Embed Size (px)
Citation preview

HECToR User Group Meeting 2010
12 Oct 2010
Manchester

Phase 2b – Cray XT6
Current and Past Projects
SBLI
LUDWIG
HiGEM
GADGET
HELIUM
Future Projects
Cray XE6
GEMINI results
New Cray Centre of Excellence for HECToR website!
Cray Exascale Research Initiative Europe
Training and Conferences
HECToR User Group Meeting, 12 Oct, Manchester 14/10/2010 2

• Cray XT4 Compute Nodes• 3072 x 2.3 GHz Quad Core Opteron Nodes• 12,238 Cores• 8GB per node – 2GB per Core
• Cray X2 Compute Nodes• 28 x 4 Cray X2 Compute nodes• 32 GB per node 8GB per Core
• Cray XT6 Compute Nodes• 1856 x 2.1 GHz Dual 12 Core OpteronNodes• 44,544 Cores•32GB per node – 1.33 GB per Core
14/10/2010HECToR User Group Meeting, 12 Oct, Manchester 3

DDR3 Channel
DDR3 Channel
DDR3 Channel
DDR3 Channel
DDR3 Channel
DDR3 Channel
DDR3 Channel
DDR3 Channel
6MB L3
Cache
Greyhound
Greyhound
Greyhound
Greyhound
Greyhound
Greyhound
6MB L3
Cache
Greyhound
Greyhound
Greyhound
Greyhound
Greyhound
Greyhound
6MB L3
Cache
Greyhound
Greyhound
Greyhound
Greyhound
Greyhound
Greyhound
6MB L3
Cache
Greyhound
Greyhound
Greyhound
Greyhound
Greyhound
GreyhoundHT
3
HT
3
2 Multi-Chip Modules, 4 Opteron Dies
8 Channels of DDR3 Bandwidth to 8 DIMMs
24 (or 16) Computational Cores, 24 MB of L3 cache
Dies are fully connected with HT3
Snoop Filter Feature Allows 4 Die SMP to scale well
To Interconnect
HT3
HT3
HT3
HT1 / HT3
14/10/2010HECToR User Group Meeting, 12 Oct, Manchester 4
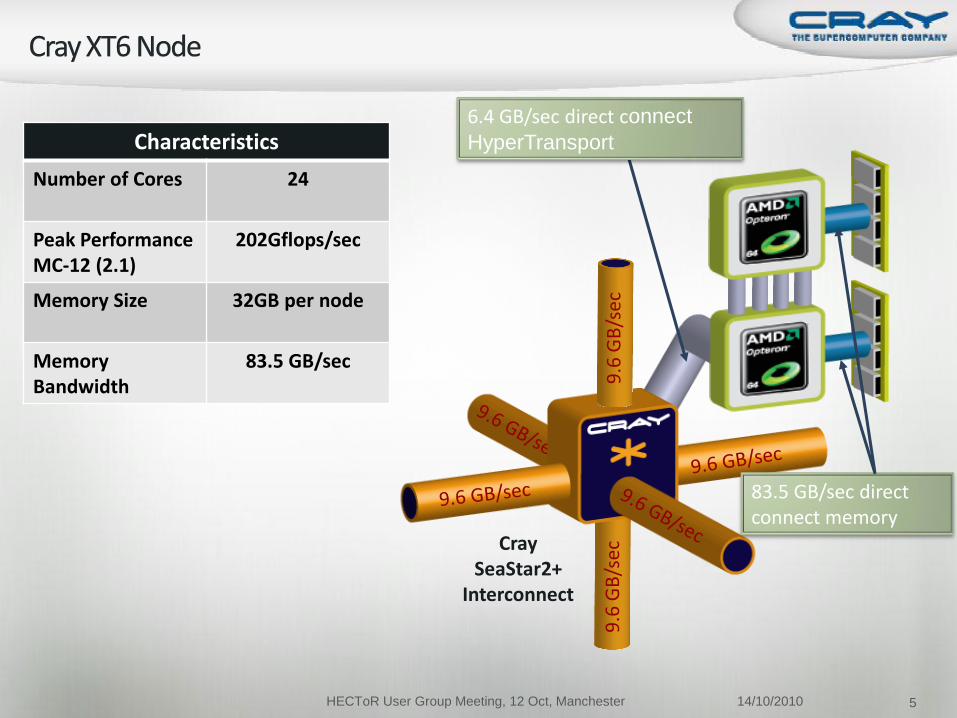
6.4 GB/sec direct connect
HyperTransport
CraySeaStar2+
Interconnect
83.5 GB/sec direct connect memory
Characteristics
Number of Cores 24
Peak Performance MC-12 (2.1)
202Gflops/sec
Memory Size 32GB per node
Memory Bandwidth
83.5 GB/sec
14/10/2010HECToR User Group Meeting, 12 Oct, Manchester 5

HECToR User Group Meeting, 12 Oct, Manchester 14/10/2010 6
HECToR User Group Meeting, 12 Oct, Manchester
0
2000
4000
6000
8000
10000
12000
14000
16000
18000
0 50000 100000 150000 200000 250000
Pe
rfo
rman
ce (
Mgr
id-p
oin
ts *
ite
rati
on
s/se
c)
Cores
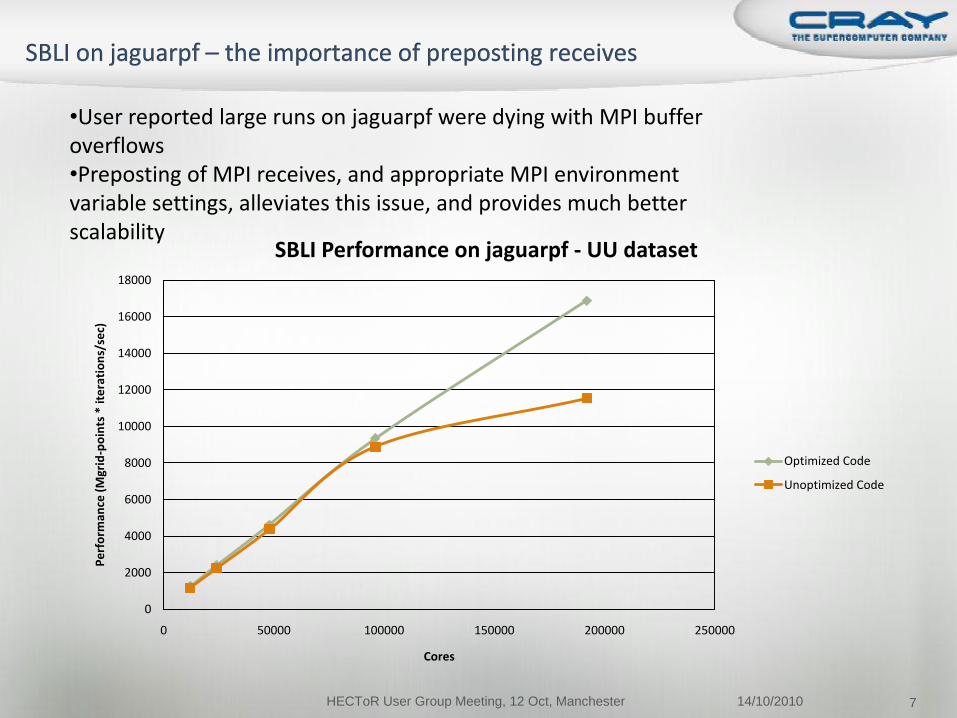
SBLI Performance on jaguarpf - UU dataset
Optimized Code
Unoptimized Code
•User reported large runs on jaguarpf were dying with MPI buffer overflows•Preposting of MPI receives, and appropriate MPI environment variable settings, alleviates this issue, and provides much better scalability
14/10/2010 7
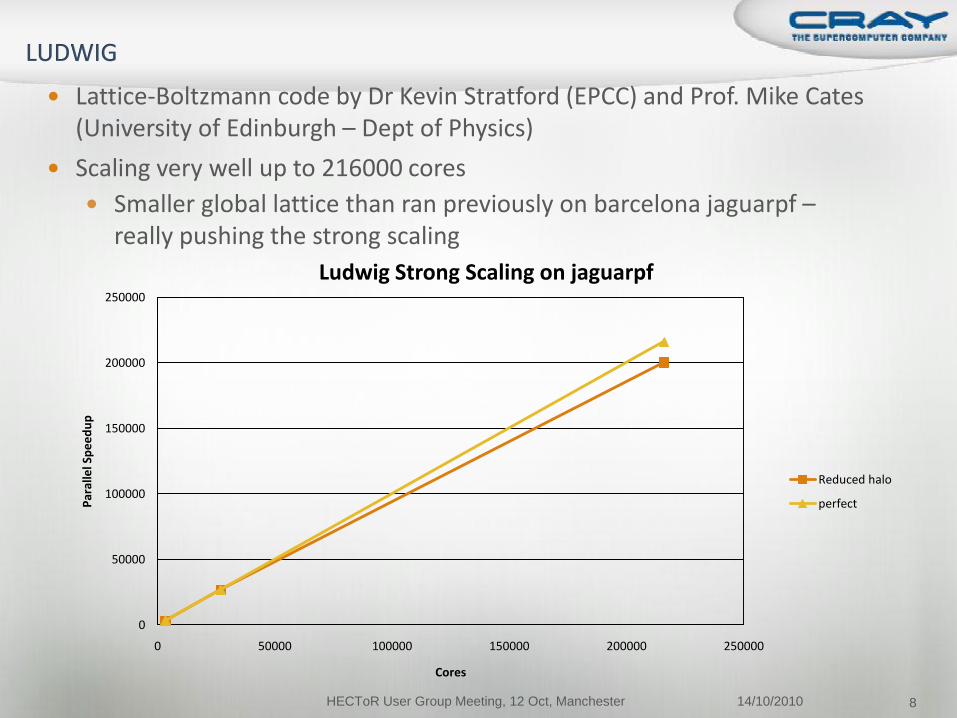
Lattice-Boltzmann code by Dr Kevin Stratford (EPCC) and Prof. Mike Cates (University of Edinburgh – Dept of Physics)
Scaling very well up to 216000 cores
Smaller global lattice than ran previously on barcelona jaguarpf –really pushing the strong scaling
HECToR User Group Meeting, 12 Oct, Manchester
0
50000
100000
150000
200000
250000
0 50000 100000 150000 200000 250000
Par
alle
l Sp
ee
du
p
Cores
Ludwig Strong Scaling on jaguarpf
Reduced halo
perfect
14/10/2010 8

Dr Len Shaffrey, University of Reading
High resolution coupled climate model
The CoE is collaborating with NCAS researchers to refine UM I/O performance
I/O servers now overlap communication and computation.
First stages complete
Currently applied to a single version of the Unified Model
Requires a moderate effort to back port code to earlier versions of the UM Large numbers of different versions of the UM being used on HECToR
I/O server technique has been employed in other applications as well –HELIUM, CARP
HECToR User Group Meeting, 12 Oct, Manchester 14/10/2010 9
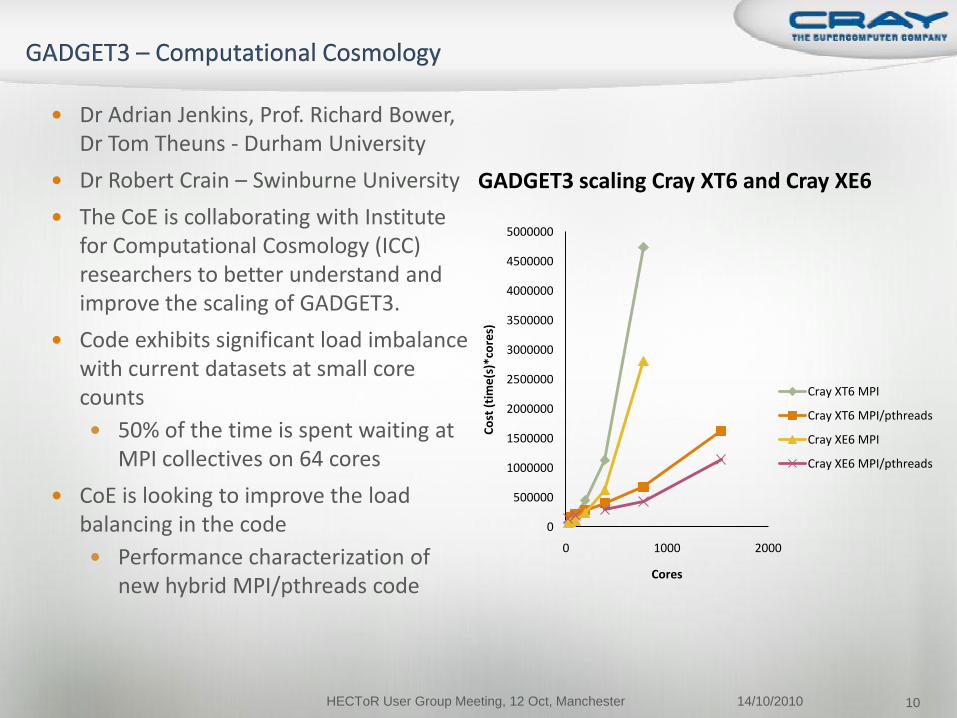
Dr Adrian Jenkins, Prof. Richard Bower, Dr Tom Theuns - Durham University
Dr Robert Crain – Swinburne University
The CoE is collaborating with Institute for Computational Cosmology (ICC) researchers to better understand and improve the scaling of GADGET3.
Code exhibits significant load imbalance with current datasets at small core counts
50% of the time is spent waiting at MPI collectives on 64 cores
CoE is looking to improve the load balancing in the code
Performance characterization of new hybrid MPI/pthreads code
HECToR User Group Meeting, 12 Oct, Manchester 14/10/2010 10
0
500000
1000000
1500000
2000000
2500000
3000000
3500000
4000000
4500000
5000000
0 1000 2000
Co
st (
tim
e(s
)*co
res)
Cores
GADGET3 scaling Cray XT6 and Cray XE6
Cray XT6 MPI
Cray XT6 MPI/pthreads
Cray XE6 MPI
Cray XE6 MPI/pthreads

Collaboration with Prof. Ken Taylor, Queen’s University Belfast
CoE work involved implementation of an I/O server
Work reported at the Cray User Group in Edinburgh – May 2010
“Optimising Application Performance using I/O Servers on Cray XT Technology”
Use of I/O server allows for full overlap of I/O with computation and communication
I/O time hidden as I/O requests are offloaded to dedicated I/O servers
HECToR User Group Meeting, 12 Oct, Manchester
0
50
100
150
200
100 1000 10000
Tim
e (
s)
cores
HELIUM I/O Performance
I/O servers
no I/O servers
14/10/2010 11

Both of the 800 nm runs were successful.
Both required 16,110 cores - near the maximum available on HECToR.
The results confirmed present understanding of the high-energy cutofflaw.
The results were consistent with results at 390nm, 248nm, and 195nm.
Calculations at higher intensities are not really feasible on 16,110 cores of HECToR, and remain very much a grand challenge.
HECToR User Group Meeting, 12 Oct, Manchester 14/10/2010 12
HECToR User Group Meeting, 12 Oct, Manchester 14/10/2010 13

Supports 2 Nodes per ASIC
168 GB/sec routing capacity
Scales to over 100,000 network endpoints
Link Level Reliability and Adaptive Routing
Advanced Resiliency Features
Provides global address space
Advanced NIC designed to efficiently support
MPI
One-sided MPI
Shmem
UPC, Coarray FORTRAN
HECToR User Group Meeting, 12 Oct, Manchester
LOProcessor
Gemini
Hyper
Transport 3
NIC 0
Hyper
Transport 3
NIC 1
Netlink
BlockSB
48-Port
YARC Router
14/10/2010 14

HECToR User Group Meeting, 12 Oct, Manchester
10 12X GeminiChannels
(Each Gemini acts like two nodes on
the 3D Torus)
Cray XE6 Node Characteristics
Number of Cores
16 or 24MC
Peak Performance
210 Gflops
Memory Size 32 or 64 GB
Memory Bandwidth
85 GB/s
High RadixYARC Router
with adaptiveRouting
168 GB/seccapacity
14/10/2010 15

Module with SeaStar
Module with Gemini
Y
X
Z
HECToR User Group Meeting, 12 Oct, Manchester 14/10/2010 16

Like SeaStar, Gemini has a DMA offload engine allowing large transfers to proceed asynchronously
Gemini provides low-overhead OS-bypass features for short transfers MPI latency around 1.4us in current release NIC provides for many millions of MPI messages per second – 20 times better than
Seastar
Much improved one-sided communication mechanism with hardware support
AMOs provide a faster synchronization method for barriers
Gemini supports adaptive routing, which Reduces problems with network hot spots Allows MPI to survive link failures
Much improved injection bandwidth – 6 GB/s user data injection with HT3 link
HECToR User Group Meeting, 12 Oct, Manchester 14/10/2010 17

Globally addressable memory provides efficient support for UPC, Co-array FORTRAN, Shmem and Global Arrays Cray compiler targets this capability directly
Pipelined global loads and stores Allows for fast irregular communication patterns
Atomic memory operations Provides fast synchronization needed for one-sided
communication models
HECToR User Group Meeting, 12 Oct, Manchester 14/10/2010 18

14/10/2010HECToR User Group Meeting, 12 Oct, Manchester 19
0
20
40
60
80
100
120
0 500 1000 1500 2000 2500
(Mgr
id p
oin
ts *
ite
rati
on
s/se
c)
cores
SBLI T1 dataset Cray XE6 and Cray XT6
Cray XT6
Cray XE6

14/10/2010HECToR User Group Meeting, 12 Oct, Manchester 20

http://www.hector.ac.uk/coe/
HECToR User Group Meeting, 12 Oct, Manchester 14/10/2010 21

Launched December 2009
Initial research partners are EPCC and CSCS
Cray increased Edinburgh based team with Alistair Hart and Harvey Richardson
Exploring how real applications can exploit future Exascalearchitectures, specifically:
Programming models for PGAS languages
Programming GPU accelerators
Improved algorithms for FFTs
Network and I/O profiling
Strong interactions with Cray R&D
14/10/2010HECToR User Group Meeting, 12 Oct, Manchester 22

CUG 2010 24-27 May
Using I/O servers to improve performance on Cray XT technology– Tom Edwards and Kevin Roy
NAIS HPC Workshop 23-24 June
PGAS Programming with UPC and Fortran coarrays – Jason Beech-Brandt and Harvey Richardson
DEISA Training Course 14-16 September
Performance Optimization on Cray XT Systems
Coarray Fortran Tutorial
Hybrid Manycore Programming and Accelerators in High Performance Computing 22 October
Challenges in Programming Multicore and Accelerated Nodes – John Levesque and Alistair Hart
SC10
Poster - Performance Tuning of Scientific Applications on HPC Systems
Poster – GPU Acceleration of Scientific Applications
Tutorial – Introduction to Coarray Fortran
EPCC MSc project supervision
Global Arrays and NWChem Tuning on the Cray XT – Jason Beech-Brandt
Co-arrays for sparse matrix methods – Tom Edwards
Visits to NAG and Daresbury and various user sites (Reading, Southampton, Durham, Cambridge amongst others)HECToR User Group Meeting, 12 Oct, Manchester 14/10/2010 23
Questions?
Jason Beech-Brandt: [email protected]
Tom Edwards: [email protected]
Kevin Roy: [email protected]
HECToR User Group Meeting, 12 Oct, Manchester 14/10/2010 24





























