Embed Size (px)
Citation preview

Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 1
Internet Video SearchInternet Video Search
CeesCees G.M. G.M. SnoekSnoek & Arnold W.M. & Arnold W.M. SmeuldersSmeulders
Intelligent Systems Lab Amsterdam,U i it f A t d Th N th l dUniversity of Amsterdam, The Netherlands
A brief history of televisionA brief history of television
•• From broadcasting to narrowcastingFrom broadcasting to narrowcasting
•• …to …to thincastingthincasting
~1955 ~1985 ~2005
~>2008
~2010
…as of May 2011
The international business caseThe international business case
•• Everybody with a message uses video for deliveryEverybody with a message uses video for delivery
•• Growing Growing unmanageableunmanageable amounts of videoamounts of video
CrowdCrowd--given searchgiven search
What others say is in the video.
RawRaw--driven searchdriven search
www.science.uva.nl/research/isla
MultimediaN project

Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 2
1. Short course outline1. Short course outline
.0 Problem statement.0 Problem statement
.1 Measuring features.1 Measuring features
.2 Concept detection.2 Concept detection
.3 Lexicon learning.3 Lexicon learning
.4 Telling stories.4 Telling stories
.5 Video browsing.5 Video browsing
Problem 1:Problem 1:Variation in appearanceVariation in appearance
So many images of one thing, due to minor differences in:illuminationbackgroundbackground occlusionviewpoint, …
•• ThisThis is the is the sensorysensory gapgap
SuitBasketball
Tree
1101011011011011011011001101011011111001101011011111
1101011011011011011011001101011011111001101011011111
1101011011011011011011001101011011111001101011011111
1101011011011
110101101101101101101100110101101111100
110101101101101101101100110101101111100
Problem 2:Problem 2:What defines things?What defines things?
Machine
Multimedia Archives
Table
US flag
Aircraft
Dog TennisMountain
Fire
Building
011011011001101011011111001101011011111
01011011111001101011011111
1101011011011011011011001101011011111001101011011111
01011011111001101011011111
1101011011011011011011001101011011111001101011011111
1101011011011011011011001101011011111001101011011111
1101011011011011011011001101011011111001101011011111
1101011011011011011011001101011011111001101011011111Humans
Problem 3: Problem 3: Many things in the worldMany things in the world
•• ThisThis is the model gapis the model gap
ProblemProblem 4:4:WhatWhat story story tellstells a video?a video?
•• This is the narrative gapThis is the narrative gap
Problem 5: Problem 5: Use is openUse is open--endedended
scope
•• ThisThis is the interface gapis the interface gap
screen
keywords

Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 3
Conclusion on problemsConclusion on problems
•• Video search is a diverse and challengeVideo search is a diverse and challenge--rich rich research topicresearch topic
Sensory gapSensory gap–– Sensory gapSensory gap
–– SemanicSemanic gapgap
–– Model gapModel gap
–– Narrative gapNarrative gap
–– Interface gapInterface gap
Today’s promiseToday’s promise
•• You will be acquainted with the theory and You will be acquainted with the theory and practice of the semantic video search paradigm. practice of the semantic video search paradigm.
•• You will be able to recall the five major scientific You will be able to recall the five major scientific problems in video retrieval and explain, and value problems in video retrieval and explain, and value the presentthe present--day solutions.day solutions.
1. Short course outline1. Short course outline
.0 Problem statement.0 Problem statement
.1 Measuring features.1 Measuring featuresgg
.2 Concept detection.2 Concept detection
.3 Lexicon learning.3 Lexicon learning
.4 Telling stories.4 Telling stories
.5 Video browsing.5 Video browsing
There are a million appearances to one concept
A million appearancesA million appearances
Where are the patterns (of the same shoe)?
Somewhere the variance must be removed.
Invariance: the need for ~Invariance: the need for ~
The illumination and the viewing direction are removed as soon as the image has entered.
Common transformationsCommon transformations
Illumination transformationsIllumination transformations ContrastContrast
Intensity and ShadowIntensity and Shadow
ColorColor
ViewpointViewpoint Rotation and LateralRotation and Lateral
DistanceDistance
Viewing angleViewing angle
ProjectionProjection
CoverCover SpecularSpecular or matteor matte
Occlusion & Clutter, Wear & Tear, Aging, Night & day and Occlusion & Clutter, Wear & Tear, Aging, Night & day and so on into increasingly complex transformations.so on into increasingly complex transformations.

Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 4
Features of selected points may be good enough to describe object
More than one transformationMore than one transformation
iff the selection & the feature set are both invariant forscene-accidental conditions Gevers TIP 2000
Design of invariants: OrbitsDesign of invariants: Orbits
For a property variant under W, observations of a constant property are spread over the orbit. The purpose of an invariant is to capture all of the orbit into one value.
Example: invarianceExample: invariance
projection
Slide credit: Theo Gevers
(R,G,B)-space(c(c11,c,c22,c,c33))--spacespace
},max{arctan),,(1 BG
RBGRc =
},max{arctan),,(2 BR
GBGRc =
},max{arctan),,(3 GR
BBGRc =
shadows shading highlights ill. intensity ill. shadows shading highlights ill. intensity ill. colorcolorEE -- -- -- -- --WW -- + + -- + + --
Color invarianceColor invariance
Gevers, PRL, 1999Geusebroek, PAMI 2001
CC + + + + -- + + --MM + + + + -- + ++ +NN + + + + -- + ++ +LL + + + + + + + + --HH + + + + + + + + --
Local shape motivationLocal shape motivation
Perceptual importanceConcise data
Robust to occlusion & clutter
Tuytelaars FTCGV 2008
Meet the GaussiansMeet the Gaussians
Taylor expansion at xTaylor expansion at x
For discretely sampled signal use the Gaussians
Robust additive differentialsRobust additive differentials
Dimensions separableDimensions separable
No maxima No maxima introducedintroduced
For discretely sampled signal use the Gaussians

Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 5
Meet the Gaussians Meet the Gaussians
The basic video observables are:
Local receptive fields Local receptive fields ff((xx))
The receptive fields up to The receptive fields up to second second order.order.
Grey value as well as opponent color sets.Grey value as well as opponent color sets.
Taxonomy of image structureTaxonomy of image structure
Slide credit: Theo Gevers
T-junction
Highlight
Corner
Junction
From receptive fields to meaningFrom receptive fields to meaning
Lee et al, Comm. ACM 2011
With examples
The 2D Gabor function is:
)(22 2
22
1)( vyuxjyx
eeyxh ++
−= πδ
Meet GaborMeet Gabor
)(222
),( yjeeyxh = δ
πσTuning parameters: u, v, σ + usual invariants by combinationManjunath and Ma on Gabor for texture as seen in F-space
Local receptive fields Local receptive fields FF((xx))
The receptive fields for (u, v) measured locallyThe receptive fields for (u, v) measured locally
Greyvalue as well as opponent color sets.Greyvalue as well as opponent color sets.
Hoang 2003

Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 6
GaborGabor filters: filters: texturetexture
Hoang, ECCV 2002
Original image K-means clustering Segmentation
GaborGabor filters: filters: texturetexture
Local receptive field in f(Local receptive field in f(xx,t),t)
Gaussian equivalent over x and t:Gaussian equivalent over x and t:
zero orderzero order first order over tfirst order over t
Burghouts TIP 2006
Receptive fields: overviewReceptive fields: overview
All observables up to first order All observables up to first order colorcolor, , second order spatial scales, eight second order spatial scales, eight frequency bands & first order in time.frequency bands & first order in time.
Good observables > easy algorithmsGood observables > easy algorithms
Periodicity:
Detect periodic motion by one steered filter:
Deadly simple algorithm…
Burghouts TIP 2006
Meet the LoweansMeet the Loweans
So far we paid respect to the spatial order.So far we paid respect to the spatial order.
Now we will weakly follow the spatial order and form Now we will weakly follow the spatial order and form histograms on all directions we encounter locallyhistograms on all directions we encounter locallyhistograms on all directions we encounter locally, histograms on all directions we encounter locally, … better known as (the second part of) SIFT.… better known as (the second part of) SIFT.
Lowe IJCV 2004

Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 7
Meet the Meet the LoweansLoweans
4 x 4 Gradient window after thresholding4 x 4 Gradient window after thresholding
Histogram of 4 x 4 samples per window in 8 directionsHistogram of 4 x 4 samples per window in 8 directions
Gaussian weighting around center (Gaussian weighting around center (σσ is 1/2 of is 1/2 of σσ keypoint)keypoint)
4 x 4 x 8 = 128 dimensional feature vector4 x 4 x 8 = 128 dimensional feature vector
Image: Jonas Hurrelmann
SIFT detectionSIFT detection
Slide credit: Jepson 2005
Enriching SIFT Enriching SIFT (in a nutshell)(in a nutshell)
•• Affine SIFTAffine SIFT–– Choose prominent direction in SIFTChoose prominent direction in SIFT
Mikolajczyk, IJCV 2005Ke, CVPR 2004
Van de Sande, PAMI 2010
•• PCAPCA--SIFTSIFT–– Robust and compact representationRobust and compact representation
•• ColorSIFTColorSIFT–– Add several invariant color descriptorsAdd several invariant color descriptors
•• TimeSIFTTimeSIFT–– Anyone?Anyone?
Illumination invarianceIllumination invariance
Invariance properties of the descriptors usedLight intensity
changeLight intensity
shiftLight intensity
change and shiftLight color
changeLight color change
and shift
SIFT + + + + +
Van de Sande, PAMI 2010
SIFT + + + + +OpponentSIFT +/- + +/- +/- +/-C-SIFT + + + +/- +/-rgSIFT + + + +/- +/-RGB-SIFT + + + + +
Where to sample in the video?Where to sample in the video?
•• Video shot is set of frames representing a Video shot is set of frames representing a continuous camera action in time and spacecontinuous camera action in time and space
Analysis typically on a single key frame per shotAnalysis typically on a single key frame per shot–– Analysis typically on a single key frame per shotAnalysis typically on a single key frame per shot
Shot Key Frame
WhereWhere to sample in the frame?to sample in the frame?
Tuytelaars 2008 FTCGV

Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 8
Interest point examplesInterest point examples
Original image Harris Laplacian Color salient points
Mikolajczyk, CVPR 2006van de Weijer, PAMI 2006
DenseDense sampling sampling exampleexample
What What is the object in the is the object in the middle?middle?
No segmentation …No pixel values of the object …
FastFast densedense descriptorsdescriptors
Uijlings et al, CIVR 2009
Image Patch
Reuse sub-regions: 16x speed-up
Conclusion on Conclusion on measuring featuresmeasuring features
•• Invariance is crucial when designing featuresInvariance is crucial when designing features–– More invariance means less stable…More invariance means less stable…
b t b t tb t b t t–– …but more robustness to sensory gap…but more robustness to sensory gap
•• Effective features strike a balance between Effective features strike a balance between invariance and discriminatory powerinvariance and discriminatory power–– And for video search efficiency is helpful also…And for video search efficiency is helpful also…
And there is always more …And there is always more …
For example:For example:
Local Invariant Feature Detectors: A SurveyLocal Invariant Feature Detectors: A Survey
TinneTinne TuytelaarsTuytelaars & & KrystianKrystian MikolajczykMikolajczyk
FTCGV 3:3(177FTCGV 3:3(177——280)280)

Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 9
1. Short course outline1. Short course outline
.0 Problem statement.0 Problem statement
.1 Measuring features.1 Measuring features
.2 Concept detection.2 Concept detection
.3 Lexicon learning.3 Lexicon learning
.4 Telling stories.4 Telling stories
.5 Video browsing.5 Video browsing
The semantic gapThe semantic gap
The semantic gap is the lack of coincidenceThe semantic gap is the lack of coincidence
Quote
The semantic gap is the lack of coincidence The semantic gap is the lack of coincidence between the information that one can extract between the information that one can extract from the sensory data and the interpretation that from the sensory data and the interpretation that the same data has for a user in a given situationthe same data has for a user in a given situation
Arnold Smeulders, PAMI, 2000
The science of labelingThe science of labeling
•• To understand anything in science, things need a To understand anything in science, things need a name that is universally recognizedname that is universally recognized
•• Worldwide endeavor in Worldwide endeavor in naming visual informationnaming visual information
living organisms chemical elements human genome‘categories’ text
Naming visual informationNaming visual information
•• Concept detectionConcept detection–– Does the image contain an airplane?Does the image contain an airplane?
Slide credit: Andrew Zisserman
Focus of today’s Focus of today’s lecturelecture
•• Object localizationObject localization–– Where is the airplane, (if any)?Where is the airplane, (if any)?
•• Object segmentationObject segmentation–– Which pixels are part of an airplane, Which pixels are part of an airplane,
(if any)?(if any)?
How difficult is the problem?How difficult is the problem?
•• Human vision consumes 50% brain power…Human vision consumes 50% brain power…
Van Essen, Science 1992
Semantic concept detectionSemantic concept detection
•• The patient approachThe patient approach–– Building detectors oneBuilding detectors one--atat--aa--timetime
A face detector for frontal faces

Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 10
A simple face detectorA simple face detector
One PhD per detector requires too many students…
So how about these?So how about these?
and the thousands of others ………
Labeled
Basic concept detectionBasic concept detection
aircraftoutdoor
Feature Extraction
Supervised Learner
Training
Feature Measurement
Classification
Testing
Video
Labeled examples
It is an aircraft probability 0.7It is outdoor probability
0.95
Demo: concept detectionDemo: concept detection
Visualization byJasper Schulte
Linear classifiers Linear classifiers -- marginmargin
Slide credit: Cordelia Schmid
Nonlinear SVMNonlinear SVM
Slide credit: Cordelia Schmid
Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 11
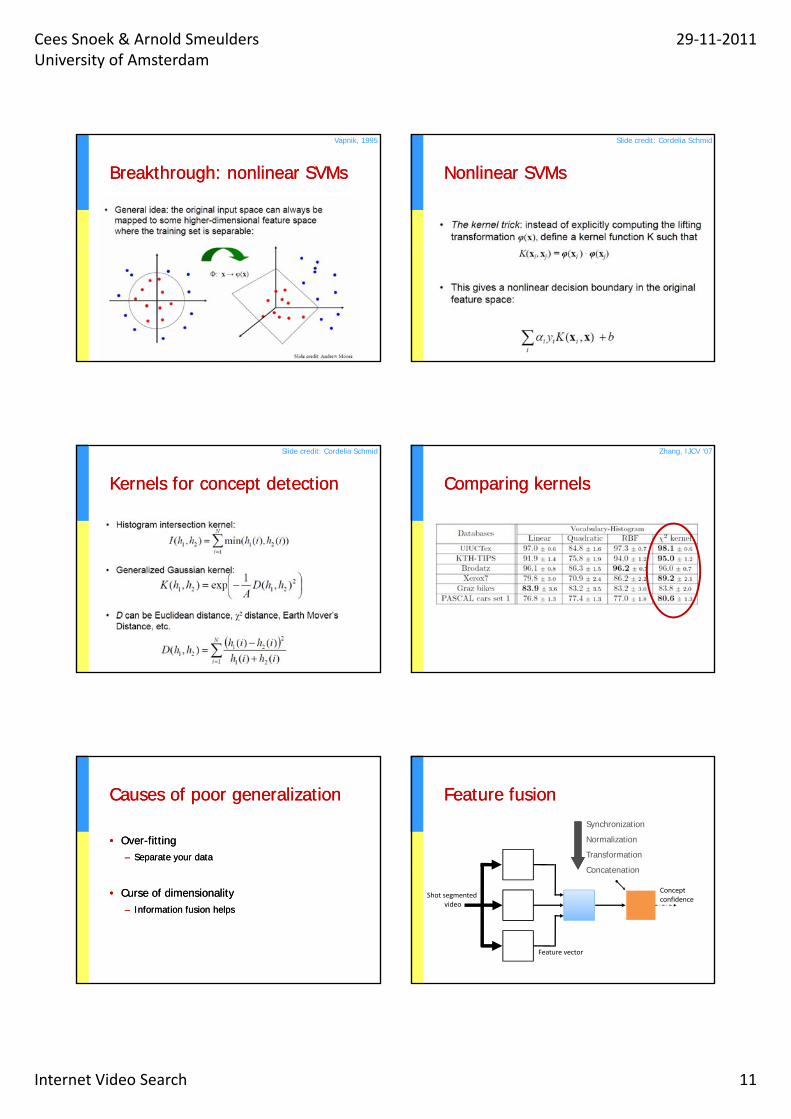
Breakthrough: nonlinear SVMsBreakthrough: nonlinear SVMs
Vapnik, 1995
Nonlinear SVMsNonlinear SVMs
Slide credit: Cordelia Schmid
Kernels for concept detectionKernels for concept detection
Slide credit: Cordelia Schmid
Comparing kernelsComparing kernels
Zhang, IJCV ‘07
Causes of poor generalizationCauses of poor generalization
•• OverOver--fittingfitting–– Separate your dataSeparate your data
•• Curse of dimensionalityCurse of dimensionality–– Information fusion helpsInformation fusion helps
Feature fusionFeature fusionSynchronization
Normalization
Transformation
Concatenation
Feature vector
Shot segmentedvideo
Concept confidence
Concatenation

Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 12
Feature fusionFeature fusionSynchronization
Normalization
Transformation
Concatenation
Feature vector
Shot segmentedvideo
Concept confidence
Concatenation
+ Only one learning phase- Combination often ad hoc - One feature may dominate- Curse of dimenisonality
Avoiding dimensionality curseAvoiding dimensionality curse
•• Codebook aka bagCodebook aka bag--ofof--words modelwords model–– Create a codeword vocabularyCreate a codeword vocabulary
Di tiDi ti i ithi ith d dd d
Leung and Malik, IJCV, 2001Sivic and Zisserman, ICCV, 2003
and many others…
–– DiscretizeDiscretize image with image with codewordscodewords
–– Count codewordsCount codewords
0 100 200 300 400 5000
10
20
30
40
50
60
70
80
EmphasizingEmphasizing spatialspatial configurationsconfigurations
•• CodebookCodebook ignoresignores geometricgeometric correspondencecorrespondence
Grauman, ICCV 2005Lazebnik, CVPR 2006
Marszalek, VOC 2007
•• For video:For video:
•• SolutionSolution: : spatialspatial pyramidpyramid–– aggregate statistics of local features over fixed aggregate statistics of local features over fixed
subregionssubregions
–– 1x1 entire image1x1 entire image
–– 2x2 image quarters2x2 image quarters
–– 1x3 horizontal bars1x3 horizontal bars
Codebook modelCodebook model
•• Codebook consists of Codebook consists of codewordscodewords–– kk--means clustering of descriptorsmeans clustering of descriptors–– Commonly 4 000Commonly 4 000 codewordscodewords per codebookper codebookCommonly 4,000 Commonly 4,000 codewordscodewords per codebookper codebook
Cluster
AssignDense+OpponentSIFT Feature vector (length 4,000)
Codebook assignmentCodebook assignment
van Gemert, PAMI 2010
Hard assignmentHard assignment Soft assignmentSoft assignment
● Codeword
–– Soft assignment: assign to multiple clusters, weighted by Soft assignment: assign to multiple clusters, weighted by distance to centerdistance to center
–– Single sigma (distance weighting) for all codebook elementsSingle sigma (distance weighting) for all codebook elements
ExtendingExtending soft soft assignmentassignment
•• FisherFisher VectorVector–– Train a Train a GaussianGaussian Mixture Model, Mixture Model, wherewhere eacheach codebookcodebook
element haselement has itsits ownown sigmasigma –– oneone per dimensionper dimension
Perronnin ECCV 2010
element has element has itsits ownown sigma sigma oneone per dimensionper dimension
–– Do Do notnot store store assigmentassigment, , butbut differencesdifferences in all descriptor in all descriptor dimensionsdimensions
•• GreatlyGreatly increasesincreases complexitycomplexity–– feature vector is feature vector is #codewords x #descriptor#codewords x #descriptor

Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 13
ExtendingExtending soft soft assignmentassignment
•• Super Vector CodingSuper Vector Coding–– also counts the dimensionalso counts the dimension--wise difference of a SIFT wise difference of a SIFT
descriptor to a visual worddescriptor to a visual word
Zhou ECCV 2010
descriptor to a visual worddescriptor to a visual word
•• Key insight: these methods propose many new Key insight: these methods propose many new components and algorithms, but components and algorithms, but difference difference coding coding is their main contributionis their main contribution
Difference codingDifference coding
•• Fisher vectorFisher vector
Perronnin ECCV 2010Zhou ECCV 2010
Jegou CVPR 2010
•• Super vector codingSuper vector coding
•• VLADVLAD
Fast quantizationFast quantization
•• Random Random forestsforests–– Randomized process makes it very fast to buildRandomized process makes it very fast to build
T t t ll f t t ti tiT t t ll f t t ti ti
Moosman, PAMI 2008Uijlings, CIVR 2009
–– Tree structure allows fast vector quantizationTree structure allows fast vector quantization
–– Logarithmic rather than linear projection timeLogarithmic rather than linear projection time
•• RealReal--timetime BoWBoW (!)(!)–– WhenWhen usedused withwith fastfast densedense samplingsampling
–– SURF 2x2 descriptor SURF 2x2 descriptor insteadinstead of 4x4of 4x4
–– RBF RBF kernelkernel
Codebooks grow big…Codebooks grow big…
•• Researchers concatenate multiple codebooksResearchers concatenate multiple codebooks
Spatial pyramid adds more dimensionsSpatial pyramid adds more dimensionsoo 1x1 = 4K1x1 = 4K
oo 2x2 = 16K2x2 = 16K
oo 1x3 = 12K1x3 = 12K
–– Feature vector length easily Feature vector length easily >100K>100K……
SVM preSVM pre--computed kernel trickcomputed kernel trick
•• Use distance between feature vectorsUse distance between feature vectors
-γ dist(f1, f2)K(f f ) = e
•• Increase efficiency significantlyIncrease efficiency significantly–– PrePre--compute the SVM kernel matrixcompute the SVM kernel matrix
–– Long vectors possible as we only need 2 in memoryLong vectors possible as we only need 2 in memory
–– Parameter optimization reParameter optimization re--uses preuses pre--computed matrixcomputed matrix
K(f1, f2) = e
GPUGPU--empowered empowered prepre--computed kernelcomputed kernel
1 CPU 4 CPU
Van de Sande, TMM 2011
40000 1x CPU Opteron 250 (2,4GHz)
1x CPU Core i7 920 (2 66GHz)
GPU0
10000
20000
30000
4000 8000 16000 32000 64000 128000
Time (s)
Total Feature Vector Length
1x CPU Core i7 920 (2,66GHz)
4x CPU Opteron 250 (2,4 GHz)
4x CPU Core i7 920 (2,66GHz)
25x CPU Opteron 250 (2,4GHz)
49x CPU Opteron 250 (2,4GHz)
1x GPU Geforce GTX260 (27 cores)
37x speed-upsingle CPU
10x speed-upquad core
2x speed-up49cpu cluster

Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 14
Efficient classificationEfficient classification
Maji et al., CVPR 2008
For the Intersection Kernel hi is piecewise linear, and quite smooth, blue plot. We can approximate with fewer uniformly spaced segments, red plot. Saves time & space!
vsvs HIKHIKHIK 75 times faster, negligible loss in average precision
χ²χ²
Moving object appearanceMoving object appearance
= Emphasis added
keyframeShot boundary Shot boundary
Prob
abili
ty
0
1
Moving object appearanceMoving object appearance
= Emphasis added
keyframeShot boundary Shot boundary
Prob
abili
ty
0
1Max
Avg
Feature Feature fusionfusion
0
1
Relative frequency
1 2 3 4 5
Codebook element
Harris -Laplace salient points
Point sampling strategy Color feature extraction Codebook model
Bag-of-features
.
.
.
Van de Sande, PAMI 2010
Spatial pyramid
Dense sampling
0
1
1 2 3 4 5
0
1
1 2 3 4 5
0
1
1 2 3 4 5
0
1
1 2 3 4 5
0
1
Relative frequency
1 2 3 4 5
Codebook element
Bag-of-features
Spatial pyramid: multiple bags-of-features
.
Image
.
.
.
.
..
+ Codebook reduces dimensionality- Combination still ad hoc - One codebook may dominate
Classifier Classifier fusionfusion
+ Focus on feature strength
+ Fusion in semantic spacep
- Expensive learning effort
- Loss of feature correlation
Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 15
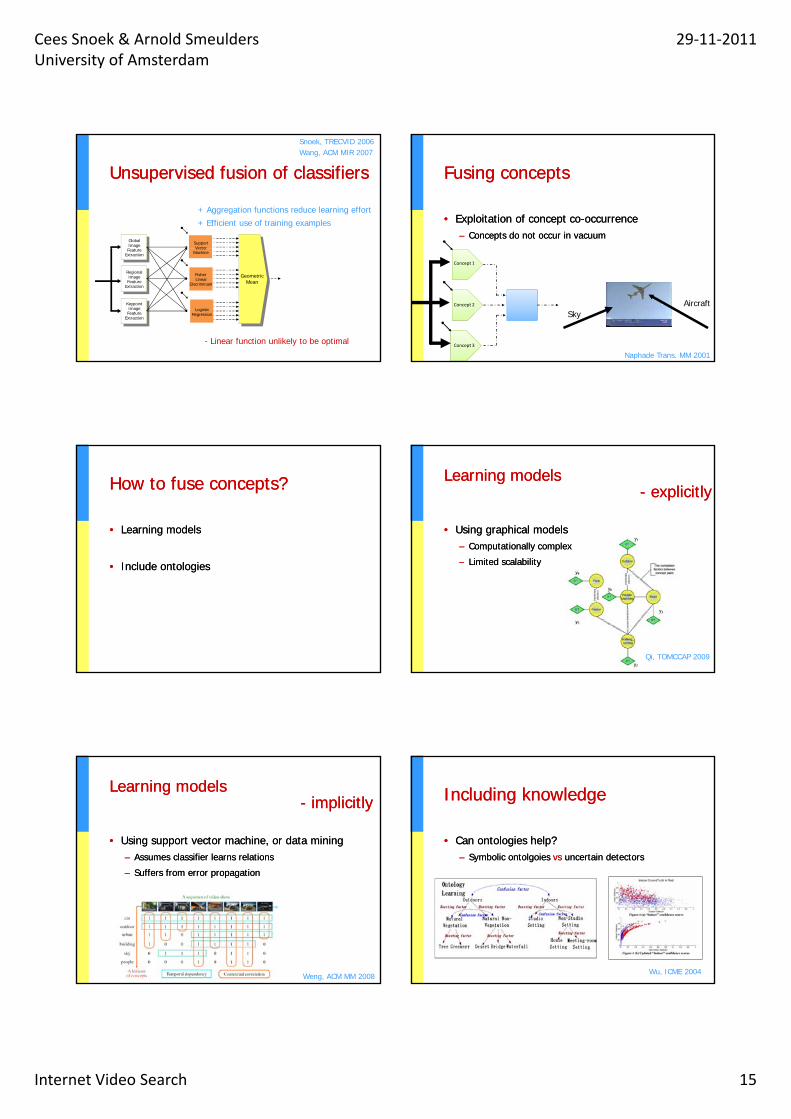
Unsupervised fusion of classifiersUnsupervised fusion of classifiers
Support Vector
Global Image
+ Aggregation functions reduce learning effort+ Efficient use of training examples
Snoek, TRECVID 2006Wang, ACM MIR 2007
Vector MachineFeature
Extraction
GeometricMean
Logistic Regression
Fisher Linear
Discriminant
Regional Image Feature
Extraction
Keypoint Image Feature
Extraction
- Linear function unlikely to be optimal
Fusing conceptsFusing concepts
•• Exploitation of concept coExploitation of concept co--occurrence occurrence –– Concepts do not occur in vacuumConcepts do not occur in vacuum
Concept 1
Concept 2
Concept 3
Naphade Trans. MM 2001
SkyAircraft
HowHow to to fusefuse conceptsconcepts??
•• LearningLearning modelsmodels
•• IncludeInclude ontologiesontologies
Learning models Learning models -- explicitlyexplicitly
•• Using graphical modelsUsing graphical models–– Computationally complexComputationally complex
Li it d l bilitLi it d l bilit–– Limited scalabilityLimited scalability
Qi, TOMCCAP 2009
Learning models Learning models -- implicitlyimplicitly
•• Using support vector machine, or data miningUsing support vector machine, or data mining–– Assumes classifier learns relationsAssumes classifier learns relations
S ff f tiS ff f ti–– Suffers from error propagationSuffers from error propagation
Weng, ACM MM 2008
Including knowledgeIncluding knowledge
•• Can ontologies help?Can ontologies help?–– Symbolic ontolgoies Symbolic ontolgoies vsvs uncertain detectorsuncertain detectors
Wu, ICME 2004
Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 16
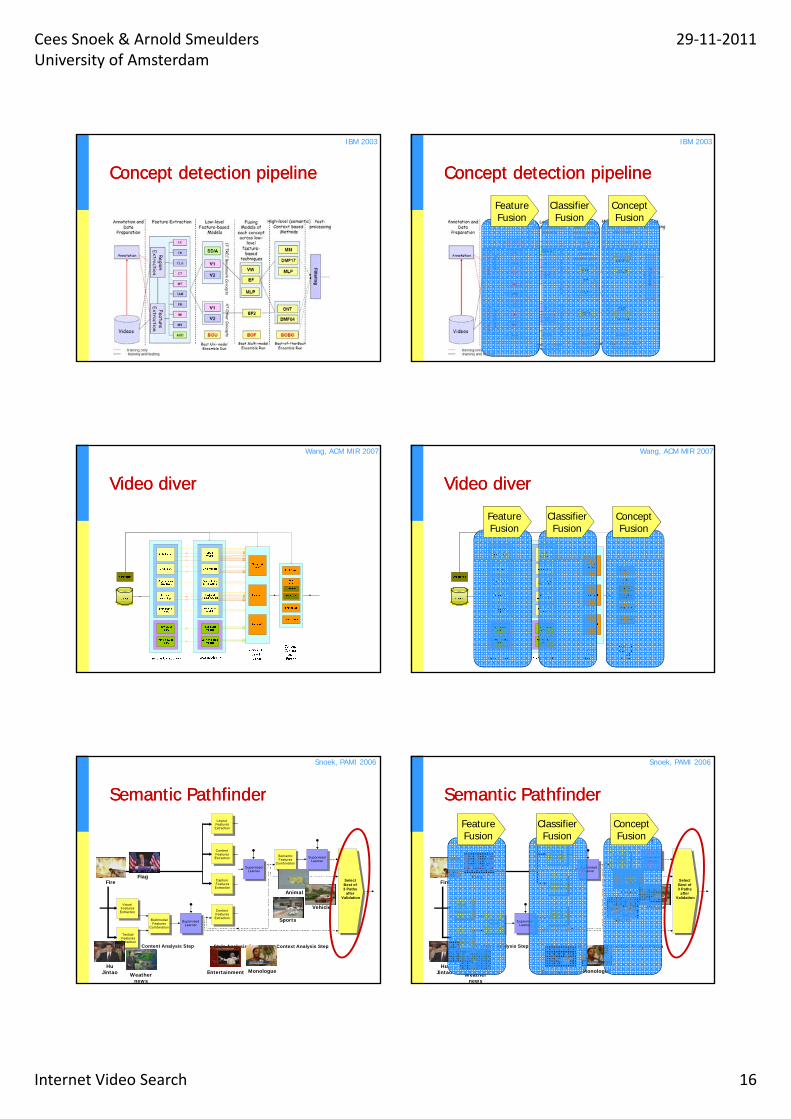
Concept detection pipelineConcept detection pipeline
IBM 2003
Concept detection pipelineConcept detection pipeline
IBM 2003
FeatureFusion
ClassifierFusion
ConceptFusion
Video diverVideo diver
Wang, ACM MIR 2007
Video diverVideo diver
FeatureFusion
ClassifierFusion
ConceptFusion
Wang, ACM MIR 2007
Supervised L
Supervised Learner
Semantic Features
Combination
Content Features Extraction
Layout Features Extraction
Semantic PathfinderSemantic Pathfinder
Snoek, PAMI 2006
Supervised Learner
Multimodal Features
Combination
Learner
Visual Features Extraction
Textual Features Extraction
Content Analysis Step Style Analysis Step Context Analysis Step
Context Features Extraction
Capture Features Extraction
Select Best of 3 Paths
after Validation
Animal
Sports
Vehicle
Entertainment Monologue
FlagFire
Weather news
Hu Jintao
Supervised L
Supervised Learner
Semantic Features
Combination
Content Features Extraction
Layout Features Extraction
Semantic PathfinderSemantic PathfinderFeatureFusion
ClassifierFusion
ConceptFusion
Snoek, PAMI 2006
Supervised Learner
Multimodal Features
Combination
Learner
Visual Features Extraction
Textual Features Extraction
Content Analysis Step Style Analysis Step Context Analysis Step
Context Features Extraction
Capture Features Extraction
Select Best of 3 Paths
after Validation
Animal
Sports
Vehicle
Entertainment Monologue
FlagFire
Weather news
Hu Jintao
Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 17
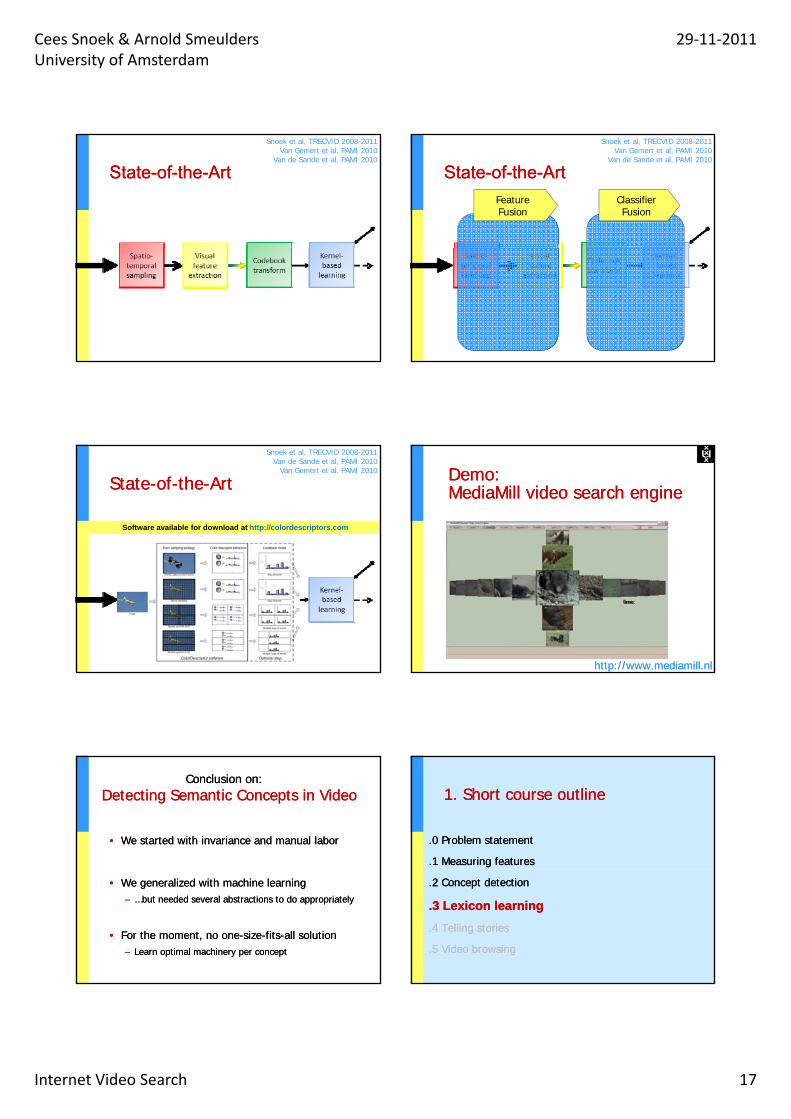
StateState--ofof--thethe--ArtArt
Snoek et al, TRECVID 2008-2011Van Gemert et al, PAMI 2010
Van de Sande et al, PAMI 2010
StateState--ofof--thethe--ArtArtFeatureFusion
ClassifierFusion
Snoek et al, TRECVID 2008-2011Van Gemert et al, PAMI 2010
Van de Sande et al, PAMI 2010
StateState--ofof--thethe--ArtArt
Snoek et al, TRECVID 2008-2011Van de Sande et al, PAMI 2010
Van Gemert et al, PAMI 2010
Software available for download at http://colordescriptors.com
Demo: Demo: MediaMillMediaMill video search enginevideo search engine
http://www.mediamill.nlhttp://www.mediamill.nl
Detecting Semantic Concepts in VideoDetecting Semantic Concepts in VideoConclusion on:Conclusion on:
•• We started with invariance and manual laborWe started with invariance and manual labor
•• We generalized with machine learningWe generalized with machine learning–– …but needed several abstractions to do appropriately…but needed several abstractions to do appropriately
•• For the moment, no oneFor the moment, no one--sizesize--fitsfits--all solution all solution –– Learn optimal machinery per conceptLearn optimal machinery per concept
1. Short course outline1. Short course outline
.0 Problem statement.0 Problem statement
.1 Measuring features.1 Measuring features
.2 Concept detection.2 Concept detection
.3 Lexicon learning.3 Lexicon learning
.4 Telling stories.4 Telling stories
.5 Video browsing.5 Video browsing

Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 18
Problem 3: Problem 3: Many things in the worldMany things in the world
•• ThisThis is the model gapis the model gap
Trial 1: counting dictionary wordsTrial 1: counting dictionary words
Biederman, Psychological Review 1987
Slide credit: Li Fei-Fei
Trial 2: reverseTrial 2: reverse--engineeringengineering
•• Estimation by Hauptmann et al.: 5000Estimation by Hauptmann et al.: 5000–– Using manually labeled queries and conceptsUsing manually labeled queries and concepts
But speculative and questionable assumptionsBut speculative and questionable assumptions
Hauptmann, PIEEE 2008
–– But speculative, and questionable assumptionsBut speculative, and questionable assumptions
‘Google performance’
Oracle Combination + Noise
‘Realistic’ Combination
How to obtain labeled examples?How to obtain labeled examples?massive amounts of
–– …but only human …but only human expertsexperts provide provide good qualitygood quality examplesexamples
•• MM078MM078--Police/Security PersonnelPolice/Security Personnel–– Shots depicting law enforcement or private Shots depicting law enforcement or private
security agency personnel.security agency personnel.
Experts start with concept definitionExperts start with concept definition
y g y py g y p
Expert annotation toolsExpert annotation tools
•• Balance between:Balance between:–– Spatiotemporal level of Spatiotemporal level of
annotation detailannotation detail
Volkmer, ACM MM 2005
annotation detailannotation detail
–– Number of conceptsNumber of concepts
–– Number of positive Number of positive and negative examplesand negative examples

Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 19
LSCOM LSCOM (Large Scale Concept Ontology for Multimedia)(Large Scale Concept Ontology for Multimedia)
•• Provides manual annotations for 449 conceptsProvides manual annotations for 449 concepts–– In international broadcast TV newsIn international broadcast TV news
Naphade, IEEE MM 2006
•• Connection to Connection to CycCyc ontologyontology
•• LSCOMLSCOM--LiteLite–– 39 semantic concepts39 semantic concepts
http://www.lscom.org/
Verified positive examplesVerified positive examples
•• ImageNetImageNet (15M images)(15M images)
–– 22,000 22,000 categoriescategories
100 l100 l–– > 100 examples> 100 examples
•• SUN SUN (130K images)(130K images)
–– 397 scene categories397 scene categories
–– > 100 examples> 100 examples
Deng et al, CVPR 2009
Xiao et al, CVPR 2010
Random negatives are not Random negatives are not necessarily informativenecessarily informative
PositivesNegatives Decision boundary
Xirong Li et al, ICMR 2011
?Active Learning?AdaBoost?
Social Negative
Bootstrapping
Sampling informative negatives Sampling informative negatives
•• Iteratively selecting the Iteratively selecting the most misclassified most misclassified negatives as the informative onesnegatives as the informative ones
Selection
Prediction*
* airplane classifier
Virtually labeled negatives
Most misclassified negatives
Social negative bootstrappingSocial negative bootstrapping
aviationstation tennis outreach
lotusvagrantsketchpeople
b hlif i ft i l cow
airplaneNegative examples
beachlife aircraft airplane cow
planesister street
tokyolithuania aeroplane aeroplane
****
tradeoff between effectiveness and efficiency
to find the most informative negatives
Concept detection Concept detection (on VOC08(on VOC08--val)val)
•• Social negative bootstrapping is much better Social negative bootstrapping is much better than the baselinesthan the baselines

Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 20
Informative negatives of ‘Informative negatives of ‘tvtv’’
Tag cloud of informative negatives
Bridging the model gapBridging the model gap
•• RequirementsRequirements–– Generic concept detection methodGeneric concept detection method
M i t fM i t f l b l dl b l d ll–– Massive amounts of Massive amounts of labeled labeled examplesexamples
–– Evaluation methodEvaluation method
–– Fair amount of computationFair amount of computation
Model gap best treated by Model gap best treated by TRECVIDTRECVID
•• Situation in 2000Situation in 2000–– Various concept definitionsVarious concept definitions
S ifiS ifi dd llll d t td t t–– SpecificSpecific and and smallsmall data setsdata sets
–– Hard to compare methodologiesHard to compare methodologies
•• Since 2001 worldwide evaluation by NISTSince 2001 worldwide evaluation by NIST–– TRECVID benchmarkTRECVID benchmark
= ResearchersNIST
NIST TRECVID benchmarkNIST TRECVID benchmark
•• Promote progress in video retrieval researchPromote progress in video retrieval research–– Provide common dataset Provide common dataset –– Challenging tasksChallenging tasks
I d d t l ti t lI d d t l ti t l–– Independent evaluation protocolIndependent evaluation protocol–– Forum for researchers to compare resultsForum for researchers to compare results
http://trecvid.nist.gov/
Video data setsVideo data sets
•• US TV news US TV news (`03/`04)(`03/`04)
•• International TV news International TV news (`05/`06)(`05/`06)
•• Dutch TV infotainment Dutch TV infotainment (`07/`08/`09)(`07/`08/`09)
TRECVID 2010 and 2011TRECVID 2010 and 2011Internet Archive web videosInternet Archive web videos

Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 21
Expert annotation effortsExpert annotation efforts
LSCOM
MediaMill - UvA
Expert annotation efforts
17 32 39101
374
500
…
LSCOM
Others
TRECVID Edition
Measuring performanceMeasuring performance
Set of retrieved itemsSet of relevant items
1.
Results
•• PrecisionPrecision Set of relevant retrieved items
inverse relationship•• RecallRecall
2.
3.
4.
5.
Evaluation measureEvaluation measure
•• Average PrecisionAverage Precision–– Combines precision and recallCombines precision and recall
A i i ft l t h tA i i ft l t h t
1.
Results
–– Averages precision after relevant shotAverages precision after relevant shot
–– Top of ranked list most important Top of ranked list most important
AP =1/1 + 2/3 + 3/4 + …
number of relevant documents
2.
3.
4.
5.
AP
De facto evaluation standardDe facto evaluation standard
Concept examplesConcept examples
Aircraft
BeachNote the variety in visual appearance
Mountain
People marching
Police/Security
Flower
pp
TRECVID TRECVID concept detection task resultsconcept detection task results
•• Hard to compareHard to compare–– Different video dataDifferent video data
2003
2004
–– Different conceptsDifferent concepts
•• Clear Clear top top performersperformers–– Median skews to leftMedian skews to left
–– Learning effectLearning effect
–– Plenty of variationPlenty of variation
2005
2006
2007
2008
2009
2010
2011

Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 22
UvAUvA--MediaMillMediaMill@TRECVID@TRECVID
Snoek et al, TRECVID 04-11
• >1000 other systems
MediaMill ChallengeMediaMill Challenge
•• The Challenge providesThe Challenge provides–– Manually annotated lexicon Manually annotated lexicon
of of 101101 semantic conceptssemantic concepts
•• The Challenge allows toThe Challenge allows to–– Gain insight in intermediate Gain insight in intermediate
video analysis stepsvideo analysis steps
http:/www.mediamill.nl/challenge/
–– PrePre--computed lowcomputed low--level level featuresfeatures
–– Trained classifier modelsTrained classifier models
–– 55 experimentsexperiments
–– Implementation + resultsImplementation + results
–– Foster repeatability of Foster repeatability of experimentsexperiments
–– Optimize video analysis Optimize video analysis systems on a component levelsystems on a component level
–– Compare and improveCompare and improve
• The Challenge lowers threshold for novice researchers
Columbia374 + VIREO374Columbia374 + VIREO374
•• Baseline detectors for 374 conceptsBaseline detectors for 374 concepts
http://www.ee.columbia.edu/ln/dvmm/columbia374/http://www.cs.cityu.edu.hk/~yjiang/vireo374/http://www.ee.columbia.edu/ln/dvmm/CU-VIREO374/
Community myths or facts?Community myths or facts?
•• Chua et al., Chua et al., ACM Multimedia 2007ACM Multimedia 2007
–– Video search is practically solved and progress Video search is practically solved and progress has only been incrementalhas only been incrementalhas only been incrementalhas only been incremental
•• Yang and Hauptmann, Yang and Hauptmann, ACM CIVR 2008ACM CIVR 2008
–– Current solutions are weak and generalize poorlyCurrent solutions are weak and generalize poorly
We have done an experimentWe have done an experiment
•• Two video search engines from 2006 and 2009Two video search engines from 2006 and 2009–– MediaMillMediaMill Challenge 2006 systemChallenge 2006 system
M di MillM di Mill TRECVID 2009 tTRECVID 2009 t–– MediaMillMediaMill TRECVID 2009 systemTRECVID 2009 system
•• How well do they detect 36 LSCOM concepts?How well do they detect 36 LSCOM concepts?
Four video data set mixturesFour video data set mixtures
•• TrainingTrainingBroadcast
newsDocumentary
video
TRECVID 2005 TRECVID 2007
•• TestingTestingDocumentary
videoBroadcast
news
Within domain
Cross domain

Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 23
Performance doubled in just 3 yearsPerformance doubled in just 3 years
• 36 concept detectors
–– Even when using training Even when using training data of different origindata of different origin
Snoek & Smeulders, IEEE Computer 2010
–– Vocabulary still limitedVocabulary still limited
500 detectors, a closer look500 detectors, a closer look
The number of labeled image examples used at training time seems decisive in concept detector accuracy.
Demo timeDemo time 500 detectors, a closer look500 detectors, a closer look
Learning social tag relevance by Learning social tag relevance by neighbor votingneighbor voting
•• Exploit consistency in tagging behavior of Exploit consistency in tagging behavior of different users for visually similar imagesdifferent users for visually similar images
Xirong Li, TMM 2009
Image retrieval experimentsImage retrieval experiments
•• UserUser--tagged image databasetagged image database–– 3.5 million 3.5 million labeled Flickr imageslabeled Flickr images
•• Visual feature Visual feature –– A global colorA global color--texture texture
•• Evaluation setEvaluation set–– 20 concepts20 concepts
•• Evaluation criteriaEvaluation criteria–– Average precisionAverage precision

Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 24
Image retrieval experimentsImage retrieval experiments
•• A A standardstandard tagtag--basedbased retrievalretrieval frameworkframework–– RankingRanking functionfunction: OKAPI: OKAPI--BM25BM25
•• ComparisonComparison–– Baseline:Baseline: retrieval using original tagsretrieval using original tags
–– Neighbor: Neighbor: retrieval using learned tag relevance as retrieval using learned tag relevance as tag frequencytag frequency
ResultsResults
24% relative improvement
Updated tag relevanceUpdated tag relevance
•• Objective tags are identified and reinforcedObjective tags are identified and reinforced
Based on 3.5 Million images downloaded from Flickr
Tag relevance fusionTag relevance fusion
Xirong Li et al, CIVR 2010
•• Note: fully unsupervised, adds 10% in performanceNote: fully unsupervised, adds 10% in performance
Failure case: airplaneFailure case: airplane
•• Too much consensus on wrong label…Too much consensus on wrong label…
Results suggest…Results suggest…
•• Relevance of a tag can be predicted based on Relevance of a tag can be predicted based on ‘wisdom’ of crowds‘wisdom’ of crowds
Even with a lightEven with a light weight visual featureweight visual feature–– Even with a lightEven with a light--weight visual featureweight visual feature
–– And, a small database of 3.5M imagesAnd, a small database of 3.5M images

Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 25
Conclusion on lexicon learningConclusion on lexicon learning
RequiresRequires•• Invariant featuresInvariant features
Suffers most Suffers most fromfrom•• Weakly labeled visual dataWeakly labeled visual data
•• Concept detectionConcept detection
•• Many, many, annotationsMany, many, annotations
•• Measuring performanceMeasuring performance
•• Lots of computationLots of computation
•• Transfer across domainsTransfer across domains
Special issue announcementSpecial issue announcement
Fall 2012
1. Short course outline1. Short course outline
.0 Problem statement.0 Problem statement
.1 Measuring features.1 Measuring features
.2 Concept detection.2 Concept detection
.3 Lexicon learning.3 Lexicon learning
.4 Telling stories.4 Telling stories
.5 Video browsing.5 Video browsing
StorytellingStorytelling
Storytelling is the conveying of events in words, Storytelling is the conveying of events in words,
Quotey g y g ,y g y g ,
images and sounds, often by improvisation or images and sounds, often by improvisation or embellishment. Stories or narratives have been embellishment. Stories or narratives have been shared in every culture as a means of shared in every culture as a means of entertainment, education, cultural preservation entertainment, education, cultural preservation and in order to instill moral values.and in order to instill moral values.
Wikipedia
An event in prehistoric timesAn event in prehistoric times
•• What story did they want to tell?What story did they want to tell?
Bhimbetka rock shelters, India
Arbitrary events in modern timesArbitrary events in modern times
•• …but what defines an event in video?…but what defines an event in video?
Attempting a board trickFlash mob gathering Changing a vehicle tire

Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 26
Definition 1Definition 1
•• Complex activity occurring at a specific place and Complex activity occurring at a specific place and time;time;
•• Involves people interacting with other people Involves people interacting with other people and/or objects;and/or objects;
•• Consists of a number of human actions, Consists of a number of human actions, processes, and activities that are loosely or tightly processes, and activities that are loosely or tightly organized and that have significant temporal and organized and that have significant temporal and semantic relationships to the overarching activity;semantic relationships to the overarching activity;
•• Is directly observable.Is directly observable.
Definition 2Definition 2
•• An event happens over timeAn event happens over time–– Track semantics over time, model dynamic Track semantics over time, model dynamic
interactions and identify goalinteractions and identify goal--directed movementdirected movementinteractions, and identify goalinteractions, and identify goal directed movement.directed movement.
•• An event happens in spaceAn event happens in space–– Identify the most semantic regions in an image to Identify the most semantic regions in an image to
express spatial relations and interactions.express spatial relations and interactions.
•• An event has a recountAn event has a recount–– Must be able to provide a understandable recounting Must be able to provide a understandable recounting
on what visual information is decisive for relevance.on what visual information is decisive for relevance.
An event is a bagAn event is a bag--ofof--featuresfeatures
Jiang et al, TRECVID 2010
Video Event
fid
•• Fusing multiple audioFusing multiple audio--visual features is effectivevisual features is effective–– No notion whether the event is really foundNo notion whether the event is really found
Feature vector
Video confidence
An event is a bagAn event is a bag--ofof--conceptsconcepts
Gkalelis et al, CBMI 2011Merler et al, TMM, in press
Video Eventconfidence
Concept Detector 1
Concept
•• Combine available detector scores in single vectorCombine available detector scores in single vector–– No notion what concept (ordering) is important for eventsNo notion what concept (ordering) is important for events
Concept Detector 2
Concept Detector N
Horse, horse, horse?Horse, horse, horse? Chair, chair, chair?Chair, chair, chair?

Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 27
An event is concepts over timeAn event is concepts over time
Ebadollahi, ICME 2006
•• Exploit concept evidence over timeExploit concept evidence over time–– Proof of concept, unclear how to determine automaticallyProof of concept, unclear how to determine automatically
The event retrieval paradoxThe event retrieval paradox
cura
cy
Bag-of-
???good
Even
t de
tect
ion
acc
Event recounting ability
features
Bag-of-concepts
Conceptsover time
goodbad
bad
Benchmarking the paradoxBenchmarking the paradox
•• NIST Multimedia event detection taskNIST Multimedia event detection task
•• NIST Multimedia event recounting taskNIST Multimedia event recounting task
Multimedia Event Detection taskMultimedia Event Detection task
•• Given an event specified by an Given an event specified by an –– event kit (query) which consists of: event kit (query) which consists of:
d fi itid fi iti–– definition, definition,
–– event explication, event explication,
–– evidential description, andevidential description, and
–– illustrative examples, illustrative examples,
•• Search video for events.Search video for events.
Example Event Kit Example Event Kit
zE id i l D i i
Definition: One or more people fashion an object out of wood.
Event Explication: Woodworking is a popular hobby that involves crafting an object out
of wood. Typical woodworking projects may range from creating large pieces of furniture to small decorative items or toys. The process for making objects out of wood can include cutting wood into smaller pieces…. (continues)
Mnemonic
Textual Definition
Expresses event domain specific knowledge to understand the event
Event Name: Working on a woodworking project
zEvidential Description: scene: Often indoors in a workshop, garage, artificial lighting.
Occasionally outdoorsobjects/people: Woodworking tools (automatic or non-automatic
saws, sander, knife), paint, stains, sawhorses, toolbox, safety goggles
activities: Cutting and shaping wood, attaching pieces of wood together, smoothing/sanding wood
audio: power tool sounds; hand tool sounds (hammer, saw, etc.); narration of process
definition
Textual listing of attributes that are often associated with the event
Exemplars: HVC334271.mp4, HVC393428.mp4, HVC875424.mp4, etc.
Specific clips from the “Event Kits” data set that are known to contain the event being defined.
Target User: An Internet information analyst or experienced Internet searcher with event-specialized knowledge.
Multimedia Event Recounting taskMultimedia Event Recounting task
•• An event detector will rapidly and automatically An event detector will rapidly and automatically produce a textual Englishproduce a textual English--language recounting of language recounting of each event occurrence it finds in a video collection,each event occurrence it finds in a video collection,–– describing the particular scene, actors, objects, and describing the particular scene, actors, objects, and
activities involved.activities involved.
•• Task starts in 2012Task starts in 2012

Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 28
Video collectionsVideo collections
Collection Name Designated Uses Target sizes AnnotationPilot 2010
Development collectionTest collection
1,723 clips1,742 clips(100 hours)
Clip content annotation for both sets
Development (DEV) 2011Split into two subsets:
44K clips,(~ 1400
For MED ‘11: Clip content p
(1) Transparent (DEV‐T)(2) Opaque (DEV‐O)
2012‐2015(1) and (2) merged to a single training collection
(hours)
pannotation for the transparent subsetAfter MED ‘11:Clip content annotation for the opaque subset
Progress 2012‐2015: test collection 120K clips,4000 hrs
No clip content annotation
Novel 1 2014: test collection 120K clips,4000 hrs.
No clip content annotation
Novel 2 2015: test collection 120K clips,4000 hrs.
No clip content annotation
The TRECVID MED ‘11 eventsThe TRECVID MED ‘11 events
Process‐Observed EventsAttempting a board trickFeeding an animalLanding a fishWorking on a woodworking project
Life EventsWedding ceremony
Trai
ning
Ev
ents
Test
ing
Even
ts Process‐Observed EventsChanging a vehicle tireGetting a vehicle unstuckGrooming an animalMaking a sandwichParkourRepairing an applianceWorking on a sewing project
Life EventsBirthday partyFlash mob gatheringParade
Conclusion on telling storiesConclusion on telling stories
•• Not much to conclude yetNot much to conclude yet–– Due to benchmarks, much will happen coming yearsDue to benchmarks, much will happen coming years
•• Field is currently obsessed with bagField is currently obsessed with bag--ofof--featuresfeatures–– Does not solve the event retrieval Does not solve the event retrieval paradoxparadox
–– Can multimedia help?Can multimedia help?
–– Can concepts help?Can concepts help?
•• The topic is wide openThe topic is wide open–– Perfect for (many) PhD’sPerfect for (many) PhD’s
1. Short course outline1. Short course outline
.0 Problem statement.0 Problem statement
.1 Measuring features.1 Measuring features
.2 Concept detection.2 Concept detection
.3 Lexicon learning.3 Lexicon learning
.4 Telling stories.4 Telling stories
.5 Video browsing.5 Video browsing
Problem 5: Problem 5: Use is openUse is open--endedended
scope
•• ThisThis is the interface gapis the interface gap
screen
keywords
Video search 1.0Video search 1.0
Note the influence of textual meta data, such as the video title, on the search results.

Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 29
Query selectionQuery selection ‘Classic’ Informedia system‘Classic’ Informedia system
•• First multimodal video search engineFirst multimodal video search engine
Carnegie Mellon University
FíschlárFíschlár
•• Optimized for use by “real” usersOptimized for use by “real” users
Dublin City University
IBM iMARSIBM iMARS
•• A web based systemA web based system
IBM Research
http://mp7.watson.ibm.com/
MediaMagicMediaMagic
•• Focus on the story levelFocus on the story level
FxPal
VisionGoVisionGo
•• Extremely fast and efficientExtremely fast and efficient
NUS & ICT-CAS

Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 30
RankRank
CrossBrowsing through resultsCrossBrowsing through results
Snoek, TMM 2007
TimeTime
Sphere variant
Extreme video retrievalExtreme video retrieval
•• ObservationObservation–– Correct results are retrieved, but not optimally rankedCorrect results are retrieved, but not optimally ranked
If h ti t lt h ti l t i l iIf h ti t lt h ti l t i l i
= very demanding!= very demanding!
Carnegie Mellon University
–– If user has time to scan results exhaustively, retrieval is If user has time to scan results exhaustively, retrieval is a matter of watching, selecting, and sorting a matter of watching, selecting, and sorting quicklyquickly
ForkBrowserForkBrowser
de Rooij, CIVR 2008
CrowdsourcingCrowdsourcing via timelinevia timeline
Snoek et al. ACM MM 2010
•• Poster by Poster by BaukeBauke FreiburgFreiburg–– Tuesday, Tuesday, 12:30 PM 12:30 PM -- 2:00 PM 2:00 PM
Multimedia event browsersMultimedia event browsers
•• ACM Multimedia 2012?ACM Multimedia 2012?
The future of video retrieval?The future of video retrieval?
Jonathan Wang, Carnegie Mellon University

Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 31
Interface gap best addressed byInterface gap best addressed by
•• TRECVID interactive search taskTRECVID interactive search task–– Interactively solve 20+ search topics Interactively solve 20+ search topics (10/15 minutes)(10/15 minutes)
R t 1 000 k d h tR t 1 000 k d h t b d lt t ib d lt t i–– Return 1,000 ranked shotReturn 1,000 ranked shot--based results per topicbased results per topic
–– Evaluate using Average PrecisionEvaluate using Average Precision
•• VideOlympicsVideOlympics showcaseshowcase
Video browsing at TRECVIDVideo browsing at TRECVID
•• Wide performance variationWide performance variation–– # concept detectors# concept detectors
2003
2004
–– Search interfaceSearch interface
–– Expert Expert vsvs novice user novice user
•• Most pronouncedMost pronounced–– 2003: 2003: InformediaInformedia classicclassic
–– 2005: Large semantic lexicon2005: Large semantic lexicon
–– 2008: Online learning2008: Online learning
2005
2006
2008
2009
2007
UvAUvA--MediaMillMediaMill@TRECVID@TRECVID
CrossBrowser
Snoek et al. TRECVID 04-09
• 200+ other interactive systemsTraditional systems
CriticismCriticism
•• Retrieval performance cannot be the only Retrieval performance cannot be the only evaluation criterionevaluation criterion–– Quality of detectors countsQuality of detectors counts–– Quality of detectors countsQuality of detectors counts
–– Experience of searcher countsExperience of searcher counts
–– Visualization of interface countsVisualization of interface counts
–– Ease of use countsEase of use counts
–– ……
Video browsing at Video browsing at VideOlympicsVideOlympics
•• Promote multiple facets of video searchPromote multiple facets of video search–– RealReal--time interactive video search ‘competition’time interactive video search ‘competition’
Si lt f lti l id h iSi lt f lti l id h i–– Simultaneous exposure of multiple video search enginesSimultaneous exposure of multiple video search engines
–– Highlight possibilities and limitations of stateHighlight possibilities and limitations of state--ofof--thethe--artart
ParticipantsParticipants

Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 32
Video trailerVideo trailer
http://www.VideOlympics.org
Conclusion on video browsingConclusion on video browsing
•• Interaction by browsing indispensible for any Interaction by browsing indispensible for any practical video search enginepractical video search engine
•• System should support user by learning and System should support user by learning and intuitive (mobile) intuitive (mobile) visualizationsvisualizations
Internet Video SearchInternet Video SearchConclusion on:Conclusion on:
conceptdetection
tellingstories
browsingvideovideo
videomeasuringfeatures
lexiconlearning
And there is always more …And there is always more …
•• Content Based Multimedia Retrieval: Lessons Content Based Multimedia Retrieval: Lessons Learned from Two Decades of Research Learned from Two Decades of Research
ShihShih Fu Chang Columbia UniversityFu Chang Columbia University–– ShihShih--Fu Chang, Columbia University Fu Chang, Columbia University
•• SIGMM Technical Achievement SIGMM Technical Achievement AwardAward–– Tomorrow: Tomorrow: 10:15 10:15 AMAM--12:30 12:30 PM PM
And there is always more …And there is always more …
•• Recommended special issues Recommended special issues –– IEEE Transactions on Pattern Analysis and Machine IEEE Transactions on Pattern Analysis and Machine
Intelligence, 30(11), November 2008Intelligence, 30(11), November 2008–– Proceedings of the IEEE, 96(4), April 2008Proceedings of the IEEE, 96(4), April 2008–– IEEE Transactions on Multimedia, 9(5), August 2007IEEE Transactions on Multimedia, 9(5), August 2007
•• 300 references on video search300 references on video search–– Snoek and Snoek and WorringWorring, Concept, Concept--Based Video Retrieval, Based Video Retrieval,
Foundations and Trends in Information Retrieval, Foundations and Trends in Information Retrieval, Vol. 2: No 4, pp 215Vol. 2: No 4, pp 215--322, 322, 2009.2009.
General references IGeneral references IColor Invariance. Jan-Mark Geusebroek, R. van den Boomgaard, Arnold W. M. Smeulders, H. Geerts. IEEE Trans. Pattern Analysis and Machine Intelligence, Volume 23 (12), page 1338-1350, 2001.
Distinctive Image Features from Scale-Invariant Keypoints. D. G. Lowe. Int'l Journal of Computer Vision, vol. 60, pp. 91-110, 2004.
Large-Scale Concept Ontology for Multimedia. M. R. Naphade, J. R. Smith, J. g p gy p , ,Tesic, S.-F. Chang, W. Hsu, L. S. Kennedy, A. G. Hauptmann, and J. Curtis,. IEEE MultiMedia, vol. 13, pp. 86-91, 2006.
Efficient Visual Search for Objects in Videos. J. Sivic and A. Zisserman. Proceedings of the IEEE, vol. 96, pp. 548-566, 2008.
High Level Feature Detection from Video in TRECVid: A 5-year Retrospective of Achievements. A. F. Smeaton, P. Over, and W. Kraaij, In Multimedia Content Analysis, Theory and Applications, (A. Divakaran, ed.), Springer, 2008.
Visually Searching the Web for Content. J. R. Smith and S.-F. Chang. IEEE MultiMedia, vol. 4, pp. 12-20, 1997.
Content Based Image Retrieval at the End of the Early Years. Arnold W. M. Smeulders, Marcel Worring, S. Santini, A. Gupta, R. Jain. IEEE Trans. Pattern Analysis and Machine Intelligence, Volume 22 (12), page 1349-1380, 2000.

Cees Snoek & Arnold SmeuldersUniversity of Amsterdam
29‐11‐2011
Internet Video Search 33
General references IIGeneral references IIThe Challenge Problem for Automated Detection of 101 Semantic Concepts in Multimedia. Cees G. M. Snoek, Marcel Worring, Jan C. van Gemert, Jan-Mark Geusebroek, Arnold W. M. Smeulders. ACM Multimedia, page 421-430, 2006.
The Semantic Pathfinder: Using an Authoring Metaphor for Generic Multimedia Indexing. Cees G. M. Snoek, Marcel Worring, Jan-Mark Geusebroek, Dennis C. Koelma, Frank J. Seinstra, Arnold W. M. Smeulders. IEEE Trans. Pattern Analysis and Machine Intelligence, Volume 28 (10), page 1678-1689, 2006.y g , ( ), p g ,
A Learned Lexicon-Driven Paradigm for Interactive Video Retrieval. Cees G. M. Snoek, Marcel Worring, Dennis C. Koelma, Arnold W. M. Smeulders. IEEE Trans. Multimedia, Volume 9 (2), page 280-292, 2007.
Adding Semantics to Detectors for Video Retrieval. Cees G. M. Snoek, BoukeHuurnink, Laura Hollink, Maarten de Rijke, Guus Schreiber, Marcel Worring. IEEE Trans. Multimedia, Volume 9 (5), page 975-986, 2007.
The MediaMill TRECVID 2004-2011 Semantic Video Search Engine. Cees G. M. Snoek et al. Proceedings of the TRECVID Workshop, 2004-2011.
Visual-Concept Search Solved?. Cees G.M. Snoek and Arnold W.M. Smeulders. IEEE Computer, Volume 43 (6), page 76-78, 2010.
General references IIIGeneral references IIIConcept-Based Video Retrieval. Cees G. M. Snoek, Marcel Worring. Foundations and Trends in Information Retrieval, Vol. 4 (2), page 215-322, 2009.
Local Invariant Feature Detectors: A Survey. T. Tuytelaars and K. Mikolajczyk. Foundations and Trends in Computer Graphics and Vision, vol. 3, pp. 177-280, 2008.
Evaluating Color Descriptors for Object and Scene Recognition. Koen E. A. van de Sande, Theo Gevers, Cees G. M. Snoek. IEEE Trans. Pattern Analysis d hi lli (i ) 2010
http://www.science.uva.nl/research/publications/
and Machine Intelligence (in press), 2010.
Visual Word Ambiguity. Jan C. van Gemert, Cor J. Veenman, Arnold W. M. Smeulders, Jan-Mark Geusebroek. IEEE Trans. Pattern Analysis and Machine Intelligence (in press), 2009.
Real-Time Bag of Words, Approximately. Jasper R. R. Uijlings, Arnold W. M. Smeulders, R. J. H. Scha. ACM Int'l Conference on Image and Video Retrieval, 2009.
Lessons Learned from Building a Terabyte Digital Video Library. H. D. Wactlar, M. G. Christel, Y. Gong, and A. G. Hauptmann. IEEE Computer, vol. 32, pp. 66-73, 1999.
Local Features and Kernels for Classification of Texture and Object Categories: A Comprehensive Study. J. Zhang, M. Marszalek, S. Lazebnik, and C. Schmid. Int'l Journal of Computer Vision, vol. 73, pp. 213-238, 2007.
Contact infoContact info
•• Cees Snoek Cees Snoek http://www.CeesSnoek.infohttp://www.CeesSnoek.info
•• Arnold Arnold SmeuldersSmeuldershttp://staff.science.uva.nl/~smeulderhttp://staff.science.uva.nl/~smeulder





























