Embed Size (px)
Citation preview

Journal of Memory and Language 88 (2016) 117–132
Contents lists available at ScienceDirect
Journal of Memory and Language
journal homepage: www.elsevier .com/locate / jml
Modeling the role of distributional information in children’s useof phonemic contrasts
http://dx.doi.org/10.1016/j.jml.2016.01.0030749-596X/� 2016 Elsevier Inc. All rights reserved.
⇑ Corresponding author at: Department of Psychology, Carnegie MellonUniversity, Pittsburgh, PA 15213, United States.
E-mail address: [email protected] (E.D. Thiessen).
Erik D. Thiessen a,⇑, Philip I. Pavlik Jr. b
aCarnegie Mellon University, United StatesbUniversity of Memphis, United States
a r t i c l e i n f o
Article history:Received 1 December 2014revision received 13 January 2016
Keywords:Statistical learningWord learningExemplar memory modelMemoryAbstractionLanguage
a b s t r a c t
Between the first and the second year of life, children improve in their ability to use phone-mic contrasts when learning label–object pairings. This improvement may be related tochildren’s experience with the distribution of phonemes across lexical forms. Because pho-nemes typically occur in different lexical frames (e.g., /d/ and /t/ in ‘‘doggy” and ‘‘teddy”rather than ‘‘doggy” and ‘‘toggy”), familiarity with words makes similar phonemes moredistinct through acquired distinctiveness. In a series of simulations, we demonstrate thatEnglish input has the distributional characteristics necessary to facilitate use of phonemiccontrasts as a function of increasing familiarity with the lexicon. Further, these simulationssupport a novel prediction: that less common phonemes should take longer to be used pro-ductively. We tested this prediction with children between 18 and 25 months, and foundthat the relatively infrequent /s/ and /z/ contrast takes longer to emerge than frequent con-trasts such as /b/–/d/ or /d/–/t/.
� 2016 Elsevier Inc. All rights reserved.
By the first birthday, the average monolingual infant isalready familiar with the meaning of nearly 100 words(Fenson et al., 2002). But despite infants’ success in discov-ering word–object associations at this age, they appear tohave difficulty taking advantage of phonemic distinctionswhen making connections between word forms and mean-ing. One striking example of this is infants’ failure torespond differentially to lexical forms that differ by onlya single phoneme (i.e., minimal pairs) in label–object asso-ciation tasks. For example, 14-month-old infants who havelearned (via habituation) that a novel object is associatedwith the label /da/ respond equivalently when that objectis labeled /ta/ as when it is labeled /da/. This failure to dif-ferentiate between the labels is not limited to /da/ and /ta/,and has been replicated with a variety of phonemic con-trasts in word–object association tasks (e.g., Pater, Stager,
& Werker, 2004; Thiessen & Yee, 2010). Infants’ failure torespond to these phonemic differences is not due to aninability to hear them, but is instead specific to settingswhere they are asked to use these contrasts to differentiateword meanings (e.g., Stager & Werker, 1997; Swingley &Aslin, 2000; Thiessen, 2007; Yoshida, Fennell, Swingley, &Werker, 2009). Instead of a perceptual failure, infants’ fail-ures to use phonemic differences in label–object associa-tion tasks appear to results from a difficulty in makinguse of some phonemic distinctions that they can perceiveand encode (e.g., Shvachkin, 1973; Thiessen, 2011).
That is, though infants perceive and encode the phone-mic distinctions that are relevant to their native languagewhen they are building a lexicon, they initially fail to treatthese phonemic distinctions as signifying the distinctionbetween tokens of different lexical categories (Swingley& Aslin, 2007). Over the course of development, this diffi-culty is substantially alleviated. By 18 months, infantsuse phonemic distinctions (at least, the word-initial stopconsonant contrasts typically used in laboratory tasks)

118 E.D. Thiessen, P.I. Pavlik Jr. / Journal of Memory and Language 88 (2016) 117–132
contrastively in word–object association tasks (e.g.,Thiessen, 2007; Thiessen & Yee, 2010). Three potentialexplanations have been forwarded for this developmentalchange. The first is a capacity account. On this account,young infants’ failures are due to the fact that the task isdemanding – it requires infants to encode the label, theobject, and the link between them. Because young infantshave less capacity than older infants and adults, they can-not encode all of this information simultaneously, and sub-sequently fail to detect subtle changes in the identity of thelabel. Older infants succeed because they have more capac-ity (Werker, Fennell, Corcoran, & Stager, 2002). The secondis a social inference account. From this perspective, thereason that infants fail is that the label–object tasks usedin the lab lack sufficient social support for infants to reactto the labels as though they are meaningful. As such,infants ignore distinctions that they would treat as infor-mative in a ‘‘real” or ‘‘linguistic” label–object associationsetting (Fennell & Waxman, 2010). While it is clear thatsocial factors influence infants’ word learning, this per-spective does not make strong claims about what differen-tiates younger infants (who fail to use phonemicdistinctions in laboratory tasks) from older infants (whosucceed).
A final account suggests that infants’ success and failurein using phonemic distinctions in laboratory tasks is due totheir experience with the distributions of phonemes intheir native language. In particular, Thiessen and col-leagues (Thiessen, 2007, 2011; Thiessen & Pavlik, 2013;Thiessen & Yee, 2010) have proposed that experience withlexical forms helps to differentiate phonemic contrasts. Onthis account, infants are encoding a great deal of acousticinformation associated with lexical forms. In addition tophonemic identity, for example, infants also encode index-ical information about the speaker of a word (e.g., Houston& Jusczyk, 2003; Singh, 2008; Werker & Curtin, 2005). Ini-tially, it may not be apparent which aspects of the acousticvariability in the encoded word forms are relevant for dif-ferentiating among different tokens of spoken words.Experience with lexical forms is informative to the extentthat these forms help infants resolve the ambiguity inher-ent in the perceptual input and lead infants to weightphonemic distinctions more heavily (e.g., Swingley,2009). This resolution occurs because experience with lex-ical forms is not random. Instead, infants are especiallylikely to encounter phonemes in distinct lexical contexts(such as /d/ and /t/ in doggy and teddy) as they develop alexicon. Compared with the adult lexicon, children’s lexi-cons contain fewer words where phonemes occur in iden-tical contexts (i.e., fewer minimal pairs, such as /d/ and /t/in dip and tip). For example, Swingley and Aslin (2007)found that over two thirds of the words in the vocabulariesof 18-month-old Dutch learning infants had no minimalpair neighbors. Similarly, there are no single-feature mini-mal pairs in the first 50 words that children are most likelyto comprehend (Caselli et al., 1995).
The experience of phonemic contrasts in distinct lexicalcontexts may serve to differentiate the contrasts due to aprocess known as acquired distinctiveness. Two similarstimuli, when paired with distinct outcomes, become moredifferentiable (e.g., Hall, 1991). That is, if an organism has
difficulty differentiating between stimuli A and B (i.e.,two similar phonemes), they can be repeatedly paired withtwo more easily distinguished outcomes X and Y (e.g., Xmight be reward and Y punishment), such that the organ-ism consistently experiences AX and BY pairings. Overtime, these pairings reinforce the original (difficult) dis-tinction between A and B and the distinction becomesmore robust. In the child’s developing lexicon, phonemesthat are initially difficult to distinguish become more dif-ferentiable as they are paired with distinct lexical contexts.Because children know so few minimal pair words, theyare unlikely to experience two phonemes in identical con-texts (like /d/ and /t/ in dip and tip). Instead, they experi-ence phonemes primarily in distinct contexts, and thisexperience with lexical could potentially help to differenti-ate similar phonemes.
To test this hypothesis, Thiessen (2007) conducted alaboratory training procedure intended to facilitate chil-dren’s use of a phonemic contrast in a word–object associ-ation task. In that procedure, 15-month-olds who typicallyfail to respond differentially to the /d/–/t/ distinction in aword–object association task were exposed to the contrastin distinct lexical contexts, /dabo/ and /tagu/. After expo-sure to these labels, infants succeeded in responding differ-entially to the labels /da/ and /ta/ (for a replication, seeThiessen, 2011). This result is not simply due to increasedfamiliarity with /d/ and /t/. When infants were exposed tothese consonants for the same amount of time in identicallexical contexts (such as /dagu/ and /tagu/), they showedno benefit from the exposure and continued to respondto /d/ and /t/ as though they were interchangeable. Theseresults are consistent with the hypothesis that exposureto phonemes in distinct lexical contexts helps to make sim-ilar phonemes more differentiable. More generally, thissuggests that the distribution of phonemes in lexical forms,and infants’ increasing familiarity with those lexical forms,plays an important role in infants’ improving ability tomake use of phonemic contrasts in word–object associa-tion tasks (e.g., Stager & Werker, 1997; Werker et al.,2002).
Of the three accounts discussed here, the distributionalexperience account makes a unique prediction: it suggeststhat children’s ability to make use of particular phonemiccontrasts in a label–object association task should be pre-dictable from the frequency and distribution with whichchildren have experienced those specific contrasts. Thatis, when two phonemes are similar to each other – forexample, phonemes that differ by only a single phoneticfeature such as voicing, which we will refer to as ‘‘minimalpair” phonemes – children need to experience the pho-neme in distinct contexts for the members of the phonemeto become distinct enough to respond to them differen-tially in a label–object association task. This will take dif-ferent amounts of time for different phonemes, as afunction of the frequency with which children experiencethem in their language, such that children should succeedwith more frequent contrasts (such as /d/ and /t/) beforethey succeed with less frequent contrast (such as /s/ and/z/). By contrast, the capacity account (Werker et al.,2002) suggests that children should succeed with allphonemes once they have enough capacity to encode the

E.D. Thiessen, P.I. Pavlik Jr. / Journal of Memory and Language 88 (2016) 117–132 119
information in the task. While the social support accountdoes not make explicit developmental predictions, to theextent that it’s causal claims relate to children’s under-standing of the experimental setting, it should similarlypredict that children succeed on most or all phonemessimultaneously: once children understand that the experi-mental setting is a communicative setting, they shouldtreat the labels (whatever their phonemic content) asinformative.
We will explore the predictions of the distributionallearning account in two interrelated ways. First, we willconduct a simulation using iMinerva, a computationalapproach that is capable of simulating this kind of learning(Thiessen & Pavlik, 2013). The simulation will allow us toverify, first, that the distributional properties of the plausi-ble input to children are such that phonemic contrasts willbecome more distinctive – and thus more likely to beresponded to differentially – over the course of experiencewith lexical forms in the input. Second, the simulation willlend quantitative precision to the intuitive prediction thatsome contrasts should emerge later than others. Using thestimulation as a guide, we will also run a series of behav-ioral experiments, using a common variant of the label–object association task (e.g., Stager & Werker, 1997;Thiessen, 2007) to assess the prediction that less frequentcontrasts emerge later than more frequent contrasts. Whilethis prediction is intuitive, and has been explored indomains such as speech perception (e.g., Abbs & Minifie,1969; Anderson, Morgan, & White, 2003) and production(Nissen & Fox, 2005), to our knowledge this is the firstinvestigation of the role of phoneme frequency in chil-dren’s differentiation of phonemic contrasts in word–object association tasks.
Introduction to iMinerva
In previous work, we have found that the iMinervamodel is capable of simulating the facilitative effects ofdistinct artificial lexical contexts (like dabo and tagu) onphonemic contrasts in laboratory setting (Thiessen &Pavlik, 2013). iMinerva is an exemplar memory model thatrelies on four interrelated processes: similarity-based acti-vation, integration of current experience with prior exem-plars, decay of previously experienced exemplars overtime, and abstraction. Like all exemplar memory models,iMinerva stores prior experience in the form of discreteexemplars, which are coded as n-dimensional vectors withpositive and negative feature values. Each featuredescribes some characteristic of the stimuli, and thevalence of the feature describes whether the characteristicis present (positive values) or contradicted (negative val-ues). For example, a vector description of a square wouldhave a positive value for the feature 4-sided, and a negativevalue for the feature 5-sided. The magnitude of the featuredescribes the degree of certainty that the feature is presentor contradicted. Due to the effect of decay, magnitude has atendency to converge toward zero.
When a new exemplar is presented to iMinerva, previ-ously stored exemplars are activated as a function of theirsimilarity. Similarity between exemplars is computed on a
feature-by-feature basis, considering both the magnitudeand valence of each feature (for a complete description,see Thiessen & Pavlik, 2013). The most similar of theseprior exemplars then ‘‘engages” with the current exemplarto create an interpretation (a new third vector that isstored in memory) of the current experience in light ofprior experience. Interpretations are created through anadditive merging of the current exemplar with the mostsimilar prior exemplar. If the current exemplar has featuresthat are consistent with the exemplar, then the engage-ment increases the magnitude of these features in theresulting interpretation. If the two vectors have featureswith opposing valences, then the interpretation resultingfrom their engagement will have less extreme feature val-ues than the original exemplars.
Interpretations are stored in the same manner as exem-plars, and the creation and storage of these interpretationsyields sensitivity to the central tendency of exemplars inthe input. For example, consider what would happen ifiMinerva were exposed to a series of two-feature vectors,where the first feature of all of the vectors is 1, while thesecond feature alternates between 1 and �1. Across a ser-ies of engagements, the first feature will be reinforced andincrease in magnitude. In contrast, the magnitude of thesecond feature will decrease, because the engagementbetween current and prior vectors will often have inconsis-tent valences. Over time this inconsistency, coupled withthe effect of decay, will lead the value of the second featureof novel interpretations to converge toward zero. Featuresthat fall toward zero will not be retained forever in iMin-erva’s representation. iMinerva transforms features to nullvalues when an interpretation contains features whosevalues fall below some fraction (determined by a parame-ter) of the average absolute feature strength for that inter-pretation. Features that are nullified in this manner are nolonger used to compute similarity ratings, which facilitatesgeneralization to novel stimuli that vary on ‘‘uninforma-tive” features (e.g., McClelland & Plaut, 1999). The abstrac-tion process simulates the fact that experience oftenresults in a decrease in similarity to certain features ofthe input (e.g., Werker & Tees, 1984). As this example illus-trates, iMinerva continually refines its interpretations in away that is consistent with the central tendency of theinput, and emphasizing those features that are consistentand abstracting away features that are inconsistent.
The four processes invoked by iMinerva – similaritybased activation, engagement, decay, and abstraction –allow iMinerva to discover distributional regularities inthe input. One of these distributional regularities is the lex-ical context in which phonemes occur. iMinerva respondsto /d/ and /t/ as more similar when they consistently occurin the same context than when they consistently occur indifferent contexts (Thiessen & Pavlik, 2013). However, thatsimulation was based entirely on laboratory materials. Inthe set of simulations described below, we extend thisprinciple to simulations based on the most common wordsin a developing child’s English lexicon, as estimated by theMacArthur-Bates Communicative Development Inventory(MBCDI, Fenson et al., 2002). The characteristics of the lex-icon will lead to behavioral predictions that we will test ina population of 15-month-old children.

120 E.D. Thiessen, P.I. Pavlik Jr. / Journal of Memory and Language 88 (2016) 117–132
Simulation
Thiessen (2007) found that exposure to /d/ and /t/ indistinct lexical contexts (/dabo/ and /tagu/) facilitated useof the /da/–/ta/ contrast in a word–object association task,while exposure to /d/ and /t/ in identical lexical contexts(/dagu/ and /tagu/) did not. Thiessen and Pavlik (2013)have demonstrated that iMinerva is able to simulate thiseffect. When the model is exposed to /dabo/ and /tagu/, atest probe of /da/ activates a different interpretation (onethat incorporates traces of the second syllable /bo/) thana test probe of /ta/. However, if the model is exposed tothe syllables /da/ and /ta/ in identical contexts (/dagu/and /tagu/), a test probe of either syllable activates thesame interpretation. That is, the model’s response to /da/and /ta/ is more similar after exposure to /dagu/ and /tagu/than is its response to the same syllables after exposure to/dabo/ and /tagu/. This result is consistent with the perfor-mance of infants after exposure to the same sets of lexicalcontexts (Thiessen, 2011).
However, prior iMinerva simulations of distributionallearning were focused on the input children receive inthe experimental setting. In this set of simulations, ourgoal is to investigate two interrelated predictions. The firstis that the characteristics of the lexicon support distribu-tional learning, such that the words to which children areexposed make minimal pair phonemes more differentiableover the course of experience. Prior investigations of thedeveloping lexicon support this prediction. Phonemesbecome more differentiable when they occur in distinctlexical contexts (e.g., /d/ and /t/ in ‘‘doggy” and ‘‘tele-phone”) rather than identical lexical contexts (e.g., /d/and /t/ in ‘‘door” and ‘‘tore”). Children, however, know veryfew of these kinds of identical context word pairs (e.g.,Caselli et al., 1995; Charles-Luce & Luce, 1990, 1995;Coady & Aslin, 2003; Swingley & Aslin, 2007). Instead, mostof the words with which children are familiar provide evi-dence of phonemes occurring in distinct contexts. In thissimulation, we will investigate the distributional proper-ties of common lexical forms by looking to see whetherthey provide evidence that would make the representationof phonemes more distinct. That is, phonemes that are ini-tially confusable (similar in representational space) shouldgradually become more differentiable as children accruemore experience with their distribution in distinct lexicalcontexts.
Because we propose differentiation occurs gradually, amore frequent pair of phonemes should be more differen-tiable than a less frequent pair. This simulation exploresthis prediction by comparing the degree of differentiationfor the /d/–/t/ voicing contrast and the /s/–/z/ voicing con-trast. The /d/–/t/ contrast is more frequent than the /s/–/z/contrast in word-initial position (we focused solely onoccurrence in word-initial position because prior experi-mental work suggests that children do not readily general-ize distributional information across word position;Thiessen & Yee, 2010). The Macarthur CDI lists 48 wordsthat start with either /d/ or /t/, and each phoneme occursin word-initial position for over 20 words on the CDI.Words beginning with /s/ are also quite common (there
are 34), but children are exposed to very few /z/-initialwords. The only two such words on the MBCDI are ‘‘zoo”and ‘‘zipper.” Because of this distribution, an infant hasample opportunity to learn that /d/ and /t/ occur in differ-ent lexical contexts, but less experience with the fact that/s/ and /z/ occur in different contexts due to the fact thatinfants have comparatively little information about thecontexts in which /z/ occurs.
Critically, though, the effect of phoneme frequencyshould not be estimated solely on the basis of the numberof words in which a phoneme occurs. The token frequencyof those words also plays an important role. In this simula-tion, we will vary how often each individual lexical formoccurs, to simulate the fact that some words occur morefrequently than other words. Most word frequency esti-mates have been derived from adult corpora, which neces-sarily have some systematic differences from corpora ofutterances directed to infants and young children. In thissimulation, we used the CHILDES database to calculateword frequencies of the items that children are likely toknow, according to the MBCDI. The token frequencies ofthese items were then used to create an input to our sim-ulated learners in which the proportion of token frequen-cies in the simulated input matched the proportion oftoken frequencies estimated from CHILDES.
Method
StimuliThe model was presented with 800 tokens of 321 possi-
ble mono- and bisyllabic words present on the MBCDI.These words were translated into feature vectors using asimilar coding scheme to one we have used previously(Thiessen & Pavlik, 2013). Each syllable was representedby 74 features, 14 each for the 2 possible initial conso-nants, 18 features for the vowel, and 28 more features forthe 2 final consonant. In the case of our set of one and 2syllable words (the MBCDI words beginning with /d/ and/t/), we represented each word with a vector of 148 values,where 0 indicates the feature is not present, 1 indicates apositive valence of the feature (e.g., voiced) and �1 repre-sents a negative valence of the feature (e.g., unvoiced). Fea-tures of the input always range between �1 and 1, whilefeatures in the model’s memory interpretations may takeany real values since their strength measures the salienceof the feature in the models interpretation. Additionally,when features have low strength in the representationthey are set to null to simulate abstraction processes; how-ever this mechanism is not important to the results in thispaper (because we are not assessing abstraction) and weset the abstraction parameter at the typical default fromThiessen and Pavlik (2013), as shown in Table A2 in theappendix.
ProcedureWe ran 250 simulations of exposure to our corpus; each
simulation models an individual learner. The corpora foreach simulation were not identical. Instead, words wereselected according to their probability of being directedat a child as computed from their relative frequency in

E.D. Thiessen, P.I. Pavlik Jr. / Journal of Memory and Language 88 (2016) 117–132 121
the CHILDES database. As such, while the corpora for eachsimulation are generally similar (e.g., more frequent wordsare more likely to occur), individual simulations experi-enced individualized input. We probed each simulation’sknowledge after it had received 200, 400, 600, and 800tokens. Note that these numerical values are not intendedto be indicative of the actual number of times that a childwould need to hear a particular word; instead, they areselected to provide an appropriate number of exposuresfor the model to learn. For each individual simulation, weanalyzed how that simulated infant differentiated the fourphonemes of interest (/d/, /t/, /s/, and /z/) at these fourtimepoints. During testing, we found our decay parameterwas excessive for long simulations (because the input tookmuch longer to unspool over the vastly increased numberof exemplars) and decay was much reduced compared toThiessen and Pavlik (2013). For precise specification of allparameters, see Table A2.
Our primary prediction was that discrimination of the/d/–/t/ contrast would emerge sooner than discriminationof the /s/–/z/ contrast. To model discrimination we neededto develop a novel way to compare the echo resulting froma probe with the echoes from other possible probes, whilealso accounting for the effect of strength (i.e., frequency)in a plausible manner. This function is described in detailin the appendix;what follows is a general overview. Thefirststep in the function is to calculate the similarity of the speci-fic probewith echoes fromall 4 phonemes. This value is thennormalizedbydividing the resulting similarity values by thehighest similarity value (which in all cases is an identicalphoneme; i.e., out of the 4 possible phonemes, /d/ is alwaysmost similar to /d/). This means that themaximumnormal-ized similarity is 1, andgives rise to similarity scores rangingbetween 0 (no featural overlap) and 1 (perfect overlap).
Then, this value is raised to the exponent of the absolutevalue of the vector (overall memory strength), which com-presses the similarities according to their strength. Thisreflects a memory resonance process (MacWhinney,2004), where stronger comparators have a high power,causing multiple resonant comparisons, each of whichreduces the perceived similarity with the dissimilar probe(because the correct probe has a similarity of 1, this pro-cess only depresses incorrect matches as a function of theirstrength). Finally, we also multiplied this compressed sim-ilarity by the overall memory strength to capture the otherpart of the effect, the increased ‘‘volume” or salience of thestronger memory. This occurs because the stronger com-petitors compete better regardless of their similarity, inmuch the same way that more frequent words are recog-nized more easily.
This equation works well because the general positivelinear effect of strength early in learning is overwhelmedby the discriminative exponential resonance of strongmemories. We will see this equation produces a patternwhere discrimination is largely controlled by the strength(i.e., frequency) of a category of exemplars early on, butthen as strength accumulates pattern match becomesmore important. We will measure the discrimination foreach probe by computing this recall strength discrimina-tion value for each of the 4 echoes. We do this for eachof the 4 possible phoneme echoes (which we consider to
be the long-term memory trace for each phoneme) to seewhich is most strongly active (or discriminated) giventhe presence of each probe.
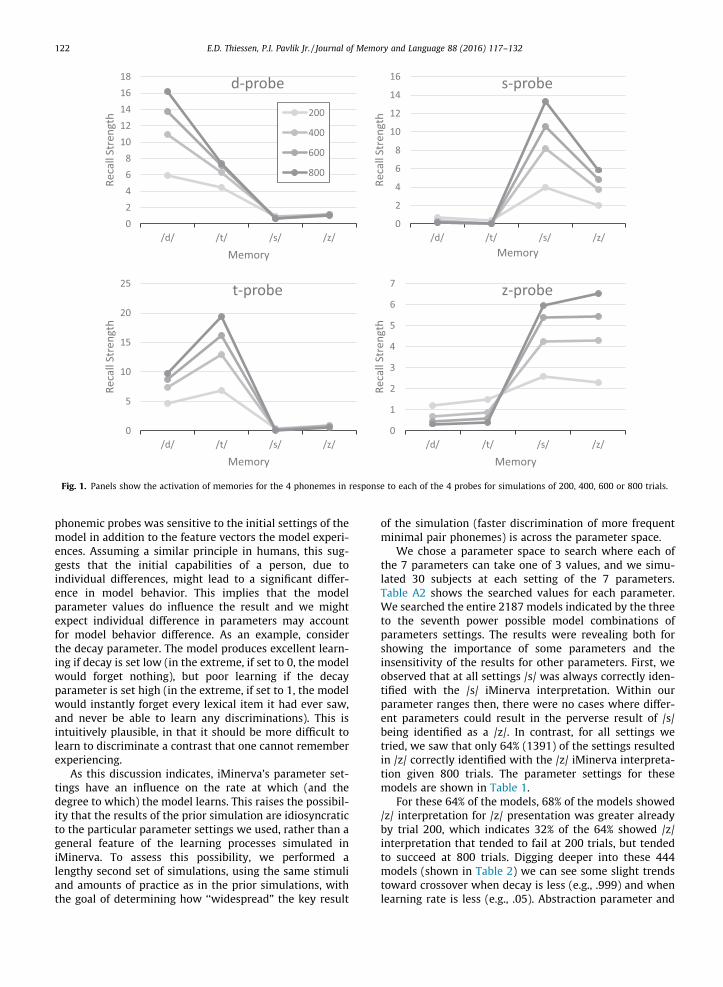
Results and discussion
Fig. 1 shows a four panel graph where the four panelsrepresent /d/ and /t/ probes in the top left and right respec-tively, and /s/ and /z/ probes in the bottom left and rightrespectively. The values were plotted for simulations of250 children for conditions of 200, 400, 600 or 800 lexicaltokens. The figures graph the simulations’ recall strengthfor each of the phonemes when probed with the test pho-neme. The recall discrimination strength represents thepropensity to identify that representation as fitting in the/d/, /t/, /s/ or /z/ categories. It is important to note thatour use of 200, 400, 600 and 800 example trials greatlyunderrepresents how many words children actually see.For this reason we again emphasize the purpose of thisresult is to show the principles behind our explanation ofthe human data, not to provide a tight quantitative fit.
Fig. 1 illustrates two major conclusions. The first is thatthe degree of perceptual difference in the phonetic inputmatters to iMinerva. Early in learning, the model often con-fuses phonemes that are differentiated by only a single pho-netic feature (i.e., /d/ and /t/ are only differentiated byvoicing, as are /s/ and /z/). By contrast, themodel never con-fuses phonemes that are differentiated bymultiple features(e.g., /s/ and /d/ differ not only on voicing, but also on man-ner and place of articulation). While the role of the degreeof perceptual distinctiveness on children’s use of phonemiccontrasts in the Switch task has not been exhaustivelyinvestigated, these simulations are consistent with evi-dence that more similar phonemes present more difficultyfor children in the Switch task (White & Morgan, 2008).
The second conclusion is that, for confusable contrasts(here, /d/–/t/, and /s/–/z/), discrimination improves withexposure. The rate of this improvement is related to the fre-quencywithwhich themodel experienced the phonemes inthe input corpus. The frequent phonemes in the input (/d/,/t/ and /s/) have positive discrimination early, whichimproves with time. While minimal pair phoneme strengthalso growswith learning, the difference between the correctphoneme (e.g., /d/) and its minimal pair (e.g., /t/) increasesover experience, and the degree to which a phoneme acti-vates its minimal pair begins to plateau around 800 trials,while the degree to which the phoneme activates itself con-tinues to increase across the entire corpus.
Finally, as predicted, the low frequency comparator /z/,at 200 trials is dominated by the strength of the /s/ mem-ories, which are recalled more strongly. We can see thatthis difference flattens out across the 400 and 600 trialtests, as the simulations gained stronger representations,and that finally we see at 800 trials that /z/ is the dominantchunk recalled for /z/ probes.
Exploring the parameter space
While developing our discrimination function, wediscovered that the model’s discrimination between
0 2 4 6 8
10 12 14 16 18
/d/ /t/ /s/ /z/
Reca
ll St
reng
th
Memory
d-probe
200
400
600
800
0
2
4
6
8
10
12
14
16
/d/ /t/ /s/ /z/
Reca
ll St
reng
th
Memory
s-probe
0
5
10
15
20
25
/d/ /t/ /s/ /z/
Reca
ll St
reng
th
Memory
t-probe
0
1
2
3
4
5
6
7
/d/ /t/ /s/ /z/
Reca
ll St
reng
th
Memory
z-probe
Fig. 1. Panels show the activation of memories for the 4 phonemes in response to each of the 4 probes for simulations of 200, 400, 600 or 800 trials.
122 E.D. Thiessen, P.I. Pavlik Jr. / Journal of Memory and Language 88 (2016) 117–132
phonemic probes was sensitive to the initial settings of themodel in addition to the feature vectors the model experi-ences. Assuming a similar principle in humans, this sug-gests that the initial capabilities of a person, due toindividual differences, might lead to a significant differ-ence in model behavior. This implies that the modelparameter values do influence the result and we mightexpect individual difference in parameters may accountfor model behavior difference. As an example, considerthe decay parameter. The model produces excellent learn-ing if decay is set low (in the extreme, if set to 0, the modelwould forget nothing), but poor learning if the decayparameter is set high (in the extreme, if set to 1, the modelwould instantly forget every lexical item it had ever saw,and never be able to learn any discriminations). This isintuitively plausible, in that it should be more difficult tolearn to discriminate a contrast that one cannot rememberexperiencing.
As this discussion indicates, iMinerva’s parameter set-tings have an influence on the rate at which (and thedegree to which) the model learns. This raises the possibil-ity that the results of the prior simulation are idiosyncraticto the particular parameter settings we used, rather than ageneral feature of the learning processes simulated iniMinerva. To assess this possibility, we performed alengthy second set of simulations, using the same stimuliand amounts of practice as in the prior simulations, withthe goal of determining how ‘‘widespread” the key result
of the simulation (faster discrimination of more frequentminimal pair phonemes) is across the parameter space.
We chose a parameter space to search where each ofthe 7 parameters can take one of 3 values, and we simu-lated 30 subjects at each setting of the 7 parameters.Table A2 shows the searched values for each parameter.We searched the entire 2187 models indicated by the threeto the seventh power possible model combinations ofparameters settings. The results were revealing both forshowing the importance of some parameters and theinsensitivity of the results for other parameters. First, weobserved that at all settings /s/ was always correctly iden-tified with the /s/ iMinerva interpretation. Within ourparameter ranges then, there were no cases where differ-ent parameters could result in the perverse result of /s/being identified as a /z/. In contrast, for all settings wetried, we saw that only 64% (1391) of the settings resultedin /z/ correctly identified with the /z/ iMinerva interpreta-tion given 800 trials. The parameter settings for thesemodels are shown in Table 1.
For these 64% of the models, 68% of the models showed/z/ interpretation for /z/ presentation was greater alreadyby trial 200, which indicates 32% of the 64% showed /z/interpretation that tended to fail at 200 trials, but tendedto succeed at 800 trials. Digging deeper into these 444models (shown in Table 2) we can see some slight trendstoward crossover when decay is less (e.g., .999) and whenlearning rate is less (e.g., .05). Abstraction parameter and
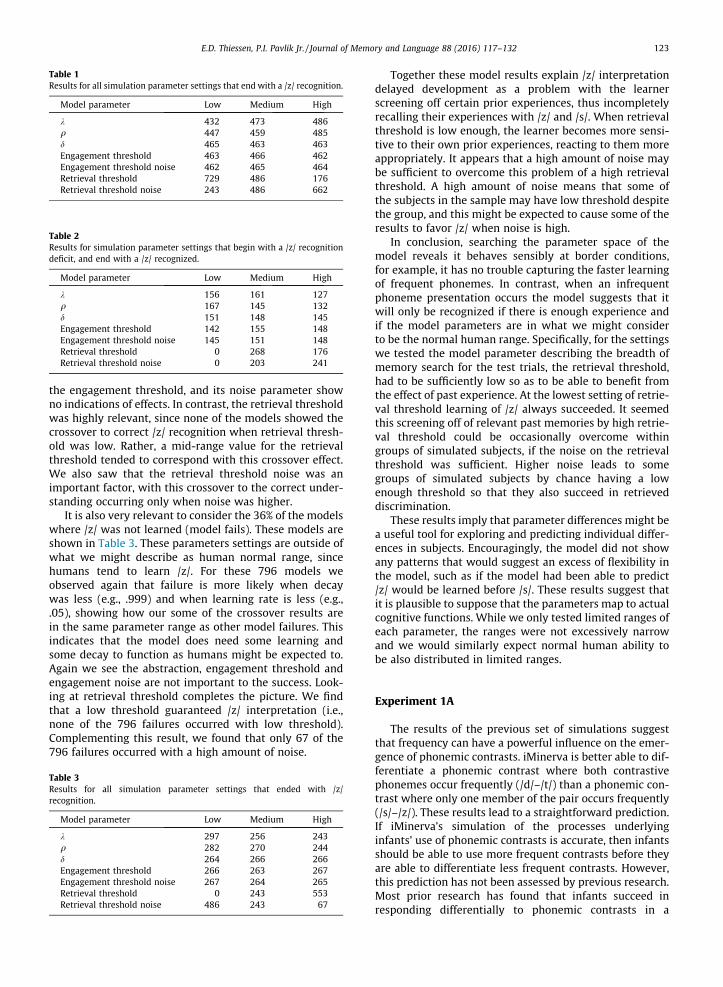
Table 1Results for all simulation parameter settings that end with a /z/ recognition.
Model parameter Low Medium High
k 432 473 486q 447 459 485d 465 463 463Engagement threshold 463 466 462Engagement threshold noise 462 465 464Retrieval threshold 729 486 176Retrieval threshold noise 243 486 662
Table 2Results for simulation parameter settings that begin with a /z/ recognitiondeficit, and end with a /z/ recognized.
Model parameter Low Medium High
k 156 161 127q 167 145 132d 151 148 145Engagement threshold 142 155 148Engagement threshold noise 145 151 148Retrieval threshold 0 268 176Retrieval threshold noise 0 203 241
E.D. Thiessen, P.I. Pavlik Jr. / Journal of Memory and Language 88 (2016) 117–132 123
the engagement threshold, and its noise parameter showno indications of effects. In contrast, the retrieval thresholdwas highly relevant, since none of the models showed thecrossover to correct /z/ recognition when retrieval thresh-old was low. Rather, a mid-range value for the retrievalthreshold tended to correspond with this crossover effect.We also saw that the retrieval threshold noise was animportant factor, with this crossover to the correct under-standing occurring only when noise was higher.
It is also very relevant to consider the 36% of the modelswhere /z/ was not learned (model fails). These models areshown in Table 3. These parameters settings are outside ofwhat we might describe as human normal range, sincehumans tend to learn /z/. For these 796 models weobserved again that failure is more likely when decaywas less (e.g., .999) and when learning rate is less (e.g.,.05), showing how our some of the crossover results arein the same parameter range as other model failures. Thisindicates that the model does need some learning andsome decay to function as humans might be expected to.Again we see the abstraction, engagement threshold andengagement noise are not important to the success. Look-ing at retrieval threshold completes the picture. We findthat a low threshold guaranteed /z/ interpretation (i.e.,none of the 796 failures occurred with low threshold).Complementing this result, we found that only 67 of the796 failures occurred with a high amount of noise.
Table 3Results for all simulation parameter settings that ended with /z/recognition.
Model parameter Low Medium High
k 297 256 243q 282 270 244d 264 266 266Engagement threshold 266 263 267Engagement threshold noise 267 264 265Retrieval threshold 0 243 553Retrieval threshold noise 486 243 67
Together these model results explain /z/ interpretationdelayed development as a problem with the learnerscreening off certain prior experiences, thus incompletelyrecalling their experiences with /z/ and /s/. When retrievalthreshold is low enough, the learner becomes more sensi-tive to their own prior experiences, reacting to them moreappropriately. It appears that a high amount of noise maybe sufficient to overcome this problem of a high retrievalthreshold. A high amount of noise means that some ofthe subjects in the sample may have low threshold despitethe group, and this might be expected to cause some of theresults to favor /z/ when noise is high.
In conclusion, searching the parameter space of themodel reveals it behaves sensibly at border conditions,for example, it has no trouble capturing the faster learningof frequent phonemes. In contrast, when an infrequentphoneme presentation occurs the model suggests that itwill only be recognized if there is enough experience andif the model parameters are in what we might considerto be the normal human range. Specifically, for the settingswe tested the model parameter describing the breadth ofmemory search for the test trials, the retrieval threshold,had to be sufficiently low so as to be able to benefit fromthe effect of past experience. At the lowest setting of retrie-val threshold learning of /z/ always succeeded. It seemedthis screening off of relevant past memories by high retrie-val threshold could be occasionally overcome withingroups of simulated subjects, if the noise on the retrievalthreshold was sufficient. Higher noise leads to somegroups of simulated subjects by chance having a lowenough threshold so that they also succeed in retrieveddiscrimination.
These results imply that parameter differences might bea useful tool for exploring and predicting individual differ-ences in subjects. Encouragingly, the model did not showany patterns that would suggest an excess of flexibility inthe model, such as if the model had been able to predict/z/ would be learned before /s/. These results suggest thatit is plausible to suppose that the parameters map to actualcognitive functions. While we only tested limited ranges ofeach parameter, the ranges were not excessively narrowand we would similarly expect normal human ability tobe also distributed in limited ranges.
Experiment 1A
The results of the previous set of simulations suggestthat frequency can have a powerful influence on the emer-gence of phonemic contrasts. iMinerva is better able to dif-ferentiate a phonemic contrast where both contrastivephonemes occur frequently (/d/–/t/) than a phonemic con-trast where only one member of the pair occurs frequently(/s/–/z/). These results lead to a straightforward prediction.If iMinerva’s simulation of the processes underlyinginfants’ use of phonemic contrasts is accurate, then infantsshould be able to use more frequent contrasts before theyare able to differentiate less frequent contrasts. However,this prediction has not been assessed by previous research.Most prior research has found that infants succeed inresponding differentially to phonemic contrasts in a

124 E.D. Thiessen, P.I. Pavlik Jr. / Journal of Memory and Language 88 (2016) 117–132
word–object association task by 17 or 18 months (e.g.,Thiessen, 2007; Werker et al., 2002). But all of this researchhas focused on word-initial stop contrasts in which bothphonemes are highly frequent.
In Experiment 1 and Experiment 2, we will examine thedevelopmental progression of the use of the /s/–/z/ con-trast. Such an examination is informative in its own right,because infants’ use of a fricative contrast has not previ-ously been explored using the Switch task, the most com-mon word–object association task in this area of research(Stager & Werker, 1997; though see Shvachkin, 1973, fora discussion of children’s use of fricatives in a different ref-erential task). In addition, assessing infants’ use of the /s/–/z/ contrast will allow us to test iMinerva’s prediction thatinfants’ use of this contrast should emerge later than thestop consonant contrasts (such as /d/–/t/) typically testedin the Switch task (e.g., Thiessen, 2007; Thiessen & Yee,2010). But because fricatives have not previously beenused in the Switch task, it is important to first demonstratethat the expected inability to take advantage of phonemiccontrasts in word–object association tasks is present. Thisis our goal in Experiment 1. In Experiment 2, we will lookto see at what age infants can begin to successfully differ-entiate between /s/ and /z/ in the Switch task.
Method
ParticipantsParticipants were 25 toddlers between the ages of 17
and 18 months (M = 17.35). In order to obtain data fromthese 25 children, it was necessary to test 30. The addi-tional five participants were excluded for the followingreasons: fussing or crying (3), failure to habituate (1),and experimental error (1). According to parental report,all children were free of ear infection at the time of testing,and reported no history of hearing problems.
StimuliParticipants were exposed to a novel computer-
animated object, paired with a novel label. The objectwas animated, and moved against a black background; thisobject has been previously used in several variants of theSwitch procedure (Stager & Werker, 1997; Thiessen,2007; Thiessen & Yee, 2010). The object was paired withthe label ‘‘seer” or ‘‘zeer” (IPA: /sir/ and /zir/; the identityof the label was counterbalanced across infants). The labelswere recorded by a female native speaker of English in aninfant-directed prosody. Each label was repeated for aslong as the object remained on screen, with pauses of 1.4s between repetitions.
ProcedureThis experiment used a habituation procedure identical
to that used in Thiessen (2007). Participants, seated on aparent’s lap in a sound-attenuated room, controlled theduration of the presentation of the stimuli by the lengthof their gaze at a central monitor. To eliminate bias, par-ents wore headphones, and the experimenters sat in anadjacent room, blind to the nature of the stimulus beingpresented. The experimenter coded the duration of thechild’s looking time online, using a Macintosh running
the Habit program for OS X (Cohen, Atkinson, & Chaput,2004). After the child reached the habituation criterion(looking time less than 50% of the average of the first threetrials), six test trials were presented.
The child controlled the duration of stimulus presenta-tion, during both the habituation and test phases, by gaz-ing at a 3200 video monitor 150 cm in front of their seatedposition. The child’s attention was attracted to the monitorby a colorful video of Winnie the Pooh coupled with arecorded verbal encouragement. Once the experimenterbelieved the child’s attention was fixated on the monitor,stimulus presentation was initiated. An object thenappeared on the screen and the speakers adjacent to themonitor began to repeat label associated with that object.The stimulus presentation continued until the child lookedaway for more than 1 s, or until the child had gazed at themonitor for 20 s (the maximum time allowed per trial). Thevideo of Winnie the Pooh appeared at the end of each trialto recapture the child’s attention.
The experiment began with two familiarization trials, inwhich participants saw a nonsense object paired with theword ‘‘neem.” The familiarization trials were used to helpparticipants become accustomed to the pairing of audioand visual stimuli. Once these trials were finished, thehabituation phase began.
During the habituation trials, the novel object appearedon screen, and was paired with the label (either ‘‘seer” or‘‘zeer,” counterbalanced across infants); for all children,the label was an identical token repeated multiple times.The object moved onscreen while the label was repeated,with pauses of 1.4 s between each repetition. The objectand the label were presented until the child looked awayfrom the monitor for 1.5 s, at which point the attention-getting stimulus reappeared. Looking times to each trialwere calculated in real time, and the habituation trials con-tinued in random order until the child met the habituationcriterion: average looking time for three consecutive trialsthat fell below 50% of their looking time to the first threehabituation trials.
Once the child met the habituation criterion the 6 testtrials began. In all test trials, the child saw the object fromthe habituation phase on the monitor. There were twokinds of test trials: Same and Switch trials. In the Same tri-als, the children heard the syllable that they had previouslyheard paired with the object. In the Switch trials, the objectwas paired with a minimal pair of the label infants hadheard in the habituation phase. For infants exposed tothe object paired with ‘‘seer,” the Switch trial paired theobject with the novel label ‘‘zeer.” The opposite was truefor infants exposed to ‘‘zeer” during the habituation phase.
Same and Switch trials alternated, and the nature of theinitial test trial was counterbalanced across participants.As in the habituation trials, the object stayed on the screen,and the label continued to repeat, for as long as the partic-ipant continued to look at the monitor.
Results and discussion
On average, children habituated in 13.4 trials. This is asomewhat longer habituation phase than has been seenin prior experiments with stop consonants (see Table 4),
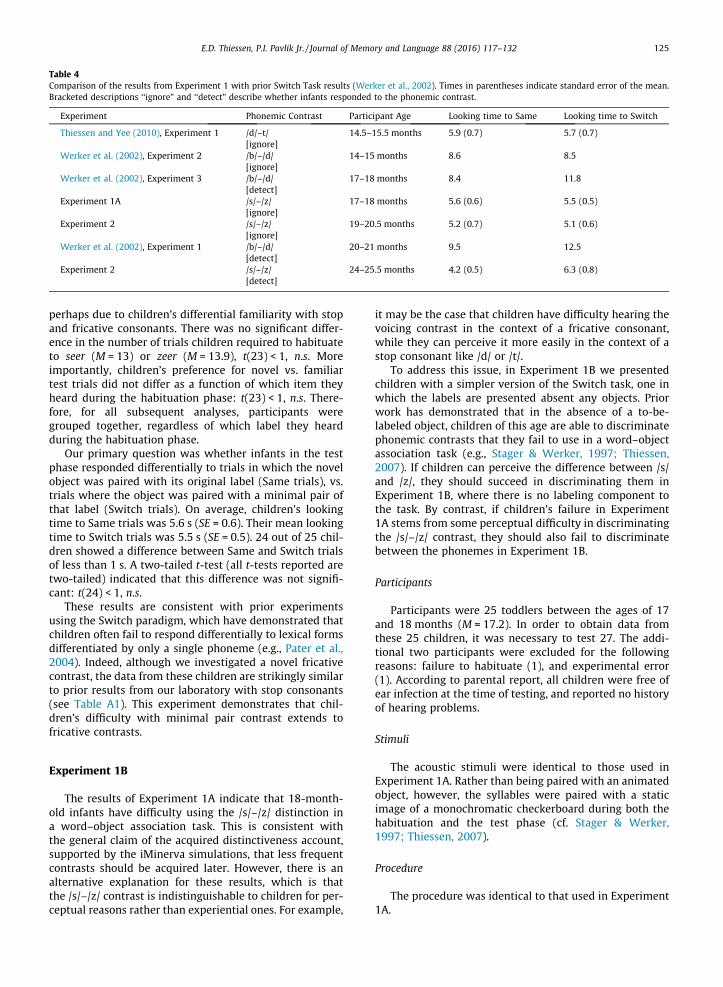
Table 4Comparison of the results from Experiment 1 with prior Switch Task results (Werker et al., 2002). Times in parentheses indicate standard error of the mean.Bracketed descriptions ‘‘ignore” and ‘‘detect” describe whether infants responded to the phonemic contrast.
Experiment Phonemic Contrast Participant Age Looking time to Same Looking time to Switch
Thiessen and Yee (2010), Experiment 1 /d/–t/[ignore]
14.5–15.5 months 5.9 (0.7) 5.7 (0.7)
Werker et al. (2002), Experiment 2 /b/–/d/[ignore]
14–15 months 8.6 8.5
Werker et al. (2002), Experiment 3 /b/–/d/[detect]
17–18 months 8.4 11.8
Experiment 1A /s/–/z/[ignore]
17–18 months 5.6 (0.6) 5.5 (0.5)
Experiment 2 /s/–/z/[ignore]
19–20.5 months 5.2 (0.7) 5.1 (0.6)
Werker et al. (2002), Experiment 1 /b/–/d/[detect]
20–21 months 9.5 12.5
Experiment 2 /s/–/z/[detect]
24–25.5 months 4.2 (0.5) 6.3 (0.8)
E.D. Thiessen, P.I. Pavlik Jr. / Journal of Memory and Language 88 (2016) 117–132 125
perhaps due to children’s differential familiarity with stopand fricative consonants. There was no significant differ-ence in the number of trials children required to habituateto seer (M = 13) or zeer (M = 13.9), t(23) < 1, n.s. Moreimportantly, children’s preference for novel vs. familiartest trials did not differ as a function of which item theyheard during the habituation phase: t(23) < 1, n.s. There-fore, for all subsequent analyses, participants weregrouped together, regardless of which label they heardduring the habituation phase.
Our primary question was whether infants in the testphase responded differentially to trials in which the novelobject was paired with its original label (Same trials), vs.trials where the object was paired with a minimal pair ofthat label (Switch trials). On average, children’s lookingtime to Same trials was 5.6 s (SE = 0.6). Their mean lookingtime to Switch trials was 5.5 s (SE = 0.5). 24 out of 25 chil-dren showed a difference between Same and Switch trialsof less than 1 s. A two-tailed t-test (all t-tests reported aretwo-tailed) indicated that this difference was not signifi-cant: t(24) < 1, n.s.
These results are consistent with prior experimentsusing the Switch paradigm, which have demonstrated thatchildren often fail to respond differentially to lexical formsdifferentiated by only a single phoneme (e.g., Pater et al.,2004). Indeed, although we investigated a novel fricativecontrast, the data from these children are strikingly similarto prior results from our laboratory with stop consonants(see Table A1). This experiment demonstrates that chil-dren’s difficulty with minimal pair contrast extends tofricative contrasts.
Experiment 1B
The results of Experiment 1A indicate that 18-month-old infants have difficulty using the /s/–/z/ distinction ina word–object association task. This is consistent withthe general claim of the acquired distinctiveness account,supported by the iMinerva simulations, that less frequentcontrasts should be acquired later. However, there is analternative explanation for these results, which is thatthe /s/–/z/ contrast is indistinguishable to children for per-ceptual reasons rather than experiential ones. For example,
it may be the case that children have difficulty hearing thevoicing contrast in the context of a fricative consonant,while they can perceive it more easily in the context of astop consonant like /d/ or /t/.
To address this issue, in Experiment 1B we presentedchildren with a simpler version of the Switch task, one inwhich the labels are presented absent any objects. Priorwork has demonstrated that in the absence of a to-be-labeled object, children of this age are able to discriminatephonemic contrasts that they fail to use in a word–objectassociation task (e.g., Stager & Werker, 1997; Thiessen,2007). If children can perceive the difference between /s/and /z/, they should succeed in discriminating them inExperiment 1B, where there is no labeling component tothe task. By contrast, if children’s failure in Experiment1A stems from some perceptual difficulty in discriminatingthe /s/–/z/ contrast, they should also fail to discriminatebetween the phonemes in Experiment 1B.
Participants
Participants were 25 toddlers between the ages of 17and 18 months (M = 17.2). In order to obtain data fromthese 25 children, it was necessary to test 27. The addi-tional two participants were excluded for the followingreasons: failure to habituate (1), and experimental error(1). According to parental report, all children were free ofear infection at the time of testing, and reported no historyof hearing problems.
Stimuli
The acoustic stimuli were identical to those used inExperiment 1A. Rather than being paired with an animatedobject, however, the syllables were paired with a staticimage of a monochromatic checkerboard during both thehabituation and the test phase (cf. Stager & Werker,1997; Thiessen, 2007).
Procedure
The procedure was identical to that used in Experiment1A.

126 E.D. Thiessen, P.I. Pavlik Jr. / Journal of Memory and Language 88 (2016) 117–132
Results and discussion
On average, children habituated in 8.9 trials. There wasno significant difference in the number of trials childrenrequired to habituate to seer (M = 8.8) or zeer (M = 9), t(23) < 1, n.s. After habituation, children’s preference fornovel vs. familiar test trials did not differ as a function ofwhich item they heard during the habituation phase: t(23) < 1, n.s. Therefore, for all subsequent analyses, partic-ipants were grouped together, regardless of which labelthey heard during the habituation phase.
On average, children’s looking time to Same trials was3.5 s (SE = 0.5). Their mean looking time to Switch trialswas 5.6 s (SE = 0.7). 22 out of 25 infants looked longer toSwitch trials than to Same trials. A two-tailed t-test indi-cated that this difference was significant: t(24) = 3.1,p < .05. This result demonstrates that children are able toperceive the /s/–/z/ contrast. The difficulty in respondingdifferentially to this contrast is selectively present in aword–object association task.
Experiment 2
The results of Experiment 1 demonstrate that the /s/–/z/phonemic contrast results in the same kind of difficulty inthe Switch task as do more common (and commonlytested) stop consonants: once infants have associated anobject with the label /sir/, they accept /zir/ as an inter-changeable label for the same object. Prior research hasshown that for stop consonants, children can succeed inthe Switch task by 18 months (e.g., Thiessen, 2007;Thiessen & Yee, 2010; Werker et al., 2002). One possibleexplanation for this is that young children have limitedprocessing capacity, which prevents them from encodingthe label in the context of a label–object matching task.From this perspective, the reason why children succeedonce they have reached a threshold age is that they haveexceeded some critical capacity threshold (for discussion,see Werker et al., 2002). If this account is correct, we wouldexpect that 20-month-olds would succeed with a widerange of consonants, not just stop consonants, becausethey have the necessary cognitive capacity to representboth the auditory and visual information necessary to suc-ceed in the Switch task.
Alternatively, we have proposed that the developmen-tal change in children’s use of phonemic contrasts is notrelated to overall gains in capacity, but to children’sincreasing familiarity with phonemes due to an expandingvocabulary (Thiessen, 2007). If this is the case, childrenshould succeed at 18–20 months with phonemic contrastswith which they are more familiar, but potentially fail withphonemic contrasts with which they are less familiar. Thisis consistent with the prediction emerging from iMinervathat children’s differentiation of phonemic contrastsdepends on the number of different lexical contexts inwhich the contrast occurs. Because /s/–/z/ occurs muchless frequently in word-initial position than the stop con-sonants previously tested in the Switch paradigm, wehypothesize that 20 month-olds will fail to respond differ-entially to this contrast. To test this hypothesis, we used
the stimuli and procedure from Experiment 1 to test both20- and 25-month-old children on their ability to use the/s/–/z/ contrast in a word–object association task.
Method
ParticipantsParticipants were two groups of 25 toddlers, one group
between the ages of 19.0 and 20.5 months (M = 19.8), andthe other group between the ages of 24.0 and 25.5 months(M = 24.9). In order to obtain data from 25 20-month-olds,it was necessary to test 29 participants. The additional fourparticipants were excluded for fussing or crying (3) or fail-ure to habituate (1). In order to obtain data from 25 25-month-olds, it was necessary to 33 participants. The addi-tional eight participants were excluded for fussing or cry-ing (6) and failure to habituate (2). According to parentalreport, all children were free of ear infection at the timeof testing, and reported no history of hearing problems.All participants were given a questionnaire for parents tocomplete prior to visiting the lab. This questionnaire con-tained all of the /s/- and /z/-initial words found on theMacArthur CDI: Words and Sentences form. As in the orig-inal MacArthur, for each word parents were asked to indi-cate whether their child comprehended and/or producedthe word.
Stimuli and procedureThe stimuli and procedure were identical to those used
in Experiment 1A.
Results and discussion
20-month-oldsOn average, 20-month-old children habituated in 7.6
trials. There was no significant difference in the numberof trials children required to habituate to seer (M = 7.8) orzeer (M = 7.5), t(23) < 1, n.s. Subsequent to habituation,children’s preference for novel vs. familiar test trials didnot differ as a function of which item they heard duringthe habituation phase: t(23) < 1, n.s. Therefore, for all sub-sequent analyses, participants were grouped together,regardless of which label they heard during the habitua-tion phase.
Like the younger children in Experiment 1A, 20-month-old children failed to respond differentially to Same andSwitch trials. 21 out of 25 children showed looking timesto Same and Switch trials that were within 1 s of eachother. On average, children’s looking time to Same trialswas 5.2 s (SE = 0.7). Their mean looking time to Switch tri-als was 5.1 s (SE = 0.6). A two-tailed t-test indicated thatthis difference was not significant: t(24) < 1, n.s. Theseresults are consistent with iMinerva’s predictions: while20-month-olds can succeed with more frequent phonemiccontrasts (e.g., Thiessen & Yee, 2010; Werker et al., 2002),they do not respond differentially to the less frequent /s/–/z/ contrast.
25-month-oldsOn average, 25-month-old children habituated in 8.5
trials. There was no significant difference in the number

Fig. 2. Scatterplot of individual 25-month-old children’s degree ofdishabituation in Experiment 2 related to the number of /s/ and /z/words children comprehend, via parental report on a subset of theMacArthur-Bates CDI. Negative values on the Y-axis (dishabituationscore) indicate a preference for the Same test item; positive valuesindicate a preference for the Switch test item.
E.D. Thiessen, P.I. Pavlik Jr. / Journal of Memory and Language 88 (2016) 117–132 127
of trials children required to habituate to seer (M = 8.0) orzeer (M = 8.9), t(23) < 1, n.s. Subsequent to habituation,children’s preference for novel vs. familiar test trials didnot differ as a function of which item they heard duringthe habituation phase: t(23) < 1, n.s. Therefore, for all sub-sequent analyses, participants were grouped together,regardless of which label they heard during the habitua-tion phase.
Unlike 20-month-olds, 25-month-olds responded dif-ferentially to the /s/–/z/ distinction. 16 out of 25 childrenlooked longer to Switch trials than to Same trials. On aver-age, children’s looking time to Same trials was 4.2 s(SE = 0.5), while their looking time to Switch trials was6.3 s (SE = 0.8). This difference was significant, t(24) = 2.4,p < .05. These results are consistent with iMinerva’s predic-tion that use of the /s/–/z/ contrast will take longer toemerge because children experience it less frequently.
Note that at least in one respect, however, the iMinervasimulations are potentially discrepant from the behavioralresults. iMinerva is even more sensitive to phoneme fre-quency than our behavioral results, in that iMinerva showsan asymmetry in its response to the less frequent /z/ andthe more frequent /s/; at some points in learning, iMinervadiscriminates an /s/-probe from /z/, but does not distin-guish a /z/-probe from /s/. By contrast, our 17–20 monthsolds (who failed to respond differentially to either con-trast) and our 25-month-olds (who responded differen-tially to both) showed no such asymmetry. Onepossibility is that there is an intermediate age group (e.g.,23-month-olds) who would succeed in the task whentrained on /s/ but fail on when trained on /z/; the 25-month-olds may simply be too old to show iMinerva’s pre-dicted asymmetry. Another (not mutually exclusive) possi-bility is that our experiments were insensitive to thepredicted asymmetry. One reason for this is that whilewe counterbalanced /s/ and /z/ initial words during famil-iarization, this resulted in a smaller sample size for eitherkind of word, so the experiments may have been insensi-tive to any differences between the phonemes. The Switchtask itself may also be a poor instrument for detecting rel-atively subtle differences between phonemes. Recall thatin the Switch task, the child simply has to respond differ-entially to the novel trial. It may be the case that even aweaker representation of /z/ is sufficient for the child todetect that the novel stimulus (‘‘seer”) is not identical tothe familiarized stimulus (‘‘zeer”). If this is the case, exper-iments using a more sensitive measure, such as reactiontime (e.g., Yoshida et al., 2009), may detect differences inchildren’s response to /s/-initial and /z/-initial words.
A related prediction of the acquired distinctivenessaccount, and the iMinerva simulations, is that individualdifferences in children’s familiarity with the /s/–/z/ con-trast should be related to individual differences in theirresponse to the contrast. That is, children who have moreexperience with /s/ and /z/ in distinct lexical contextsshould be more likely to make use of the contrast in aword–object association task. To explore this prediction,we assessed how children’s parent-reported familiaritywith /s/–/z/ words predicted the degree to which childrendishabituated. If the simulations reported above are cor-rect, there should be a positive correlation between
reported vocabulary size and children’s use of the /s/–/z/contrast. If the protracted emergence of the /s/–/z/ contrastis due to some acoustic idiosyncrasy, there is no reason toexpect such a correlation.
Twenty-one of 25 participants’ parents completed thevocabulary questionnaire, which assessed their knowledgeof /s/- and /z/-initial words (note that only /s/ and /z/words were assessed, as the full MacArthur CDI took toolong for parents to complete given the number of vocabu-lary items children of this age were familiar with). Com-prehension scores ranged from 0 to 71 (M = 30.1,SD = 17.1). We correlated the number of words a childcomprehended with a difference score (looking time toSwitch trial – looking time to Same trial) representing theirdegree of dishabituation. There was a significant positivecorrelation between these scores, r = .44, p < .05 (seeFig. 2). This correlation indicates that the more /s/–/z/ ini-tial words a child knew, the greater the magnitude of theirdishabituation to Switch trials. This is consistent withiMinerva’s prediction that more experience with /s/ and /z/ in lexical contexts should make children better able todifferentiate between them.
General discussion
Despite the rapid gains infants make in adapting to thephonemic structure of their native language in the firstyear of life (e.g., Werker & Tees, 1984), children still strug-gle to use these phonemic contrasts in the Switch task wellinto the second year of life (e.g., Pater et al., 2004; Stager &Werker, 1997; Thiessen, 2007; Thiessen & Yee, 2010). Wepropose that the later emergence of the ability to usephonemic contrasts in a word–object association task isthat not all perceptual contrasts are lexical contrasts. Forexample, indexical information also varies across lexicalexemplars, and is readily perceptible to infants, but theseindexical differences do not indicate a difference in lexicalcategory.
The acquired distinctiveness account suggests an ave-nue via which infants can identify which perceptual dis-tinctions are relevant in differentiating lexical items: bylearning from the distribution in the input (for a related

128 E.D. Thiessen, P.I. Pavlik Jr. / Journal of Memory and Language 88 (2016) 117–132
argument, see Apfelbaum & McMurray, 2011). When twophonemes occur in distinct lexical contexts (such as /d/and /t/ in ‘‘doggy” and ‘‘teddy”), they become more distinc-tiveness and more readily available for use. Because infantsknow relatively few minimal pair words (Caselli et al.,1995), most of the lexical items that infants learn shouldserve to make phonemic contrasts more distinctive. There-fore, as infants become familiar with more lexical forms,they should become better able to use the phonemesembedded in those forms.
This account differs from prior computational accountsof the acquisition of phonetic contrasts in a variety of ways.First, unlike most computational accounts of the acquisi-tion of phonetic categories (e.g., Vallabha, McClelland,Pons, Werker, & Amano, 2007), it is not focused on howinfants learn to discriminate among phonetic exemplarsto identify category structure; it is focused on how infantslearn to use these distinctions. Merely being able to make aperceptual distinction is not sufficient for knowing that adistinction is informative about a difference in meaning,as many perceptual distinctions (e.g., speaker identity)are uninformative with respect to lexical meaning. The dis-tributional learning account is unique in that it focuses onthe context in which these phonemes occur, and the fre-quency with which children receive that contextual infor-mation, to predict when and how children treat a phoneticcontrast as semantically contrastive. Second, iMinervainvokes a novel (at least, with respect to phonetic learning)mechanism to explain the role of variability in the develop-ment of phonetic contrasts. The most compelling priorcomputational account of the role of variability in phoneticlearning is an associative learning account (Apfelbaum &McMurray, 2011). On this account, when children experi-ence a phonetic contrast in different contexts (e.g., pro-duced by different speakers), they downweight attentionto the variable dimensions, to focus on the information(the phonetic contrast) that is predictive. By contrast, inour computational approach, the variability becomes anessential part of the representation of the contrast. Whena child hears /d/ in one set of contexts, and /t/ in a differentset of contexts, these different contexts are automatically‘‘called to mind” in subsequent experiences with thosephonemes, and serve to pull them apart in representationalspace. While we have focused on lexical context, anintriguing possibility of this approach is that other con-texts – such as the object with which an object is paired(e.g., Yeung & Werker, 2009), or the speakers who producethe contrasts – may be part of that representational space.
The current results provide two novel pieces of evi-dence in support of the acquired distinctiveness account.First, our simulations suggest that natural input (at leastin English) provides the kind of distributional structurenecessary for children to learn to use phonemic categoriesvia acquired distinctiveness. Across those lexical itemswith which English-learning children are familiar, pho-nemes tend to occur in distinct lexical contexts, and thesecontexts provide enough evidence for a simulated learnerto become better able to differentiate phonemic contrastsas a function of increasing familiarity with a set of lexicalitems. This suggests that the developing lexicon may playa crucial role in driving children’s increasing ability to
make use of phonemic contrasts in a word–object associa-tion task (cf. Werker et al., 2002). As children learn morewords, they acquire more evidence differentiating the rep-resentations of similar phonemes, because those pho-nemes tend to occur in different lexical frames. Thissuggests that children’s failures in the Switch task arenot due to capacity limitations or a lack of social support,but are instead informative about their developing phone-mic representations.
Necessarily, simulations like iMinerva provide only anexistence proof that learning from the input is possible,not a demonstration that humans learn in the same wayas the model. However, the acquired distinctivenessframework, instantiated in iMinerva, makes a novel predic-tion about human learning: the more frequent phonemesshould emerge sooner than less frequent phonemes. Notethat this is not the only possible developmental account.For example, Werker et al. (2002) suggested a capacityaccount in which failures in the Switch task could beexplained via children’s lack of sufficient capacity toencode and maintain acoustic detail in the context of aword–object association task. This account predicts thatonce children have reached a certain threshold of capacity,they should be able to succeed in the Switch task, regard-less of which contrast they are asked to use. Indeed, this isa common implicit assumption in the literature. On thebasis of children’s success at 18–20 months with stop con-sonants (like /b/–/d/), it is often assumed that children cansucceed with all consonantal distinctions in the Switchtask by this age.
As our results demonstrate, this is not the case. Even20-month-old infants fail to make use the /s/–/z/ distinc-tion in a word–object association task. To our knowledge,this is the first demonstration of failure in the Switch taskat this older age. Experiment 1B indicates that this is notdue to an inability to discriminate the /s/–/z/ contrast.Rather, we suggest that it is due to the fact that the /s/–/z/ contrast is much less frequent than the stop consonantsthat have been previously used in the Switch task (e.g.,Pater et al., 2004; Stager & Werker, 1997; Thiessen, 2007;Thiessen & Yee, 2010). Because the contrast is less fre-quent, it takes children longer to begin to use it produc-tively. This should not be taken to mean that frequency isthe only reason that children use fricative contrasts laterthan stop consonants. A variety of empirical work suggeststhat fricatives may present a more difficult perceptualchallenge than common stop consonants (e.g., Abbs &Minifie, 1969). Indeed, the lower frequency of fricativecontrasts – especially in infant directed speech – may bethe result of linguistic adaptation to the kinds of contraststhat infants find easier to perceive. Instead, these resultssuggest that frequency and context play a role, but cer-tainly not the only role, in making a contrast accessibleto the semantic system. An important avenue for futurework will be to replicate this role of frequency and contextacross a wider array of contrasts to begin to tease apart theindependent contributions of distributional informationand perceptual information.
What these results suggest, however, is that failure inthe Switch task cannot solely be ascribed to infants’ andyoung children’s inability to represent perceptual detail

E.D. Thiessen, P.I. Pavlik Jr. / Journal of Memory and Language 88 (2016) 117–132 129
(for related arguments, see Swingley & Aslin, 2000, 2002;Yoshida et al., 2009). Instead, performance in the Switchtask reflects howmuch evidence infants have acquired thata phonetic contrast reflects differences at the lexical level.The more information infants have acquired indicatingthat two phonemes are distributed in two different setsof lexical items, the more like they are to use the contrastbetween those phonemes. Because the /s/–/z/ contrast isrelatively rare, it takes longer to emerge productively. Fur-thermore, consistent with the acquired distinctivenessaccount, when children are on the cusp of using a contrastin the Switch task it is possible to predict how well theywill do as a function of their experience with that particu-lar contrast. In Experiment 2, the children who had moredistributional information about /s/ and /z/ (that is, whoknew more /s/ and /z/-initial words) were more likely tosucceed in the task.
Taken together, these results provide strong support forthe acquired distinctiveness account. They demonstratethat natural language provides the necessary distributions,and they demonstrate that the degree of experience thatinfants have with those distributions is predictive of theirperformance in the Switch task. Furthermore, these resultssuggest that iMinerva is a potentially useful tool for simu-lating distributional learning tasks, insofar as it makes nov-el, testable predictions about development in response tothese patterns.
Acknowledgments
This research was funded by an NSF career award toErik D. Thiessen, NSF BCS-0642415. We would like to thankMeagan Yee, Teresa Pegors, and Ashley Episcopo for help inthe conduct of this research, as well as the parents of all ofthe infants who participated.
Appendix A
Our model is called interpretative Minerva (iMinerva)because it is an extends Hintzman’s MINERVA 2 model(Goldinger, 1998; Hintzman, 1988) with the capability tomaintain not only examples in memory, but also interpre-tations of examples. In the model, each new example thatthe learner encounters is compared with prior examples todetermine the similarity with these prior examples. Thiscomparison is proposed to be an automatic process ofhuman cognition according to the model and correspondsto learner’s basic ability to interpret new experiencethrough the lens of old experience (learning is construc-tive). If multiple prior examples are similar, the learnerselects the strongest of them. Assuming a prior exampleis selected; the learner engages with the prior example tomodify it and create an interpretation. This synthetic inter-pretation is then recorded as a new memory item.
Each interpretation the learner forms functions like anexample according to the model, so that once interpreta-tions are formed, they are themselves engaged with bynew examples. In this way, interpretations are like con-cepts that originally develop from a perceptual experience,but then get increasingly divorced from perceptual experi-
ences as multiple perceptual encounters shape conceptuallearning (Sloutsky, 2009). Learning in the model occurs assimple adjustment of the prior example or interpretationtrace (or more simply, the memory) using an additivelearning rule to determine how prior memories grow bya proportion of the new similar example. This mechanismcreates a more general representation by blending togetheritems that originally share some similarity. If the newexample has a feature that is different than an old example,despite being similar overall, this learning averages the oldfeature with a portion of the new feature to reduce thestrength of the feature that is different in theinterpretation.
Interpretation in this way is a mechanism for prototypecreation in the model. If, for example, prior example A andnew example B are found to be similar, they may beengaged. In this case, if A has feature 1 = �1 and B has fea-ture 1 = 1, then the interpretation created will show a fea-ture 1 that is moved from �1 closer to 1 during learning.While this means that the interpretation is more general,that generality will still not generalize well because feature1 is still included in the interpretation. For this reason, ifexample A is repeated it will still match with prior exampleA better than the interpretation, while if example B isrepeated it will also match with prior example B betterthan the interpretation.
To resolve this issue we introduce a very simpleabstraction mechanism that removes features from inter-pretations when those features are some fraction of themaximum absolute feature strength. This abstractionmechanism seems a natural addition to the system, sincesalience is something that the brain seems to encodedirectly (Gottlieb, 2007) and our abstraction mechanismis inherently a mechanism that abstracts away less salientfeatures. Not only do we find evidence for salience relatedinformation at the level of parietal cortex activity, but wealso see that there appear to be cognitive benefits of usingprototypes (Winkielman, Halberstadt, Fazendeiro, & Catty,2006). Furthermore, there are very good reasons to believethat humans are limited in their focus of attention (Miller,1956), and so, interpretations must necessarily becomeabstract because of the lack of an ability to attend to allthe features in a stimulus and learn them all each timethe stimulus is encountered in the environment.
A.1. Prior specification
In iMinerva memory traces are represented as vectorsof real numbers where some features may be null values.In contrast, MINERVA 2 requires 1, 0 or �1 values. Thischange in the feature coding provides a representation thatallows us to capture both the strength and durability of aninterpretation as the absolute value of a feature’s strength.In this formalism, 0 comes to mean either a weak or veryequivocal feature, and in either case, we allow features totransition to a null value when they are near 0. This mech-anism (abstraction, described below) allows us to repre-sent salience as a binary quantity that depends uponfeature strength. This binary salience was a simplificationof more complex alternatives that would have requiredfeature salience as a continuous quantity for each feature.

130 E.D. Thiessen, P.I. Pavlik Jr. / Journal of Memory and Language 88 (2016) 117–132
Table A1 shows how each syllable’s consonants and vowelswere represented.
Since we use this representation format for our inter-pretations, we also needed a new similarity function, asMINERA 2 simply uses the weighted average of featureagreement. Because our features now represent thestrength of each feature in the interpretation, we are nolonger looking for the mere binary agreement of features,but rather how the pattern of strengths in the exemplaris similar to the pattern of strengths in the interpretation.Because of this we have adopted a well-established mea-sure, cosine similarity, because cosine similarity comparesthe magnitude pattern while MINERVA 2 similarity onlyweights yes or no agreement of features. In addition tohandling the magnitudes, cosines similarity has a long his-tory of use in text classification (Salton, 1989). Eq. (1)below shows the cosine similarity function. Like Hintz-man’s MINERVA 2, we compress the results of this metricto compute similarity by cubing the raw cosine similaritiesto increase dispersion among the values obtained. Hintz-man refers to the cubed value as representing activationthe activation of a memory be a similar probe (Goldinger,1998; Hintzman, 1988). The calculation of our similaritymeasure, cosine similarity cubed, is shown in Eq. (1). Fur-thermore, we have modified this traditional equation suchthat if a feature is missing (has been abstracted away in thecase of interpretations, or was not present in the stimuli in
Table A1Descriptions of the feature meanings for the phoneme vectors used byiMinerva.
Type Index Description
C 1 voicingC 2 manner: stopC 3 manner: fricativeC 4 manner: africateC 5 manner: nasalC 6 manner: lateralC 7 manner: retroflexC 8 manner: glideC 9 place: labialC 10 place: interdentalC 11 place: alveolarC 12 place: alveopalatalC 13 place: velarC 14 place: glottalV 1 vowel [bead]V 2 vowel [bid]V 3 vowel [bayed]V 4 vowel [bed]V 5 vowel [bad]V 6 vowel [bod]V 7 vowel [foot]V 8 vowel [bode]V 9 vowel [bood]V 10 vowel [bud]V 11 vowel [bird]V 12 vowel [bide]V 13 vowel [boy]V 14 vowel [bore]V 15 vowel [blouse]V 16 vowel [bear]V 17 vowel [beer]V 18 vowel [bard]
the case of examples) from either trace A or trace B, thatfeature is ignored in the computation.
SimilarityA;B ¼Pn
i¼1AiBiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiPni¼1A
2i
q ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiPni¼1B
2i
q0B@
1CA
3
ð1Þ
iMinerva processes the example input stream in dis-crete time steps representing the cognitive cycle (Madl,Baars, & Franklin, 2011) for each word encounter. Eachnew example is compared with all prior memory traces(both interpretations and examples) to see if the engage-ment threshold parameter is exceeded. If the engagementthreshold is exceeded, it indicates that the learner noticesthe match(s) with prior stimuli. If nothing is matched, nointerpretation is formed. While the underlying comparisonprocess is assumed to unfold over time, the model opera-tionalises the outcome by a simple ‘‘max similarity rule.‘‘Eq. (3) shows how a prior trace, A, accumulates a portionof the strength of B when the similarity of B exceedsengagement threshold and is the maximum similaritytrace that exceeds engagement threshold. The learning ratefor this accumulation is represented by k.
Given probe example A; and Xn;
the nth item from the set of i memoriesif SimilarityA;Xn
> threshold
andSimilarityA;Xn
¼ argmaxðSimilarityA;X1::iÞ
thencreate a new memory; Xiþ1 ¼ Xn þ kA ð2Þ
This learning process is both strengthening (Eq. (2)) andabstractive. The abstractive component is captured in Eq.(4) with specifies that given any feature in the interpreta-tion, it will be removed if it is weak relative to the maximalfeature. This means that the absolute value of the strengthof any feature must exceed the engagement threshold forthat feature to be retained. Eq. (3) describes how each fea-ture must exceed this criterion. Eq. (3) uses the q parame-ter which is the fraction of the maximum absolute valuethat must be exceeded to retain a feature, otherwise thatfeature is set to null.
Given Xm;where m indexes features 1 . . . j for memory X
if jXmj < qðargmaxjX1...jjÞset Xm ¼ null
ð3ÞFinally, we included forgetting in the model, which we
simulate with simple exponential decay. While exponen-tial decay may be a less accurate than power law or otherfunctions in modeling forgetting (Rubin & Wenzel, 1996),in this model where forgetting is not a key factor, thisdecay mechanism adds plausibility to the model becauseit illustrates how memory traces are lost and why themodel does not need to be concerned about the criticismthat storing unlimited examples is implausible. The modelis explicitly limited in the examples it can store becauseold examples eventually decay to the point they are neverengaged, and are therefore essentially deleted. Further, we

E.D. Thiessen, P.I. Pavlik Jr. / Journal of Memory and Language 88 (2016) 117–132 131
should not that we do not have a ‘‘theory of decay” otherthan to argue that interference appears to be a primarycause of decay (Pavlik & Anderson, 2005). Eq. (4) showsdecay in the model for some example feature vector, N.
Given Xm;t; where m indexes features 1 . . . jfor memory item X at trial tXm;tþ1 ¼ dXm;t ð4Þ
A.2. New mechanisms
Similarity figures into our analysis both in running themodel as it makes interpretations, but also in the morebasic process of computing the memory echo. While wedid not discuss it in our previous paper, the overall similar-ity our model retains with Hintzman’s MINERVA 2 meansthat we can use the MINERVA 2 memory echo intensityand content functions as a way to measure the memorystructures created under different conditions. Echo inten-sity is simply defined as the sum of the similarity (Eq.(1)) of the probe to all of the prior memories. Echo contentis created by multiplying each memory’s similarity (a mea-sure that determines how ‘‘activated” a memory becomesby a probe) by the memory vector, and then in a secondstep sums all these individual activated traces to get thesummed echo content for a specific probe.
Using this standard method (Goldinger, 1998) to com-pute echo content we considered how to compare the echocontents to different probes to see what is recalled undervarious circumstance by the model. We desired to testthe idea that the distributional pattern differences in theecho content allow the infant to discriminate the probesounds. We propose that the ‘‘echo content” allows infantsto attach different labels to sounds. To the extent that twosounds cue memory patterns that are very similar, theywill not be differentiated. Conversely, if the overall patternof features recalled for two different probes differs, theywill be considered as members of unique classes. However,we also realized that strength of the memory would needto play a role, and we needed a recall equation that wouldrepresent both strength and match of prior memories. Wedid not get that from MINERVA 2.
In the paper we describe in detail howwe used the echocontent function to create a new discriminative recallstrength equation that asks the question: given the echocontents of the possible probes, which echo is most likelyto be the identified given a particular probe. The meansthat the echo contents to the possible probes are used asthe model’s measurement of the categories in memory.
Table A2Parameter values used in the simulations.
Parameter Represents
k Learning rateq Abstraction proportiond Decay rateEngagement threshold Engagement thresholdEngagement threshold noise SD of engagement thresholRetrieval threshold Retrieval thresholdRetrieval threshold noise SD of retrieval threshold
In the paper this meant that for each simulation we com-puted 4 echo content vectors that were compared to seewhich was identified (i.e., most active) for each probe.We do this with Eq. (5), where we first normalize the acti-vation similarity of the probe with the possible memories(since the correct memory echo contents is a derived fromthe probe, this normalizes that value to 1, and other valuesare less than 1, generally positive).
Following this step we take this value to the exponentof the average absolute value of the echo contents, whichmeans that strong memories will cause increased discrim-ination by increasing dispersion of values less than 1.Finally the value was also multiplied by the average abso-lute value of the echo contents, which means that strongmemories will tend to dominate recall. As detailed in thebody of the paper, as practice accumulates, at first the mul-tiplicative term dominates, meaning frequency of priorlearning controls recall reducing discrimination, but lateron, the exponential ‘‘resonance” term dominates as stron-ger memories resonate and allow more opportunities forincorrect match rejection, thus improving discrimination.
Given probe example A; and echo content from probe x; Qx :
Pni¼1jQxjn
CosineA;Qx
CosineA;Qa
� �Pn
i¼1jQx j
n
ð5ÞAdditionally, for the new simulation in this paper we
changed the echo content function that feeds into Eq. (2),by only including the echoes from memories that wereabove some retrieval threshold similarity with the probe.This recall breadth parameter was found to control thespeed of discrimination from Eq. (5), such that more broadrecall results in better discrimination, due to increased res-onance from the strong memory signal. We find it plausi-ble to suppose that in addition to improvement indiscrimination due to learning, shown in the paper, theimproved discrimination in children may come fromreductions in the retrieval threshold (increases in thebreadth of recall) as a child’s brain develops, and we coulduse our retrieval threshold parameter as one way to modelthis development. In other words, our model can be easilyused to suggest the combination of maturation and fre-quency of phonemes experienced contribute to discrimina-tion growth across infancy. However, it is important topoint out that other mechanisms like a higher learning ratecould also be used to capture this improved discriminationcapability we presume is gained as children mature.
Table A2 shows the parameters across the models,which are discussed in the paper body where appropriate.
Simulation Search
.2 .05, .15, .25
.1 .05, .15, .25
.998 .997, .998, .999
.75 .65, .80, .90d .05 .05, .15, .25
.425 .325, .475, .625
.05 .05, .15, .25

132 E.D. Thiessen, P.I. Pavlik Jr. / Journal of Memory and Language 88 (2016) 117–132
The model above is highly simplified to clarify explanation,but we argue that it captures the basic process of generalexemplar learning, prototype extraction and prototyperecall as it occurs in learners without complex language.We do not argue that the model above is correct or com-plete, merely that it adds to our understanding by showinga minimal set of principles that can achieve the learning ofphonemic discrimination from words. It seems likely thatinfants have minimal ways to direct the above processes,and that the cycle of experience, learning, and abstractionis driven by physical needs or by attraction to similaritiesin the environment (particularly similarities to items thatwere associated with reward in the past). No doubt,humans become quite skilled at guiding this cycle andsculpting their learning as their capabilities for action growand they develop complex symbolic representations andgoal structures.
References
Abbs, M. S., & Minifie, F. D. (1969). Effect of acoustic cues in fricatives onperceptual confusions in preschool children. Journal of the AcousticalSociety of America, 46, 1535–1542.
Anderson, J. L., Morgan, J. L., & White, K. S. (2003). A statistical basis forspeech sound discrimination. Language and Speech, 46, 155–182.
Apfelbaum, K., & McMurray, B. (2011). Using variability to guidedimensional weighting: Associative mechanisms in early wordlearning. Cognitive Science, 35, 1105–1138.
Caselli, M. C., Bates, E., Casadio, P., Fenson, J., Fenson, L., Sanderl, L., & Weir,J. (1995). A cross-linguistic study of early lexical development.Cognitive Development, 10, 159–199.
Charles-Luce, J., & Luce, P. A. (1990). Similarity neighborhoods in youngchildren’s lexicons. Journal of Child Language, 17, 205–215.
Charles-Luce, J., & Luce, P. A. (1995). An examination of similarityneighborhoods in young children’s receptive vocabularies. Journal ofChild Language, 22, 727–735.
Coady, J. A., & Aslin, R. N. (2003). Phonological neighborhoods in thedeveloping lexicon. Journal of Child Language, 30, 441–469.
Cohen, L. B., Atkinson, D. J., & Chaput, H. H. (2004). Habit X: A new programfor obtaining and organizing data in infant perception and cognitionstudies (Version 1.0). Austin: University of Texas.
Fennell, C., & Waxman, S. R. (2010). What paradox? Referential cues allowfor infant use of phonetic detail in word learning. Child Development,81, 1376–1383.
Fenson, F., Dale, P. S., Reznick, J. S., Thal, D., Bates, E., Hartung, J. P., ...Reilly, J. S. (2002). MacArthur communicative development inventories:User’s guide and technical manual. Baltimore: Paul H. Brookes.
Goldinger, S. D. (1998). Echoes of echoes? An episodic theory of lexicalaccess. Psychological Review, 105, 251–279.
Gottlieb, J. (2007). From thought to action: The parietal cortex as a bridgebetween perception, action, and cognition. Neuron, 53(1), 9–16[10.1016/j.neuron.2006.12.009].
Hall, G. (1991). Perceptual and associative learning. Oxford: ClarendonPress.
Hintzman, D. L. (1988). Judgments of frequency and recognition memoryin a multiple-trace memory model. Psychological Review, 95, 528–551.
Houston, D. M., & Jusczyk, P. W. (2003). Infants’ long-termmemory for thesound patterns of words and voices. Journal of ExperimentalPsychology: Human Perception and Performance, 29, 1143–1154.
MacWhinney, B. (2004). A multiple process solution to the logicalproblem of language acquisition. Journal of Child Language, 31,883–914.
Madl, T., Baars, B. J., & Franklin, S. (2011). The timing of the cognitivecycle. PLoS ONE, 6(4), e14803. http://dx.doi.org/10.1371/journal.pone.001480.
McClelland, J. L., & Plaut, D. C. (1999). Does generalization in infantlearning implicate abstract algebraic-like rules? Trends in CognitiveScience, 3, 166–168.
Miller, G. A. (1956). The magical number seven, plus or minus two: Somelimits on our capacity for processing information. PsychologicalReview, 63, 81–97.
Nissen, S. L., & Fox, R. A. (2005). Acoustic and spectral characteristics ofyoung children’s fricative productions: A developmental perspective.Journal of the Acoustical Society of America, 118, 2570–2578.
Pater, J., Stager, C. L., & Werker, J. F. (2004). The lexical acquisition ofphonological contrasts. Language, 80, 361–379.
Pavlik, P. I., Jr., & Anderson, J. R. (2005). Practice and forgetting effects onvocabulary memory: An activation-based model of the spacing effect.Cognitive Science, 29, 559–586.
Rubin, D. C., & Wenzel, A. E. (1996). One hundred years of forgetting: Aquantitative description of retention. Psychological Review, 103,734–760.
Salton, G. (1989). Automatic text processing: The transformation, analysis,and retrieval of information by computer. Addison-Wesley LongmanPublishing Co., Inc.
Shvachkin, N. Kh. (1973). The development of phonemic speechperception in early childhood. In C. Ferguson & D. Slobin (Eds.),Studies of child language development (pp. 91–127). New York: Holt,Rinehart, & Winston (Original work published in 1948).
Singh, L. (2008). Influences of high and low variability on infant wordrecognition. Cognition, 106, 833–870.
Sloutsky, V. M. (2009). From perceptual categories to concepts: Whatdevelops?
Stager, C. L., & Werker, J. F. (1997). Infants listen for more phonetic detailin speech perception than word-learning tasks. Nature, 388, 381–382.
Swingley, D. (2009). Contributions of infant word learning to languagedevelopment. Philosophical Transactions of the Royal Society B, 364,3617–3622.
Swingley, D., & Aslin, R. N. (2000). Spoken word recognition and lexicalrepresentation in very young children. Cognition, 76, 147–166.
Swingley, D., & Aslin, R. N. (2002). Lexical neighborhoods and the word-form representations of 14-month-olds. Psychological Science, 13,480–484.
Swingley, D., & Aslin, R. N. (2007). Lexical competition in young children’sword learning. Cognitive Psychology, 54, 99–132.
Thiessen, E. D. (2007). The effect of distributional information onchildren’s use of phonemic contrasts. Journal of Memory andLanguage, 56, 16–34.
Thiessen, E. D. (2011). When variability matters more than meaning: Theeffect of lexical forms on use of phonemic contrasts. DevelopmentalPsychology, 47, 1448–1458.
Thiessen, E. D., & Pavlik, P. I. Jr., (2013). IMinerva: A mathematical modelof distributional statistical learning. Cognitive Science, 37, 310–343.
Thiessen, E. D., & Yee, M. N. (2010). Dogs, bogs, labs, and lads: Whatphonemic generalizations indicate about the nature of children’searly word-form representations. Child Development, 81(4),1287–1303.
Vallabha, G. K., McClelland, J. L., Pons, F., Werker, J. F., & Amano, S. (2007).Unsupervised learning of vowel categories from infant-directedspeech. Proceedings of the National Academy of Sciences, 104,13273–13278.
Werker, J. F., & Curtin, S. (2005). PRIMIR: A developmental framework ofinfant speech processing. Language Learning and Development, 1,197–234.
Werker, J. F., Fennell, C. T., Corcoran, K. M., & Stager, C. L. (2002). Infants’ability to learn phonetically similar words: Effects of age andvocabulary size. Infancy, 3, 1–30.
Werker, J. F., & Tees, R. C. (1984). Cross language speech perception:Evidence for perceptual reorganization during the first year of life.Infant Behavior and Development, 7, 49–63.
White, K. S., & Morgan, J. L. (2008). Sub-segmental detail in early lexicalrepresentations. Journal of Memory and Language, 59, 114–132.
Winkielman, P., Halberstadt, J., Fazendeiro, T., & Catty, S. (2006).Prototypes are attractive because they are easy on the mind.Psychological Science, 17, 799–806.
Yeung, H. H., & Werker, J. F. (2009). Learning words’ sounds beforelearning how words sound: 9-Month-olds use distinct object cues tocategorize speech information. Cognition, 113, 234–243.
Yoshida, K., Fennell, C., Swingley, D., & Werker, J. F. (2009). 14-month-oldslearn similar-sounding words. Developmental Science.





![THE DISTINCTIVENESS OF A FASHION MONOPOLY - …jipel.law.nyu.edu/wp-content/uploads/2015/05/NYU_JIPEL_Vol-3-No-1... · Acquired Distinctiveness ... 2013] THE DISTINCTIVENESS OF A](https://img.pdfslide.us/doc/110x75/5af7d8f87f8b9a9e59914356/the-distinctiveness-of-a-fashion-monopoly-jipellawnyueduwp-contentuploads201505nyujipelvol-3-no-1acquired.jpg)























