Embed Size (px)
Citation preview

L3S Research Center, University of Hannover
Dynamics Dynamics ofof Distributed Hash Distributed Hash TablesTables
WolfWolf--TiloTilo Balke and Wolf Balke and Wolf SiberskiSiberski21.11.200721.11.2007
1Peer-to-Peer Systems and Applications, Springer LNCS 3485
*Original slides provided by S. Rieche, H. Niedermayer, S. Götz, K. Wehrle (University of Tübingen)and A. Datta, K. Aberer (EPFL Lausanne)
Overview
1. CHORD (again)
2 New node joins: Stabilization2. New node joins: Stabilization
3. Reliability in Distributed Hash Tables
4. Storage Load Balancing in Distributed Hash Tables
2Distributed Hash TablesL3S Research Center
5. The P-GRID Approach

Distributed Hash Tables
Distributed Hash Tables (DHTs)Also known as structured Peer-to-Peer systems
Efficient, scalable, and self-organizing algorithms
For data retrieval and management
Chord (Stoica et al., 2001)Scalable Peer-to-peer Lookup Service for Internet Applications
Nodes and data are mapped with hash function on a Chord ring
3Distributed Hash TablesL3S Research Center
RoutingRouting (“Finger”) - Tables
O (log N)
CHORD
A consistent hash function assigns each node and each key an m-bit identifier using SHA 1 (Secure Hash Standard).
b bi h t k lli i i b blm = any number big enough to make collisions improbable
Key identifier = SHA-1(key)
Node identifier = SHA-1(IP address)
Both are uniformly distributed
Both exist in the same ID space
4Distributed Hash TablesL3S Research Center

CHORD
Identifiers are arranged on a
closed identifier circle ( d l 26) (e.g. modulo 26)
=> Chord Ring
5Distributed Hash TablesL3S Research Center
CHORD
A key k is assigned to the
node whose identifier is equal
to or greater than the key‘s g y
identifier
This node is called
successor(k) and is the first
node clockwise from k
6Distributed Hash TablesL3S Research Center

CHORD
// ask node n to find the successor of id
n.find_successor(id)
if (id (n; successor])
return successor;
else
// forward the query around the
circle
return successor.find_successor(id);
7Distributed Hash TablesL3S Research Center
=> Number of messages linear in the number of nodes !
CHORD
Additional routing information to accelerate lookups
Each node n contains a routing table with up to m entries (m: number of bits of the identifiers) => finger table
ith entry in the table at node n contains the first node s that succeeds n by at least 2
s = successor (n + 2i-1)
8Distributed Hash TablesL3S Research Center
s is called the ith finger of node n

CHORD
Finger table:Finger table:
finger[i] := successor (n + 2 i)
9Distributed Hash TablesL3S Research Center
CHORD
Search in finger table for
the nodes which most the nodes which most
immediatly precedes id
Invoke find_successor
from that node
=> Number of messages O(log N)
10Distributed Hash TablesL3S Research Center
=> Number of messages O(log N)

CHORD
Important characteristics of this scheme:Each node stores information about only a small number of nodes (m)nodes (m)
Each nodes knows more about nodes closely following it than about nodes farther away
A finger table generally does not contain enough information to directly determine the successor of an arbitrary key k
11Distributed Hash TablesL3S Research Center
Overview
1. CHORD (again)
2 New node joins: Stabilization2. New node joins: Stabilization
3. Reliability in Distributed Hash Tables
4. Storage Load Balancing in Distributed Hash Tables
12Distributed Hash TablesL3S Research Center
5. The P-GRID Approach

Volatility
Stable CHORD networks can always rely on their finger tables for routing
But what happens, if the network is volatile (churn)?
Lecture 3: Nodes can fail, depart or joinFailure is handled by ‘soft-state‘ approach with periodical republish by nodes
( )
13Distributed Hash TablesL3S Research Center
Departure can be handled by clean shutdown (unpublish) or simply as failure
Joining needs stabilization of the CHORD ring
CHORD Stabilization
?
14Distributed Hash TablesL3S Research Center
(1) (2) (3)

CHORD Stabilization
Stabilization protocol for a node x:
x.stabilize():ask successor y for its predecessor p
if p ∈ (x; y] then p is x‘s new successor
x.notify():notify x‘s successor p of x‘s existence
15Distributed Hash TablesL3S Research Center
notified node may change predecessor to x
CHORD Stabilization
• N26 joins the system
• N26 aquires N32 as its successor
• N26 notifies N32
16Distributed Hash TablesL3S Research Center
• N32 aquires N26 as its predecessor
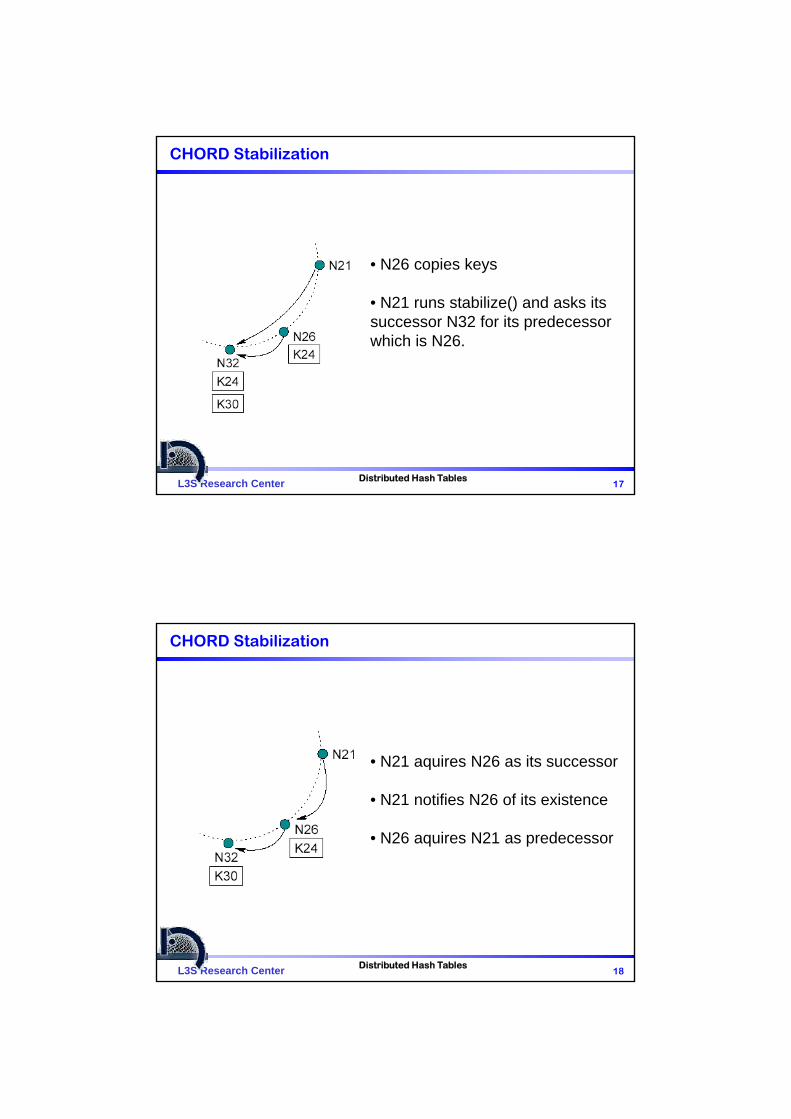
CHORD Stabilization
• N26 copies keys
• N21 runs stabilize() and asks its successor N32 for its predecessor which is N26.
17Distributed Hash TablesL3S Research Center
CHORD Stabilization
• N21 aquires N26 as its successor
• N21 notifies N26 of its existence
• N26 aquires N21 as predecessor
18Distributed Hash TablesL3S Research Center

CHORD Stabilization
19Distributed Hash TablesL3S Research Center
(1) (2) (3)
Overview
1. CHORD (again)
2 New node joins: Stabilization2. New node joins: Stabilization
3. Reliability in Distributed Hash Tables
4. Storage Load Balancing in Distributed Hash Tables
20Distributed Hash TablesL3S Research Center
5. The P-GRID Approach

“Stabilize” Function
Stabilize Function to correct inconsistent connections
Remember:Periodically done by each node n
n asks its successor for its predecessor p
n checks if p equals n
n also periodically refreshes random finger x by (re)locating successor
Successor-List to find new successorIf successor is not reachable use next node in successor list
21Distributed Hash TablesL3S Research Center
If successor is not reachable use next node in successor-list
Start stabilize function
But what happens to data in case of node failure?
Reliability of Data in Chord
OriginalNo Reliability of data
Recommendation Use of Successor-List
The reliability of data is an application task
Replicate inserted data to the next f other nodes
Chord informs application of arriving or failing nodes
22Distributed Hash TablesL3S Research Center
……
……

Properties
AdvantagesAfter failure of a node its successor has the data already stored
DisadvantagesNode stores f intervals
More data load
After breakdown of a node Find new successor
Replicate data to next node
More message overhead at breakdown
23Distributed Hash TablesL3S Research Center
g
Stabilize-function has to check every Successor-list Find inconsistent links
More message overhead
Multiple Nodes in One Interval
Fixed positive number f Indicates how many nodes have to act within one interval at least
ProcedureFirst node takes a random position
A new node is assigned to any existing node
Node is announced to all other nodes in same interval
910
12
45
67
24Distributed Hash TablesL3S Research Center
……
……
1023
5 78
Node
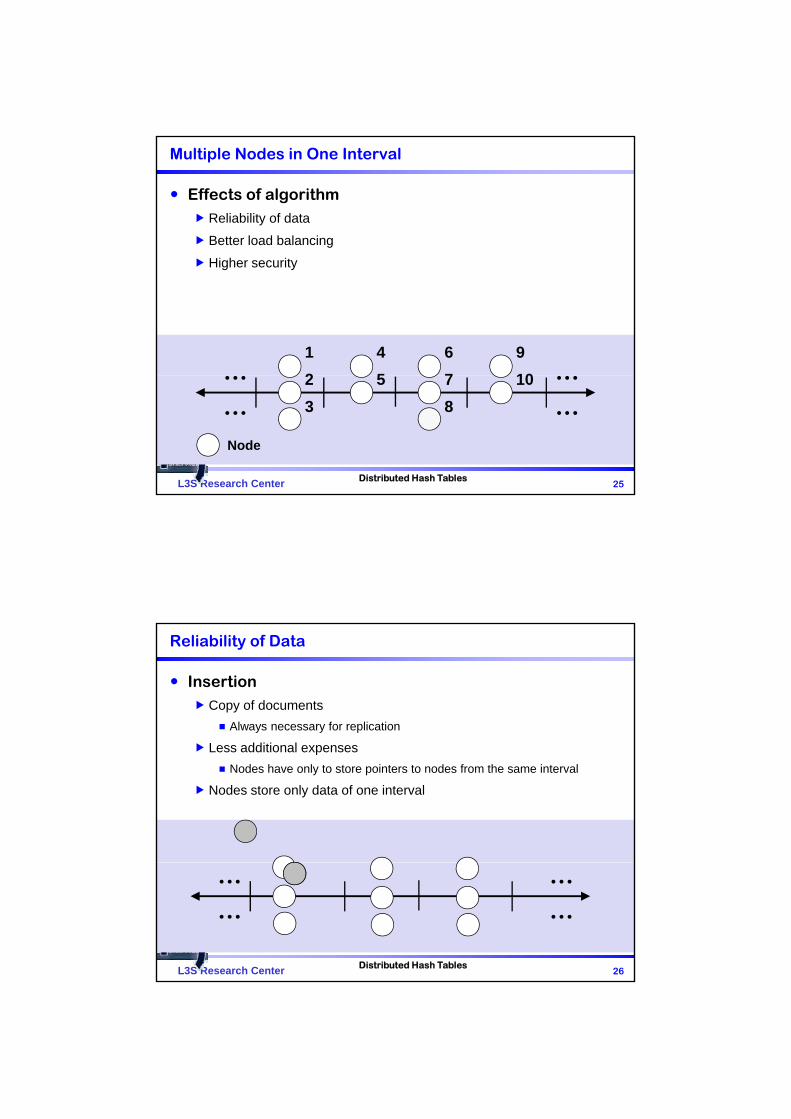
Multiple Nodes in One Interval
Effects of algorithmReliability of data
Better load balancing
Higher security
910
12
45
67
25Distributed Hash TablesL3S Research Center
……
……
1023
5 78
Node
Reliability of Data
InsertionCopy of documents
Always necessary for replication
Less additional expensesNodes have only to store pointers to nodes from the same interval
Nodes store only data of one interval
26Distributed Hash TablesL3S Research Center
……
……

Reliability of Data
ReliabilityFailure: no copy of data needed
Data are already stored within same interval
fUse stabilization procedure to correct fingersAs in original Chord
910
12
45
67
27Distributed Hash TablesL3S Research Center
……
……
1023
5 78
Node
Properties
AdvantagesFailure: no copy of data needed
Rebuild intervals with neighbors only if critical
Requests can be answered by f different nodes
DisadvantagesLess number of intervals as in original Chord
Solution: Virtual Servers
28Distributed Hash TablesL3S Research Center

Fault Tolerance: Replication vs. Redundancy
ReplicationEach data item is replicated K times
K replicas are stored on different nodes
RedundancyEach data item is split into M fragments
K redundant fragments are computed
Use of an "erasure-code“ (see e.g. V. Pless: Introduction to the Theory of Error-Correcting Codes. Wiley-Interscience, 1998)
Any M fragments allow to reconstruct the original data
29Distributed Hash TablesL3S Research Center
For each fragment we compute its keyM + K different fragments have different keys
Overview
1. CHORD (again)
2 New node joins: Stabilization2. New node joins: Stabilization
3. Reliability in Distributed Hash Tables
4. Storage Load Balancing in Distributed Hash Tables
30Distributed Hash TablesL3S Research Center
5. The P-GRID Approach

Storage Load Balancing in Distributed Hash Tables
Suitable hash function (easy to compute, few collisions)
Standard assumption 1: uniform key distributionE d ith l l dEvery node with equal load
No load balancing is needed
Standard assumption 2: equal distributionNodes across address space
Data across nodes
31Distributed Hash TablesL3S Research Center
But is this assumption justifiable?Analysis of distribution of data using simulation
Analysis of distribution of data
Example
Storage Load Balancing in Distributed Hash Tables
Optimal distribution of documents across nodes
Parameters4,096 nodes
500,000 documents
Optimum~122 documents per node
32Distributed Hash TablesL3S Research Center
No optimal distribution in Chord without load balancing

Storage Load Balancing in Distributed Hash Tables
Number of nodes without storing any document
Parameters4 096 nodes4,096 nodes
100,000 to 1,000,000 documents
Some nodes without any load
Why is the load unbalanced?
33Distributed Hash TablesL3S Research Center
Why is the load unbalanced?
We need load balancing to keep the complexityof DHT management low
Definitions
DefinitionsSystem with N nodes
The load is optimally balanced, Load of each node is around 1/N of the total load.
A node is overloaded (heavy)Node has a significantly higher load compared to the optimal distribution of load.
Else the node is light
34Distributed Hash TablesL3S Research Center

ProblemSignificant difference in the load of nodes
Several techniques to ensure an equal data distribution
Load Balancing Algorithms
Several techniques to ensure an equal data distribution Power of Two Choices (Byers et. al, 2003)
Virtual Servers (Rao et. al, 2003)
Thermal-Dissipation-based Approach (Rieche et. al, 2004)
A Simple Address-Space and Item Balancing (Karger et. al, 2004)
…
35Distributed Hash TablesL3S Research Center
Outline
AlgorithmsPower of Two Choices (Byers et. al, 2003)Virtual Servers (Rao et. al, 2003)
John Byers, Jeffrey Considine, and Michael Mitzen-macher: “Simple Load Balancing for Distributed Hash Tables“ in Second International Workshop on Peer-to-Peer Systems (IPTPS), Berkeley, CA, USA, 2003.
36Distributed Hash TablesL3S Research Center
Peer Systems (IPTPS), Berkeley, CA, USA, 2003.

Power of Two Choices
IdeaOne hash function for all nodes
h0
Multiple hash functions for dataMultiple hash functions for datah1, h2, h3, …hd
Two optionsData is stored at one node
Data is stored at one node &th d t i t
37Distributed Hash TablesL3S Research Center
other nodes store a pointer
Power of Two Choices
Inserting DataResults of all hash functions are calculated
h1(x), h2(x), h3(x), …hd(x)
Data is stored on the retrieved node with the lowest loadData is stored on the retrieved node with the lowest load
AlternativeOther nodes stores pointer
The owner of a data has to insert the document periodicallyPrevent removal of data after a timeout (soft state)
38Distributed Hash TablesL3S Research Center

Power of Two Choices (cont'd)
RetrievingWithout pointers
Results of all hash functions are calculated
R t ll f th ibl d i ll lRequest all of the possible nodes in parallel
One node will answer
With pointersRequest only one of the possible nodes.
Node can forward the request directly to the final node
39Distributed Hash TablesL3S Research Center
Power of Two Choices (cont'd)
AdvantagesSimple
DisadvantagesMessage overhead at inserting data
With pointersAdditional administration of pointers
More load
Without pointers
40Distributed Hash TablesL3S Research Center
Without pointersMessage overhead at every search

Outline
AlgorithmsPower of Two Choices (Byers et. al, 2003)
Virtual Servers (Rao et. al, 2003)
Ananth Rao, Karthik Lakshminarayanan, Sonesh Surana, Richard Karp, and Ion Stoica “Load Balancing in Structured P2P Systems” in Second International
41Distributed Hash TablesL3S Research Center
yWorkshop on Peer-to-Peer Systems (IPTPS), Berkeley, CA, USA, 2003.
Virtual Server
Each node is responsible for several intervals"Virtual server"
ExampleChord
Chord RingNode C
Node A
Node B
42Distributed Hash TablesL3S Research Center
Node B
[Rao 2003]

Rules
Rules for transferring a virtual server From heavy node to light node
1. The transfer of an virtual server makes the receiving node not heavy
2. The virtual server is the lightest virtual server that makes the heavy node light
3. If there is no virtual server whose transfer can make a node light, the heaviest virtual server from this node would be transferred
43Distributed Hash TablesL3S Research Center
Each node is responsible for several intervalslog (n) virtual servers
Load balancing
Virtual Server
Different possibilities to change serversOne-to-one
One-to-many
Many-to-many
Copy of an interval is like removing and inserting a node in a DHT
Chord Ring
44Distributed Hash TablesL3S Research Center
Chord Ring
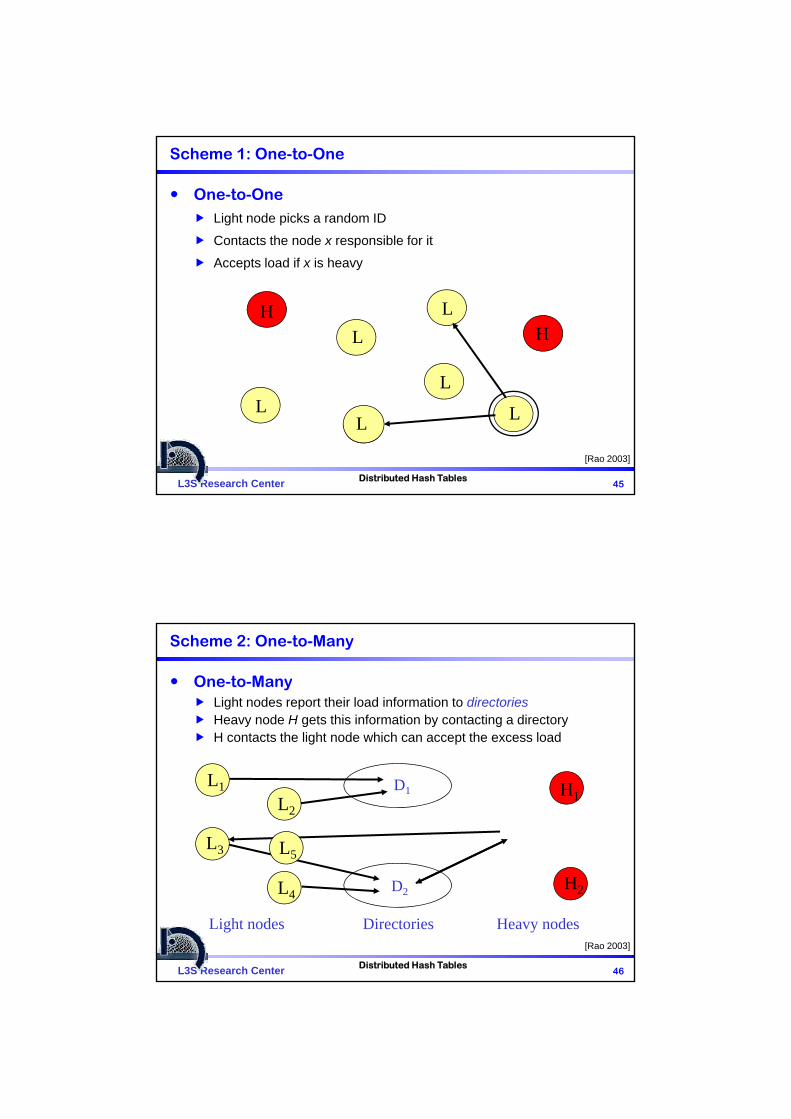
Scheme 1: One-to-One
One-to-OneLight node picks a random ID
Contacts the node x responsible for it
LLH
H
Accepts load if x is heavy
45Distributed Hash TablesL3S Research Center
L L
L
HL
[Rao 2003]
Scheme 2: One-to-Many
One-to-ManyLight nodes report their load information to directoriesHeavy node H gets this information by contacting a directoryH contacts the light node which can accept the excess load
L1L2
L3H3
H1D1
L5
g p
46Distributed Hash TablesL3S Research Center
Light nodes
L4
Heavy nodes
H2
Directories
D2
[Rao 2003]

Scheme 3: Many-to-Many
Many-to-ManyMany heavy and light nodes rendezvous at each step
Directories periodically compute the transfer schedule and report it b k t th d hi h th d th t l t f
H3
H1D1
L1L2
L3 L5
back to the nodes, which then do the actual transfer
47Distributed Hash TablesL3S Research Center
Heavy nodes
H2
Directories
D2L4
Light nodes
L4
[Rao 2003]
Virtual Server
AdvantagesEasy shifting of load
Whole Virtual Servers are shifted
DisadvantagesIncreased administrative and messages overhead
Maintenance of all Finger-Tables
Much load is shifted
48Distributed Hash TablesL3S Research Center
[Rao 2003]

Simulation
Scenario4,096 nodes (comparison with other measurements)
100,000 to 1,000,000 documents
Chordm= 22 bits.
Consequently, 222 = 4,194,304 nodes and documents
Hash function sha-1 (mod 2m)
d
49Distributed Hash TablesL3S Research Center
random
AnalysisUp to 25 runs per test
Results
Without load balancing Power of Two Choices
50Distributed Hash TablesL3S Research Center
+ Simple
+ Original
– Bad load balancing
+ Simple
+ Lower load
– Nodes w/o load

Results (cont'd)
Virtual server
51Distributed Hash TablesL3S Research Center
+ No nodes w/o load– Higher max. load than
Power of Two Choices
Overview
1. CHORD (again)
2 New node joins: Stabilization2. New node joins: Stabilization
3. Reliability in Distributed Hash Tables
4. Storage Load Balancing in Distributed Hash Tables
52Distributed Hash TablesL3S Research Center
5. The P-GRID Approach

L3S Research Center, University of Hannover
1
23
4
8• Toy example: Distributing
0 1
45
6 7
Key-space
Distributing skewed load
53Peer-to-Peer Systems and Applications, Springer LNCS 3485
Load-distribution
L3S Research Center, University of Hannover
• A globally coordi-nated recursive
1 23
45
6
7
8
bisection approach
• Key-space can be divided in two partitions
Assign peers propor-ti l t th l d i
0 1
54Peer-to-Peer Systems and Applications, Springer LNCS 3485
tional to the load in the two sub-partitions
Load-distribution

L3S Research Center, University of Hannover
• Recursively repeat the 1
2
6
8repeat the process to repartition the sub-partitions
0 1
1
3
457
8
55Peer-to-Peer Systems and Applications, Springer LNCS 3485
Load-distribution
L3S Research Center, University of Hannover
• Partitioning of the key-space s.t. there is equal load in 1
2
6
is equal load in each partition
Uniform replication of the partitionsImportant for fault-tolerance
• Note: A novel and general load 10
34
5
7
8
56Peer-to-Peer Systems and Applications, Springer LNCS 3485
general load-balancing problem
Load-distribution

L3S Research Center, University of Hannover
Lessons from the globally coordinated algorithm
A hi i t l d b l• Achieves an approximate load-balance
• The intermediate partitions may be such that they can not be perfectly repartitioned
There’s a fundamental limitation with any bisection based approach, as well as for any fixed key-space partitioned overlay network
57Peer-to-Peer Systems and Applications, Springer LNCS 3485
• Nonetheless practicalFor realistic load-skews and peer populations
L3S Research Center, University of Hannover
Distributed proportional partitioning for overlay construction
A mechanism to meet other random peersA parameter p for partitioning the space
*
1
*
3Randominteraction
A parameter p for partitioning the space• Proportional partitioning: Peers
partition proportional to the load distribution
In a ratio p:1-pLet’s call the sub-partitions as 0 and 1
• Referential integrity: Obtain reference to the other partition
000,010,100 101,001
1: 3
1
0: 1
30 1
partitioning
58Peer-to-Peer Systems and Applications, Springer LNCS 3485
to the other partitionNeeded to enable overlay routing
• Sorting the load/keys: Peers exchange locally stored keys in order to store only keys for its own partition
000,010,001 101,100
Routing table
pid
Keys (only part of the prefix is shown)
Legend
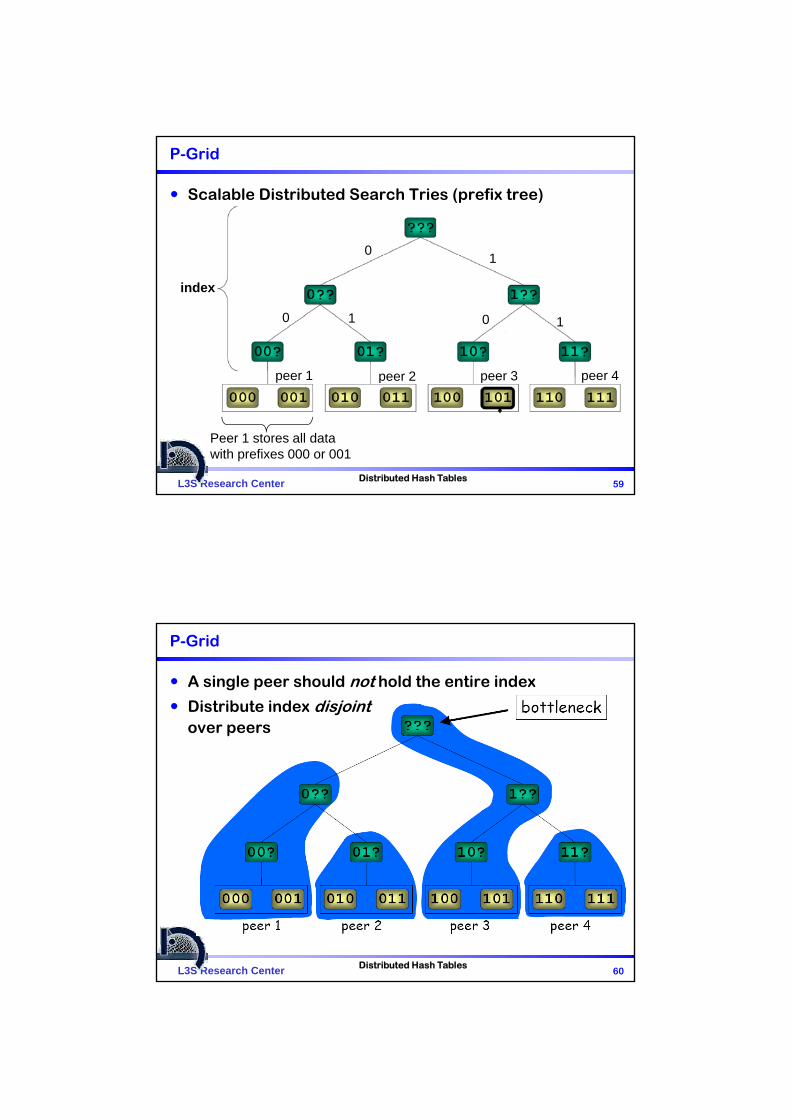
P-Grid
Scalable Distributed Search Tries (prefix tree)
10 1
0 10 1
index
peer 4peer 3peer 2peer 1
59Distributed Hash TablesL3S Research Center
peer 4peer 3peer 2peer 1
Peer 1 stores all data with prefixes 000 or 001
P-Grid
A single peer should not hold the entire index
Distribute index disjointover peers
60Distributed Hash TablesL3S Research Center

P-Grid
Scalable Distribution of Index
61Distributed Hash TablesL3S Research Center
P-Grid
Routing information at each peer is only logarithmic (height of trie)
4
62Distributed Hash TablesL3S Research Center
peer 4
peer 3

P-Grid
Prefix Routing
63Distributed Hash TablesL3S Research Center
P-Grid
Two basic approaches for new nodes to join
Splitting approach (P-Grid)peers meet (randomly) and decide whether to extend search tree by splitting the data space
peers can perform load balancing considering their storage load
networks with different origins can merge, like Gnutella, FreeNet(loose coupling)
Node insertion approach (Plaxton, OceanStore, …)peers determine their "leaf position" based on their IP address
64Distributed Hash TablesL3S Research Center
peers determine their leaf position based on their IP address
nodes route from a gateway node to their node-id to populate the routing table
network has to start from single origin (strong coupling)

P-Grid
Load balance effectAlgorithm converges quickly
Peers have similar load
E.g. leaf load in case of 25 = 32 possible prefixes of length 5:
65Distributed Hash TablesL3S Research Center
P-Grid
Replication of data items and routing table entries is used to increase failure resilience
66Distributed Hash TablesL3S Research Center





























