Embed Size (px)
Citation preview

Hendrik J GroenewaldCentre for Text Technology (CTexT™)
Research Unit: Languages and Literature in the South African ContextNorth-West University, Potchefstroom Campus (PUK)
South AfricaE-mail: [email protected]
Using Technology Transfer to Advance Automatic Lemmatisation
for Setswana
31 March 2009; Athens

Hendrik J Groenewald
IntroductionLemmatisation
MethodologyConclusion
Overview
31 March 2009; Athens
• Introduction• Lemmatisation
– Lemmatisation in Setswana– Lemmatisation in Afrikaans
• Methodology– Memory-based Learning– Architecture– Data– Implementation
• Conclusion

Hendrik J Groenewald
IntroductionLemmatisation
MethodologyConclusion
Introduction I
• South Africa has 11 official languages– English has the most HLT resources
• Situation is changing
• SA Government is supporting initiatives to develop core linguistic resources and technologies
31 March 2009; Athens

Hendrik J Groenewald
IntroductionLemmatisation
MethodologyConclusion
Introduction II
• Focus: Using technology transfer for– Improving existing linguistic resources– Fast-tracking development
• Improving an existing Setswana lemmatiser by applying a method developed for Afrikaans
31 March 2009; Athens

Hendrik J Groenewald
IntroductionLemmatisation
MethodologyConclusion
OverviewSetswanaAfrikaans
Lemmatisation: Overview
• Process whereby the inflected forms of a word are converted/normalised under the lemma or base form– swim, swimming, swam -> swim
• Lemmatisation is an important process for many NLP tasks– Information Retrieval– Morphological Analysis
31 March 2009; Athens

Hendrik J Groenewald
IntroductionLemmatisation
MethodologyConclusion
OverviewSetswanaAfrikaans
Lemmatisation: Overview
• Not to be confused with Stemming– The process whereby a word is reduced to its
stem by removing both inflectional and derivational morphemes
• Two popular approaches to lemmatisation– Rule-based approach– Statistically/data-driven approach
31 March 2009; Athens

Hendrik J Groenewald
IntroductionLemmatisation
MethodologyConclusion
OverviewSetswanaAfrikaans
Lemmatisation: Setswana
• First Automatic Lemmatiser for Setswana developed by Brits (2006)– Found that only stems (and not roots) can act
independently as words– Stems should be accepted as lemmas
• Brits formalised rules for determining lemmas– Implemented as Finite-state transducers
• Accuracy: 62.17% when evaluated on a dataset containing 295 randomly selected words
31 March 2009; Athens

Hendrik J Groenewald
IntroductionLemmatisation
MethodologyConclusion
OverviewSetswanaAfrikaans
Lemmatisation: Afrikaans
• 2003: Ragel – Accuracy of 67% when evaluated on a 1,000 word data set
• Disappointing accuracy motivated development of another lemmatiser using a different approach
• New Lemmatiser called Lia – Based on data-driven machine learning method– 73,000 lemma-annotated words– Accuracy 92,8% on new data
• Motivated the application of machine learning methods for lemmatisation in Setswana
31 March 2009; Athens

Hendrik J Groenewald
IntroductionLemmatisation
MethodologyConclusion
Memory-based LearningArchitectureDataImplementation
Methodology: Memory-based Learning• Based on k-NN algorithm
– All instances of a certain problem correspond to points in a n-dimensional space
– Nearest neighbours computed by some form of distance metric
Xq
1-Nearest Neighbour
5-Nearest Neighbours
31 March 2009; Athens
Hendrik J Groenewald
IntroductionLemmatisation
MethodologyConclusion
Memory-based LearningArchitectureDataImplementation
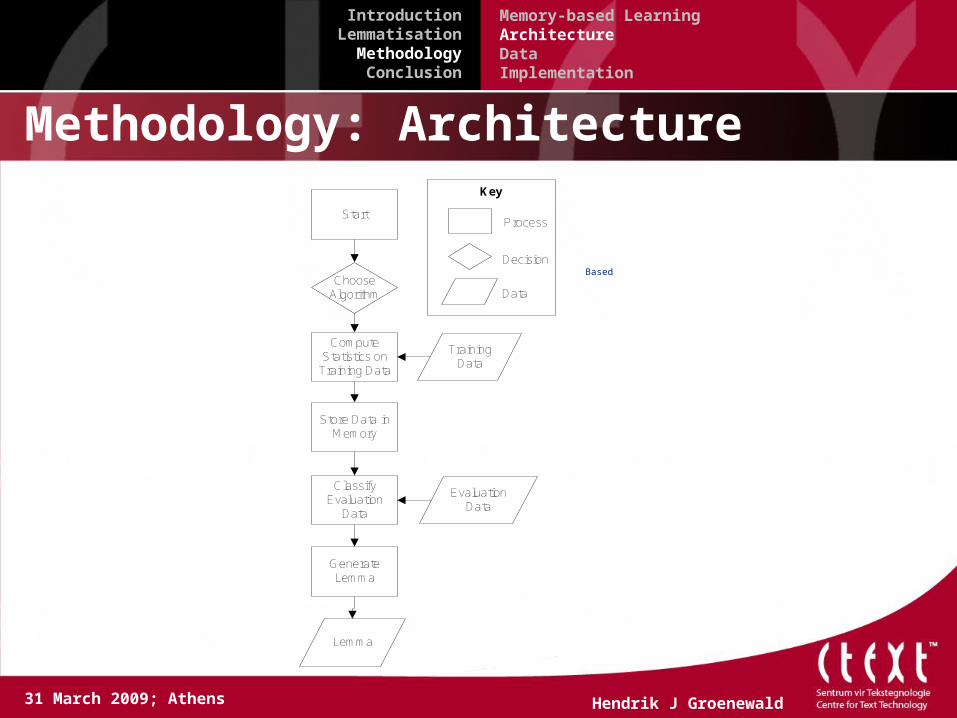
Methodology: Architecture
Based on k-NN algorithm– All instances of a certain problem correspond to points
in a n-dimensional space– Nearest neighbours computed by some form of
distance metric
Start
Choose Algorithm
Compute Statistics on
Training Data
Store Data in Memory
Classify Evaluation
Data
Generate Lemma
Lemma
Evaluation Data
Training Data
Process
Decision
Data
Key
31 March 2009; Athens

Hendrik J Groenewald
IntroductionLemmatisation
MethodologyConclusion
Memory-based LearningArchitectureDataImplementation
Methodology: Data
• MBL requires large amounts of data• Only 2,947 lemma-annotated Setswana words
available (Brits’s evaluation set)• 2,947 words are a very small data set in memory-
based learning terms
31 March 2009; Athens

Hendrik J Groenewald
IntroductionLemmatisation
MethodologyConclusion
Memory-based LearningArchitectureDataImplementation
Methodology: Data
• MBL requires that lemmatisation be performed as a classification task
• Data should consist of feature vectors with assigned class labels– Feature vectors: letters of the word– Class label: Transformation from word to lemma
31 March 2009; Athens

Hendrik J Groenewald
IntroductionLemmatisation
MethodologyConclusion
Memory-based LearningArchitectureDataImplementation
Methodology: Data
• Deriving class labels– Longest common substring– Indicates the string that needs to be removed, as well as possible
replacement strings during the transformation from word form to lemma– Positions of the character strings that need to be removed are indicated as
L (left) or R (right)– If the word form and lemma are identical, the awarded class is “0”
31 March 2009; Athens

Hendrik J Groenewald
IntroductionLemmatisation
MethodologyConclusion
Memory-based LearningArchitectureDataImplementation
Methodology: Data
• Deriving classes
31 March 2009; Athens

Hendrik J Groenewald
IntroductionLemmatisation
MethodologyConclusion
Memory-based LearningArchitectureDataImplementation
Methodology: Implementation• Data
– 90% for training– 10% for evaluation
• First version (default algorithmic parameters)– 46.25% Accuracy
• Parameter optimisation– 58.98%
• Accuracy is below that of the rule-based version of Brits
31 March 2009; Athens

Hendrik J Groenewald
IntroductionLemmatisation
MethodologyConclusion
Memory-based LearningArchitectureDataImplementation
Methodology: Implementation
• Error analysis indicated obvious mistakes
31 March 2009; Athens
Hendrik J Groenewald
IntroductionLemmatisation
MethodologyConclusion
Memory-based LearningArchitectureDataImplementation
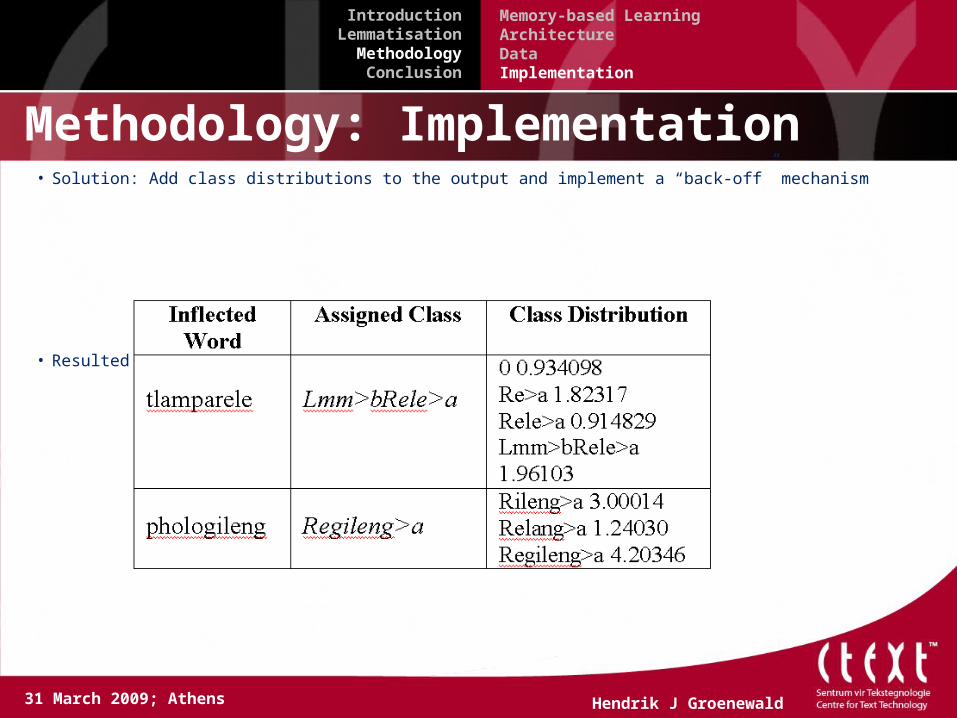
Methodology: Implementation• Solution: Add class distributions to the output and implement a “back-off” mechanism
• Resulted in a further increase in accuracy: 64.06%
31 March 2009; Athens

Hendrik J Groenewald
IntroductionLemmatisation
MethodologyConclusion
Conclusion• The machine learning-based lemmatiser is only 1.9% more accurate than the
rule-based version• Small in comparison to the 25% increase obtained for Afrikaans• Size of the training data
– 2,652 words compared to 73,000 for Afrikaans
• Increasing the amount of training data will increase the accuracy• Most important result: Technology Transfer
31 March 2009; Athens

Hendrik J Groenewald
IntroductionLemmatisation
MethodologyConclusion
Acknowledgements• The work of Jeanetta H. Brits, performed under
the supervision of Rigardt Pretorius and Gerhard B. van Huyssteen
31 March 2009; Athens





























