Embed Size (px)
Citation preview

Generating efficient local memoryaccess sequences for coupled subscripts
in data-parallel programs
Tsung-Chuan Huang *, Liang-Cheng Shiu, Yi-Jay Lin
Department of Electrical Engineering, National Sun Yat-Sen University, 70 Lien-hai Road,
Kaohsiung 804, Taiwan, ROC
Received 30 December 2000; received in revised form 23 February 2002; accepted 28 April 2002
Abstract
Generating the local memory access sequences is an integral part of compiling a
data-parallel program into an SPMD code. Most previous research into local memory
access sequences have focused on one-dimensional arrays distributed with CYCLIC(k)
distribution. The local memory access sequences for multidimensional arrays with in-
dependent subscripts are produced by repeatedly applying the method for one-dimen-
sional arrays. However, the task becomes highly complex when subscripts are coupled
such that the subscripts in different dimensions depend on the same loop induction
variables. This paper presents an efficient approach to computing the iterations executed
on each processor by exploiting repetitive patterns in memory accesses. Smaller iteration
tables than those of Ramanujam [Code generation for complex subscripts in data-
parallel programs, in: Z. Li et al. (Eds.), Languages and Compilers for Parallel Com-
puting, Lecture Notes in Computer Science, vol. 1366, Springer-Verlag, Berlin, 1998,
pp. 49–63] are used, the iteration gap table is not required. The method has been im-
plemented on an IBM SP2. Experimental results demonstrate the efficiency of the
proposed method.
� 2002 Elsevier Science Inc. All rights reserved.
Keywords: Coupled subscript; Block–cyclic distribution; Distributed memory machines;
Local memory access sequence
Information Sciences 149 (2003) 249–261
www.elsevier.com/locate/ins
*Corresponding author. Tel.: +886-7-525-4140; fax: +886-7-525-4199.
E-mail address: [email protected] (T.-C. Huang).
0020-0255/02/$ - see front matter � 2002 Elsevier Science Inc. All rights reserved.
PII: S0020 -0255 (02 )00278 -5

1. Introduction
Programming languages such as High Performance Fortran (HPF) [8], For-
tran D [5] and Vienna Fortran [1,2] provide ALIGN and DISTRIBUTEdirectives to describe how data are distributed among the processors in distrib-
uted-memory multiprocessors. Block, cyclic and block–cyclic distributions are
three regular data distributions offered by these languages. The computations
must be partitioned among the processors when the array statement is complied
with distributed arrays for parallel execution. Usually, the compilers apply the
owner computes rule to partition the computations such that the processor
owning the left-hand side array element performs the computations of that
assignment. A compiler must generate the local memory access sequences of anode code for each active processor to execute the array statements efficiently.
The problem of generating local memory access sequences when compiling
array references with block or cyclic distributions for simple subscripts has been
investigated in [6,11,12]. The solutions of this problem for a more general type
of distribution – cyclic(k) – for simple subscripts are also discussed in
[3,7,10,13,15,19,20]. In [3], Chatterjee et al. proposed a table-based approach
that used a finite state machine (FSM) to generate local memory access se-
quences. This method solves k linear Diophantine equations and requiressorting in the table�s construction. Refs. [10] and [20] improve on [3] by
avoiding the sorting operation through using the integer lattice to enumerate
the local memory access sequences. In [7], Gupta et al. developed the virtual-
block and virtual-cyclic schemes. The virtual-block (or cyclic) scheme considers
a block–cyclic distribution as a block (or cyclic) distribution on a set of virtual
processors, which are cyclically (or block-wise) mapped onto processors. The
other approaches are similar to either the table-based or the virtual processor
approach.Chatterjee et al. [3], Gupta et al. [7] and Stichnoth [18] have discussed the
local address generation problem for multidimensional array references with
independent subscripts. They reduced the problem to multiple loops and solved
repetitively by applying the algorithm for a single dimension.
However, generating local memory access sequences becomes rather com-
plicated when the array references involve complex subscripts. A range of
methods has been proposed [4,9,14,16,17] to handle this case. This paper focuses
on a particular type of complex subscript – coupled subscripts in which the sameloop index variable occurs in two dimensions. An efficient scheme is devised to
compute the iterations executed on processor pxy when a two-dimensional array
is distributed with CYCLIC(k1; k2) onto P1 � P2 processors (denoted pxy , for
x 2 ½0; P1 � 1� and y 2 ½0; P2 � 1�); that is, the array is distributed with CY-
CLIC(k1) over P1 processors in its first dimension and distributed with CY-
CLIC(k2) over P2 processors in its second dimension, where the access strides for
the first and second dimension are assumed to be s1 and s2, respectively. The
250 T.-C. Huang et al. / Information Sciences 149 (2003) 249–261

dimensional iteration table is first computed for each processor in each dimen-
sion, and then the common iteration table is evaluated for each processor, pxy .The common iteration table is used to produce the SPMD code.
The rest of this paper is organized as follows. Section 2 reviews related work.Section 3 elucidates the method used here. Section 4 demonstrates the algo-
rithms. Section 5 discusses the experimental results and conclusions are finally
made in Section 6.
2. Related work
Kennedy et al. [9] determined the starting location of array element on each
processor by first computing the minimum common iteration in both the first
and the second dimensions, and then accessing all the active elements using a
DM table. Two versions of SPMD code were provided to complete this task.
The first uses a DM table to record the local memory gaps between two con-
secutive active elements on a single processor and a Next table to store the
states of the subsequently active elements. Each entry in both tables has twovalues – one for each array dimension; restated, these tables are two-dimen-
sional arrays. Local memory access sequences can be obtained by the following
steps. First, find the state (s1; s2) associated with the starting location. Second,
add the local memory gap stored in DM(s1; s2) to the starting location, to
compute the memory location of the subsequent element from the current
location. Third, obtain the state of the next element using the Nextðs1; s2Þ table.Repeat the last two steps until the final element is determined. The second
version employs two one-dimensional DM tables, two Next tables and twoadditional DI tables. The formats of the DM and Next tables are similar to
those in the first version, but one table is required for each array dimension. DItables contain the iteration gaps between each pair of two consecutive active
elements. All the active elements can be determined by traversing each di-
mension to find the common iterations. Although the theoretical complexity of
the algorithm is low, the implementation requires expensive integer arithmetic
[16].
Ramanujam et al. [16] presented a procedure that avoided solving k1 � k2equations and the time-consuming sorting operation involved in [9]. This
method requires an iteration gap table, Diter, for each processor to construct
the iteration table in each dimension. The iteration gap table contains the it-
eration gap between two consecutive active elements in a single dimension and
on a single processor. This table is as long as the DM table and can be obtained
by modifying the code for creating the DM table [3]. By tracing the DM table,
the iterations of each active element can be evaluated using the Diter table and
are stored in the iteration tables. (Note that each dimension corresponds to oneiteration table.) This process is repeated until a total of
T.-C. Huang et al. / Information Sciences 149 (2003) 249–261 251

lcmP1k1
gcdðs1; P1k1Þ;
P2k2gcdðs2; P2k2Þ
� �
active elements have been visited. The length of each dimensional iteration
table must be a multiple of the length of its corresponding DM table. Search
and hashing methods were developed to compute the common iteration table
for each processor.
This paper proposes a method which does not require the iteration gap
table. The length of the dimensional iteration table is the same as that of the
DM table, and smaller than that in [16] since it need not be a multiple of thelength of the DM table as in [16].
3. The proposed method
This section presents our method, based on the following HPF code with
coupled subscripts.
The single loop includes a two-dimensional array reference in which both
subscripts contain the same induction variable, i. The first dimension of arrayA is distributed with CYCLIC(k1) over P1 processors, while the second is dis-
tributed with CYCLIC(k2) over P2 processors. The strides of array A are as-
sumed to be s1 and s2, for the first and second dimension, respectively.
3.1. Dimensional iteration tables
In dealing with a two-dimensional array distributed onto P1 � P2 processors,according to the ‘‘owner computes’’ rule, the iterations that will be executed on
each processor pxy must be computed first. The local memory access sequences
can be easily evaluated once the iterations executed on each processor are
known. To do this, the iterations executed on px for x 2 ½0; P1 � 1� and py for
y 2 ½0; P2 � 1�, namely for the processors in the first and second dimension,
respectively, must be computed. Then, because the distance between two
consecutive iterations executed on px or py will repeat cyclically, the problem
can be solved by determining the iteration numbers in the first cycle for eachprocessor. The iteration numbers in the first cycle of px and py will be recorded
in arrays DI1x½ � and DI2y ½ �, respectively, for x 2 ½0; P1 � 1� and y 2 ½0; P2 � 1�.DI1x½ � and DI2y ½ � are here called as the ‘‘dimensional iteration tables’’.
The FSM table and the starting memory location for each processor can be
obtained by using the algorithm for computing local memory access sequences
in [3]. The first iteration, DI1x½1� or DI2y ½1�, executed on processors px or py canthen be computed easily using the starting memory location. When the first
iteration for each processor has been determined, the subsequent iterations canbe evaluated by the following equation:
252 T.-C. Huang et al. / Information Sciences 149 (2003) 249–261

next iteration ¼ s� iþ DM ½offset� � DC½offset� � ðP � 1Þ � ks
;
where s and k are the access stride and block size, respectively, for the di-
mension in question; i is the current iteration number; offset ¼ s� i mod k is
the relative location of the array element within a block, and DM and DC are
the local memory gap and the number of courses, respectively, between two
successive active elements within a processor (and both of which are given in
the FSM table in [3]). In this paper, iterations are numbered from zero.Consider the example in Fig. 2, where array A is distributed with CY-
CLIC(4,2) onto 3� 4 processors (px ¼ fp0; p1; p2g and py ¼ fp0; p1; p2; p3g) andis accessed with strides s1 ¼ 5 and s2 ¼ 3, for the first and second dimension,
respectively. Fig. 3 depicts the layout of array A, distributed in the first di-
mension with the shaded grids� denoting the active elements. The computation
of the dimensional iteration table DI11½ � for the first dimension is as follows.
The algorithm in [3] can be used to obtain the FSM table for the first di-
mension as in Fig. 4, and the starting memory locations: 0, 5 and 10, for p0, p1and p2, respectively (which can be seen from Fig. 3). Given the starting memory
location of p1, 5, the starting iteration of p1 is computed as 5=s1 ¼ 1 (thus
DI11½1� ¼ 1) and the offset as 5 mod 4 ¼ 1. Since the FSM table in Fig. 4 shows
that DM ½1� ¼ 9 and DC½1� ¼ 2, the next iteration can be computed:
next iteration ¼ s1 � iþ DM ½offset� þ DC½offset� � ðP � 1Þ � ks1
¼ 5� 1þ 9þ 2� ð3� 1Þ � 4
5¼ 6:
Accordingly, DI11½2� ¼ 6. Now, the next iteration can be computed. Since
the current iteration is 6, the current subscript is 6� s1 ¼ 30, and the offset
Fig. 1. HPF-like program model considered in this paper.
Fig. 2. An example loop with coupled subscripts.
T.-C. Huang et al. / Information Sciences 149 (2003) 249–261 253

equals 30 mod 4 ¼ 2. Again, from the FSM table in Fig. 4, DM ½2� ¼ 2 and
DC½2� ¼ 1. Hence, the next iteration equals ð5� 6þ 2þ 1� 2� 4Þ=5 ¼ 8 that
is, DI11½3� ¼ 8. Repeating this procedure yields DI11½4� ¼ 11. DI10½ � and
DI12½ � can be computed similarly. Fig. 5 displays the final results. Fig. 6 depictsthe layout of array A for the second dimension and Fig. 7 shows the final
dimensional iteration tables.
The next section will use these dimensional iteration tables to construct the
common iteration table. Like the dimensional iteration table, the common it-
eration table records the value of each iteration in the first cycle, executed on
processor pxy . The node code of each processor can then enumerate all the it-
erations to be executed according to the common iteration table and the cycle
length.
3.2. Common iteration tables
For simplicity, the array elements are labeled from zero, which designates
the active element accessed by iteration 0. In this way, for a given dimension
Fig. 5. Dimensional iteration table for each processor in the first dimension.
Fig. 3. Layout of array A distributed over three processors in the first dimension with CYCLIC(4)
and accessed with stride s1 ¼ 5.
Fig. 4. FSM table for the first dimension of array A.
254 T.-C. Huang et al. / Information Sciences 149 (2003) 249–261

and processor, let i and i0 be the two nearest iterations that operate on the array
elements with the same relative offset in a block; then s� i and s� i0 will be the
global indices of array elements manipulated by these two iterations, respec-
tively. Fig. 8 shows that,
s� iþ lcmðs; P � kÞ ¼ s� i0;
where P is the number of processors, s is the access stride and k is the block
size of the given dimension. Substituting ðP � k � sÞ=ðgcdðs; P � kÞÞ for
lcmðs; P � kÞ yields,
Di ¼ i0 � i ¼ P � kgcdðs; P � kÞ :
Now, consider the dimensional iteration table of px in the first dimension,
and that of py in the second dimension, as shown in Fig. 9. Because
Fig. 7. Dimensional iteration table for each processor in the second dimension.
Fig. 8. Two consecutive array elements with the same relative offset (assume k ¼ 4, s ¼ 5).
Fig. 6. Layout of array A distributed over four processors in the second dimension with CY-
CLIC(2) and accessed with stride s2 ¼ 3.
T.-C. Huang et al. / Information Sciences 149 (2003) 249–261 255

Di ¼ ðP � kÞ=ðgcd s; P � kÞ and the iterations executed on pxy are the common
iterations of px in the first dimension and py in the second dimension, to enu-
merate these iterations, we must find two smallest positive integers n1 and n2 to
satisfy the following equation:
ai þ n1 P1k1
gcdðs1; P1k1Þ¼ bj þ n2
P2k2gcdðs2; P2k2Þ
for i 2 ½1; 4� and j 2 ½1; 2�:
Restated, let N1, N2 be the solutions of n1 and n2, respectively, for the following
Diophantine equation:
n1 P1k1
gcdðs1; P1k1Þ� n2
P2k2gcdðs2; P2k2Þ
¼ bj � ai for i 2 ½1; 4� and j 2 ½1; 2�:
ð1Þ
Then the iteration,
ai þ N1 P1k1
gcdðs1; P1k1Þor bj
�þ N2
P2k2gcdðs2; P2k2Þ
�ð2Þ
will be executed on pxy .The construction of the common iteration table for pxy , for the example in
Fig. 2, is now considered. Assuming that the processor is p21, Figs. 5 and 7 give
DI12 ¼ f2; 4; 7; 9g and DI21 ¼ f1; 6g. Substituting a4 ¼ 9, b1 ¼ 1 into Eq. (1), a
solution ð0; 1Þ exists for (n1; n2). Substituting a1 ¼ 2, b2 ¼ 6 yields another
solution ð1; 1Þ for ðn1; n2). Substituting N1 ¼ 0 (or N2 ¼ 1Þ and N1 ¼ 1 (or
N2 ¼ 1Þ into Eq. (2) yields the common iteration table for p12 as CI12 ¼ f9; 14g.Finally, the cycle length (that is, the distance between the two nearest iter-
ations on pxy that operate on the array elements with the same relative offset) ofthe common iteration table must be computed, since the iterations executed on
pxy are also repeated cyclically. Fig. 8 showed that the common iterations are
repeated every P1k1= gcdðs1; P1k1Þ iterations in the first dimension, and every
P2k2= gcdðs2; P2k2Þ iterations in the second dimension. Consequently, the cycle
length of the iterations executed by pxy will equal
lcmP1k1
gcdðs1; P1k1Þ;
P2k2gcdðs2; P2k2Þ
� �:
In this example, the cycle length is lcm(8,12)¼ 24 and the iteration table of p12is f9; 14g [ f9þ 24� i; 14þ 24� ig ¼ f9; 14; 33; 38; 57; 62; . . .g.
Fig. 9. Two dimensional iteration tables.
256 T.-C. Huang et al. / Information Sciences 149 (2003) 249–261

4. Algorithms
This section presents two algorithms. Algorithm 1 computes the common
iteration table for processor pxy and Algorithm 2 gives the SPMD code basedon the HPF program model in Fig. 1. Lines 2–7 construct the dimensional
iteration table for the first dimension, according to the formula in Section 3.1.
Line 8 similarly establishes the dimensional iteration table of the second di-
mension. Lines 10–17 generate the common iteration table CIxy ½ � for processor
pxy , according to the method developed in Section 3.2. Line 20 enumerates all
of the iterations executed on pxy by adding the cycle length,
lcmP1K1
gcdðs1; P1K1Þ;
P2K2
gcdðs2; P2K2Þ
� �;
proposed in Section 3.2. Line 21 accesses the memory location of the array ele-
ment operated by pxy according to the iteration number determined in line 20.
Algorithm 1. Computing the common iteration table for pxyInput: FSM table(start1; start2;DC1;DC2;DM1;DM2)
Output: Common iteration table for any processor pxyðCIxy ½ �)Method:
1 cur it1 start it1; start1=s12 for i ¼ 0 to length1 � 1 // length1 is the length of DM1
3 DI1x½i� cur it14 offset1 ðcur it1 � s1Þmod k15 next it1 s1�cur it1þDM ½offset1�þDC½offset1��ðP�1Þ�k
s16 cur it1 next it17 endfor8 compute the dimensional iteration table DI2y ½ � as above
9 length 0
10 for i ¼ 1 to length of DI1x11 for j ¼ 1 to length of DI2y12 let N1; N2 be the solutions of n1 and n2 in
n1 � P1k1gcdðs1;P1k1Þ � n2 � P2k2
gcdðs2;P2k2Þ ¼ DI2y ½j� �DI1x½i�13 CIxy ½length� DI1x½i� þN1� P1k1
gcdðs1;P1k1Þ
ðor CIxy ½length� DI2y ½j� þN2� P2k2gcdðs2;P2k2Þ
Þ14 length lengthþ 1
15 endfor16 endfor17 sort CIxy ½length� in ascending
Algorithm 2. SPMD node code for processor pxy using the common iterationtable
T.-C. Huang et al. / Information Sciences 149 (2003) 249–261 257

18 j 1; k 0; i CIxy ½1�19 while (i � u) do // u is the upper bound of loop index as shown in
Fig. 1
20 i ¼ CIxy ½j� þ k � lcm�
P1k1gcdðs1;P1k1Þ;
P2k2gcdðs2;P2k2Þ
�21 Aðs1iþ l1; s2iþ l2Þ ¼ . . . . . .22 j jþ 1
23 ifj ¼ length then24 j ¼ 1
25 k k þ 1
26 endif27 endwhile
5. Experimental results
Efficiently generating the common iteration table is crucial when compilinga data-parallel program with coupled subscripts. This section compares the
Table 1
Table construction times (in ls) for 4� 5 processors and s1 ¼ 11; s2 ¼ 17
k1 k2 Ramanujam’s Ours
4 4 71.9 41.8
4 8 57.3 50.4
8 4 124.8 65.8
8 8 123.0 78.0
16 4 332.4 112.1
16 8 338.9 141.3
8 16 123.5 104.6
16 16 342.8 186.4
32 4 1100.3 211.8
32 8 1093.6 258.1
8 32 124.7 153.1
32 32 1098.6 496.6
64 4 3967.2 407.2
64 8 3926.2 493.3
8 64 317.0 290.5
64 64 3967.9 1612.5
128 4 14597.1 797.6
128 8 14935.4 961.5
8 128 996.6 543.1
128 128 14843.1 5588.2
256 4 57231.7 1661.9
256 8 57500.9 1966.1
8 256 3652.4 1064.6
256 256 58216.5 20919.7
258 T.-C. Huang et al. / Information Sciences 149 (2003) 249–261
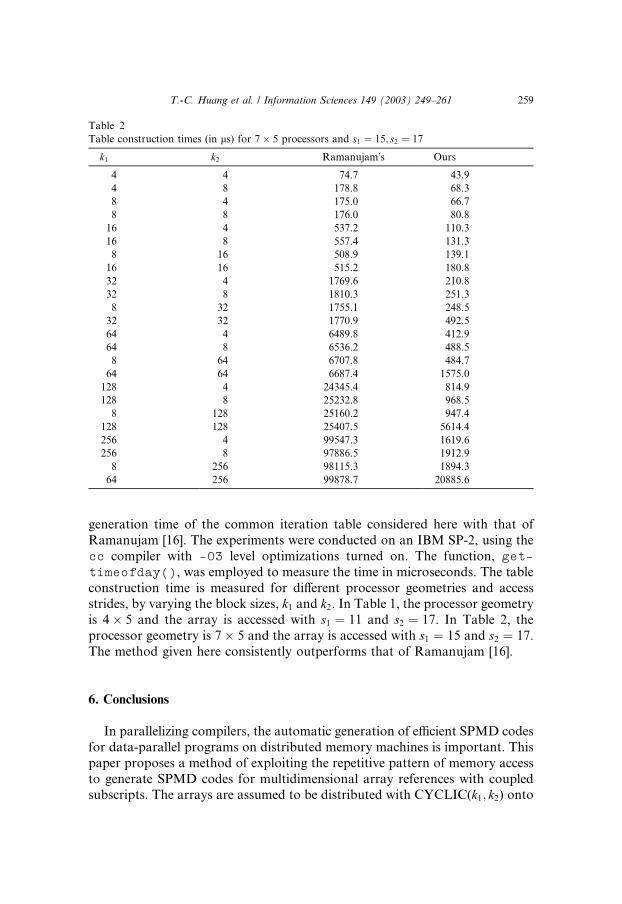
generation time of the common iteration table considered here with that of
Ramanujam [16]. The experiments were conducted on an IBM SP-2, using the
cc compiler with -03 level optimizations turned on. The function, get-
timeofday(), was employed to measure the time in microseconds. The table
construction time is measured for different processor geometries and accessstrides, by varying the block sizes, k1 and k2. In Table 1, the processor geometry
is 4� 5 and the array is accessed with s1 ¼ 11 and s2 ¼ 17. In Table 2, the
processor geometry is 7� 5 and the array is accessed with s1 ¼ 15 and s2 ¼ 17.
The method given here consistently outperforms that of Ramanujam [16].
6. Conclusions
In parallelizing compilers, the automatic generation of efficient SPMD codes
for data-parallel programs on distributed memory machines is important. This
paper proposes a method of exploiting the repetitive pattern of memory access
to generate SPMD codes for multidimensional array references with coupledsubscripts. The arrays are assumed to be distributed with CYCLIC(k1; k2) onto
Table 2
Table construction times (in ls) for 7� 5 processors and s1 ¼ 15; s2 ¼ 17
k1 k2 Ramanujam�s Ours
4 4 74.7 43.9
4 8 178.8 68.3
8 4 175.0 66.7
8 8 176.0 80.8
16 4 537.2 110.3
16 8 557.4 131.3
8 16 508.9 139.1
16 16 515.2 180.8
32 4 1769.6 210.8
32 8 1810.3 251.3
8 32 1755.1 248.5
32 32 1770.9 492.5
64 4 6489.8 412.9
64 8 6536.2 488.5
8 64 6707.8 484.7
64 64 6687.4 1575.0
128 4 24345.4 814.9
128 8 25232.8 968.5
8 128 25160.2 947.4
128 128 25407.5 5614.4
256 4 99547.3 1619.6
256 8 97886.5 1912.9
8 256 98115.3 1894.3
64 256 99878.7 20885.6
T.-C. Huang et al. / Information Sciences 149 (2003) 249–261 259

P1 � P2 processors. Computing the iterations executed on processor pxy does
not require use of the iteration gap table. The iteration table presented here is
shorter than Ramanujam�s [16]. Our dimensional iteration table is only as long
as the DM table, rather than a multiple of its length, as in [16]. The experi-mental results show the efficiency of our method.
References
[1] B.M. Chapman, P. Mehrotra, H.P. Zima, Programming in Vienna Fortran, Sci. Program. 1 (1)
(1992).
[2] B.M. Chapman, P. Mehrotra, H.P. Zima, Vienna Fortran – a Fortran language extension for
distributed memory multiprocessors, in: J. Saltz, P. Mehrotra (Eds.), Language, Compilers
and Runtime Environments for Distributed Memory Machines, 1992, pp. 39–62.
[3] S. Chatterjee, J. Gilbert, F. Long, R. Schreber, S. Teng, Generating local addresses and
communication sets for data parallel programs, J. Parallel Distrib. Comput. 26 (1) (1995) 72–
84.
[4] Swaroop Dutta, Compilation and run-time techniques for data-parallel programs, M.S.
Thesis, Department of Electrical and Computer Engineering, Louisiana State University,
December 1997.
[5] G. Fox, S. Hiranandani, K. Kennedy, C. Koelbel, U. Kremer, C.W. Tseng, M. Wu, Fortran D
language specification. Technical Report TR-91-170, Department of Computer Science, Rice
University, December 1991.
[6] M. Gerndt, Automatic parallelization for distributed-memory multiprocessing systems, Ph.D.
Thesis, University of Bonn, December 1989.
[7] S.K.S. Gupta, S.D. Kaushik, C.-H. Huang, P. Sadayappan, On compiling array expressions
for efficient execution on distributed-memory machines, J. Parallel Distrib. Comput. 32 (2)
(1996) 155–172.
[8] High Performance Fortran Forum, High Performance Fortran Language Specification,
November 1994 (Version 1.1).
[9] K. Kennedy, N. Nedeljkovic, A. Sethi, Efficient address generation for block–cyclic
distributions, in: Proceedings of the ACM International Conference on Supercomputing,
Madrid, Spain, July 1995, pp. 180–184.
[10] K. Kennedy, N. Nedeljkovic, A. Sethi, A linear-time algorithm for computing the memory
access sequence in data-parallel programs, in: Proceedings of the Fifth ACM SIGPLAN
Symposium on Principles and Practice of Parallel Programming, July 1995, pp. 102–111.
[11] C. Koelbel, Compile-time generation of regular communication patterns, in: Proceedings of
Supercomputing�91, Albuquerque, New Mexico, November 1991, pp. 101–110.
[12] C. Koelbel, P. Mehrotra, Compiling global name-space parallel loops for distributed
execution, IEEE Trans. Parallel Distrib. Syst. 2 (4) (1991) 440–451.
[13] S. Midkiff, Local iteration set computation for block–cyclic distributions, in: Proceedings of
International Conference on Parallel Processing volume, vol. II, August 1995, pp. 77–84.
[14] S. Midkiff, Computing the local iteration set of a block–cyclically distributed reference with
affine subscripts, in: Proceedings of the 6th Workshop on Compilers for Parallel Computers,
Aachen, Germany, December 1996.
[15] S. Midkiff, Optimizing the representation of local iteration sets and access sequence for block–
cyclic distributions, in: D. Sehr, et al. (Eds.), Languages and Compilers for Parallel
Computing, Lecture Notes in Computer Science, vol. 1239, Springer, Berlin, 1997, pp. 420–
434.
260 T.-C. Huang et al. / Information Sciences 149 (2003) 249–261

[16] J. Ramanujam, S. Dutta, A. Venkatachar, Code generation for complex subscripts in data-
parallel programs, in: Z. Li et al. (Eds.), Languages and Compilers for Parallel Computing,
Lecture Notes in Computer Science, vol. 1366, Springer, Berlin, 1998, pp. 49–63.
[17] Ajay Sethi, Communication generation for data-parallel languages, Ph.D. Thesis, Department
of Computer Science, Rice University, December 1996.
[18] J.M. Stichnoth, Efficient compilation of array statements for private memory multicomputers,
Technical Report CMU-CS-93-109, School of Computer Science, Carnegie-Mellon University,
February 1993.
[19] J.M. Stichnoth, D. O�Hallaron, T. Gross, Generating communication for array statements:
Design, implementation, and evaluation, J. Parallel Distrib. Comput. 21 (1996) 150–159.
[20] Thirumalai, J. Ramanujam, Efficient computation of address sequences in data parallel
programs using closed form for basis vectors, J. Parallel Distrib. Comput. 38 (2) (1996) 188–
203.
T.-C. Huang et al. / Information Sciences 149 (2003) 249–261 261











![ATHLET/KIKO3D results of the OECD/NEA benchmark for coupled … · 2015. 2. 7. · Main scenario sequences recovered from the measured data histories can be systematized so [3]: Manually](https://img.pdfslide.us/doc/110x75/6068ff56f9ecb87b3017e227/athletkiko3d-results-of-the-oecdnea-benchmark-for-coupled-2015-2-7-main-scenario.jpg)

















