Embed Size (px)
Citation preview

April 18, 2023Data Mining: Concepts and
Techniques 1
What is Data?
Collection of data objects and their attributes
An attribute is a property or characteristic of an object Examples: eye color of a
person, temperature, etc. Attribute is also known as
variable, field, characteristic, or feature
A collection of attributes describe an object Object is also known as
record, point, case, sample, entity, or instance
Tid Refund Marital Status
Taxable Income Cheat
1 Yes Single 125K No
2 No Married 100K No
3 No Single 70K No
4 Yes Married 120K No
5 No Divorced 95K Yes
6 No Married 60K No
7 Yes Divorced 220K No
8 No Single 85K Yes
9 No Married 75K No
10 No Single 90K Yes 10
Attributes
Objects

April 18, 2023Data Mining: Concepts and
Techniques 2
Transaction Data
Market-Basket transactions
TID Items
1 Bread, Milk
2 Bread, Diaper, Beer, Eggs
3 Milk, Diaper, Beer, Coke
4 Bread, Milk, Diaper, Beer
5 Bread, Milk, Diaper, Coke

April 18, 2023Data Mining: Concepts and
Techniques 3
Data Matrix
[ 1 4 5 6 2 3 3 4 2 2 1 1 ]

April 18, 2023Data Mining: Concepts and
Techniques 4
% 1. Title: Iris Plants Database % % 2. Sources: % (a) Creator: R.A. Fisher % (b) Donor: Michael Marshall (MARSHALL%[email protected]) % (c) Date: July, 1988 % @RELATION iris @ATTRIBUTE sepallength NUMERIC @ATTRIBUTE sepalwidth NUMERIC @ATTRIBUTE petallength NUMERIC @ATTRIBUTE petalwidth NUMERIC @ATTRIBUTE class {Iris-setosa,Iris-versicolor,Iris-virginica} The Data of the ARFF file looks like the following: @DATA 5.1,3.5,1.4,0.2,Iris-setosa 4.9,3.0,1.4,0.2,Iris-setosa 4.7,3.2,1.3,0.2,Iris-setosa

April 18, 2023Data Mining: Concepts and
Techniques 5
uci machine learning repository http://mlearn.ics.uci.edu/databases/

April 18, 2023Data Mining: Concepts and
Techniques 6
uci machine learning repository http://archive.ics.uci.edu/ml/datasets.html/

April 18, 2023Data Mining: Concepts and
Techniques 7
Attribute Values Attribute values are numbers or symbols assigned to
an attribute
Distinction between attributes and attribute values Same attribute can be mapped to different attribute values
Example: height can be measured in feet or meters
Different attributes can be mapped to the same set of values Example: Attribute values for ID and age are integers But properties of attribute values can be different
ID has no limit but age has a maximum and minimum value

April 18, 2023Data Mining: Concepts and
Techniques 8
Discrete and Continuous Attributes Discrete Attribute (Categorical Attribute)
Has only a finite or countably infinite set of values Examples: zip codes, counts, or the set of words in a collection of
documents Often represented as integer variables. Note: binary attributes are a special case of discrete attributes
Continuous Attribute (Numerical Attribute) Has real numbers as attribute values Examples: temperature, height, or weight. Practically, real values can only be measured and represented
using a finite number of digits. Continuous attributes are typically represented as floating-point
variables.

April 18, 2023Data Mining: Concepts and
Techniques 9
Discrete and Continuous Attributes

April 18, 2023Data Mining: Concepts and
Techniques 10
Chapter 3: Data Preprocessing
Why preprocess the data?
Data cleaning
Data integration and transformation
Data reduction
Discretization and concept hierarchy generation
Summary

April 18, 2023Data Mining: Concepts and
Techniques 11
Why Data Preprocessing?
Data in the real world is dirty incomplete: lacking attribute values, lacking
certain attributes of interest, or containing only aggregate data
noisy: containing errors or outliers inconsistent: containing discrepancies in codes or
names No quality data, no quality mining results!
Quality decisions must be based on quality data Data warehouse needs consistent integration of
quality data

April 18, 2023Data Mining: Concepts and
Techniques 12
Multi-Dimensional Measure of Data Quality
A well-accepted multidimensional view: Accuracy Completeness Consistency Timeliness Believability Value added Interpretability Accessibility
Broad categories: intrinsic, contextual, representational, and accessibility.

April 18, 2023Data Mining: Concepts and
Techniques 13
Major Tasks in Data Preprocessing
Data cleaning Fill in missing values, smooth noisy data, identify or remove
outliers, and resolve inconsistencies
Data integration Integration of multiple databases, data cubes, or files
Data transformation Normalization and aggregation
Data reduction Obtains reduced representation in volume but produces the same
or similar analytical results
Data discretization Part of data reduction but with particular importance, especially for
numerical data

April 18, 2023Data Mining: Concepts and
Techniques 14
Chapter 3: Data Preprocessing
Why preprocess the data?
Data cleaning
Data integration and transformation
Data reduction
Discretization and concept hierarchy generation
Summary

April 18, 2023Data Mining: Concepts and
Techniques 15
Data Cleaning
Data cleaning tasks
Fill in missing values
Identify outliers and smooth out noisy data
Correct inconsistent data

April 18, 2023Data Mining: Concepts and
Techniques 16
Missing Data
Data is not always available E.g., many tuples have no recorded value for several attributes,
such as customer income in sales data
Missing data may be due to equipment malfunction
inconsistent with other recorded data and thus deleted
data not entered due to misunderstanding
certain data may not be considered important at the time of
entry
not register history or changes of the data
Missing data may need to be inferred.

April 18, 2023Data Mining: Concepts and
Techniques 17
Imputing Values to Missing Data
In federated data, between 30%-70% of the data points will have at least one missing attribute - data wastage if we ignore all records with a missing value
Remaining data is seriously biased Lack of confidence in results Understanding pattern of missing data
unearths data integrity issues

April 18, 2023Data Mining: Concepts and
Techniques 18
How to Handle Missing Data?
Ignore the tuple: usually done when class label is missing
(assuming the tasks in classification—not effective when the
percentage of missing values per attribute varies considerably.
Fill in the missing value manually: tedious + infeasible?
Use a global constant to fill in the missing value: e.g., “unknown”, a
new class?!
Use the attribute mean to fill in the missing value
Use the attribute mean for all samples belonging to the same class
to fill in the missing value: smarter
Use the most probable value to fill in the missing value: inference-
based such as Bayesian formula or decision tree
April 18, 2023Data Mining: Concepts and
Techniques 19
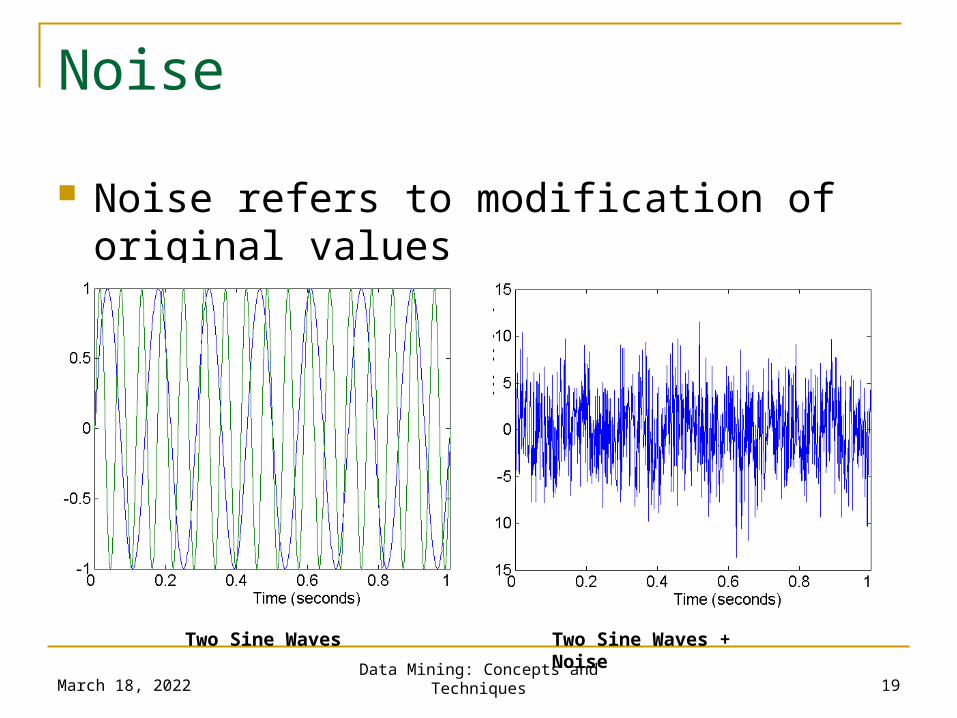
Noise
Noise refers to modification of original values Examples: distortion of a person’s voice when
talking on a poor phone and “snow” on television screen
Two Sine Waves Two Sine Waves + Noise

April 18, 2023Data Mining: Concepts and
Techniques 20
Outliers
Outliers are data objects with characteristics that are considerably different than most of the other data objects in the data set

April 18, 2023Data Mining: Concepts and
Techniques 21
Outliers
Outliers are data objects with characteristics that are considerably different than most of the other data objects in the data set

April 18, 2023Data Mining: Concepts and
Techniques 22
Noisy Data
Noise: random error or variance in a measured variable
Incorrect attribute values may due to faulty data collection instruments data entry problems data transmission problems technology limitation inconsistency in naming convention

April 18, 2023Data Mining: Concepts and
Techniques 23
How to Handle Noisy Data?
Binning method: first sort data and partition into (equi-depth) bins then one can smooth by bin means, smooth by bin
median, smooth by bin boundaries, etc. Clustering
detect and remove outliers Combined computer and human inspection
detect suspicious values and check by human Regression
smooth by fitting the data into regression functions

April 18, 2023Data Mining: Concepts and
Techniques 24
Binning Methods for Data Smoothing
* Sorted data for price (in dollars): 4, 8, 9, 15, 21, 21, 24, 25, 26, 28, 29, 34
* Partition into (equi-depth) bins: - Bin 1: 4, 8, 9, 15 - Bin 2: 21, 21, 24, 25 - Bin 3: 26, 28, 29, 34* Smoothing by bin means: - Bin 1: 9, 9, 9, 9 - Bin 2: 23, 23, 23, 23 - Bin 3: 29, 29, 29, 29* Smoothing by bin boundaries: - Bin 1: 4, 4, 4, 15 - Bin 2: 21, 21, 25, 25 - Bin 3: 26, 26, 26, 34

April 18, 2023Data Mining: Concepts and
Techniques 25
Simple Discretization Methods: Binning
Equal-width (distance) partitioning: It divides the range into N intervals of equal size: uniform
grid if A and B are the lowest and highest values of the
attribute, the width of intervals will be: W = (B-A)/N. The most straightforward But outliers may dominate presentation Skewed data is not handled well.
Equal-depth (frequency) partitioning: It divides the range into N intervals, each containing
approximately same number of samples Good data scaling Managing categorical attributes can be tricky.

April 18, 2023Data Mining: Concepts and
Techniques 26
Cluster Analysis

April 18, 2023Data Mining: Concepts and
Techniques 27
Regression
x
y
y = x + 1
X1
Y1
Y1’

April 18, 2023Data Mining: Concepts and
Techniques 28
Chapter 3: Data Preprocessing
Why preprocess the data?
Data cleaning
Data integration and transformation
Data reduction
Discretization and concept hierarchy generation
Summary

April 18, 2023Data Mining: Concepts and
Techniques 29
Data Integration
Data integration: combines data from multiple sources into a coherent store
Schema integration integrate metadata from different sources Entity identification problem: identify real world entities from
multiple data sources, e.g., A.cust-id B.cust-# Detecting and resolving data value conflicts
for the same real world entity, attribute values from different sources are different
possible reasons: different representations, different scales, e.g., metric vs. British units

April 18, 2023Data Mining: Concepts and
Techniques 30
Handling Redundant Data in Data Integration Redundant data occur often when integration of
multiple databases The same attribute may have different names in different
databases One attribute may be a “derived” attribute in another table,
e.g., annual revenue
Redundant data may be able to be detected by correlational analysis
Careful integration of the data from multiple sources may help reduce/avoid redundancies and inconsistencies and improve mining speed and quality

April 18, 2023Data Mining: Concepts and
Techniques 31
Data Transformation
Smoothing: remove noise from data Aggregation: summarization, data cube construction Generalization: concept hierarchy climbing Normalization: scaled to fall within a small, specified
range min-max normalization z-score normalization normalization by decimal scaling
Attribute/feature construction New attributes constructed from the given ones

April 18, 2023Data Mining: Concepts and
Techniques 32
Data Transformation: Normalization min-max normalization
z-score normalization
normalization by decimal scaling
AAA
AA
A
minnewminnewmaxnewminmax
minvv _)__('
A
A
devstand
meanvv
_'
j
vv
10' Where j is the smallest integer such that Max(| |)<1'v

April 18, 2023Data Mining: Concepts and
Techniques 33
Chapter 3: Data Preprocessing
Why preprocess the data?
Data cleaning
Data integration and transformation
Data reduction
Discretization and concept hierarchy generation
Summary

April 18, 2023Data Mining: Concepts and
Techniques 34
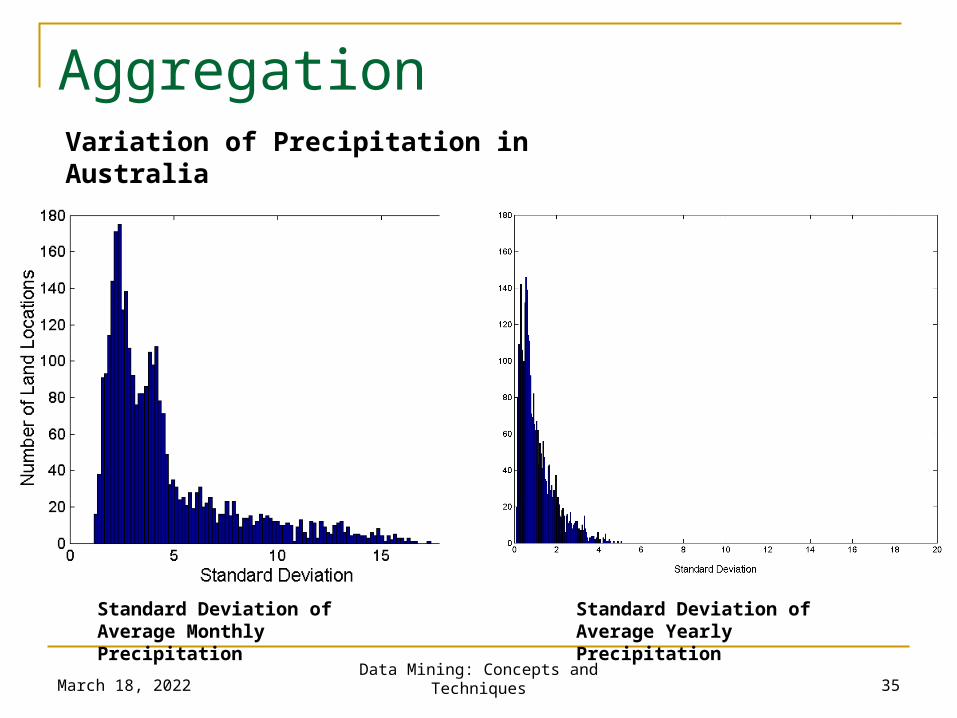
Aggregation
Combining two or more attributes (or objects) into a single attribute (or object)
Purpose Data reduction
Reduce the number of attributes or objects Change of scale
Cities aggregated into regions, states, countries, etc More “stable” data
Aggregated data tends to have less variability
April 18, 2023Data Mining: Concepts and
Techniques 35
Aggregation
Standard Deviation of Average Monthly Precipitation
Standard Deviation of Average Yearly Precipitation
Variation of Precipitation in Australia

April 18, 2023Data Mining: Concepts and
Techniques 36
Sampling Sampling is the main technique employed for data
selection. It is often used for both the preliminary investigation of the
data and the final data analysis.
Statisticians sample because obtaining the entire set of
data of interest is too expensive or time consuming.
Sampling is used in data mining because processing the
entire set of data of interest is too expensive or time consuming.

April 18, 2023Data Mining: Concepts and
Techniques 37
Sampling …
The key principle for effective sampling is the following: using a sample will work almost as well as using
the entire data sets, if the sample is representative
A sample is representative if it has approximately the same property (of interest) as the original set of data

April 18, 2023Data Mining: Concepts and
Techniques 38
Types of Sampling
Simple Random Sampling There is an equal probability of selecting any particular item
Sampling without replacement As each item is selected, it is removed from the population
Sampling with replacement Objects are not removed from the population as they are selected for
the sample. In sampling with replacement, the same object can be picked up more
than once
Stratified sampling Split the data into several partitions; then draw random samples from
each partition

April 18, 2023Data Mining: Concepts and
Techniques 39
Sample Size
8000 points 2000 Points 500 Points

April 18, 2023Data Mining: Concepts and
Techniques 40
Sampling
Raw Data Cluster/Stratified Sample

April 18, 2023Data Mining: Concepts and
Techniques 41
Curse of Dimensionality
When dimensionality increases, data becomes increasingly sparse in the space that it occupies
Definitions of density and distance between points, which is critical for clustering and outlier detection, become less meaningful
• Randomly generate 500 points
• Compute difference between max and min distance between any pair of points

April 18, 2023Data Mining: Concepts and
Techniques 42
Dimensionality Reduction
Purpose: Avoid curse of dimensionality Reduce amount of time and memory required by data
mining algorithms Allow data to be more easily visualized May help to eliminate irrelevant features or reduce
noise
Techniques Principle Component Analysis Singular Value Decomposition Others: supervised and non-linear techniques

April 18, 2023Data Mining: Concepts and
Techniques 43
Feature Subset Selection
Another way to reduce dimensionality of data
Redundant features duplicate much or all of the information contained in one or
more other attributes Example: purchase price of a product and the amount of
sales tax paid
Irrelevant features contain no information that is useful for the data mining
task at hand Example: students' ID is often irrelevant to the task of
predicting students' GPA

April 18, 2023Data Mining: Concepts and
Techniques 44
Feature Creation
Create new attributes that can capture the important information in a data set much more efficiently than the original attributes
Three general methodologies: Feature Extraction
domain-specific Mapping Data to New Space Feature Construction
combining features

April 18, 2023Data Mining: Concepts and
Techniques 45
Clustering
Partition data set into clusters, and one can store
cluster representation only
Can be very effective if data is clustered but not if
data is “smeared”
Can have hierarchical clustering and be stored in
multi-dimensional index tree structures
There are many choices of clustering definitions and
clustering algorithms, further detailed in Chapter 8

April 18, 2023Data Mining: Concepts and
Techniques 46
Chapter 3: Data Preprocessing
Why preprocess the data?
Data cleaning
Data integration and transformation
Data reduction
Discretization and concept hierarchy generation
Summary

April 18, 2023Data Mining: Concepts and
Techniques 47
Discretization
Three types of attributes: Nominal — values from an unordered set Ordinal — values from an ordered set Continuous — real numbers
Discretization: divide the range of a continuous attribute into intervals Some classification algorithms only accept categorical
attributes. Reduce data size by discretization Prepare for further analysis

April 18, 2023Data Mining: Concepts and
Techniques 48
Discretization and Concept hierachy
Discretization reduce the number of values for a given continuous
attribute by dividing the range of the attribute into intervals. Interval labels can then be used to replace actual data values.
Concept hierarchies reduce the data by collecting and replacing low level
concepts (such as numeric values for the attribute age) by higher level concepts (such as young, middle-aged, or senior).

April 18, 2023Data Mining: Concepts and
Techniques 49
Concept hierarchy generation for categorical data Specification of a partial ordering of attributes
explicitly at the schema level by users or experts
Specification of a portion of a hierarchy by explicit
data grouping
Specification of a set of attributes, but not of their
partial ordering
Specification of only a partial set of attributes

April 18, 2023Data Mining: Concepts and
Techniques 50
Specification of a set of attributes
Concept hierarchy can be automatically generated based on the number of distinct values per attribute in the given attribute set. The attribute with the most distinct values is placed at the lowest level of the hierarchy.
country
province_or_ state
city
street
15 distinct values
65 distinct values
3567 distinct values
674,339 distinct values





















![[MS-PAC]: Privilege Attribute Certificate Data Structure](https://img.pdfslide.us/doc/110x75/620edbadd251ab18242d6ead/ms-pac-privilege-attribute-certificate-data-structure.jpg)







