Embed Size (px)
Citation preview

June 16, 2011 0:33 WSPC/INSTRUCTION FILE xttform-ijait
International Journal on Arti�cial Intelligence Toolsc© World Scienti�c Publishing Company
FORMALIZATION AND MODELING OF RULES
USING THE XTT2 METHOD∗
Grzegorz J. Nalepa
Antoni Lig¦za
Krzysztof Kaczor
AGH University of Science and Technology
al. A. Mickiewicza 30, 30-059 Krakow, Poland
[email protected], [email protected], [email protected]
Received (Day Month Year)Revised (Day Month Year)Accepted (Day Month Year)
The paper discusses a new knowledge representation for rule-based systems called XTT2.It combines decision trees and decision tables forming a transparent and hierarchicalvisual representation of the decision units linked into a work�ow-like structure. Thereare two levels of abstraction in the XTT2 model: the lower level, where a single knowledgecomponent de�ned by a set of rules working in the same context is represented by a singledecision table, and the higher level, where the structure of the whole knowledge base isconsidered. This model has a concise formalization which opens up possibility of well-de�ned, structured design and veri�cation of formal characteristics. Based on the visualXTT2 model, a textual representation of the rule base is generated. A dedicated engineprovides a uni�ed run-time environment for the XTT2 rule bases. The focus of the paperis on the formalization of the presented approach. It is based on the so-called ALSV(FD)logic that provides an expressive calculus for rules.
Keywords: rules; rule-based systems; knowledge-representation; inference engine.
1. Introduction
Rule-based systems still constitute one of the most powerful and most popular
knowledge representation formalisms 7,5 for intelligent systems 26,25. Formalization
of knowledge within a rule-based system can be based on logic 8 or performed
on the basis of engineering intuition, constituting a kind of superstructure with a
programming language such as Lisp or Java in the background. Modern rule-based
shells, including CLIPS, Jess, Drools, Aion, Ilog Rules, or G2 of Gensym, follow the
latter, classical paradigm, where the rule language is a programming solution, with
no formal de�nition. For example, CLIPS and Jess follow the Lisp syntax, while
Drools, build upon Java o�ers more user-friendly knowledge encoding.
∗The paper is supported by the PARNAS Project funded from NCN (National Science Center)resources for science.
1

June 16, 2011 0:33 WSPC/INSTRUCTION FILE xttform-ijait
2 Grzegorz J. Nalepa, Antoni Lig¦za, Krzysztof Kaczor
On the other hand, development of a strict, logical rule representation language
from scratch seems to o�er indisputable chance with respect to formal design and
evaluation. The main objectives for introducing a logic-based formalization of the
rule language are as follows:
• providing a clear framework enabling uniform knowledge modeling with
well-de�ned expressive power,
• speeding up the design process � logic-based rule language opens possibility
to partially formalize the design process which can in turn lead to better
detection of design errors, possibly at early development stages,
• allowing for a superior knowledge base quality control � formal methods
can be used to identify logical errors in rule formulation,
• simplifying knowledge translation � partially formalized translation to other
knowledge representation formats are possible, and
• proposing custom inference modes � structured rule bases require inference
strategies alternative to the classical inference algorithms.
In fact, well-formalized knowledge bases are easier to design, develop and verify;
the ultimate goal is to enable e�cient Knowledge Management, in a way analogous
to data management in Database Management Systems.
The rule representation discussed in this paper is called XTT2 (eXtended Tab-
ular Trees) 17,20. This hybrid knowledge representation combines decision trees and
decision tables. It forms a transparent and hierarchical visual representation of
the decision tables linked into a decision network structure. The name XTT2 was
kept to provide compatibility with previous works.
There are two levels of abstraction in the XTT2 model: the lower level � where
a single knowledge component de�ned by a set of rules working in the same context
is represented as a single XTT2 table, and the higher level � where the structure
of the whole XTT2 knowledge base (consisting of XTT2 tables) is considered. Such
knowledge representation provides not only high density of knowledge visualization,
but assures transparency and readability.
Contrary to majority of other systems, where a basic knowledge item is a single
rule, in the XTT2 formalism the basic component displayed, edited and managed
at a time is an extended decision table. Such table is logically equivalent to a set of
rules. Due to the fact that the XTT2 model represents rules using the ALSV(FD)
(Attributive Logic with Set of Values over Finite Domains) logic 20, it is much more
expressive than the classic (mostly propositional) rule languages, e.g. it allows for
formal speci�cation of non-atomic values in rule conditions.
The approach discussed in this paper is based on certain concepts related to
dynamic system modeling. The primary assumption is that the rule-based model is
a model of a dynamic system having certain internal state. The state is described
using attributes, that refer to certain crucial properties of the system. The state is
represented by the set of current attribute values. A statement that an attribute
has a given value can be interpreted as a fact in terms of classic expert systems.

June 16, 2011 0:33 WSPC/INSTRUCTION FILE xttform-ijait
Formalization and Modeling of Rules Using the XTT2 Method 3
The dynamics of the system � transitions between states � is modeled using rules.
Rules are described using the ALSV(FD) logic. The conditional part of the rule is
a conjunction of atomic formulae in the ALSV(FD) logic which are the attribute-
relation-value triples. The decision part of the rule includes statements that modify
system state in case the rule is �red (the proper decision) and actions that do not
change attribute values, thus the state.
The paper is organized as follows: In the following section an introduction to
the ALSV(FD) is given. Then, in Sect. 3 a proposal of the formalization of the
approach is introduced. General concepts of the inference control are then presented
in Sect. 4. A description of a prototype implementation follows in Sect. 5. Then a
short discussion of the related works and evaluation is presented in Sect. 6. The
paper ends with concluding remarks.
The results presented in this paper follow the research line described in 20,9.
This paper is partially based on the recent developments presented in detail in 14.
2. Overview of the ALSV(FD) Logic
In 8 a thorough discussion of attributive logics and their application in rule-based
systems was given. It includes a formal framework of SAL (Set Attributive Logic)
that provides syntax, semantics and some notes on inference rules for a logical
calculus in which attributes can take set values.
Here, an improved and extended version of SAL, namely ALSV(FD) (Attribu-
tive Logic with Set Values over Finite Domains) 18,19,20 is considered. It is ori-
ented towards Finite Domains (FD) and its expressive power is increased through
the introduction of new relational symbols enabling de�nitions of atomic formulae.
Moreover, ALSV(FD) introduces a formal speci�cation of the partitioning of the
attribute set needed for practical implementation, and a more coherent notation.
Simple and Generalized Attributes Let A denote the set of all attributes
used to describe the system. Each attribute has a set of admissible values that
it takes (a domain). Let D denote the set of all possible attribute values; D =
D1 ∪ D2 ∪ · · · ∪ Dn where Di is the domain of attribute Ai ∈ A, i = 1 . . . n. Any
domain Di is assumed to be a �nite. In the general case, the domain can be ordered,
partially ordered or unordered (this depends on the speci�cation of an attribute,
see Sect. 5).
In ALSV(FD) two types of attributes are identi�ed: simple ones taking only one
value at a time, and generalized ones taking multiple values. Therefore, we introduce
the following partitioning of the set of all attributes: A = As ∪ Ag, As ∩ Ag = ∅where: As is the set of simple attributes, and Ag is the set of generalized attributes.
A simple attribute Ai is a function (or a partial function) of the form:
Ai : O→ Di (1)
where: O is a set of objects, Di is the domain of attribute Ai.

June 16, 2011 0:33 WSPC/INSTRUCTION FILE xttform-ijait
4 Grzegorz J. Nalepa, Antoni Lig¦za, Krzysztof Kaczor
The de�nition of generalized attribute is as follows:
Ai : O→ 2Di (2)
where: O is a set of objects, 2Di is the set of all possible subsets of the domain Di.
Attribute Ai denotes a property of an object. The formula Ai(o), where o ∈ O,denotes the value of property Ai of object o.
For simplicity, in the rest of the paper no objects are speci�ed in an explicit way.
It is assumed that only one object (in this case it is the system being described) with
a speci�c property name exists. This is why, the following notational convention is
used: the formula Ai = V simply denotes a value (V ) of the attribute Ai.
Consider the following example of a system recommending books to di�erent
groups of people depending on their age and reading preferences. The age of a
reader and his/her preference could be represented by the following attributes: A =
{fav_genres, age, age_filter, rec_book}. In this case we assume that the second
attribute is a simple one, whereas the others are generalized ones. The fourth one
contains book titles that can be recommended to a reader. The attributes have the
following domains: D = Dfav_genres ∪ Dage ∪ Dage_filter ∪ Drec_book, where:
• Dfav_genres = {horror, handbook, fantasy, science, historical, poetry},• Dage = {1 . . . 99},• Dage_filter = {youngHorrors, youngPoetry, adultHorrors, adultPoetry},• Drec_book = { 'It', 'Logical Foundations for RBS', 'The Call of Cthulhu'}.
The system that is described using the attributes is in a certain state. The state
of the system is described by the values of attributes.
State Representation The current values of all attributes are speci�ed within
the contents of the knowledge base. From logical point of view the state of the
system is represented as a logical formula of the form:
s : (A1 = S1) ∧ (A2 = S2) ∧ . . . ∧ (An = Sn) (3)
where Ai are the attributes and Si are their current values. Note that Si ∈ Di for
simple attributes and Si ⊆ Di for generalized ones.
An explicit notation for covering unspeci�ed, unknown values is proposed: Ai =
null means that the value of Ai is unspeci�ed.
Following the example, a state can be de�ned as: (age = 16) ∧ (fav_genres =
{horror, fantasy}). This means that a given person is 16 years old and she or he
likes reading horror and fantasy books. In fact, it is a partial state where only the
values of the input attributes are de�ned. In this example, it will be su�cient to
start the inference process. To specify the full state, the values of the remaining
attributes should be de�ned as null .
Attribute Classes Considering the practical implementation of the commu-
nication architecture, where several attribute classes are identi�ed, the following
partitioning of the set of attributes is introduced:

June 16, 2011 0:33 WSPC/INSTRUCTION FILE xttform-ijait
Formalization and Modeling of Rules Using the XTT2 Method 5
As = Asin ∪ As
int ∪ Asout ∪ As
io (4)
Ag = Agin ∪ Ag
int ∪ Agout ∪ Ag
io (5)
where all these sets are pairwise disjoint:
• Asin,A
gin are the sets of input attributes,
• Asint,A
gint are the sets of internal attributes,
• Asout,A
gout are the sets of output attributes, and
• Asio,A
gio are the sets of attributes that can be simultaneously input and
output (communication attributes).
These attribute classes (i.e. input, internal, output, and communication) are used in
the rule speci�cation to support the interaction of the system with its environment.
They are handled by dedicated callbacks. Callbacks are procedures providing means
for reading and writing attribute values (see Sect. 5).
In the example, both fav_genres and age attributes are input ones, age_filter
is an internal one, and rec_book is an output one.
Atomic Formulae Syntax Let Ai be an attribute from A, and Di the domain
related to it. Let Vi denote an arbitrary subset of Di and let di ∈ Di be a single
element of the domain. The legal atomic formulae of ALSV(FD) along with their
semantics are presented, for simple and general attributes respectively.
If Vi is an empty set (the attribute takes no value), we shall write Ai = ∅. Inthe case when the value of Ai is unspeci�ed, we shall write Ai = null . If the current
attribute value is of no importance, we shall write A = any.
More complex formulae can be constructed with conjunction (∧) and disjunction(∨); both of these have classical meaning and interpretation. For enabling e�cient
veri�cation, there is no explicit use of negation in the formulae. The proposed set
of relations is selected for convenience and they are not completely independent.
The meaning of these formulae is as follows:
• Ai = di � the value of Ai is precisely de�ned as di,
• Ai ∈ Vi � the current value of Ai belongs to Vi,
• Ai 6= di � shorthand for Ai ∈ Di \ {di},• Ai 6∈ Vi � shorthand for Ai ∈ Di \ Vi,• Ai = Vi � Ai equals to Vi (and nothing more),
• Ai 6= Vi � Ai is di�erent from Vi (at least at one element),
• Ai ⊆ Vi � Ai is a subset of Vi,
• Ai ⊇ Vi � Ai is a superset of Vi,
• Ai ∼ Vi � Ai has a non-empty intersection with Vi.
Formulae Semantics The semantics of the atomic formulae is as follows:
• If Vi = {d1, d2, . . . , dk}, then Ai = Vi means that the attribute takes as its
value the set of all the values speci�ed with Vi (and nothing more).

June 16, 2011 0:33 WSPC/INSTRUCTION FILE xttform-ijait
6 Grzegorz J. Nalepa, Antoni Lig¦za, Krzysztof Kaczor
• (Ai ⊆ Vi) ≡ (Ai = Ui) for some Ui such that Ui ⊆ Vi, i.e. Ai takes some of
the values from Vi (and nothing out of Vi),
• (Ai ⊇ Vi) ≡ (Ai = W ), for some W such that Vi ⊆ W , i.e. Ai takes all of
the values from Vi (and perhaps some out of Vi), and
• (Ai ∼ Vi) ≡ (Ai = Xi), for some Xi such that Vi ∩ Xi 6= ∅, i.e. Ai takes
some of the values from Vi (and perhaps some out of Vi).
In the example, the following atomic formulae could be present: age ∈{1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17}, which could also be denoted as
age < 18 and fav_genres ⊆ {science, fantasy, horror}. The interpretation of the
second one is: the person likes a subset of science, fantasy, horror books.
ALSV(FD) was introduced with practical applications for rule languages in
mind. In fact, the primary aim of the presented language is to formalize and extend
the notational possibilities and expressive power of rule languages for modularized
Rule-Based Systems (RBS). The atomic formulae of ALSV(FD) correspond to
simple statements (facts) about attribute values. These formulae are then used to
express certain conditions or constraints. Using this formalism, a complete solution
that allows for building decision rules is discussed in the following section.
3. Formalization of Modularized Rule Bases
The rule formalism considered here is called XTT2. It provides a formalized rule
speci�cation, based on some preliminary results presented in 10,17. This section
starts from single rule formulation using the ALSV(FD) concepts. Then provides
de�nitions for grouping similar rules into decision components (tables) linked into
an inference network. A number of structural de�nitions is given; their goal is to
formalize the structure of the knowledge base. Moreover, they are used to organize
the process of the design and possible translation of the knowledge base.
Conclusion and Decision Let us consider the following convention where two
identi�ers are used to denote attributes as well as operators in rule parts: cond
corresponds to the conditional part of a rule, and dec corresponds to the decision
part. Using it, two subsets of the attribute set can be identi�ed. Acond is a subset
of attribute set A that contains attributes present in the conditional part of a rule.
Adec is a subset of attribute set A containing attributes in the decision part.
Relational Operators in Rules Considering the syntax of the legal
ALSV(FD) formulae, the legal use of the relational operators in rules is speci-
�ed. With respect to the previously identi�ed attribute classes, not every operator
can be used with any attribute or in any rule part. Hence, the set of all operators
is divided into smaller subsets that contain all the operators, which can be used at
the same time.
The set of all relational operators that can be used in rules is de�ned as follows:
F = Fcond ∪ Fdec where:
• Fcond is a set of all operators that can be used in the conditional part of a

June 16, 2011 0:33 WSPC/INSTRUCTION FILE xttform-ijait
Formalization and Modeling of Rules Using the XTT2 Method 7
rule Fcond = Fconda ∪ Fcond
s ∪ Fcondg where:
� Fconda contains operators, that can be used in the rule conditional part
with all attributes. The set is de�ned as: Fconda = {=, 6=}.
� Fconds is the set that contains the operators, which can be used in a rule
conditional part with simple attributes. The set is de�ned as: Fconds =
{∈, /∈}. ALSV(FD) also allows for using the following operators <,>,≤,≥ which provide only a variation for ∈ operator. These operators
can be used only with attributes whose domains are ordered sets.
• Fcondg contains operators that can also be used in the rule conditional part
with generalized attributes. The set is de�ned as: Fcondg = {⊆,⊇,∼, 6∼}.
• Fdec is a set of all operators that can be used in a rule decision part Fdec =
{:=}. The operator := allows for assigning a new value to an attribute.
Moreover, to specify in the rule condition that the value of the attribute is to be
null (unknown) or any (unimportant) the operator = is used. To specify in the
same rule part that the value of the attribute is not null the operator 6= is used.
ALSV(FD) Triples Let us consider the E set that contains all the triples that
are legal atomic formulae in ALSV(FD). The triples are built using the previously
de�ned relational operators:
E ={(Ai,∝, di), Ai ∈ As,∝∈ F \ Fcondg , di ∈ Di} ∪ (6)
{(Ai,∝, Vi), Ai ∈ Ag,∝∈ F \ Fconds , Vi ∈ 2Di}
The ALSV(FD) triples are the basic components of rules.
XTT2 Rule Let us consider the set of all rules de�ned in the knowledge base
denoted as R. A single XTT2 rule is a triple: r = (COND,DEC,ACT), where:COND ⊆ E, DEC ⊆ E, and ACT is a set of actions to be executed when a rule is
�red. A rule can be written using LHS (Left Hand Side) and RHS (Right Hand
Side): LHS(r) → RHS(r),DO(ACT) where LHS(r) and RHS(r) correspond re-
spectively to the condition and decision parts of the rule r, and DO(ACT) involvesexecuting actions from a prede�ned set. Actions are not included in the RHS of the
rule, because it is assumed that they are independent from the considered system,
and the execution of actions does not change the state of the system.
A rule can also be presented in the following form: r : [φ1 ∧ φ2 ∧ · · · ∧ φn] →[θ1 ∧ θ2 ∧ · · · ∧ θm],DO(ACT) where: {1, . . . , n} and {1, . . . ,m} are the sets of
identi�ers, n ∈ N, m ∈ N, φ1, . . . , φn ∈ COND, θ1, . . . , θm ∈ DEC.From a logical point of view, the order of the atomic formulae in both the
precondition and conclusion parts is unimportant. In general, rules with empty
decisions can also be considered. They are helpful to take better control of the
inference process. A rule with no conditions can be used to set the attribute value.
In fact, such rules are used in real-life XTT2 systems to �ll the knowledge base
with facts or import sets of values.

June 16, 2011 0:33 WSPC/INSTRUCTION FILE xttform-ijait
8 Grzegorz J. Nalepa, Antoni Lig¦za, Krzysztof Kaczor
Consider example of the following rules:
r1 : [age < 18 ∧ fav_genres ⊇ {horror}] −→ [age_filter := youngHorrors]
r2 : [age = _ ∧ fav_genres ⊆ {science}] −→ [age_filter := allScience]
r3 : [age_filter ∈ {youngHorrors, adultHorrors}] −→ [rec_book := 'It']
Now, having the previously de�ned state: (age = 16) ∧ (fav_genres =
{horror, fantasy}), it can be observed, that rules r1 and r3 could be �red. The
notion of rule �ring is explained next.
Having the structure of a single rule de�ned, the structure of the complete
knowledge base is introduced. The knowledge base is composed of tables grouping
rules having the same attributes lists (rule schemas).
Rule Schema Now let us introduce a concept of a rule schema. It can be de�ned
as follows. Consider a rule r = (COND,DEC,ACT). Then the rule schema h(r) is
de�ned as h(r) = (trunc(COND), trunc(DEC)) where: the function trunc extracts
from a set of atomic formulae a set of attributes that are used in these triples.
Therefore, each rule has a schema that is a pair of attributes sets: h = (Hcond, Hdec)
where Hcond and Hdec sets de�ne the attributes occurring in the conditional and
decision part of the rule. ThereforeHcond = trunc(COND) andHdec = trunc(DEC).A schema is used to identify rules working in the same operational context.
Such a set of rules can form a decision component in the form of a decision table.
A schema can also be considered a table header.
Decision Component (Table) Let us consider a decision component (or ta-
ble). It is an ordered set (sequence) of rules having the same rule schema, de�ned as
follows: t = (r1, r2, . . . , rn) such that ∀i,j : ri, rj ∈ t → h(ri) = h(rj) where h(ri) is
the schema of the rule ri. In XTT2 the rule schema h can also be called the schema
of the component (or table). Note that all the rules incorporated in the same table
must have the same schema. Considering the rule schema notation, a table schema
h(t) can be de�ned as h(t) = h(r), which holds for any rule r in table t .
Consider the following illustration given in Figure 1. On the left table t1 is
represented. It is an example of a table having three rules: r1, r2, r3. These rules
have the same schema h1 = ({A1, A2, A3}, {A4, A5}). This means that the respectiveALSV(FD) triples contain given attribute e.g. a triple e2,3 is a part of rule r2 and
it contains the attribute A3. To simplify the visual representation a convention is
introduced, where the schema of a table is depicted on the top of the table.
Inference Link An inference link l is an ordered pair: l = (r, t), l ∈ R×T, whereR is the set of rules in the knowledge base, and T is the set of tables. Components
(tables) are connected (linked) in order to provide inference control. A single link
connects a single rule (a row in a table) with another table. A structure composed
of linked decision components is called a XTT2 knowledge base.
XTT2 Knowledge Base The XTT2 knowledge base is the set of components
connected with links. It can be de�ned as an ordered pair: X = (T,L), where T is
a set of components (tables), L is a set of links, and all the links from L connect
rules from R with tables from T. Links are introduced during the design process
according to the speci�cation provided by the designer. The knowledge base can be

June 16, 2011 0:33 WSPC/INSTRUCTION FILE xttform-ijait
Formalization and Modeling of Rules Using the XTT2 Method 9
perceived as an inference network.
An example of a simple XTT2 knowledge base is presented in Figure 1. It is
composed of three tables X1 = ({t1, t2, t3} and two links {l1, l2}). In the �rst table
(t1) the table schema is indicated in an explicit way. In this table also the conditional
and decision parts are presented explicitly (action-related part is optional).
There are nine rules, three in each of the tables. Rules in a table are �red starting
from the �rst one. The order in which tables are �red depends on a speci�c inference
mode (see Sect. 4). In the simple forward chaining (data-driven) mode, the inference
process would be as follows: If rule r1 from the table t1 is �red the inference control
would be passed to table t2 through link l1, otherwise �re rule r2. If rule r2 is �red
then proceed to rule r3. If rule r3 is �red the inference control is passed to table t3through link l2. If it is not �red then the inference process stops.
DEC
Schema
Links
1 2 3 4 5
4
5
6 7 8 9
8 91 110t
t
t
r
r
r
r
r
r
r
r
r
1
2
2
3
1
3
4
5
6
7
8
9
l
l2
1
A AAAA
A AAAA
A AAAA
e e e e e
eeeee
e e e e e
1 1 1 1 1
2 2 2 2 2
3 3 3 3 3
2
2
2
1
1
1
3
3
4
4
4 5
5
53
h 1
COND
Fig. 1. An example of an XTT2 knowledge base
Let us observe that a number of speci�c structures of knowledge bases could
be considered including decision trees. In such a decision tree-like structure nodes
would consist of single decision components. So, the XTT2 knowledge base can be
seen as a generalization of classic decision trees and tables.
This section provides a logic-based formalism for decision rules. The formalism
allows for building a modularized knowledge base. Such a solution is superior to
the one found in the classic rule-based shells. The XTT2 knowledge base is highly
modularized and hence XTT2 tables are not only a mechanism for managing large
knowledge bases, but they also allow for context-aware reasoning. It is due to the
fact that each XTT2 table groups rules that belong to the same operational context

June 16, 2011 0:33 WSPC/INSTRUCTION FILE xttform-ijait
10 Grzegorz J. Nalepa, Antoni Lig¦za, Krzysztof Kaczor
(have similar LHS and RHS). In practice, building such a modularized knowledge
base is not a straightforward task.
Practical inference in such a system cannot use the classic inference algorithms 1.
This is why custom inference modes are introduced.
4. Inference Control in Structured Rule Bases
Because of the non-trivial structure of the XTT2 knowledge base, custom inference
modes need to be formulated. They have been presented in this section. They should
be perceived as prototype solutions with di�erent optimized implementations pos-
sible. For a more formalized description see 15. Moreover, the development of other
modes is considered as the future work.
Any XTT2 table can have input links (inputs), as well as output links (outputs).
Links are related to the possible inference order. Tables to which no connections
point are referred to as input tables. Tables with no connections pointing to other
tables are called output tables. All the other tables (ones having both input and
output links) are considered middle tables.
The �rst most basic algorithm consists of a hard-coded order of inference. Every
table is assigned a unique integer number. The tables are �red in order from the
lowest number to the highest one. After starting the inference process, the prede-
�ned order of inference is followed. The inference stops after �ring the last table.
In case a table contains a complete set of rules (w.r.t. possible outputs generated
by preceding tables) the inference process should end with all the attribute values
de�ned by all the output tables being produced. This approach is suitable for rel-
atively small knowledge bases, where the manual analysis is possible but also for
quite large systems, provided that a speci�cation of inference process is available;
the latter is the case well-de�ned service procedures or formalized knowledge pro-
cessing in organizations such as insurance companies, telecom companies, banks,
etc. Therefore, more complex modes are considered, including DDI (Data-Driven
Inference), TDI (Token-Driven Inference), and GDI (Goal-Driven Inference). The
preliminary formalization was introduced in 15.
The Data-Driven Inference algorithm identi�es start tables, and puts all the
tables that are linked to the initial ones in the XTT2 network into a FIFO queue.
When there are no more tables to be added to the queue, the algorithm �res selected
tables in the order they are popped from the queue. The forward-chaining strategy
is suitable for simple tree-like inference structures. However, it has limitations in a
general case, because it cannot determine tables having multiple dependants.
Token-Driven Inference approach is based on monitoring the partial inference
order de�ned by the network structure with tokens assigned to tables. A table can
be �red only when there is a token at each input. Intuitively, a token is a �ag,
signalling that the necessary data generated by the preceding table is ready for use.
Note that this model of inference execution covers the case of possible loops in the
network. For example, if there is a loop and a table should be �red several times,

June 16, 2011 0:33 WSPC/INSTRUCTION FILE xttform-ijait
Formalization and Modeling of Rules Using the XTT2 Method 11
the token is passed from its output to its input, and it is analyzed if can be �red; if
so, it is placed in the queue.
The goal-driven approach works backwards with respect to selecting the tables
necessary for a speci�c task, and then �res the tables forward so as to achieve the
goal. The previous models of inference control can be considered blind procedures
because they do not take into consideration the goal of inference. Hence, it may
happen that numerous tables are �red without purpose � the results they produce
are of no interest. This, in fact, is a de�ciency of most of the forward-chaining rule-
based inference control strategies. In the goal-driven approach, one or more output
tables are identi�ed as the ones that can generate the desired goal values and are
put on a stack. As a consequence, only the tables that lead to the desired solution
are �red, and no rules are �red without purpose. The Goal-Driven Inference may be
particularly suitable for situations where the context of the operation can be clearly
de�ned and it is possible to clearly identify the knowledge component that needs
to be evaluated.
It can be observed that having the same rule base de�ned, a number of inference
scenarios can be applied. Their use depends on the given application and expected
results. The XTT2 representation does not enforce any single interpretation of the
rule sets (the only assumption is, that rules in a table are �red sequentially). Such
an approach allows for the reuse of the same logical model in several applications.
In Figure 2 selected aspects of the operation of the inference modes are visualized.
The concept of the XTT2 formalism has been implemented in the HeKatE
(see http://hekate.ia.agh.edu.pl) (Hybrid Knowledge Engineering) project, as
described in the following section.
5. XTT2 Implementation
For practical design and implementation of rules the XTT2 method includes two
representations: textual suitable for processing by a rule engine, and visual aimed
at a design tool. The textual representation of XTT2 is called HMR (HeKatE Meta
Representation). HMR allows for textual de�nition of all the XTT2 concepts (at-
tributes, tables, rules, links, etc). The important advantage of this representation
is the fact that it can be easily read and automatically processed by an inference
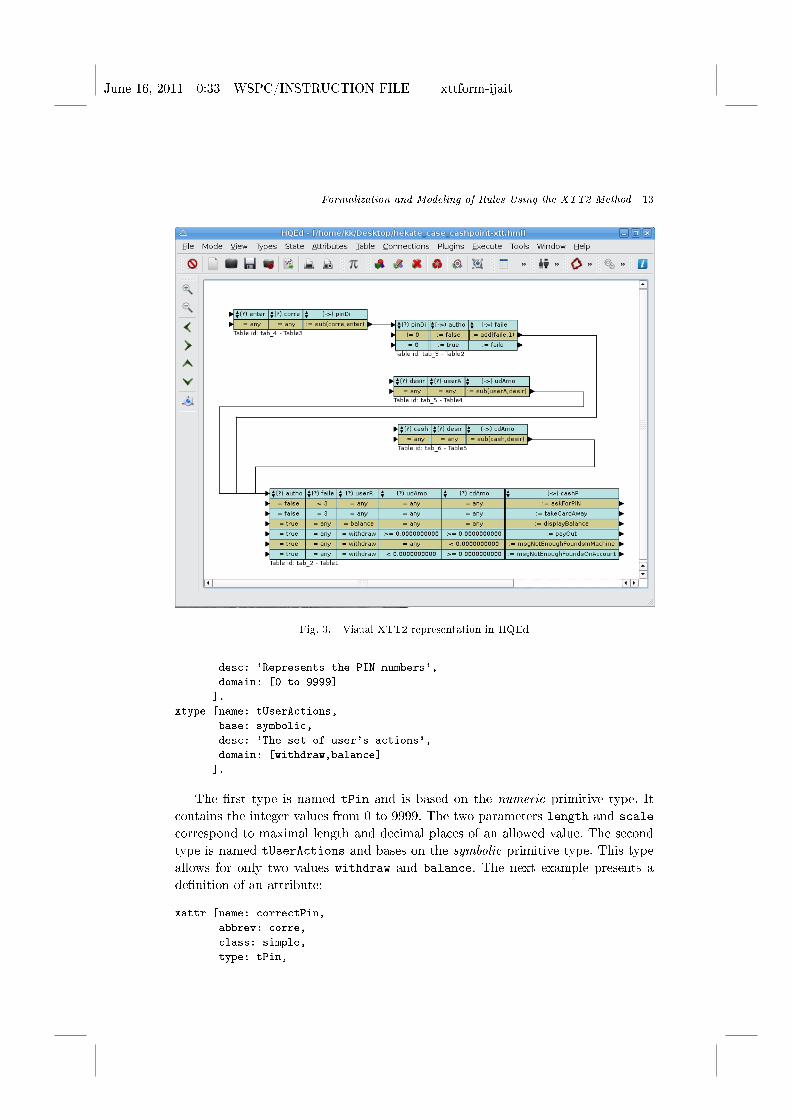
engine. The visual representation is supported by the HQEd (HeKatE Qt Editor) 22
graphical editor. In the Figure 3 the example of an editing session is depicted.
Both representations can be used to design the system. However, the visual rep-
resentation is more convenient. In fact, the textual form of HMR can be written
directly or automatically generated by the HQEd tool for a given visual representa-
tion. The HMR representation is processed by HeaRT 13 tool which is a dedicated
inference engine implemented in Prolog for reasoning with XTT2 rule bases.
The syntax of HMR provides appropriate predicates for the XTT2 concepts:
xattr allows for attributes de�nition,
xschm de�nes the table and rule schema,

June 16, 2011 0:33 WSPC/INSTRUCTION FILE xttform-ijait
12 Grzegorz J. Nalepa, Antoni Lig¦za, Krzysztof Kaczor
Table 6
Table 7
Table 2Table 5
A1
Table 1
B1
A2 B2
C1 D1
C2 D2
B1
Table 3
F1
B2 F2
B1
Table 4
H1
B2 H2
D1 J1
D2 J2
H2 Z2
J1 Z5
J2 Z6
F1
H1
H1
Input tables Middle tables Output tables
H1 Z3
H2 Z4
F2
F2
J1 Z7
J2 Z8
H2
H2
T
T
T
T
DDI with assumption that fact A1 is in knowledge base and Table 1 is a start table
TDI with assumption that facts A2 and C1 are in knowledge base and Table 6 and Table 7 are goal tables
GDI with assumption that facts A1 and C2 are in knowledge base, and Table 7 is a goal table
T Token sent from one table to another
H1 Z1F1
Fig. 2. Main Inference Modes for XTT2
xrule represents rules,
xstat allows for state de�nition,
xcall allows for callback de�nition.
HMR allows for de�ning the attribute domains using types. A given type directly
de�nes a set of allowed attribute values. There are two built-in primitive types:
numeric and symbolic. The semantics of the numeric type is straightforward. The
symbolic type allows for de�ning the symbolic domains, which can contain numbers,
characters, words, etc. A named type is derived from a primitive type and can be
considered as a set of constraints imposed on a primitive type, including speci�c
domain de�nition. Every attribute is of a named type (e.g. temperature). This
makes the design easier and faster because only one type must be de�ned for all the
attributes, which have the same domain.
Here, several HMR examples from the Cashpoint case study 2 are given. The
following example shows the part of HMR �le that de�nes two named types:
xtype [name: tPin,
base: numeric,
length: 4,
scale: 0,
June 16, 2011 0:33 WSPC/INSTRUCTION FILE xttform-ijait
Formalization and Modeling of Rules Using the XTT2 Method 13
Fig. 3. Visual XTT2 representation in HQEd
desc: 'Represents the PIN numbers',
domain: [0 to 9999]
].
xtype [name: tUserActions,
base: symbolic,
desc: 'The set of user's actions',
domain: [withdraw,balance]
].
The �rst type is named tPin and is based on the numeric primitive type. It
contains the integer values from 0 to 9999. The two parameters length and scale
correspond to maximal length and decimal places of an allowed value. The second
type is named tUserActions and bases on the symbolic primitive type. This type
allows for only two values withdraw and balance. The next example presents a
de�nition of an attribute:
xattr [name: correctPin,
abbrev: corre,
class: simple,
type: tPin,

June 16, 2011 0:33 WSPC/INSTRUCTION FILE xttform-ijait
14 Grzegorz J. Nalepa, Antoni Lig¦za, Krzysztof Kaczor
comm: in,
callback: [xpce_ask_numeric,[correctPin]]
].
The attribute has a de�ned name (correctPin) and a name abbreviation
(corre). The third line de�nes a class of the attribute (see attribute partition-
ing). In this case the attribute can take only one value at one time. In the next line
a type (domain) of the attribute is de�ned. According to the previous example, the
set of allowed values of the attribute contains the integer values from 0 to 9999.
The �fth line de�nes the relation between an attribute and an external system. In
this case the value of the attribute is provided by a system. The sixth line de�nes
a callback action that allows for getting a value of the attribute from an external
system. The callback action can receive the value from any source: sensor, Internet
or simply from a user. The following Prolog code de�nes the callback action that
uses GUI to receive the value from the user.
xcall xpce_ask_numeric: [AttName] >>>
(alsv_domain(AttName,[Min to Max],numeric),
dynamic(end), new(@dialog,dialog('Select a value')),
send_list(@dialog,append,
[new(I,int_item(AttName,low := Min, high := Max)),
new(_,button('Select',and(message(@prolog,assert,end),
and(message(@prolog,alsv_new_val,AttName,I?selection),
message(@dialog,destroy)))))]),
send(@dialog,open),
repeat,send(@display,dispatch),end,!,retractall(end)).
The next example shows the de�nition of the table schema:
xschm 'isPinCorrect': [enteredPin,correctPin] ==> [pinDifference].
The decision table de�ned by this schema is named isPinCorrect. The ta-
ble can contain the rules that have three attributes: enteredPin, correctPin and
pinDifference. The �rst two must be placed in a conditional part of the rules and
the last one in a decision part. In the following example, a single rule is de�ned.
The rule belongs to the table de�ned by the former schema:
xrule 'isPinCorrect'/1:
[enteredPin eq any, correctPin eq any]
==>
[pinDifference set (correctPin-enteredPin)]
:'authorization'.
Note that the �rst line contains information about rule schema. This information
can be considered as redundant but from the implementation point of view it allows
for convenient processing of the code. Further, the rule stays human readable. After
the / character the rule identi�er is de�ned. The second and third lines constitute a
conditional part of the rule while the �fth line a decision part. The last line de�nes

June 16, 2011 0:33 WSPC/INSTRUCTION FILE xttform-ijait
Formalization and Modeling of Rules Using the XTT2 Method 15
a link to the authorization table. The last example presents the HMR syntax that
allows for state de�nition:
xstat init0: [enteredPin, 1111].
xstat init0: [correctPin, 1234].
Both lines de�ne values of attributes for the state init0. HMR allows for the
de�nitions of any number of states. This can be especially useful during the system
testing. The test cases can be generated in the form of states.
The HMR representation provides a callback mechanism. This mechanism is re-
lated with the attributes and allows for receiving a value from the environment. The
HeaRT tool supports this mechanism in a two ways: all the callbacks are executed
before the inference starts, and a single callback is executed during the inference
when the value of an attribute is unknown.
A very important feature of XTT2 that has been implemented is a formal
veri�cation. HeaRT supports the veri�cation of the rules on the tables level The
rules can be checked against a number of of anomalies, see 16 for more details.
6. Related Work
This paper describes the formalization of XTT2 method that provides a complete
rule modeling framework, which includes a visual design method supported by tools,
formal veri�cation methods as well as execution environment.
Currently, a number of modern rule-based shells exist, e.g. Clips, Jess or Drools.
They provide new high-level features in the area of current software technologies,
such as Java-integration, network services, etc., However, the rule representation
and inference methods do not evolve. The rule languages found in these tools tend
to be logically trivial, and conceptually simple, with no formalization at all. They
mostly reuse very basic logic solutions, and combine them with new programming
language features, building on top of classic inference approaches, such as the blind,
forward-checking inference engines employing the Rete-style algorithm 4.
Historically, an important approach that aimed at full formalization of the
knowledge representation including basic inference tasks was KADS. In fact, in this
area an important e�ort was done, see3,27. However, KADS had a very broad per-
spective on the knowledge representation, with rules being one of several methods.
Due to this complexity, KADS-oriented research did not result in practical tools for
rule-based systems. Compared to it, the approach presented here is a focused one,
where a concrete, well-de�ned syntax and semantics of the rule language is given.
Moreover, the approach is supported by practical tools.
Considering the use of decision tables our approach is similar to Vanthienen's re-
search on decision tables. In the paper 30 it is presented how the rule-based system
can be created with the help of PROLOGA (Procedural Logic Analyzer) system,
which is an interactive rule-based tool for computer-supported construction and
manipulation of decision tables. The problems of maintenance, e�ciency and ver-
i�cation of a large knowledge bases are also discussed. A proposal of knowledge

June 16, 2011 0:33 WSPC/INSTRUCTION FILE xttform-ijait
16 Grzegorz J. Nalepa, Antoni Lig¦za, Krzysztof Kaczor
clustering is described in 29, where some formalisms and algorithms are introduced.
The paper 28 describes an approach to a knowledge modularization in order to
increase an e�ciency of veri�cation.
However, in XTT2 the perspective is on state-based representation. Moreover,
the formalization is more complete, and practical inference issues in structured rule
bases are considered. Vanthienen's works do not describe an in�uence of the knowl-
edge base modularization on the inference process. This is why, XTT2 provides
dedicated inference engine, which allows for using the advanced inference strate-
gies. In comparison to Vanthienen's works, XTT2 provides a stronger formalism
and more expressive rule language based on the ALSV(FD) logic.
In terms of the formalization of decision tables other approaches can also be
pointed out. In 24 Petri net representation of decision tables is presented. However,
it is aimed mainly at distributed concurrent systems. Moreover, the rule language
used in the tables is a basic propositional one.
To summarize, it can be stated that the introduced formalization allows for
a knowledge base quality control, where formal methods can be used to identify
logical errors in rule formulation on an early stage. Ultimately, this can speed up
the design process which becomes more transparent 20. This rule language opens
possibility for simplifying knowledge translation. In fact a proposal of the XTT2 to
Drools translation has been formulated 6 Moreover, the method introduces custom
inference modes, required for a structured rule base.
7. Concluding Remarks and Future Work
In this paper a rigorous formalized approach, called XTT2, for developing rule-
based systems has been presented in detail. The approach is based on the idea of
using a formal, attributive logic based approach for rule description. Moreover, it
allows for identi�cation of a structure of the rule base, by using extended decision
tables grouping rules working in the same context.
The main original contribution of the proposed approach consists in:
• introducing a network-like structure of the rule-base, consisting of com-
plex decision tables connected with inference links; in this way the purely
declarative knowledge is enriched with inference-control component,
• building the knowledge representation scheme upon a powerful, well-
formalized attribute logic, namely the ALSV(FD),
• providing the formalized de�nitions of system components, i.e. system ta-
bles and links,
• building a set of tools providing the proof-of-a-concept.
This approach is superior to wide-spread rule-based solutions thanks to the trans-
parent and scalable visual representation 21, possibility of formal veri�cation on the
logical level 16, as well as the introduction of custom inference algorithms 15. In the
paper a prototype implementation as well as supporting tools have been presented.

June 16, 2011 0:33 WSPC/INSTRUCTION FILE xttform-ijait
Formalization and Modeling of Rules Using the XTT2 Method 17
See also 22 and http://ai.ia.agh.edu.pl/wiki/hekate:hades for the complete
design toolset. The approach has been evaluated using a number of illustrative
system cases that have been selected, analyzed, designed and implemented. Impor-
tant cases were made available online: http://ai.ia.agh.edu.pl/wiki/hekate:
cases:start. Cases were selected in order to investigate and possibly boost the
selected language features of XTT2.
The XTT2 representation has been invented to support knowledge engineering
and management in classic rule systems. However, one of the considered future ap-
plications includes distributed agent systems. In such an approach several attribute
pools are considered. Some attributes are used by all agents, where as some other
correspond to features of single agents. A knowledge base of a single agent is de-
scribed by a single rule set represented by a decision table. Therefore inference is
simpli�ed. A simple communication protocol allowing for synchronizing input and
output attribute values is considered. Moreover, another application of the approach
is related to Business Rules 23 modelling and implementation 11,12. A formalized
translation between the XTT2 language and other rule languages used in Business
Rules systems could be formulated. In order to do so, a model-theoretic speci�ca-
tion of the language semantics is also planned. A related approach using the R2ML
intermediate language was proposed in 31.
References
1. Szymon Bobek, Krzysztof Kaczor, and Grzegorz J. Nalepa. Overview of rule inferencealgorithms for structured rule bases. Gdansk University of Technology Faculty of ETIAnnals, 18(8):57�62, 2010.
2. Tim Denvir, Jose Oliveira, and Nico Plat. The Cash-Point (ATM) 'Problem'. FormalAspects of Computing, 12(4):211�215, December 2000.
3. Dieter Fensel, Jürgen Angele, and Dieter Landes. KARL: a knowledge acquisition andrepresentation language. In J. C. Rault, editor, Proceedings of the 11th InternationalConference Expert Systems and their Applications, volume 1 (Tools, Techniques &Methods), pages 513�528, Avignon, 1991. EC2, Nanterre.
4. Charles Forgy. Rete: A fast algorithm for the many patterns/many objects matchproblem. Artif. Intell., 19(1):17�37, 1982.
5. Joseph Giarratano and Gary Riley. Expert Systems. Principles and Programming.Thomson Course Technology, Boston, MA, United States, 4th edition, 2005.
6. Krzysztof Kluza, Grzegorz J. Nalepa, and �ukasz �ysik. Visual inference speci�cationmethods for modularized rulebases. Overview and integration proposal. In Grzegorz J.Nalepa and Joachim Baumeister, editors, 6th Workshop on Knowledge Engineeringand Software Engineering (KESE2009) at the 32nd German conference on Arti�cialIntelligence: September 21, 2010, Karlsruhe, Germany, pages 6�17, Karlsruhe, Ger-many, 2010.
7. Jay Liebowitz, editor. The Handbook of Applied Expert Systems. CRC Press, BocaRaton, 1998.
8. Antoni Lig¦za. Logical Foundations for Rule-Based Systems. Springer-Verlag, Berlin,Heidelberg, 2006.
9. Antoni Lig¦za and Grzegorz J. Nalepa. A study of methodological issues in designand development of rule-based systems: proposal of a new approach. Wiley Interdis-

June 16, 2011 0:33 WSPC/INSTRUCTION FILE xttform-ijait
18 Grzegorz J. Nalepa, Antoni Lig¦za, Krzysztof Kaczor
ciplinary Reviews: Data Mining and Knowledge Discovery, 1(2):117�137, 2011.10. Grzegorz J. Nalepa. A new approach to the rule-based systems design and implemen-
tation process. Computer Science, 6:65�79, 2004.11. Grzegorz J. Nalepa. Business Rules design and re�nement using the XTT approach.
In David C. Wilson, Geo�rey C. J. Sutcli�e, and FLAIRS, editors, FLAIRS-20: Pro-ceedings of the 20th International Florida Arti�cial Intelligence Research Society Con-ference: Key West, Florida, May 7-9, 2007, pages 536�541, Menlo Park, California,2007. Florida Arti�cial Intelligence Research Society, AAAI Press.
12. Grzegorz J. Nalepa. Proposal of business process and rules modeling with the XTTmethod. In Viorel Negru and et al., editors, Symbolic and numeric algorithms for sci-enti�c computing: SYNASC'07: 9th international symposium: RuleApps'2007 � work-shop on Rule-based applications: Timisoara, Romania, September 26�29, 2007, pages500�506, Los Alamitos, California ; Washington ; Tokyo, 2007. IEEE, CPS ConferencePublishing Service.
13. Grzegorz J. Nalepa. Architecture of the HeaRT hybrid rule engine. In LeszekRutkowski and [et al.], editors, Arti�cial Intelligence and Soft Computing: 10th In-ternational Conference, ICAISC 2010: Zakopane, Poland, June 13�17, 2010, Pt. II,volume 6114 of Lecture Notes in Arti�cial Intelligence, pages 598�605. Springer, 2010.
14. Grzegorz J. Nalepa. Semantic Knowledge Engineering. A Rule-Based Approach.Wydawnictwa AGH, Kraków, 2011.
15. Grzegorz J. Nalepa, Szymon Bobek, Antoni Lig¦za, and Krzysztof Kaczor. Algorithmsfor rule inference in modularized rule bases. In N. Bassiliades, G. Governatori, andA. Pasckhe, editors, RuleML2011 - International Symposium on Rules, Lecture Notesin Computer Science. Springer-Verlag, 2011. accepted for publication.
16. Grzegorz J. Nalepa, Szymon Bobek, Antoni Lig¦za, and Krzysztof Kaczor. HalVA �rule analysis framework for XTT2 rules. In N. Bassiliades, G. Governatori, andA. Pasckhe, editors, RuleML2011 - International Symposium on Rules, Lecture Notesin Computer Science. Springer-Verlag, 2011. accepted for publication.
17. Grzegorz J. Nalepa and Antoni Lig¦za. A graphical tabular model for rule-based logicprogramming and veri�cation. Systems Science, 31(2):89�95, 2005.
18. Grzegorz J. Nalepa and Antoni Lig¦za. XTT+ rule design using the ALSV(FD). InAdrian Giurca, Anastasia Analyti, and Gerd Wagner, editors, ECAI 2008: 18th Euro-pean Conference on Arti�cial Intelligence: 2nd East European Workshop on Rule-basedapplications, RuleApps2008: Patras, 22 July 2008, pages 11�15, Patras, 2008. Univer-sity of Patras.
19. Grzegorz J. Nalepa and Antoni Lig¦za. On ALSV rules formulation and inference. InH. Chad Lane and Hans W. Guesgen, editors, FLAIRS-22: Proceedings of the twenty-second international Florida Arti�cial Intelligence Research Society conference: 19�21May 2009, Sanibel Island, Florida, USA, pages 396�401, Menlo Park, California, 2009.FLAIRS, AAAI Press.
20. Grzegorz J. Nalepa and Antoni Lig¦za. HeKatE methodology, hybrid engineering ofintelligent systems. International Journal of Applied Mathematics and Computer Sci-ence, 20(1):35�53, 2010.
21. Grzegorz J. Nalepa, Antoni Lig¦za, and Krzysztof Kaczor. Overview of knowledgeformalization with XTT2 rules. In N. Bassiliades, G. Governatori, and A. Pasckhe,editors, RuleML2011 - International Symposium on Rules, Lecture Notes in ComputerScience. Springer-Verlag, 2011. accepted for publication.
22. Grzegorz J. Nalepa, Antoni Lig¦za, Krzysztof Kaczor, and Weronika T. Furma«ska.HeKatE rule runtime and design framework. In Adrian Giurca, Grzegorz J. Nalepa,and Gerd Wagner, editors, Proceedings of the 3rd East European Workshop on Rule-

June 16, 2011 0:33 WSPC/INSTRUCTION FILE xttform-ijait
Formalization and Modeling of Rules Using the XTT2 Method 19
Based Applications (RuleApps 2009) Cottbus, Germany, September 21, 2009, pages21�30, Cottbus, Germany, 2009.
23. Ronald G. Ross. Principles of the Business Rule Approach. Addison-Wesley Profes-sional, 2003.
24. Marcin Szpyrka and Tomasz Szmuc. Decision tables in petri net models. In MarzenaKryszkiewicz, James F. Peters, Henryk Rybinski, and Andrzej Skowron, editors, RoughSets and Intelligent Systems Paradigms, International Conference, RSEISP 2007,Warsaw, Poland, June 28-30, 2007, Proceedings, volume 4585 of Lecture Notes inComputer Science, pages 648�657. Springer, 2007.
25. Ryszard Tadeusiewicz. Introduction to intelligent systems. In Bogdan M. Wilamowskiand J. David Irwin, editors, Intelligent systems, The Electrical Engineering HandbookSeries. The Industrial Electronics Handbook, pages 1�1�1�12. Boca Raton; London;New York: CRC Press Taylor & Francis Group, second edition edition, 2011.
26. I. S. Torsun. Foundations of Intelligent Knowledge-Based Systems. Academic Press,London, San Diego, New York, Boston, Sydney, Tokyo, Toronto, 1995.
27. Frank van Harmelen and John Balder. (ML)2: A formal language for KADS models.In ECAI, pages 582�586, 1992.
28. J. Vanthienen, C. Mues, A. Aerts, and G. Wets. A modularization approach to theveri�cation of knowledge based systems. In 14th International Joint Conference on Ar-ti�cial Intelligence (IJCAI'95) - Workshop on Validation & Veri�cation of KnowledgeBased Systems, Montreal, Canada 20 - 25 Aug 1995., aug 1995.
29. Jan Vanthienen, E. Dries, and J. Keppens. Clustering knowledge in tabular knowledgebases. In ICTAI, pages 88�95, 1996.
30. Jan Vanthienen and F. Robben. Developing legal knowledge based systems using de-cision tables. In ICAIL, pages 282�291, 1993.
31. G. Wagner, A.Giurca, and S. Lukichev. R2ml: A general approach for marking uprules. In F. Bry, F. Fages, M. Marchiori, and H. Ohlbach, editors, Principles andPractices of Semantic Web Reasoning, Dagstuhl Seminar Proceedings 05371, 2005.





























