Embed Size (px)
Citation preview

Extraction and Indexing of Triplet-Based Knowledge Using Natural Language
Processing
From Text to Information

Issues with Current Search Methods
•Entity Placement Problem - When an entity is hashed to a location in memory this provides no understanding of the specificity, generality, or relationship the term has to other entities.
2.Relationship Recognition Problem - Indexing based on term location causes any relationships between entities presented in the text to go unprocessed.

Solution
• Sophisticated Natural Language Processing
• Text is first parsed by our natural language processing engine to allow recognition of entities and relationships
• Entities and relationships are then stored in a manner that injects a schema and maintains relationships
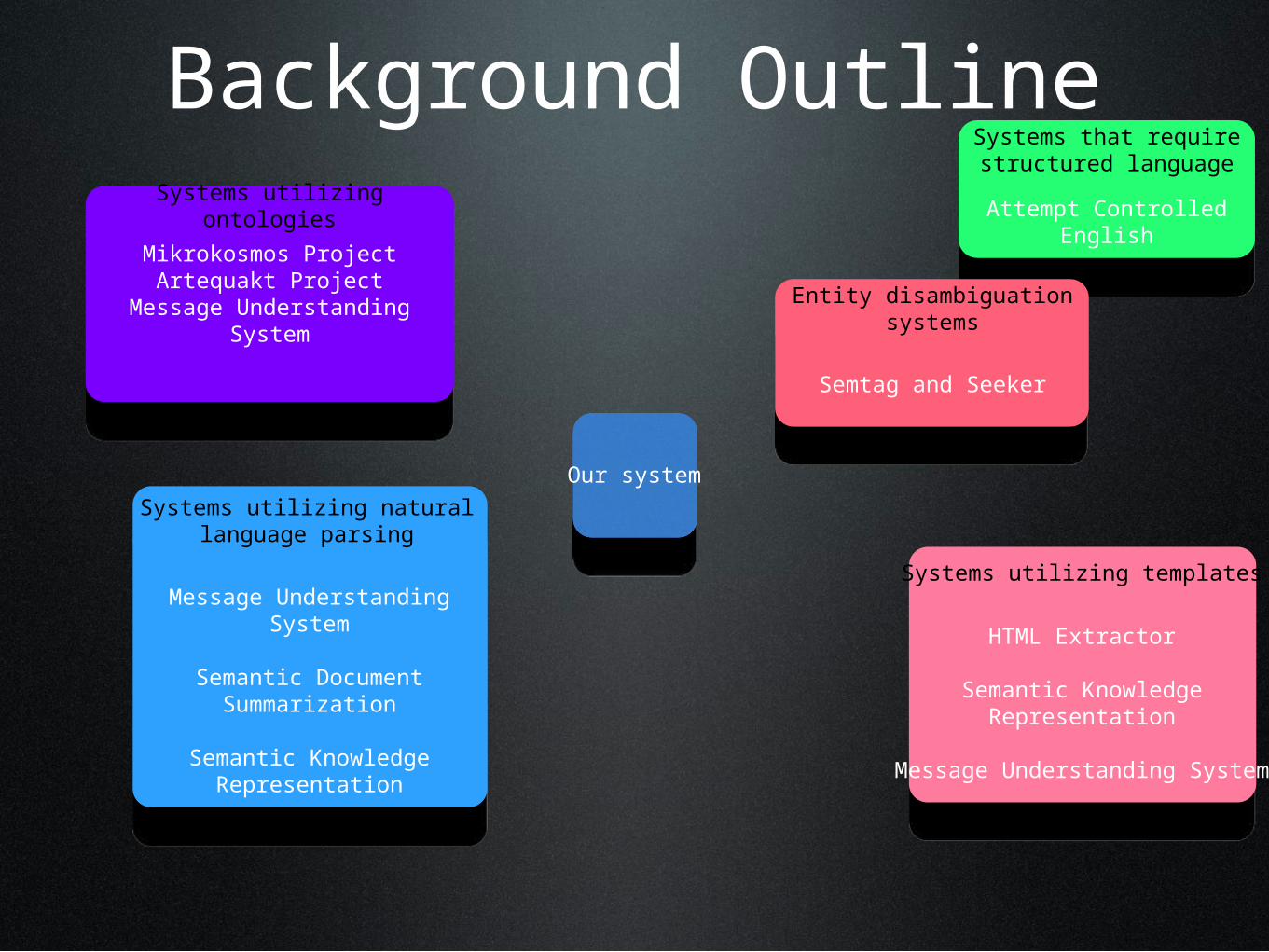
Background OutlineSystems utilizing ontologies
Systems utilizing templates
Systems utilizing natural language parsing
Systems that require structured language
Entity disambiguation systems
Our system
Mikrokosmos ProjectArtequakt Project
Message Understanding System
Semtag and Seeker
Attempt Controlled English
HTML Extractor
Semantic Knowledge Representation
Message Understanding System
Message Understanding System
Semantic Document Summarization
Semantic Knowledge Representation

Background
• The Mikrokosmos Project
• Utilizes a situated ontology for in-depth domain understanding
• Limited learning of new concepts
• Difference from our work:
• Our system requires no previously created ontology
• Works with any domain
K. Mahesh, and S. Nirenburg, A Situated Ontology for Practical NLP. In Proceedings Workshop on Basic Ontological Issues in Knowledge Sharing, 1995.

Background
• Message Understand System
• Extracts information based on language understanding
• Uses WordNet in addition to domain information
• Difference from our work:
• No template needed
• No specific domain understanding neededA. Bagga, J.Y. Chai, and A.W. Bierman. The role of WordNet in the creation of a trainable message
understanding system. In Proceedings of the Thirteenth National Conference on Artificial Intelligence and the Eighth Innovative Applications of Artificial Intelligence Conference. 1997.

Background
• Semtag and Seeker
• Tags entity with a proper disambiguated TAP reference
• Provides indexing system to quickly locate entities
• Difference from our work:
• We extract information regarding entities
• Semtag represents future workS. Dill, N. Eiron, D. Gibson, D. Gruhl, R. Guha, A. Jhingran, T. Kanungo, S. Rajagopalan, A.
Tomkins, J. A. Tomlin, and J. Y. Zien. SemTag and Seeker: Bootstrapping the semantic Web via automated semantic annotation. World Wide Web Conference Budapest, Hungary (2003)

Background
• Artequakt Project
• Uses classification ontology
• Searches web to locate information
• Difference from our work:
• No classification ontology needed
• No need to crawl web-pages to extract even simple bits of information
H. Alani, S. Kim, D. Millard, M. Weal, W. Hall, P. Lewis, and N. Shadbot. Automatic ontology-based knowledge extraction from web documents. IEEE Intelligent Systems, 2003; pp 14-21.

Background• Semantic Document Summarization
• Documents are translated into semantic graph
• Graph is then inspected to determined representative sentences to be used for summarization
• Difference from our work:
• Graph used is an internal representation and does not properly represent information
• Reduces documents to summary sentences rather than to triplet formJure Leskovec, Marko Grobelnik, and Natasa Milic-Frayling. Learning sub-structures of Docment
Semantic Graphs for Document Summarization. In Link Analysis and Group Detection, 2004.

Background
• HTML Extractor
• Uses HTML code and natural language to create a semantic graph of a web-page
• Uses scrubbers to extract information
• Differences from our work:
• No scrubbers needed
• Works over any text
V. Svatek, J. Braza, and V. Sklenak. Towards Triple-Based Information Extraction from Visually-Structured HTML Pages. In Poster Track of the 12th International World Wide Web Conference,
Budapest, 2003.

Background
• Semantic Knowledge Representation
• Natural language parsing is used to locate noun phrases in biomedical abstracts
• Noun phrases are compared against terms in a thesaurus for disambiguation
• Differences from our work:
• We extract information regarding entities
• More sophisticate natural language processing
Suresh Srinivasan, Thomas C. Rindflesch, William T. Hole, Alan R. Aronson, and James G. Mork. Finding UMLS Metathesaurus Concepts in MEDLINE. Proceedings of the American Medical
Infomatics Association, 2002.

Background
• Attempto Controlled English
• Authors are asked to represent the major information in their writings in ACE format
• This allows rapid language processing and data mining
• Differences from our work:
• No secondary language needed
• Text mining and information processing directly from the written text
Tobias Kuhn, Loic Royer, Norbert E. Fuchs, Michael Schroeder. Improving Text Mining with Controlled Natural Language: A Case Study for Protein Interactions. In Third International
Workshop on Data Integration in the Life Sciences, Hinxton, UK, 2006.
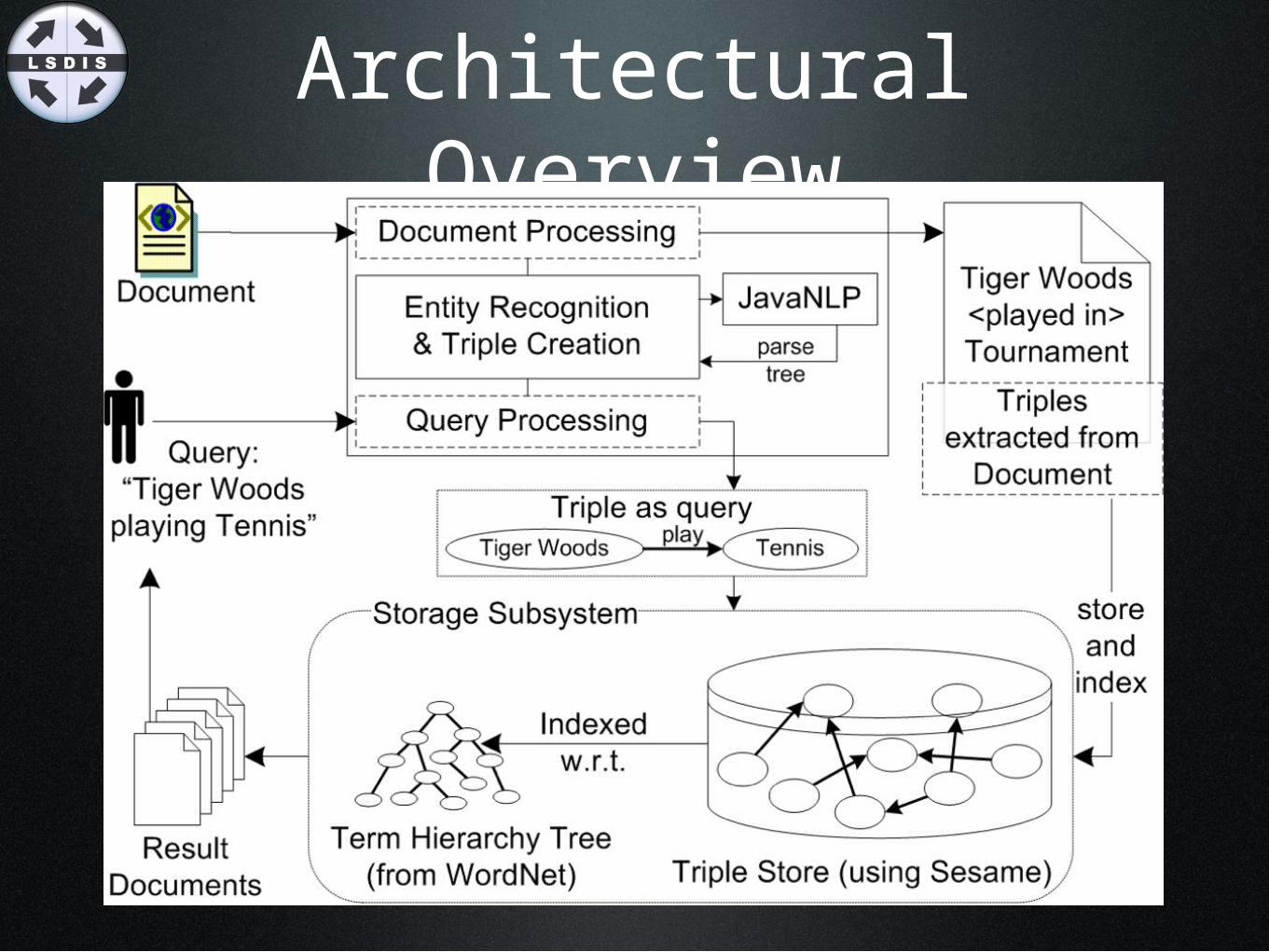
Architectural Overview

Natural Language Processing Engine Overview
• Text is first parsed by JavaNLP to create a sentence tree object
• Sentence tree object is then parsed to create triplets

Natural Language Parsing
• It is possible to use other parsers, however Stanford’s Natural Language Parser was chosen over other parsers for a number of reasons:
• Java implementation
• Log Linear Time
• Older more established code base

The Sentence Tree(ROOT [69.474] (S [69.371] (NP [20.560] (NNP [8.264] Tiger) (NNP [9.812] Woods)) (VP [47.672] (VBZ [11.074] donates) (PP [31.541] (TO [0.003] to) (NP [27.963] (NP [15.561] (DT [1.413] a) (JJ [5.475] large) (NN [5.979] number)) (PP [11.856] (IN [0.669] of) (NP [10.784] (NNS [7.814] charities)))))) (. [0.002] .)))

Parsing the Sentence Tree
•Entity Recognition
•Predicate - Object Recognition
•Predicate - Object Augmentation
•Triplet Creation
•Pronoun Resolution
•Triplet Filtration
7.Secondary Predicate Parsing

Parsing the Sentence Tree
Triplet Creation StepPortions of Parse Tree Inspected
Product of Parse
Entity Recognition(NP [20.560](NNP [8.264] Tiger) (NNP [9.812] Woods))
“Tiger Woods”
Predicate – Object Recognition
(VP [47.672](VBZ [11.074] donates)(PP [31.541] (TO [0.003] to) (NP [27.963] (NP [15.561] (DT [1.413] a) (JJ [5.475] large) (NN [5.979] number))
“Tiger Woods”<donates to>
“a large number”
Predicate – Object Augmentation
(PP [11.856] (IN [0.669] of) (NP [10.784] (NNS [7.814] charities))))))
“Tiger Woods” <donates to a large
number of>“charities”

Triplet Storage
• Triplets are then stored in the Term Hierarchy Tree
• Composed of information in TAP and WordNet
• Ability to add other ontologies
• Lends a schema to the information extracted from text

Thing
Sports Books
Golf FictionBowling Nonfiction
Tiger Woods Dune
ESPN
The Term Hierarchy Tree

What is the use of the Tree?
• We are able to not only locate information directly related to the searched for entity but also know its relation to other entities.
• In the previous example “Tiger Woods” is found under Golf, beyond this we also get the information that Golf is a Sport.

Query Processing
• The query entered by the user is first passed to the Natural Language Parser before other processing occurs
• Simple searches are reduced to their component entities
• Complex searches are reduced to triplets and then both the triplet and the contained entities are searched on

Entity and Relationship Searching
• Not only entities searched for but also specified relations.
Tiger Woods works with Charities

How is the Query Executed?
• The entity or relationship provides a “link” into the Term Hierarchy Tree.
Root
Sports Books
KidsGolf
Entity Term Hierarchy Tree
Tiger Woods
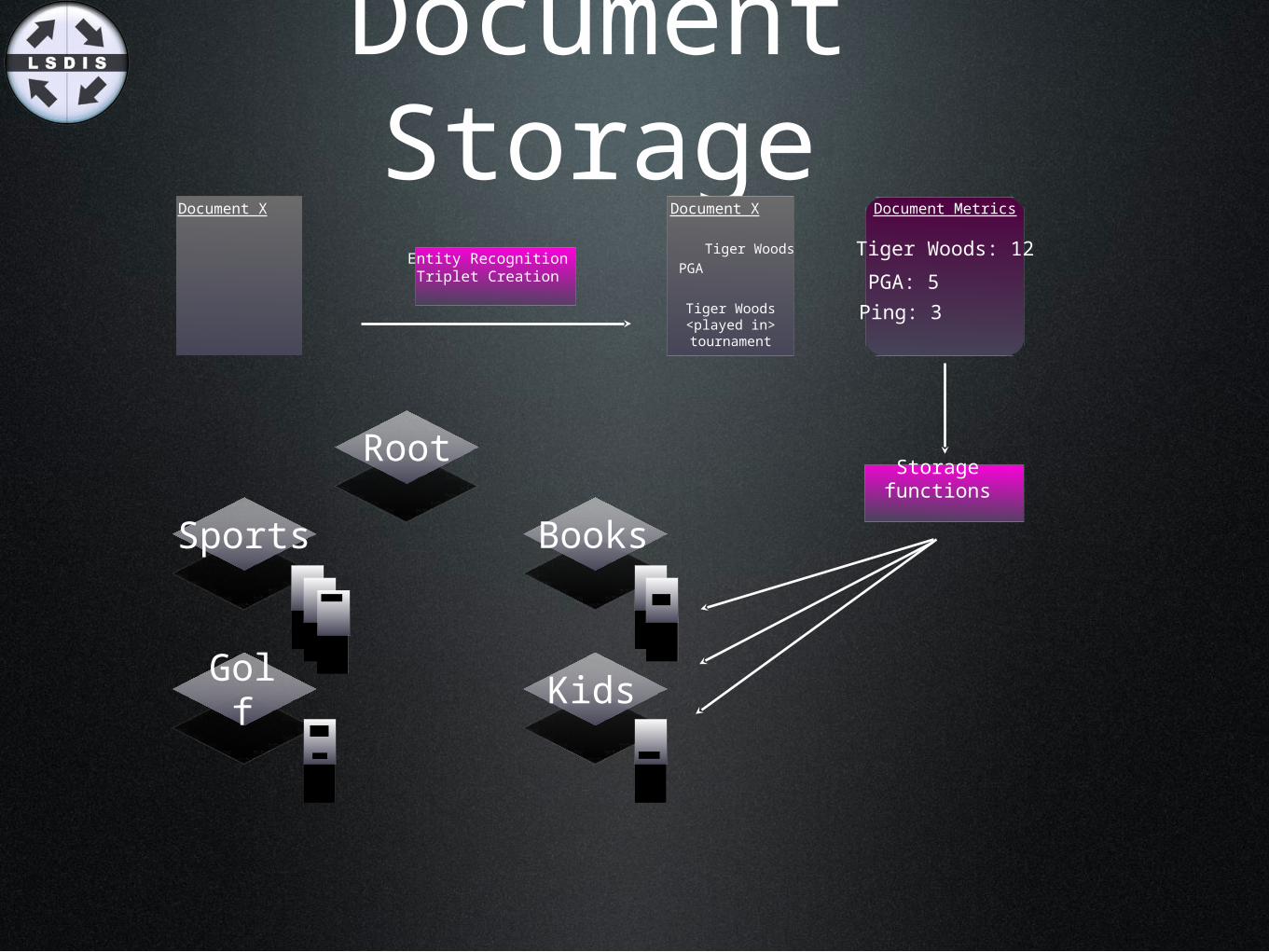
Document Storage
Document X
Entity Recognition Triplet Creation
Document X
Tiger WoodsPGA
Tiger Woods<played in>tournament
Document Metrics
Tiger Woods: 12
PGA: 5
Ping: 3
Root
Sports Books
KidsGolf
Storage functions
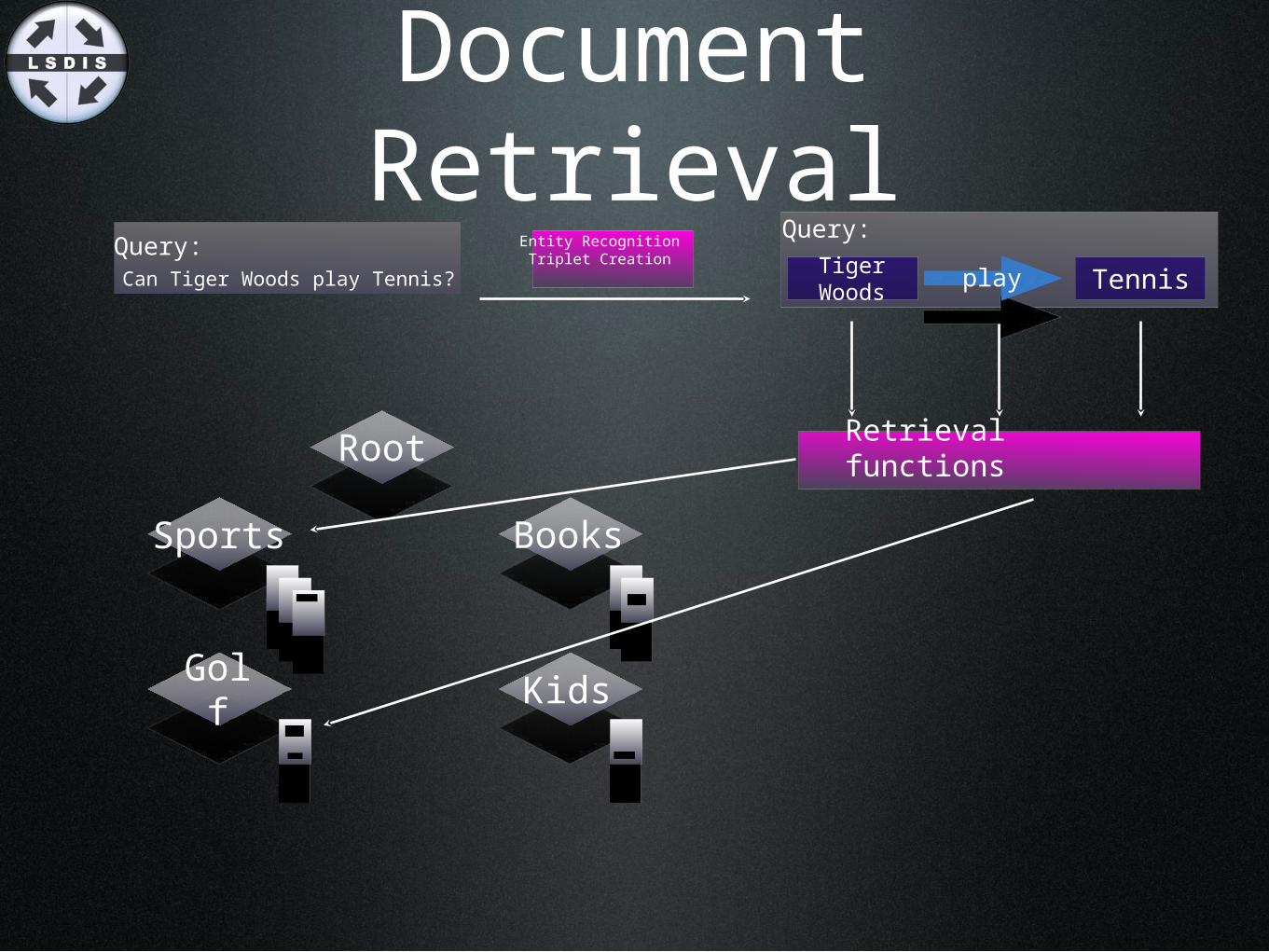
Document Retrieval
Can Tiger Woods play Tennis?
Query: Entity Recognition Triplet Creation
Query:Tiger
Woods
Retrieval functionsRoot
Sports Books
KidsGolf
play Tennis

Related Concepts
• Term Frequency / Inverse Document Frequency (TF/IDF)
• TF/IDF’s concepts are used in how the system stores documents
• This work adds the relations between entities

Triplet Production Testing
• Testing occurred in two phases:
• Expert Testing
• Inexpert Testing
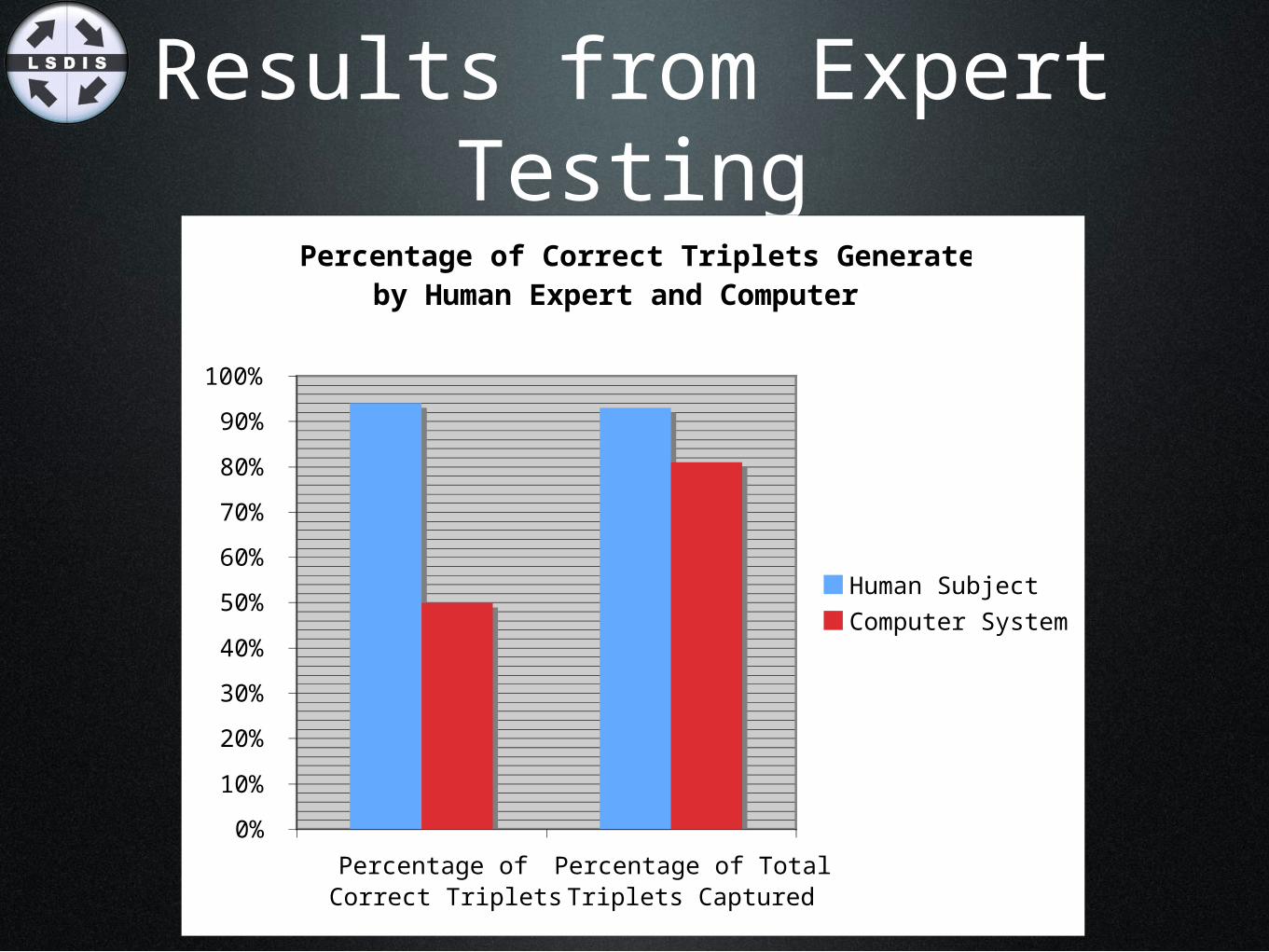
Results from Expert Testing
Percentage of Correct Triplets Generated by Human Expert and Computer
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
Percentage ofCorrect Triplets
Percentage of TotalTriplets Captured
Human Subject
Computer System
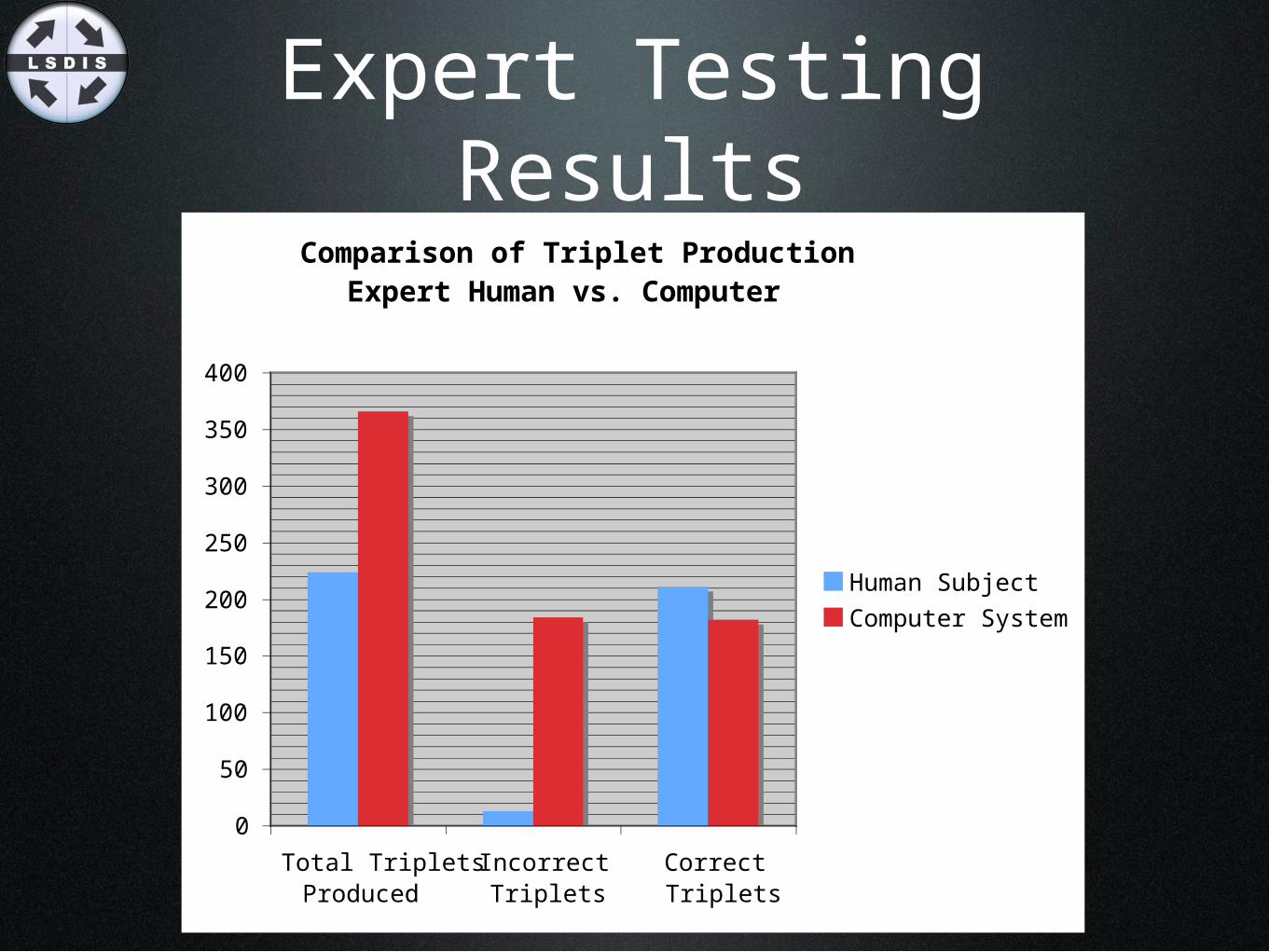
Expert Testing ResultsComparison of Triplet Production:
Expert Human vs. Computer
0
50
100
150
200
250
300
350
400
Total TripletsProduced
IncorrectTriplets
CorrectTriplets
Human Subject
Computer System

Inexpert Testing Results
• All triplets generated by the nine students were inspected and a set of unique triplets was determined
• This was compared to the triplets generated by the system
• 53% overlap between the two
• Average of 27% of human created triplets were incorrect

Addressing Inexpert Testing
• The seeming decline in accuracy stems from two major causes:
• The computer system captured more triplets
• The human subject made inferences regarding the information

Contributions
• Automated method of creating semantic information
• Capture of the relationships among entities
• Understanding of an entity’s place in the “grand scheme of things”






![SoftTriple Loss: Deep Metric Learning Without Triplet Sampling · works [15,21]. Without the explicit feature extraction, deep metric learning boosts the performance by a large mar-gin](https://img.pdfslide.us/doc/110x75/5f067c3f7e708231d4183a21/softtriple-loss-deep-metric-learning-without-triplet-sampling-works-1521-without.jpg)






















