Embed Size (px)
Citation preview

© 2008 IBM Corporation
From early RISC to CMPs
Perspectives on Computer Architecture
Valentina [email protected] T.J. Watson Research Center

IBM Research
© 2008 IBM CorporationV. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture2
Hi, My name is Valentina Salapura
And I am a Computer ArchitectI work at IBM T.J. Watson research center
I used to be a professor of Computer Architecture at TechnischeUniversität Wien in Vienna
I always wanted to be an Architect (but of a different kind of architect)

IBM Research
© 2008 IBM CorporationV. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture3
What Is Computer Architecture?
The manner in which the components of a computer or computer system are organized and integrated.
Mirriam-Webster Dictionary
The term architecture is used here to describe the attributes ofa system as seen by the programmer, i.e., the conceptual structure and functional behavior as distinct from the organization of the dataflow and controls, the logic design, andthe physical implementation.
Gene Amdahl, IBM Journal of R&D, Apr 1964
In this book the word architecture is intended to cover all three aspects of computer design – instruction set architecture, organization, and hardware.
Hennessy and Patterson, Computer Architecture: A Quantitative Approach

IBM Research
© 2008 IBM CorporationV. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture4
Let us look at real Architecture
Building ArchitectureSand, clay, wood, etc
Bricks, timber, …
Compose them to form buildings
Build cities
Computer ArchitectureTransistors, logic gates
ALUs, flip-flops, bit cells, crossbars, …
Compose them to form processors
Build machines

IBM Research
© 2008 IBM CorporationV. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture5
My Opinion: Architecture vs. Design
Computer architecture applies at many levelsSystem architectureMemory system architectureCache architectureNetwork architecture…
Architecture is the plan; design is the implementation
Good architects understand design; good designers understand architecture
You have to know both!

IBM Research
© 2008 IBM CorporationV. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture6
Architecture of the IBM System/360
First separation of architecture from designIBM 360 instruction set architecture (ISA) completely hid the underlying technological differences between various models
The first true ISA designed as portable hardware-software interface
“Before 1964, each new computer model was designed independently; the system/360 was the first computer system designed as a family of machines, all sharing the same instruction set.“
– IBM Journal of R&D
Amdahl, Blaauw and Brooks, IBM Journal of R&D, Apr 1964

IBM Research
© 2008 IBM CorporationV. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture7
My Opinion: Architecture vs. Software
Architecture – software interaction at many levels Applications and algorithms
Programming models
Compilers
Operating systems
…Architecture is the plan; software exploits it
Good architects understand software; good software developers understand architecture
You have to understand both!

IBM Research
© 2008 IBM CorporationV. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture8
CMOS Scaling
Semiconductor scaling - driving force behind computer architecture research
Dennard’s scaling theory Feature size decreases about 15% each year Compute density increases about 35% each year Enables higher compute speed Die size increases about 10-20% each year Therefore, transistor count per chip increases about 55% per year
+2 GenerationsCMOS
room to addfunction
corecore
+1 GenerationsCMOS
corecore
Current Gen.CMOS
corecore

IBM Research
© 2008 IBM CorporationV. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture9
History of Computer architecture
Computer architecture research has changed over timeBuild better adders
Build better units
Build better ISA
Build better microarchitecture
Todaybuild better multiprocessor and better synchronization, coherence, communication, programming models and languages

IBM Research
© 2008 IBM CorporationV. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture10
Impact of IC Scaling
Much more fits on a chipEarly 1980s – entire 32-bit microprocessorLate 1980s – on-chip cachesLate 1990s – dynamic+static ILPEarly 2000s – on-chip routerFuture – billion transistors – multiprocessors? wide-issue ILP? ??
System balances always changingPipelining – cycle time vs. wire delayMemory wall – cycle time vs. memory latencyI/O bottleneck – transistor count vs. pin countPower wall – transistor count vs. power consumptionILP wall – increasing Instruction Level Parallelism vs. performance increase

IBM Research
© 2008 IBM CorporationV. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture11
Predicting future trends for computer systems
“Computers in the future may weigh no more than 1.5 tons. ”
Popular Mechanics, 1949
“There is no reason anyone would want a computer in their home. ”
Ken Olsen, founder of DEC, 1977
“640K ought to be enough for anybody. ”
Bill Gates, 1981
“Prediction is difficult, especially about the future”
Yogi Berra
Source: IBM GTO

IBM Research
© 2008 IBM CorporationV. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture12
pre-history her-story

IBM Research
© 2008 IBM CorporationV. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture13
Early 80s
LSI became VLSI
Challenges:Can we fit a whole processor on one chip?
– Yes, if it is sufficiently simple– RISC processor revolution– Keep it simple
Can we design 115 thousand transistors– Yes, with discipline and tools– Mead-Conway VLSI design revolution– Keep it simple

© 2008 IBM Corporation14 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
Research agenda for 80s – 90s
Build better processor cores– Riding up Moore’s Law
– CMOS Scaling means we can use more transistors
– Find ways to use the transistors profitably
Build better design methodologies and tools– More complex systems require
better ability to control design complexity
– More complex systems require better performance prediction Graph Source: www.physics.udel.edu/~watson/scen103/intel.html

15V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
15
Technische Universität Wien
Better modeling of microprocessors
MIPS R2000 clone
FPU & System Components model working with SiemensBehavioral timing-exact modeling using a new language – VHDLExploration of other modeling approaches
StateCharts – David Harel
MIPS cloneModeling and design using a new approachLogic synthesis and VHDL

16V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
16
Technische Universität Wien
MIPS-I processor core
processor core as starting pointMIPS-I architecturedesigned from public information
compatible MIPS-I ISA implementation compatible hardware interface different internal operation
not a clone
written in VHDLdescribed at behavioral/register transfer level
hardware implementation using logic synthesis
17V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
17
Technische Universität Wien
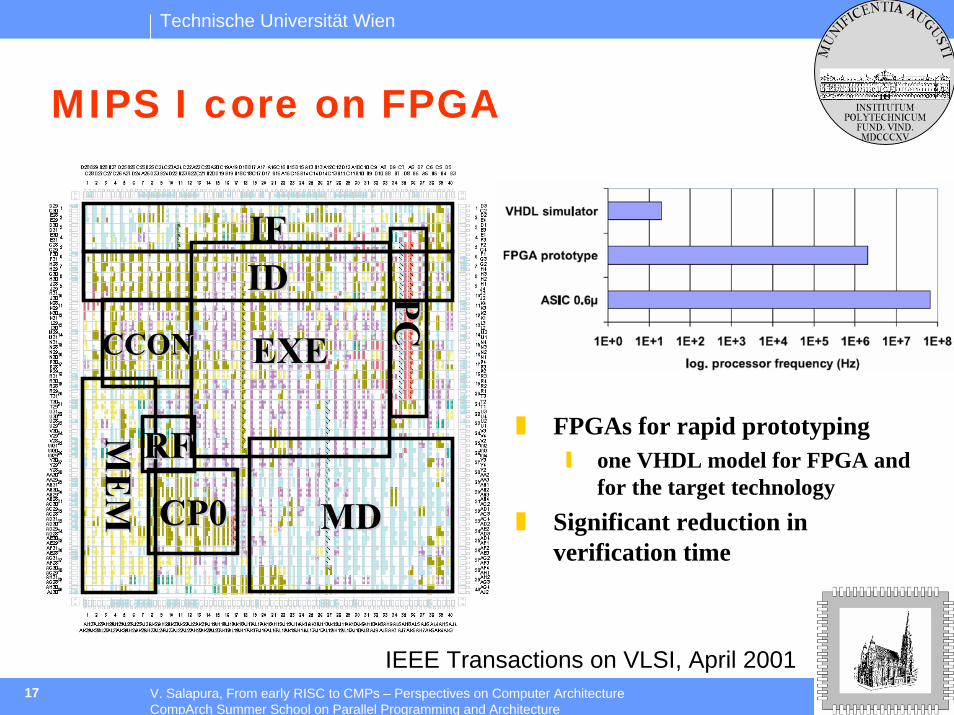
MIPS I core on FPGA
FPGAs for rapid prototypingone VHDL model for FPGA and for the target technology
Significant reduction in verification time
IEEE Transactions on VLSI, April 2001

18V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
18
Technische Universität Wien
Building better cores
Application-specific processorsCan we optimize functions for specific applications?Extend processor with application-specific units
Prototyping with FPGAsA nascent technology taking advantage of increased integrationMethodology for FPGA design with synthesis
Share the same design for prototype and actual fabrication

19V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
19
Technische Universität Wien
Hardware/Software Co-evaluation
instruction set design based mostly on software benchmarks
minimize cycle countminimize code size
but introducing new instructions changes hardware implementation
cycle timeresource usage
software analysis is not enough for a balanced view of costs and benefits ⇒ co-design
integrates hardware and software analysis
Core
Program
Profiling
Partitioning
Interface Compiler
Prototyping Adapt Compiler
New Compiler
Synthesis
Processor
Compilation
Code
Simulation
RTL Model

© 2008 IBM Corporation20 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
Joining IBM
Projects I worked on at IBM– Cyclops
– SANlite
– Blue Gene/L
– Blue Gene/P

© 2008 IBM Corporation21 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
Late-late nineties and on
Diminishing returns on investment in transistors
Massively parallel many-threaded CMPs– Cyclops
– SANlite
Application-specific accelerations– Networking & Protocol Processing
– Networked Storage

© 2008 IBM Corporation22 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
SANlite: Multiprocessor subsystem for network processing
Self-contained, scalable multiprocessor system– With its own general-
purpose processors, interconnect, interfaces and memory
Connected to the SoCbus via a bridge– Easy integration in the
basic SoC structure
Inner structure and complexity is hidden from the SoC designer – Significantly simplifies
the SoC design
On-chip Peripheral B
us (OPB
)
UART (2)
I2C (2)
GPIO
Arb
Processor Local Bus (PLB)
Timers
InterruptController
RAM/ROM/Peripheral controller
Ext Bus Master
GPIO
GPT
OPBBridge
PCI-XBridge
Processor Local Bus (PLB)
10/100/1GEthernet
MAC
440 PowerPC
DMADDR
SDRAM controller
DMAController
SRAM
Multiprocessormacro
FibreChannel
Acc.
P0
x
...
Mem
P1 PN
Patent US7353362: Multiprocessor subsystem in SoC with bridge between processor clusters interconnection and SoC system bus

© 2008 IBM Corporation23 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
Details of the multiprocessor subsystem
One or more multiple processor clusters– Cyclops cluster has 8 processor
cores, 32 KB shared instruction cache, local SRAM
– Very simple processor cores• Single-issue, in-order
execution; • four stages deep pipeline
One or more local memory banks – For storing data and instructionsBridge to the SoC busOne or more application-specific hardware interfaces– Gigabit Ethernet, Fibre Channel,
Infiniband, etc.
crossbar switch
MemoryBank 0
DRAM
Bank 15
. . . MemoryBank n
PLB
bridge
Proc. core cluster 0
PLB bus1G/10GEMAC
Proc. core cluster m
1G/2G/4G/MAC
Fibre Channel
Interface
Gb Ethernet
Interface

© 2008 IBM Corporation24 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
The 00’s
The Power Challenge and how to build supercomputers in a power-constrained regime– Scale-out
– SIMD
– Cost-effective scaling of multicore

© 2008 IBM Corporation25 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
Key Supercomputer Challenges
More Performance More Power– Systems limited by data center power supplies and
cooling capacity• New buildings for new supercomputers
Scaling single core performance degrades power-efficiency– FLOPS/W not improving from technology
traditional supercomputer design hitting power & cost limits

© 2008 IBM Corporation26 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
2.8/5.6 GF/s4 MB
2 processors
2 chips, 1x2x1
11.2 GF/s1.0 GB
(32 chips 4x4x2)16 compute, 0-2 IO cards
180 GF/s16 GB
32 node cards
5.6 TF/s512 GB
104 Racks - LLNL
596 TF/s53 TB
Rack
System
Node card
Compute card
Chip
Blue Gene/L: from Chip to System
The Blue Gene/L project has been supported and partially funded by the Lawrence Livermore National Laboratories on behalf of theUnited States Department of Energy under Lawrence Livermore National Laboratories Subcontract No. B517552.

© 2008 IBM Corporation27 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
Blue Gene/L compute ASIC
PLB (4:1)
L2L2
SharedSRAM
SharedSRAM
JTAGGbitEthernet
144b DDRinterface
256
256
128
256snoop
128
32k I1/32k D132k I1/32k D1
PPC440PPC440
Double FPUDouble FPU
EthernetGbit
EthernetGbit JTAG
Access
JTAGAccess CollectiveCollectiveTorusTorus Global
Barrier
GlobalBarrier
DDRControllerw/ ECC
DDRControllerw/ ECC
32k I1/32k D132k I1/32k D1
PPC440PPC440
Double FPUDouble FPU4MB
eDRAM
L3 Cacheor
On-ChipMemory
4MBeDRAM
L3 Cacheor
On-ChipMemory
Shared L3 Directory
for eDRAM
w/ECC
Shared L3 Directory
for eDRAM
w/ECC
1024b data 144b ECC
L2L2128
256
6b out, 6b in1.4Gb/sper link
3b out, 3b in2.8Gb/sper link
4 globalbarriers orinterrupts
High integration
eDRAM
Leverage components
DFPU

© 2008 IBM Corporation28 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
BlueGene/L ASIC
IBM Cu-11 0.13µ CMOS ASIC process technology 11 x 11 mm die size 1.5/2.5VCBGA package, 474 pinsTransistor count 95MClock frequency 700 MHzPower dissipation 12.9 W

© 2008 IBM Corporation29 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
Blue Gene/L Exploring the Benefits of SIMD
Power efficient
Low overhead (doubles data computation without paying cost of instruction decode, issue etc.)
UMT2K runs on 1024 nodes
Code optimized to exploit SIMD floating point IEEE Micro, Vol. 26 No. 5. 2006
0
0.2
0.4
0.6
0.8
1
1.2
t E E tmetrics
norm
aliz
ed
scalarSIMD
smal
ler i
s be
tter
smal
ler i
s be
tter

© 2008 IBM Corporation30 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
Blue Gene/L packaging

© 2008 IBM Corporation31 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
Trends ’00: Processor performance slowing down
1
10
100
1000
10000
1978 1980 1982 1984 1986 1988 1990 1992 1994 1996 1998 2000 2002 2004 2006
Perfo
rman
ce (v
s. V
AX-1
1/78
0)
25%/year
52%/year
??%/year
Hennessy and Patterson, Computer Architecture: A Quantitative Approach, 4th edition, 2006
(SPECint)

© 2008 IBM Corporation32 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
Microprocessors are dead!
“Today's microprocessors will become extinct by the end of the decade, to be replaced by computers built onto a single chip.”– Greg Papadopoulos, Sun Microsystems, Fall processor
forum 2003

© 2008 IBM Corporation33 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
Leakage Power
Yesterday: – Power to clock latches dominant
power dissipation component
– Active power dominates
Today: – Power consumed even if not
clocking latches
– Leakage power has become a significant component
– Must develop means to “disconnect” unused circuits
0
10
20
30
40
50
60
70
80
90
100
0.010.11Gate length (µm)
Active Power
Leakage Power

© 2008 IBM Corporation34 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
Hardware Synthesis and Floorplanning
Synthesis– Yesterday: reduce number of gates to make timing
– Today: Placement Driven Synthesis (PDS)• Wires have delays we have to consider
Floorplan– Yesterday: did not worry about a floorplan
– Today: do not have architecture without a floorplan• Floor-plan the architecture from the beginning• Process variability makes timing closure hard

© 2008 IBM Corporation35 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
Improving Performance
0.18um 0.13um 90nm 65nm
Technology Generation
0
20
40
60
80
100
Rel
ativ
e G
ain
in P
erfo
rman
ce
Innovation Scaling
No longer possible by scaling alone
– New Device Structures
– New Device Design point
– New Materials
Before 90’s1hydrogen
H
5
boron
B
8oxygen
O
15
phosphorus
P14
silicon
Si
33arsenic
As
13
aluminum
Al
Since the 90’s 7
nitrogen
N
9
fluorine
F
32germanium
Ge
22Ti22titanium
Ti
73Ta73tantalum
Ta
29
copper
Cu
29tungsten
W
17
chlorine
Cl
39yttrium
Y40
zirconium
Zr
72hafnium
Hf
23vanadium
V
41niobium
Nb
24chromium
Cr
42molybdenum
Mo
21scandium
Sc
75Rhenium
Re
43ruthenium
Ru
77iridium
Ir
45rhodium
Rh
27cobalt
Co
78platinum
Pt
45palladium
Pd
28nickel
Ni
57lanthanium
La58
cerium
Ce59
Praeseodymium
Pr
60neodymium
Nd62
samarium
Sm63
europlum
Eu64
gadollinium
Gd65
terbium
Tb66
dysprosium
Dy67
holmium
Ho68
erbium
Er69
thullium
Tm70
ytterbium
Yb
20calcium
Ca
38strontium
Sr
56barium
Ba
12magnesium
Mg
Beyond 2006
35Br35Bromine
Br30zinc
Zn
83bismuth
Bi
6carbon
C
2helium
He
54
xenon
Xe51
antimony
Sb52
tellurium
Te
Source: IBM GTO

© 2008 IBM Corporation36 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
The Discontinuity
Then 2002– Scaling drives performance
– Performance constrained– Active power dominates– Performance tailoring in
manufacturing– Focus on technology performance– Single core architectures
Now– Architecture drives performance
• Scaling drives down cost– Power constrained
– Standby power dominates
– Performance tailoring in design
– Focus on system performance
– Multi core architecture

© 2008 IBM Corporation37 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
POWER4 POWER4+
174 mtrs./115/125 W
10/01 11/02
2001 2002
3Q 4Q 3Q 4Q
~~ ~~
2005
1Q 2Q
~~3Q 4Q
2007
3Q 4Q 1Q
20082Q 2Q
180 nm/412 mm2
184 mtrs./70 W130 nm/380 mm2
8+ cores, new paradigms
Product Data: Sima, Goetz, Gschwind, Hofstee, 2007/2008Graphics: Sima 2007, Gschwind 2008
8
4/MT
4
2/MT
2
# C
ores
279 mtrs./63 W
Cell BE
10/2005
234 mtrs./95 W90 nm/221 mm2
(PPE:2-way MT)(SPEs: no MT)
SPARC Niagara
11/2005
90 nm/379 mm2
4-way MT/core
POWER5
5/04
276 mtrs./80W (est.)130 nm/389 mm2
2-way MT/core
POWER5+
10/05
276 mtrs./70 W90 nm/230 mm2
2-way MT/core
Xbox360
3Q/2005
90 nm2/ / 165 mtrs(3 cores, each 2-way MT)
Pentium D 800(Smithfield)
5/05
90 nm/206mm2
130 W
Same Gen
~~
Core 2 Duo(Conroe)
8/06
65 nm/143mm2
2x1 core/65 W
2006
SPARCNiagara II
2007
65 nm/342 mm2
8-way MT/core72 W (est.)
Core 2 Quad(Kentsfield)
1/07
65 nm/2x2 cores

© 2008 IBM Corporation38 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
Designing Blue Gene/P
Emphasis on modular design and component reuse
Reuse of Blue Gene/L design components when feasible– Optimized SIMD floating point unit
• Protect investment in Blue Gene/L application tuning– Basic network architecture
Add new capabilities when profitable– PPC 450 embedded core with hardware coherence support
– New data moving engine to improve network operation• DMA transfers from network into memory
– New performance monitor unit• Improved application analysis and tuning

© 2008 IBM Corporation39 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
JTAG 10 Gb/s
256
256
32k I1/32k D132k I1/32k D1
PPC450PPC450
Double FPUDouble FPU
Ethernet10 Gbit
Ethernet10 GbitJTAG
Access
JTAGAccess Collective
CollectiveTorus
Torus GlobalBarrier
GlobalBarrier
DDR-2Controllerw/ ECC
DDR-2Controllerw/ ECC
32k I1/32k D132k I1/32k D1
PPC450PPC450
Double FPUDouble FPU
4MBeDRAM
L3 Cacheor
On-ChipMemory
4MBeDRAM
L3 Cacheor
On-ChipMemory
6 3.4Gb/sbidirectional
4 globalbarriers orinterrupts
128
32k I1/32k D132k I1/32k D1
PPC450PPC450
Double FPUDouble FPU
32k I1/32k D132k I1/32k D1
PPC450PPC450
Double FPUDouble FPU L2L2
Snoop filter
Snoop filter
4MBeDRAM
L3 Cacheor
On-ChipMemory
4MBeDRAM
L3 Cacheor
On-ChipMemory
512b data 72b ECC
128
L2L2
Snoop filter
Snoop filter
128
L2L2
Snoop filter
Snoop filter
128
L2L2
Snoop filter
Snoop filter
Multiplexing
switch
Multiplexing
switch
DMADMA
Multiplexing
switch
Multiplexing
switch
3 6.8Gb/sbidirectional
DDR-2Controllerw/ ECC
DDR-2Controllerw/ ECC
13.6 GB/sDDR2 DRAM bus
32
SharedSRAM
SharedSRAM
Hybrid PMU
w/ SRAM256x64b
Hybrid PMU
w/ SRAM256x64b
Shared L3 Directory
for eDRAM
w/ECC
Shared L3 Directory
for eDRAM
w/ECC
Shared L3 Directory
for eDRAM
w/ECC
Shared L3 Directory
for eDRAM
w/ECC
ArbArb
512b data 72b ECC
Blue Gene/P - next generation node design

© 2008 IBM Corporation40 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
PPC450PPC450
Multiprocessor cache management issues
Address DataAddress Data Address DataAddress Data
PPC450PPC450
L1D L1D
Address DataAddress Datamemory
FF00 5FF00 5FF00 5
FF00 7FF00 6
In multiprocessor systems, each processor has a separate privatecacheWhat happens when multiple processors cache and write the same data?

© 2008 IBM Corporation41 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
Multiprocessor cache management issues:Coherence protocol
Address DataAddress Data
PPC450PPC450
Address DataAddress Data
PPC450PPC450
L1D L1D
Address DataAddress Data
FF00 5FF00 5FF00 5
FF00 6 FF00 7
memory
Every time any processor modifies data – Every other processor needs to check its cacheHigh overhead cost– Cache busy snooping for significant fraction of cycles– Increasing penalty as more processors added

© 2008 IBM Corporation42 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
Snoop filtering of unnecessary coherence requests
Processor 0
snoop
SnoopUnit
Processor 1
snoop
Processor 2
snoop
Processor 3
snoop
L2 Cache
SnoopUnit
L2 Cache
SnoopUnit
L2 Cache
SnoopUnit
L2 Cache
L3 CacheDMA
Coherence traffic
Data transfer
Increases performance (remove unnecessary lookups, reduced cache interference)
Reduces power (and energy)

© 2008 IBM Corporation43 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
Snoop filtering improves power and performance
50%
60%
70%
80%
90%
100%
110%
time power E E × t
snoop disabled snoop filter
Actual hardware
measurements
UMT2k application
smal
ler i
s be
tter
smal
ler i
s be
tter
HPCA 2008

© 2008 IBM Corporation44 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
Blue Gene/P ASIC
IBM Cu-08 90nmCMOS ASIC process technology Die size 173 mm2
Clock frequency 850MHzTransistor count 208MPower dissipation 16W

© 2008 IBM Corporation45 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
Blue Gene/P compute card and node card
The Blue Gene/P project has been supported and partially funded by Argonne National Laboratory and the Lawrence Livermore National Laboratory on behalf of the United States Department of Energy under Subcontract No. B554331.

© 2008 IBM Corporation46 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
Blue Gene/P cabinet
16 node cards in a half-cabinet (midplane)
512 nodes (8 x 8 x 8)
all wiring up to this level (>90%) card-level
1024 nodes in a cabinet
Pictured 512 way prototype (upper cabinet)

© 2008 IBM Corporation47 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
Research and Engineering is a team sport
Wherever you want to go, you will likely not get there alone– Find like-minded colleagues for technical and moral support
– You will not get there alone, so share success with the team and treat everybody with respect
Being part of a successful team is key– Enthusiasm and commitment to team success
– Learn to understand how your team works and how to get results

© 2008 IBM Corporation48 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
Building the World’s Fastest Supercomputer:The Blue Gene/L team
Team
BlueGene
No. 1

© 2008 IBM Corporation49 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
The Blue Gene/P team – Yorktown

© 2008 IBM Corporation50 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
My support team

© 2008 IBM Corporation51 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
Career Opportunities and Challenges
Find an interesting subject that you are passionate about– To make it work, you will spend many hours with it
Find interesting challenges of TOMORROW– Everybody else is already working on TODAY’s problems
– And solving today’s problems by tomorrow is usually too late

© 2008 IBM Corporation52 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
Challenges which influenced the course of Computer Architecture
What can we build?– Technology opportunities
and threats• VLSI & Dennard Scaling• Power Crisis• SER exposures
How can we build it – Tools
– Methodology
– Controlling complexity• Humans• Tools

© 2008 IBM Corporation53 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
Pioneers of Computer Architecture (and Related Fields)

© 2008 IBM Corporation54 V. Salapura, From early RISC to CMPs – Perspectives on Computer ArchitectureCompArch Summer School on Parallel Programming and Architecture
IBM Research
Future Pioneers: 2006 Summer School





























