Embed Size (px)
Citation preview

Extreme Re-balancing for SVMs and other classifiers
Presenter: Cui, Shuoyang
2005/03/02
Authors: Bhavani Raskutti & Adam Kowalczyk Telstra Croporation Victoria, Austalia

Imbalance makes the minority-classes samples farther from the true boundary than the majority-class samples.
Majority-class samples dominate the penalty introduced by soft margin.
ideal
Majority
Minority

Data Balancing• up/down samplings• No convincing evidence for how the balanced data
sampled
Imbalance-free algorithm design• Objective function should not be accuracy any longer
Reference:Machine Learning from Imbalanced Data Sets 101http://pages.stern.nyu.edu/~fprovost/Papers/skew.PDF

In this paper
Exploring the characters of two class learning and analyses situations with supervised learning.
In the experiments offered later, comparing one-class learning with two class learning and list different forms of imbalance compensation.

Two class discrimination
to take examples from these two classes generate a model for discriminating them
for many machine learning algorithms, the training data should include the example form two classes.

When the data has heavily unbalanced representatives of these two class.
• design re-balancing
• ignore the large pool of negative examples
• learn from positive examples only

Why extreme re-balancing
• Extreme imbalance in very high dimensional input spaces
• Minority class consisting of 1-3% of the total data
• Learning sample size is much below the dimensionality of the input space
• Data site has more than 10,000 features

The kernel machine
The kernel machine is solved iteratively using the conjugate gradient method.
Designing a kernel machine is to take a standardalgorithm and massage it so that all references to the original data vectors x appear only in dot products ( xi; xj).
Given a training sequence(xi,yi) of binary n—vectors and bipolar labels

Two different cases of kernel machines used here

Two forms of imbalance compensation
• Sample balancing
• Weight balancing

Sample balancing
1:0------the case of 1-class learner using all of the negative examples1:1------ the case of 2-class learner using all training examples 0:1------ the case of 1-class learner using all of the positive examples

Weight balancing
Using different values of the regularisation of the regulation constants for both the minority and majority class data
B is a parameter called a balance factor

Experiments
Real world data collections
• AHR-data
• Reuters data

• Combined training and test data set
• Each training instance labeled with
“control”, “change” or “nc”
• Convert all of the info from different files to a sparse matrix containing 18330 features
AHR-data
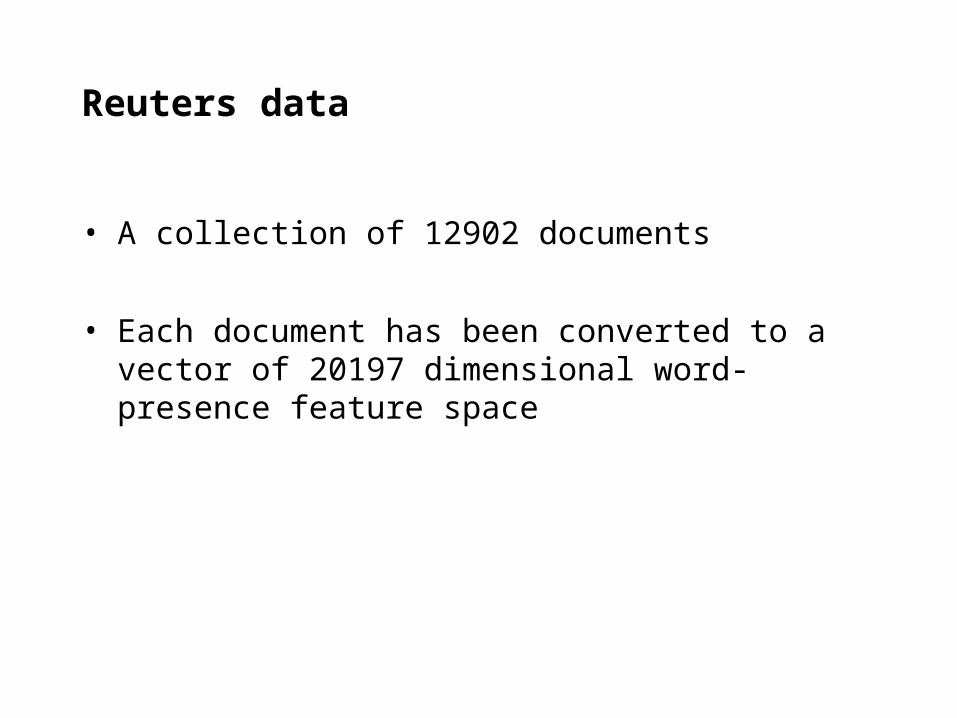
Reuters data
• A collection of 12902 documents
• Each document has been converted to a vector of 20197 dimensional word-presence feature space

AROC is used as performance measure
AROC is the Area under the ROC
Receiver operating characteristic (ROC) curves are used to describe and compare the performance of diagnostic technology and diagnostic algorithms.

Experiments with Real World Data
• Impact of regularisation constant
• Experiment with sample balancing
• Experiments with weight balancing
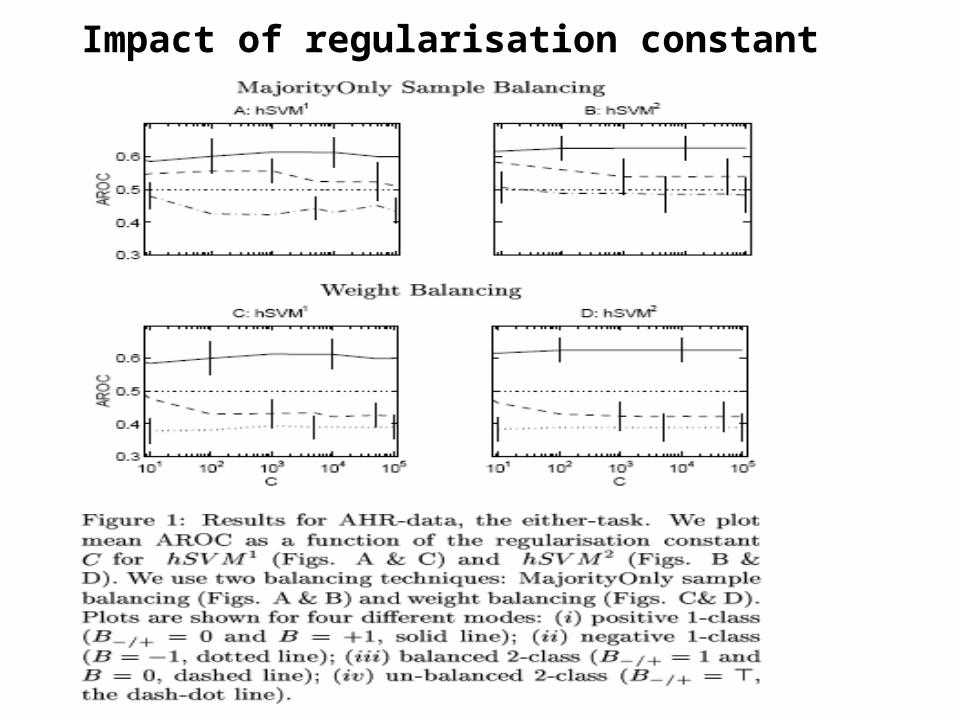
Impact of regularisation constant
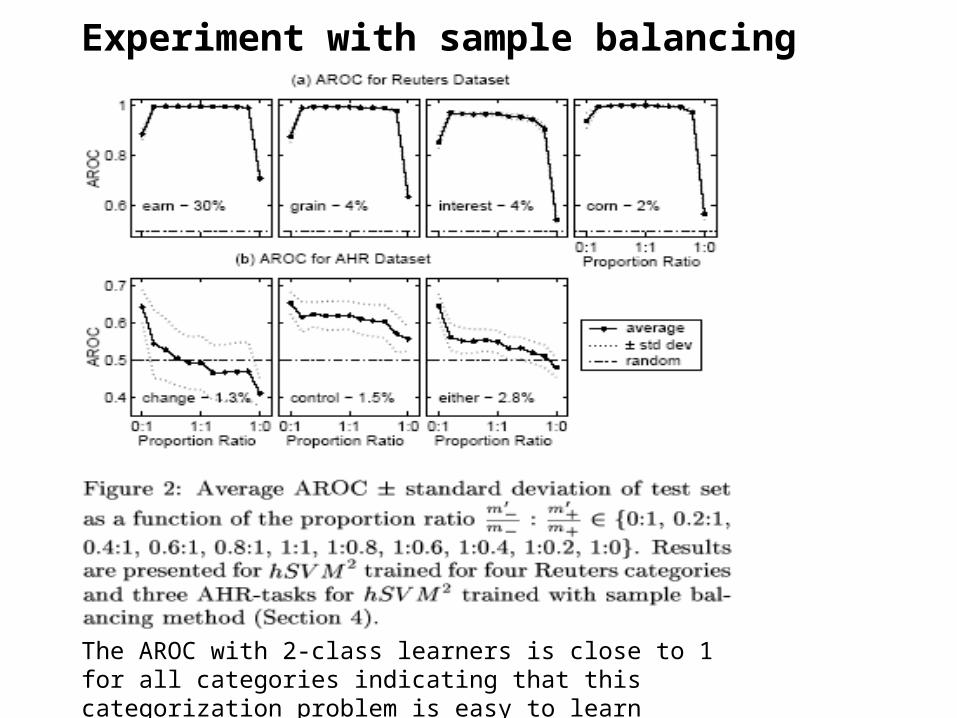
Experiment with sample balancing
The AROC with 2-class learners is close to 1 for all categories indicating that this categorization problem is easy to learn
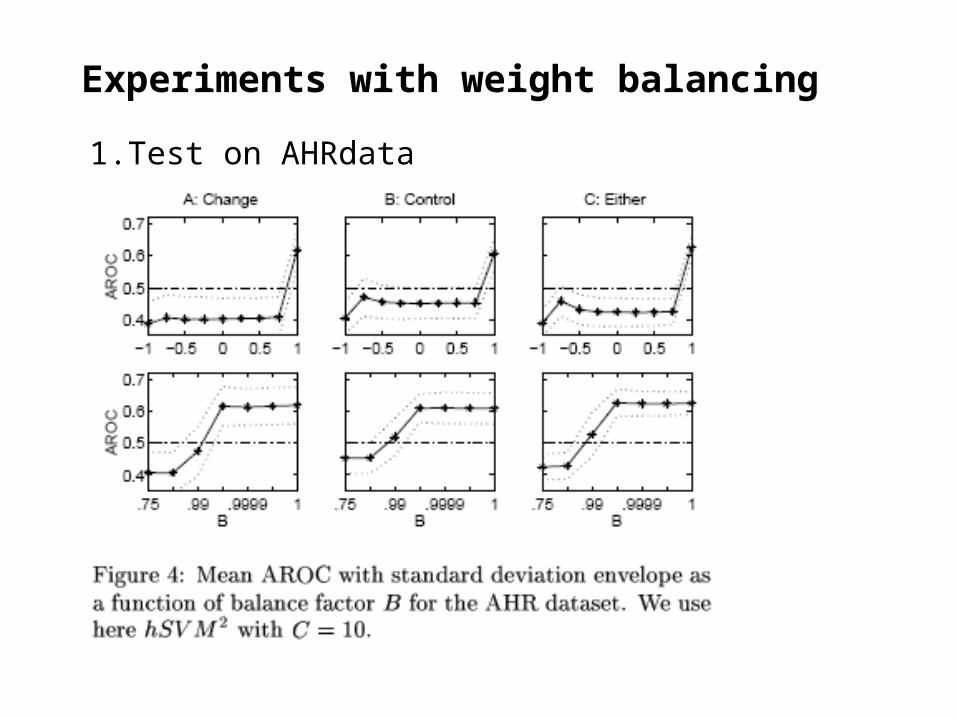
Experiments with weight balancing
1.Test on AHRdata

Experiments with weight balancing
2.Test on ReutersTo observe the performance ouf 1-class and 2-class SVMs when the most features are moved

The characters of test on Reuters
• The accuracy of all classifiers is very high
• SVM models start degenerating, the drop in performance for 2-class SVM is larger.
• 1-class SVM models start outperforming 2-class models
• Similar trends
• AROC is always bigger than 0.5