Embed Size (px)
Citation preview

NREL is a na*onal laboratory of the U.S. Department of Energy, Office of Energy Efficiency and Renewable Energy, operated by the Alliance for Sustainable Energy, LLC.
Heterogeneous CPU+GPU Molecular Dynamics Engine in CHARMM
25th March, GTC 2014, San Jose CA
AnE-‐Pekka Hynninen

2
What is CHARMM?
• Chemistry at HARvard Molecular Mechanics o Molecular simula*on package with wild range of features, force fields, and analysis methods
o Started late 1960s by Mar*n Karplus o Network of developers all over the world o Mostly Fortran 90 code
• Recently re-‐wriPen CPU Molecular Dynamics (MD) engine is now compeSSve in performance with other MD packages o A.-‐P. Hynninen, M. F. Crowley, Journal of Computa*onal Chemistry, 35, 406 (2014)

3
CHARMM approach to GPU MD engine
• Incremental o Started as a simple offload of the non-‐bonded force calcula*on
o Unable to rewrite the en*re 760 000 lines of Fortran code • Limited to ParScle Mesh Ewald (PME) simulaSons
o This is what most users want o Unable to support all CHARMM features from the get-‐go
• Modular o Core rou*nes wriZen as a standalone C++ library o Easy switch to different accelerator architecture (Intel Xeon Phi, AMD GPU)
• CPU code threaded with OpenMP • MPI used for MulS-‐CPU/GPU support

4
Domain decomposiSon method
4
bx
bz
by
bz Rcut
*K. J. Bowers, R. O. Dror, and D. E. Shaw, J. Comput. Phys., 221, p. 303 (2007).
• SimulaSon box is divided into sub-‐boxes of size bx x by x bz
• Single MPI task is assigned to each sub-‐box
• The MPI task is responsible for updaSng the coordinates within the sub-‐box (local-‐box)
• In order to calculate the forces, we need to coordinates from an import volume o Eighth-‐shell method by D.E. Shaw research*
• Import volume extends Rcut away from the local-‐box boundary in posSve x, y, and z direcSons
Local
Import

5
Domain decomposiSon method
bz Rcut
Local
Import
Local
bz Rcut
• Coordinates are communicated from all the MPI tasks that overlap with the import volume
MPI
MPI MPI
MPI
MPI
MPI
MPI
MPI
6
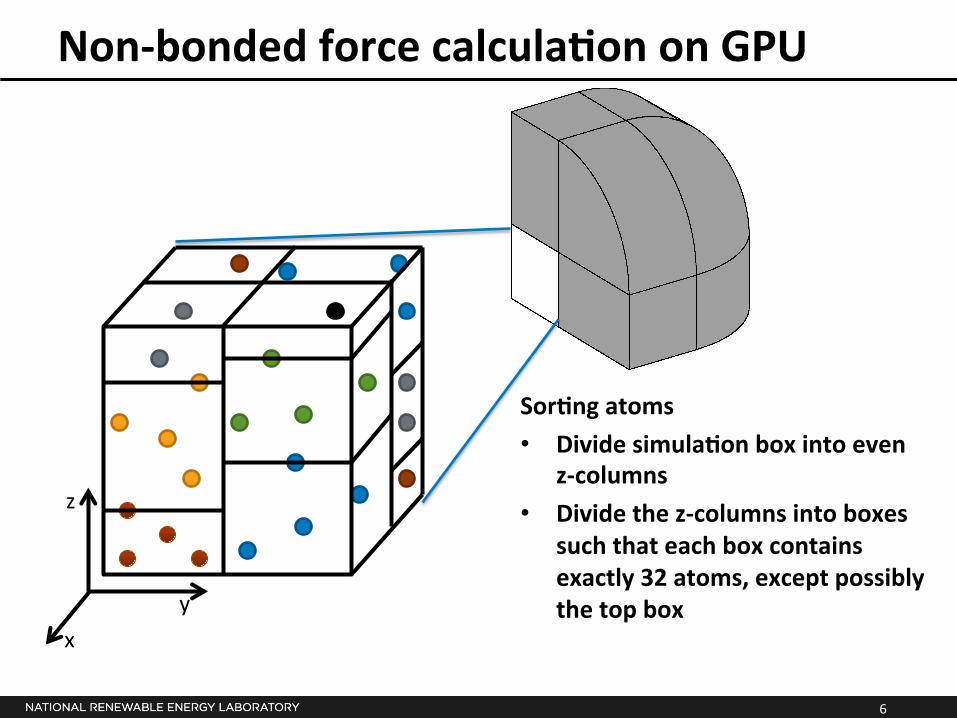
Non-‐bonded force calculaSon on GPU
SorSng atoms • Divide simulaSon box into even
z-‐columns • Divide the z-‐columns into boxes
such that each box contains exactly 32 atoms, except possibly the top box
z
y x

7
Neighborlist search
z
y
Rcut
• Neighborlist search finds interacSng pairs I – J • Neighborlist search is done on CPU using bounding boxes
o Detailed distance exclusions done on GPU o Topological exclusions done on CPU
• Non-‐bonded calculaSon on GPU is performed on the 32x32 Sle
I
J J
I
32
32
Excluded to avoid double coun*ng
Natom
Natom

8
Non-‐bonded force calculaSon on GPU
0 31 ...
0
31
...
i atoms
j atoms
• Single warp (32 threads) • Iterate t=0…31 and calculate interacSons in the 32x32 Sle • Thread p calculates the interacSon between atoms i[(p+t)%32] and j[p]
o Index i is offset by p to avoid race condi*on when wri*ng atom i forces
• Atom i coordinates are kept in shared memory, atom j coordinates are in registers • Exclusion mask (= 32 x 32bit integers) takes care of topological and distance
exclusions
t=0
t=31
...

9
Force and energy accumulaSon on GPU
• Force calculated in single precision (SP), accumulated in fixed precision (FP) o FP Q24.40 model used for direct non-‐bonded calcula*on (long long int)
o FP Q1.31 used for reciprocal grid (int) o Allows for fast force accumula*on using hardware integer atomic opera*ons
o No need for mul*ple force arrays and reduc*on
• Energy calculated in SP, accumulated in double precision (DP)
24 bits 40 bits 15.34762
10
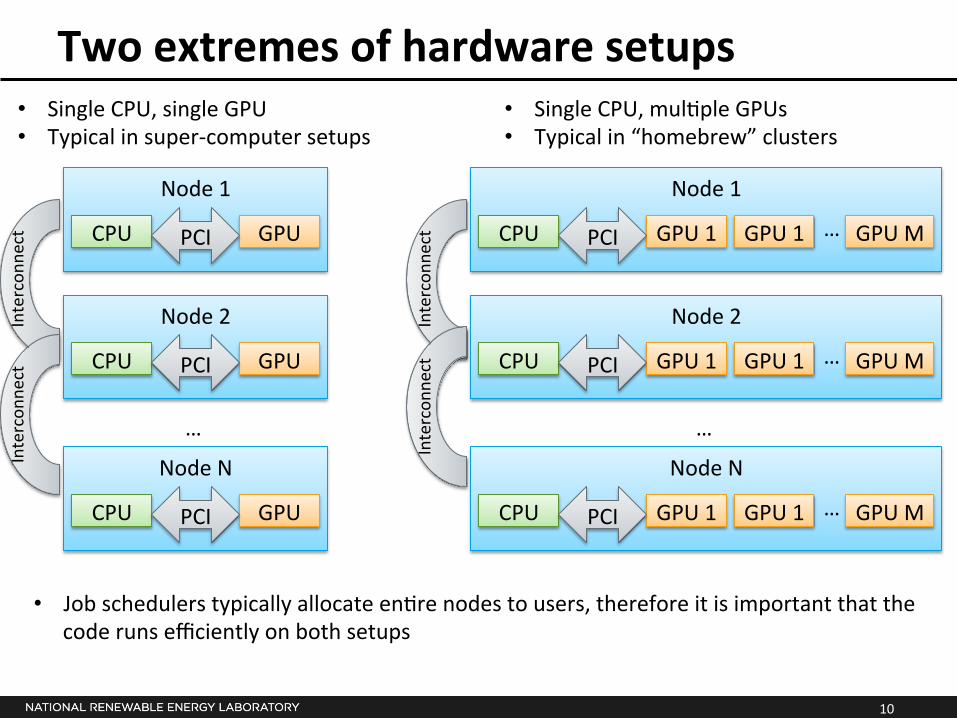
Two extremes of hardware setups • Single CPU, single GPU • Typical in super-‐computer setups
• Single CPU, mul*ple GPUs • Typical in “homebrew” clusters
Node 1
CPU GPU PCI
Intercon
nect
…
Node 2
CPU GPU PCI
Node N
CPU GPU PCI
Intercon
nect
Intercon
nect
…
Node 1
CPU GPU 1 PCI GPU 1 GPU M …
Node 2
CPU GPU 1 PCI GPU 1 GPU M …
Node N
CPU GPU 1 PCI GPU 1 GPU M …
Intercon
nect
• Job schedulers typically allocate en*re nodes to users, therefore it is important that the code runs efficiently on both setups
11
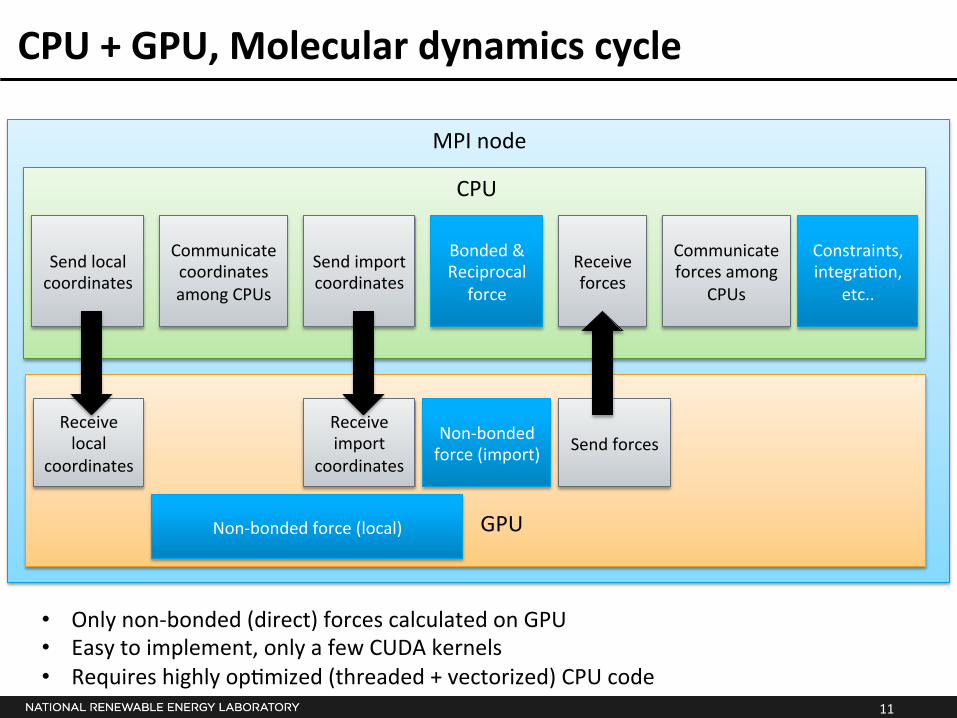
CPU + GPU, Molecular dynamics cycle
Bonded & Reciprocal
force
Non-‐bonded force (local)
Constraints, integra*on,
etc..
Send forces
Send local coordinates
Non-‐bonded force (import)
Receive local
coordinates
Communicate coordinates among CPUs
Send import coordinates
Receive import
coordinates
Receive forces
CPU
GPU
Communicate forces among
CPUs
MPI node
• Only non-‐bonded (direct) forces calculated on GPU • Easy to implement, only a few CUDA kernels • Requires highly op*mized (threaded + vectorized) CPU code
12
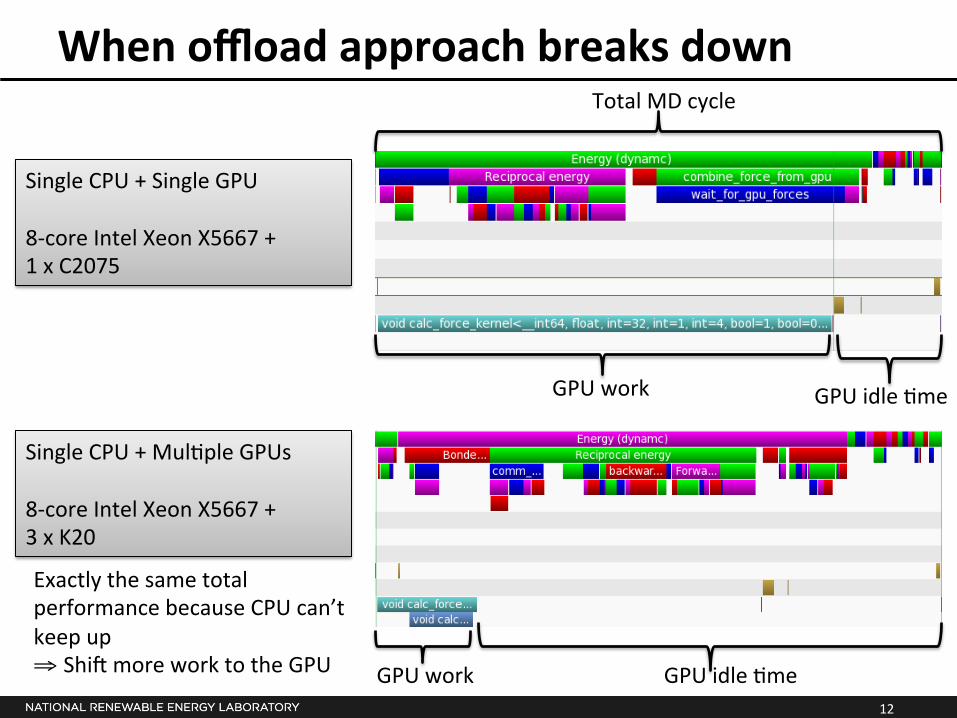
When offload approach breaks down
Single CPU + Single GPU 8-‐core Intel Xeon X5667 + 1 x C2075
Single CPU + Mul*ple GPUs 8-‐core Intel Xeon X5667 + 3 x K20
Exactly the same total performance because CPU can’t keep up ⇒ Shio more work to the GPU
GPU work
GPU work
Total MD cycle
GPU idle *me
GPU idle *me
13
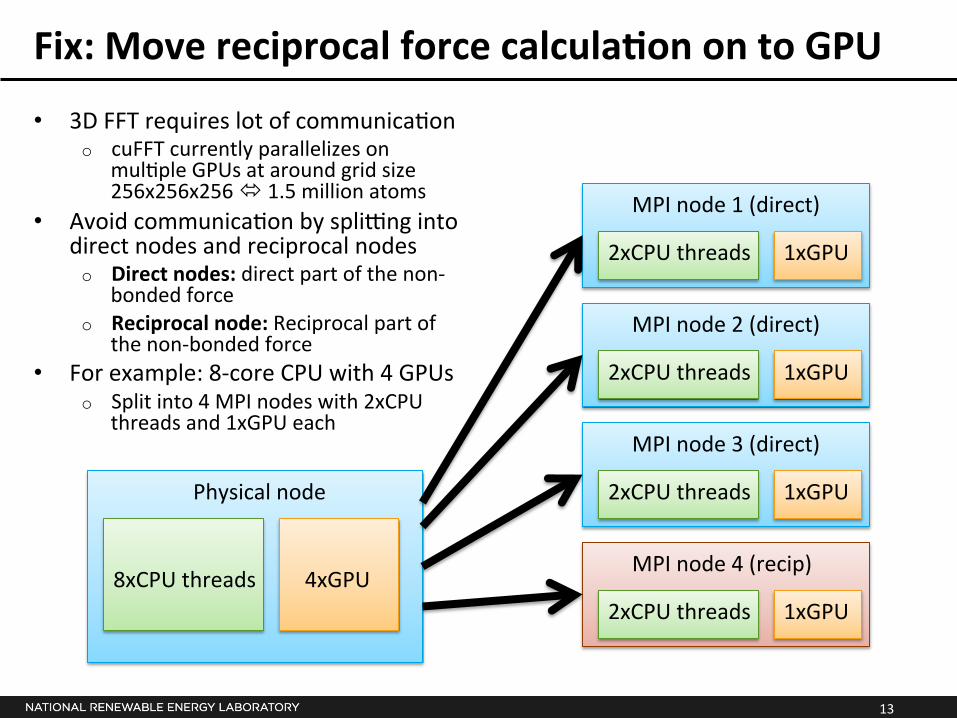
Fix: Move reciprocal force calculaSon on to GPU
• 3D FFT requires lot of communica*on o cuFFT currently parallelizes on
mul*ple GPUs at around grid size 256x256x256 ó 1.5 million atoms
• Avoid communica*on by splipng into direct nodes and reciprocal nodes o Direct nodes: direct part of the non-‐
bonded force o Reciprocal node: Reciprocal part of
the non-‐bonded force • For example: 8-‐core CPU with 4 GPUs
o Split into 4 MPI nodes with 2xCPU threads and 1xGPU each
2xCPU threads 1xGPU
MPI node 1 (direct)
8xCPU threads 4xGPU
Physical node
2xCPU threads 1xGPU
MPI node 2 (direct)
2xCPU threads 1xGPU
MPI node 3 (direct)
2xCPU threads 1xGPU
MPI node 4 (recip)
14
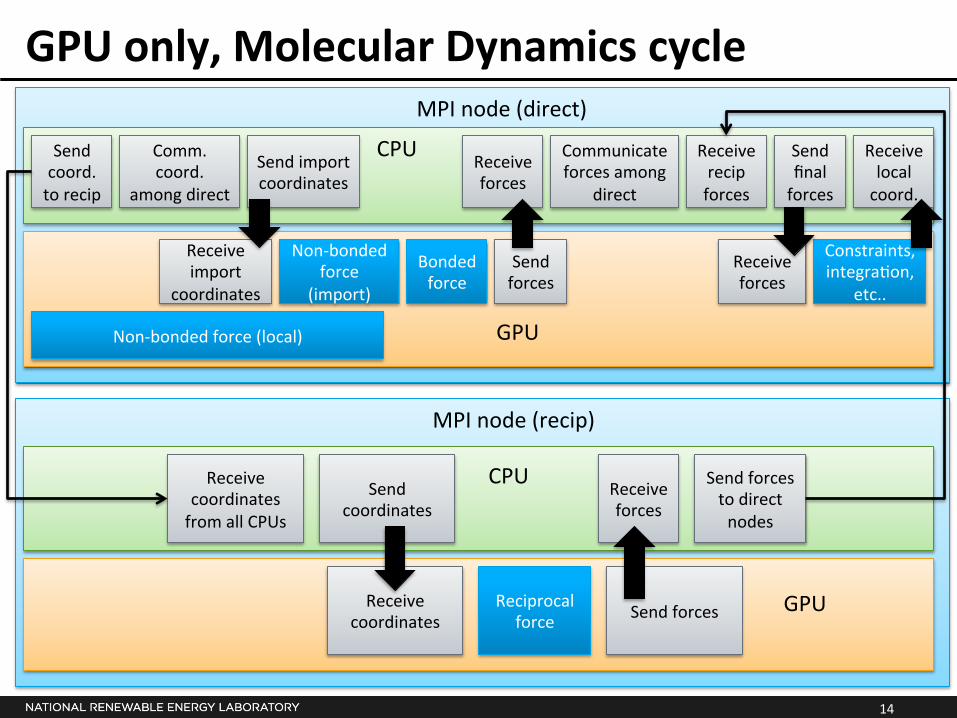
GPU only, Molecular Dynamics cycle
Bonded force
Non-‐bonded force (local)
Constraints, integra*on,
etc..
Send forces
Non-‐bonded force
(import)
Comm. coord.
among direct
Send import coordinates
Receive import
coordinates
Receive forces
CPU
GPU
Communicate forces among
direct
Send final forces
Receive forces
Reciprocal force
GPU
Receive coordinates from all CPUs
CPU Send coordinates
Receive coordinates Send forces
Receive forces
MPI node (direct)
MPI node (recip)
Send forces to direct nodes
Receive recip forces
Send coord. to recip
Receive local coord.
15
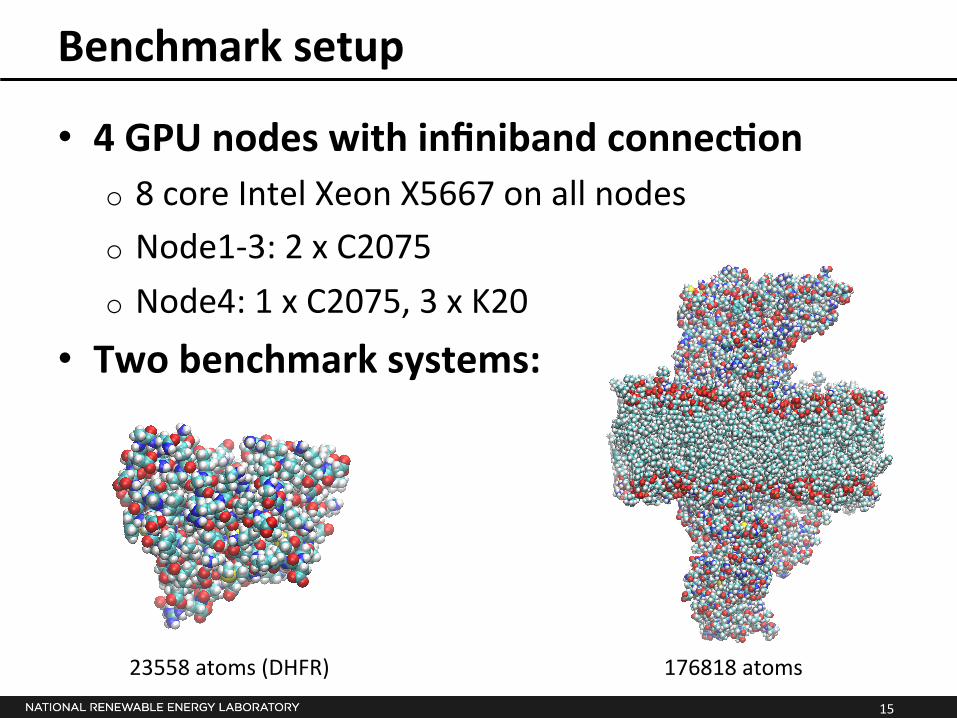
Benchmark setup
• 4 GPU nodes with infiniband connecSon o 8 core Intel Xeon X5667 on all nodes o Node1-‐3: 2 x C2075 o Node4: 1 x C2075, 3 x K20
• Two benchmark systems:
23558 atoms (DHFR) 176818 atoms
16
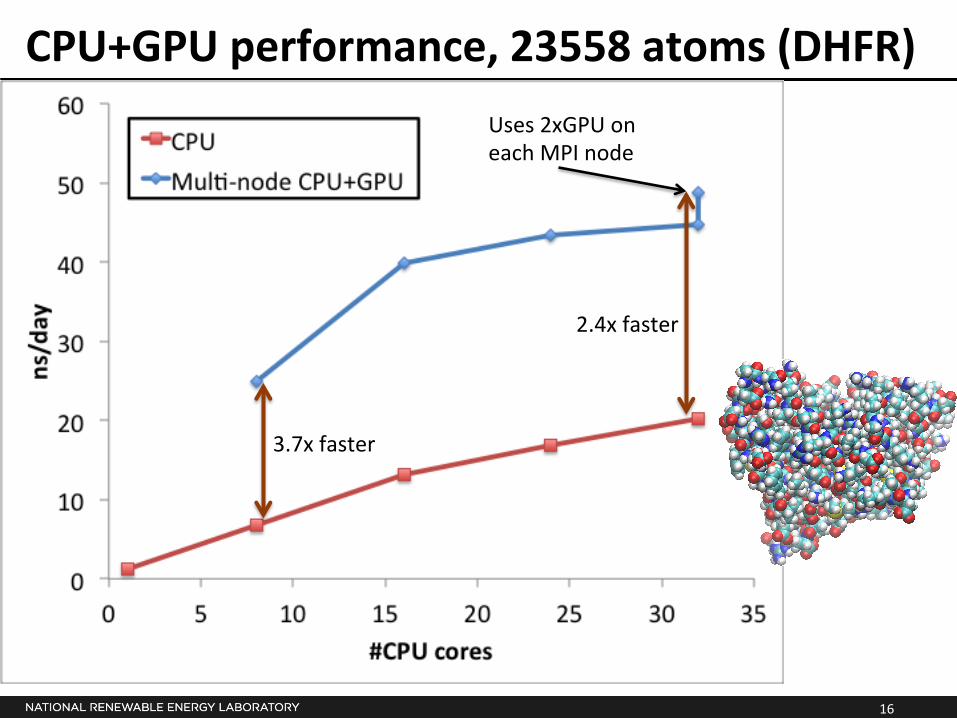
CPU+GPU performance, 23558 atoms (DHFR)
3.7x faster
2.4x faster
Uses 2xGPU on each MPI node

17
CPU+GPU Performance, 176818 atoms
9.3x faster
5.7x faster

18
Performance, 23558 atoms (DHFR)
1 direct 1 recip
2 direct 1 recip
19
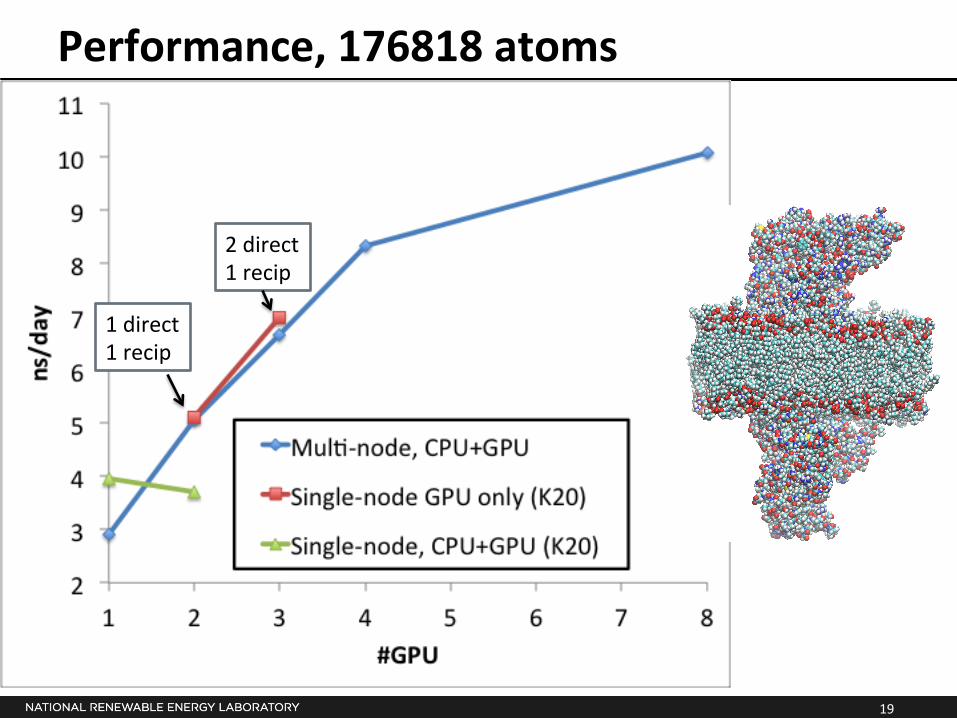
Performance, 176818 atoms
1 direct 1 recip
2 direct 1 recip

20
Conclusions & Future Work
• Heterogeneous CPU + GPU Molecular Dynamics engine implemented for CHARMM o Na*vely mul*-‐GPU capable
• Two ways of running the simula*on o CPU + GPU
– For setups with fast CPUs o GPU only
– For setups with fast GPUs – Split into direct + reciprocal nodes
• GPU only o BeZer load balancing by fusing
reciprocal node as one of the direct nodes
o CUDA aware MPI o Move neighbor list build on GPU
(when more efficient) o Single-‐GPU special case
• CPU + GPU o Tuning for supercomputer
setups
Conclusions Future Work
Acknowledgements: • Michael Crowley, NREL • Charles Brooks, University of Michigan • NVIDIA for hardware support • NIH for funding





























