Embed Size (px)
Citation preview


I I I C o n g r e s o I n t e r n a c i o n a l d e C o m p u t a c i ó n y Te l e c o m u n i c a c i o n e s
1 9 a l 2 1 d e o c t u b r e d e 2 0 1 1
M e m o r i a
Facultad de Ingeniería de Sistemas, Cómputo y Telecomunicaciones

UNIVERSIDAD INCA GARCILASO DE LA VEGA
III CONGRESO INTERNACIONAL DE COMPUTACIÓN Y TELECOMUNICACIONES (COMTEL 2011) 19 AL 21 DE OCTUBRE - LIMA, PERÚ
Rector
Dr. Luis Cervantes Liñán
Vicerrector
Dr. Jorge Lazo Manrique
FACULTAD DE INGENIERÍA DE SISTEMAS, CÓMPUTO Y TELECOMUNICACIONES
EDITORES
Dr. José Eduardo Ugaz BurgaDecano de la Facultad de Ingeniería de Sistemas, Cómputo y Telecomunicaciones
Msc. Santiago Raúl Gonzales SánchezFacultad de Ingeniería de Sistemas, Cómputo y Telecomunicaciones
Lic. Cipriano Torres GuerraFacultad de Ingeniería de Sistemas, Cómputo y Telecomunicaciones
Página web: www.comtel.pe
© Universidad Inca Garcilaso de la Vega Av. Arequipa 1841 - Lince
Teléf.: 471-1919 Página web: www.uigv.edu.pe
Fondo Editorial Editor: Lucas Lavado
Correo electrónico: [email protected] Jr. Luis N. Sáenz 557 - Jesús María
Teléf.: 461-2745 Anexo: 3712 Correo electrónico: [email protected]
Hecho el Depósito Legal en la Biblioteca Nacional del Perú Nº 2011-12366ISBN: 978-612-4050-40-4
Ficha TécnicaMemoria: Comtel 2011
Categoría: Memoria/Ingeniería de Sistemas, Cómputo y Telecomunicaciones
Código: MEM-FIS/003-2011Edición: Fondo Editorial de la UIGV
Formato: 205 mm. x 280 mm. 201 pp.Impresión: Offsett y encuadernación encolado
Soporte: Couche mate 150 gInteriores: Bond alisado 75 g
Publicado: Lima, Perú. Octubre de 2011Tiraje: 500 ejemplares

UIGV3
Índice
Prólogo ................................................................................................................................................................................................7
Comité de programa ...........................................................................................................................................................................9
Comité organizador ..........................................................................................................................................................................11
TRABAJOS ÁREA DE COMPUTACIÓN ................................................................................................................................................13
Diseño de un sistema embebido que apoye la generación de hábitos de autonomía,responsabilidad y organización en la población infantil en edad de 6 a 12 años ...........................................................................15
Jenny Carolina Ramírez Leal, Maritza Torres Barrero, Carolina Valenzuela Botero
Acesso Mágico: Um Sítio Acessível ....................................................................................................................................................19Cristivon Silva Cruz, Maristela Terto de Holanda
Segurança em Sistemas de E-learning: uma Análise do Ambiente Tidia-Ae/Sakai........................................................................23Eduardo H. Gomes, Edson P. Pimentel, João H. Kleinschmidt
Reduciendo la Ambigüedad en el Modelo del Dominio mediante Especificaciones Formales Ligeras en VDM++ .....................29Elizabeth Vidal-Duarte, César Mogrovejo Ramirez, Eveling Castro Gutierrez
Web Usage Mining, aplicado a servidores Web Apache ...................................................................................................................33Julián Alberto Monsalve Pulido
Um Perfil UML para o Paradigma Orientado a Notificações (PON) ................................................................................................37Luciana V. B. Wiecheteck, Paulo C. Stadzisz, Jean M. Simão
Evaluación de la calidad sobre la aplicación móvil fiscal para hacer eficiente el cálculodel pago provisional mensual de arrendadores en México ..............................................................................................................41
Juan Pedro Benítez Guadarrama, Ana Luisa Ramírez Roja, Carlos Robles Acosta
Proposta de um Simulador para o Ensino de Escalonamento FIFO e DRR ......................................................................................45Rodrigo Ap. Morbach, Tatiana Annoni Pazeto
Aplicación de la Técnica Regresión Logística de la Minería de Datos en el procesode Descubrimiento de Conocimiento (KDD) en Bases de Datos Operativas o Transaccionales ........................................................49
Juan Camilo Giraldo Mejía, Fabio Alberto Vargas Agudelo
Uma comparação entre o Paradigma Orientado a Notificações (PON) e o ParadigmaOrientado a Objetos (POO) realizado por meio da implementação de um Sistema de Vendas .....................................................53
Márcio V. Batista, Roni F. Banaszewski1, Adriano F. Ronszcka1, Glauber Z. Valença,Robson R. Linhares, Paulo C. Stadzisz, Cesar A. Tacla, Jean M. Simão

UIGV4
Nuevas Estrategias para el entrenamiento de Redes Neuronales que propagan Números Difusos ...............................................57Edwin Villarreal López, Oscar Duarte, Daniel Alejandro Arango
Comparações quantitativas e qualitativas entre o Paradigma Orientado a Objetose o Paradigma Orientado a Notificações sobre um simulador de jogo ............................................................................................61
Adriano F. Ronszcka, Danillo L. Belmonte, Glauber Z. Valença, Márcio V. Batista,Robson R. Linhares, Cesar A. Tacla, Paulo C. Stadzisz, Jean M. Simão
Proposta de uma Abordagem para Especificação de Requisitos Baseada em Projeto Axiomático ..................................................65Ana Maria Pereira, Paulo Cézar Stadzisz, Jean Marcelo Simão
Sistema Inteligente de Diagnóstico de Anemia Ferropénica basado en Redes Neuronales Artificiales ..........................................69Edinson Muñoz, Jorge Espinoza, Luis Rivera
Modelo Tridimensional para a Qualidade de Sítios Web .................................................................................................................73Álvaro Rocha, José Avelino Victor, Patrícia Leite Brandão
Autenticación basada en Java card y en certificado X.509 para ambientes universitarios ..............................................................77María Ortega, Sergio Sánchez
Clasificación de residuos de construcción y demolición mediante un kernel modificado de Laws ...................................................81Albert Miyer Suárez Castrillón, Sir Alexci Suárez Castrillón, Maribel González Rodriguez
Un estudio del Escalamiento de Imágenes mediante Interpolaciónbasada en la Transformada Discreta Wavelet de Daubechies ..........................................................................................................85
Marks Calderón-Niquín, Jorge Valverde-Rebaza
Desenvolvimento de um sistema distribuído em sala de aula de forma colaborativa.....................................................................89Katia de Paiva Lopes, Sandro Renato Dias
Sistemas para la identificación de señales de audio ........................................................................................................................93Daniel Alejandro Arango Parrado, Edwin Villarreal López, Pedro Raúl Vizcaya Guarín
Generación de Valor en las Pyme Peruanas utilizandoTecnologías de la Información: Modelo de Implementación de ERP ...............................................................................................97
Jorge Armando Saucedo Ascona, José Hamblett Villegas Ortega
Comparações entre o Paradigma Orientado a Objetos e o Paradigma Orientadoa Notificações sob o contexto de um simulador de sistema telefônico ...........................................................................................103
Robson R. Linhares, Adriano F. Ronszcka, Glauber Z.Valença, Márcio V. Batista,Fernando Witt, Carlos R. Erig Lima, Jean M. Simão, Paulo C. Stadzisz
Un Modelo de Aula Virtual en la enseñanza universitariade pregrado en la Facultad de Medicina Humana de la USMP .....................................................................................................107
Jorge Raúl Carreño Escobedo, Inés Victoria Cotrina Giraldo, José Hamblett Villegas Ortega
Framework de Testes para Algoritmos de Decisão de Handover Vertical em Redes Heterogêneas ...............................................111Anderson S. F. da Silva, Ricardo J. de P. B. Salgueiro, Edilayne M. Salgueiro
Sistema Inteligente basado en Redes Bayesianas para el diagnóstico Clínico de Enfermedades Cutáneas ..................................115Rosangela Abregu M., Joseph Gonzales M., Nancy Laurente G., Jorge L. Távara, Virgilio Tito C.
Modelo de Evaluación de desempeño para Docentes Peruanos basado en TIC .............................................................................119Pierre Paul Loncán Salazar, José Hamblett Villegas Ortega

UIGV5
Swarm Intelligence para un Modelo de Optimización de Stocksbasado en Reposiciones Conjuntas y Descuentos por Cantidad ......................................................................................................123
Orlando Durán, Sergio Soto C.
Innovación en el desarrollo de una plataforma tecnológica institucionalcomo escritorio de trabajo (Proyecto USBnet Linux 5). ..................................................................................................................127
Frederyk Luy, Leyvin A. Yépez G., Ronald Mendez, Milagros Del C. González B.
Reconstrução de Mapas por meio de Fluxo Veicular .......................................................................................................................131Edwar Velarde Allazo, Yuzo Iano, Vicente Sablon Becerra
TRABAJOS ÁREA DE TELECOMUNICACIONES ................................................................................................................................135
Scalable Video Content Adaptation.................................................................................................................................................137Livio Lima, Nicola Adami, Riccardo Leonardi
Modelo de Gestión de Dominios de Servicios en Redes Inalámbricas ............................................................................................141Chadwick Carreto, Rolando Menchaca, Salvador Alvarez
Sistema de Telecomunicaciones: ITVNET ........................................................................................................................................145Juan Diego López Vargas, Liliana Gómez Meza, Carlos Díaz
Creando contenidos para la Televisión Digital................................................................................................................................153Adriana X. Reyes, Claudia Rosero, Gustavo Moreno
Cálculo de Cobertura de un Sistema de Telefonía Celulara lo largo de una Carretera usando Software de Simulación ........................................................................................................157
Mauricio Postigo, Ronald Coaguila, Wildor Ferrel, José Chilo
Streaming de Vídeo Escalável em Rede Celular de 3ª Geração .....................................................................................................161Vanice Canuto Cunha, Paulo Roberto de Lira Gondim, Rodrigo Mulinari
Distribuição de Vídeo sob Demanda sobre redes P2P ....................................................................................................................165Valmiro José Rangel Galvis, Paulo Roberto de Lira Gondim
Diseño de un Sistema de Monitoreo Móvil para gestantes en el Distrito de Balsapuerto, Loreto ................................................169Sandy Lucy Maldonado Panduro, Luis Montes Bazalar
Descripción, Evaluación y Proyecciones de la Implementación del Área Virtual Móvil en Perú .....................................................171Cynthia Natali Alvarez Huaraca, Percy Fernandez P., Luis Montes B.
Estudio, Diseño e Instalación de un Retransmisor Isofrecuencialde Televisión Digital Terrestre para el Cono Norte de Lima ...........................................................................................................175
Carlos Enrique Barraza Flores, Marco Mayorga Montoya
Aplicación Interactiva para registro de citas médicas por Televisión utilizando GINGA-NCL ........................................................177Herminio Paucar Curasma, Nilton Ugarte Vera, Ronald Paucar Curasma
Sistema de Monitoreo remoto usando la tecnología ZigBee y mensajes SMS ...............................................................................181Yauri Rodriguez, Rubén Acosta Jacinto, Antuanet Adanaqué Infante

UIGV6
CONFERENCIAS MAGISTRALES ......................................................................................................................................................185
Doing business with Open Source software ....................................................................................................................................187Michael Widenius (Finlandia)
The MySQL / MariaDB success stories .............................................................................................................................................188Michael Widenius (Finlandia)
Middeware Ginga-NCL: Estado Atual e Perspectivas Futuras de Pesquisa e Inovação ..................................................................189Luiz Fernando Gomes Soares (Brasil)
Evolución de la criptografía: desde la criptografía simétrica hasta la criptografía basada en identidad......................................190José Luis Muñóz Tapia (España)
Emergency Information Broadcast By the use of ISDB-T “EWBS” (Emergency Warning Broadcasting System) ...........................191Yasuji Sakaguchi (Japón)
Inteligencia de Negocios para incrementar la productividad de las Empresas ..............................................................................192Nicolás Kémper Valverde (México)
Oportunidades 3D – Blender, Libre para Crear .............................................................................................................................193Eraldo Martins Guerra Filho (Brasil)
TD Digital, HDTV e IPTV sobre la red óptica “Argentina Conectada”.............................................................................................194Mario Mastriani (Argentina)
Mobile Multimedia for Outreach Across the Digital Divide ............................................................................................................195César Bandera (Estados Unidos)
Creando Animaciones, Motion Graphics y VFX para cine y televisión digital con software libre ...................................................196Octavio Augusto Méndez Sánchez (México)
“Neuro Copter” Linear Quadratic Gaussian Design LQG and implementation of theControl System of an unmanned aerial vehicle UAV with state space modelling andKalman Filtering and autonoumous Guidance with Computer Vision and data link Communications .........................................197
Fernando Jiménez Motte (Perú)
Cloud Computing: ¿Una nueva tecnología? ....................................................................................................................................198Jorge Yaqui (Perú)
Evaluando la seguridad de aplicaciones Web .................................................................................................................................199Mauricio Velazco Corrales (Perú)
Desarrollo Tecnológico y Software Libre .........................................................................................................................................200Alfonso de la Guarda Reyes (Perú)

UIGV7
Prólogo
COMTEL, congreso internacional cuyo objetivo primordial es la difusión e intercambio de conocimientos y la muestra de experiencias académico-científicas y soluciones en las áreas de computación, telecomunicaciones y afines, se inscribe en la misión de la Universidad Inca Garcilaso de la Vega, que se propone impulsar una educación innovadora basada en la investi-gación y formar profesionales cualificados que asuman con éxito los retos de la globalización.
COMTEL 2011 cuenta con la participación de renombrados ponentes nacionales e inter-nacionales quienes tratan temas importantes y de actualidad, entre los que destacan: Com-putación y Telecomunicaciones al servicio de la sociedad, Televisión Digital, transferencia de Tecnología de Información y Comunicación a la empresa, la investigación como motor del de-sarrollo de software para la empresa y el gobierno, colaboración universidad-empresa como medio de consolidación del desarrollo.
Los trabajos presentados para este Congreso fueron sometidos a la evaluación de revisores del Comité de Programa, integrado por expertos de Brasil, Colombia, Cuba, España, Estados Unidos, Italia, México, Perú, Uruguay y Venezuela. Se recibieron 88 trabajos, 72 en el área de computación y 16 en el área de telecomunicaciones. Fueron aceptados, para su presentación, 44 trabajos, 29 en el área de computación y 15 en el área de telecomunicaciones. La mayor cantidad de trabajos recibidos provienen de: Perú, Brasil y Colombia.
Las áreas de investigación con interés por parte de los autores fueron:
Área de Computación:• Aplicaciones tecnológicas.• Educación y computación.• Ingeniería de software y programación.
Área de Telecomunicaciones:• TV digital, HDTV, IPTV.• Redes inalámbricas.• Calidad de servicio de las telecomunicaciones.
Los trabajos aceptados en COMTEL 2011 están publicados en esta memoria del Congreso donde se abordan, además, temas de interés para la sociedad y de gran aporte para la comu-nidad académica y científica.
Agradecemos a los participantes y a los expositores nacionales e internacionales por su participación en COMTEL 2011.
Dr. José Eduardo Ugaz BurgaComisión Organizadora
COMTEL 2011

UIGV8

UIGV9
Comité de programa
ÁREA DE COMPUTACIÓN
Presidente (chair)
Dr. Luis Rivera Escriba, Estadual do Norte Fluminense, Brasil
Miembros:
• Dr. Alessandro Fabricio Garcia, Pontifícia Universidade Católica do Rio de Janeiro, Brasil.
• Dr. Alex Cuadros Vargas, Universidad Católica San Pablo, Perú.
• MSc. Aleksandro Montanha, UNIFAMMA - Faculdade Metropolitana de Maringa, Brasil.
• Dr. Alvaro Cuno Parari, Universidad Nacional Mayor de San Marcos, Perú.
• PhD. Annabell del Real Tamariz, Universidade Estadual do Norte Fluminense, Brasil.
• Dr. Angel Guillermo Coca Balta, Universidade Estadual Norte Fluminense, Brasil.
• Mg. Angel Hermoza Salas, Universidad Inca Garcilaso de la Veja, Perú.
• MSc. Carlos Peña Peña, Universidad Inca Garcilaso de la Vega, Perú.
• Dr. César Bandera, New Jersey Institute of Technology, USA.
• Dr. César Beltrán Castañón, Universidad Nacional San Agustín, Perú.
• Mg. Daniel Yucra Sotomayor, Universidad Inca Garcilaso de la Vega, Perú.
• Dr. Dennis Barrios Aranibar, Universidad Católica San Pablo, Perú.
• Dr. Erik Alex Papa Quiroz, Universidad Nacional Mayor de San Marcos, Perú.
• Dr. Ernesto Cuadros Vargas, Universidad Católica San Pablo, Perú.
• Dr. Fabrizio Luccio, Universidad de Pisa, Italia.
• Dr. Francisco Javier Soriano Camino, Universidad Politécnica de Madrid, España.
• Dr. Glen Darío Rodríguez Rafael, Universidad Ricardo Palma, Perú.
• Dr. José Luis Segovia Juárez, CONCYTEC, Perú.
• Dra. Luciana Salete Buriol, Universidade Federal do Rio Grande do Sul, Brasil.
• Dr. Luis Joyanes Aguilar, Universidad Pontificia de Salamanca, España.
• Mg. Marco A. Álvarez Vega, Utah State University, USA.
• MSc. Mario Borja Borja, Universidad Inca Garcilaso de la Vega, Perú.
• Dr. Nicolás Kémper Valverde, Universidad Nacional Autónoma de México, México.

UIGV10
• Mg. Omar U. Florez, Utah State University, Estados Unidos.
• Dr. Roger Ríos Mercado, Universidad Autónoma de Nuevo León, México.
• Dr. Silverio Bustos Díaz, Universidad Ricardo Palma, Perú.
• Dra. Sofía Álvarez Cárdenas, Universidad de Ciencias Informáticas, Cuba.
• MSc. Wender Antônio da Silva, Faculdade Estácio/Atual - Roraima, Brasil.
ÁREA DE TELECOMUNICACIONES
Presidente (chair)
Dr. Carlos Silva Cárdenas, Pontificia Universidad Católica del Perú, Perú
Miembros:
• MBA. Carlos García Godos Naveda, Telefónica del Perú, Perú.
• Dr. Carlos Valdez Velásquez López, Ministerio de Transportes y Comunicaciones, Perú.
• Ing. David Chávez Muñoz, Pontificia Universidad Católica del Perú, Perú.
• MSc. Dick Carrillo Melgarejo, CPqD – Centro de Pesquisa en Telecomunicaciones –
Campinas, Brasil.
• Dr(c). Efraín Mayhua López, Universidad Carlos III de Madrid, España.
• Phd. Fernando Jiménez Motte, Universidad Peruana de Ciencias Aplicadas, Perú.
• Dr. Gonzalo Fernández Del Carpio, Universidad Católica San Pablo, Perú.
• Dr. Guillermo Leopoldo Kémper Vásquez, Universidad San Martín de Porres, Perú.
• Dr. Jordi Casademont Serra, Universidad Politécnica de Catalunya, España.
• Dr. Jorge del Carpio Salinas, Universidad Nacional de Ingeniería, Perú.
• Mg. José Gregorio Cotúa, Universidad Católica Andrés Bello, Venezuela.
• Mg. José Luis Muñoz Meza, Organismo Supervisor de Inversión Privada en
Telecomunicaciones - OSIPTEL, Perú.
• Dr. José Luis Muñóz Tapia, Universidad Politécnica de Catalunya, España.
• Ing. Luis Montes Bazalar, Pontificia Universidad Católica del Perú, Perú.
• MSc. Luis Pacheco Zevallos, Pontifica Universidad Católica del Perú, Perú.
• Ing. Marco Mayorga Montoya, Pontificia Universidad Católica del Perú, Perú.
• Dr. Manuel Yarlequé Medina, Pontificia Universidad Católica del Perú, Perú.
• Dr. Néstor Misael Peña Traslaviña, Universidad de los Andes, Colombia.
• MSc. Óscar Agurto, IBM del Perú, Perú.
• MSc. Óscar Núñez Mori, Pontificia Universidad Católica del Perú, Perú.
• MSc. Patricia Castillo Araníbar, Universidad Católica San Pablo, Perú.
• MSc. Patricia Díaz Ubillus, Pontificia Universidad Católica del Perú, Perú.
• MSc. Raúl Ramiro Peralta Meza, Universidad Católica San Pablo, Perú.

UIGV11
PRESIDENTE
Dr. Luis Cervantes Liñán
VICEPRESIDENCIA
Dr. josé Eduardo Ugaz Burga
MSc. Santiago Raúl Gonzales Sánchez
COMISIONES
Comisión de Coordinación
• César Luza Montero
• Evelyn Elizabeth Ayala Ñiquen
Comisión de Auspicio y Financiamiento
• Daniel Yucra Sotomayor
• Félix Fermín Pérez
Comisión de Protocolo
• Evelyn Elizabeth Ayala Ñiquen
• Raúl Díaz Rojas
• Rubén Alberto Cueva Zúñiga
• Silvana Rosario Steffanie Ñaupari Jara
Comisión de Finanzas y Presupuesto
• Cecilia Milagros Marín Tena
Comité organizador

UIGV12
Comisión Logística y Ambientación del Local
• Rubén Alberto Cueva Zúñiga
• Eduardo Alcántara Becerra
Comisión Logística de Materiales
• Silvana Rosario Steffanie Ñaupari Jara
• Freddy Benavides Cárdenas
Comisión de Talleres y Minicursos
• Rubén Acosta Jacinto
Comisión Portal y Aplicaciones Web
• Luis Li Prado
• Juan Carlos Carbonel
Comisión de Difusión y Publicidad
• Eduardo Alcántara Becerra
• Cipriano Torres Guerra
• Paul Troncoso Castro
Comisión de Relaciones Públicas
• Daniel Yucra Sotomayor
Comisión de Desarrollo de Programación
• José Cruz Estupiñán
• Silvana Rosario Steffanie Ñaupari Jara
Comisión de Inscripción y Registro
• Lucy Cristina Chíncaro Egúsquiza
• Sally Torres Alvarado
Comisión de Traducción
• Gabriela García Salazar

UIGV13
Trabajos aceptadosen el área de computación

UIGV14

UIGV15
Diseño de un sistema embebido que apoye la generación de hábitos de autonomía, responsabilidad y organización en la población infantilen edad de 6 a 12 años
Jenny Carolina Ramírez Leal, Maritza Torres Barrero, Carolina Valenzuela BoteroUniversidad La Gran Colombia Seccional Armenia{ramirezljennycarolina, torresbmaritza, valenzuelabcarolina}@miugca.edu.co
Resumen
La población infantil, como base de la sociedad futura, presenta un comportamiento desordenado donde se evidencia la carencia de marcos de referencia espacio-temporales que contribuyen a incrementar los desórdenes alimentarios, escolares y sociales. Estas conductas están asociadas a patrones de crianza actuales que incluyen el uso de dispositivos tecnológicos, como el televisor, los videojuegos y reproductores de sonido que generan un grado de dependencia en los niños de la época.
Los expertos en el tema recomiendan el establecimiento de rutinas que ayuden al niño(a) a interiorizar ritmos que le permitan organizar el horario de sus responsabilidades. La hipótesis del proyecto plantea que un sistema embebido para la programación de rutinas en población infantil permite mitigar las falencias en hábitos de autonomía, responsa-bilidad y organización en problemas conductuales de índole escolar, alimentaria y relaciones familiares.
Las autoras del proyecto pretenden integrar una solución que involucre el uso de la tecnología a la que están ex-puestos los menores para inducir la generación de hábitos y rutinas, de forma tal que permita programar las rutinas infantiles sin el uso del ordenador. Para la integración del sistema propuesto se ha aprovechado uno de los aparatos electrónicos más utilizados por los niños.
Palabras clave:
Hábito, población infantil, programación de rutinas, Sistema embebido.
Abstract
Childhood as one of the stages in human life in which naturally major disorders in daily routines happen; where lack of temporary spacial reference frames can be evidenced, all contributing to increase the mentioned disorders, fall in well defined fields suchs as the social field, feeding, and scholar system. This behavior is associated with current parenting patterns which include the use of technological devices such as TV, video games, I pods etc. generating a state of dependence with the era.
Experts in the field recommend the establishement of routines to help kids internalizing rythms, and to organize schedules of responsability. From this point the hypothesis in the present project states that an embedded system for children´s routines programming allows to mitigate the lack of habits such as autonomy, responsability and the orga-nization of scholar´s behavioral problems, feeding and family relations.
The authors of the project intend to integrate a solution which involves using the technology to which they are exposed to, in order to induce a generation of routines and habits without using the computer, taking adventage of one of the most used electronic devices towards the integration of the proposed system.
Keywords:
Habit, Child Population, Routine Schedule, Embedded System.

UIGV16
Introducción
Las TIC han logrado incidir en el estilo de vida de la sociedad actual generando cambios drásticos que obligan a los padres a afrontar nuevos retos en la educación de sus hijos, relacionados principalmente con problemas de autonomía, responsabilidad y organización. Adicional a esto, la limitación de tiempo de los padres conduce al niño a un acompañamiento tecnológico permanente, que en la mayoría de los casos, genera dependencia. Por esta razón, esta investigación pretende mejorar el problema expuesto mediante la construcción de un sistema em-bebido y haciendo uso del televisor como dispositivo cotidiano de interacción.
Hasta el momento no se conocen trabajos similares que involucren ayudas tecnológicas para apoyar estos procesos conductuales. Diversos textos, Autismo Diario, 2008; Del Prado, Cómo crear hábitos en los niños, 2009; Patentes en España, 2007; MOBIUS Corporation, 2004, han propuesto métodos que incluyen carteles o tableros didácticos para generar hábitos en los niños, pero ninguno de éstos ha logrado sumergirse en el entorno tecnoló-gico en el que ellos se desenvuelven.
Este artículo está dividido en 8 secciones. En la sección 2, se presenta brevemente el marco de antecedentes de la investigación. En la sección 3, se da una visión general del dominio. En la sección 4, se presentan los materiales y métodos utilizados en la investigación. En la sección 5, se muestran los resultados más importantes del diseño del sistema embebido. En la sección 6, se discuten los resultados. Finalmente, en las secciones 7 y 8, se incluyen las conclusiones y los trabajos futuros.
Conclusiones
Para los padres de niños en edades entre 6 y 12 años, las actividades más importantes en las rutinas diarias de sus hijos son: acostarse, bañarse y estudiar, al igual que realizar tareas domésticas y reforzar competencias de lectoescritura, las últimas sugeridas por iniciativa de los padres. Además, se evidenció que la actividad más relevante para los profesionales en el área es practicar algún deporte, la cual no es contemplada por los padres.
Dada la población usuaria y contexto de uso, los requisitos de calidad identificados para la construcción del sistema embebido son Usabilidad y Portabilidad. Además, se concluyó que deben definirse actividades personali-zables que puedan ser asignadas por los padres según sus necesidades.
El componente hardware debe montarse en una arquitectura de 32 bits para optimizar los procesos, incluyendo comunicación con periféricos; siendo factible la utilización de los lenguajes C o ensamblador para implementar la funcionalidad del sistema.
Referencias
[1] Autismo Diario. (2008). Autismo Diario.Org. Recuperado el 11 de 2011, de http://autismodiario.org/2008/10/21/agendas-personales-para-ninos-con-autismo/
[2] Casado, L. (26 de 11 de 2007). Escalabilidad, conectividad, compatibilid en μC. Obtenido de http://www.bairesrobotics.com.ar/data/flexis.pdf
[3] Centers For Disease Control and Prevention. (26 de 01 de 2011). CDC HOME. Obtenido de http://wwwn.cdc.gov/epiinfo/
[4] Del Prado, I. L. (10 de 04 de 2009). Cómo crear hábitos en los niños.
[5] Departamento Administrativo Nacional de Estadísticas (2005) Informe demográfico municipio de Armenia (Quindío). Bogotá.

UIGV17
[6] Granollers, T. (s.f.). Modelo de proceso de la ingeniería de la usabilidad y la accesibilidad. Recuperado el 05 de Diciembre de 2010, de http://www.grihohcitools.udl.cat/mpiua/modelo.htm
[7] Llinares, A. N. (2005). Sistemas Embebidos. Recuperado el 02 de 2011, de http://server-die.alc.upv.es/asignaturas/PAEEES/2005-06/A07%20-%20Sistemas%20Embebidos.pdf
[8] Massey University. (2007). Massey University. Recuperado el 03 de 2011, de http://www.massey.ac.nz/massey/about-massey/news/article.cfm?mnarticle=virtual-eve-first-in-human-computer-interaction-16-11-2007
[9] MOBIUS Corporation. (2004). Kidware. Recuperado el 30 de 03 de 2011, de http://www.kidware.com/indexspa2.htm
[10] Patentes en España. (2007). Patentes.com. Recuperado el 03 de 2011, de http://patentados.com/invento/tablero-didactico-multifuncion.html
[11] Perez, D. A. (2009). Sistemas Embebidos y Sistemas Operativos para Embebidos. Caracas: Universidad Central de Venezuela.
[12] Rodríguez Solís, S. E. (21 de 05 de 2008). Monografias. Obtenido de http://www.monografias.com/trabajos60/tamano-muestra-archivistica/tamano-muestra-archivistica2.shtml
[13] Sánchez Navarro, J. D. (1995). Electrónica Moderna Práctica. Mc Graw Hill.
[14] Universidad Autónoma de Madrid. (1999). UAM. Obtenido de http://www.uam.es/personal_pdi/stmaria/jmurillo/Metodos/Materiales/Apuntes%20Cuestionario.pdf

UIGV18

UIGV19
Cristivon Silva Cruz1, Maristela Terto de Holanda2
1 Universidade Católica de Brasília2 Universidade de Brasí[email protected], [email protected]
Acesso Mágico: Um Sítio Acessível
Resumo
A era digital permitiu a aproximação entre as pessoas como jamais foi visto em outra fase da história humana, con-tudo, ela também pode ser fator de exclusão, especialmente para pessoas com alguma deficiência. Nesse contexto, este trabalho apresenta conceitos, padrões, legislações e regras relacionadas à acessibilidade na web. Essa pesquisa foi aplicada na construção de um sítio acessível em tecnologia Flash, voltado para o entretenimento e atividades edu-cacionais para crianças portadoras de deficiência.
Palavra chave:
ATAG, WCAG 2.0, WCAG 2.0, W3C
Abstract
The digital age has allowed a rapprochement between the people like never was seen in another phase of human history, however, it can also be an exclusion factor, especially for people with disabilities. In this context, this paper presents concepts, standards, laws and rules related to web accessibility. This research was applied in the construction of an accessible site in Flash technology, aimed at providing entertainment and educational activities for children with disabilities.
Keywords:
ATAG, WCAG 2.0, WCAG 2.0, W3C
Introdução
O acesso de pessoas portadoras com alguma deficiência física ao uso de serviços e informações, respeitando as necessidades e a preferência de cada indivíduo ao longo da história desencadeou a conscientização de polí-ticas inclusivas, onde todos devem participar igualmente.
A preocupação em garantir meios de acessibilidade vem crescendo com o passar do tempo, visando à cons-trução de uma sociedade onde haja participação e igualdade efetiva de todos os cidadãos [Brewer, 1999], [Conforto, 2002].
Os resultados do censo 2000 mostram que, aproximadamente, 24,6 milhões de pessoas, ou 14,5% da popu-lação total, apresentaram algum tipo de incapacidade ou deficiência. São pessoas com alguma dificuldade de

UIGV20
enxergar, ouvir, locomover-se ou alguma deficiência física ou mental. Entre 16,6 milhões de pessoas com algum grau de deficiência visual, quase 150 mil se declararam cegos. Já entre os 5,7 milhões de brasileiros com algum grau de deficiência auditiva, um pouco menos de 170 mil se declararam surdos [IBGE, 2010]. Segundo a Orga-nização Mundial de Saúde (OMS) e Organização das Nações Unidas (ONU), cerca de 500 pessoas tornam-se deficientes diariamente no Brasil, vítimas de acidentes, doenças ou violência.
Nesse contexto, esse trabalho traz uma pesquisa aplicada de acessibilidade na web, o Acesso Mágico, um sítio acessível para crianças portadoras de deficiência.
As próximas seções desse artigo são: 2, apresenta uma descrição breve sobre o trabalho; 3, um resumo das principais normas e software é apresentado; 4, como desenvolver aplicativos acessível usando o Flash; 5, resulta-dos obtidos com o prometo; 6, conclusão.
Conclusão
A acessibilidade na web é um ponto fundamental onde tem-se uma gama de conteúdo e serviços disponíveis através da Internet. Especialmente para crianças a criação de sítios acessíveis é uma questão muito importante.
Através da implementação do sítio Acesso Mágico foi possível criar um sítio na Internet com ferramenta de animação, como o Flash, aplicado para a criação de um sítio atraente para qualquer criança, ao mesmo tempo, totalmente acessível àquelas portadoras de deficiência auditiva e visual.
Como continuação desse trabalho pretende-se validar o sítio com um grupo de crianças com deficiência visual para avaliar a facilidade de uso, pois nesse trabalho foi aplicado apenas validadores automáticos e a leitores de tela. Uma outra questão importante que será analisada é a inclusão de alguma técnica pedagogia para criar mais jogos educacionais voltado a crianças portadoras de deficiência.
Referencias
[1] [Brewer, 1999] Brewer, J.; Jacobs, L. (1999). Accessibility Features of CSS. http://www.w3.org/1999/08/NOTE-CSS-access-19990804.
[2] [Brewer, 2002] Brewer, J. et al. (2002). Implementation Plan for Web Accessibility. http://www.w3.org/WAI/impl/expanded.
[3] [Caldwell, 2008] Caldwell, B. et al. Editors (2008). Recomendações de Acessibilidade para Conteúdo Web (WCAG) 2.0. http://www.ilearn.com.br/TR/WCAG20/.
[4] [Conforto, 2002] Conforto, D. e Santarosa, L. M. C. (2002). Acessibilidade a web: Internet para Todos. Revista de Informática na Educação: Teoria, Prática, v.5 nº. 2, 2002.
[5] [Crisholm, 2000] Crisholm, W.;Vanderheiden, G.; Jacobs, I., CSS Techniques for Web Content Accessibility Guidelines 1.0. http://www.w3.org/TR/WCAG10-CSS- TECHS/.
[6] [Henry, 2005] Henry, S. L. et al. (2005). Introduction to Web Accessibility. http://www.w3.org/WAI/intro/accessibility.php.
[7] [Henry, 2006] Henry, S. L. et al. Editors (2006). Essential Components of Web Accessibility. http://www.w3.org/WAI/intro/components.php.

UIGV21
[8] [Henry, 2006] Henry, S. L. et al. (2006). User Agent Accessibility Guidelines (UAAG) Overview. http://www.w3.org/WAI/intro/uaag.php.
[9] [IBGE, 2010] IBGE. Censo Demográfico 2000 - Resultados do universo. http://www.ibge.gov.br/home/presidencia/noticias/noticia_visualiza.php?id_noticia=438&id_pagina=1.
[10] [MPOG, 2007] MPOG. Ministério do Planejamento, Orçamento e Gestão. Modelo de acessibilidade de Governo Eletrônico – versão 2.0, Portaria nº 03, de 07 de maio de 2007. http://www.governoeletronico.gov.br/acoes-e-projetos/e-MAG.
[11] [NVDA, 2010] Sítio oficial do NVDA. www.nvda-project.org.

UIGV22

UIGV23
Segurança em Sistemas de E-learning: uma Análise do Ambiente Tidia-Ae/Sakai
Eduardo H. Gomes 1,2, Edson P. Pimentel 1, João H. Kleinschmidt 1
1 Universidade Federal do ABC2 Instituto Federal de Educação Ciência e Tecnologia de São Paulo{eduardo.gomes, edson.pimentel, joao.kleinschmidt}@ufabc.edu.br
Resumo
Com os avanços e popularização da Internet houve uma expansão da Educação a Distância através da Web e conseqüentemente um aumento no uso de sistemas de e-learning. Esses sistemas armazenam dados de estudantes, professores, conteúdos, avaliações e podem ser alvo de vários tipos de ataques de segurança. Em qualquer sistema o acesso a informações confidenciais é uma violação e no âmbito da educação isso não é diferente. Este artigo tem por objetivo apresentar um estudo sobre vulnerabilidades de segurança nos aspectos de confidencialidade e auten-ticação em sistemas de aprendizagem eletrônica baseada na web. Os experimentos foram realizados no ambiente Tidia-Ae/Sakai. Espera-se que a detecção de falhas de segurança encontrada e relatada nesse trabalho possa chamar a atenção dos desenvolvedores para esses aspectos no desenvolvimento de sistemas de e-learning.
Palavras chave:
E-learning, Scanner de vulnerabilidades, Segurança, Tidia-Ae, Sakai.
Abstract
The expansion of internet access was followed by a growth of distance education via Web and consequently an increased use of e-learning systems. These systems store data of students, teachers, content, assessments and may be vulnerable to various types of security attacks. In any system, non granted access to confidential information is a violation and in the Education field is no different. This article aims to present a study on security vulnerabilities in the aspects of confidentiality and authentication in e-learning systems based on the web. The experiments were perfor-med in the environment Tidia-Ae/Sakai. It is expected that the detection of security flaws found and reported in this work can draw attention of the developers to those aspects in the development of e-learning systems.
Keywords:
E-learning, Vulnerability Scanner, Security, Tidia-Ae, Sakai.
Introdução
Segundo Moore [Moore, 1996] a integração da Web com as práticas antigas de EAD proporcionaram o sur-gimento do termo “Educação baseada na Web” (EBW). Com o crescimento no uso da internet, houve um aumento da demanda por cursos a distância e conseqüentemente surgiram várias plataformas no conceito de Sistemas Ge-renciadores de Aprendizagem (designados de LMS - Learning Management Systems) que são muito bem sucedidos na educação em relação ao número de usuários, Devedzic [Devedzic, 2004].

UIGV24
É de suma importância que esses sistemas estejam alinhados a uma teoria pedagógica adequada aos obje-tivos de aprendizagem em questão. Além disso, busca-se melhorar as características técnicas nas ferramentas de criação, distribuição e gestão do conhecimento, visando um melhor grau de comunicação, trabalho colaborativo, acompanhamento do progresso do aluno, variedade nos métodos de avaliação, auto-avaliação e a estruturação dos conteúdos de aprendizagem conforme Crosetti [Crosetti, 2000].
Alguns autores consideram que a modalidade de e-learning é a próxima evolução da formação e uma estratégia fundamental para maximizar o capital humano na economia do conhecimento [PrimeLearning, 2001].
Dado que os sistemas de e-learning tem se tornado muito populares ao longo dos últimos anos e são acessados por uma ampla gama de usuários, a segurança é um requisito essencial pois esses sistemas podem se tornar alvo de vários tipos de ataque.
Por isso, a autenticação, não repúdio, a confidencialidade dos dados, integridade e outras questões de segu-rança são aspectos importantes a serem considerados no desenvolvimento desses sistemas, pois é de vital impor-tância garantir a integridade tanto de avaliações e trabalhos desenvolvidos pelos alunos como a prevenção da falsificação dessas avaliações.
Com isso o objetivo desse artigo em particular é investigar possíveis vulnerabilidades de segurança em aspectos de confidencialidade e autenticação do ambiente Tidia-Ae / Sakai.
Este artigo está organizado da seguinte forma. Seção 2 apresenta os trabalhos relacionados com o presente trabalho. Seção 3fornece Informações básicas sobre o ambiente Tidia-Ae / Sakai. Seção 4 descreve brevemente a segurança em sistemas de E-learning e apresenta uma análise do problema. Seção 5 descreve o funcionamento dos Scanners de vulnerabilidades. Seção 6 é dedicada à parte experimental do presente trabalho onde os ex-perimentos, a metodologia e os resultados são apresentados. Finalmente, a seção 7 propõe as soluções para as vulnerabilidades e apresenta algumas conclusões sobre este trabalho.
Conclusões
Neste trabalho questões de segurança relacionadas com o LMS Tidia-Ae / Sakai são estudadas. Dentre vários aspectos de segurança como a autenticação, a disponibilidade, confidencialidade e integridade, neste artigo optou-se por investigar ataques de confidencialidade e autenticação.
Além disso, este trabalho mostrou que uma instalação padrão de um servidor Tidia-Ae / Sakai é vulnerável a ataques. As principais vulnerabilidades encontradas foram: o ambiente permite a utilização de senhas fracas e ataques de adivinhação, permitindo o uso de técnicas de força bruta para adivinhação de nomes de usuários e senhas. A solução para essas vulnerabilidades seria uma política de senhas fortes, a utilização de Captcha nas te-las de login e a implementação de mecanismos de bloqueio de acesso, ao se detectar múltiplas tentativas erradas de acesso ao ambiente em determinado tempo.
Outra vulnerabilidade encontrada foi o tráfego de dados na rede sem criptografia, ocasionada pela utilização do Protocolo HTTP durante a instalação, o que permite a utilização de analisadores de pacotes para revelar no-mes de usuários e senhas. A solução para essa vulnerabilidade é a utilização de SSL (secure socket layer) que é a tecnologia padrão de segurança para o estabelecimento de uma conexão criptografada entre um servidor web e um navegador (HTTPS).
A vulnerabilidade de Cross Site Scripting (XSS) encontrada permite que um atacante envie códigos maliciosos para outro usuário. A proteção contra esse ataque é baseado no tratamento dos inputs do ambiente, filtrando variáveis de entrada de dados.

UIGV25
Outras vulnerabilidades estudadas neste artigo estão diretamente ligadas a uma errônea configuração do siste-ma ou utilização de serviços desatualizados que poderiam ser evitadas se houvesse uma documentação atualizada e de fácil entendimento.
A grande quantidade de publicações sobre a necessidade de segurança em sistemas de e-learning nos últimos anos já traz grande relevância à pesquisa acerca desse assunto. Com a chegada dessas novas aplicações ou tecnologias surge à necessidade de estudos específicos para a proteção dos dados e o desafio nesses sistemas de e-learning é pensar sempre no tripé segurança, desempenho e usabilidade.
Os resultados desse trabalho sugerem que as instituições e organizações mesmo investindo significativos recursos na implementação de sistemas de e-learning, o fazem com foco voltado a provisão de conteúdo, às vezes negli-genciando as questões de segurança ou não as priorizando. Para criar ambientes de aprendizagem mais seguros e confiáveis, é essencial a remoção de todas as falhas de segurança em sistemas como o Tidia-Ae / Sakai.
Referências
[1] [Acunetix, 2011] Acunetix, Web Vulnerability Scanner, http://www.acunetix.com. Acessado em 28/03/2011.
[2] [Anantasec, 2011] Ananta Security. Web Vulnerability Scanners Evaluation, http://anantasec.blogspot.com. Acessado em 28/03/2011.
[3] [Appscan, 2001] Appscan – IBM, http://www-01.ibm.com/software/awdtools/appscan/#. Acessado em 28/03/2011.
[4] [Asha, 2008] S.Asha, C.Chellappan, Authentication of E-Learners Using Multimodal Biometric Technology. (2008). Biometrics and Security Technologies, 2008. ISBAST 2008. International Symposium on. DOI: 0.1109/ISBAST.2008.4547640.
[5] [Atutor, 2011] Atutor , http://www.atutor.ca. Acessado em 04/06/2011.
[6] [AulaNet, 2011] AulaNet, http://www.eduweb.com.br. Acessado em 04/06/2011.
[7] [Beder, 2005] Beder, D. M. ; Otsuka, J. L. ; Silva, C. G. DA ; Silva, A. C. DA; Talarico Neto, Americo; Oliveira, Alessandro ; Rocha, H. V. ; Ricarte, Ivan ; Silva, Júnia Coutinho Anacleto. (2005). The TIDIA-Ae Portfolio Tool: a case study of its development following a component-based layered architecture, II Workshop TIDIA FAPESP 2005, São Paulo.
[8] [Crosetti, 2000] Crosetti, B. d. B. (2000).Possibilidades educativas de las Webtools. Palma: Universitat de les Illes Balears.
[9] [CVE, 2011] Common Vulnerabilities and Exposures (CVE®), http://cve.mitre.org/about/index.html. Aces-sado em 17/04/2011.
[10] [Desira, 2009] Desira M. (2009). An Open Source Vulnerability Scanner for E-Commerce Web Applications, University of Malta.
[11] [Devedzic, 2004] Devedzic, V.; Simic, G.;Gasevic, D. (2004). Semantic Web and Intelligent Learning Man-agement Systems. In: Proceedings of International Workshop on Applications of Semantic Web for E-Learning, Maceió, Brasil.
[12] [Gonçalves, 2007] Gonçalves, V. M. B. (2007). A Web Semântica no Contexto Educativo. Tese de douto-rado. Porto: Universidade do Porto.

UIGV26
[13] [Gordon, 2006] L. Gordon, M. Loeb, W. Lucyshyn, R. Richardson. (2006). “Computer crime and security survey”, Computer Security Institute.
[14] [Gualberto, 2009] Gualberto, T. M.; Abib, S ; Zorzo, S D. (2009). “INCA: A Security Service for Collabora-tive Learning Environments”. International Conference on Education Technology and Computer (ICETC), IEEE Computer Society, 111-115.
[15] [Hernández, 2008] J. C. G. Hernández, M. A. L. Chávez, Moodle Security Vulnerabilities.(2008). 5th Inter-national Conference on Electrical Engineering Computing Science and Automatic Control.
[16] [Hoobienet, 2011] Hoobienet, http://www.hoobie.net/brutus/. Acessado em 28/03/2011.
[17] [Kumar, 2011] Kumar S., Dutta K. (2011). Investigation on security in LMS Moodle, International Journal of Information Technology and Knowledge Management.
[18] [Lin, 2004] N. Lin, L. Korba, G. Yee, T. Shih e H. Lin. (2004). Security and privacy technologies for distance education applications. Proc. of the 18th International Conference on Advanced Information Networking and Applications (AINA), IEEE Press, pp. 580-585, doi:10.1109/AINA.2004.1283972.
[19] [Lince-dc-Ufscar, 2010] Lince-dc-Ufscar. (2010). Avaliação do Projeto Tidia-Ae e suas Aplicações, projeto reuso de software fapesp. São Carlos, SP - Brasil.
[20] [Lotus, 2011] Lotus, http://www.lotus.com. Acessado em 04/06/2011.
[21] [Luvit, 2011] Luvit, http://www.grade.com. Acessado em 04/06/2011.
[22] [Madeira, 2007] J. Fonseca, M. Vieira, H. Madeira. (2007). “Testing and Comparing Web Vulnerability Scanning Tools for SQL Injection and XSS Attacks”, 13º IEEE Pacific Rim Dependable Computing Conference (PRDC 2007), Melbourne, Victoria, Australia.
[23] [Moodle, 2011] Moodle, http://moodle.org. Acessado em 28/03/2011.
[24] [Moore, 1996] Moore, M. G., Kearsley, G. (1996). Distance Education: a systems view. Belmont (EUA): Wadsworth Publishing Company.
[25] [NTOSpider,2011] NTOSpider, NT OBJECTives, http://www.ntobjectives.com/ntospider. Acessado em 28/03/2011.
[26] [Pimentel, 2010] André P. Freire *, Flávia Linhalis, Sandro L. Bianchini, Renata P.M. Fortes, Maria da Graça C. Pimentel. (2010). Computers & Education, Vol. 54, No. 4. (16 May 2010), pp. 866-876. Revealing the whiteboard to blind students: An inclusive approach to provide mediation in synchronous e-learning activities.
[27] [PrimeLearning, 2001] PrimeLearning Inc., eLearning. (2001) A key strategy for maximizing human capital in the knowledge economy, W.R. Hambrecht & Co, http://www.astd.org.
[28] [Raitman, 2005] R. Raitman, L. Ngo e N. Augar. (2005). Security in the Online E-Learning Environment. Proc. of the 5th International Conference Advanced Learning Technologies (ICALT), IEEE Press, July 2005, pp. 702– 706, doi=10.1109/ICALT.2005.236.
[29] [Sakai, 2011] Sakai Project, http://www.sakaiproject.org. Acessado em 28/03/2011.
[30] [Suto, 2010] Suto L. (2010) Analyzing the Accuracy and Time Costs of Web Application Security Scanners, San Francisco, February.
[31] [TelEduc, 2011] TelEduc, http://teleduc.nied.unicamp.br. Acessado em 04/06/2011.

UIGV27
[32] [Tidia-Ae, 2011] Tidia-Ae, http://tidia-ae.usp.br/download. Acessado em 28/03/2011.
[33] [WebCT, 2011] WebCT e Blackboard, http://www.blackboard.com. Acessado em 04/06/2011.
[34] [WebInspect, 2011] HP WebInspect, https://www.fortify.com. Acessado em 28/03/2011.
[35] [Wireshark, 2011] Wireshark, http://www.wireshark.org. Acessado em 04/07/2011 2011.

UIGV28

UIGV29
Reduciendo la Ambigüedad en el Modelo del Dominio mediante Especificaciones Formales Ligeras en VDM++
Elizabeth Vidal-Duarte1, César Mogrovejo Ramirez1, Eveling Castro Gutierrez2
1 Universidad Católica San Pablo2 Universidad Nacional de San Agustín
Resumen
Una de las herramientas más utilizadas para modelar los requerimientos funcionales es el Modelo del Dominio. Muchas veces, dependiendo de la complejidad de los requerimientos a ser modelados, no es posible que dicho mo-delo capture todos los detalles y restricciones relacionados. Esto puede causar que el Modelo del Dominio sea sujeto de interpretaciones subjetivas que conlleven a errores de implementación más adelante. Este artículo presenta una forma de reducir la ambigüedad en el Modelo del Dominio mediante el uso de especificaciones formales ligeras en VDM++. A modo de ejemplo, presentamos la especificación formal de un electrocardiógrafo digital. La especificación está basada en la descripción de las características del funcionamiento del electrocardiógrafo. Se pone especial aten-ción en las características de la captura de la señal electrocardiográfica. Se ha identificado propiedades y restricciones importantes que permiten incrementar la confiabilidad al momento de la implementación. Las propiedades y restric-ciones se han especificado en forma de invariantes y precondiciones. La validación de la propuesta se realizó con la herramienta VDM++ToolBox.
Palabras clave:
VDM++ToolBox, desarrollo de software, electrocardiógrafo
Abstract
One of the most used tools for modeling the functional requirements is the Domain Model. Many times, depen-ding on the complexity of the requirements to be modeled is not possible that this model captures all the details and restrictions related. This can cause the Domain Model is subject to subjective interpretations that lead to implementa-tion errors later. This article presents a way to reduce ambiguity in the domain model by using lightweight formal speci-fication in VDM++. As an example, we present the formal specification of a digital electrocardiograph. The specification is based on the description of the operation of the electrocardiograph. It pays special attention to the characteristics of the capture of the electrocardiogram. Properties have been identified and significant restrictions that increase relia-bility at the time of implementation. The properties and restrictions are specified as invariants and preconditions. The validation of the proposal was made VDM++ tool ToolBox.
Keywords:
VDM ++ Toolbox, software development, electrocardiograph

UIGV30
Introducción
Es ampliamente conocido que la parte más crítica del desarrollo de software corresponde a la identificación y especificación de requerimientos [Sommerville, 2001]. Para facilitar el proceso de desarrollo de software, muchos desarrolladores trabajan con una variedad de métodos y herramientas reconocidos, por ejemplo el Lenguaje de Modelado Unificado (UML) [Rumbaugh etal, 1998]. Aunque UML es el lenguaje estándar para modelamiento aún no está suficientemente refinado como para proveer toda la información relevante en una especificación [Ai-cherning, 2001]. Los diagramas UML están sujetos muchas veces a interpretaciones subjetivas. Esto podría llevar a implementaciones que corren el riesgo de no cumplir con los requerimientos reales.
Existe la necesidad de describir restricciones adicionales acerca de los objetos en el modelo, sobre todo si el sistema a describir es de carácter crítico, como es el caso de un Electrocardiógrafo. Dichas restricciones son des-critas por lo general en lenguaje natural. La experiencia ha mostrado que esto siempre resulta en ambigüedades. Para evitar dichas ambigüedades, se hace necesario el uso de los llamados lenguajes formales [Fitzgerald and Gorm Larsen, 1998].
Si queremos que los métodos formales sean utilizados en el desarrollo de proyectos de software, necesitamos habilitar a los desarrolladores en el uso de especificaciones formales. En este artículo, se muestra una forma de especi-ficación formal ligera [Jones, 1996]. Para este propósito, haremos uso de VDM++ (Vienna Development Method++) [CSK SYSTEMS a, 2009]. VDM++ permite expresar restricciones adicionales en los modelos orientados a objetos. Permite la especificación de restricciones formales en el contexto de diagramas de clase de UML [Booch etal, 1998].
El resultado de este trabajo no nos proporciona una especificación completa del electrocardiógrafo, sino brinda una descripción razonable de la especificación de una de las funcionalidades consideradas como críticas: la co-rrecta captura de la señal electrocardiográfica.
El principal aporte del presente trabajo es mostrar que la aplicación de especificaciones formales ligeras contri-buye a incrementar la confiabilidad en la correctitud para la implementación.
El resto del artículo está organizado de la siguiente manera: en la sección 2, se presenta las principales carac-terísticas del electrocardiógrafo. En la sección 3, se presenta la definición de métodos formales y especificaciones formales ligeras. En la sección 4, se explica las principales características de VDM++, así como la sintaxis que será utilizada en nuestro caso de estudio. En la sección 5, se describe la metodología seguida. En la sección 6, se presenta, como caso de estudio, la especificación formal del electrocardiógrafo. Se describen los requerimien-tos funcionales de manera informal para luego modelar la clase UML junto con la especificación formal VDM++. Además, se presenta el análisis y validación del modelo propuesto utilizando la herramienta VDMToolBox. En la sección 7, se exponden nuestras conclusiones y el trabajo futuro.
Conclusiones
En este artículo, se ha presentado una forma de incrementar la confiabilidad en la correctitud para la captura de la señal electrocardiográfica. Para ello, se han aplicado especificaciones formales ligeras. Nos hemos centrado en la especificación de restricciones que no son evidentes en el diagrama de clases UML. Se ha aplicado invarian-tes y precondiciones utilizando VDM++.
Las especificaciones fueron ejecutadas en VDM++ToolBox para validar la propuesta. Los casos de prueba fueron elegidos de acuerdo con la técnica de Clases de Equivalencia. Los resultados obtenidos nos permitieron incrementar la confiabilidad en la correctitud para la implementación de la captura de señales del electrocardiógrafo.
Si bien, VDM++ presenta muchas más características que las descritas en este artículo, hemos tomado solo una pequeña parte para mostrar cómo especificar restricciones de manera formal para complementar los diagrama de clases. Nuestro objetivo es incrementar el uso de especificaciones formales en el proceso de desarrollo. Creemos

UIGV31
que el uso de especificaciones formales en las primeras etapas del desarrollo nos permite incrementar la correctitud del software que estamos desarrollando.
Como trabajo futuro, pretendemos ampliar la especificación del electrocardiógrafo centrándonos un poco más en la especificación de la señal.
Referencias
[1] [Aicherning, 2001] B. K. Aichernig (2001).Systematic Black-Box Testing of Computer-Based Systems through Formal Abstraction Techniques. Doctoral Thesis. Technischen Universitat Graz.
[2] [Bjørner and Jones, 1982] D. Bjørner and C.B. Jones. Formal Specification and Software Development. Pren-tice-Hall International.
[3] [Booch etal, 1998] G. Booch, J. Rumbaugh, and I. Jacobson (1998). The Unified Modeling Language User Guide, Addison-Wesley.
[4] [CSK SYSTEMS a, 2009] CSK SYSTEMS a (2009). The VDM++ Language. Technical Report.
[5] [CSK SYSTEMS b, 2009] CSK SYSTEMS b (2009). VDM Tools User Manual. Technica Report.
[6] [CSK SYSTEMS c, 2009] CSK SYSTEMS b (2009). The VDM++ Method Guideline. Technica Report.
[7] [Dubin, 1986] D. Dubin (1986). Electrocardiografía Práctica: Lesión Trazado e Interpretacion, 3ra Ed; Mc-Graw hill Interamericana
[8] [Easterbrook et al, 1998] S. M. Easterbrook, R. Lutz, R. Covington, J. Kelly, Y. Ampo, and D. Hamilton. (1998) Experiences using lightweight formal methods for re-quirements modeling. IEEE Transactions on Software Engi-neering, 24(1), January 1998.
[9] [Fitzgerald and Gorm Larsen,1998] J. Fitzgerald and P.Gorm Larsen (1998). Modelling Systems Practical Tools and Techniques in Software Development. Cambridge University Press, The Edinburgh Building, Cambridge CB2 2RU, UK.
[10] [Fitzgerald etal, 2005] J. Fitzgerald, P. Gorm Larsen, P. Mukherjee, N. Plat, and M. Verhoef (2005). Vali-dated Designs for Object-oriented Systems. Springer, New York.
[11] [Gom Larser etal,1996] P. Gorm Larsen, J. Fitzgerald, and T. Brookes (1996). Applying Formal Specification in Industry. IEEE Software, 13(3):48–56.
[12] [Garcia and Yavar, 2007]D. O. Garcia and L.F. Yavar (2007). Captación y Visualización de Señales ECG Bipolares: Diseño y Desarrollo. VII Congreso de la Sociedad Cubana de BioIngenieria.
[13] [Jackson and Wing,1996] D. Jackson and J. Wing (1996). Formal methods light: Lightweight formal methods. IEEE Computer, 29(4):21–22, April 1996
[14] Jones, 1996] C. B. Jones. (1996). Formal methods light: A rigorous approach to formal methods. IEEE Com-puter, 29(4):20–21, April 1996.
[15] [Kurita et al, 2008] T. Kurita, Y. Nakatsugawa & M. Chiba (2008). Application of a Formal Specification Lan-guage in the Development of the “Mobile FeliCa” IC Chip Firmware for Embedding in Mobile Phone. FM’08 Proceedings of the 15th international symposium on Formal Methods.

UIGV32
[16] [Rumbaugh etal, 1998] J. Rumbaugh, I. Jacobson, and G. Booch, (1998). The Unified Modeling Language Reference Manual, Addison-Wesley.
[17] [Sommerville, 2001] I. Sommerville (2001). Software Engineering, Sixth Edition, Addison Wesley.
[18] [The UK Ministery of Defence, 1989] The UK Ministry of Defence (1989). Defence standard for military safety- critical software 00-59. draft.
[19] [Wartak, 1985] J. Wartak (1985). Interpretación de Electrocardiogramas. 2 Ed., Nueva Editorial Interameri-cana.

UIGV33
Julián Alberto Monsalve Pulido1
Grupo de Investigación GIBRAN, Facultad de Ingeniería de Sistemas.Universidad Santo Tomás Seccional Tunja Boyacá, [email protected], [email protected]
Web Usage Mining, aplicado a servidores Web Apache
1 Ingeniero de Sistemas, Magister en Software libre con especialidad en desarrollo de aplicaciones de la Universidad Autónoma de Bucaramanga - Universitat Oberta de Catalunya España.
Resumen
El presente artículo muestra algunos avances de investigación en el análisis de patrones de comportamiento de usuarios en el uso de servidores Web Apache utilizando técnicas de minería de datos. Como resultado de la investiga-ción, se presenta un análisis teórico y un proceso de ingeniería para la creación de un software que pretende mejorar los procesos de minería Web para la toma de decisiones en la aplicación de técnicas científicas y analíticas en la in-formática forense, principal objetivo de la investigación. La investigación se centró en el desarrollo de una aplicación web de libre distribución, donde carga el archivo log de conexión Apache y aplica los procesos de minería de datos para descubrir comportamientos de usabilidad en los usuarios y posteriormente realizar informes que ayudarán a la detección de problemas de seguridad, análisis de informática forense y análisis de web usage mining.
Palabras clave:
Minería web, usabilidad, Apache.
Abstract
This article shows some research advances in the analysis of user behavior patterns in the use of apache web servers, using data mining techniques. As a result of the investigation presents a theoretical analysis and software engineering process for creating software that aims to improve Web mining processes for decision making in the appli-cation of scientific and analytical techniques in computer forensics, main objective of the investigation. The research is centered on developing a web application for free distribution, which loads the apache log connection and applies data mining process to discover usability behaviors in users and then make reports to help detect security issues, com-puter forensics and analysis of web usage mining analysis.
Keywords:
Web mining, usability, Apache.

UIGV34
Introducción
El análisis de usabilidad de los sitios Web en los portales de las empresas brinda al usuario poder participar en los procesos de diseño y desarrollo dentro del portal garantizando la calidad de la información e interacción. Esta investigación se centra en un portal universitario donde se tomó las muestras para la investigación y presenta reportes de usabilidad del mismo.
Se desarrolló un software para garantizar la aplicación de la técnica de la minería Web por medio de un al-goritmo apriori donde identifico las reglas de asociación para la identificación de comportamientos de uso de los usuarios en el portal.
Algunos resultados de la investigación se presentan por medio de informes y gráficas estadísticas que genera la aplicación desarrollada después de hacerle minería de datos a la información recolectada por el Log de conexión del servidor Web Apache.
Este artículo se estructura en cuatro capítulos: el primero muestra la conceptualización básica de servidores web y de usabilidad; en la segunda parte, se describe la obtención de datos del servidor; en la tercera parte, se descri-be el proceso de desarrollo de la herramienta de libre distribución y, por último, se muestra las conclusiones de la investigación y referencias que se utilizaron en el proceso.
Conclusiones
Medir la usabilidad de un sitio web, brinda al Webmaster una gran ayuda para la administración, da los argu-mentos para generar estrategias de cambios de contenidos, estructura y uso.
Actualmente, los modelos de negocios incluyen el cumplimiento de los requerimientos, como publicidad, canti-dad de usuarios perfilados, líneas de comunicación enmarcadas en la satisfacción del cliente y desarrollos basados en la opinión y criterios del usuario final.
La minería Web beneficiará a la evolución de los negocios que tiene presencia en Internet, ya que se puede mejorar cada día la usabilidad del mismo para que el usuario sea protagonista del proceso empresarial.
El desarrollo y el potencial del Web Mining permite detectar información invisible, pero de gran importancia para consolidar y ampliar el criterio de la W3. La determinación de los patrones de conducta se establece como redes de relaciones existentes que permiten identificar grupos homogéneos de usuarios para encauzar sus intereses comunes al desarrollo de grupos participativos y líneas de investigación con personas dedicadas a temáticas afines.
La informática forense es una ciencia que identifica delitos informáticos, pero los resultados son difíciles de iden-tificar por la cantidad de información. Una solución es la aplicación de técnicas de minería de datos por medio de una herramienta de libre distribución.
Referencias
[1] MapR Technologies, Inc.; MapR Technologies Signs Corporate Contributor License Agreement for Apache Software Foundation. (2011, June). Computers, Networks & Communications, 387. Retrieved June 14, 2011, from ProQuest Computing. (Document ID: 2369059991).
[2] Hernández, J.; Ramírez, M.J.; Ferri, C. (2004); “Introducción a la Minería de Datos”, Pearson Educación, Madrid. 2004.

UIGV35
[3] COOLEY, Robert. Discovery and Application of Interesting Patterns from Web Data. Ph. D. Thesis. University of Minnesota. May 2000.
[4] MOBASHER, Bamshad. Web Usage Mining and Personalitation. CRC. Estados Unidos: Press LLC, 2004, 129 p.
[5] Raymond Kosala, Hendrik Blockeel. Web Mining Research: A Survey. SIGKDD Explorations. ACM SIGKDD. July 2000.
[6] S. K. Madria et al. Research issues in web data mining. Proceedings of Data Warehousing and Knowledge Discovery, First International Conference, DaWaK ’99. 1999.
[7] Sankar, Paul. Web Mining in soft Computing Framework. Estados Unidos: World Scientific Publishing Co Pte Ltd. 2004, 133 p
[8] Witten & Frank, Clark, P.; Boswell, R. (2000); “Data Mining. Practical Machine Learning Tools and Techniques with Java Implementations”, Morgan Kaufmann Publishers, 2000.
[9] Jeimy J. Cano, Introducción a la informática forense, Revista Sistemas Seguridad y computación forense ACIS. Junio 2006.
[10] Botia Valderrama, Diego José Luis. Aplicación de las herramientas de software libre Sleuthkit y Autopsy a la informática forense, Revista Intekhnia Volumen 3 No 7 Diciembre 2008.

UIGV36

UIGV37
Luciana V. B. Wiecheteck1, Paulo C. Stadzisz1, Jean M. Simão1 [email protected], stadzisz, jeansimao {@utfpr.edu.br}Universidade Tecnológica Federal do Paraná - UTFPR1 Programa de Pós-Graduação em Engenharia Elétrica e Informática Industrial - CPGEI
Um Perfil UML para o Paradigma Orientado a Notificações (PON)
Resumo
Este artigo apresenta uma proposta de perfil UML para a modelagem de software utilizando o Paradigma Orienta-do a Notificações (PON). A UML possui mecanismos de extensão que permitem a adição de novas sintaxe e semân-tica aos seus elementos visando a modelagem de domínios particulares de aplicação. Um conjunto desses mecanis-mos de extensão agrupados dentro de um pacote UML é denominado Perfil UML. Por sua vez, o PON se apresenta como uma alternativa aos Paradigmas de Programação Imperativa (PI), incluindo o Paradigma Orientado a Objetos (POO), e aos Paradigmas de Programação Declarativa (PD), propondo-se a eliminar deficiências destes nos aspectos de redundâncias e acoplamento de avaliações causais que impactam no desempenho e paralelismo/distribuição de aplicações. Este novo paradigma tem sido materializado em termos de programação, mas não possuía ainda um mé-todo formalizado para orientar os desenvolvedores na elaboração de projetos de software. Portanto, o perfil proposto define um primeiro passo na criação deste método: formalizar os principais conceitos do PON por meio da utilização de mecanismos de extensão - como estereótipos, valores etiquetados e restrições – que melhor adéquam a sua mo-delagem em UML. A aplicação do perfil UML é ilustrada com exemplos envolvendo a modelagem de um Simulador de Portão Eletrônico. Os resultados demonstram que o perfil criado possui grande valia na definição de programas em PON e visa sua aplicação em processos de projetos de software que utilizam este paradigma de programação.
Palavras chave:
Modelagem de Software, Perfil UML, Paradigma Orientado a Notificações (PON)
Abstract
This article presents a UML Profile for software modeling using the Notification Oriented Paradigm (NOP). UML has extension mechanisms that allow the addition of new syntax and semantic to its elements aiming at software modeling for specific domain applications. A set of these extension mechanisms grouped into a UML package is na-med UML Profile. NOP presents itself as an alternative to the Imperative Programming (IP) paradigms, such as Object Oriented Paradigm (OOP), as well as to the Declarative Programming (DP) paradigms, with the purpose of eliminating deficiencies of those paradigms concerning to redundancy issues and coupling of causal expressions, which affect the execution performance and parallelism/distribution of applications. This paradigm has already been consolidated in terms of programming but did not possess a formalized method for software design. Thus, the proposed profile defines a first step in the definition of this method: to formalize the main concepts of this paradigm by means of ex-tension mechanisms usage – as stereotypes, tagged values and constraints – that better fit its modeling in the UML. The proposed UML Profile usage is illustrated by means of a modeling example of an electronic gate application. The results showed that the proposed UML profile has an important value in the modeling of NOP programs and can be used in software design processes that use this new programming paradigm.
Keywords:
Software Modeling, UML Profile, Notification Oriented Paradigm (NOP)

UIGV38
Introdução
A capacidade de processamento computacional tem crescido em função da evolução das tecnologias neste contexto [Tanenbaum e Van Steen, 2002]. Entretanto, recursos oferecidos por soluções computacionais modernas, tais como paralelismo e distribuição ou mesmo a utilização da capacidade plena de cada processador, nem sempre são devidamente aproveitados em função de limitações das técnicas de programação [Simão e Stadzisz, 2008, 2009].
Na verdade, técnicas de programação baseadas no estado da arte, como o chamado Paradigma de Progra-mação Orientada a Objetos (POO) ou Sistema Baseados em Regras (SBR), sofrem de limitações intrínsecas de seus paradigmas. Estes paradigmas poderiam ser genericamente classificados como Paradigma Imperativo (PI) e Paradigma Declarativo (PD) que englobam respectivamente o POO e os SBR [Banaszewski, 2009].
Particularmente, estes paradigmas levam ao forte acoplamento de expressões causais e redundâncias decorrentes das suas avaliações. Estas limitações dificultam a execução paralela ou distribuída de programas e frequentemente comprometem o seu desempenho pleno mesmo em sistemas monoprocessados. Assim, existem motivações para buscas de alternativas aos PI e PD, com o objetivo de eliminar ou diminuir as desvantagens deles [Banaszewski et al., 2007][Banaszewski, 2009][Gabbrielli, Martini, 2010][Roy e Haridi, 2004][Simão e Stadzisz, 2008, 2009].
Neste âmbito, uma alternativa é o Paradigma Orientado a Notificações (PON). O PON foi concebido a partir de uma teoria de Controle Discreto e Inferência [Simão, 2005][Simão e Stadzisz, 2008, 2009][Simão, Stadzisz e Tacla, 2009]. Ele se propõe a eliminar algumas das deficiências dos atuais paradigmas em relação a avaliações causais desnecessárias e acopladas, evitando o processo de inferência monolítico baseado em pesquisas por meio de um mecanismo baseado no relacionamento de entidades computacionais notificantes [Banaszewski et al., 2007][Banaszewski, 2009][Simão e Stadzisz, 2008, 2009].
Atualmente, o PON tende a se consolidar em termos de programação. Entretanto, não há um método formali-zado para orientar os desenvolvedores na elaboração de projetos de software baseados em PON. Embora seja possível o emprego convencional da UML (Unified Modeling Language) e processos conhecidos no desenvolvimen-to de software com o PON, suas especialidades motivam o uso mais particularizado de modelagem e processos de software.
A UML fornece um conjunto rico de conceitos de modelagem e notações que foram desenvolvidos para satisfa-zer as necessidades de projetos típicos de software. No entanto, há casos em que são necessárias características adicionais de modelagem, além daquelas definidas pela UML padrão, como no caso de domínios particulares de aplicação (ex: tempo-real) ou implementação de tecnologias (ex: CORBA).
A UML permite a modelagem dessas necessidades específicas por meio dos seus mecanismos de extensão, que permitem a adição de novos elementos de modelagem ao metamodelo da UML. Oportunamente, um metamodelo define e descreve a estrutura e semântica de modelos, no caso, modelos UML. Um conjunto desses mecanismos de extensão, agrupados dentro de um pacote UML estereotipado <<profile>>, forma um Perfil UML [OMG, 2003][Fuentes e Vallecillo, 2004]. Atualmente, existem vários perfis UML disponíveis para uso público, sendo que alguns têm sido adotados e padronizados pela OMG, como o Perfil UML CCM (CORBA Component Model) [OMG, 2005a] e o Perfil UML para Scheduling, Performance e Time [OMG, 2005b].
Neste contexto, este artigo apresenta um perfil UML por meio da especificação de mecanismos de extensão da UML - como estereótipos, valores etiquetados e restrições - que definem os principais conceitos do PON, melhor adequando sua modelagem em UML. O perfil UML criado para o PON é denominado Perfil PON (NOP Profile em inglês) e particulariza o metamodelo da UML a fim de suprir as necessidades específicas deste novo paradigma de programação.
O artigo está organizado da seguinte maneira: a seção 2 apresenta o Paradigma Orientado a Notificações (PON). A seção 3 descreve sucintamente a UML e seus mecanismos de extensão. A seção 4 apresenta o perfil UML criado para o PON. A seção 5 ilustra um exemplo de uso do perfil UML desenvolvido. E, por fim, na seção 6 são apresentadas as conclusões do trabalho.

UIGV39
Conclusões
O Paradigma Orientado a Notificações (PON) tem sido materializado em termos de programação, mas não possuía ainda um método formalizado para orientar os desenvolvedores na elaboração de projetos de software. Portanto, como primeiro passo na construção deste método, o presente artigo apresentou o NOP Profile, um perfil UML criado para o PON. O NOP Profile tem por objetivo propor convenções na utilização da UML para mode-lagem de software neste novo paradigma. A aplicação do perfil UML foi ilustrada com exemplos envolvendo a modelagem de um simulador de Portão Eletrônico.
A extensão proposta é suportada pela UML e, portanto, pode ser facilmente integrada em ferramentas CASE que suportam a UML. O NOP Profile está sendo avaliado por meio da sua aplicação em diferentes projetos de software. Adicionalmente, os modelos UML criados, que utilizam o NOP Profile, podem ser verificados quanto à sua sintaxe por meio de funcionalidades padrões disponíveis nas ferramentas CASE que validam as restrições OCL definidas no perfil. Assim, foi apresentada uma primeira versão do NOP Profile que pode vir a ter evoluções con-forme ele seja aplicado nos diferentes projetos e sejam identificadas novas necessidades.
Com base nos resultados produzidos, os autores julgam que o emprego de um Perfil UML para fins de meta-modelagem não só é viável quanto representa uma abordagem muito prática a alinhada com a linguagem UML. O perfil criado possui grande valia na definição de programas em PON e visa sua aplicação em processos de projetos com esse paradigma de programação. Portanto, o próximo passo é a aplicação do NOP Profile em um processo de software. O objetivo é criar um método que será empregado em projetos de software baseados em PON. Para tanto, o NOP Profile deve ser aplicado nas fases de modelagem, viabilizando uma modelagem consis-tente com os conceitos do framework do PON.
Referências
[1] [Banaszewski et al., 2007] Banaszewski, R. F.; Stadzisz, P. C.; Tacla, C. A.; Simão, J. M. “Notification Oriented Paradigm (NOP): A software development approach based on artificial intelligence concepts,” in Proceedings of the VI Congress of LAPTEC, Santos, Brazil, 2007.
[2] [Banaszewski, 2009] Banaszewski, R. F. “Paradigma Orientado a Notificações: Avanços e Comparações”. Dissertação de Mestrado, CPGEI/UTFPR, Curitiba, 2009. Disponível em: http://arquivos.cpgei.ct.utfpr.edu.br/Ano_2009/dissertacoes/Dissertacao_500_2009.pdf.
[3] [Döll, 2002] Döll, L. M. (2002). Proposta de uma metodologia para a modelagem da dinâmica de sistemas orientados a objetos usando redes de petri predicado/transição. Dissertação de mestrado, CEFET-PR.
[4] [Fuentes e Vallecillo, 2004] Fuentes, L., Vallecillo, A.(2004). An Introduction to UML Profiles. The European Journal for the Informatics Professional, vol. 5, nº2.
[5] [Gabbrielli e Martini, 2010] Gabbrielli, M., Martini, S. “Programming Languages: Principles and
[6] Paradigms. Series: Undergraduate Topics in Computer Science”. 1st Edition, 2010, XIX, 440 p., Softcover. ISBN: 978-1-84882-913-8.
[7] [Guedes, 2004] Guedes, G. T. (2004). UML Uma abordagem Prática. Novatec.
[8] [Lima, 2008] Lima, A. S. (2008). UML 2.0: do requisito à solução. São Paulo, Editora Érica, 3ªed.
[9] [OMG, 2003] OMG Unified Modeling Language Specification (2003). Version 1.5, OMG document for-mal/03-03-01.

UIGV40
[10] [OMG, 2005a] UML Profile for CORBA Components (2005). Version 1.0, OMG documen formal/05-07-06.
[11] [OMG, 2005b] UML Profile for Schedulability, Performance, and Time Specification (2005). Version 1.1, OMG document formal/05-01-02.
[12] [Roy e Haridi, 2004] Roy, P, V., Haridi, S. “Concepts, Techniques, and Models of Computer Programming”. MIT Press, 2004.
[13] [Simão, 2005] Simão, J. M. “A Contribution to the Development of a HMS Simulation Tool and Proposition of a Meta-Model for Holonic Control”. Tese de Doutorado, CPGEI/UTFPR, Curitiba, 2005. Disponível em: http://arquivos.cpgei.ct.utfpr.edu.br/Ano_2005/teses/Tese_012_2005.pdf.
[14] [Simão e Stadzisz, 2008] Simão, J. M.; Stadzisz, P. C. “Paradigma Orientado a Notificações (PON) - Uma Técnica de Composição e Execução de Software Orientado a Notificações”. Pedido de Patente submetida ao INPI/Brazil (Instituto Nacional de Propriedade Industrial) em 2008 e a Agência de Inovação/UTFPR em 2007. Nº INPI Provisório 015080004262. Nº INPI Efetivo PI0805518-1. Patente submetida ao INPI. Brasil, 2008.
[15] [Simão e Stadzisz, 2009] Simão, J. M.; Stadzisz, P. C. “Inference Process Based on Notifications: The Ker-nel of a Holonic Inference Meta-Model Applied to Control Issues”. IEEE Transactions on Systems, Man and Cybernetics. Part A, Systems and Humans, Vol. 39, Issue 1, 238-250, Digital Object Identifier 10.1109/TSMCA.2008.20066371, 2009.
[16] [Simão, Stadzisz e Tacla, 2009] J. M. Simão, C. A. Tacla, and P. C. Stadzisz, “Holonic Control Meta-Model”. IEEE Transactions on Systems Man & Cybernetics, Part A. Vol. 39, NO. 5, September 2009 Pg. 1126-1139.
[17] [Tanenbaum e Van Steen, 2002] Tanenbaum, A.S.; Van Steen, M. “Distributed Systems: Principles and Para-digms”, Prentice Hall, 2002.

UIGV41
Juan Pedro Benítez Guadarrama 1, Ana Luisa Ramírez Roja 2, Carlos Robles Acosta 3
123 Universidad Autónoma del Estado de Mé[email protected], [email protected], [email protected]
Evaluación de la calidad sobre la aplicación móvil fiscal para hacer eficiente el cálculo del pago provisional mensual de arrendadores en México
Resumen
En este documento, se presenta la evaluación de la calidad de una aplicación móvil fiscal (AMF11) mediante el uso del teléfono móvil como una herramienta digital para hacer eficiente el cálculo de los pagos provisionales mensuales de los impuestos federales en México (Impuestos Sobre la Renta, Impuesto Empresarial a Tasa Única e Impuesto al Valor Agregado). A partir del m-gobierno como instrumento de mejora en el desempeño de las actividades en la ges-tión tributaria, la aplicación se crea con base en las disposiciones fiscales mexicanas que establecen el procedimiento al pago de los impuestos y con base en el método programación extrema (XP). Su propósito es generar aplicaciones que proporcionen valor adicional al Estado, contribuyente o prestador del servicio. Se ha utilizado la plataforma java 2 microEdición para obtener la aplicación fiscal en dispositivos móviles. Se diseñó el instrumento de medición de la cali-dad basado en los criterios e indicadores de la Norma ISO 9126 conformado por 20 ítemes, estructurado a escala tipo Likert. La evaluación se realizó aplicando 300 instrumentos a contadores públicos expertos en materia fiscal dedicados a brindar asesoría a personas físicas arrendadores de locales comerciales en México. En el análisis de datos, se aplicó estadística descriptiva e inferencial utilizando el programa estadístico SPSS. Se presentan resultados que muestran la calidad del uso de la aplicación fiscal en el teléfono móvil para incorporarlo en las prácticas fiscales. Sin embargo, se puede inferir que en términos de calidad, muestra aceptación por parte del usuario al utilizar la aplicación en el telé-fono móvil como herramienta digital para la gestión ante las autoridades fiscales.
Palabras clave:
Pagos provisionales, aplicación fiscal, calidad, ISO 9126, arrendamiento.
Abstract
In this document one presents the evaluation of the quality of a mobile fiscal application (AMF11) by means of the use of the cell phone as a digital tool for eficientar the calculation of the provisional monthly payments of the federal taxes in Mexico (Income taxes, Managerial Tax to The Only Rate and Value-added tax). From the m-government like instrument of improvement in the performance of the activities in the tax planning, the application believes itself with base in the fiscal Mexican dispositions that they establish the procedure to the payment of the taxes and with base in the methodology programming carries to extremes (XP), his intention is to generate applications that provide additional value to the con-dition, contributor or lender of the service, the platform has been in use java 2 mike Edition for obtaining the fiscal appli-cation in mobile devices, I design the instrument of measurement of the quality based on the criteria and indicators of the ISO Norm 9126 shaped by 20 articles, structured to scale type Likert. The evaluation I realize applying 300 instruments to public book-keepers expert in fiscal matter dedicated when lessors of business premises offering advising to natural persons in Mexico. In the analysis of information I apply descriptive statistics to him and inferencial using the statistical program SPSS. They present results that show the quality of the use of the fiscal application in the cell phone to incorpo-rate it in the fiscal practices, nevertheless, it is possible to infer that in qualit terms it shows acceptance on the part of the user on having used the application in the cell phone as digital tool for the management before the fiscal authorities.
Keywords:
Provisional Payments, fiscal application, quality, ISO 9126, lease.

UIGV42
Introducción
En el contexto fiscal, se establece un vínculo jurídico entre dos sujetos: el sujeto activo representado por el Go-bierno, quien se encuentra facultado para exigir el cumplimiento y pago de los impuestos en México, mientras que el sujeto pasivo es representado por el contribuyente, quien tiene la obligación de cumplir con las disposiciones establecidas en las leyes fiscales mexicanas que se materializan a través del pago de los impuestos.
A partir de este fenómeno, el Gobierno, al procurar el bien común de la sociedad, tiene como propósito fun-damental la obtención, administración y aplicación de las recaudaciones de los impuestos. Para ello, implementa estrategias de e-gobierno o gobierno electrónico permitiendo hacer más eficiente y efectiva la gestión guberna-mental, además tiene la obligación de asesorar y proveer programas tecnológicos fiscales a los contribuyentes con la finalidad de brindar, con mayor oportunidad, el cumplir con las obligaciones fiscales establecidas en las disposiciones fiscales. No es común que la autoridad hacendaria proporcione herramientas tecnológicas móviles en teléfono móvil que auxilien al contribuyente en la determinación y cálculo de los pagos provisionales mensuales en los impuestos federales.
En tal sentido, debido a la complejidad del contenido de las leyes fiscales mexicanas incluyen obligaciones que deben cumplir las personas físicas dedicadas a la renta de bienes inmuebles, locales comerciales, bodegas, almacenes, oficinas, talleres, entre otros. En territorio mexicano, se tiene la necesidad de desplazarse a las oficinas de administración tributaria más cercana del domicilio del contribuyente, para que un asesor de la autoridad hacen-daria les auxilie en la determinación y cálculo de los impuestos que tiene que pagar. A pesar del exceso del tiempo que le invierten por la espera y la mala atención por parte del asesor no proporcionan una atención adecuada ni ofrece diferentes alternativas que tiene el contribuyente para realizar un pago justo del impuesto.
Por tal motivo, hemos desarrollado una aplicación móvil fiscal que permita al Gobierno mayor oportunidad en la captación de la recaudación de impuestos e incorporar nuevas tecnologías en la gestión tributaria que mejore el proceso y permita obtener los resultados del Impuesto Sobre la Renta, Impuesto al Valor Agregado e Impuesto Empresarial a Tasa Única de las personas físicas dedicadas al arrendamiento de bienes inmuebles.
El resto del documento está organizado de la siguiente manera: en la sección 2, trabajos previos, se muestra el estado del arte acerca de la evaluación de las aplicaciones. La sección 3 describe la actividad financiera del Estado, la aplicación del m-gobierno, la plataforma j2me y el uso de la aplicación móvil en la práctica fiscal. La sección 4 muestra el Experimento y Resultados. La sección 5 muestra discusión del Experimento y, finalmente, la sección 6 muestra las conclusiones.
Conclusiones
Si la aplicación móvil fiscal presenta excelente calidad, es oportuno que las autoridades hacendarias incorporen las aplicaciones a favor de incrementar la recaudación fiscal. El verdadero progreso es el que pone la tecnología al alcance de todos (Henry Ford).
La aplicación móvil fiscal es considerada de calidad por el usuario debido a que cumple con los criterios exi-gibles por la norma ISO 9126. Para mejorar el proceso con el fin de dar cumplimiento a los pagos provisionales mensuales, muestra un excelente nivel de manejo en sus funciones para los cuales fue diseñado, muestra excelentes conjuntos de atributos por el uso sin que el usuario puede invertir mucho esfuerzo al utilizar el programa. Presenta excelente nivel de eficiencia por el tiempo de respuesta inmediata y la utilización del tipo de recurso, muestra excelente nivel de mantenibilidad por el mínimo esfuerzo para realizar la modificación y muestra una buena porta-bilidad al ser transferido de un ambiente a otro. Por cuanto hace a la confiabilidad, ésta tiende a ser positiva por la capacidad de ejecución; atributos que proporcionan los elementos suficientes para ser considerada como una herramienta fiscal con miras a la contribución política fiscal y económica del Estado-nación.
El mundo globalizado exige cada vez más la aplicación de tecnologías sencillas para la realización de una gestión tributaria eficiente y evitar accesorios que compliquen el quehacer de las actividades empresariales. Debido

UIGV43
a este fenómeno hemos desarrollado aplicaciones móviles en beneficio de los actores tributarios para mejora de los procesos gubernamentales.
Al desarrollar tecnologías que justifiquen la calidad en los procesos fiscales en un régimen fiscal en particular el de arrendamiento, como el que versa este trabajo, se podrán desarrollar aplicaciones fiscales con los requerimien-tos particulares a los demás regímenes fiscales en las diferentes actividades que les permitan determinar y calcular con oportunidad el monto del pago de los impuesto, a enterar ante las autoridades fiscales.
Los trabajos futuros consisten en incorporar este tipo de tecnología para la trasferencia electrónica de datos a través del teléfono móvil que permita obtener la información suficiente para verificar y comprobar la forma de determinación, cálculo, y pago del impuesto por este medio electrónico, tan solo en México, con el fin de evitar desplazamiento, pérdida de tiempo y lo pueda realizar desde su casa, oficina o de cualquier lugar donde se ubi-que dentro o fuera de la República Mexicana.
Referencias
[1] [Carrillo, Linares, 2009] Carrillo, Linares, 2009. Gobierno electrónico. http://grupoalfaro.org/imaginar.org/docs/L_mgobierno_NED.pdf
[2] [Carranza, J., 2002] Carranza, J. (2002) VII Congreso Internacional del CLAD sobre la Reforma del Estado y de la Administración Pública, Lisboa, Portugal. http://unpan1.un.org/intradoc/groups/public/documents/CLAD/clad0043821.pdf
[3] [Constitución Política de los Estados Unidos Mexicanos, 2011] Constitución Política de los Estados Unidos Mexicanos (2011). México: Edición BOB. Pág. 40,41. [Flores, D., Valero, J., Chapa, J. y Bedoy, B. 2007] Flores, D., Valero, J., Chapa, J. y Bedoy, B. (2007) El sector informal en México: medición y cálculo para la recaudación potencial. Ciencia. Universidad Autónoma de Nuevo León, octubre-diciembre, VIII, 004, 490 – 494.
[4] [Garza, S. 2005] Garza, S. (2005). Derecho financiero Mexicano. 26ª. Edición México: Porrúa.
[5] [Gálvez, S. y Ortega, L. 2003] Gálvez, S. y Ortega, L. (2003). Java a tope J2ME (JAVA 2 MICRO EDITION). Málaga: Universidad de Málaga. Pág.1.
[6] [Malo, S., Casas C. & González, M. 2006]. Malo, S., Casas C. & González, M. (2006). El teléfono móvil: disponibilidad, usos y relaciones por parte de los adolescentes entre 12 y 16 años. Estudios sobre Educación, 2006, 10, 55-78
[7] [Moreno, 2008] Moreno, S.; González, C. & Echartea, C. Evaluación de la Calidad en Uso de Sitios Web Asistida por Software: SW – AQUA. Avances en Sistemas e Informática, vol. 5, núm. 1, mayo, 2008, pp. 147-154. Universidad Nacional de Colombia.
8] [Norma ISO/IEC 9126, 2001] Norma ISO/IEC (2011). http://www.hagalepues.net/ universidades/60547-descargar-norma-iso-iec-9126-ingenieria-de-software.html
[9] [Omaña y Cadenas, 2010] Omaña, M. y Cadenas, J. (2010). Manufactura Esbelta: una contribución para el desarrollo de software con calidad. Enl@ce Revista Venezolana de Información, Tecnología y Conocimien-to, 7 (3), 11-26.
[10] [Prieto, M. 2005] Prieto, M. (2005). Desarrollo de juegos con J2ME Java Micro Edition. México: Alfa Ome-ga, 9

UIGV44
[11] [Prontuario fiscal. 2011] Prontuario fiscal (2011) Ley del Impuesto Sobre la Renta. México: ECAFSA.
[12] [Prontuario fiscal. 2011] Prontuario fiscal (2011) Ley del Impuesto Empresarial a Tasa Única. México: ECAF-SA.
[13] [Prontuario fiscal. 2011] Prontuario fiscal (2011) Ley del Impuesto al Valor Agregado México: ECAFSA.
[14] [Quintanilla, J. y Rojas J., 1999] Quintanilla, J. y Rojas J., (1999). Derecho tributario mexicano. 4ª. Ed. México: Trillas.
[15] [Rodríguez, 2010] Rodríguez, M.; Verdugo, J.; Coloma, R.; Genero, M. & Piattini, M. (2010). Metodología para la evaluación de la calidad en los modelos UML. REICIS Revista Española de Innovación, Calidad e Ing-eniería del Software, Vol. 6, Núm. 1, abril-sin mes, 2010, pp. 16-35. Asociación de Técnicos de Informática. España.
[16] [Santoveña, 2010] Santoveña, S. (2010). Cuestionario de evaluación de la calidad de los cursos virtuales de la UNED. RED. Revista de Educación a Distancia, núm. 25, 2010, pp. 1-22. Universidad de Murcia. Murcia, España.
[17] [Secretaría de la Función Pública, 2011] Secretaria de la Función Pública, (2011). Gobierno digital. http://www.funcionpublica.gob.mx/index.php/unidades-administrativas/ssfp/mejor-gobierno/faq/gobierno-digi-tal.html
[18] [Solarte, 2009] Solarte, G.; Muñoz, L.; Arias, B.; Modelos de calidad para procesos de software. Scientia Et Technica, vol. XV, núm. 42, agosto, 2009, pp. 375-379. Universidad Tecnológica de Pereira. Colombia.
[19] [Zorrilla, J. 2006] Zorrilla, J. (2006) La información como estrategia en un contexto global y competitivo: una revisión teórica. Intangible capital. Barcelona España, abril-junio, 2, 002, 258-276.

UIGV45
Proposta de um Simulador para o Ensino de Escalonamento FIFO e DRR
Rodrigo Ap. Morbach1,2, Tatiana Annoni Pazeto2
1,2 Universidade Federal de Mato Grosso – Campus Universitário de Rondonó[email protected], [email protected]
Resumo
O escalonamento de pacotes em redes de computadores é uma tarefa de suma importância para o bom funcio-namento das redes. Porém, mesmo sendo tão importante, não é conhecido software que seja de uso específico para o ensino de escalonamento. Assim, com base no simulador de escalonamento FIFO e DRR desenvolvido por Renato Silva (2009), Santana (2010) construiu o REDESIM, um simulador que conta com interface gráfica baseada no estilo de aprendizagem VAK. O REDESIM apresenta também uma animação com os resultados da simulação e permite análi-ses estatísticas dos simuladores através de planilhas de texto. Porém, o REDESIM não chegou a ser desenvolvido por completo, contemplando apenas a análise de fontes geradoras de tráfego. Além disso, do modo como foi criado, não poderia ser facilmente disponibilizado. Deste modo, com a interface do simulador validada, este trabalho tem por objetivo concluir a criação do REDESIM, possibilitando a utilização na WEB, uma vez que está sendo implementado em linguagem HTML e Javascript. Com isso foram aproveitados os códigos desenvolvidos em C++ Builder, melhorando o layout e contribuindo com o aprendizado de um número maior de estudantes.
Palavras chave:
Redes, Simulação, Ferramentas Educacionais
Abstract
The packets scheduling in computer networks is a task of utmost importance to the smooth operation of networks. But even being as important, there is no known software that is of particular use for teaching the scheduling. Thus, based on FIFO and DRR scheduling simulators developed by Renato Silva (2009), Santana (2010) built the REDESIM, a simulator that has graphic interface based in the learning VAK style. The REDESIM also features an animation of the results and statistics analysis of the simulators through spreadsheets of text. However, the REDESIM was never fully developed, comprising only the analysis of traffic sources. Moreover, as it was created, could not be readily available. Thus, with the interface the simulator validated, this work aids to complete the creation of REDESIM, allowing the use on by the web, because it is being implemented in HTML and JavaScript. This was taken advantage of the developed code in C++ Builder, improving layout and contributing to the learning of a larger number of students.
Keywords:
Networks, Simulation, Educational tools

UIGV46
Introdução
Segundo Cholvi e Echague (2007), um número crescente de aplicações de rede tem restrições em termos de atraso na transmissão dos dados, taxa de perda de pacotes, largura de banda, disponibilidade, entre outros. Para lidar com isto, uma alternativa é o uso de escalonadores de tráfego. Stialidis e Varma (1998) corroboram a afirmação mencionando que para oferecer Qualidade de Serviço (QoS) em uma rede de pacotes é necessário o uso de escalonamento de tráfego. A função do escalonamento é selecionar, para cada link de saída, o pacote a ser transmitido dentre os que aguardam na fila. Diante disso, a maior preocupação é em relação à qualidade dos serviços oferecidos, pois um congestionamento pode ocasionar atraso ou perda de pacotes, principalmente quando não existe uma boa estratégia de gerenciamento para atender a todas as aplicações.
Com base nos simuladores de escalonamento de tráfego FIFO e DRR para avaliação de desempenho das fontes On/Off, criados por Renato Silva (2009), Santana (2010) propôs uma ferramenta para o ensino de escalonamen-to FIFO, com implementação de uma interface que contribuísse para esse processo, e representação do mesmo através de uma animação. A ideia surgiu considerando a complexidade do conteúdo e tendo em vista que a maioria das aulas a respeito desse assunto ocorre de maneira expositiva, sendo que o aluno não consegue verificar na prática como funciona o que está sendo discutido em sala de aula, dificultando a aprendizagem. Contudo, em função da amplitude do trabalho e do tempo disponível para a sua realização, apenas as fontes de tráfego foram implementadas, bem como um comparativo entre elas.
Neste sentido, o presente trabalho visa dar continuidade ao trabalho iniciado por Santana (2010), apresentan-do o desenvolvimento da ferramenta REDESIM, que tem como propósito auxiliar no processo de ensino/aprendi-zagem sobre escalonamento de tráfego, com ênfase nos algoritmos FIFO e DRR. Para tanto, este artigo se baseia nos simuladores FIFO e DRR desenvolvidos por Renato Silva (2009), os quais não tinham a pretensão de atender ao ensino de escalonamento. Assim, para fazer uso dos simuladores era necessário um conhecimento avançado sobre o assunto.
O trabalho encontra-se organizado em cinco seções. A seção 2 versa sobre escalonadores de tráfego e fontes geradoras. A interface de Renato Silva (2009) e a de Santana (2010) são apresentadas na seção 3. A seção 4 justifica a escolha para as novas ferramentas usadas para o desenvolvimento do REDESIM, bem como apresenta a interface proposta para escalonamento FIFO e DRR visando à aprendizagem. Por fim, na seção 5 são mencionadas as principais conclusões do trabalho seguido das referências.
Conclusões
Através das pesquisas realizadas foi possível desenvolver uma ferramenta de auxílio ao ensino de escalonamen-to, o REDESIM, baseado nos simuladores de escalonamento FIFO e DRR desenvolvidos por Renato Silva (2009).
Desta forma, o REDESIM atende aos princípios de aprendizagem VAK, visto que o usuário pode identificar os tipos de dados tratados através das imagens inseridas no programa, bem como da animação. Atende também ao princípio sinestésico, uma vez que todos os parâmetros são definidos pelo usuário, gerando impacto nos resultados, possibilitando comparações e visualização da fonte que mais se adéqua a determinada situação.
Embora não estar contemplado no artigo, um resultado importante do REDESIM é a geração de formas de análise dos resultados baseada em gráficos, os quais permitem visualizar o impacto causado pelos parâmetros digitados pelo usuário.
Futuramente pretende-se acrescentar ao simulador REDESIM um tutorial com áudio e vídeo para que se possa atender de maneira completa o princípio de aprendizagem VAK, aprimorando ainda mais o ensino de escalo-namento de redes. Também pretende-se incorporar uma série de exercícios baseados nos dados gerados pelo simulador para verificação do grau de conhecimento adquirido pelo aluno com a utilização do simulador.

UIGV47
Referências
[1] [Chevalier e Wein, 1990] Chevalier, Philippe B; Wein, Lawrence M. (1990). Scheduling Networks of Queues: Heavy Traffic Analysis of a Multistation Closed Network. Massachusetts Institute of Techonology, Cambridge, Massachusetts. Disponível em: http://faculty-gsb.stanford.edu/wein/personal/SchedulingNet-work.pdf, acesso dia 23-03-2011.
[2] [Chovi e Echague, 2007] Chovi, Vicent; Echague, Juan (2007). Stability of FIFO: Networks under Adversarial Models: State of the Art. Universitat Jaume I, Campus de Riu sec, 12071 Castell´on (Spain), 2007. Disponível em: http://www3.uji.es/~echague/page5/files/page5_2.pdf, acesso dia 29-05-2011.
[3] [Duan, Zhang e Hou, 2005] Duan, Zhenhai; Zhang, Zhi-Li; Hou, Yimei Thomas (2005). Fundamental Trade-Offs in Aggregate Packet Scheduling. IEEE Transaction On Parallel and Distributed Systems, Vol. 16, NO. 12, 2005.
[4] [Junior, 2007] Junior, Antonio (2007). K. Protótipo para gerenciar um escalonador de tráfego no sistema operacional Linux para priorização de determinados serviços em redes de computadores. 2007. 88 f. Mono-grafia (Bacharel em Ciências da Computação) – Universidade Unochapecó, Chapecó, 2007.
[5] [Mata, 2002] Mata, Renê Souza da (2002). Dimensionamento de enlaces em redes com integra-ção de serviços. 2002. 81 f. Dissertação (Mestrado) - Universidade Estadual de Campinas - Faculdade de Engenharia Elétrica e de Computação, Campinas, 2002. Disponível em: http://libdigi.unicamp.br/document/?code=vtls000252448. Acesso em: 23 de abril de 2011.
[6] [Rezende, 2000]Rezende, José (2000). Escalonamento (Scheduling). 2000. Disponível em: http://www.gta.ufrj.br/~rezende/cursos/coe889/aulas/aula3/index.htm. Acesso em: 26 de abril de 2011
[7] [Santana, 2010] Santana (2010), Gustavo Xavier. Protótipo de um Simulador Multimídia para o Ensino de Escalonamento FIFO. Monografia (Licenciatura Plena em Informática). Universidade Federal de Mato Grosso, Rondonópolis, 2010.
[8] [Semeria, 2001] Semeria, Chuck (2001). Supporting Differentiated Service Classes: Queue Scheduling Disci-plines - White Paper, tech. report, Juniper Networks, 2001
[9] [Silva, 2009] Silva, Renato Moraes (2009). Avaliação de Desempenho de Fontes On/Off Através do Desen-volvimento de um Simulador para Escalonamento FIFO E DRR. Monografia (Licenciatura Plena em Informática). Universidade Federal de Mato Grosso, Rondonópolis, 2009.
[10] [Stamoulis, Anagnostou e Georgantas, 1993] Stamoulis, GD; Anagnostou, ME; Georgantas, AD (1993). “Traffic Source models for ATM networks: a survey”. National Technical University of Athens, Department of Electrical and Computer Engineering, Division of Computer Science, 157 73 Zographou, Athens, Greece Received 5 February 1993; revised 20 May 1993.
[11] [Stialidis e Varma, 1998] Stialidis, Dimitrios; Varma, Anujan (1998). Latency-Rate Servers: A General Model for Analysis of Traffic Scheduling Algorithms. IEEE/ACM Transactions On Networking, Vol. 6, No. 5, October 1998.
[12] [Shreedhar e Varghese, 1996] Shreedhar, M; Varghese, George (1996). Efficient Fair Queuing Using Deficit Round-Robin. IEEE/ACM Transactions On Networking, Vol. 4, No. 3, June 1996.
[13] [Veríssimo, 2005] Veríssimo, Fernando. C. A (2005). Propostas e Avaliações de Protocolos de Acesso Alter-nativos ao Padrão IEEE 802.11e. 2005. 124 f. Tese (Doutorado em Engenharia de Sistemas e Computação) – Tese, Universidade Federal do Rio de Janeiro, COPPE, Rio de Janeiro, 2005.
[14] [Wrege e Liebeherr, 1997] Wrege, Dallas E; Liebeherr, Jorg (1997). A Near-Optimal Packet Scheduler for QoS Networks. Proceedings of the IEEE. Departament of Computer Science, University of Virginia, Charlot-tesville, 1997.

UIGV48

UIGV49
Juan Camilo Giraldo Mejía1, Fabio Alberto Vargas Agudelo1
Tecnológico de Antioquia, TdeA. Institución [email protected], [email protected]
Resumen
El artículo presenta la caracterización de la técnica Regresión Logística de la Minería de Datos (Data Mining). Igual-mente, se muestra la funcionalidad y aplicación de la técnica para apoyar al proceso de obtención de conocimiento (Knowledge Discovery in Databases o KDD), a encontrar información interesante a partir de Datos “ocultos”. La funcionalidad de la técnica se ejemplifica con los resultados obtenidos en un trabajo de investigación que se realizó buscando encontrar el nivel de innovación y desarrollo tecnológico en algunas empresas de Colombia.
La finalidad es mostrar el proceso de obtención de conocimiento de un sistema de bases de datos Transaccionales u operativos para empresas de bienes y servicios. En él, se desarrollan los antecedentes conceptuales e investigativos y la caracterización de los conceptos fundamentales relacionados con el proceso de descubrir conocimiento, Minería de Datos y la Técnica de Regresión Logística.
Palabras clave:
SGBD, KDD, Minería de Datos.
Abstract
The article presents the characterization of the logistic regression technique of data mining (Data Mining). Also shows the functionality and application of technology to support the process of obtaining knowledge (Knowledge Discovery in Databases or KDD), to find interesting information from data “hidden”. The functionality of the technique is exemplified by the results of a research which was carried out seeking to find the level of innovation and technolo-gical development in some companies in Colombia.
The aim is to show the process of obtaining knowledge of a database system Transactional or operational goods and services companies. In the develop conceptual and research background and characterization of the fundamental concepts related to the process of discovering knowledge, data mining and logistic regression.
Keywords:
DBMS, KDD, Data Mining
Aplicación de la Técnica Regresión Logística de la Minería de Datos en el proceso de Descubrimiento de Conocimiento (KDD) en Bases de Datos Operativas o Transaccionales

UIGV50
Introducción
En los últimos años, ha existido un gran crecimiento en nuestras capacidades de generar y colectar datos debido básicamente, al gran poder de procesamiento de las máquinas como a su bajo coste de almacenamiento.
Sin embargo, dentro de estas enormes masas de datos existe una gran cantidad de información oculta de gran importancia estratégica a la que no se puede acceder por las técnicas clásicas de recuperación de la información. El descubrimiento de esta información oculta es posible gracias a la Minería de Datos (DataMining), que entre otras sofisticadas técnicas aplica la inteligencia artificial para encontrar patrones y relaciones dentro de los datos permitiendo la creación de modelos, es decir, representaciones abstractas de la realidad, pero es el descubrimiento del conocimiento (KDD) el que se encarga de la preparación de los datos y la interpretación de los resultados obtenidos, los cuales dan un significado a estos patrones encontrados (Vallejos, 2006).
“La posesión real de toda la información obtenida depende de nuestra capacidad para hacer ciertas operacio-nes con la información textual, por ejemplo: buscar información interesante” Guzmán (2005).
Posteriormente, con el apoyo de la tecnología de información, justificada en las bases de datos relacionales, los ordenadores personales y la computación gráfica, el acceso a la información y su representación por parte de los usuarios finales, comenzaron a ser cada día más frecuentes. Todo esto enmarcado en el concepto de Descubri-miento u obtención de Conocimiento (KDD).
Existen diversos métodos durante el proceso de KDD para el análisis de la información. Cada una de ellos ofrece herramientas conceptuales para extraer cierta inteligencia o conocimiento de los datos acumulados en la empresa. Estas tecnologías son las técnicas de Minería de Datos. La Minería de Datos utiliza algoritmos, como Regresión Logística, para explorar los repositorios de datos y extraer conocimiento a partir de los datos.
“La técnica de la regresión logística se originó en la década de los 60 con el trabajo de Cornfield, Gordon y Smith. En 1967 Walter y Duncan la utilizan ya en la forma que la conocemos actualmente, o sea para estimar la probabilidad de ocurrencia de un proceso en función de ciertas variables. Su uso se incrementa desde principios de los 80 como consecuencia de los adelantos ocurridos en el campo de la computación.” Domínguez (2001).
La regresión logística es un procedimiento cuantitativo de gran utilidad para problemas donde la variable depen-diente toma valores en un conjunto finito.
El objetivo primordial que resuelve esta técnica es el de modelar cómo influye en la probabilidad de aparición de un suceso, habitualmente dicotómico, la presencia o no de diversos factores y el valor o nivel de los mismos. También puede ser usada para estimar la probabilidad de aparición de cada una de las posibilidades de un suceso con más de dos categorías (politómico). (Molinero, 2001)
Conclusiones
La regresión logística es una de las herramientas estadísticas con mejor capacidad para el análisis de datos en investigación de diferente contexto, de ahí su amplia utilización.
El momento en que la mayoría de los profesionales tenga acceso a herramientas de Minería de Datos para obtener conocimiento de las Bases de Datos transaccionales u operativas trae consigo un mejoramiento en el tipo de organizaciones que se encuentran compitiendo en el mercado debido a que se elevan los niveles de calidad desde las mejores tomas de decisiones por parte de sus analistas.

UIGV51
Referencias
[1] [Molinero, 2001] Molinero, L. (2001). “La Regresión Logística”, Asociación de la sociedad Española de Hipertension, España.
[2] [Molinero, 2006] Vallejos, S. (2006). “Minería de Datos”, Facultad de Ciencias Exactas, Naturales, y Agri-mensura, Universidad Nacional del Nordeste.
[3] [Domínguez, 2001] Domínguez, E. (2001). “Regresión Logística, un ejemplo de su uso en endocrinología”, Instituto Nacional de Endocrinología, Revista Cubana Endocrinol, Cuba.
[4] [Valcárcel, 2004] Valcárcel, V. (2004). “Data Mining y el descubrimiento de conocimiento”. Revista de la Facultad de Ingeniería Industrial. Vol. (7) 2: pp. 83-86 (2004) UNMSM ISSN: 1560-9146. Diciembre de 2004.
[5] [Lezcano, 2002] Lezcano, R. (2002). “Minería de Datos”. Trabajo de Investigación. Universidad Nacional del Nordeste. 2002.
[6] [Guzmán, 2005] Guzmán, G. (2005). “Búsqueda de colocaciones en la Web para sinónimos de Wordnet”. Universidad de Guanajuato. 2005.
[7] [Mures, 2005] Mures, J. (2005). “Aplicación del Análisis Discriminante y Regresión Logística en el estudio de la morosidad en las entidades financieras. Comparación de Resultados”, Revista pecvnia, Universidad de León.
[8] [Puga, 2011] Puga, J. “Eventos por Variable en Regresión Logística y Redes Bayesianas para Predecir Acti-tudes Emprendedoras”, Revista Electrónica de Metodología Aplicada, Universidad de Almeria.
[9] [Aguayo, 2007] Aguayo, M. (2007). “Como hacer una Regresión Logística con SPSS paso a paso”, Servicio de Medicina Interna, Hospital Universitario Virgen Macarena, Sevilla España.

UIGV52

UIGV53
Márcio V. Batista1, Roni F. Banaszewski1, Adriano F. Ronszcka1, Glauber Z. Valença2,Robson R. Linhares1,2, Paulo C. Stadzisz1,2, Cesar A. Tacla1,2, Jean M. Simão1,2
Universidade Tecnológica Federal do Paraná - UTFPR1 Programa de Pós-Graduação em Engenharia Elétrica e Informática Industrial - CPGEI2 Programa de Pós-Graduação em Computação Aplicada - PPGCAmarcio.venancio, ronifabio, ronszcka, gvalencio {@gmail.com}, [email protected], stadzisz, tacla, jeansimao {utfpr.edu.br}
Uma comparação entre o Paradigma Orientado a Notificações (PON) e o Paradigma Orientado a Objetos (POO) realizado por meio da implementação de um Sistema de Vendas
Resumo
Este artigo apresenta uma revisão dos conceitos relacionados ao Paradigma Orientado a Notificações (PON) e uma comparação, qualitativa e quantitativa, de duas versões de uma mesma aplicação. A primeira desenvolvida de acordo com os princípios do Paradigma Orientado a Objetos (POO) e a segunda inclusive de acordo com os princípios do PON. O PON se apresenta como uma alternativa aos Paradigmas de Programação Imperativa (PI), incluindo o POO, e aos Paradigmas de Programação Declarativa (PD), propondo-se a eliminar deficiências destes no que tange a aspectos de redundâncias e acoplamento de avaliações causais que impactam no desempenho e paralelismo/distribuição de aplicações. A comparação apresentada neste artigo abrange particularmente questões relacionadas à implementação e ao desempenho. O experimento demonstra que, embora o desempenho do PON tenha sido inferior ao do POO para a aplicação desenvolvida, em função de características da aplicação e de um ambiente de execução ainda não totalmente adaptado ao paradigma, existem aspectos relativos à maneira como se concebe os programas em PON que podem ser levados em consideração e incentivar a utilização deste em aplicações com requisitos de paralelismo ou distribuição.
Palavras chave:
Paradigma Orientado a Notificações (PON), Sistema de Vendas em POO e PON, Comparações entre POO e PON.
Abstract
This paper presents a review of the concepts related to the Notification-Oriented Paradigm (NOP) and a qualitative and quantitative comparison of two versions of a certain application. The first developed according to the Object-Oriented Paradigm (OOP) principles and the second developed according to the NOP principles. The NOP presents itself as an alternative to the Imperative Programming (IP) paradigms, such as OOP, as well as to the Declarative Progra-mming (DP) paradigms, with the purpose of eliminating deficiencies of those paradigms concerning to redundancy issues and coupling of causal evaluations, which affect the execution performance and parallelism/distribution of applications. The presented comparison includes issues related to implementation and relative performance of the applications. The experiment demonstrates that, even though the NOP performance is worse than OOP performance for the developed application, due to application characteristics and a runtime environment not completely adapted to NOP, there are some aspects related to the manner with the programs are designed in NOP which can be taken into consideration and encourage the use of NOP on applications requiring parallelism and distribution.
Keywords:
Notification Oriented Paradigm (NOP), Sales Order System in OOP, Comparisons between OOP and NOP.

UIGV54
Introdução
A capacidade de processamento computacional tem crescido em função da evolução das tecnologias neste contexto [Tanenbaum e Van Steen, 2002]. Entretanto, recursos oferecidos por soluções computacionais modernas, tais como paralelismo e distribuição ou mesmo a utilização da capacidade plena de cada processador, nem sempre são devidamente aproveitados em função de limitações das técnicas de programação [Simão e Stadzisz, 2008, 2009].
Na verdade, técnicas de programação baseadas no estado da arte, como o chamado Paradigma de Progra-mação Orientada a Objetos (POO) ou os Sistemas Baseados em Regras (SBR), sofrem de limitações intrínsecas de seus paradigmas. Estes paradigmas poderiam ser genericamente classificados como Paradigma Imperativo (PI) e Paradigma Declarativo (PD) que englobam respectivamente o POO e os SBR [Banaszewski, 2009].
Particularmente, estes paradigmas levam ao forte acoplamento de expressões causais e redundâncias decorren-tes das suas avaliações. Estas limitações dificultam a execução paralela ou distribuída de programas e freqüente-mente comprometem o seu desempenho pleno mesmo em sistemas monoprocessados. Assim, existem motivações para buscas de alternativas aos PI e PD, com o objetivo de eliminar ou diminuir as desvantagens deles [Banaszews-ki et al., 2007][Banaszewski, 2009][Gabbrielli, Martini, 2010][Roy e Haridi, 2004][Simão e Stadzisz, 2008, 2009].
Neste âmbito, uma alternativa é o Paradigma Orientado a Notificações (PON). O PON foi concebido a partir de uma teoria de Controle Discreto e Inferência [Simão, 2001, 2005; Simão e Stadzisz, 2002, 2008, 2009; Simão, Stadzisz e Tacla, 2009; Simão, Stadzisz e Künzle, 2003]. Ele se propõe a eliminar algumas das deficiên-cias dos atuais paradigmas em relação a avaliações causais desnecessárias e acopladas, evitando o processo de inferência monolítico baseado em pesquisas por meio de um mecanismo baseado no relacionamento de entidades computacionais notificantes [Banaszewski et al., 2007][Banaszewski, 2009][Simão e Stadzisz, 2008, 2009].
Neste artigo é apresentada uma aplicação comercial, relativa a pedidos de venda de mercadorias. A apli-cação foi construída primeiramente em POO e posteriormente em PON. O artigo contempla mais precisamente os resultados da comparação do desempenho nas implementações em POO e PON e também contempla reflexões sobre a mudança de paradigma de programação e o impacto dessa mudança no tocante ao desenvolvimento de programas.
Este artigo está organizado como segue: a Seção 2 sucintamente reflete o estado da arte em paradigmas de programação. A Seção 3 apresenta o PON. A Seção 4 apresenta o caso de estudo abordado neste artigo. A Seção 5 apresenta os experimentos e resultados obtidos das comparações entre POO e PON. A Seção 6 apre-senta as considerações finais e perspectiva para trabalhos.
Conclusões
Esse artigo apresentou um sistema comercial relativo a pedidos de venda de mercadorias. O sistema foi desenvol-vido a priori em POO e posteriormente em PON. Contemplou-se ainda o desempenho das duas implementações.
Os dados dos experimentos em geral posicionaram o POO com resultados um pouco melhores ante ao PON. Entretanto, essas constatações não são suficientes para julgar a versão do sistema sobre os princípios do POO como superior a versão em PON. Isto se dá porque estas primeiras comparações se deram em ambiente preemp-tivo, portanto passível de “ruído”, e devido a atual materialização do PON na forma de um Framework/wizard desenvolvido sobre a linguagem C++.
Neste âmbito, apesar de não ser a materialização ideal, o Framework do PON tem sido freqüentemente otimizado e, com isso, ganhos de desempenho consideráveis vêm sendo alcançados. Não obstante, o PON carece de um compilador próprio, bem como técnicas para composição de sistemas de forma mais simples. Definitivamente, uma linguagem de programação e um compilador devem ser desenvolvidos para que o PON alcance todo o seu potencial.

UIGV55
Como um ensejo para trabalhos futuros, a mesma aplicação poderá ser estendida com a criação e ativação de mais regras. Outrossim, a aplicação poderá apresentar efetivamente testes mais fidedignos com número maior de repetições, particularmente em um ambiente mais puro e sem preempções (e.g. Linux).
Por fim, os experimentos realizados constatam que o desenvolvimento de sistemas concebidos em PON são plausíveis. Apesar de o Framework utilizado para a materialização do paradigma necessitar de algumas correções e melhorias, o seu estado atual permite o desenvolvimento de sistemas funcionais.
Referências
[1] [Banaszewski et al., 2007] Banaszewski, R. F.; Stadzisz, P. C.; Tacla, C. A.; Simão, J. M. “Notification Oriented Paradigm (NOP): A software development approach based on artificial intelligence concepts,” in Proceedings of the VI Congress of LAPTEC, Santos, Brazil, 2007.
[2] [Banaszewski, 2009] Banaszewski, R. F. “Paradigma Orientado a Notificações: Avanços e Comparações”. Dissertação de Mestrado, CPGEI/UTFPR, Curitiba, 2009. Disponível em: http://arquivos.cpgei.ct.utfpr.edu.br/Ano_2009/dissertacoes/Dissertacao_500_2009.pdf.
[3] [Brookshear, 2006] Brookshear, J. G. “Computer Science: An Overview”. Addison Wesley, 2006.
[4] [Gabbrielli e Martini, 2010] Gabbrielli, M., Martini, S. “Programming Languages: Principles and Paradigms. Series: Undergraduate Topics in Computer Science”. 1st Edition, 2010, XIX, 440 p., Softcover. ISBN: 978-1-84882-913-8.
[5] [Forgy, 1982] Forgy, C. L. “RETE: A Fast Algorithm for the Many Pattern/Many Object Pattern Match Problem”, Artificial Intelligence N. 19, pg 17-37 - North- Holland, 1982.
[6] [Friedman-Hill, 2003] Friedman-Hill, E. Jess in Action: Rule Based System in Java. Greenwich, CT, USA: Man-ning Publications Co, 2003.
[7] [Roy e Haridi, 2004] Roy, P, V., Haridi, S. “Concepts, Techniques, and Models of Computer Programming”. MIT Press, 2004.
[8] [Scott, 2000] Scott, M. L. “Programming Language Pragmatics”, 2º Edition, p. 8, San Francisco, CA, USA: Morgan Kaufmann Publishers Inc, 2000.
[9] [Simão, 2001] Simão, J. M. “Proposta de uma Arquitetura de Controle para Sistemas Flexíveis de Manufatura Baseada em Regras e Agentes”. Dissertação de Mestrado, CPGEI/UTFPR, Curitiba, 2001.
[10] [Simão, 2005] Simão, J. M. “A Contribution to the Development of a HMS Simulation Tool and Proposition of a Meta-Model for Holonic Control”. Tese de Doutorado, CPGEI/UTFPR, Curitiba, 2005. Disponível em: http://arquivos.cpgei.ct.utfpr.edu.br/Ano_2005/teses/Tese_012_2005.pdf.
[11] [Simão e Stadzisz, 2002] Simão, J. M.; Stadzisz, P. C. “An Agent-Oriented Inference Engine applied for Su-pervisory Control of Automated Manufacturing Systems”. In: J. Abe & J. Silva Filho, Advances in Logic, Artificial Intelligence and Robotics (Vol. 85, pp. 234-241). Amsterdam, The Netherlands: IOS Press Books, 2002.
[12] [Simão e Stadzisz, 2008] Simão, J. M.; Stadzisz, P. C. “Paradigma Orientado a Notificações (PON) – Uma Técnica de Composição e Execução de Software Orientado a Notificações”. Pedido de Patente submetida ao INPI/Brazil (Instituto Nacional de Propriedade Industrial) em 2008 e a Agência de Inovação/UTFPR em 2007. Nº INPI Provisório 015080004262. Nº INPI Efetivo PI0805518-1. Patente submetida ao INPI. Brasil, 2008.

UIGV56
[13] [Simão e Stadzisz, 2009] Simão, J. M.; Stadzisz, P. C. “Inference Process Based on Notifications: The Ker-nel of a Holonic Inference Meta-Model Applied to Control Issues”. IEEE Transactions on Systems, Man and Cybernetics. Part A, Systems and Humans, Vol. 39, Issue 1, 238-250, Digital Object Identifier 10.1109/TSMCA.2008.20066371, 2009.
[14] [Simão, Stadzisz e Künzle, 2003] Simão, J. M.; Stadzisz, P. C.; Künzle, L. “Rule and Agent-oriented Architec-ture to Discrete Control Applied as Petri Net Player”. 4th Congress of Logic Applied to Technology, LAPTEC, 101, p. 217, 2003.
[15] [Simão, Stadzisz e Tacla, 2009] Simão, J. M., Stadzisz, P. C.; Tacla, C. A. “Holonic Control Meta-Model”. IEEE Transactions on Systems, Man and Cybernetics. Part A, Systems and Humans, Vol. 39, NO 5, September 2009. Pg. 1126-1139.
[16] [Tanenbaum e Van Steen, 2002] Tanenbaum, A.S.; Van Steen, M. “Distributed Systems: Principles and Para-digms”, Prentice Hall, 2002.

UIGV57
Edwin Villarreal López1, Oscar Duarte2, Daniel Alejandro Arango3
1 Universidad Nacional de Colombia2 Universidad Manuela Beltrá[email protected]
Nuevas Estrategias para el entrenamiento de Redes Neuronales que propagan Números Difusos
Resumen
Se presenta la arquitectura básica de una red neuronal feedfordward con la capacidad de propagar números difu-sos. Se exponen brevemente las principales tendencias en el entrenamiento de este tipo de sistemas y con base en ellas se proponen nuevas estrategias. La primera de ellas se basa en la retropropagación del error cuadrático medio en todos los -cortes para pesos crisp. La segunda hace uso de un algoritmo genético con codificación real para redes con pesos crisp. La tercera consiste en la retropropagación del error en el valor promedio y la ambigüedad en todos los -cortes para pesos difusos, y por último se tiene una basada en la retropropagación de una medida difusa del error para redes con pesos difusos. Luego se describen algunos experimentos realizados permitiendo identificar para qué conjuntos de datos particulares resulta útil cada una de las estrategias.
Palabras clave:
red neuronal, algoritmos, retropropagación
Abstract
A novel architecture of a feedfordward neural network for fuzzy numbers is presented. We shortly analyze the main trends in the training of this kind of systems and from that point, we propose new strategies. The first of them is based onthebackpropagationofthemeansquareerrorinalltheα-cutsforcrispweights.Thesecondstrategyusesarealcodification genetic algorithm for crisp weights networks. The third is based in the backpropagation of the mean error valueandtheambiguityofalltheα-cutsforfuzzyweights,andthelastoneusesthebackpropagationofafuzzyerrormeasure for a fuzzy weighted network. A comparison analysis is then presented and some conclusions are given.
Keywords:
neural network algorithms, backpropagation.
Introducción
La mayor parte de los sistemas para el manejo y tratamiento de la información que existen en la actualidad se basan en una arquitectura de procesamiento digital, esquema que, aunque ha demostrado ser de gran utilidad, se encuentra limitado por su incapacidad de representar de manera eficaz la información procedente del mundo real en una forma legible para las máquinas, información que, por lo general, se encuentra contaminada con impreci-siones y distorsiones.

UIGV58
La lógica difusa y, en general, la teoría de los conjuntos difusos (Zadeh, 1975) es un área de la inteligencia artificial que se ha enfocado en desarrollar herramientas que permitan representar y realizar operaciones con can-tidades inexactas e imprecisas.
Uno de los principales conceptos manejados dentro de esta teoría es el número difuso que facilita la tarea de modelar la imprecisión del mundo real, lo que permite a los sistemas operar a partir de mediciones y percepciones no muy exactas del medio. Con el objetivo de aprovechar esta cualidad y combinarla con las ventajas de otros tipos de sistemas de información, se han desarrollado múltiples técnicas híbridas, y entre éstas se destacan las redes neuronales difusas.
Una red neuronal difusa de este tipo puede verse como la generalización de una red neuronal feedforward convencional, en la que, tanto las cantidades manipuladas (entradas, salidas y pesos de las conexiones), como las operaciones necesarias para realizar la propagación (adición, multiplicación, función sigmoide) son extendidas al dominio de los números difusos mediante el principio de extensión formulado en (Zadeh, 1975), el cual ha sido reformulado de distintas formas (Klimke, 2006), entre otras, resulta sencillo llevar estas operaciones a los números difusos. Sin embargo, dicha extensión no puede realizarse a los métodos de entrenamiento.
Diversos grupos de investigadores han venido desarrollando estrategias de entrenamiento para estas redes, las cuales, en su mayoría, se simplifican las formas de las funciones de pertenencia de los números difusos propagados por la red, o se desarrollan algoritmos aplicables únicamente a ciertas topologías.
En este trabajo, se presentan nuevas estrategias de entrenamiento más generales con respecto a la geometría de los pesos difusos y la arquitectura de la red. Se utiliza la notación barra para denotar un número difuso. Además, se define un α-corte de un número difuso como el conjunto de todos los x que pertenecen al conjunto difuso con, al menos, un grado de pertenencia α
Conclusiones
El uso de pesos crisp es una alternativa que debe ser tenida en cuenta a la hora de modelar la relación presente en un conjunto de datos difusos. El desempeño de esta estrategia se destacó en el problema del sistema de eva-luación difusa del impacto ambiental en vertederos.
La totalidad de las estrategias de entrenamiento planteadas en este proyecto son válidas para redes con cual-quier número de capas ocultas.
El entrenamiento de una ABCWN con pesos crisp mediante algoritmos genéticos con codificación real, puede arrojar resultados similares a los encontrados con BCrisp, en cuanto a la calidad de la aproximación. Sin embargo, el elevado tiempo de cálculo, debido a la gran cantidad de parámetros a ajustar, limita la aplicación de esta estrategia a problemas relativamente pequeños. Este hecho hace dudar de la viabilidad del empleo de alguna técnica similar que considere pesos difusos, puesto que se tendría una cantidad aún mayor de parámetros a ajustar.
Ninguna de las dos estrategias para pesos difusos formuladas (BαFuzzy, BEFuzzy) presentan limitaciones en cuanto a la geometría de los pesos difusos (siempre que sean números difusos).
A pesar de que la estrategia BαFuzzy no maneja una función de error global, sino múltiples funciones de error independientes, mostró tener un comportamiento aceptable en los experimentos realizados, con excepción del problema EDIAV.
La estrategia fundamentada en la retropropagación de un error difuso (BEFuzzy) se obtuvo al extender algunos conceptos del cálculo crisp al dominio de los números difusos.

UIGV59
Las redes con pesos difusos mostraron ser el mecanismo más adecuado para representar la incertidumbre propia de un sistema. Los resultados de este enfoque se destacaron en especial a la hora de aproximar conjuntos de datos con entradas crisp y salidas difusas.
Las estrategias para redes con pesos crisp mostraron los mejores desempeños a la hora de aproximar conjuntos de datos provenientes de funciones extendidas a los números difusos.
Referencias
[1] [Bede, Rudas, & Benscsik, 2007] Bede, B., Rudas, I., & Benscsik, A. (2007). First order linear fuzzy differential equations under generalized differentiability. Information Sciences, 177, 1648-1662.
[2] [Buckley, Czogala, & Hayashi, 2003] Buckley, J., Czogala, E., & Hayashi, Y. (2003). Fuzzy neural networks with fuzzy signals and fuzzy weights. Inter. J. Intelligent Systems, 8, 527-537.
[3] [Buckley, Czogala, & Hayashi, 2008] Buckley, J., Czogala, E., & Hayashi, Y. (2008). Adjusting fuzzy weights in fuzzy neural nets. Second international conference on Knowledge-based intelligent electronic systems.
[4] [Delgadillo, Madrid, & Velez, 2004] Delgadillo, A., Madrid, J., & Velez, J. (2004). Ampliación de UN-genético: Una Librería en C++ de Algoritmos genéticos con Codificación Híbrida. Universidad Nacional de Colombia.
[5] [Duarte, 2005] Duarte, O. (2005). FUZZYNET 1.0 Software Para el Diseño e Implementación de Redes de Sistemas de Computación con Palabras. Universidad Nacional de Colombia.
[6] [Dunyak & Wunsch, 1997] Dunyak, J., & Wunsch, D. (1997). A training technique for fuzzy number neural networks. Proc. of the International Conference on Neural Networks.
[7] [Dunyak & Wunsch, 2000] Dunyak, J., & Wunsch, D. (2000). Fuzzy regression by fuzzy number neural net-works. Fuzzy Sets and Systems, 112, 371-380.
[8] [Ishibuchi & Nii, 2001] Ishibuchi, H., & Nii, M. (2001). Numerical analysis of the learning of fuzzified neural networks from fuzzy if-then rules. Fuzzy Sets and Systems, 120, 281-307.
[9] [Ishibuchi, Okada, & Tanaka, 1993] Ishibuchi, H., Okada, H., & Tanaka, H. (1993). Fuzzy neural networks with fuzzy weights anf fuzzy biases. Proc. of ICNN’93, San Francisco.
[10] [Klimke, 2006] Klimke, A. (2006). Uncertainty Modeling using Fuzzy Arithmetic and Sparse Grids (PhD Tesis). Universitát Stuttgart, Alemania.
[11] [Krishnamraju, Buckley, Hayashi, & Reilly, 2004] Krishnamraju, P., Buckley, J., Hayashi, Y., & Reilly, K. (2004). Genetic learning algorithms for fuzzy neural nets. IEEE World Congress on Computational Intelligence (págs. 26-29).
[12] [Lippe, Feuring, & Mischke, 2006] Lippe, W., Feuring, T., & Mischke, L. (2006). Supervised learning in fuzzy neural networks. Department of Computer Science, University of Munster.
[13] [Riedmiller, 1994] Riedmiller, M. (1994). Rprop-Description and Implementation Details.
[14] [Rumelhart, Hinton, & Willimas, 1986] Rumelhart, D., Hinton, G., & Willimas, R. (1986). Learning representa-tions by back-propagating errors. Nature, 323, 533-536.

UIGV60
[15] [Villarreal, 2008] Villarreal, E. (2008). Estrategias de Entrenamiento para un Red Neuronal Difusa (Tesis de Maestría en Automatización Industrial). Universidad Nacional de Colombia.
[16] [Zadeh, 1975] Zadeh, L. (1975). The Concept of a Linguistic Variable and its Application to Approximate Reasoning. IEEE Trans. Systems, Man, and Cybernet.

UIGV61
Adriano F. Ronszcka1, Danillo L. Belmonte1, Glauber Z. Valença2, Márcio V. Batista1,Robson R. Linhares1,2, Cesar A. Tacla1,2, Paulo C. Stadzisz1,2, Jean M. Simão1,2
Universidade Tecnológica Federal do Paraná - UTFPR1 Programa de Pós-Graduação em Engenharia Elétrica e Informática Industrial - CPGEI2 Programa de Pós-Graduação em Computação Aplicada - PPGCAronszcka, belmontepg, gvalencio, marcio.venancio {@gmail.com}, [email protected], tacla, sta-dzisz, jeansimao {@utfpr.edu.br}
Comparações quantitativas e qualitativas entre o Paradigma Orientado a Objetos e o Paradigma Orientado a Notificações sobre um simulador de jogo
Resumo
Este artigo apresenta uma revisão dos conceitos relacionados ao Paradigma Orientado a Notificações (PON) e uma comparação, qualitativa e quantitativa, de duas versões de uma mesma aplicação. A primeira desenvolvida de acordo com os princípios do Paradigma Orientado a Objetos (POO) e a segunda inclusive de acordo com os princípios do PON. O PON se apresenta como uma alternativa aos Paradigmas de Programação Imperativa (PI), incluindo o POO, e aos Paradigmas de Programação Declarativa (PD), propondo-se a eliminar deficiências destes no que tange a aspectos de redundâncias e acoplamento de avaliações causais que impactam no desempenho e paralelismo/distribuição de aplicações. A comparação apresentada neste artigo abrange particularmente questões relacionadas à implementação e ao desempenho. O experimento demonstra que, embora o desempenho do PON tenha sido um tanto inferior ao do POO para a aplicação desenvolvida, em função de características da aplicação e de um ambiente de execução ainda não totalmente adaptado ao paradigma, existem aspectos relativos à maneira como se concebe os programas em PON que podem ser levados em consideração e incentivar a utilização deste em aplicações com requisitos de paralelismo ou distribuição.
Palavras chave:
Paradigma Orientado a Notificações (PON), Simulador de jogo em POO e PON, Comparações entre POO e PON.
Abstract
This paper presents a review of the concepts related to the Notification-Oriented Paradigm (NOP) and a qualitative and quantitative comparison of two versions of a certain application. The first developed according to the Object-Oriented Paradigm (OOP) principles and the second developed according to the NOP principles. The NOP presents itself as an alternative to the Imperative Programming (IP) paradigms, such as OOP, as well as to the Declarative Progra-mming (DP) paradigms, with the purpose of eliminating deficiencies of those paradigms concerning to redundancy issues and coupling of causal evaluations, which affect the execution performance and parallelism/distribution of applications. The presented comparison includes issues related to implementation and relative performance of the applications. The experiment demonstrates that, even though the NOP performance is somewhat worse than OOP performance for the developed application, due to application characteristics and a runtime environment not com-pletely adapted to NOP, there are some aspects related to the manner with the programs are designed in NOP which can be taken into consideration and encourage the use of NOP on applications requiring parallelism and distribution.
Keywords:
Notification-Oriented Paradigm (NOP), Game simulator in OOP and NOP, Comparisons between OOP and NOP.

UIGV62
Introdução
A capacidade de processamento computacional tem crescido em função da evolução das tecnologias neste contexto [Tanenbaum e Van Steen, 2002]. Entretanto, recursos oferecidos por soluções computacionais modernas, tais como paralelismo e distribuição ou mesmo a utilização da capacidade plena de cada processador, nem sempre são devidamente aproveitados em função de limitações das técnicas de programação [Simão e Stadzisz, 2008, 2009].
Na verdade, técnicas de programação baseadas no estado da arte, como o chamado Paradigma de Progra-mação Orientada a Objetos (POO) ou os Sistemas Baseados em Regras (SBR), sofrem de limitações intrínsecas de seus paradigmas. Estes paradigmas poderiam ser genericamente classificados como Paradigma Imperativo (PI) e Paradigma Declarativo (PD) que englobam respectivamente o POO e os SBR [Banaszewski, 2009].
Particularmente, estes paradigmas levam ao forte acoplamento de expressões causais e redundâncias decorren-tes das suas avaliações. Estas limitações dificultam a execução paralela ou distribuída de programas e frequente-mente comprometem o seu desempenho pleno mesmo em sistemas monoprocessados. Assim, existem motivações para buscas de alternativas aos PI e PD, com o objetivo de eliminar ou diminuir as desvantagens deles [Banaszews-ki et al., 2007][Banaszewski, 2009][Gabbrielli, Martini, 2010][Roy e Haridi, 2004][Simão e Stadzisz, 2008, 2009].
Neste âmbito, uma alternativa é o Paradigma Orientado a Notificações (PON). O PON foi concebido a partir de uma teoria de Controle Discreto e Inferência [Simão, 2001, 2005; Simão e Stadzisz, 2002, 2008, 2009; Simão, Stadzisz e Tacla, 2009; Simão, Stadzisz e Künzle, 2003]. Ele se propõe a eliminar algumas das deficiên-cias dos atuais paradigmas em relação a avaliações causais desnecessárias e acopladas, evitando o processo de inferência monolítico baseado em pesquisas por meio de um mecanismo baseado no relacionamento de entidades computacionais notificantes [Banaszewski et al., 2007][Banaszewski, 2009][Simão e Stadzisz, 2008, 2009].
Neste artigo são apresentados resultados de comparações efetuadas entre uma implementação segundo o POO de um simulador de um jogo similar ao conhecido Pacman1 e outra implementação deste mesmo simulador segundo o PON. A análise dos resultados tem como foco primário os aspectos de desempenho. Não obstante, também é objetivo do artigo refletir sobre a aplicabilidade do PON e as potencialidades em relação ao desenvol-vimento de técnicas e ferramentas voltadas para este paradigma.
Este artigo está organizado como segue: a Seção 2 sucintamente reflete o estado da arte em paradigmas de programação. A Seção 3 apresenta o PON. A Seção 4 apresenta o caso de estudo, com os detalhes de imple-mentação do simulador do jogo. A Seção 5 apresenta a discussão sobre os experimentos. A Seção 6, por fim, apresenta as conclusões e perspectivas de trabalhos.
Conclusões
Apesar dos resultados com a versão do simulador concebido em POO apresentar melhor desempenho do que as versões do simulador concebidas em PON, tais resultados não são suficientes para julgar o POO superior em relação ao PON. Além disso, alguns fatores contribuíram para essa discrepância entre os resultados, tais como a falta de um compilador próprio para o PON, a falta de técnicas concretas de modelagem visando à facilidade de composição de programas neste paradigma e a falta de uma versão do simulador desenvolvida completamente sobre os conceitos do PON.
Conforme citado na Seção 3, o PON atualmente está materializado na forma de um framework/wizard desen-volvido sobre a linguagem C++. Apesar de não ser o cenário ideal, o PON tem sido frequentemente otimizado e com isso, ganhos de desempenho consideráveis vem sendo alcançados. Definitivamente, uma linguagem de programação e um compilador devem ser desenvolvidos para que o PON alcance todo o seu potencial.
1 Os créditos do jogo e seus direitos autorais pertencem ao indivíduo que o produziu ou a empresa que o publicou. A utilização neste trabalho visa apenas o estudo acadêmico, sem fins lucrativos. Portanto, qualquer outro uso para este conteúdo, poderá estar violando os direitos do autor.

UIGV63
Observou-se que a hibridização de paradigmas e, principalmente, a conversão de estruturas de decisão (i.e. ifs) do POO para Rules do PON, não foram suficientes para manter o fluxo de execução dos programas operando de maneira semelhante. Tal fato implicou na criação de Rules adicionais para a coordenação do fluxo de notificações do PON, de maneira a operar de maneira sequencial como no POO.
De fato, esta alternativa se mostrou inviável e indesejável, uma vez que impactou diretamente no desempenho das aplicações. Certamente, o simulador deveria ser totalmente repensado e refeito em PON, partindo da remo-delagem totalmente baseada em notificações, uma vez que a mudança de paradigma implica na mudança no estilo de conceber programas.
Em trabalhos futuros, uma versão completa do simulador, com todas as classes desenvolvidas sobre os princípios do PON, deve ser desenvolvida, possivelmente aplicando técnicas de Inteligência Artificial para a criação auto-mática de regras. Ainda, o simulador apresenta características interessantes que permitem explorar a distribuição ou paralelização dos elementos PON, visando um melhor aproveitamento do processamento dos computadores disponíveis atualmente.
Referências
[1] [Banaszewski et al., 2007] Banaszewski, R. F.; Stadzisz, P. C.; Tacla, C. A.; Simão, J. M. “Notification Oriented Paradigm (NOP): A software development approach based on artificial intelligence concepts,” in Proceedings of the VI Congress of LAPTEC, Santos, Brazil, 2007.
[2] [Banaszewski, 2009] Banaszewski, R. F. “Paradigma Orientado a Notificações: Avanços e Comparações”. Dissertação de Mestrado, CPGEI/UTFPR, Curitiba, 2009. Disponível em: http://arquivos.cpgei.ct.utfpr.edu.br/Ano_2009/dissertacoes/Dissertacao_500_2009.pdf.
[3] [Brookshear, 2006] Brookshear, J. G. “Computer Science: An Overview”. Addison Wesley, 2006.
[4] [Forgy, 1982] Forgy, C. L. “RETE: A Fast Algorithm for the Many Pattern/Many Object Pattern Match Problem”, Artificial Intelligence N. 19, pg 17-37 - North- Holland, 1982.
[5] [Friedman-Hill, 2003] Friedman-Hill, E. Jess in Action: Rule Based System in Java. Greenwich, CT, USA: Man-ning Publications Co, 2003.
[6] [Gabbrielli e Martini, 2010] Gabbrielli, M., Martini, S. “Programming Languages: Principles and Paradigms. Series: Undergraduate Topics in Computer Science”. 1st Edition, 2010, XIX, 440 p., Softcover. ISBN: 978-1-84882-913-8.
[7] [Pittman, 2011] Pittman, J. “The Pac-Man Dossier”. Disponível em: http://home.comcast.net/~jpittman2/pacman/pacmandossier.html. Acessado em: 16 de Junho de 2011.
[8] [Roy e Haridi, 2004] Roy, P, V., Haridi, S. “Concepts, Techniques, and Models of Computer Programming”. MIT Press, 2004.
[9] [Scott, 2000] Scott, M. L. “Programming Language Pragmatics”, 2º Edition, p. 8, San Francisco, CA, USA: Morgan Kaufmann Publishers Inc, 2000.
[10] [Simão, 2001] Simão, J. M. “Proposta de uma Arquitetura de Controle para Sistemas Flexíveis de Manufatura Baseada em Regras e Agentes”. Dissertação de Mestrado, CPGEI/UTFPR, Curitiba, 2001.
[11] [Simão, 2005] Simão, J. M. “A Contribution to the Development of a HMS Simulation Tool and Proposition of a Meta-Model for Holonic Control”. Tese de Doutorado, CPGEI/UTFPR, Curitiba, 2005. Disponível em: http://arquivos.cpgei.ct.utfpr.edu.br/Ano_2005/teses/Tese_012_2005.pdf.

UIGV64
[12] [Simão e Stadzisz, 2002] Simão, J. M.; Stadzisz, P. C. “An Agent-Oriented Inference Engine applied for Su-pervisory Control of Automated Manufacturing Systems”. In: J. Abe & J. Silva Filho, Advances in Logic, Artificial Intelligence and Robotics (Vol. 85, pp. 234-241). Amsterdam, The Netherlands: IOS Press Books, 2002.
[13] [Simão e Stadzisz, 2008] Simão, J. M.; Stadzisz, P. C. “Paradigma Orientado a Notificações (PON) – Uma Técnica de Composição e Execução de Software Orientado a Notificações”. Pedido de Patente submetida ao INPI/Brazil (Instituto Nacional de Propriedade Industrial) em 2008 e a Agência de Inovação/UTFPR em 2007. Nº INPI Provisório 015080004262. Nº INPI Efetivo PI0805518-1. Patente submetida ao INPI. Brasil, 2008.
[14] [Simão e Stadzisz, 2009] Simão, J. M.; Stadzisz, P. C. “Inference Process Based on Notifications: The Ker-nel of a Holonic Inference Meta-Model Applied to Control Issues”. IEEE Transactions on Systems, Man and Cybernetics. Part A, Systems and Humans, Vol. 39, Issue 1, 238-250, Digital Object Identifier 10.1109/TSMCA.2008.20066371, 2009.
[15] [Simão, Stadzisz e Künzle, 2003] Simão, J. M.; Stadzisz, P. C.; Künzle, L. “Rule and Agent-oriented Architec-ture to Discrete Control Applied as Petri Net Player”. 4th Congress of Logic Applied to Technology, LAPTEC, 101, p. 217, 2003.
[16] [Simão, Stadzisz e Tacla, 2009] Simão, J. M., Stadzisz, P. C.; Tacla, C. A. “Holonic Control Meta-Model”. IEEE Transactions on Systems, Man and Cybernetics. Part A, Systems and Humans, Vol. 39, NO 5, September 2009. Pg. 1126-1139.
[17] [Tanenbaum e Van Steen, 2002] Tanenbaum, A.S.; Van Steen, M. “Distributed Systems: Principles and Para-digms”, Prentice Hall, 2002.

UIGV65
Ana Maria Pereira1, Paulo Cézar Stadzisz1, Jean Marcelo Simão1
Universidade Tecnológica Federal do Paraná1 Programa de Pós-graduação em Engenharia Elétrica e Informática Industrial (CPGEI)[email protected], [email protected], [email protected]
Proposta de uma Abordagem para Especificação de Requisitos Baseada em Projeto Axiomático
Resumo
Desde as primeiras décadas do surgimento da informática são identificados problemas relativos à definição de re-quisitos de sistemas de software. Entender o que o cliente espera de um sistema de software é uma das tarefas mais difíceis enfrentadas pelos analistas de negócios e requisitos. Com o objetivo de contornar este problema, foram cria-das diversas técnicas de especificação de requisitos, como especificações textuais, casos de uso, etc. Apesar destas técnicas oferecerem resultados promissores na descrição dos requisitos, elas falham na cobertura das necessidades do cliente. Sendo assim, o uso de um método focado no detalhamento e avaliação dos problemas resultaria em um software mais contundentes com as necessidades levantadas. Neste contexto, este trabalho apresenta uma proposta de abordagem para a especificação de requisitos baseada em Projeto Axiomático. Este método consiste de três pas-sos: (1) o mapaemento de problemas, necessidades e requisitos em uma matriz de rastreabilidade, (2) avaliação da matriz segundo o Axioma da Independência e, por fim, (3) a decomposição dos problemas, necessidades e requisitos. Estes passos são repetidos ciclicamente até que se atinja um nível de detalhamento satisfatório. Os resultados dos experimentos atestaram que este método oferece auxílio na elaboração de um conjunto de requisitos de sistema mais consistente.
Palavras chave:
Requisitos, Necessidades do Cliente, Problema, Projeto Axiomático, Matriz de Rastreabilidade
Abstract
Since the early decades of the rise of computer science it has been identified problems on the definition of requi-rements for software systems. Understanding what the customer expects from a software system is one of the hardest tasks faced by business analysts and requirements. In order to overcome this problem, have been created several techniques for requirements specification, such as textual specifications, use cases, etc. Although these techniques offer promising results in the description of requirements, they fail to cover the needs of the client. Therefore, the use of a method focused in detailing and evaluating of the problems can result in software more coherent with the client needs. In this context, this paper presents a proposed approach to requirements specification based on axiomatic design. This method consists of three steps: (1) mapping the problems, needs and requirements through a traceability matrix, (2) evaluating the matrix according to the Axiom of Independence and, finally, (3) decomposing problems, needs and requirements. These steps are cyclically repeated until it reaches a satisfactory level of detail. The results of experiments testified that this method offers good results in preparing a more consistent set of system requirements.
Keywords:
Requirements, Client Needs, Problem, Axiomatic Design, Traceability Matrix

UIGV66
Introdução
Desde as primeiras décadas do surgimento da informática identificaram-se problemas relativos à elaboração e desenvolvimento de projetos de software. Logo no início dos anos 70 foi criado o termo “Crise de Software” para expressar as dificuldades enfrentadas pelos desenvolvedores na elaboração de seus projetos (DIJKSTRA, 1972). Naquela época, a engenharia de software era quase que inexistente e os problemas mais comuns costumavam ser: estouro no orçamento ou no prazo; baixa qualidade dos projetos; produtos que muitas vezes não atendiam os requisitos; e códigos difíceis de manter. Nos dias atuais, embora muitos avanços tenham sido realizados na área da engenharia de software, os problemas parecem continuar sendo os mesmos. Estatísticas apresentadas pelo Chaos Report 2009 (DOMINGUEZ, 2009) demonstram que os projetos de software têm percentuais de sucesso que giram em torno de apenas 30% como apresenta a Tabela 1. Além disso, estudos relacionados à Engenharia de Software apontam fortes evidências de que os mais sérios problemas de projetos estão diretamente relacionados à definição e entendimento de requisitos (LEFFINGWELL & WIDRIG, 2003).
Neste contexto, pode-se afirmar que um dos principais desafios de um projeto de software está em especificar e construir um produto que garanta a satisfação das necessidades do cliente com alta qualidade e dentro dos prazos e custos estimados. Tendo em vista esse desafio de atender as necessidades do cliente, procura-se garantir que todas elas sejam atendidas por meio da especificação e rastreamento de requisitos. Ao bem da verdade, a maioria das abordagens de especificação de requisitos foca na solução. Entretanto, ainda assim, uma grande parte dos projetos não tem o resultado esperado.
Distribuição de resultados de projetos de softwarePercentual Resultados32% Sucesso (no prazo, dentro do orçamento e com escopo completo) 44% Mudaram (atrasaram, estourou o orçamento, e/ou reduziram escopo) 24% Falharam (cancelados ou nunca usados)
Tabela 1 Distribuição de resultados de projetos – Adaptado de (DOMINGUEZ, 2009)
Estudando-se os trabalhos de inúmeros autores é possível perceber que boa parte deles trata superficialmente os termos “problema” e “necessidade do cliente”, como é possível observar em (LEFFINGWELL & WIDRIG, 2003), (SUH & DO, 2000) e (BALMELLI, 2007) somente para citar alguns exemplos. Por outro lado, observa-se que o claro entendimento dos problemas e necessidades do cliente costuma ser um ponto chave para o desenvolvimento da especificação de requisitos de software. Por esta razão, um dos principais objetivos deste trabalho foi estudar mais atentamente os Problemas e as Necessidades dos clientes e seu mapeamento para requisitos de software.
Outro objetivo desta pesquisa foi estudar e demonstrar a aplicabilidade do Axioma da Independência proposto por Suh (SUH, 2001) às atividade de análise do problema e especificação der requisitos de software por meio de matrizes de rastreabilidade. A abordagem proposta pretende oferecer aos engenheiros de requisitos um método eficaz para diminuir as dificuldades em compreender e modelar os requisitos do sistema que deve ser construído. Assim sendo, o objetivo principal desse artigo é propor uma abordagem de especificação baseada no Axioma da Independência da Teoria de Projeto Axiomático.
O restante deste artigo está organizado da seguinte maneira. Na seção 2 apresentam-se alguns trabalhos anteriores, tanto relacionados ao tema de Projeto Axiomático como de especificação de requisitos. Na seção 3 trata-se da abordagem proposta de especificação de requisitos baseada em Projeto Axiomático. A seção 4 apre-senta a metodologia utilizada nos experimentos realizados e traz um exemplo da aplicação desta abordagem. As discussões referentes aos resultados obtidos nos experimentos encontram-se na seção 5 e, finalmente, na seção 6 apresenta-se uma breve conclusão do trabalho.

UIGV67
Conclusões
Este trabalho apresenta uma abordagem de especificação de requisitos de sistemas de software baseada na Teoria de Projeto Axiomático, que pode ser aplicada em conjunto com um processo de desenvolvimento de soft-ware como o Processo Unificado, abordagem proposta provê um modelo para auxiliar os analistas de negócios e requisitos na definição dos requisitos adequados para o projeto. O entendimento do negócio do cliente, bem como de seus problemas, e a identificação dos requisitos corretos contribuem para a realização de um bom projeto.
Foi possível concluir, durante esta pesquisa, que o detalhamento dos problemas e/ou desejos que levam o clien-te a tomar a decisão de adquirir um produto permite que os Engenheiros de Sistemas tenham uma visão ampliada do contexto em que a solução deverá se inserir e, desta maneira, possam propor soluções alternativas. É possível que estas soluções sejam até mais eficientes do que aquelas imaginadas pelo cliente através das características e necessidades apontadas por ele. Ou seja, buscar conhecer os problemas do cliente, sem se prender as necessida-des ou características citadas por ele, ajuda a equipe de engenharia de requisitos a encontrar soluções inovadoras ou melhor fundamentadas para o problema.
Outra conclusão importante deste trabalho é que a estrutura formada pela decomposição entre os diversos domí-nios pode ser triangular. Isso quer dizer que o número de necessidades pode ser maior que o número de problemas assim como o número de requisitos pode ser maior que o número de necessidades. O importante é, que até de-terminado nível de decomposição, exista uma correspondência no número de itens de cada domínio. A partir do momento em que o número de itens de um domínio não puder mais ser detalhado deixa-se de utilizar a matriz entre estes domínios e passa-se a fazer o mapeamento apenas dos outros domínios que ainda podem ser detalhados.
A respeito do mapeamento de elementos de dois domínios em uma matriz, com objetivo de avaliá-la do ponto de vista do Axioma da Independência, concluiu-se que essa atividade pode auxiliar na identificação de inconsis-tências na interpretação dos elementos de cada domínio. Eventualmente, essa análise pode ajudar a identificar elementos que estão faltando ou sobrando e assim levar a melhorias na matriz e, consequentemente, no projeto. A utilização da matriz de projeto para o mapeamento entre os diversos domínios ajuda a manter a consistência e a rastreabilidade de problemas, necessidades, requisitos e elementos de arquitetura do sistema. Embora este trabal-ho tenha trazido algumas conclusões importantes, o tema de Especificação de Requisitos é bastante complexo e trabalhos futuros certamente poderão trazer novos avanços que irão agregar ainda mais conhecimento a respeito deste assunto.
Referências
[1] BALMELLI, L. (2007). An Overview of the Systems Modeling Language for Products and Systems Development. Journal of Object Technology , 6, pp. 149-177.
[2] BOOCH, G., RUMBAUGH, J., & JACOBSON, I. (2006). UML – Guia do Usuário (2 ed.).
[3] CARVER, C. S., & SCHEIER, M. F. (2007). Perspectives on Personality. Boston: Allyn and Bacon.
[4] DIJKSTRA, E. W. (Oct de 1972). The humble programmer. ACM , 859–866.
[5] DOMINGUEZ, J. (2009). Acesso em 14 de Junho de 2010, disponível em ProjectSmart: http://www.proj-ectsmart.co.uk/pdf/the-curious-case-of-the-chaos-report-2009.pdf
[6] DORFMAN, M., & THAYER, R. H. (1990). Standards, Guidelines, and Examples on System and Software Requirements Engineering. IEEE Computer Society Press.
[7] JACKSON, M. (1995). Problems & Requirements. Proceedings of the IEEE Second International Symposium on Requirements Engineering (pp. 2-8). ACM Press.

UIGV68
[8] KIM, S. J., SUH, N. P., & KIM, S. K. (1992). Design of software systems based on axiomatic design. Anais do CIRP General Assembly .
[9] LEE, T., & JEZIOREK, P. N. (2006). Understanding the Value of Eliminating An Off-Diagonal Term in a Design Matrix. Proceedings of ICAD 2006. Firenze.
[10] LEFFINGWELL, D., & WIDRIG, D. (2003). Managing Software Requirements. Boston: Addison Wesley.
[11] LI, Z. (2007). Progressing Problems from Requirements to Specifications in Problem Frames. London, United Kingdom: Department of Computing - The Open University.
[12] PIMENTEL, A. R. (2007). Uma abordagem para projeto de software orientado a objetos baseado na teoria de projeto axiomático. Curitiba-PR: UTFPR.
[13] SUH, N. P. (2001). Axiomatic Design: advances and applications. New York, EUA: Oxford University Press.
[14] SUH, N. P. (1990). The Principles of Desgin. New York: Oxford University Press.
[15] SUH, N. P., & DO, S. H. (2000). Axiomatic design of software systems. CIRP annals. Sidney, Australia.

UIGV69
Sistema Inteligente de Diagnóstico de Anemia Ferropénica basado en Redes Neuronales Artificiales
Edinson Muñoz(1), Jorge Espinoza(1), Luis Rivera(2)
(1) Facultad de Ingeniería de Sistemas e InformáticaUniversidad Nacional Mayor de San MarcosAv. Germán Amézaga s/n, Ciudad Universitaria, Lima 01, Perú{edinsonmunoz, jorluis841}@gmail.com
(2) Laboratorio de Ciências Matemáticas - LCMATUniversidade Estadual do Norte Fluminense – UENFAv. Alberto Lamego, 2000, CEP 28013-602, Campos dos Goytacazes, RJ, [email protected]
Resumen
Los médicos confunden en identificar los tipos de anemias con otras enfermedades, generando errores irreversi-bles en muchos de los casos. Frente a esto, se plantea un sistema inteligente basado en Redes Neuronales Artificiales para el Diagnóstico de Anemia Ferropénica y sus similares Megaloblástica y Hemolítica, dado que sus síntomas y factores en fases iniciales son parecidos, que permita auxiliar al profesional de salud tomar acciones adecuadas. Para ese propósito se establece una metodología propia, con la adecuación de la arquitectura clásica de un sistema exper-to a una basada en redes neuronales. Como resultado se obtiene un 99% de certeza en los diagnósticos realizados durante la evaluación del sistema.
Palabras clave:
Red neuronal artificial, anemia ferropénica, sistema inteligente, sistema experto.
Abstract
Doctors mistake in identifying the types of anemias with other diseases, resulting in many cases irreversible cases. Against this, there is an intelligent system based on Artificial Neural Networks for Diagnosis of iron deficiency anemia and megaloblastic and hemolytic similar, since their symptoms and factors in the early stages are similar, allowing the health professional assistant to take appropriate action. For this purpose a methodology of its own, adapting the classical architecture of an expert system to one based on neural networks. The result is a 99% certainty in diagnoses made during the appraisal.
Keywords:
Artificial neural network, iron deficiency anemia, smart, expert system.
Introducción
Los diagnósticos de la situación alimentaria y nutricional de Perú, realizada por el Ministerio de Salud - Instituto Nacional de Medicina Tropical, y a las Encuestas Demográfica y de Salud Familiar ENDES (2000, 2005 y 2009) [MINSA00], demuestran, en los primeros años, un aumento acelerado de anemia, en particular la ferropénica, y en los últimos años una pequeña disminución. Ese comportamiento se observa en la población infantil de las zonas urbano-marginales.

UIGV70
Existen varios tipos de anemias, como la ferropénica, la megaloblástica, la hemolítica, la anemia por deficiencia de folato, etc. [PFRSCH99], que afectan a la gente de bajos recursos económicos. Muchas veces, las similitudes de síntomas que generan algunos de esos tipos, o sus mutaciones, inducen a los médicos a diagnosticar el mal en forma errada, y como tal dando tratamiento no adecuado del paciente. A eso se suma la desnutrición, que es más pronunciada en las zonas rurales, en particular en el interior del país donde la atención oportuna es bastante deficiente por falta de especialistas médicos y falta de infraestructuras adecuadas. Ese panorama que ocurre en Perú es solo un ejemplo de los casos complejos que se dan en muchos otros Estados no desarrollados del planeta.
En este trabajo, se plantea una alternativa tecnológica computacional de diagnóstico de la anemia ferropénica, incluyendo las anemias megaloblástica y hemolítica dado sus similitudes de síntomas en fases iniciales de las en-fermedades. Esta alternativa tecnológica es un sistema de diagnóstico que servirá de apoyo y consulta al médico para obtener un diagnóstico oportuno, con un porcentaje aceptable de certeza.
El resto del documento está organizado de la siguiente forma: La Sección 2 presenta la anemia ferropénica y sus variantes desde el punto de vista de su uso para el modelado del sistema inteligente. La Sección 3 presenta la estructura de sistemas inteligentes y su relación con redes neuronales. La Sección 4 aborda el modelado de sistema inteligente para diagnóstico de anemias ferropénicas. En la Sección 5, se validan los resultados para que, finalmente, en la Sección 6, concluir e incluir trabajos futuros.
Conclusiones
La anemia ferropénica es una de las más comunes en nuestra realidad, siendo los más afectados los niños debido a los efectos irreversibles que les ocasiona. Se consideraron en este trabajo las anemias megaloblástica y hemolítica debido a que los síntomas de éstas, en fases iniciales, son similares y además también son anemias que aquejan a la población en menores grados. Este sistema construido tiene un certeza de 99% en sus resultados, con ello se logra la confianza del usuario necesario para este tipo de sistemas, así como también un tratamiento de acuerdo con la anemia diagnosticada y de sus factores activados. Esto se ha obtenido gracias a los casos registra-dos anteriormente de pacientes que padecen estas enfermedades y que sirvieron de experiencia para el sistema, con lo cual se logró el aprendizaje para poder diagnosticar las anemias. Cabe recalcar que mientras más casos se tengan para entrenar las redes, mejores resultados se obtendrán.
También podemos mencionar que el sistema sólo diagnostica las anemias Ferropénica, Megaloblástica y He-molítica, ya que para lograr ello es necesario saber los estados de los 27 factores o características relevantes para detectar dichas enfermedades.
Como trabajos futuros, podemos mencionar que aún queda poder realizar un sistema de diagnóstico de los diferentes tipos de anemias que existen, poder unificarlos y que trabajen en forma conjunta. Debido a que cada anemia cuenta con diferentes números de características a la hora de tomar un diagnóstico, lo cual implicaría dife-rentes redes que trabajen en forma colaborativa.
Referencias
[1] [BARBKLEI+01] Barbosa, L.; Kleisinger, G.; Valdez, A; Monzón, J. Utilización del Modelo de Kohonen y del Perceptrón Multicapa para detectar arritmias cardiacas. Congreso Latinoamericano de Ingeniería Biomédica, 2001, La Habana – Cuba.
[2] [CARDGUAD+05]. Dr. Cardozo Zepeda, Carlos M.; Dr. Guadarrama Quijada, Francisco; Dr. Reyes Corona, Jesús; Dra. Fernández Capistrán, Rosamelia; Dra. Becerra, Dora M.; Dr. Hernández, Manuel Adolfo; Dr. Lázaro León, Miguel; Dr. Martínez Sánchez, Jesús. Entrenamiento prospectivo y prueba de una red neuronal artificial diagnóstico en el dolor abdominal agudo en un servicio de urgencias. Revista de la Asociación Mexi-cana de Medicina Crítica y Terapia Intensiva, Volumen XIV, Nro. 5, 2005, México D.F.

UIGV71
[3] [CARLOS02] Carlos Soto, Marlene. Sistema Experto para el Diagnóstico Médico del Síndrome de Guil-lian Barre. Tesis para obtener el Título de Licenciado en Computación, Facultad de Ciencias Matemáticas, UNMSM, Lima – Perú, 2002.
[4] [FISTERRA09] Guias Clinicas: Anemia Ferropénica. Atención Primaria en la Red, disponible en http://www.fisterra.com/guias2/aFerropénica.asp#algoritmo, accesado en Sep - 2009.
[5] [GIARRATANO01] Giarratano Riley. Sistema Experto Principios y Programación, 3ra. Edición, México, 2001
[6] [INEI09] Instituto Nacional de Estadística e Informática. Perú – Encuesta Demográfica y de Salud Familiar ENDES Continua: 2009, Visión Nacional y Departamental Lima – Perú, 2009.
[7] [MINSA00] Ministerio de Salud – Instituto Nacional de Medicina Tropical. Diagnóstico de la Situación Ali-mentaria y Nutricional del Perú. Programa Nutricional de Apoyo, Principales Indicadores y Factores Condicio-nales, Lima – Perú, 2000.
[8] [MUÑOZESPINOZA11] Muñoz, Edison y Espinoza, Jorge. Sistema Inteligente de Diagnóstico de Anemia Ferropénica basado en Redes Neuronales Artificiales. Tesis de Título, Facultad de Ingeniería de Sistemas e Informática, UNMSM, Lima-Perú, 2011 (a defenderse en octubre).
[9] [PAJLIZORIH+99] Pajuelo, J.; Lizarzaburu, P; Orihuela, P; Acevedo, M. Aportes al estudio del crecimiento de los niños en el Perú. Tesis de Título, Facultad de Farmacia y Bioquímica, UNMSM, Lima - Perú, 1999.
[10] [PFRSCH99] Pfreundschuh M; Schölmerich J. Fisiopatología y Bioquímica. Ediciones Harcourt S.A., Madrid – España, 1999.
[11] [SALCEDO02] Salcedo Girón, Pablo Edwin. Sistema Experto para el Diagnóstico de Enfermedades: Epilep-sias y Crisis Epilépticas. Tesis de Título. Facultad de Ingeniería de Sistemas e Informática, UNMSM, Lima – Perú, 2002.
[12] [SORIBLAN01] Soria, Emilio; Blanco, Antonio. Redes Neuronales Artificiales. Autores Científico-Técnicos y Académicos, España, 2001.

UIGV72

UIGV73
Álvaro Rocha1, José Avelino Victor2, Patrícia Leite Brandão3
1 Universidade Fernando Pessoa, Porto, Portugal2 Instituto Superior da Maia, Maia, Portugal3 Instituto Politécnico do Cávado e do Ave, Barcelos, [email protected], [email protected], [email protected]
Modelo Tridimensional para a Qualidade de Sítios Web
Resumo
A qualidade de sítios Web é de importância estratégica para as organizações e para a satisfação dos seus clientes. Neste artigo propomos uma estrutura de alto nível inovadora para a qualidade global de um sítio Web. Essa estrutura assenta em três dimensões principais (conteúdos, serviços, técnica), características, sub-características e atributos, que potenciarão o desenvolvimento de metodologias abrangentes de avaliação, comparação e melhoria da qualidade de sítios Web, alinhadas com sectores de actividade específicos.
Palavras chave:
Qualidade de Sítios Web, qualidade de serviços, qualidade técnica.
Abstract
Websites quality is strategically important for organizations and for the satisfaction of their clients. In this paper we propose an innovative high-level structure for a global quality evaluation of a website. This structure is based in three main dimensions (contents, services, technical), characteristics, sub-characteristics and attributes, that will substantiate the development of broad websites quality evaluation, comparison and improvement methodologies, according to particular sectors of activity.
Keywords:
Quality of Web sites, service quality, technical quality.
Introdução
Com a proliferação de sítios Web e investimentos efectuados nos mesmos, a avaliação da qualidade de sítios Web tem-se tornado uma actividade importante [23]. As organizações investem tempo e dinheiro para desenvolve-rem e manterem a qualidade dos seus sítios Web. Estes sítios Web devem proporcionar um canal efectivo de infor-mação e comunicação entre as organizações e os seus clientes. Nalguns casos, são parte do produto oferecido, disponibilizando serviços úteis aos clientes [7].
Obviamente que um sítio Web deve reflectir claramente os esforços de qualidade levados a cabo por uma organização, uma vez que é uma parte importante da ligação com os clientes. Os sítios Web modernos apre-sentam uma variedade significativa de características, complexidade de estrutura e pluralidade de serviços ofe-recidos [17]. Como no caso de todos os sistemas de informação, a avaliação de sítios Web é um aspecto do seu desenvolvimento e operação que pode contribuir para o aumento da satisfação dos utilizadores [7] e para a maximização dos recursos investidos [6].

UIGV74
Com esta investigação pretendemos propor uma estrutura de alto nível para avaliação da qualidade global de um sítio Web. Essa estrutura poderá servir de base ao desenvolvimento de metodologias específicas de avaliação, comparação e melhoria da qualidade de sítios Web, para diferentes sectores de actividade. Assim, nas próximas secções introduzimos o conceito de qualidade, propomos três dimensões principais para a qualidade de sítios Web e identificamos as formas de avaliar a qualidade em cada uma destas dimensões, apresentamos a proposta de estrutura para avaliação da qualidade global de um sítio Web e, por último, elencamos algumas conclusões.
Conclusão
Com este artigo pretendemos apresentar uma proposta de estrutura de alto nível inovadora para avaliação da qualidade global de um sítio Web. Como conclusão alguns aspectos poderão ser salientados:
a) A qualidade de sítios Web é de importância estratégica para as organizações e para a satisfação dos seus clientes;
b) A qualidade de sítios Web deve assentar na medição da qualidade de três dimensões principais: conteúdos, serviços e técnica;
c) Uma estrutura assente nestas três dimensões, características, sub-características e atributos potenciará uma avaliação transversal, integrada e pormenorizada da qualidade de um sítio Web;
d) Uma boa metodologia de avaliação, comparação e melhoria da qualidade de sítios Web deve integrar adequadamente as três dimensões de qualidade consideradas e proporcionar a possibilidade de adap-tação ao sector de actividade visado.
O próximo passo da nossa investigação consistirá no desenvolvimento de uma metodologia de avaliação, comparação e melhoria da qualidade de sítios Web institucionais de hospitais, baseada na estrutura de alto nível proposta neste artigo, e será construída e validada com a ajuda de peritos em Engenharia Web e utilizadores de sítios Web hospitalares. A necessidade desta metodologia justifica-se pelo facto de não conhecermos nenhuma que proporcione uma avaliação abrangente e pormenorizada, integrando as três dimensões principais de um sítio Web: conteúdos, serviços e técnica.
Referências
[1] Al-Momani, K. & Noor, N. (2009). E- Service Quality, Ease of Use, Usability and Enjoyment as Antecedents of E-CRM Performance: An Empirical Investigation in Jordan Mobile Phone Services. The Asian Journal of Technol-ogy Management, 2, 2, 2009, 11-25.
[2] Arshad, N., Ahmad, F. & Janom, N. (2007). Empirical Study on Electronic Service Quality. Public Sector ICT Management Review, 2, 1, pp. 29-37.
[3] Bernstam, E. V., Shelton, D., Walji, M., Meric-Bernstam, F. (2005). Instruments to assess the quality of health information on the World Wide Web: What can our patients actually use? International Journal of Medical Informatics, 74, pp. 13-19.
[4] Caro, A., Calero, C., Caballero, I., Piattini, M. (2008). A proposal for a set of attributes relevant for Web portal data quality. Software Quality Journal. 16, pp. 513-542.
[5] Cernea, S.O., Sîrbu J. & Mărginean, N. (2009). Determination of Users Satisfaction Level Regarding the Quality of E-Services Provided by Bogdan-Voda University. Annales Universitatis Apulensis Series Oeconomica, 11, 2, pp. 652-661.

UIGV75
[6] Cheung, C and Lee, M. (2008), The Structure of Web-Based Information Systems Satisfaction: Testing of Compet-ing Models. Journal of the American Society for Information Science and Technology, 59, 10, pp. 1617-1630.
[7] Grigoroudis, E., Litos, C., Moustakis, V., Politis, Y. and Tsironis, L. (2008), The assessment of user-perceived web quality: Application of a satisfaction benchmarking approach, European Journal of Operational Research, Vol. 187, No. 3, pp. 1346-1357,
[8] Hamadi, C. (2010). The Impact of Quality of Online Banking on Customer Commitment, Communications of the IBIMA, Vol. 2010, pp. 1-8.
[9] Hargrave, D.R., Hargrave, U.A. and Bouffet, E. (2006). Quality of health information on the Internet, Neuro-Oncology, 8, pp. 175–182.
[10] Hinchliffe, A. and Mummery, W.K. (2008). Applying usability testing techniques to improve a health promotion website, Health Promotion Journal of Australia, 19 (1), pp. 29-35.
[11] Ho-Won, J. Seung-Gweon, K. and Chang-Shin Chung (2004). Measuring Software Product Quality: A Survey of ISO/IEC 9126, IEEE Software, Vol. 21, nº.5, pp. 88-92
[12] ISO/IEC (2011). ISO/IEC 25010:2011, Systems and software engineering -- Systems and software Quality Requirements and Evaluation (SQuaRE) -- System and software quality models, International Organization for Standardization.
[13] ISO/IEC (2008). ISO/IEC 25012:2008, Software engineering -- Software product Quality Requirements and Evaluation (SQuaRE) -- Data quality model. International Organization for Standardization.
[14] ISO/IEC (2001). ISO 9126-1:2001, Software engineering -- Product quality -- Part 1: Quality model. Interna-tional Organization for Standardization.
[15] ISO/IEC (1998). ISO 9241-11:1998 - Ergonomic requirements for office work with visual display terminals (VDTs) -- Part 11: Guidance on usability. International Organization for Standardization.
[16] ISO/IEC. (2005). ISO/IEC 25000: Software Engineering -- Software product Quality Requirements and Evaluation (SQuaRE) -- Guide to SQuaRE. International Organization for Standardization.
[17] Kappel, G., Proll, B., Reich, S. and Retschitzegger, W. (2006), Web Engineering: The Discipline of Systematic Development of Web Applications, Wiley.
[18] Li, H. and Suomi, R. (2007) Evaluating Electronic Service Quality: A Transaction Process Based Evaluation Model. In Remenyi, Dan (editor) Proceedings of ECIME 2007 The European Conference on Information Man-agement and Evaluation. Montpellier, France, 20-21 September 2007, 331-340. ISBN 9781905305551.
[19] Li, H. and Suomi, R. (2009). A Proposed Scale for Measuring E-service Quality, International Journal of u- and e-Service, Science and Technology, 2, 1, 1-10.
[20] Machado, R. e Rocha, A. (2008). Avaliação da Qualidade de Sítios Web Institucionais: Aplicação de Métrica às Faculdades de Medicina do Espaço Ibérico. Revista da Faculdade de Ciência e Tecnologia da Universidade Fernando Pessoa, Nº. 3, pp. 76-87. ISSN: 1646-0502.
[21] Mich, L., Franch, M. and Gaio, L. (2003). Evaluating and Designing Web Site Quality. IEEE Multimedia, 10, 1, pp. 34-43.
[22] Moraga, C. Moraga, M.A., Caro, A. & Calero, C. (2009). SPDQM: SQuaRE-Aligned Portal Data Quality Model, Proceedings of 2009 Ninth International Conference on Quality Software, Jeju, Korea, August 24-Au-gust 25, 2009, pp. 117-122, ISBN: 978-0-7695-3828-0.

UIGV76
[23] Naik, K. & Tripathy, P. (2008). Software Testing and Quality Assurance. Wiley.
[24] Obeso, M. (2004). Metodología de Medición y Evaluación de la Usabilidad en Sitios Web Educativos. Tesis Doctoral. Universidad de Oviedo.
[25] Olsina, L. (2000). Metodología Cuantitativa para la Evaluación y Comparación de la Calidad de Sitios Web. Tesis Doctoral. Universidad Nacional de La Plata, Argentina.
[26] Parker, M. B., Moleshe, V., De la Harpe, R. & Wills, G. B. (2006). An evaluation of Information quality frame-works for the World Wide Web. In: 8th Annual Conference on WWW Applications, 6-8th September 2006, Bloemfontein, Free State Province, South Africa.
[27] Parasuraman, A., Valarie A. Zeithaml, and Arvind Malhotra (2005). E-S-QUAL a multiple-item scale for assess-ing electronic service quality. Journal of Service Research, 7, 213–233.
[28] Reis, T. (2004). REQE - Uma Metodologia para Medição de Qualidade de Aplicações Web na Fase de Requisitos. Dissertação de Mestrado, Universidade de Pernambuco, Brasil.
[29] Richard JL, Schuldiner S, Jourdan N, Daurès JP, Vannerau D, Rodier M, Lavit P. (2007). The Internet and the diabetic foot: quality of online information in French language. Diabetes & Metabolism, 33, 3: 197-204.
[30] Rocha, A. and Victor, A. (2010). Quality of Hotel Websites - Proposal for Development of an Assessment Methodology. TOURISMOS - An International Multidisciplinary Journal of Tourism, 5, 1: 173-178.
[31] Zhao, P. (2005). Relationship between Online Service Quality and Customer Satisfaction: A Study in Internet Banking. Master Thesis, Luleå University of Technology, Sweden.

UIGV77
María Ortega1, Sergio Sánchez 2
1 Universidad Tecnológica de Panamá2 Universidad Politécnica de [email protected], [email protected]
Autenticación basada en Java card y en certificado X.509 para ambientes universitarios
Resumen
Este artículo presenta la tecnología Java Card y los certificados X.509 como métodos de autenticación en aplicacio-nes web en ambientes universitarios, en el caso concreto la Universidad Tecnológica de Panamá (UTP). La solución consiste en mejorar el escenario de acceso a los servicios de la UTP tratando de extender el uso de la Infraestructura de Clave Pública, llevando a cabo la integración de estas tecnologías que aporten mayor seguridad a todos los usua-rios y que gocen de un acceso a los servicios ofrecidos de manera flexible, segura y garantizando la autenticidad, confidencialidad, integridad y no repudio.
Palabras claves:
Autenticación, certificados X.509, tarjeta java.
Abstract
This paper presents the Java Card technology and X.509 certificates as authentication method in web applications in university settings in the specific case the Technological University of Panama (UTP). The solution is to improve the access scenario UTP services trying to extend the use of public key infrastructure, carrying out the integration of these technologies to provide greater certainty for all users and an access services offered in a flexible, secure, ensuring the authenticity, confidentiality, integrity and non repudiation.
Keywords:
Authentication, X.509 certificates, java card.
Introducción
Existen diversos mecanismos de protección de la información que aseguran el cumplimiento de las medidas de seguridad establecidas para el acceso y la utilización de dicha información [Bauer, 2010; Hurtado, 2009]. La au-tenticación es uno de esos mecanismos y se basa en la identificación de usuarios, es decir, en el proceso mediante el cual se comprueba la identidad de una persona o entidad en base a un conjunto de características [Chávez, 2006].
Atendiendo a qué tipo de características utilizan los sistemas de autenticación para identificar al usuario, se pueden clasificar, de forma genérica, en cuatro tipos: los basados en algo que la entidad sabe, los basados en algo que la entidad hace, los basados en algo que la entidad posee y los basados en algo que la entidad es [Hildebrandt et al. 2005; Carracedo, 2004]. Por lo tanto, los sistemas de autenticación comprenden procesos tan simples como el empleo de parejas usuario/contraseña o tan complejos como el análisis de patrones biométricos.

UIGV78
Con los avances tecnológicos y el mayor poder de proceso de los ordenadores actuales, se da la necesidad de incrementar la seguridad en los procesos de autenticación e incorporar nuevas tecnologías que aumenten y proporcionen un mayor nivel de seguridad. Diversas instituciones cuentan con sistemas de autenticación para el acceso a datos y aplicaciones de autenticación caracterizadas por el uso de usuario/contraseña [Vatra, 2010], denominado acceso clásico, que presentan el problema de que pueden ser fácilmente vulnerados con la tecnolo-gía actual, reduciendo la seguridad de las aplicaciones. Sin embargo, existen otras instituciones que han decidido contar con tecnología más segura a la hora de proteger el acceso a las aplicaciones e información [Díaz et al., 2001; Watts et al., 2010; Harn and Ren, 2011; Watts, J. et al., 2010].
En el caso del estudio concreto abordado en este artículo, el de la Universidad Tecnológica de Panamá (UTP), ésta cuenta con una Infraestructura de Clave Pública (PKI) [Vatra, 2010] utilizada solo por profesores para el registro de calificaciones y por administrativos para la evaluación anual, pero que no está disponible, actualmente, a todos los miembros de la comunidad universitaria.
El objetivo de este trabajo es tratar de mejorar el escenario de acceso a los servicios en la UTP tratando de ex-tender el uso de la PKI [Elfadil and Al-raisi, 2008] y llevando a cabo una integración de tecnologías que aporten mayor seguridad a todos los usuarios (profesores, administrativos y estudiantes) y que garanticen un acceso a los servicios ofrecidos, flexible, seguro y con garantías.
En un entorno de uso de clave pública, resulta vital asegurarse de que la clave pública que se está utilizando, ya sea para cifrar o firmar datos, es en realidad la clave pública adecuada y no una falsificación. Se requiere, por lo tanto, de un intercambio de información que garantice o demuestre que la clave pública le pertenece al propietario. El mecanismo para garantizar esto es el certificado digital.
El certificado digital es un documento electrónico que demuestra la identidad de un usuario [Network Associates, Inc., 2004] y contiene otros atributos, por ejemplo, las fechas de inicio y fin de la validez del certificado. El certificado digital asocia una clave pública a un usuario y garantiza que la clave es válida y que pertenece al usuario que dice que es quien dice ser. Para ello se designan una o más entidades denominadas Autoridades de Certificación (CA), cuya función es generar los certificados de clave pública de la organización y luego darlos por buenos. El certificado está firmado por la clave privada (Ks) de la CA y cualquier usuario u organización que pertenece a una red puede verificar con la CA la validez de la clave pública certificada. Las CA y la administración de certificados digitales utilizan los sistemas de criptografía asimétrica ofreciendo un modelo de confianza que permite construir aplicaciones de alto nivel [Díaz, 2001].
La utilización de criptografía asimétrica [Ramió, 2006] ofrece ventajas como la confidencialidad para asegu-rar que ha sido esa persona y no otra la que ha leído o enviado un mensaje; la integridad, para asegurar que el mensaje no podrá ser modificado o alterado, y el no repudio de origen, que imposibilita al usuario negar su participación en una transacción si ha utilizado su firma electrónica, puesto que nadie más que él puede haber generado esa firma. Además, la firma permite asegurar la integridad de un documento.
Otro mecanismo de securización que ha tenido una gran aceptación en el mercado actual y está siendo ampliamente utilizado son las tarjetas inteligentes (Smart Cards) [S. C. Allience, 2006]. Ejemplos de uso de este tipo de tarjetas en dife-rentes ámbitos los encontramos en las tarjetas bancarias de pago seguro o las tarjetas de identificación utilizadas en la ad-ministración pública −por ejemplo, el Documento Nacional de Identidad electrónico en España (DNI electrónico, 2010)−.
Las tarjetas inteligentes son aquellas que almacenan y procesan información a través de circuitos electrónicos mediante un microordenador formado por un único chip que se encuentra situado en una tarjeta de plástico típica-mente del tamaño de una tarjeta de crédito [Chen, 2000].
Existen diversos tipos de tarjetas inteligentes, pero las más interesantes, fundamentalmente por su flexibilidad y fácil adaptación a distintos entornos de utilización, son las tarjetas Java (Java Card). Se trata de tarjetas que utilizan la tecnología Java como base de programación para sus aplicaciones. Se trabaja en Java aplicado a entornos en los que existen ciertas limitaciones en los recursos de memoria, lo que permite la ejecución de pequeñas aplicacio-nes (applets) escritas en Java dentro del propio microprocesador de la tarjeta, haciendo uso de una máquina virtual Java reducida [Chen, 2000]. Cabe destacar que esta tecnología es compatible con los estándares de tarjetas inteligentes ISO 7816 [ORSI, 2010; Chen, Z. and Di Giorgio, R., 1998].

UIGV79
El resto de este trabajo está organizado de la siguiente manera. En la sección 2, se muestra los Trabajos Previos. La sección 3 describe la metodología utilizada en el desarrollo del proyecto. Los resultados y discusión se encuen-tran en la sección 4 y, finalmente, las conclusiones en la sección 5.
Conclusiones
Para el desarrollo de este trabajo, se ha utilizado una metodología basada en varias fases, comenzando con el análisis de requisitos y llegando hasta la implementación y pruebas de parte de lo diseñado.
Como se ha visto a lo largo del texto, se parte del estudio del caso concreto de la UTP, donde la autenticación para algunos usuarios se basa en certificados digitales de identidad almacenados en forma centralizada y para otros en el sistema clásico de usuario y contraseña. El cual, por su propia constitución resulta un poco inapropiado, ya que se requiere mayor seguridad en la institución.
De igual manera, se hace necesario involucrar a todo el personal en general que requiere de los servicios ofrecidos por la institución, pero manteniendo una comunicación segura. En este artículo, se propuso la utili-zación de la criptografía asimétrica que proporciona medios para asegurar la comunicación y el uso de la tecnología Java.
La solución se basa en el uso de PKI para el acceso a los servicios ofrecidos por la institución, utilizando algo-ritmos asimétricos para la creación de las claves del usuario. Se ha creado una infraestructura de seguridad que está compuesta por CA y RA que son las entidades encargadas de la generación y registro de los certificados digitales utilizados por los usuarios de acuerdo con su papel. Además, se ha incluido el uso de tarjetas Java para el almacenamiento del certificado y autenticación del usuario. La flexibilidad, practicidad y comodidad son algunas de las ventajas que ofrece esta tecnología.
Para comprobar la funcionalidad de lo diseñado, se ha desarrollado un pequeño demostrador de usuario/ser-vidor o implementación de referencia. Se hace mención que es a pequeña escala para futuras ampliaciones. Éste consiste en el almacenamiento del certificado X.509 en la tarjeta Java y de una aplicación para acceder al recurso mediante la autenticación de la tarjeta y luego del certificado del usuario.
Con la integración de las dos tecnologías, se ha obtenido los beneficios de cada una como mayor escalabili-dad, portabilidad, interoperabilidad y seguridad de la información en las aplicaciones.
Esto ha permitido una comunicación más segura que garantiza la autenticidad, la confidencialidad, la integridad y el no repudio de origen que es un punto importante porque es un servicio de seguridad que permite probar la participación de un usuario o entidad en una comunicación.
Como trabajo futuro, se pretende mejorar el acceso a la tarjeta Java mediante identificación biométrica, la cual dará mayor seguridad al momento de autenticarse.
Referencias
[1] [Bauer, 2010] Bauer, L., et al., (2010). Constraining Credential Usage in Logic-Based Access Control. Pro-ceding of the 2010 23rd IEEE Computer Security Foundations Symposium (CSF), Edimburgo, Escocia, pp. 154-168.
[2] [Carracedo, 2004] Carracedo, J. (2004). Seguridad en redes telemáticas. McGraw-Hill, Madrid, España.
[3] [Chávez, 2006] Chávez, P. (2006). Autenticación y Control de Acceso. http://lsc.fie.umich.mx/~pedro/autenticacion_ac.pdf

UIGV80
[4] [Chen, 2000] Chen, Z. (2000). Java Card™ Technology for Smart Cards: Architecture and Programmer’s Guide. Addison-Wesley, California, USA.
[5] [Chen, 1998] Chen, Z. and Di Giorgio, R., InfoWorld JavaWorld, Solutions for java Developers, Understand-ing Java Card 2.0. http://www.javaworld.com/javaworld/jw-03-1998/jw-03-javadev.html
[6] [Díaz, 2001] Díaz, I. et al. (2001). Autenticación en la Red: ACerO y JCCM*: Java Card Certicate Manage-ment. III Jornadas de Ingeniería Telemática. JITEL. Barcelona, España, pp. 405-412.
[7] [DNI electrónico, 2010] DNI electrónico, Guía de Referencia Básica, v1.3, 2010. http://www.dnielectro-nico.es/PDFs/Guia_de_referencia_basica_v1_3.pdf
[8] [Elfadil, 2008] Elfadil, N. A. et al. (2008). An Approach for Multi Factor Authentication for Securing Smart Cards’ Applications. Proceedings of the International Conference on Computer and Communication Engineer-ing IEEE. Kuala Lumpur, Malasia, pp. 368-372.
[9] [Harn, 2011] Harn, L. and Ren, J., 2011. Generalized Digital Certificate for User Authentication and Key Establish-ment for Secure Communications. IEEE Transactions on Wireless Communications. Vol. 10, No. 7, pp. 2372 – 2379.
[10] [Henniger, 2006] Henniger, O. et al. Verifying X.509 Certificates on Smart Cards. In proceeding World Academy of Science, Engineering and Technology 22 2006.
[11] [Hilderbart, 2005] Hildebrandt, M. Et al. (2005). Future of Identity in the Information Society. FIDIS Inventory of Topics and Clusters, Deliverable 2.1, pp 38-39 [online] Disponible en: http://www.cosic.esat.kuleuven.be/publications/article-829.pdf
[12] [Hurtado, 2009] Hurtado, D. et al., 2009. Modelado de la seguridad de objetos de aprendizaje. Gener-ación Digital, Vol. 8, No. 1. pp. 38-42.
[13] [ISO, 2011] International Organization for Standardization (ISO). International Standard. Identification Cards-Integrated circuit cards. ISO/IEC 7816-1:2011(E). http://webstore.iec.ch/preview/info_isoiec7816-1%7Bed2.0%7Den.pdf
[14] [Netvork Associates, 2004] Network Associates, Inc. and its Affiliated Companies, 2004. An Introduction to Cryptography. Network Associates, Inc. California, USA.
[15] [Ramió, 2006] Ramió, J., 2006. Libro Electrónico de Seguridad Informática y Criptografía. http://www.criptored.upm.es/descarga/SegInfoCrip_v41.zip
[16] [S.C.Alliance, 2006] S. C. Allience, 2006, Uso de tarjetas inteligentes para un control de acceso físico seguro, Informe de la Smart Card Alliance Latin America (SCALA). http://www.smartcardalliance.org/latina-merica/translations/Secure_Physical_Access_Spanish.pdf
[17] [ORSI, 2010] Observatorio Regional de la Sociedad de la Información de Castilla y León (ORSI), Tarjeta ciudada-na, una visión de las tarjetas inteligentes y su aplicación en los ayuntamientos, 2010. http://www.jcyl.es/web/jcyl/binarios/910/900/TARJETA_CIUDADANA.pdf?blobheader=application%2Fpdf%3Bcharset%3DUTF-8
[18] [Vatra, 2010] Vatra N. (2010). Public Key Infrastructure for Public Administration in Romania. Communications (COMM), 2010 8th International Conference, IEEE. Bucarest, Rumania, pp. 481-484.
[19] [Vossaert, 2010] Vossaert, J. (2010). Developing secure Java Card applications.
[20] [Watts, 2010] Watts, J.et al., 2010. Case Study: Using Smart Cards with PKI to Implement Data Access Control for Health Information Systems. Proceding of the IEEE SoutheastCon 2010 (SoutheastCon). Concord, NC, USA, pp. 163-167.

UIGV81
Albert Miyer Suárez Castrillón1, Sir Alexci Suárez Castrillón2, Maribel González Rodriguez3
1 Universidad de Pamplona. Colombia2 Universidad Simón Bolívar. Ext. Cúcuta. Colombia3 Universidad de León, Españ[email protected], [email protected], [email protected]
Clasificación de residuos de construcción y demolición mediante un kernel modificado de Laws
Resumen
En el artículo, se presenta un sistema de visión que permite clasificar materiales que provienen de residuos de construcción y demolición. En la extracción de la información de las imágenes, se ha utilizado un kernel modificado de la energía de la textura de Laws, correlacionándolo con los kernels tradicionales y descriptores de textura estadís-ticos de primer y segundo orden. Se ha realizado una clasificación supervisada utilizando análisis discriminante lineal y cuadrático. Los resultados demuestran que el kernel modificado puede ser utilizado para discriminar las imágenes generando una reducción en la utilización de descriptores de textura estadísticos, obteniendo una tasa de acierto comprendida entre 94% y 98%.
Palabras clave:
Kernel, residuos de construcción y demolición, matriz de coocurrencia.
Abstract
A vision system that employs texture descriptors to classify different materials used in construction and demolition waste. A developed kernel for quantifying of texture is based mask presented by energy of Laws, correlating with tra-ditional kernels, texture descriptors in combination with statistical first and second order. The classification was carried out using linear and quadratic discriminant analysis. Results show the good performance of the Laws mask, achieving higher hit rates between 94% and 98%.
Keywords:
Kernel, construction and demolition waste, co-occurrence matrix.
Introducción
En los últimos años, los desechos de residuos de construcción y demolición (RCD), se han convertido en áreas muy estudiadas debido al enorme problema que generan dichos residuos, ya sea por la contaminación, el volumen o la oportunidad de recuperar algunos materiales para ser reciclados que permitan, finalmente, disminuir el impacto ambiental. Aunque la Unión Europea y últimamente los Estados en vías de desarrollo han implementado políticas de gestión de los RCD [Martínez 2008, Hernández 2008] hacia un reciclaje masivo de los mismos, todavía sigue siendo constante la necesidad de métodos concretos que permitan implantar un sistema adecuado a bajo coste.
Es de resaltar que los RCD son peligrosos debido a los materiales utilizados para su fabricación, como: fi-brocementos, plomo, alquitranes, adhesivos, sellantes y ciertos plásticos. Algunos RCD pueden mezclarse con otros originando una combinación peligrosa o simplemente el estado donde han permanecido durante años, producien-

UIGV82
do reacciones en el material original. Aunque los residuos generados de la construcción implican un riesgo menor que los residuos de demolición, son considerados generalmente como un conjunto con iguales propiedades. Los RCD son residuos de naturaleza fundamentalmente inerte generados en obras de excavación, nueva construcción, reparación, remodelación, rehabilitación y demolición, incluidos los de obra menor y reparación domiciliaria. Estos residuos incluyen varios materiales inertes y sustancias reactivas que resultan de la demolición no discrimi-natoria de estructuras. También pueden incluir desechos que se generan de la demolición discriminatoria de las mismas estructuras. El proceso de separación e identificación de objetos es generalmente realizado por un operario, originando que el proceso se convierta en algo lento e inexacto.
En cuanto a las técnicas de visión artificial implementados para resolver el problema, se puede mencionar el trabajo desarrollado por [Alegre 2005], obteniendo una tasa de acierto de 87% al clasificar diferentes materiales, como: ladrillo, baldosas, cemento. Los descriptores de textura utilizados han sido los momentos de Hu, momentos de Zernike y el variograma. Recientemente, han clasificado materiales metálicos en función del valor de la rugosi-dad utilizando la matriz de coocurrencia (GLCM) y la energía textural de Laws obteniendo buenos resultados con el kernel R5R5 [Suárez 2010].
La importancia en la clasificación e identificación del material en diferentes áreas industriales queda reflejado en trabajos de inspección por medio de análisis de textura en la fabricación de textiles, alimentos, papel, cuero, madera, corcho, cerámica y metales [Morala-Arguello 2009, Alegre 2011]. En líneas generales, se encuentran los trabajos implantados en el control de calidad de la industria textil. Uno de estos trabajos es el desarrollado por [Latif-Amet 2000] que aplica la matriz de coocurrencia (GLCM) para detectar defectos en tejidos, utilizando la transformada Wavelet y extrayendo los descriptores de Haralick [Haralick 1973, Haralick 1979]. También [Bod-narova 2000] abordan la detección de defectos de textiles utilizando la GLCM para garantizar un producto final de alta calidad. Después de aplicar las técnicas de textura se comprobó que con la GLCM lograban porcentajes de aciertos entre 88%.
[Novak 2005] examina materiales cerámicos, donde extraen características a partir del patrón binario local (LBP). En el análisis de la calidad del corcho, el trabajo efectuado por [Panigua 2007] demuestran que la matriz de confusión para la característica E5L5 [Laws 1980a, Laws 1980b] es la más positiva. También, se han implantado la automatización en procesos de degradación de superficies tanto en azulejos, granito y madera [López 2008]. En la industria alimentaria, los descriptores de textura estadísticos son los más utilizados para detectar y clasificar la calidad del producto. Dentro de estos métodos, se ha aplicado la GLCM para discriminar diferentes alimentos, como las patatas fritas [Pedreschi 2004] y clasificar la carne de bovino [Zheng 2006].
De acuerdo con los trabajos expuestos anteriormente, es importante contar con un sistema de visión que permita determinar cuáles son las técnicas más confiables de extracción de características que permitan clasificar diferentes materiales de RCD, a la vez que el proceso utilice un número inferior de descriptores de textura al utilizar el kernel modificado R5SR5S [Alegre 2011].
El presente artículo se ha organizado de la siguiente manera. En la sección 2, se muestra el conjunto de datos utilizados y la adquisición de las imágenes. La sección 3 describe los descriptores de textura utilizados. La sección 4 muestra los experimentos y resultados correspondientes. La discusión de los experimentos se muestra en la sección 5, y en la sección 6, se presentan las conclusiones.
Conclusiones
Los resultados demuestran que se puede utilizar un solo kernel modificado en la clasificación de materiales origi-nados de RCD logrando resultados muy cercanos a los obtenidos con los kernels tradicionales. El tipo de material y la variación del medio donde se obtiene repercuten considerablemente en el reconocimiento, demostrando que la selección del descriptor puede ayudar a disminuir el impacto ambiental, al lograr una buena clasificación. En futuros trabajos se pretende utilizar un conjunto de datos más representativos de los materiales de RCD.

UIGV83
Referencias
[1] [Alegre 2005] E. Alegre, L. Sánchez, V. Robles, A. Ferreras; Clasificación de residuos de construcción y de-molición utilizando descriptores de textura. XXVI Jornadas de automática. Universidad de Alicante. Septiembre de 2005. España.
[2] [Alegre 2011] E. Alegre, J. Barreiro, S.A. Suárez; A new improved Laws-based descriptor for surface roughness evaluation’, Int J Adv Manuf Technol., 2011. DOI: 10.1007/s00170-011-3507-z
[3] [Bodnarova 2000] A. Bodnarova, M. Bennamoun, K. Kubik; Suitability Analysis of Techniques for Flaw De-tection in Textiles using Texture Analysis, Pattern Analysis and Applications, 2000, (3), pp. 254-266.
[4] [Haralick 1973] R.M. Haralick, K. Shanmugam, I. Dinstein; ‘Textural features for image classification, IEEE Transactions on Systems, Man, and Cybernetics., 1973, SMC-3,(6), pp. 610-621.
[5] [Haralick 1979] R.M. Haralick; Statistical and Structural Approaches to Texture. Proceedings of the IEEE. 1979, 67, (5), pp. 786-804.
[6] [Hernández 2008] J. D. Hernández, M. A. Rodríguez, A. Macht, E. Ramos; El manejo de los residuos de la construcción en el estado de México en el marco de la cooperación técnica alemana en México. Revista Desarrollo Local Sostenible. Grupo Eumed.net y Red Académica Iberoamericana Local Global. 2008, 1, (3), pp. 1-11.
[7] [Latif-Amet 2000] A. Latif-Amet, A. Ertüzün, A. Ereçil; An efficient method for texture defect detection. Image Vision Computing. 2000,18, (5), pp. 377-387.
[8] [Laws 1980a] K. I. Laws; Rapid texture identification,.In SPIE Image Processing for Missile Guidance., 1980, (238), pp. 376-380.
[9] [Laws 1980b] K.I. Laws; Textured Image Segmentation. Ph.D. Dissertation, University of Southern California. January, 1980
[10] [López 2008] F. López, J.M. Valiente, J.M. Prats, A. Ferrer, A; Performance evaluation of soft color texture descriptors for surface grading using experimental design and logistic regression. Pattern Recognition. 2008, 41(5):1744 -1755.
[11] [Martínez 2008] C. Martinez; Gestión de residuos de construcción y demolición (RCDS): importancia de la recogida para optimizar su posterior valorización. Congreso Nacional del Medio Ambiente. Cumbre del Desarrollo Sostenible. Diciembre 2008, Madrid, España.
[12] [Morala-Arguello 2009] P. Morala-Argüello, J. Barreiro, E. Alegre, V. González-Castro; Application of textural descriptors for the evaluation of surface roughness class in the machining of metals. 3rd Manufacturing Engi-neering Society International Conference (MESIC’09), Conference Proceedings, 2009, pp. 833-839.
[13] [Novak 2005] I. Novak, Z. Hocenski; Texture feature extraction for a visual inspection of ceramic tiles. Indus-trial Electronics, ISIE 2005. Proc. of the IEEE International Symposium on, 2005, pp. 1279-1283.
[14] [Panigua 2007] B. Panigua-Panigua, M.A. Vega-Rodriguez, P. Bustos-Garcia, J.A Gomez-Pulido, J. M. San-chez-Perez; Análisis avanzado de texturas para la detección automática de la calidad del corcho. Proc. XXVIII Jornadas de automática. Huelva, 2007, España.
[15] [Pedreschi 2004] F. Pedreschi, D. Mery, F. Mendoza, J.M. Aguilera; Classification of Potato Chips using Pattern Recognition. Journal of Food Science, 2004, 69(6):E264-E270.

UIGV84
[16] [Suarez 2010] S.A. Suarez, E. Alegre, J. Barreiro, P. Morala-Arguello, L. Fernandez; Surface Roughness Classi-fication in Metallic Parts Using Haralick Descriptors and Quadratic Discriminant Analysis’. Annals of DAAAM for 2010 & Proceedings of the 21st International DAAAM Symposium, Editor B. Katalinic, Published by DAAAM International, Vienna, Austria, pp. 0435.
[17] [Zheng 2006] C. Zheng, D.W. Sun, L. Zheng; (2006) Recent applications of image texture for evaluation of food qualities - a review. Trends in Food Science & Technology, 2006 17(3):113 - 128.

UIGV85
Un estudio del Escalamiento de Imágenes mediante Interpolación basada en la Transformada Discreta Wavelet de Daubechies
Marks Calderón-Niquín1, Jorge Valverde-Rebaza2
1 Escuela Académico Profesional de Informática, Universidad Nacional de Trujillo, Perú2 Instituto de Ciências Matemáticas e de Computação, Universidade de São Paulo, [email protected], [email protected]
Resumen
En este artículo, se presentan los resultados obtenidos al realizar interpolación de imágenes basada en la Trans-formada Discreta Wavelet (DWT) con la wavelet de Daubechies de orden 4 (DB4) para lograr el escalamiento de imágenes. Los experimentos son realizados sobre una base de datos de 2500 imágenes las cuales se encuentran naturalmente en espacio de color RGB, siendo transformadas hacia los espacios de color CIE Lab y HSV para evaluar el desempeño de la DWT con DB4 en cada uno de los tres espacios de color y utilizando además diferentes factores de escala. Los resultados mostraron que hasta un determinado nivel de escalamiento de la imagen se presentan variacio-nes en el error obtenido por la interpolación, para después mantenerse constante.
Palabras clave:
Interpolación de imágenes, transformada wavelet, wavelet de Daubechies, espacios de color.
Abstract
In this paper presents the results obtained by performing interpolation of images based on Discrete Wavelet Trans-form (DWT) with the fourth order Daubechies wavelet (DB4) to achieve the scaling of images. Experiments are con-ducted on a database of 2500 images which are found in RGB color space, this images were transformed into the CIE Lab and HSV space color to evaluate the performance of the DWT with DB4 in each of the three color spaces. The results showed to until certain level of scaling the image have variations in the error obtained by interpolation, and then remain constant.
Keywords:
Image interpolation, wavelet transform, Daubechies wavelet, color space.
Introducción
En nuestra era, la cantidad de información multimedia aumenta en grandes cantidades día a día, el acceso a In-ternet y la proliferación de dispositivos electrónicos que permiten la digitalización de documentos son los principales agentes para este crecimiento desbordante de la información. Las imágenes son los principales tipos de archivo mul-timedia con los que interactuamos de manera cotidiana, por este motivo existen diversas herramientas que permiten captar mayor cantidad de características de las imágenes digitales, como por ejemplo, una mayor resolución. Ante esto, con archivos de imágenes de mayor dimensión, surgen nuevas necesidades para la visualización, transmisión, descarga, compartición, edición, entre otras, cuya cobertura eficiente por parte de las herramientas de software de imágenes ha llegado a tener carácter vital.

UIGV86
La interpolación es una poderosa herramienta matemática cuya versatilidad ha permitido que sea aplicada so-bre imágenes, alcanzando buena aceptación por la comunidad. Entre las principales áreas en que se encuentran aplicaciones de la interpolación de imágenes destacan: computación gráfica, renderizado, edición de imágenes, reconstrucción de imágenes médicas, visualización de imágenes online, entre otras.
Las diversas técnicas de interpolación de imágenes son referidas en la literatura por diferentes terminologías, como: re-dimensionamiento de imágenes, re-muestreo de imágenes, zooming digital, magnificación de imágenes, entre otros. Estas diferentes terminologías, pero que brindan una misma idea, se debe básicamente a que los algorit-mos de interpolación de imágenes convierten o redimensionan una imagen digital desde una resolución (dimensión) inicial hacia otra resolución sin pérdida de la información visual contenida en la imagen inicial [Acharya, 2007].
Una imagen es considerada como una señal bidimensional que puede encontrarse en diferentes espacios y que necesita ser digitalizada para poder procesarla computacionalmente. Al encontrarse en formato digital, la señal es muestreada basándose en el criterio de Nyquist, de esta manera, cada punto muestreado es quantizado a un valor discreto formado por números enteros. Cada uno de estos puntos muestreados son llamados píxeles [Acharya, 2005]. La resolución o dimensión de una imagen es el número de puntos muestreados de la señal bidimensional [Acharya, 2007]. En el caso de imágenes a color, cada píxel contiene tres valores de intensidad que representan contribuciones de ciertos parámetros, por ejemplo, el RGB que representa las contribuciones de los colores rojo (red), verde (green) y azul (blue) [Acharya, 2007].
Cuando la imagen es interpolada desde una alta resolución hacia una resolución menor, llamamos a este proce-so downscaling o downsampling. De otro lado, cuando la imagen es interpolada desde una resolución baja hacia una mayor, llamamos a este proceso upscaling o upsampling [Acharya, 2006].
Las técnicas de interpolación de imágenes se agrupan en dos categorías: técnicas adaptativas y no adaptativas. Los principios de los algoritmos de interpolación adaptativa se basan en las características intrínsecas de la imagen a diferencia de los algoritmos no adaptativos que no consideran esto y repiten un procedimiento por cada píxel o grupos de píxeles de una imagen [Zhu, 2001], [Acharya, 2007]. Por otro lado, la interpolación de imágenes basada en técnicas en el dominio de las transformadas son escasas en la literatura [Acharya, 2006].
Siendo la Transformada Discreta de Wavelets (DWT) una técnica utilizada en diferentes aplicaciones de proce-samiento digital de imágenes debido a que brinda mejores herramientas para realizar análisis multiresolución1 de señales y basados en los trabajos de [Acharya, 2006] y [Acharya, 2007], en este documento presentamos los resultados obtenidos al realizar el escalamiento de imágenes en tres diferentes espacios de color (RGB, CIE Lab y HSV) utilizando interpolación basada en la DWT de Daubechies de orden 4.
El resto de este artículo está organizado de la siguiente manera. En la sección 2, se muestran algunos trabajos previos que sirven de base para nuestro estudio. En la sección 3, se muestra el fundamento teórico de las wavelets y su transformada continua y discreta. En la sección 4, mostramos el proceso de interpolación de imágenes basada en la DWT. Los experimentos realizados, así como los resultados obtenidos son presentados en la sección 5. La dis-cusión de los experimentos se muestra en la sección 6. Finalmente, las conclusiones son presentadas en la sección 6.
Conclusiones
El algoritmo de interpolación de imágenes basada en la Transformada Discreta Wavelet utilizando la wavelet de Daubechies de orden 4 aplicada al escalamiento de imágenes en diferentes espacios de color, presenta mejores resultados para imágenes en el espacio de color RGB cuando la escala tiene por valor 16, al obtener un PSNR mayor con respecto a los otros modelos de color, lo que significa menor presencia de ruido.
El uso de los otros factores de escala no pueden ser descartados debido a que la DTW tiene entre sus ventajas el tiempo de ejecución de O(p) (donde p es la dimensión total m ×n de cada imagen original) con respecto a los
1 El análisis multi-resolución (multiresolution analysis - MRA) permite analizar una señal en diferentes frecuencias con diferentes resoluciones, véase [Merry, 2005].

UIGV87
algoritmos del tipo no adaptativos tradicionales [Acharya, 2007], también podemos obtener información extra en los diferentes niveles de resolución y es una técnica paralelizable.
Las desventajas de este método son la pérdida de datos debido a sus operaciones de punto flotante, el upsam-pling o downsampling de una imagen solo se puede realizar con potencias de 2.
Entre los trabajos futuros podemos trabajar con imágenes que se encuentren de manera natural en espacios de color, para evaluar si la transformación de RGB hacia un determinado espacio de color influye en el acarreo de error. El desempeño de la DWT con otros tipos de wavelets además de la Daubechies también estaría contemplado.
Referencias
[1] [Addison, 2002] Addison, P.S. (2002). The Illustrated Wavelet Transform Handbook. IOP Publishing Ltd. 2002, ISBN 0-7503-0692-0.
[2] [Acharya, 2005] Acharya, Tinku and A.K. Ray (2005). Image Processing: Principles and Applications, John Wiley & Sons, Inc. Hoboken, NJ.
[3] [Acharya, 2006] Acharya, Tinku and Ping-Sing, Tsai. (2006). Image up-sampling using Discrete Wavelet Transform. In Proceedings of the 7th International Conference on Computer Vision, Pattern Recognition and Im-age Processing (CVPRIP 2006), in conjunction with 9th Joint Conference on Information Sciences (JCIS 2006), pp. 1078-1081.
[4] [Acharya, 2007] Acharya, Tinku and Ping-Sing, Tsai. (2007). Computational Foundations of Image Interpola-tion Algorithms. ACM Ubiquity’ 07, vol. 8 Art. 14, DOI 10.1145/1317487.1317488.
[5] [Akima, 1974] Akima, Hiroshi (1974). A method of bivariate interpolation and smooth surface fitting based on local procedures. Commun. ACM vol. 17, 1, pp.18-20.
[6] [Carrato, 2000] Carrato, S. and L. Tenze (2000). A High Quality 2 × Image Interpolator. IEEE Signal Process-ing Letter, vol.7, no.6, pp. 132-134.
[7] [Daubechies, 1992] Daubechies I. (1992). Ten Lectures on Wavelets. Society for Industrial and Applied Math-ematics, ISBN 0-89871-274-2.
[8] [Dengwen, 2010] Dengwen, Z. (2010). An edge-directed bicubic interpolation algorithm. Image and Signal Processing (CISP), 2010 3rd International Congress on, vol. 3, pp.1186-1189.
[9] [Foley, 1987] Tomas A. Foley (1987). Weighted bicubic spline interpolation to rapidly varying data. ACM Trans. Graph. vol. 6, 1, pp.1-18, DOI 10.1145/27625.27626.
[10] [Harry, 1976] Harry, A. and Patterson, C. (1976). Digital Interpolation of Discrete Images. Computers, IEEE Trans. on, vol.C-25, no2, pp.196-202.
[11] [Hong, 1996] Hong, K.P., J.K. Paik, H.J. Kim and C.H. Lee (1996). An Edge-Preserving Image Interpolation System for a Digital Camcorder. IEEE Trans. on Consumer Electronics, vol.42, no.3.
[12] [Htwe, 2010] Htwe, Ah Nge (2010). Image Interpolation framework using non-adaptive approach and NL means. International Journal of Network and Mobile Technologies, vol. 1 (1), pp.28-32, ISN 1832-6758.
[13] [Jenkins, 1985] Jenkins, W., B. Mather and D. Jr. Munson (1985). Nearest Neighbor and generalized inverse distance interpolation for Fourier domain image reconstruction. Acoustics, Speech, and Signal Processing, IEEE International Conference on ICASSP’85, vol.10, pp.1069-1072.

UIGV88
[14] [Jense, 2001] Jense, A. and la Cour-Harbo, A. (2001). Ripples in Mathematics: the Discrete Wavelet Trans-form. Springer, 246 pp., Softcover ISBN 3-540-41662-5.
[15] [Jing, 2009] Jing, L., S. Xiong and W. Shihong (2009). An Improved Bilinear Interpolation Algorithm of Coverting Standard-Definition Television Images to High-Definition Television Images. Information Engineering ICIE’09, WASE International Conference on, vol.2, pp.441-444. DOI 10.1109/ICIE.2009.251.
[16] [Kraker, 2000] de Kraker, B. (2000). A numerical-experimental approach in structural dynamics. Technical Report, Department of Mechanical Engineering, Eindhoven University of Technology, Netherlands.
[17] [Merry, 2005] Merry, R.J.E. (2005). Wavelet Theory and Applications: A literature study. Technical Report, Department of Mechanical Engineering, Eindhoven University of Technology, Netherlands.
[18] [Neto, 1983] Neto, G.C. and N. Mascarenhas (1983). Methods for image interpolation through FIR filter design techniques. Acoustics, Speech and Signal Processing, IEEE International Conference on ICASSP’83, vol. 8, pp.391-394.
[19] [Ni, 2009] Ni, K.S. and T.Q. Nguyen (2009). An adaptable k-Nearest Neighbors Algorithm for MMSE Im-age Interpolation. Image Processing, IEEE Trans. on, vol.18, no.9, pp.1976-1987.
[20] [Nuno-Maganda, 2005] Nuno-Maganda, M.A. and M.O. Arias-Estrada (2005). Real-time FPGA-based architecture for bicubic interpolation: an application for digital image scaling. Reconfigurable Computing and FPGAs International Conference on, vol. 8 pp.28-30.
[21] [Parker, 1983] Parker, J.A., R.V. Kenyon and D.E. Troxel (1983). Comparison of Interpolating Methods for Im-age Reampling. IEEE Trans. On Medical Imaging, vol. 2 MI-2, pp.31-39.
[22] [Schneiders, 2001] Schneiders, M.G.E. (2001). Wavelets in control engineering. Master’s thesis, Eindhoven University of Technology, Agosto 2001, DCT nr. 2001.38.
[23] [Strang, 1997] Strang, G. and T. Nguyen (1997). Wavelets and Filter Banks. Wellesley-Cambridge Press, second edition, ISBN 0-9614088-7-1.
[24] [Thurnhofer, 1993] Thurnhofer, S., M. Lightstone and S. Mitra (1993). Adaptive Interpolation of Images with application to Interlaced-to-Progressive Conversion. Proc. SPIE-int. Soc. Opt. Eng., vol.2094, pp.614-625.
[25] [Wang, 1988] Wang, Y. and S. Mitra (1988). Edge Preserved Image Zooming. Proc. of European Signal Process, EURASIP’88, pp.1445-1448, Grenoble, France.
[26] [Wang, 1996] Wang, X., E. Chan, M.K. Mandal and S. Panchanathan (1996). Wavelet-based image cod-ing using nonlinear interpolative vector quantization. Image Processing, IEEE Trans. on, vol.5 no.3, pp.518-522.
[27] [Wang, 2010] Wang, Y., W. Wanggen, W. Rui and X. Zhou (2010). An improved interpolation algorithm using nearest neighbor from VTK. Audio Language and Image Processing (ICALIP), 2010 International Confer-ence on, pp. 1062-1065.
[28] [Zhu, 2001] Zhu, Ying, S.C. Schwartz, M.T. Orchard (2001). Wavelet domain image interpolation via statisti-cal estimation. Image Processing 2001 Proceedings International Conference on, vol.3, pp.840-843.

UIGV89
Desenvolvimento de um sistema distribuído em sala de aula de forma colaborativa
Katia de Paiva Lopes1, Sandro Renato Dias2
1 Universidade Federal do Paraná, Departamento de Bioinformática Curitiba - PR, Brasil2 Faculdade Anhanguera de Belo Horizonte, Departamento de Sistemas de Informação Belo Horizonte - MG, [email protected], [email protected]
Resumo
Este artigo apresenta um modelo de sistema distribuído (SD) para ser utilizadas de forma didática em disciplinas de Sistemas Distribuídos, Redes de Computadores ou Sistemas Operacionais. Foi desenvolvido em sala de aula um sistema visando dividir uma tarefa entre vários computadores a fim de terminá-la mais rapidamente, de forma dis-tribuída. Para a caracterização e fixação dos conceitos de sistemas distribuídos, a turma foi dividida em grupos que se responsabilizaram por desenvolver cada módulo referente àquela característica do SD. Este trabalho apresenta o sistema desenvolvido bem como a metodologia utilizada para o seu desenvolvimento, de forma colaborativa. Os tó-picos abordados no sistema são tolerância a falhas, escalabilidade, armazenamento distribuído, dentre outros. Como resultado, foi possível obter um sistema distribuído completo, modularizado e que permite que esses módulos sejam utilizados em outras aplicações.
Palavras chave:
Sistema distribuído, código, SGBD,
Abstract
This paper presents a distributed system (DS) model that can be used as an didactic exercise in Distributed Systems, Computer Networks or Operating Systems classes. It was developed in the classroom a system to divide a task among several computers in order to finish it more quickly, in a distributed way. For distributed systems concepts characteriza-tion and determination, the class was divided into groups that were designed to develop each module related to one characteristic of DS. This paper presents the system developed and the methodology used for its development in a collaborative way. The topics covered in the system are fault tolerance, scalability, distributed storage, among others. As a result, it was possible to achieve a complete distributed system, modularized in a way that these modules can be used in other applications.
Keywords:
Distributed system, code, DBMS.
Introdução
Um sistema distribuído é definido como “Um sistema em que componentes de hardware e software localizados em computadores em rede se comunicam e coordenam suas ações por passagem de mensagens” (COULOURIS et al. 2001). Por meio deles é possível a comunicação entre servidor e cliente, integração de sistemas diversos, difusão de conteúdos, entre outras aplicações (FERRAZ, 2002).

UIGV90
“Um Sistema distribuído é composto por um conjunto de processos, interconectados através de uma rede de comunicação, que realizam um processamento distribuído baseado exclusivamente na troca de mensagens. Os processos são distribuídos individualmente em diferentes computadores, com diversas capacidades de processa-mento.” (BULIGON et al. 2004). Também é definido como “(…) um conjunto de computadores independentes entre si que se apresenta a seus usuários como um sistema único e coerente” (TANEMBAUM e VAN STEEN, 2002).
Sistema Distribuído é utilizado principalmente pela busca por maior desempenho, alto custo de supercomputado-res, desenvolvimento de redes de computadores de alta velocidade, desenvolvimento tecnológico na construção de microprocessadores e para aplicações intrinsecamente paralelas (GPACP, 2011). É utilizado em diversas situações, dentre elas: Processamento e sobreposição de imagens, comparação de arquivos, além de pesquisas na área de biologia molecular, por exemplo, que envolvem elevado custo de processamento: montagem de genoma, análise proteômica ou mesmo alinhamento de sequências de DNA.
Portanto, foi desenvolvido em sala de aula, um sistema visando dividir uma tarefa entre vários computadores a fim de terminá-la mais rapidamente, de forma distribuída. Para a caracterização e fixação dos conceitos de siste-mas distribuídos, a turma foi dividida em grupos que se responsabilizaram por desenvolver cada módulo referente àquela característica do sistema. Como resultado, foi possível obter um sistema distribuído completo, modularizado e que permite que esses módulos sejam utilizados em outras aplicações.
Este artigo está organizado da seguinte maneira: Na seção 2 são apresentados trabalhos relacionados. Nas seções 3 e 4 é descrita a metodologia de desenvolvimento realizada, como os grupos foram organizados e quais tarefas deveriam ser concluídas. Em seguida, nas seções 5 e 6 (Resultados e Conclusão), este artigo aborda os detalhes que fizeram esse trabalho ser possível de ser desenvolvido em sala de aula de maneira colaborativa.
Conclusão
A metodologia de ensino e desenvolvimento de um sistema distribuído totalmente colaborativo apresentados nesse artigo, mostrou-se eficaz para aprendizado e aplicação de conceitos por parte dos alunos. A aula deixou de ser excessivamente teórica e passou a ser totalmente prática, com implementação de código e teste de cada fun-cionalidade, antes que o sistema pudesse ser finalmente, integrado. Portanto, a contribuição desse trabalho se deve principalmente à metodologia abordada para desenvolvimento de um sistema distribuído de forma colaborativa e didática em disciplinas de Sistemas Distribuídos, Redes de Computadores ou Sistemas Operacionais.
Referências
[1] [Berman, 2000] Berman, H.M. et. al.,(2000). The Protein Data Bank, Oxford Journals, Vol. 28, No. 1 235-242, Disponível em: < http://nar.oxfordjournals.org/cgi/content/full/28/1/235>. Acesso em: 8 nov 2009.
[2] [Buligon et. al., 2004] Buligon C., Cechin S, Jansch-pôrto I. (2004). Implementando recuperação por retorno baseada em checkpointing em Sistemas Distribuídos assíncronos. Universidade Federal do Rio Grande do Sul, Porto Alegre/ RS.
[3] [Coulouris et. al., 2001] Coulouris G., Dollimore J., Kindberg T. (2001). Distributed Systems: Concepts and Design. 3. ed. Editora Addison-Wesley.
[4] [Ferraz, 2002] Ferraz, C. Sistemas distribuídos. Pernambuco: Universidade Federal de Pernambuco (UFPE), 2002. 17 slides: color. Acompanha texto.
[5] [GPACP, 2011] GPACP, Grupo de pesquisa de aplicações em computação paralela. Introdução à Computa-ção Paralela. São Paulo, Unesp, 2011. 18 slides: color. Acompanha texto.

UIGV91
[6] [GSORT, 2011] GSORT, Grupo de sistemas distribuídos: otimização, redes e tempo-real. (2011). Disponível em: <http://www.wiki.ifba.edu.br/gsort/tiki-index.php?page=Projetos >. Acesso em: 29 jul 2011.
[7] [Tanenbaum A. S.; Steen M.V, 2002] Tanenbaum A. S.; Steen M.V. (2002), Distributed Systems: Principles and Paradigms. Editora Prentice Hall.

UIGV92

UIGV93
Sistemas para la identificación de señales de audio
Daniel Alejandro Arango Parrado1, Edwin Villarreal López1, Pedro Raúl Vizcaya Guarín2
1 Universidad Manuela Beltrán2 Pontificia Universidad [email protected], [email protected], [email protected]
Resumen
En el presente artículo, se describe un método para la inserción y detección de una marca de agua en una señal de audio basado en secuencias Gold y mediante la cual se puede realizar una posterior identificación de la señal. Tam-bién se expone un método para la generación y detección de una huella de audio basada en la diferencia de energía entre bandas logarítmicas de frecuencia y segmentos continuos de tiempo, y con la cual se pueda identificar señales de audio transmitidas. Ambos métodos son implementados en tiempo real y comparados en cuanto a degradación de la señal, velocidad del proceso y comportamiento de las curvas de falsa aceptación y falso rechazo.
Palabras clave:
Marcas de agua, señal de audio, huella de audio.
Abstract
This paper describes a method for detecting and inserting a watermark in an audio signal, based on Gold sequen-ces. This technique can be used for a subsequent identification of the audio signal. It also introduces a method for generating and detecting an audio fingerprinting, based on the energy difference between logarithmic frequency bands and segments of continuous time, this can be used for the identification of audio broadcast. Both methods are implemented in real time and compared in terms of the signal degradation, process speed and the behavior of the false acceptance and false rejection curves.
Keywords:
Watermark, audio, audio fingerprint
Introducción
Las técnicas de marcas de agua y huellas de audio son usadas principalmente en la protección de derechos de autor de documentos multimedia [1]. Adicionalmente, pueden utilizarse para la identificación de secuencias de audio, como canciones o pautas comerciales.
Dentro de la literatura consultada, se resaltan algunas investigaciones afines encontradas, como: J. A. Haitsma [4], quien describe en su artículo un sistema robusto de audio fingerprinting adaptable a un gran número de apli-

UIGV94
caciones, que está basado en la obtención de la energía como característica principal de la huella generada. R. Bardeli y F. Kurth [6], proponen en este artículo una técnica de audio fingerprinting diseñada para la identificación de datos de audio y robusta ante escalizaciones en tiempo. Está basado en una segmentación robusta de señales de audio que genera segmentos no simétricos y un promedio de energías en el dominio de la frecuencia, para la generación del vector de características que forma la huella. P. Bassia y I. Pitas [5], proponem los métodos que se discuten en este artículo investigan el potencial de las marcas de agua en señales de audio tomando en cuenta las especificaciones de percepción del oído humano.
Como trabajo adscrito al grupo de Bioingeniería, análisis de señales y procesamiento de imágenes de la Pontificia Universidad Javeriana, P. Vizcaya y R. Carrillo [7] presentaron un método para la auditoría automática de comerciales al aire basado en marcas de agua de espectro expandido como una aplicación de sus carac-terísticas.
La identificación de pautas comerciales es de gran importancia, puesto que tanto la empresa dueña del producto promocionado como la empresa creadora de la publicidad se interesan en saber si sus comerciales fueron transmi-tidos en el horario pactado con los diferentes medios de comunicación radial o televisiva.
En el presente trabajo, se elige una técnica correspondiente a marcas de agua y una a huellas de audio. Se realiza su implementación en tiempo real y se compara su desempeño.
Este artículo se encuentra dividido en cinco secciones. Las secciones dos (2) y tres (3) describen cada una de las técnicas elegidas para la implementación en tiempo real. En la sección cuatro (4), se realiza la comparación de estos dos métodos respecto a su confiabilidad y velocidad del proceso. Por último, en la sección cinco (5), se discute cuál de estos dos sistemas presenta un mejor desempeño y por qué.
Conclusiones
a) Marcas de agua
El desarrollo de sistemas basados en la inserción de información para el reconocimiento de señales tiene la des-ventaja de ser invasivo, lo cual condiciona el uso de éstos en la manera que se debe reemplazar para la transmisión del comercial original por uno que tenga el código insertado.
Respecto a la confiabilidad, esta técnica tiene un desempeño aceptable, excepto cuando la señal es pasada a través de un filtro pasabanda, el cual disminuye la potencia de la marca de agua, haciendo que la pauta no sea identificada.
La principal limitante de este método es que sólo es posible detectar 30 comerciales a la vez. Esto se debe a que el sistema realiza correlaciones cruzadas con todos los códigos Gold utilizados.
b) Huellas de audio
Los sistemas basados en huellas generadas a partir de la diferencia de energía para la identificación de señales de audio presentan un gran potencial en el desarrollo de aplicaciones debido a que es un proceso robusto y no invasivo.
Ante las pruebas de confiabilidad realizadas, el sistema respondió de una manera muy positiva, lo que se ve reflejado en las bajas probabilidades de falsa aceptación y falso rechazo.
El sistema implementado toma 1.2 segundos en generar el bloque de 256 subhuellas de 16 bits equivalente a 3.3 segundos de audio y 0.8 segundos en identificarlo en una base de datos con 146 pautas de 10 segundos. Esto permite agregar más pautas hasta completar el tiempo límite.

UIGV95
En consecuencia, al comparar estas dos técnicas mediante las implementaciones realizadas en tiempo real, el algoritmo de huellas es más versátil, eficiente y robusto para la identificación de pautas comerciales al aire.
Referencias
[1] LAM, D., “Audio watermarking”. Department of Electronic and Electrical Engineering, University of Auckland, 2003
[2] GÓMEZ, E., “Marcas de agua en audio digital: Conceptos y aplicaciones,” Instituto Universitario del Audio-visual, Universidad Pompeu Fabra, Barcelona.
[3] RODRIGUEZ, F. J. M. HENRÍQUEZ .ROCHA-PÉREZ y F. SÁNCHEZ ,A. “Generation of Gold-sequences with applications to spread spectrum systems”. Centro de Investigación y de Estudios Avanzados del Instituto Politéc-nico Nacional CINVESTAV-IPN, Computer Science Section, México D. F. 2000.
[4] HAITSMA, J, “A New Technology To Identify Music”. Audio Fingerprinting. Nat. Lab. Unclassified Report 2002/824.
[5] BASSIAS, P. and I. Pitas, “Robust audio watermarking in the time domain”, Dept. of informatics, University of Thessaloniki, Greece.
[6] BARDELI, R. and KURTH, F., “Robust Identification of Time-Scaled Audio”. Department of Computer Science III, University of Bonn, Bonn, Germany, 2004.
[7] CARRILLO, R. y VIZCAYA., “Control de pautas comerciales al aire empleando marcas de agua de espectro expandido”, Trabajo adscrito al grupo de Bioingeniería, análisis de señales y procesamiento de imágenes de la Pontificia Universidad Javeriana., 2003.

UIGV96

UIGV97
Jorge Armando Saucedo Ascona1, José Hamblett Villegas Ortega12
1 Universidad Nacional Mayor de San Marcos2 Magister en Ingeniería de Sistemas - UNMSMMBA(c) - Universidad del Pací[email protected], [email protected]
Generación de Valor en las Pyme Peruanas utilizando Tecnologías de la Información: Modelo de Implementación de ERP
Resumen
La presente investigación muestra la evaluación de 5 modelos de implementación de ERP (Asap, Epicor Signature, Sure Step, OpenErp y el Proven Path) con la finalidad de elegir uno como base para la creación de un modelo de implementación de ERP para las Pymes peruanas. Como resultado de esta evaluación, se eligió el modelo propuesto por Thomas F. Wallace y Michael H. Kremzar “ERP PROVEN PATH–QUICK SLICE”, al cual se propone agregar 2 nuevos constructores (uno de medición de aceptación e impacto y el otro de gestión de cambio) y además incluir un aspecto adicional al constructor de mejora de procesos físicos (la aplicación de la teoría de restricciones).
Palabras clave:
ERP, PYME, procesos.
Abstract
This research shows the evaluation of 5 models of ERP implementation (Asap, Epicor Signature, Sure Step, OpenERP and Proven Path), in order to choose a basis for creating a model of ERP implementation for SMEs Peru. As a result of this evaluation we chose the model proposed by Thomas F. Wallace and Michael H. Kremze “ERP-QUICK SLICE PROVEN PATH”, which aims to add 2 new constructors (a measurement of acceptance and impact the other change manage-ment) and also include an additional aspect to the builder for improvement of physical processes (the application the theory of constraints).
Keywords:
ERP, SME, processes.
Introducción
No hay duda del interés que despierta la utilización de las tecnologías de la información para mejorar el des-empeño de las empresas y, en los últimos años, la tendencia de lograr que a las Tecnologías de la Información (TI) agreguen valor a sus empresas y estén alineadas con las estrategias del negocio (Luftman et al, 1999; Croteau, et al 2001).
Según Ariss (Ariss et al, 2000) PYME (Pequeñas y Medianas Empresas) que adoptan sistemas ERP lo hacen debido a:

UIGV98
• Los beneficios relacionados con el producto / mercado (mejora de la calidad del producto, la mejora en el diseño del producto).
• Los beneficios financieros (flujo de caja, la disponibilidad de los programas de financiamiento del gobierno, de asistencia financiera).
• Gestión y los beneficios de la organización (orientación estratégica en lo que respecta a la tecnología, la exposición de la gestión de la tecnología).
• Las relaciones entre la gerencia y los empleados (la competencia de los empleados, aumento de la produc-tividad).
• Los beneficios relacionados con el sector de actividad (la competitividad en términos de coste, los requisitos ambientales).
Cómo los ERP pueden generar valor para las PYME si:
1. A pesar de la adopción a gran escala de los sistemas ERP y el impulso que están logrando en el mercado de las PYME, la investigación existente sugiere que los beneficios esperados de estos sistemas no siempre son alcanzados (Millet y Grabot 2005).
2. La mayor parte de las investigaciones acerca de modelos y metodología de implementación de ERP en PYME analizan Pyme de otras realidades culturales, sociales y económicas, podemos tomar como ejemplo la definición de empresa media que hace el grupo Garnerd para su Cuadrante mágico de Gartner para productos ERP para compañías medio centradas en el producto (Hestermann et al 2010):
• Compañías medias bajas: Las organizaciones con ingresos anuales de aproximadamente menos de $100 millones.
• Compañías medias centrales: Las organizaciones con ingresos anuales de aproximadamente entre $ 100 millones y US $250 millones.
• Compañías medias Altas: Las organizaciones con ingresos anuales de aproximadamente más de $250 millones.
3. Y además debemos tener en cuenta que los Enterprise Resource Planning (ERP) son complejos y la aplicación de uno puede ser un proyecto difícil, largo y costoso para cualquier empresa (Davenport, 1998). Y especialmente difícil es para las PYME que no cuentan con recursos suficientes, capacidad y experiencia del proyecto ERP. A pesar de importantes inversiones de tiempo y recursos, no hay ninguna garantía de éxito (Mabert et al, 2003).
En consecuencia, para lograr los beneficios deseados, la implementación de ERP debe ser cuidadosamente gestionada y supervisada para obtener el máximo provecho (Bingi et al, 1999).
Por ello es necesario un modelo de implementación que tenga en cuenta:
• Los principales factores críticos de éxito de una implementación de ERP en PYME (Loh & Koh, 2004, Estebes & Pastor, 2004).
• Las principales desventajas de las PYME (Wong & Aspinwall, 2004).
• El ciclo de vida del ERP (Esteves & Pastor, 1999).
a. El modelo debe comprender la fase de decisión de adopción, fase de adquisición, fase de implementación, fase de uso y mantenimiento, fase de la evolución. En caso de las PYME, la fase de decisión de adopción es la más importante, porque en ésta se define si la empresa necesita realmente un ERP.

UIGV99
b. Y también debe tener en cuenta las dimensiones de gestión de cambio, personas y procesos.
En un principio, se establece la premisa de la utilización de soluciones ERP Open Source para la implementa-ción en las PYME debido a los menores costes en comparación a los altos costes de los ERP propietarios (incluye coste inicial y de mantenimiento), costes a los que no podrían acceder este tipo de empresas debido a su tamaño (Johansson, 2008), el aumento en la capacidad de adaptación de los ERP, y su menor dependencia de un único proveedor (Serrano and Sarriegi, 2006).
El resto del trabajo tendrá la siguiente estructura: el capítulo 2, evaluación de modelos de implementación de ERP. En el capítulo 3, vemos modelo de implementación; en el capítulo 4, de los aportes hechos al modelo elegido; en el capítulo 5, la discusión; en el capítulo 6, las conclusiones; en el capítulo 7, la referencia a trabajos futuros, y en el 8, la bibliografía.
Conclusiones
Se concluye debido a que los modelos evaluados son aplicados en realidades distintas y a empresas de mayor tamaño. Se tiene que tomar en cuenta los factores de aceptación de tecnologías de la información e impacto que tendrá la implementación de un ERP en los recursos humanos.
Como las PYME, donde se sugiere comenzar los pilotos de implementación (PYME textiles), difícilmente cuentan con sistemas de información, entonces la gestión de cambio resulta un aspecto primordial. También tenemos que tener en cuenta que la mayoría de las PYME no tienen procesos formalizados, para lo cual la implementación de la teoría de restricciones será muy beneficiosa y además ayudará a promover una cultura de mejoramiento continuo.
Referencias
[1] [Brown & Lockett, 2004] Brown, D.H. and Lockett, N. (2004), Potential of critical e-applications for engaging SMEs in e-business: a provider perspective, European Journal of Information Systems, Vol. 13 No. 1, pp. 21-34.
[2] [Millet y Grabot 2005] Botta-Genoulaz, V., Millet, P., and Grabot, B. (2005). A survey on the recent research literature on ERP systems, Computers in Industry, 56, 510-522.
[3] [Luftman et al, 1999] Luftman, J, Papp, R & Brier, T (1999), “Enablers and inhibitors of business-IT alignment”, Communications of the association for information system, Vol. 1, Issue 3es, Article No. 1. [Croteau, et al, 2001] Croteau, AM; Solomon, S; Raymond, L & Bergeron, F (2001), “Organizational and technological infrastructures alignment”, in System Sciences 2001, Proceedings of the 34th Hawaii International Conference on System Sciences, 9pp.
[4] [Hestermann et al 2010] Christian Hestermann, Chris Pang, Nigel Montgomery (2010): Magic Quadrant for ERP for Product-Centric Midmarket Companies. - Gartner’s, 17 December 2010.
[5] [Johansson & Sudzina, 2008] B. Johansson, F. Sudzina, (2008) ERP systems and open source: an initial review and some implications for SMEs, Journal of Enterprise Information Management, Vol. 21 Iss: 6, pp.649 – 658.
[6] [Serrano & Sarriegi, 2006] Serrano, N.S. and Sarriegi, J.M. (2006), Open source software ERPs: a new Alternative for an old need, IEEE Software, Vol. 23 No. 3, pp. 94-7.
[7] [Yusof & Aspinwall, 2000] Yusof, S.M., & Aspinwall, E. (2000). A conceptual framework for TQM implemen-tation for SMEs. The TQM Magazine, 12, 31-36.

UIGV100
[8] [Yusof, 2000] Yusof, S.M. (2000). Development of a framework for TQM implementation in small businesses. University of Birmingham, Birmingham.
[9] [Hudson, 2003] Hudson, M. (2003). Continuous strategic improvement through efective performance mea-surement: A guide for SMEs. Plymouth: Plym consulting.
[10] [Hudson et al, 2001] Hudson, M., Smart, A.& Bourne,M. (2001). Theory and practice in SME performance measurement systems. International Journal of Operations & Production Management, 21, 1096-1115.
[11] [Wiegers, 1998] Wiegers, K. (1998) Know your enemy: software risk management. Software Development, 6.
[12] [Brown & Vessey, 998] Brown and Vessey (1998) started the identification of ERP implementation variables that may be critical to a successful implementation. These variables are then incorporated into a preliminary contingency framework.
[13] [Ariss et al, 2000] S. S. Ariss, T. S. Raghunathan, and A. Kunnathar (2000), “Factors affecting the adoption of advanced manufacturing technology in small firms,” S.A.M. Advanced Management Journal, 2000, vol. 65, no. 2, pp. 14-29.
[14] [Davenport, 1998] T. H. Davenport (1998), “Putting the enterprise into the enterprise system,” Harvard Business Review, July-August, 1998, pp. 121-131.
[15] [Mabert et al, 2003] V. A. Mabert, A. Soni and M. A. Venkataramanan (2003), “Enterprise resource plan-ning: Managing the implementation process,” European Journal of Operational Research, 2003, vol. 146, pp. 302-314.
[16] [Bingi et al, 1999] P. Bingi, M. K. Sharma and J. K. Godla (1999), “Critical issues affecting an ERP imple-mentation,” Information Systems Management, 1999, vol. 16, no. 3, pp. 7–14.
[17] [Sumner, 2000] Sumner, M. (2000). “Risk Factors in Enterprise-Wide/ERP Projects”. Journal of Information Technology, vol. 15, n. 4, December (2000), 317-328.
[18] [Estebes & Pastor, 2004] Estebes, J., & Pastor, J. (2004). Proyectos ERP exitosos como base de ventajas com-petitivas. Revista de empresa nº 9, 32-44.
[19] [Flores, 2004] Flores, K. A. (2004). Metodología de Gestión para las Micro, pequeñas y medianas empresas en Lima Metropolitana. Lima, Perú: Universidad Nacional Mayor de San Marcos.
[20] [Goldratt, 1997] Goldratt, E. (1997). Critical Chain. Madrid, España: Díaz Santos.
[21] [Goldratt, 2004] Goldratt, E. (2004). La Meta. Uruguay, Montevideo: Ediciones Granica S.A.
[22] [Muñiz, 2004] Muñiz, L. (2004). ERP, guía práctica para la selección e implantación: ERP, enterprise resource planning o sistema de planificación de recursos empresariales. España: Gestión 2000.
[23] [Wallace & Kremzar, 2001] Wallace, T., & Kremzar, M. (2001). ERP: Making It Happen “The Implementers’ Guide to Success with Enterprise Resource Planning”. John Wiley & Sons, Inc.
[24] [Yong, 2004] Yong, L. (2004). Modelo de Aceptación Tecnológica (TAM) para determinara efectos de las Dimensiones de Cultura Nacional en la Aceptación de las TIC. Revista Internacional de Ciencias Sociales y Humanidades, SOCIOTAM, 131-171.
[24] [Loh & Koh, 2004] Loh, T. C., & Koh, S. L. (2004). Critical elements for a successful enterprise resource planning implementation in small-and medium-sized enterprises. International Journal of Production Research, 42(17),3433-3455.

UIGV101
[25] [Hestermann et al, 2010] Christian Hestermann, Chris Pang, Nigel Montgomery (2010): Magic Quadrant for ERP for Product-Centric Midmarket Companies. - Gartner’s, 17 December 2010.
[26] [Wong & Aspinwall, 2004] Wong, K.Y., & Aspinwall, E. (2004). Characterizing knowledge management in the small business environment. Journal of Knowledge Management, 8(3), 44-6.
[27] [Esteves & Pastor, 1999] Esteves, J & Pastor, J (1999). An ERP Life-cycle-based Research Agenda. First Interna-tional workshop in Enterprise Management and Resource.
[28] [Umble et al, 2006] Umble M, Umble E, Murakami S (2006) Implementing theory of constraints in a traditional Japanese manufacturing environment: The case of Hitachi Tool Engineering. IJPR 44: 1863–1880

UIGV102

UIGV103
Comparações entre o Paradigma Orientado a Objetos e o Paradigma Orientado a Notificações sob o contexto de um simulador de sistema telefônicoRobson R. Linhares1,2, Adriano F. Ronszcka1, Glauber Z.Valença2, Márcio V. Batista1,Fernando Witt, Carlos R. Erig Lima1, Jean M. Simão1,2, Paulo C. Stadzisz1,2
Universidade Tecnológica Federal do Paraná 1 Programa de Pós-graduação em Engenharia Elétrica e Informática Industrial (CPGEI) 2 Programa de Pós-graduação em Computação Aplicada (PPGCA) [email protected], ronszcka, gvalencio, marcio.venancio {@gmail.com}, [email protected], erig, stadzisz, jeansimao {@utfpr.edu.br}
Resumo
Este artigo apresenta uma revisão dos conceitos relacionados ao Paradigma Orientado a Notificações (PON) e uma comparação, qualitativa e quantitativa, de uma mesma aplicação (simulador de sistema de telefonia) desenvol-vida segundo os princípios do PON e segundo os princípios do Paradigma Orientado a Objetos (POO). O PON se apresenta como uma alternativa aos Paradigmas de Programação Imperativa (PI), incluindo o POO, e aos Paradigmas de Programação Declarativa (PD), propondo-se a eliminar deficiências destes no que tange a aspectos de redundân-cias e acoplamento de avaliações causais que impactam no desempenho e paralelismo/distribuição de aplicações. A comparação apresentada neste artigo abrange desde aspectos de modelagem, por meio de técnicas tais como UML e Redes de Petri, até questões relacionadas à implementação e ao desempenho relativo entre as aplicações. O experimento demonstra que, embora o desempenho do PON tenha sido inferior ao do POO para a aplicação desen-volvida, em função de características da aplicação e de um ambiente de execução ainda não totalmente adaptado ao paradigma, existem aspectos relativos à modelagem que podem ser levados em consideração e incentivar a utilização do PON em aplicações com requisitos de paralelismo ou distribuição.
Palavras chave:
Comparações qualitativas e quantitativas, paradigmas de programação, simulador de sistema de telefonia.
Abstract
This paper presents a review of the concepts related to the Notification-Oriented Paradigm (NOP) and a qualitative and quantitative comparison of a certain application (simulator of a telephone switch) developed according to NOP principles and the same application developed according to Object-Oriented Paradigm (OOP) principles. NOP pre-sents itself as an alternative to the Imperative Programming (IP) paradigms, such as OOP, as well as to the Declarative Programming (DP) paradigms, with the purpose of eliminating deficiencies of those paradigms concerning to redun-dancy issues and coupling of causal expressions, which affect the execution performance and parallelism/distribution of applications. The presented comparison includes not only modelling aspects, by means of techniques such as UML and Petri Nets, but also issues related to implementation and relative performance of the applications. The experiment demonstrates that, even though the NOP performance is worse than OOP performance for the developed application, due to application characteristics and a runtime environment not completely adapted to NOP, there are some aspects related to modelling which can be taken into consideration and encourage the use of NOP on applications requiring parallelism and distribution.
Keywords:
Qualitative and quantitative comparisons, programming paradigms, simulator of a telephone switch.

UIGV104
Introdução
A capacidade de processamento computacional tem crescido em função da evolução das tecnologias neste contexto [Tanenbaum e Van Steen, 2002]. Entretanto, recursos oferecidos por soluções computacionais modernas, tais como paralelismo e distribuição ou mesmo a utilização da capacidade plena de cada processador, nem sempre são devidamente aproveitados em função de limitações das técnicas de programação [Simão e Stadzisz, 2008, 2009].
Na verdade, técnicas de programação baseadas no estado da arte, como o chamado Paradigma de Progra-mação Orientada a Objetos (POO) ou os Sistemas Baseados em Regras (SBR), sofrem de limitações intrínsecas de seus paradigmas. Estes paradigmas poderiam ser genericamente classificados como Paradigma Imperativo (PI) e Paradigma Declarativo (PD) que englobam respectivamente o POO e os SBR [Banaszewski, 2009].
Particularmente, estes paradigmas levam ao forte acoplamento de expressões causais e redundâncias decorrentes das suas avaliações. Estas limitações dificultam a execução paralela ou distribuída de programas e frequentemente comprometem o seu desempenho pleno mesmo em sistemas monoprocessados. Assim, existem motivações para buscas de alternativas aos PI e PD, com o objetivo de eliminar ou diminuir as desvantagens deles [Banaszewski et al., 2007][Banaszewski, 2009][Gabbrielli, Martini, 2010][Roy e Haridi, 2004][Simão e Stadzisz, 2008, 2009].
Neste âmbito, uma alternativa é o Paradigma Orientado a Notificações (PON). O PON foi concebido a partir de uma teoria de Controle Discreto e Inferência [Simão, 2001, 2005; Simão e Stadzisz, 2002, 2008, 2009; Simão, Stadzisz e Tacla, 2009; Simão, Stadzisz e Künzle, 2003]. Ele se propõe a eliminar algumas das deficiên-cias dos atuais paradigmas em relação a avaliações causais desnecessárias e acopladas, evitando o processo de inferência monolítico baseado em pesquisas por meio de um mecanismo baseado no relacionamento de entidades computacionais notificantes [Banaszewski et al., 2007][Banaszewski, 2009][Simão e Stadzisz, 2008, 2009].
Neste artigo são apresentados resultados de uma comparação efetuada entre uma implementação de software segundo o POO e outra segundo o PON, no contexto de uma simulação de terminais telefônicos. A análise dos resultados tem como foco os aspectos de facilidade de modelagem, facilidade de implementação e desempenho relativo, de maneira a apresentar uma visão crítica sobre a aplicabilidade do PON e as potencialidades em re-lação ao desenvolvimento de técnicas e ferramentas voltadas para este paradigma.
Este artigo está organizado como segue: a Seção 2 reflete sobre o estado da arte. A Seção 3 apresenta o PON. As Seções 4 e 5 apresentam o software em POO e PON. A Seção 6 discute os experimentos. A Seção 7, por fim, apresenta conclusões e perspectivas de trabalhos.
Conclusões
O caso de estudo utilizado não favorece o PON na comparação com o POO no que tange ao desempenho. No entanto, tendo em vista as limitações apresentadas, que são peculiares para o conceito de sistema utilizado como caso de estudo e para a plataforma de execução, ainda assim é possível afirmar que a implementação de sistemas segundo PON pode trazer ganhos de desempenho. Isto foi verificado em um caso de estudo baseado em um sistema de condicionamento de ar [Banaszewski, 2009], o qual apresenta muito mais relações causais e, portanto, redundâncias temporais e estruturais do que o caso de estudo proposto neste trabalho.
Além disso, um outro trabalho está em curso investigando a modelagem e implementação dos elementos PON em lógica reconfigurável por hardware. Os resultados preliminares mostram que o desempenho é superior à versão POO implementada segundo a mesma abordagem, comprovando a hipótese de que um ambiente de execução concebido segundo os princípios de paralelismo do PON pode eliminar muitas das limitações de desempenho impostas por ambientes baseados no modelo tradicional de execução sequencial de instruções.
No que tange à modelagem e implementação, a modelagem PON proposta com o uso de RdP deve ser inves-tigada e aprimorada, visto que pode se constituir em uma ferramenta importante para o processo de desenvolvi-

UIGV105
mento de software segundo o PON. A existência de um processo de desenvolvimento com técnicas bem definidas e de eficácia verificada, por sua vez, é fundamental para a aceitação e disseminação do uso do paradigma.
Ainda, como extensão deste trabalho sugere-se os seguintes temas:
• Aplicação da técnica de modelagem utilizada em casos de estudo nos quais se evidencie a existência de redundâncias estruturais e temporais, verificando as consequências e as influências da técnica de modela-gem nestas condições.
• Estender a análise comparativa entre POO e PON para questões relacionadas ao comportamento temporal do software, principalmente em relação a técnicas de estimação de tempo de execução de programas quando aplicadas a software concebido segundo o PON.
• Prosseguir com o trabalho relativo à implementação do PON em lógica reconfigurável por hardware.
Referências
[1] [Banaszewski et al., 2007] Banaszewski, R. F.; Stadzisz, P. C.; Tacla, C. A.; Simão, J. M. “Notification Oriented Paradigm (NOP): A software development approach based on artificial intelligence concepts,” in Proceedings of the VI Congress of LAPTEC, Santos, Brazil, 2007
[2] [Brookshear, 2006] Brookshear, J. G. “Computer Science: An Overview”. Addison Wesley, 2006.
[3] [Banaszewski, 2009] Banaszewski, R. F. “Paradigma orientado a notificações: avanços e comparações”. Dissertação de Mestrado - CPGEI/UTFPR, 2009 – Disponível em: http://arquivos.cpgei.ct.utfpr.edu.br/Ano_2009/dissertacoes/Dissertacao_500_2009.pdf.
[4] [eSysTech, 2006] eSysTech. “eAT55 ARM Evaluation Board: Manual do Usuário”. Rev 4. March 2006.
[5] [Gabbrielli e Martini, 2010] Gabbrielli, M., Martini, S. “Programming Languages: Principles and Paradigms. Series: Undergraduate Topics in Computer Science”. 1st Edition, 2010, XIX, 440 p., Softcover. ISBN: 978-1-84882-913-8.
[IAR Systems, 2005] IAR Systems. “ARM IAR Embedded Workbench IDE User Guide”. 11th Edition, June 2005
[6] [Roy e Haridi, 2004] Roy, P. V.; Haridi, S. “Concepts, Techniques, and Models of Computer Programming”. MIT Press, 2004.
[7] [Scott, 2000] Scott, M. L. “Programming Language Pragmatics”, 2º Edition, p. 8, San Francisco, CA, USA: Morgan Kaufmann Publishers Inc, 2000.
[8] [Silva et al., 1998] Silva, M.; Teruel, E.; Valette, R.; Pingaud, H. “Petri nets and production systems,” in Lectures on Petri Nets II: Applications, vol. 1492. New York: Springer-Verlag, 1998, pp. 85–124.
[9] [Simão, 2001] Simão, J. M. “Proposta de uma Arquitetura de Controle para Sistemas Flexíveis de Manufatura Baseada em Regras e Agentes”. Dissertação de Mestrado, CPGEI/UTFPR, Curitiba, 2001.
[10] [Simão, 2005] Simão, J. M. “A Contribution to the Development of a HMS Simulation Tool and Proposition of a Meta-Model for Holonic Control”. Tese de Doutorado, CPGEI/UTFPR, Curitiba, 2005. Disponível em: http://arquivos.cpgei.ct.utfpr.edu.br/Ano_2005/teses/Tese_012_2005.pdf.
[11] [Simão e Stadzisz, 2002] Simão, J. M.; Stadzisz, P. C. “An Agent-Oriented Inference Engine applied for Su-pervisory Control of Automated Manufacturing Systems”. In: J. Abe & J. Silva Filho, Advances in Logic, Artificial Intelligence and Robotics (Vol. 85, pp. 234-241). Amsterdam, The Netherlands: IOS Press Books, 2002.

UIGV106
[12] [Simão, Stadzisz e Künzle, 2003] Simão, J. M.; Stadzisz, P. C.; Künzle, L. “Rule and Agent-oriented Architec-ture to Discrete Control Applied as Petri Net Player”. 4th Congress of Logic Applied to Technology, LAPTEC, 101, p. 217, 2003.
[13] [Simão e Stadzisz, 2008] Simão, J. M.; Stadzisz, P. C. “Paradigma Orientado a Notificações (PON) – Uma Técnica de Composição e Execução de Software Orientado a Notificações”. Pedido de Patente submetida ao INPI/Brazil (Instituto Nacional de Propriedade Industrial) em 2008 e a Agência de Inovação/UTFPR em 2007. No. INPI Provisório 015080004262. Nº INPI Efetivo PI0805518-1. Patente submetida ao INPI. Brasil, 2008.
[14] [Simão e Stadzisz, 2009] Simão, J. M.; Stadzisz, P. C. “Inference Process Based on Notifications: The Ker-nel of a Holonic Inference Meta-Model Applied to Control Issues”. IEEE Transactions on Systems, Man and Cybernetics. Part A, Systems and Humans, Vol. 39, Issue 1, 238-250, Digital Object Identifier 10.1109/TSMCA.2008.20066371, 2009.
[15] [Simão, Stadzisz e Tacla, 2009] Simão, J. M., Stadzisz, P. C.; Tacla, C. A. “Holonic Control Meta-Model”. IEEE Transactions on Systems, Man and Cybernetics. Part A, Systems and Humans, Vol. 39, No. 5, September 2009 Pg. 1126-1139.
[16] [Tanenbaum, Steen, 2002] Tanenbaum, A.S.; Van Steen, M. “Distributed Systems: Principles and Paradigms”, Prentice Hall, 2002.
[17] [Watanabe et al., 1997] Watanabe, H.; Tokuoka, H.; Wu, W.; Saeki, M. “A Technique for Analysing and Testing Object-oriented Software Using Coloured Petri Nets”, IPSJ SIGNotes Software Engineering No.117, 1997.

UIGV107
Un Modelo de Aula Virtual en la enseñanza universitaria de pregrado en la Facultad de Medicina Humana de la USMP
Jorge Raúl Carreño Escobedo1, Inés Victoria Cotrina Giraldo2
José Hamblett Villegas Ortega3
Unidad de Post Grado de la Facultad de Ingeniería de Sistemas e InformáticaUniversidad Nacional Mayor de San [email protected], [email protected], [email protected]
Resumen
En el presente trabajo, se presentan diversos problemas en el manejo actual del aula virtual de la USMP, como es en la administración de la accesibilidad, mantenimiento, entre otras. Para esto, se hace la revisión de varios modelos de educación, como los de las universidades de Bío Bío en Chile, Alcalá de España y de Yucatán en México. Así mismo, se estudia la metodología de Kolb que se orienta al aprendizaje a distancia. Ninguna tiene el modelo perfecto para solucionar el caso particular, sin embargo se propone un modelo híbrido que resume los modelos anteriormente mencionados, añadiéndose el aporte del autor.
Palabras clave:
TIC, aula virtual, aprendizaje virtual.
Abstract
There are various problems in the current management of virtual classroom of the USMP, as in the administration of accessibility, maintenance, among others. For this, it makes the review of several models of education such as uni-versities Bio Bio in Chile, Alcalá in Spain and Yucatan in Mexico. It also examines the methodology that is geared Kolb distance learning. Neither has the perfect model to solve the case, however, proposes a hybrid model that summari-zes the above mentioned models, adding the contribution of the author.
Keywords:
ICT, virtual classroom, learning
Introducción
Hoy, las instituciones están dando un giro de 180° en la modalidad de la educación. La educación tradicional se ve afectada positivamente por los recursos TIC, los cuales sirven de apoyo en la educación a distancia.
Haciendo uso de la tecnología, la enseñanza tradicional in situ se ve complementada, es decir, las clases, im-partidas por los docentes de alguna materia de estudio, ahora se puede hacer remotamente.
Las universidades, también son afectadas por las herramientas tecnológicas que apoyan a la educación a dis-tancia o valga decir de la enseñanza e-learning (aprendizaje a distancia), las cuales mejoran la competitividad del alumno) [GÁMEZ, 2008].

UIGV108
Se presenta varios modelos de educación que incluyen el uso de tecnología para aprendizaje a distancia. Para el caso de una Universidad que se dedica a la enseñanza de Medicina, complementa muy bien el tema cuando se hace la publicación de las clases oportunamente.
Actualmente, la Universidad de San Martín de Porres de La Molina, Lima - Perú, cuenta con una Aula Virtual que “acoge” a todas las facultades por lo que resulta confuso la administración de usuarios; el tiempo de respuesta ante cualquier suceso es de hasta un mes, el funcionamiento del Aula Virtual se ve constantemente interrumpido, no pudiéndose tener un servicio óptimo las 24 horas del día.
Para el caso de la Universidad de San Martín de Porres, como propuesta, se estima una plataforma virtual (aula virtual) que sea propia de la facultad de Medicina, dedicada a tiempo completo, y que sea administrable de acuerdo con las necesidades emergentes actuales, tanto de los alumnos, docentes como de los administrativos involucrados en el tema de la enseñanza. Además, debe darse el soporte oportuno en el momento indicado, sin demoras, ni confusiones de usuarios.
Esta investigación pretende presentar un modelo de aula virtual para la Universidad de San Martín de Porres, en la Facultad de Medicina Humana acorde con la enseñanza a distancia.
En la parte 2, se considera las metodologías propias de diversas universidades que desarrollaron, así como de la metodología de Kolb que se orienta a la enseñanza e-learning.
Podemos mencionar algunos problemas priorizados:
• Se ha observado una mala administración del aula virtual actual de la USMP, provocando errores en los usuarios y contraseñas, así como de constante interrupción del servicio de la plataforma actual.
• Clases no estandarizadas para los alumnos debido a que el Sistema de Educación tradicional no coordina constantemente en el uso adecuado de herramientas que apoyen la enseñanza.
• Conexión a Internet con constantes “caídas” (fallas) del servicio que dificultan el acceso a la publicación de material universitario a los alumnos en la Universidad de San Martín de Porres, Área de Ciencias Básicas de la Facultad de Medicina Humana.
Conclusiones
La indagación y documentación obtenida concluye que existen numerosos autores, como Alonso y Gallego (1999), que abordan el tema de estilos de aprendizaje desde el ámbito de la educación tradicional. Asimismo, se encontró que, a la fecha, ha sido incipiente lo indagado sobre los estilos de aprendizaje en la modalidad de educación virtual y a distancia: faltan más estudios.
De todos los modelos de educación que abordan el uso de TIC para el aprendizaje, el que está mejor orientado es el modelo de Kolb para el aprendizaje virtual.
La intención de este artículo es presentar un híbrido como modelo propuesto de aula virtual en base a los ya existentes.
Es recomendable que se tenga en cuenta, como mínimo, los dos siguientes elementos:
Uso de la plataforma Moodle como recurso tecnológico basado en el constructivismo que integra el desarrollo de habilidades y competencias cognitivas y sociales, como pensar, comprender, reflexionar y proponer.
Para lograr el uso pedagógico de la plataforma Moodle es importante comprender que ésta sólo es el medio a través del cual se interactúa en el proceso de transferencia y construcción de conocimientos, pero subyace a ella

UIGV109
la propuesta pedagógica establecida desde el diseño del curso, con estrategias metodológicas que respondan a las diversas necesidades de los estudiantes, con base en los estilos de aprendizaje del modelo de Kolb (divergente, asimilador, convergente y acomodador).
Referencias
[1] [Alcalá, 2010] Alcalá, U. (2010). Modelo Educativo de la Universidad de Alcalá. Obtenido de http://www.uah.es/medicina/facultad/documentos/documents/Modelo_Educativo_UAH.pdf
[2] [articuloz, 2011] Ventajas De Utilizar Moodle, http://www.articuloz.com/internet-articulos/ventajas-de-utili-zar-moodle-4155126.html
[3] [Bío Bío, 2009] Bío-Bío, V. A. (2009). Universidad de Bío Bío. Recuperado el 2011, de Modelo Educativo de la Unviersidad del Bío Bío:
http://www.ubiobio.cl/web/descargas/Modelo_Educativo_08.07.08.pdf
[4] [GÁMEZ, 2008] ALICIA GÁMEZ DE MOSQUERA, El uso de nuevas tecnologías como perspectiva para una universidad competitiva:
http://www.rieoei.org/deloslectores/2162Mosquera.pdf, Universidad Nacional Experimental Simón Rodrí-guez, Venezuela, Revista Iberoamericana de Educación, ISSN: 1681-5653.
[5] [Higuera, 2007] Higuera, & Ehil Contreras, W. (2007). Obtenido de EVOLUCIÓN DE LAS AULAS VIRTUALES EN LAS UNIVERSIDADES TRADICIONALES CHILENAS: EL CASO DE LA UNIVERSIDAD DEL BÍO-BÍO. (Span-ish):
https://search.ebscohost.com/login.aspx?direct=true&db=zbh&AN=33247763&lang=es&site=ehost-live
[6] [Kolb, 1984,a] Kolb, D. (1984a). Experiential learning experiences as the source of learning development. Nueva York: Prentice Hall.
[7] [Kolb, 1984,b] Kolb, D. (1984b). Psicología de las organizaciones: experiencia. México: Prentice Hall.
[8] [Romero, 2010]Romero Agudelo, L. N., Salinas Urbina, V., & Mortera Gutiérrez, F. J. (Abril de 2010). Ebsco. Obtenido de Estilos de aprendizaje basados en el modelo de Kolb en la educación virtual:
https://search.ebscohost.com/login.aspx?direct=true&db=zbh&AN=52762764&lang=es&site=ehost-live
[9] [Yucatán, 2011] Yucatán, U. A. (2011). Obtenido de Comisión para la Elaboración de la Propuesta del Nuevo Modelo Educativo: http://www.uady.mx/pdfs/me.pdf

UIGV110

UIGV111
Framework de Testes para Algoritmos de Decisão de Handover Vertical em Redes Heterogêneas
Anderson S. F. da Silva1, Ricardo J. de P. B. Salgueiro1, Edilayne M. Salgueiro1
1 Universidade Federal de [email protected], [email protected], [email protected]
Resumo
Diante de um contexto de heterogeneidade de redes, surge a necessidade de decidir a que rede um dispositivo móvel se associará em um dado momento, para oferecer ao usuário a rede que melhor se adéqüe às suas necessi-dades. Nesse sentido, têm sido propostos diversos algoritmos de decisão para auxiliar no processo de handover. O trabalho aqui apresentado consiste na proposição de um framework de testes para algoritmos de decisão de hando-ver em redes heterogêneas. Com o framework proposto averiguou-se o funcionamento de um método de decisão baseado no Processo Analítico Hierárquico. Observamos também o impacto dos parâmetros de QoS utilizados como critério para a decisão.
Palavras chave:
Wi-Fi, WiMAX, QoS.
Abstract
Given the context of heterogeneous networks, there is a need to decide which network to associate a mobile devi-ce at any given time, to give the user the network that best fits your needs. Accordingly, several algorithms have been proposed to assist in the decision process of handover. The work presented here is to propose a testing framework for handover decision algorithms in heterogeneous networks. With the proposed framework was examined the operation of a decision method based on Analytic Hierarchy Process. We also observed the impact of QoS parameters used as criteria for the decision.
Keywords:
Wi-Fi, WiMAX, QoS
Introdução
Atualmente observa-se uma grande diversidade de tecnologias de redes sem fio. O Bluetooth, ZigBee, Wi-Fi, WiMAX e os padrões 3G (Redes de telefonia celular de terceira geração) UMTS e CDMA2000 são exemplos de redes sem fio existentes. Vários dispositivos como notebooks, palmtops e smartphones já vêm equipados com mais de uma interface de rede para suportar mais de um tipo de rede sem fio.
Um dos objetivos das redes sem fio é liberar os seus usuários das limitações decorrentes das redes cabeadas, fornecendo-lhes o recurso da mobilidade. Usuários altamente móveis, isto é, que constantemente estão mudando de localização, possivelmente em altas velocidades, desejam estar sempre conectados a uma rede e manter suas aplicações funcionando enquanto eles estão se deslocando entre vários lugares. Isto aumenta bastante a complexi-dade destas redes ao fornecerem os seus serviços.

UIGV112
Com a crescente popularidade das redes sem fio e as diversas tecnologias desenvolvidas para estes tipos de redes, surgiu a necessidade de se promover uma convergência entre essas tecnologias, visando oferecer aos usuá-rios maior pervasividade e a possibilidade de estabelecer uma comunicação sem interrupções.
Acredita-se que o IP (Internet Protocol) será o meio pelo qual se dará a integração das diversas tecnologias de redes existentes, sejam elas sem fio ou não, definindo assim uma nova geração de redes móveis denominada 4G (quarta geração de redes wireless) [19]. A proposta da quarta geração é integrar um número potencialmente grande de diferentes tecnologias wireless, o que pode ser considerado um grande passo em direção ao acesso universal sem fio e à computação ubíqua, através de uma mobilidade que seja transparente ao usuário [15]. Os principais esforços para se atingir estes objetivos estão focados no desenvolvimento de dispositivos de rede que sejam multi-adaptativos, na definição de padrões que estabelecerão como será a alocação de largura de banda para um ambiente onde haja diversas redes envolvidas e na forma com a qual os dispositivos se associarão a uma determinada rede neste ambiente.
Um desafio sempre presente na área de redes sem fio é garantir a mobilidade de usuário quando ele se desas-socia de uma rede para se conectar a outra, muito provavelmente devido a uma mudança de localização. A essa mudança dá-se o nome de handover ou handoff. O handover pode ser caracterizado de duas formas: horizontal, quando as redes envolvidas na mudança pertencem à mesma tecnologia, e vertical, quando as tecnologias envol-vidas são diferentes.
Para realização de handovers horizontais, normalmente se considera como critério de decisão a potência dos sinais das redes que chegam ao terminal móvel. Outros critérios, porém, deverão ser considerados em handovers verticais, pois as diversas tecnologias muito provavelmente possuirão diferentes tipos de serviços, protocolos, políti-cas de acesso, níveis de qualidade, faixas de freqüência e custos monetários. Esses critérios, utilizados na seleção da rede de acesso mais adequada, poderão ser definidos em função das preferências do usuário, aplicações em execução e características das redes.
Dois fatores bastante importantes em handovers estão relacionados à necessidade deles serem efetuados de forma imperceptível ao usuário e a sua automação. Em ambientes onde há diversas tecnologias de acesso, surge o conceito ABC (Always Best Conected) [10], onde um nó móvel poderá realizar handovers para sempre se manter conectado à rede que melhor se adéqüe às necessidades definidas pelo usuário. Critérios como parâmetros de QoS (Quality of Service - Qualidade de Serviço) exigidos por determinados tipos de aplicações, ou características do terminal móvel, como consumo de energia, resolução da tela, poderão ser utilizados para manter essa política.
Neste sentido, têm sido desenvolvidas várias técnicas para auxiliar no processo de handover. Algoritmos de tomada de decisão comumente levam em consideração os critérios como os que foram mencionados anteriormente, para selecionar a rede que mais se adéqüe às necessidades do usuário e satisfaça as exigências das aplicações que estão sendo executadas no terminal móvel. Tendo em vista a importância destes métodos de decisão no pro-cesso de realização de handover, se faz necessário prover um meio para executá-los e validá-los. Ferramentas de simulação e emulação de redes são formas de testar tecnologias de rede, de tal forma que se possa reproduzir o comportamento real dessas tecnologias em um ambiente computacional controlado.
Este trabalho tem como objetivo disponibilizar uma forma de executar e testar algoritmos de decisão de hando-ver em redes heterogêneas. Para tal, propôs-se um framework de testes que promove um ambiente no qual os algo-ritmos de decisão possam obter as informações das redes envolvidas de forma mais próxima de um ambiente real.
A ênfase deste trabalho consiste em obter um meio de reproduzir o comportamento de redes de computadores, para representar as redes de acesso envolvidas no processo de execução de handover, considerando as infor-mações obtidas a partir dessas redes que servem como entrada para os algoritmos de decisão. Consideramos a utilização de emuladores de rede em conjunto com simulações para atingir esta finalidade. Utilizamos as redes Wi-Fi e WiMAX, respectivamente definidas pelos padrões IEEE 802.11 e 802.16, para testar o framework proposto.
O restante deste trabalho está organizado da seguinte forma: a seção 2 apresenta trabalhos relacionados que têm como objetivo a avaliação de handover vertical em redes heterogêneas. A seção 3 descreve as ferramentas utilizadas e o framework proposto. Na seção 4 são descritos os experimentos realizados. Os resultados obtidos

UIGV113
são apresentados na seção 5. Na seção 6, são apresentadas as conclusões alcançadas, as contribuições feitas e trabalhos futuros.
Referências
[1] 3GPP, Services and service capabilities 3.6.0 (1999). http://www.3gpp.org/ftp/Specs/archive/22{_}series/22.105/22105-360.zip.
[2] Advanced Network Technology Division, National Institute of Standards and Technology, Seamless and Secure Mobility.
http://www.antd.nist.gov/seamlessandsecure.
[3] Ahmed, T., K. Kyamakya, M. Ludwig, K. Anne, J. Schroeder, S. Galler, K. Kyamakya, K. Jobmann, S. Rass, J. Eder et al., A context-aware vertical handover decision algorithm for multimode mobile terminals and its per-formance, in: The 13th International Conference on Neural Information Processing (ICONIP’06), Hong Kong, 2006.
[4] Baldo, N., Maguolo, F., Miozzo, M., Rossi, M., Zorzi, M. ns2-MIRACLE: a modular framework for multi-technology and cross-layer support in network simulator 2, in: Proceedings of the 2nd International Conference on Performance Evaluation Methodologies and Tools, ICST, Brussels, Belgium, 2007, pp. 1–8.
[5] Bazzi, A., Pasolini, G., Gambetti, C. Shine: simulation platform for heterogeneous interworking networks, in: IEEE International Conference on Communications, 2006, pp. 5534–5539.
[6] Bridge-utils, IEEE 802.1d Ethernet bridging. http://sourceforge.net/projects/bridge/files
[7] Carbone, M. and L. Rizzo, Dummynet revisited, ACM SIGCOMM Computer Communication Review 40 (2010), pp. 12-20.
[8] Chen, J., C. Wang, F. Tsai, C. Chang, S. Liu, J. Guo, W. Lien, J. Sum and C. Hung, The design and implemen-tation of WiMAX module for ns-2 simulator, in: Proceeding from the 2006 workshop on ns-2: the IP network simulator, ACM, 2006, p. 5.
[9] Chen, Y., T. Farley and N. Ye, Qos requirements of network applications on the internet, Inf. Knowl. Syst. Manag. 4 (2004), pp. 55-76.
[10] Gustafsson, E. and A. Jonsson, Always best connected, IEEE Wireless Communications 10 (2003), pp. 49-55.
[11] Iperf. Página do projeto no sourceforge (2010). URL http://sourceforge.net/projects/iperf
[12] James, J., B. Chen and L. Garrison, Implementing VoIP: A voice transmission performance progress report, IEEE Communications Magazine 42 (2004), pp. 36-41.
[13] Kassar, M. and Kervella, B. and Pujolle, G. An overview of vertical handover decision strategies in heteroge-neous wireless networks, Computer Communications, Elsevier (2008).
[14] Mapp G., Shaikh F., Cottingham, D., Crowcroft, J., Baliosian, J. Y-Comm: a global architecture for heteroge-neous networking, in: 3rd ICST/ACM International Conference on Wireless Internet, Belgium, 2007, pp. 1–5.
[15] Nasser, N., A. Hasswa and H. Hassanein, Handoffs in fourth generation heterogeneous networks, IEEE Com-munications Magazine 44 (2006), pp. 96-103.
[16] Saaty, T., How to make a decision: the analytic hierarchy process, Interfaces 24 (1994), pp. 19-43.

UIGV114
[17] Seeling, P., M. Reisslein and B. Kulapala, Network performance evaluation using frame size and quality traces of single-layer and two-layer video: A tutorial, Technical report, Arizona State University (2004).
[18] Traces, Video traces for network performance evaluation (2010). URL http://trace.eas.asu.edu/tracemain.html
[19] Zhang, W., J. Jaehnert and K. Dolzer, Design and evaluation of a handover decision strategy for 4th genera-tion mobile networks, 3, 2003, pp. 1969-1973.

UIGV115
Sistema Inteligente basado en Redes Bayesianas para el diagnóstico Clínico de Enfermedades CutáneasRosangela Abregu M.1, Joseph Gonzales M.1, Nancy Laurente G.1, Jorge L. Távara1,Virgilio Tito C.1
1 Universidad César [email protected], [email protected], [email protected], [email protected], [email protected]
Resumen
En este artículo, se presenta un sistema inteligente para el diagnóstico clínico de las enfermedades cutáneas basa-do en las redes bayesianas, para lo cual se aplicaron algunos clasificadores bayesianos, tales como, el naïve bayes y el bayesnet que proporciona el software de aprendizaje automático y reconocimiento de patrones WEKA (http://www.cs.waikato.ac.nz/ml/weka/). Los datos con los que se trabajó fueron extraídos de la Clínica de la Piel (http://www.clinicadelapiel.com/) y se logró una clasificación correcta de datos del 98%.
Para llegar a esta clasificación se tuvieron que realizar pruebas utilizando el clasificador BayesNet que utiliza un algoritmo de búsqueda KÏ Hill Climbing y se utilizó el estimador simple como condición de probabilidad (Bouckaert, 2004) y el clasificador Naive bayes, siendo en este caso el clasificador BayesNet el que nos proporciona un mejor re-sultado y la red bayesiana óptima considera a seis padres como máximo en cada nodo. Finalmente, se implementa el aplicativo en java utilizando las probabilidades obtenidas en la red bayesiana.
Palabras clave:
Weka, BayesNet, Naïve bayes, enfermedades cutáneas.
Abstract
This article presents an intelligent system for the clinical diagnosis of skin diseases based on Bayesian networks, for which applied some Bayesian classifiers such as Naïve Bayes and bayesnet provided by the software of machine learning and pattern recognition WEKA (http://www.cs.waikato.ac.nz/ml/weka/). The data with which we worked were extracted from the Skin Clinic (http://www.clinicadelapiel.com/) and achieved a correct classification of data for 98%.
To achieve this classification had to test the classifier using BayesNet using a search algorithm K2 Climbing Hill and used the simple estimator as a condition of probability (Bouckaert, 2004) and the Naïve Bayes classifier, being in this case the classifier BayesNet which gives us a better result and the optimal Bayesian network sees a maximum of six parents in each node. Finally, the application is implemented in Java using the probabilities obtained in the Bayesian network.
Keywords:
Weka, BayesNet, Naive Bayes, skin diseases.

UIGV116
Introducción
Una de los principales males que afecta nuestra vida social son las enfermedades de la piel. Estas enfermedades de la piel afectan a personas de todas las edades, ya que todos en general estamos expuestos a la contaminación por gases tóxicos, los rayos ultravioletas y otros.
En la actualidad, hay un gran número de programas informáticos dedicados a la medicina y a sus diversas especialidades, sin embargo, no hay muchos programas dedicados a la dermatología.
Entre los que se pueden encontrar, destacan:
• Nail-TutorTM: un programa informático basado en imágenes, que enseña la anatomía, patrones patológi-cos y enfermedades de las uñas.
• Mycin: es un sistema experto desarrollado a principios de los años 70 por Edgar ShortLiffe, en la Universi-dad de Stanford, para diagnosticar enfermedades hematológicas. Fue escrito en Lisp y además era capaz de “razonar” el proceso seguido para llegar a estos diagnósticos, y de recetar medicaciones personalizadas a cada paciente (según su estatura, peso, etc.).
Para efectos de realizar el diagnóstico de enfermedades cutáneas, se extrajeron datos obtenidos en junio de la Clínica de la Piel. El número de casos con el que se trabaja es de 200, donde cada instancia tiene 14 atributos que diagnostican 6 enfermedades. En este trabajo, se muestran los resultados obtenidos por los clasificadores bayesianos Naïve Bayes y BayesNet para finalmente implementar en el lenguaje de programación Java el sistema inteligente.
El resto de este artículo está organizado de la siguiente manera. En la sección 2, se muestran los trabajos pre-vios. La sección 3 describe las redes bayesianas y los clasificadores bayesianos utilizados. La forma de colocar los Experimentos y Resultados se encuentra en la sección 4. La Discusión de los Experimentos se muestra en la sección 5 y, finalmente, la manera de redactar las conclusiones están en la sección 6.
Conclusiones
En el presente trabajo se han utilizado clasificadores bayesianos para el diagnóstico de enfermedades, esto a partir de los datos proporcionados por la Clínica de la Piel durante el mes de junio. Para este tipo de datos el clasificador BayesNet usando el algoritmo de búsqueda KÏ con 6 padres y como estimador de parámetros el de-nominado SimpleEstimator fue el que logró una clasificación correcta del 98%.
Podemos, por lo tanto, decir que los clasificadores bayesianos no solamente obtienen buenos resultados en la clasificación de este tipo de problemas, sino que además, en los casos en los que no hallan la hipótesis correcta proporcionan buenas alternativas, tomando como éstas las siguientes con mayor probabilidad a posteriori.
Una mejora al presente trabajo es recolectar mayor cantidad de información y mayor cantidad de enfermeda-des. Lo que se quiso comprobar con este trabajo es que los clasificadores bayesianos se pueden utilizar para el proceso de diagnóstico de enfermedades.
Es necesario evaluar con otros algoritmos de búsqueda dentro del clasificador BayesNet que proporciona WEKA, para visualizar las diferencias en el cálculo de las clasificaciones correctas, así mismo, el uso de otros estimadores.

UIGV117
Referencias
[1] [Bouckaert, 2004] Bouckaert Remco R. (2004) Bayesian Network Classiers in Weka.
[2] [Cooper, 1992] G. Cooper, E. Herskovits. (1992) A Bayesian method for the induction of probabilistic net-works from data. Machine Learning.
[3] [Cox, 2009] Cox N.H. (2009). Diagnosis of Skin Disease. Department of Dermatology. Cumberland Infi rmary, Carlisle, UK.
[4] [Hergueta, 2006] Hergueta G. Celia (2006). Sistema de Detección y Tratamiento de Enfermedades Cu-táneas. Escuela Técnica Superior de Ingeniería. Universidad Pontificia Comillas.
[5] [Issa, 2006] Issa O. (2006). Desarrollo de sistemas inteligentes para clasificación y diagnóstico en medicina. Departamento de arquitectura y tecnología de computadoras. Universidad de Granada.
[6] [Jouffe, 2011] Jouffe L. (2011). Introduction to Bayesian Networks Practical and Technical Perspectives. http://www.bayesia.com/en/applications/health.php
[7] [Korb, 2004] Korb K.B. y Nicholson A.E. (2004). Bayesian Artificial Intelligence. Chapman & Hall/CRC computer science and data analysis.
[8] [Orozco, 2010] Orozco E. (2010). Métodos de clasificación para identificar lesiones en piel partir de espe-ctros de reflexión difusa. Escuela de Ingeniería de Antioquia-Universidad CES, Medellín, Colombia.
[9] [Pessete, 2002] Pessete R.(2002). Redes Bayesianas no Diagnóstico Médico. Universidade Federal de Santa Catarina.
[10] [Weka, 2011] Weka (2011). Data Mining Software in Java. http://www.cs.waikato.ac.nz/ml/weka/
[11] [Zhang, 2002] Zhang H. (2002). The Optimality of Naive Bayes. Faculty of Computer Science. University of New Brunswick.

UIGV118

UIGV119
Modelo de Evaluación de desempeño para Docentes Peruanos basado en TIC
Pierre Paul Loncán Salazar1
1 Ingeniero de Sistemas - UNJFSCUnidad de Post Grado de la Facultad deIngeniería de Sistemas e Informática - [email protected]
José Hamblett Villegas Ortega2
2 Licenciado en Computación - UNMSMMagister en Ingeniería de Sistemas - UNMSMMBA(c) - Universidad del Pací[email protected]
Resumen
En este artículo, se presenta un Modelo de Evaluación de Desempeño Docente en Perú basado en TIC. Es bien sabido que la evaluación del desempeño resulta ser una necesidad que toda organización debe utilizar para medir el desempeño de sus empleados y así alinear los objetivos de la organización. Existen diversos modelos de evaluación creados a partir de distintos métodos de evaluación de desempeño, los cuales podemos llegar a conocer a través de autores como Alles (2004) y Cardozo (2007). Para este tipo de evaluaciones, existe una gama de software disponible en el mercado, muchos de los cuales se basan en evaluaciones por objetivos o por competencias y ofrecen soluciones en la web. Las instituciones educativas no son ajenas a este tipo de evaluaciones. En varios países se han planteado modelos de evaluación de desempeño que buscan mejorar el rendimiento de los docentes. En Perú existe el pro-blema de la falta de indicadores apropiados, lo cual no permite medir y comparar el desempeño de los docentes, ya que actualmente las evaluaciones son de tipo examen de admisión y esto, según varios autores, no es una verdadera evaluación de desempeño.
Palabras clave:
Educación a Distancia, evaluación, docente.
Abstract
This article presents a model for assessing teacher performance based on ICTs in Peru. It is well known that perfor-mance appraisal is a necessity that every organization should use to measure employee performance and thus align the objectives of the organization. Various assessment models created from different methods of performance evalua-tion, which can come to know through authors such as Alles (2004) and Cardozo (2007). For this type of evaluation is a range of software available on the market, many of which are based on assessments by objectives or competencies and offer solutions on the web. Educational institutions are not immune to this type of evaluation. Several countries have raised performance assessment models that seek to improve the performance of teachers. In Peru there is a problem of lack of appropriate indicators, which is not possible to measure and compare the performance of teachers and evaluations are currently entrance exam type and this, according to several authors, is not a true assessment of performance.
Keywords:
Distance Education, assessment, teacher.

UIGV120
Introducción
La educación es el proceso multidireccional mediante el cual se transmiten: conocimientos, valores, costumbres y formas de actuar (Berger, 2007, p. 7).
La Educación ha sido y es un elemento importante para la sociedad, ya que permite el desarrollo del ser huma-no como un individuo con la capacidad de emplear dichos conocimientos, valores, costumbres, etc. en beneficio propio y de la sociedad. Los encargados de llevar a cabo este proceso son los docentes, quienes tienen la misión de brindar una educación que cumpla con los estándares de calidad establecidos (Valdés, 2000).
Con el fin de medir el desempeño de los docentes y constatar que efectivamente se están alcanzando los objeti-vos educativos planteados, es necesario realizar periódicamente evaluaciones a estos profesores (Reis, 2007, p. 5). Sin embargo, la realidad demuestra que no siempre la tarea de evaluar es simple de realizar, ya que puede caerse en la subjetividad, alejándose de la objetividad del resultado esperado (Alles, 2004, p. 29).
Por ello, existen toda clase de métodos de evaluación de desempeño que pretenden, desde distintos enfoques, tratar de obtener resultados que ayuden a mejorar la educación en sus distintos aspectos (Alles, 2004, pp. 32-35).
Hoy, la tecnología ha abarcado muchas áreas, entre las cuales se encuentra la educación. El vínculo formado, tecnología-educación ha hecho que ambas evolucionen según los avances tecnológicos y nuevos usos del primero vs las necesidades y nuevos modelos del segundo. El proceso de enseñanza-aprendizaje ya no está restringido a un aula con un grupo de estudiantes y un docente, todos ubicados físicamente en un mismo lugar. Ahora, es posible, a través de la tecnología, enlazar virtualmente a distintos participantes heterogéneos, permitiendo de este modo mejo-rar su nivel de aprendizaje al compartir conocimientos y experiencias en grupo (Gómez & Lao, 2005, pp. 86-89).
Ante lo dicho previamente y viendo la realidad del entorno educativo en Perú, surge para el autor el deseo de brindar, con este trabajo de investigación, una herramienta que pueda servir de base para medir el desempeño de los docentes peruanos y con ello permitirle a las entidades involucradas en el ámbito educativo, el poder realizar las regulaciones y gestiones apropiadas que permitan mejorar la calidad del desempeño docente.
El resto de este artículo está organizado de la siguiente manera. En la sección 2, se mencionan trabajos previos relacionados con el tema de investigación. La sección 3 trata sobre los hallazgos relacionados con el problema de la investigación. La sección 4 responde a la pregunta ¿Para qué sirve la evaluación de desempeño? La sección 5 trata sobre la relación entre la estrategia de la organización y el desempeño. La sesión 6 menciona los modelos de evaluación de desempeño en otros países. La sección 7 muestra el Modelo Propuesto, su descripción general y detallada. La sección 8 trata sobre la discusión del trabajo de investigación. Finalmente, la sección 9 da a conocer las conclusiones a las que se ha llegado hasta el momento en este trabajo de investigación.
Conclusiones
Una Evaluación de Desempeño Basada en la Administración por Objetivos sobre un entorno web resultaría ser la más adecuada, esto debido al hecho de que según lo encontrado, a las organizaciones les interesa evaluar a sus empleados de tal forma que los objetivos de dichos empleados estén alineados a los objetivos de la organiza-ción a través de un continuo proceso de realimentación, todo esto sobre un sistema de información que les permita administrar y evaluar el desempeño de sus empleados en forma más rápida, eficiente y económica sin preocuparse de la ubicación geográfica del individuo.
Referencias
[1] Alles, M. (2004). Desempeño por Competencias. Evaluación de 360º. Buenos Aires, Argentina: Ediciones Granica S.A.

UIGV121
[2] Barnett, L., et. al. (2003). Motivación, tratamiento de la diversidad y rendimiento académico. El aprendizaje cooperativo. Caracas, Venezuela: Editorial Laboratorio Educativo.
[3] Berger, K (2007). Psicología del desarrollo: infancia y adolescencia (7º ed.). Madrid, España: Editorial Médica Panamericana.
[4] Cárdenas, A. (s.f.). Testimoniales SIIGO. Recuperado el 21 de Febrero de 2011, de http://www.siigo.com/docs/SysWebSite.aspx?Portal=2
[5] Cardozo, H. (2007). Gestión empresarial del sector solidario. Bogotá, Colombia: ECOE Ediciones.
[6] Dessler, G. (2004) Administración de recursos humanos: enfoque latinoamericano. México: Pearson Educa-tion.
[7] Gavilán, P. (2009). Aprendizaje cooperativo. Papel del conflicto socio cognitivo en el desarrollo intelectual. Consecuencias pedagógicas. Revista Española de Pedagogía, (242), 131-148.
[8] Gómez, M.& Lao, J. (2005). La dinámica del proceso docente educativo en la educación superior, con el empleo de las tecnologías de la información y las comunicaciones. Revista Pedagogía Universitaria, 10(5), 83-96
[9] González, A. (2006). Métodos de compensación basados en competencias. Barranquilla: Ediciones Uninorte.
[10] González, M. (2006). Mundo de unos y ceros en la gerencia empresarial. Recuperado el 21 de Febrero de 2011, dehttp://www.eumed.net/libros/2006a/mga-01/
[11] González, R. (2005). Nuevas Tecnologías Aplicadas a la Gestión de los Recursos Humanos. España: Ideaspropias.
[12] Guba, E. G. y Lincoln. Y. S. (1989): Fourth Generation Evaluation. Londres, Inglaterra: SAGE Publications
[13] Izquierdo, B. (2008). De la evaluación clásica a la evaluación pluralista. Criterios para clasificar los distintos tipos de evaluación. EMPIRIA: Revista de Metodología de Ciencias Sociales, 16, 115-134.
[14] Izquierdo, J.& Pardo, M. (2007). Las Tecnologías de la Información y Las Comunicaciones (TIC) en la Gestión Académica del Proceso Docente Educativo en la Educación Superior. Pedagogía Universitaria, 12(1), 58-68.
[15] Krathwohl, D. R. (2002). A Revision of Bloom’s Taxonomy: An Overview. Theory Into Practice, 41(4), 212
[16] Lyster, S. & Anne, A. (2006).199 Pre-Written Employee Performance Appraisals: The Complete Guide to Suc-cessful Employee Evaluations And Documentation. Florida, Estados Unidos: Atlantic Publishing Company.
[17] Marzano, R. & Kendall, J. (2007).The New Taxonomy of Educational Objectives (2da ed.). California: Cor-winPress.
[18] Montenegro, I.A. (2007). Evaluación del Desempeño Docente. Fundamentos, Modelos e Instrumentos. Bo-gotá, Colombia: Cooperativa Editorial Magisterio.
[19] Montes I, I. (2006). ¿Es posible tomar buenas decisiones con información poco relevante?: El caso de la evaluación de profesores. Lima: Signo Educativo.
[20] Piajet, J. (1983). La psicología de la inteligencia. Barcelona, España: Crítica.
[21] Patton, M. Q. (1990). Qualitative evaluation and research methods (2nd Edition).Londres, Inglaterra: SAGE Publications.

UIGV122
[22] Reis, P. (2007).Evaluación de Desempeño. Madrid, España: VerlagDashöfer Ediciones Profesionales, S. L. U.
[23] Rivero J.,et. al. (2003). Propuesta: Nueva Docencia en el Perú. Lima: Ministerio de Educación.
[24] Rodríguez, J. (2004). El modelo de gestión de recursos humanos. Barcelona, España: Editorial UOC.
[25] Rosales, C. (2003). Criterios para una evaluación formativa: objetivos, contenido, profesor, aprendizaje, Re-cursos. Madrid, España: Narcea, S. A. de Ediciones.
[26] Saavedra R., M. (2001). Evaluación del Aprendizaje Conceptos y Técnicas. México: Editorial Pax.
[27] Saravia L. &López de Castilla, M. (2008). La Evaluación del Desempeño Docente. Perú, una Experiencia en Construcción. Revista Iberoamericana de Evaluación Educativa, 1 (2), 76-91.
[28] Valdés H. (2000). Evaluación del Desempeño Docente. Ponencia presentada en el Encuentro Iberoamericano sobre Evaluación del Desempeño Docente realizado en la Ciudad de México del 23 al 25 de mayo de 2000.Recuperado el 24 de Noviembre de 2010, de http://www.oei.es/de/rifad01.htm

UIGV123
Swarm Intelligence para un Modelo de Optimización de Stocks basado en Reposiciones Conjuntas y Descuentos por Cantidad
Orlando Durán, Sergio Soto C., Escuela de Ingeniería Mecánica, Pontificia Universidad Católica de Valparaíso, Quilpue, V region, [email protected], [email protected]
Resumen
Este trabajo presenta la definición y solución de un modelo de optimización usando técnicas basadas en el algorit-mo Particle Swarm Optimization (PSO) u Optimización por Enjambre de Partículas. El modelo presentado es el llamado problema de reaprovisionamiento conjunto (Joint Replenishment Problem) en un sistema que opera con descuentos por cantidad. Se presentan los resultados en problemas cuyo tamaño hacen difícil o imposible conocer la solución óptima (por búsqueda exhaustiva), además de presentar comparaciones con los resultados obtenidos a través de Algoritmos Genéticos.
Palabras clave:
Metaheurísticas, Enjambre de Partículas, Joint Replenishment Problem, Descuentos por Cantidad, Optimización Combinatorial.
Abstract
This paper presents the definition and solution of an optimization model using techniques based on Particle Swarm Optimization algorithm (PSO) or Particle Swarm Optimization for. The model is called the joint replenishment problem (Joint Replenishment Problem) in a system that operates with quantity discounts. We present results on problems whose size makes it difficult or impossible to know the optimal solution (by exhaustive search) as well as presenting comparisons with results obtained through genetic algorithms.
Keywords:
metaheuristics, particle swarm, Joint Replenishment Problem, Quantity Discounts, Combinatorial Optimization.
Introducción
Goyal [1] presentó una heurística para resolver el Joint Replenishmnet Problem, (JRP), problema del reaprovisiona-miento conjunto, en situaciones de multiproducto adquiridos del mismo proveedor. Si bien es cierto, en la literatura anterior el trabajo de Shu [2] ya trata el JRP, pero para dos ítems, desde esos dos trabajos, una gran cantidad de artículos tratan de este problema usando diversos supuestos. Una revisión exhaustiva de la literatura hasta fines de los ochenta puede ser encontrada en Goyal y Satir [3]. Los principales supuestos que se mencionan en la literatura, para abordar el JRP, pasan por el tipo de agrupamiento de los ítems, hecho éste de manera directa (Direct Grou-ping strategy – DGS) y la del agrupamiento indirecto (Indirect Grouping Strategy – IGS). Otra forma de variantes

UIGV124
sobre el problema JRP es el comportamiento de la demanda. Así, existen estrategias de solución para demanda constante, demanda estocástica y demanda dinámica. Uno de las heurísticas clásicas para el problema es cono-cido como el RAND (Kaspi y Rosenblatt, [4]).
Más recientemente aparecen algunas estrategias basadas en algoritmos evolutivos para solucionar el JRP. Khouja [5] desarrollan un algoritmo genético (Genetic Algorithm – GA) y lo comparan su desempeño con el del RAND. Del punto de vista del JRP bajo demanda con comportamiento estocástico, dos políticas se destacan en la litera-tura. Johansen y Melchiors [6] consideran una política de reaprovisionamiento periódico y una política del tipo “can-order”. Para el caso de demanda dinámica, el trabajo de Boctor [7] presenta un procedimiento que combina diversas heurísticas presentando excelentes resultados.
Otros trabajos para casos especiales del JRP son presentados por Klein y Ventura [8] que resuelven el problema con tiempo de reaprovisionamiento y con tiempo discreto. Khouja et al. [5] resuelven el problema bajo la condición de disminución continua de los costes unitarios de los ítems. Otros trabajos han sido presentados problemas ope-racionales que incluyen el JRP como un subproblema. Siajadi et al. [6] desarrollaron un modelo para optimizar las decisiones de inventarios de un proveedor que repone conjuntamente n piezas que son usadas para producir un producto final. Chan et al. [7] desarrollar un modelo de solución para el agendamiento (scheduling) de entregas desde un proveedor a muchos clientes que usan el JRP para hacer sus reaprovisionamientos. Otros trabajos apuntan al JRP con ciertas restricciones, por ejemplo, Hoque [8] abordan el JRP con restricciones presupuestarias y capaci-dad de almacenamiento y transporte definido.
Los trabajos de Porras y Dekker [10] abordan el JRP con minimización de las cantidades pedidas. Bayindir et al. [11] incorporan costes variables de producción al JRP. Otros autores abordan el problema JRP con aspectos de obsolescencia (Goyal y Giri, [12]). Siajadi et al. [13] aborda el JRP con calidad imperfecta, o sea que parte de los ítems llegados pueden contener algunos defectos. Finalmente, podemos considerar que solo existe un único trabajo que aborda el JRP con existencia de descuentos por cantidad (Cha y Moon, 2005, [14]). El mencionado trabajo presenta un modelo que usa dos proposiciones para desarrollar dos algoritmos de solución. Estos algoritmos fueron probados en un total de 1600 problemas generados aleatoriamente.
Del punto de vista del uso de algoritmos evolutivos para el JRP, podemos citar a Hong y Kim [15], quienes de-sarrollaron un algoritmo genético para abordar el problema de solucionar el JRP relajando la restricción de que el ciclo de reaprovisionamiento sea múltiplo del ciclo del ítem que tiene mayor frecuencia entre los considerados en el sistema. Con esto, según los autores, se logra una mayor precisión en el cálculo del coste del sistema. Leung et al. [16] presenta una extensión al problema JRP clásico con multi-cliente y multi-item. Propone y prueba una combina-ción de simulated annealing (SA) -genetic algorithm y (GA) llamado SAGA. Los autores prueban la aplicabilidad de la estrategia sugerida en un banco de Hong Kong. Chan et al. (2003) [17] presenta una extensión al problema JRP clásico con multi-cliente y multi-item. Propone un algoritmo genético.
Khouja (2000) [18] compara el desempeño de un algoritmo genético frente al JRP con el comportamiento del RAND. Olsen (2005) [19] usa un algoritmo genético para el problema JR usando el concepto de agrupamiento directo. Según su autor, este algoritmo supera al algoritmo tradicional (RAND) en situaciones donde el cociente entre el coste fijo de ordenar y el coste variable de ordenar es considerado alto. En 2008, Olsen [20] ahonda en el uso de AG frente al problema JRP, de esta vez aborda la situación donde los costes de ordenar un ítem depen-den de los otros ítems que serán reaprovisionados en conjunto (costes interdependientes). Dye y Hsieh (2010) [21] prueban la eficiencia de usar otro algoritmo evolutivo, el de Enjambre de Partículas (Particle Swarm Optimization) en un problema JR.
Conclusiones
La mayor diferencia entre este trabajo y trabajos previos yace en que este proyecto combina el problema del reaprovisionamiento conjunto con la existencia de descuentos en el coste unitario de los ítems en función de la can-tidad adquirida. Sólo existe un trabajo en la literatura que presenta un modelo para esta situación. Sin embargo, el mecanismo de solución presentado es una heurística que sólo considera una cantidad limitada de ítems.

UIGV125
No se encuentran trabajos anteriores en la literatura que se hayan dedicado al uso de estas técnicas en la optimización de situaciones con una gran cantidad de ítems. El modelo fue evaluado, solucionado y comparado usando métricas establecidas en la literatura. Este tipo de problemas se aplican en situaciones donde las empresas desean sacar partido de las economías de escala, optimizando a su vez los costes de ordenar. Estos últimos pue-den traducirse por ejemplo en costes de embarque, tramitación o en locales de difícil acceso, tales como faenas mineras o en construcción de grandes obras civiles.
Referencias
[1] Goyal S (1974) Determination of optimum packaging frequency of items jointly replenished. Management Sci-ence 23: 436–443
[2] Goyal S, Satir A (1989) Joint replenishment inventory control: deterministic and stochastic models. European Journal of Operational Research 38: 2–13
[3] Kaspi M, Rosenblatt M (1991) On the economic ordering quantity for jointly replenished items. International Journal of Production Research 29: 107–114.
[4] Khouja M, Michalewicz Z, Satoskar S (2000) A comparison between genetic algorithms and the RAND method for solving the joint replenishment problem. Production Planning & Control 11: 556–564
[5] Johansen and Melchiors, 2003 S.G. Johansen and P. Melchiors, Can-order policy for the periodic review joint replenishment problem, Journal of the Operational Research Society 54 (2003), pp. 283–290.
[6] Boctor, G. Laporte and J. Renaud, Models and algorithms for the dynamic demand joint replenishment prob-lem, International Journal of Production Research 42 (2004), pp. 2667–2678
[7] C. M. Klein and J. A. Ventura , An Optimal Method for a Deterministic Joint Replenishment Inventory Policy in Discrete Time, The Journal of the Operational Research Society Vol. 46, No. 5 (May, 1995), pp. 649-657
[8] M. Khouja, Z. Michalewicz and S. Satoskar, ‘‘A comparison between genetic algorithms and the RAND method for solving the joint replenishment problem’’, Prod. Plan. Control, 11, pp. 556–564, 2000.
[9] H. Siajadi, R.N. Ibrahim, P.B. Lochert and W.M. Chan, Joint replenishment policy in inventory-production sys-tems, Production Planning and Control 16 (2005), pp. 255–262
[10] Chan CK, Cheung BKS, Langevin A (2003) Solving the multi-buyer joint replenishment problem with a modified genetic algorithm TRANSPORTATION RESEARCH PART B-METHODOLOGICAL Vol: 37, n. 3: 291-299.
[11] M.A. Hoque, An optimal solution technique for the joint replenishment problem with storage and transport capacities and budget constraints, European Journal of Operational Research 175 (2006), pp. 1033–1042.
[12] Moon, and B. Cha, ‘‘The joint replenishment problem with resource restrictions’’, Eur. J. Oper. Res., 173, pp. 190–198, 2006.
[13] E. Porras and R. Dekker, An efficient optimal solution method for the joint replenishment problem with minimum order quantities, European Journal of Operational Research 174 (2006), pp. 1595–1615.
[14] Pelin Bayindir, S. Ilker Birbil, J. B. G. Frenk: The joint replenishment problem with variable production costs. European Journal of Operational Research 175(1): 622-640 (2006)
[15] Goyal, Bibhas Chandra Giri: Recent trends in modeling of deteriorating inventory. European Journal of Opera-tional Research 134(1): 1-16 (2001)

UIGV126
[16] Siajadi, R.N. Ibrahim, P.B. Lochert and W.M. Chan, Joint replenishment policy in inventory-production systems, Production Planning and Control 16 (2005), pp. 255–262.
[17] B. Cha and I. Moon, ‘‘The joint replenishment problem with quantity discounts’’, OR Spectrum, 27, pp. 569–581, 2005.
[18] Sung-Pil Hong, Yong-Hyuk Kim: A genetic algorithm for joint replenishment based on the exact inventory cost. Computers & OR 36(1): 167-175 (2009)
[19] Leung TW, Chan CK, Troutt MD (2008) A mixed simulated annealing-genetic algorithm approach to the multi-buyer multi-item joint replenishment problem: Advantages of meta-heuristics JOURNAL OF INDUSTRIAL AND MANAGEMENT OPTIMIZATION. Vol: 4, n.:1: 53-66.
[20] Chan CK, Cheung BKS, Langevin A (2003) Solving the multi-buyer joint replenishment problem with a modified genetic algorithm TRANSPORTATION RESEARCH PART B-METHODOLOGICAL Vol: 37, n. 3: 291-299.
[21] Khouja M, Michalewicz Z, Satoskar SS (2000) A comparison between genetic algorithms and the RAND method for solving the joint replenishment problem. PRODUCTION PLANNING & CONTROL, Vol: 11, n.6: 556-564
[22] Olsen AL (2005) An evolutionary algorithm to solve the joint replenishment problem using direct grouping, COMPUTERS & INDUSTRIAL ENGINEERING. Vol: 48, n.: 2: 223-235.
[23] Dye CY, Hsieh TP (2010), A particle swarm optimization for solving joint pricing and lot-sizing problem with fluctuating demand and unit purchasing cost. : COMPUTERS & MATHEMATICS WITH APPLICATIONS. Vol.60, n.7: 1895-1907
[24] Olsen AL (2008) Inventory replenishment with interdependent ordering costs: An evolutionary algorithm solu-tion, INTERNATIONAL JOURNAL OF PRODUCTION ECONOMICS Vol: 113, 1: 359-369.
[25] Dye CY, Hsieh TP (2010), A particle swarm optimization for solving joint pricing and lot-sizing problem with fluctuating demand and unit purchasing cost. : COMPUTERS & MATHEMATICS WITH APPLICATIONS. Vol.60, n.7: 1895-1907
[26] Coello C.; Introducción a la computación evolutiva. Apuntes de curso, CINVESTAV – IPN, Departamento de computación, México, 2008.
[27] Eberhart, R. C. and Kennedy, J. A new optimizer using particle swarm theory. Proceedings of the Sixth Interna-tional Symposium on Micromachine and Human Science, Nagoya, Japan. pp. 39-43, 1995
[28] Correa, E.S., Freitas, A., Johnson, C.G. (2006). A new discrete particle swarm algorithm applied to attribute selection in a bioinformatics data set. In M. K. et al., editor, Proceedings of the Genetic and Evolutionary Computation Conference - GECCO-2006, pages 35–42, Seattle, WA, USA. ACM Press.

UIGV127
Innovación en el desarrollo de una plataforma tecnológica institucional como escritorio de trabajo (Proyecto USBnet Linux 5)
Frederyk Luy, Leyvin A. Yépez G., Ronald Mendez, Milagros Del C. González B.Dirección de Servicios Telemáticos - Universidad Simón Bolívar – [email protected]
Resumen
El uso de alternativas de software libre ofrece un inmenso potencial debido a sus posibilidades de adaptabilidad y aplicabilidad a distintas necesidades de una organización, aunado a las posibilidades de modificación e incorporación de nuevas características al software existente, sin restricciones de ningún tipo. En el ámbito de la Universidad, puede ofrecer herramientas y recursos tecnológicos invaluables disponibles en cualquier momento para todos los miembros de la comunidad y un espacio para el desarrollo e investigación de productos y soluciones tecnológicas útiles a la sociedad. En función de todo esto y tomando como referencia un enriquecedor marco de antecedentes en el uso e implementación de software libre en el campus de la Universidad Simón Bolívar, se tomó la iniciativa de lograr el desa-rrollo de una plataforma tecnológica como escritorio de trabajo basada en una meta distribución GNU Linux, orientada en una primera fase para cubrir en forma eficiente las necesidades de las unidades con funciones administrativas del campus y ofreciendo las condiciones más adecuadas posibles para facilitar un proceso de migración.
Tomando como base una distribución existente que se adaptara en forma más cercana a las necesidades plantea-das y considerando múltiples aspectos de interés clave para aplicar las modificaciones, se estableció la construcción de un prototipo cuyos resultados estéticos y funcionales aportaron un valor altamente significativo para su imple-mentación en el campus. Validando, depurando e incorporando características con la información recolectada en las pruebas de las versiones alfa y beta de la metadistribución se dispone en la actualidad de un producto viable para la realización de pruebas piloto en el campus.
Palabras clave:
USBnet, GNU Linux, versión Alfa, versión beta
Abstract
The use of free software alternatives offers a huge potential due to its ability to adapt and apply to different needs of an organization, coupled with the possibilities for changing and adding new features to existing software without any restrictions. In the area of the university may offer invaluable tools and technology resources available at any time for all members of the community and a space for research and development of technology products and solutions useful to society. Based on this and with reference to a rich history in the context of use and implementation of free software on the campus of the Universidad Simon Bolivar took the initiative to achieve the development of a technology platform as a desk-based work in a goal GNU Linux distribution, aimed at an early stage in an efficient manner to meet the needs of administrative units on campus and offering the best possible conditions to facilitate the migration process.
Based on an existing distribution that would fit in more closely to the needs expressed and considering multiple aspects of key interest to apply the amendments established the construction of a prototype whose aesthetic and functional results provided a highly significant value for its implementation in the campus. Validating, debugging, and adding features to the information gathered in testing alpha and beta versions of the target distribution is currently available for a viable product for pilot testing on campus.
Keywords:
USBnet, GNU Linux, version Alfa, version beta

UIGV128
Introducción
En la actualidad, el uso extendido de sistemas de operación y aplicaciones computacionales constituye una parte de la cotidianidad del contexto laboral, social y cultural del mundo. Todo tipo de organizaciones emplean variedad de productos para el adecuado desempeño de sus actividades. Considerando este contexto general la Universidad en sí tiene, como cualquier otra organización, el reto de mantener su propia plataforma tecnológica ajustada a las necesidades del presente y con perspectivas a futuro, pero, adicionalmente posee dos retos, los cuales radican en ofrecer a sus estudiantes herramientas adecuadas para asumir las exigencias en el desempeño de sus profesiones y la capacidad de poder ofrecer nuevos desarrollos y herramientas adaptadas a las necesidades y exigencias de la sociedad.
A nivel de software, considerando los retos descritos anteriormente, la disponibilidad y uso en el campus de productos sobre los cuales puedan establecerse modificaciones, realizar pruebas y distribuirlos a otras personas, constituye en sí misma una necesidad y condición de trabajo. Igualmente, la formación de los estudiantes en el uso de este tipo de productos les brindaría la posibilidad de incursionar en el entorno laboral con un juego de recursos tecnológicos propios y con la posibilidad de desarrollar, sin inconveniente, nuevas características a futuro, provechosas mediante el uso de su capacidad intelectual y creatividad.
Tomando todo este marco de referencia, se puede sintetizar en la necesidad de un ambiente universitario con la existencia de una plataforma de software que brinde la libertad de poder usarlo, con cualquier propósito, así como la libertad de estudio de funcionamiento para modificarlo, aunado a la posibilidad de distribuir copias de él y la libertad de mejorarlo, hacer públicas esas mejoras a los demás, de modo que toda la comunidad se beneficie. Estas posibilidades, en forma literal solo se encuentran englobadas en productos de software libre y esto abre a su vez como interrogante el hecho de si se debe utilizar exclusivamente software Libre en la Universidad o bien, desde qué nivel de la plataforma tecnológica del campus es conveniente el uso de este tipo de software.
Para responder esto es necesario recordar que las instituciones universitarias deben disponer de la variedad y riqueza de recursos para ofrecer formación adecuada para un campo laboral. En sí, la variedad de condiciones y requerimientos en el medio laboral enriquecerá las necesidades del ambiente de la Universidad con los productos que puedan satisfacerlas en forma eficiente. Considerando esto es poco viable la existencia rígida y exclusiva de determinado tipo de software en un ambiente universitario.
Ahora bien, considerar la implementación de un sistema de operación libre con un conjunto de aplicaciones, aunado a la posibilidad de virtualización de otras plataformas y la instalación de aplicaciones de otros sistemas, brindaría una base estable para el desarrollo de una inmensa variedad de experiencias de aprendizaje con pro-ductos informáticos sin ningún tipo de restricción asociada a las licencias de uso de la plataforma y abriendo a su vez el potencial de desarrollo de nuevas herramientas libres que puedan ser incorporadas y distribuidas al sistema base, y redistribuidas a la comunidad en forma de nuevas plataformas tecnológicas integradas a un sistema de operación. Actualmente, las distribuciones GNU-Linux ofrecen la posibilidad de incorporar todos los elementos descritos con anterioridad y la facilidad de adaptabilidad a requerimientos mediante la remasterización.
Conclusiones
La aceptación inicial por parte de una institución a un sistema alternativo está fuertemente ligada a un estudio de necesidades del usuario final, unido a un estudio de las herramientas en uso y a la identificación del producto con la imagen organizacional. Así mismo, la participación de estos usuarios en los procesos de evaluación ofrece valiosa información adicional para la realización de ajustes y vincula a toda la organización con el proyecto. Au-nado a todo esto, la estructura de un equipo de desarrollo formado por representantes de cada una de las áreas relacionadas con el soporte tecnológico aporta las perspectivas necesarias para un concepto integral del producto, adaptado a la realidad tecnológica existente en el lugar. Toda la información y expectativas recolectadas en un estudio podrán concretarse en un producto viable y sostenible si existe en principio la formación especializada ade-cuada para el personal técnico y si se considera para su fase de implementación la importancia de la aplicación de un programa estructurado de inducción dirigido a los usuarios con un seguimiento efectivo.

UIGV129
Referencias
[1] Hill, B. M., Helmke, M., Graner, A. & Burger, C. (2011). The Official Ubuntu Book Sixth Edition. USA: Prentice Hall.
[2] Helmke, M., Hudson, A. & Hudson ,P. (2011). Ubuntu UNLEASHED 2011Edition. USA: Pearson Education, Inc.
[3] Thomas, K. (2009). Ubuntu Pocket Guide and Reference. USA: MacFreda Publishing.
[4] Thomas, K. (2008). Ubuntu Kung Fu. USA: Pragmantic Bookshelf.
[5] Von Hagen, W. (2007). Ubuntu linux Bible, USA: Wesley Publishing, Inc.
[6] Proyecto ajdpsoft, (2010, 3 de Noviembre). Cambiar opciones de configuración avanzadas de Mozilla Firefox. Extraído el 21 de Abril de 2011 desde http://www.ajpdsoft.com/modules.php?name=News&file=print&sid=354
[7] Archwiki, (2011, 3 de Marzo). PulseAudio. Extraído el 15 de Abril de 2011 desde https://wiki.archlinux.org/index.php/PulseAudio
[8] laure, (2011, 14 de Enero). Cambia el tema Plymouth de tu Ubuntu 10.10. Extraído el 25 de Abril de 2011 desde http://grupoed2kmagazine.activoforo.com/t1251-cambia-el-tema-plymouth-de-tu-ubuntu-1010
[9] tuxapuntes, (2009, 20 de Mayo). AWN sin instalar compiz fusión. Extraído el 12 de Abril de 2011 desde http://www.tuxapuntes.com/drupal/node/1356
[10] Ubuntu documentation, (2011, 22 de Febrero) How to Customise the Ubuntu Desktop CD. Extraído el 25 de Marzo de 2011 desde https://help.ubuntu.com/community/LiveCDCustomization

UIGV130

UIGV131
Reconstrução de Mapas por meio de Fluxo Veicular
Edwar Velarde Allazo1, Yuzo Iano 2, Vicente Sablon Becerra 3
1 Universidad Católica San Pablo (UCSP)2 Universidad Estadual de Campinas (UNICAMP)3 Universidad Salesiana São José (UNISAL)[email protected], [email protected], [email protected]
Resumo
Este artigo tem como objetivo analisar algumas informações obtidas a fim de se obter uma metodologia para iden-tificar as intersecções, sentido, capacidade das vias, e outros dados correlatos. As informações de interesse são o fluxo de veículos, feições de terreno, tipos de terreno entre outras que serão abstraídas. Elas podem influenciar diretamente na análise de fluxo e nas relações com o ambiente viário urbano. A manutenção e atualização do mapeamento ur-bano podem ser melhorados por meio desse estudo usando-se tratamento estatístico, processamento de imagens e computacional dos dados de fluxo de veículos.
Palavras chave:
mineração de dados, morfologia matemática, grafos.
Abstract
This article aims to study the information obtained from analysis of traffic flow, terrain features, land types and among others that will be abstracted. We can achieve a methodology to obtain intersections, direction, capacity of the roads, and other related data. The results can directly influence the flow analysis and its relations with the environment for urban road maintenance and updated of urban mapping. The study can be done through the study and statistical treatment, image and computer processing of data traffic flow.
Keywords:
data mining, mathematical morphology, graphs.
Introdução
A revolução industrial que ocorreu em meados do século XVIII causou um profundo impacto no processo produ-tivo, bem como no nível econômico, social e político da população. Toda essa transformação foi possível devido a uma combinação de diferentes fatores, tais como o liberalismo econômico, o acúmulo de capital e uma série de invenções (motor a vapor). O capitalismo tornou-se o sistema econômico vigente até hoje, e desencadeou um processo de concentração populacional nos grandes centros urbanos.
As cidades cresceram em demasia e de maneira rápida. Isso dificultou a ação dos planejadores urbanos para que pudessem ter um melhor controle do tráfego urbano. Esse controle atualmente é problemático em cidades grandes como São Paulo (Brasil), New York (USA), Cidade do México (México).
Em relação ao problema de extração de características viárias urbanas e reconstrução do mapeamento viário urbano por meio da observação de sensoriamento de fluxo de veículos, busca-se identificar inconsistências entre

UIGV132
um mapa cartográfico de uma dada região de interesse em comparação ao fluxo atual de veículos. Dessa forma, ao observar a existência de um fluxo regular de veículos em uma nova via ou em um sentido diferente de infor-mação no mapa cartográfico é possível inferir a existência de uma nova via não relacionada no mapeamento ou a mudança da orientação de trânsito pelo orgão governamental gestor de planejamento e controle de trânsito. Em disciplinas bem estudadas da ciência cartográfica despende-se muito esforço para extração, captura e inter-pretação de características viárias por meio de sensoriamento remoto que pode ser a utilização de GPS (posição, velocidade e direção). No entanto, a maioria dos trabalhos nessa área de conhecimento concentra-se em obter e gerar tais informações por meio de métodos que não levam em consideração o fluxo de veículos. Esse dado pode gerar algum tipo de informação importante que permita solucionar alguns dos problemas existentes em grandes centros urbanos.
Conclusões
O presente artigo mostra que por meio da informação obtida de tráfego veicular pode-se criar uma estrutura de mapeamento urbano versátil. Ela pode ser utilizada em vários cenários com a finalidade de se obter informação válida, como quantidade de número de junções e vértices dentro de uma região determinada, que permita criar grafos que sejam indispensáveis para a atualização automática do mapeamento urbano.
A modelagem proposta pode ser útil para conhecer a situação de mapas atuais em tempo real. Podem-se pre-venir problemas com antecedência e reduzir custos para criação de novos mapas.
Referencias
[1] [Curoto, 2003] C.Curotto (2003), “Integração de Recursos Data Mining com Gerenciadores de Banco de Dados Relacionais”, Universidade Federal do Rio de Janeiro.
[2] [Stanella, 2004] T.Stanella e E. Antonio da Silva (2004), Morfologia Matemática: Extração de Feições a partir de Imagens Orbitais, Universidade Estadual Paulista – UNESP.
[3] [Gonzales, 2009] Gonzales e R. Davies (2009), “Digital Image Processing and Computer Vision”. Academic Press.
[4] [Fabio, 2005] C.Fabio e R. Filho(2005), “Filtros de Convolução Proporcionais para Realce de Imagens”, Universidadede São Paulo, Instituto de Geociências e Universidade Estadual de Campinas.
[5] [Witten, 2005] I. H. Witten e E Frank (2005), “Data Mining Concepts and Techniques”, Morgan Kaufmann.
[6] [Antonio, 2010] E. Antonio da Silva e F. Leonardi (2010), “Extraction Cartographic Targets from the Use of Techniques of Mathematical Morphology”, Universidade Estadual Paulista, Unesp, Faculdade de Ciências e Tecnologia, FCT.
[7] [Gonzales, 2003] Gonzales e Rafael Davies (2003), “Digital Image Processing and Computer Vision”, Aca-demic Press.
[8] [Serra, 1982] J. Serra (1982), “Image Analysis and Mathematical Morphology”, London, Academic Press.
[9] [Ray, 2005] M. Ray Pmeenen e R. Adhami (2005), “A Novel Aproacch to Fingerprint Pore Extraction”, Proced-dings of the Thirty-seven Southeastern Symposium on System theory.
[10] [Moreira, 2002] R. Moreira (2002), “Mineração de Regras de Associação nos Canais de Informação Dire-tos”, Universidade Federal do Rio Grande Do Sul, Setembro.

UIGV133
[11] [Brito, 2007] H. Brito Meneses e C. Gangeiro (2007), “Modelagem e Análise de Dados Dinâmicos do Trafego Urbano: uma Revisão Conceitual e Aplicada”, Universidade Federal do Ceará, UFC.
[12] [Nehme, 2000] D.Nehme e E. Daronco (2000), “Filtros Espaciais Passa Baixa”, Universidade Federal Rio Grande do Sul.
[13] [Berretti, 2001] S. Berretti, A. Del Bimbo e A.Vicario (2001), “Indexing of Graph Models in Content-Based Retrivial”, IEEE Transactions on Pattern Analysis and Machine Intelligence.
[14] [Dikson, 2007] S. Dikson (2007), “Introduction to the Special Sction on Graph Algorithms in Computer Vision”, IEEE Transactions on Patter Analysis and Machine.
[15] [Silva, 2003] Silva e D. Poz (2003), “Deteção e Reconstrução Automatica de Junções de Rodovia em Ima-gens Digitais em Cenas Rurais”, Boletim de Ciências Geodésicas.

UIGV134

UIGV135
Trabajos área detelecomunicaciones

UIGV136

UIGV137
Scalable Video Content Adaptation
Livio Lima, Nicola Adami, Riccardo LeonardiDEA - University of Brescia, via Branze 38, 25123 Brescia, ItalyEmail: [email protected], [email protected], [email protected]
Abstract
Scalable Video Coding technology allows the efficient distribution of videos through heterogeneous networks. In this work a method for automatically adapting video contents, according to the available andwidth and user preferen-ces, is proposed and evaluated. By exploiting video stream scalability, the proposed solution uses bridge firewalls to perform adaptation. The scalable bitstream is packetized by assigning different Type of Service values, according to the corresponding spatial, temporal and quality resolutions. According to the given bandwidth constraints, an intermediate bridge node, which provides Quality of Service functionalities, discards high resolutions information by using appro-priate Priority Queueing filtering policies. A real testbed has been used for the evaluation, proving the feasibility and the effectiveness of the proposed solution.
Keywords:
Scalability, MPEG-21, IP protocol
Introduction
The distribution of a given video content to several clients, characterized by having different rendering capabilities and connected by means of links with different bandwidth restriction, is in general a heavy task. Till today, this goal has been achieved mainly using two alternative methods: by using video transcoders, properly placed in the nodes of the distribution network or by encoding and successively distributing different coded version of the same content. These methods are clearly inefficient; in the first case a high computational power is required for successively adap-ting the content while in the second there is a waste of storage space and channel bandwidth. Additionally, these solutions are not effective in case of dynamic bandwidth variation.
The recently developed Scalable Video Coding (SVC) methods [1], [2], are a key technology to overcome these limitations. SVC codecs generate a bitstream with a unique feature, the possibility of extracting decodable sub-streams corresponding to a scaled version, i.e. with a lower spatiotemporal resolution or a lower quality, of the original video. Moreover, this is achieved providing coding performances comparable with those of single point coding methods and requiring a very low sub-stream extraction complexity, actually comparable with read and write operations. Scalability is then suitable to ease video content adaptation when there are bandwidth fluctuations or when the bandwidth required to transmit the requested resolution is not available. In these situations, only a bit-stream subset can be transmitted, or forwarded by one of the node in the network to the clients.
Scalable Video Coding is a relatively new technology and a commonly adopted delivery method has not been defined yet. However, several solutions have been proposed, concerning different aspects of a complete scalable video streaming chain. In [3], a MPEG4-FGS scalable stream, with one spatial resolution and multiple quality layers,

UIGV138
is transmitted using a client-server collaborative system with the aim of avoiding congestion. The client estimates the rate of occupancy of its receiving buffer, which is assumed to depend on the congestion level. The estimation is then transmitted to the server, on a feedback channel, which dynamically adapts the quality of transmitted video in order to avoid congestion at the client’s side. Similar approaches have been proposed by Nguyen et al. [4] and by Hillestad et al. [5] in the context of wireless video streaming. In [6] the use of Differentiated Services (DiffServ) [7] of IP protocol is used to provide QoS with MPEG4-FGS and H.264-SVC. The main drawback is that only two classes of service are used, Expedited Forwarding (EF) for base layer and Assured Forwarding (AF) with three groups of priority to differentiate the types of pictures (I, P and B) in the enhancement layer. In [8] a real-time system based on the scalable extension of H.264 (H.264-SVC) scalable and MPEG-21 Digital Item Adaptation (DIA) is proposed. In particular QoS is obtained using Adaptation QoS (AQoS) and Universal Constrain Description (UCD) tools of MPEG-21 DIA. The main drawback of this approach is the complexity of MPEG-21 descriptors determination, which depends on the content itself, needed for the configuration of the adaptation nodes.
This work also aims at providing solutions for scalable video content adaptation by considering a real client-server application framework. The network architecture, here considered, is composed by a server that can store and send the video contents, different clients and a bridge that adapts the transmitted stream according to the available bandwidth. The key aspect of the proposed application, with respect to the work described in [8], is the way video adaptation is realized. Instead of using dedicated extractors for scaling the distributed stream, the system relays on the packet filtering policies realized by network Quality of Service (QoS).
The presentation is organized as follows. Section II provides some hints on Scalable Video Coding focusing on the generated bitstream structure. Section III describes the structure and the elements of the considered distribution network. In Section IV the obtained results are presented.
Conclusions
In this paper an efficient method for automatically adapting a scalable video stream has been proposed. Adap-tation is performed by opportunely using the functionalities provided by Quality of Service systems. Different con-figurations have been evaluated, in order to enable flexibility and adaptation with respect to client’s preferences concerning the preferred scalability dimension. It has been shown that, thanks to the characteristics of the proposed congestion management method and of the scalable video streams, it is possible to decode a video sequence at a lower spatial resolution or frame rate preserving good quality also in presence of strong bandwidth reduction. The advantage of proposed method compared with other works in literature is the low complexity of the adaptation device, the use of well known mechanisms for providing Quality of Service as Packet Filter, the absence of feedback channel and no needs of bandwidth estimation algorithms. Future works could address the robustness against the errors on communication channel and consider the retransmission of lost packets which are important issues in real video streaming applications.
References
[1] ITU-T and ISO/IEC JTC 1, “Advanced video coding for generic audiovisual services,” Tech. Rep., ITU-T Rec. H.264 and ISO/IEC 14496-10 (MPEG-4 AVC), Version 8 (including SVC extension): Consented in July 2007.
[2] N. Adami, A. Signoroni, and R. Leonardi, “State-of-the-art and trends in scalable video compression with wavelet-based approaches,” CSVT, IEEE Transactions on, vol. 17, no. 9, pp. 1238–1255, Sept. 2007.
[3] P. B. Ssesanga and M. K. Mandal, “Efficient congestion control for streaming scalable video over unreliable IP networks,” in Proc. of IEEE ICIP 2004, October 2004.
[4] Dieu Nguyen and Joern Ostermann, “Streaming and congestion control using scalable video coding based on H.264/AVC,” Journal of Zhejiang University - Science A, vol. 7, no. 5, pp. 749–754, May 2006.

UIGV139
[5] Odd Inge Hillestad, Andrew Perkis, Vasken Genc, Sean Murphy, and John Murphy, “Adaptive H.264/MPEG-4 SVC video over IEEE 802.16 broadband wireless networks,” Packet Video 2007, pp. 26–35, 12-13 Nov. 2007.
[6] T. Pliakas and G. Kormentzas, “Scalable video streaming traffic delivery in IP/UMTS networking enviroments,” Journal of Multimedia, vol. 2, no. 9, pp. 37–46, April 2007.
[7] S. Blake, D. Black, M. Carlson, E. Davies, Z. Wang, and W. weiss, “An architecture for differentiated services,” Tech. Rep., RFC 2475, December 1998.
[8] M. Wien, R. Cazoulat, A. Graffunder, A. Hutter, and P. Amon, “Realtime system for adaptive video streaming based on SVC,” CSVT, IEEE Transactions on, vol. 17, no. 9, pp. 1227–1237, Sept. 2007.
[9] L. Lima, F. Manerba, N. Adami, R. Leonardi, and A. Signoroni, “Wavelet based encoding for HD appplica-tions,” in Proc. of the IEEE ICME, July 2007.
[10] K. Ramakrishnan, S. Floyd, and D. Black, “The addition of explicit congestion notification (ECN) to IP,” Tech. Rep., RFC 3168, September 2001.

UIGV140

UIGV141
Modelo de Gestión de Dominios de Servicios en Redes Inalámbricas
Chadwick Carreto1, Rolando Menchaca2, Salvador Alvarez21Escuela Superior de Cómputo – Instituto Politécnico Nacional2Escuela Superior de Ingeniería Mecánica y Eléctrica - Instituto Politécnico Nacional [email protected], [email protected], [email protected]
Resumen
En el presente documento, se muestra la propuesta de un modelo para la implementación de entornos de co-laboración y dominios de trabajo siguiendo el esquema de Inteligencia Ambiental. De acuerdo con la arquitectura propuesta, la información y servicios estarán disponibles para los usuarios mediante diferentes dispositivos móviles a cualquier hora y en cualquier lugar. Esta información y servicios serán distintos en cada uno de los dominios de trabajo y colaboración dependiendo de la actividad que se lleve a cabo en ellos de una forma oportuna.
En un aula, se tendrían los servicios de apuntes y la información de la materia que se esté impartiendo en ese mo-mento, registro de asistencia, evaluación y en un entorno de una Biblioteca se tendrían otros servicios, como consulta de material, publicaciones, videoteca, etc. Este esquema está basado en servicios de dominios móviles independien-tes de la tecnología que se implemente (Wi Fi, Bluetooth, Radio frecuencia, etc.).
Palabras clave:
Inteligencia Ambiental, Dominios de Servicio, Servicios, Móviles.
Abstract
In this paper, we propose a model to implement a set of collaborative environments and work domains, following a environmental intelligence schema. According to the proposed architecture, information and services will be able for users, by means of different mobile devices in any time and any place. This information and services will be different in each work domain and collaborative environment depending on the activity that can be carried out in them.
For instance, in a room class could have teaching services and information related to the subject, which has been provided at this moment. Other services are related to assistance records, evaluations and the library environment. In the last case, the library environment can dispose of other services such as material reference, publications, videos and so on. This schema is based on services for mobile domains independently of the platforms and implementation technologies (Wi Fi, Bluetooth, radio frequency, etc.).
Keywords:
environmental intelligence, work domains, services, mobile.
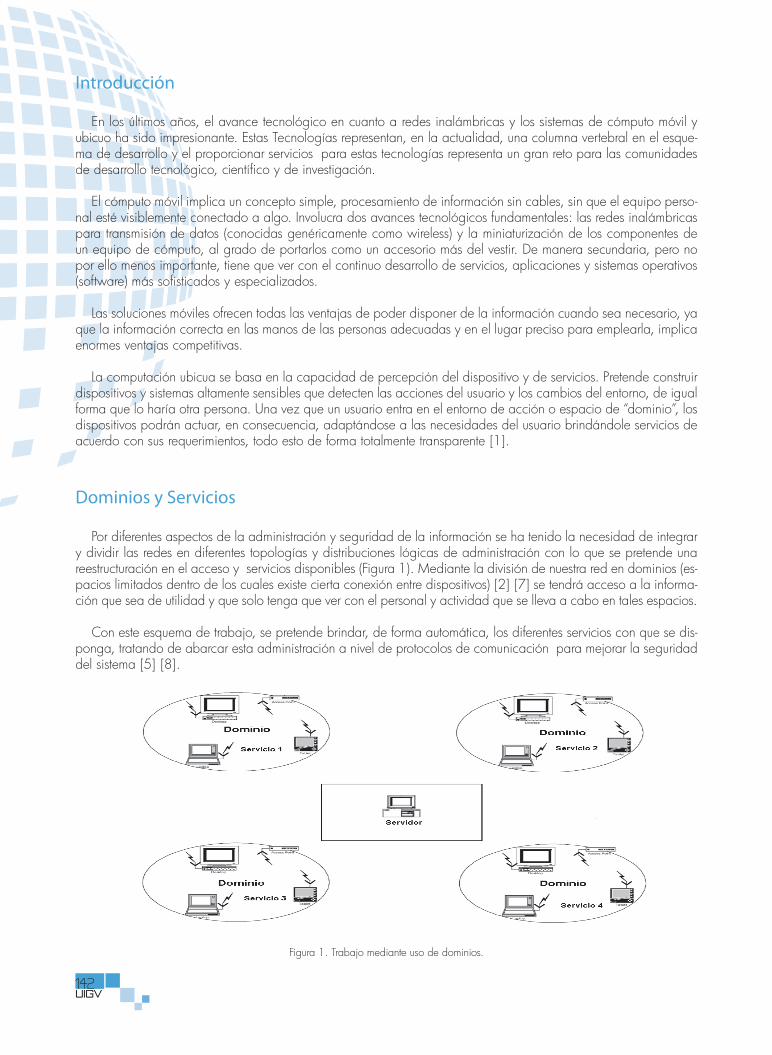
UIGV142
Introducción
En los últimos años, el avance tecnológico en cuanto a redes inalámbricas y los sistemas de cómputo móvil y ubicuo ha sido impresionante. Estas Tecnologías representan, en la actualidad, una columna vertebral en el esque-ma de desarrollo y el proporcionar servicios para estas tecnologías representa un gran reto para las comunidades de desarrollo tecnológico, científico y de investigación.
El cómputo móvil implica un concepto simple, procesamiento de información sin cables, sin que el equipo perso-nal esté visiblemente conectado a algo. Involucra dos avances tecnológicos fundamentales: las redes inalámbricas para transmisión de datos (conocidas genéricamente como wireless) y la miniaturización de los componentes de un equipo de cómputo, al grado de portarlos como un accesorio más del vestir. De manera secundaria, pero no por ello menos importante, tiene que ver con el continuo desarrollo de servicios, aplicaciones y sistemas operativos (software) más sofisticados y especializados.
Las soluciones móviles ofrecen todas las ventajas de poder disponer de la información cuando sea necesario, ya que la información correcta en las manos de las personas adecuadas y en el lugar preciso para emplearla, implica enormes ventajas competitivas.
La computación ubicua se basa en la capacidad de percepción del dispositivo y de servicios. Pretende construir dispositivos y sistemas altamente sensibles que detecten las acciones del usuario y los cambios del entorno, de igual forma que lo haría otra persona. Una vez que un usuario entra en el entorno de acción o espacio de “dominio”, los dispositivos podrán actuar, en consecuencia, adaptándose a las necesidades del usuario brindándole servicios de acuerdo con sus requerimientos, todo esto de forma totalmente transparente [1].
Dominios y Servicios
Por diferentes aspectos de la administración y seguridad de la información se ha tenido la necesidad de integrar y dividir las redes en diferentes topologías y distribuciones lógicas de administración con lo que se pretende una reestructuración en el acceso y servicios disponibles (Figura 1). Mediante la división de nuestra red en dominios (es-pacios limitados dentro de los cuales existe cierta conexión entre dispositivos) [2] [7] se tendrá acceso a la informa-ción que sea de utilidad y que solo tenga que ver con el personal y actividad que se lleva a cabo en tales espacios.
Con este esquema de trabajo, se pretende brindar, de forma automática, los diferentes servicios con que se dis-ponga, tratando de abarcar esta administración a nivel de protocolos de comunicación para mejorar la seguridad del sistema [5] [8].
Figura 1. Trabajo mediante uso de dominios.

UIGV143
Los servicios que se pueden proporcionar en un entorno de red son muchos y de muy diversos tipos, una clasifi-cación de acuerdo con su evolución y con la forma que extienden la interacción entre humano−sistema son:
1. Servicio Web. Conjunto de aplicaciones o de tecnologías con capacidad para interoperar en la Web.
2. Servicio Móvil. Acompaña al usuario sin importar cuál sea su localización en la red.
3. Servicio Interactivo. Es aquél que ofrece un conjunto de funcionalidades de interés para el usuario con las que puede “interaccionar” sin retardos significativos para su percepción de la calidad por medio de experiencias interactivas. De aquí, surge el término “experiencia interactiva”, siendo aquélla en la que el usuario desarrolla una acción de forma libre con una o varias personas en tiempo real.
4. Servicio Distribuido. Se define como una colección de ordenadores autónomos conectados por una red, y con el software distribuido adecuado para que el sistema sea visto por los usuarios como una única entidad capaz de proporcionar facilidades de computación.
5. Servicio Colaborativo. Basados en ordenadores que soportan grupos de personas involucradas en una tarea común (u objetivo) y que proveen una interfaz a un ambiente compartido.
6. Servicio Federado. Se encuentra disponible en una zona, región o dominio determinado. Los servicios no federados están limitados a un dominio en específico y pueden ser accesados desde cualquier parte de la red.
Teniendo en cuenta todos estos aspectos, el cómputo móvil y ubicuo puede brindar múltiples soluciones para problemas de diversa índole, que van desde el simple intercambio de información hasta sistemas que permitan a los usuarios colaborar en cualquier lugar y en cualquier momento. El objetivo principal de este trabajo es proponer un modelo el cual tendrá como principal finalidad el administrar la información dentro de diversos dominios de tra-bajo y colaboración. Estos dominios son entornos de trabajo bien definidos que pueden ser desde un aula, salón, oficina, biblioteca hasta un edificio completo o zonas de trabajo.
A los servicios que se ofrecen de forma transparente se le conoce como servicios con Inteligencia Ambiental [3] en el cual los usuarios interactuarán con un dominio de trabajo que será consciente de su presencia y del contexto general de la situación, pudiendo adaptarse y responder a las necesidades, costumbres y emociones del usuario. El concepto original de Inteligencia Ambiental se enfocaba más hacia sensores y actuadores y los dispositivos de respuesta. El modelo que se propone en el presente documento implementa la inteligencia ambiental, pero hacia el entorno y los servicios de información independientemente de los dispositivos con que se interactúe en el domino.
A continuación, en la sección 2, se describe el modelo a desarrollar, así como las características de los elemen-tos que la componen. La sección 3 explica el diseño y el desarrollo del modelo. Finalmente, en la sección 4, damos una conclusión del trabajo expuesto y se establece el trabajo a futuro.
Conclusiones
La principal aportación del modelo propuesto es la de permitir actuar con más movilidad ahorrando tiempo y esfuerzo en el acceso a la información. El sistema por sí mismo es otra forma de ayudar a las personas a llevar a cabo sus funciones en cualquier área que se desarrollen, no solo porque facilita el trabajo, sino porque nos abre una puerta a la innovación y una contribución a la sociedad.
Las redes móviles son cada día más comunes tanto en instituciones como en empresas. Actualmente, se ha vuelto un objetivo conseguir un cómputo ubicuo que asegure una total interactividad en todo momento y en todo lugar. Así, este proyecto está enfocado a acercarnos a dichos objetivos, pretendiendo así desarrollar un entorno capaz de ofrecer los servicios requeridos para usuarios específicos de la manera más transparentemente posible. El sistema podría ser además una buena base para desarrollar un ambiente computacional ubicuo en cualquier lugar que lo

UIGV144
amerite, estableciendo un protocolo para la implantación de servicios para equipos móviles de diversos tipos. La aplicación de esta arquitectura puede ser en muchas áreas de conocimiento, entre ellas:
Medicina. En esta área se puede implementar, en un hospital, para cuando llegue un paciente a recepción, con su celular puede hacer una cita, o puede obtener información de un paciente internado.
Economía. Aquí se puede obtener información sobre sus cuentas al acercarse a un punto de acceso en un ban-co, o en el caso de la bolsa de valores, puede obtener información en tiempo real de las inversiones.
Educación. Una forma de aplicación es que pueden obtener miniaplicaciones en su dispositivo móvil, como servicios de información, búsquedas, laboratorios virtuales, sistemas de simulación, etc.
Referencias
[1] [Carreto, 2004] Carreto Chadwick, Menchaca Rolando (2004) “Arquitectura de Colaboración mediante dis-positivos Móviles Aplicada a la Administración del Conocimiento”. TCM2004. ENC. Universidad de Colima, México 2004.
[2] [Muñoz, 2003] Miguel Angel Muñoz Duarte. Cómputo colaborativo consciente del contexto. Tesis de Mae-stría, CICESE.
[3] [Akyildiz, 2002] Ian F. Akyildiz, (2002) “A Survey on Sensor Networks”. IEEE Communications Magazine.
[4] [Garcia, 2000] C. Parsa and J.J. Garcia-Luna-Aceves, (2000). `Improving TCP Performance over Wireless Networks at The Link Layer,’’ ACM Mobile Networks and Applications Journal, Special Issue on Mobile Data Networks: Advanced Technologies and Services, Vol. 5, No. 1, 2000, pp. 57-71.
[5] [Rajendran, 2006] V. Rajendran, K. Obrazcka, and J.J. Garcia-Luna-Aceves (2006). ``Energy-Efficient, Colli-sion-Free Medium Access Control for Wireless Sensor Networks,’’ Wireless Networks Journal (ACM, Springer), Vol. 12, No. 1.
[6] [Weiser, 1994] Weiser (2006). Ubiquitous computing. Intel Architecture Labs; 1994 November 28; Hillsboro, OR.
[7] [Kay, 1991] Kay, Alan (1991). Computers, Networks, and Education. Scientific American, September 1991. pp. 138-148.

UIGV145
Sistema de Telecomunicaciones: ITVNET
Juan Diego López Vargas, Liliana Gómez Meza, Carlos Díaz Universidad Santo Tomás - ColombiaUniversidad Politécnica de Madrid - Españ[email protected]
Resumen
El presente artículo tiene como objetivo fundamental presentar un proyecto en desarrollo por un consorcio Co-lombo-Español, que busca transformar la plataforma iiTV, de difusión y sindicación multiformato orientada hacia los contenidos audiovisuales digitales en un sistema inteligente que clasifique los contenidos a partir de un proceso de filtrado de imagen y audio y de los metadatos extraídos de un proceso de segmentación automática.
Palabras clave:
IPTV, OCW, MPEG, Contenidos
Abstract
This article aims to present a major development project by a consortium Colombo-Spanish, where it seeks to transform the platform iiTV, broadcast and syndication-oriented multiformat digital audiovisual content in an intelligent system that classifies the content based a process of filtering image and audio and metadata drawn from an automatic segmentation process.
Keywords:
IPTV, OCW, MPEG, Contents
Introducción
El objetivo principal del proyecto iTVNet (Interactive TV Net) es fortalecer y mejorar el acceso y la gestión de los contenidos que, en estos tiempos de crisis generalizada, son más demandados por los usuarios, como son los contenidos formativos y educativos.
Facilitar y optimizar el acceso a los contenidos educativos permitirá un profundo desarrollo de las habilidades de los usuarios del sistema. Esto, que es algo que solicita actualmente el mercado laboral, ayudará a obtener una plena inclusión profesional. Este punto es un claro valor añadido para las empresas que hagan uso del sistema.
Para lograr el objetivo previsto, se plantea obtener una plataforma web de contenidos audiovisuales formativos y educativos completa. Con “completa” queremos decir que disponga de todas las facilidades y funcionalidades que permitan al usuario del sistema optimizar las búsquedas de los contenidos que necesita o solicita, minimizar los tiempos de las mismas, asegurar que los resultados devueltos por estas búsquedas están alineados con las pre-ferencias de los usuarios, entrenar con el propio sistema para que mejore los resultados a medida que se utiliza. En definitiva, lograr un sistema de información multimedia cuyos contenidos estén plenamente indexados.

UIGV146
Optiva Media, USTA, UMB y sus socios quieren estar presentes en el nicho de mercado donde se sitúa iTVNet. Para ello se articula este proyecto de colaboración, para que cada socio aporte su experiencia y sus recursos y así conseguir ser pioneros en un mercado tan específico.
Figura 1: El contenido es la clave Fuente: Autores
Para obtener la plataforma web de contenidos audiovisuales formativos y educativos, se desarrollarán tres sub-sistemas:
Subsistema de segmentación automática: será capaz de filtrar audio y vídeo en los contenidos audiovisuales digitales que los usuarios hayan ingresado en el sistema para extraer metainformación de los mismos y poner a disposición de los usuarios únicamente los segmentos que más se ajusten al contenido que solicitan. Este subsistema irá de la mano del módulo de segmentación manual que ya se encuentra desarrollado y que permitirá optimizar los resultados devueltos por el segmentador automático.
Subsistema de perfilado de usuarios: se encargará de recoger información de los usuarios del sistema y del contexto que les rodea con el fin de disponer de un perfil detallado de los mismos.
Subsistema de recomendación: hará uso de los resultados obtenidos por los dos subsistemas anteriores para ofre-cer a los usuarios los contenidos que mejor se adapten a sus necesidades o preferencias de la forma más concreta posible (segmentando el contenido original).
Estos tres elementos se basarán en un sistema ontológico que permitirá establecer un esquema conceptual claro y exhaustivo que defina el dominio concreto de los contenidos formativos y educativos. Esta ontología hará posible, entre otras cosas, la comunicación entre diferentes agentes software sin necesidad de intervención humana.
Además, se plantean como objetivos la creación de un módulo de comunicaciones móviles que permita ofrecer los contenidos difundidos por Internet TV a casi todos los entornos de comunicaciones móviles y, del mismo modo, otro módulo para integrar el sistema en una plataforma de TV digital (satélite, cable o terrestre).
Por otro lado, se aplicarán los principios del Diseño para Todos que permitirán que el sistema sea accesible y usable por cualquier persona independientemente de sus limitaciones, ya sean éstas de carácter físico, psicológico, motriz, por razones culturales, demográficas, etc.
Conclusiones
a. Innovaciones Tecnológicas y Ventajas para la Empresa
El carácter innovador del proyecto iTVNet viene dado, principalmente, por dos aspectos:

UIGV147
• La segmentación automática de los contenidos, que va a permitir al usuario escoger la parte que realmente es interesante para él del contenido completo que se encuentra en el sistema.
• La indexación semántica de esos fragmentos de los contenidos, lo cual va a facilitar la búsqueda y la recu-peración por parte del usuario.
Estos dos aspectos van a obligar a ahondar en trabajos que, aunque ya han supuesto estudios y desarrollo previo, se encuentran, hoy muy por detrás de lo que precisa el consumo de contenido audiovisual. Como sabemos, en estos días de convergencia digital y de hibridación de dispositivos, este tipo de consumo está sufriendo grandes cambios. El panorama audiovisual ha experimentado una revolución radical en los últimos años en que las premisas del sector han cambiado de forma absoluta.
Hoy, podemos descartar la idea de que los contenidos audiovisuales sólo se consumen en casa –a través de la televisión o el vídeo– o en el cine. Aunque la televisión sigue siendo la forma de visionado más universal y el cine sobrevive renqueante como escaparate de las principales novedades del sector audiovisual, han aparecido nuevos competidores. Ordenadores y teléfonos móviles se han ido transformando desde sus funciones originales hasta convertirse en nuevos soportes multimedia provocando que los cimientos del sector se tambaleen. A éstos se unen otros dispositivos a través de los que también se puede acceder al mercado audiovisual, como agendas electrónicas, televisores de bolsillo o incluso consolas originalmente diseñadas para juegos.
Figura 2: Disfrute de Contenidos en Entornos Multiplataforma Fuente: Autores
El reciente Barómetro Motorola de Consumo Multimedia en España durante 2010 [9] es revelador en cuanto al calibre de los cambios que estamos viviendo en el consumo de productos audiovisuales. De acuerdo con los datos de este estudio, aunque todavía un 72% de los españoles consume televisión en directo todas las semanas, un creciente porcentaje de consumidores de contenidos audiovisuales los obtiene por otros medios. Así, prácticamente un 50% de los espectadores consume al menos una vez por semana vídeos por streaming a través de Internet, un 28% se descarga algún vídeo y un 18% ve televisión a la carta. Las cifras absolutas de consumo en streaming son realmente impresionantes, pues el portal Youtube, que es el máximo exponente de este tipo de consumo audiovi-sual, alcanzó, durante 2009, los mil millones de visitas diarias (La Vanguardia, 2011).
Los paradigmas han cambiado no sólo respecto al soporte del visionado, sino también respecto al momento y el lugar del mismo. La clásica emisión lineal de contenidos, en la que la voluntad del espectador se limitaba a escoger si veía o no la emisión broadcast que tenía disponible en su región, no ha desaparecido, es evidente,
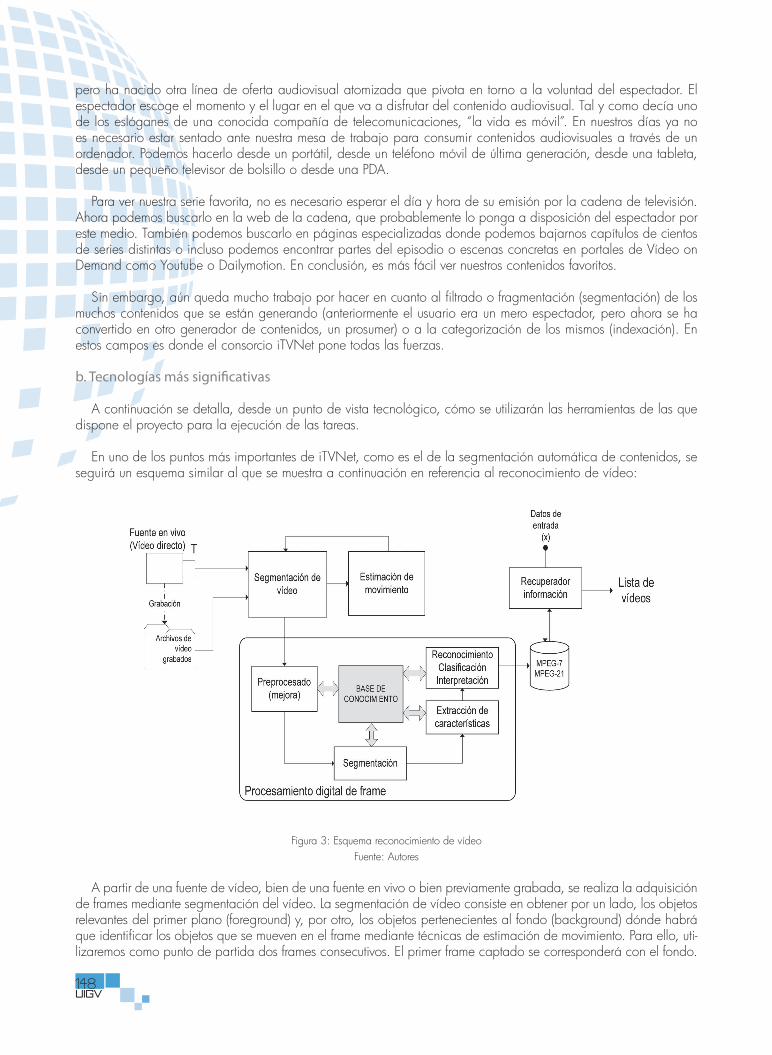
UIGV148
pero ha nacido otra línea de oferta audiovisual atomizada que pivota en torno a la voluntad del espectador. El espectador escoge el momento y el lugar en el que va a disfrutar del contenido audiovisual. Tal y como decía uno de los eslóganes de una conocida compañía de telecomunicaciones, “la vida es móvil”. En nuestros días ya no es necesario estar sentado ante nuestra mesa de trabajo para consumir contenidos audiovisuales a través de un ordenador. Podemos hacerlo desde un portátil, desde un teléfono móvil de última generación, desde una tableta, desde un pequeño televisor de bolsillo o desde una PDA.
Para ver nuestra serie favorita, no es necesario esperar el día y hora de su emisión por la cadena de televisión. Ahora podemos buscarlo en la web de la cadena, que probablemente lo ponga a disposición del espectador por este medio. También podemos buscarlo en páginas especializadas donde podemos bajarnos capítulos de cientos de series distintas o incluso podemos encontrar partes del episodio o escenas concretas en portales de Vídeo on Demand como Youtube o Dailymotion. En conclusión, es más fácil ver nuestros contenidos favoritos.
Sin embargo, aún queda mucho trabajo por hacer en cuanto al filtrado o fragmentación (segmentación) de los muchos contenidos que se están generando (anteriormente el usuario era un mero espectador, pero ahora se ha convertido en otro generador de contenidos, un prosumer) o a la categorización de los mismos (indexación). En estos campos es donde el consorcio iTVNet pone todas las fuerzas.
b. Tecnologías más significativas
A continuación se detalla, desde un punto de vista tecnológico, cómo se utilizarán las herramientas de las que dispone el proyecto para la ejecución de las tareas.
En uno de los puntos más importantes de iTVNet, como es el de la segmentación automática de contenidos, se seguirá un esquema similar al que se muestra a continuación en referencia al reconocimiento de vídeo:
Figura 3: Esquema reconocimiento de vídeo Fuente: Autores
A partir de una fuente de vídeo, bien de una fuente en vivo o bien previamente grabada, se realiza la adquisición de frames mediante segmentación del vídeo. La segmentación de vídeo consiste en obtener por un lado, los objetos relevantes del primer plano (foreground) y, por otro, los objetos pertenecientes al fondo (background) dónde habrá que identificar los objetos que se mueven en el frame mediante técnicas de estimación de movimiento. Para ello, uti-lizaremos como punto de partida dos frames consecutivos. El primer frame captado se corresponderá con el fondo.

UIGV149
La estimación de movimiento indica el factor de cambio entre frames en el tiempo. La técnica de detección de movimiento que se empleará es la estimación de flujo óptico. El flujo óptico mide el movimiento de los objetos en una secuencia. Los objetos cercanos generan mucho flujo, mientras que los lejanos apenas se mueven. El flujo óptico indica la dirección, el sentido y la intensidad del movimiento, describiendo adecuadamente los desplazamientos que se producen en la imagen. Se utilizará la variante del método basado en bloques del frame.
Una vez segmentado el vídeo y detectado el flujo óptico, se pasará al procesamiento digital de cada plano del frame, foreground y background, pasando por los siguientes bloques:
• Preprocesado: en este bloque se realizará una mejora del frame (a partir de ahora imagen) para conseguir un plano más limpio para que así aumenten las probabilidades de éxito en las etapas posteriores. Se eli-mina el ruido, sombras, cambios de iluminación, etc. que se pueden confundir con regiones. Las técnicas que actualmente existen son:
- Aumento del contraste / luminosidad. Se utilizan técnicas de umbralización de histograma de la ima-gen. El umbral se calcula en función de la información que se pretenda modificar.
- Realce de bordes o contornos. El realce de bordes o contornos es muy interesante para resaltar objetos que queremos detectar o clasificar. Se consigue mediante el uso de filtros paso alto.
- Reducción de ruido. Mediante operaciones de filtrado paso bajo se consigue reducir el ruido de la imagen.
• Segmentación: éste es uno de los bloques principales del sistema ya que es el punto donde, en función de unas características, se divide la imagen en áreas con significado.
La segmentación es la operación de bajo nivel que determina regiones homogéneas y disjuntas o, equivalen-temente, que encuentra los bordes de dichas regiones. Estas regiones homogéneas, o los bordes, corresponden a los objetos, o partes de ellos, dentro de la imagen. Por lo tanto, la segmentación juega un papel muy importante como el primer paso antes de aplicar operaciones de alto nivel, como reconocimiento, interpretación semántica y representación.
Las técnicas de segmentación son muy dependientes del propósito de la aplicación y del tipo de imagen a analizar. Antes de segmentar, es preciso definir qué objetos/características interesa determinar.
Los tipos de segmentación de imágenes se reparten en cinco grandes grupos:
• Basadas en características. Se asigna cada píxel a una región en función de características locales de la imagen en el píxel y en su vecindad.
• Basadas en transiciones. Los métodos de segmentación basada en transiciones aplican sobra la imagen un detector de bordes. Las regiones se definen a partir de las fronteras delimitadas por los bordes detectados. La detección de bordes se realiza mediante la medición del gradiente de la imagen en dirección determi-nada a lo largo de una recta.
• Basadas en modelos. Estas técnicas se presuponen conocidas algunas características de los objetos o regio-nes en la imagen, tales como, rectas, objetos circulares, etc. La transformada de Hough es la más utilizada permitiendo localizar objetos dentro de una imagen.
• Basadas en homogeneidad. Son técnicas de crecimiento de regiones, métodos de abajo-arriba. Parte de unos puntos o semillas, incluye en la misma región píxeles vecinos con características (niveles de gris, textura, color) similares hasta que todo los píxeles se han asignado a uno de los puntos de partida.
• Basadas en morfología matemática (Transformada watershed). La transformada watershed es una técnica morfológica de segmentación de imágenes de niveles de gris. Es un método basado en regiones, que

UIGV150
divide todo el dominio de la imagen en conjuntos conexos. Esta técnica no va a ser implementada ya que es un método difícil de automatizar.
• Extracción de características. Una vez dividida la imagen en zonas con características de más alto nivel, se pasará a su extracción de características de tipo morfológico, como el área, perímetro o excentricidad o características basadas en la textura o en el color.
• Reconocimiento / clasificación / interpretación. Con las características analizadas de cada región, se clasificarán las regiones analizadas, bien en aspectos de color y textura o bien en objetos pertenecientes a clases, como personas, vehículos, etc.
A partir de este punto, se guardará la información obtenida de cada plano del frame etiquetando los contenidos mediante metadatos siguiendo el estándar MPEG-7.
La información obtenida seguirá un esquema conceptual definido en una ontología. Las ontologías tienen los siguientes componentes que sirven para representar el conocimiento de un dominio:
• Conceptos: son las ideas básicas que se intentan formalizar. Los conceptos pueden ser clases de objetos, métodos, planes, estrategias, procesos de razonamiento, etc.
• Relaciones: representan la interacción y enlace entre los conceptos del dominio. Suelen formar la taxonomía del dominio. Por ejemplo: subclase-de, parte-de, parte-exhaustiva-de, conectado-a, etc.
• Funciones: son un tipo concreto de relación donde se identifica un elemento mediante el cálculo de una función que considera varios elementos de la ontología. Por ejemplo, pueden parecer funciones como categorizar-clase, asignarFecha, etc.
• Instancias: se utilizan para representar objetos determinados de un concepto.
• Axiomas: son teoremas que se declaran sobre relaciones que deben cumplir los elementos de la ontología. Por ejemplo: “Si A y B son de la clase C, entonces A no es subclase de B”, “Para todo A que cumpla la condición C1, A es B”, etc.
Para poder realizar la definición de ontologías, se necesitan lenguajes de marcado apropiados que representen el conocimiento de estas ontologías. Uno de los lenguajes con gran capacidad expresiva que se ha convertido en estándar para realizar anotaciones de ontologías es OWL (Ontology Web Language).
Referencias
[1] R. Ll. Roberto. “Especificación owl de una ontología para teleeducación en la web semántica” Tesis doctoral, valencia, 2007.
[2] R. P. Keily, R. L Rodrigo, Web semántica: un nuevo enfoque para la organización y recuperación de infor-mación en el web. ISSN 1024-9435 ACIMED v.13 n.6 Ciudad de La Habana nov.-dic. 2005
[3] Optiva Media [Online]. Available: http://www.optivamedia.com/productos_broadbandtv.html.
[4] V.G. Rafael. Un Entorno para la Extracción Incremental de Conocimiento desde Texto en Lenguaje Natural, Departamento de Ingeniería de la Información y las Comunicaciones. Tesis doctoral Murcia, 2005.
[5] S. M. Aurelio, Desarrollo de una aplicación Web 2.0 para la captura y análisis de la Valoración del usuario Proyecto Final De Carrera , Valencia, 2010.

UIGV151
[6] C, L, Angel. Estudio Técnico de factibilidad para la implementación de un canal de Televisión digital, Proyecto Final de Carrera, Quito 2008.
[7] Aragall, Presidente de la Coordinadora del Dpt en España
[8] G. Vanderheiden. M. Cooper. Comprender las WCAG 2.0 .W3C, University of Wisconsin-Madison Ben Caldwell, Trace R&D Center, Universidad de Wisconsin-Madison.
[9] Mediacenter Motorola, El reciente Barómetro Motorola de Consumo Multimedia en España durante 2010.

UIGV152

UIGV153
Creando contenidos para la Televisión Digital
Adriana X. Reyes1, Claudia Rosero1, Gustavo Moreno1
1 Politécnico Colombiano Jaime Isaza [email protected], [email protected], [email protected]
Resumen
Este artículo presenta los resultados parciales del proyecto CONTEDI, contenidos educativos para la televisión digital (TVD), el cual surge como una iniciativa dentro de la Universidad para ir profundizando en el desarrollo de aplicacio-nes educativas basadas en la plataforma de TVD. Se presentan los aspectos claves, la metodología, y la herramienta definida para desarrollar aplicaciones y los primeros resultados de prueba del aplicativo.
Palabras clave:
Televisión digital interactiva, TVD, educación, t-learning, CONTEDI.
Abstract
This article presents partial results of the project CONTEDI, educational content to digital television (DTV), which is an initiative within the University to go deeper into the development of applications based educational platform TVD. We present the key issues, methodology and tool set for developing applications and the early test results of the application.
Keywords:
Interactive digital television, TVD, education, t-learning, CONTEDI.
Introducción
La TV ha sido por años un medio de comunicación de fácil uso y de amplia cobertura. Actualmente, se presenta la televisión digital terrestre (TDT). La aplicación de esta nueva tecnología brinda muchas ventajas y posibilidades sobre la señal estándar, por ejemplo: mejor calidad de imagen (en alta definición) y una mejor calidad en el soni-do, así como la posibilidad de desarrollar nuevos servicios y aplicaciones (t-comercio, t-gobierno, t-salud, t-juegos, t-empleo y t-educación, entre otros) en convergencia en favor del usuario.
La televisión digital está tomando importancia en procesos de enseñanza y aprendizaje, campo de aplicación que se conoce como t-learning (Bellotti, 2008). Es decir, aprendizaje interactivo y personalizado a través del tele-visor, siendo un nuevo enfoque para la educación virtual, complementaria a la basada en el PC, en donde se han hecho desde cursos informales hasta títulos universitarios. Además, la televisión digital brinda otra alternativa para aquellas personas que no tienen o que les da dificultad manejar el ordenador, siendo el TV más amigable y que se encuentra en la mayoría de los hogares, aportando así a la inclusión digital.
Este artículo presenta los resultados parciales del proyecto CONTEDI investigación en t-learning, articulando la educación con el uso de la televisión digital interactiva. El documento está dividido así: en una primera parte, se

UIGV154
enuncian los trabajos previos analizados sobre este tema, en la tercera unidad se propone las fases de estructura-ción general del proyecto; en la otra unidad, los aspectos a tener en cuenta como la tecnología y estándar de TVD en Colombia, la arquitectura de t-learning, y otras recomendaciones, por último, las pruebas de implementación inicial del prototipo para el proyecto CONTEDI.
Conclusiones
Se presentó unas bases de conocimiento adquiridas en el proyecto de investigación CONTEDI, la propuesta metodológica, arquitectura t-learning y elementos de infraestructura tanto de hardware como de software y la expe-rimentación inicial con la herramienta iTV suite para desarrollo de aplicaciones interactivas en TVD.
El proyecto continúa en fase de depuración de la implementación del prototipo y pruebas, y se espera a futuro cercano poder implementar y evaluar su aplicación real con estudiantes de un curso normal. Así mismo, el proyecto sigue avanzando en los aspectos pedagógicos, educativo, el lenguaje televisivo y el desarrollo de contenidos. El sistema de TVD y el desarrollo de aplicaciones y contenidos deben involucrar muchos aspectos a tener en cuenta.
El gobierno Colombiano, con la elección del estándar DVB, para la difusión de la señal de televisión digital, ha abierto las puertas para la implementación y masificación en los próximos años. Esto indica que se deben realizar todos los esfuerzos para su apropiación y desarrollo de contenidos. La Universidad tiene una oportunidad de pro-poner aplicaciones educativas para la televisión digital, y el proyecto CONTEDI se hace partícipe en este esfuerzo.
Referencias
[1] Aarreniemi, P. “Modelling and Content Production of Distance Learning Concept for Interactive Digital Televi-sion”, Helsinki, 2006, 204p. Doctor of Science in Technology, thesis. Helsinki University of Technology. De-partment of Computer Science and Engineering.
[2] Bellotti, F. “T-learning Courses Development and Presentation Framework”. En: IEEE Multidisciplinary Engineer-ing Education Magazine. Vol. 3, No. 3 (Sep. 2008); p. 69 -76.
[3] O. PINTO, Lady Daiana, et al (2008). An Engineering Educational Application Developed for the Brazilian Digital TV System. En: ASEE/IEEE Frontiers in Education Conference [on line]. (38: 2008: New York).
[4] EDiTV (2008). “Educación Virtual basada en Televisión Interactiva para Apoyar Procesos Educativos a Distan-cia”. [on line].<Disponible en: http://www.unicauca.edu.co/EDiTV/index.php?op=0>
[5] DAMASIO, Q., y QUICO, C. (2004). T-Learning and Interactive Television Edutainment: the Portuguese Case Study. En: 2nd European Conference on Interactive Television, Brighton (Reino Unido).
[6] DIAZ REDONDO, Rebeca y FERNANDEZ VILAS, Ana (2008). Proyecto Suma. Estudio bibliográfico de t-learning. 18p.
[7] HANSEN, Vibeke. (2005). Designing for interactive television v 1.0. BBCi & Interactive tv programmes.
[8] ARVID. A Guide for Digital TV Service Producer. Helsinki, (2004). p.35
[9] FSPUGT. Tecnoloxías de comunicación e información aplicadas á formació. (2008) FEDERACIÓN DE SERVI-ZOS PÚBLICOS DA UGT DE GALICIA.
[10] OSMOSYS. [en línea]. <Disponible en: http://www.osmosys.tv/>, 09/10/10

UIGV155
[11] Authoringtool composer. [en línea]. <Disponible en: http://www.alticast.com/solutions/authoringtool_composer.html>
[12] ICAREUS. iTV Suite Author. [en línea]. <Disponible en: http://icareus.com/web/guest/technologies/itvsuite/author>
[13] LIKE COMPOSER. [en línea]. <Disponible en: http://www.ncl.org.br/index_.html.>, 20/03/10
[14] GRiNS Pro Editor. [en línea]. <Disponible en: http://wareseeker.com/Audio-Multimedia/grins-pro-editor-for-smil-2.0-2.2.zip/1f77da4d4>
[15] MHPGen. [en línea]. <Disponible en: http://www.mhpgen.com/>, 01/15/10.
[16] Moreno, Gustavo Alberto (2010). Modelo t-learning para procesos de formación en la educación superior, Msc. Tesis, Universidad Pontificia Bolivariana, Medellín, Colombia.
[17] OpenTV. [en línea]. <Disponible en: http://www.opentv.com/support/dev_tools.htm>, 12/15/09.
[18] ELU educational authoring tools (2007) [en línea]. <Disponible en: http://www.elu-project.com/business/products.html>
[19] Xletview. [en línea]. <Disponible en: http://www.xletview.org/>, 04/01/10.
[20] OpenMHP. [en línea]. <Disponible en: http://www.openmhp.org/>, 04/01/10.
[21] BBC. Cbeebies. [en línea]. <Disponible en: http://www.bbc.co.uk/cbeebies/bobthebuilder/>, 20/08/09.
[22] TV Scola (2003). Ministério da Educação. [on line]. <Disponible en: http://portal.mec.gov.br/tvescola/>, 23/08/09.
[23] DVB. Digital video broadcasting. <Disponible en: http://www.dvb.org/>, 09/07/09.
[24] COMISION NACIONAL DE TELEVISION. Cronograma. CNTV (2009). <Disponible en: http://www.cntv.org.co/cntv_bop/tdt/contenido4.html>, 14/08/09.
[25] Multimedia Home Platform. MHP. <Disponible en: http://www.mhp.org/>, 09/07/09
[26] Icareus. Technologies. [On line]. <Disponible en: http://icareus.com/web/guest/home>, 02/07/10.

UIGV156

UIGV157
Cálculo de Cobertura de un Sistema de Telefonía Móvil a lo largo de una Carretera usando Software de Simulación
Mauricio Postigo1, Ronald Coaguila1,2, Wildor Ferrel1, José Chilo3 1 Universidad Nacional de San Agustín de Arequipa, Perú2 Universidad Católica Santa María, Perú3 University of Gävle, [email protected], [email protected], [email protected], [email protected]
Resumen
En este artículo, se describe el cálculo de cobertura de un sistema de telefonía móvil en puntos de una carretera utilizando un programa de software de simulación. Se calcula la pérdida de propagación por trayectoria en puntos de la carretera; luego, se determina la potencia recibida en estos puntos en dos casos: cuando todas las estaciones del sistema de telefonía móvil funcionan y cuando algunas estaciones están fuera de funcionamiento. En ambos casos se halla la función de distribución acumulada complementaria de la potencia recibida en puntos de la vía para analizar la performance de la cobertura.
Palabras clave:
Cobertura, software de simulación, estaciones base, telefonía móvil, pérdida de propagación, WRAP, CCDF.
Abstract
This article describes the calculation of coverage of a cellular telephone system at points of a road using a software simulation program. Path loss propagation is calculated at points on the road; then, the received power is found at these points in two cases: when all the stations of cellular telephone system are working and in the case when some stations are not functioning. In both cases the complementary cumulative distribution function is calculated for the received power at points of the road to analyze the performance of the coverage
Keywords:
Coverage, simulation software, base stations, mobile phone, propagation loss, WRAP, CCDF.
Introducción
En la actualidad, la telefonía móvil e Internet constituyen servicios de gran demanda en todos los países. Estos servicios son necesarios no solamente en las áreas urbanas sino también a lo largo de las vías de comunicación terrestre interurbanas, como las carreteras y los ferrocarriles. De esta forma, en los vehículos de transporte interurba-no, los pasajeros pueden hacer uso de sus teléfonos móviles y los servicios de Internet durante todo el tiempo que dure su viaje.

UIGV158
En el análisis y diseño de los sistemas de telefonía celular que dan cobertura a una carretera o a un ferrocarril es importante conocer el valor de ciertas magnitudes, como la pérdida de propagación por trayectoria (path loss propagation), la potencia recibida, la intensidad de campo, la densidad de flujo de potencia, etc., en determina-dos puntos sobre la vía.
Existen programas de software de simulación de sistemas de comunicación inalámbrica que permiten predecir las magnitudes indicadas en áreas donde opera el sistema. Como ejemplo, podemos mencionar el programa WRAP que es un software orientado a la planificación de redes de radiofrecuencia y a la administración del espec-tro proporcionando soporte de computación para el cálculo de cobertura, interferencia, capacidad de tráfico, etc. Este programa dispone de hasta 25 modelos de propagación [WRAP, 2010], otros programas de software sólo trabajan con uno o dos. Esta última característica es muy relevante al momento de elegir el software de simulación.
En el presente trabajo, utilizamos WRAP para calcular la pérdida de propagación por trayectoria y la potencia recibida en puntos de una vía terrestre para un sistema de comunicación de telefonía celular.
En la sección 2, se mencionan los trabajos previos. En la sección 3, se plantea el problema. En la sección 4, describimos brevemente la creación del proyecto en WRAP. En la sección 5, calculamos la pérdida de propagación por trayectoria. En la sección 6, se realiza el cálculo de la potencia recibida. Luego, en la sección 7, se determina la función de distribución acumulada (CDF) y la función de distribución acumulada complementaria (CCDF). En la sección 8, se discuten los experimentos realizados. Finalmente, en la sección 9, se dan las conclusiones y recomen-daciones.
Conclusiones
Dados los puntos geográficos de una vía de comunicación terrestre y conocidos los datos de un sistema de telefonía móvil, se ha calculado la pérdida de propagación por trayectoria sobre la vía utilizando un programa de software de simulación. También, se ha determinado la potencia recibida en la vía, cuando están en funciona-miento todas las estaciones, y cuando dejan de funcionar algunas estaciones. En ambos casos, se ha determinado la función de distribución acumulada complementaria (CCDF). Los gráficos de las CCDF revelan cuantitativamente la diferencia en la cobertura sobre la vía cuando funcionan todas las estaciones y cuando algunas están fuera de funcionamiento.
Se ha aplicado un software de simulación existente, en la predicción de la cobertura en una carretera de longi-tud relativamente pequeña que ha sido tomada como ejemplo con fines académicos. Es posible aplicar el procedi-miento descrito en este artículo para predecir la cobertura en carreteras de longitud mayor; como por ejemplo, en Sudamérica a lo largo de toda la carretera Panamericana o la carretera Interoceánica.
En trabajos futuros, se sugiere realizar los cálculos de pérdida de propagación por trayectoria, potencia recibida utilizando los otros modelos de propagación terreno-dependientes aplicables al problema planteado y comparar los resultados. También se sugiere estudiar la cobertura en la carretera cuando se usan sólo antenas direccionales.
Finalmente, este trabajo permitió conocer más las bondades de los programas de simulación de sistemas de co-municaciones móviles en la resolución de problemas prácticos; por lo que, sugerimos a las entidades académicas de los Estados en vías de desarrollo la creación de programas de software similares al empleado en este trabajo.
Referencias
[1] [Gallegos, 2006] E. D. Gallegos Rodríguez, W. J. Galindo Hidalgo. Diseño y Planificación de Cobertura Celular CDMA 2000 1X mediante un Sistema Repetidor(es) -BTS(s) para la Carretera Aloag-Santo Domingo. Quito, 2006.

UIGV159
[2] [WRAP, 2010] WRAP International, WRAP Win User’s Manual. Introduction and Tutorial, Linköping, Sweden, 2010.
[3] [Ahlin, 2010] L. Ahlin, J. Zander, B. Slimane, Principles of Wireless Communications, Ed. Denmark: Narayana Press, 2010.
[4] [Mawjoud, 2008] S. A. Mawjoud, Evaluation of Power Budget and Cell Coverage Range in Cellular GSM System. Al-Rafidain Engineering Vol.16 No.1. 2008.
[5] [Agilent, 2000] Agilent Technologies, Characterizing Digitally Modulated Signals with CCDF Curves, Applica-tion Note. 2000.
[6] [Walke, 2002] Walke Bernhard H., Mobile Radio Networks. Networking, Protocols and Traffic Performance, John Wiley & Sons, LTD, England, 2002

UIGV160

UIGV161
Streaming de Vídeo Escalável em Rede Celular de 3ª Geração
Vanice Canuto Cunha¹, Paulo Roberto de Lira Gondim¹, Rodrigo Mulinari¹¹ Universidade de Brasília - Faculdade de [email protected], [email protected], [email protected]
Resumo
Este artigo apresenta um estudo da avaliação objetiva da qualidade do vídeo codificado no padrão H.264/SVC (Scalable Video Coding), transmitido por meio de redes de comunicação móvel de 3ª Geração (3G). O padrão H.264 permite o ajuste do bit rate de acordo com as condições da rede e pode ser utilizado em diferentes cenários, onde múltiplos fluxos de bits são enviados a partir de uma mesma fonte, com diferenciação na taxa de quadros e de bits por segundo. Com a ajuda de um esquema auto-adaptativo que considera feedbacks dos receptores, o conteúdo codificado na origem é então transmitido de acordo com as condições de rede e capacidade do terminal, permitindo avaliar o desempenho do esquema adaptativo para streaming de vídeo escalável por meio de redes 3G.
Palavras chave:
Vídeo escalável, redes 3G, QoV.
Abstract
This article presents a study of objective evaluation of the quality of video encoded in H.264/SVC (Scalable Video Coding) standard, transmitted via 3rd Generation (3G) mobile communication networks. The H.264 standard allows adjustment of the bit rate according to network condition and can be used in different scenarios, where multiple streams of bits are sent from one source, with differentiation in frame rate and bit per second. With the help of a self-adaptive scheme which considers feedback from receivers, the encoded content is then transmitted according to network conditions and terminal capacities, allowing to evaluate the performance of the adaptive scheme for scalable video streaming through 3G.
Keywords:
Scalable Video, networks 3G, QoV.
Introdução
A transmissão de vídeo em tempo real gera uma série de novos desafios. Alguns desses desafios incluem garan-tir qualidade de serviços para os diferentes receptores, utilizar ao máximo a capacidade de cada receptor, prover o melhor aproveitamento de banda permanecendo em níveis aceitáveis de qualidade, evitar ou reagir rapidamente a congestionamentos na rede e atender a variações repentinas do número de usuários.
Nestas circunstâncias, as aplicações de transmissão de vídeo precisam se adaptar às mudanças das condições da rede e às diferentes demandas. Assim, elas podem adotar técnicas escaláveis e adaptativas tanto em termos de conteúdo quanto em termos de taxas de transmissão para poderem lidar com as variações de tráfego da rede e heterogeneidades de dispositivos.

UIGV162
O objetivo deste trabalho é avaliar a qualidade do vídeo transmitido em uma rede 3G, utilizando um esque-ma adaptativo de transmissão de vídeo que faz uso de um codificador de vídeo escalável, baseado no padrão H.264/SVC.
O presente trabalho está dividido da seguinte forma: na seção 2 são apresentados os trabalhos relacionados, juntamente com a contribuição desses para o desenvolvimento deste artigo. Na seção 3 são apresentados os aspectos da transmissão de vídeo escalável, bem como o padrão utilizado para a transmissão de streaming de vídeo em redes de 3ª geração. Na seção 4 é apresentado o esquema adaptativo utilizado na transmissão do streaming de vídeo, com detalhamento dos componentes que compõem o servidor e o cliente do esquema. Na seção 5 são apresentados o ambiente de teste e a análise dos resultados obtidos nos experimentos. Na seção 6 são apresentadas conclusões e indicados trabalhos futuros.
Conclusão
Neste trabalho foram apresentados os resultados obtidos com a transmissão de vídeo escalável em redes de 3ª geração. Com a utilização do esquema adaptativo, foi possível adaptar a taxa de transmissão do streaming de vídeo de acordo com as mudanças e oscilações ocorridas na rede e avaliar o desempenho do vídeo em redes sem fio de 3ª geração, garantindo assim uma qualidade de vídeo aceitável para o usuário, mesmo em horários considerados de pico e grande tráfego na rede. Com a análise feita dos resultados deste trabalho, pode-se concluir que o esquema adaptativo funciona de maneira eficiente e se adapta às oscilações e mudanças das condições de rede.
Para trabalhos futuros, deve ser criada uma quantidade maior de seqüências de vídeo, tanto em classificação e características de cenas quanto em taxas de quadros e diferentes combinações de escalabilidade. Outras suges-tões são: a avaliação da qualidade subjetiva de vídeo utilizando a métrica subjetiva MOS (Mean Opinion Score) e a recepção de vídeo utilizando diferentes receptores, tais como: PDA’s e smartphones.
Referências
[1] [3GPP TS 26.244, 2010] 3gpp ts 26.244 (2010-06) “Technical Specification Group Services and System Aspects;Transparent end-to-end packet switched streaming service (PSS)”; 3GPP file format (3GP) (Release 9) V9.2.0.
[2] [Alexiou et al., 2005] Alexiou, A.G. Bouras, C.J. Igglesis, V.G. (2005) “A decision feedback scheme for multi-media transmission over 3G mobile networks”. Second IFIP International Conference on Wireless and Optical Communications Networks. WOCN.pg 357-361.
[3] [Antoniou et al., 2007] Antoniou P., Vassiliou V., Pitsilides A. (2007) “ADIVIS: A Novel Adaptive Algorithm for Video Streaming over the Internet”. 18th Annual IEEE International Symposium on Personal, Indoor and Mobile Radio Communications.
[4] [Bouras et al., 2003] Bouras C., Gkamas A. (2003) “Performance of Adaptive Multimedia Transmission: The case of Unicast Technique”, Research Academic Computer Technology Institute, Greece.
[5] [Chih-Heng Ke et al., 2008] Chih-Heng Ke, Ce-Kuen Shieh, Wen-Shyang Hwang, Artur Ziviani (2008) “An Evaluation Framework for More Realistic Simulations of MPEG Video Transmission” Journal of Information Sci-ence And Engineering 24, 425-440.
[6] [Davies et al., 2008] Davies, M., Dantcheva, A., Fröhlich, P. (2008) “Comparing Access Methods and Qual-ity of 3G Mobile Video Streaming Services”. Proceeding of the twenty-sixth annual CHI conference extended abstracts on Human factors in computing systems - CHI ‘08, pg 2817.

UIGV163
[7] [Diaz et al., 2007] Diaz A., Merino P., Panizo L., Recio, A. M. (2007) “Evaluating Video Streaming over GPRS / UMTS networks: A practical case”. IEEE 65th Vehicular Technology Conference - VTC2007-Spring. 2007. pg 624-628.
[8] [Elsen et al., 2001] Elsen, I., Hartung, F., Horn, U., Kampmann, M., Peters, L. (2001) “Streaming Technology in 3G Mobile Communication Systems”. IEEE Computer Society Press. Computer Journal. Vol. 34. Pg. 46-52. September.
[9] [Fajardo et al., 2007] Fajardo J. O., Liberal F., Bilbao N. (2007) “Impact of the video slice size on the visual quality for H.264 over 3G UMTS services”. Methodology.
[10] [Hartung et al., 2007] Hartung, F., Horn, U., Huschke J., Kampmann M., Lohmar T., Lundevall M., (2007) “Delivery of Broadcast Services in 3G Networks”. IEEE Transactions on Broadcasting. Vol. 53. Pg 188-199. March.
[11] [Iain Richardson, 2003] Iain E. G. Richardson (2003) “H.264 and MPEG-4 Video Compression Video Cod-ing for Next-generation Multimedia”, WILEY.
[12] [Kang et al., 2007] Kang, K., Cho, Y., Cho, J., Shin, H. (2007) “Scheduling Scalable Multimedia Streams for 3G Cellular Broadcast and Multicast Services” IEEE Transactions on Vehicular Technology, Vol. 56. Pg 2655-2672.
[13] [Liu et al., 2009] Liu, Y., Zhang S., Xu S., Yin Z. (2009) “Research on H.264/SVC Compressed Video Com-munication in 3G. 4th International Conference on Computer Science e Education, IEEE. pg 327-332.
[14] [Mulinari e Gondim, 2009] Mulinari R., Gondim P. R. L. (2009) “Esquemas Adaptativos para Distribuição de Vídeo na Internet”. Dissertação de Mestrado – Departamento de Engenharia Elétrica. UnB.
[15] [Ries et al., 2008] Ries, M., Nemethova, O., Rupp, M. (2008) “Video Quality Estimation for Mobile H.264/AVC Video Streaming”. Journal of Communications. Vol. 3. pg 41-50.
[16] [Schwarz and Wien, 2008] Schwarz, H., and Wien, M. (2008) “The Scalable Video Coding Extension of the H.264/AVC Standard”. IEEE Signal Processing Magazine p.135 March.
[17] [Singh et al., 2009] Singh, V., Ott, J., Curcio, I.D.D (2009)“Rate Adaptation for Conversational 3G Video”. IEEE Infocom Workshops. pg 1-7.
[18] [Thomas and George, 2007] Thomas, P., George K. (2007)“Scalable Video Streaming Traffic Delivery in IP/UMTS Networking Environments”, Journal of Multimedia, Vol. 2, Nr. 2, Abril.

UIGV164

UIGV165
Distribuição de Vídeo sob Demanda sobre redes P2P
Valmiro José Rangel Galvis1, Paulo Roberto de Lira Gondim1
1 Universidade de BrasíliaFT - Departamento de Engenharia Elé[email protected], [email protected]
Resumo
Este documento apresenta um overview sobre a distribuição de Vídeo sob Demanda sobre redes Peer-to-Peer (P2P-VoD). Nos últimos anos o mundo tem dado muita atenção para pesquisas sobre o uso das redes P2P, de distribuição de conteúdo, para distribuir vídeo ao vivo (Live Streaming) e sob demanda (VoD). Esse tipo de redes promete ser mais econômico e com maior escalabilidade do que as redes baseadas na arquitetura Cliente/Servidor tradicional, além de solucionar o problema do gargalo do lado do servidor quando muitos usuários querem acessar a um mesmo con-teúdo ao mesmo tempo. O trabalho relatado neste artigo é focado na distribuição de vídeo sob demanda nas redes P2P, levando em conta que o serviço de VoD é o serviço mais importante nas aplicações de multimídia. Mas, mesmo focado no VoD, o artigo ainda tenta comparar os sistemas de VoD com os sistemas de Live Streaming desde o ponto de vista da sincronização dos clientes, dos comportamentos dos usuários e as características do Streaming de cada sistema. São apresentadas as arquiteturas, as estruturas, os mecanismos de descoberta de conteúdo, os mecanismos de detecção e recuperação de falhas, e o gerenciamento da rede. Além disso, também serão apresentadas as princi-pais técnicas de busca e publicação de conteúdo entre os pares, e as considerações essenciais para o desenho ótimo de sistemas P2PVoD.
Palavras chave:
VoD, redes P2P, arquitetura, estrutura, gerenciamento, overlay
Abstract
This document introduces an overview about Video-on-Demand over Peer-to-Peer networks (P2PVoD). In re-cent years the researchers all over the world has given much attention to research about the use of P2P networks, file distribution networks, to distribute live streaming video and video on demand. Such networks promise to be more economical and scalable than networks based on the traditional architecture Client / Server, and troubleshoot the server-side bottleneck when many users want to access the same content at the same time. The work reported in this paper focuses on on-demand video distribution in P2P networks, taking into consideration that the VoD service is the most important service in multimedia applications. But even focused on VoD, this article also tries to compare systems of Live Streaming with systems of VoD from the viewpoint of users’ synchronization and behaviors, and the characte-ristics of each one of the streamings of the two systems (Live Streaming e VoD). We talk about the architectures, the structures, the mechanism of content discovery, the mechanism of failure detection and recovery, and the network management. Besides, the main techniques of content discovery and publishing between peers, and the essentials issues for the optimal design of P2PVoD systems, will be introduced too.
Keywords:
VoD, P2P network, architectures estrutura, management, overlay

UIGV166
Introdução
As redes P2P têm evoluído como um paradigma promissório no compartilhamento de conteúdos em larga escala [1]. Devido à sobrecarga do lado do servidor em sistemas tradicionais baseados na arquitetura Unicast Cliente/Servidor, onde se experimentam gargalos assim que o número de clientes aumenta na rede, tendo perdas na largura de banda e na velocidade do serviço. As redes P2P surgem como uma alternativa para aliviar a carga no servidor nos sistemas de distribuição de conteúdo. Soluções alternativas como o IP Multicast e as redes de distri-buição de conteúdo (CDN, do inglês Content Distribution Network), mas o IP Multicast é muito complexo para se implementar e precisa de mudanças nos roteadores da rede [13] e as CDN’s são muito caras, em março de 2008 o custo da largura de banda de Youtube foi calculado em U$1,000,000 aproximadamente [10].
Existem duas grandes categorias para classificar os sistemas de distribuição de vídeo sobre redes P2P: de Live Streaming (vídeo ao vivo) e Video-on-Demand. Neste artigo esses sistemas são chamados de P2PLive e P2PVoD [2]. O foco deste artigo é estudar os sistemas P2PVoD. Mas mesmo assim são mencionados sistemas P2PLive, para efeitos de esclarecimentos e comparações que ajudam a melhorar o entendimento da nossa abordagem. Os sistemas P2PVoD são classificados de acordo ao grau de descentralização da rede P2P, à estrutura da rede P2P e ao mecanismo de descoberta de conteúdo.
O restante deste artigo está organizado da seguinte forma. Na seção 2 se apresentam os trabalhos relacio-nados ao trabalho feito neste artigo. Na seção 3 são apresentadas as características essenciais da distribuição de vídeo sobre redes P2P e são comparadas as duas grandes categorias: os sistemas de distribuição de vídeo ao vivo e sob demanda. Na seção 4 são apresentadas diversas formas de classificar as redes de distribuição de vídeo sob demanda sobre redes P2P. Na seção 5 são consideradas algumas questões de desenho e de melhoras nos sistemas P2PVoD. Finalmente na seção 6 são apresentadas as conclusões e são sugeridos trabalhos futuros.
Conclusões
Neste artigo se apresentou uma classificação que não tinha sido feita antes dos sistemas P2PVoD, mesmo assim que tenham sido feitos vários estudos e pesquisas sobre esse tipo de sistemas, o nosso escopo é totalmente dife-rente, e logrou-se classificar os sistemas P2PVoD segundo o grau de descentralização da rede P2P, a estrutura da rede P2P e o mecanismo de descoberta de conteúdo.
Mostraram-se as estruturas baseadas em árvore e malha, apontando as vantagens e desvantagens das duas estruturas e a complexidade de implementar uma estrutura híbrida árvore - malha.
Apontamos também fatores chave no desenho dos sistemas P2PVoD e alguns mecanismos para melhorar o desempenho desses sistemas como o prefetching e o incentivo à interação entre os pares.
Como apenas estamos começando o trabalho, não se tem resultados experimentais, mas o resultado do artigo é satisfatório como um primeiro passo no estudo dos sistemas P2PVoD.
Uma proposta para trabalho futuro é adicionar mais uma forma de classificar os sistemas, os que oferecem supor-te à transmissão de vídeo escalável (H.264/SVC, MPEG2, etc.) e os que não. Além disso, estudar como são usados os mecanismos, de descoberta de conteúdo, expostos em 4.3 para o gerenciamento e a manutenção da rede P2P sobreposta. Outra proposta é a de estudar os diferentes sistemas existentes atualmente e classificá-los de acordo à taxonomia proposta neste artigo. Estudar com mais profundidade os algoritmos usados na construção, no gerencia-mento e na manutenção rede. A maioria dos sistemas estudados neste artigo foi desenhada para operar com um canal só, faltaria testar o que acontece ou que soluções podem ser propostas no caso de um ambiente de múltiplos canais. E finalmente também pode ser viável a criação do nosso próprio framework para um sistema de P2PVoD.
O trabalho futuro vai ser desenvolvido usando o GoalBit [28], uma plataforma de transmissão de conteúdo de vídeo sobre redes P2P de código aberto disponível para vários sistemas operativos, vários formatos de vídeo e que segue o padrão PPSP (Peer-to-Peer Streaming Protocol) da IETF (Internet Engineering Task Force).

UIGV167
Referências
[1] Y. Ding, J. Liu, D. Wang, e H. Jiang, “Peer-to-peer video-on-demand with scalable video coding,” Computer Communications, vol. 33, Sep. 2010, pp. 1589-1597.
[2] Y. Liu, Y. Guo, e C. Liang, “A survey on peer-to-peer video streaming systems,” Peer-to-Peer Networking and Applications, vol. 1, Jan. 2008, pp. 18-28.
[3] L. Yu, X. Liao, H. Jin, e W. Jiang, “Integrated buffering schemes for P2P VoD services,” Peer-to-Peer Networking and Applications, vol. 4, Nov. 2010, pp. 63-74.
[4] Y. He e Y. Liu, “VOVO: VCR-Oriented Video-on-Demand in Large-Scale Peer-to-Peer Networks,” IEEE Transac-tions on Parallel and Distributed Systems, vol. 20, Abr. 2009, pp. 528-539.
[5] Y. Huang, T.Z.J. Fu, D.-M. Chiu, J.C.S. Lui, e C. Huang, “Challenges, design and analysis of a large-scale p2p-vod system,” Proceedings of the ACM SIGCOMM 2008 conference on Data communication - SIGCOMM ’08, 2008, p. 375.
[6] K. Huguenin, A.-M. Kermarrec, V. Rai, e M. Van Steen, “Designing a tit-for-tat based peer-to-peer video-on-demand system,” Proceedings of the 20th international workshop on Network and operating systems support for digital audio and video - NOSSDAV ’10, 2010, p. 93.
[7] X. Qiu, C. Wu, X. Lin, e F. Lau, “InstantLeap: fast neighbor discovery in P2P VoD streaming,” Proceedings of the 18th international workshop on Network and operating systems support for digital audio and video, ACM, 2009, p. 19–24.
[8] T.T. Do, K. a Hua, e M. a Tantaoui, “P2VoD: providing fault tolerant video-on-demand streaming in peer-to-peer environment,” 2004 IEEE International Conference on Communications (IEEE Cat. No.04CH37577), 2004, Vol.3, pp. 1467-1472.
[9] A. Bhattacharya, Z. Yang, and S. Zhang, “Temporal-DHT and Its Application in P2P-VoD Systems,” 2010 IEEE International Symposium on Multimedia, Dez. 2010, pp. 81-88.
[10] D. Wang e C.K. Yeo, “Exploring Locality of Reference in P2P VoD Systems,” 2010 IEEE Global Telecommuni-cations Conference, GLOBECOM ‘10, 2010, pp. 1-6.
[11] D. Xie, B. Qian, Y. Peng, e T. Chen, “A Model of Job Scheduling with Deadline for Video-on-Demand System,” 2009 International Conference on Web Information Systems and Mining, Nov. 2009, pp. 661-668.
[12] B. Cai, Z. Luo, e Y. Luo, “A Special Topology for Files Pre-Fetch in Large Scale Video on Demand,” 2010 International Conference on Biomedical Engineering and Computer Science, Abr. 2010, pp. 1-4.
[13] J.-H. Roh e S.-H. Jin, “Video-on-Demand Streaming in P2P Environment,” 2007 IEEE International Symposium on Consumer Electronics, Jun. 2007, pp. 1-5.
[14] I. Stoica, R. Morris, D. Karger, M. F. Kaashoek, e H. Balakrishnan, “Chord: A scalable peer-to-peer lookup service for internet applications,” Proceedings of the ACM SIGCOMM 2001 conference on Data communica-tion - SIGCOMM ’01, 2001, pp. 149–160
[15] Z. Lu, S. Zhang, J. Wu, W. Fu, e Y. Zhong, “Design and Implementation of a Novel P2P-Based VOD System Using Media File Segments Selecting Algorithm,” 7th IEEE International Conference on Computer and Informa-tion Technology (CIT 2007), Oct. 2007, pp. 599-604.
[16] U.C. Kozat, O. Harmanci, S. Kanumuri, M.U. Demircin, e M.R. Civanlar, “Peer Assisted Video Streaming With Supply-Demand-Based Cache Optimization,” IEEE Transactions on Multimedia, vol. 11, Apr. 2009, pp. 494-508.

UIGV168
[17] A. Wu, L. Yuan, X. Liu, e K. Liu, “A P2P Architecture for Large-scale VoD Service,” Eighth ACIS International Conference on Software Engineering, Artificial Intelligence, Networking, and Parallel/Distributed Computing (SNPD 2007), Jul. 2007, pp. 841-846.
[18] Z. Lian-ying e Z. Xiao, “The research of VoD system performance based on CDN and P2P technologies,” 2010 The 2nd International Conference on Computer and Automation Engineering (ICCAE), vol. 4, Fev. 2010, pp. 385-388.
[19] S. Androutsellis-Theotokis e D. Spinellis, “A survey of peer-to-peer content distribution technologies,” ACM Com-puting Surveys, vol. 36, Dez. 2004, pp. 335-371.
[20] M. Zhang e B. Feng, “A P2P VoD system using dynamic priority,” 2009 IEEE 9th Malaysia International Confer-ence on Communications (MICC), Dez. 2009, pp. 518-523.
[21] Q. Gu, “A schedule algorithm of peer-to-peer VoD system,” Computer and Communication Technologies in Agriculture Engineering (CCTAE), 2010 International Conference On, IEEE, 2010, p. 583–586.
[22] S. Annapureddy, S. Guha, C. Gkantsidis, D. Gunawardena, e P.R. Rodriguez, “Is high-quality VoD feasible using P2P swarming?,” Proceedings of the 16th international conference on World Wide Web, ACM, 2007, pp. 903–912.
[23] R.P. Leal, E.P. Martín, e J.Á. Cachinero, “Internet TV Broadcast: What Next?,” 2009 Fourth International Confer-ence on Digital Telecommunications, Jul. 2009, pp. 71-74.
[24] X. Zhang, J. Liu, B. Li, e T. Yum, CoolStreaming/DONet: “A data-driven overlay network for efficient live media streaming,” IEEE INFOCOM’05, vol. 3, 2005, pp. 2102–2111.
[25] BitTorrent Homepage http://www.bittorrent.com acessado em 30/07/2011
[26] L. Kai, S. Xiao, Q. Zhigang, P. Lingjuan, e L. Hui, “Peers Segment Replacement Strategies in P2P Vod System Based On Client-Side Segmented Cache,” 2009 WRI International Conference on Communications and Mo-bile Computing, Jan. 2009, pp. 26-33.
[27] M. Zhang, Y. Xiong, Q. Zhang, L. Sun, e S. Yang, “Optimizing the throughput of data-driven peer-to-peer streaming,” IEEE Transactions on Parallel and Distributed systems, vol. 20, Jan. 2008, p. 97–110.
[28] http://goalbit.sourceforge.net

UIGV169
Diseño de un Sistema de Monitoreo Móvil para gestantes en el Distrito de Balsapuerto, Loreto
Sandy Lucy Maldonado Panduro, Luis Montes Bazalar [email protected] - [email protected]ú, Lima
Resumen
La selva peruana es una zona de difícil acceso debido a su geografía, y más aún son sus comunidades rurales, donde se tienen altos índices de pobreza, de mortalidad materno-infantil, entre otros; tal es el caso del distrito de Bal-sapuerto. Esta zona ha sido descuidada por parte de entidades públicas y privadas, quienes la consideran poco atracti-va en cuanto a términos de rentabilidad, ya que la inversión necesaria sería mucho mayor comparada a inversiones en zonas urbanas. En este artículo, se propone el uso de una tecnología de comunicación móvil aplicado al monitoreo de gestantes en zonas rurales con la finalidad de reducir, de alguna manera, los altos índices expuestos anteriormente.
Palabras clave:
OpenBTS, Telecomunicaciones Rurales, Telemedicina, USRP, Software Libre.
Abstract
The Peruvian Amazon is an area of difficult access due to geography, and even more are their rural communities, which have high poverty rates, maternal mortality - children, among others, as is the case Balsapuerto district. This area has been neglected by public and private entities who consider unattractive as to terms of profitability, because the investment required would be much higher compared to investments in urban areas. In this paper, we propose the use of mobile communication technology applied to the monitoring of pregnant women in rural areas in order to reduce somewhat the high rates set forth above.
Keywords:
OpenBTS, Rural Telecommunications, Telemedicine, USRP, Free Software.
Introducción
El distrito de Balsapuerto, como en la mayor parte de la selva amazónica, tiene una significante tasa de morta-lidad de gestantes y recién nacidos. Esto se debe a muchos factores, como: la ausencia de un adecuado sistema de control prenatal y posnatal, pobladores que no acuden al centro de salud por las distancias que deben recorrer y prefieren atenderse con parteras de la zona, entre otros.
Según el Ministerio de Salud, en el Centro de Salud de Balsapuerto, de 127 gestantes, 116 son nacimientos exitosos, representando un 8,66% de mortalidad infantil.
La mayoría de las muertes maternas y recién nacidos son prevenibles. Esto se puede lograr con un control materno-fetal adecuado y un parto bajo la dirección de un personal de salud capacitado.

UIGV170
De acuerdo con el problema presentado, se ha visto por conveniente utilizar un sistema de comunicación móvil para monitorear a las gestantes de Balsapuerto, por las siguientes razones:
Movilidad a las gestantes, sin tener que limitar un reducido espacio, de donde se pueda comunicar con el per-sonal médico en el caso de una urgencia.
Facilidad en el traspaso del terminal.
Facilidad de transporte del equipo terminal para el usuario.
Conclusiones
• OpenBTS es una tecnología diseñada para zonas rurales. Ofrece un coste cero (0) por el servicio de llama-das y mensajería de texto dentro de la cobertura de los transmisores. Además, puede ser aprovechada por los pobladores de Balsapuerto sin contar con la presencia de un operador de telecomunicaciones.
• El presente proyecto busca demostrar los beneficios sociales, de una tecnología basada en software libre, para zonas rurales. Y de esta manera, captar la atención del regulador de telecomunicaciones con la fi-nalidad de permitir el uso legal de las bandas de GSM en zonas donde el operador licenciado no tiene presencia.
Referencias
[1] Sitio Oficial del Ministerio de Salud URL: http://www.minsa.gob.pe
[2] Sitio Oficial de Gnu Radio URL: http://gnuradio.org
[3] Sitio Oficial de Kestrel Signal Processing. URL: http://kestrelsignalprocessing.mybigcommerce.com/
[4] Sitio Oficial de Ehas URL: http://www.ehas.org
[5] Sitio Oficial de Teleco URL: http://www.teleco.com.br

UIGV171
Descripción, Evaluación y Proyecciones de la Implementación del Área Virtual Móvil en Perú
Cynthia Natali Alvarez Huaraca, Percy Fernandez P., Luis Montes B. Ingeniería de las telecomunicaciones Pontificia Universidad Católica del Perú [email protected], [email protected]
Resumen
El presente artículo tiene como objetivo describir y analizar la implementación del Área Virtual Móvil en Perú. Asi-mismo, evalúa su impacto económico y los efectos de su despliegue en términos de líneas, tarifas y tráfico cursado. Se analiza todos los aspectos implicados en la implementación y en el funcionamiento de este nuevo sistema, tales como los puntos de interconexión, las disposiciones tarifarias y los aspectos legales implicados. De la misma forma, se realiza una evaluación de los efectos de su despliegue en los principales indicadores del mercado móvil, tales como, líneas móviles, tarifas y tráfico cursado. Tras la evaluación, se puede concluir que la implementación de este nuevo sistema ha favorecido el incremento de la penetración móvil en el país, así como el mayor incremento del tráfico promedio por abonado móvil.
Palabras clave:
LDN, NDC, DN, On net, Off net
Abstract
This article aims to describe and analyze the implementation of Mobile Virtual Area in Peru. It also assesses their economic impact and the effects of deployment in terms of lines, rates and traffic carried. We analyze all aspects involved in the implementation and operation of this new system, such as points of interconnection, tariff provisions, and legal issues involved. Likewise, it assesses the effects of their deployment in the mobile market indicators such as moving lines, rates and traffic carried. After the evaluation we can conclude that the implementation of this new system has helped to increase mobile penetration in the country and the largest increase in average traffic per mobile subscriber.
Keywords:
LDN, NDC, DN, On net, Off net
Introducción
Existe una creciente demanda de los servicios móviles que requiere mejoras en el sistema de numeración, así como, mejores mecanismos para el establecimiento de llamadas de larga distancia nacional. Así surge el Área virtual móvil, el cual es un cambio que afecta a millones de usuarios en el país, que no se encuentran debidamente informados, pues no existe una documentación que integre toda la información e investigación neutral y objetiva sobre el tema.
El despliegue del Área Virtual Móvil es un importante cambio en el país que requiere que tanto los usuarios como aquellas personas con conocimientos en telecomunicaciones estén debidamente informados. Se requiere contar con

UIGV172
una amplia información y evaluación imparcial sobre el nuevo sistema implantado. Asimismo, contar con un análisis detallado de su impacto y sus implicancias a futuro.
Conclusiones
La implementación del área virtual móvil en el país permite una mejor distribución de la numeración móvil, incre-mentando la capacidad de este recurso escaso. Los usuarios móviles cuentan con números únicos a nivel nacional sin ser asociados a un determinado departamento, además ahora pueden contar con tarifa única a nivel nacional para los distintos escenarios de llamadas como móvil-móvil y móvil-fijo. Incentivándose de este modo la tendencia de unificación de tarifas.
Los efectos del despliegue del Área Virtual Móvil han sido positivos en la telefonía móvil del país. En la evalua-ción de su impacto, en el caso de las líneas móviles, se obtuvo que este nuevo sistema implementado favoreció un mayor incremento de líneas móviles. Antes del A.V.M se tenía 26.479.230 líneas móviles en promedio desde enero hasta agosto. Este valor aumentó la cantidad de 2.111.935 llegando a 28.591.165 líneas promedio después del A.V.M, es decir, en el periodo septiembre-diciembre. Asimismo, la densidad promedio de líneas aumentó, en el escenario antes del A.V.M. se tenía 93,1 líneas por cada 100 habitantes y después de la implementación del A.V.M. se llegó a 97,4 líneas como promedio desde septiembre hasta diciembre de 2010. Al cierre del año 2010 se llegó a 29.115.149 líneas móviles con una densidad de 98,3.
En cuanto al impacto del Área Virtual Móvil en el tráfico cursado, se observa un notable crecimiento del tráfico saliente después de la entrada en vigencia del nuevo sistema, pues antes de la implementación del A.V.M se tenía un promedio de 1.661 millones de minutos en el periodo enero-junio y después del A.V.M éste pasó a 2.004 millones de minutos promedio durante el periodo analizado (septiembre- diciembre).
El incremento señalado fue de 343 millones de minutos. Esto se debe a que los usuarios puedan realizar llama-das desde sus móviles a todo el territorio peruano con un único precio de llamada local. Por otro lado, el tráfico entrante ha disminuido en 13,25 % ante este nuevo escenario, pues se tenía 265 millones de minutos promedio antes del A.V.M y después se pasó a 234 millones de minutos promedio después del A.V.M, esto evidencia que ahora se tiene mayor originación que terminación en el sistema móvil. Asimismo, es importante señalar que el tráfico promedio saliente por abonado móvil era de 64 minutos promedio antes del A.V.M y después del A.V.M llegó a 70 minutos.
Con respecto al efecto del Área Virtual Móvil en las tarifas, según los resultados obtenidos, se puede señalar que las tarifas prepago tanto en On Net, Off Net se mantuvieron constantes después del A.V.M. En cuanto a las tarifas pospago, en la modalidad de minutos incluidos y minutos adicionales Telefónica Móviles presenta pequeñas reducciones en sus tarifas después de la implementación del A.V.M. Es importante señalar que las operadoras móviles han incentivado el incremento de la originación de las llamadas desde las redes móviles, mediante el es-tablecimiento de promociones y planes promocionales que atraen a sus clientes para realizar más llamadas desde su móvil hacia fijos.
Respecto a la comparativa internacional realizada, la metodología empleada en el país para la implementación del nuevo sistema de numeración móvil fue muy similar al realizado en Chile y Ecuador. De igual forma, el impacto del Área virtual móvil en relación con el incremento de la penetración y tráfico promedio por abonado presentados en el país es muy parecido a lo ocurrido en Chile y Ecuador.
Finalmente, según los resultados obtenidos en las proyecciones realizadas, se puede señalar que se seguirá la tendencia creciente de la demanda de los servicios móviles. Se estima que dentro de 5 años, es decir para el 2016, se llegue a alcanzar los 54 millones de líneas. Además, se puede señalar que en el periodo proyectado la densidad se incrementará un 51% desde el 2011. Por otro lado, para el año 2016 se espera que el tráfico saliente llegue a 90.184.894.731 minutos, el cual representará un 30% de incremento anual. Asimismo, se estima que el tráfico saliente promedio anual por abonado móvil llegue a 1670 minutos en el 2016.

UIGV173
Referencias
[1] [AMP2010] América Móvil Perú S.A.C. Brochure de tarifas móviles - Lima.
[2] [AVM2010] Ministerio de Transporte y Comunicaciones Área Virtual Móvil. Lima. Consulta: 11 de Noviembre de 2010. http://www.mtc.gob.pe/portal/avm2/avm.pdf
[3] [CON2007] Consejo Nacional de Telecomunicaciones del Ecuador Plan técnico fundamental de numer-ación (PTFN).Consulta: 27 de marzo de 2011. http://www.conatel.gob.ec/site_conatel/index.php?option=com_content&view=article&id=145&Itemid=451
[4] [INS2010] Instituto Nacional de Estadística e Informática Perú: Estimaciones y Proyecciones de Población por departamentos. Lima. Consulta: 10 de diciembre de 2010.
http://www.inei.gob.pe/Biblioinei4.asp
[5] [MED2010] América Móvil Perú S.A.C. Mediciones de trafico año 2010 - Dirección de operación y manten-imiento. Lima.
[6] [MIN2009] Ministerio de Transporte y Comunicaciones. Resolución Ministerial N 477-2009-MTC/03.Establ-ecen Disposiciones para la Entrada en Vigencia del Área Virtual Móvil y Aprueban Cronograma que Guiará el Proceso de Implementación.Consulta: 21 de Noviembre de 2010.
http://www.mtc.gob.pe/portal/comunicacion/politicas/normaslegales/R%20M%20N%C2%BA%20477.PDF
[7] [MIN2010] Ministerio de Transporte y Comunicaciones Servicio Canales Multiples de Selección Automatica. Lima. Consulta: 13 de Noviembre de 2010. http://www.mtc.gob.pe/portal/comunicacion/concesion/pubicos/teleservicio/tronca.htm
[8] [MTC2002] Ministerio de Transporte y Comunicaciones. Resolución Suprema N 022-2002-MTC.Plan Téc-nico Fundamental de Numeración. 31 de agosto. Consulta: 20 de Octubre de 2010.
http://www.mtc.gob.pe/portal/comunicacion/politicas/normaslegales/numeracion/RS022-2002-MTC(8).pdf
[9] [MTC2007] Ministerio de Transporte y Comunicaciones. Resolución Ministerial N 251-2007-MTC/03.Dis-posiciones para Facilitar la Implementación Posterior de la Segunda Etapa del Plan Técnico Fundamental de Numeración Referente al Servicio Público Móvil. 30 de mayo.Consulta: 21 de Noviembre de 2010.
http://www.mtc.gob.pe/portal/comunicacion/politicas/normaslegales/RM_251_2007.pdf
[10] [MTC2008] Ministerio de Transporte y Comunicaciones. Resolución Ministerial N 153-2008-MTC/03.Modi-fican la R.M N 251-2007-MTC/03.Lima.Consulta: 21 de Noviembre de 2010.
http://www.mtc.gob.pe/portal/comunicacion/politicas/normaslegales/RM_153_2008_MTC_03.pdf
[11] [MTC2009] Ministerio de Transporte y Comunicaciones. Líneas en servicio y densidad en la telefonía fija y móvil: 1993-2009. Lima. Consulta: 11 de diciembre de 2010. http://www.mtc.gob.pe/estadisticas/index.html
[12] [NEX2010] Nextel del Perú S.A. Mediciones de trafico año 2010 - Dirección de operación y mantenimiento. Lima. [NPS2010] Nextel del Perú S.A. Brochure de tarifas móviles - Lima.
[13] [OSI2009] Organismo Supervisor de Inversión Privada en Telecomunicaciones. Resolución De Consejo Direc-tivo N 045-2009-CD/OSIPTEL. 27 de Agosto.
[14] [OSI2010] Organismo Supervisor de Inversión Privada en Telecomunicaciones. Resolución De Consejo Direc-tivo N 093-2010-CD/OSIPTEL. 19 de Agosto. Consulta: 15 de agosto de 2010.
http://www.osiptel.gob.pe/WebSiteAjax/WebFormGeneral/normas_regulaciones/wfrm_ResolucionesAlt-aDireccionDetalles.aspx?CS=1242

UIGV174
[15] [REP2010] Organismo Supervisor de Inversión Privada en Telecomunicaciones. Reporte de líneas en servicio – Dirección de estadísticas, investigaciones y publicaciones. Lima
[16] [TEL2010] Telefónica Móviles S.A. Mediciones de trafico año 2010 - Dirección de operación y manten-imiento. Lima.
[17] [TMS2010] Telefónica Móviles S.A. Brochure de tarifas móviles - Lima.
[18] [UIT2006] Unión Internacional de Telecomunicaciones. Boletín de explotación de la UIT No 860 Consulta: 21 de agosto de 2011. www.itu.int/dms_pub/itu-t/opb/sp/T-SP-OB.860-2006-OAS-MSW-S.doc

UIGV175
Estudio, Diseño e Instalación de un Retransmisor Isofrecuencial de Televisión Digital Terrestre para el Cono Norte de Lima
Carlos Enrique Barraza Flores1, Marco Mayorga Montoya2
1 Pontificia Universidad Católica del Perú2 Pontificia Universidad Católica del Perú [email protected], [email protected]
Resumen
En este artículo, se presenta una solución económica para brindar cobertura del servicio de radiodifusión de Tele-visión Digital Terrestre a la zona del Cono Norte de Lima mediante el uso de reemisores denominados Gap-Fillers, los cuales operan con redes de difusión de frecuencia única.
Palabras clave:
Televisión Digital Terrestre, ISDB-T, Gap-Filler.
Abstract
This paper presents an economical solution to provide service coverage of digital terrestrial television broadcasting in the area of the Northern Cone of Lima, using repeaters called Gap-Fillers.The networks which operate single fre-quency distribution.
Keywords:
Digital Terrestrial Television, ISDB-T, Gap-Filler.
Introducción
En la actualidad, en nuestro país, son cinco los proveedores de Televisión Digital Terrestre (TDT) que vienen emitiendo sus señales de radiodifusión digital. Los cuales lo están realizando con un único transmisor ubicado en el Cerro Marcavilca (Morro Solar).
Por este motivo, estas casas televisivas no presentan una cobertura completa para el departamento de Lima. Por lo que se requieren sistemas repetidores que permitan ampliar la cobertura del servicio de TDT, para lo cual existen diferentes alternativas diferenciadas tanto tecnológica como económicamente.
Para ello, se propone un sistema repetidor isofrecuencial usando Gap-Filler, particularmente para el canal de TV Perú.
El resto del presente paper está organizado de la siguiente manera. En la sección 2, se hace una breve mención de los trabajos previos realizados respecto a la TDT en nuestro país. La sección 3, describe la situación actual de

UIGV176
la TDT en Perú. El diagnóstico del problema se realiza en la sección 4. Las alternativas de solución, elección de la mejor de ellas y desarrollo del concepto y problemas con los Gap Fillers se realiza en la sección 5. En la sección 6, se describe la instalación realizada y se muestran los resultados obtenidos antes y después de ésta. El análisis de los resultados obtenidos se realiza en la sección 7. Finalmente, en la sección 8, se redactan conclusiones y recomendaciones.
Conclusiones
El retardo entre las señales del Morro Solar y la del cerro Shangrilá es menor que el intervalo de guarda de la modulación OFDM (64 QAM) en todo el área de estudio. Por lo que sí se puede implementar SFN entre los dos transmisores.
En las zonas que la intensidad de señal del Morro Solar es alta, se hizo el experimento de apuntar la antena yagui de las pruebas hacia el Morro. Se obtuvieron medidas que el nivel de señal del Morro Solar era muy similar al del cerro Shangrilá. El resultado del MER era de 13,5 dB.
En todos los puntos de prueba la imagen del HD, SD y one-seg fueron de muy buena calidad, calificaciones de 4 y 5 de acuerdo con la recomendación UIT-R-2035.
Los reemisores isofrecuenciales o Gap-Fillers representan la alternativa más económica y adecuada para dar cobertura a zonas de sombra pequeñas con orografías complicadas.
En nuestro país, existe un campo abierto para el desarrollo de la Televisión Digital Terrestre debido a las bajas tasas de penetración de televisión pagada que posee.
Referencias
[1] TV Digital Perú – MTC. URL: http://tvdigitalperu.mtc.gob.pe. Última consulta: 31 de julio del 2010
[2] Cáceda, Oscar. Situación Actual de la TDT en el Perú, 2011. Documento en línea, URL: http://www.con-cortv.gob.pe/file/participacion/eventos/2011/05-chiclayo-tdt/oc.pdf.
[3] BNaméricas. El camino hacia la televisión digital en Latinoamérica comienza en Brasil, 2011. Telecom Intel-ligence Series.
[4] Molina, Mariano. Extensión de la cobertura. Despliegue e instalación de Gap Fillers: Proyectos Técnicos. España, 2009.
[5] Associacao Brasileira de Normas Técnicas. NBR 15604. Norma Brasilera ABNT.1 de diciembre del 2007.
[6] Barreda, Víctor. Trabajo de final de carrera: “Estudio, diseño e instalación de un centro emisor de TDT con Gapfillers”. Universidad Politécnica de Cataluña, 2009

UIGV177
Aplicación Interactiva para registro de citas médicas por Televisión utilizando GINGA-NCL
Herminio Paucar Curasma1, Nilton Ugarte Vera2, Ronald Paucar Curasma3 1,2 Universidad Nacional Mayor de San Marcos3 [email protected], [email protected], [email protected]
Resumen
Una de las principales características del estándar ISDB-T de la televisión digital terrestre es la interactividad que permite al telespectador interactuar a través del televisor con aplicaciones, como: T-Learning, T-Voting, T-Commerce, T-Goverment, entre otros. En este panorama, se desarrolló una aplicación interactiva para el registro o solicitud de citas médicas por televisión. Esta aplicación permitirá a los pobladores con domicilios alejados de los hospitales, reservar su cita médica remotamente. Para el desarrollo de esta aplicación, se utilizaron los lenguajes Ginga NCL y Lua. Posterior-mente, las pruebas de validación se realizaron en un escenario implementado en laboratorio.
Palabras clave:
Cita Médica, TdT, ISDB-T, middleware, Ginga-NCL, Lua, interactividad.
Abstract
One of the main features of ISDB-T digital terrestrial television is interactivity, allowing viewers to interact via the TV applications, such as: T-Learning, T-Voting, T-Commerce, T-Goverment, among others. In this scenario, we developed an interactive application for registration or request appointments on television, this application will allow people with homes away from hospitals, book your appointment remotely. For the development of this application is used NCL and Ginga languages Lua, then the validation tests were performed in a laboratory setting implemented.
Keywords:
appointment, TdT, ISDB-T, middleware Ginga-NCL, Lua, interactivity.
Introducción
Actualmente, Perú se encuentra en una época de evolución tecnológica. Prueba de ello es el gran avance que se dio al adoptar el estándar de la Televisión Digital Terrestre (TdT) bajo la norma ISDB –T [MTC, 2009]. Esta tec-nología nos permite plantear soluciones a problemas cotidianos de nuestra sociedad, como en las áreas de salud, educación, desastres naturales, turismo y otros. Uno de los componentes principales de ISDB-T es el middleware Ginga NCL (Nested Context Languaje) [Ribeiro, 2008], que permite el desarrollo de aplicaciones interactivas para que el telespectador pueda interactuar mediante el televisor con aplicaciones de diferentes rubros (educación, salud, gobierno, etc.).
En Perú, el servicio de los centros de Salud públicos (hospitales del estado) [EsSalud, 2011] [MINSA, 2011] son deficientes. Existe una inadecuada atención en la solicitud de citas médicas en una determinada especialidad que

UIGV178
genera disconformidad de la población. Además, las personas con discapacidad y ancianos no tienen oportuni-dades iguales que una persona normal. A la fecha, existen dos maneras de solicitar una cita médica, por teléfono y personalmente en las oficinas del centro de salud, y recientemente por Internet. Los pobladores que viven en lugares alejadas de la capital de provincia no cuentan con servicios básicos de telecomunicaciones, como telefonía o Inter-net. Como consecuencia, no será posible solicitar una cita médica mediante una llamada telefónica; por lo tanto la única manera será acudir personalmente. Esto genera a la población de bajos ingresos económicos, la pérdida de tiempo y dinero; que a su vez ello puede ser utilizado para otros fines.
Por su naturaleza, la señal de televisión es la que tiene mayor cobertura frente a otros servicios de telecomuni-caciones, y aprovechando las bondades de la tecnología ISDB-T, se plantea desarrollar una aplicación interactiva para el registro o solicitud de citas médicas por televisión, donde el poblador o telespectador, desde su domicilio, por medio de la televisión, podrá solicitar o reservar una cita médica en cualquiera de los centros de salud; de esta manera, el poblador ahorrará tiempo y dinero que generaría al desplazarse desde su domicilio. La información que registra el telespectador desde el televisor, se envía por Internet que se utiliza como canal de retorno para la televisión digital terrestre. La información de registro que envía el telespectador son: DNI (Documento Nacional de Identidad), Nombre, Apellido Paterno, Apellido Materno, Edad, Sexo, Correo, Teléfono, Fecha de Nacimiento, Departamento, Especialidad, Consulta, Día, Turno, entre otros. Como parte del análisis y diseño de aplicativo, se presenta el modelamiento de la aplicación y su implementación utilizando el lenguaje Ginga NCL [NCL, 2011] y Lua [Ierusalimschy, 2011]; la cual es simulada en un escenario de laboratorio utilizando el Virtual Set Top Box Ginga NCL.
Conclusiones
El registro de cita médica por televisión permitirá la inclusión social de las personas de menor ingreso económico y con domicilio alejado de los hospitales.
Los pobladores, al solicitar citas por televisión, no generarán gastos de transporte al desplazarse hasta los hos-pitales, que normalmente están alejados de sus domicilios.
La señal de televisión se caracteriza por presentar mayor cobertura que otros servicios de telecomunicaciones, como el teléfono; por lo tanto, la aplicación interactiva desarrollada, llegará a la mayoría de la población.
Esta aplicación de registro de cita sirve de base para el desarrollo de aplicaciones de mayor importancia en el área de la salud y la educación.
Para el desarrollo de esta aplicación, se utilizaron los lenguajes NCL y Lua, con las librerías tcp lua para el envío de datos a través del canal de retorno.
Referencias
[1] [Eclipse, 2011] Entorno de Desarrollo Integrado IDE Eclipse. http://www.eclipse.org/
[2] [El Club NCL, 2011] Es un repositorio de aplicaciones interactivas donde los autores pueden publicar sus ideas, talentos, y técnicas de desarrollo utilizando el lenguaje NCL y scripts Lua. http://elclub.ncl.org.br/
[3] [EsSalud, 2011] Seguro Social de Salud. EsSalud. http://www.essalud.gob.pe/
[4] [Ierusalimschy, 2011] Lua 5.1 Reference Manual by R. Ierusalimschy, L. H. de Figueiredo, W. Celes Lua.org, August 2006 ISBN 85-903798-3-3. La traducción al español ha sido realizada por Julio Manuel Fernández-Díaz.

UIGV179
[5] [LuaEclipse, 2011] Plugin Lua para Eclipse-LuaEclipse. http://luaeclipse.luaforge.net/
[6] [MINSA, 2011] Hospitales del Ministerio de Salud. http://www.minsa.gob.pe/portada/inst_hospitales.asp
[7] [MTC, 2009] Ministerio de Transportes y Comunicaciones (MTC), Resolución Suprema N° 019-2009-MTC. http://www.mtc.gob.pe/portal/tdt/Documentos/RS019_2009_MTC.pdf
[8] [NCL, 2011] Web principalmente enfocado al desarrollo y difusión del lenguaje de programación NCL. http://www.ncl.org.br/
[9] [NCLEclipse, 2011] Plugin NCL para Eclipse-NCLEclipse. http://www.ncl.org.br/ferramentas.html
[10] [Paucar, 2011] Paucar, R. (2011). Análisis del Canal de Retorno para la Televisión Digital Interactiva utili-zando la clase TCP-Lua, Universidad de Campinas-UNICAMP, Brasil, 2010.
[11] [Ribeiro, 2008] Jean Ribeiro Damasceno. Middleware Ginga. Escola de Engenharia Universidade Federal Fluminense (UFF), Brasil, 2008.
[12] [Francisco, 2010] Francisco. Tutorial de NCLua. Disponible en internet en: http://www.telemidia.puc-rio.br/~francisco/nclua/tutorial/exemplo_05.html.
[13] [Velásquez, 2010] Velásquez, C. Aplicación Interactiva Basada en el Ginga-NCL para el Área de Salud, Universidad de Campinas-UNICAMP, Brasil, 2010.
[14] [Velarde, 2008] Velarde, E. Televisão Digital Móvel para Aplicações de Governo utilizando Ginga NCL, Universidade Estadual de Campinas (UNICAMP), Brasil, 2008.

UIGV180

UIGV181
Yauri Rodriguez1, Rubén Acosta Jacinto1, Antuanet Adanaqué Infante1,1
1Instituto Nacional de Investigación y Capacitación de Telecomunicaciones de la Universidad Nacional de Ingenierí[email protected], [email protected], [email protected]
Sistema de Monitoreo remoto usando la tecnología ZigBee y mensajes SMS
Resumen
En este artículo, se expone el diseño, desarrollo e implementación del Sistema de Monitoreo Remoto para acui-cultura usando redes inalámbricas de sensores de bajo consumo denominada ZigBee y el monitoreo remoto usando mensajes SMS. El sistema de monitoreo remoto requiere el cumplimiento de las siguientes funciones: captura y cen-tralización de información, formateo y control, organización y almacenamiento de la información, y acceso remoto a la información. Para que el sistema cumpla con la primera función, se desarrolló un equipo Terminal que captura los datos de los sensores y los envía a un equipo Coordinador usando una red ZigBee. El equipo Terminal se ubica cerca del ambiente que se desea monitorear y el equipo Coordinador se ubica junto a un ordenador que almacena los datos. La segunda función se logra con el programa implementado en el microcontrolador del equipo Coordinador, el cual verifica que los datos se encuentren en el formato correcto para enviarlos a una aplicación de escritorio en un ordenador usando una red LAN. El equipo Coordinador tiene un módulo GSM con el que nos comunicamos usando el puerto serial del microcontrolador y enviando comandos AT. Para cumplir con la tercera función, se desarrollaron aplicaciones en el ordenador las cuales se encargan de recibir los datos usando un servidor TCP/IP y almacenarlos en una Base de Datos. La última función se consigue con el acceso remoto a la información usando mensajes SMS por medio de una aplicación de escritorio que se comunica con un equipo móvil usando comandos AT. Otra de las herramientas usadas para realizar el monitoreo remoto es una aplicación Web.
Palabras clave:
IEEE 802.15.4, SMS, WSN, ZigBee.
Abstract
This paper introduces the technological development and implementation of a Remote monitoring system for aqua-culture using TIC, a technology used in low power wireless sensor networks called ZigBee and remote monitoring using SMS messages. A remote monitoring system requires the fulfillment of the following functions: information capture and centralization, information formatting and control, information storage and management, and remote access to infor-mation. A Terminal equipment was developed to meet the first function. This equipment captures data from sensors and sends them to a Coordinating equipment using a ZigBee network. The Terminal equipment is located near the area to be monitored and the Coordinating equipment is located next to a computer that will store the data. The second function is achieved implementing a program in the coordinator equipment microcontroller, which verifies the data for-mat to send it to a desktop application on a computer using a LAN. Using the microcontroller’s serial port and sending AT commands we can communicate with the GSM module of the coordinator equipment. To carry out the third function software applications were developed which are responsible for receiving data using a TCP/IP server and storing it on a database. They are desktop applications and they are designed to be used by staff that performs local monitoring. The last function is achieved through remote access to information using SMS messages via a desktop application that communicates with a mobile device using AT commands. A Web application is also used to perform remote monitoring.
Keywords:
IEEE 802.15.4, SMS, WSN, ZigBee.

UIGV182
Introducción
Actualmente, existen actividades de monitoreo que se realizan en forma localizada y donde es necesario co-nocer las variables a monitorear en cualquier momento. Podemos tomar como ejemplo a las empresas o personas dedicadas a la producción de recursos alimentarios en cautiverio (acuicultura, piscicultura) o al control del estado de las tierras usadas para la agricultura y ganadería donde existen factores de riesgo que hacen necesario el mo-nitoreo y control del ambiente destinado al desarrollo de sus productos. Un caso particular, desarrollado en este trabajo, es en el monitoreo de variables de temperatura y de pH del agua en la actividad de acuicultura dedicada a la crianza de peces en cautiverio, donde es necesario conocer el estado del agua en los estanques de crianza. La motivación de este proyecto surge de la necesidad de mejorar el monitoreo de los estanques del laboratorio de crianza de peces amazónicos de la Facultad de Zootecnia en la Universidad Nacional Agraria La Molina UNALM y que tiene como solución el diseño e implementación de un sistema monitoreo remoto usando redes de sensores inalámbricos y mensajes SMS.
El sistema aquí propuesto usa la tecnología ZigBee y su función es la recolección de datos provenientes de sensores de forma automática y en lugares donde el acceso es difícil. Una vez que la información se encuentra cen-tralizada, se hace uso de las TIC para que un usuario tenga disponible esta información a través de la red celular mediante el uso de mensajes SMS o el acceso a aplicaciones Web en Internet.
El trabajo está organizado de la siguiente manera:
• La sección 2 muestra algunas referencias relacionadas con el sistema desarrollado en este trabajo.
• La sección 3 muestra conceptos teóricos sobre los temas que se tratarán posteriormente.
• La sección 4 describe el diseño de la solución considerando los criterios de diseño y etapas del sistema.
• La sección 5 muestra los experimentos y resultados que se tuvieron durante el desarrollo del sistema.
• La sección 6 muestra algunos resultados obtenidos de las pruebas más importantes realizadas en la sección anterior.
• La sección 7 describe la implementación final del sistema en el laboratorio de crianza de la UNALM.
• La sección 8 muestra las conclusiones del diseño e implementación del sistema.
Conclusiones
• Con el diseño de este Sistema de Telemetría, se consiguió realizar el monitoreo remoto de las lecturas entre-gadas por los sensores en lugar de realizar el monitoreo de forma local.
• Realizando capturas múltiples de valores desde los sensores de temperatura y pH (sobre un mismo canal ADC), se lograron lecturas estables con menos del 0,5% de variación.
• Se logró la comunicación de un microcontrolador MC98S12NE64 con un ordenador usando una red LAN observando que no había pérdida de datos de los sensores enviados sobre el protocolo TCP/IP.
• El hardware diseñado en este trabajo sirven como base para el desarrollo de sistemas de monitoreo de otros parámetros de interés que puedan aplicarse a otras áreas.

UIGV183
Referencias
[1] Chris Punk y Joshua Hoiland, Remote Aquarium Monitor and Control System, Rochester Institute of Technology. [Online]. Disponible:
http://www.ce.rit.edu/research/projects/2002_fall/rt_bubbles/
[2] Adolfo Chávez, Freddy Araya y Víctor Yepez, Desarrollo de una red monitoreo por sensores remotos de la calidad del agua, Tecnológico de Costa Rica.[Online]. Disponible : http://www.tec.cr/sitios/Vicerrectoria/vie/editorial_tecnologica/Revista_Tecnologia_Marcha/p df/tecnologia_marcha2/desarrollo%20de%20una%20red%20de%20monitoreo.pdf
[3] Jimmy Du, Elnaz Ebrahimi, Wireless Sensor Network for Monitoring Water Quality, San José State University. [Online]. Disponible: http://www.cyyan.net/wqm/about.html
[4] M. Kuorilehto, M. Kohvakka & J. Suhonen, Ultra low energy wireless sensor networks in practice, John Wiley and Sons, 2007.
[5] ILX Lihgtwave, Thermistor Constant Conversions Beta to Steinhart Hart. http://www.ilxlightwave.com/tech-notes/thermistor_constant_conversions_beta_steinhart hart.pdf Acceso 17 Mayo de 2010.
[6] Dirección de Investigación y Desarrollo Tecnológico, INICTEL UNI, Informe Técnico Final del Diseño y desar-rollo de un sistema de monitoreo de acuarios destinados a la determinación de estándares nutricionales para peces amazónicos, Diciembre de 2009.
[7] Steven Torres, MC9S12NE64 Integrated Ethernet Controller, Freescale Semiconductor. http://www.freescale.com/files/microcontrollers/doc/app_note/AN2692.pdf Acceso 23 Mayo de 2010.
[8] Instituto de Investigación de la Amazonía del Perú, Investigación busca elevar la sobrevivencia de alevinos de doncella, Perú, Marzo de 2009.
http://www.iiap.org.pe/Upload/Difusion/DOC72.pdf Acceso 18 de abril de 2009.
[9] Fred Eady, Hands On ZigBee: Implementing 802.15.4 with Microcontrollers, Newnes, 2007.
[10] ZigBee TM Networks, XBee TM Series 2 OEM RF Modules. http://www.compel.ru/images/catalog/868/product manual_XBee_Series2_OEM_RF Modules_ZigBee.
pdf Acceso 17 Mayo de 2010.
[11] Dino Esposito, Programming Microsoft ASP.NET 2.0 Core Reference, Microsoft Press, 2006.

UIGV184

UIGV185
Conferencias magistrales

UIGV186

UIGV187
Doing business with Open Source software
Michael WideniusFinlandiaMonty Program [email protected]
Abstract
A talk about the different licenses and business models that exists in open source and what license makes sense for what kind of business. The talk also covers how to take an open source business to an investor and what the investor will be looking at.
Biography
Author of the original version of the database open source MySQL and founding member of the company MySQL AB. In 1985 he founded TCX Datakonsulter AB (data storage company in Sweden) with Allan Larsson. In 1995 he created the first version of the MySQL database David Axmark, launched in 1996. Co-author of the MySQL Refe-rence Manual, published by O’Reilly in June 2002 and in 2003 awarded the Finnish software entrepreneur of the year. Until the sale of MySQL AB Sun Microsystems in January 2008, he served as technical director and principal leader MySQL AB in the development of MySQL. Company founder Monty Program Ab, which has been working on transactional storage engine for MySQL Maria (a crash-safe version of MyISAM), and also in MariaDB, a new development branch of MySQL 5.1

UIGV188
The MySQL / MariaDB success stories
Michael WideniusFinlandiaMonty Program [email protected]
Abstract
The MySQL and MariaDB history from start to now. What made MySQL a success and how we plan to repeat it with MariaDB.
Biography
Author of the original version of the database open source MySQL and founding member of the company MySQL AB. In 1985 he founded TCX Datakonsulter AB (data storage company in Sweden) with Allan Larsson. In 1995 he created the first version of the MySQL database David Axmark, launched in 1996. Co-author of the MySQL Refe-rence Manual, published by O’Reilly in June 2002 and in 2003 awarded the Finnish software entrepreneur of the year. Until the sale of MySQL AB Sun Microsystems in January 2008, he served as technical director and principal leader MySQL AB in the development of MySQL. Company founder Monty Program Ab, which has been working on transactional storage engine for MySQL Maria (a crash-safe version of MyISAM), and also in MariaDB, a new development branch of MySQL 5.1

UIGV189
Middeware Ginga-NCL: Estado Atual e Perspectivas Futuras de Pesquisa e Inovação
Luiz Fernando Gomes SoaresBrasilPontificia Universidad Católica de Rio de Janeiro [email protected]
Resumo
A palestra apresentará a linguagem NCL no contexto da TV digital terrestre e IPTV, salientando sua adoção como padrão internacional. As diferenças entre o middleware Ginga-NCL e outros middlewares serão apresentadas, salien-tando, com exemplos, as funcionalidades hoje presentes na linguagem. Finalmente, os próximos passos em direção à NCL 4.0 serão abordados, bem como os principais pontos de pesquisa e inovação com relação a transmissão, rece-pção e execução de aplicações para TV digital interativa.
Biography
Possui graduação em Engenharia Elétrica (1976) pela Pontifícia Universidade Católica do Rio de Janeiro (PUC-Rio), mestrado em Engenharia Elétrica pela PUC-Rio (1979), doutorado em Informática pela PUC-Rio (1983) e pós-doutorado pela Ecole Nationale Supérieure des Télécommunications. Líder do grupo criador da linguagem NCL e do middleware Ginga-NCL, padrão do Sistema Brasileiro de TV Digital e primeiro padrão internacional, com tecnologia integralmente nacional, ITU-T para Serviços IPTV (2009). Prêmio ASSESPRO 2008 - Personalidade do Ano, na categoria ‘Academia’ (2008). Pesquisador Inovador - Cientistas do Nosso Estado (FAPERJ, 2005). Prêmio Newton Faller, da Sociedade Brasileira de Computação (2006). Atualmente é professor titular da Pontifícia Univer-sidade Católica do Rio de Janeiro, invited expert do World Wide Web Consortium, representante da academia no Fórum Brasiliero de TV Digital e editor da Recomendação H.761 do ITU-T para serviços IPTV. Tem experiência na área de Ciência da Computação, com ênfase em sistemas multimídia e hipermídia, redes de computadores e TV Digital.

UIGV190
Evolución de la criptografía: desde la criptografía simétrica hasta la criptografía basada en identidad
José Luis Muñóz TapiaEspaña Universidad Politécnica de Catalunya [email protected]
Resumen
En esta conferencia, se presenta una evolución cronológica de las principales contribuciones en el área de la crip-tografía. Se iniciará la conferencia discutiendo la criptografía simétrica para pasar a la criptografía asimétrica. Dentro de esta última, se comentarán sus principales aplicaciones y su evolución hacia criptografía basada en identidad. Por último, se comentarán los nuevos paradigmas como la criptografía homomórfica.
Biografía
Doctor en Ingeniería de Telecomunicaciones de la Universidad Politécnica de Cataluña (UPC). En el año 2000, se unió al Grupo de Seguridad de la Información (ISG) del Departamento de Ingeniería Telemática de la UPC. Actualmente, profesor asociado en el Departamento de Ingeniería Telemática de la UPC. A nivel de investigación, sus intereses son la criptografía, la seguridad en redes y en la Telemática en general. Ha participado activamente en más de una decena de proyectos de transferencia de tecnología e investigación, tanto con empresas privadas como en proyectos de financiación pública. Ha publicado más de cincuenta artículos en revistas indexadas y en congresos internacionales. Además, participa como revisor en diversas revistas, comités de programa de conferen-cias y es asesor en diversos programas nacionales de subvención.

UIGV191
Emergency Information Broadcast By the use of ISDB-T“EWBS” (Emergency Warning Broadcasting System)
Yasuji SakaguchiJapónJICA (Japan International Cooperation Agency)
Abstract
Alert in “One-Seg” mobile TV right after the earthquake saved 40 lives from Tsunami attack. Two policemen in the train noticed Tsunami alert by mobile phone and lead 40 passengers to the hill. All passengers safely evacuated before Tsunami struck the train.
Biography
Expert engineer appointed by Japanese government and being work for MTC as an advisor for implementation of TDT (Digital Terrestrial Television) in Peru. He is originally from NHK (Japan Broadcasting Cooperation) and has long experience and knowledge about the implementation of Digital Broadcasting in Japan. Peru adopted Japanese ISDB-T standard in April 2009 and already inaugurated TDT in March 2010 with his great assistance. Mr. Saka-guchi also plays important role for the standardization of TDT Operational Guideline among all the ISDB-T adapting countries in Latin America.

UIGV192
Inteligencia de Negocios para incrementarla productividad de las Empresas
Nicolás Kemper ValverdeMéxicoUniversidad Nacional Autónoma de Mé[email protected]
Resumen
La inteligencia de negocios es un modelo conceptual dentro de la empresa que soporta la colección, integración, administración, distribución y análisis de un conjunto balanceado de datos para la efectiva y positiva toma de decisio-nes de los diferentes usuarios que conforman la empresa. Optimiza y enriquece el sistema actual de administración de desempeño integrando los procesos de toma de decisiones con la tecnología necesaria. Principalmente, se trata de proveer a las personas de negocio con la información y las herramientas que necesitan para hacer decisiones tanto de la operación del día a día como de la estrategia a seguir en corto, medio y largo plazo. Los negocios recolectan grandes cantidades de datos en sus operaciones acerca de sus órdenes, inventarios, cuentas por pagar, transacciones en sus puntos de venta o clientes. Adicionalmente, los negocios adquieren datos de información demográfica o de listas de correos de fuentes externas. La inteligencia de Negocios habilita a los usuarios poder consolidar y analizar toda la información para elaborar mejores decisiones que, por lo regular, llevan a una ventaja competitiva. Permite aprender y descubrir esas ventajas.
En la conferencia, se trata de familiarizar a los participantes con el tema de la Inteligencia de Negocios, ofrecién-doles una visión integral de la importancia que tiene en el entorno empresarial actual, cómo utilizarla como herra-mienta estratégica para alcanzar los objetivos de la organización y cómo plantear el marco estratégico para utilizarla como ventaja competitiva. Se abordan aspectos de cómo identificar las distintas fuentes de datos de la empresa para extraerlos, organizarlos, analizarlos, realizar simulaciones en función de las estrategias de la empresa y generar infor-mación relevante distribuible a toda la organización y de esa manera, mejorar el desempeño gerencial y operativo de la empresa. Así mismo, se comentan los componentes de la Inteligencia de Negocios como el Data Warehouse, OLAP y la de minería de datos (data mining).
Biografía
Doctor en Ingeniería, especialidad en Inteligencia Artificial, de la Universidad Nacional Autónoma de México. Sus líneas de investigación y desarrollo tecnológico destacan: desarrollo de sistemas inteligentes aplicando diversas técnicas de Inteligencia Artificial, como sistemas expertos, lógica difusa, redes neuronales, algoritmos genéticos, razonamiento basado en casos, sistemas inteligentes basados en sitios Web; representación del Conocimiento, Modelos de Razonamiento y Modelos de Aprendizaje; Administración del Conocimiento y Organizaciones Inte-ligentes; Manufactura Inteligente, Instrumentación Virtual Inteligente y Robótica Adaptativa; y Minería de datos y KDD (Knowledge Discovery in Databases). Actualmente, responsable del Grupo de Sistemas Inteligentes de este Centro de Investigación del Centro de Ciencias Aplicadas y Desarrollo Tecnológico de la Universidad Nacional Autónoma de México.

UIGV193
Oportunidades 3D – Blender, Libre para Crear
Eraldo Martins Guerra FilhoBrasilUniversidade Federal Rural de Pernambuco (UFRPE)[email protected]
Resumo
Realidade em três dimensões. Certamente você já ouviu falar sobre esse conceito. Os efeitos em terceira dimensão estão se tornando cada vez mais comuns em nosso cotidiano e, para um futuro próximo, parecem estar encaminhan-do para se tornar a nova febre do mundo do entretenimento, sendo uma ótima oportunidade para novos negócios.
Foi assim sendo um apaixonado por essa tecnologia que conheci a suite Blender um ambiente livre 3D que possi-bilita ao usuário desenvolver projetos, animações e games.
Biografia
Atualmente é professor - Desenvolvimento de Games e interatividade - da Escola de Referência Cícero Dias em Recife - PE, Professor profissionalizante em “Blender 3D” da Fucutura Tecnologia, Professor profissionalizante em Logística da Escola Técnica Professor Agamenon Magalhães (ETEPAM), Professor Universitário do Curso de Bacha-relado de Sistema de Informação da Faculdade Joaquim Nabuco, Professor Tutor On line da Universidade Federal Rural de Pernambuco (UFRPE). Palestrante e Oficineiro Nacional e Internacional em Blender 3D. Tem experiência na área de Informática, com ênfase em Desenvolvimento de Softwares, Desenvolvimento 3D e Realidade Virtual. Atuação em elaboração de projetos de Games e Computação Gráfica; Colaborador do Portal do Software Públi-co em ambientes livres 3d, Colaborador e desenvolvedor da Comunidade Nacional Blender Pró.

UIGV194
TD Digital, HDTV e IPTV sobre la red óptica “Argentina Conectada”
Mario MastrianiArgentinaUniversidad Nacional de Tres de Febrero (UNTreF)[email protected]
Resumen
El problema del limitado ancho de banda en las redes utilizadas en el interior de los países latinoamericanos, así como lanecesidaddeuncanalde retorno−confines interactivos−para laTVDigitalqueseestá implementandoactualmente, obliga a los gobiernos de la región al desarrollo de una red óptica nacional, de libre acceso, con una in-versión –solo en el caso argentino– de 2.000.000.000 U$S en 5 años. Esta red permitirá la libre circulación de imágenes médicas de gran porte, tanto en formato DICOM 3.0 como así también de formatos propietarios, al mismo tiempo que dará lugar a la transmisión de TV Digital de extremadamente alta resolución, es decir, 3840x2160 pixeles de escaneo progresivo, 3D (o sea, stereo) y de 120 a 600 cuadros-por-segundo. Esta resolución se la conoce como 4K-3D. Otras aplicaciones posibles lo constituyen el Cine Digital, de resoluciones 9K (9334x7000 pixeles) y 28K (28000x9334 pixeles).
Este tipo de resoluciones no admiten pérdidas de compresión/descompresión, así como tratamiento inter-cuadro de los algoritmos empleados, debido a la inadmisible latencia (demora) que dicho tratamiento provocaría, del orden de minutos. Por otra parte, si se deseara utilizar la mencionada red empleando simultáneamente todos los servicios enumerados, dicha red colapsaría de inmediato, lo cual es notable, considerando que la misma posee un piso de 10 Mbits/seg en cada hogar y 100 Gbits troncal. Lo mencionado hasta aquí obliga al uso de algoritmos de compresión lossless (sin pérdida) altamente paralelizables, a los efectos de paliar su elevada complejidad computacional.
Los appliances anfitriones de dichos algoritmos lo constituyen las hoy famosas placas General-Purpose computa-tion on Graphics Processing Units (GPGPU). Con el advenimiento de estas placas, se logró la integración de un gran número de mini-procesadores en un espacio extremadamente reducido, con la notable ventaja que representa la posibilidad de programación distribuida a un precio extremadamente reducido, comparado con los clusters y GRIDs. No obstante, el gran problema de esta tecnología era la ausencia de un job-manager el cual permitiera el tiempo com-partido de distintos algoritmos ejecutándose en la misma GPU al mismo tiempo, dándole a estos sistemas el status de cluster. Precisamente, el desarrollo en el ámbito local del tan requerido job-manager, le da proyección internacional a este proyecto, permitiendo por primera vez que la tecnología GPGPU alcance el mencionado status. Por otra parte, este job-manager permite además, la convivencia eficiente de dos tecnologías, otrora irreconciliables como son multi-core y multi-GPU. En esta conferencia, se presenta la tecnología combinada multi-core/multi-GPU aplicada a todos los servicios mencionados.
Biografía
Doctor en Ciencias de la Computación. Actualmente, Director del Laboratorio de Imágenes y Señales (LIS) del Sistema UVT-CPA-NeoTVLabs y Coordinador de Ingeniería en Computación (CIC) en la Universidad Nacional de Tres de Febrero (UNTreF). Referee de 15 journals internacionales de la IEEE, Springer-Verlag, Taylor & Francis, IET, SPIE, OSA, Elsevier, etc. Profesor Titular de Procesamiento de Imágenes de la Carrera de Ingeniería en Computación y Director del Grupo de Investigación en Procesamiento de Señales e Imágenes (GIPSI) de la UNTreF. Coordinador del área de Innovación Técnica de la Gerencia de Informática e Innovación Tecnológica (GIIT) de ANSES. Eva-luador Consejo de Investigación Científica (CIC) de la Provincia de Buenos Aires, en Tecnología Informática, de Comunicaciones y Electrónica. Representante por UNTreF ante el Programa de Desarrollo de Software para la TV Digital Interactiva del Ministerio de Planificación Federal, Inversión Pública y Servicios de la República de Argentina.

UIGV195
Mobile Multimedia for Outreach Across the Digital Divide
César BanderaEstados UnidosNew Jersey Institute of [email protected]
Abstract
Outreach stakeholders often use the web as a medium for education and notification. Over half of the adults among vulnerable populations are not active users of the Internet, but their adoption of cell phone multimedia mes-saging is greater than the national average, and this emerging behavior enables a new medium for outreach. Like text messaging, multimedia messaging pushes information onto cell phones and the user’s attention without user intervention, access to the Internet, web-enabled cell phones, the installation of apps, or hoping for a web site to be visited. However, while limited capacity of text messaging supports only brief text notifications, multimedia messaging supports diverse content including videos and animated slide shows with voice narration. We describe several mobile multimedia outreach campaigns for vulnerable populations conducted by the National Institutes of Health and the Centers for Disease Control and Prevention. The campaigns include just-in-time training for emergency responders, research translation for breast cancer survivors, and winter weather preparedness for the general civilian population. Areas discussed include content creation and adaptation from existing outreach material, enrollment and privacy, peer-to-peer dissemination, and interactivity.
Biography
PhD in Computer Engineering specializing in computer vision and multimedia systems. He currently teaches at the School of Computer Engineering and the Faculty of Management at NJIT and is also president of two private companies: BanDeMar Networks, a provider of technology for video processing in autonomous systems, and Cell Podium, a provider of synthesis and transmission of multimedia for education through mobile phones. Previously he was head engineer at the research center of AT & T. He was awarded Entrepreneur of New Jersey, received the NASA Space Act and several patents, was named Entrepreneur of the Year by the air forces of the United States, and has published extensively and conducted six doctoral theses in the field of vision for autonomous systems.

UIGV196
Creando Animaciones, Motion Graphics y VFX para cine y televisión digital con software libre
Octavio Augusto Méndez SánchezMéxicoITESM (Instituto Tecnológico y de Estudios Superiores de Monterrey) Campus Lé[email protected]
Resumen
Durante esta conferencia se describirá el papel que desempeña el software libre, su impacto económico, y las oportunidades de negocios que brindan, dentro de la industria de la animación, los efectos visuales.
• El rol que desempeña el software libre en la industria.• Ventajas competitivas del uso del software libre. (costo, calidad, soporte, innovación, versatilidad, aplicación
de las libertades).• El software libre trabajando de la mano con software propietario.• Las herramientas:• Linux como sistema operativo base en la industria de la animación y VFX.• Uso de Blender 3D en la producción.• Procesos productivos.• Modelado y animación.• Motion Graphics.• Edición.• Compositing.• VFX.• Motion Tracking.
Biografía
Miembro fundador de la comunidad de GBlender, la comunidad en línea de Blender 3D más grande de habla hispana. CEO de Guanajuato Virtual Multimedia Studios. Docente de la materia “Desarrollo de videojuegos” en la Licenciatura en Animación y Arte Digital en el Tecnológico de Monterrey Campus León. Ha impartido, cursos, talleres, conferencias de Blender en diferentes universidades y eventos de software libre (ITESM, UAM, U de GTO, UTL, IPN, CONSOL, FISOL, FSL, ENLI, Campus Party, etc). Colaboró cercanamente con el ITESM Campus León en la definición de la carrera de Animación y Arte Digital (LAD). Actualmente, imparte cursos de Blender 3D en el Centro 3D. Docente en el ITESM Campus Léon y se encuentra envuelto en la producción de tres cortometrajes. Actualmente, se encuentra trabajando de forma activa en la generación de células especializadas de producción con Blender 3D.

UIGV197
“Neuro Copter” Linear Quadratic Gaussian Design LQG and implementation of the Control System of an unmanned aerial vehicle UAV with state space modelling and Kalman Filtering and autonoumous Guidance with Computer Vision and data link Communications
Fernando Jiménez MotteUniversidad Peruana de Ciencias [email protected]
Abstract
Controlling scale helicopters in its various flight modes is a complex task due to the nonlinearity of its structure and strong coupled motion dynamics. In this paper, an adaptive neural controller is developed for a scale helicopter using data of an artificial vision stage and from sensors installed in the air vehicle. Data is transmitted from the helicopter through a data link stage and is received on a computer where the neuronal controller is implemented. The outputs of the control stage return to the helicopter through the same data link in order to close the control loop. It is show that a proper communication between various stages that constitute the project, allows an accurate control of a scale helicopter through a computer.
Biography
Experto Mundial en Tecnologìa. Ex Director de las Carreras de Ingenierìa Electrònica y de Telecomunicaciones y Redes de la UPC. Ha reportado cuentas de resultados en Telefònica Empresas en el orden de $140 Millones de Dólares en el Sector de Telecomunicaciones. Su pasión por el Product Management, el Desarrollo de Productos y la Innovaciòn han guiado su exitosa carrera profesional dedicada a obtener resultados sobresalientes. Tiene una formación de Ph.D in Electrical Engineering en Florida Atlantic University, USA, un Master in Electrical Engineering del Naval Postgraduate School, CA, USA, Project Management y Manufacturing Cost Strategies en el California Institute of Technology, Caltech, USA. Ha sido reconocido como Experto Global por el Gerson Lehrman Group y el Society of Industry Leaders de Vista Research USA. Es miembro del International Neural Network Society INNS. Reconocido en la prestigiosa publicación 2000 Outstanding Intellectuals of the XXI Century , IBC Cambridge, UK y Great Minds of the XXI Century , ABC , USA. Reconocido en lista Who is Who in Science and Engineering y Quien es Quien, Red de Cientìficos Peruanos de Concytec, Perù.

UIGV198
Cloud Computing: ¿Una nueva tecnología?
Jorge YaquiIBM del Perú
Resumen
Cloud Computing es un término que se comenta con mucho entusiasmo y bajo diversos puntos de vista en el medio comercial y quizá sea la razón por la cual muchas personas y empresas tienen un entendimiento tan disímil de este modelo emergente de provisión de tecnología de información.
¿Cuáles son las ventajas que aporta este modelo a las empresas, cuál será su impacto en la sociedad? ¿Es una nueva tecnología? ¿Ya está disponible para todos en Perú?
La presente ponencia busca ilustrar a los participantes en los mitos y realidades que se han creado en torno a Clo-ud Computing, así como presentarles los diversos escenarios bajo los cuales podemos acceder a este nuevo modelo indicando sus riesgos y potenciales y actuales beneficios. Se presentan casos de referencia para ilustrar los conceptos.
Biografía
Máster en Finanzas de EADA Barcelona y Centrum Católica. Magíster en Administración de ESAN con mención en Dirección General. Ingeniero Industrial titulado de la Pontificia Universidad Católica del Perú. Veintitrés años de experiencia en el área de gestión de sistemas y servicio a clientes. Actualmente, se desempeña como Gerente responsable por el desarrollo de los nuevos servicios y proyectos de innovación de IBM Perú, Bolivia, Ecuador, Uruguay y Paraguay. Docente en cursos de maestría y diplomado. Past-vicepresidente del Comité de Tecnologías de Información de la Cámara de Comercio de Lima.

UIGV199
Evaluando la seguridad de aplicaciones Web
Mauricio Velazco [email protected]
Resumen
En la actualidad, los sistemas informáticos juegan un papel primordial debido a que son los encargados de guardar y procesar la información indispensable para el funcionamiento de la organización. Esta información es ahora un acti-vo fundamental. No solo es necesario tener sistemas buenos que cumplan la funcionalidad requerida, hay que tener sistemas seguros y que cuenten con protecciones contra la privacidad, confiabilidad y disponibilidad de los datos. En la mayoría de casos la seguridad queda relegada desde las primeras etapas del desarrollo de software debido a las restricciones propias de cada proyecto y el coste que ésta presupone.
Las organizaciones utilizan Internet como un medio para mostrarse al público, tener una imagen accesible desde cualquier parte del mundo y hasta ofertar sus productos a través del comercio electrónico. Con el desarrollo de la World Wide Web, las páginas Web dejaron de ser plantillas de contenido estático para convertirse en lo que son ahora: aplicaciones dinámicas actualizables que interactúan con bases de datos, y son utilizadas en ambientes de seguridad críticos, como el médico, financiero, académico y militar. En el desarrollo de aplicaciones Web, muchas veces los programadores trabajan con presiones de tiempo, se enfocan en la funcionalidad y en la apariencia de ésta, pero no ponen atención en resolver los problemas de seguridad. Debido a esto, surgen vulnerabilidades en la aplicación que permitirán a un intruso hacerse de información confidencial e indispensable para la empresa y hasta modificarla.
Las evaluaciones de seguridad, también llamadas pruebas de pentración o hackeo ético, surgen como una herra-mienta importante para detectar y mitigar debilidades y vulnerabilidades de las aplicaciones Web antes de que éstas sean aprovechadas por un atacante malicioso. En esta presentación, se dará a una introducción sobre cómo realizar evaluaciones de seguridad en aplicaciones Web basado en la metodología OWASP.
Biografía
Profesional en Seguridad de la información e Informática en el campo del Ethical Hacking y pruebas de pe-netración. En los últimos 2 años, ha trabajado junto al equipo de hackers éticos de Open-Sec, empresa líder en servicios de Seguridad Informática en Perú, llevando a cabo procesos de análisis de vulnerabilidades, pruebas de penetración y computación forense en organizaciones públicas y privadas del sector gobierno, financiero y comer-cial en Perú, Ecuador y Panamá.

UIGV200
Desarrollo Tecnológico y Software Libre
Alfonso de la Guarda ReyesICTEC [email protected]
Resumen
Empleo de soluciones FLOSS para el desarrollo tecnológico dentro del Ejército Peruano, en particular la experiencia del Centro de Investigación y Desarrollo, la experiencia de implementar desde simuladores hasta sistemas logísticos o tácticos, todo esto con ayuda de Python, C, C++, Blender y GIS.
La presentación busca mostrar la experiencia a nivel organizativo y práctico (productos) de un centro de investi-gación y desarrollo tecnológico y en particular del Centro de Investigación y Desarrollo del Ejército Peruano (CICTE). Desde la implementación de desktops o workstations Linux hasta el uso y adaptación de herramientas o lenguajes, como Blender, Python, C++, Ruby, FlightGear, GPU clustering, etc. Todo esto para poder producir soluciones de buena calidad en corto tiempo gracias a la colaboración y la distribución.
Biografía
Con más 25 años de experiencia en Tecnología informática. Director del Centro Open Source y Gerente de Investigación y Desarrollo de ICTEC SAC. Se dedicó a implementar soluciones LINUX a diversas instituciones y empresas, invitado a diversos certámenes sobre FLOSS (Free and Open Source Software). Se ha dedicado a la investigación y desarrollo de aplicaciones para negocios con Business Intelligence (con licencia GPL), abrió el primer Centro de Investigación y Desarrollo Independiente de Tecnologías FLOSS de América Latina (Centro Open Source).

UIGV201
Este documento se terminó de imprimir en el mes de octubre de 2011 en los talleres gráficos de
PUNTOYGRAFÍAS.A.C.Av. Del Río 113 Pueblo Libre / Telf.: 332-2328
Lima- Perú






























