
−4
−2
02
46
Rolle's Theorem
x
f(x)
f'(x) = 0
- Rolle’s theoremguarantee’s that, atsome point, f
′(x) = 0
- Intuition fromproof—what happens aswe approach from theleft?
- Intuition fromproof—what happens aswe approach from theright?
- critical intuition first,second derivatives
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 3 / 1

Intuition: Optimization with Derivatives, Known wellbehaved functions
−3 −2 −1 0 1 2 3
−4
−2
02
46
Rolle's Theorem
x
f(x)
f'(x) = 0
- Rolle’s theoremguarantee’s that, atsome point, f
′(x) = 0
- Intuition fromproof—what happens aswe approach from theleft?
- Intuition fromproof—what happens aswe approach from theright?
- critical intuition first,second derivatives
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 3 / 1

Second Derivatives
Definition
Suppose f : < → < is differentiable. Recall we write this as f′
andsuppose that f
′: < → <. Then if the limit,
limx→x0
R(x) =f′(x)− f
′(x0)
x − x0
exists, we call this the second derivative at x0, f′′
(x0).
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 4 / 1

Example of Second Derivatives
f (x) = x
f′(x) = 1
f′′
(x) = 0
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 5 / 1

Example of Second Derivatives
f (x) = ex
f′(x) = ex
f′′
(x) = ex
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 5 / 1

Example of Second Derivatives
f (x) = log(x)
f′(x) =
1
x
f′′
(x) =−1
x2
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 5 / 1

Example of Second Derivatives
f (x) =1
x
f′(x) =
−1
x2
f′′
(x) =2
x3
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 5 / 1

Example of Second Derivatives
f (x) = −x2 + 20
f′(x) = −2x
f′′
(x) = −2
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 5 / 1

Approximating functions and second order conditions
Theorem
Taylor’s Theorem Suppose f : < → <, f (x) is infinitely differentiablefunction. Then, the taylor expansion of f (x) around a is given by
f (x) = f (a) +f′(a)
1!(x − a) +
f′′
(a)
2!(x − a)2 +
f′′′
(a)
3!(x − a)3 + . . .
f (x) =∞∑n=0
f n(a)
n!(x − a)n
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 6 / 1

R Code!
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 7 / 1

Concavity, Convexity, Inflections
Second derivatives provide further information about functions
0 1 2 3 4 5
050
100
150
e^(x)
X
f(x)
0 1 2 3 4 5
−5
−4
−3
−2
−1
01
Log(x)
Xf(
x)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 8 / 1

Concavity, Convexity, Inflections
Second derivatives provide further information about functions
1 2 3 4 5
0.5
1.0
1.5
2.0
1/X
X
f(x)
0 1 2 3 4 5
−5
05
1015
20
−x^2 + 20
Xf(
x)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 8 / 1

Concave Up/ Convex
Definition
Suppose f : [a, b]→ < is a twice differentiable function. If, for allx ∈ [a, b] and y ∈ [a, b] and t ∈ (0, 1)
f ((1− t)x + ty) < (1− t)f (x) + tf (y)
We say that f is strictly concave up or convex. Equivalently if f′′
(x) > 0for all x ∈ [a, b], we say that f is strictly concave up.
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 9 / 1

Concave Up, Graphical Testf (x) = ex , [1, 4]
0 1 2 3 4 5
050
100
150
e^(x)
X
f(x)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 10 / 1

Concave Up, Graphical Testf (x) = ex , [1, 4]
0 1 2 3 4 5
050
100
150
e^(x)
X
f(x)
●(1, e^(1))
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 10 / 1

Concave Up, Graphical Testf (x) = ex , [1, 4]
0 1 2 3 4 5
050
100
150
e^(x)
X
f(x)
●(1, e^(1))
● (4, e^(4))
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 10 / 1

Concave Up, Graphical Testf (x) = ex , [1, 4]
0 1 2 3 4 5
050
100
150
e^(x)
X
f(x)
●(1, e^(1))
● (4, e^(4))
●●
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 10 / 1

Concave Up, Graphical Testf (x) = ex , [1, 4]
0 1 2 3 4 5
050
100
150
e^(x)
X
f(x)
●(1, e^(1))
● (4, e^(4))
●● ●
●
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 10 / 1

Concave Up, Graphical Testf (x) = ex , [1, 4]
0 1 2 3 4 5
050
100
150
e^(x)
X
f(x)
●(1, e^(1))
● (4, e^(4))
●● ●
● ●
●
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 10 / 1

Concave Up, Graphical Testf (x) = ex , [1, 4]
0 1 2 3 4 5
050
100
150
e^(x)
X
f(x)
●(1, e^(1))
● (4, e^(4))
●● ●
● ●
●
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 10 / 1

Concave Up, Second Derivative
0 1 2 3 4 5
050
100
150
e^(x)
X
f(x)
f (x) = ex
f′(x) = ex
f′′
(x) = ex
ex > 0 for all x ∈ [1, 4]
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 11 / 1

Concave Up, Second Derivative
0 1 2 3 4 5
050
100
150
e^(x)
X
f(x) f (x) = ex
f′(x) = ex
f′′
(x) = ex
ex > 0 for all x ∈ [1, 4]
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 11 / 1

Concave Up, Second Derivative
0 1 2 3 4 5
050
100
150
e^(x)
X
f(x) f (x) = ex
f′(x) = ex
f′′
(x) = ex
ex > 0 for all x ∈ [1, 4]
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 11 / 1

Concave Up, Second Derivative
0 1 2 3 4 5
050
100
150
e^(x)
X
f(x) f (x) = ex
f′(x) = ex
f′′
(x) = ex
ex > 0 for all x ∈ [1, 4]
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 11 / 1

Concave Up, Second Derivative
0 1 2 3 4 5
050
100
150
e^(x)
X
f(x) f (x) = ex
f′(x) = ex
f′′
(x) = ex
ex > 0 for all x ∈ [1, 4]
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 11 / 1

Concave Down
Definition
Suppose f : [a, b]→ < is a twice differentiable function. If, for allx ∈ [a, b] and y ∈ [a, b] and t ∈ (0, 1)
f ((1− t)x + ty) > (1− t)f (x) + tf (y)
We say that f is strictly concave down. Equivalently if f′′
(x) < 0 for allx ∈ [a, b], we say that f is strictly concave down.
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 12 / 1

Concave Down
0 1 2 3 4 5
−5
−4
−3
−2
−1
01
Log(x)
X
f(x)
- Show Concave down with graph test for x ∈ [1, 4]
- Show concave down with second derivative test for x ∈ [1, 4]
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 13 / 1

Optimization
Theorem
Extreme Value Theorem Suppose f : [a, b]→ < and that f is continuous.Then f obtains its extreme value on [a, b].
Corollary
Suppose f : [a, b]→ <, that f is continuous and differentiable, and thatf (a) nor f (b) is the extreme value. Then f obtains its maximum on (a, b)and if f (x0) is the extreme value of f x0 ∈ (a, b) then, f
′(x0) = 0.
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 14 / 1

Extrema on End Points
0 1 2 3 4 5
01
23
45
f(x) = x
X
f(X
)
●
●
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 15 / 1

Maximum in Middle, Concave Down
f (x) = −x2 + 5.
−3 −2 −1 0 1 2 3
−4
−2
02
46
Rolle's Theorem
x
f(x)
f'(x) = 0
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 16 / 1

Minimum in Interior, Concave Upf (x) = x2 + 9x + 9
−10 −8 −6 −4 −2 0
−10
−5
05
1015
20
x
f(x)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 17 / 1

Local Optimaf (x) = sin(x)
−20 −10 0 10 20
−1.
0−
0.5
0.0
0.5
1.0
x
f(x)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 18 / 1

Inflection pointsf (x) = x3
−3 −2 −1 0 1 2 3
−20
−10
010
20
x
f(x)
●
●
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 19 / 1

Framework for Optimization
Recipe for optimization
- Find f′(x).
- Set f′(x) = 0 and solve for x . Call all x0 such that f
′(x0) = 0 critical
values.
- Find f′′
(x). Evaluate at each x0.
- If f′′
(x) > 0, Concave up, local minimum- If f
′′(x) < 0, Concave down, local maximum
- If f′′
(x) = 0, No knowledge—local minimum, maximum, or inflectionpoint
- Check End Points!
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 20 / 1

Framework for Optimization
Recipe for optimization
- Find f′(x).
- Set f′(x) = 0 and solve for x . Call all x0 such that f
′(x0) = 0 critical
values.
- Find f′′
(x). Evaluate at each x0.
- If f′′
(x) > 0, Concave up, local minimum- If f
′′(x) < 0, Concave down, local maximum
- If f′′
(x) = 0, No knowledge—local minimum, maximum, or inflectionpoint
- Check End Points!
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 20 / 1

Framework for Optimization
Recipe for optimization
- Find f′(x).
- Set f′(x) = 0 and solve for x . Call all x0 such that f
′(x0) = 0 critical
values.
- Find f′′
(x). Evaluate at each x0.
- If f′′
(x) > 0, Concave up, local minimum- If f
′′(x) < 0, Concave down, local maximum
- If f′′
(x) = 0, No knowledge—local minimum, maximum, or inflectionpoint
- Check End Points!
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 20 / 1

Framework for Optimization
Recipe for optimization
- Find f′(x).
- Set f′(x) = 0 and solve for x . Call all x0 such that f
′(x0) = 0 critical
values.
- Find f′′
(x). Evaluate at each x0.
- If f′′
(x) > 0, Concave up, local minimum- If f
′′(x) < 0, Concave down, local maximum
- If f′′
(x) = 0, No knowledge—local minimum, maximum, or inflectionpoint
- Check End Points!
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 20 / 1

Framework for Optimization
Recipe for optimization
- Find f′(x).
- Set f′(x) = 0 and solve for x . Call all x0 such that f
′(x0) = 0 critical
values.
- Find f′′
(x). Evaluate at each x0.
- If f′′
(x) > 0, Concave up, local minimum
- If f′′
(x) < 0, Concave down, local maximum- If f
′′(x) = 0, No knowledge—local minimum, maximum, or inflection
point
- Check End Points!
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 20 / 1

Framework for Optimization
Recipe for optimization
- Find f′(x).
- Set f′(x) = 0 and solve for x . Call all x0 such that f
′(x0) = 0 critical
values.
- Find f′′
(x). Evaluate at each x0.
- If f′′
(x) > 0, Concave up, local minimum- If f
′′(x) < 0, Concave down, local maximum
- If f′′
(x) = 0, No knowledge—local minimum, maximum, or inflectionpoint
- Check End Points!
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 20 / 1

Framework for Optimization
Recipe for optimization
- Find f′(x).
- Set f′(x) = 0 and solve for x . Call all x0 such that f
′(x0) = 0 critical
values.
- Find f′′
(x). Evaluate at each x0.
- If f′′
(x) > 0, Concave up, local minimum- If f
′′(x) < 0, Concave down, local maximum
- If f′′
(x) = 0, No knowledge—local minimum, maximum, or inflectionpoint
- Check End Points!
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 20 / 1

Framework for Optimization
Recipe for optimization
- Find f′(x).
- Set f′(x) = 0 and solve for x . Call all x0 such that f
′(x0) = 0 critical
values.
- Find f′′
(x). Evaluate at each x0.
- If f′′
(x) > 0, Concave up, local minimum- If f
′′(x) < 0, Concave down, local maximum
- If f′′
(x) = 0, No knowledge—local minimum, maximum, or inflectionpoint
- Check End Points!
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 20 / 1

Example 1: f (x) = −x2, x ∈ [−3, 3]
−4 −2 0 2 4
−25
−20
−15
−10
−5
0
−x^2
X
f(x)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 21 / 1

Example 1: f (x) = −x2, x ∈ [−3, 3]
1) Critical Value:
f′(x) = −2x
0 = −2x∗
x∗ = 0
2) Second Derivative:
f′(x) = −2x
f′′
(x) = −2
f′′
(x) < 0, local maximum
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 21 / 1

Example 1: f (x) = −x2, x ∈ [−3, 3]
1) Critical Value:
f′(x) = −2x
0 = −2x∗
x∗ = 0
2) Second Derivative:
f′(x) = −2x
f′′
(x) = −2
f′′
(x) < 0, local maximum
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 21 / 1

Example 1: f (x) = −x2, x ∈ [−3, 3]
1) Critical Value:
f′(x) = −2x
0 = −2x∗
x∗ = 0
2) Second Derivative:
f′(x) = −2x
f′′
(x) = −2
f′′
(x) < 0, local maximum
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 21 / 1

Example 1: f (x) = −x2, x ∈ [−3, 3]
1) Critical Value:
f′(x) = −2x
0 = −2x∗
x∗ = 0
2) Second Derivative:
f′(x) = −2x
f′′
(x) = −2
f′′
(x) < 0, local maximum
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 21 / 1

Example 1: f (x) = −x2, x ∈ [−3, 3]
3) Check end points
f (0) = −02 = 0
f (−3) = −(−3)2 = −9
f (3) = −(3)2 = −9
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 22 / 1

Example 2: f (x) = x3, x ∈ [−3, 3]
−4 −2 0 2 4
−10
0−
500
5010
0
x^3
X
f(x)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 23 / 1

Example 2: f (x) = x3, x ∈ [−3, 3]
1) Critical Values:
f′(x) = 3x2
0 = 3(x∗)2
x∗ = 0
2) Second Derivative:
f′′
(x) = 6x
f′′
(0) = 0
No information
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 23 / 1

Example 2: f (x) = x3, x ∈ [−3, 3]
1) Critical Values:
f′(x) = 3x2
0 = 3(x∗)2
x∗ = 0
2) Second Derivative:
f′′
(x) = 6x
f′′
(0) = 0
No information
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 23 / 1

Example 2: f (x) = x3, x ∈ [−3, 3]
3) Check End Points:
f (0) = 03 = 0
f (−3) = −33 = −27
f (3) = 33 = 27
Neither maximum nor minimum, saddle point
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 24 / 1

Example 3: Spatial ModelA large literature in Congress supposes legislators and policies can besituated in policy space
Suppose legislator i and policies x , i ∈ <.Define legislator i ’s utility as, U : < → <,
Ui (x) = −(x − µ)2
Ui (x) = −x2 + 2xµ− µ2
What is i ’s optimal policy over the range x ∈ [µ− 2, µ+ 2]?
U′i (x) = −2(x − µ)
0 = −2x∗ + 2µ
x∗ = µ
Second Derivative Test
U′′i (x) = −2 < 0→ Concave Down
We call µ legislator i ’s ideal point
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 25 / 1

Example 3: Spatial ModelA large literature in Congress supposes legislators and policies can besituated in policy spaceSuppose legislator i and policies x , i ∈ <.
Define legislator i ’s utility as, U : < → <,
Ui (x) = −(x − µ)2
Ui (x) = −x2 + 2xµ− µ2
What is i ’s optimal policy over the range x ∈ [µ− 2, µ+ 2]?
U′i (x) = −2(x − µ)
0 = −2x∗ + 2µ
x∗ = µ
Second Derivative Test
U′′i (x) = −2 < 0→ Concave Down
We call µ legislator i ’s ideal point
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 25 / 1

Example 3: Spatial ModelA large literature in Congress supposes legislators and policies can besituated in policy spaceSuppose legislator i and policies x , i ∈ <.Define legislator i ’s utility as, U : < → <,
Ui (x) = −(x − µ)2
Ui (x) = −x2 + 2xµ− µ2
What is i ’s optimal policy over the range x ∈ [µ− 2, µ+ 2]?
U′i (x) = −2(x − µ)
0 = −2x∗ + 2µ
x∗ = µ
Second Derivative Test
U′′i (x) = −2 < 0→ Concave Down
We call µ legislator i ’s ideal point
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 25 / 1

Example 3: Spatial ModelA large literature in Congress supposes legislators and policies can besituated in policy spaceSuppose legislator i and policies x , i ∈ <.Define legislator i ’s utility as, U : < → <,
Ui (x) = −(x − µ)2
Ui (x) = −x2 + 2xµ− µ2
What is i ’s optimal policy over the range x ∈ [µ− 2, µ+ 2]?
U′i (x) = −2(x − µ)
0 = −2x∗ + 2µ
x∗ = µ
Second Derivative Test
U′′i (x) = −2 < 0→ Concave Down
We call µ legislator i ’s ideal point
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 25 / 1

Example 3: Spatial ModelA large literature in Congress supposes legislators and policies can besituated in policy spaceSuppose legislator i and policies x , i ∈ <.Define legislator i ’s utility as, U : < → <,
Ui (x) = −(x − µ)2
Ui (x) = −x2 + 2xµ− µ2
What is i ’s optimal policy over the range x ∈ [µ− 2, µ+ 2]?
U′i (x) = −2(x − µ)
0 = −2x∗ + 2µ
x∗ = µ
Second Derivative Test
U′′i (x) = −2 < 0→ Concave Down
We call µ legislator i ’s ideal point
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 25 / 1

Example 3: Spatial ModelA large literature in Congress supposes legislators and policies can besituated in policy spaceSuppose legislator i and policies x , i ∈ <.Define legislator i ’s utility as, U : < → <,
Ui (x) = −(x − µ)2
Ui (x) = −x2 + 2xµ− µ2
What is i ’s optimal policy over the range x ∈ [µ− 2, µ+ 2]?
U′i (x) = −2(x − µ)
0 = −2x∗ + 2µ
x∗ = µ
Second Derivative Test
U′′i (x) = −2 < 0→ Concave Down
We call µ legislator i ’s ideal point
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 25 / 1

Example 3: Spatial ModelA large literature in Congress supposes legislators and policies can besituated in policy spaceSuppose legislator i and policies x , i ∈ <.Define legislator i ’s utility as, U : < → <,
Ui (x) = −(x − µ)2
Ui (x) = −x2 + 2xµ− µ2
What is i ’s optimal policy over the range x ∈ [µ− 2, µ+ 2]?
U′i (x) = −2(x − µ)
0 = −2x∗ + 2µ
x∗ = µ
Second Derivative Test
U′′i (x) = −2 < 0→ Concave Down
We call µ legislator i ’s ideal point
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 25 / 1

Example 3: Spatial ModelA large literature in Congress supposes legislators and policies can besituated in policy spaceSuppose legislator i and policies x , i ∈ <.Define legislator i ’s utility as, U : < → <,
Ui (x) = −(x − µ)2
Ui (x) = −x2 + 2xµ− µ2
What is i ’s optimal policy over the range x ∈ [µ− 2, µ+ 2]?
U′i (x) = −2(x − µ)
0 = −2x∗ + 2µ
x∗ = µ
Second Derivative Test
U′′i (x) = −2 < 0→ Concave Down
We call µ legislator i ’s ideal point
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 25 / 1

Example 3: Spatial ModelA large literature in Congress supposes legislators and policies can besituated in policy spaceSuppose legislator i and policies x , i ∈ <.Define legislator i ’s utility as, U : < → <,
Ui (x) = −(x − µ)2
Ui (x) = −x2 + 2xµ− µ2
What is i ’s optimal policy over the range x ∈ [µ− 2, µ+ 2]?
U′i (x) = −2(x − µ)
0 = −2x∗ + 2µ
x∗ = µ
Second Derivative Test
U′′i (x) = −2 < 0→ Concave Down
We call µ legislator i ’s ideal point
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 25 / 1

Example 3: Spatial ModelA large literature in Congress supposes legislators and policies can besituated in policy spaceSuppose legislator i and policies x , i ∈ <.Define legislator i ’s utility as, U : < → <,
Ui (x) = −(x − µ)2
Ui (x) = −x2 + 2xµ− µ2
What is i ’s optimal policy over the range x ∈ [µ− 2, µ+ 2]?
U′i (x) = −2(x − µ)
0 = −2x∗ + 2µ
x∗ = µ
Second Derivative Test
U′′i (x) = −2 < 0→ Concave Down
We call µ legislator i ’s ideal point
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 25 / 1

Example 3: Spatial ModelA large literature in Congress supposes legislators and policies can besituated in policy spaceSuppose legislator i and policies x , i ∈ <.Define legislator i ’s utility as, U : < → <,
Ui (x) = −(x − µ)2
Ui (x) = −x2 + 2xµ− µ2
What is i ’s optimal policy over the range x ∈ [µ− 2, µ+ 2]?
U′i (x) = −2(x − µ)
0 = −2x∗ + 2µ
x∗ = µ
Second Derivative Test
U′′i (x) = −2 < 0→ Concave Down
We call µ legislator i ’s ideal point
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 25 / 1

Example 3: Spatial ModelA large literature in Congress supposes legislators and policies can besituated in policy spaceSuppose legislator i and policies x , i ∈ <.Define legislator i ’s utility as, U : < → <,
Ui (x) = −(x − µ)2
Ui (x) = −x2 + 2xµ− µ2
What is i ’s optimal policy over the range x ∈ [µ− 2, µ+ 2]?
U′i (x) = −2(x − µ)
0 = −2x∗ + 2µ
x∗ = µ
Second Derivative Test
U′′i (x) = −2 < 0→ Concave Down
We call µ legislator i ’s ideal pointJustin Grimmer (Stanford University) Methodology I September 7th, 2016 25 / 1

Example 3: Spatial Model
Ui (µ) = −(µ− µ)2 = 0
Ui (µ− 2) = −(µ− 2− µ)2 = −4
Ui (µ+ 2) = −(µ+ 2− µ)2 = −4
Maximize utility at µ
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 26 / 1

Example 4: Maximum Likelihood Estimation
In 350a, we’ll learn about parameters from data.
Here is an example likelihood function: We want to find the Maximumlikelihood estimate
f (µ) =N∏i=1
exp(−(Yi − µ)2
2)
= exp(−(Y1 − µ)2
2)× . . .× exp(−(YN − µ)2
2)
= exp(−∑N
i=1(Yi − µ)2
2)
Theorem
Suppose f : < → (0,∞). If x0 maximizes f , then x0 maximizes log(f (x)).
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 27 / 1

Example 4: Maximum Likelihood Estimation
In 350a, we’ll learn about parameters from data.Here is an example likelihood function: We want to find the Maximumlikelihood estimate
f (µ) =N∏i=1
exp(−(Yi − µ)2
2)
= exp(−(Y1 − µ)2
2)× . . .× exp(−(YN − µ)2
2)
= exp(−∑N
i=1(Yi − µ)2
2)
Theorem
Suppose f : < → (0,∞). If x0 maximizes f , then x0 maximizes log(f (x)).
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 27 / 1

Example 4: Maximum Likelihood Estimation
In 350a, we’ll learn about parameters from data.Here is an example likelihood function: We want to find the Maximumlikelihood estimate
f (µ) =N∏i=1
exp(−(Yi − µ)2
2)
= exp(−(Y1 − µ)2
2)× . . .× exp(−(YN − µ)2
2)
= exp(−∑N
i=1(Yi − µ)2
2)
Theorem
Suppose f : < → (0,∞). If x0 maximizes f , then x0 maximizes log(f (x)).
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 27 / 1

Example 4: Maximum Likelihood Estimation
In 350a, we’ll learn about parameters from data.Here is an example likelihood function: We want to find the Maximumlikelihood estimate
f (µ) =N∏i=1
exp(−(Yi − µ)2
2)
= exp(−(Y1 − µ)2
2)× . . .× exp(−(YN − µ)2
2)
= exp(−∑N
i=1(Yi − µ)2
2)
Theorem
Suppose f : < → (0,∞). If x0 maximizes f , then x0 maximizes log(f (x)).
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 27 / 1

Example 4: Maximum Likelihood Estimation
In 350a, we’ll learn about parameters from data.Here is an example likelihood function: We want to find the Maximumlikelihood estimate
f (µ) =N∏i=1
exp(−(Yi − µ)2
2)
= exp(−(Y1 − µ)2
2)× . . .× exp(−(YN − µ)2
2)
= exp(−∑N
i=1(Yi − µ)2
2)
Theorem
Suppose f : < → (0,∞). If x0 maximizes f , then x0 maximizes log(f (x)).
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 27 / 1

Example 4: Maximum Likelihood Estimation
In 350a, we’ll learn about parameters from data.Here is an example likelihood function: We want to find the Maximumlikelihood estimate
f (µ) =N∏i=1
exp(−(Yi − µ)2
2)
= exp(−(Y1 − µ)2
2)× . . .× exp(−(YN − µ)2
2)
= exp(−∑N
i=1(Yi − µ)2
2)
Theorem
Suppose f : < → (0,∞). If x0 maximizes f , then x0 maximizes log(f (x)).
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 27 / 1

Example 4: Maximum LIkelihood Estimation
log f (µ) = log
(exp(−
∑Ni=1(Yi − µ)2
2)
)
= −∑N
i=1(Yi − µ)2
2)
= −1
2
(N∑i=1
Y 2i − 2µ
N∑i=1
Yi + N × µ2
)∂ log f (µ)
∂µ= −1
2
(−2
N∑i=1
Yi + 2Nµ
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 28 / 1

Example 4: Maximum LIkelihood Estimation
log f (µ) = log
(exp(−
∑Ni=1(Yi − µ)2
2)
)
= −∑N
i=1(Yi − µ)2
2)
= −1
2
(N∑i=1
Y 2i − 2µ
N∑i=1
Yi + N × µ2
)∂ log f (µ)
∂µ= −1
2
(−2
N∑i=1
Yi + 2Nµ
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 28 / 1

Example 4: Maximum LIkelihood Estimation
log f (µ) = log
(exp(−
∑Ni=1(Yi − µ)2
2)
)
= −∑N
i=1(Yi − µ)2
2)
= −1
2
(N∑i=1
Y 2i − 2µ
N∑i=1
Yi + N × µ2
)∂ log f (µ)
∂µ= −1
2
(−2
N∑i=1
Yi + 2Nµ
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 28 / 1

Example 4: Maximum LIkelihood Estimation
log f (µ) = log
(exp(−
∑Ni=1(Yi − µ)2
2)
)
= −∑N
i=1(Yi − µ)2
2)
= −1
2
(N∑i=1
Y 2i − 2µ
N∑i=1
Yi + N × µ2
)
∂ log f (µ)
∂µ= −1
2
(−2
N∑i=1
Yi + 2Nµ
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 28 / 1

Example 4: Maximum LIkelihood Estimation
log f (µ) = log
(exp(−
∑Ni=1(Yi − µ)2
2)
)
= −∑N
i=1(Yi − µ)2
2)
= −1
2
(N∑i=1
Y 2i − 2µ
N∑i=1
Yi + N × µ2
)∂ log f (µ)
∂µ= −1
2
(−2
N∑i=1
Yi + 2Nµ
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 28 / 1

Example 4: Maximum Likelihood Estimation
0 = −1
2
(−
N∑i=1
Yi + 2Nµ∗
)
2N∑i=1
Yi = 2Nµ∗
∑Ni=1 Yi
N= µ∗
Y = µ∗
Second Derivative Test
f′(µ) = −1
2
(−2
N∑i=1
Yi + 2Nµ
)f′′
(µ) = −N
−N < 0, concave down, maximum(!!)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 29 / 1

Example 4: Maximum Likelihood Estimation
0 = −1
2
(−
N∑i=1
Yi + 2Nµ∗
)
2N∑i=1
Yi = 2Nµ∗
∑Ni=1 Yi
N= µ∗
Y = µ∗
Second Derivative Test
f′(µ) = −1
2
(−2
N∑i=1
Yi + 2Nµ
)f′′
(µ) = −N
−N < 0, concave down, maximum(!!)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 29 / 1

Example 4: Maximum Likelihood Estimation
0 = −1
2
(−
N∑i=1
Yi + 2Nµ∗
)
2N∑i=1
Yi = 2Nµ∗
∑Ni=1 Yi
N= µ∗
Y = µ∗
Second Derivative Test
f′(µ) = −1
2
(−2
N∑i=1
Yi + 2Nµ
)f′′
(µ) = −N
−N < 0, concave down, maximum(!!)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 29 / 1

Example 4: Maximum Likelihood Estimation
0 = −1
2
(−
N∑i=1
Yi + 2Nµ∗
)
2N∑i=1
Yi = 2Nµ∗
∑Ni=1 Yi
N= µ∗
Y = µ∗
Second Derivative Test
f′(µ) = −1
2
(−2
N∑i=1
Yi + 2Nµ
)f′′
(µ) = −N
−N < 0, concave down, maximum(!!)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 29 / 1

Example 4: Maximum Likelihood Estimation
0 = −1
2
(−
N∑i=1
Yi + 2Nµ∗
)
2N∑i=1
Yi = 2Nµ∗
∑Ni=1 Yi
N= µ∗
Y = µ∗
Second Derivative Test
f′(µ) = −1
2
(−2
N∑i=1
Yi + 2Nµ
)f′′
(µ) = −N
−N < 0, concave down, maximum(!!)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 29 / 1

Example 4: Maximum Likelihood Estimation
0 = −1
2
(−
N∑i=1
Yi + 2Nµ∗
)
2N∑i=1
Yi = 2Nµ∗
∑Ni=1 Yi
N= µ∗
Y = µ∗
Second Derivative Test
f′(µ) = −1
2
(−2
N∑i=1
Yi + 2Nµ
)f′′
(µ) = −N
−N < 0, concave down, maximum(!!)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 29 / 1

Example 4: Maximum Likelihood Estimation
0 = −1
2
(−
N∑i=1
Yi + 2Nµ∗
)
2N∑i=1
Yi = 2Nµ∗
∑Ni=1 Yi
N= µ∗
Y = µ∗
Second Derivative Test
f′(µ) = −1
2
(−2
N∑i=1
Yi + 2Nµ
)
f′′
(µ) = −N
−N < 0, concave down, maximum(!!)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 29 / 1

Example 4: Maximum Likelihood Estimation
0 = −1
2
(−
N∑i=1
Yi + 2Nµ∗
)
2N∑i=1
Yi = 2Nµ∗
∑Ni=1 Yi
N= µ∗
Y = µ∗
Second Derivative Test
f′(µ) = −1
2
(−2
N∑i=1
Yi + 2Nµ
)f′′
(µ) = −N
−N < 0, concave down, maximum(!!)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 29 / 1

Example 5: IR Bargaining (from Jim Fearon, Part 1)Countries fight wars, usually to get stuff.
- Suppose two countries 1, 2 are fighting for something they value at v .
- Each country decides to invest a1 ∈ [0, 1] and a2 ∈ [0, 1].
- The probability of country 1 winning the war is
p(a1, a2) =an1
an1 + an2
- Country 1’s utility is given by
U1(a1) = 1− a1︸ ︷︷ ︸cost
+ p(a1, a2)v︸ ︷︷ ︸Expected Benefit
= 1− a1 +an1
an1 + an2v
- Suppose country 2 selected value x . What should country 1 invest tomaximize utility?
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 30 / 1

Example 5: IR Bargaining (from Jim Fearon, Part 1)Countries fight wars, usually to get stuff.
- Suppose two countries 1, 2 are fighting for something they value at v .
- Each country decides to invest a1 ∈ [0, 1] and a2 ∈ [0, 1].
- The probability of country 1 winning the war is
p(a1, a2) =an1
an1 + an2
- Country 1’s utility is given by
U1(a1) = 1− a1︸ ︷︷ ︸cost
+ p(a1, a2)v︸ ︷︷ ︸Expected Benefit
= 1− a1 +an1
an1 + an2v
- Suppose country 2 selected value x . What should country 1 invest tomaximize utility?
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 30 / 1

Example 5: IR Bargaining (from Jim Fearon, Part 1)Countries fight wars, usually to get stuff.
- Suppose two countries 1, 2 are fighting for something they value at v .
- Each country decides to invest a1 ∈ [0, 1] and a2 ∈ [0, 1].
- The probability of country 1 winning the war is
p(a1, a2) =an1
an1 + an2
- Country 1’s utility is given by
U1(a1) = 1− a1︸ ︷︷ ︸cost
+ p(a1, a2)v︸ ︷︷ ︸Expected Benefit
= 1− a1 +an1
an1 + an2v
- Suppose country 2 selected value x . What should country 1 invest tomaximize utility?
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 30 / 1

Example 5: IR Bargaining (from Jim Fearon, Part 1)Countries fight wars, usually to get stuff.
- Suppose two countries 1, 2 are fighting for something they value at v .
- Each country decides to invest a1 ∈ [0, 1] and a2 ∈ [0, 1].
- The probability of country 1 winning the war is
p(a1, a2) =an1
an1 + an2
- Country 1’s utility is given by
U1(a1) = 1− a1︸ ︷︷ ︸cost
+ p(a1, a2)v︸ ︷︷ ︸Expected Benefit
= 1− a1 +an1
an1 + an2v
- Suppose country 2 selected value x . What should country 1 invest tomaximize utility?
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 30 / 1

Example 5: IR Bargaining (from Jim Fearon, Part 1)Countries fight wars, usually to get stuff.
- Suppose two countries 1, 2 are fighting for something they value at v .
- Each country decides to invest a1 ∈ [0, 1] and a2 ∈ [0, 1].
- The probability of country 1 winning the war is
p(a1, a2) =an1
an1 + an2
- Country 1’s utility is given by
U1(a1) = 1− a1︸ ︷︷ ︸cost
+ p(a1, a2)v︸ ︷︷ ︸Expected Benefit
= 1− a1 +an1
an1 + an2v
- Suppose country 2 selected value x . What should country 1 invest tomaximize utility?
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 30 / 1

Example 5: IR Bargaining (from Jim Fearon, Part 1)Countries fight wars, usually to get stuff.
- Suppose two countries 1, 2 are fighting for something they value at v .
- Each country decides to invest a1 ∈ [0, 1] and a2 ∈ [0, 1].
- The probability of country 1 winning the war is
p(a1, a2) =an1
an1 + an2
- Country 1’s utility is given by
U1(a1) = 1− a1︸ ︷︷ ︸cost
+ p(a1, a2)v︸ ︷︷ ︸Expected Benefit
= 1− a1 +an1
an1 + an2v
- Suppose country 2 selected value x . What should country 1 invest tomaximize utility?
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 30 / 1

Example 5: IR Bargaining (from Jim Fearon, Part 1)Countries fight wars, usually to get stuff.
- Suppose two countries 1, 2 are fighting for something they value at v .
- Each country decides to invest a1 ∈ [0, 1] and a2 ∈ [0, 1].
- The probability of country 1 winning the war is
p(a1, a2) =an1
an1 + an2
- Country 1’s utility is given by
U1(a1) = 1− a1︸ ︷︷ ︸cost
+ p(a1, a2)v︸ ︷︷ ︸Expected Benefit
= 1− a1 +an1
an1 + an2v
- Suppose country 2 selected value x . What should country 1 invest tomaximize utility?
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 30 / 1

Example 5: IR Bargaining (from Jim Fearon, Part 1)Countries fight wars, usually to get stuff.
- Suppose two countries 1, 2 are fighting for something they value at v .
- Each country decides to invest a1 ∈ [0, 1] and a2 ∈ [0, 1].
- The probability of country 1 winning the war is
p(a1, a2) =an1
an1 + an2
- Country 1’s utility is given by
U1(a1) = 1− a1︸ ︷︷ ︸cost
+ p(a1, a2)v︸ ︷︷ ︸Expected Benefit
= 1− a1 +an1
an1 + an2v
- Suppose country 2 selected value x . What should country 1 invest tomaximize utility?
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 30 / 1

Example 5: IR Bargaining (from Jim Fearon, Part 1)
0.0 0.2 0.4 0.6 0.8 1.0
0.4
0.5
0.6
0.7
0.8
0.9
1.0
n = 1,v = 0.5
a1
Util
ity
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 31 / 1

Example 5: IR War (from Jim Fearon, Part 1)
∂U1(a1)
∂a1= −1 +
nan−11 (an1 + xn)− (nan−1
1 an1)
(an1 + xn)2v
= −1 +nan−1
1 xn
(an1 + xn)2v
Set n = 1 (for simplicity)
0 = −1 +x
(a1 + x)2v
a∗1 =√v√x − x
(0.1)
Second derivative!
U′′1 (a1) =
−2vx
(a1 + x)3
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 32 / 1

Example 5: IR Bargaining (from Jim Fearon, Part 1)
One more—check endpoints
a∗1 = 0, if√v√x − x < 0
a∗1 = 0, if√v <√x
a∗1 =√v√x − x otherwise
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 33 / 1

Optimization Challenge Problem- Suppose a candidate is attempting to mobilize voters. Suppose that
for each investment of x ∈ [0,∞) the candidate receives return ofx1/2, but incurs cost of ax . So, candidate utility is,
Ui = x1/2 − ax
What is the optimal investment x∗?
0.0 0.1 0.2 0.3 0.4 0.5
−1.
0−
0.5
0.0
0.5
1.0
x
Util
ity
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 34 / 1

Computational Optimization Approaches
Analytic (Closed form) Often difficult, impractical, or unavailable
Computational iterative algorithm that converges to a solution(hopefully the right one!)
- Methods for optimization:
- Newton’s method and related methods- Gradient descent (ascent)- Expectation Maximization- Genetic Optimization- Branch and Bound ...
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 35 / 1

Computational Optimization Approaches
Analytic (Closed form) Often difficult, impractical, or unavailableComputational
iterative algorithm that converges to a solution(hopefully the right one!)
- Methods for optimization:
- Newton’s method and related methods- Gradient descent (ascent)- Expectation Maximization- Genetic Optimization- Branch and Bound ...
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 35 / 1

Computational Optimization Approaches
Analytic (Closed form) Often difficult, impractical, or unavailableComputational iterative algorithm that converges to a solution(hopefully the right one!)
- Methods for optimization:
- Newton’s method and related methods- Gradient descent (ascent)- Expectation Maximization- Genetic Optimization- Branch and Bound ...
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 35 / 1

Computational Optimization Approaches
Analytic (Closed form) Often difficult, impractical, or unavailableComputational iterative algorithm that converges to a solution(hopefully the right one!)
- Methods for optimization:
- Newton’s method and related methods- Gradient descent (ascent)- Expectation Maximization- Genetic Optimization- Branch and Bound ...
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 35 / 1

Computational Optimization Approaches
Analytic (Closed form) Often difficult, impractical, or unavailableComputational iterative algorithm that converges to a solution(hopefully the right one!)
- Methods for optimization:
- Newton’s method and related methods
- Gradient descent (ascent)- Expectation Maximization- Genetic Optimization- Branch and Bound ...
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 35 / 1

Computational Optimization Approaches
Analytic (Closed form) Often difficult, impractical, or unavailableComputational iterative algorithm that converges to a solution(hopefully the right one!)
- Methods for optimization:
- Newton’s method and related methods- Gradient descent (ascent)
- Expectation Maximization- Genetic Optimization- Branch and Bound ...
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 35 / 1

Computational Optimization Approaches
Analytic (Closed form) Often difficult, impractical, or unavailableComputational iterative algorithm that converges to a solution(hopefully the right one!)
- Methods for optimization:
- Newton’s method and related methods- Gradient descent (ascent)- Expectation Maximization
- Genetic Optimization- Branch and Bound ...
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 35 / 1

Computational Optimization Approaches
Analytic (Closed form) Often difficult, impractical, or unavailableComputational iterative algorithm that converges to a solution(hopefully the right one!)
- Methods for optimization:
- Newton’s method and related methods- Gradient descent (ascent)- Expectation Maximization- Genetic Optimization
- Branch and Bound ...
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 35 / 1

Computational Optimization Approaches
Analytic (Closed form) Often difficult, impractical, or unavailableComputational iterative algorithm that converges to a solution(hopefully the right one!)
- Methods for optimization:
- Newton’s method and related methods- Gradient descent (ascent)- Expectation Maximization- Genetic Optimization- Branch and Bound ...
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 35 / 1

Newton-Raphson Method
Iterative procedure to find a root
Often solving for x when f (x) = 0 is hard complicated functionSolving for x when f (x) is linear easyApproximate with tangent line, iteratively update
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 36 / 1

Newton-Raphson Method
Iterative procedure to find a rootOften solving for x when f (x) = 0 is hard complicated function
Solving for x when f (x) is linear easyApproximate with tangent line, iteratively update
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 36 / 1

Newton-Raphson Method
Iterative procedure to find a rootOften solving for x when f (x) = 0 is hard complicated functionSolving for x when f (x) is linear easy
Approximate with tangent line, iteratively update
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 36 / 1

Newton-Raphson Method
Iterative procedure to find a rootOften solving for x when f (x) = 0 is hard complicated functionSolving for x when f (x) is linear easyApproximate with tangent line, iteratively update
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 36 / 1

Tangent Line
2 4 6 8 10
0.0
0.5
1.0
1.5
2.0
X
F(x
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 37 / 1

Tangent Line
2 4 6 8 10
0.0
0.5
1.0
1.5
2.0
X
F(x
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 37 / 1

Tangent Line
2 4 6 8 10
0.0
0.5
1.0
1.5
2.0
X
F(x
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 37 / 1

Tangent Line
2 4 6 8 10
0.0
0.5
1.0
1.5
2.0
X
F(x
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 37 / 1

Tangent Line
2 4 6 8 10
0.0
0.5
1.0
1.5
2.0
X
F(x
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 37 / 1

Tangent Line
2 4 6 8 10
0.0
0.5
1.0
1.5
2.0
X
F(x
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 37 / 1

Tangent Line
2 4 6 8 10
0.0
0.5
1.0
1.5
2.0
X
F(x
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 37 / 1

Tangent Line
2 4 6 8 10
0.0
0.5
1.0
1.5
2.0
X
F(x
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 37 / 1

Tangent Line
2 4 6 8 10
0.0
0.5
1.0
1.5
2.0
X
F(x
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 37 / 1

Tangent Line
2 4 6 8 10
0.0
0.5
1.0
1.5
2.0
X
F(x
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 37 / 1

Tangent Line
2 4 6 8 10
0.0
0.5
1.0
1.5
2.0
X
F(x
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 37 / 1

Tangent Line
2 4 6 8 10
0.0
0.5
1.0
1.5
2.0
X
F(x
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 37 / 1

Tangent Line
2 4 6 8 10
0.0
0.5
1.0
1.5
2.0
X
F(x
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 37 / 1

Tangent Line
2 4 6 8 10
0.0
0.5
1.0
1.5
2.0
X
F(x
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 37 / 1

Tangent Line
2 4 6 8 10
0.0
0.5
1.0
1.5
2.0
X
F(x
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 37 / 1

Tangent Line
2 4 6 8 10
0.0
0.5
1.0
1.5
2.0
X
F(x
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 37 / 1

Tangent Line
2 4 6 8 10
0.0
0.5
1.0
1.5
2.0
X
F(x
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 37 / 1

Tangent Line
2 4 6 8 10
0.0
0.5
1.0
1.5
2.0
X
F(x
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 37 / 1

Tangent Line
2 4 6 8 10
0.0
0.5
1.0
1.5
2.0
X
F(x
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 37 / 1

Tangent Line
2 4 6 8 10
0.0
0.5
1.0
1.5
2.0
X
F(x
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 37 / 1

Tangent Line
2 4 6 8 10
0.0
0.5
1.0
1.5
2.0
X
F(x
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 37 / 1

Tangent Line
2 4 6 8 10
0.0
0.5
1.0
1.5
2.0
X
F(x
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 37 / 1

Tangent Line
2 4 6 8 10
0.0
0.5
1.0
1.5
2.0
X
F(x
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 37 / 1

Tangent Line
2 4 6 8 10
0.0
0.5
1.0
1.5
2.0
X
F(x
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 37 / 1

Tangent Line
2 4 6 8 10
0.0
0.5
1.0
1.5
2.0
X
F(x
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 37 / 1

Tangent Line
2 4 6 8 10
0.0
0.5
1.0
1.5
2.0
X
F(x
)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 37 / 1

Tangent Line
Formula for Tangent line at x0:
g(x) = f′(x0)(x − x0) + f (x0)
We’ll use formula for tangent line to generate updates
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 38 / 1

Tangent Line
Formula for Tangent line at x0:
g(x) = f′(x0)(x − x0) + f (x0)
We’ll use formula for tangent line to generate updates
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 38 / 1

Tangent Line
Formula for Tangent line at x0:
g(x) = f′(x0)(x − x0) + f (x0)
We’ll use formula for tangent line to generate updates
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 38 / 1

Tangent Line
Formula for Tangent line at x0:
g(x) = f′(x0)(x − x0) + f (x0)
We’ll use formula for tangent line to generate updates
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 38 / 1

Tangent Line
Formula for Tangent line at x0:
g(x) = f′(x0)(x − x0) + f (x0)
We’ll use formula for tangent line to generate updates
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 38 / 1

Newton-Raphson Method
Suppose we have some initial guess x0. We’re going to approximate f′(x)
with the tangent line to generate a new guess
g(x) = f′′
(x0)(x − x0) + f′(x0)
0 = f′′
(x0)(x1 − x0) + f′(x0)
x1 = x0 −f′(x0)
f ′′(x0)
Perform iteratively until change in |xt+1 − xt | < threshold
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 39 / 1

Newton-Raphson Method
Suppose we have some initial guess x0. We’re going to approximate f′(x)
with the tangent line to generate a new guess
g(x) = f′′
(x0)(x − x0) + f′(x0)
0 = f′′
(x0)(x1 − x0) + f′(x0)
x1 = x0 −f′(x0)
f ′′(x0)
Perform iteratively until change in |xt+1 − xt | < threshold
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 39 / 1

Newton-Raphson Method
Suppose we have some initial guess x0. We’re going to approximate f′(x)
with the tangent line to generate a new guess
g(x) = f′′
(x0)(x − x0) + f′(x0)
0 = f′′
(x0)(x1 − x0) + f′(x0)
x1 = x0 −f′(x0)
f ′′(x0)
Perform iteratively until change in |xt+1 − xt | < threshold
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 39 / 1

Newton-Raphson Method
Suppose we have some initial guess x0. We’re going to approximate f′(x)
with the tangent line to generate a new guess
g(x) = f′′
(x0)(x − x0) + f′(x0)
0 = f′′
(x0)(x1 − x0) + f′(x0)
x1 = x0 −f′(x0)
f ′′(x0)
Perform iteratively until change in |xt+1 − xt | < threshold
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 39 / 1

Example Functionf (x) = x3 + 2x2 − 1 find x that maximizes f (x) with x ∈ [−3, 0]
−3 −2 −1 0 1 2 3
−10
010
2030
40
x^3 + 2 x^2 − 1
X
f(x)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 40 / 1

f′(x) = 3x2 + 4x
f′′
(x) = 6x + 4
Suppose we have guess xt then the next step is:
xt+1 = xt −3x2
t + 4xt6xt + 4
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 41 / 1

−3 −2 −1 0 1 2 3
−10
010
2030
40
x^3 + 2 x^2 − 1
X
f(x)
●
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 42 / 1

−3 −2 −1 0 1 2 3
−10
010
2030
40
x^3 + 2 x^2 − 1
X
f(x)
●
●
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 42 / 1

−3 −2 −1 0 1 2 3
−10
010
2030
40
x^3 + 2 x^2 − 1
X
f(x)
●
●●
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 42 / 1

−3 −2 −1 0 1 2 3
−10
010
2030
40
x^3 + 2 x^2 − 1
X
f(x)
●
●●●
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 42 / 1

−3 −2 −1 0 1 2 3
−10
010
2030
40
x^3 + 2 x^2 − 1
X
f(x)
●
●●●●
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 42 / 1

−3 −2 −1 0 1 2 3
−10
010
2030
40
x^3 + 2 x^2 − 1
X
f(x)
●
●●●●●
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 42 / 1

x∗ = −1.3333
−3 −2 −1 0 1 2 3
−10
010
2030
40
x^3 + 2 x^2 − 1
X
f(x)
●
●●●●●●
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 42 / 1

What is Happening with the Roots
−3 −2 −1 0 1 2 3
010
2030
40
3x^2 + 4x
X
f'(x)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 43 / 1

What is Happening with the Roots
−3 −2 −1 0 1 2 3
010
2030
40
3x^2 + 4x
X
f'(x)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 43 / 1

What is Happening with the Roots
−3 −2 −1 0 1 2 3
010
2030
40
3x^2 + 4x
X
f'(x)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 43 / 1

What is Happening with the Roots
−3 −2 −1 0 1 2 3
010
2030
40
3x^2 + 4x
X
f'(x)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 43 / 1

What is Happening with the Roots
−3 −2 −1 0 1 2 3
010
2030
40
3x^2 + 4x
X
f'(x)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 43 / 1

What is Happening with the Roots
−3 −2 −1 0 1 2 3
010
2030
40
3x^2 + 4x
X
f'(x)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 43 / 1

What is Happening with the Roots
−3 −2 −1 0 1 2 3
010
2030
40
3x^2 + 4x
X
f'(x)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 43 / 1

What is Happening with the Roots
−3 −2 −1 0 1 2 3
010
2030
40
3x^2 + 4x
X
f'(x)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 43 / 1

What is Happening with the Roots
−3 −2 −1 0 1 2 3
010
2030
40
3x^2 + 4x
X
f'(x)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 43 / 1

What is Happening with the Roots
−3 −2 −1 0 1 2 3
010
2030
40
3x^2 + 4x
X
f'(x)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 43 / 1

What is Happening with the Roots
−3 −2 −1 0 1 2 3
010
2030
40
3x^2 + 4x
X
f'(x)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 43 / 1

What is Happening with the Roots
−3 −2 −1 0 1 2 3
010
2030
40
3x^2 + 4x
X
f'(x)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 43 / 1

What is Happening with the Roots
−3 −2 −1 0 1 2 3
010
2030
40
3x^2 + 4x
X
f'(x)
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 43 / 1

−3 −2 −1 0 1 2 3
−10
010
2030
40
x^3 + 2 x^2 − 1
X
f(x)
●
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 44 / 1

−3 −2 −1 0 1 2 3
−10
010
2030
40
x^3 + 2 x^2 − 1
X
f(x)
●●
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 44 / 1

−3 −2 −1 0 1 2 3
−10
010
2030
40
x^3 + 2 x^2 − 1
X
f(x)
●● ●
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 44 / 1

−3 −2 −1 0 1 2 3
−10
010
2030
40
x^3 + 2 x^2 − 1
X
f(x)
●● ●●
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 44 / 1

−3 −2 −1 0 1 2 3
−10
010
2030
40
x^3 + 2 x^2 − 1
X
f(x)
●● ●●●
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 44 / 1

−3 −2 −1 0 1 2 3
−10
010
2030
40
x^3 + 2 x^2 − 1
X
f(x)
●● ●●●●
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 44 / 1

−3 −2 −1 0 1 2 3
−10
010
2030
40
x^3 + 2 x^2 − 1
X
f(x)
●
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 44 / 1

−3 −2 −1 0 1 2 3
−10
010
2030
40
x^3 + 2 x^2 − 1
X
f(x)
●
●
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 44 / 1

−3 −2 −1 0 1 2 3
−10
010
2030
40
x^3 + 2 x^2 − 1
X
f(x)
●
●●
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 44 / 1

−3 −2 −1 0 1 2 3
−10
010
2030
40
x^3 + 2 x^2 − 1
X
f(x)
●
●●●
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 44 / 1

−3 −2 −1 0 1 2 3
−10
010
2030
40
x^3 + 2 x^2 − 1
X
f(x)
●
●●●●
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 44 / 1

−3 −2 −1 0 1 2 3
−10
010
2030
40
x^3 + 2 x^2 − 1
X
f(x)
●
●●●●●
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 44 / 1

To the R Code!
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 44 / 1

Today/Tomorrow
- A Framework for optimization
- Analytic: pencil and paper math- Computational: iterative algorithm that aids in solution
- Integration: antidifferentation/area finding
Justin Grimmer (Stanford University) Methodology I September 7th, 2016 45 / 1