Embed Size (px)
Citation preview

Extracting Structured Data from Web Page
Arvind Arasu, Hector Garcia-MolinaACM SIGMOD 2003

Outline
• Introduction
• Model, Problem Formulation
• Equivalence Classes– Observations and Properties
• Build Template and Extract Values
• Experiments
• Conclusion

Introduction• Keyword: Schema (Data having a structure)• Problem Definition: automatically extracting
schema encoded in a given collection of pages, without any human input
• Cue: characteristic of pages belonging to the same site and encoding data of the same schema, is that data encoding in a consistent manner
= > a common template by plugging-in value

Figuration

Goal and Challenge• Previous IE Techniques rely on heuristic by
human. ex. wrapper• Goal: to deduce the template without human
– Time consuming and error-prone– Optional attributes are ignored
• Challenge: – No obvious way of differentiating what text is template or data– The schema of data in pages isn’t flat but more complex and semi-structured of attributes

Model, Problem Formulation
• Structured Data
• Model of Page Creation
• Optionals and Disjunctions
• Problem Statement
• Miscellaneous Terminology, Definition

Structured Data• Token: A token is some basic unit of text• Structured Data: any set of data values conforming
to a common schema or type• Define “Type”:
– 1. Basic Type (β): string of tokens
eg. < html > , text– 2. Ordered List Type: tuple constructor of order “n”
eg. < T1, T2, …, Tn > , T1, T2, …, Tn : type
– 3. Define Type: set constructor – eg. {T} , T: type

Define term value and example• Define “instance”:
– 1. An instance of basic type, β, is any string of tokens
– 2. An instance of type < T1, T2, …, Tn> is a
tuple of the form < i1, i2, …, in > , where attributes
i1, i2, …, in are instances of typesT1, T2, …, Tn
– 3. An instance of type {T}, is any set of elements
{e1, e2, …, em}, such ei is an instance of type T
• Instance → Value; String → a string of tokens• Example:
– Schema S1=
– Value =
3
21
, , ,B B B B
1 1 1 2 2, , , , ,x t f l f l c 2 0 0, , ,x t f l c
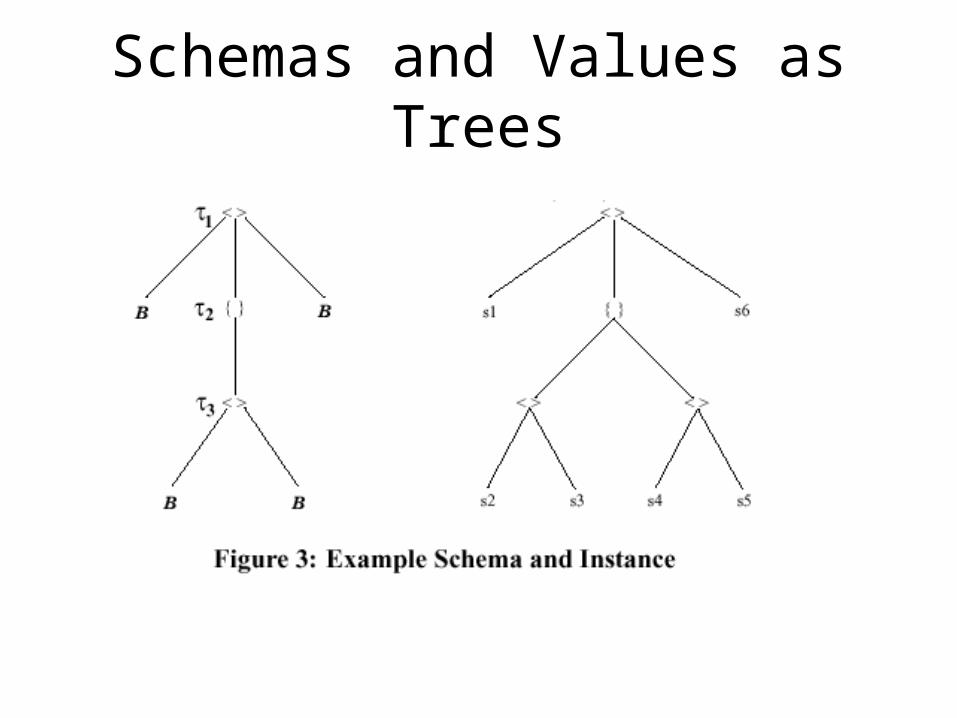
Schemas and Values as Trees

Model of Page Creation
• Definition: A template T for a schema S (as shown TS), is defined as a function that maps each type constructor τ of S into an ordered set of strings T(τ ), such that,– Ifτis the tuple constructor of order n, T(τ) is an order set of n+1
string <Cτ1, Cτ2 , Cτ3,…Cτ(n+1) >
– Ifτis the set constructor, T(τ) is a string Sτ

Example
• A template T for schema S1 is given by the mapping:– T(1)=<A,B,C,D>– T(2)=H– T(3)=<E,F,G>
1 ( 1),..., nC C

Encoding of a value x S
• 1. if x β, then λ (T,x)→x• 2. if x <x1, x2, …, xn > τt
λ (T,x) → C1 λ (T, x1) C2 …λ (T, xn) Cn+1
• 3. if x {e1, e2, …, em}τs , τs S
λ (T,x) → λ (T, e1) S λ (T, e2) ….S λ (T, em)

Example of Schema S1
3
21
1 , , ,S B B B B
1 1( ) , , ,T A B C D
1 3( ) , ,T E F G 1 2( )T H
1 1 1 2 2, , , , ,x t f l f l c
1 1 1 2 2
1 1 2 2
2 1 1 2 2
1 1 2 2
3 1 1
1 1
1 1 2 2
( ) ( , , , , , ) , , ,
, , ,
( ) ( , , , )
, ,
( ) ( , ) , ,
T T t f l f l c A B C D
String AtB f l f l CcD
T T f l f l H
Substring f l H f l
T T f l E F G
Substring Ef Fl G
String AtBEf Fl GHEf Fl GCcD
Re
H
gularExpression
A B E F G C D

Optionals and Disjunctions
• Optional: – If T is a type, optional type (T)?≡{T}τ
|τ| = 0 or 1
• Disjunction:– If T1 and T2 is type, disjunction type
(T1| T2) ≡ < {T1}τ1, {T2}τ2 > τ
|τ1|+|τ2| = 1

Problem Statement
• Extract Problem: n pages, each page pi = λ(T, xi) (1 ≤ i ≤ n), is created from some unknown deduction template T and values {x1,. . .,xn} from the set of pages alone

Example of correct solution of EXTRACT
1 2 3 4, , ,e e e e eP p p p p

Example of correct solution of EXTRACT (cont.)
( , )eSei iP T x
1 2 3, , ,e e e e
S B B B B
T(e1)=<li><b>Reviewer Name</b>, <b>Rating</b>, <b>Text</b>, </li>T(e2)=T(e3)=<html><body><b>Book Name</b>, <b>Reviewers</b><ol>, </ol></body></html>

Miscellaneous Terminology, Definition
• A token is a word or a HTML tag• An occurrence of a token in page (resp. value,
template) is called a page-token (resp. value-token, template-token)
• Each page token is created from either a template-token or a value-token
• 2 page-token in Pe have the same role iff they have been generated by the same template-token

Overview Approach - EXALG
(ECGM)
Stage 1
Stage 2

Equivalence Classes
Pages P = { p1, … , pn } , pi = λ(TS, xi)TS = {τ1, … , τk }: type constructor
• Definition (Occurrence Vector):– The occurrence-vector of a token t, is defined as the
vector <f1, f2,…, fn>, where fi is the number of occurrences of t in pi
• Definition (Equivalence Classes):All tokens of equivalence class have the same occurrence
vector.– Ex. ε1: { <html>, <body>, Book, Reviews, <ol>, </ol>, </body>, </html> } <1,1,1,1>– Ex. ε2: {Data, Mining, Jeff, 2, Jane, 6} <0,1,0,0>– Ex. ε3: { <li>, Reviewer, Rating, Text, </li> } <1,2,1,0>

Equivalence Classes: Observations
• Observation1 : – Tokens associated with the same type constructor τj
in T that have unique-roles occur in the same equivalence class. (used to decide EQ valid or not)
• Observation2: – For real pages, an equivalence class of large size
and support is usually valid
• Definition– Support of token: #(page contain)– Size of EQ class: #(token of EQ)

Properties of EQ class
• Definition (Ordered Equivalence Classes):– An EQ class is ordered, if its tokens can be ordered <t1,t2,…, tm>,
such that, for every page pi and every pair of tj, tk (1jkm)• If tj occurs at least l times in pi, the lth occurrence of tj in pi occurs before
the lth occurrence of tk in pi and• If tj occurs at least (l+1) times in pi, the (l+1)th occurrence of tj in pi is
after the lth occurrence of tk in pi.
• Definition (Nesting of EQ classes): – A pair of EQ classes εi and εj is nested if,
• The span of any occurrence of εi does not overlap with the span of any occurrence of εj , or
• The span of all occurrences of εi is within Pos(p) of some occurrence of εj for some fixed p; or vice-versa.

EQ Classes: Observations (Cont.)
• Observation3 : – A valid equivalence class is ordered and a pair of
two valid equivalence classes is nested.
• Handling Invalid Equivalence Classes– Detect the existence of invalid LFEQs using
violation of ordered and nesting– Yes, discard some of LFEQs and break other
into smaller LFEQs

Differentiating roles of tokens
• By Path – different roles of tokens are in different path of HTML parse tree
• By Position – different roles of tokens locates at different Position (non-empty)
• Observation4: – In practice, two page-tokens with different occurrence
paths have different roles.
• Observation5: – For a valid EQ class . The role of an occurrence of t,
which is within Pos(l) of some occurrence of is different from the role of an occurrence of t which is within Pos(m) (ml) of some occurrence of .

DIFFFORM (step1) and DIFFEQ (step4)
• These module are used to add more tokens to LFEQ by “differentiating” roles– Ex. Name has multiple “role”, one occurs in Book Name
and the other occurs in Reviewer Name
• Differentiate the multiple roles :– The multiple tokens occur in different path from root in
the HTML parse tree (DIFFFORM)– The multiple tokens occur in different “Position” with
respect to LFEQ εe1(DIFFEQ)
• dtoken (differentiated tokens): – ex. Name5 and Name14 are regarded as different tokens
NameA and NameB

Stage 1: ECGM
Find dtoken from pathin html parse tree
Find LFEQ
Detect and removeinvalid LFEQ (using
violation of order and nesting)
Find dtoken from position in valid LFEQ

Running Example
• ECGM:– OUTPUT: set of LFEQs of dtokens and page
represented as string of dtokens– Two parameters used to consider LFEQs
• SIZETHRES=3, SUPTHRES=3

Iteration 1: DiffFORM, FindEQ
• <1,1,1,1>={<html>,<body>, Book, Name, Reviews, <ol>, </ol>, </body>, </html>}
• <2,2,2,2>={<b>,</b>} : <html><body>• <3,6,3,0>={<b>,</b>} : <html><body><ol> • <1,2,1,0>={<li>, Reviewer, Name, Rating, Text, </li>}• <1,0,0,0>={Database}• <0,1,0,0>={Data, Mining, Jeff, Jane}• <0,0,1,0>={Query, Opt.}• <0,0,0,1>={Transactions}• <1,0,1,0>={John}
Use path
Not LFEQ

Iteration 1: DiffEQ
• <1,1,1,1>={<html>,<body>, Book, Name, Reviews, <ol>, </ol>, </body>, </html>}
• <b>: at pos 2 or pos 4• </b>: at pos 4 or pos 5• εe1 : <1,1,1,1>= { <html><body><b>Book Name</b>,
<b>Reviews</b><ol>, </ol></body></html> } 8 →13
• <1,2,1,0>={<li>, Reviewer, Name, Rating, Text, </li>}• <b>: at pos 1 or pos 3 or pos 4• </b>: at pos 3 or pos 4 or pos 5• εe3: <1,2,0,1>={ <li><b>Reviewer Name</b>, <b>Rating
</b>, <b>Text</b>, </li>} 6 →12
Use position

Stage 2: Construct Schema from ECGM
• Input to this module is {ε1 ,ε2 , … ,εm }
• The ANALYSIS consist of 2 modules – CONSTTEMP and EXVAL
• CONSTTEMP ,εi = { d1, d2, … , dl }
– Start the basic ε1= { <html>, <body>, … ,</body>, </html> }
– recursively constructs a template Tεi , corresponding toεi , and template Tεi, p, corresponding to each non-empty position p ofεi
– Checks if the set of strings, PosString(εi ,p), corresponding has some recognizable pattern

• Construct Schema S’ fromεe1
εe1: { <html>, <body>, <b>, Book, Name, </b>, <b>,
Reviews, </b>, <ol>, </ol>, </body>, </html> }
→ T(τe1) = <Te1,1, Te1,2><C11, C12,C13>

Cont.
• PosString(εe1+ ,6) is a string of dtokens for every
occurrence of εe1+, which matches Pattern 5 of
table; →T(Te1,1)= β
• PosString(εe1+ ,10) is always a string of 0 or more
occurrences of εe3+, which matches Pattern 1
→ T(Te1,2) ={τe3} → T(τe3) = < Te3,1, Te3,2, Te3,3 >< C31, C32,C33,C34 >
<li><b>Reviewer Name</b> <b>Rating </b> <b>Text</b> </li>

(Cont.)
• The three non-empty positions are all Basic Type β→T(Te3,1)= β
→T(Te3,2)= β
→T(Te3,3)= β
S = < β,{ <β,β,β,>τe3 } >τe1

Example of correct solution of EXTRACT

EvaluationData sets:
http://www-db.stanford.edu/~arvind/extract/
Leaf attribute Am in schema Sm
• Correct: the set of Am in the page is equal to the set of extracted value Ae in the page
• Partially Correct: the set of Am in the page is not equal to the set of extracted value Ae in the page, but as part of value of Ae
• Incorrect: not correct and Partially correct

Assumption• The 4 assumptions:
(A1) A large number of tokens occurring in
template have unique roles
(A2) The EQ class derived from a type constructor
is recognized as an LFEQ
(A3) Irregularity in encoded data that leads to
invalid EQ class
(A4) The separators are around data values. In
this model, strings associated with type
construction are non-empty position

Result• 18 or 40% of input collections
our System correctly extracted all the attribute
• Around 80% of the attributes were extracted correctly
• Normalized average• Input size <=10• Parameter = 3

Conclusion• EXALG: use 2 novel concepts
– equivalence classes and– differentiate roles, to discovery the template
• Impact of the failed assumption is limit to a few attributes
• Future work: – Develop techniques for crawling, indexing, and
providing querying support for the structured pages in the web
– Develop techniques for automatically annotating the extracted data, possibly using the words that appear in the template














![Searching the Web [ Arasu 01 ]](https://img.pdfslide.us/doc/110x75/56813dc0550346895da78b99/searching-the-web-arasu-01-.jpg)














