Embed Size (px)
Citation preview

Hash VerificationA key part of working on a forensic investigation is being able to prove that none of the evidence has been altered. To do this, one thing digital forensic scientists can do is verify hashes.
By verifying hashes they are able to prove that the evidence they recovered is the same as the original data as well as determine whether similar data is identical

In this module, you will learn:
1. What hashes are?
2. Where you can see them?
3. What they can be used for?
4. Most importantly, how to generate them?

What is a hash?• A hash is a value returned by a hash function, which is an algorithm that
turns something of variable size into an output of a fixed size. A simpler way to think of a hash would be as a fingerprint for a piece of data such as a file or image. Just like no two humans have the same fingerprint, no two distinct pieces of data can have the same hash*.
• The two most common types of hashes are MD5 and SHA-1.• MD5 stands for Message Digest algorithm 5. This type of hash generates
a 128-bit hash value, meaning that the value is expressed as a 32 digit hexadecimal number as shown below:d41d8cd98f00b204e9800998ecf8427e
• SHA-1 stands for Secure Hash Algorithm 1. This type of hash generates a 160-bit hash value. This means that the value is expressed as a 40 digit hexadecimal number as shown below:b48cf0140bea12734db05ebcdb012f1d265bed84
• *There are some, extreme cases when two different pieces of data can have the same hash. This is called Collision, and is not covered here.

Where do you see them?• When downloading something from the internet,
you will often see a random looking line of text near the download. That random line of text is a hash. Here is a sample from the CSAW website:
• Download Evidence Here [Direct and Torrent]: http://isis.poly.edu/~egavas/csaw2013-hsf/Download SHA1: 1861d664c1516a6a3e77627832e203deeeb0b049
• Note: that sometimes the provider will specify the presence of a hash, but other times, the string will appear alone.

What can they be used for?• Since no two hashes can be the same*, hashes come
in handy during digital forensic investigations when a file or image appears in more than one place.
• Hashes are also helpful in proving that evidence has not been altered since the hash for the original artifact and the hash of the examined artifact can be compared. (If they match, nothing has been compromised!)
• *There are some, extreme cases when two different pieces of data can have the same hash. This is called Collision, and is not covered here.

Sample Challenge:• Now that you know a little bit about hashing,
let’s make sure you really understand.• Here are two images:
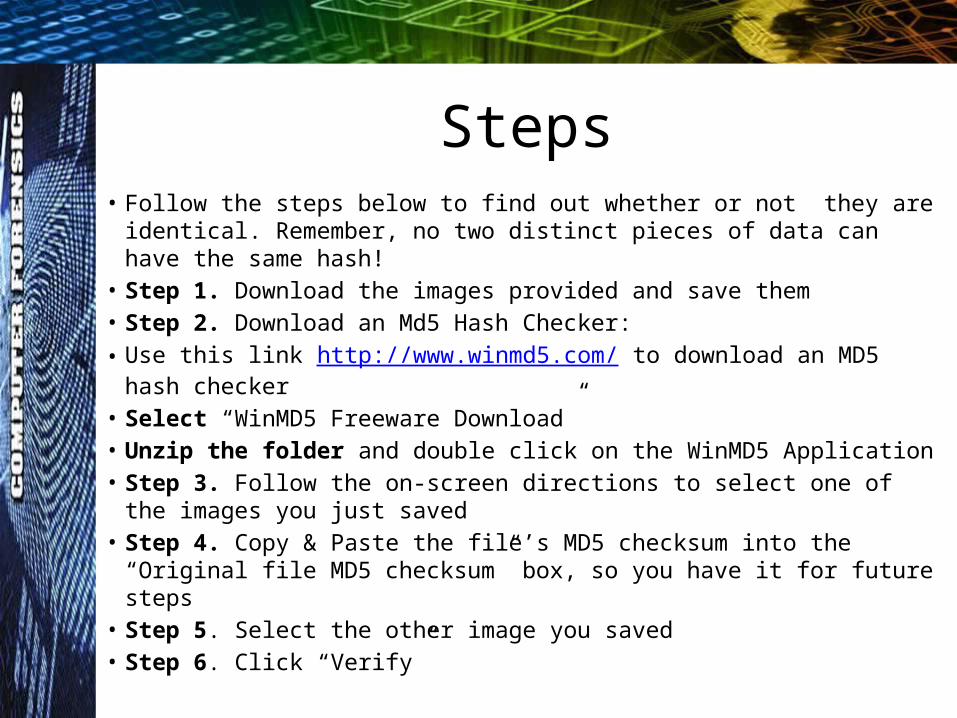
Steps• Follow the steps below to find out whether or not they are identical.
Remember, no two distinct pieces of data can have the same hash!• Step 1. Download the images provided and save them• Step 2. Download an Md5 Hash Checker:• Use this link http://www.winmd5.com/ to download an MD5 hash
checker• Select “WinMD5 Freeware Download”• Unzip the folder and double click on the WinMD5 Application• Step 3. Follow the on-screen directions to select one of the images
you just saved• Step 4. Copy & Paste the file’s MD5 checksum into the “Original file
MD5 checksum” box, so you have it for future steps• Step 5. Select the other image you saved• Step 6. Click “Verify”

Do the two hashes match?• The hashes should not match. While the images
look the same, I retrieved them from two different websites! The images are not exactly the same. You can use a checker like this one to verify the hashes of all sorts of data including audio files, document files, and even video files.
• For more information, and more tools, please
visit the module for md5deep & hashdeep

Image hashing• While normally hashing a file hashes the
individual bits of data of the file, image hashing works on a slightly higher level. The difference is that with image hashing, if two pictures look practically identical but are in a different format, or resolution (or there is minor corruption, perhaps due to compression) they should hash to the same number. Despite the actual bits of their data being totally different, if they look practically identical to a human, they hash to the same thing.

TinEye.com• One application of this is search. TinEye.com allows
you to upload an image and find many of its occurrences on the internet. like google, it has a web crawler that crawls through web pages and looks for images. It then hashes these images and stores the hash and url in a database. When you upload an image, it simply calculates the hash and retrieves all the urls linking to that hash in the database. Sample uses of TinEye include finding higher resolution versions of pictures, or finding someone's public facebook/myspace/etc. profile from their picture (assuming these profiles use the same photo.

Image hashing• Image hashing can also be used with caching
or local storage to prevent retransmission of a photo or storage of duplicates, respectively.
• There are plenty of other possibilities including image authentication and finding similar frames in a video

Hash Verification• What is a Hash Value?• A hash value is a result of a calculation (hash algorithm) that can
be performed on a string of text, electronic file or entire hard drives contents. The result is also referred to as a checksum, hash code or hashes. Hash values are used to identify and filter duplicate files (i.e. email, attachments, and loose files) from an ESI collection or verify that a forensic image or clone was captured successfully.
• Each hashing algorithm uses a specific number of bytes to store a “ thumbprint” of the contents. The following is a list of hash values for the same text file. Regardless of the amount of data feed into a specific hash algorithm or checksum it will return the same number of characters. For example, an MD5 hash uses 32 characters for the thumbprint whether it’s a single character in a text file or an entire hard drive.

HASHMD5: 464668D58274A7840E264E8739884247SHA-1: 4698215F643BECFF6C6F3D2BF447ACE0C067149ESHA-256: F2ADD4D612E23C9B18B0166BBDE1DB839BFB8A376ED01E32FADB03A0D1B720C7SHA-384:2707F06FE57800134129D8E10BBE08E2FEB622B76537A7C4295802FBB94755BBEE814B101ED18CC2D0126BD66E5D77B6SHA-512:C526BC709E2C771F9EC039C25965C91EAA3451A8CB43651EA4CD813F338235F495D37891DD25FE456FE2A8CA89457629378BE63FB3A9A5AD54D9E11E4272D60CRIPEMD-128: A868B98EAEC84891A7B7BA620EDDE621TIGER: F31A22CEED5848E69316649D4BAFBE8F9274DED53E25C02DPANAMA: 7E703B1798A26A0AF21ECD661CBADB9C72B419455814CA7B82E29EE0C03FA493CHECKSUMCRC16: 117CCRC32: FA2D47D4ADLER32: CF7D65FFAs you can see there are also various length hashes within a family (SHA-1, SHA-256 et.) The most common hash values are MD5, SHA-1 and SHA-256. The longer hash values require more time to calculate and are designed to reduce the probability of a collision.

From PinPoint Labs Blog

A few other ways that hash values are used:
• - Verify a downloaded file was created by the publisher (oppose to a virus infected version)
• - Identify and filter files on the NSRL/NIST list (“deNISTing”)
• - Locate known contraband (illegal images and videos)

Here are a few reasons why hash values are so widely used as a means to validate and compare content:
• 1) Privileged Data – There would be obvious issues storing and providing multiple copies of the contents of a company’s files or entire hard drives data in a database to perform a byte comparison. Not to mention illegal images and videos (child pornography) would have to be stored and used in each system scan. These scenarios are unacceptable.
• 2) Speed – Comparing an indexed hash value versus what could be billions or trillions of bytes or source data is much quicker. Optimized hash engines (Pinpoint Harvester) can compare thousands of hash values in a second.
• 3) Security – Hashing data is a one way trip. The original data can’t be recreated or reverse engineered from the hash value. This provides additional security that a person can’t determine the source data from the hash.

Things to think of• The argument that data sources could be different and have the same hash
value has raised a lot of concern. There are countless threads related to this issue on the litigation support and computer forensic forums. The bottom line is the only way to do an exact comparison of the original data is to store it everywhere you need to deduplicate or verify the information, however, as mentioned about this isn’t a practical alternative.
• More complex hashing functions have been introduced (SHA-256, SHA-512 etc.) which will further reduce the likely hood of a collision. It is also worth noting that even in those cases where scientists have created collisions it was a result of exploiting the weaknesses in a specific hash algorithm. The same alterations would not create a collision in a different hashing algorithm.
• So, if you still aren’t satisfied with the incredibly remote possibility a collision could happen using a single hash value then the easiest way to implement an extra precaution is to take the time to have your processes calculate hash values from two separate algorithms (i.e. MD5/SHA256) for each item. Unfortunately, most EED applications and forensic imaging tools don’t support this option, especially in a single pass

What to Remember
• Hash values are a reliable, fast, and a secure way to compare the contents of individual files and media. Whether it’s a single text file containing a phone number or five terabytes of data on a server, calculating hash values are an invaluable process for Deduplication and evidence verification in electronic discovery and computer forensics.

Credits• NYC POLYTECHIC INSITUTE – Redistribution Policy: All of the material created by CyFor is intended for public usage. Please use, modify, and redistribute it as you wish. In addition, we encourage you to submit to CyFor any modifications you make so that others can benefit.
• PinPoint Labs Blog -















![Hash Functions and Hash Tablestcs/ds/lecture6.pdf · Hash Functions and Hash Tables A hash function h maps keys of a given type to integers in a fixed interval [0;:::;N -1]. We call](https://img.pdfslide.us/doc/110x75/5ade96e97f8b9a595f8e5db8/hash-functions-and-hash-tables-tcsds-functions-and-hash-tables-a-hash-function.jpg)













