Embed Size (px)
Citation preview

Experiments in Automatic Library of Congress Classif ication
Ray R. Larson School of Library and Information Studies, University of California at Berkeley, Berkeley, CA 94720
This article presents the results of research into the au- tomatic selection of Library of Congress Classification numbers based on the titles and subject headings in MARC records. The method used in this study was based on partial match retrieval techniques using vari- ous elements of new records (i.e., those to be classi- fied) as “queries,” and a test database of classification clusters generated from previously classified MARC records. Sixty individual methods for automatic classifi- cation were tested on a set of 283 new records, using all combinations of four different partial match methods, five query types, and three representations of search terms. The results indicate that if the best method for a particular case can be determined, then up to 88% of the new records may be correctly classified. The single method with the best accuracy was able to select the correct classification for about 46% of the new records.
Introduction
Classification is an important form of topical access to library collections that has, until recently, often been overlooked in studying the process of topical searching by library users, and in the development of online cata- log systems. Library classification schemes have often been viewed simply as a means of arranging books on shelves. However, these schemes also provide remark- ably extensive conceptual frameworks for recorded knowledge.
Classification offers an alternative approach to the topical contents of a work that differs from the simple alphabetic organization used in most controlled vocabu- laries, such as thesauri or lists of subject headings. The major library classification schemes (i.e., those in com- mon use in the U.S. and abroad, including the Dewey Decimal Classification (DDC), the Library of Congress Classification (LCC), the Universal Decimal Classifica- tion (UDC), Bliss Bibliographic Classification, and
Received October 1, 1990; revised May 27, 1991; accepted June 25, 1991.
01992 by John Wiley & Sons, Inc.
Ranganathan’s Colon Classification) are broadly orga- nized by discipline, so that given work is primarily considered in its relationship to a discipline or area of knowledge. Within a particular discipline, a classifi- cation scheme provides a systematic arrangement of topics, This arrangement is usually hierarchical or chronological although other arrangements may be used depending on the classification scheme and par- ticular discipline.
Although different classification schemes diverge considerably in the ways that the main classes and subtopics are organized (e.g., O’Neill, Dillon & Vizine- Goetz (1987)), all of them have systematic structures for relating works to each other based on similarities of dis- cipline, topic and treatment. In contrast, the verbal sub- ject analysis associated with controlled vocabularies usually considers the specific topic first and may, at best, consider the discipline as a subdivision of the topic or may ignore it altogether. In the alphabetical ordering of controlled vocabulary terms, the broader context of a topic and its relationship to similar topics is often lost. As Chan observed: “giving a work a class number not only groups it with similar works but also gives it a place in a systematic hierarchy and array of related subjects” (Chan, 1989a, p. 530).
Various specialized classification schemes have also been developed to provide a structure for organizing terms in thesauri. These classifications provide a sys- tematic structure for the terms in the thesaurus, usually representing a specific field of knowledge, that places them in a hierarchic relationship with other terms or concepts in that field. These relationships may be ex- ploited in online retrieval for query expansion and browsing (for example, the “explode” command in MEDLINE which uses the MESH tree structure classi- fication to retrieve all subordinate classes to the one being “exploded.“) Library classification schemes, by necessity, attempt to be universal in coverage because they must deal with all aspects of recorded knowledge as represented in the holdings of a general library. They may, therefore, provide less detailed, or broader classes
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE. 43(2):130-148, 1992 CCC 0002-8231/92/020130-19$04.00

than those used in some thesauri for a specific field of pared the results of retrieval experiments between the knowledge. On the other hand, many of the classifica- library-assigned DDC classes and the automatically tion schemes used in conjunction with thesauri offer generated clusters for a small set of artificially con- only a small set of broad categories, and may provide structed queries, and suggests that the automatically less detailed classes than those in a traditional library generated clusters were more effective at retrieving the classification scheme. relevant books.
Over the past decade researchers have been taking a new look at library classification, particularly as an ad- ditional form of subject or topical access to supplement subject headings for online catalogs. Markey (1985, 1987), Williamson (1985, 1986, 1989a,b), Cochrane and Markey (1985), Mandel (1986), Svenonius (1983), Chan (1986, 1989a), Huestis (1988), and Broadbent (1989) have all examined the problems and potential of classifica- tion to enhance subject retrieval in online catalogs and other bibliographic retrieval systems. Cochrane and Markey (1985) provide a historical review of the use of library classification schemes in online retrieval sys- tems. The most common suggestion is that a machine- readable form of the classification schedules be incorporated into the online catalog to provide addi- tional keyword access points and to provide a browsing structure for users.
Garland (1983) used the single-link clustering method (see van Rijsbergen, 1979) to generate clusters based on the titles and first assigned Library of Con- gress Subject Heading (LCSH) of a sample of books drawn from one area of the LC classification. She found a relationship between the LC assigned classes and the automatically generated clusters for the same docu- ments. This relationship was quite strong for clusters generated at a fairly high threshold of similarity (.55).
A study by Hancock (1987) has suggested that library classification may actually be the most frequently used form of subject access to a collection. She examined the use of shelf browsing in conjunction with catalog and index use in a library and found that virtually all sub- ject searches, and most “known item” searches involved browsing of the shelves within a particular classifica- tion to select additional relevant documents.
The experiments presented in this article return, in some sense, to the early work in automatic classification by attemping to select the correct predefined class based on the characteristics of the document to be clas- sified and the characteristics of documents previously assigned to that class. They differ, however, in that the predefined classes used are drawn from the Library of Congress Classification, and the database of previously classified documents used to define the characteristics of the classes consists of over 30,000 MARC records. These experiments differ from most automatic classifi- cation studies in that the only content representation used in the classification process is that available in or- dinary MARC records, specifically, the titles and sub- ject headings of a given book.
Another stream of research has concentrated on the development of algorithms for automatically classifying documents. Early work by Maron (1961) and Borko and Bernick (1962, 1963) concentrated on automatically as- signing documents to broad predefined classes based on terms used in the abstract of the document. Later ex- amples of automatic classification using predefined classes may be found in Hoyle (1973) and Kar and White (1978). However, much of the work on automatic classification carried out in the 1970s and 1980s was
concerned with clustering or grouping documents based on similarities between their content, without reference to predefined classes. Van Rijsbergen (1979) provides a good discussion of these automatic clustering methods, their theoretical basis, and their use in information re- trieval. One advantage of these automatic classification methods for retrieval is that the class description sub- sumes the individual document descriptions, and pro- vides a larger “target” for searching and matching operations.
The following sections describe the construction of the classification clusters representing the LC classes, the matching methods, document representatives, and term representatives used in the experiments. The ex- periments are then described and results are examined. Finally the implications of these experiments for re- trieval systems and other applications are described, and some further research is suggested.
Classification Clustering and Matching Techniques
More recently, some comparisons between tradi- tional library classifications and the classes generated by clustering algorithms have been made. Enser (1985a,b) examined the use of automatic clustering methods using the titles, tables of contents, index, and DDC class number for a small set of books. He com-
The classification scheme used in this research is the Library of Congress Classification (LCC). It is widely used in large research libraries, and LCC class numbers are provided on all LC MARC records. LCC uses an enumerative, and largely nonhierarchical, structure for its classes. The detailed enumeration of topics found in LCC is responsible for the large size of its schedules (47 volumes for the 21 main classes). The enumerative na- ture of LCC enhances its ability to provide very precise and specific descriptions in many topical areas. Much of this precision is achieved by alphabetic arrangements of specific topics under broader “umbrella” topics. Only some of the potential specific topics are given in the schedules, and often the classifier must provide an ap- propriate topical description, which is then placed al-
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE-March 1992 131

phabetically in the shelflist. Other areas in the LCC schedules may be organized chronologically, geographi- cally, or on occasion hierarchically. Different parts of the LCC schedules have their own internal arrange- ments, and it has been frequently pointed out (Chan, 1986; Williamson, 1986; Broadbent, 1989) that LCC can be considered as a collection of specialized classifica- tion schemes, and there are no consistent principles of organization for the LCC scheme as a whole. Many of the individual schedules have their own indexes and organization, but LCC lacks a comprehensive general index to the entire scheme, although the Library of Congress Subject Headings list provides some guidance to LCC classes for particular topics. However, not all subject headings in LCSH are provided with LCC num- bers, and some have multiple numbers (for different disciplinary treatments) or ranges of numbers, relying on the classifier’s judgement to determine the correct class among those suggested. Vizine-Goetz and Markey (1989), in examining the machine-readable LCSH, found that only 43% of the topical subject entries in- cluded such class numbers or ranges of numbers.
Chan (1986) has suggested that the specificity and enumerative nature of LCC makes it suitable for high precision searches, while the hierarchic structure of schemes like the Dewey Decimal Classification is bet- ter for broader, high recall searches. However, to effec- tively search for a class number in most online catalogs, the user must know the specific number and, more im- portantly, which topic it represents. To provide a usable form of classification searching, some form of index to the individual topics of the classes is required. One way to provide such an index is through the subject head- ings and title terms associated with a particular LC class number. An index of this type was published by Williams, Manheimer, and Daily (1972) based on the class numbers appearing in the LCSH list. That work, however, takes into account only those classes with as- sociated LCSH in the printed list and lacks subject headings that appear only in bibliographic records. The following section describes an automatic method of generating a similar index based on term assignments in bibliographic records.
Classification Clustering
The LC classes of the experimental database used in this research are represented by a weighted vector of index terms generated by the process of “classification clustering.” This process and the characteristics of the classification clusters generated by it have been dis- cussed elsewhere (Larson, 1989, 1991), and will only be summarized here.
In any document retrieval system, such as the CHESHIRE system used in this research, the database or collection can be characterized as a set, D, of N docu- ments indexed by a set, T of M unique index terms or
attributes. An individual document in the collection, D,, may be represented as a vector of index term weights
The index term weights are determined by the particu- lar indexing technique used in creating the database, and the retrieval method to be used in searching the collection. The weights may represent binary indexing, (where xii = 1 if term I; occurs in document Di, and xij = 0 otherwise), simple term frequency weights (where each x;j represents the number of times index term T occurs in document Di), or other weighting functions relating the documents and terms.
The set of index terms, T, can be any element, or attribute, of the documents in the collection that is used for access. Examples of attributes commonly used are keywords, word stems, and phrases, that appear in the document. Access to the individual index terms can be provided by an inverted file, where each index term, I; has an associated vector of weights, Zj such that
Ij = (Xlj, XZj, Xij, *. ’ 3 XNj) 9
where the weights represent the weight of the term in each of the N documents of the collection. For retrieval purposes, the queries submitted to the system by users may also be represented as a vector of index term weights
Qk = (ykl, yk2, ykj, *” 7 YkM) 9
where yk, is the weight assigned by the user or system to term Tj in the kth query.
In a classified document collection, such as a library database of MARC records or a database with classes generated by an automatic clustering method, the indi- vidual documents, Di, can each be considered as mem- bers of a set of classifications, C. In the database examined in this research the individual classes, Cl, are formed according to the rule:
D, E Cl iff the class number of Di
= the class number of C,.
That is, a document is considered a member of a given classification only if it has the same manually assigned LC class number as all other documents in the class.
As with documents, an individual classification, C,, may be represented by a vector of index term weights
c/ = (xi,, x;z, xi, ’ * - ) xh),
such that each element, xi, of the vector represents the union, sum, or other function combining the corre- sponding term weights, xij, of the individual documents in the classification. The C, classification vectors are therefore representatives of the combined attributes of all of the individual documents in a particular classifi- cation. These vectors will be referred to as clamfica- tion clusters.
132 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE--March 1992

Classification clustering (Larson, 1991) is simple method for creating document clusters based on the manually assigned class numbers for those documents. The cluster generation is accomplished by the follow- ing steps:
(1)
(2)
(3)
(4)
(3
Document representatives consisting of the Li- brary of Congress Classification (LCC) number, the title, and all subject headings for each work are extracted from the full MARC record for the work. The LCC number is normalized by isolating the topical portion of the number (i.e., the $a subfield) and eliminating shelving information such as the Cutter number for the author, dates, copy infor- mation, and special shelving locations. The main (alphabetic) class, subclass (numerical), fractional subdivisions, and topical Cutter numbers are iso- lated and put into a fixed length formatted field in the document representative. The document representatives are sorted on the normalized class number. The document representatives are scanned and those with the same normalized class number are combined into a new cluster text record which contains the following elements:
(4
69
(0
A unique cluster ID number. The normalized class number. All proper titles and subtitles (MARC field 245, subfields $a and $b) from the document representatives. All subject headings (all MARC 6xx fields) from the document representatives. Various statistical information on the cluster, including the number of document repre- sentatives merged to generate the cluster, the number of subject headings, the num- ber of unique subject headings in the cluster, and the frequency of each subject head- ing that occurs in more than one document representative. The document ID of each bibliographic record that was merged to form the cluster.
The cluster text records are converted to vector form by:
(4
@I
(cl
(4
63
Parsing the titles and subject heading into sets of title and subject keywords (or subject phrases, as discussed below). Eliminating common words (initial articles, conjunctions, etc.) using a stop list. Reducing the remaining keywords to word stems, using one of the stemming methods discussed below. Each stem (or phrase) is replaced by its ID number from a term dictionary, or is added to the dictionary and given a new ID number if it has not been encountered before. The vector form of the classification cluster is generated by collecting all unique term IDS and the frequency of occurrence for that term in the cluster text record. The cluster vector (Cl, above) consists of a set of term frequency
weights (xl;) for each unique term (stem, phrase, or class number) that occurs in the cluster.
(6) The cluster vectors are used to generate inverted files (1,) consisting of vectors of term weights for each unique term. The term weights used in the automatic classification experiments are described below.
The classification clustering process can be viewed as a way of increasing the number of terms associated with individual MARC records. In retrieval these addi- tional terms can function in much the same way as USE and RT (related term) references in a thesaurus, direct-
ing the user to the concepts represented by the class numbers.
Classification clusters can also be considered as simi- lar to the cluster representatives (sometimes called the centroid vector) generated by some automatic document clustering algorithms. The study by Garland (1983), noted above, provides some support for this view. As with other automatically generated clusters, classifica- tion clusters subsume the individual document descrip- tions, and offer a more broadly described object for searching and matching operations.
In the experiments described below, the classifica- tion process is treated as a search process, where the goal is retrieve the classification cluster that represents the “correct” classification for a given document used as a query. Instead of trying to select one classification cluster out of the many that have the possibility of rep- resenting the correct class, the various search methods tested here rank the clusters in order of their degree of match, similarity, or probability of relevance for the particular query. Thus, an important factor is the choice of the matching and ranking technique. The techniques used in these experiments are described in the following section.
Matching Methods
A variety of methods for retrieval and ranking of documents have been developed in information re- trieval research. These have been the subject of a good review by Belkin and Croft (1987), so only the tech- niques used, or developed, in this study will be dis- cussed here. Each of these matching techniques uses the vector form for both documents (or, in this case, classification clusters) and queries (or the records to be classified). The function of the matching operation is to provide a retrieval weight, or score, that may be used to rank the documents with the best matches first. In the classification experiments described below, four match- ing methods were tested to determine which most often placed the correct class at or near the top of the rank- ing. The four matching methods, and their rationales, are described in this section. In this discussion the clas- sification clusters are considered as vectors of index term weights (i.e., C,, as described above). The new
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE-March 1992 133

documents to be classified are also treated as query vec- tors of index term weights
QD~ = (ykl, yk2, ykj, “’ T YkM) 7
where yk) is the index term weight calculated by the sys- tem for term 7; in the kth new document.
In each of the matching methods used, product of the classification cluster and new vectors
M
INNER(Ci, QD,, = 2 Xbyk, , j=O
the inner document
is used to provide the retrieval scores that rank the classification clusters in decreasing order of their simi- larity to the new document. The difference between the methods lies in the calculation of the index term weights, xi and ykje
The first, and simplest, form of matching (used pri- marily as a baseline for comparison with the other methods) is coordination level matching (COORD). In coordination level matching the term weights for clus- ters (xi) and new documents (ykj) are simple binary val- ues (i.e., 1 if the term is present in the cluster or document, and 0 otherwise). The retrieval score calcu- lated by the inner product of these vectors is simply the number of terms in common between the cluster and the document to be classified.
The second matching technique uses term frequency information and normalization of vector lengths in the calculation of term weights. The TFIDF (Term Fre- quency x Inverse Document Frequency) weights use the within-document frequency of a term (Jj), as well as collection-wide statistics on term usage. The form of the TFIDF weight used here is suggested by Salton and Buckley (1990) to provide a high level of performance in initial retrieval before relevance feedback in conven- tional document retrieval. In TFIDF matching, term weights are calculated as follows
[ 0.5 + 0.5--- 51
, max(ji) 1 . log:
Xij = I 4 0.5 2 + osA f.
max (.f2
I[ 2 . log; I These denote the probability that a new document (or query) uses term y;, given that classification cluster C, is found to be the relevant, or correct, classification, and similarly for nonrelevance.
(and similarly for ylj), where nj is the number of docu- ments that contain term q, and max(fi) is the maxi- mum value of fij for cluster Ci or new document QD,. This method gives the highest weights to terms that occur frequently in a given document, but relatively in- frequently in the collection as a whole, and low weights to terms that occur infrequently in a given document, but are very common throughout the collection.
In implementing Model lC, a term weight based on estimates of these probabilities is calculated and stored in an inverted file for each term/classification pair in the collection. This weight is
p:u - 4:) WI* = ‘%(1 _ p;)q/ + K2r
where KZ is a constant. In the third matching technique examined, the clas- The probability estimates are derived from the man-
sification “search” process and classification assign- ual classification assignments of the records in classifi- ments are modeled probabilistically. Under this cation clusters, which are treated as previous “queries” probabilistic model, called Model lC, the probability of of the system. If the frequency of ith term in the Ith relevance for a given classification is the conditional classification isf,,, then based on this interpretation of
probability that, if a person were seeking to classify a document, and was using a document description that contains the jth term, then he or she would judge a particular class to be the relevant class. The complete derivation of this model is given elsewhere (Larson, in press), but can be summarized as follows.
The probability of relevance for a particular classifi- cation cluster is defined as
where C, is represented by a binary vector and QD is a query or, in the case of automatic classification, new document represented as a binary index term vector. R is the event that a cluster is judged to be relevant, or to be the “correct” classification. R,, is used to denote the event that a particular classification cluster is relevant, and similarly Rc, to denote nonrelevance.
By applying Bayes theorem, and assuming that indi- vidual terms (y;) of QU occur independently in the rele- vant and nonrelevant clusters, a discrimination function of the following form may be derived
gc,(QD) = iyi log” (I - “) M
1 - p: ~
i=l qi(l - p;) + ,F; log 1 - q;
P(R I Cl) - + logP(R)C,)
= :b,yi + K*
i=l
Where
b; = log p:u - 4:)
q:u - p:)
and K is a constant for any given classification and will not effect the ranking produced by gc, (QD). The impor- tant elements of this function are
p: = P(yi = 11&J,
and
ql = P(y, = l&J.
134 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE-March 1992

classification assignments, the probability of relevance may be estimated as
where L is the total number of classification Similarly an estimate for the probability of Vance can be based on this number
clusters. nonrele-
where nb is the number of classification clusters that include the ith index term. These estimates of the proba- bilities are essentially the same as used in the early automatic classification work of Maron (1961). A simi- lar probabilistic model for “bottom-up” searching of automatically generated clusters was developed Croft (1980), which also used similar estimates for the corre- sponding probabilities.
In the automatic classification process using this model, the ranking of the retrieved clusters is deter- mined from the inner product of the prestored term/ cluster weights and the binary query term weights, i.e.,
for the M index terms in the collection (although only the nonzero index terms specified in the binary QD vec- tor are actually used in matching).
The final matching technique used is a simple term weighting scheme based on a combination of coordina- tion level matching and the relative frequency of the term in the classification clusters. The term weights for a given cluster are calculated as:
where K3 is a constant. This is the same as the esti- mated probability of relevance for a given term/ classification pair (pl) used in Model lC, with the addi-
tion of a constant term. In this weighting scheme the probabilistic component is not treated as a probability, but as a simple score. The retrieval scores using this
method are calculated as the inner product of the bi- nary new document vector and the index term weights for each cluster. This is essentially an augmented form of the coordination level match. In a simple coordina- tion level match, the ranking of the documents within a given level (i.e., those with the same number of terms matching the query) is random. In this matching func- tion the order within levels is controlled by the sum of the relative frequencies. Classification clusters with matching terms that have high relative frequencies may be “promoted” to a higher level.
In the following discussion, the four matching meth- ods described above will be referred to as: “COORD”- for coordination level matching, “TFIDF’‘-for the
term frequency x inverse document frequency match- ing method, “MODELlC”-for the Model 1C proba- bilistic matching method, and WTPROB for the weighted relative frequency matching method.
New Document and Term Representation
The documents to be classified are represented in these experiments by a number of elements. The five following forms of document “queries” are tested:
(1)
(2)
(3)
(4)
(5)
All Elements-the title and all subject headings as- signed to the document to be classified are used in formulating the query. Title and First Subject-the title and the first sub- ject heading in the document are used. All Subjects-all subject headings from the docu- ment are used, with no title information. First Subject Only-only the first subject heading in the document is used. Title Only-only the title of the document is used.
The LC rules for assignment of classification num- bers (Library of Congress, 1987, p. G060) state that the class number should be determined based on the first subject heading. Thus, it might be expected that using the first subject should provide better automatic classi- fication than the other methods. However, experience and research have shown that there is considerable in- consistency in subject heading assignments (Chan, 1989b), and classification assignments, especially locally assigned class numbers, can be expected to reflect this.
Within each of these “query types” there is a choice of how the information concerning terms and headings is treated in constructing the vector representation. The method of generating the vector form of the “query” documents follows exactly the same steps as described above for generating the classification cluster vectors from the cluster text records. In this research two stem- ming methods are used for representing individual terms and a phrase normalization method for represent- ing subject headings. The methods used were:
(1)
(2)
Full Stemming--keywords from the headings (title or subject) are reduced to word stems by removing suffixes. Thus terms such as “library,” “libraries,” “librarian,” and “librarians” are all reduced to the common stem “librar.” The full stemming process uses the algorithm provided in the SMART system (Buckley, 1987). Plural Stemming-keywords from the headings that have recognized plural endings are converted to singular form. For example, “library” and “libraries” both become “library,” and “librarian” and “librarians” both become “librarian”. The al- gorithm does not handle more complex cases such as “thesaurus” and “thesauri,” both of which are left in their original form.
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE-March 1992 135
(3) LCSH Phrases-in this method the individual sub- ject headings are normalized by conversion to lower case letters and the removal of all punctua- tion and spacing. All subfields of the subject head- ing are included, and the resulting string is treated as a single term. Only subject headings are treated in this fashion. For query types combining subjects and titles, the title keywords are stemmed using
plural stemming, as above.
Automatic Classification Experiments
The test database used in these experiments consists of 30,471 MARC records representing most of the hold- ings of the U.C. Berkeley Library School Library. The database represents a specialized collection highly con- centrated in one area of the LC classification (Library and Information Sciences). The classification clustering method described above was applied to these records,
generating 8435 classification clusters (an average of just under four bibliographic records per cluster with a standard deviation of 19.50). Most of the records in the
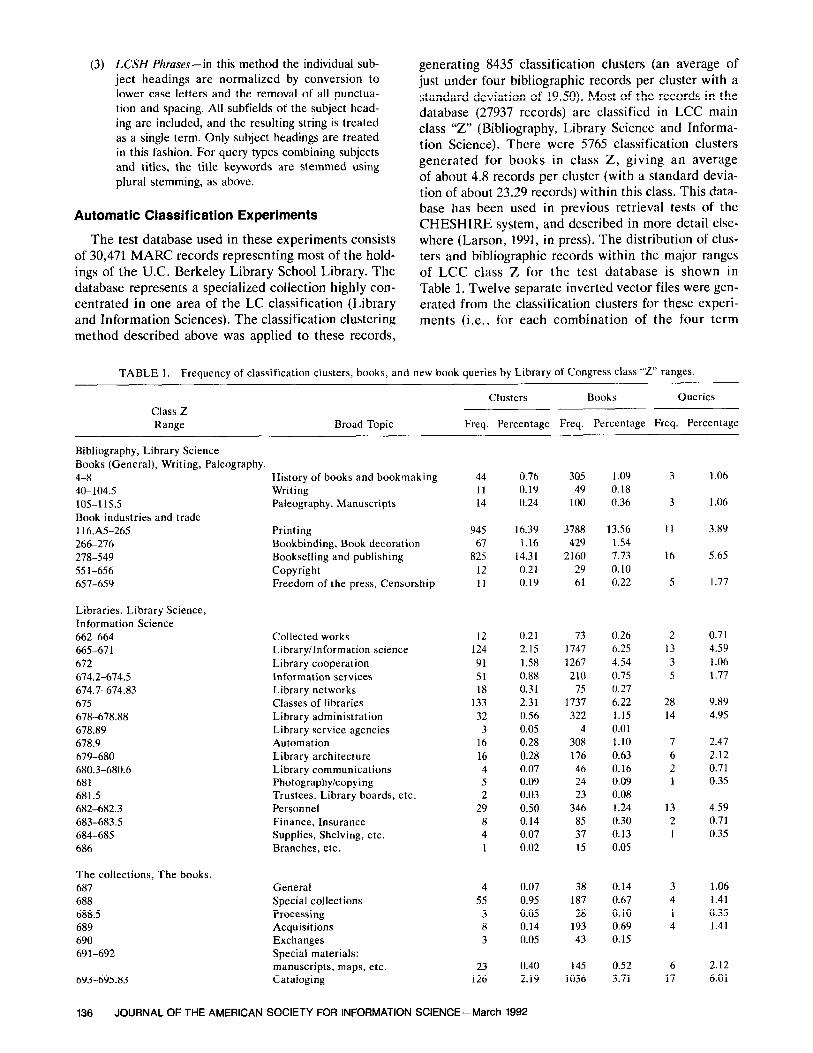
database (27937 records) are classified in LCC main class “Z” (Bibliography, Library Science and Informa- tion Science). There were 5765 classification clusters generated for books in class Z, giving an average of about 4.8 records per cluster (with a standard devia- tion of about 23.29 records) within this class. This data- base has been used in previous retrieval tests of the CHESHIRE system, and described in more detail else- where (Larson, 1991, in press). The distribution of clus- ters and bibliographic records within the major ranges of LCC class Z for the test database is shown in Table 1. Twelve separate inverted vector files were gen- erated from the classification clusters for these experi-
ments (i.e., for each combination of the four term
TABLE 1. Frequency of classification clusters, books, and new book queries by Library of Congress class “Z” ranges.
Clusters Books Queries Class Z Range Broad Topic Freq. Percentage Freq. Percentage Freq. Percentage
Bibliography, Library Science Books (General), Writing, Paleography. 4-8 40-104s 105-115.5 Book industries and trade 1 l6.A5-265 266-276 278-549 551-656 657-659
Libraries. Library Science, Information Science 662-664 665-671 672 674.2-674.5 674.7-674.83 675 678-678.88 678.89 678.9 679-680 680.3-680.6 681 681.5 682-682.3 683-683.5 684-685 686
The collections, The books. 687 688 688.5 689 690 691-692
693-695.83
History of books and bookmaking Writing Paleography. Manuscripts
Printing Bookbinding, Book decoration Bookselling and publishing Copyright Freedom of the press, Censorship
Collected works 12 0.21 73 0.26 Library/Information science 124 2.15 1747 6.25 Library cooperation 91 1.58 1267 4.54 Information services 51 0.88 210 0.75 Library networks 18 0.31 75 0.27 Classes of libraries 133 2.31 1737 6.22 Library administration 32 0.56 322 1.15 Library service agencies 3 0.05 4 0.01 Automation 16 0.28 308 1.10 Library architecture 16 0.28 176 0.63 Library communications 4 0.07 46 0.16 Photography/copying 5 0.09 24 0.09 Trustees. Library boards, etc. 2 0.03 23 0.08 Personnel 29 0.50 346 1.24 Finance, Insurance 8 0.14 85 0.30 Supplies, Shelving, etc. 4 0.07 37 0.13 Branches, etc. 1 0.02 15 0.05
General Special collections Processing Acquisitions Exchanges Special materials: manuscripts, maps, etc. Cataloging
44 0.76 305 1.09 11 0.19 49 0.18 14 0.24 100 0.36
3 1.06
3 1.06
945 16.39 3788 13.56 67 1.16 429 1.54
825 14.31 2160 7.73 12 0.21 29 0.10 11 0.19 61 0.22
11 3.89
16 5.65
5 1.77
2 0.71 13 4.59 3 1.06 5 1.77
28 9.89 14 4.95
7 2.47 6 2.12 2 0.71 1 0.35
13 2 1
4.59 0.71 0.35
4 0.07 38 0.14 55 0.95 187 0.67
3 0.05 28 0.10 8 0.14 193 0.69 3 0.05 43 0.15
3 1.06 4 1.41 1 0.35 4 1.41
23 0.40 14.5 0.52 6 2.12 126 2.19 1036 3.71 17 6.01
136 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE-March 1992
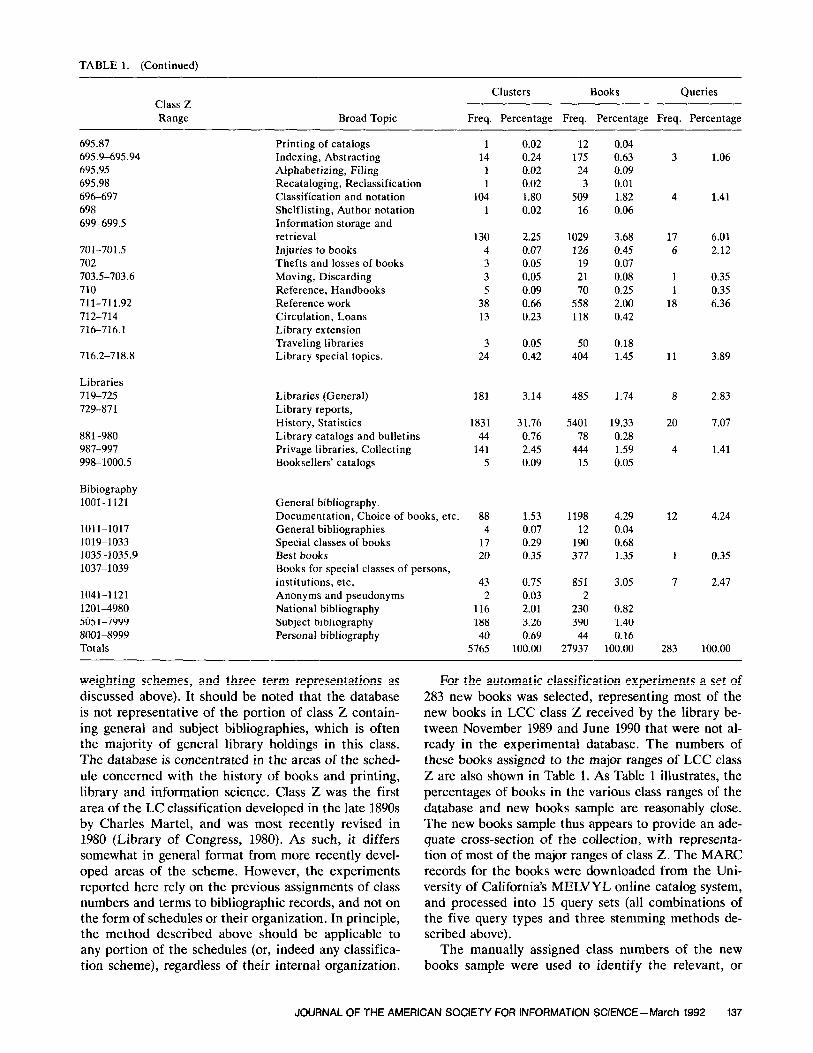
TABLE 1. (Continued)
Class Z Range Broad Topic
Clusters Books Queries
Freq. Percentage Freq. Percentage Freq. Percentage
695.87 695.9-695.94 695.95 695.98 696-697 698 699-699.5
701-701.5 702 703.5-703.6 710 711-711.92 712-714 716-716.1
716.2-718.8
Libraries 7 19-725 729-871
881-980 987-997 998-1000.5
Bibiography 1001-l 121
1011-1017 1019-1033 1035-1035.9 1037-1039
1041-1121 1201-4980 5051-7999 8001-8999 Totals
Printing of catalogs Indexing, Abstracting Alphabetizing, Filing Recataloging, Reclassification Classification and notation Shelflisting, Author notation Information storage and retrieval Injuries to books Thefts and losses of books Moving, Discarding Reference, Handbooks Reference work Circulation, Loans Library extension Traveling libraries Library special topics.
Libraries (General) Library reports, History, Statistics Library catalogs and bulletins Privage libraries, Collecting Booksellers’ catalogs
General bibliography. Documentation, Choice of books, etc. General bibliographies Special classes of books Best books Books for special classes of persons, institutions, etc. Anonyms and pseudonyms National bibliography Subject bibliography Personal bibliography
1 14
104 1
130 2.25 1029 3.68 4 0.07 126 0.45 3 0.05 19 0.07 3 0.05 21 0.08 5 0.09 70 0.25
38 0.66 558 2.00 13 0.23 118 0.42
3 0.05 50 0.18 24 0.42 404 1.45
181
1831 31.76 5401 19.33 44 0.76 78 0.28
141 2.45 444 1.59 5 0.09 15 0.05
88 1.53 1198 4.29 4 0.07 12 0.04
17 0.29 190 0.68 20 0.35 377 1.35
43 0.75 851 2 0.03 2
116 2.01 230 188 3.26 390 40 0.69 44
5765 100.00 27937
0.02 12 0.04 0.24 175 0.63 0.02 24 0.09 0.02 3 0.01 1.80 509 1.82 0.02 16 0.06
3.14 485 1.74
3.05
0.82 1.40 0.16
100.00
3 1.06
4 1.41
17 6.01 6 2.12
1 0.35 1 0.35
18 6.36
11 3.89
8 2.83
20 7.07
4 1.41
12 4.24
1 0.35
7 2.47
283 100.00
weighting schemes, and three term representations as discussed above). It should be noted that the database is not representative of the portion of class Z contain- ing general and subject bibliographies, which is often the majority of general library holdings in this class. The database is concentrated in the areas of the sched- ule concerned with the history of books and printing, library and information science. Class Z was the first area of the LC classification developed in the late 1890s by Charles Martel, and was most recently revised in 1980 (Library of Congress, 1980). As such, it differs somewhat in general format from more recently devel- oped areas of the scheme. However, the experiments reported here rely on the previous assignments of class numbers and terms to bibliographic records, and not on the form of schedules or their organization. In principle, the method described above should be applicable to any portion of the schedules (or, indeed any classifica- tion scheme), regardless of their internal organization.
For the automatic classification experiments a set of 283 new books was selected, representing most of the new books in LCC class Z received by the library be- tween November 1989 and June 1990 that were not al- ready in the experimental database. The numbers of these books assigned to the major ranges of LCC class Z are also shown in Table 1. As Table 1 illustrates, the percentages of books in the various class ranges of the database and new books sample are reasonably close. The new books sample thus appears to provide an ade- quate cross-section of the collection, with representa- tion of most of the major ranges of class Z. The MARC records for the books were downloaded from the Uni- versity of California’s MELVYL online catalog system, and processed into 1.5 query sets (all combinations of the five query types and three stemming methods de- scribed above).
The manually assigned class numbers of the new books sample were used to identify the relevant, or
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE--March 1992 137

“correct” clusters in the test database for each book. In 50 cases of the 283 new books there was no exact match with a cluster. In these cases, a cluster representing the next higher level in the classification hierarchy was se- lected to be the “correct” cluster. In the following dis- cussion, the results for both the complete set of 283 new books, and the subset of 233 books that had exact class number matches are examined. The 50 books with no exact matches were not eliminated from the tests, because in a real situation (i.e. where the items to be classified had no preexisting class numbers) there would be no way to identify such records, other than failure to achieve a good automatic classification for them.
The 283 new books were submitted as queries against the classification cluster database using each combination of the four matching methods, five query types, and three term representations, for a total of 60 classification tests. (Actually, only 56 tests were unique, because the title-only searches using the plural stem- ming method and the LCSH phrase method both used plural stemming only.)
Results
As noted previously, in these experiments the process of automatic classification may be seen as analogous to more conventional information retrieval experiments where the “query” is the description of the book to be classified, and there is just one relevant docu- ment. The relevant “document” is the classification cluster representing the correct, or manually assigned, LC classification for the book. It is assumed that the manually assigned classes are the correct classes, even though there is often a large element of error and in- consistency in such assignments (see, for example, Chan
(1989b), and Borko (1963)). In this situation, with a single relevant class in a fairly large collection of classes, the conventional retrieval effectiveness measures (such as recall and precision) are not very illuminating for characterizing the successes and failures of the classifi- cation process. In their place, this discussion will con- centrate on the rank position of each nominally correct classification in the ranked output produced by the matching methods.
To analyze and compare the overall performance of the automatic classification techniques tested, the mea- sures of central tendency (mean, standard deviation, and median) are examined for the ranks of the correct class over the 283 queries (and the subset of 233 queries with potential exact matches). Tables 2-7 show the re- sults of this analysis. Each of the tables presents the results for one type of term representative. The individ- ual cells in each table show the mean, standard devia- tion, median, and missing cases for each combination of matching method (the columns) and query type (the rows). The missing value is the number of queries that failed to match the correct cluster at any coordination level (that is, there were no terms in common between the query and the nominally correct cluster). Tables 2, 4, and 6 show the results for the full set of 283 new records, and Tables 3, 5, and 7 show the results for those with potential exact matches (i.e., where the manually assigned classification was present in the database).
Perfect classification of the new records would re- sults in a table entry with a mean and median rank of 1 for the correct classification (over all the queries for a given method), with a standard deviation of 0, and no missing cases (that is, all queries would have placed the correct class first in the ranking). If a particular match-
TABLE 2. Mean ranks of relevant classes for full stemming, five query types, four methods, 283 queries.
Query Type COORD TFIDF WTPROB MODELlC
All Titles and subjects
Title and first subject
All subjects
First subject only
Title only
Mean 86.24 Std Dev 336.87 Median 8 Missing 1 Mean 114.35 Std Dev 381.07 Median 10 Missing 2 Mean 86.85 Std Dev 326.32 Median 11 Missing 3 Mean 104.76 Std Dev 295.31 Median 22 Missing 17 Mean 147.15 Std Dev 384.38 Median 18 Missing 14
187.97 421.96
57 1
220.70 473.91
66 ?
25i.42 549.85
68 3
332.60 624.02
73 17
309.69 606.52
97 14
72.07 295.73
6 1
64.20 238.73
6 2
72.37 363.69
4 3
42.71 189.24
2 17
100.42 316.21
10 14
91.39 393.49
4 1
75.43 282.73
5 2
81.44 375.56
3
50.98 202.91
2 17
106.20 333.11
8 14
138 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE-March 1992

TABLE 3. Mean ranks of relevant classes for full stemming, five query types, four methods, 233 queries (possible matches only).
Query Type COORD TFIDF WTPROB MODELlC
All Titles and subjects
Title and first subject
All subjects
First subject only
Title only
Mean 54.54 142.06 35.80 40.06 Std Dev 246.03 356.87 138.46 194.89 Median 7 44 4 3 Missing 0 0 0 0 Mean 55.68 170.14 28.64 34.36 Std Dev 221.26 393.78 98.42 139.53 Median 8 53 4.5 3 Missing 1 1 1 1 Mean 55.681 220.22 34.90 37.97 Std Dev 188.15 505.72 176.81 191.47 Median 10 59 3 2 Missing 0 0 0 0 Mean 76.48 307.52 19.63 24.66 Std Dev 230.52 592.99 79.22 97.69 Median 20 67 1 1 Missing 6 6 6 6 Mean 109.28 230.92 60.96 65.91 Std Dev 338.05 496.43 233.28 259.47 Median 15 86 8 6 Missing 10 10 10 10
TABLE 4. Mean ranks of relevant classes for plural stemming, five query types, four methods, 283 queries.
Query Type COORD TFIDF WTPROB MODELlC
All Titles and subjects
Title and first subject
All subjects
First subject only
Title only
Mean Std Dev Median Missing Mean Std Dev Median Missing Mean Std Dev Median Missing Mean Std Dev Median Missing Mean Std Dev Median Missing
63.18 165.94 233.63 394.36
6.5 47 1 1
73.75 170.46 243.14 406.32
8 50
7;.32 23i.71 262.71 536.43
10 67 3 3
101.98 307.96 316.84 617.98
16 66.5 17 17
115.10 242.22 303.03 480.99
15 80.5 15 15
59.14 250.17
5 1
51.27 188.93
5 2
62.28 317.36
3 3
42.44 223.76
2 17 81.39
239.44 7
15
75.35 333.96
3 1
58.86 227.32
4
6G.50 328.56
3 3
47.97 231.04
2 17 83.51
245.52 6.5
15
ing method was selecting clusters at random, then the mean rank of the correct class should be in the neigh- borhood of 4217.5. As might be expected, none of the methods tested achieved perfection, and none per- formed completely at random. Although the method with the best (i.e., lowest) mean rank can be consid- ered, in some sense, the best method, other criteria must be weighed. All of the methods examined had distributions of ranks that followed a typical Zipfian pattern, that is, a large proportion of the correct clus- ters appeared at rank 1, a considerably smaller number at rank 2, and so on, with many of the higher ranks occurring only once. This distribution is reflected in
the large standard deviations for most of the cells in Tables 2-7. In such highly skewed distributions, the median provides an alternative indication of the rank- ing performance of the various methods (i.e., at least half of the correct clusters were ranked at, or below, the media value by a given method).
Differences between the mean ranks obtained with the four search methods were tested for significance using t-ratio calculated by the direct difference method for paired samples. The difference between the rank obtained for each query (new book) under different matching methods was calculated where the query type and term representation were the same. The t-ratio was
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE-March 1992 139

TABLE 5. Mean ranks of relevant classes for plural stemming, five query types, four methods, 233 queries (possible matches only).
Query Type COORD TFIDF WTPROB MODELlC
All Titles Mean 35.37 129.81 29.72 33.05 and subjects Std Dev 128.75 359.47 128.18 174.55
Median 5 36 4 2 Missing 0 0 0 0
Title and Mean 41.10 126.62 22.22 23.74 first Std Dev 176.27 302.68 80.91 108.27 subject Median 7 41.5 4 3
Missing 1 1 1 1 All subjects Mean 45.97 211.86 31.80 34.10
Std Dev 144.04 514.86 180.80 192.26 Median 9 51 2 2 Missing 0 0 0 0
First Mean 75.51 279.23 19.24 23.37 subject Std Dev 255.31 558.09 115.56 126.15 only Median 15 57 1 1
Missing 6 6 6 6 Title Mean 81.29 184.55 50.53 51.56 only Std Dev 252.06 402.93 179.94 188.65
Median 11 66.5 6 5 Missing 11 11 11 11
TABLE 6. Mean ranks of relevant classes for LCSH phrases, five query types, four methods, 283 queries.
Query Type COORD TFIDF WTPROB MODELlC
All Titles Mean 103.18 145.84 70.76 71.02 and subjects Std Dev 332.37 389.06 239.88 246.66
Median 5 20 3 2 Missing 12 12 12 12
Title and Mean 104.59 173.11 72.79 72.62 first Std Dev 302.04 410.98 222.85 229.79 subject Median 8 34 4 2
Missing 12 12 12 12 All subjects Mean 7.45 12.30 2.91 3.03
Std Dev 12.33 15.89 6.23 6.46 Median 3 6 1 1 Missing 102 102 102 102
First Mean 8.64 9.47 1.37 1.37 subject Std Dev 14.79 12.14 1.60 1.60 only Median 3 5 1 1
Missing 140 140 140 140 Title Mean 115.10 244.5 1 81.39 83.51 only Std Dev 303.03 490.56 239.44 245.52
Median 15 83.5 I 6.5 Missing 15 15 15 15
calculated for the mean difference between each pair of matching methods. Under the null hypothesis, there would be no difference between methods other than that introduced by random errors in the ranking (such as a different rank ordering of clusters with the same matching weight). A statistically significant difference between the ranks indicates that one method provides a better overall ranking than another.
In Table 2, which shows the results for each match- ing method and query type when full stemming was used, the lowest mean rank (42.71) was provided by the WTPROB method, using the first subject heading
only as a query. The median shows that for this method and query type, at least half (the actual number was 53.4%) of the correct clusters were ranked at 1 or 2. The WTPROB method provided the lowest mean ranks of all the methods tested, over all query types. How- ever, MODELlC provided better, or equal, median ranks for all of the query types. In the case of queries using the first subject heading only, 54.9% of the MODELlC searches ranked the correct cluster at 1 or 2. This indicates that MODELlC is doing a better job in the high end of the rankings (particularly in select- ing rank 1 for the correct classes), but the WTPROB
140 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE-March 1992

TABLE 7. Mean ranks of relevant classes for LCSH phrases, five query types, four methods, 233 queries (possible matches only).
Query Type COORD TFIDF WTPROB MODELlC
All Titles and subjects
Title and first subject
All subjects
First subject
only
Title only
Mean 67.82 86.10
Std Dev 284.29 274.70
Median 4 15 Missing 8 8
Mean 72.26 107.86
Std Dev 251.20 282.42 Median 5 24 Missing 8 8 Mean 7.40 11.40 Std Dev 12.52 15.73 Median 3 6
Missing 65 65 Mean 8.95 9.62
Std Dev 15.09 12.40
Median 3 4.5
Missing 97 97 Mean 81.29 188.45
Std Dev 252.07 417.04
Median 11 68.5
Missing 11 11
34.86 33.38 143.16 154.57
2 2
8 8
40.83 39.04
151.07 161.41 3 2
8 8
2.85 2.95 6.31 6.53
65 65
1.36 1.36
1.62 1.62
97 97
50.53 51.56 179.94 188.65
6 5
11 11
method provides somewhat better rankings for poorly matching clusters. The t-tests on the difference between MODELlC and WTPROB matching for full stemming showed no significant difference (at the 0.05 level) be- tween the methods when the title only, and title and first subject query types were used. The WTPROB method provided a significantly better mean ranking (at the 0.01 level) than MODELlC when the first sub- ject only was used as a query, and somewhat better ranking (significant at the 0.05 level) when the title and all subjects, or all subjects only were used as a query. In most cases neither the COORD or TFIDF methods performed as well as either MODELlC or WTPROB. The one exception was the better mean rank for coordi- nation level matching than for MODELlC, when all titles and subject headings were used as a query. How- ever, the t-test for this pair showed that the difference was not significant at the 0.05 level.
Table 3 shows the same tests as Table 2 when the 50 books with no exact matches have been eliminated. As the numbers in Table 3 show, removing those impos- sible matches considerably improves the mean and me- dian ranks for each method and query type. However, the elimination of those records did not change the overall effectiveness of the methods relative to each other. The WTPROB method still provides the best mean rankings, and MODELlC still provides the best median ranks. However, the t-tests on mean difference between WTPROB and MODELlC no longer show a significant difference between the two methods (at the 0.05 level) for any of the query types. Given no signifi- cant difference between the mean rankings obtained, the median acquires more weight in choosing the “bet- ter” method. Note that in Table 3 the higher mean rank for coordination level matching over MODELlC (for
queries using all titles and subjects) seen in Table 2 has disappeared, indicating that this was probably due to chance in the ranking of the neighbor clusters used to represent the correct cluster in the full sample.
Tables 4 and 5 show the results for each matching method and query type when plural stemming was used. Table 4 contains the results for the complete set of queries, and Table 5 for the subset where the correct clusters exist in the database. The overall results in these tables are not drastically different than those in Tables 3 and 4. The major difference is a general reduc- tion in the mean and median ranks when plural stem- ming is used. This is not too suprising, because plural stemming has the primary effect of increasing the pre- cision of retrieval. In both sets of tables, the queries using only the first subject heading and the WTPROB matching method provided the best mean ranking, and MODELlC provided the best median rankings. There was no significant difference between WTPROB and MODELlC when the possible match subset was exam- ined. There was very little difference in the mean and median results between full stemming and plural stem- ming for first subject queries. A greater improvement was seen in the queries where title information was used. In general, it appears that full stemming is not as useful in automatic classification as it is in normal re- trieval, where it can overcome some of the variety of expression in user queries.
Tables 6 and 7 show the results for each matching method and query type when LCSH phrases were used. Table 6 contains the results for the complete set of queries, and Table 7 for the subset where the correct clusters exist in the database. The results of these tests are somewhat more dramatic than those for either of the stemming methods. The improvement in mean
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE-March 1992 141

ranking for queries that contain only subject informa- tion (first subject only or all subjects), was particularly marked over the corresponding searches using either of the stemming methods. (The title only queries, natu- rally, provided identical results to those where plural stemming was used, because only subject headings were searched as phrases, and title information was searched as plural-stemmed terms.) The best methods were again WTPROB and MODELlC. In searches using only the first subject heading as a query, both the WTPROB and MODELlC methods performed identically in their mean and median ranks. In both cases the mean rank was 1.37 for all queries (Table 6) and 1.36 for the subset of queries with possible matches (Table 7). The correct cluster appeared as the first ranked cluster in about 82% of the queries, and as the second ranked cluster in about 12%, for those queries where the correct cluster showed up in the rankings. This good ranking was ac- companied, however, by a large number of missing cases, where the search completely failed to match the nominally correct cluster (140 cases, or 49.4% missing for all queries and 97 cases, or 41.6% missing for the possible match subset).
The measures of central tendency shown in the ta- bles provide only a summarized view of the rankings produced by the various methods studied. In some cases they may disguise some significant differences be- tween the methods. An alternative is to examine the
FREQUENCY 300
frequency with which a given rank (or range of ranks) occurs under each of the matching methods, term rep- resentations, and query types. Figures l-5 illustrate these frequency distributions for each of the five query types when all queries are included. The distributions for the subset of queries with possible matches are not examined here, in all cases they are quite similar to the full sample, although in the full sample the numbers of “correct” clusters in the higher rank ranges is larger.
Each vertical bar in these figures represents one ex- periment, and the bars are divided into segments repre- senting the number of queries where the correct cluster fell into a given range in the ranking. The ranges dis- played are 1, 2-10, 11-20, 21-30, 31-100, and over 100. These ranges are somewhat arbitrary, and were chosen primarily to emphasize the lower (better) ranks. The number of queries (283) is indicated in each figure by a horizontal line, any gap between the line and the top of a bar represents the number of missing cases for the experiment (i.e., where the correct cluster had no terms in common with the query).
Figure 1 shows the results of the automatic classifi- cation experiments that used all title and subject head- ing information from the new books as a query. The best ranking of the retrieved clusters using this query type was provided by MODELlC using LCSH phrases, indicated by the largest numbers of correct clusters with ranks of 1, or in the range 2-10. As the figure illus-
P P F P P F P P F P P F H L U H L U H L U H L U R U L R U L R U L R U L A R L A R L A R L A R L S A S A S A S A E L E L E L E L
TERMS
COORD TFIDF WTPROB MODELlC MATCH
RANK - 21-3:
I 2-10 11-20 31-100 101-MAX
FIG. 1. Ranking results using title and all subject information.
142 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE-March 1992

FREQUENCY 300-j
FREQUENCY 300
200
100
0
P P F P P F P P F P P F H L U H L U H L U H L U R U L R U L R U L R U L A R L A R L A R L A R L S A S A S A S A E L E L E L E L
COORD TFIDF WTPROB MODELlC
RANK - 1 I I 2-10 !i!TxFa 11-20 21-30 31-100 101-MAX
FIG. 2. Ranking results using title and first subject heading only.
-
P P F P P F P P F P P F H L U H L U H L U H L U R U L R U L R U L R U L A R L A R L A R L A R L S A S A S A S A E L E L E L E L
COORD TFIDF WTPROB MODELlC
1 2-10 !Y?Gzza 11-20 21-30 31-100 lOl-MAX
TERMS
MATCH
TERMS
MATCH
FIG. 3. Ranking results using all subject headings.
FREQUENCY 300 -j
P P F P P F P P F P P F TERMS H L U H L U H L U H L U R U L R U L R U L R U L A R L A R L A R L A R L S A S A S A S A E L E L E L E L
COORD TFIDF WTPROB MODELlC MATCH
RANK - 1 I 1 2-10 L??izza 11-20 21-30 31-100 101-MAX
FIG. 4. Ranking results using first subject heading only.
trates, MODELlC consistently provided the correct cluster as the first ranked more often than any corre- sponding combinations of term representation and matching method.
Figure 2 illustrates the results from experiments using title and the first subject heading from the new books as a query. The best ranking of the retrieved clusters for this query type was again provided by MODELlC using LCSH phrases. MODELlC also again provides the correct cluster as the first ranked more often than the other combinations of term representation and matching method. Figure 1 and Figure 2 are quite simi- lar, as might be expected from the similarity of the query types (both include title and subject informa- tion). There were, however slightly more correct clus- ters retrieved as rank 1 or in the range 2-10 using title and all subjects (Fig. 1) than for title and first subject only (Fig. 2).
Figure 3 shows the results of the experiments that used all subject headings from the new books as a query. Once again, MODELlC matching using LCSH phrases provided the largest number of correct clusters in the first rank. However, when the rank 1 and ranks 2-10 are combined, the plural stemming method with MODELlC provided more correct clusters for the range.
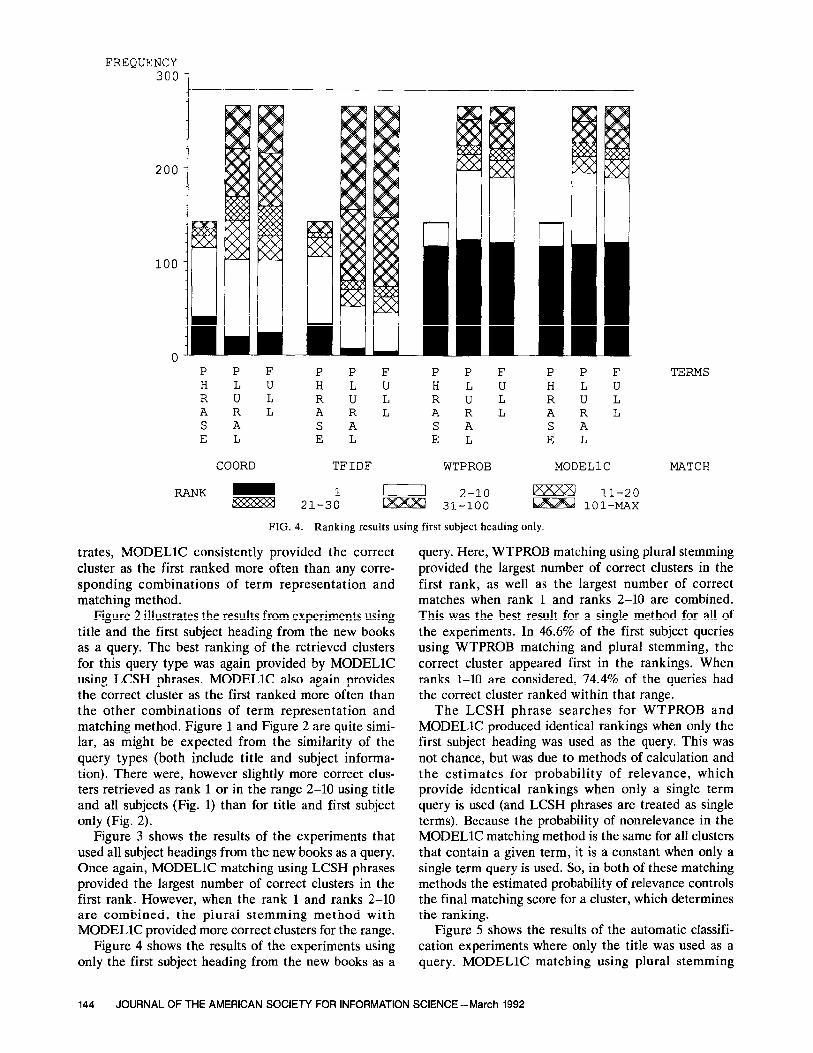
Figure 4 shows the results of the experiments using only the first subject heading from the new books as a
query. Here, WTPROB matching using plural stemming provided the largest number of correct clusters in the first rank, as well as the largest number of correct matches when rank 1 and ranks 2-10 are combined. This was the best result for a single method for all of the experiments. In 46.6% of the first subject queries using WTPROB matching and plural stemming, the correct cluster appeared first in the rankings. When ranks l-10 are considered, 74.4% of the queries had the correct cluster ranked within that range.
The LCSH phrase searches for WTPROB and MODELlC produced identical rankings when only the first subject heading was used as the query. This was not chance, but was due to methods of calculation and the estimates for probability of relevance, which provide identical rankings when only a single term query is used (and LCSH phrases are treated as single terms). Because the probability of nonrelevance in the MODELlC matching method is the same for all clusters that contain a given term, it is a constant when only a single term query is used. So, in both of these matching methods the estimated probability of relevance controls the final matching score for a cluster, which determines the ranking.
Figure 5 shows the results of the automatic classifi- cation experiments where only the title was used as a query. MODELlC matching using plural stemming
144 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE--March 1992

FREQUENCY
3oo&
P P F P P F P P F P P F TERMS H L U H L U H L U H L U R U L R U L R U L R U L A R L A R L A R L A R L S A S A S A S A E L E L E L E L
COORD TFIDF WTPROB MODEL1 C MATCH
RANK - 1 2-10 11-20 21-30 31-100 lOl-MAX
FIG. 5. Ranking results using only title information.
gave the largest number of correct clusters in the first rank, as well as the largest number of correct matches when rank 1 and ranks 2-10 are combined. WTPROB matching using plural stemming was a close second. As previously noted, the LCSH phrase query type uses plural stemming for title terms, so the phrase and plural stemming results are identical for all matching methods (with the exception of TFIDF, which appears to be due to random ordering of clusters with identical matching scores).
Discussion
The preceding analyses indicate that the best auto- matic classification of the new books sample tested here (i.e., the method with the largest number of correct clusters ranked first) was obtained using the first sub- ject heading, plural stemming, and the WTPROB matching method. This method ranked 46.6% of the correct clusters first. Examination of the top-ranked clusters that did not have the same class number as the new book query showed that many of these were quite reasonable alternatives to the human-assigned class. But in these experiments the author did not try to “second-guess” the manual classification.
The results also show that the first assigned subject heading of a record is, as expected, a good guide to the
classification for a given book. It is not, however, a per- fect guide, indicating that the LC rules for classifica- tion based on the first subject are not always followed. One reviewer of this article suggested that what was being tested here is the success of LC policy. Some ad- ditional analyses of the first subject headings in the new books sample were carried out to determine the amount to guidance provided to (manual) classifiers in the LCSH list. Of the 283 first subjects assigned to books in the sample, 75 (26.5%) had specific suggested class numbers in LCSH which matched the assigned class, 12 (4.2%) had a single suggested class number in LCSH which partially matched the assigned class (e.g., the assigned class included an additional topical Cutter number), 47 (16.6%) had a range of class numbers sug- gested in LCSH and the assigned class fell within the range, 4 (1.4%) had a range of class numbers suggested but the assigned number was outside of the range, and 145 (51.2%) had no suggested class number in LCSH.
However, the lack of a class number, or ranges of class numbers, in LCSH did prevent the methods tested here from obtaining correct matches (the correct cluster ranked first) with assigned class numbers. In the best automatic classification experiment (first subject head- ing, plural stemming, and WTPROB matching) 45.16% of the correct matches were from headings that had an exact class number specified in LCSH, the remain-
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE-March 1992 145

ing 54.84% of correct matches had only partial class numbers, ranges of class numbers, or no class number specified in LCSH. It should be reiterated that the methods tested here did not use LCSH or the LCC schedules in matching, but only the information in bib- liographic records.
The searches using LCSH phrases for the first sub- ject heading did not perform quite as well as plural or full stemming using either the WTPROB or MODELlC matching method. However, one benefit of LCSH phases for automatic classification is that they can cor- rectly reject a large number of incorrect clusters. This may be seen in the large number of missing cases in Tables 6 and 7, and the very low mean ranks for the remainder. Using only the first subject heading with LCSH phrases also rejects many of the correct clusters. One source of this problem appears to be the use of free-floating subdivisions in the query subject headings that were not in the cluster (or vice-versa) causing the exact phrase matching to fail. In other cases the first subject heading in the query was a personal or corpo- rate name subject with no exact match in the correct cluster. Further research is needed to isolate the causes of the search failures and to see if solutions are pos- sible. Some preliminary explorations in this area indi- cate that the simple solutions (such as using only topical subjects and eliminating personal and corporate name subjects) will correct some of the failures, but will also cause some previously successful matches to fail. Use of plural stemming in place of LCSH phrases removes the need for eliminating subdivisions, but tends to in- crease the number of correct clusters placed further down in the ranking.
As the mean and median values in Tables 2-7, and the low number of first ranked clusters in Figures 1-5, indicate, TFIDF matching did not perform well in these tests. Indeed, for all of the methods tested TFIDF matching did not even perform as well as simple coordi- nation level matching. This is somewhat surprising, because this method has usually provided good perfor- mance in conventional information retrieval tests on other databases. The poor performance seen here may be the result of differences in the characteristics of the document database. Classification clusters are quite dif- ferent from the documents usually used in IR tests, which commonly provide at least an abstract in addition to titles, and may also include a large number of manu- ally assigned index terms. In classification clusters, there is no abstract, and about half of the terms in the cluster come from manually assigned subject headings (with a fair amount of duplication for the headings fre- quently assigned to the class). The results seen here may be due, in part, to the inverse document frequency portion of the TFIDF term weights. The IDF portion tends to “downgrade” terms that appear frequently in the database, and it may be that subject headings (or terms extracted from them) occur too often to be con- sidered useful under TFIDF matching. The normaliza-
tion of the within-document term frequency may also be less appropriate in classification clusters than in ab- stracts or full-text documents.
The results examined above do not tell the whole story. Although many of the combinations of matching method, term representation, and query type provide a large number of correct clusters in the first rank, they do not always choose the same clusters to be so ranked. There is, naturally, a certain amount of overlap in the rankings produced by similar methods, but they are rarely identical. In some cases the same new book used as query may have its correct cluster ranked first by one method, and yet it would be placed much further down in the rankings by another method. This phenomena has also been observed in more conventional informa- tion retrieval tests (Croft et al., 1989).
Some preliminary analyses were carried out to ex- amine this effect. The best ranks obtained for the cor- rect cluster of each new book query were determined, across all the methods tested. Analysis of these “best ranks” found that if the appropriate method for each individual book was used, then 76.3% of the correct clusters could be selected as the first ranked cluster for the full sample, and 86.3% could be selected using the possible match subset. It should be noted that there were cases where even TFIDF matching provided the correct cluster as the first in the ranking, while the other methods did not. However, choosing the se- quence of methods to provide optimal rankings is not a simple problem, and more research is needed to deter- mine if it would even be possible to select the appropri- ate method for each book to be classified, or if some “quorum” among multiple methods could be reached. For example, the top 10 clusters retrieved by several methods might be combined and the mean rank score for each cluster could be used to determine a final ranking among them. Further research is needed to evaluate such combinations or sequences of retrieval methods, for both automatic classification and more conventional document retrieval. Further research is also needed to examine the differences between the classification achieved here using only LC main class Z, and other areas of the LC classification scheme. Be- cause the method used here does not rely on direct ref- erence to the LCC schedules themselves, or to the LC Subject Headings list, it is expected that it will perform similarly in other areas of the classification scheme.
The results presented above indicate that fully auto- matic LC classification may not be possible for all books. A semiautomatic method of classification, using one or a combination of the methods tested here, fol- lowed by human examination and selection of the highly ranked clusters, appears to be feasible. The methods tested can be seen as providing an index to the classifi- cation schedules for the classifier. Some potential uses for automatic or semiautomatic classification include:
(1) Use by an original cataloger or classifier to aid in determine the appropriate class for new book.
146 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE-March 1992

(2)
(3)
(4)
(5)
Use as an aid in conversion from one classification scheme to another (i.e., reclassification of a collec- tion), to supplement and clarify simple class-to- class mappings (see Dean (1984) and O’Neill, Dillon, and Vizine-Goetz, (1987)). Use as an aid in providing classification numbers for unclassified parts of a library collection, or those without conventional class number (e.g., mi- crofilm collections), in order to provide additional access in an online catalog. To provide multiple alternative classes for existing documents in a collection, for use in online brows- ing. Use in retrieval for query expansion, and browsing of classes. (Larson, in press).
The use of these automatic classification methods for retrieval and query expansion imposes a different set of conditions on the method selected. In a retrieval situ- ation, the “book to be classified” is the user’s query, which usually will not have correct or complete LC sub- ject headings. Therefore, LCSH phrases would not be a viable term representation, and plural or full stemming should be used instead. The MODELlC matching method seems to offer better precision in the low end of the ranking than the WTPROB method, especially when used with both title and subject information, so it may be the best choice in a retrieval situation.
One of the main benefits of classification, as op- posed to alphabetical subject headings, is that it pro- vides a systematic context for a given work, or set of works, in relationship to the structure of knowledge embodied in the classification scheme. An early study of desirable features for subject access in online cata- logs (Kaske & Sanders, 1980) suggested that users liked the idea of approaching the classification as a “tree of knowledge,” where the user’s search term was displayed in its relationship to the overall classification hierarchy. When machine-readable versions of classification schedules are available, it is possible to let users browse through this “tree of knowledge.” The system described by Markey (1987) provided one form of this browsing capability for the Dewey Decimal Classification.
A browsing system would probably not be very effec- tive for retrieval because the synthesis of complete class numbers requires the use of auxiliary tables, and (in LCC) generation of topical Cutter numbers. Some sort of rule-based (or “expert”) system would probably be needed to guide the user in following the rules involved in class number building. But it is not clear that a top- down progression through the classification hierarchy is the best approach. The use of classification clusters can provide a “bottom-up” classification search (Croft, 1980), so that the user may proceed directly to the best- ranked classes for a stated topic and browse in that neighborhood.
Conclusions
In these experiments, 60 variant methods for auto- matic classification were tested on a set of 283 new
books. The methods attempted to locate the correct Library of Congress Class from a database of classifica- tion clusters that combined all of the title and subject information for a given class number in a single record. The most effective methods combined the use of the first subject heading as the representative for the item to be classified, with either the complete heading (LCSH phrases) or keywords from the heading with plural suffixes converted to singular form, and the use of one of the probabilistic search methods (WTPROB or MODELlC). The best results for this sample and database were obtained using the WTPROB matching method and plural stemming, where 46.6% of the sample books were correctly classified, and 74.4% of the correct classes were ranked within the top 10 classes retrieved.
These results, while quite good considering the size and diversity of the LCC scheme, indicate that fully automatic classification may not be possible. However, semiautomatic classification (where the classifier selects the most appropriate classification from among those given high ranks by the automatic methods described) appears to be effective. Further research is suggested to determine the causes of classification failure, to exam- ine the effectiveness of the method in other areas of the classification scheme, and to determine optimal methods for semiautomatic classification.
Acknowledgments
This research was supported in part by grants from OCLC, Inc. and the Committee on Research of the University of California at Berkeley.
References
Belkin, N. J., & Croft, W. B. (1987). Retrieval techniques. Annual Review of Information Science and Technology, 22, 109-145.
Borko, H. (1964). Measuring the reliability of subject classification by men and machines. American Documentation, 15, 268-273.
Borko, H., & Bernick, M.D. (1962). Automatic document classifi- cation. (Report TM-771). Santa Monica, CA: System Develop- ment Corporation.
Borko, H., & Bernick, M. D. (1963). Automatic document classifi- cation. Journal of the ACM, 10, 151-163.
Broadbent, E. (1989). The online catalog: Dictionary, classified, or both? Cataloging and Classification Quarterly, 10, 105-124.
Buckley, C. (1987). Implementation of the SMART information re- trieval system. Ithaca, N.Y.: Cornell University, Dept. of Com- puter Science.
Chan, L. M. (1986). Library of Congress Classification as an online retrieval tool: Potentials and limitations. Information TechnoIogy and Libraries, 5, 181-192.
Chan, L. M. (1989a). Library of Congress class numbers in online catalog searching. RQ, 28, 530-536.
Chan, L. M. (1989b). Inter-indexer consistency in subject catalog-
ing. Information Technology and Libraries, 8, 349-358. Cochrane, P.A., & Markey, K. (1985). Preparing for the use of
classification in online cataloging systems and online catalogs. Information Technology and Libraries, 4, 91-111.
Croft, W. B. (1980). A model of cluster searching based on classifi-
cation. Information Systems, 5, 189-195. Croft, W. B., Lucia, T. J., Cringean, J., & Willett, P. (1989). Re-
trieving documents by plausible inference: an experimental study. Information Processing & Management, 25, 599-614.
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE-March 1992 147

Dean, B.C. (1984). Reclassification in an automated environment. Cataloging & Classification Quarterly, 5(2), l-11.
Enser, P. G. E. (1985a). Experimenting with the automatic classifi- cation of books. In M. Rowbottom (Ed.), Advances in intelligent retrieval: Informatics 8 (pp. 66-83). London: ASLIB.
Enser, P. G. B. (1985b). Automatic classification of book material represented by back-of-the-book index. Journal of Documenta- tion, 41, 135-155.
Field, B. J. (1975). Towards automatic indexing-I: Relationship between free- and controlled-language indexing and the auto- matic generation of controlled subject headings and classifica- tions. (Report R75/20). London: INSPEC, The Institution of Electrical Engineers.
Garland, K. (1983). An experiment in automatic hierarchic docu- ment classification. Information Processing and Management, 19, 113-120.
Hoyle, W. G. (1973). Automatic indexing and generation of classifi- cation systems by algorithm. Information Storage and Retrieval, 9, 233-242.
Huestis, J.C. (1988). Clustering LC classification numbers in an online catalog for improved browsability. Information Technology and Libraries, Z; 381-393.
Hancock, M. (1987). Subject Search Behaviour at the Library Cata- logue and at the Shelves: Implications for Online Interactive Catalogues. Journal of Documentation 43, 303-321.
Kar, G., & White, L. J. (1978). A distance measure for automatic document classification by sequential analysis. Information Pro- cessing & Management, 14, 57-69.
Kaske, N. K., & Sanders, N. P. (1980). On-line subject access: The human side of the problem. Reference Quarterly (RQ), 20, 52-58.
Larson, R.R. (1989). Managing information overload in online catalog subject searching. In J. Katzer & G. B. Newby, (Eds.), Managing information and technology: Proceedings of the S2nd annual meeting of Ihe American Society for Information Science (pp. 129-135). Medford, NJ: Learned Information, Inc.
Larson, R. R. (1991). Classification clustering, probabilistic infor- mation retrieval and the online catalog. Library Quarterly, 61, 133-173.
Larson, R. R. (in press). Evaluation of advanced retrieval tech- niques in an experimental online catalog. Journal of the American Society for Information Science.
Library of Congress (Subject Cataloging Division). (1980). Bibliog- raphy and library science: Classification class Z (5th ed.). Wash- ington, DC: Library of Congress.
Library of Congress (Subject Cataloging Division). (1987). Subject cataloging manual: Shelflisting. Washington, DC: Library of Congress.
Mandel, C. A. (1986). Classification schedules as subject enhance- ment in online catalogs: A review of a conference sponsored by Forest Press, the OCLC Online Computer Library Center, and the Council on Library Resources. Washington, DC: Council on Library Resources.
Markey, K. (1985). Subject-searching experiences and needs of on- line catalog users: Implications for library classification. Library Resources and Technical Services, 29, 34-51.
Markey, K. (1987). Searching and browsing the Dewey Decimal Classification in an online catalog. Cataloging and classification
Quarterly, 7(3), 37-68. Markey, K., & Demeyer, A. N. (1986). Dewey Decimal Classification
Online Project: Evaluation of a library schedule and index inte- grated into the subject searching capabilities of an online catalog. (OCLC Research Report Number OCLC/OPR/RR-86/l). Dublin, OH: OCLC, Inc.
Maron, M.E. (1961). Automatic indexing: An experimental in- quiry. Journal of the ACM, 8, 404-417.
O’Neill, E.T., Dillon, M., & Vizine-Goetz, D. (1987). Class disper- sion between the Library of Congress Classification and the Dewey Decimal Classification. Journal of the American Society for Information Science, 38, 197-205.
Salton, G. (1989). Automatic text processing: The transformation, analysis and retrieval of information by computer. New York: Addison-Wesley.
Salton, G., & Buckley, C. (1990). Improving retrieval performance by relevance feedback. Journal of the American Society for Infor- mation Science, 41, 288-297.
Svenonius, E. (1983). Use of classification in online retrieval. Library Resources and Technical Services, 27 76-80.
Svenonius, E., & Molto, M. (1990). Automatic derivation of name access points in cataloging. Journal of the American Society for Information Science, 41, 254-263.
van Rijsbergen, C. J. (1979). Information Retrieval (2nd ed.) London: Butterworths.
Vizine-Goetz, D., & Markey, K. (1989). Characteristics of subject heading records in the machine-readable Library of Congress subject headings. Information Technology and Libraries, 8, 203- 209.
Williams, J.G., Manheimer, M. L., & Daily, J. E. (Eds). (1972). Classified Library of Congress subject headings. New York: Marcel Dekker.
Williamson, N. J. (1985). Classification in online systems: research and the North American perspective. International Cataloguing, 14(3), 29-30.
Williamson, N. J. (1986). The Library of Congress classification: Problems and prospects in online retrieval. Inrernarional Cata- loguing, H(4), 45-48.
Williamson, N. J. (1989a). Towards machine-readable Library of Congress Classification schedules: A progress report (Abstract). In J. Katzer & G. B. Newby, (Eds.), Managing information and technology: Proceedings of the 52nd annual meeting of the Ameri- can Society for Information Science (p. 205). Medford, NJ: Learned Information, Inc.
Williamson, N. J. (1989b). The role of classification in online sys- tems. Cataloging and Classification Quarterly, IO, 95-104.
148 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE-March 1992