Embed Size (px)
Citation preview

Heuristic Mechanism Design
Joint with Florin Constantin, Ben Lubin and Quang Duong
Cornell CS/Econ Workshop September 4, 2009
David C. ParkesHarvard University

Embracing messiness
• Early development of MD theory focused on an “in principle” mathematical approach.
• Today, we see great demand for mechanisms and markets that need to manage (messy) real world details– e.g., dynamics, complex preferences, scalability,
transparency, stability, ...

• Krugman, 9/2/09 New York Times
• How did Economists Get it So Wrong?“...economists, as a group, mistook beauty, clad in
impressive-looking mathematics, for truth. ... economists will have to learn to live with messiness.”
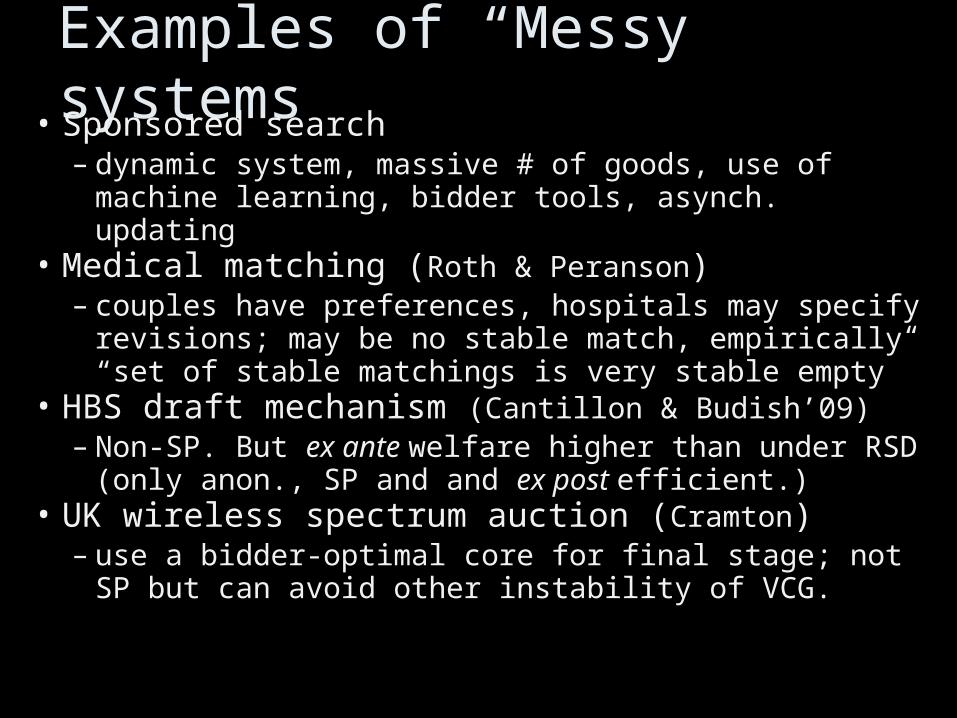
Examples of “Messy” systems• Sponsored search
– dynamic system, massive # of goods, use of machine learning, bidder tools, asynch. updating
• Medical matching (Roth & Peranson)– couples have preferences, hospitals may specify
revisions; may be no stable match, empirically “set of stable matchings is very stable empty”
• HBS draft mechanism (Cantillon & Budish’09)– Non-SP. But ex ante welfare higher than under
RSD (only anon., SP and and ex post efficient.)• UK wireless spectrum auction (Cramton)
– use a bidder-optimal core for final stage; not SP but can avoid other instability of VCG.

Observations• Most deployed mechanisms and markets are
not strategyproof– need to develop solutions that are “truthful and
stable enough” given complexities of environ.– balance SP with other considerations
• Real-world problems are multi-dimensional, and dynamic. Not isolated events.– need theory and engineering knowledge to guide
practical design• Al Roth, 1999 “...if we fail to develop... an
"engineering" literature, we will fail to profit from design experience in a cumulative way.”
• c.f. Yoav’s comment

One starting point• Adopt computational approach that would be
desirable without incentive/stability concerns
• Modify decisions, and/or design payments to make the method truthful and stable enough.
• How to evaluate?– comparative study of initial algorithm and
modified algorithm– analysis of strategic properties (through comput.
and/or theoretical approaches)– identify good and bad cases

Two examples• Dynamic knapsack auctions
– would use an online stochastic algorithm to solve– with incentive concerns, adopt a “self-correction”
approach to obtain SP
• CAs and CEs– would use a branch-and-bound, cutting-plane
approach to solve – with incentive concerns, adopt a “reference
mechanism” approach to obtain approx-SP

Dynamic knapsack auction
• Input: { (a1, d1, v1, q1), ... (an, dn, vn, qn) }
• Capacity C to sell. Probabilistic arrival model.
• Patience ) no simple characterization of optimal policies available– c.f., threshold policies; optimal mechanisms
(Kleywegt & Papastavrou’01, Pai & Vohra’08, Dizdar et al.’09.)
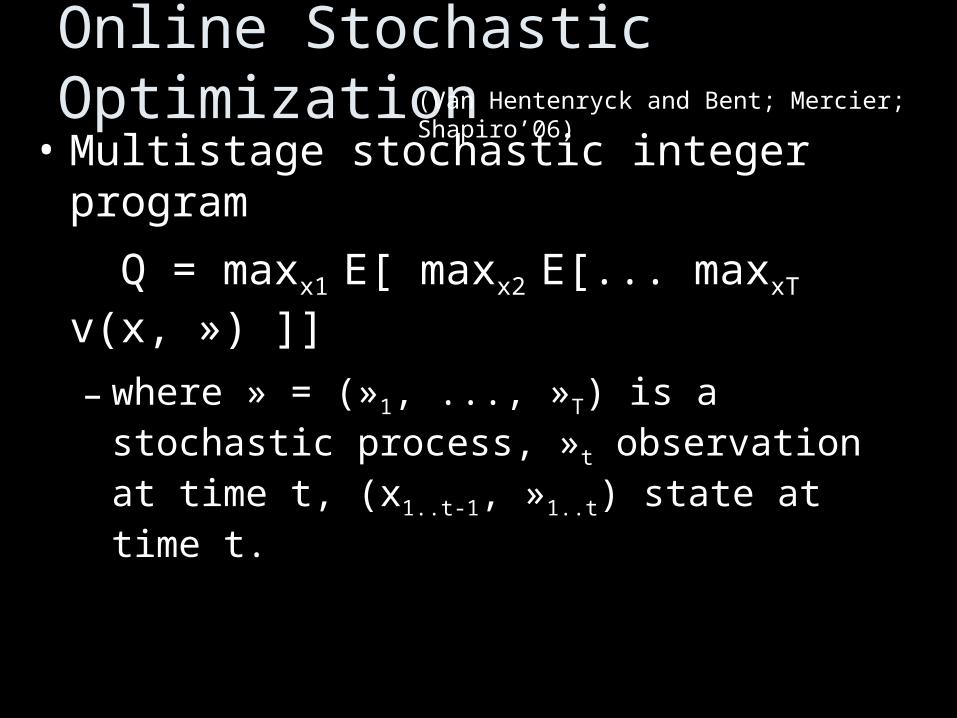
Online Stochastic Optimization• Multistage stochastic integer program
Q = maxx1 E[ maxx2 E[... maxxT v(x, ») ]]
– where » = (»1, ..., »T) is a stochastic process, »t observation at time t, (x1..t-1, »1..t) state at time t.
(Van Hentenryck and Bent; Mercier; Shapiro’06)

Online Stochastic Optimization• Multistage stochastic integer program
Q = maxx1 E[ maxx2 E[... maxxT v(x, ») ]]
– where » = (»1, ..., »T) is a stochastic process, »t observation at time t, (x1..t-1, »1..t) state at time t.
• Solve anticipatory relaxation: maxxt E» [Opt(st, xt, »>t)]
– i.e., construct scenarios »1,..., »w. For each xt, compute g(xt) = 1/w i Opt(st, xt, »i). Pick best.
– need exogenous uncertainty
(Van Hentenryck and Bent; Mercier; Shapiro’06)
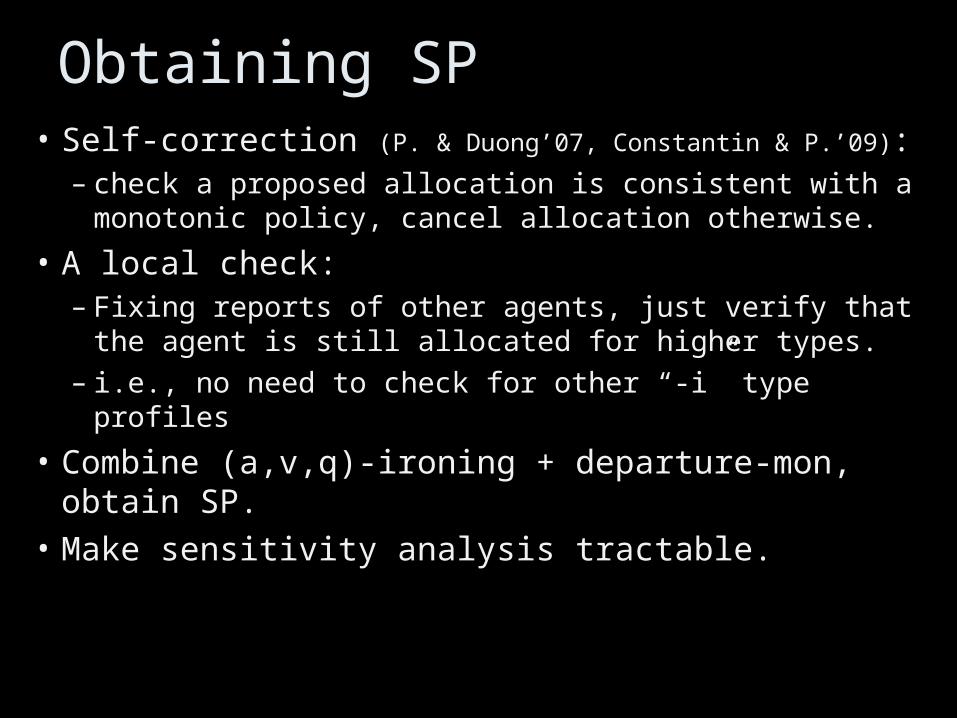
• Self-correction (P. & Duong’07, Constantin & P.’09):– check a proposed allocation is consistent with a
monotonic policy, cancel allocation otherwise.
• A local check:– Fixing reports of other agents, just verify that the
agent is still allocated for higher types.– i.e., no need to check for other “-i” type profiles
• Combine (a,v,q)-ironing + departure-mon, obtain SP.
• Make sensitivity analysis tractable.
Obtaining SP
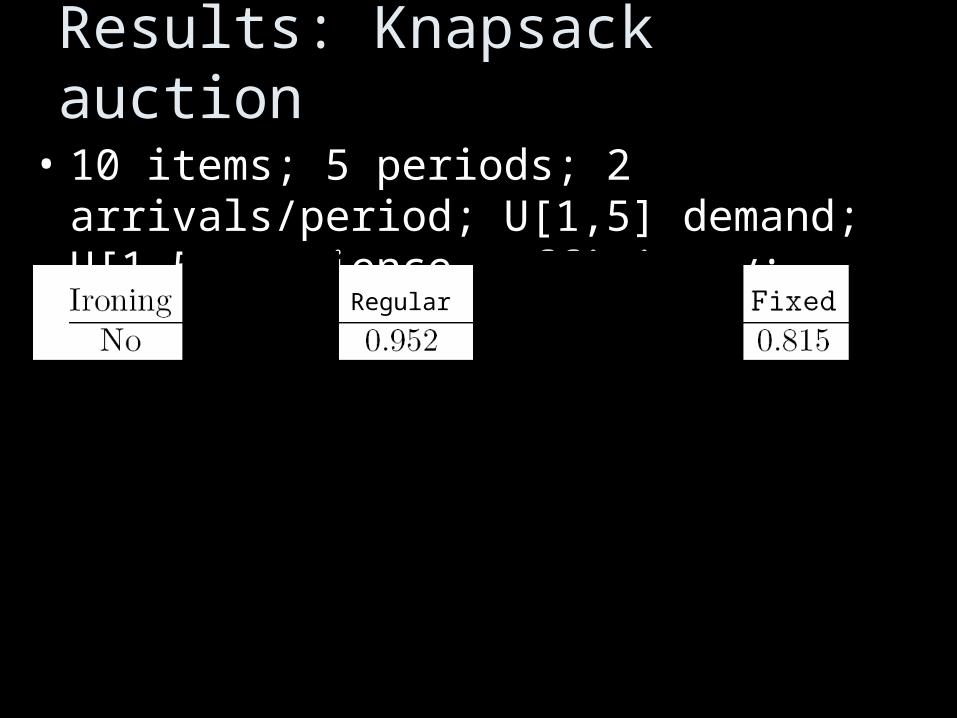
Results: Knapsack auction
• 10 items; 5 periods; 2 arrivals/period; U[1,5] demand; U[1,5] patience. Efficiency:
Regular
Results: Knapsack auction
• 10 items; 5 periods; 2 arrivals/period; U[1,5] demand; U[1,5] patience. Efficiency:
Regular

Results: Knapsack auction
• 10 items; 5 periods; 2 arrivals/period; U[1,5] demand; U[1,5] patience. Efficiency:
Regular
strategyproof(via output-ironing)
consensus algorithm

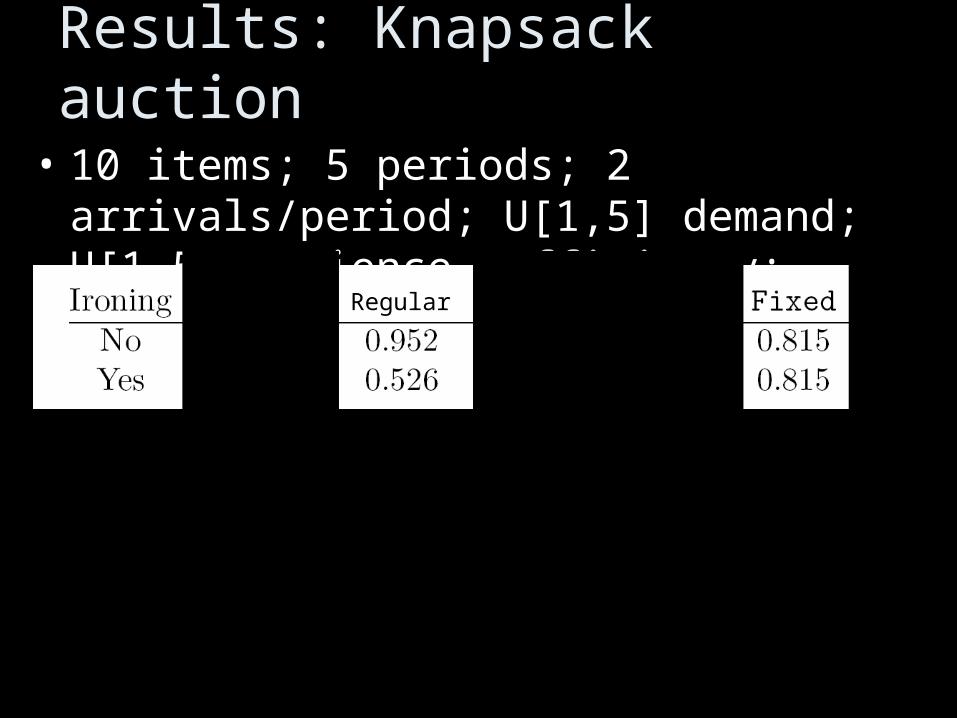
Results: Knapsack auction
• 10 items; 5 periods; 2 arrivals/period; U[1,5] demand; U[1,5] patience. Efficiency:
• Typical: IgnoDep <5% NowWait <5% OSCO
• w/ VVs; as much as 35% rev. improvement
Regular
strategyproof(via output-ironing)
consensus algorithm

CAs and CEs• NP-hard WD, but generally solvable on (current!)
problems of practical importance.• But, VCG mechanism not desirable:
– outside core for CAs– budget deficit for CEs
) can’t obtain SP together with desired computational approach.
• How should we set prices, to achieve “almost SP” and stability?

• Example: (A,$10), (B,$10), (AB,$15)• “It doesn’t matter”
– Just use first price, and in any NE agents will have an efficient outcome with core payoffs
– E.g., outcome (A,$6) (B,$9) (AB,$15)
Possible Answers

• Example: (A,$10), (B,$10), (AB,$15)• “It doesn’t matter”
– Just use first price, and in any NE agents will have an efficient outcome with core payoffs
– E.g., outcome (A,$6) (B,$9) (AB,$15)
• “At least minimize distance to VCG”– respecting no-deficit in CEs (Parkes et al.’01) – respecting core in CAs (Day & Milgrom ‘07)– E.g., outcome (A,$7.50) (B,$7.50)
Possible Answers

• Agent can always extract profit ¢vcg,i
• Regret = ¢vcg,i - ¢i
Example: Threshold rule
1 2 3 4
¢vcg,1
¢vcg,4 = b4 – pvcg,4
...
...
• pvcg,i = bid - ¢vcg,i
(Parkes et al.’01)
¢1

• Agent can always extract profit ¢vcg,i
• Regret = ¢vcg,i - ¢i
• Threshold rule minimizes max regret
• “²-SP” for minimal ². “Truthful most often,” for costly manipulation C.
Example: Threshold rule
1 2 3 4
¢i
¢vcg,1
¢vcg,4 = b4 – pvcg,4
...
...
• pvcg,i = bid - ¢vcg,i
(Parkes et al.’01)

A Surprise!• Single-minded. Computing approx. BNE
– c.f., Reeves & Wellman’04, Vorobeychik & Wellman ‘08, Rabinovich et al, ‘09

• max Count(¢i = 0)
• maximizes # of agents with nothing to gain
• ... also maximizes worst-case regret!
Small Rule
1 2 3 4

• Agent with type vi responds to distribution on strategic environments induced by F(b-i)
• Maximize expected utility: faces uncertainty– e.g., consider Eb-i
[ |¼i (vi, b-i)/vi| ]
– set prices to minimize expected marginal gain(c.f., Erdil & Klemperer’09)
• Sensitivity of bid price in distr., not regret.
A Bayesian viewpoint

• Agent with type vi responds to distribution on strategic environments induced by F(b-i)
• Maximize expected utility: faces uncertainty– e.g., consider Eb-i
[ |¼i (vi, b-i)/vi| ]
– set prices to minimize expected marginal gain(c.f., Erdil & Klemperer’09)
• Sensitivity of bid price in distr., not regret.
• SP mechanisms provide a reference ) try to “best conform” to payments in distribution!
A Bayesian viewpoint

• z = (p1, b1,... bn) instance
• H*(z), Hm(z): if ||H*(z), Hm(z)|| small then payments in m almost always = reference.
Distributional analysis

• z = (p1, b1,... bn) instance
• H*(z), Hm(z): if ||H*(z), Hm(z)|| small then payments in m almost always = reference.
• Simplify, obtain univariate distribution:
(p1, v1, ..., vn)
(¼1, v1, ..., vn)
(¼i, V)
(¼i / V)
Distributional analysis
where V is total value for allocation.

average ||H*, Hm ||over all environments

• 3 equilibrium x 3 environments x 6 rules
• 54 data points {(eff,metric), (shaving,metric)}
• corr(KL,eff) = -0.381; corr(KL,shave)=+0.379, both at 0.05 signif. level.
average ||H*, Hm ||over all environments
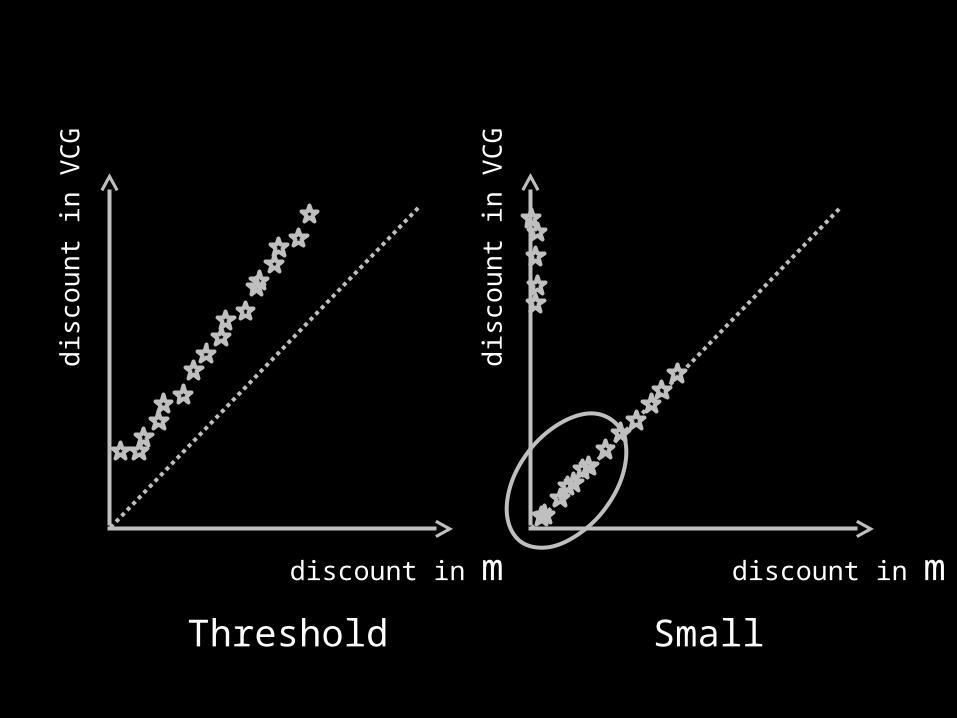
discount in m
dis
cou
nt i
n V
CG
dis
cou
nt i
n V
CG
discount in m
Threshold Small
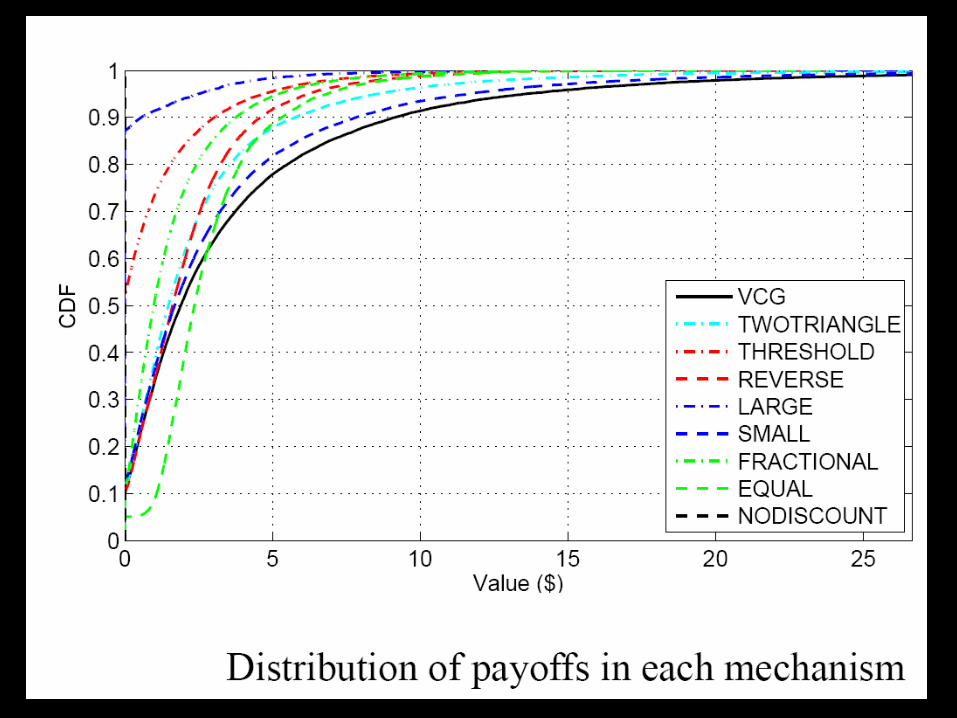

Summary: Heuristic approach• Start with good, cooperative algorithm• Modify it, or associate payments with it, to
achieve “good enough” SP, stability.– output ironing; reference mechanism fitting.
• Still need theory – in which problems can “local correction” work
in achieving SP?– a theory for “approximate SP”, “approximate
stability” and so forth,– alt. models of behavior
Thank you!





























