Embed Size (px)
DESCRIPTION
Inthispaper,wepresentthedesign,implementationand evaluationofHapori(meaningcommunityinMaori),the firstcontextdrivenlocalsearchframeworkbuiltonafounda- tionofcommunitybehavioralmodelingandsimilarity.The goalofHaporiistomeetthediverseneedsofdifferentpeo- ple(suchastheteenagerandsenior)takingintoaccounttheir context,behavioralprofileandbehavioralsimilaritieswith othersinthebroadercommunityoflocalsearchusers.With ABSTRACT INTRODUCTION 109 H.4.mInformationSystemsApplication:Miscellaneous.
Citation preview

Hapori: Context-based Local Search for Mobile Phonesusing Community Behavioral Modeling and Similarity
Nicholas D. Lane, Dimitrios Lymberopoulos†, Feng Zhao† and Andrew T. CampbellDartmouth College, Microsoft Research†
{niclane,campbell}@cs.dartmouth.edu, {dlymper,zhao}@microsoft.com†
ABSTRACTLocal search engines are very popular but limited. We presentHapori, a next-generation local search technology for mo-bile phones that not only takes into account location in thesearch query but richer context such as the time, weather andthe activity of the user. Hapori also builds behavioral mod-els of users and exploits the similarity between users to tai-lor search results to personal tastes rather than provide staticgeo-driven points of interest. We discuss the design, im-plementation and evaluation of the Hapori framework whichcombines data mining, information preserving embeddingand distance metric learning to address the challenge of cre-ating efficient multidimensional models from context-richlocal search logs. Our experimental results using 80,000queries extracted from search logs show that contextual andbehavioral similarity information can improve the relevanceof local search results by up to ten times when comparedto the results currently provided by commercially availablesearch engine technology.
Author KeywordsLocal Search, Context-ware Mobile Search, Mobile PhoneSensing
ACM Classification KeywordsH.4.m Information Systems Application: Miscellaneous.
General TermsDesign, Experimentation, Performance.
INTRODUCTIONLocation-based services on mobile phones have been stan-dard fare for several years. People on-the-go regularly use avariety of mobile local search applications throughout theirday to find, for example, nearby restaurants, gyms and cafesto name just a few of a growing number of local search cat-egories. Local search that takes into account the location ofthe phone as context for the search is perhaps one of the mostexciting, popular and useful mobile applications today.
Existingmobile local search engines performwell when usedfor a particular narrow range of queries where the relevance
Permission to make digital or hard copies of all or part of this work forpersonal or classroom use is granted without fee provided that copies arenot made or distributed for profit or commercial advantage and that copiesbear this notice and the full citation on the first page. To copy otherwise, orrepublish, to post on servers or to redistribute to lists, requires prior specificpermission and/or a fee.Ubicomp 2010, Sep 26-Sep 29, 2010, Copenhagen, Denmark.Copyright 2010 ACM 978-1-60558-843-8/10/09...$10.00.
of different Points of Interest (POIs) is clear, such as, findingthe nearest coffee shop. As a result local search is limited.We imagine, for example, future search engines capable oftaking into account more contextual information than justthe location of the user as is the norm today. Mobile phonesoffer significantly richer context than simply location; forexample, future queries could include any or all of the fol-lowing context in a query: time of day, day of the week,weather conditions, the current activity of the user (e.g., jog-ging, biking, traveling by car or bus through the use of em-bedded sensors in smartphones [3]), whether the user is withfriends or alone. Other innovations are possible too. We be-lieve that local search can be advanced considerably by en-abling search engines to personalize responses for each userby: 1) incorporating behavioral profiles and preferenceswithrespect to contextual factors (e.g., weather); and 2) exploit-ing the choices made by others in the broader communitywho have similar behavioral histories.
To illustrate what we think is possible consider the follow-ing scenario. Two people, a senior and a teenager are locatedat the same position in a city and unbeknown to each otheruse the same service to issue the exact same query (e.g., en-tertainment) – not surprisingly they are both presented withthe exact same geo-driven list of places using existing localsearch technology. Both are disappointed at their choices.Now, consider a next generation local search engine thatis capable of understanding context and building behavioralmodels – i.e., time, date, weather, as well as taking into ac-count the popular choices of other people in the communitywith behavioral similarity – then, it is not surprising that thesenior and teenager are presented with a ranked list of POIsthat are radically different from each other and as a conse-quence much more appealing to their individual tastes; as aresult the teenager heads off in one direction to a free rockconcert in Central Park and the senior heads off in the op-posite direction to catch a popular foreign movie playing atLincoln Center Cinemas (which, our senior is happy to beinformed is air conditioned) at the exact same time on a veryhot Saturday evening in the summer in Manhattan.
In this paper, we present the design, implementation andevaluation of Hapori (meaning community in Maori), thefirst context driven local search framework built on a founda-tion of community behavioral modeling and similarity. Thegoal of Hapori is to meet the diverse needs of different peo-ple (such as the teenager and senior) taking into account theircontext, behavioral profile and behavioral similarities withothers in the broader community of local search users. With
109

Hapori POI choices of the entire community drive the searchresults that everyone receives. We model the POI prefer-ences of people, based on the context (e.g., weather, time,location) under which they make these choices. The prefer-ences of people are then linked to form a community modelbased on behavioral similarity between people which deter-mines how appropriate the preferences displayed by one per-son are to another person.
The Hapori framework discussed in this paper captures theknowledge of a community to improve the overall POI searchrelevance by: i) computing features that capture significantaspects of context that effect people’s POI decisions; ii) learn-ing customized ranking metrics that emphasize the specificimportant elements in a POI decision for a particular cate-gory of POI (be it for example the popularity and personalpreference for a music club or weather and proximity to arunning track), iii) modeling differences between people;and finally, iv) adapting to changes in community behavior(e.g., a new restaurant opens up, traffic patterns change, pref-erences shift). By mining the local search decisions of thou-sands of people, Hapori recognizes how the appeal of placesof interest can change not only from location to location but,for example, change from weekday to weekend, from per-son to person, from season to season, or from morning toevening within a day.
Hapori makes two important contributions. First, it com-bines several data mining, information preserving embed-ding and learning techniques to address the challenges ofcreating efficient multidimensionalmodels from local searchlogs. Second, it uses local search logs from Mobile BingLocal [11] containing queries from more than 11,000 usersover a period of 6 months to identify the different contextparameters and to quantify their effect on the way peopleclick on businesses. Our experimental results using 80,000queries extracted from the search logs of a leading com-mercial mobile search engine show that personalized resultsbased on contextual and behavioral similarity informationcan improve the relevance of local search results by up to 10times when compared to the results currently provided byMobile Bing Local.
In our current prototype implementation of Hapori, we onlyuse context information that we can extract from the mobilesearch logs (i.e. time of day, day of week, weather, searchhistory etc.). However, the techniques employed in Hapori’sdesign could be applied to any possible context informationavailable. For instance, the available sensors on the phonecould provide information about the context of the querysuch as if the person is inside or outside, if she is alone orwith company, if she is driving or walking, or even if she haskids in the car. In practice, any sensing information couldbe used within the existing design of Hapori to better definethe context of the query, narrow the intent of the user andprovide more relevant POI information.
CONTEXT AND COMMUNITY BEHAVIOR ARTIFACTSIn this section, we analyze over 80,000 local search queriessubmitted to Mobile Bing Local [11] by more than 11,000users over a period of six months beginning January 1st 2009.
By analyzing search logs we clearly identify that POI selec-tion of people is noticeably shaped by both context and thepreferences within cliques of people – that is, the commu-nity preferences. We use this analysis to motivate and guidethe design of the Hapori framework presented in next sec-tion. The results presented in this section are not meant tobe exhaustive but illustrative of the fact that the artifacts dueto context and user behavior can already be observed in ex-isting systems. Hapori makes advanced context, behavioralmodeling and the computation of similarity a first class citi-zen in the design of local search.
Search LogsEvery entry in the search logs we analyzed contain: queryterms, a unique identifier for the POI that is clicked afterthe query is submitted, the location of the user, the exactdate and time the query is submitted and an anonymized useridentifier that can be used to link together queries submittedby the same user over time. Note, that to preserve the privacyof users, the exact location of the user (i.e., GPS location) isnot recorded. Rather, coarse-grained location information atthe resolution level of a map tile is stored for every query.
The analysis presented also uses the information providedin the search logs to reconstruct other pieces of useful in-formation related to submitted queries. In particular, we usea unique POI (e.g., business) identifier to identify the loca-tion of the POI that is clicked for every query. This allowsus to study the spatial correlations between the location ofthe query and the location of the clicked POI. In addition,we use the time and date of each query to retrieve weatherconditions (e.g., temperature) at the time the query is submit-ted. This extended context allows us to study how, for exam-ple, weather conditions affect the way mobile users click onPOIs. In what follows, we discuss our main findings fromthe analysis of the search logs.
Impact of Temporal ContextWe find that temporal patterns play an important role in thedecision process of mobile users. People’s behavior and theactivities they wish to engage in vary depending on if it is aweekday or weekend, or if it is an evening or morning. Fig-ure 1(a) shows the click probability of 1500 different restau-rants for 4 different time windows: weekdaymorning, week-day evening, weekend morning and weekend evening. Note,that during a weekday morning there are about 100 POIs(i.e., businesses positioned on the x-axis between 200 and300) with very high click probabilities. These POIs mainlyconsist of fast-food places, informal restaurants and localcoffee shops. In other words, eateries that most people visitbefore they go to work or during their day, e.g., getting a cupof coffee. The click probability for these POIs reduces sig-nificantly during weekends and weekday evenings with thehighest drop happening during weekend evenings. The re-sults intuitively indicate that mobile users are interested ina different set of POIs during weekend evenings (businesseswith an x-axis position from 450 to 550 and from 800 to1050). Note, also that these POIs show low click probabil-ities during weekday mornings. On the other hand, popularbusinesses during evenings seem to be similarly independentof the actual day considered (weekday versus weekend). Fi-
110
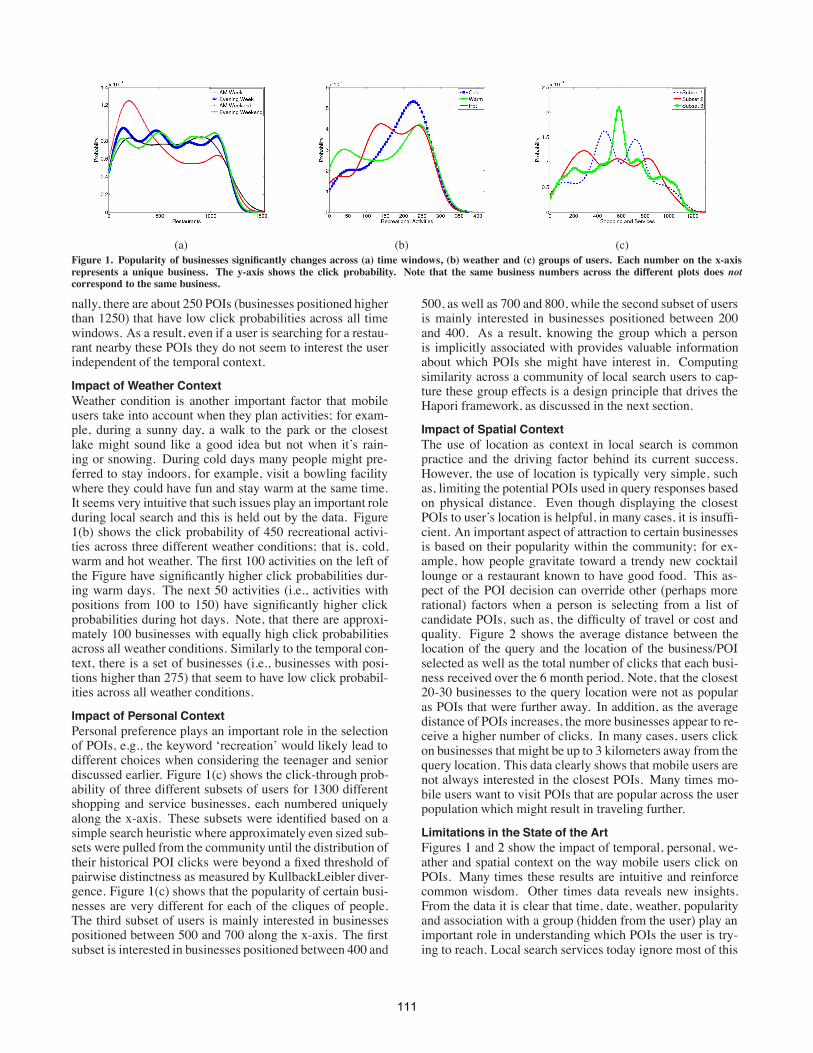
(a) (b) (c)Figure 1. Popularity of businesses significantly changes across (a) time windows, (b) weather and (c) groups of users. Each number on the x-axisrepresents a unique business. The y-axis shows the click probability. Note that the same business numbers across the different plots does notcorrespond to the same business.
nally, there are about 250 POIs (businesses positioned higherthan 1250) that have low click probabilities across all timewindows. As a result, even if a user is searching for a restau-rant nearby these POIs they do not seem to interest the userindependent of the temporal context.
Impact of Weather ContextWeather condition is another important factor that mobileusers take into account when they plan activities; for exam-ple, during a sunny day, a walk to the park or the closestlake might sound like a good idea but not when it’s rain-ing or snowing. During cold days many people might pre-ferred to stay indoors, for example, visit a bowling facilitywhere they could have fun and stay warm at the same time.It seems very intuitive that such issues play an important roleduring local search and this is held out by the data. Figure1(b) shows the click probability of 450 recreational activi-ties across three different weather conditions; that is, cold,warm and hot weather. The first 100 activities on the left ofthe Figure have significantly higher click probabilities dur-ing warm days. The next 50 activities (i.e., activities withpositions from 100 to 150) have significantly higher clickprobabilities during hot days. Note, that there are approxi-mately 100 businesses with equally high click probabilitiesacross all weather conditions. Similarly to the temporal con-text, there is a set of businesses (i.e., businesses with posi-tions higher than 275) that seem to have low click probabil-ities across all weather conditions.
Impact of Personal ContextPersonal preference plays an important role in the selectionof POIs, e.g., the keyword ‘recreation’ would likely lead todifferent choices when considering the teenager and seniordiscussed earlier. Figure 1(c) shows the click-through prob-ability of three different subsets of users for 1300 differentshopping and service businesses, each numbered uniquelyalong the x-axis. These subsets were identified based on asimple search heuristic where approximately even sized sub-sets were pulled from the community until the distribution oftheir historical POI clicks were beyond a fixed threshold ofpairwise distinctness as measured by KullbackLeibler diver-gence. Figure 1(c) shows that the popularity of certain busi-nesses are very different for each of the cliques of people.The third subset of users is mainly interested in businessespositioned between 500 and 700 along the x-axis. The firstsubset is interested in businesses positioned between 400 and
500, as well as 700 and 800, while the second subset of usersis mainly interested in businesses positioned between 200and 400. As a result, knowing the group which a personis implicitly associated with provides valuable informationabout which POIs she might have interest in. Computingsimilarity across a community of local search users to cap-ture these group effects is a design principle that drives theHapori framework, as discussed in the next section.
Impact of Spatial ContextThe use of location as context in local search is commonpractice and the driving factor behind its current success.However, the use of location is typically very simple, suchas, limiting the potential POIs used in query responses basedon physical distance. Even though displaying the closestPOIs to user’s location is helpful, in many cases, it is insuffi-cient. An important aspect of attraction to certain businessesis based on their popularity within the community; for ex-ample, how people gravitate toward a trendy new cocktaillounge or a restaurant known to have good food. This as-pect of the POI decision can override other (perhaps morerational) factors when a person is selecting from a list ofcandidate POIs, such as, the difficulty of travel or cost andquality. Figure 2 shows the average distance between thelocation of the query and the location of the business/POIselected as well as the total number of clicks that each busi-ness received over the 6 month period. Note, that the closest20-30 businesses to the query location were not as popularas POIs that were further away. In addition, as the averagedistance of POIs increases, the more businesses appear to re-ceive a higher number of clicks. In many cases, users clickon businesses that might be up to 3 kilometers away from thequery location. This data clearly shows that mobile users arenot always interested in the closest POIs. Many times mo-bile users want to visit POIs that are popular across the userpopulation which might result in traveling further.
Limitations in the State of the ArtFigures 1 and 2 show the impact of temporal, personal, we-ather and spatial context on the way mobile users click onPOIs. Many times these results are intuitive and reinforcecommon wisdom. Other times data reveals new insights.From the data it is clear that time, date, weather, popularityand association with a group (hidden from the user) play animportant role in understanding which POIs the user is try-ing to reach. Local search services today ignore most of this
111
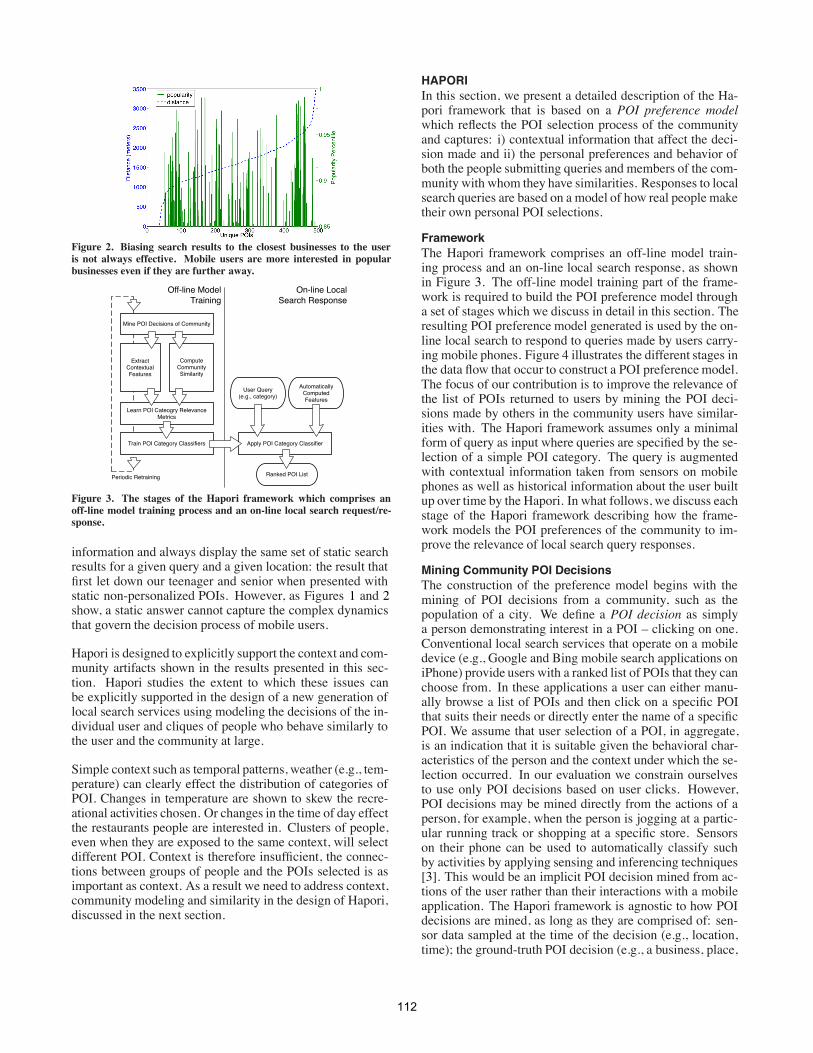
Figure 2. Biasing search results to the closest businesses to the useris not always effective. Mobile users are more interested in popularbusinesses even if they are further away.
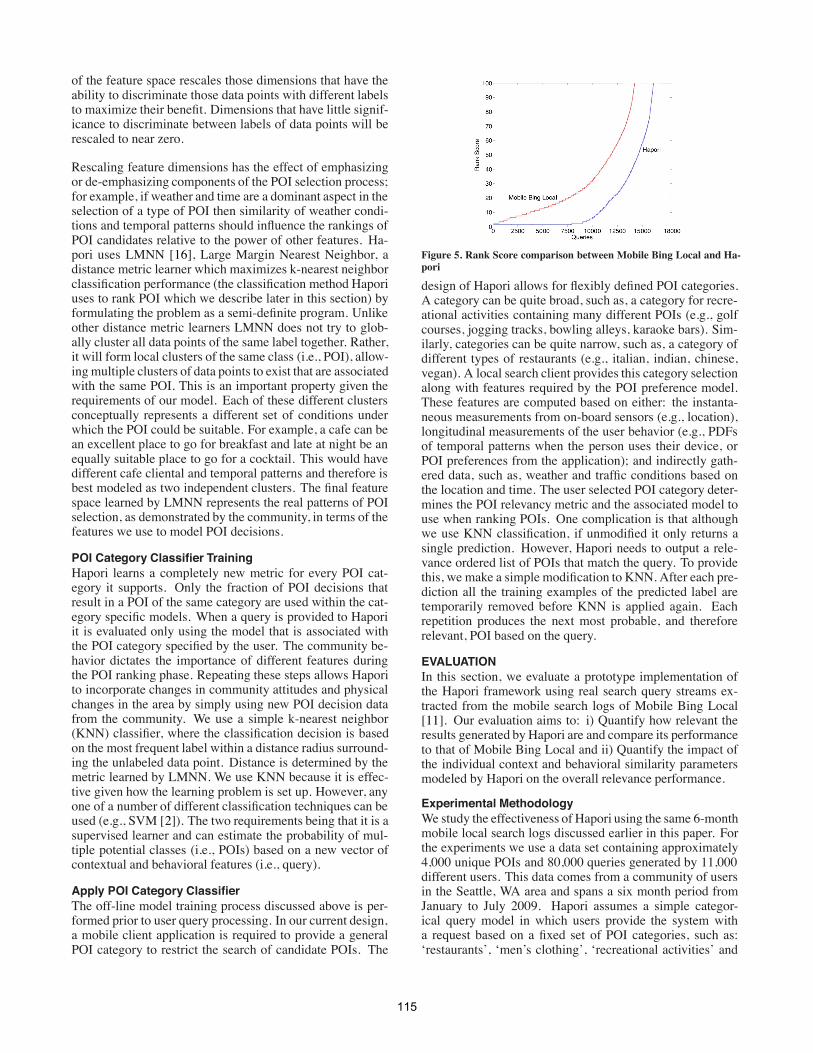
Mine POI Decisions of Community
Extract Contextual Features
Compute Community Similarity
Learn POI Cateogry Relevance Metrics
Train POI Category Classiers
Periodic Retraining
User Query(e.g., category)
Automatically Computed Features
Apply POI Category Classier
Ranked POI List
Off-line Model Training
On-line Local Search Response
Figure 3. The stages of the Hapori framework which comprises anoff-line model training process and an on-line local search request/re-sponse.
information and always display the same set of static searchresults for a given query and a given location: the result thatfirst let down our teenager and senior when presented withstatic non-personalized POIs. However, as Figures 1 and 2show, a static answer cannot capture the complex dynamicsthat govern the decision process of mobile users.
Hapori is designed to explicitly support the context and com-munity artifacts shown in the results presented in this sec-tion. Hapori studies the extent to which these issues canbe explicitly supported in the design of a new generation oflocal search services using modeling the decisions of the in-dividual user and cliques of people who behave similarly tothe user and the community at large.
Simple context such as temporal patterns, weather (e.g., tem-perature) can clearly effect the distribution of categories ofPOI. Changes in temperature are shown to skew the recre-ational activities chosen. Or changes in the time of day effectthe restaurants people are interested in. Clusters of people,even when they are exposed to the same context, will selectdifferent POI. Context is therefore insufficient, the connec-tions between groups of people and the POIs selected is asimportant as context. As a result we need to address context,community modeling and similarity in the design of Hapori,discussed in the next section.
HAPORIIn this section, we present a detailed description of the Ha-pori framework that is based on a POI preference modelwhich reflects the POI selection process of the communityand captures: i) contextual information that affect the deci-sion made and ii) the personal preferences and behavior ofboth the people submitting queries and members of the com-munity with whom they have similarities. Responses to localsearch queries are based on a model of how real people maketheir own personal POI selections.
FrameworkThe Hapori framework comprises an off-line model train-ing process and an on-line local search response, as shownin Figure 3. The off-line model training part of the frame-work is required to build the POI preference model througha set of stages which we discuss in detail in this section. Theresulting POI preference model generated is used by the on-line local search to respond to queries made by users carry-ing mobile phones. Figure 4 illustrates the different stages inthe data flow that occur to construct a POI preferencemodel.The focus of our contribution is to improve the relevance ofthe list of POIs returned to users by mining the POI deci-sions made by others in the community users have similar-ities with. The Hapori framework assumes only a minimalform of query as input where queries are specified by the se-lection of a simple POI category. The query is augmentedwith contextual information taken from sensors on mobilephones as well as historical information about the user builtup over time by the Hapori. In what follows, we discuss eachstage of the Hapori framework describing how the frame-work models the POI preferences of the community to im-prove the relevance of local search query responses.
Mining Community POI DecisionsThe construction of the preference model begins with themining of POI decisions from a community, such as thepopulation of a city. We define a POI decision as simplya person demonstrating interest in a POI – clicking on one.Conventional local search services that operate on a mobiledevice (e.g., Google and Bing mobile search applications oniPhone) provide users with a ranked list of POIs that they canchoose from. In these applications a user can either manu-ally browse a list of POIs and then click on a specific POIthat suits their needs or directly enter the name of a specificPOI. We assume that user selection of a POI, in aggregate,is an indication that it is suitable given the behavioral char-acteristics of the person and the context under which the se-lection occurred. In our evaluation we constrain ourselvesto use only POI decisions based on user clicks. However,POI decisions may be mined directly from the actions of aperson, for example, when the person is jogging at a partic-ular running track or shopping at a specific store. Sensorson their phone can be used to automatically classify suchby activities by applying sensing and inferencing techniques[3]. This would be an implicit POI decision mined from ac-tions of the user rather than their interactions with a mobileapplication. The Hapori framework is agnostic to how POIdecisions are mined, as long as they are comprised of: sen-sor data sampled at the time of the decision (e.g., location,time); the ground-truth POI decision (e.g., a business, place,
112

Context RichMobile
Search Logs
LocationWeather
Timeetc...
Context Feature Space
Similarity Feature Space
Mobility
Diurnal Preference
Person
Location Weather
POI Decision
POI Category Classifer
MobilePhones
Joint Context/Behavior Feature Space
POI Decision
Training
Time
POI Decision Mining and Feature Extraction
Learn POI Category Relevance Metrics
Figure 4. A POI preference model is trained for each POI category. Hapori begins this process with the mining of mobile local search logs from whichit constructs context and behavioral similarity feature spaces. Before the model is trained both these feature spaces are fused. During this step afeature space is found that emphasizes the most important elements of both context and behavioral similarity for POI relevance given a POI category.
i.e., the POI selected by the person); and a session identifieror some type of token that can link together the POI deci-sions of an individual over a period of time.
Extract Contextual FeaturesFor each mined POI decision a series of features are com-puted which are chosen to capture the contextual informa-tion associated with each decision. The extracted featuresallow the model to learn contextual patterns of POI deci-sions made by a community. In Figure 4 this is illustratedas the construction of a context feature space based on themined POI decisions. Currently, Hapori incorporates fourtypes of contextual features: temporal, spacial, weather andPOI popularity features. We use these features because theyrepresent different types of context that has strong influenceover the POI decisions made by people. Most phones withGPS can compute these features. Clearly, this is not an ex-haustive set of features and could be extended to cover othercategories, such as, traffic levels, air quality, etc., as wellas use richer descriptors of locations (e.g., land-use, demo-graphics). These types of extensions to context would likelyimprove Hapori’s ability to capture more interesting contex-tual patterns. In what follows, we discuss each of the fourcontextual feature categories in more detail.
Temporal Features. To capture the different types of tem-poral patterns people exhibit, different temporal features areused corresponding to the time-scales over which people al-ter their behavior. The following features are calculated basedon the time and day when the POI decision occurs: the dayof the week; a binary indicator for weekend or weekday;an intra-day count of elapsed four-hour windows; and intra-week versions of the same count of four-hour windows.
Spacial Features. The use of location in local search ser-vices is common practice. Typically this leads to simple re-sponses such as scoping the potential POIs used in queryresponses based on physical distance from the user. Haporicaptures more complex spacial relationships by computingfeatures based on both the location where the POI decision(referred to as the source) is made and the location of thecorresponding ground-truth POI (referred to as the destina-tion). The following features are extracted for each POI de-cision: rounded latitude and longitude of both source anddestination; the tile of both source and destination given atessellation of the city area which is repeated for tile counts
of {102, 2562, 5122, 10242}. Spacial patterns operate partic-ularly well in combination with temporal features, for exam-ple, combining to capture the fact that people are willing totravel further on certain days (e.g., weekends) because theyhave more free time than during the week.
Weather Features. The weather has a large impact on therange of activities people will consider when they are search-ing for POIs. Hapori uses weather statistics from the dayon which the POI decision is made, including: rainfall andsnowfall totals; and the average temperature of the day. Thesethree statistics are represented as separate features with dif-ferent levels of discretization applied.
POI Popularity Features. An important aspect of the at-traction of certain POIs is based on their popularity withina community. Two forms of such popularity exist: i) sharpspikes of interest in the community when for instance a newPOI is created or improved; and ii) longer time-scale stablePOI preferences in the community (e.g., perennially popularbars or fishing holes). Hapori measures popularity in termsof the percentile of POI decisions associated with each dif-ferent POI. To capture the two forms of popularity Haporicomputes this percentile relative to different sets of POI de-cisions. Sets are made up from POIs based on a series offiltering rules that are based on some aspect of the sourcequery, such as: POIs that have the same POI category as thequery, POIs within the same spacial tile assuming a 5122
sized tessellation (as described in the spacial feature subsec-tion) or a POI decision that is less than 3 weeks.
Computing Community SimilarityHapori uses contextual features (discussed above) to modeleach POI decision, capturing the circumstances associatedwith the decision made. Not all POI decisions are givenequal influence in effecting the results provided to users,however. A large component of the relevance of a POI toa local search query is subjective. This requires that the dif-ferences between people contributing POI decisions need tobe captured in the model. Hapori uses a community similar-ity metric computed between all users to address this need.Illustrated in Figure 4 is the process of building a similarityfeature space to complement the context feature space. TheFigure shows similarity features based on the mined POI de-cisions of each person being used to compute a metric re-quired for the similarity space.
113

Similarity Features. Five features mined from the POI de-cisions of a user are used to compute community similarity:i) two temporal features based on when queries are submit-ted – an intra-day count of elapsed four-hour windows andthe day of the week; ii) one spacial feature – the tile of thesource location tessellated assuming 5122 tiles; and iii) twofeatures based on the POI itself – the POI category (e.g., hairdressing) and the specific POI itself (e.g., joe’s hair design)both of which are treated as discrete categorical features.
The temporal and spacial features capture the diurnal andspacial patterns of the life of the individual based on the ac-cumulation of POI decisions over time; as observed from thepoints in time when a user submits a local search query.Thesepatterns act as a latent observation on aspects of the personsuch as demographic characteristics (e.g., given the connec-tion to where a person lives, works and spends most of theirtime) and lifestyle (e.g., regularity of their schedule, earlymorning or night-owl personality traits). However, two dif-ferent types of people could potentially live in the same areaand have fairly similar schedules (e.g., a parent and theirteenage children) but have very divergent POI preferences.For this reason Hapori augments the temporal and spacialfeatures with information about POI preferences based onthe frequency at which specific POIs and POI categories oc-cur over time within the stream of POI decisions made byindividuals. Category and specific POI information allowHapori to represent different degrees of similarity; for ex-ample, two people may like the same POI category, such as,evening entertainment or dancing, but have different prefer-ences in terms of the type of entertainment that appeals tothem. Category only information ignores this difference. If,however, only specific POI information is considered Haporiwould ignore similarity based on the common categories.As in the case of the contextual features the current designof Hapori limits itself to only the sources of data which arereadily available in mobile phones in use today (e.g., GPS).
Similarity Metric. The similarity measurement computedbyHapori uses FINE [4], Fisher InformationNon-parametricEmbedding. This technique that takes high-dimensional datarepresenting different classes (e.g., different document types)and computes a low-dimensional space based on the proba-bility density functions (PDFs) of the original high-dimensio-nal data for each class. In this low-dimensional space the eu-clidean distance between the data points representing differ-ent classes approximates an information distance (e.g., fisherinformation) between the original PDFs. This technique isused successfully in recognizing different objects from im-ages, clustering different documents types and classifyinghuman poses from a video sequence. In the Evaluation sec-tion, we show that this approach is effective in clusteringpeople with common POI preferences based on readily avail-able measurements of their behavior.
To create the similarity metric the POI decisions from thecommunity are projected into a feature space defined by thesimilarity features discussed in the previous subsection. Foreach person a multi-variate PDF is computed based on thePOI decisions they contributed to the system. Similarity be-
tween people is computed based on the Fisher Informationdistance [2] between their respective PDFs. We use FINE toapproximate these same distances using Hellinger distance[2] but within a lower dimensional space where every per-son is represented not by a data point for each POI decisionbut by a single data point. During this process off-the-shelfMultidimensional Scaling [2] is used to perform the dimen-sionality reduction. The resulting lower dimensional spacerepresents the similarity metric. Between each single point(which represents a single person) the euclidean distanceto another point (of another person) is proportional to theoriginal Fisher Information distances from the initial featurespace in which all the POI decisions are represented.
Hapori does not use the similarity metric directly, instead therelative coordinates of each data point representing each per-son become additional features of every POI decision con-tributed by the person. The addition of these features allowthe model to represent POI decisions that have identical con-textual feature values but yet correspond to different POIsby capturing behavioral differences between the people whomake the decision. We use features based on the relativecoordinates in the similarity space to avoid making hard as-signments of people to specific groups. In practice the be-havior of people does not allow them to be neatly placedinto a fixed set of groups. Our design allows behavioral ten-dencies to be captured more naturally, relative coordinatesrepresent how people are similar, to varying degrees, withmore than one cluster of people at the same time.
Learn POI Category Relevance MetricsOne of the reasons local search is such a difficult problemis because the criteria for relevancy is difficult to specifyand parameterize. Intuitively, it is possible to identify fac-tors that alter the appeal of a POI to an individual, suchas, personal preferences, ease of transportation, reputation,popularity. However, it is difficult to formalize these intu-itions into a criteria to rank potential POIs in response to aquery. This problem is even more difficult given that differ-ent POI categories each require their own specific criteria,for example, the most important factors in selecting eveningentertainment will be different to those factors important toselecting places to shop. Hapori frames the problem of de-termining relevance metrics to rank potential POIs as a su-pervised distance metric learning problem. The general ob-jective of this class of problem is to learn a transformation ofa feature space to maximize classification performance. Ha-pori sets up the classification problem as follows. A featurespace is used containing all the context and community sim-ilarity features each as dimensions. All POI decisions frompeople are represented in this space by their respective fea-ture vector with the actual ground-truth POIs selected duringthese POI decisions acting as a label. The learning problemrelates to correctly labeling a new unknown data point basedon its features and the examples provided by the POI deci-sions from the community. In essence, the metric learnercomputes a transformation of the feature space to clusterthose POI decisions (data points) that have identical labels.Figure 4 shows this fusion of context and similarity featurespaces occurring and the application of the metric learnerto find an appropriate transformation. The transformation
114
of the feature space rescales those dimensions that have theability to discriminate those data points with different labelsto maximize their benefit. Dimensions that have little signif-icance to discriminate between labels of data points will berescaled to near zero.
Rescaling feature dimensions has the effect of emphasizingor de-emphasizing components of the POI selection process;for example, if weather and time are a dominant aspect in theselection of a type of POI then similarity of weather condi-tions and temporal patterns should influence the rankings ofPOI candidates relative to the power of other features. Ha-pori uses LMNN [16], Large Margin Nearest Neighbor, adistance metric learner which maximizes k-nearest neighborclassification performance (the classification method Haporiuses to rank POI which we describe later in this section) byformulating the problem as a semi-definite program. Unlikeother distance metric learners LMNN does not try to glob-ally cluster all data points of the same label together. Rather,it will form local clusters of the same class (i.e., POI), allow-ingmultiple clusters of data points to exist that are associatedwith the same POI. This is an important property given therequirements of our model. Each of these different clustersconceptually represents a different set of conditions underwhich the POI could be suitable. For example, a cafe can bean excellent place to go for breakfast and late at night be anequally suitable place to go for a cocktail. This would havedifferent cafe cliental and temporal patterns and therefore isbest modeled as two independent clusters. The final featurespace learned by LMNN represents the real patterns of POIselection, as demonstrated by the community, in terms of thefeatures we use to model POI decisions.
POI Category Classifier TrainingHapori learns a completely new metric for every POI cat-egory it supports. Only the fraction of POI decisions thatresult in a POI of the same category are used within the cat-egory specific models. When a query is provided to Haporiit is evaluated only using the model that is associated withthe POI category specified by the user. The community be-havior dictates the importance of different features duringthe POI ranking phase. Repeating these steps allows Haporito incorporate changes in community attitudes and physicalchanges in the area by simply using new POI decision datafrom the community. We use a simple k-nearest neighbor(KNN) classifier, where the classification decision is basedon the most frequent label within a distance radius surround-ing the unlabeled data point. Distance is determined by themetric learned by LMNN. We use KNN because it is effec-tive given how the learning problem is set up. However, anyone of a number of different classification techniques can beused (e.g., SVM [2]). The two requirements being that it is asupervised learner and can estimate the probability of mul-tiple potential classes (i.e., POIs) based on a new vector ofcontextual and behavioral features (i.e., query).
Apply POI Category ClassifierThe off-line model training process discussed above is per-formed prior to user query processing. In our current design,a mobile client application is required to provide a generalPOI category to restrict the search of candidate POIs. The
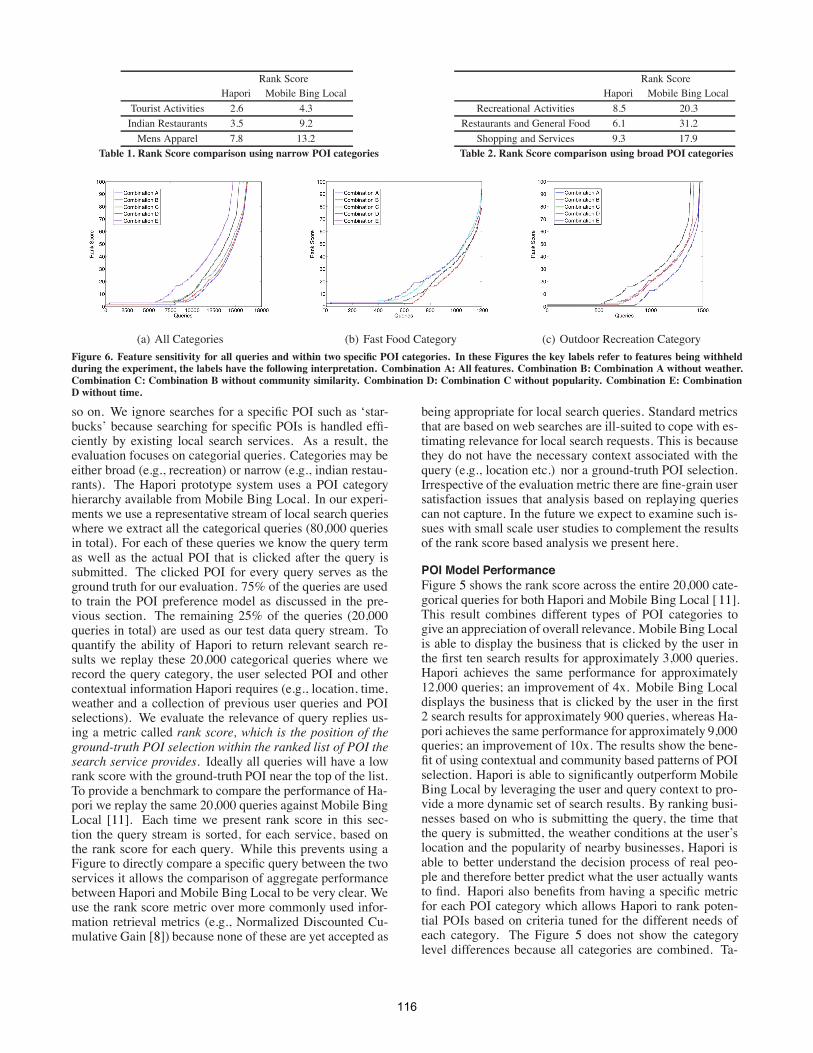
Figure 5. Rank Score comparison between Mobile Bing Local and Ha-pori
design of Hapori allows for flexibly defined POI categories.A category can be quite broad, such as, a category for recre-ational activities containing many different POIs (e.g., golfcourses, jogging tracks, bowling alleys, karaoke bars). Sim-ilarly, categories can be quite narrow, such as, a category ofdifferent types of restaurants (e.g., italian, indian, chinese,vegan). A local search client provides this category selectionalong with features required by the POI preference model.These features are computed based on either: the instanta-neous measurements from on-board sensors (e.g., location),longitudinal measurements of the user behavior (e.g., PDFsof temporal patterns when the person uses their device, orPOI preferences from the application); and indirectly gath-ered data, such as, weather and traffic conditions based onthe location and time. The user selected POI category deter-mines the POI relevancy metric and the associated model touse when ranking POIs. One complication is that althoughwe use KNN classification, if unmodified it only returns asingle prediction. However, Hapori needs to output a rele-vance ordered list of POIs that match the query. To providethis, we make a simple modification to KNN. After each pre-diction all the training examples of the predicted label aretemporarily removed before KNN is applied again. Eachrepetition produces the next most probable, and thereforerelevant, POI based on the query.
EVALUATIONIn this section, we evaluate a prototype implementation ofthe Hapori framework using real search query streams ex-tracted from the mobile search logs of Mobile Bing Local[11]. Our evaluation aims to: i) Quantify how relevant theresults generated by Hapori are and compare its performanceto that of Mobile Bing Local and ii) Quantify the impact ofthe individual context and behavioral similarity parametersmodeled by Hapori on the overall relevance performance.
Experimental MethodologyWe study the effectiveness of Hapori using the same 6-monthmobile local search logs discussed earlier in this paper. Forthe experiments we use a data set containing approximately4,000 unique POIs and 80,000 queries generated by 11,000different users. This data comes from a community of usersin the Seattle, WA area and spans a six month period fromJanuary to July 2009. Hapori assumes a simple categor-ical query model in which users provide the system witha request based on a fixed set of POI categories, such as:‘restaurants’, ‘men’s clothing’, ‘recreational activities’ and
115
Rank ScoreHapori Mobile Bing Local
Tourist Activities 2.6 4.3Indian Restaurants 3.5 9.2Mens Apparel 7.8 13.2
Table 1. Rank Score comparison using narrow POI categories
Rank ScoreHapori Mobile Bing Local
Recreational Activities 8.5 20.3Restaurants and General Food 6.1 31.2
Shopping and Services 9.3 17.9Table 2. Rank Score comparison using broad POI categories
(a) All Categories (b) Fast Food Category (c) Outdoor Recreation CategoryFigure 6. Feature sensitivity for all queries and within two specific POI categories. In these Figures the key labels refer to features being withheldduring the experiment, the labels have the following interpretation. Combination A: All features. Combination B: Combination A without weather.Combination C: Combination B without community similarity. Combination D: Combination C without popularity. Combination E: CombinationD without time.
so on. We ignore searches for a specific POI such as ‘star-bucks’ because searching for specific POIs is handled effi-ciently by existing local search services. As a result, theevaluation focuses on categorial queries. Categories may beeither broad (e.g., recreation) or narrow (e.g., indian restau-rants). The Hapori prototype system uses a POI categoryhierarchy available from Mobile Bing Local. In our experi-ments we use a representative stream of local search querieswhere we extract all the categorical queries (80,000 queriesin total). For each of these queries we know the query termas well as the actual POI that is clicked after the query issubmitted. The clicked POI for every query serves as theground truth for our evaluation. 75% of the queries are usedto train the POI preference model as discussed in the pre-vious section. The remaining 25% of the queries (20,000queries in total) are used as our test data query stream. Toquantify the ability of Hapori to return relevant search re-sults we replay these 20,000 categorical queries where werecord the query category, the user selected POI and othercontextual information Hapori requires (e.g., location, time,weather and a collection of previous user queries and POIselections). We evaluate the relevance of query replies us-ing a metric called rank score, which is the position of theground-truth POI selection within the ranked list of POI thesearch service provides. Ideally all queries will have a lowrank score with the ground-truth POI near the top of the list.To provide a benchmark to compare the performance of Ha-pori we replay the same 20,000 queries against Mobile BingLocal [11]. Each time we present rank score in this sec-tion the query stream is sorted, for each service, based onthe rank score for each query. While this prevents using aFigure to directly compare a specific query between the twoservices it allows the comparison of aggregate performancebetween Hapori and Mobile Bing Local to be very clear. Weuse the rank score metric over more commonly used infor-mation retrieval metrics (e.g., Normalized Discounted Cu-mulative Gain [8]) because none of these are yet accepted as
being appropriate for local search queries. Standard metricsthat are based on web searches are ill-suited to cope with es-timating relevance for local search requests. This is becausethey do not have the necessary context associated with thequery (e.g., location etc.) nor a ground-truth POI selection.Irrespective of the evaluation metric there are fine-grain usersatisfaction issues that analysis based on replaying queriescan not capture. In the future we expect to examine such is-sues with small scale user studies to complement the resultsof the rank score based analysis we present here.
POI Model PerformanceFigure 5 shows the rank score across the entire 20,000 cate-gorical queries for both Hapori and Mobile Bing Local [ 11].This result combines different types of POI categories togive an appreciation of overall relevance. Mobile Bing Localis able to display the business that is clicked by the user inthe first ten search results for approximately 3,000 queries.Hapori achieves the same performance for approximately12,000 queries; an improvement of 4x. Mobile Bing Localdisplays the business that is clicked by the user in the first2 search results for approximately 900 queries, whereas Ha-pori achieves the same performance for approximately 9,000queries; an improvement of 10x. The results show the bene-fit of using contextual and community based patterns of POIselection. Hapori is able to significantly outperform MobileBing Local by leveraging the user and query context to pro-vide a more dynamic set of search results. By ranking busi-nesses based on who is submitting the query, the time thatthe query is submitted, the weather conditions at the user’slocation and the popularity of nearby businesses, Hapori isable to better understand the decision process of real peo-ple and therefore better predict what the user actually wantsto find. Hapori also benefits from having a specific metricfor each POI category which allows Hapori to rank poten-tial POIs based on criteria tuned for the different needs ofeach category. The Figure 5 does not show the categorylevel differences because all categories are combined. Ta-
116
ble 1 and Table 2 show the mean rank score of queries fromsix different POI categories. Three of these are narrow cat-egories that are fairly specific as to the type of POI, whilethe other three categories are much broader. Hapori deliv-ers a better mean rank score for all categories in compari-son to Mobile Bing Local. Some categories are very broad,for instance more than 1500 POIs are considered within the‘restaurants and general food’ category, which makes thelarge rank score within this category more understandable,others, such as, ‘indian restaurants’ only have 93 differentPOIs which makes the 9.2 rank score less impressive. Ha-pori outperforms the baseline search service by different de-grees depending on the category. The variation of out perfor-mance is dependent on what degree the POI category bene-fits from the additional factors incorporated into the selec-tion process. For instance, the ‘recreational activities’ and‘restaurants and general food’ are sensitive to the weather,popularity and temporal features. The large improvementis due to these important factors being incorporated effec-tively into the search process. In contrast, ‘shopping andservices’ and ‘men’s apparel’ show little benefit from thesesame features. However, these two shopping categories of-fer improved performance through personalization and useof community similarity.
Feature SensitivityTo understand the impact of the variety of different types offeatures used by Hapori we group together the different fea-tures we use into feature families, these being: popularity,spacial, temporal, weather and community similarity. Wethen perform sensitivity analysis on rank score with differentquery loads, as illustrated in Figure 6. In this experiment, werepeatedly replay the same query load but each time removeone of the feature families. The amount by which the rankscore decreases indicates how important the feature familyis to generating the rank score. All three subfigures in Fig-ure 6 show the same baseline result which uses all featurefamilies, this is the line on the furthest lower right indicat-ing the curve has the best rank score performance. Figure6(a) shows feature sensitivity across all the queries. We findthat the most significant features in decreasing order are:temporal features, community similarity features, popular-ity and weather. Temporal features contribute significantlyto rank score with the average rank score increasing by ap-proximately 11 when temporal features are added back to thesystem. This has a greater benefit than location and weatherfeatures with community similarity being responsible for achange in rank score of about half that of temporal features.The large impact of temporal features on people’s choices isintuitive and we find time is critical for all categories.
Figures 6(b) and 6(c) repeat the same experiment but for twospecific POI categories i.e., fast food and outdoor recreation.By examining two POI categories in isolation we observethe variation in sensitivity to different features across differ-ent categories. For the POI category ‘outdoor recreation’the weather feature family becomes the second most im-portant influencer. Community similarity is dominant herebecause ‘outdoor recreation’ is sensitive to personal prefer-ence. In contrast, Figure 6(b) shows an example of a cate-gory in which many of the features of Hapori are not useful
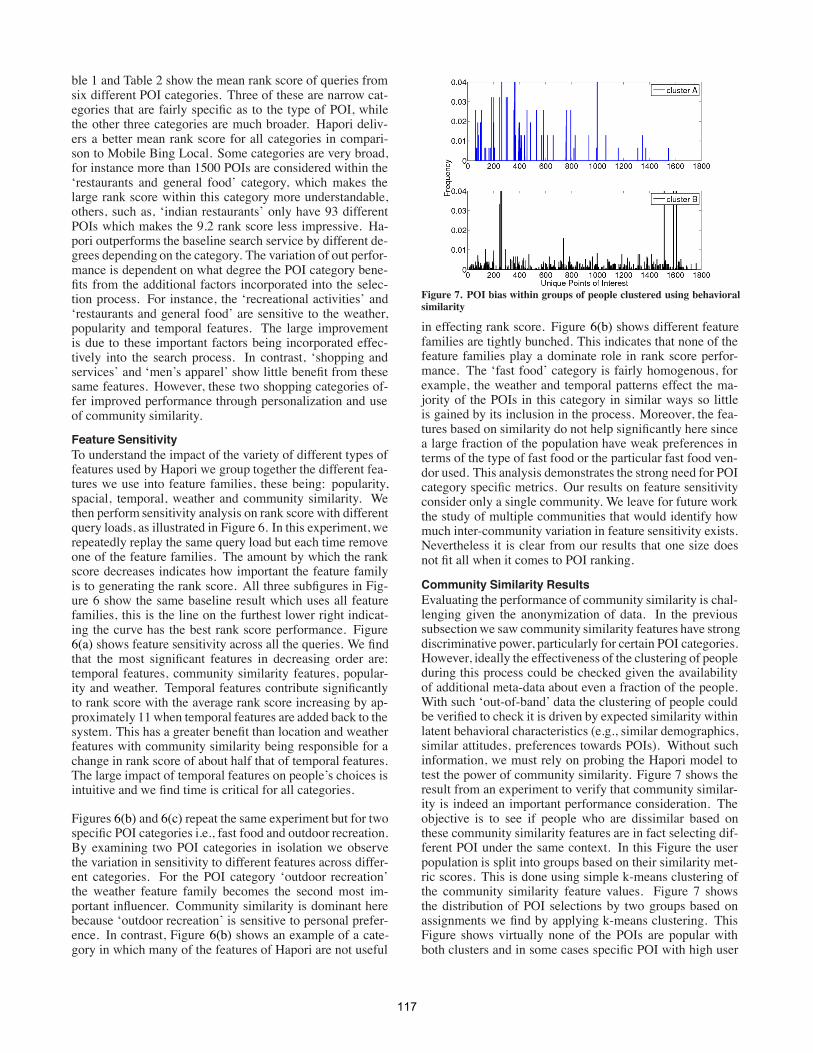
Figure 7. POI bias within groups of people clustered using behavioralsimilarity
in effecting rank score. Figure 6(b) shows different featurefamilies are tightly bunched. This indicates that none of thefeature families play a dominate role in rank score perfor-mance. The ‘fast food’ category is fairly homogenous, forexample, the weather and temporal patterns effect the ma-jority of the POIs in this category in similar ways so littleis gained by its inclusion in the process. Moreover, the fea-tures based on similarity do not help significantly here sincea large fraction of the population have weak preferences interms of the type of fast food or the particular fast food ven-dor used. This analysis demonstrates the strong need for POIcategory specific metrics. Our results on feature sensitivityconsider only a single community. We leave for future workthe study of multiple communities that would identify howmuch inter-community variation in feature sensitivity exists.Nevertheless it is clear from our results that one size doesnot fit all when it comes to POI ranking.
Community Similarity ResultsEvaluating the performance of community similarity is chal-lenging given the anonymization of data. In the previoussubsectionwe saw community similarity features have strongdiscriminative power, particularly for certain POI categories.However, ideally the effectiveness of the clustering of peopleduring this process could be checked given the availabilityof additional meta-data about even a fraction of the people.With such ‘out-of-band’ data the clustering of people couldbe verified to check it is driven by expected similarity withinlatent behavioral characteristics (e.g., similar demographics,similar attitudes, preferences towards POIs). Without suchinformation, we must rely on probing the Hapori model totest the power of community similarity. Figure 7 shows theresult from an experiment to verify that community similar-ity is indeed an important performance consideration. Theobjective is to see if people who are dissimilar based onthese community similarity features are in fact selecting dif-ferent POI under the same context. In this Figure the userpopulation is split into groups based on their similarity met-ric scores. This is done using simple k-means clustering ofthe community similarity feature values. Figure 7 showsthe distribution of POI selections by two groups based onassignments we find by applying k-means clustering. ThisFigure shows virtually none of the POIs are popular withboth clusters and in some cases specific POI with high user
117

click-throughs for one cluster are found to have no user in-terest from the other cluster. We observe the distribution ofPOIs are distinctly different from each cluster even thoughthe context is the same. In one cluster there is a wide disper-sal in the distribution spread over a large fraction of all POIs.In contrast the other cluster has a much narrower focus in thedistribution. These observations are inline with the expecta-tions of how the similarity mechanism is functioning.
RELATED WORKSurprisingly little is known about local search, with few pro-posed systems or analysis. Our log analysis represents to thebest of our knowledge some of the most interesting localsearch specific characterization performed today. It comple-ments well the small but growing body of work on web fo-cused search from mobile devices (e.g.,[7]). These papersroutinely report that for mobile devices the typical user ex-perience is poor when performing general web search. Inrecognition of this researchers are pursuing approaches toimprove mobile search (e.g., [17]). However very few ofthese proposals are applicable to the problem we addresswith Hapori since local search, the problem of finding per-sonally relevant POIs, has very different characteristics com-pared to those found in web searching from a mobile device.
The benefit of personalization for search, particularly to over-come poorly specified user search intent has been an ac-tive area of investigation [15] for desktop web search. Re-searchers have sought to not only improve results based ondata from the user in isolation but from communities of desk-top web searchers [14]. However, this body of work pro-vides limited guidance as to how to apply personalizationand leverage the community effectively for a local searchservice rather than desktop web search. A promising sourceof information looks to be query logs, which researchers arebeginning to explore. For instance, [6] uses query logs toimprove local search results however the author’s propose toessentially expose these logs to other users within a naviga-ble map interface. This leaves all the work in the hands ofthe users as to how to interpret this community sourced in-formation. In [9] a more transparent method of identifyinguser preferences for POIs is explored. User POI preferenceis shown to be correlated to how often they visit these places.
Hapori has commonalities with systems that provide recom-mendations [13] to people such as tourists or shoppers. Ineach of these cases the target user often does not know pre-cisely what they are searching for and lack the knowledgeneeded to provide a fully specified query. One example,MovieLens Unplugged [12], provides movie recommenda-tions while on the go. Such systems fall into the category ofcollaborative filters. Conceptually collaborative filters andour use of community similarity have parallels in that bothattempt to leverage a collection of people to improve a sug-gestion provided to the user. However, our novel approach tomodeling user intent and preferences as captured by a com-bination of context and behavioral similarity reaches beyondproposed collaborative filtering systems.
Our system heavily exploits context information and in thisrespect Hapori is building upon a long line of projects such
as the pioneering systems of: Cyberguide [1] and GUIDE[5], which developed location-based intelligent guides andrecommendation systems. We do not claim to be the first toidentify the value of context within a search service, manyhave already been proposed (e.g., [10]). Still, Hapori isclearly novel in how it uses context to capture the importantinfluences that impact the POI choices of people as a keycomponent within a community guided local search service.
CONCLUSIONWe believe that a major transformation of local search ser-vices is underway. Local search services are shifting theirgoal from answering static questions,such as, ‘Where is theclosest Dennys?’ to answering more dynamic questions,such as, ‘Where is a little martini bar around here, that ispopular with people like myself and that has live jazz?’. TheHapori search service introduced in this paper, takes the firsttwo steps in this direction. First, it demonstrates the effectthat different query and personal context parameters have onthe way mobile users make their POI selections, using a 6-month long search query stream from a major, commerciallyavailable search engine, Mobile Bing Local. Second, Haporiis the first local search service that leverages contextual fac-tors, personal preferences as well as similarity across mobileusers to deliver dynamic, highly contextual and personalizedinformation in response to queries. Under Hapori responsesto local search queries are generated based on a model ofhow real people make their own personal POI selections.
REFERENCES1. G. D. Abowd, et al. Cyberguide: a mobile context-aware tour guide. Wirel.
Netw., 3(5):421–433, 1997.2. C. M. Bishop. Pattern Recognition and Machine Learning (Information Science
and Statistics). Springer-Verlag New York, Inc., Secaucus, NJ, 2006.3. A. T. Campbell, et al. The rise of people-centric sensing. IEEE Internet
Computing, 12:12–21, 2008.4. K. M. Carter, et al. Fine: Fisher information nonparametric embedding. IEEE
Trans. Pattern Anal. Mach. Intell., 31(11):2093–2098, 2009.5. K. Cheverst, et al. Developing a context-aware electronic tourist guide: someissues and experiences. In CHI ’00: Proceedings of the SIGCHI conference onHuman factors in computing systems, pages 17–24, New York, NY, 2000. ACM.
6. K. Church and B. Smyth. Who, what, where & when: a new approach to mobilesearch. In IUI ’08: Proceedings of the 13th international conference onIntelligent user interfaces, pages 309–312, New York, NY, 2008. ACM.
7. K. Church, et al. Mobile information access: A study of emerging searchbehavior on the mobile internet. ACM Trans. Web, 1(1):4, 2007.
8. B. Croft, D. Metzler, and T. Strohman. Search Engines: Information Retrieval inPractice. Addison-Wesley Publishing Company, USA, 2009.
9. J. Froehlich, et al. Voting with your feet: An investigative study of therelationship between place visit behavior and preference. In Ubicomp, volume4206 of Lecture Notes in Computer Science, pages 333–350. Springer, 2006.
10. S. Hattori, T. Tezuka, and K. Tanaka. Context-aware query refinement for mobileweb search. In SAINT-W ’07: Proceedings of the 2007 International Symposiumon Applications and the Internet Workshops, page 15, Washington, DC, 2007.IEEE Computer Society.
11. Microsoft. Mobile Bing Local. http://m.bing.com/.12. B. N. Miller, et al. Movielens unplugged: experiences with an occasionally
connected recommender system. In IUI ’03: Proceedings of the 8th internationalconference on Intelligent user interfaces, pages 263–266, New York, NY, 2003.
13. P. Resnick and H. R. Varian. Recommender systems. Commun. ACM,40(3):56–58, 1997.
14. B. Smyth, et al. Exploiting query repetition and regularity in an adaptivecommunity-based web search engine. User Modeling and User-AdaptedInteraction, 14(5):383–423, 2005.
15. J. Teevan, S. T. Dumais, and E. Horvitz. Personalizing search via automatedanalysis of interests and activities. In SIGIR ’05: Proceedings of the 28th annualinternational ACM SIGIR conference on Research and development ininformation retrieval, pages 449–456, New York, NY, 2005. ACM.
16. K. Q. Weinberger and L. K. Saul. Distance metric learning for large marginnearest neighbor classification. J. Mach. Learn. Res., 10:207–244, 2009.
17. J. Yi, F. Maghoul, and J. Pedersen. Deciphering mobile search patterns: a studyof yahoo! mobile search queries. In WWW ’08: Proceeding of the 17thinternational conference on World Wide Web, pages 257–266, New York, NY,2008. ACM.
118





























