Embed Size (px)
Citation preview

Hitachi Streaming Data PlatformProduct Overview
MK-93HSDP003-04

© 2014 , 2016 Hitachi, Ltd. All rights reserved.
No part of this publication may be reproduced or transmitted in any form or by any means, electronicor mechanical, including photocopying and recording, or stored in a database or retrieval system forany purpose without the express written permission of Hitachi, Ltd.
Hitachi , Ltd., reserves the right to make changes to this document at any time without notice andassumes no responsibility for its use. This document contains the most current information availableat the time of publication. When new or revised information becomes available, this entire documentwill be updated and distributed to all registered users.
Some of the features described in this document might not be currently available. Refer to the mostrecent product announcement for information about feature and product availability, or contactHitachi, Ltd., at https://support.hds.com/en_us/contact-us.html.
Notice:Hitachi , Ltd. products and services can be ordered only under the terms and conditions of theapplicable Hitachi Data Systems Corporation agreements. The use of Hitachi , Ltd., products isgoverned by the terms of your agreements with Hitachi Data Systems Corporation.
By using this software, you agree that you are responsible for:1. Acquiring the relevant consents as may be required under local privacy laws or otherwise from
employees and other individuals to access relevant data; and2. Verifying that data continues to be held, retrieved, deleted, or otherwise processed in
accordance with relevant laws.
Hitachi is a registered trademark of Hitachi, Ltd., in the United States and other countries. HitachiData Systems is a registered trademark and service mark of Hitachi, Ltd., in the United States andother countries.
Archivas, BlueArc, Essential NAS Platform, HiCommand, Hi-Track, ShadowImage, Tagmaserve,Tagmasoft, Tagmasolve, Tagmastore, TrueCopy, Universal Star Network, and Universal StoragePlatform are registered trademarks of Hitachi Data Systems Corporation.
AIX, AS/400, DB2, Domino, DS6000, DS8000, Enterprise Storage Server, ESCON, FICON, FlashCopy,IBM, Lotus, MVS, OS/390, RS/6000, S/390, System z9, System z10, Tivoli, VM/ESA, z/OS, z9, z10,zSeries, z/VM, and z/VSE are registered trademarks and DS6000, MVS, and z10 are trademarks ofInternational Business Machines Corporation.
Microsoft is either a registered trademark or a trademark of Microsoft Corporation in the United Statesand/or other countries.
Linux(R) is the registered trademark of Linus Torvalds in the U.S. and other countries.
Oracle and Java are registered trademarks of Oracle and/or its affiliates.
Red Hat is a trademark or a registered trademark of Red Hat Inc. in the United States and othercountries.
SL, RTView, SL Corporation, and the SL logo are trademarks or registered trademarks of Sherrill-Lubinski Corporation in the United States and other countries.
SUSE is a registered trademark or a trademark of SUSE LLC in the United States and other countries.
RSA and BSAFE are either registered trademarks or trademarks of EMC Corporation in the UnitedStates and/or other countries.
Windows is either a registered trademark or a trademark of Microsoft Corporation in the United Statesand/or other countries.
All other trademarks, service marks, and company names in this document or website are propertiesof their respective owners.
Microsoft product screen shots are reprinted with permission from Microsoft Corporation.
Notice on Export Controls. The technical data and technology inherent in this Document may besubject to U.S. export control laws, including the U.S. Export Administration Act and its associatedregulations, and may be subject to export or import regulations in other countries. Reader agrees tocomply strictly with all such regulations and acknowledges that Reader has the responsibility to obtainlicenses to export, re-export, or import the Document and any Compliant Products.
Third-party copyright notices
Hitachi Streaming Data Platform includes RSA BSAFE(R) Cryptographic software of EMC Corporation.
Portions of this software were developed at the National Center for Supercomputing Applications(NCSA) at the University of Illinois at Urbana-Champaign.
2Hitachi Streaming Data Platform

Regular expression support is provided by the PCRE library package, which is open source software, written byPhilip Hazel, and copyright by the University of Cambridge, England. The original software is available fromftp://ftp.csx.cam.ac.uk/pub/software/programming/pcre/
This product includes software developed by Andy Clark.
This product includes software developed by Ben Laurie for use in the Apache-SSL HTTP server project.
This product includes software developed by Daisuke Okajima and Kohsuke Kawaguchi (http://relaxngcc.sf.net/).
This product includes software developed by IAIK of Graz University of Technology.
This product includes software developed by Ralf S. Engelschall <[email protected]> for use in the mod_sslproject (http://www.modssl.org/).
This product includes software developed by the Apache Software Foundation (http://www.apache.org/).
This product includes software developed by the Java Apache Project for use in the Apache JServ servlet engineproject (http://java.apache.org/).
This product includes software developed by the University of California, Berkeley and its contributors.
This software contains code derived from the RSA Data Security Inc. MD5 Message-Digest Algorithm, includingvarious modifications by Spyglass Inc., Carnegie Mellon University, and Bell Communications Research, Inc(Bellcore).
Java is a registered trademark of Oracle and/or its affiliates.
Export of technical data contained in this document may require an export license from the United Statesgovernment and/or the government of Japan. Contact the Hitachi Data Systems Legal Department for anyexport compliance questions.
3Hitachi Streaming Data Platform

4Hitachi Streaming Data Platform

Contents
Preface................................................................................................. 9
1 What is Streaming Data Platform?.........................................................13A data processing system that analyzes the "right now"............................................14Streaming Data Platform features............................................................................18
High-speed processing of large sets of time-sequenced data................................18Summary analysis scenario definitions that require no programming.................... 19
2 Hardware components......................................................................... 21System components............................................................................................... 22Components of Streaming Data Platform and Streaming Data Platform softwaredevelopment kit..................................................................................................... 24SDP servers........................................................................................................... 26
3 Software components.......................................................................... 29Components used in stream data processing............................................................30
Stream data..................................................................................................... 30Input and output stream queues........................................................................31Tuple............................................................................................................... 31Query.............................................................................................................. 32Query group.....................................................................................................34Window........................................................................................................... 34Stream data processing engine..........................................................................34
Using CQL to process stream data...........................................................................35Using definition CQL to define streams and queries............................................. 35Using data manipulation CQL to specify operations on stream data...................... 35C External Definition Function............................................................................36
Coordinator groups................................................................................................ 36SDP broker and SDP coordinator............................................................................. 39SDP manager.........................................................................................................41
Log notifications............................................................................................... 42Restart feature................................................................................................. 43
5Hitachi Streaming Data Platform

4 Data processing...................................................................................47Filtering records..................................................................................................... 48Extracting records.................................................................................................. 50
5 Internal adapters................................................................................. 53Internal input adapters...........................................................................................54TCP data input adaptor...........................................................................................54
Overview of the TCP data input adaptor............................................................. 54Prerequisites for using the TCP input adaptor..................................................... 55Input adaptor configuration of the TCP data input adaptor...................................55User program that acts as data senders............................................................. 56TCP data input connector.................................................................................. 56
Number of connections................................................................................56TCP data format..........................................................................................57Byte order of data....................................................................................... 60Restart reception of TCP connection............................................................. 60Setting for using the TCP data input adaptor................................................. 60
Comparison of supported functions.................................................................... 61Inputting files........................................................................................................ 62Inputting HTTP packets.......................................................................................... 63Outputting to the dashboard...................................................................................63Cascading adaptor..................................................................................................64
Cascading adaptor processing overview..............................................................66Communication method.................................................................................... 67Features...........................................................................................................68Connection details............................................................................................ 73Time synchronization settings............................................................................73
Internal output adapters.........................................................................................76SNMP adaptor........................................................................................................77SMTP adaptor........................................................................................................ 77Distributed send connector..................................................................................... 77Auto-generated adapters........................................................................................ 77
6 External adapters.................................................................................81External input adapters...........................................................................................82External output adapters........................................................................................ 82External adapter library.......................................................................................... 83
Workflow for creating external input adapters.....................................................83Workflow for creating external output adapters...................................................85Creating callbacks.............................................................................................86
Connecting to parallel-processing SDP servers..........................................................87Custom dispatchers................................................................................................87
Rules for creating class files...............................................................................88Examples of implementing dispatch methods......................................................89
Heartbeat transmission...........................................................................................90Troubleshooting..................................................................................................... 90
7 RTView Custom Data Adapter............................................................... 91Setting up the RTView Custom Data Adapter............................................................92
6Hitachi Streaming Data Platform

Environment setup................................................................................................. 92Editing the system definition file..............................................................................93Environment variable settings................................................................................. 95Data connection settings.........................................................................................95Uninstallation.........................................................................................................98File list.................................................................................................................. 98Operating the RTView Custom Data Adapter............................................................ 98
Types of operations...........................................................................................98Operation procedure......................................................................................... 99Starting the RTView Custom Data Adapter..........................................................99Stopping the RTView Custom Data Adapter.......................................................100
8 Scale-up, scale-out, and data-parallel configurations.............................103Data-parallel configurations...................................................................................104
Scale-up configuration.....................................................................................104Scale-out configuration....................................................................................106
Data-parallel settings............................................................................................107
9 Data replication................................................................................. 109Examples of using data replication.........................................................................110Data-replication setup...........................................................................................111
10 Setting parameter values in definition files........................................... 113Relationship between parameters files and definition files........................................114Examples of setting parameter values in query-definition files and query-groupproperties files..................................................................................................... 116Adapter schema automatic resolution.................................................................... 117
11 Logger.............................................................................................. 123Log-file generation............................................................................................... 124
Glossary................................................................................................1
7Hitachi Streaming Data Platform

8Hitachi Streaming Data Platform

PrefaceThis manual provides an overview and a basic understanding of HitachiStreaming Data Platform (Streaming Data Platform). It is intended to providean overview of the features and system configurations of Streaming DataPlatform, and to give you the basic knowledge needed to set up and operatesuch a system.
This preface includes the following information:
Intended audience
This document is intended for solution developers and integration developers.
Product version
This document revision applies to Streaming Data Platform version 3.0 orlater.
Release notes
Read the release notes before installing and using this product. They maycontain requirements or restrictions that are not fully described in thisdocument or updates or corrections to this document. The latest releasenotes are available on Hitachi Data Systems Support Connect: https://support.hds.com/en_us/documents.html.
Referenced documents
Hitachi Streaming Data Platform documents:• Hitachi Streaming Data Platform Getting Started Guide, MK-93HSDP006
• Hitachi Streaming Data Platform Setup and Configuration Guide,MK-93HSDP000
• Hitachi Streaming Data Platform Application Development Guide,MK-93HSDP001
• Hitachi Streaming Data Platform Messages, MK-93HSDP002
Preface 9Hitachi Streaming Data Platform

Hitachi Data Systems Portal, http://portal.hds.com
Document conventions
This document uses the following terminology conventions:
Abbreviation Full name or meaning
HSDP Hitachi Streaming Data Platform
Streaming DataPlatform
HSDP softwaredevelopment kit
Hitachi Streaming Data Platform software development kit
Streaming DataPlatform softwaredevelopment kit
Java Java™
JavaVM Java™ Virtual Machine
Linux • Red Hat Enterprise Linux®
• SUSE Linux Enterprise Server
This document uses the following typographic conventions:
Convention Description
Regular text bold In text: keyboard key, parameter name, property name, hardware labels,hardware button, hardware switch
In a procedure: user interface item
Italic Variable, emphasis, reference to document title, called-out term
Screen text Command name and option, drive name, file name, folder name, directoryname, code, file content, system and application output, user input
< > angled brackets Variable (used when italic is not enough to identify variable)
[ ] square brackets Optional value
{ } braces Required or expected value
| vertical bar Choice between two or more options or arguments.
... The item preceding this symbol can be repeated as needed.
This document uses the following icons to draw attention to information:
Icon Label Description
Note Calls attention to important or additional information.
10 PrefaceHitachi Streaming Data Platform

Icon Label Description
Tip Provides helpful information, guidelines, or suggestions for performingtasks more effectively.
Caution Warns the user of adverse conditions or consequences (for example,disruptive operations).
Warning Warns the user of severe conditions or consequences (for example,destructive operations).
Getting help
Hitachi Data Systems Support Connect is the destination for technical supportof products and solutions sold by Hitachi Data Systems. To contact technicalsupport, log on to Hitachi Data Systems Support Connect for contactinformation: https://support.hds.com/en_us/contact-us.html.
Hitachi Data Systems Community is a global online community for HDScustomers, partners, independent software vendors, employees, andprospects. It is the destination to get answers, discover insights, and makeconnections. Join the conversation today! Go to community.hds.com,register, and complete your profile.
Comments
Please send us your comments on this document to [email protected] the document title and number, including the revision level (forexample, -07), and refer to specific sections and paragraphs wheneverpossible. All comments become the property of Hitachi Data SystemsCorporation.
Thank you!
Preface 11Hitachi Streaming Data Platform

12 PrefaceHitachi Streaming Data Platform

1What is Streaming Data Platform?Streaming Data Platform is a product that enables you to process streamdata; that is, it allows you to analyze in real-time large sets of data as theyare being created. This chapter provides an overview of Streaming DataPlatform and explains its features. This chapter also gives an example ofadding Streaming Data Platform to your current workflow, and it describesthe system configuration needed to set up and run Streaming Data Platform.
□ A data processing system that analyzes the "right now"
□ Streaming Data Platform features
What is Streaming Data Platform? 13Hitachi Streaming Data Platform

A data processing system that analyzes the "right now"Our societal infrastructure has been transformed by the massive amounts ofdata being packed into our mobile telephones, IC cards, home appliances,and other electronic devices. As a result, the amount of data handled by dataprocessing systems continues to grow daily. The ability to quickly summarizeand analyze this data can provide us with valuable new insights. To be useful,any real-time data processing system must have the ability to create newvalue from the massive amounts of data that is being created every second.
Streaming Data Platform responds to this challenge by giving you the abilityto perform stream data processing. Stream data processing gives you real-time summary analysis of the large quantities of time-sequenced data that isalways being generated, as soon as the data is generated.
For example, think how obtaining real-time summary information on whatwas searched for from peoples PCs and mobile phones could increase yourproduct sales opportunities. If a particular product becomes a hot topic onproduct discussion sites, you expect the demand for it to increase, so morepeople would tend to search for that product on the various search sites. Youcan identify such products by using stream data processing to analyze thenumber of searches in real-time and provide summary results. Thisinformation allows retail outlets to increase their orders for the productbefore the demand hits, and for the manufacturer to quickly ramp upproduction of the product.
On the IT systems side, demand for higher operating efficiencies and lowercosts continues to grow. At the same time, the increasing use of virtualizationand cloud computing results in ever larger and more complex systems,making it even more difficult for IT to get a good overview of their system'sstate of operation. This means that it often takes too long to detect andresolve problems when they occur. Now, by using stream data processing tomonitor the operating state of the system in real-time, a problem can bequickly dealt with as soon as it occurs. Moreover, by analyzing trends andcorrelations in the information about the system's operations, warning signscan be detected, which can be used to prevent errors from ever occurring.
Adding Streaming Data Platform to your data processing system gives you atool that is designed for processing these large volumes of data.
The following figure provides an overview of a configuration that usesStreaming Data Platform to implement stream data processing.
14 What is Streaming Data Platform?Hitachi Streaming Data Platform

Figure 1 Overview of a stream data processing configuration that usesStreaming Data Platform
Introducing Streaming Data Platform into your stream data processingsystem allows you to perform summary analysis of data as it is beingcreated.
For example, by using a stream data processing system to monitor systemoperations, you can summarize and analyze log files output by a server andHTTP packets sent over a network. These results can then be outputted to afile, allowing you to monitor your system's operations in real-time. In thisway, you can quickly resolve system problems as they occur, improvingoperation and maintenance efficiencies. You can also store the processingresults in a file, allowing you to use other applications to further review orprocess the results.
To give you a better idea of how stream data processing carries out real-timeprocessing, stream data processing is compared to conventional stored dataprocessing in the following example.
Figure 2 Stored data processing on page 16 shows conventional storeddata processing.
What is Streaming Data Platform? 15Hitachi Streaming Data Platform

Figure 2 Stored data processing
Data processed using stored data begins by storing the data sequentially in adatabase as it occurs. Processing is not actually performed until a user issuesa query for the data stored in the database, and summary analysis resultsare returned. Because data that is already stored in a database is searchedwhen the query is received, there is a time lag between the time the data iscollected and the time the data summary analysis results are produced. Inthe figure, processing of data that was collected at 09:00:00 is performed bya query issued at 09:05:00, obviously lagging behind the time the data wascollected.
Figure 3 Stream data processing on page 17 shows stream dataprocessing.
16 What is Streaming Data Platform?Hitachi Streaming Data Platform

Figure 3 Stream data processing
With stream data processing, you pre-load a query (summary analysisscenario) that will perform incremental data analysis, thus minimizing theamount of computing that is required. Moreover, because data analysis istriggered by the data being input, there is no time lag between it and thetime the data is collected, providing you with real-time data summaryanalysis. This kind of stream data processing, in which processing is triggeredby the input data itself, is a superior approach for data that is generatedsequentially.
Therefore, the ability to perform stream data processing that you gain byintegrating Streaming Data Platform into your system allows you to get areal-time summary and analysis of the data.
What is Streaming Data Platform? 17Hitachi Streaming Data Platform

Streaming Data Platform featuresStreaming Data Platform has the following features:• High-speed processing of large sets of time-sequenced data
• Summary analysis scenario definitions that require no programming
The following subsections explain these features.
High-speed processing of large sets of time-sequenced dataStreaming Data Platform uses both in-memory processing and incrementalcomputational processing, which allows it to quickly process large sets oftime-sequenced data.
In-memory processing
With in-memory processing, data is processed while it is still in memory, thuseliminating unnecessary disk access.
When processing large data sets, the time required to perform disk I/O canbe significant. By processing data while it is still in memory, Streaming DataPlatform avoids excess disk I/O, enabling data to be processed faster.
Incremental computational processing
With incremental computational processing, a pre-loaded query is processediteratively when triggered by the input data, and the processing results areavailable for the next iteration. This means that the next set of computationsdoes not need to process all of the target data elements; only those elementsthat have changed need to be processed.
The following figure shows incremental computation on stream data asperformed by Streaming Data Platform.
18 What is Streaming Data Platform?Hitachi Streaming Data Platform

Figure 4 Incremental computation performed on stream data
As shown in the figure, when the first stream data element arrives,Streaming Data Platform performs computational process 1. When the nextstream data element arrives, computational process 2 simply removes dataelement 3 from the process range and adds data element 7 to the processrange, building on the results of computational process 1. This minimizes thetotal processing required, thus enabling the data to be processed faster.
Summary analysis scenario definitions that require no programmingThe actions performed in stream data processing are defined by queries thatare called summary analysis scenarios. Definitions for these summaryanalysis scenarios are written in a language called CQL, which is very similarto SQL, the standard language used to manipulate databases. This meansthat you do not need to create a custom analysis application to createsummary analysis scenarios. Summary analysis scenarios can also bemodified simply by changing the definition files written in CQL.
Stream data processing actions written in CQL are called queries. In a singlesummary analysis scenario, multiple queries can be coded.
For example, the following figure shows a summary analysis scenario writtenin CQL for a temperature monitoring system that has multiple observationsites, each with an assigned ID. The purpose of the query is to summarizeand analyze all of the below freezing point data found in the observed dataset.
What is Streaming Data Platform? 19Hitachi Streaming Data Platform

Figure 5 Example of using CQL to write a summary analysis scenario
CQL is a general-purpose query language that can be used to specify a widerange of processing. By combining multiple queries, you can define summaryanalysis scenarios to handle a variety of operations.
20 What is Streaming Data Platform?Hitachi Streaming Data Platform

2Hardware components
This chapter provides information about the details of system components,components of Streaming Data Platform and Streaming Data Platformsoftware development kit, and SDP servers.
□ System components
□ Components of Streaming Data Platform and Streaming Data Platformsoftware development kit
□ SDP servers
Hardware components 21Hitachi Streaming Data Platform

System componentsHitachi Streaming Data Platform offers real-time processing of chronologicaldata (stream data) that is generated sequentially (in-memory). The streamdata is generated based on a user-defined (through CQL) analysis scenariothrough CQL. The structure and components of SDP systems aredevelopment server, data-transfer server, data-analysis server, anddashboard server.
Example of an SDP system
Description
The components of Streaming Data Platform are as follows.
22 Hardware componentsHitachi Streaming Data Platform

Table 1 SDP system components
S. No. Component Description
1 Development server • Streaming Data Platform and Streaming Data Platformsoftware development kit are installed on thedevelopment server.
• This server provides a development environment foranalysis scenarios. It also provides a developmentenvironment for adapters that send and receive thestream data that is used by the SDP system.
• A system developer can use the API and tools providedwith Streaming Data Platform software development kitto develop and test analysis scenarios and adapters.
2 Data-transfer server • Streaming Data Platform is installed on the data-transfer server.
• This server outputs stream data from a data source tothe data-analysis server.
• The output formats that are supported include text filesand HTTP packets.
• A system architect enables the system to support awide range of data types by applying various adapters,which are developed through the API of StreamingData Platform software development kit, to the data-transfer server.
3 Data-analysis server • Streaming Data Platform is installed on the data-analysis server.
• This server processes the stream data that is receivedfrom a data-transfer server (based on a user-developed analysis scenarios) to output the processedstream data.
• The output formats that are supported include textfiles, SNMP traps, and email.
• A data-analysis server is also able to send processedstream data to other data-analysis servers anddashboard servers. Therefore, a system architect canbuild a scalable system by connecting multiple data-analysis servers.
4 Dashboard server RTView of SL Corp. and HSDP are installed. HSDP inputsstream data from the data analysis server and outputs tothe dashboard on the Viewer client of RTView. The usercan build a system that collects data from data sourcesand analyzes in real time by HSDP and visualizes andmonitors the analysis results on the dashboard by RTView.
Hardware components 23Hitachi Streaming Data Platform

Components of Streaming Data Platform and StreamingData Platform software development kit
The components of SDP systems are as follows: SDP servers, stream-dataprocessing engine, internal adapters, external adapters, SDP brokers, SDPcoordinators, SDP managers, custom data adapters, CQL debug tool, andadapter library.
SDP and SDP SDK components in a development system
SDP components in a business system
24 Hardware componentsHitachi Streaming Data Platform

Description
The components and features of Streaming Data Platform and StreamingData Platform software development kit in SDP systems are as follows.
Table 2 Streaming Data Platform components and features
S.No. Component Feature description
1 SDP server • The SDP server receives, processes, and outputsstream data.
• This server comprises the stream-data processingengine and internal adapters, which are used to inputand output stream data.
2 Stream-data processingengine
The stream-data processing engine processes stream databased on analysis scenarios that are defined (throughCQL) by the user.
3 Internal adapter The internal adapters include the internal input adapterand internal output adapter.
4 External adapter The external adapters include the external input adapterand external output adapter.
Hardware components 25Hitachi Streaming Data Platform

S.No. Component Feature description
5 SDP broker • An SDP broker gets the I/O address of the stream datafrom an SDP coordinator.
• This address is sent by the SDP broker to the SDPservers and external adapters.
• The internal output adapters of the SDP servers andexternal adapters connect to other SDP servers andexternal adapters, based on the I/O address, to sendand receive stream data.
6 SDP coordinator • An SDP coordinator manages the operation informationof the SDP servers such as I/O addresses for streamdata.
• The SDP coordinator can also form a cluster(coordinator group) with the SDP coordinators of otherhosts.
• The cluster will be used to multiplex the operationinformation of SDP servers.
7 SDP manager • An SDP manager controls SDP servers, the SDP broker,and SDP coordinator.
• If any SDP server fails, then the SDP manager canrecover the SDP servers based on the operationinformation of the SDP servers.
8 Custom data adapter A custom data adapter receives processed stream datafrom the internal output adapter of SDP servers andoutputs it to RTView.
Table 3 Streaming Data Platform software development kit componentsand features
S.No. Component Feature description
1 CQL debugging tool The CQL debugging tool debugs analysisscenarios. The user operates the tool to test theanalysis scenarios developed by using CQL.
2 Adapter library The adapter library consists of the API modulesand headers of the external and internaladapters. The user can use these utilities todevelop external and internal custom adapters.
SDP serversAn SDP server name is assigned as a unique identifier for each server that isrunning in a working directory. Normally, SDP servers start with 1 and wheneach server is added, it is incremented by 1.
26 Hardware componentsHitachi Streaming Data Platform

Description
The details of the server name are as follows:• The rule for naming servers is N * N, where N is an integer whose value is
greater than or equal to 1 (a sequential unique number in a workingdirectory).
• If an SDP server is terminated normally, then its server name is releasedand assigned to the next SDP server that starts.
• If an SDP server is restarted after an abnormal termination, then theserver name that was assigned earlier will be reassigned.
• Server names can be verified using the hsdpstatusshow command.
For more information about the options of the hsdpstatusshow command,see Hitachi Streaming Data Platform Setup and Configuration Guide
Hardware components 27Hitachi Streaming Data Platform

28 Hardware componentsHitachi Streaming Data Platform

3Software components
This chapter provides information about the following components that areused for processing streaming data: tuples, queries, query groups, windows,and stream-data processing engine. Additionally, it provides informationabout using CQL to process stream data, define streams and queries, andusing data-manipulation CQL to specify operations on stream data.
□ Components used in stream data processing
□ Using CQL to process stream data
□ Coordinator groups
□ SDP broker and SDP coordinator
□ SDP manager
Software components 29Hitachi Streaming Data Platform

Components used in stream data processingThis section describes the components used in stream data processing.
The following figure shows the components used in stream data processing.
Figure 6 Components used in stream data processing
This section explains the following components shown in the figure.1. Stream data : Large quantities of time-sequenced data that is
continuously generated.
2. Input and output stream queues : Parts of the stream data path.
3. Stream data processing engine : The part of the stream data processingsystem that actually processes the stream data.
4. Tuple : A stream data element that consists of a combination of two ormore data values, one of which is a time (timestamp).
5. Query group : A summary analysis scenario used in stream dataprocessing. Different query groups are created for different operationalobjectives.
6. Query : The action performed in stream data processing. Queries arewritten in CQL.
7. Window : The target range of the stream data processing. The amount ofstream data that is included in the window is the process range. It isdefined in the query.
Stream dataStream data refers to large quantities of time-sequenced data that iscontinuously generated.
30 Software componentsHitachi Streaming Data Platform

Stream data flows based on the stream data type (STREAM) defined in CQL,enters through the input stream queue, and is processed by the query. Thequery's processing results are converted back to stream data, and thenpassed to the output stream queue and output.
Input and output stream queuesThe input stream queue is the path through which the input stream data isreceived. The input stream queue is coded in the query using CQL statementsfor reading streams.
The output stream queue is the path through which the processing results(stream data) of the stream data processing engine are output. The outputstream queue is coded in the query using CQL statements for outputtingstream data.
The type of stream data that passes through the input stream queue is calledan input stream, and the type of stream data that passes through the outputstream queue is called an output stream.
TupleA tuple is a stream data element that consists of a combination of datavalues and a time value (timestamp).
For example, for temperatures observed at observation sites 1 (ID: 1) and 2(ID: 2), the following figure compares data items, which have only values,with tuples, which combine both values and time.
Figure 7 Comparison of data items, which have only values, with tuples,which combine both values and time
By setting a timestamp indicating the observation time to each tuple asshown in the figure, data can be processed as stream data, rather thanhandled simply as temperature information from each observation site.
There are two ways to set the tuple's timestamp: the server mode method,where the timestamp is set based on the time the tuple arrives at the stream
Software components 31Hitachi Streaming Data Platform

data processing engine, and the data source mode method, where thetimestamp is set at the time that the data was generated. Use the datasource mode when you want to process stream data sequentially based onthe time information in the data source, such as when you perform loganalysis.
The following subsections explain each mode.
QueryA query defines the processing that is performed on stream data. Queries arewritten in a query definition file using CQL. For details about the querydefinition file, see the Hitachi Streaming Data Platform Setup andConfiguration Guide.
Queries define the following three types of operations:• Window operations, which retrieve the data to be analyzed from the
stream data
• Relation operations, which process the retrieved data
• Stream operations, which convert and output the processing results
• Stream to stream operations, which convert data from one data stream toanother
The following figures show the relationship between these operations.
Figure 8 Relationship between the operations defined by a query
32 Software componentsHitachi Streaming Data Platform

Figure 9 Stream to stream operation
A window operation retrieves stream data elements within a specific timewindow. The data gathered in this process (tuple group) is called an inputrelation.
A relation operation processes the data retrieved by the window operation.The tuple group generated in this process is called an output relation.
A stream operation takes the data that was processed by the relationoperation, converts it to stream data and outputs it.
Stream to stream operations convert data from one data stream toanother by directly performing operations on the stream data withoutcreating a relation. In stream to stream operations, any processing can beperformed on the input stream data because there are no specific rules forthe data except that the input and output data must be stream data. Toperform processing, implement the processing logic for the stream to streamfunction as a method in the class file created by a user with Java.
Interval calculations whereby data is calculated at fixed intervals (times) bycombining window operations, relational operations, and stream operationsused to be difficult. Now, interval calculations can be processed by usingstream to stream operations.
To use stream to stream operations, it is necessary to define the stream tostream functions with CQL and create external definition functions. For detailson how to create external definition functions, see the Hitachi StreamingData Platform Application Development Guide.
For details about each of these operations, see Using data manipulation CQLto specify operations on stream data on page 35.
Stream data is processed according to the definitions in the query definitionfile used by the stream data processing engine. For details about thecontents of a query definition file, see Using CQL to process stream data onpage 35.
Software components 33Hitachi Streaming Data Platform

Query groupA query group is a summary analysis scenario for stream data that hasalready been created by the user. A query group consists of an input streamqueue (input stream), an output stream queue (output stream), and a query.
You create and load query groups to accomplish specific operations. You canregister multiple query groups.
WindowA window is a time range set for the purpose of summarizing and analyzingstream data. It is defined in a query.
In order to summarize and analyze any data, you must clearly define a targetscope. With stream data as well, you must first decide on a fixed range, andthen process data in that range.
The following figure shows the relationship between stream data and thewindow.
Figure 10 Relationship between stream data and the window
The stream data (tuples) in the range defined by the window shown in thisfigure are temporarily stored in memory for processing.
A window defines the range of the stream data elements being processed,which can be defined in terms such as time, number of tuples, and so on. Fordetails about specifying windows, see Using data manipulation CQL to specifyoperations on stream data on page 35.
Stream data processing engineThe stream data processing engine is the main component of Streaming DataPlatform and actually processes the stream data. The stream data processingengine performs real-time processing of stream data sent from the inputadaptor, according to the definitions in a pre-loaded query. It then outputsthe processing results to the output adaptor.
34 Software componentsHitachi Streaming Data Platform

Using CQL to process stream dataStream data is processed according to the instructions in the query definitionfile used by the system. The query definition file uses CQL to describe thestream data type (STREAM) and the queries. These CQL instructions are calledCQL statements.
There are two types of CQL statements used for writing query definition files:• Definition CQL
These CQL statements are used to define streams and queries.
• Data manipulation CQLThese CQL statements are used to process the stream data.
This section describes how to use definition CQL to define streams andqueries, and how to use data manipulation CQL to perform processing onstream data.
For additional details about CQL, see the Hitachi Streaming Data PlatformApplication Development Guide.
CQL statements consist of keywords, which have preassigned meanings, anditems that you specify following a keyword. An item you specify, combinedwith one or more keywords, is called a clause. The code fragments discussedon the following pages are all clauses. For example, REGISTER STREAMstream-name, consisting of the keywords REGISTER STREAM and the user-specified item stream-name, is known as a REGISTER STREAM clause.
Using definition CQL to define streams and queriesCQL statements that are used to define streams and queries are calleddefinition CQL. There are two types of definition CQL.• REGISTER STREAM clauses
• REGISTER QUERY clauses
The following subsections explain how to specify each of these clauses.
Using data manipulation CQL to specify operations on stream dataThere are three types of data manipulation CQL operations:• Window operations
• Relation operations
• Stream operations
• Stream to stream operations
Software components 35Hitachi Streaming Data Platform

C External Definition FunctionBy using the External Definition Function in the C language, the externaldefinition stream to stream operation of the acceleration CQL engine can beused.
To develop the C External Definition Function, you need to include theheaders that the library for the C EDF provides. The library for C EDFprovides structures and functions.
Coordinator groupsSDP coordinators can share information about the connection destinations ofquery groups and streams across multiple hosts. SDP coordinators that sharesuch information are set in a coordinator group using the -chosts option ofthe hsdpsetup command. For more details, see the Hitachi Streaming DataPlatform Setup and Configuration Guide. The SDP broker can find the streamson all the hosts that use the same coordinator group by using the data that isshared by a coordinator group. Therefore, external adapters and cascadingadapters can use the SDP broker on a host to connect to the streams that areon multiple hosts. Additionally, if you set the SDP broker of a different hostthat uses the same coordinator group as the connection destination, then thesame streams can be connected.
Coordinator group
Information multiplexing
36 Software componentsHitachi Streaming Data Platform

Description
A coordinator group that excludes the local host can be set. If the local hostis not specified in a coordinator group, then the SDP coordinator will not bestarted. The SDP broker will use the SDP coordinator of another host to storeand find the information about the local host. In this case, the SDP broker,which is available on the host that uses the same coordinator group, canconnect to the streams of the same host. Additionally, if the SDP broker usesthe SDP coordinator of another host, then a maximum of 1,024 SDP brokers(including those that exist on the host of the reference destination SDPcoordinator) can connect to the coordinator group at the informationreference destination.
Coordinator group that does not include the local host
Software components 37Hitachi Streaming Data Platform

You can set up data multiplicity by using the -cmulti option of thehsdpsetup command.
When you configure a coordinator group that comprises three or more SDPcoordinators, multiple SDP coordinators can redundantly store identicalinformation. (You should set up data multiplicity by using the -cmulti optionof the hsdpsetup command. For more information, see the Setup andConfiguration guide.)
When data multiplicity is set to 2 or more, if the SDP coordinators fail withina coordinator group because the number is less than the multiplicity that hasbeen set, then the SDP coordinators on another host can be used to continuethe operation. If the number of SDP coordinators that have failed is equal toor greater than the multiplicity that has been set, then all the SDPcoordinators must be restarted. Additionally, if a query group was started andrunning before the SDP coordinator failed, then the query group must be alsorestarted.
If the coordinator group was running with two SDP coordinators, then youcan restore the coordinator group to the original state by restarting thestopped SDP coordinators.
For more information, see Hitachi Streaming Data Platform Setup andConfiguration Guide.
38 Software componentsHitachi Streaming Data Platform

SDP broker and SDP coordinatorThe SDP broker and SDP coordinator provide the functions that are used byexternal adapters and cascading adapters to connect to the data-transmission or reception-destination stream. A maximum of one SDP brokerand SDP coordinator can be run on a host. Additionally, you can use thehsdp_broker operand in the SDP manager-definition file to specify whetherto start the process of the SDP broker. You can use the -chosts option of thehsdpsetup command to specify whether to start the process of the SDPcoordinator. The SDP coordinator manages the locations of the SDP serverswhere the streams are registered that can be connected on the host. TheSDP broker provides a function to search (from the SDP coordinator) forinformation that is needed to locate the connection destination stream,connect to it, and then pass the information to the external adapter andcascading adapter. If a stream is re-registered to another SDP server later,the SDP broker and SDP coordinator ensure that the operator can still run theexternal adapters and cascading adapters by using the same settings.
Finding streams
Consolidating TCP ports
Software components 39Hitachi Streaming Data Platform

Description
SDP brokers
An SDP broker obtains the I/O address of stream data from an SDPcoordinator and sends it to the SDP servers and external adapters. Theinternal output adapters of the SDP servers and external adaptersconnect other SDP servers and external adapters based on the addressinformation to send and receive stream data.
SDP brokers have the function to transfer connections through TCP(communication established with external adapters or with cascadingadapters) to internal adapters, where data is sent to and received fromthe streams on the local host.
By using this function, SDP brokers can relay connections between theexternal adapters or cascading adapters and internal adapters, so that,connections to different streams on the host can be received by using asingle port number.
40 Software componentsHitachi Streaming Data Platform

SDP coordinators
An SDP coordinator manages the operation information about the SDPservers such as the I/O addresses of stream data. The SDP coordinatorcan also form a cluster (coordinator group) with the SDP coordinators ofother hosts to multiplex the operation information of the SDP servers.
Information managed by the SDP coordinator
The query group that is registered to the SDP server is started by theSDP broker. When the query group is deleted from the SDP server, thecorresponding registration information is deleted from the SDP broker.When any information is registered or deleted, if a coordinator group isset up, then the current registration information is shared immediatelyby all SDP coordinators in the coordinator group. The information that isregistered to the SDP coordinator is as follows.
Table 4 Information managed by the SDP coordinator
# Item Description
1 Host Host name or IP address of the HSDPsystem where the connection destinationstream is registered
2 HSDP-working-directory Absolute path of the working directory ofthe SDP server where the connectiondestination stream is registered
3 Server cluster name Name of the server cluster to which theserver belongs
4 Server name Name of the SDP server
5 Query group name Name of the query group where theconnection destination stream is defined
6 Stream name Name of the connection destination stream
7 TCP connection port TCP port
8 RMI connection port RMI port
9 Stream type Stream type: Input/output
10 Timestamp mode Time stamp mode of the connectiondestination stream
11 Dispatch type Property information that describes themethod for dispatching data to theconnection destination stream
12 Schema information Schema information of the connectiondestination stream
SDP managerAn SDP manager controls SDP servers, an SDP broker, and an SDPcoordinator.
Software components 41Hitachi Streaming Data Platform

Description
When an SDP server fails, the SDP manager recovers the SDP server basedon the operation information (of the SDP server) that is retained by the SDPcoordinator.
Log notificationsThe log notification feature of the SDP manager is used to monitor theprocesses of the various components that are available in a host. When aprocess shutdown is detected, the log notification feature outputs messagesto log files.
Process monitoring
Description
The log notification feature monitors the performance of the followingcomponents (in a host):• SDP broker
• SDP coordinator
• SDP servers
A maximum of one SDP manager can run on a host.
42 Software componentsHitachi Streaming Data Platform

The processes of the SDP broker, SDP coordinator and SDP servercomponents can be started by running the hsdpmanager or hsdpstartcommand.
The processes of the components are activated when the processes arestarted. When the processes of the components are activated, the SDPmanager starts monitoring these processes. While monitoring , if a processshuts down because of a failure, then the SDP manager detects the shutdownand outputs a message to the log files of the SDP manager. The messagecomprises the details about the failure and subsequent shutdown. For moreinformation about the log files of SDP manager, see Hitachi Streaming DataPlatform Setup and Configuration Guide.
The SDP manager does not monitor the processes of any of the componentsif either of the following conditions is met:• If the SDP manager has not been started by running the hsdpmanager
command.
• If a component has not been started by running the hsdpmanager orhsdpstart command and the hsdpcql command.
Restart featureThe restart feature of the SDP manager provides the functionality to monitorthe processes of each component that is displayed in log notifications andrestart any processes that have shut down.
Description
When the SDP server is restarted, the query groups and internal adapters(running on the server before the server shut down) are also restarted.Additionally, the SDP manager also restarts its own processes that have shutdown. You can enable or disable the restart feature in the hsdp_restartproperty of the SDP manager-definition file. For more information about theSDP manager-definition file, see Hitachi Streaming Data Platform Setup andConfiguration Guide. The CPU, which is specified for the hsdp_cpu_no_listproperty of the SDP manager-definition file, is assigned to the process of thecomponent that has been restarted.
The SDP manager does not restart the processes of a specific component ifany of the following conditions are met:• If the SDP manager has not been started by running the hsdpmanager
command, then it does not restart any of the processes (including its ownprocesses) of any of the components.
• If a component has not been started by running the hsdpmanager orhsdpstart command and the hsdpcql command, then the SDP managerdoes not restart the processes of any of the components.
Software components 43Hitachi Streaming Data Platform

• If the restart setting has been disabled, then the SDP manager does notrestart any of the processes (including its own processes) that aredisplayed in the log notifications.
• If a specific operating system is specified as a prerequisite, then based onthe type of operating system, the SDP manager does not restart any of itsown components even if restart has been enabled.
Table 5 Availability of the restart feature of the SDP manager
Prerequisite operating system VersionsSDP manager can be
restarted
Red Hat Enterprise Linux 6.5 Yes
Red Hat Enterprise Linux Advanced Platform 6.6 Yes
7.1 Yes
SUSE Linux Enterprise Server 11 SP2 No
11 SP3 No
12 Yes
Note: When a process is shut down, if the restart feature is unavailable, thenthe user must manually restart the process of the SDP manager by using thehsdpmanager command.
While a component is restarting, if an inter-process connection fails, then theSDP manager tries a restart request again. You can specify the number ofretries and the corresponding wait intervals in the hsdp_retry_times andhsdp_retry_interval properties (of the SDP manager-definition file)respectively. For more information about SDP manager-definition file, seeHitachi Streaming Data Platform Setup and Configuration Guide. If ashutdown process fails to restart even after the restart request has been runfor the specified number of times, then the SDP manager stops attempting torestart the component and starts monitoring other components.
If the SDP coordinators meet both the following conditions, then the SDPcoordinators cannot be restarted by the SDP manager:• Coordinator group comprises of three or more SDP coordinators
• Number of SDP coordinators equal to or greater than the specifiedmultiplicity have stopped
If the SDP coordinators cannot be restarted, then all the SDP coordinatorsthat are running within the coordinator group should be stopped by using thehsdpmanager -stop command. After stopping all the SDP coordinators, theyhave to be manually restarted by running the hsdpmanager -startcommand. In this case, if a query group is running, then the stream
44 Software componentsHitachi Streaming Data Platform

information registered to the SDP coordinators is lost. Therefore, the querygroup should be restarted.
Software components 45Hitachi Streaming Data Platform

46 Software componentsHitachi Streaming Data Platform

4Data processing
This chapter provides information about filtering and extracting records.Additionally, it provides information about file input adapters, HTTP inputadapters, and dashboard output adapters.
□ Filtering records
□ Extracting records
Data processing 47Hitachi Streaming Data Platform

Filtering recordsTo perform stream data processing only on specific records, you use a filteras the data editing callback.
For example, if you are monitoring temperatures from a number ofobservation sites and you want to summarize and analyze temperatures fromonly one particular observation site, you can filter on that observation site'sID.
Only common records can be filtered. If the input source is a file, after aninput record is extracted by the file input connector, you must use the formatconversion callback to convert it to a common record before filtering it.
When specifying the evaluation conditions you want to filter on, you can useany of the record formats and values that are defined in the records. Thefollowing figure shows the positioning and processing of the callback involvedin record filtering.
48 Data processingHitachi Streaming Data Platform

Figure 11 Positioning and processing of the callback involved in recordfiltering
1. The records passed to the filter are first filtered by record format.Only records of record format R1 meet the first condition, so only theserecords are selected for processing by the next condition. Records thatdo not satisfy this condition are passed to the next callback.
2. After the records are filtered by record format, they are then filtered byrecord value.This condition specifies that only those records whose ID has a value of 1are to be passed to the next callback. In this way, only those recordsthat satisfy both conditions will be processed by the next callback.Records that do not satisfy these conditions are discarded.
Data processing 49Hitachi Streaming Data Platform

Extracting recordsAfter you have filtered for the desired records, you use a record extractioncallback to collect all of the necessary information from the filtered recordsinto a single record.
For example, to summarize and analyze the responsiveness between a clientand a server, after the HTTP packet input connector is used as the inputcallback, you could use a record extraction callback as the data editingcallback. You could then use the record extraction callback to join an HTTPrequest and response packet pair into one record, based on the transmissionsource IP addresses and the transmission destination IP addresses. Thiswould allow you to gain a clear understanding of response times, and toeasily summarize and analyze the resulting data.
In the following figure, after records are filtered by record format and recordvalue so that only the desired records are selected, the record extractioncallback joins the resulting records, and generates a new record. Thefollowing figure shows the positioning and processing of the callback involvedin record extraction.
50 Data processingHitachi Streaming Data Platform
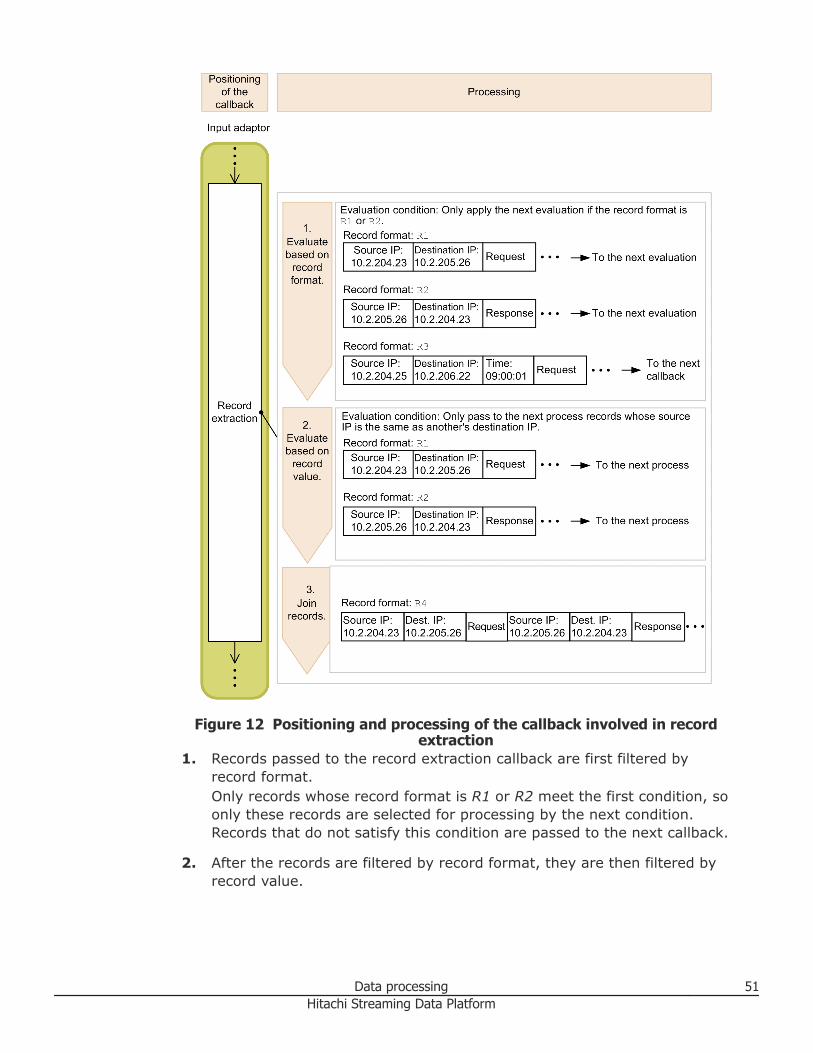
Figure 12 Positioning and processing of the callback involved in recordextraction
1. Records passed to the record extraction callback are first filtered byrecord format.Only records whose record format is R1 or R2 meet the first condition, soonly these records are selected for processing by the next condition.Records that do not satisfy this condition are passed to the next callback.
2. After the records are filtered by record format, they are then filtered byrecord value.
Data processing 51Hitachi Streaming Data Platform

This condition specifies that records are to be passed to the next processonly if the source IP of the request matches the destination IP of theresponse, and the destination IP of the request matches the source IP ofthe response. This means that only those records that match thiscondition are passed to the next process.
3. Records filtered by record format and record value are joined to producea single record.Records joined in this step are selected for processing by the nextcallback.
52 Data processingHitachi Streaming Data Platform

5Internal adapters
This chapter provides information about internal adapters. The internaladapters provided with SDP are also called internal standard adapters. Thetwo types of internal adapters are as follows: internal input adapters andinternal output adapters. User-developed internal adapters, also calledinternal custom adapters, can be developed by using the Streaming DataPlatform software development kit APIs.
□ Internal input adapters
□ TCP data input adaptor
□ Inputting files
□ Inputting HTTP packets
□ Outputting to the dashboard
□ Cascading adaptor
□ Internal output adapters
□ SNMP adaptor
□ SMTP adaptor
□ Distributed send connector
□ Auto-generated adapters
Internal adapters 53Hitachi Streaming Data Platform

Internal input adaptersInternal input adapters receive stream data in specific formats and send thedata to the stream-data processing engine.
Description
The formats that are supported by the internal input adapters are as follows:• Text files
• HTTP packets
TCP data input adaptor
Overview of the TCP data input adaptorStreaming Data Platform provides TCP-data input adapters for one of theinternal standard adapters. When a user program or cascading adapter sendsa connection request for data transmission to Streaming Data Platform, aTCP-data input adapter receives a connection notification through the SDPbroker. The TCP-data input adapter receives data from the source programthrough an established TCP connection. It converts the TCP data that hasbeen received into tuples and sends the tuples to the SDP servers. The TCP-data input adapter receives data from the connection source through anestablished TCP connection. It converts the TCP data, which has beenreceived, into tuples and sends the tuples to the SDP server.
54 Internal adaptersHitachi Streaming Data Platform

Figure 13 Receive TCP data and send tuples
TCP data input adaptor: Sends the tuples to a Java stream in the SDP server.
Prerequisites for using the TCP input adaptorThe following are prerequisites for using this adaptor.
Input adaptor configuration of the TCP data input adaptorThe TCP data input connector must be set as an input connector of inputadaptor. The following figure and list shows the combination of callbacks inthe input data adaptor configuration. If the TCP data is sent by using anexternal input adapter as a program, then the SDP broker must be runningon a host that is using a TCP-data input adapter. If you use an external inputadapter as the transmission source of TCP data, then the SDP broker must berunning on the host on which you want to use the TCP-data input adapter.When a connection request is received from the external input adapter, theSDP broker starts the TCP input adapter, which is required forcommunication.
Internal adapters 55Hitachi Streaming Data Platform

Figure 14 Input adaptor configuration
Table 6 List of the callback combinations
Adaptor
Type
Callback combination
Input Callback Editing Callback Sending Callback
Java TCP data inputconnector
Any kind of editingcallback can be set oromitted
Any kind of sendingcallback
C - Sending callback
User program that acts as data sendersUser programs that send data to the TCP data input adaptor for C must beimplemented with the external-adapter library. When the external-adapterlibrary is used to implement a TCP-data input adapter, the user programspecifies both the stream information and address of the SDP broker for thehost (running in the TCP input adapter) in the definition file of the externalinput adapter. This enables the external input adapter to establishcommunication.
TCP data input connectorThis section describes details of the TCP data input connector that isprocessing of the input adaptor.
Number of connections
After the TCP-data input adapter has been started, the TCP-data inputconnector receives data from the data source through a TCP connection.. Thefollowing table shows the number of connections that are establishedbetween the user program and this adaptor for Java.
56 Internal adaptersHitachi Streaming Data Platform

Table 7 Number of connections
Adaptor type Number of connections Output tuples
Java 1 to 16 connections (per adaptor) canbe established as indicated in Figure 15 Number of connections (forJava) on page 57.
Tuples that are sent to the Javastream in the HSDP server by thisadaptor are time-sequenced data.
Figure 15 Number of connections (for Java)
TCP data format
This connector input TCP data as follows:
Figure 16 TCP data format
As shown above, TCP data consists of header data and a series of one ormore units of data. Each unit of data consists of a given number of dataitems. This connector processes header data and units of data as follows:
Internal adapters 57Hitachi Streaming Data Platform

Figure 17 Form unit data into record
The sections shown in the above figure are as follows:1. Seek the byte size of the header data as an offset.
2. Seek the byte size of the fixed-length data as an offset.
3. Seek the byte size of the data as an offset.
4. Form the data into a record field.
5. Repeat section 3 and 4.
6. When the connector has performed the seek to the end of the unit ofdata, the connector outputs the record to the next callback.
7. Repeat section 2 to 6.
The user defines each byte size of the offset and data of the target to beformed in the adaptor composition file, and can select the data to be formedinto record fields. The details of header information are as follows.
Item Description Size Data type
Data kind Specifies the kind of data.
0: Normal data
2 bytes short
(Reserved) A domain reserved for futureextension.
2 bytes short
If the TCP data input connector inputs data whose data type is variable-length character (VARCHAR) and then forms input data into a record field, the
58 Internal adaptersHitachi Streaming Data Platform

user program that acts as data senders has to send the data to the TCP datainput connector with the following data format:
Figure 18 Data format of the TCP data input connector
Table 8 Description of the data format
Item Description Size Data type Value
Data length Specifies thelength of the bytearray that storesvariable-lengthcharacter data.
If this value ismore than thesize attributevalue of the TCPdata inputconnectordefinition in theadaptorconfigurationdefinition file, theTCP data inputconnector outputsthe KFSP48916warning message,inputs thevariable-lengthcharacter datafrom thebeginning to thesize attributevalue, and then
2 bytes short An integer from 0to 32767
Internal adapters 59Hitachi Streaming Data Platform

Item Description Size Data type Value
forms input datainto a record field.
If a value of zerois specified, thevariable-lengthcharacter datamust be omitted.In this case, theTCP data inputconnector forms anull character intoa record field.
Variable-lengthcharacter data
Specifies the bytearray that storesvariable-lengthcharacter data.The length of thebyte array mustbe same as thevalue specified inthe data length.
Note that the TCPdata inputconnector doesnot check thevalue of this data(for example, thecharacter codeand controlcharacters), andthen forms thespecified bytearray into a recordfield without anychanges.
1 to 32767 bytes varchar Any characters
Byte order of data
This connector forms data into the record fields according to the big-endianbyte order.
Restart reception of TCP connection
When a user program closes the TCP connection, this connector restartsreception of TCP connections and the input adaptor continues processing. Ifthe user program closes the TCP connection while sending TCP data, thisconnector deletes the TCP data that this connector is receiving, and restartsreception of TCP connections.
Setting for using the TCP data input adaptor
When starting a TCP-data input adapter, you do not require an adapter-definition file to work with the SDP broker. However, for SDP servers that
60 Internal adaptersHitachi Streaming Data Platform

connect with the SDP broker and run in a scale-up or scale-out configuration,you need to define (in the query-group properties file) how to distribute datafrom the adapter to the input streams. If the TCP-data input adapter waitsfor data at a certain port number, the user must determine the connectorsettings by specifying the TCP data input connector definition in the adaptorcomposition file. For more information, see TCP data input connectordefinition section in the Hitachi Streaming Data Platform Setup andConfiguration Guide.
Comparison of supported functionsThe following is a comparison list of supported functions between Java and C.
Table 9 Comparison list of supported functions
Function Supported
Large classification Middle classification Small classification Java adaptor
Fixed length data types BYTE - Yes
SHORT - Yes
INT - Yes
LONG - Yes
FLOAT - Yes
DOUBLE - Yes
BIG_DECIMAL - No
CHAR ASCII Yes
Multi-byte character No
DATE - No
TIME - No
TIMESTAMP - Yes
Variable length data type VARCHAR ASCII Yes
Multi-byte character No
Data format Fixed length data - Yes
Variable length data - No
Data offset setting 1 - - Yes
Zero extension - - Yes
Record format Single record - Yes
Multiple record - No
Connection control
(between TCP data sender andadaptor)
Single connection - Yes
Multi connection - No
SDP broker connections Integration of TCPconnections
- Yes
Type check Adaptor-input stream - No
Internal adapters 61Hitachi Streaming Data Platform

Function Supported
Large classification Middle classification Small classification Java adaptor
Connectivity of adaptor with TCPdata sender
TCP cascading adaptor - Yes
C TCP cascadingadaptor
- Yes
External input adapter - Yes
Inputting filesTo perform stream data processing on data files, such as log files, you usethe file input connector as the input callback.
The file input connector extracts records to be processed from an inputsource file. Because these records are retrieved as input records, the formatconversion callback must be used to convert them to common records so thatthe stream data processing engine can process them. The following figureshows the positioning and processing of the callbacks involved in file input.
Figure 19 Positioning and processing of the callbacks involved in file input1. The file input connector extracts the first line (record) from the input file.
The record that it extracts is called an input record.
62 Internal adaptersHitachi Streaming Data Platform

2. The format conversion callback converts the input record to a commonrecord.
Tip: You can also extract and process multiple records at a time from theinput source file.
Inputting HTTP packetsTo perform stream data processing on HTTP packets carried over a network,you use the HTTP packet input connector as the input callback.
This packet input connector extracts HTTP packets from the output of apacket analyzer. The following figure shows the positioning and processing ofthe callback involved in HTTP packet input.
Figure 20 Positioning and processing of the callback involved in HTTPpacket input
As shown in the figure, the packet input connector extracts the HTTP packet,and then converts it to a common record data format that the stream dataprocessing engine can handle.
Outputting to the dashboardTo display the results of stream data processing to the dashboard, you usethe dashboard output connector as the output callback. Data output to thedashboard can be displayed as a line chart, a bar chart, or in other chartformats.
Internal adapters 63Hitachi Streaming Data Platform

The dashboard output connector gets common records from the previouscallback. The dashboard output connector then converts these records todata that can be displayed on the dashboard. The following figure shows thepositioning and processing of the callback involved in dashboard output.
Figure 21 Positioning and processing of the callback involved indashboard output
Cascading adaptorStreaming Data Platform provides cascading adapters for one of the internalstandard adapters. The cascading adapters send data (analysis results) fromStreaming Data Platform to the destination SDP server or external outputadapter through TCP sockets. Cascading adapters are generatedautomatically to use while transmitting data internally. You cannot use yourinternal adapters for the internal-data transmission process.
64 Internal adaptersHitachi Streaming Data Platform

Figure 22 Example of a connection for the cascading adaptor
Data transmission to an SDP server
The figure illustrates the configuration of a cascading adapter thatconnects host A to an SDP server in host B. The adapter transmits datafrom the output stream of host A to the input stream of host B. Theinformation about the connected input/output streams is defined in thequery-group properties files for host A. Information about the connectedstream is defined so that the adapter starts (automatically) at the sametime as the query group. After starting, the adapter inquires and getsthe address of the stream that is connecting to the SDP broker of host Aand then establishes a connection through the SDP broker of host B. Themethod of distributing the input stream data of host B must be definedin the query-group definition file of host B.
Data transmission to external output adapters
The figure illustrates the configuration of a cascading adapter thatconnects to an external output adapter. When the external outputadapter requests a TCP connection, the broker starts the cascadingadapter. After starting, the cascading adapter uses the establishedconnection to send data to the external output adapter.
In this configuration, you can omit creation of the adapter configurationdefinition file. In addition, if you want to change the action of theconnection-retry method from the default action, follow the proceduredescribed in Release note.
Internal adapters 65Hitachi Streaming Data Platform

Figure 23 Example of a connection for the cascading adaptor 2
Cascading adaptor processing overviewA cascading adaptor consists of the following callbacks.
Figure 24 Cascading adaptor configuration
Callbacks
Receive tuple
This callback receives tuples from an HSDP server.
Edit data
This callback changes the format of the received data. This callback canbe omitted.
RMIClient
66 Internal adaptersHitachi Streaming Data Platform

This callback inputs a tuple into the stream of an HSDP server of Host Busing RMI communication.
TcpClientThis callback inputs a tuple into the stream of an HSDP server of Host Busing TCP socket. If the socket option TCP_NODELAY is enabled, data issent immediately.
Output adaptor configuration
The following table lists the combination of callbacks in the configuration ofthe output data adaptor.
Table 10 List of the callback combinations
Adaptor Type Callback combination
Receiving Callback Editing Callback Output Callback
Java Any kind of receivingcallback
Any kind of editingcallback can be set oromitted
Cascading callback(RMI / TCP client)
Communication methodWhen using the cascading adaptor, the communication method between thefrontend and backend servers has to be chosen from among Java RMI andTCP socket. The operator needs to specify the selected method in thecascading properties file.
The two types of methods have different features as shown in the followingtable.
Table 11 Using Java RMI or TCP socket
Item Using Java RMI Using TCP socket
Connectivity * The adaptor can connect to theStream engine in the SDP server.
The adaptor can connect to the TCPdata input adaptor for Java/C that isrunning on the stream engine in theHSDP server.
Available datatypes inside atuple being sent
All data types listed in Table 12 UsingJava RMI or TCP socket on page 68are available.
For details on data types, see theHitachi Streaming Data PlatformSetup and Configuration Guide.
The available data types are listed in Table 12 Using Java RMI or TCP socketon page 68.
For details on data types, see theHitachi Streaming Data Platform Setupand Configuration Guide
TCP port Destination port
The adaptor uses the following twotypes of TCP ports:
Destination port
The adaptor uses the standby portnumber of the SDP broker in thedestination host.
Internal adapters 67Hitachi Streaming Data Platform

Item Using Java RMI Using TCP socket
• The port number defined in thecascading properties file.
• An ephemeral port, where anumber is assigned to eachdestination randomly.
Source port
The adaptor uses TCP ports that arerandomly assigned for eachdestination.
Source port
The adaptor uses TCP ports that arerandomly assigned for eachdestination.
* For details, see Table 15 Connection details for cascading adaptors on page 73.
Table 12 Using Java RMI or TCP socket
Data type Java RMI TCP socket Remarks
INT Y Y -
SHORT Y Y -
BYTE Y Y -
LONG Y Y -
BIG_DECIMAL Y N -
FLOAT Y Y -
DOUBLE Y Y -
STRING Y Y Before sending data, the Java cascading adaptorwith TCP socket converts STRING data into abyte array of the specific character encodingspecified in the cascading client connectordefinition. If STRING data cannot be convertedinto a byte array of specified encoding, theadaptor discards a tuple.
DATE Y N -
TIME Y N -
TIMESTAMP Y Y -
Legend:• Y: Available data type
• N: Unavailable data type
FeaturesCascading adaptors can connect to multiple HSDP servers as destinations.When multiple HSDP servers connect with a cascading adaptor, the adaptordecides the destination based on the dispatch type that is specified in theadaptor definition file. For more information about definition file formats, seeCascading section in the Hitachi Streaming Data Platform Setup andConfiguration Guide.
68 Internal adaptersHitachi Streaming Data Platform

The available dispatch types are described below. Only one of them can beused.
Table 13 Dispatch types
Dispatch type Description Figure
Hashing A destination of each type of data is determinedby the hash value of column data in a tuple.
Figure 25 Hashing overview onpage 69
Round-robin Data is distributed to the HSDP servers byround-robin
Figure 26 Round-robin overview onpage 70
Static rule A destination for each type of data is determinedby the user defined static rule. This rule can bespecified for each column value in a tuple. Forexample, if the tuple has an "ID" column, youcan specify it so that data with ID="port1" issent to HSDP server1, and data with ID="port2"is sent to HSDP server2. If a tuple does notmatch any static rule, the adaptor discards thattuple and outputs a message to a log file.
Figure 27 Staticrule overview onpage 70
All Equivalent data has to be sent to all thedestination SDP servers.
Figure 28 Alloverview onpage 70
Hashing
Figure 25 Hashing overview
Round-robin
Internal adapters 69Hitachi Streaming Data Platform

Figure 26 Round-robin overview
Static rule
Figure 27 Static rule overview
Hashing
Figure 28 All overview
The features of cascading adaptors are as follows:• The cascading adapters that connect to the input stream of another SDP
server can start automatically when the query group starts. If you definethe information on the source and destination streams in the query-groupproperties file, then the cascading adapters will start automatically whenthe query group starts.
• The cascading adapter, that connects to an external output adapter startsautomatically when the external output adapter requests a connection.
70 Internal adaptersHitachi Streaming Data Platform

• Cascading adaptors connect to the host defined in the cascading propertiesfile using an RMI connection. The path of that file is defined in the adaptorcomposition file.
• When an SDP server is connected to a data-parallel configuration, the datais sent by the cascading adapter based on the distribution method (used inthe query-group definition file of the destination SDP server). Thedistribution method in the adapter-definition file is defined by using an RMIconnection.(In an RMI connection, define the distribution method in the adapter-definition file.For more information about the formats of the definition file, see theHitachi Streaming Data Platform Setup and Configuration Guide.
• Host-to-host communication between a cascading adaptor and an HSDPserver is possible.
• When you want to connect a cascading adapter with an SDP sever to senddata, the destination SDP server should be started before you start thequery group that runs the adapter.
• If an error in connection occurs while transmitting the data, then thecascading adapter tries to transmit the data again.For cascading adapters that connect to an SDP server:If an adapter is disconnected from the input stream of the destination SDPserver, then the cascading adapter tries to connect again. You can specifythe number of retries, the retry interval, and whether to send theremaining data (in a query-group properties file) after reconnection. Whenthe number of failures exceed the number of retries, the process to senddata to the connection destination stream (where the error occurred) isstopped.For cascading adapters that connect to an external output adapter:If an adapter is disconnected from the external output adapter, then theexternal output adapter tries to connect again. You can specify the waittime for each retry (in an adapter-definition file). If the connection is notre-established after the wait time for retrying the connection has lapsed,then the process that waits for a reconnection by the external adapter isstopped.
• If a dispatch type is either HASHING or STATIC rule, the destination ofdispatched data is fixed. Even if a cascading adaptor cannot send data to adestination because of a communication error, the destination of thedispatched data does not change.
• If the number of pending tuples exceeds the internal queue size in thecascading adaptor, the oldest pending tuple will be removed from thequeue.
Internal adapters 71Hitachi Streaming Data Platform

• When a custom developer uses multiple cascading adaptors and wants tosend data to the same input stream of an HSDP server, data must besorted by timestamps. The following are two configurations that can beused to send data to the same input stream.
Table 14 Configurations of multiple cascading adaptors
Configuration Description
Figure 29 Example 1 onpage 72
Multiple output streams connect to a single input stream
This configuration is effective when a latency delay is allowed.
When analyzing time series data, input tuples must be sorted bytimestamp in the backend server.
Figure 30 Example 2 onpage 73
Multiple output streams connect to multiple input streams.
The numbers of output and input streams are equal.
This configuration is effective when a latency delay is not allowed.
When analyzing time series data, input tuples are sorted bytimestamp when the UNION query is executed in HSDP server 2.
If one of the streams stops, the HSDP server 2 in the figure will stop.
When HSDP server 2 is the acceleration engine, this configurationcannot be used.
Figure 29 Example 1
When a HSDP server 1 is the acceleration engine, TCP data input adaptors forC needs to be added to the figure.
72 Internal adaptersHitachi Streaming Data Platform

Figure 30 Example 2
To send data through a firewall, the person who deploys the HSDP serversshould open the source and destination ports in the firewall settings. Fordetails about using ports, see Table 11 Using Java RMI or TCP socket onpage 67.
Connection detailsThe following table shows connection details for cascading adaptor.
Table 15 Connection details for cascading adaptors
Item Cascading adaptor
JavaRMI
TCP(Java)
TCP(C)
Destination to connectto
Standard adaptor TCP data input adaptor(for Java)
N Y Y
TCP data input adaptor(for C)
N Y Y
CQL engine Stream engine
(Java Engine)
Y N N
Acceleration CQLengine
N N N
Legend:• Y: Can be connected
• N: Cannot be connected
Time synchronization settingsYou can use the time synchronization feature of the cascading adaptor or youcan define and control synchronization on your own. When you choose to usethe synchronization function of the system, HSDP achieves stream data
Internal adapters 73Hitachi Streaming Data Platform

processing by continuously processing time-series data in real-time as thedata is created. As a result, stream data processing is generally based on aunique time axis. When you construct a query by connecting multiple streamengines, the cascading adaptor performs time synchronization among thoseengines. The following table describes the time synchronization function ofthe cascading adaptor.
Table 16 Time synchronization function of the cascading adaptor
Function Description
Time synchronization ofanalysis*
The cascading adaptor sets an analysis time for the system time fieldof the tuple (the systemTime field of the StreamTuple class) andpasses the tuple to the destination stream engine.
The timestamp mode of the destination stream engine must be setto data source mode for the destination stream engine to use thetime.
Heartbeat The cascading adaptor periodically sends a heartbeat to synchronizethe time for the destination stream engines.
Figure 31 System composition on page 74 and Table 17 Setting details onpage 74 provide examples of using the time synchronization function of thecascading adaptor.
Figure 31 System composition
Table 17 Setting details
Server Component Setting Description
HSDP server 1 Stream
engine
Set the one of the following:
stream.timestampMode=Server
stream.timestampMode=DataSource 1
You can specify eithertimestamp mode.
CQL Register a query based on timecontrol of the stream engine.
-
Cascading heartbeat=ON2 The cascading adaptorsynchronizes the time of the
74 Internal adaptersHitachi Streaming Data Platform

Server Component Setting Description
Adaptor HSDP servers by sending aheartbeat.
HSDP server 2 Stream engine stream.timestampMode=DataSource1
HSDP server 2 must set to thedata source mode.
stream.timestampPosition =__systemtime__1
By setting __systemtime__ forthe input stream to which thecascading adaptor connects,you can specify for HSDP server2 to use the system time oftuple.
CQL Register a query based on timecontrol of the stream engine.
-
For more information about the settings for the cascading adapters, see System configurationproperty file (system_config.properties) section in the Hitachi Streaming Data Platform Setup andConfiguration Guide.
Instead of using the time synchronization, you can control timesynchronization by using the external definition function. To do this, the usermust turn off the time synchronization. The following figure and table showhow to use the external definition function to control time synchronization.
Figure 32 System composition
Table 18 Setting details
Server Component Setting Description
HSDP server 1 Stream Set the one of the following: You can specify eithertimestamp mode.
Internal adapters 75Hitachi Streaming Data Platform

Server Component Setting Description
engine stream.timestampMode=Server
stream.timestampMode=DataSource 1
CQL Register a query that has thetimestamp column in theschema of the output streamand that outputs the tuplecreated by the externaldefinition function.
-
Cascading
Adaptor
heartbeat=OFF2 Because the cascading adaptoris not used to synchronize thetime, turn off the function forsending heartbeats.
Externaldefinitionfunction
Make an external definitionfunction that does the following:• Controls time
synchronization and sets thetime for the tuple it creates.
• Periodically creates aheartbeat tuple (If thecascading adaptor isconnected to multiplestream engines, the externaldefinition function mustsend a heartbeat tuple toeach stream engine.).
-
HSDP server 2 Stream engine stream.timestampMode=DataSource1
HSDP server 2 must be set tothe data source mode.
stream.timestampPosition =column-name1
The user must specify the nameof the time-data column for theinput tuple so that the streamengine uses the time of thetuple created by the externaldefinition function.
CQL Specify the timestamp columnfor the schema of the inputstream.
-
Notes:1. For more information, see the Hitachi Streaming Data Platform Setup and Configuration
Guide.
2. For details about the settings for the cascading adapor, see the manual Hitachi StreamingData Platform Setup and Configuration Guide.
Internal output adaptersInternal output adapters receive processed stream data from a stream-dataprocessing engine and output the data in a specific format.
The formats supported by the internal output adapters are as follows:
76 Internal adaptersHitachi Streaming Data Platform

• Text files
• SNMP traps
Internal output adapters can output the processed stream data to internalinput adapters, internal output adapters, and custom data adapters.
SNMP adaptorThe Simple Network Management Protocol (SNMP) is a protocol to monitorand manage networks using UDP. The SNMP versions are listed below andHSDP supports SNMP v1 and v2c:• SNMP v1: RFC1155-1157
• SNMP v2c: RFC1901-1908
SMTP adaptorHSDP provides an email-sending feature, in which an SMTP adaptor receivesa tuple as an event from an HSDP server, and then sends the event via emailby using Simple Mail Transfer Protocol (SMTP).
Distributed send connectorThis section describes detail about distributed send connector that isprocessing of this adaptor.
Auto-generated adaptersInternal standard adapters are generated, started, or stopped automaticallyby using a function that is provided with HSDP. While communicating withthis function by using an external adapter, you need not create an adapter-definition file or in-process connection properties file. Additionally, you neednot use commands to start and stop an adapter.
Generation of adapters
When a query group is registered, the following adapters are generatedautomatically:• TCP input adapter (for connecting the external input adapter)
• Cascading adapter (for connecting the external output adapter)
• Cascading adapter (for connecting the TCP input adapter)
Internal adapters 77Hitachi Streaming Data Platform

Starting of adapters
The internal standard adapters are started automatically in the followingcases:• An internal or external adapter requests a connection to an input or output
stream.
• The query group is started.
Based on the type of configuration, the adapters are started as follows:
Scale-out configuration
In a scale-out configuration, when a connection is requested from anexternal adapter, the internal adapter is automatically started in each ofthe working directories that have been scaled out. When a query groupis started, the adapter is automatically started only in the workingdirectory in which the hsdpcqlstart command was run.
Scale-up configuration
In a scale-up configuration, when an adapter (auto-generated) is startedautomatically, the same number of adapters (equal to the number ofscaled-up query groups) are started. This means that one adapter groupis started with the predefined number of adapters.
TCP input adapter (for connecting the external input adapter)
The TCP input adapter receives data and puts it into the stream-dataprocessing engine through the input stream. When a connection isrequested by an external input adapter or a cascading adapter, if theSDP broker is started and running, then the TCP input adapter isautomatically started.
The details of the TCP input adapter are as follows:
• Name of the adapter group to be startedtcpinput-query-group-name-input-stream-name-to-connectThe value in query-group-name indicates the name of the query groupthat defines the stream that should be connected.
• Name of the adaptertcpinput[-N]The number -N is only added for a scale-out configuration. The value of Nis one or more (three-digit decimal number, that is, the scale-up number,such as 001, 002, and so on).
Cascading adapter (for connecting the external output adapter)
78 Internal adaptersHitachi Streaming Data Platform

The cascading adapter gets data from the stream-data processingengine and sends it through the output stream. When a connection isrequested by an external output adapter, if the SDP broker is startedand running, then the cascading adapter is started automatically.
The details of the cascading adapter are as follows:
• Name of the adapter group to be startedcascading-out-query-group-name-output-stream-name-to-connectThe value in query-group-name indicates the name of the query groupthat defines the stream that should be connected.
• Name of the adaptercascading[-N]The number -N is only added for a scale-up configuration. The value of N isone or more (three-digit decimal number, that is, the scale-up number,such as 001, 002, and so on).
Cascading adapter (for connecting the TCP input adapter)
The cascading adapter gets data from the output stream and sends it tothe connection destination input stream. When the query group starts,the cascading adapter that sends data to the input stream* of theconnection destination that is specified in the properties file (of thequery group) is started.
Legend: * Refers to the input stream that is specified as the value of thestream.output.stream-name.link property.
The details of the cascading adapter are as follows:
• Name of the adapter groupcascading-query-group-name-output-stream-name-MThe value in query-group-name indicates the name of the query groupthat defines the stream that should be connected.The value in output-stream-name indicates the name of the output streamthat is specified as stream-name in the stream.output.stream-name.link property.The value in M indicates a three-digit decimal number that displays theserial number of the input stream of the connection destination. Forexample, 001, 002, and so on.
• Name of the adaptercascading[-N]
Internal adapters 79Hitachi Streaming Data Platform

The number -N is only added for a scale-out configuration. The value of Nis one or more (three-digit decimal number, that is, the scale-up number,such as 001, 002, and so on).
Stopping of adapters
When the query group is stopped, the adapters that were startedautomatically are also stopped.
80 Internal adaptersHitachi Streaming Data Platform

6External adapters
This chapter provides information about the features of external adapters,which are used for transmitting and receiving analysis data to and from SDPservers respectively.
□ External input adapters
□ External output adapters
□ External adapter library
□ Connecting to parallel-processing SDP servers
□ Custom dispatchers
□ Heartbeat transmission
□ Troubleshooting
External adapters 81Hitachi Streaming Data Platform

External input adaptersExternal input adapters send analysis data to SDP servers.
Overview of external adapters
Overview of external input adapters
Description
External adapters are used to send the data that should be analyzed to theSDP server and to receive the results of the analysis from the SDP server.External adapters get the address of the data-transmission stream orreception-destination stream from the SDP broker and connect to thecorresponding target streams. If the SDP servers are running in a parallelconfiguration, then the adapters connect all the servers. Therefore, Whiledeveloping external adapters, developers need not be aware of individualSDP servers.
Note: You can also deploy external adapters into hosts other than SDPservers.
External input adapters connect with TCP data input adapters, which areavailable on an SDP server to send the data through the TCP IP protocol.
External output adaptersExternal output adapters receive analysis results from SDP servers.
82 External adaptersHitachi Streaming Data Platform

Overview of external output adapters
Description
External output adapters receive analysis results from an SDP server. Theseadapters connect with TCP cascading adapters on an SDP server to receivedata through the TCP protocol.
When the external output adapter receives data, the callback registered bythe external output adapter is called asynchronously. The integrationdeveloper can process the received data by implementing processing on thereceived data as a callback.
External adapter libraryIntegration developers use an external adapter library to create externalinput and output adapters.
Overview of an external adapter library
Description
The external adapter library can be used to create an external input or outputadapter as a Java application.
Workflow for creating external input adaptersYou can create an external input adapter by using the external adapterlibrary.
Flow of external input adapter operations and the implementation methodsand functions of the external adapter library
External adapters 83Hitachi Streaming Data Platform

Description
The operations to be performed for creating an external input adapter are asfollows:1. Configure the initial settings of the external adapter. Specify the path of
the external adapter-definition file.
Note: The initial settings should be configured only once after theexternal adapter has been started.
2. Connect to the input stream of an SDP server. If the SDP servers arerunning in a parallel configuration (*), then the external adapter libraryconnects to all the input streams.
Note: *: This includes instances where the destination querygroup has been registered using the count that was specifiedduring parallel processing.
3. Transmit data by sending the data to the input stream. If the destinationSDP server is running in a parallel configuration, then the specified SDPserver setting determines the data-dispatching method. However, if acustom dispatcher is specified for the application, then the rules of thecustom dispatcher control the dispatching of data.
84 External adaptersHitachi Streaming Data Platform

4. Disconnect the external adapter library from the input stream, whenthere is no data to be sent to the input stream.
5. To terminate the operation of the external adapter, call the terminationmethod or function of the external adapter library.
An example of an external input-adapter program is available in the samplefile of Streaming Data Platform software development kit, which is availableat the following location:/opt/hitachi/hsdp/sdk/samples/exadaptor/inputadaptor/src/ExternalInputAdaptor.java
Workflow for creating external output adaptersYou can create an external output adapter by using external adapter library.
Flow of external output adapter operations and the implementation methodsand functions of the external adapter library
External adapters 85Hitachi Streaming Data Platform

Description1. Configure the initial settings of the external adapter library. Specify the
path of the external adapter-definition file.
Note: The initial settings should be configured only once after theexternal adapter has been started.
2. Find the output stream of an SDP server. If the SDP servers are runningin a parallel configuration, then the external adapter library tries to findall the output streams.
3. Register a callback to conduct the data-receiving process. After thecallback has been registered, it connects to the output streams that werefound. You should set a wait time in the external adapter to ensure thatthe callback registration is not cancelled until the analysis by theconnection destination has been completed. When the analysis of theconnection destination stops, cancel the callback registration.
4. Get the necessary data from the data notification that was received andthen sent to the callback. The data that was notified to the callback wasthe data that was received after the callback was registered.
5. Cancel the registration of the callback to end the reception of data.
6. Disconnect from the output stream to end the reception from the outputstream.
7. To terminate the external adapter, perform the termination process of theexternal adapter library.
Examples of external output-adapter programs are available in the samplefile of Streaming Data Platform software development kit, which is availableat the following location:/opt/hitachi/hsdp/sdk/samples/exadaptor/outputadaptor/src/ExternalOutputAdaptor.java
Creating callbacksYou can create callbacks by creating a class that implements theHSDPEventListener interface and by describing the process that should beperformed during the callback in the onEvent() method.
Description
After you register the object of the class that implements theHSDPEventListener interface by using the register() method of theHSDPStreamOutput interface, the onEvent() method of the object that isregistered will be called back when a tuple is created on the SDP server.
86 External adaptersHitachi Streaming Data Platform

An example of the callback program is available in the sample file ofStreaming Data Platform software development kit, which is available at thefollowing location:/opt/hitachi/hsdp/sdk/samples/exadaptor/outputadaptor/src/ExternalOutputAdaptor.java
Connecting to parallel-processing SDP serversWhen SDP servers are running in a parallel configuration, an external adaptergets all the addresses, which are used to connect to any targeted SDP server,from the broker. Therefore, while developing external adapters, developersneed not consider individual SDP servers.
Using the timestamp-adjustment function to sort tuples in chronologicalorder
Description
The SDP server settings confirm the data-dispatching method used by theexternal input adapter to send data to parallel-processing SDP servers. Formore information about each of the dispatching methods (for example,hashing and round-robin), see Cascading adaptor on page 64. Alternatively,using the custom dispatcher, the dispatching method is determined by usingthe external adapter settings rather than the SDP server settings. For moreinformation about custom dispatchers, see Custom dispatchers on page 87
When an external output adapter receives data from multiple parallel-processing SDP servers, the callback sends notifications (of the data) in theorder in which the data was received. These data notifications will not be inchronological order. If you want to receive notifications in chronological order,then the data must be sorted at the SDP server, which sends the data to theexternal output adapter.
Custom dispatchersCustom dispatchers enable you to determine the data-dispatching method atthe external adapter rather than at the SDP server.
Overview of a custom dispatcher
External adapters 87Hitachi Streaming Data Platform

Description
Use custom dispatchers to determine the dispatching points based onarbitrary configurations in external adapters.
Note: Do not use custom dispatchers to determine dispatching points basedon SDP standard dispatching methods.
The following conditions must be met to use custom dispatchers:• A custom dispatcher has been created for external adapter files. These
files include .jar or .class file for Java.
• The stream.input.stream-name.dispatch.type=custom is set in thequery-group properties file of the destination SDP server.
Rules for creating class filesClass files that implement a custom dispatcher will use a constructor withoutarguments to generate instances. Any package name or class name can bespecified.
Description
The following conditions must be met to create a class file:• The value public must always be specified for the class modifier. Abstract
classes (abstract) are not available.
• Avoid instances where only the constructors with arguments are availableeither by using the default constructor (do not create a constructor) orcreating a constructor without arguments. The value public (withoutarguments) must always be specified for the modifier of the constructor.
Note: If the conditions required to create a class file are not met,then no instance can be generated from a class file that isimplementing a custom dispatcher. This results in an error from theloadDispatcher method of the HSDPStreamInput interface file,which registers the custom dispatchers.
88 External adaptersHitachi Streaming Data Platform

• The HSDPDispatch interface should be implemented in the class files thatimplement a custom dispatcher. The following method must beimplemented by the interface:public int dispatch(HSDPDispatchInfo dispatchInfo, byte[] data);
• Implement a method that returns the IDs of the dispatching destinations.
Note: The IDs are assigned based on the number of destinations,starting from 1. This applies to both the destinations in the scale-upand scale-out configurations.
This method is driven by the execution of the put method of theHSDPStreamInput interface file.
Ensure that the class name that contains the name of the class-file package(which implements the custom dispatcher) is not the same class name as theclass file in the class path that is specified when the external adapter is run.If both have the same name, when the external adapter is run, the class thatis specified in the class path takes precedence in loading and the externaladapter may not operate normally.
When the external adapter is run, the path of a class file that implements thecustom dispatcher should not be specified in the classpath for the externaladapter. If specified, you cannot replace the custom dispatcher while theexternal adapter is running.
Examples of implementing dispatch methodsThe Java and C external adapters are used as examples for implementing thedispatch method of a custom dispatcher.
Description
Java external adapter
Implement a dispatch method that returns the IDs of the dispatchingdestinations. An example of referencing integer-type initial columns todetermine the dispatch destinations is as follows:public class Dispatcher implements HSDPDispatch {
@Override public int dispatch(HSDPDispatchInfo dispatchInfo, byte[] data) { // Destination ID int destID; // The number of destinations int destNum = dispatchInfo.getDestNum();
External adapters 89Hitachi Streaming Data Platform

// The First column is of VARCHAR type (two byte header + String -type data). ByteBuffer buffer = ByteBuffer.wrap(data); byte[] val1 = new byte[buffer.getShort()]; buffer.get(val1); // Determine the destination. destID = new String(val1).hashCode() % destNum + 1; return destID; }}
Heartbeat transmissionThe heartbeat() method is used to obtain the result of the latest data thatwas transmitted from a query.
When an SDP server is running in the data source mode, the time of the SDPserver does not progress if the data to be input runs out. Therefore, there willnot be any output of an analysis result from the query. Therefore, there willnot be any output of an analysis result from the query.
This issue can be resolved by stopping the analysis and removing the targetstream from the query. Alternatively, you can send heartbeats at regularintervals to make the time of the SDP server progress without stopping theanalysis. The heartbeat() method of the HSDPStreamInput interface in Javacan be used to send a heartbeat.
TroubleshootingIf an error occurs while the external adapter is running, then the message logfile and trace log file are output to the respective file locations. However, thelog file is not output before the init() method is run or after the term()method of the HSDPAdaptorManager class is run.
Related topics
For more information about the file locations and specifications of log files,see the Hitachi Streaming Data Platform Setup and Configuration Guide.
90 External adaptersHitachi Streaming Data Platform

7RTView Custom Data Adapter
The RTView Custom Data Adapter of Hitachi Streaming Data Platform(hereinafter referred to as "HSDP") works with a third-party product,Enterprise RTView (hereinafter referred to as "RTView") to make the analysisresults of the HSDP visible in real time.
□ Setting up the RTView Custom Data Adapter
□ Environment setup
□ Editing the system definition file
□ Environment variable settings
□ Data connection settings
□ Uninstallation
□ File list
□ Operating the RTView Custom Data Adapter
RTView Custom Data Adapter 91Hitachi Streaming Data Platform

Setting up the RTView Custom Data AdapterWhen setting up a system that displays analysis results in the RTViewwindow, you can use the RTView Custom Data Adapter of HSDP (hereinafterreferred to as "RTView Custom Data Adapter") to specify data from the SDPserver as a data source for RTView. By configuring the settings of the RTViewCustom Data Adapter, you can reduce the number of work hours necessary toset up a system that acquires the analysis results of HSDP and displays themin the RTView window (you do not need to develop a user application toacquire data from the SDP server, and to register and display the data inRTView).
The following diagram illustrates how the RTView Custom Data Adapterworks.
Figure 33 Employment of the RTView Custom Data Adapter
After the data is analyzed in real time on the SDP server, it is automaticallycollected by the RTView Custom Data Adapter (installed together withRTView) on the host RTView is running, processed to suit the RTViewinterface, and then displayed in the RTView window. In detail, the customdata adapter added on the RTView receives data from dashboard outputconnector on HSDP.
Environment setupIf the system operator uses the dashboard adapter on the dashboard server(such as RTView), the system operator needs to set up the dashboardadapter.
Installation
92 RTView Custom Data AdapterHitachi Streaming Data Platform

Prerequisites
The RTView Custom Data Adapter must be installed on a machine onwhich RTView is installed.
Procedure
The RTView Custom Data Adapter files are included in the HSDPpackage. No RTView Custom Data Adapter installer is available. Copythe files stored on the project to a folder in the machine that is to runRTView with the RTView Custom Data Adapter.
Procedure
1. Transfer the dashboard adapter library file.
Transfer the following file with a file transfer method such as the scpcommand to the host on which the RTView runs:
/opt/hitachi/hsdp/conf/hsdpcdalib.tar.gz2. Extract files from the dashboard adapter library file.
Extract the files from the dashboard adapter library file with adecompression method such as the tar command, and put all of them inthe same directory.
For details on the RTView Custom Data Adapter files, see section File liston page 98.
Editing the system definition fileAfter installing the RTView Custom Data Adapter, edit the system definitionfile as needed. Parameters for the dashboard adapter are defined in theucsdpcda_config.properties file that was one of the extracted files. In theRTView Custom Data Adapter system definition file, specify the host of SDPserver and port number used to connect to a dashboard output connector ofHSDP.
To set parameters for the dashboard adaptor, edit theucsdpcda_config.properties file manually or run the hsdpcdasetcommand for the extracted file. The value of theucsdpcda_config.properties file can be changed by running thehsdpcdaset command.
For the detail about the hsdpcdaset command, see Hitachi Streaming DataPlatform Setup and Configuration Guide.
RTView Custom Data Adapter 93Hitachi Streaming Data Platform

File name
The following table shows the name of the RTView Custom Data Adaptersystem definition file.
Table 19 System definition file
File Name Description Path
ucsdpcda_config.properties RTView Custom Data Adapter systemdefinition file
Folder where the file iscopied, as explained in Environment setup onpage 92 .
Definition format
The RTView Custom Data Adapter system definitions must be specified in theJava property format (key=value).
Definition items
The following table describes the definition items of the RTView Custom DataAdapter system definition file.
Table 20 System definition of RTView Custom Data Adapter
key Type Value Description
serverName String indicating theserver name
1 to 255 bytecharacters (in bytes)
(Required)
Specify the IP addressor host name of theHSDP server on whichthe dashboard outputconnector runs.
If the specified name isinvalid, KFSP46902-Wwill be output.
portNo Numeric valueindicating the portnumber
Numeric value in therange from 1024 to65535
(Optional)
The default value is20421.
Specify the portnumber for RMIconnection to thedashboard outputconnector on the SDPserver.
If the specified value isinvalid, KFSP46902-Wwill be output, and thedefault value will beset.
communicateRetryInterval
Numeric valueindicating the retryinterval (inmilliseconds) for RMIconnection
0 or a numeric value inthe range from 1000 to9223372036854775807
(Optional)
The default value is10000.
Specify the retryinterval (inmilliseconds) for RMIconnection when theconnection to thedashboard outputconnector on the HSDPserver is disconnected.
94 RTView Custom Data AdapterHitachi Streaming Data Platform

key Type Value Description
If 0 is set, thedashboard adaptor willnot attempt to re-establish the RMIconnection.
Definitions
An example of the RTView Custom Data Adapter system definition file is asfollows:
serverName = StreamServer
portNo = 20421
Note:• Copy the RTView Custom Data Adapter system definition file to the
directory where you start the RTView (RTView Display Builder or RTViewDisplay Viewer).
• If the specified server name is invalid, the specified server name and portnumber are ignored. In such a case, the error messages (KFSP46911-W toKFSP46914-W) will contain the text "server name = null, port number =0".
Environment variable settingsYou must set the RTView environment variables before using the RTViewCustom Data Adapter. On the machine on which the RTView Custom DataAdapter is installed, set the RTV_USERPATH environment variable used byRTView as follows:
directory-to-which-the-file-is-copied\sdpcda\lib\sdpcda.jar;
In the RTV_USERPATH environment variable, set the absolute path ofsdpcda.jar, which is provided when the RTView Custom Data Adapter isinstalled.
Data connection settingsAt building displays with RTView display builder, configure the connectionsettings to connect the HSDP output to the tables and graphs that will bedisplayed on the screen.
RTView Custom Data Adapter 95Hitachi Streaming Data Platform

1. Click Attach to Data to connect an object property to your data source foreach object and to display the analysis results in the window created inRTView Display Builder, such as tables and graphs.
2. 2. In the selection dialog box, from list of active data sources, selectHITACHI_STREAM as the data source name for HSDP.
Figure 34 Selecting Custom Data AdapterAfter specifying the data source to connect, in the Attach to Data dialogbox, specify the analysis data to be displayed in objects, such as tables
96 RTView Custom Data AdapterHitachi Streaming Data Platform

and graphs. The items to be specified in the Attach to Data dialog boxare as follows:
Figure 35 Attach to Data dialog box
Field Description
Name Either manually enter the distinguished name to identify thedashboard output connector containing the data that you want todisplay, or select the appropriate name from the list.
For you to select a distinguished name from the list, at least onedashboard output connector must be started before you open thedialog box. If you specify a nonexistent distinguished name inthis field, after you confirm the entry by pressing the Enter keyor by moving to another field, the background color turns red. (Ifyou enter an existing name, the background color turns white.
Column(s) Either manually enter the column name, or select it from the list.
To select a column name from the list, the dashboard outputconnector that corresponds to the distinguished name specifiedin the Data Name field must be started before you open thedialog box.
If you specify a nonexistent column name in this field, after youconfirm the entry by pressing the Enter key or moving toanother field, the background color turns red. (If you enter anexisting name, the background color turns white.)
Notes- In Attach to Data dialog box, the field surrounded by the dotted line isprovided by the RTView Custom Data Adapter, and the other fields areprovided by RTView. For details, see the RTView documentation.
RTView Custom Data Adapter 97Hitachi Streaming Data Platform

- If you enter a nonexistent distinguished name in the Data Name field,the Column field will not be updated. After you enter an existingdistinguished name in the Data Name field, the corresponding columnnames are automatically entered in the Column field. Reconfigure thecolumn as needed.
UninstallationTo uninstall the RTView Custom Data Adapter, manually delete the files thatyou copied from the media during installation.
File listThe RTView Custom Data Adaptor files are stored in the directory:HSDP-installation-directory/conf/hsdpcdalib.tar.gzFor Dashboard adaptor library file detail see Hitachi Streaming Data PlatformSetup and Configuration Guide.
Table 21 File list
File name Description
sdpcda.jar Library
ucsdpcda_config.properties System definition file
HITACHI_STREAM.properties Resource file
The following table shows the jar component of the RTView Custom DataAdaptor.
Table 22 jar component list
File Name jar component Description
sdpcda.jar jp.co.Hitachi.soft.sdp.cda.Sdpcda
RTView Custom Data Adapter
Operating the RTView Custom Data Adapter
Types of operationsThe following table lists the types of operations.
Table 23 Types of operations
Operation Description Procedure
98 RTView Custom Data AdapterHitachi Streaming Data Platform

Starting the RTView CustomData Adapter
Start the RTView Custom DataAdapter.
(1) Prepare the RTViewCustom Data Adapter
(2) Start the RTView DisplayViewer*
Stopping the RTViewCustom Data Adapter
Stop the RTView Custom Data Adapter. (1) Stop the RTView DisplayViewer*
Changing the analysissettings
As needed, change the RTView CustomData Adapter settings according tochange in analysis settings of HSDP.
(1) Stop the RTView DisplayViewer*
(2) Prepare the RTViewCustom Data Adapter
(3) Start the RTView DisplayViewer*
* During normal operation, if you are using the RTView Display Builder tomonitor real-time analysis results, you start and stop the RTView DisplayBuilder.
Operation procedureThe RTView Custom Data Adaptor Adapter operation procedure is as follows.
Procedure
1. Editing the system definition file:
Edit the RTView Custom Data Adapter system definition file to matchyour environment.
For details about the system definition file, see Editing the systemdefinition file on page 93.
2. Copying the files:
Copy the RTView Custom Data Adapter system definition and resourcefiles to the project directory for RTView where you will run the RTView(RTView Display Builder or RTView Display Viewer).
For details about the files, see the file list on page 98.3. Starting HSDP:
Start HSDP.
For details, see Hitachi Streaming Data Platform Setup and ConfigurationGuide.
Starting the RTView Custom Data AdapterThis topic explains the command execution procedure for starting the RTViewCustom Data Adapter. The RTView Custom Data Adapter runs in the RTViewDisplay Builder or RTView Display Viewer process.
RTView Custom Data Adapter 99Hitachi Streaming Data Platform

Procedure
1. At the command prompt, execute the RTView Display Builder or RTViewDisplay Viewer startup command provided by RTView with specifying theRTView Custom Data Adapter component name(jp.co.Hitachi.soft.sdp.cda.Sdpcda) as an argument of the command.
2. If an incorrect procedure was used to start the system, stop and restartthe system following correct procedures.
3. To start RTView Display Builder:
run_builder -customds:jp.co.Hitachi.soft.sdp.cda.Sdpcda
4. To start RTView Display Viewer:
run_viewer -customds:jp.co.Hitachi.soft.sdp.cda.Sdpcda display-file-name
or
run_viewer -customds:jp.co.Hitachi.soft.sdp.cda.Sdpcda display-file-name.rtv
Stopping the RTView Custom Data Adapter
Procedure
1. Stop the RTView Display Builder or the RTView Display Viewer.For details on how to stop the RTView Display Builder or the RTViewDisplay Viewer, see the RTView documentation. Data that needs to becollected for each event below lists the data that need to be collected forevents:- When an error message is displayed:When an internal systemerror occurs or when an illegal execution exception occurs- When theserver process terminates:The server process terminates: When theJavaVM process of the RTView Display Viewer unexpectedly terminateswithout a message being output- When the analysis results cannot beacquired:The analysis results cannot be acquired: When the analysisresults are not output to the RTView Display Viewer
Result
Table 24 Data that needs to be collected for each event
Data Action When an errormessage isdisplayed
When the serverprocessterminates
When the analysisresults cannot beacquired
Standard output,standard erroroutput
Retrieve thestandard output /standard erroroutputinformation.
Must be collected Must be collected Must be collected
System definitionfile
Retrieve the filelisted in System
Must be collected Must be collected Must be collected
100 RTView Custom Data AdapterHitachi Streaming Data Platform

definition filelocation.
Table 25 System definition file
RTView Custom Data Adapter system definition file
project-directory/ucsdpcda_config.properties
RTView Custom Data Adapter 101Hitachi Streaming Data Platform

102 RTView Custom Data AdapterHitachi Streaming Data Platform

8Scale-up, scale-out, and data-parallel
configurationsThis chapter provides information about scale-up, scale-out, and data-parallelconfigurations.
□ Data-parallel configurations
□ Data-parallel settings
Scale-up, scale-out, and data-parallel configurations 103Hitachi Streaming Data Platform

Data-parallel configurationsThe division of an analysis-scenario process into multiple processes orthreads is called 'data parallel'. A data-parallel configuration enables the loadbalancing of the query process thus resulting in a higher performance.
By using a data-parallel configuration you can distribute the load of theprocessing of the analysis-scenario queries. This distribution will help youanalyze data at a higher speed when compared to a configuration that runsanalysis scenarios in a single process or thread.
Data-parallel system configurations include scale-up and scale-outconfigurations. The figure illustrates the details of scale-up and scale-outconfigurations. It also illustrates the modification of a configuration(comprising query groups 1 and 2) into a data-parallel configuration.
Scale-up configurationIn a scale-up configuration, query groups analyze (in parallel) multiplethreads (that are to be processed) of an SDP server. If there are sufficientCPU resources for process-multiplexing but the usage of memory resourcesshould be limited, then to establish a high-performance system choose ascale-up configuration instead of a scale-out configuration.
Scale-up configuration for processing query groups
Description
The figure illustrates the scale-up configuration for processing query groups 1and 2. In this configuration, the relevant data is transmitted separately fromthe external input adapter to each query group.
104 Scale-up, scale-out, and data-parallel configurationsHitachi Streaming Data Platform

(a) Usage method
Query groups can be registered by running the hsdpcql command withthe scale-up number in the –thread option.
(b) Query group name
When you use the -thread option of the hsdpcql command to specifythe scale-up number as 2 or more for registering query groups, thequery groups with the following names are registered on the SDP server.These query groups correspond to the threads that are running parallelon the SDP server.
defined-query-group-name-N
defined-query-group-name: Query group name to be specified in thehsdpcql command
N: From 1 to the scale-up number (three-digit decimal number)
(c) Internal standard adapters
When you use the hsdpstartinpro command to start internal standardadapters, a single adapter is started (irrespective of the availability of ascale-up configuration). In the adapter-definition file, you must specifythe definition for connecting to the query group as detailed in the querygroup name. To run the adapters in scale-up query groups, run thehsdpstartinpro command multiple times. The number of times that thecommand is run must be equal to the scale-up number.
While connecting internal standard adapters from an external adapter(or due to any other trigger), the number of adapters equal to thenumber of scaled-up query groups are started automatically by HSDP.
When the internal standard adapters are started automatically by HSDP,the number of adapters equal to the number of scaled-up query groupsare started automatically at the time of connection from the externaladapter (or due to another trigger).
(d) Internal custom adapters
Unlike standard adapters, when query groups start or when thehsdpstartinpro command is used to start internal adapters, only asingle custom adapter is started. The names of the query groups, whichhave to be accessed by the custom adapter can be obtained based onthe query group names that are defined by using the APIs as specified inthe Hitachi Streaming Data Platform Application Development Guide.
When the hsdpstartinpro command is used to start a custom adapter,only one custom adapter is started regardless of whether there is ascale-up configuration. For the name of the query group to which the
Scale-up, scale-out, and data-parallel configurations 105Hitachi Streaming Data Platform

custom adapter connects, you should specify the query group name asspecified in the Query group name section.
Scale-out configurationA scale-out configuration analyzes (in parallel) query groups in multiple SDPserver processes. If there are sufficient CPU and memory resources formultiplexing, then to establish a high-performance system, choose a scale-out configuration instead of a scale-up configuration.
Scale-out configuration for processing query groups
Description
The figure illustrates the scale-out configuration for processing query groups1 and 2. In this configuration, the relevant data is transmitted separatelyfrom the external input adapter to each query group.• Usage method
Multiple working directories that have the same server cluster name on thehosts of the same coordinator group and register query groups that havethe same query group name can be created. After creating the workingdirectories, start the query groups. It is also possible that a scale-outconfiguration is present between multiple hosts.
• Internal standard adaptersAn internal standard adapter can be used by running the hsdpstartinprocommand, which starts the adapters in the working directories thatcomprise the scale-out configuration. When the adapters are connected byan internal or external adapter, the internal standard adapters (available inall the working directories) of the scale-out configuration are startedautomatically by Streaming Data Platform.
• Internal custom adaptersIn a scale-out configuration, the internal custom adapters (developed byyou) can be used by running the hsdpstartinpro command, which startsthe adapters in the working directories that comprise the scale-outconfiguration.
106 Scale-up, scale-out, and data-parallel configurationsHitachi Streaming Data Platform

Data-parallel settingsA data-parallel configuration requires an adapter to distribute data to theinput streams of query groups that are running in parallel.
Description
Query groups can be used in a data-parallel configuration by specifying themethod of the input-stream distribution in the query-group properties file ofthe query groups that are running in parallel.
Scale-up, scale-out, and data-parallel configurations 107Hitachi Streaming Data Platform

108 Scale-up, scale-out, and data-parallel configurationsHitachi Streaming Data Platform

9Data replication
This chapter provides information about the data-replication feature, whichenables an adapter to send the same data to multiple destination streams.The data-replication feature is available in the external input adapters andinternal cascading adapters. The data-replication method is different from theALL distribution method of the cascading adapter. Data replication is used totransmit the same data to different input streams, and the distributionmethod is a function used to transmit identical data to input streams that arerunning in parallel, in a data-parallel configuration.
Related topics
For more information about examples of using data replication and setting updata replication, see Examples of using data replication on page 110 and Data-replication setup on page 111 respectively.
For more information about the ALL distribution method, see Figure 28 Alloverview on page 70.
□ Examples of using data replication
□ Data-replication setup
Data replication 109Hitachi Streaming Data Platform

Examples of using data replicationThe data-replication feature is used for analysis in task-parallel configurationsand while using a redundant configuration with two active systems (systemredundancy).
Example of a task-parallel configuration
Example of system redundancy configuration
Description
Examples of the data-replication feature are as follows.
110 Data replicationHitachi Streaming Data Platform

Table 26 SDP system components
S. No. Example Description
1 Analysis in task-parallel configurations A task-parallel configuration analyzes a data setthrough multiple analysis methods. This analysiscan be achieved by using the data-replicationfeature. It is possible to create a task-parallelconfiguration by using the data-replicationfeature.
2 System redundancy When there are two active systems, a redundantconfiguration is used to achieve higher systemavailability. Identical data is sent to therespective systems and identical analysis isperformed in the respective coordinator groups.Even if one system stops, the analysis will beperformed in the other system.
Data-replication setupThe data-replication feature can be used by setting multiple destinationstreams in the definition file of each adapter. However, to set up a redundantsystem with two active flows, the input streams must be assigned to differentbroker addresses for managing different coordinator groups.
Example of data replication performed by an external input adapter
Example of system redundancy configuration
Data replication 111Hitachi Streaming Data Platform

Description
The following table provides information about the actions to be performedwhen specific adapters are used to replicate data.
Types ofadapters
Action Example
External inputadapter
When an external input adapterperforms data replication, specify(using commas as delimiters) multiplestreams to send the same data to thedestination stream definition in theexternal input adapter-definition file.
target.name.1= /192.168.12.40:20425/qg1/s1,/192.168.12.41:20425/qg1/s1
If you assign target.name.1 to theStreamInput() method of theHSDPAdaptorManager class, then thesame data is sent to multipledestinations.
Identical data can be sent to multipledestinations by specifyingtarget.name.1 for theopenStreamInput() method of theHSDPAdaptorManager class.
Internal cascadingadapter
When an internal cascading adapterperforms data replication, specify(using commas as delimiters)multiple-destination input streams forthe output streams in the query-groupdefinition file.
stream.output.q1.link=qg1/s1,qg2/s1
112 Data replicationHitachi Streaming Data Platform

10Setting parameter values in definition
filesThis chapter provides information about the relationship between parametervalues and definition files. It also provides examples of setting parametervalues in query-definition files.
□ Relationship between parameters files and definition files
□ Examples of setting parameter values in query-definition files and query-group properties files
□ Adapter schema automatic resolution
Setting parameter values in definition files 113Hitachi Streaming Data Platform

Relationship between parameters files and definition filesThe parameter values of any SDP-definition file items can be set up, asrequired. The parameter values (that allows you to separate definitions intothose you want to modify or keep fixed) that are set in a parameters file arecollected which results in simpler definition design and configurations.
Merging values from multiple parameters files into a definition file
The example given shows the usage of the same key name in multipleparameters files. If there are multiple parameters files, then SDP loads theparameters files in ascending order of the file names in ASCII code.
If an identical key name is used in multiple parameters files, then the valueof the file that is loaded later is used.
Merging values (through analysis) from a parameters file to multipledefinition files
114 Setting parameter values in definition filesHitachi Streaming Data Platform

Description
The parameter values can be set for the content of an SDP-definition file.
The actual values of the sections for which the parameter values have to beset should be specified. These actual values are specified in the key-valueformat in a separate file called the "parameters file".
By setting the parameter values, you can clearly differentiate between theparts that have to be fixed and that have to be tuned in the definition file. Toset identical values in multiple definition files, set the parameter values,which enables you to consolidate the parts to be modified.
The file names and storage locations of the definition files should follow thespecifications of the definition files. This should not be modified once theparameter values have been set. A parameters file with the extension .paramshould be created and stored in the HSDP-installation- directory/conf/directory.
While loading a definition file for which the parameter values can be set, SDPmerges the content of the parameters file into the definition file. Similarly,while merging the files, SDP replaces the parts for which the parametervalues have been set with the values that have been specified in theparameters file. Once the files are merged, SDP runs according to the contentof the merged definition file. The content of the merged definition file isstored in a separate file (using the file name of the definition file and the fileextension .out) and output to the same directory of the definition file. If afile with the same name exists, then this file (which contains the content ofthe merged definition file) is overwritten. You can refer to the output file toverify the replacement result.
The file with the extension .out remains even after SDP has stopped. If youwant to delete this file, then delete after SDP has stopped. Additionally, do
Setting parameter values in definition files 115Hitachi Streaming Data Platform

not modify the content of this file because it can be used as a reference toverify the replacement result.
List of definition files for which parameter values can be set
The definition files for which the parameter values can be set are as follows:
Note: Parameter values cannot be set for definition files that are not listed. Ifsuch files do accept parameter values, then an error occurs when you run thecommand.
• Query-definition file
• Query-group properties file
• External-definition function file
• Adaptor-composition definition file
Examples of setting parameter values in query-definitionfiles and query-group properties files
While setting parameter values in query-definition files, the names andstorage locations of the definition files must not be modified. The names andstorage locations must conform with the specifications of each definition file.The parameters files with the extension .param should be stored in theworking directory/conf/ directory. By using the SDP command, therelated definition files and all the parameters files are loaded and analyzed(merged) in the working directory/conf directory. After analysis(merging), the definition files are output to the same directory (definition-file-name) in which the definition files are stored. The output files are storedwith the extension .out. The .out files are only for your reference. Thecommands do not load or analyze files that have been modified. If you wantto modify the contents of the definitions, then edit definition files (for whichparameters have been set) and parameters file.
Examples of query-group properties files (with and without parameters) andparameters files (with the extension .param)
For more information about the formats of definition files and parameter files,see the Hitachi Streaming Data Platform Setup and Configuration Guide.
Query-group properties file (without parameters)querygroup.cqlFilePath=/home/user1/wk1/query/q001stream.input.S1.dispatch.type= hashingstream.input.S1.dispatch.rule= column11,column12,column13stream.input.S2.dispatch.type= hashingstream.input.S2.dispatch.rule= column21,column22 :(snip)
116 Setting parameter values in definition filesHitachi Streaming Data Platform

Query-group properties file (with parameters)querygroup.cqlFilePath=${cqlFilePath}stream.input.S1.dispatch.type=${S1_type}stream.input.S1.dispatch.rule=${S1_rule}stream.input.S2.dispatch.type=${S2_type}stream.input.S2.dispatch.rule=${S2_rule} :(snip)Parameters files (with the extension .param)cqlFilePath=/home/user1/wk1/query/q001S1_type=hashingS1_rule=column11,column12,column13S2_type=hashingS2_rule=column21,column22 :(snip)
Adapter schema automatic resolutionWith adapter schema auto resolution, the user need not specify the schemainformation regarding the data in the adapter-configuration definition file.Additionally, it gets the schema information about the data from the querygroup and the stream of the connection destination to automatically resolvethe schema information about the data handled by the adapter.
Description
When the standard adapter that comes with SDP is used, the schema of theinput or output data of the query group in the adapter-configurationdefinition file should be defined in advance to exchange tuples with the querygroup. However, if the data to be sent and received by the adapter has thesame data structure as that of the input and output data of the query group,then this definition can be ignored.
By modifying the template that comes with the HSDP, an adapter-configuration definition file for the standard adapter should be created by theuser. Additionally, the user has to specify the connection-destination querygroup name and stream name in the command, when the adapter is started.The user need not retain information regarding the schema of the data thatwill be input to or output from the query group.
When this function is used, the definitions of multiple SDP standard adaptersin a single adapter-configuration definition file should not be included. Tocreate multiple adapters, a separate adapter-configuration definition file foreach adapter should be created. If multiple adapters are included in a singleadapter-configuration definition file, then SDP resolves the schemainformation such that all adapters included in the adapter-configurationdefinition file connect to the same single stream.
Setting parameter values in definition files 117Hitachi Streaming Data Platform

Some examples of the adapter-configuration definition file of the TCP datainput adapter in which the user describes the schema and where the schemais automatically resolved, are as follows.
Content of the query definition file to input data from the TCP-data inputadapter to the input query group:register stream DATA0(name VARCHAR(10), num BIGINT);register query FILTER1 ISTREAM(SELECT name FROM DATA0[ROWS 1]);Content of the adapter-configuration definition file in which the schema hasbeen described by the user:<?xml version="1.0" encoding="UTF-8"?><!-- All Rights Reserved. Copyright (C) 2016, Hitachi, Ltd. --><root:AdaptorCompositionDefinition xmlns:root="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition" xmlns:cmn="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/common" xmlns:adp="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/adaptor" xmlns:cb="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/callback" xmlns:ficon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/callback/FileInputConnectorDefinition" xmlns:docon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/callback/DashboardOutputConnectorDefinition" xmlns:focon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/callback/FileOutputConnectorDefinition" xmlns:form="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/callback/FormatDefinition" xmlns:scon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/callback/SendConnectorDefinition" xmlns:rcon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/callback/ReceiveConnectorDefinition" xmlns:tocon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/callback/SNMPTrapOutputConnectorDefinition" xmlns:smtpocon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/callback/SMTPOutputConnectorDefinition" xmlns:tcpicon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/callback/TcpDataInputConnectorDefinition" xmlns:dscon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/callback/DistributedSendConnectorDefinition" xmlns:caclcon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/callback/CascadingClientConnectorDefinition" xmlns:lwicon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/callback/ForwardingInputConnectorDefinition" xmlns:lwscon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/callback/ForwardingSendConnectorDefinition">
<cmn:CommonDefinition> <cmn:AdaptorTraceDefinition/> </cmn:CommonDefinition>
<adp:InprocessGroupDefinition name="tcp">
118 Setting parameter values in definition filesHitachi Streaming Data Platform

<adp:InputAdaptorDefinition name="tcp" charCode="UTF-8" lineFeed="LF" language="Java">
<cb:InputCBDefinition class="jp.co.Hitachi.soft.sdp.adaptor.callback.io.tcpinput.TcpDataInputCBImpl" name="Inputer"> <tcpicon:TCPDataInputConnectorDefinition> <tcpicon:input port="25452" charCode="ASCII"> <tcpicon:binary> <tcpicon:data name="NAME" type="STRING" size="10" /> <tcpicon:data name="NUM" type="LONG" size="8" /> </tcpicon:binary> </tcpicon:input> <tcpicon:output> <tcpicon:record name="RECORD"> <tcpicon:fields> <tcpicon:field name="NAME" /> <tcpicon:field name="NUM" /> </tcpicon:fields> </tcpicon:record> </tcpicon:output> </tcpicon:TCPDataInputConnectorDefinition> </cb:InputCBDefinition>
<cb:SendCBDefinition class="jp.co.Hitachi.soft.sdp.adaptor.callback.sendreceive.SendConnectorCBImpl" name="Sender"> <scon:SendConnectorDefinition> <scon:streamInputs> <scon:streamInput> <scon:record name="RECORD" /> <scon:stream name="DATA0" querygroup="Inprocess_QueryGroupTest" /> </scon:streamInput> </scon:streamInputs> </scon:SendConnectorDefinition> </cb:SendCBDefinition> </adp:InputAdaptorDefinition>
</adp:InprocessGroupDefinition>
</root:AdaptorCompositionDefinition>Content of the adapter-configuration definition file in the automatic schemaresolution format is as follows:<?xml version="1.0" encoding="UTF-8"?><!-- All Rights Reserved. Copyright (C) 2016, Hitachi, Ltd. --><root:AdaptorCompositionDefinition xmlns:root="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition" xmlns:cmn="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/common" xmlns:adp="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/adaptor" xmlns:cb="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
Setting parameter values in definition files 119Hitachi Streaming Data Platform

definition/callback" xmlns:ficon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/callback/FileInputConnectorDefinition" xmlns:docon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/callback/DashboardOutputConnectorDefinition" xmlns:focon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/callback/FileOutputConnectorDefinition" xmlns:form="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/callback/FormatDefinition" xmlns:scon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/callback/SendConnectorDefinition" xmlns:rcon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/callback/ReceiveConnectorDefinition" xmlns:tocon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/callback/SNMPTrapOutputConnectorDefinition" xmlns:smtpocon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/callback/SMTPOutputConnectorDefinition" xmlns:tcpicon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/callback/TcpDataInputConnectorDefinition" xmlns:dscon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/callback/DistributedSendConnectorDefinition" xmlns:caclcon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/callback/CascadingClientConnectorDefinition" xmlns:lwicon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/callback/ForwardingInputConnectorDefinition" xmlns:lwscon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/definition/callback/ForwardingSendConnectorDefinition">
<cmn:CommonDefinition> <cmn:AdaptorTraceDefinition/> </cmn:CommonDefinition>
<adp:InprocessGroupDefinition name="tcp">
<adp:InputAdaptorDefinition name="tcp" charCode="UTF-8" lineFeed="LF" language="Java">
<cb:InputCBDefinition class="jp.co.Hitachi.soft.sdp.adaptor.callback.io.tcpinput.TcpDataInputCBImpl" name="Inputer"> <tcpicon:TCPDataInputConnectorDefinition> <tcpicon:input port="25452" charCode="ASCII"> <tcpicon:binary> ${hsdp_adp_tcpBinary} </tcpicon:binary> </tcpicon:input> <tcpicon:output> <tcpicon:record name="RECORD"> <tcpicon:fields> ${hsdp_adp_tcpFields} </tcpicon:fields> </tcpicon:record> </tcpicon:output> </tcpicon:TCPDataInputConnectorDefinition> </cb:InputCBDefinition>
<cb:SendCBDefinition
120 Setting parameter values in definition filesHitachi Streaming Data Platform

class="jp.co.Hitachi.soft.sdp.adaptor.callback.sendreceive.SendConnectorCBImpl" name="Sender"> <scon:SendConnectorDefinition> <scon:streamInputs> <scon:streamInput> <scon:record name="RECORD" /> <scon:stream name="${hsdp_adp_inputStreamName}" querygroup="${hsdp_adp_inputQueryGroupName}" /> </scon:streamInput> </scon:streamInputs> </scon:SendConnectorDefinition> </cb:SendCBDefinition> </adp:InputAdaptorDefinition>
</adp:InprocessGroupDefinition>
</root:AdaptorCompositionDefinition>As mentioned in these examples, in an adapter-configuration definition fileused for automatic schema resolution, the schema information can beresolved automatically by setting the parameter values of the sections fordescribing schema information by using specific variable names.
In addition to the schema information, you can also set the parameter valuesof the name of the query group connected by the adapter and the name ofthe stream. The actual query group name and stream name that you specifywhen the adapter is started are automatically placed into the query groupname and stream name, which have set parameter values.
Setting parameter values in definition files 121Hitachi Streaming Data Platform

122 Setting parameter values in definition filesHitachi Streaming Data Platform

11Logger
The chapter provides information about the logger feature, which is used tooutput messages from SDP components to log files.
□ Log-file generation
Logger 123Hitachi Streaming Data Platform

Log-file generationThe logger feature is used to output messages from SDP components to logfiles.
Description
The log files that are output by the logger are as follows.
For more information about log files, see the Hitachi Streaming Data PlatformSetup and Configuration Guide.
Table 27 Log files generated by the logger
S. No. Components Generated log files Reference
1 Common Command hsdpcommandmessageN1.log Hitachi StreamingData PlatformSetup andConfigurationGuide
2 Logger hsdpservermessageN1.log Hitachi StreamingData PlatformSetup andConfigurationGuide
3 SDP server SDPServerMessageN1.log
SDPServerCMessageN1.log
Hitachi StreamingData PlatformSetup andConfigurationGuide
4 Hitachi StreamingData PlatformSetup andConfigurationGuide
5 Internal adapter ADP_XXX2-AdaptorMessageN1.log
ADP_XXX2-AdaptorCMessageN1.log
Hitachi StreamingData PlatformSetup andConfigurationGuide
6 External adapter ExAdaptorMessageN1.log Hitachi StreamingData PlatformSetup andConfigurationGuide
7 SDP broker BrokerMessageN1.log Hitachi StreamingData PlatformSetup andConfigurationGuide
8 SDP coordinator CoordinatorMessageN1.log Hitachi StreamingData Platform
124 LoggerHitachi Streaming Data Platform

S. No. Components Generated log files Reference
Setup andConfigurationGuide
9 SDP manager ManagerMessageN1.log Hitachi StreamingData PlatformSetup andConfigurationGuide
10 hsdpsetup command hsdpsetup.log Hitachi StreamingData PlatformSetup andConfigurationGuide
hsdpmanagersetup.log Hitachi StreamingData PlatformSetup andConfigurationGuide
11 hsdpexport command hsdpexport.log Hitachi StreamingData PlatformSetup andConfigurationGuide
12 hsdpmanager command hsdpmanagercommandmessageN1.log
Hitachi StreamingData PlatformSetup andConfigurationGuide
• 1 : Serial number for the message log file.
• 2 : Name of the adapter group.
Logger 125Hitachi Streaming Data Platform

126 LoggerHitachi Streaming Data Platform

GlossaryThis section lists the terms that are referenced in this manual.
adaptor
A program required to exchange data between input sources, outputdestinations and the stream data processing engine.
Adaptor types include the standard adaptors provided with the product,and custom adaptors that you can program in Java.
Each of these adaptor types are further classified into input adaptors,which are used between input data and the stream data processingengine; and output adaptors, which are used between the stream dataprocessing engine and output data.
adaptor definition file
A file used to configure the operation of standard adaptors. It specifiesdetails about the organization of the adaptor groups, and the I/Oconnectors used by the adaptors.
adaptor group
A group of I/O adaptors. Standard adaptors operate in adaptor groups.
Adaptor groups that implement in-process connections are called in-process adaptor groups.
built-in functions
Functions provided by HSDP. These include built-in aggregate functionsthat provide statistical functions and built-in scalar functions thatprovide mathematical and string functions.
callback
A processing unit that controls the functionality provided in the standardadaptors.
common record
An internal record format that enables records to be processed by astream data processing system.
connector
An interface defined in the standard adaptors for connecting StreamingData Platform to the outside world.
For input to Streaming Data Platform, the file input connector and theHTTP packet input connector are provided. For output from StreamingData Platform, the file output connector is provided.
Glossary 1Hitachi Streaming Data Platform

CQL (Continuous Query Language)
A query language designed for writing continuous queries.
custom adaptor
An adaptor created by the user with the Java APIs provided byStreaming Data Platform.
data reception application
A client application that performs event processing on stream dataoutput by an SDP server.
data source mode
A mode for assigning timestamps to tuples. In this mode, when the logfile or other data source being input contains time information, that timeinformation is assigned to the tuple.
data transmission application
A client application that sends stream data to an SDP server.
external definition function
A function that is created by a user with tools such as the Java API. Anyprocessing can be performed by implementing the processing logic forthe external definition function as a method in the class file created by auser with Java.
external definition function file
A file that defines a class on which external definition functionprocessing is implemented and a method.
field
The basic unit of value in a record.
in-process connection
An architecture for connecting adaptors and SDP servers. Adaptors andSDP servers that run in the same process use an in-process connectionto exchange data.
input record
A record that is read when the input source is a file.
input relation
A tuple group retrieved by means of a window operation. A relationoperation is then performed on the tuple group.
intermediate relation
A tuple group retrieved by the WHERE clause during relation operationprocessing.
2 GlossaryHitachi Streaming Data Platform

operator
The smallest unit of stream data processing. A query consists of one ormore operators.
output record
A record format for outputting stream data processing results to a file.
output relation
A tuple group output from a relation operation. A stream operation isthen performed on the tuple group.
query
Code that defines the processing to perform on stream data. Queries arewritten using CQL.
query group
A stream data summary analysis scenario created in advance by theuser. A query group consists of an input stream queue (input stream),an output stream queue (output stream), and relational queries.
record
A single row of data handled by stream data processing.
record organization
An organization expressed as a particular combination of two or morefields (field names and their associated values).
relation
A set of records with a given life span. Using a CQL window specification,records are converted from stream data to a relation that will persist forthe amount of time specified in the window operation.
relation operation
An operation that specifies what processing is to be performed on thedata retrieved by a window operation. Available actions includecalculation, summarization, joining, and others.
SDP server
A server process running a stream data processing engine to processstream data.
SDP server definition file
A file used to configure SDP server operations. It specifies settings suchas the Java VM startup options for running an SDP server and adaptors,and SDP server port numbers.
server mode
Glossary 3Hitachi Streaming Data Platform

A mode for assigning timestamps to tuples. In this mode, when a tuplearrives at the stream data processing engine, the system time of theserver on which Streaming Data Platform is running is assigned to thetuple.
standard adaptor
An adaptor provided by Streaming Data Platform. Standard adaptors canhandle files or HTTP packets as input data, and they can output theprocessing results to a file.
stream
Data that is in a streaming (time sequence) format. Stream data thatpasses through an input stream queue is called an input stream, andstream data that passes through an output stream queue is called anoutput stream.
stream data
Large quantities of time-sequenced data that is continuously generated.
stream data processing engine
The part of a stream data processing system that actually processesstream data, as instructed by queries.
stream operation
An operation that specifies how to output data in an output relation.
stream queue
A path used for input and output of stream data. A stream queue that isused as input to the stream data processing engine is called an inputstream queue, and a stream queue that is used as output from thestream data processing engine is called an output stream queue.
Stream to stream operations
An operation that converts stream data from one data stream to anotherby performing the operation directly on the stream data without creatinga relation.
To use stream to stream operations, it is necessary to define the streamto stream functions with CQL and create external definition functions.
time division function
A function by which a RANGE window is partitioned into desired units oftime (meshing), and the data in each of these partitioned time units isprocessed separately.
timestamp
The data time in a tuple.
4 GlossaryHitachi Streaming Data Platform

tuple
A stream data element that consists of a combination of values and time(timestamp).
window
A range that specifies the extent of stream data that is to besummarized and analyzed. Windows are defined in queries.
window operation
An operation used to specify a window. Window operations are coded inCQL queries.
Glossary 5Hitachi Streaming Data Platform

6 GlossaryHitachi Streaming Data Platform

Hitachi Streaming Data Platform

Hitachi Data Systems
Corporate Headquarters2845 Lafayette StreetSanta Clara, California 95050-2639U.S.A.www.hds.com
Regional Contact Information
Americas+1 408 970 [email protected]
Europe, Middle East, and Africa+44 (0) 1753 [email protected]
Asia Pacific+852 3189 [email protected]
MK-93HSDP003-04