Embed Size (px)
Citation preview

Design of Parallel and High-Performance Computing Fall 2014 Lecture: Introduction
Instructor: Torsten Hoefler & Markus Püschel
TA: Timo Schneider
Goals of this lecture
Motivate you!
What is parallel computing?
And why do we need it?
What is high-performance computing?
What’s a Supercomputer and why do we care?
Basic overview of
Programming models
Some examples
Architectures
Some case-studies
Provide context for coming lectures
2
Let us assume …
… you were to build a machine like this …
… we know how each part works
There are just many of them!
Question: How many calculations per second are needed to emulate a brain? 3
Source: wikipedia
4
Source: www.singularity.com Can we do this today?
5
Source: www.singularity.com Blue Waters, ~13 PF (2012)
Tianhe-2, ~55 PF (2013)
1 Exaflop! ~2022?
Human Brain – No Problem!
… not so fast, we need to understand how to program those machines …
6

Human Brain – No Problem!
7
Scooped!
Source: extremetech.com
Under the Kei Computer
8
Other problem areas: Scientific Computing
Most natural sciences are simulation driven or are moving towards simulation Theoretical physics (solving the Schrödinger equation, QCD) Biology (Gene sequencing) Chemistry (Material science) Astronomy (Colliding black holes) Medicine (Protein folding for drug discovery) Meteorology (Storm/Tornado prediction) Geology (Oil reservoir management, oil exploration) and many more … (even Pringles uses HPC)
9
Other problem areas: Commercial Computing
Databases, data mining, search Amazon, Facebook, Google
Transaction processing Visa, Mastercard
Decision support Stock markets, Wall Street, Military applications
Parallelism in high-end systems and back-ends Often throughput-oriented Used equipment varies from COTS (Google) to high-end redundant
mainframes (banks)
10
Other problem areas: Industrial Computing
Aeronautics (airflow, engine, structural mechanics, electromagnetism)
Automotive (crash, combustion, airflow)
Computer-aided design (CAD)
Pharmaceuticals (molecular modeling, protein folding, drug design)
Petroleum (Reservoir analysis)
Visualization (all of the above, movies, 3d)
11
What can faster computers do for us?
Solving bigger problems than we could solve before!
E.g., Gene sequencing and search, simulation of whole cells, mathematics of the brain, …
The size of the problem grows with the machine power
Weak Scaling
Solve today’s problems faster!
E.g., large (combinatorial) searches, mechanical simulations (aircrafts, cars, weapons, …)
The machine power grows with constant problem size
Strong Scaling
12

High-Performance Computing (HPC)
a.k.a. “Supercomputing”
Question: define “Supercomputer”!
13
High-Performance Computing (HPC)
a.k.a. “Supercomputing”
Question: define “Supercomputer”!
“A supercomputer is a computer at the frontline of contemporary processing capacity--particularly speed of calculation.” (Wikipedia)
Usually quite expensive ($s and kWh) and big (space)
HPC is a quickly growing niche market
Not all “supercomputers”, wide base
Important enough for vendors to specialize
Very important in research settings (up to 40% of university spending)
“Goodyear Puts the Rubber to the Road with High Performance Computing”
“High Performance Computing Helps Create New Treatment For Stroke Victims”
“Procter & Gamble: Supercomputers and the Secret Life of Coffee”
“Motorola: Driving the Cellular Revolution With the Help of High Performance Computing”
“Microsoft: Delivering High Performance Computing to the Masses”
14
The Top500 List
A benchmark, solve Ax=b
As fast as possible! as big as possible
Reflects some applications, not all, not even many
Very good historic data!
Speed comparison for computing centers, states, countries, nations, continents
Politicized (sometimes good, sometimes bad)
Yet, fun to watch
15
The Top500 List (June 2014)
16
Piz Daint @ CSCS
18
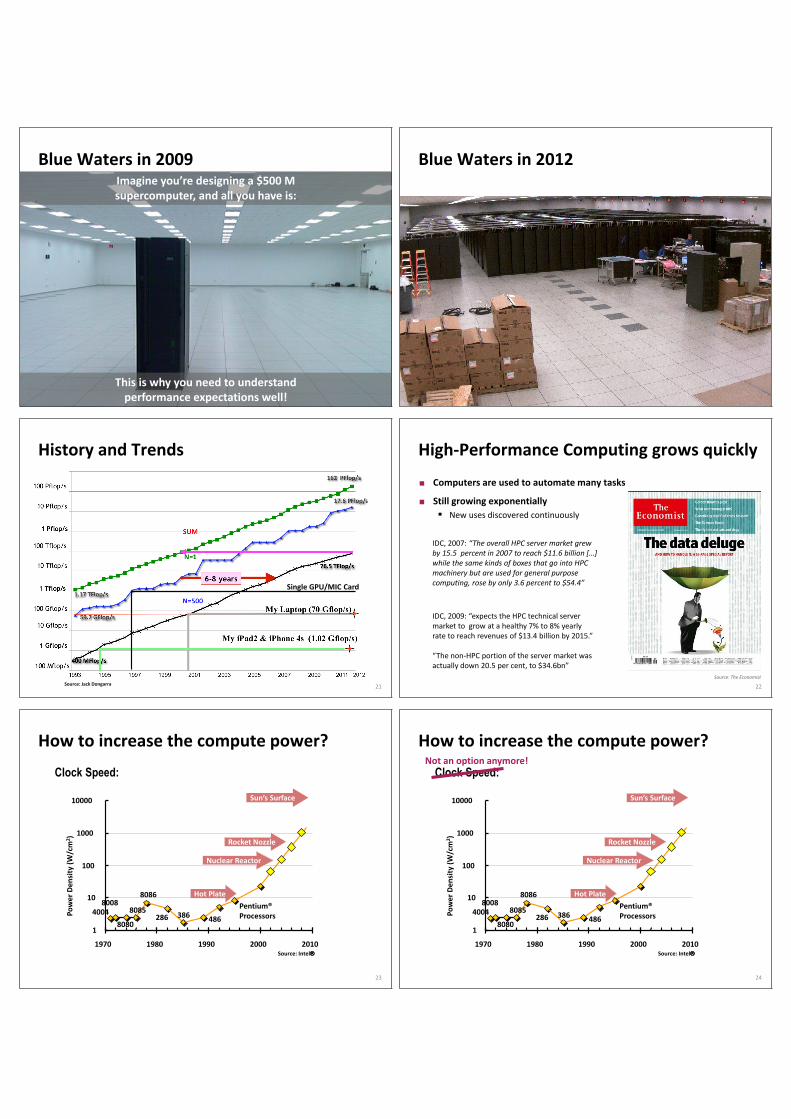
Blue Waters in 2009
This is why you need to understand performance expectations well!
Imagine you’re designing a $500 M supercomputer, and all you have is:
Blue Waters in 2012
History and Trends
21 Source: Jack Dongarra
Single GPU/MIC Card
High-Performance Computing grows quickly
Computers are used to automate many tasks
Still growing exponentially
New uses discovered continuously
22
Source: The Economist
IDC, 2007: “The overall HPC server market grew by 15.5 percent in 2007 to reach $11.6 billion […] while the same kinds of boxes that go into HPC machinery but are used for general purpose computing, rose by only 3.6 percent to $54.4”
IDC, 2009: “expects the HPC technical server market to grow at a healthy 7% to 8% yearly rate to reach revenues of $13.4 billion by 2015.” “The non-HPC portion of the server market was actually down 20.5 per cent, to $34.6bn”
How to increase the compute power?
23
4004 8008
8080
8085
8086
286 386 486
Pentium® Processors
1
10
100
1000
10000
1970 1980 1990 2000 2010
Po
we
r D
en
sity
(W
/cm
2)
Source: Intel
Hot Plate
Nuclear Reactor
Rocket Nozzle
Sun’s Surface
Clock Speed:
How to increase the compute power?
24
4004 8008
8080
8085
8086
286 386 486
Pentium® Processors
1
10
100
1000
10000
1970 1980 1990 2000 2010
Po
we
r D
en
sity
(W
/cm
2)
Source: Intel
Hot Plate
Nuclear Reactor
Rocket Nozzle
Sun’s Surface
Clock Speed: Not an option anymore!

25
Source: Wikipedia
A more complete view
26
So how to invest the transistors?
Architectural innovations Branch prediction, Tomasulo logic/rename register, speculative execution,
…
Help only so much
What else? Simplification is beneficial, less transistors per CPU, more CPUs, e.g., Cell
B.E., GPUs, MIC
We call this “cores” these days
Also, more intelligent devices or higher bandwidths (e.g., DMA controller, intelligent NICs)
27
Source: IBM Source: NVIDIA Source: Intel
Towards the age of massive parallelism
Everything goes parallel
Desktop computers get more cores
2,4,8, soon dozens, hundreds?
Supercomputers get more PEs (cores, nodes)
> 3 million today
> 50 million on the horizon
1 billion in a couple of years (after 2020)
Parallel Computing is inevitable!
28
Parallel vs. Concurrent computing Concurrent activities may be executed in parallel Example: A1 starts at T1, ends at T2; A2 starts at T3, ends at T4 Intervals (T1,T2) and (T3,T4) may overlap! Parallel activities: A1 is executed while A2 is running Usually requires separate resources!
Goals of this lecture
Motivate you!
What is parallel computing?
And why do we need it?
What is high-performance computing?
What’s a Supercomputer and why do we care?
Basic overview of
Programming models
Some examples
Architectures
Some case-studies
Provide context for coming lectures
29
Granularity and Resources
30
Activities
Micro-code instruction
Machine-code instruction (complex or simple)
Sequence of machine-code instructions:
Blocks
Loops
Loop nests
Functions
Function sequences
Parallel Resource
Instruction-level parallelism
Pipelining
VLIW
Superscalar
SIMD operations
Vector operations
Instruction sequences
Multiprocessors
Multicores
Multithreading

Resources and Programming
31
Parallel Resource
Instruction-level parallelism
Pipelining
VLIW
Superscalar
SIMD operations
Vector operations
Instruction sequences
Multiprocessors
Multicores
Multithreading
Programming
Compiler
(inline assembly)
Hardware scheduling
Compiler (inline assembly)
Libraries
Compilers (very limited)
Expert programmers
Parallel languages
Parallel libraries
Hints
Historic Architecture Examples
Systolic Array
Data-stream driven (data counters)
Multiple streams for parallelism
Specialized for applications (reconfigurable)
Dataflow Architectures
No program counter, execute instructions when all input arguments are available
Fine-grained, high overheads
Example: compute f = (a+b) * (c+d)
32
Source: ni.com
Source: isi.edu
Von Neumann Architecture
Program counter Inherently serial! Retrospectively define parallelism in instructions and data
33
SISD Standard Serial Computer
(nearly extinct)
SIMD Vector Machines or Extensions
(very common)
MISD Redundant Execution
(fault tolerance)
MIMD Multicore
(ubiquituous)
Parallel Architectures 101
… and mixtures of those
34
Today’s laptops Today’s servers
Yesterday’s clusters Today’s clusters
Programming Models
Shared Memory Programming (SM/UMA)
Shared address space
Implicit communication
Hardware for cache-coherent remote memory access
Cache-coherent Non Uniform Memory Access (cc NUMA)
(Partitioned) Global Address Space (PGAS)
Remote Memory Access
Remote vs. local memory (cf. ncc-NUMA)
Distributed Memory Programming (DM)
Explicit communication (typically messages)
Message Passing
35
Shared Memory Machines
Two historical architectures:
“Mainframe” – all-to-all connection between memory, I/O and PEs
Often used if PE is the most expensive part
Bandwidth scales with P
PE Cost scales with P, Question: what about network cost?
36
Source: IBM

Shared Memory Machines
Two historical architectures:
“Mainframe” – all-to-all connection between memory, I/O and PEs
Often used if PE is the most expensive part
Bandwidth scales with P
PE Cost scales with P, Question: what about network cost?
Answer: Cost can be cut with multistage connections (butterfly)
“Minicomputer” – bus-based connection All traditional SMP systems
High latency, low bandwidth (cache is important)
Tricky to achieve highest performance (contention)
Low cost, extensible
37
Source: IBM
Shared Memory Machine Abstractions
Any PE can access all memory
Any I/O can access all memory (maybe limited)
OS (resource management) can run on any PE
Can run multiple threads in shared memory
Used since 40+ years
Communication through shared memory
Load/store commands to memory controller
Communication is implicit
Requires coordination
Coordination through shared memory
Complex topic
Memory models
38
Shared Memory Machine Programming
Threads or processes
Communication through memory
Synchronization through memory or OS objects
Lock/mutex (protect critical region)
Semaphore (generalization of mutex (binary sem.))
Barrier (synchronize a group of activities)
Atomic Operations (CAS, Fetch-and-add)
Transactional Memory (execute regions atomically)
Practical Models:
Posix threads
MPI-3
OpenMP
Others: Java Threads, Qthreads, …
39
An SMM Example: Compute Pi
40
Using Gregory-Leibnitz Series:
Iterations of sum can be computed in parallel
Needs to sum all contributions at the end
Source: mathworld.wolfram.com
Pthreads Compute Pi Example
41
int main( int argc, char *argv[] )
{
// definitions …
thread_arr = (pthread_t*)malloc(nthreads * sizeof(pthread_t));
resultarr= (double*)malloc(nthreads * sizeof(double));
for (i=0; i<nthreads; ++i) {
int ret = pthread_create( &thread_arr[i], NULL,
compute_pi, (void*) i);
}
for (i=0; i<nthreads; ++i) {
pthread_join( thread_arr[i], NULL);
}
pi = 0;
for (i=0; i<nthreads; ++i) pi += resultarr[i];
printf ("pi is approximately %.16f, Error is %.16f\n",
pi, fabs(pi - PI25DT));
}
int n=10000;
double *resultarr;
int nthreads;
void *compute_pi(void *data) {
int i, j;
int myid = (int)(long)data;
double mypi, h, x, sum;
for (j=0; j<n; ++j) {
h = 1.0 / (double) n;
sum = 0.0;
for (i = myid + 1; i <= n; i += nthreads) {
x = h * ((double)i - 0.5);
sum += (4.0 / (1.0 + x*x));
}
mypi = h * sum;
}
resultarr[myid] = mypi;
}
Additional comments on SMM
OpenMP would allow to implement this example much simpler (but has other issues)
Transparent shared memory has some issues in practice:
False sharing (e.g., resultarr[])
Race conditions (complex mutual exclusion protocols)
Little tool support (debuggers need some work)
Achieving performance is harder than it seems!
42

Distributed Memory Machine Programming
Explicit communication between PEs
Message passing or channels
Only local memory access, no direct access to remote memory
No shared resources (well, the network)
Programming model: Message Passing (MPI, PVM)
Communication through messages or group operations (broadcast, reduce, etc.)
Synchronization through messages (sometimes unwanted side effect) or group operations (barrier)
Typically supports message matching and communication contexts
43
Send specifies buffer to be transmitted
Recv specifies buffer to receive into
Implies copy operation between named PEs
Optional tag matching
Pair-wise synchronization (cf. happens before)
DMM Example: Message Passing
44
Pr ocess P Pr ocess Q
Addr ess Y
Addr ess X
Send X, Q, t
Receive Y , P , t Match
Local pr ocess addr ess space
Local pr ocess addr ess space
Source: John Mellor-Crummey
DMM MPI Compute Pi Example
45
int main( int argc, char *argv[] ) {
// definitions
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD, &numprocs);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
double t = -MPI_Wtime();
for (j=0; j<n; ++j) {
h = 1.0 / (double) n;
sum = 0.0;
for (i = myid + 1; i <= n; i += numprocs) { x = h * ((double)i - 0.5); sum += (4.0 / (1.0 + x*x)); }
mypi = h * sum;
MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
}
t+=MPI_Wtime();
if (!myid) {
printf("pi is approximately %.16f, Error is %.16f\n", pi, fabs(pi - PI25DT));
printf("time: %f\n", t);
}
MPI_Finalize();
}
DMM Example: PGAS
Partitioned Global Address Space
Shared memory emulation for DMM
Usually non-coherent
“Distributed Shared Memory”
Usually coherent
Simplifies shared access to distributed data
Has similar problems as SMM programming
Sometimes lacks performance transparency
Local vs. remote accesses
Examples:
UPC, CAF, Titanium, X10, …
46
How to Tame the Beast?
How to program large machines?
No single approach, PMs are not converging yet
MPI, PGAS, OpenMP, Hybrid (MPI+OpenMP, MPI+MPI, MPI+PGAS?), …
Architectures converge
General purpose nodes connected by general purpose or specialized networks
Small scale often uses commodity networks
Specialized networks become necessary at scale
Even worse: accelerators (not covered in this class, yet)
47
Practical SMM Programming: Pthreads
48
Kernel
User
CPU 0 CPU 1
Kernel
User
CPU 0 CPU 1
User-level Threads Kernel-level Threads
Covered in example, small set of functions for thread creation and management

Practical SMM Programming:
Fork-join model
Types of constructs:
Source: OpenMP.org
Source: Blaise Barney, LLNL
+ Tasks
OpenMP General Code Structure
50
#include <omp.h>
main () {
int var1, var2, var3;
// Serial code
// Beginning of parallel section. Fork a team of threads. Specify variable scoping
#pragma omp parallel private(var1, var2) shared(var3)
{
// Parallel section executed by all threads
// Other OpenMP directives
// Run-time Library calls
// All threads join master thread and disband
}
// Resume serial code
}
Source: Blaise Barney, LLNL
Practical PGAS Programming: UPC
PGAS extension to the C99 language
Many helper library functions
Collective and remote allocation
Collective operations
Complex consistency model
51
Practical DMM Programming: MPI-1
52 Collection of 1D address spaces
Helper Functions
many more (>600 total)
Source: Blaise Barney, LLNL
Complete Six Function MPI-1 Example
53
#include <mpi.h>
int main(int argc, char **argv) {
int myrank, sbuf=23, rbuf=32;
MPI_Init(&argc, &argv);
/* Find out my identity in the default communicator */
MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
if (myrank == 0) {
MPI_Send(&sbuf, /* message buffer */
1, /* one data item */
MPI_INT, /* data item is an integer */
rank, /* destination process rank */
99, /* user chosen message tag */
MPI_COMM_WORLD); /* default communicator */
} else {
MPI_Recv(&rbuf, MPI_DOUBLE, 0, 99, MPI_COMM_WORLD, &status);
printf(“received: %i\n”, rbuf);
}
MPI_Finalize();
}
MPI-2/3: Greatly enhanced functionality
Support for shared memory in SMM domains
Support for Remote Memory Access Programming
Direct use of RDMA
Essentially PGAS
Enhanced support for message passing communication
Scalable topologies
More nonblocking features
… many more
54

MPI: de-facto large-scale prog. standard
55 To appear at SC14 (11/17/2014)
Basic MPI Advanced MPI, including MPI-3
Accelerator example: CUDA
56
Hierarchy of Threads
Complex Memory Model
Simple Architecture
Source: NVIDIA
Accelerator example: CUDA
57
#define N 10
int main( void ) {
int a[N], b[N], c[N];
int *dev_a, *dev_b, *dev_c;
// allocate the memory on the GPU
cudaMalloc( (void**)&dev_a, N * sizeof(int) );
cudaMalloc( (void**)&dev_b, N * sizeof(int) );
cudaMalloc( (void**)&dev_c, N * sizeof(int) );
// fill the arrays 'a' and 'b' on the CPU
for (int i=0; i<N; i++) { a[i] = -i; b[i] = i * i; }
// copy the arrays 'a' and 'b' to the GPU
cudaMemcpy( dev_a, a, N * sizeof(int), cudaMemcpyHostToDevice );
cudaMemcpy( dev_b, b, N * sizeof(int), cudaMemcpyHostToDevice );
add<<<N,1>>>( dev_a, dev_b, dev_c );
// copy the array 'c' back from the GPU to the CPU
cudaMemcpy( c, dev_c, N * sizeof(int), cudaMemcpyDeviceToHost );
// free the memory allocated on the GPU
cudaFree( dev_a ); cudaFree( dev_b ); cudaFree( dev_c );
}
__global__ void add( int *a, int *b, int *c ) {
int tid = blockIdx.x;
// handle the data at this index
if (tid < N)
c[tid] = a[tid] + b[tid];
}
The Kernel
Host Code
OpenACC / OpenMP 4.0
Aims to simplify GPU programming
Compiler support
Annotations!
58
#define N 10
int main( void ) {
int a[N], b[N], c[N];
#pragma acc kernels
for (int i = 0; i < N; ++i)
c[i] = a[i] + b[i];
}
More programming models/frameworks
Not covered:
SMM: Intel Cilk / Cilk Plus, Intel TBB, …
Directives: OpenHMPP, PVM, …
PGAS: Coarray Fortran (Fortran 2008), …
HPCS: IBM X10, Fortress, Chapel, …
Accelerator: OpenCL, C++AMP, …
This class will not describe any model in more detail!
There are too many and they will change quickly (only MPI made it >15 yrs)
No consensus, but fundamental questions remain:
Data movement
Synchronization
Memory Models
Algorithmics
Foundations
59
Goals of this lecture
Motivate you!
What is parallel computing?
And why do we need it?
What is high-performance computing?
What’s a Supercomputer and why do we care?
Basic overview of
Programming models
Some examples
Architectures
Some case-studies
Provide context for coming lectures
60

large cache-
coherent multicore
machines
communicating
through coherent
memory access
and remote direct
memory access
Architecture Developments
’00-’05 <1999 ’06-’12 ’13-’20 >2020
distributed
memory
machines
communicating
through
messages
large cache-
coherent multicore
machines
communicating
through coherent
memory access
and messages
coherent and non-
coherent
manycore
accelerators and
multicores
communicating
through memory
access and remote
direct memory
access
largely non-
coherent
accelerators and
multicores
communicating
through remote
direct memory
access
Sources: various vendors
Case Study 1: IBM POWER7 IH (BW)
62
On-line Storage
Near-line Storage
L-L
ink C
ab
les
Super Node(32 Nodes / 4 CEC)
P7 Chip (8 cores)
SMP node (32 cores)
Drawer (256 cores)
SuperNode (1024 cores)
Building Block
Blue Waters System
NPCF
Source: IBM Source: IBM/NCSA
POWER7 Core
63 Source: IBM Source: IBM/NCSA
POWER7 Chip (8 cores)
64
Base Technology
45 nm, 576 mm2
1.2 B transistors
Chip
8 cores
4 FMAs/cycle/core
32 MB L3 (private/shared)
Dual DDR3 memory
128 GiB/s peak bandwidth
(1/2 byte/flop)
Clock range of 3.5 – 4 GHz
Quad-chip MCM
Source: IBM Source: IBM/NCSA
MC
1M
C 0
8c uP
MC
1M
C0
8c uP
MC
0M
C1
8c uP
MC
0M
C1
8c uP
P7-0 P7-1
P7-3 P7-2
A
B
X
W
B
A
W
X
B A
Y X
A B
X Y
C
Z
C
Z
W
Z
Z
W
C
Y
C
Y
A Clk Grp
B Clk Grp
C Clk Grp
D Clk Grp
A Clk Grp
B Clk Grp
C Clk Grp
D Clk Grp
A Clk Grp
B Clk Grp
C Clk Grp
D Clk Grp
A Clk Grp
B Clk Grp
C Clk Grp
D Clk Grp
A Clk Grp
B Clk Grp
C Clk Grp
D Clk Grp
A Clk Grp
B Clk Grp
C Clk Grp
D Clk Grp
A Clk Grp
B Clk Grp
C Clk Grp
D Clk Grp
A Clk Grp
B Clk Grp
C Clk Grp
D Clk Grp
MC
0M
C 1
MC
0M
C 1
MC
0M
C 1
MC
0M
C 1
Quad Chip Module (4 chips)
65
32 cores
32 cores*8 F/core*4 GHz = 1 TF
4 threads per core (max)
128 threads per package
4x32 MiB L3 cache
512 GB/s RAM BW (0.5 B/F)
800 W (0.8 W/F)
Source: IBM Source: IBM/NCSA
Adding a Network Interface (Hub)
66
DIM
M 1
5D
IMM
8D
IMM
9D
IMM
14
DIM
M 4
DIM
M 1
2D
IMM
13
DIM
M 5
DIM
M 1
1D
IMM
3D
IMM
2D
IMM
10
DIM
M 0
DIM
M 7
DIM
M 6
DIM
M 1
P7-IH Quad Block Diagram32w SMP w/ 2 Tier SMP Fabric, 4 chip Processor MCM + Hub SCM w/ On-Board Optics
MC
1
Mem
Mem
Mem
Mem
MC
0
Mem
Mem
8c uP
MC
1
Mem
Mem
Mem
Mem
MC
0
Mem
Mem
Mem
Mem
8c uP
7 Inter-Hub Board Level L-Buses
3.0Gb/s @ 8B+8B, 90% sus. peak
D0-D15 Lr0-Lr23
320 GB/s 240 GB/s
28x XMIT/RCV pairs@ 10 Gb/s
832
624
5+
5G
B/s
(6
x=
5+
1)
Hub Chip Module
22
+2
2G
B/s
164
Ll0
22
+2
2G
B/s
164
Ll1
22
+2
2G
B/s
164
Ll2
22
+2
2G
B/s
164
Ll3
22
+2
2G
B/s
164
Ll4
22
+2
2G
B/s
164
Ll5
22
+2
2G
B/s
164
Ll6
12x 12x
12x 12x
12x 12x
12x 12x
12x 12x
12x 12x
10
+1
0G
B/s
(1
2x=
10
+2
)
12x 12x 12x 12x
12x 12x 12x 12x
12x 12x 12x 12x
12x 12x 12x 12x
7+
7G
B/s
72
EG2
PC
Ie 6
1x
7+
7G
B/s
72
EG1
PC
Ie 1
6x
7+
7G
B/s
72
EG2
PC
Ie 8
x
MC
0
Mem
Mem
Mem
Mem
MC
1
Mem
Mem
Mem
Mem
8c uP
MC
0
Mem
Mem
Mem
Mem
MC
1
Mem
Mem
Mem
Mem
8c uP
Mem
Mem
P7-0 P7-1
P7-3 P7-2
A
B
X
W
B
A
W
X
B A
Y X
A B
X Y
C
Z
C
Z
W
Z
Z
W
C
Y
C
Y
Z
W
Y
X
A Clk Grp
B Clk Grp
C Clk Grp
D Clk Grp
A Clk Grp
B Clk Grp
C Clk Grp
D Clk Grp
A Clk Grp
B Clk Grp
C Clk Grp
D Clk Grp
A Clk Grp
B Clk Grp
C Clk Grp
D Clk Grp
A Clk Grp
B Clk Grp
C Clk Grp
D Clk Grp
A Clk Grp
B Clk Grp
C Clk Grp
D Clk Grp
A Clk Grp
B Clk Grp
C Clk Grp
D Clk Grp
A Clk Grp
B Clk Grp
C Clk Grp
D Clk Grp
MC
0M
C 1
MC
0M
C 1
MC
0M
C 1
MC
0M
C 1
DIM
M 1
Mem
Mem
DIM
M 0
Mem
Mem
DIM
M 5Mem
Mem
DIM
M 4Mem
Mem
DIM
M 7
Mem
Mem
DIM
M 6
Mem
Mem
DIM
M 1
0
Mem
Mem
DIM
M 1
1
Mem
Mem
DIM
M 2
Mem
Mem
DIM
M 3
Mem
Mem
DIM
M 1
4Mem
Mem
DIM
M 1
5Mem
Mem
DIM
M 8Mem
Mem
DIM
M 9Mem
Mem
DIM
M 1
2Mem
Mem
DIM
M 1
3Mem
Mem
Connects QCM to PCI-e
Two 16x and one 8x PCI-e slot
Connects 8 QCM's via low
latency, high bandwidth,
copper fabric.
Provides a message passing
mechanism with very
high bandwidth
Provides the lowest possible
latency between 8 QCM's
Source: IBM Source: IBM/NCSA

1.1 TB/s POWER7 IH HUB
67
EI-
3 P
HY
s
Torrent
Diff PHYs
L lo
ca
l
HU
B T
o H
UB
Co
pp
er
Bo
ard
Wir
ing
L remote
4 Drawer Interconnect to Create a Supernode
Optical
LR
0 B
us
Op
tic
al
6x 6x
LR
23
Bu
s
Op
tic
al
6x 6x
LL0 Bus
Copper
8B
8B
8B
8B
LL1 Bus
Copper
8B
8B
LL2 Bus
Copper
8B
8B
LL4 Bus
Copper
8B
8B
LL5 Bus
Copper
8B
8B
LL6 Bus
Copper
8B
8B
LL3 Bus
Copper
Dif
f P
HY
s
PX
0 B
us
16
x
16
x
PC
I-E
IO P
HY
Ho
t P
lug
Ctl
PX
1 B
us
16
x
16
x
PC
I-E
IO P
HY
Ho
t P
lug
Ctl
PX
2 B
us
8x8x
PC
I-E
IO P
HY
Ho
t P
lug
Ctl
FS
I
FS
P1
-A
FS
I
FS
P1
-B
I2C
TP
MD
-A, T
MP
D-B
SV
IC
MD
C-A
SV
IC
MD
C-B
I2C
SE
EP
RO
M 1
I2C
SE
EP
RO
M 2
24
L remote
BusesHUB to QCM Connections
Address/Data
D B
us
Inte
rco
nn
ec
t o
f S
up
ern
od
es
Op
tic
al
D0 Bus
Optical
12x
12x
D15 Bus
Optical
12x
12x
16
D B
us
es
28
I2C
I2C_0 + Int
I2C_27 + Int
I2C
To
Op
tic
al
Mo
du
les
TO
D S
yn
c
8B
Z-B
us
8B
Z-B
us
TO
D S
yn
c
8B
Y-B
us
8B
Y-B
us
TO
D S
yn
c
8B
X-B
us
8B
X-B
us
TO
D S
yn
c
8B
W-B
us
8B
W-B
us
192 GB/s Host Connection
336 GB/s to 7 other local nodes
240 GB/s to local-remote nodes
320 GB/s to remote nodes
40 GB/s to general purpose I/O
cf. “The PERCS interconnect” @HotI’10
Hub Chip
Source: IBM Source: IBM/NCSA
P7 IH Drawer
68
First Level Interconnect
L-Local
HUB to HUB Copper Wiring
256 Cores
DCA-0 Connector (Top DCA)
DCA-1 Connector (Bottom DCA)
1st Level Local Interconnect (256 cores)
HUB
7
HUB
6
HUB
4
HUB
3
HUB
5
HUB
1
HUB
0
HUB
2
P
C
I
e
9
P
C
I
e
10
P
C
I
e
11
P
C
I
e
12
P
C
I
e
13
P
C
I
e
14
P
C
I
e
15
P
C
I
e
16
P
C
I
e
17
P1-C
17
-C1
P
C
I
e
1
P
C
I
e
2
P
C
I
e
3
P
C
I
e
4
P
C
I
e
5
P
C
I
e
6
P
C
I
e
7
P
C
I
e
8
Op
tica
l F
an-o
ut fr
om
HU
B M
od
ule
s
2,3
04
Fib
er
'L-L
ink'
64/40 Optical'D-Link'
64/40 Optical'D-Link'
P7-0
P7-2
P7-3P7-1
QCM 0
U-P1-M1
P7-0
P7-2
P7-3P7-1
QCM 1
U-P1-M2
P7-0
P7-2
P7-3P7-1
QCM 2
U-P1-M3
P7-0
P7-2
P7-3P7-1
QCM 3
U-P1-M4
P7-0
P7-2
P7-3P7-1
QCM 4
U-P1-M5
P7-0
P7-2
P7-3P7-1
QCM 5
U-P1-M6
P7-0
P7-2
P7-3P7-1
QCM 6
U-P1-M7
P7-0
P7-2
P7-3P7-1
QCM 7
U-P1-M8
P1-C
16
-C1
P1-C
15
-C1
P1-C
14
-C1
P1-C
13
-C1
P1-C
12
-C1
P1-C
11
-C1
P1-C
10
-C1
P1-C
9-C
1
P1-C
8-C
1
P1-C
7-C
1
P1-C
6-C
1
P1-C
5-C
1
P1-C
4-C
1
P1-C
3-C
1
P1-C
2-C
1
P1-C
1-C
1
N0
-DIM
M1
5N
0-D
IMM
14
N0
-DIM
M1
3N
0-D
IMM
12
N0
-DIM
M1
1N
0-D
IMM
10
N0
-DIM
M0
9N
0-D
IMM
08
N0-D
IMM
07
N0-D
IMM
06
N0-D
IMM
05
N0-D
IMM
04
N0-D
IMM
03
N0-D
IMM
02
N0-D
IMM
01
N0-D
IMM
00
N1
-DIM
M1
5N
1-D
IMM
14
N1
-DIM
M1
3N
1-D
IMM
12
N1
-DIM
M1
1N
1-D
IMM
10
N1
-DIM
M0
9N
1-D
IMM
08
N1-D
IMM
07
N1-D
IMM
06
N1-D
IMM
05
N1-D
IMM
04
N1-D
IMM
03
N1-D
IMM
02
N1-D
IMM
01
N1-D
IMM
00
N2
-DIM
M1
5N
2-D
IMM
14
N2
-DIM
M1
3N
2-D
IMM
12
N2
-DIM
M1
1N
2-D
IMM
10
N2
-DIM
M0
9N
2-D
IMM
08
N2-D
IMM
07
N2-D
IMM
06
N2-D
IMM
05
N2-D
IMM
04
N2-D
IMM
03
N2-D
IMM
02
N2-D
IMM
01
N2-D
IMM
00
N3
-DIM
M1
5N
3-D
IMM
14
N3
-DIM
M1
3N
3-D
IMM
12
N3
-DIM
M1
1N
3-D
IMM
10
N3
-DIM
M0
9N
3-D
IMM
08
N3-D
IMM
07
N3-D
IMM
06
N3-D
IMM
05
N3-D
IMM
04
N3-D
IMM
03
N3-D
IMM
02
N3-D
IMM
01
N3-D
IMM
00
N4
-DIM
M1
5N
4-D
IMM
14
N4
-DIM
M1
3N
4-D
IMM
12
N4
-DIM
M1
1N
4-D
IMM
10
N4
-DIM
M0
9N
4-D
IMM
08
N4-D
IMM
07
N4-D
IMM
06
N4-D
IMM
05
N4-D
IMM
04
N4-D
IMM
03
N4-D
IMM
02
N4-D
IMM
01
N4-D
IMM
00
N5
-DIM
M1
5N
5-D
IMM
14
N5
-DIM
M1
3N
5-D
IMM
12
N5
-DIM
M1
1N
5-D
IMM
10
N5
-DIM
M0
9N
5-D
IMM
08
N5-D
IMM
07
N5-D
IMM
06
N5-D
IMM
05
N5-D
IMM
04
N5-D
IMM
03
N5-D
IMM
02
N5-D
IMM
01
N5-D
IMM
00
N6
-DIM
M1
5N
6-D
IMM
14
N6
-DIM
M1
3N
6-D
IMM
12
N6
-DIM
M1
1N
6-D
IMM
10
N6
-DIM
M0
9N
6-D
IMM
08
N6-D
IMM
07
N6-D
IMM
06
N6-D
IMM
05
N6-D
IMM
04
N6-D
IMM
03
N6-D
IMM
02
N6-D
IMM
01
N6-D
IMM
00
N7
-DIM
M1
5N
7-D
IMM
14
N7
-DIM
M1
3N
7-D
IMM
12
N7
-DIM
M1
1N
7-D
IMM
10
N7
-DIM
M0
9N
7-D
IMM
08
N7-D
IMM
07
N7-D
IMM
06
N7-D
IMM
05
N7-D
IMM
04
N7-D
IMM
03
N7-D
IMM
02
N7-D
IMM
01
N7-D
IMM
00
• 8 nodes
• 32 chips
• 256 cores
Source: IBM Source: IBM/NCSA
POWER7 IH Drawer @ SC09 P7 IH Supernode
70
P7-IH Board Layout 2nd Level of Interconnect (1,024 cores)
4.6 TB/s
Bisection BWBW of 1150
10G-E ports
DCA-0 Connector (Top DCA)
DCA-1 Connector (Bottom DCA)
2nd
Level Interconnect (1,024 cores)
HUB
7
61x96mm
HUB
6
61x96mm
HUB
4
61x96mm
HUB
3
61x96mm
HUB
5
61x96mm
HUB
1
61x96mm
HUB
0
61x96mm
HUB
2
61x96mm
P
C
I
e
9
P
C
I
e
10
P
C
I
e
11
P
C
I
e
12
P
C
I
e
13
P
C
I
e
14
P
C
I
e
15
P
C
I
e
16
P
C
I
e
17
P
C
I
e
1
P
C
I
e
2
P
C
I
e
3
P
C
I
e
4
P
C
I
e
5
P
C
I
e
6
P
C
I
e
7
P
C
I
e
8
Op
tica
l Fa
n-o
ut fro
m
HU
B M
od
ule
s
2,3
04
Fib
er 'L
-Lin
k'
64/40 Optical'D-Link'
FSP/CLK-A
64/40 Optical'D-Link'
FSP/CLK-B
P7-0
P7-2
P7-3P7-1
QCM 0
P7-0
P7-2
P7-3P7-1
QCM 1
P7-0
P7-2
P7-3P7-1
QCM 2
P7-0
P7-2
P7-3P7-1
QCM 3
P7-0
P7-2
P7-3P7-1
QCM 4
P7-0
P7-2
P7-3P7-1
QCM 5
P7-0
P7-2
P7-3P7-1
QCM 6
P7-0
P7-2
P7-3P7-1
QCM 7
DCA-0 Connector (Top DCA)
DCA-1 Connector (Bottom DCA)
2nd
Level Interconnect (1,024 cores)
HUB
7
61x96mm
HUB
6
61x96mm
HUB
4
61x96mm
HUB
3
61x96mm
HUB
5
61x96mm
HUB
1
61x96mm
HUB
0
61x96mm
HUB
2
61x96mm
P
C
I
e
9
P
C
I
e
10
P
C
I
e
11
P
C
I
e
12
P
C
I
e
13
P
C
I
e
14
P
C
I
e
15
P
C
I
e
16
P
C
I
e
17
P
C
I
e
1
P
C
I
e
2
P
C
I
e
3
P
C
I
e
4
P
C
I
e
5
P
C
I
e
6
P
C
I
e
7
P
C
I
e
8
Op
tica
l Fa
n-o
ut fro
m
HU
B M
od
ule
s
2,3
04
Fib
er 'L
-Lin
k'
64/40 Optical'D-Link'
FSP/CLK-A
64/40 Optical'D-Link'
FSP/CLK-B
P7-0
P7-2
P7-3P7-1
QCM 0
P7-0
P7-2
P7-3P7-1
QCM 1
P7-0
P7-2
P7-3P7-1
QCM 2
P7-0
P7-2
P7-3P7-1
QCM 3
P7-0
P7-2
P7-3P7-1
QCM 4
P7-0
P7-2
P7-3P7-1
QCM 5
P7-0
P7-2
P7-3P7-1
QCM 6
P7-0
P7-2
P7-3P7-1
QCM 7
DCA-0 Connector (Top DCA)
DCA-1 Connector (Bottom DCA)
2nd
Level Interconnect (1,024 cores)
HUB
761x96mm
HUB
661x96mm
HUB
461x96mm
HUB
361x96mm
HUB
561x96mm
HUB
161x96mm
HUB
061x96mm
HUB
261x96mm
P
C
I
e
9
P
C
I
e
10
P
C
I
e
11
P
C
I
e
12
P
C
I
e
13
P
C
I
e
14
P
C
I
e
15
P
C
I
e
16
P
C
I
e
17
P
C
I
e
1
P
C
I
e
2
P
C
I
e
3
P
C
I
e
4
P
C
I
e
5
P
C
I
e
6
P
C
I
e
7
P
C
I
e
8
Op
tica
l F
an-o
ut fr
om
HU
B M
od
ule
s
2,3
04
Fib
er
'L-L
ink'
64/40 Optical'D-Link'
FSP/CLK-A
64/40 Optical'D-Link'
FSP/CLK-B
P7-0
P7-2
P7-3P7-1
QCM 0
P7-0
P7-2
P7-3P7-1
QCM 1
P7-0
P7-2
P7-3P7-1
QCM 2
P7-0
P7-2
P7-3P7-1
QCM 3
P7-0
P7-2
P7-3P7-1
QCM 4
P7-0
P7-2
P7-3P7-1
QCM 5
P7-0
P7-2
P7-3P7-1
QCM 6
P7-0
P7-2
P7-3P7-1
QCM 7
DCA-0 Connector (Top DCA)
DCA-1 Connector (Bottom DCA)
2nd
Level Interconnect (1,024 cores)
HUB
761x96mm
HUB
661x96mm
HUB
461x96mm
HUB
361x96mm
HUB
561x96mm
HUB
161x96mm
HUB
061x96mm
HUB
261x96mm
P
C
I
e
9
P
C
I
e
10
P
C
I
e
11
P
C
I
e
12
P
C
I
e
13
P
C
I
e
14
P
C
I
e
15
P
C
I
e
16
P
C
I
e
17
P
C
I
e
1
P
C
I
e
2
P
C
I
e
3
P
C
I
e
4
P
C
I
e
5
P
C
I
e
6
P
C
I
e
7
P
C
I
e
8
Op
tica
l F
an-o
ut fr
om
HU
B M
od
ule
s
2,3
04
Fib
er
'L-L
ink'
64/40 Optical'D-Link'
FSP/CLK-A
64/40 Optical'D-Link'
FSP/CLK-B
P7-0
P7-2
P7-3P7-1
QCM 0
P7-0
P7-2
P7-3P7-1
QCM 1
P7-0
P7-2
P7-3P7-1
QCM 2
P7-0
P7-2
P7-3P7-1
QCM 3
P7-0
P7-2
P7-3P7-1
QCM 4
P7-0
P7-2
P7-3P7-1
QCM 5
P7-0
P7-2
P7-3P7-1
QCM 6
P7-0
P7-2
P7-3P7-1
QCM 7
Second Level Interconnect
Optical ‘L-Remote’ Links from HUB
4 drawers
1,024 Cores
L-L
ink C
ab
les
Super Node(32 Nodes / 4 CEC)
Source: IBM Source: IBM/NCSA
1. Chip
16 cores
2. Module
Single Chip 4. Node Card
32 Compute Cards,
Optical Modules, Link Chips, Torus
5a. Midplane
16 Node Cards
6. Rack
2 Midplanes
1, 2 or 4 I/O Drawers
7. System
20PF/s
3. Compute Card
One single chip module,
16 GB DDR3 Memory
5b. I/O Drawer
8 I/O Cards
8 PCIe Gen2 slots
Case Study 2: IBM Blue Gene/Q packaging
Source: IBM, SC10
16
16 16
512
8192
16384 ~2 Mio
© Markus Püschel Computer Science
Blue Gene/Q Compute chip 360 mm² Cu-45 technology (SOI)
~ 1.47 B transistors
16 user + 1 service processors plus 1 redundant processor all processors are symmetric each 4-way multi-threaded 64 bits PowerISA™
1.6 GHz L1 I/D cache = 16kB/16kB L1 prefetch engines each processor has Quad FPU (4-wide double precision, SIMD) peak performance 204.8 GFLOPS@55W
Central shared L2 cache: 32 MB
eDRAM multiversioned cache/transactional
memory/speculative execution. supports atomic ops
Dual memory controller
16 GB external DDR3 memory 1.33 Gb/s 2 * 16 byte-wide interface (+ECC)
Chip-to-chip networking
Router logic integrated into BQC chip.
System-on-a-Chip design : integrates processors,
memory and networking logic into a single chip
Source: IBM, PACT’11

Blue Gene/Q Network
73
On-chip external network Message Unit Torus Switch Serdes Everything!
Only 55-60 W per node Top of Green500 and
GreenGraph500
Source: IBM, PACT’11
Case Study 3: Cray Cascade (XC30)
Biggest current installation at CSCS!
>2k nodes
Standard Intel x86 Sandy Bridge Server-class CPUs
74
Source: Bob Alverson, Cray
Cray Cascade Network Topology
All-to-all connection among groups (“blue network”)
What does that remind you of?
75
Source: Bob Alverson, Cray
Goals of this lecture
Motivate you!
What is parallel computing?
And why do we need it?
What is high-performance computing?
What’s a Supercomputer and why do we care?
Basic overview of
Programming models
Some examples
Architectures
Some case-studies
Provide context for coming lectures
76
DPHPC Lecture
You will most likely not have access to the largest machines
But our desktop/laptop will be a “large machine” soon
HPC is often seen as “Formula 1” of computing (architecture experiments)
DPHPC will teach you concepts!
Enable to understand and use all parallel architectures
From a quad-core mobile phone to the largest machine on the planet!
MCAPI vs. MPI – same concepts, different syntax
No particular language (but you should pick/learn one for your project!)
Parallelism is the future:
77
Related classes in the SE focus
263-2910-00L Program Analysis http://www.srl.inf.ethz.ch/pa.php Spring 2015 Lecturer: Prof. M. Vechev
263-2300-00L How to Write Fast Numerical Code http://www.inf.ethz.ch/personal/markusp/teaching/263-2300-ETH-spring14/course.html Spring 2015 Lecturer: Prof. M. Pueschel
This list is not exhaustive!
78

DPHPC Overview
79




























