Embed Size (px)
Citation preview

1057-7149 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TIP.2016.2537215, IEEETransactions on Image Processing
IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. XX, NO. XX, MONTH XX 1
Dynamic Facial Expression Recognition with AtlasConstruction and Sparse RepresentationYimo Guo, Guoying Zhao, Senior Member, IEEE, and Matti Pietikainen, Fellow, IEEE
Abstract—In this paper, a new dynamic facial expression recog-nition method is proposed. Dynamic facial expression recognitionis formulated as a longitudinal groupwise registration problem.The main contributions of this method lie in the following aspects:(1) subject-specific facial feature movements of different expres-sions are described by a diffeomorphic growth model; (2) salientlongitudinal facial expression atlas is built for each expressionby a sparse groupwise image registration method, which candescribe the overall facial feature changes among the wholepopulation and can suppress the bias due to large inter-subjectfacial variations; (3) both the image appearance information inspatial domain and topological evolution information in temporaldomain are used to guide recognition by a sparse representationmethod. The proposed framework has been extensively evalu-ated on five databases for different applications: the extendedCohn-Kanade, MMI, FERA, and AFEW databases for dynamicfacial expression recognition, and UNBC-McMaster database forspontaneous pain expression monitoring. This framework is alsocompared with several state-of-the-art dynamic facial expressionrecognition methods. The experimental results demonstrate thatthe recognition rates of the new method are consistently higherthan other methods under comparison.
Index Terms—Dynamic Facial Expression Recognition, Diffeo-morphic Growth Model, Groupwise Registration, Sparse Repre-sentation.
I. INTRODUCTION
Automatic facial expression recognition (AFER) has essen-tial real world applications. Its applications include, but arenot limited to, human computer interaction (HCI), psychologyand telecommunications. It remains a challenging problemand active research topic in computer vision, and many novelmethods have been proposed to tackle the automatic facialexpression recognition problem.
Intensive studies have been carried out on AFER problemin static images during the last decade [1], [2]: Given a queryfacial image, estimate the correct facial expression type, suchas anger, disgust, happiness, sadness, fear or surprise. It mainlyconsists of two steps: feature extraction and classifier design.For feature extraction, Gabor wavelet [3], local binary pattern(LBP) [4], and geometric features such as active appearancemodel (AAM) [5] are in common use. For classifier, supportvector machine is frequently used. Joint alignment of facialimages under unconstrained condition has also become anactive research topic in AFER [6].
In recent years, dynamic facial expression recognition hasbecome a new research topic and receives more and more
The authors are with the Center for Machine Vision Research, Departmentof Computer Science and Engineering, University of Oulu, Finland. E-mail:[email protected],[email protected],[email protected]
Manuscript received XX, XXXX; revised XXX.
attention [7], [8], [9], [10], [11], [12]. Different from therecognition problem in static images, the aim of dynamicfacial expression recognition is to estimate facial expressiontype from an image sequence captured during physical facialexpression process of a subject. The facial expression imagesequence contains not only image appearance information inthe spatial domain, but also evolution details in the tem-poral domain. The image appearance information togetherwith the expression evolution information can further enhancerecognition performance. Although the dynamic informationprovided is useful, there are challenges regarding how tocapture this information reliably and robustly. For instance, afacial expression sequence normally constitutes of one or moreonset, apex and offset phases. In order to capture temporalinformation and make temporal information of training andquery sequences comparable, correspondences between differ-ent temporal phases need to be established. As facial actionsover time are different across subjects, it remains an open issuehow a common temporal feature for each expression amongthe population can be effectively encoded while suppressingsubject-specific facial shape variations.
In this paper, a new dynamic facial expression recognitionmethod is presented. It is motivated by the fact that facialexpression can be described by diffeomorphic motions of mus-cles beneath the face [13], [14]. Intuitively, ‘diffeomorphic’means the motion is topologically preserved and reversible[15]. The formal definition of ‘diffeomorphic’ transformationis given in Section II. Different from previous works [10], [16]by using pairwise registration to capture the temporal motion,this method considers both the subject-specific and popula-tion information by a groupwise diffeomorphic registrationscheme. Moreover, both the spatial and temporal informationare captured with a unified sparse representation framework.Our method consists of two stages: atlas construction stageand recognition stage. Atlases, which are unbiased images, areestimated from all the training images belonging to the sameexpression type with groupwise registration. Atlases capturegeneral features of each expression across the population andcan suppress differences due to inter-subject facial shape vari-ations. In the atlas construction stage, a diffeomorphic growthmodel is estimated for each image sequence to capture subject-specific facial expression characteristics. To reflect the overallevolution process of each expression among the population,longitudinal atlases are then constructed for each expressionwith groupwise registration and sparse representation. In therecognition stage, we first register the query image sequenceto atlas of each expression. Then, the comparison is conductedfrom two aspects: image appearance information and temporal

1057-7149 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TIP.2016.2537215, IEEETransactions on Image Processing
2 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. XX, NO. XX, MONTH XX
evolution information. The preliminary work has been reportedin [17].
For the proposed method, there are three main contributionsand differences compared to the preliminary work in [17]:(1) A more advanced atlas construction scheme is used.In previous method [17], the atlases are constructed usingthe conventional groupwise registration method, thus lots ofsubtle and important anatomical details are lost due to thenaive mean operation. To overcome this shortage, a sparserepresentation based atlas construction method is proposedin this paper. It is capable of capturing subtle and salientimage appearance details to guide recognition, and preservingcommon expression characteristics. (2) In the recognitionstage, the previous method in [17] compared image differencesbetween the warped query sequence and atlas sequence, whichis based on image appearance information only. In this paper,the temporal evolution information is also taken into accountto drive the recognition process. It has shown to providecomplementary information to image appearance informationand can significantly improve the recognition performance.(3) The proposed method has been evaluated in a systematicmanner on five databases whose applications vary from poseddynamic facial expression recognition to spontaneous painexpression monitoring. Moreover, possible alternatives havebeen carefully analyzed and studied with different experimen-tal settings.
The rest of the paper is organized as follows: SectionII gives an overview of related works on dynamic facialexpression and diffeomorphic image registration. Section IIIdescribes the proposed method. Section IV analyzes experi-mental results. Section V concludes the paper.
II. RELATED WORK
A. Methods for Dynamic Facial Expression RecognitionMany novel approaches have been proposed for dynamic
facial expression recognition [18], [19], [20], [10], [21]. Theycan be broadly classified into three categories: shape basedmethods, appearance based methods and motion based meth-ods.
Shape based methods describe facial component shapesbased on salient landmarks detected on facial images, suchas corners of eyes and mouths. The movement of thoselandmarks provides discriminant information to guide therecognition process. For instance, the active appearance model(AAM) [22] and the constrained local model (CLM) [23] arewidely used. Also, Chang et al. [18] inferred facial expressionmanifold by applying active wavelets network (AWN) to afacial shape model which is defined by 58 landmarks that areused by Pantic and Patras [19].
Appearance based methods extract image intensity or othertexture features from facial images to characterize facial ex-pressions. Commonly used feature extraction methods includeLBPTOP [7], Gabor wavelets [3], HOG [24], SIFT [25]and subspace learning [20]. For a more thorough review ofappearance features, readers may refer to the survey paper[26].
Motion based methods aim to model spatial-temporal evolu-tion process of facial expressions, which are usually developed
in virtue of image registration techniques. For instance, Koel-stra et al. [10] used the free-form deformation (FFD) [27] tocapture motions between frames. The optical flow was adoptedby Yeasin et al. [21]. The recognition performance of motionbased methods is highly dependent on face alignment methodsused. Many advanced techniques have been proposed for facealignment, such as the supervised descent method developedby Xiong and De la Torre [28], the parameterized kernel prin-cipal component analysis based alignment method proposed byDe la Torre and Nguyen [29], the FFT-based scale invariantimage registration method proposed by Tzimiropoulos et al.[30], and the explicit shape regression based face alignmentmethod proposed by Cao et al. [31].
B. Diffeomorphic Image Registration
Image registration is an active research topic in computervision and medical image analysis [32], [33]. The goal ofimage registration is to transform a set of images which areobtained from different space, time or imaging protocols into acommon coordinate system, namely the template space. Imageregistration can be formulated as an optimization problem.Figure 1 illustrates the flow chart of pairwise registrationbetween two images.
Similarity
Measure Optimizer
Transformation
Model Interpolator
Fixed Image
Moving Image
Current Measure
Value
Optimal transform
parameters
Transform the
Moving Image
Fig. 1. A typical flow chart for pairwise image registration: the movingimage is transformed to fixed image space. In each iteration, the optimizerminimizes the similarity measure function between two images and calculatesthe optimal corresponding transformation parameters.
Equation 1 summaries the general optimization process ofpairwise registration problem.
Topt = arg minT∈Φ
E(Ifix, T (Imov)), (1)
where Ifix is the fixed image, Imov is the moving image, Φdenotes the whole possible transformation space and E(·) isthe similarity measure metric. This equation aims to find theoptimal transformation Topt which minimizes E(·) betweenIfix and Imov .
The transformation model for registration is application spe-cific. It can be rigid or affine transformations that contain onlythree and six degrees of freedom; or deformable transforma-tions, such as B-spline [27] and diffeomorphic transformations[15], [34] that contain thousands degrees of freedom.
In this paper, the diffeomorphic transformation is used dueto its excellent properties, such as topology preservation and

1057-7149 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TIP.2016.2537215, IEEETransactions on Image Processing
SHELL et al.: BARE DEMO OF IEEETRAN.CLS FOR JOURNALS 3
Neutral
Apex
Neutral
Fig. 2. Illustration of the whole facial expression process. The neutral face gradually evolves to the apex state, and then facial muscles get it back to anotherneutral state. Therefore, this can be considered as a diffeomorphic transformation process (i.e., topologically preserved and reversible).
reversibility [15]. These properties are essential and requiredto model facial feature movements and suppress registrationerrors. Otherwise, unrealistic deformations (e.g., twisted facialexpressions) may occur and introduce large registration errors.The formal definition of diffeomorphic transformation is:Given two manifolds Υ1 and Υ2, and a mapping functionF : Υ1 → Υ2, F is a diffeomorphic transformation if it isdifferentiable and its inverse mapping F−1: Υ2 → Υ1 is alsodifferentiable. F is a Cξ diffeomorphic transformation if Fand F−1 are ξ times differentiable. For a registration task, Fis often built in an infinite-dimensional manifold [15]. It shouldbe noted that the group of diffeomorphic transformations F isalso a manifold.
C. Groupwise Registration
As facial expression process is topologically preserved andreversible, as illustrated in Figure 2, it can be considered asa diffeomorphic transformation of facial muscles. Therefore,the diffeomorphic transformation during the evolution processof facial expression can be used to reconstruct facial featuremovements and further guide the recognition task.
Given P facial expression images I1, ..., IP , a straightfor-ward solution to transform them to a common space is to selectone image as the template, then register the remaining P − 1images to the template by applying P−1 pairwise registration.However, the registration quality is sensitive to the selectionof template. Therefore, the idea of groupwise registration wasprovided [35], [36], where the template is estimated to be theFrechet mean on the Riemannian manifold whose geodesicdistances are measured based on diffeomorphisms.
The diffeomorphic groupwise registration problem can beformulated as the optimization problem by minimizing:
Iopt, ψopt1 , ..., ψoptP =
arg minI,ψ1,...,ψP
P∑i=1
(d(I , ψi(Ii))
2 + λR(ψi)),
(2)
where both the template Iopt and the optimal diffeomorphictransformation ψopti (i = 1, ..., P ) that transforms Ii to Iopt
are variables to be estimated. d(·) is the similarity functionthat measures the matching degree between two images, R(·)denotes the regularization term to control the smoothness oftransformation, and λ is a parameter to control the weight ofR(·). Iopt and ψopti can be estimated by a greedy iterativeestimation strategy [35]: First, initialize I as the mean image
ψ1
ψ1-1
ψ2
ψ2-1
ψ3
ψ3-1
ψ4
ψ4-1
Template
I1 I2
I3 I4
Fig. 3. Illustration of diffeomorphic groupwise registration, where thetemplate is estimated to be the Frechet mean on Riemannian manifold. ψi
(i=1,2,3,4) denotes the diffeomorphic transformation from Ii to the template(solid black arrows), while ψ−1
i denotes the reversed transformation (dashedblack arrows).
of Ii. Fix I and estimate ψi by registering Ii to I in currentiteration. Then, fix ψi and update I as the mean image ofψi(Ii). In this way, ψi and I are iteratively updated until theyconverge.
Figure 3 illustrates an example of diffeomorphic groupwiseregistration. The estimated template, which is also namedatlas, represents overall facial feature changes of a specificexpression among the population. The atlas is unbiased to anyindividual subject and reflects the general expression informa-tion. Our dynamic facial expression recognition framework isbased on diffeomorphic groupwise registration. The details aregiven in Section III.
III. METHODOLOGY
We propose a new dynamic facial expression recognitionmethod. There are mainly two stages: atlas construction stageand recognition stage. In the atlas construction stage, atlassequence is built where salient and common features for eachexpression among the population are extracted. Meanwhile, thevariations due to inter-subject facial shapes can be suppressed.In the recognition stage, expression type is determined bycomparing the corresponding query sequence with each atlassequence.

1057-7149 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TIP.2016.2537215, IEEETransactions on Image Processing
4 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. XX, NO. XX, MONTH XX
A. Atlas Construction by Sparse Groupwise Registration
The flow chart of atlas construction stage is illustratedin Figure 4. In this stage, the longitudinal facial expressionatlases are constructed to obtain salient facial feature changesduring an expression process.
Given K types of facial expressions of interest, and Cdifferent subject image sequences for each expression, denotethe image at the jth time point of the ith subject (i = 1, ..., C)as Itij . Assume each image sequence begins at time point 0
and ends at time point 1 (i.e., tij ∈ [0, 1]). For each expression,to construct N atlases at given time points T = {t1, ..., tN},where tk ∈ [0, 1] (k = 1, ..., N), we formulate it as an energyminimization problem by minimizing:
Mt, φi =
arg minMt,φi
Σt∈TΣCi=1
{(d(Mt, φ
i(ti0→t)
(Iti0))2 + λφiR(φi)},
(3)
where Mt is the longitudinal atlas at time point t and φi isthe diffeomorphic growth model that models facial expressionprocess for subject i. φi
(ti0→t)(Iti0) denotes the warping of
subject i’s image at first time point Iti0 to time point t, andR(·) is the regularization constraint.
In the atlas construction stage, training sequences arecarefully constrained and pre-segmented to make sure thatthey begin with the neural expression and end with apexexpressions. Thus, for each training sequence, their beginningand ending stages are aligned. Given the growth model of eachsequence, the estimation of intermediate states between theneural and apex expressions is made by uniformly dividingthe time interval between the beginning and ending stages.Therefore, intermediate states are also aligned across trainingsequences, and each state is corresponding to one specific timepoint to construct the atlas sequence. The more states (i.e.,the number of time points N ) are used, the more accuratelythe atlas sequence can describe facial expression process,while the computational burden also increases. Finally, imagesbelonging to the same time point are used to initialize anditeratively refine the atlas.
In this paper, the Sobolev norm [15] is used as the regular-ization function. λφi is the parameter that controls the weightof regularization term and d(·) is the distance metric definedin non-Euclidean Riemannian manifold expressed by:
d(I1, I2)2 = min
1∫0
||vs||2Uds+1
σ2||I1(ϕ−1)− I2||22
,(4)
where ϕ(·) denotes the diffeomorphic transformation thatmatches image I1 to I2. In this paper, ϕ(·) is estimatedbased on the large deformation diffeomorphic metric mapping(LDDMM) framework [15]. || · ||2U is the Sobolev norm whichcontrols the smoothness of deformation field and ||·||2 denotesthe L2 norm. vs is the velocity field associated with ϕ(·). Therelationship between ϕ(·) and vs is defined by:
ϕ(~x) = ~x+
1∫0
vs(ϕs(~x))ds, (5)
where ϕs(~x) is the displacement of pixel ~x at time s ∈ [0, 1].Equation 3 can be interpreted as following. First, the
subject-specific growth model φi is estimated for each subjecti. Then, propagate the subject-specific information to eachtime point t ∈ T and construct atlas.
Given a subject i, there are ni images in his/her facialexpression image sequence. Itij denotes the image taken at thejth time point of subject i. The growth model φi of subject ican be estimated by minimizing the energy function:
J(φi) =
1∫0
||vis||2Uds+1
σ2Σni−1j=0 ||φ
i(ti0→tij)(Iti0)− Itij ||
22. (6)
The first term of Equation 6 controls the smoothness ofgrowth model. In the second term, the growth model is appliedto Iti0 and warped to other time points tij , then, the resultsare compared with existing observations Itij at time pointstij . A smaller difference between the warped result and theobservation indicates that the growth model can describe theexpression more accurately. With the LDDMM [15] frame-work used in this paper, velocity field vis is non-stationaryand varies over time. The variational gradient descent methodin [15] is adopted to estimate the optimal velocity field in thispaper with the regularization constraint represented by Sobolevnorm. The Sobolev norm ||vis||2U in Equation 6 is defined as||Dvis||22, where D is a differential operator. The selection ofthe best operator D in diffeomorphic image registration is stillan open question [37]. In this paper, the diffusive model is usedas differential operator [15], which restricts the velocity fieldto a space of Sobolev class two.
In Equation 6, the variables to be estimated are displace-ments of each pixel in image Iti0 , which represent the growthmodel as a diffeomorphic deformation field. For each sub-ject, there is one growth model to be estimated. Equation 6estimates the growth model by considering differences at allavailable time points, which is reflected by the summation inthe second term. The least number of images ni in the subject-specific facial expression sequence used to estimate the growthmodel is two. In this case, the problem can be reduced to apairwise image registration problem. The larger the number ofimages available in the sequence, the more precise the growthmodel describes the dynamic process of expression. We usethe Lagrange multiplier based optimization strategy similar to[15] to perform the minimization of Equation 6. The growthmodel φi is represented as a deformation field, based on whichthe facial expression images at any time point t ∈ [0, 1] ofsubject i, denoted as φi
(ti0→t)(Iti0), are interpolated, as shown
in Figure 4 (a).Given the estimated φi, we are able to construct facial
expression atlas at any time point of interest. Assume thereare N time points of interest T = {t1, ..., tN} to constructfacial expression atlas. Based on the estimated growth model

1057-7149 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TIP.2016.2537215, IEEETransactions on Image Processing
SHELL et al.: BARE DEMO OF IEEETRAN.CLS FOR JOURNALS 5
video
Growth Model Estimation
Growth Model
Interpolation
Atlas
Space
Atlas Construction with Sparse Representation
Sub 1
Sub 2
Atlas Construction with Sparse Representation
(a) (b)Fig. 4. Illustration of two main steps of atlas construction: (a) Growth model estimation for each facial expression image sequence; (b) facial expressionatlas construction from image sequences of the whole population based on longitudinal (i.e., temporal) atlas construction and sparse representation.
φi, subject i’s facial expression image can be interpolatedat time point t ∈ T with operation φi
(ti0→t)(Iti0). Moreover,
the optimization of Equation 3 with respect to variable Mt
becomes:
J(Mt) = Σt∈TΣCi=1
{(d(Mt, φ
i(ti0→t)
(Iti0))2}. (7)
The optimization of Equation 7 can be formulated as agroupwise registration problem by estimating the Frechetmean on the Riemannian manifold defined by diffeomorphisms[35]. That is, the atlas Mt at each time point t ∈ T is estimatedby a greedy iterative algorithm, summarized by Algorithm 1[17].
Algorithm 1 Estimate atlas Mt at time point t with conven-tional groupwise registration strategy.Input: Images φi
(ti0→t)(Iti0
) of each subject i (i = 1, ..., C) that are
interpolated at time point t with the growth model φi.
Output: Atlas Mt constructed at time point t.
1. Initialize Mt = 1C
∑Ci=1 φ
i(ti0→t)
(Iti0).
2. Initialize Ii = φi(ti0→t)
(Iti0).
3. FOR i = 1 to CPerform diffeomorphic image registration: registerIi to Mt to minimize the image metric defined inEquation 4 between Ii and Mt. Denote theregistered images as Ri.
END FOR4. Update Mt = 1
C
∑Ci=1Ri.
5. Repeat Steps 3 and 4 until Mt converges.6. Return Mt.
Taken the CK+ dynamic facial expression dataset for ex-ample, the fear longitudinal atlas constructed by Algorithm 1are shown in Figure 5 (a). It can be observed that althoughthe constructed atlas can present most of the facial expressioncharacteristics, they fail to include details regarding to theexpression (e.g., muscle movements around cheek and eyes).This is due to the updating rule of Mt in Operations 3 and4 in Algorithm 1: (1) Align all the images to Mt obtained inprevious iteration, and (2) update Mt by taking the average
of aligned images obtained in Step (1). Since Mt is initial-ized to the average image from all registered images, it isoversmoothed and lacks of salient details. Furthermore, thealignment of all images to this fuzzy image in Step (1) willlead to the same problems in the next iteration.
(a)
(b)
(c)
Fig. 5. Longitudinal atlas constructed at four time points for ’fear’ expressionon the extended Cohn-Kanade database using (a) conventional groupwiseregistration strategy, and the proposed sparse representation method withsparseness parameters (b) λs = 0.01 and (c) λs = 0.1, respectively. Forcomparison purpose, significant differences in (a) and (b) are highlighted bygreen circles.
Therefore, to preserve salient expression details during atlasconstruction and provide high-quality atlas, we are motivatedto present a new atlas construction scheme performed by asparse representation method due to its saliency and robustness[38]. Given C registered subject images Ri (i = 1, ..., C)obtained by Step 3 in Algorithm 1, atlas Mt is estimated basedon the sparse representation of Ri by minimizing:
E(~δ) =1
2||R~δ − ~mt||22 + λs||~δ||1, (8)
where R = [~r1, ..., ~rC ], ~ri (i = 1, ..., C) is a column vectorcorresponding to the vectorization of Ri, and ~mt is the

1057-7149 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TIP.2016.2537215, IEEETransactions on Image Processing
6 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. XX, NO. XX, MONTH XX
vectorization of Mt. || · ||1 is L1 norm and λs is the parameterthat controls sparseness degree of reconstruction coefficientvector ~δ.
The optimization of Equation 8 is the LASSO sparse repre-sentation problem [39], which can be addressed by Nesterov’smethod [40]. With the optimal solution of Equation 8, denotedas ~δopt, the atlas Mt can be updated to ~mt = R~δopt. Theinitialization of Mt is also improved by Equation 8, wherematrix R is the collection of φi
(ti0→t)(Iti0) (i = 1, ..., C). This
procedure is summarized by Algorithm 2.
Algorithm 2 Estimate atlas Mt at time point t with groupwiseregistration and sparse representation.Input: Images φi
(ti0→t)(Iti0
) of each subject i (i = 1, ..., C) that are
interpolated at time point t with the growth model φi.
Output: Atlas Mt constructed at time point t.
1. Initialize Mt = 1C
∑Ci=1 φ
i(ti0→t)
(Iti0).
2. Refine the initialization of Mt based on the sparserepresentation of φi
(ti0→t)(Iti0
) that expressed by Equation 8.
3. Initialize Ii = φi(ti0→t)
(Iti0).
4. FOR i = 1 to CPerform diffeomorphic image registration: registerIi to Mt to minimize the image metric defined inEquation 4 between Ii and Mt. Denote theregistered images as Ri.
END FOR5. Update Mt by optimizing Equation 8 with the sparse
representation of Ri .6. Repeat Steps 4 and 5 until Mt converges.7. Return Mt.
To compare the performance of Algorithm 1 in [17] andAlgorithm 2, the longitudinal atlases of fear expression con-structed by Algorithm 2 on CK+ database are shown in Figure5 (b) with sparseness parameter λs = 0.01 in Equation 8. Itcan be observed that the atlas constructed by the proposedsparse representation method can preserve more anatomicaldetails, especially for those areas around cheek and eyes whichare critical parts for facial expression recognition. It shouldbe noted that there is a tradeoff between the data matchingterm and sparseness term in Equation 8. As λs increases, thesparseness term begins to dominate the data matching term,which will affect the quality of constructed atlas. Figure 5 (c)shows atlas constructed with sparseness parameter λs = 0.1 inEquation 8. It can be observed that although the constructedatlases become even sharper than those shown in Figure 5(b), some facial features such as mouths are distorted in anunrealistic manner. In this paper, we have empirically foundthat λs = 0.01 gets a good balance between the data matchingand sparseness term, thus this setting is used through allexperiments in this paper.
B. Recognition of Query Sequences
In this paper, a new recognition scheme based on imageappearance and expression evolution information is proposed,as shown in Figure 6.
Without loss of generality, assume that there are K differentexpressions of interest. Let N denote the number of timepoints to build longitudinal facial expression atlas sequence asin Section III-A. The larger the number of N , the more precisethe atlas sequence describes the dynamic facial expression.But this will also increase computational burden. We denoteN time points as T = {t1, ..., tN} and Mk
t as the atlas of thekth (k = 1, ...,K) facial expression at time point t (t ∈ T ).
In the sparse atlas construction stage, training image se-quences can be constrained or pre-segmented to ensure thatthey begin with the neutral expression and gradually reachto the apex expression. In this way, constructed longitudinalatlases of different expressions should also follow the sametrend, as illustrated in Figure 5. However, in the recognitionstage, a new query image sequence does not necessarilybegin with the neutral expression and end with the apexexpression. And it is possible that abrupt transitions betweentwo expressions can be observed in one sequence.
Given a new facial expression sequence that consists ofnnew images Inewi (i = 0, ..., nnew − 1), correct temporalcorrespondences should be established between constructedatlas sequences and the query image sequence. This is be-cause the facial expression sequence to be classified doesnot necessarily follow the same temporal correspondence asthe constructed longitudinal atlas. First, we determine thetemporal correspondence of the first atlas image for each facialexpression k in the query image sequence, which is describedby:
b = arg minj{d(Mk
t1 , Inewj )2}, (9)
where d(·) is the distance metric defined in Equation 4 basedon diffeomorphisms. The physical meaning of Equation 9 is:(1) perform diffeomorphic image registration between Mk
t1 andeach image in the query sequence Inewj (j = 1, ..., nnew);and (2) determine the time point which gives the leastregistration error between Mk
t1 and the image in query astemporal correspondence of Mk
t1 . Similarly, we can determinethe temporal correspondence of each atlas for each expressionin query image sequence. Denote e as the index of temporalcorrespondence time in the query image sequence to the lastimage Mk
tN in the atlas sequence.It should be noted that for query sequences with multiple
expression transitions, only one neutral → onset → apex clipwill be detected and used to establish the correspondence toatlas sequence. Intuitively, this single neutral → onset →apex clip should already contain sufficient information foraccurate expression recognition. This will be further justifiedin the experiments conducted on the MMI, FERA, and AFEWdatabases in which multiple facial expression transitions existand expression sequences are obtained under real-life condi-tions.
Then, we construct growth model φnew for the query imagesequence and interpolate facial expression images at timepoints t ∈ {tb, tb+1, ..., te} by operation φnew(tb→t)(I
newb ), where
b and e are the indices of temporal correspondence time in thequery image sequence to the first and last images in the atlassequence, respectively. With the established temporal corre-spondence between the query image sequence and longitudinal

1057-7149 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TIP.2016.2537215, IEEETransactions on Image Processing
SHELL et al.: BARE DEMO OF IEEETRAN.CLS FOR JOURNALS 7
Query Image Sequence
Happiness
Atlas
Surprise
Atlas
Fear
Atlas …
Happiness
Temporal
Evolution
Surprise
Temporal
Evolution
Fear
Temporal
Evolution
Deformation filed
reconstruction error Appearance similarity
Recognition
…
Fig. 6. Both the image appearance information and dynamic evolution information are used to guide the recognition. Image appearance similarity is measuredwith respect to the registration error between query image sequence and atlas sequence. The temporal process is compared by calculating deformation fieldreconstruction error.
atlas, we can register interpolated facial expression images ofthe query image sequence to their corresponding images inthe atlas sequence. The registration errors are compared todetermine its expression type [17]. This is described by:
Lopt = arg minL
{∑e−bi=0 d(ML
t1+i, φnew(tb→tb+i)
(Inewb ))2
(e− b+ 1)
},
(10)where Lopt ∈ {1, ...,K} is the estimated facial expressionlabel for the query image sequence.
The dynamic process provides complementary informationfor image appearance to guide recognition. Given the growthmodel φi (i = 1, ..., C), the deformation field φi(tj→tj+1) (j =
b, ..., e−1) that represents temporal evolution from time pointtj to tj+1 can be calculated. φi(tj→tj+1) is represented as a2×h×w dimensional vector ~F itj→tj+1
, where h and w are theheight and width of each facial expression image (i.e., thereare h × w pixels). Each pixel’s displacement is determinedby movements in horizontal and vertical directions. Similarly,for the new image sequence, we can obtain ~Fnewtj→tj+1
(j =b, ..., e− 1).
For each expression k (k = 1, ...,K), training imagesequences are used to construct a dictionary Dk
tj→tj+1, which
represents temporal evolution of this expression from timepoint tj to tj+1 (j = b, ..., e − 1), denoted as Dk
tj→tj+1=[
~F 1tj→tj+1
, ..., ~FCtj→tj+1
].
We reconstruct ~Fnewtj→tj+1by the basis (i.e., each column) of
Dktj→tj+1
using sparse representation [38] for each expressiontype k, as shown in Figure 7. The accuracy of reconstructionindicates the similarity between temporal processes, whichserves as an important clue to determine expression type ofthe new image sequence.
Therefore, the overall energy function to drive the recogni-
tion is described by:
Lopt = arg minL
{∑e−bi=0 d(ML
t1+i, φnew(tb→tb+i)
(Inewb ))2
(e− b+ 1)
+ β ·e−1∑j=b
||~Fnewtj→tj+1−DL
tj→tj+1· ~αopttj ,L
||22},
(11)
where β is the parameter to control the weight of temporalinformation, and ~αopttj ,L
is estimated by:
~αopttj ,L=
arg min~α
{1
2||~Fnewtj→tj+1
−DLtj→tj+1
· ~α||22 + λ~α||~α||1}.
(12)
The optimization of Equation 12 can be performed byNesterov’s method [40] as it is a LASSO sparse representationproblem [39].
IV. EXPERIMENTS
To evaluate the performance of the proposed method, ithas been extensively tested on three benchmark databases fordynamic facial expression recognition: the extended Cohn-Kanade [41], MMI [42] and FERA [43] databases. Theproposed method has also been evaluated on one spontaneousexpression database: the UNBC-McMaster database [44].
A. Experiments on the Extended Cohn-Kanade Database
The extended Cohn-Kanade (CK+) database [41] contains593 facial expression sequences from 123 subjects. Similarto [41], 325 sequences from 118 subjects are selected. Eachsequence is categorized to one of the seven basic expressions:anger, contempt, disgust, fear, happy, sadness and surprise.

1057-7149 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TIP.2016.2537215, IEEETransactions on Image Processing
8 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. XX, NO. XX, MONTH XX
Subject 1
…
Subject 2 Subject C New Subject
…… …Sparse Representation
…
…
Training image sequences
Fig. 7. Illustration of reconstructing deformation field between consecutive time points by sparse representation for a new subject from the deformation fielddictionary Dk
tj→tj+1learnt from training images (Subject 1 to C).
Each image in the facial expression sequence is digitized toresolution of 240×210. For each selected sequence, we followthe same preprocessing step as in [7]. Specifically, the eyepositions in the first frame of each sequence were manuallylabeled. These positions were used to determine the facial areafor the whole sequence and to normalize facial images. Figure8 shows some examples from the CK+ database.
In all experiments, the following parameter settings are usedfor our method: N = 12 as the number of time points ofinterest to construct the longitudinal atlas, as we found thatsetting N = 12 is a good tradeoff between recognition accu-racy and computational burden; λφi = 0.02 as the parameterthat controls the smoothness of diffeomorphic growth modelfor each subject i; λs = 0.01 as sparseness parameter for atlasconstruction in Equation 8; β = 0.5 as weighting parameterassociated with the temporal evolution information in Equation11; λ~α = 0.01 as the sparse representation parameter ofgrowth model for query image sequence in Equation 12.
Fig. 8. Images from the CK+ database.
Our method is evaluated in a leave-one-subject-out mannersimilar to [41]. Figure 9 shows the constructed longitudinal
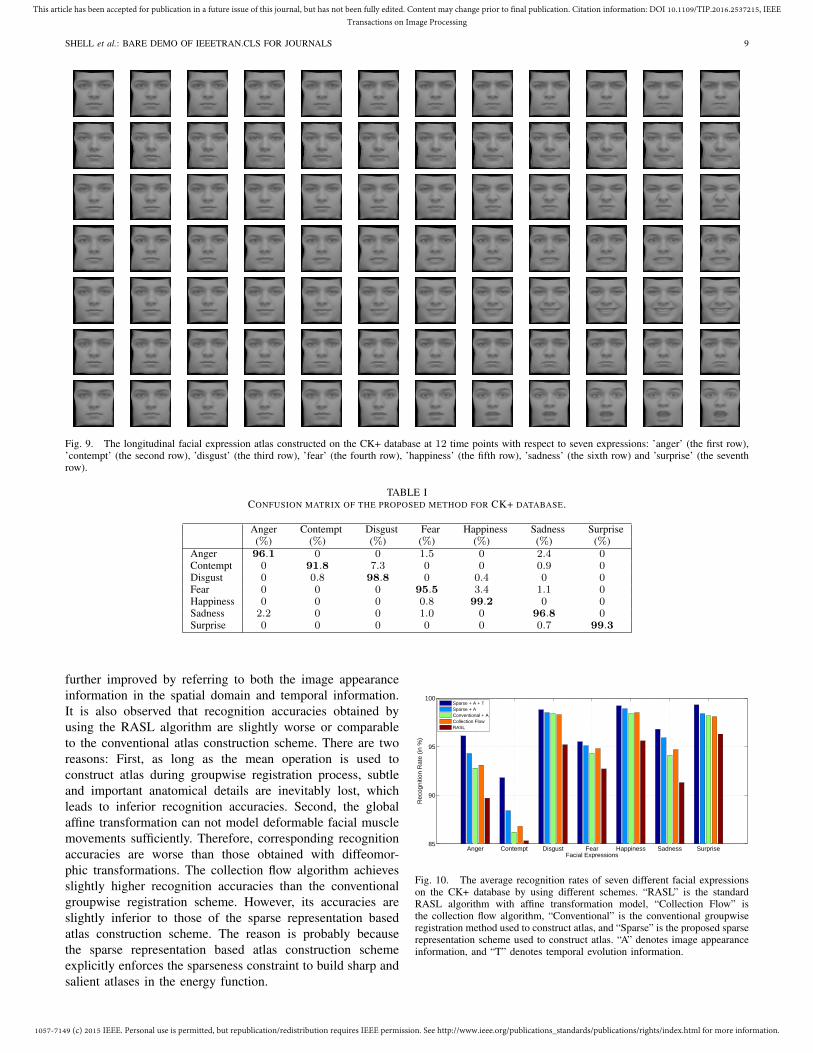
atlases of seven different expressions on the CK+ database. Itcan be visually observed that the constructed atlases are able tocapture the overall trend of facial expression evolution. TableI shows the confusion matrix for the CK+ database. It can beobserved that high recognition accuracies are obtained by theproposed method (i.e., the average recognition rate of eachexpression is higher than 90%).
Figure 10 shows the recognition rates of different expres-sions obtained by: the sparse atlas construction with newrecognition scheme, sparse atlas construction with recognitionscheme in [17] (i.e., use image appearance information only),conventional atlas construction with recognition scheme in[17], atlas construction with the collection flow algorithm [45],[46], and atlas construction with the standard RASL algorithm[47]. For the collection flow algorithm [45], [46], we adoptedthe flow estimation algorithm from Ce Liu’s implementation[48] similar to [45], [46]. For the RASL algorithm, wefollowed the same settings as in [47]. The affine transformationmodel is used which is the most complex transformation modelsupported by the standard RASL package 1. It can be observedthat the sparse atlas construction with the new recognitionscheme consistently achieves the highest recognition rates,which is consistent with the qualitative results obtained inSection III-A. The main reason for the improvement is that theenforced sparsity constraint can preserve salient informationthat discriminates different expressions and can simultaneouslysuppress subject-specific facial shape variations. In addition,it is demonstrated that the recognition performance can be
1http://perception.csl.illinois.edu/matrix-rank/rasl.html
1057-7149 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TIP.2016.2537215, IEEETransactions on Image Processing
SHELL et al.: BARE DEMO OF IEEETRAN.CLS FOR JOURNALS 9
Fig. 9. The longitudinal facial expression atlas constructed on the CK+ database at 12 time points with respect to seven expressions: ’anger’ (the first row),’contempt’ (the second row), ’disgust’ (the third row), ’fear’ (the fourth row), ’happiness’ (the fifth row), ’sadness’ (the sixth row) and ’surprise’ (the seventhrow).
TABLE ICONFUSION MATRIX OF THE PROPOSED METHOD FOR CK+ DATABASE.
Anger Contempt Disgust Fear Happiness Sadness Surprise(%) (%) (%) (%) (%) (%) (%)
Anger 96.1 0 0 1.5 0 2.4 0Contempt 0 91.8 7.3 0 0 0.9 0Disgust 0 0.8 98.8 0 0.4 0 0Fear 0 0 0 95.5 3.4 1.1 0Happiness 0 0 0 0.8 99.2 0 0Sadness 2.2 0 0 1.0 0 96.8 0Surprise 0 0 0 0 0 0.7 99.3
further improved by referring to both the image appearanceinformation in the spatial domain and temporal information.It is also observed that recognition accuracies obtained byusing the RASL algorithm are slightly worse or comparableto the conventional atlas construction scheme. There are tworeasons: First, as long as the mean operation is used toconstruct atlas during groupwise registration process, subtleand important anatomical details are inevitably lost, whichleads to inferior recognition accuracies. Second, the globalaffine transformation can not model deformable facial musclemovements sufficiently. Therefore, corresponding recognitionaccuracies are worse than those obtained with diffeomor-phic transformations. The collection flow algorithm achievesslightly higher recognition accuracies than the conventionalgroupwise registration scheme. However, its accuracies areslightly inferior to those of the sparse representation basedatlas construction scheme. The reason is probably becausethe sparse representation based atlas construction schemeexplicitly enforces the sparseness constraint to build sharp andsalient atlases in the energy function.
Anger Contempt Disgust Fear Happiness Sadness Surprise85
90
95
100
Facial Expressions
Rec
ogni
tion
Rat
e (in
%)
Sparse + A + TSparse + AConventional + ACollection FlowRASL
Fig. 10. The average recognition rates of seven different facial expressionson the CK+ database by using different schemes. “RASL” is the standardRASL algorithm with affine transformation model, “Collection Flow” isthe collection flow algorithm, “Conventional” is the conventional groupwiseregistration method used to construct atlas, and “Sparse” is the proposed sparserepresentation scheme used to construct atlas. “A” denotes image appearanceinformation, and “T” denotes temporal evolution information.
1057-7149 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TIP.2016.2537215, IEEETransactions on Image Processing
10 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. XX, NO. XX, MONTH XX
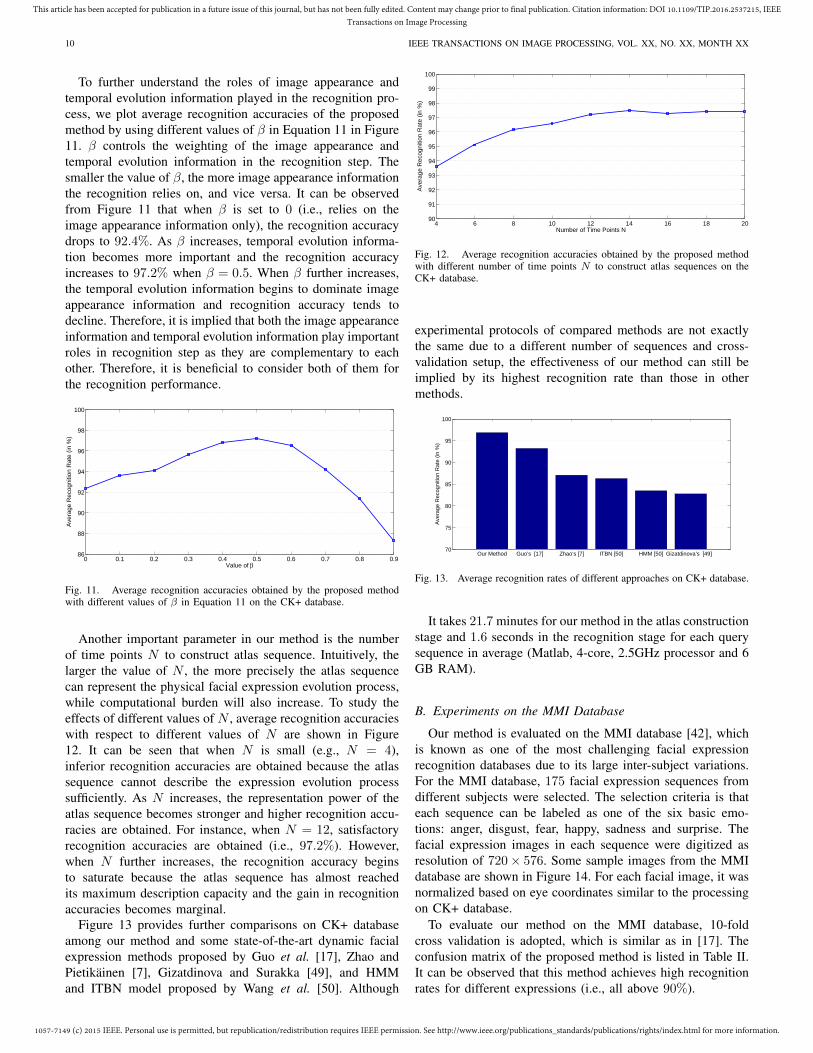
To further understand the roles of image appearance andtemporal evolution information played in the recognition pro-cess, we plot average recognition accuracies of the proposedmethod by using different values of β in Equation 11 in Figure11. β controls the weighting of the image appearance andtemporal evolution information in the recognition step. Thesmaller the value of β, the more image appearance informationthe recognition relies on, and vice versa. It can be observedfrom Figure 11 that when β is set to 0 (i.e., relies on theimage appearance information only), the recognition accuracydrops to 92.4%. As β increases, temporal evolution informa-tion becomes more important and the recognition accuracyincreases to 97.2% when β = 0.5. When β further increases,the temporal evolution information begins to dominate imageappearance information and recognition accuracy tends todecline. Therefore, it is implied that both the image appearanceinformation and temporal evolution information play importantroles in recognition step as they are complementary to eachother. Therefore, it is beneficial to consider both of them forthe recognition performance.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.986
88
90
92
94
96
98
100
Value of β
Ave
rage
Rec
ogni
tion
Rat
e (in
%)
Fig. 11. Average recognition accuracies obtained by the proposed methodwith different values of β in Equation 11 on the CK+ database.
Another important parameter in our method is the numberof time points N to construct atlas sequence. Intuitively, thelarger the value of N , the more precisely the atlas sequencecan represent the physical facial expression evolution process,while computational burden will also increase. To study theeffects of different values of N , average recognition accuracieswith respect to different values of N are shown in Figure12. It can be seen that when N is small (e.g., N = 4),inferior recognition accuracies are obtained because the atlassequence cannot describe the expression evolution processsufficiently. As N increases, the representation power of theatlas sequence becomes stronger and higher recognition accu-racies are obtained. For instance, when N = 12, satisfactoryrecognition accuracies are obtained (i.e., 97.2%). However,when N further increases, the recognition accuracy beginsto saturate because the atlas sequence has almost reachedits maximum description capacity and the gain in recognitionaccuracies becomes marginal.
Figure 13 provides further comparisons on CK+ databaseamong our method and some state-of-the-art dynamic facialexpression methods proposed by Guo et al. [17], Zhao andPietikainen [7], Gizatdinova and Surakka [49], and HMMand ITBN model proposed by Wang et al. [50]. Although
4 6 8 10 12 14 16 18 2090
91
92
93
94
95
96
97
98
99
100
Number of Time Points N
Ave
rage
Rec
ogni
tion
Rat
e (in
%)
Fig. 12. Average recognition accuracies obtained by the proposed methodwith different number of time points N to construct atlas sequences on theCK+ database.
experimental protocols of compared methods are not exactlythe same due to a different number of sequences and cross-validation setup, the effectiveness of our method can still beimplied by its highest recognition rate than those in othermethods.
Our Method Guo’s [17] Zhao’s [7] ITBN [50] HMM [50] Gizatdinova’s [49]70
75
80
85
90
95
100
Ave
rage
Rec
ogni
tion
Rat
e (in
%)
Fig. 13. Average recognition rates of different approaches on CK+ database.
It takes 21.7 minutes for our method in the atlas constructionstage and 1.6 seconds in the recognition stage for each querysequence in average (Matlab, 4-core, 2.5GHz processor and 6GB RAM).
B. Experiments on the MMI Database
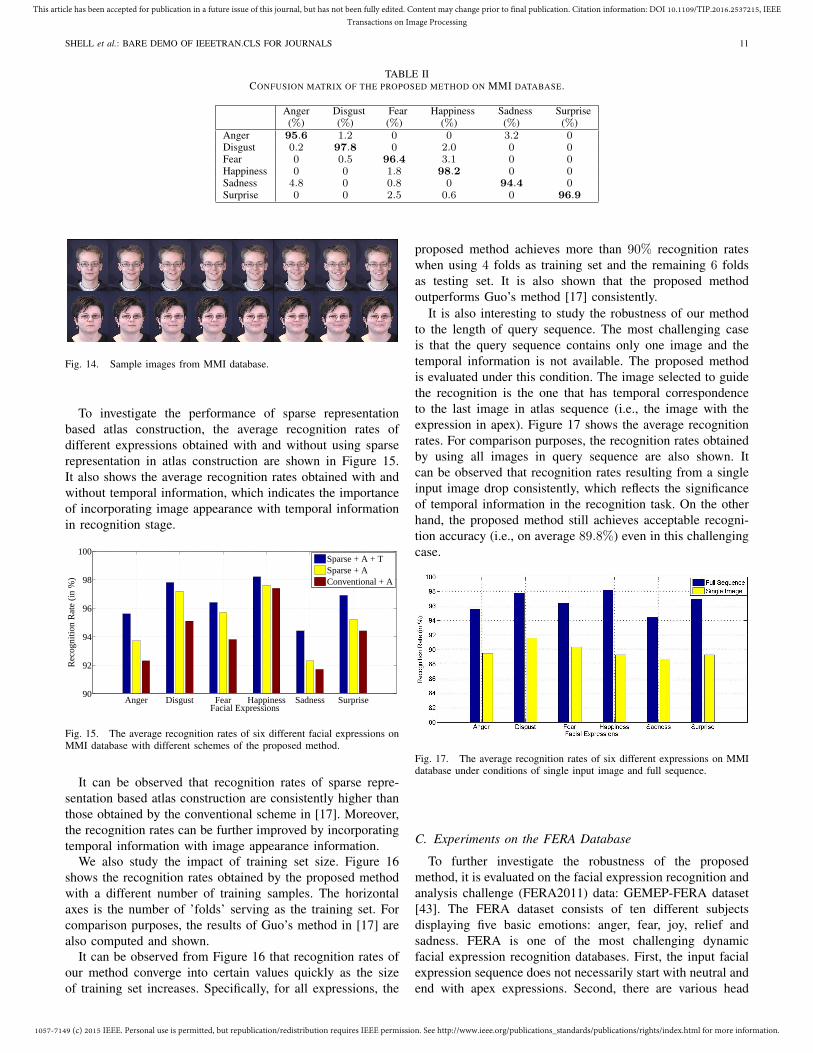
Our method is evaluated on the MMI database [42], whichis known as one of the most challenging facial expressionrecognition databases due to its large inter-subject variations.For the MMI database, 175 facial expression sequences fromdifferent subjects were selected. The selection criteria is thateach sequence can be labeled as one of the six basic emo-tions: anger, disgust, fear, happy, sadness and surprise. Thefacial expression images in each sequence were digitized asresolution of 720× 576. Some sample images from the MMIdatabase are shown in Figure 14. For each facial image, it wasnormalized based on eye coordinates similar to the processingon CK+ database.
To evaluate our method on the MMI database, 10-foldcross validation is adopted, which is similar as in [17]. Theconfusion matrix of the proposed method is listed in Table II.It can be observed that this method achieves high recognitionrates for different expressions (i.e., all above 90%).
1057-7149 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TIP.2016.2537215, IEEETransactions on Image Processing
SHELL et al.: BARE DEMO OF IEEETRAN.CLS FOR JOURNALS 11
TABLE IICONFUSION MATRIX OF THE PROPOSED METHOD ON MMI DATABASE.
Anger Disgust Fear Happiness Sadness Surprise(%) (%) (%) (%) (%) (%)
Anger 95.6 1.2 0 0 3.2 0Disgust 0.2 97.8 0 2.0 0 0Fear 0 0.5 96.4 3.1 0 0Happiness 0 0 1.8 98.2 0 0Sadness 4.8 0 0.8 0 94.4 0Surprise 0 0 2.5 0.6 0 96.9
Fig. 14. Sample images from MMI database.
To investigate the performance of sparse representationbased atlas construction, the average recognition rates ofdifferent expressions obtained with and without using sparserepresentation in atlas construction are shown in Figure 15.It also shows the average recognition rates obtained with andwithout temporal information, which indicates the importanceof incorporating image appearance with temporal informationin recognition stage.
Anger Disgust Fear Happiness Sadness Surprise90
92
94
96
98
100
Facial Expressions
Rec
ogni
tion
Rat
e (i
n %
)
Sparse + A + TSparse + AConventional + A
Fig. 15. The average recognition rates of six different facial expressions onMMI database with different schemes of the proposed method.
It can be observed that recognition rates of sparse repre-sentation based atlas construction are consistently higher thanthose obtained by the conventional scheme in [17]. Moreover,the recognition rates can be further improved by incorporatingtemporal information with image appearance information.
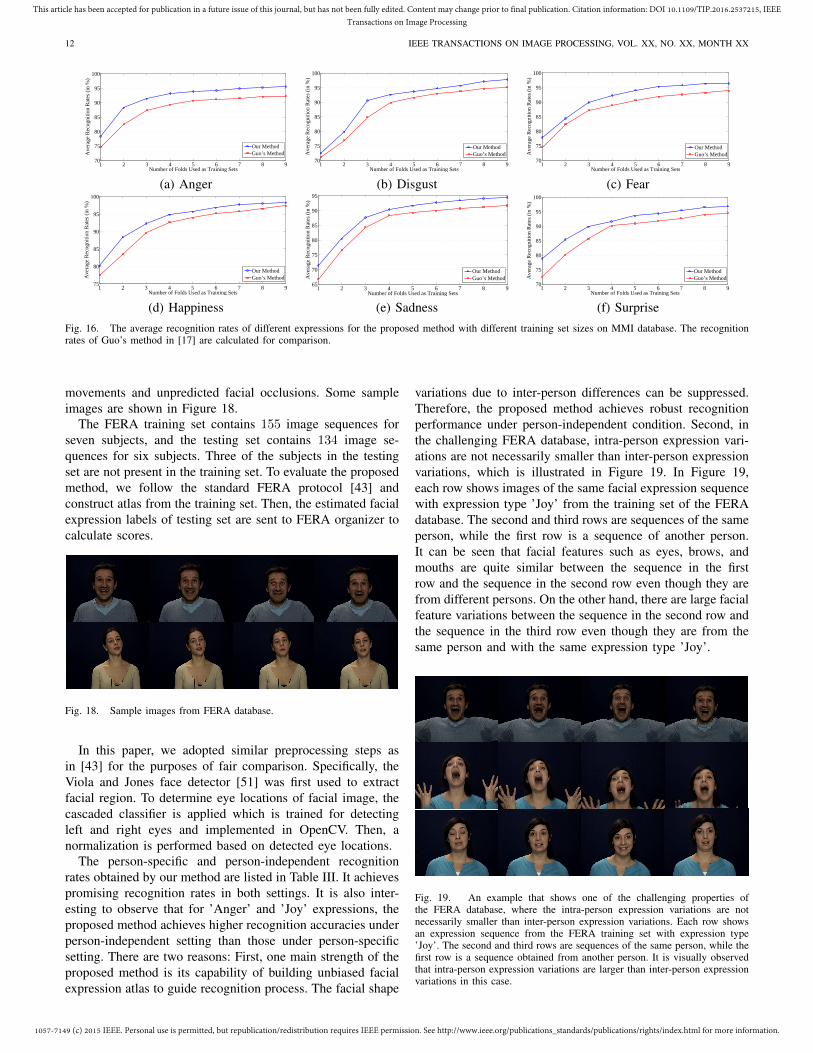
We also study the impact of training set size. Figure 16shows the recognition rates obtained by the proposed methodwith a different number of training samples. The horizontalaxes is the number of ’folds’ serving as the training set. Forcomparison purposes, the results of Guo’s method in [17] arealso computed and shown.
It can be observed from Figure 16 that recognition rates ofour method converge into certain values quickly as the sizeof training set increases. Specifically, for all expressions, the
proposed method achieves more than 90% recognition rateswhen using 4 folds as training set and the remaining 6 foldsas testing set. It is also shown that the proposed methodoutperforms Guo’s method [17] consistently.
It is also interesting to study the robustness of our methodto the length of query sequence. The most challenging caseis that the query sequence contains only one image and thetemporal information is not available. The proposed methodis evaluated under this condition. The image selected to guidethe recognition is the one that has temporal correspondenceto the last image in atlas sequence (i.e., the image with theexpression in apex). Figure 17 shows the average recognitionrates. For comparison purposes, the recognition rates obtainedby using all images in query sequence are also shown. Itcan be observed that recognition rates resulting from a singleinput image drop consistently, which reflects the significanceof temporal information in the recognition task. On the otherhand, the proposed method still achieves acceptable recogni-tion accuracy (i.e., on average 89.8%) even in this challengingcase.
Fig. 17. The average recognition rates of six different expressions on MMIdatabase under conditions of single input image and full sequence.
C. Experiments on the FERA Database
To further investigate the robustness of the proposedmethod, it is evaluated on the facial expression recognition andanalysis challenge (FERA2011) data: GEMEP-FERA dataset[43]. The FERA dataset consists of ten different subjectsdisplaying five basic emotions: anger, fear, joy, relief andsadness. FERA is one of the most challenging dynamicfacial expression recognition databases. First, the input facialexpression sequence does not necessarily start with neutral andend with apex expressions. Second, there are various head
1057-7149 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TIP.2016.2537215, IEEETransactions on Image Processing
12 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. XX, NO. XX, MONTH XX
1 2 3 4 5 6 7 8 970
75
80
85
90
95
100
Number of Folds Used as Training Sets
Ave
rage
Rec
ogni
tion
Rat
es (
in %
)
Our MethodGuo’s Method
1 2 3 4 5 6 7 8 970
75
80
85
90
95
100
Number of Folds Used as Training Sets
Ave
rage
Rec
ogni
tion
Rat
es (
in %
)
Our MethodGuo’s Method
1 2 3 4 5 6 7 8 970
75
80
85
90
95
100
Number of Folds Used as Training Sets
Ave
rage
Rec
ogni
tion
Rat
es (
in %
)
Our MethodGuo’s Method
(a) Anger (b) Disgust (c) Fear
1 2 3 4 5 6 7 8 975
80
85
90
95
100
Number of Folds Used as Training Sets
Ave
rage
Rec
ogni
tion
Rat
es (
in %
)
Our MethodGuo’s Method
1 2 3 4 5 6 7 8 965
70
75
80
85
90
95
Number of Folds Used as Training Sets
Ave
rage
Rec
ogni
tion
Rat
es (
in %
)
Our MethodGuo’s Method
1 2 3 4 5 6 7 8 970
75
80
85
90
95
100
Number of Folds Used as Training Sets
Ave
rage
Rec
ogni
tion
Rat
es (
in %
)
Our MethodGuo’s Method
(d) Happiness (e) Sadness (f) SurpriseFig. 16. The average recognition rates of different expressions for the proposed method with different training set sizes on MMI database. The recognitionrates of Guo’s method in [17] are calculated for comparison.
movements and unpredicted facial occlusions. Some sampleimages are shown in Figure 18.
The FERA training set contains 155 image sequences forseven subjects, and the testing set contains 134 image se-quences for six subjects. Three of the subjects in the testingset are not present in the training set. To evaluate the proposedmethod, we follow the standard FERA protocol [43] andconstruct atlas from the training set. Then, the estimated facialexpression labels of testing set are sent to FERA organizer tocalculate scores.
Fig. 18. Sample images from FERA database.
In this paper, we adopted similar preprocessing steps asin [43] for the purposes of fair comparison. Specifically, theViola and Jones face detector [51] was first used to extractfacial region. To determine eye locations of facial image, thecascaded classifier is applied which is trained for detectingleft and right eyes and implemented in OpenCV. Then, anormalization is performed based on detected eye locations.
The person-specific and person-independent recognitionrates obtained by our method are listed in Table III. It achievespromising recognition rates in both settings. It is also inter-esting to observe that for ’Anger’ and ’Joy’ expressions, theproposed method achieves higher recognition accuracies underperson-independent setting than those under person-specificsetting. There are two reasons: First, one main strength of theproposed method is its capability of building unbiased facialexpression atlas to guide recognition process. The facial shape
variations due to inter-person differences can be suppressed.Therefore, the proposed method achieves robust recognitionperformance under person-independent condition. Second, inthe challenging FERA database, intra-person expression vari-ations are not necessarily smaller than inter-person expressionvariations, which is illustrated in Figure 19. In Figure 19,each row shows images of the same facial expression sequencewith expression type ’Joy’ from the training set of the FERAdatabase. The second and third rows are sequences of the sameperson, while the first row is a sequence of another person.It can be seen that facial features such as eyes, brows, andmouths are quite similar between the sequence in the firstrow and the sequence in the second row even though they arefrom different persons. On the other hand, there are large facialfeature variations between the sequence in the second row andthe sequence in the third row even though they are from thesame person and with the same expression type ’Joy’.
Fig. 19. An example that shows one of the challenging properties ofthe FERA database, where the intra-person expression variations are notnecessarily smaller than inter-person expression variations. Each row showsan expression sequence from the FERA training set with expression type’Joy’. The second and third rows are sequences of the same person, while thefirst row is a sequence obtained from another person. It is visually observedthat intra-person expression variations are larger than inter-person expressionvariations in this case.

1057-7149 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TIP.2016.2537215, IEEETransactions on Image Processing
SHELL et al.: BARE DEMO OF IEEETRAN.CLS FOR JOURNALS 13
TABLE IIIRECOGNITION RATES OBTAINED BY THE PROPOSED METHOD ON FERA
DATABASE.
Person-independent Person-specific OverallAnger 1.00 0.923 0.963Fear 0.867 1.00 0.920Joy 1.00 0.727 0.903Relief 0.563 0.900 0.692Sadness 0.933 1.00 0.960Average 0.873 0.910 0.888
The overall recognition rate obtained by our method is0.888. It is higher than that of other methods reported in [43],where the highest overall recognition rate is 0.838 achievedby Yang and Bhanu [52], and it is also significantly higherthan that of the baseline method (i.e., 0.560) [43].
D. Experiments on the AFEW Database
The proposed method has also been evaluated on the ActedFacial Expression in Wild (AFEW) database [53] to studyits performance when facial expression sequences are takenunder wild and real-life conditions. The AFEW database wascollected from movies showing real-life conditions, whichdepicts or simulates spontaneous expressions in uncontrolledenvironment. Some samples are shown in Figure 20. Thetask is to classify each sequence to one of the seven basicexpression types: neutral (NE), happiness (HA), sadness (SA),disgust (DI), fear (FE), anger (AN), and surprise (SUR). Inthis paper, we follow the protocol of Emotion Recognition inthe Wild Challenge 2014 (i.e., EmotiW 2014) [53] to evaluatethe proposed method. The training set defined in the EmotiW2014 protocol is used to build atlas sequences. The recognitionaccuracies on the validation set are listed in Table IV similarto [54], [55].
Fig. 20. Sample images from the AFEW database.
TABLE IVRECOGNITION RATES OBTAINED BY THE PROPOSED METHOD ON THEVALIDATION SET OF THE AFEW DATABASE AND COMPARISONS WITH
OTHER STATE-OF-THE-ART RECOGNITION METHODS.
Method Recognition Accuracies (in %)Baseline [56] 34.4Multiple Kernel Learning [57] 40.2Improved STLMBP [58] 45.8Multiple Kernel + Manifold [59] 48.5Our Method 48.3
From the Table IV, it can be seen that our method achievessignificantly higher recognition accuracies than the baseline
algorithm [56] (i.e., LBP-TOP [7]) in the EmotiW 2014 pro-tocol. Moreover, our method achieves comparable recognitionaccuracy (with recognition accuracy 0.2% difference) to thewinner of the EmotiW 2014 challenge (i.e., Multiple Kernel +Manifold [59]) and outperforms other state-of-the-art methodsunder comparison. Therefore, the robustness of the proposedmethod in the wild condition can be implied.
E. Experiments on the UNBC Database
Our method is evaluated on the UNBC-McMaster shoulderpain expression archive database [44] for spontaneous painexpression monitoring. It consists of 200 dynamic facialexpression sequences from 25 subjects with 48, 398 frames,where each subject was self-identified as having a problemwith shoulder pain. Each sequence was obtained when thesubject was instructed by physiotherapists to move his/herlimb as far as possible. For each sequence, observers who hadconsiderable training in identification of pain expression ratedit on a 6-point scale that ranged from 0 (no pain) to 5 (strongpain). Each frame was manually FACS coded, and 66 pointactive appearance model (AAM) landmarks were provided[44]. Figure 21 shows some images from UNBC-McMasterdatabase.
Fig. 21. Images from UNBC-McMaster database.
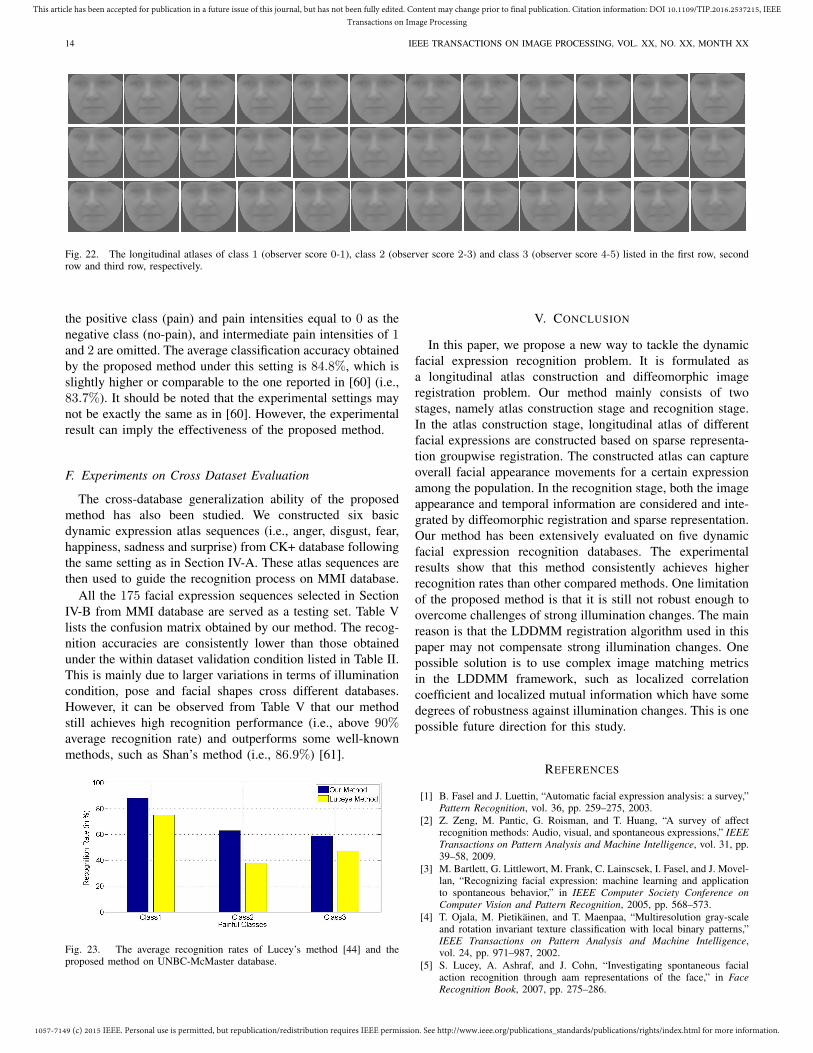
We follow the same experimental settings as in [44], whereleave-one-subject-out cross validation was adopted. Referringto observers’ 6-point scale ratings, all sequences were groupedinto three classes [44]: 0-1 as class one, 2-3 as class twoand 4-5 as class three. Similar to [44], rough alignment andinitialization are performed for our method with 66 AAMlandmarks provided for each frame. Figure 22 shows theconstructed facial expression atlases for different classes. Itcan be observed that constructed atlas successfully capturessubtle and important details, especially in areas that can reflectthe degree of pain, such as eyes and mouth.
The classification accuracies of our method are comparedwith Lucey’s method [44], as shown in Figure 23. The clas-sification accuracies for class 1, class 2 and class 3 obtainedby our method are 88%, 63% and 59%, respectively. It canbe seen that significant improvement is achieved compared tothose obtained by Lucey’s method: 75%, 38% and 47% [44].This can demonstrate the effectiveness of the proposed methodon characterizing spontaneous expressions.
The proposed method is also compared with one state-of-the-art pain classification method in [60]. For purposes of faircomparison, we adopted the same protocol as in [60]: painclass labels are binarized into ’pain’ and ’no pain’ by defininginstances with pain intensities larger than or equal to 3 as
1057-7149 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TIP.2016.2537215, IEEETransactions on Image Processing
14 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. XX, NO. XX, MONTH XX
Fig. 22. The longitudinal atlases of class 1 (observer score 0-1), class 2 (observer score 2-3) and class 3 (observer score 4-5) listed in the first row, secondrow and third row, respectively.
the positive class (pain) and pain intensities equal to 0 as thenegative class (no-pain), and intermediate pain intensities of 1and 2 are omitted. The average classification accuracy obtainedby the proposed method under this setting is 84.8%, which isslightly higher or comparable to the one reported in [60] (i.e.,83.7%). It should be noted that the experimental settings maynot be exactly the same as in [60]. However, the experimentalresult can imply the effectiveness of the proposed method.
F. Experiments on Cross Dataset Evaluation
The cross-database generalization ability of the proposedmethod has also been studied. We constructed six basicdynamic expression atlas sequences (i.e., anger, disgust, fear,happiness, sadness and surprise) from CK+ database followingthe same setting as in Section IV-A. These atlas sequences arethen used to guide the recognition process on MMI database.
All the 175 facial expression sequences selected in SectionIV-B from MMI database are served as a testing set. Table Vlists the confusion matrix obtained by our method. The recog-nition accuracies are consistently lower than those obtainedunder the within dataset validation condition listed in Table II.This is mainly due to larger variations in terms of illuminationcondition, pose and facial shapes cross different databases.However, it can be observed from Table V that our methodstill achieves high recognition performance (i.e., above 90%average recognition rate) and outperforms some well-knownmethods, such as Shan’s method (i.e., 86.9%) [61].
Fig. 23. The average recognition rates of Lucey’s method [44] and theproposed method on UNBC-McMaster database.
V. CONCLUSION
In this paper, we propose a new way to tackle the dynamicfacial expression recognition problem. It is formulated asa longitudinal atlas construction and diffeomorphic imageregistration problem. Our method mainly consists of twostages, namely atlas construction stage and recognition stage.In the atlas construction stage, longitudinal atlas of differentfacial expressions are constructed based on sparse representa-tion groupwise registration. The constructed atlas can captureoverall facial appearance movements for a certain expressionamong the population. In the recognition stage, both the imageappearance and temporal information are considered and inte-grated by diffeomorphic registration and sparse representation.Our method has been extensively evaluated on five dynamicfacial expression recognition databases. The experimentalresults show that this method consistently achieves higherrecognition rates than other compared methods. One limitationof the proposed method is that it is still not robust enough toovercome challenges of strong illumination changes. The mainreason is that the LDDMM registration algorithm used in thispaper may not compensate strong illumination changes. Onepossible solution is to use complex image matching metricsin the LDDMM framework, such as localized correlationcoefficient and localized mutual information which have somedegrees of robustness against illumination changes. This is onepossible future direction for this study.
REFERENCES
[1] B. Fasel and J. Luettin, “Automatic facial expression analysis: a survey,”Pattern Recognition, vol. 36, pp. 259–275, 2003.
[2] Z. Zeng, M. Pantic, G. Roisman, and T. Huang, “A survey of affectrecognition methods: Audio, visual, and spontaneous expressions,” IEEETransactions on Pattern Analysis and Machine Intelligence, vol. 31, pp.39–58, 2009.
[3] M. Bartlett, G. Littlewort, M. Frank, C. Lainscsek, I. Fasel, and J. Movel-lan, “Recognizing facial expression: machine learning and applicationto spontaneous behavior,” in IEEE Computer Society Conference onComputer Vision and Pattern Recognition, 2005, pp. 568–573.
[4] T. Ojala, M. Pietikainen, and T. Maenpaa, “Multiresolution gray-scaleand rotation invariant texture classification with local binary patterns,”IEEE Transactions on Pattern Analysis and Machine Intelligence,vol. 24, pp. 971–987, 2002.
[5] S. Lucey, A. Ashraf, and J. Cohn, “Investigating spontaneous facialaction recognition through aam representations of the face,” in FaceRecognition Book, 2007, pp. 275–286.

1057-7149 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TIP.2016.2537215, IEEETransactions on Image Processing
SHELL et al.: BARE DEMO OF IEEETRAN.CLS FOR JOURNALS 15
TABLE VCONFUSION MATRIX OF THE PROPOSED METHOD ON MMI DATABASE WITH ATLAS SEQUENCES TRAINED ON CK+ DATABASE.
Anger Disgust Fear Happiness Sadness Surprise(%) (%) (%) (%) (%) (%)
Anger 90.8 1.5 0 0 7.7 0Disgust 0.5 93.2 0 5.3 1.0 0Fear 0.4 0.7 93.5 5.4 0 0Happiness 0 2.1 5.3 92.6 0 0Sadness 7.6 0 2.3 0 89.7 0.4Surprise 0.7 0 4.9 2.8 0 91.6
[6] E. Learned-Miller, “Data driven image models through continuousjoint alignment,” IEEE Transactions on Pattern Analysis and MachineIntelligence, vol. 28, no. 2, pp. 236–250, 2006.
[7] G. Zhao and M. Pietikainen, “Dynamic texture recognition using localbinary patterns with an application to facial expressions,” IEEE Trans-actions on Pattern Analysis and Machine Intelligence, vol. 29, pp. 915–928, 2007.
[8] L. Cohen, N. Sebe, A. Garg, L. Chen, and T. Huang, “Facial expres-sion recognition from video sequences: temporal and static modeling,”Computer Vision and Image Understanding, vol. 91, pp. 160–187, 2003.
[9] Y. Zhang and Q. Ji, “Active and dynamic information fusion for facialexpression understanding from image sequences,” IEEE Transactions onPattern Analysis and Machine Intelligence, vol. 27, pp. 699–714, 2005.
[10] S. Koelstra, M. Pantic, and I. Patras, “A dynamic texture-based approachto recognition of facial actions and their temporal models,” IEEETransactions on Pattern Analysis and Machine Intelligence, vol. 32, pp.1940–1954, 2010.
[11] A. Ramirez and O. Chae, “Spatiotemporal directional number transi-tional graph for dynamic texture recognition,” IEEE Transactions onPattern Analysis and Machine Intelligence, p. In Press, 2015.
[12] H. Fang, N. Parthalain, A. Aubrey, G. Tam, R. Borgo, P. Rosin, P. Grant,D. Marshall, and M. Chen, “Facial expression recognition in dynamicsequences: An integrated approach,” Pattern Recognition, vol. 47, no. 3,pp. 1271–1281, 2014.
[13] L. Zhong, Q. Liu, P. Yang, B. Liu, J. Huang, and D. Metaxas, “Learningactive facial patches for expression analysis,” in IEEE Computer SocietyConference on Computer Vision and Pattern Recognition, 2012, pp.2562–2569.
[14] Z. Wang, S. Wang, and Q. Ji, “Capturing complex spatio-temporalrelations among facial muscles for facial expression recognition,” inIEEE Computer Society Conference on Computer Vision and PatternRecognition, 2013, pp. 3422–3429.
[15] M. Beg, M. Miller, A. Trouve, and L. Younes, “Computing largedeformation metric mappings via geodesic flows of diffeomorphisms,”International Journal of Computer Vision, vol. 61, pp. 139–157, 2005.
[16] S. Yousefi, P. Minh, N. Kehtarnavaz, and C. Yan, “Facial expressionrecognition based on diffeomorphic matching,” in International Confer-ence on Image Processing, 2010, pp. 4549–4552.
[17] Y. Guo, G. Zhao, and M. Pietikainen, “Dynamic facial expressionrecognition using longitudinal facial expression atlases,” in EuropeanConference on Computer Vision, 2012, pp. 631–644.
[18] Y. Chang, C. Hu, R. Feris, and M. Turk, “Manifold based analysis offacial expression,” Image and Vision Computing, vol. 24, no. 6, pp. 605–614, 2006.
[19] M. Pantic and I. Patras, “Dynamics of facial expression: Recognitionof facial actions and their temporal segments form face profile imagesequences,” IEEE Transactions on Systems, Man, and Cybernetics PartB, vol. 36, no. 2, pp. 433–449, 2006.
[20] P. Yang, Q. Liu, X. Cui, and D. Metaxas, “Facial expression recognitionusing encoded dynamic features,” in IEEE Computer Society Conferenceon Computer Vision and Pattern Recognition, 2008, pp. 1–8.
[21] M. Yeasin, B. Bullot, and R. Sharma, “From facial expression to levelof interests: A spatio-temporal approach,” in IEEE Computer SocietyConference on Computer Vision and Pattern Recognition, 2004, pp. 922–927.
[22] G. Edwards, C. Taylor, and T. Cootes, “Interpreting face images usingactive appearance models,” in IEEE FG, 1998, pp. 300–305.
[23] J. Saragih, S. Lucey, and J. Cohn, “Deformable model fitting byregularized landmark mean-shift,” International Journal of ComputerVision, vol. 91, no. 2, pp. 200–215, 2011.
[24] N. Dalal and B. Triggs, “Histograms of oriented gradients for human
detection,” in IEEE Computer Society Conference on Computer Visionand Pattern Recognition, 2005, pp. 886–893.
[25] G. David, “Distinctive image features from scale-invariant keypoints,”International Journal of Computer Vision, vol. 60, no. 2, pp. 91–110,2004.
[26] K. Mikolajczyk and C. Schmid, “A performance evaluation of localdescriptors,” IEEE Transactions on Pattern Analysis and Machine Intel-ligence, vol. 27, no. 10, pp. 1615–1630, 2005.
[27] D. Rueckert, L. Sonoda, C. Hayes, D. Hill, M. Leach, and D. Hawkes,“Nonrigid registration using free-form deformations: Application tobreast MR images,” IEEE Transactions on Medical Imaging, vol. 18,pp. 712–721, 1999.
[28] X. Xiong and F. De la Torre, “Supervised descent method and itsapplications to face alignment,” in IEEE Computer Society Conferenceon Computer Vision and Pattern Recognition, 2013, pp. 532–539.
[29] F. De la Torre and M. Nguyen, “Parameterized kernel principal compo-nent analysis: Theory and applications to supervised and unsupervisedimage alignment,” in IEEE Computer Society Conference on ComputerVision and Pattern Recognition, 2008, pp. 1–8.
[30] G. Tzimiropoulos, V. Argyriou, S. Zafeiriou, and T. Stathaki, “Robustfft-based scale-invariant image registration with image gradients,” IEEETransactions on Pattern Analysis and Machine Intelligence, vol. 32,no. 10, pp. 1899–1906, 2010.
[31] X. Cao, Y. Wei, F. Wen, and J. Sun, “Face alignment by explicit shaperegression,” in IEEE Computer Society Conference on Computer Visionand Pattern Recognition, 2012, pp. 2887–2894.
[32] S. Liao, D. Shen, and A. Chung, “A markov random field groupwiseregistration framework for face recognition,” IEEE Transactions onPattern Analysis and Machine Intelligence, vol. 36, pp. 657–669, 2014.
[33] J. Maintz and M. Viergever, “A survey of medical image registration,”Medical Image Analysis, vol. 2, pp. 1–36, 1998.
[34] M. Miller and L. Younes, “Group actions, homeomorphisms, amdmatching: A general framework,” International Journal of ComputerVision, vol. 41, pp. 61–84, 2001.
[35] S. Joshi, B. Davis, M. Jomier, and G. Gerig, “Unbiased diffeomorphicatlas construction for computational anatomy,” NeuroImage, vol. 23, pp.151–160, 2004.
[36] T. Cootes, C. Twining, V. Petrovic, K. Babalola, and C. Taylor,“Computing accurate correspondences across groups of images,” IEEETransactions on Pattern Analysis and Machine Intelligence, vol. 32,no. 11, pp. 1994–2005, 2010.
[37] M. Hernandez, S. Olmos, and X. Pennec, “Comparing algorithmsfor diffeomorphic registration: Stationary lddmm and diffeomorphicdemons,” in 2nd MICCAI Workshop on Mathematical Foundations ofComputational Anatomy, 2008, pp. 24–35.
[38] J. Wright, A. Yang, A. Ganesh, S. Sastry, and Y. Ma, “Robust facerecognition via sparse representation,” IEEE Transactions on PatternAnalysis and Machine Intelligence, vol. 31, no. 2, pp. 210–227, 2009.
[39] R. Tibshirani, “Regression shrinkage and selection via the lasso,” Jour-nal of the Royal Statistical Society: Series B, vol. 58, pp. 267–288,1996.
[40] Y. Nesterov, Introductory Lectures on Convex Optimization: A BasicCourse. Kluwer Academic Publishers, 2004.
[41] P. Lucey, J. Cohn, T. Kanade, J. Saragih, and Z. Ambadar, “The extendedcohn-kanade dataset (ck+): A complete dataset for action unit andemotion-specified expression,” in IEEE Computer Society Conferenceon Computer Vision and Pattern Recognition Workshops, 2010, pp. 94–101.
[42] M. Pantic, M. Valstar, R. Rademaker, and L. Maat, “Web-based databasefor facial expression analysis,” in IEEE International Conference onMultimedia and Expo, 2005, pp. 317–321.

1057-7149 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TIP.2016.2537215, IEEETransactions on Image Processing
16 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. XX, NO. XX, MONTH XX
[43] M. Valstar, M. Mehu, B. Jiang, M. Pantic, and S. K., “Meta-analysisof the first facial expression recognition challenge,” IEEE Transactionson Systems, Man, and Cybernetics Part B, vol. 42, no. 4, pp. 966–979,2012.
[44] P. Lucey, J. Cohn, K. Prkachin, P. Solomon, S. Chew, and I. Matthews,“Painful monitoring: Automatic pain monitoring using the unbc-mcmaster shoulder pain expression archive database,” Image and VisionComputing, vol. 30, pp. 197–205, 2012.
[45] I. Kemelmacher-Shlizerman and S. Seitz, “Collection flow,” in IEEEComputer Society Conference on Computer Vision and Pattern Recog-nition, 2012, pp. 1792–1799.
[46] I. Kemelmacher-Shlizerman, S. Suwajanakorn, and S. Seitz,“Illumination-aware age progression,” in IEEE Computer SocietyConference on Computer Vision and Pattern Recognition, 2014, pp.3334–3341.
[47] Y. Peng, A. Ganesh, J. Wright, W. Xu, and Y. Ma, “Rasl: Robustalignment by sparse and low-rank decomposition for linearly correlatedimages,” in IEEE Computer Society Conference on Computer Vision andPattern Recognition, 2010, pp. 763–770.
[48] C. Liu, Beyond Pixels: Exploring New Representations and Applicationsfor Motion Analysis. PhD thesis, MIT, 2009.
[49] Y. Gizatdinova and V. Surakka, “Feature-based detection of facial land-marks from neutral and expressive facial images,” IEEE Transactions onPattern Analysis and Machine Intelligence, vol. 28, pp. 135–139, 2006.
[50] Z. Wang, S. Wang, and Q. Ji, “Capturing complex spatio-temporalrelations among facial muscles for facial expression recognition,” inIEEE Conference on Computer Vision and Pattern Recognition, 2013,pp. 3422–3429.
[51] P. Viola and M. Jones, “Robust real-time object detection,” InternationalJournal of Computer Vision, vol. 57, no. 2, pp. 137–154, 2002.
[52] S. Yang and B. Bhanu, “Facial expression recognition using emotionavatar image,” in IEEE Int. Conf. Autom. Face Gesture Anal., 2011, pp.866–871.
[53] A. Dhall, R. Goecke, S. Lucey, and T. Gedeon, “Collecting large, richlyannotated facial-expression databases from movies,” IEEE MultiMedia,vol. 19, pp. 34–41, 2012.
[54] J. Chen, T. Takiguchi, and Y. Ariki, “Facial expression recognitionwith multithreaded cascade of rotation-invariant hog,” in InternationalConference on Affective Computing and Intelligent Interaction, 2015,pp. 636–642.
[55] M. Liu, S. Shan, R. Wang, and X. Chen, “Learning expressionlets onspatio-temporal manifold for dynamic facial expression recognition,” inIEEE Computer Society Conference on Computer Vision and PatternRecognition, 2014, pp. 1749–1756.
[56] A. Dhall, R. Goecke, J. Joshi, K. Sikka, and T. Gedeon, “Emotionrecognition in the wild challenge 2014: Baseline, data and protocol,”in ACM International Conference on Multimodal Interaction, 2014.
[57] J. Chen, Z. Chen, Z. Chi, and H. Fu, “Emotion recognition in the wildwith feature fusion and multiple kernel learning,” in ACM InternationalConference on Multimodal Interaction, 2014, pp. 508–513.
[58] X. Huang, Q. He, X. Hong, G. Zhao, and M. Pietikainen, “Emotionrecognition in the wild with feature fusion and multiple kernel learning,”in ACM International Conference on Multimodal Interaction, 2014, pp.514–520.
[59] M. Liu, R. Wang, S. Li, S. Shan, Z. Huang, and X. Chen, “Combiningmultiple kernel methods on riemannian manifold for emotion recog-nition in the wild,” in ACM International Conference on MultimodalInteraction, 2014, pp. 494–501.
[60] K. Sikka, A. Dhall, and M. Bartlett, “Classification and weakly super-vised pain localization using multiple segment representation,” Imageand Vision Computing, vol. 32, no. 10, pp. 659–670, 2014.
[61] C. Shan, S. Gong, and P. McOwan, “Facial expression recognition basedon local binary patterns: a comprehensive study,” Image and VisionComputing, vol. 27, pp. 803–816, 2009.
Yimo Guo received her B.Sc. and M.Sc. degrees incomputer science in 2004 and 2007, and received thePh.D. degree in computer science and engineeringfrom the University of Oulu, Finland, in 2013. Herresearch interests include texture analysis and videosynthesis.
Guoying Zhao received the Ph.D. degree in com-puter science from the Chinese Academy of Sci-ences, Beijing, China, in 2005. She is currently anAssociate Professor with the Center for MachineVision Research, University of Oulu, Finland, whereshe has been a researcher since 2005. In 2011, shewas selected to the highly competitive AcademyResearch Fellow position. She has authored or co-authored more than 140 papers in journals andconferences, and has served as a reviewer for many
journals and conferences. She has lectured tutorials at ICPR 2006, ICCV2009, and SCIA 2013, and authored/edited three books and four special issuesin journals. Dr. Zhao was a Co-Chair of seven International Workshops atECCV, ICCV, CVPR and ACCV, and two special sessions at FG13 and FG15.She is editorial board member for Image and Vision Computing Journal,International Journal of Applied Pattern Recognition and ISRN MachineVision. She is IEEE Senior Member. Her current research interests includeimage and video descriptors, gait analysis, dynamic-texture recognition, facial-expression recognition, human motion analysis, and person identification.
Matti Pietikainen received his Doctor of Science inTechnology degree from the University of Oulu, Fin-land. He is currently a professor, Scientific Directorof Infotech Oulu and Director of Center for MachineVision Research at the University of Oulu. From1980 to 1981 and from 1984 to 1985, he visitedthe Computer Vision Laboratory at the Universityof Maryland. He has made pioneering contributions,e.g. to local binary pattern (LBP) methodology,texture-based image and video analysis, and facial
image analysis. He has authored over 335 refereed papers. His papers havecurrently about 31,500 citations in Google Scholar (h-index 63), and six ofhis papers have over 1,000 citations. Dr. Pietikinen was Associate Editor ofIEEE Transactions on Pattern Analysis and Machine Intelligence and PatternRecognition journals, and currently serves as Associate Editor of Image andVision Computing and IEEE Transactions on Forensics and Security journals.He was President of the Pattern Recognition Society of Finland from 1989to 1992, and was named its Honorary Member in 2014. From 1989 to 2007he served as Member of the Governing Board of International Associationfor Pattern Recognition (IAPR), and became one of the founding fellows ofthe IAPR in 1994. He is IEEE Fellow for contributions to texture and facialimage analysis for machine vision. In 2014, his research on LBP-based facedescription was awarded the Koenderink Prize for Fundamental Contributionsin Computer Vision.
![Deep Diffeomorphic Transformer Networkssohau/papers/cvpr2018/... · curacy [25,42] or maintained the same performance level Original. Accuracy: 0.78. Diffeomorphic. Accuracy: 0.87](https://img.pdfslide.us/doc/110x75/60b2406c2d608f30644cde45/deep-diffeomorphic-transformer-sohaupaperscvpr2018-curacy-2542-or-maintained.jpg)



![ANALYSIS OF FACIAL EXPRESSIONS WITH RESPECT TO … · [Fig-1], is used for testing the variations in navarasa facial expres- sions the nine types of emotional changes with respect](https://img.pdfslide.us/doc/110x75/5e07504778759909ec6ec3ee/analysis-of-facial-expressions-with-respect-to-fig-1-is-used-for-testing-the.jpg)
![Deep Diffeomorphic Transformer Networks...curacy [25,42] or maintained the same performance level Original Accuracy: 0.78 Diffeomorphic Accuracy: 0.87 Affine Accuracy: 0.84 Affine+Diffeomorphic](https://img.pdfslide.us/doc/110x75/610d8e4f8e38aa26d70e5239/deep-diffeomorphic-transformer-networks-curacy-2542-or-maintained-the-same.jpg)























