Embed Size (px)
Citation preview

Gena TangPushkar Pande
Tianjun YeXing Liu
Racchit ThapliyalRobert Arthur
Kevin Lee

Biology background Algorithms
De novo - Overlap-Layout-Consensus - De Bruijn graphs
Reference Tools and Techniques Work flow & strategy Group management

Biology background Algorithms
De novo - Overlap-Layout-Consensus - De Bruijn graphs
Reference Tools and Techniques Work flow & strategy Group management
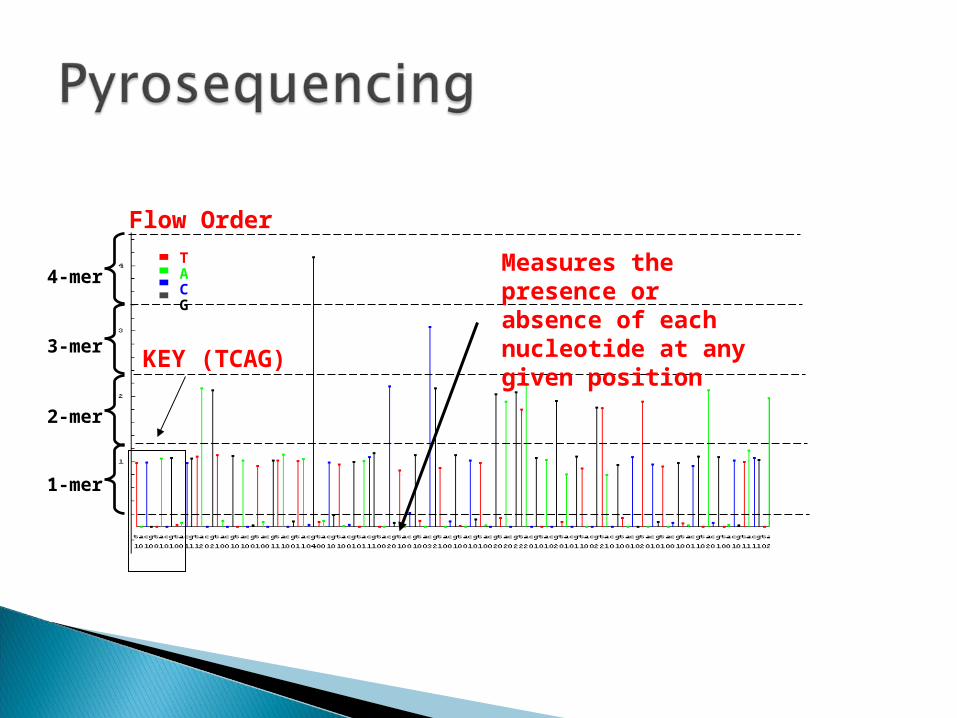
Flow OrderTACG
1-mer
2-mer
3-mer
4-mer
KEY (TCAG)
Measures the presence or absence of each nucleotide at any given position

Margulies et al., 2005
http://www.youtube.com/watch?v=kYAGFrbGl6E

~300nt per read 40X coverage (but widely varying, 12-80)

~ 2 Mb genome (1.8-2.0Mb) Mostly coding sequences
◦ Good for assembly Reference genomes of 4 closely related
species◦ H. influenzae◦ H. parasuis◦ H. ducreyi◦ H. somnus

High degree of genomic plasticity◦ 10% of genes in clinically isolated strains are
novel In situ horizontal gene transfer Supragenome – distributed genome
hypothesis Reference mapping relatively ineffective Making life difficult!!!

De novo Reference mapping
Number of large contigs
50 500+
Unmapped reads 1300 68000+
N50 contig size 28500 3000
Bases in large contigs (Mb)
2 1.3

Assemble all of the H. hemolyticus genomes together
Should give a more complete mapping because of higher coverage ◦ 40X * 5 genomes 200X coverage
But … we get 3700 contigs ◦ (average of 50 for single strain assembly)

These data hint at rampant recombination Reference mapping relatively worthless

Whole-genome alignment (intra-species)◦ On average, 27 insertions, 147 deletions (>90bp)◦ Average length of non-matching seq = 321kb (18%)

Biology background Algorithms
De novo - Overlap-Layout-Consensus - De Bruijn graphs
Reference Tools and Techniques Work flow & strategy Group management

Read: a 500-900 long word that comes out of sequencer
Mate pair: a pair of reads from two ends of the same insert fragment
Contig: a contiguous sequence formed by several overlapping reads with no gaps.
Supercontig (scaffold) an ordered and oriented set of contigs, usually by mate pairs.
Consensus sequence: sequence derived from the multiple alignment of reads in a contig

Goal: Find the shortest common sequence of a set of reads.
Input: reads {s1, s2, s3, …} Output: find the shortest string T such that
every s_i is a substring of T. Comment: This is NP-hard problem, we
need to use some approximation algorithm.

Process:(1) Calculate pairwise alignments of all
fragments.(2) Choose two fragments with the largest
overlap.(3) Merge chosen fragments.(4) Repeat step 2 and 3 until only one
fragment is left.
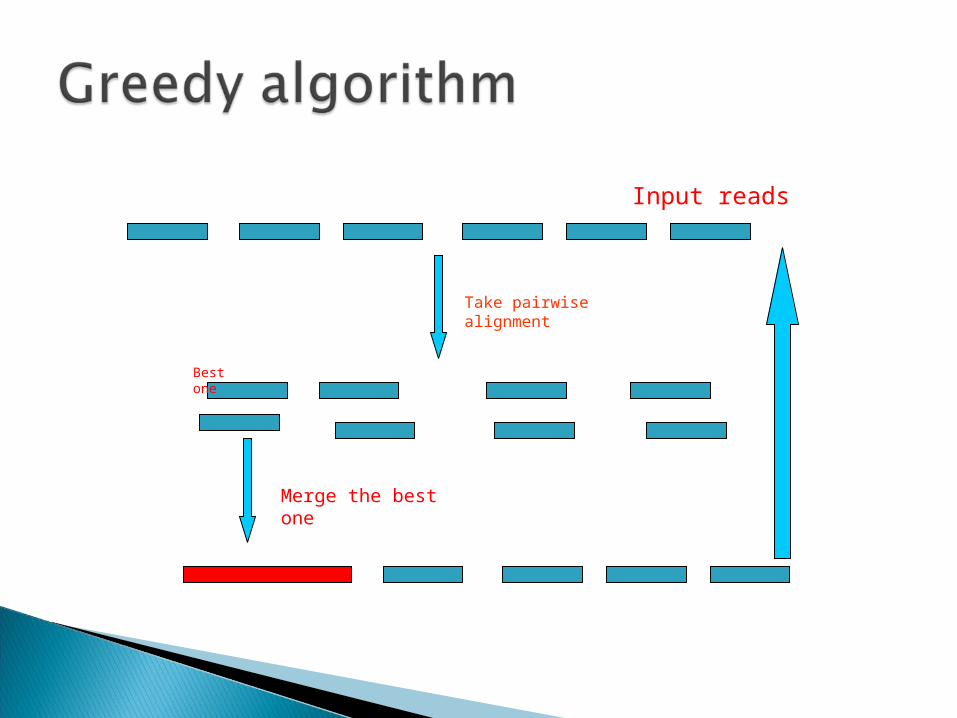
Best one
Take pairwise alignment
Merge the best one
Input reads

Comment: Greedy algorithm was the first successful
assembly algorithm implemented. Used for organisms such as bacteria, single-
celled eukaryotes. It has some efficiency limitation

This approach is based on graph theory. Assemblers based on this approach:
Arachne, Celera, Newbler etc.
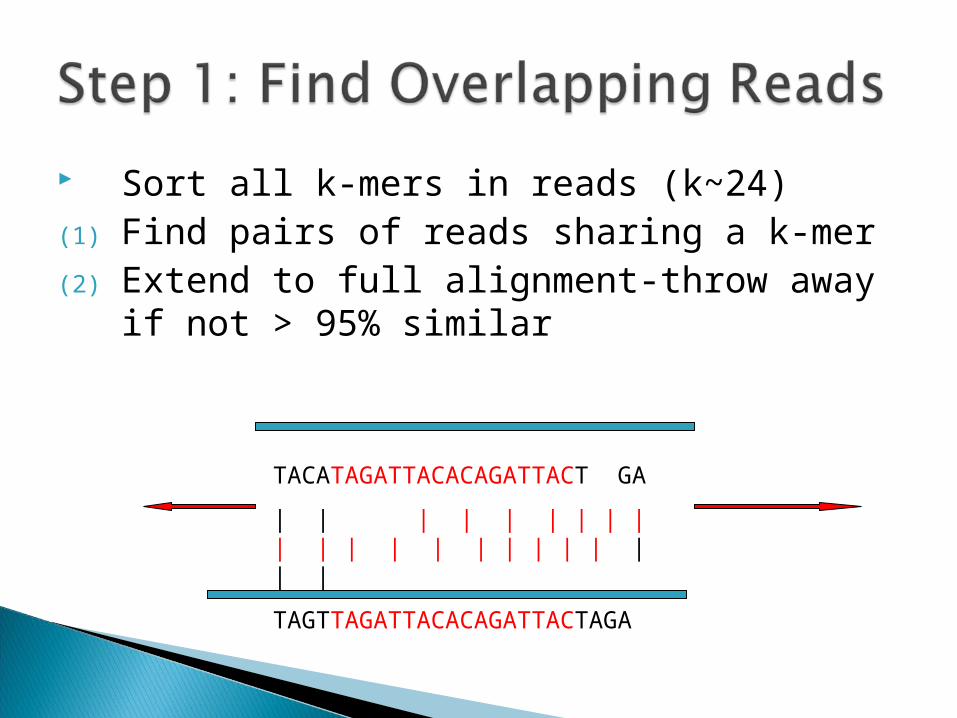
Sort all k-mers in reads (k~24)(1) Find pairs of reads sharing a k-mer(2) Extend to full alignment-throw away if not
> 95% similar
TACATAGATTACACAGATTACT GA
| | | | | | | | | | | | | | | | | | | | | |
TAGTTAGATTACACAGATTACTAGA

One caveat: repeats A k-mer that appears N times, initiates N^2
comparisons. Solution: Discard all k-mers that appear more than
c*Coverage, (c~10)
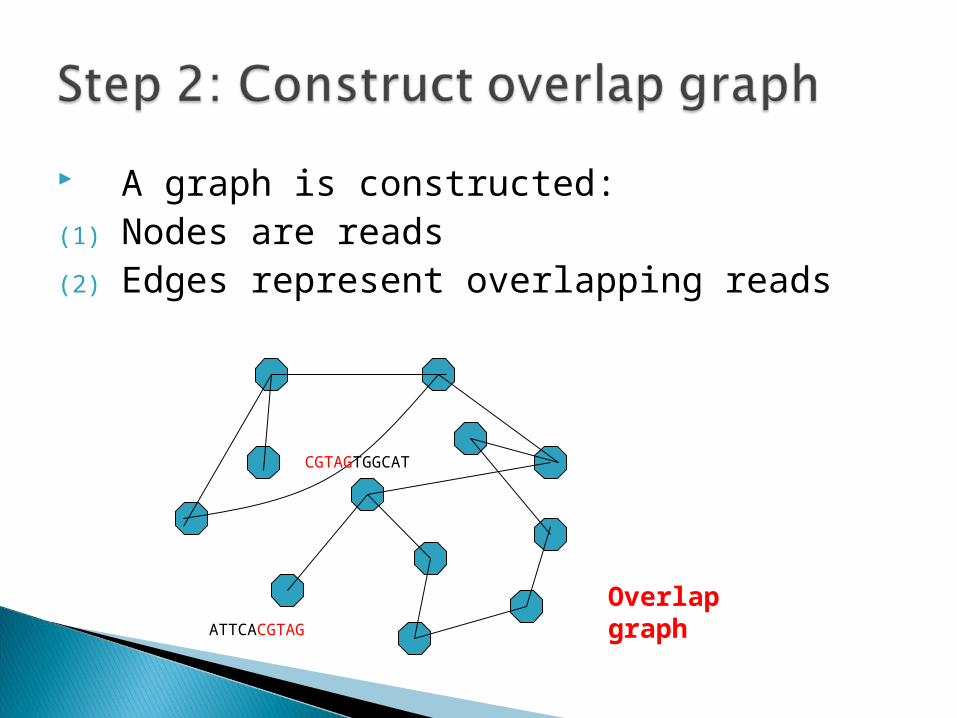
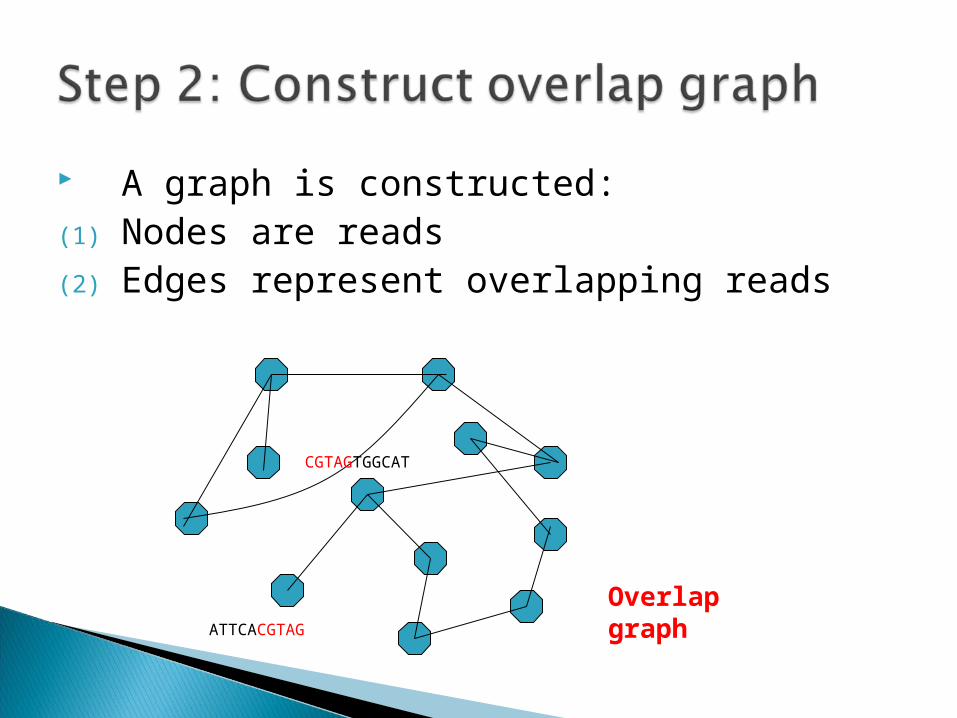
A graph is constructed:(1) Nodes are reads(2) Edges represent overlapping reads
CGTAGTGGCAT
ATTCACGTAG
Overlap graph
A graph is constructed:(1) Nodes are reads(2) Edges represent overlapping reads
CGTAGTGGCAT
ATTCACGTAG
Overlap graph
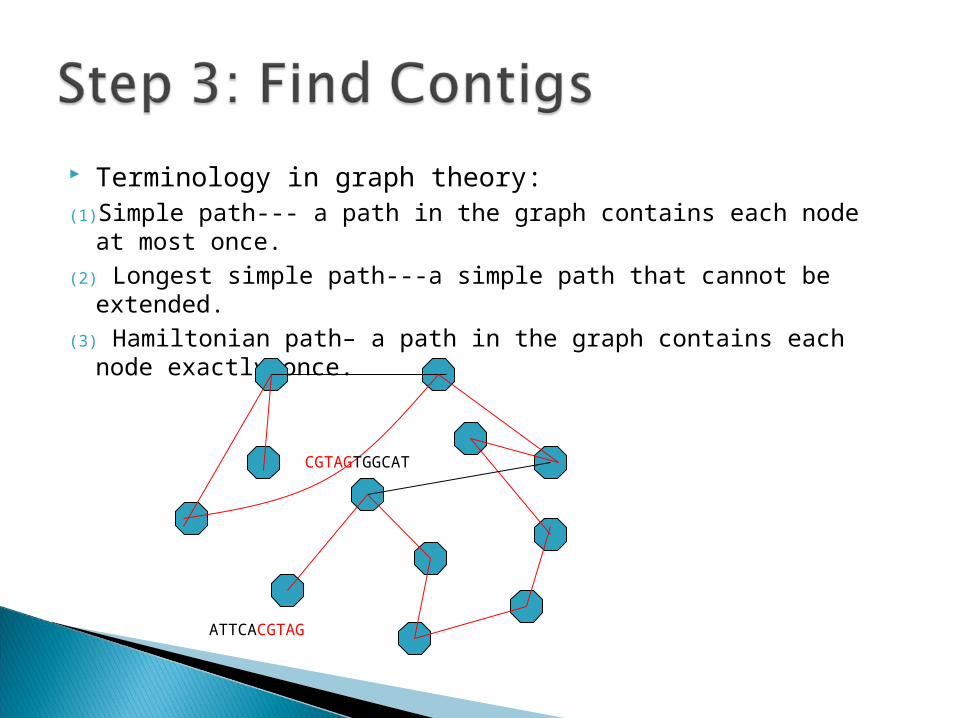
Terminology in graph theory:(1) Simple path--- a path in the graph contains each node at most
once.(2) Longest simple path---a simple path that cannot be extended.(3) Hamiltonian path– a path in the graph contains each node exactly
once.
CGTAGTGGCAT
ATTCACGTAG

Recall: Now we got several contigs(i.e. several longest simple paths)
Find the multiple alignments of these contigs, and get one consensus sequence as our final contig.

Summary:(1) Based on graph theory(2) Eularian path: a path in a graph which
visits every edge exactly once. (3) Example: Euler, Velvet, Allpath, Abyss,
SOAPdenovo…(4) Eularian path is more efficient, however, in
partice both are equally fast.
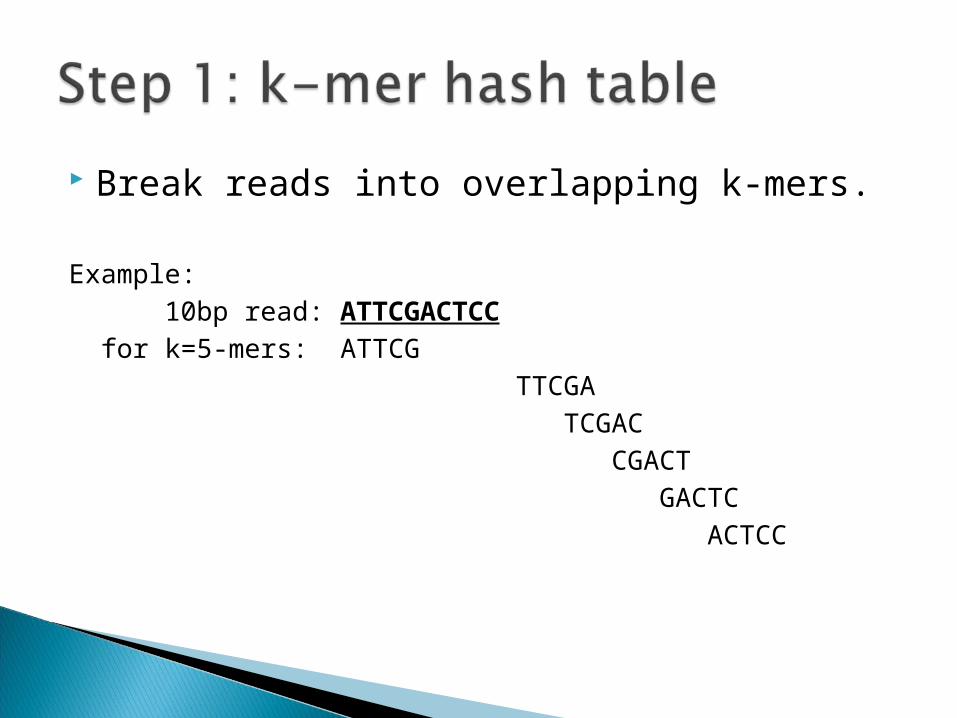
Break reads into overlapping k-mers.
Example: 10bp read: ATTCGACTCC for k=5-mers: ATTCG TTCGA TCGAC CGACT GACTC ACTCC
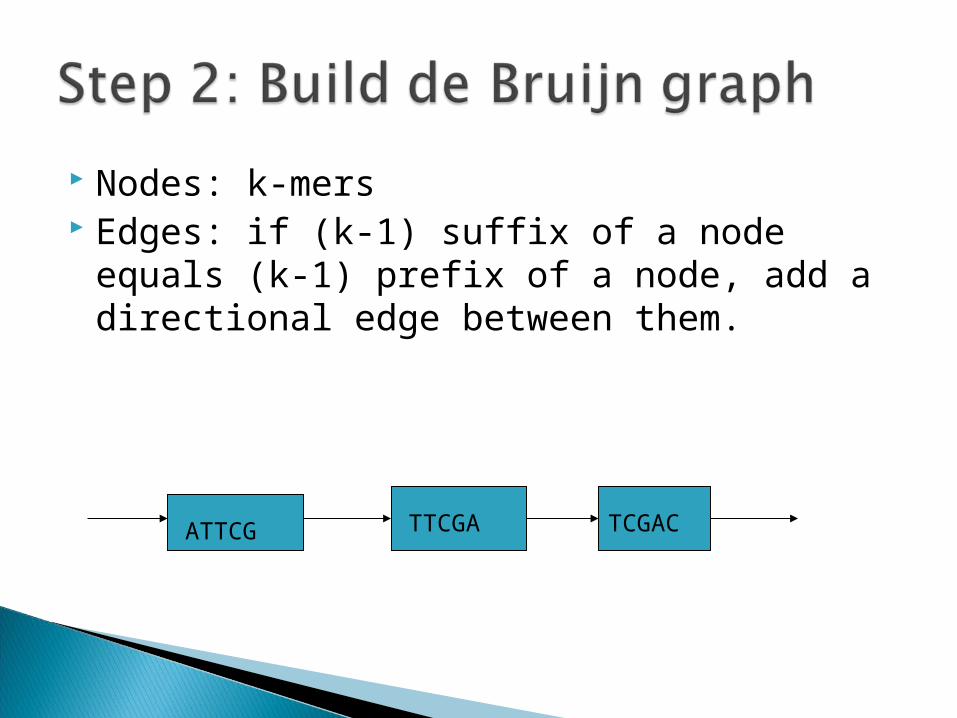
Nodes: k-mers Edges: if (k-1) suffix of a node equals (k-1)
prefix of a node, add a directional edge between them.
ATTCG TTCGA TCGAC
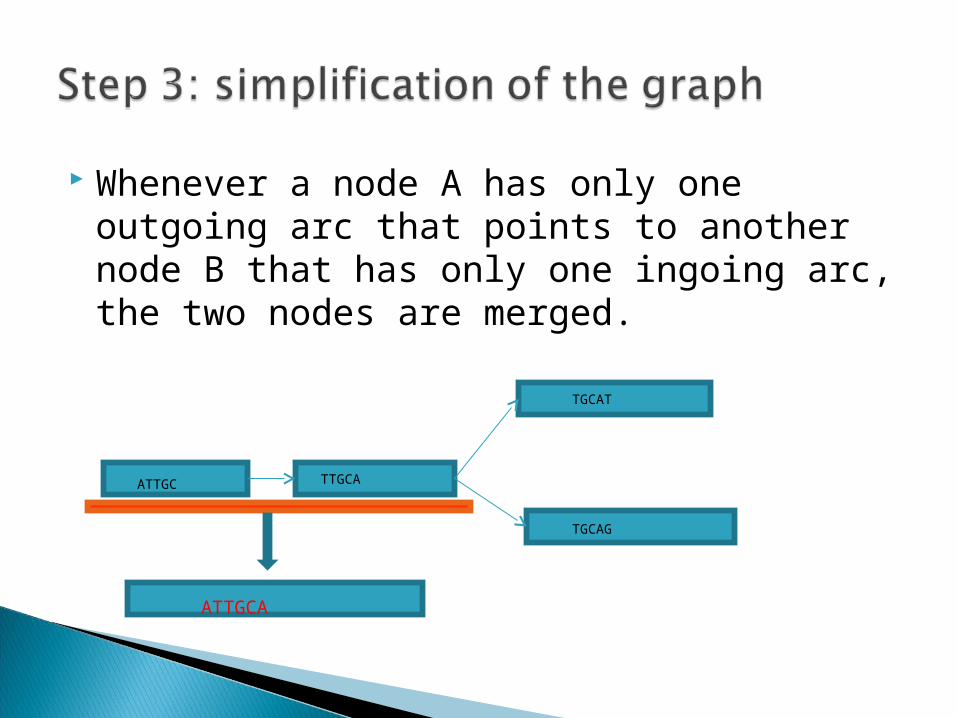
Whenever a node A has only one outgoing arc that points to another node B that has only one ingoing arc, the two nodes are merged.
ATTGC
TGCAT
TGCAG
TTGCA
ATTGCA

In Velvet:(1) Error removal(2) Removing tipsTip: a chain of nodes that is disconnected on
one end.

Consider two paths redundant if they start and end at the same nodes (forming a “bubble”) and contain similar sequences.
Such bubbles can be created by errors or biological variants, such as SNPs or cloning artifacts prior to sequencing. Erroneous bubbles are removed by an algorithm called “Tour Bus”.


Algorithm for directed graphs: (1) Start with an empty stack and an empty circuit (Eulerian path).
- If all vertices have same out-degrees as in-degrees - choose any of them.- If all but 2 vertices have same out-degree as in-degree, and one of those 2 vertices has out-degree with one greater than its in-degree, and the other has in-degree with one greater than its out-degree - then choose the vertex that has its out-degree with one greater than its in-degree.- Otherwise no Euler circuit or path exists.
(2) If current vertex has no out-going edges (i.e. neighbors) - add it to circuit, remove the last vertex from the stack and set it as the current one. Otherwise (in case it has out-going edges, i.e. neighbors) - add the vertex to the stack, take any of its neighbors, remove the edge between that vertex and selected neighbor, and set that neighbor as the current vertex.
(3) Repeat step 2 until the current vertex has no more out-going edges (neighbors) and the stack is empty.
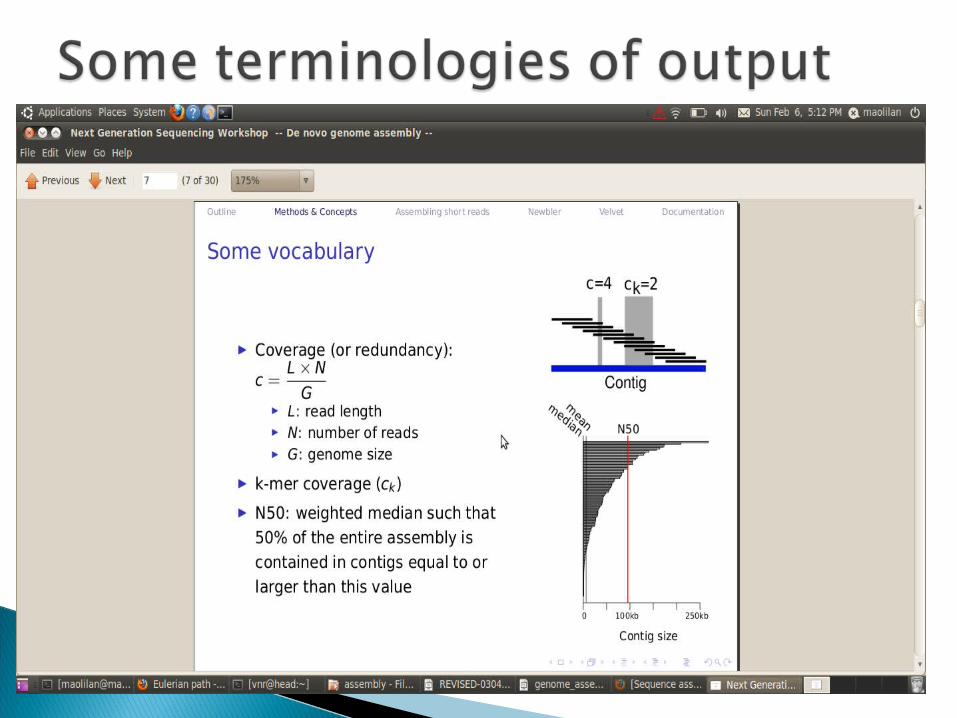

C_k=C*(L-k+1)/L N50 size: 50% of genome is in contigs larger than
N50Example:1Mbp genomeContigs: 300, 100, 50, 45, 30, 20, 15, 15, 10,…N50=30kbp(300+100+50+45+30=525>=500kbp)Note: N50 is meaningful for comparison only when
genome size is the same
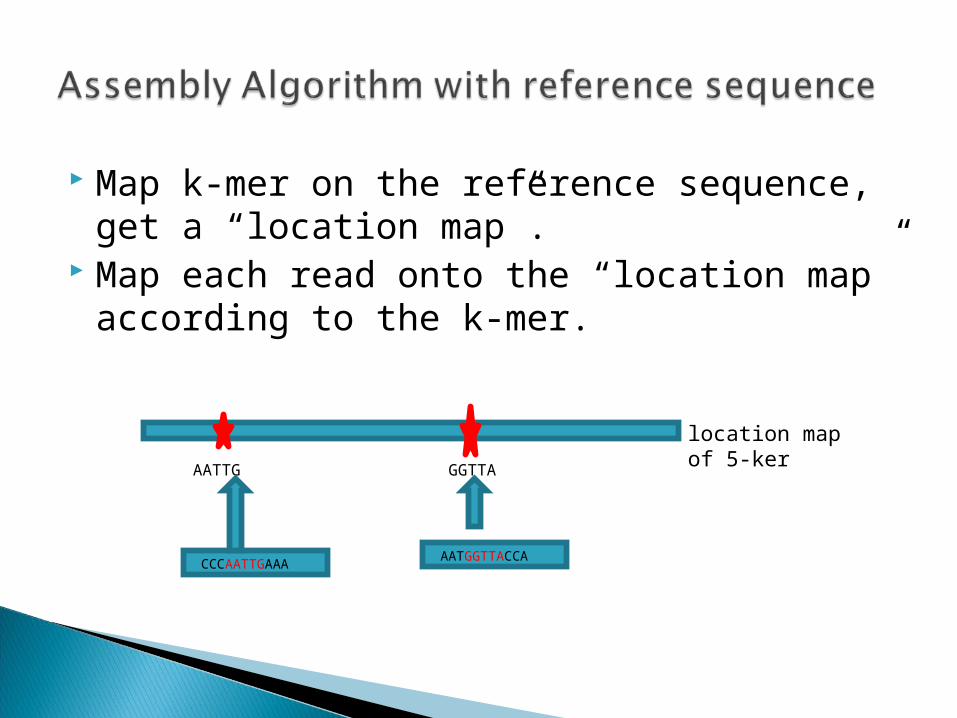
Map k-mer on the reference sequence, get a “location map”.
Map each read onto the “location map” according to the k-mer.
AATTG GGTTA
location map of 5-ker
CCCAATTGAAAAATGGTTACCA

Biology background Algorithms
De novo - Overlap-Layout-Consensus - De Bruijn graphs
Reference Tools and Techniques Work flow & strategy Group management

Standard flowgram format (SFF) A binary file format used to encode results
of pyrosequencing from the 454 Life Sciences platform for high-throughput sequencing.
a header section + read data sections

A summary of general information regarding the file content

Reads' universal accession numbers (h),sequence information (s), quality scores of basecalls (q), clipping positions (c), flowgram values (f)flowgram indices (i)
the nucleotide bases + the quality scores

6 genomes, 6 .sff files Number of reads ranges from 72548 to
391117
Reads Contigs/Scaffold
Assembler

GS De Novo Assembler: a software package designed specifically for assembling sequence data generated by pyrosequencing platforms
De novo assembly Overlap-Layout-Consensus methodology Better deal with reads greater than 250bp in length GS Reference Mapper

Algorithms for de novo assembly Short read assembly (25~50bp) Using de Bruijn graphs. Applying Velvet to very short reads and
paired-ends information only can produce contigs of significant length, up to 50-kb N50 length in simulations of prokaryotic data and 3-kb N50 on simulated mammalian BACs.

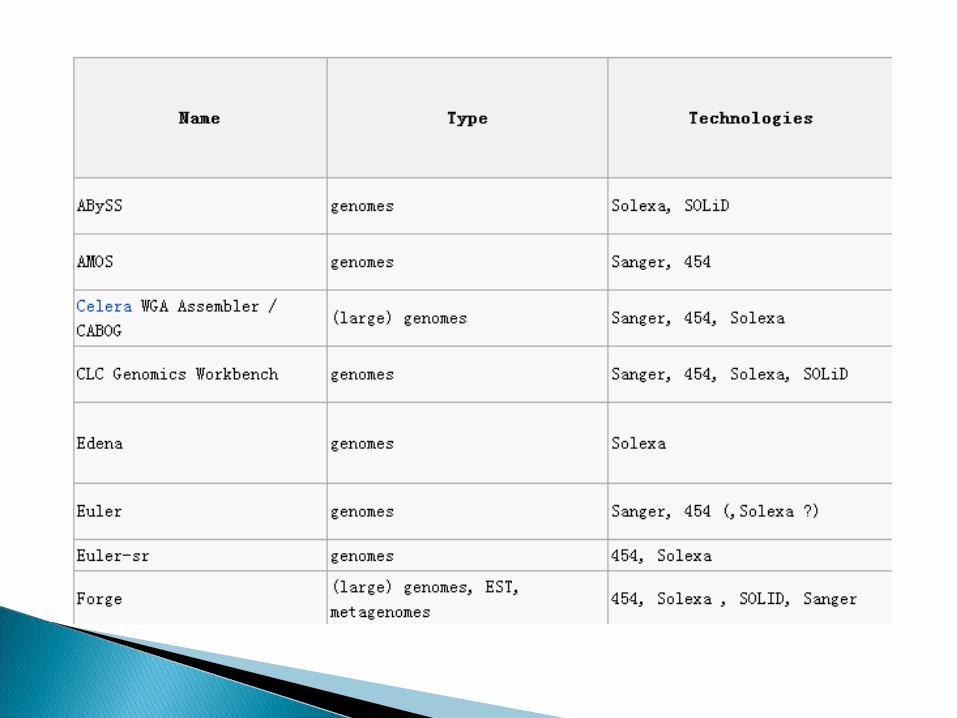
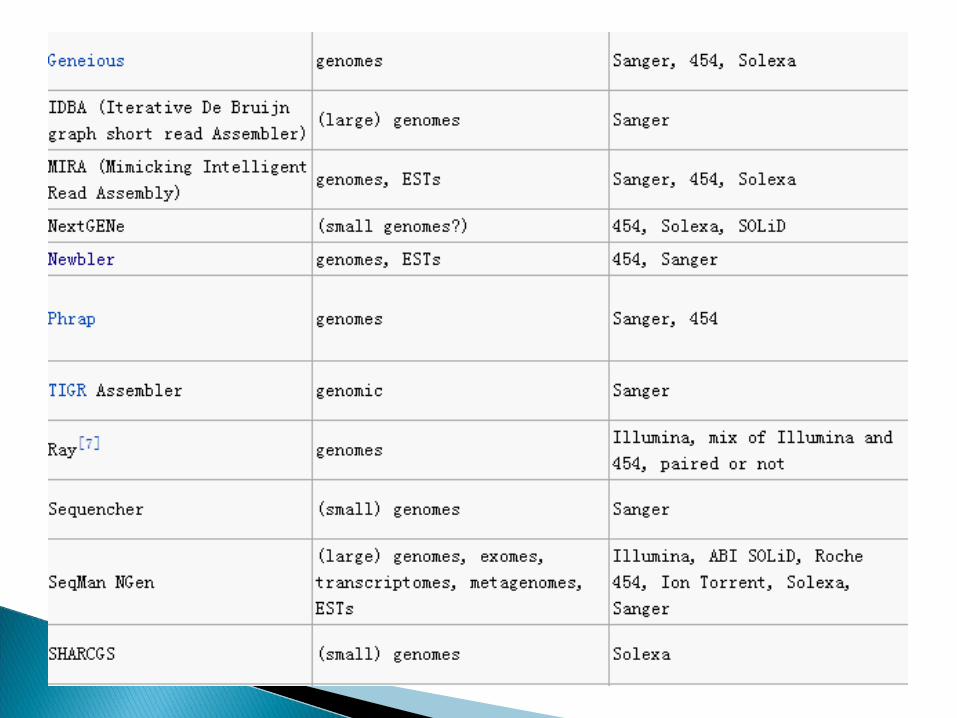
Open-source whole genome assembly software- Assemblers: Minimus2- Validation and Visualization: Hawkeye- Scaffolding: Bambus- Trimming, Overlapping, & Error Correction

Celera MIRA Edena
Finishing is a big challenge !

Sequencing errors: base pair misread, poly A…
It is possible that some portions of genomes are unsequenced
Identical and nearly identical sequences (repeats) can increase the time and space complexity of algorithms exponentially
Gaps & errors

• Finishing is taking contigs and yielding a complete sequence.
• Scaffolder orders contigs into scaffolds based on clone-mate pair information.
• Some assemblers have a simple quality-control method
• Check and manually assemble unresolved repeat regions
• Resequencing

Biology background Algorithms
De novo - Overlap-Layout-Consensus - De Bruijn graphs
Reference Tools and Techniques Work flow & strategy Group management

Plan will evolve◦ Different beast than expected
Write scripts to automate the pipeline Velvet did not work MIRA3 requires much time Edena is not optimized for 454 data
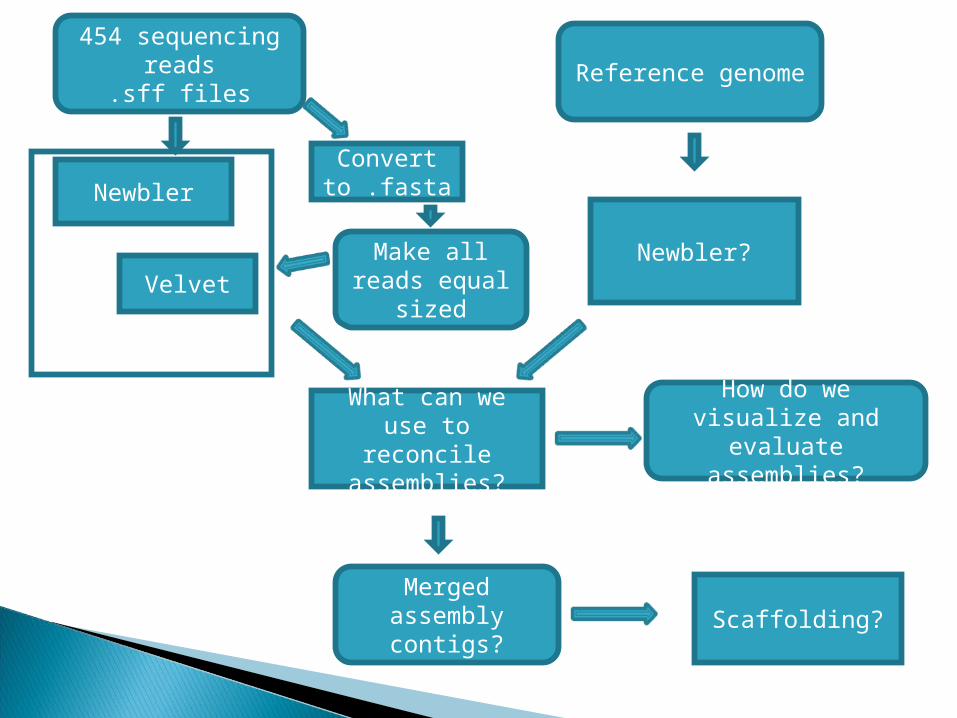
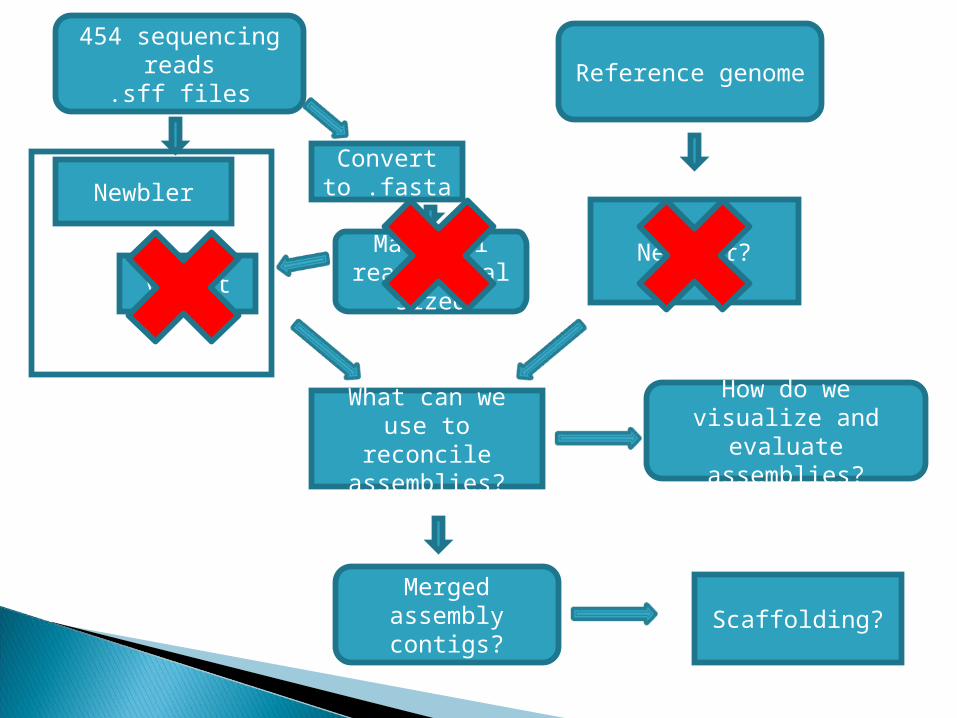
454 sequencing reads
.sff files
Newbler
Newbler?
Reference genome
What can we use to reconcile assemblies?
Merged assembly contigs?
Scaffolding?
How do we visualize and evaluate assemblies?
Convert to .fasta
Make all reads equal
sizedVelvet
454 sequencing reads
.sff files
Newbler
Newbler?
Reference genome
What can we use to reconcile assemblies?
Merged assembly contigs?
Scaffolding?
How do we visualize and evaluate assemblies?
Convert to .fasta
Make all reads equal
sizedVelvet

Human and chimp = 99% sequence similarity
H. influenzae and H. influenzae = 80% s.s. H. influenzae and H. hemolyticus = ???
(<80%)
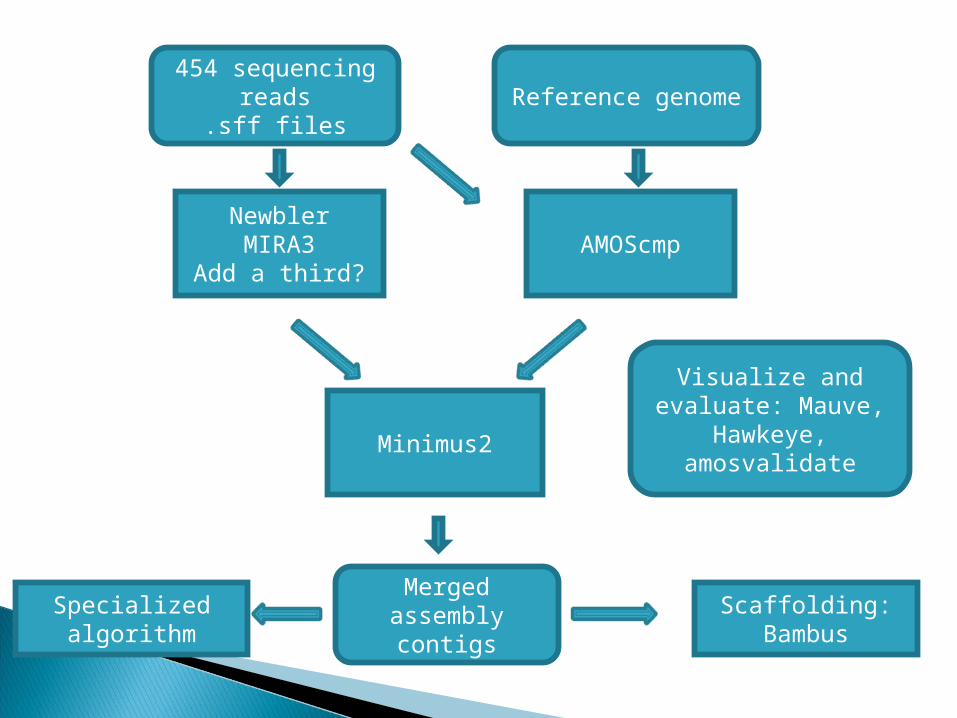
454 sequencing reads
.sff files
NewblerMIRA3
Add a third?AMOScmp
Reference genome
Minimus2
Merged assembly contigs
Scaffolding: Bambus
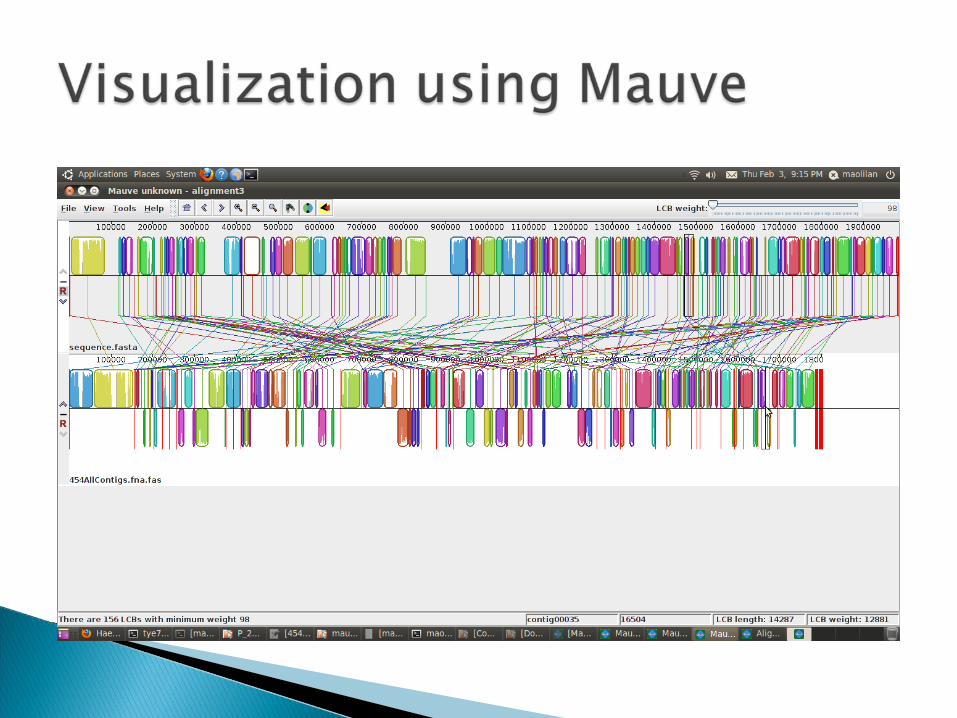
Visualize and evaluate: Mauve,
Hawkeye, amosvalidate
Specialized algorithm
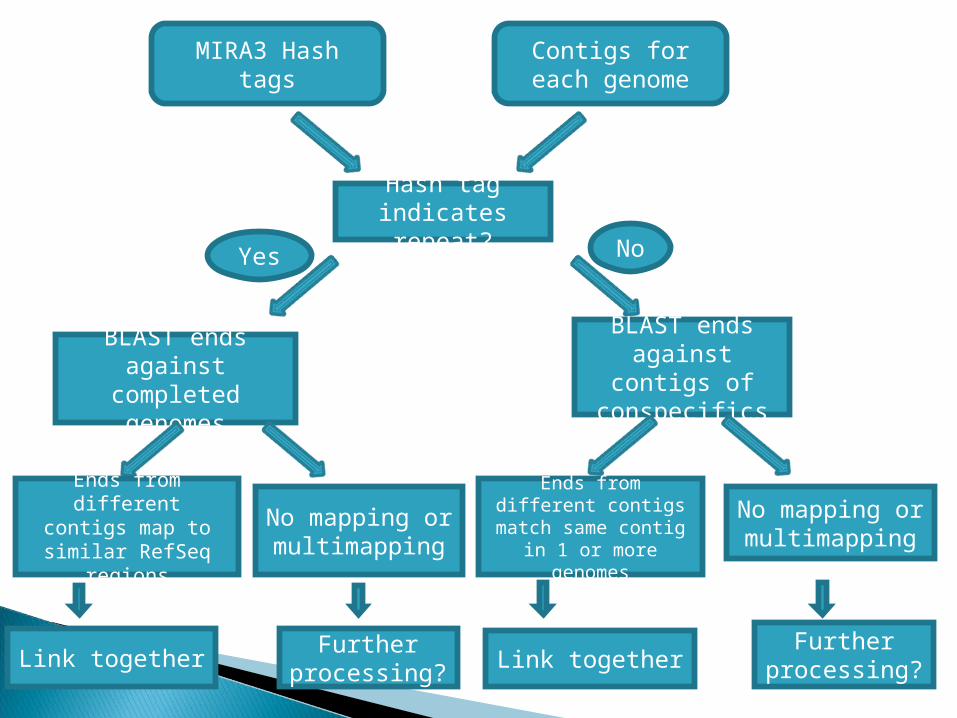
MIRA3 Hash tagsContigs for each
genome
Hash tag indicates repeat?
BLAST ends against contigs of conspecifics
BLAST ends against
completed genomes
Ends from different contigs match same contig in 1 or more
genomes
Link together
No mapping or multimapping
Further processing?
Ends from different contigs map to similar RefSeq
regions
Link together
No mapping or multimapping
Further processing?
Yes No

Plans change, and knowledge changes An automated pipeline is invaluable
◦ What if 30 15 contigs? Gene finding group◦ Just re-run the scripts

Core genes vs unique genes Gene clustering Codon usage

Biology background Algorithms
De novo - Overlap-Layout-Consensus - De Bruijn graphs
Reference Tools and Techniques Work flow & strategy Group management

Some task can be divided, some are not. Complexity of communication
The optimal group size is 3-6
Mini groups

Group meetings Wiki
main page discussion page
Everyone is special, thus valuable Start earlier, get closer to perfection






























![[Challenge:Future] GENA: Where Imaginations Become Real](https://img.pdfslide.us/doc/110x75/58ed56b21a28abc57a8b4583/challengefuture-gena-where-imaginations-become-real.jpg)