Embed Size (px)
Citation preview

EMI: Exploration with Mutual Information
Hyoungseok Kim * 1 2 Jaekyeom Kim * 1 2 Yeonwoo Jeong 1 2 Sergey Levine 3 Hyun Oh Song 1 2
AbstractReinforcement learning algorithms struggle whenthe reward signal is very sparse. In these cases,naive random exploration methods essentially relyon a random walk to stumble onto a rewardingstate. Recent works utilize intrinsic motivationto guide the exploration via generative models,predictive forward models, or discriminative mod-eling of novelty. We propose EMI, which is anexploration method that constructs embeddingrepresentation of states and actions that does notrely on generative decoding of the full observa-tion but extracts predictive signals that can beused to guide exploration based on forward pre-diction in the representation space. Our experi-ments show competitive results on challenginglocomotion tasks with continuous control and onimage-based exploration tasks with discrete ac-tions on Atari. The source code is available athttps://github.com/snu-mllab/EMI.
1. IntroductionThe central task in reinforcement learning is to learn poli-cies that would maximize the total reward received frominteracting with the unknown environment. Although re-cent methods have been demonstrated to solve a range ofcomplex tasks (Mnih et al., 2015; Schulman et al., 2015;2017), the success of these methods hinges on whether theagent constantly receives the intermediate reward feedbackor not. In case of challenging environments with sparsereward signals, these methods struggle to obtain meaningfulpolicies unless the agent luckily stumbles into the rewardingor predefined goal states.
To this end, prior works on exploration generally utilizesome kind of intrinsic motivation mechanism to provide a
*Equal contribution 1Seoul National University, Departmentof Computer Science and Engineering 2Neural Processing Re-search Center 3UC Berkeley, Department of Electrical Engineer-ing and Computer Sciences. Correspondence to: Hyun Oh Song<[email protected]>.
Proceedings of the 36 th International Conference on MachineLearning, Long Beach, California, PMLR 97, 2019. Copyright2019 by the author(s).
1
2 3
45
6
7
8
12
3
45
6
7
8
Figure 1: Visualization of a sample trajectory in our learnedembedding space.
measure of novelty. These measures can be based on densityestimation via generative models (Bellemare et al., 2016;Fu et al., 2017; Oh et al., 2015), predictive forward mod-els (Stadie et al., 2015; Houthooft et al., 2016), or discrim-inative methods that aim to approximate novelty (Pathaket al., 2017). Methods based on predictive forward mod-els and generative models must model the distribution overstate observations, which can make them difficult to scaleto complex, high-dimensional observation spaces.
Our aim in this work is to devise a method for explorationthat does not require a direct generation of high-dimensionalstate observations, while still retaining the benefits of beingable to measure novelty based on the forward prediction. Ifexploration is performed by seeking out states that maximizesurprise, the problem, in essence, is in measuring surprise,which requires a representation where functionally similarstates are close together, and functionally distinct states arefar apart.
In this paper, we propose to learn compact representationsfor both the states (φ) and actions (ψ) simultaneously satis-fying the following criteria: First, given the representationsof state and the corresponding next state, the uncertaintyof the representation of the corresponding action should beminimal. Second, given the representations of the state andthe corresponding action, the uncertainty of the representa-tion of the corresponding next state should also be minimal.Third, the action embedding representation (ψ) should seam-lessly support both continuous and discrete actions. Finally,we impose a linear dynamics model in the representationspace which can also explain the rare irreducible error underthe dynamics model. Given the representation, we guidethe exploration by measuring surprise based on forward

EMI: Exploration with Mutual Information
prediction and a relative increase in diversity in the embed-ding representation space. Figure 1 illustrates an examplevisualization of our learned state embedding representations(φ) and sample trajectories in the representation space inMontezuma’s Revenge.
We present two main technical contributions that make thisinto a practical exploration method. First, we describe howcompact state and action representations can be constructedvia variational divergence estimation of mutual informationwithout relying on generative decoding of full observations(Nowozin et al., 2016). Second, we show that imposing lin-ear topology on the learned embedding representation space(such that the transitions are linear), thereby offloading mostof the modeling burden onto the embedding function itself,provides an essential informative measure of surprise whenvisiting novel states.
For the experiments, we show that we can use our represen-tations on a range of complex image-based tasks and roboticlocomotion tasks with continuous actions. We report sig-nificantly improved results compared to a number of recentintrinsic motivation based exploration methods (Fu et al.,2017; Pathak et al., 2017) on several challenging Atari tasksand robotic locomotion tasks with sparse rewards.
2. Related worksOur work is related to the following strands of active re-search:
Unsupervised representation learning via mutual infor-mation estimation Recent literature on unsupervised rep-resentation learning generally focuses on extracting latentrepresentations maximizing an approximate lower bound onthe mutual information between the code and the data. Inthe context of generative adversarial networks (Goodfellowet al., 2014), Chen et al. (2016); Belghazi et al. (2018) aimat maximizing the approximation of mutual information be-tween the latent code and the raw data. Belghazi et al. (2018)estimates the mutual information with neural networks viaDonsker & Varadhan (1983) estimation to learn better gen-erative models. Hjelm et al. (2018) builds on the idea andtrains a decoder-free encoding representation maximizingthe mutual information between the input image and therepresentation. Furthermore, the method uses f -divergence(Nowozin et al., 2016) estimation of Jensen-Shannon diver-gence rather than the KL divergence to estimate the mutualinformation for better numerical stability. Oord et al. (2018)estimates mutual information via an autoregressive modeland makes predictions on local patches in an image. Thomaset al. (2017) aims to learn the representations that maximizethe causal relationship between the distributed policies andthe representation of changes in the state. Nachum et al.(2018) connects mutual information estimators to represen-
tation learning in hierarchical RL.
Exploration with intrinsic motivation Prior works on ex-ploration mostly employ intrinsic motivation to estimatethe measure of novelty or surprisal to guide the exploration.Mohamed & Rezende (2015) introduced the connection be-tween mutual information estimation and empowerment forintrinsic motivation. Bellemare et al. (2016); Ostrovski et al.(2017) utilize density estimation via CTS (Bellemare et al.,2014) generative model and PixelCNN (van den Oord et al.,2016) and derive pseudo-counts as the intrinsic motivation.Fu et al. (2017) avoids building explicit density models bytraining K-exemplar models that distinguish a state fromall other observed states. Some methods train predictiveforward models (Stadie et al., 2015; Houthooft et al., 2016;Oh et al., 2015) and estimate the prediction error as theintrinsic motivation. Oh et al. (2015) employs generativedecoding of the full observation via recursive autoencodersand thus can be challenging to scale for high dimensionalobservations. VIME (Houthooft et al., 2016) approximatesthe environment dynamics, uses the information gain of thelearned dynamics model as intrinsic rewards, and showedencouraging results on robotic locomotion problems. How-ever, the method needs to update the dynamics model pereach observation and is unlikely to be scalable for complextasks with high dimensional states such as Atari games.
RND (Burda et al., 2018) trains a network to predict the out-put of a fixed randomly initialized target network and usesthe prediction error as the intrinsic reward but the methoddoes not report the results on continuous control tasks. ICM(Pathak et al., 2017) transforms the high dimensional statesto feature space and imposes cross entropy and Euclideanloss so the action and the feature of the next state are pre-dictable. However, ICM does not utilize mutual informationlike VIME to directly measure the uncertainty and is limitedto discrete actions. Our method (EMI) is also reminiscent of(Kohonen & Somervuo, 1998) in the sense that we seek toconstruct a decoder-free latent space from the high dimen-sional observation data with a topology in the latent space.In contrast to the prior works on exploration, we seek toconstruct the representation under linear topology and doesnot require decoding the full observation but seek to encodethe essential predictive signal that can be used for guidingthe exploration.
3. PreliminariesWe consider a Markov decision process defined by the tuple(S,A, P, r, γ), where S is the set of states, A is the set ofactions, P : S × A × S → R+ is the environment transi-tion distribution, r : S → R is the reward function, andγ ∈ (0, 1) is the discount factor. Let π denote a stochasticpolicy over actions given states. Denote P0 : S → R+ asthe distribution of initial state s0. The discounted sum of

EMI: Exploration with Mutual Information
expected rewards under the policy π is defined by
η(π) = Eτ
[∑t=0
γtr(st)
],
where τ = (s0, a0, . . . , aT−1, sT ) denotes the trajectory,s0 ∼ P0(s0), at ∼ π(at | st), and st+1 ∼ P (st+1 | st, at).The objective in policy based reinforcement learning is tosearch over the space of parameterized policies (i.e. neuralnetwork) πθ(a | s) in order to maximize η(πθ).
Also, denote PπSAS′ as the joint probability distribution ofsingleton experience tuples (s, a, s′) starting from s0 ∼P0(s0) and following the policy π. Furthermore, definePπA =
∫S×S′ dPπSAS′ as the marginal distribution of actions,
PπSS′ =∫A dP
πSAS′ as the marginal distribution of states
and the corresponding next states, PπS′ =∫S×A dP
πSAS′
as the marginal distribution of the next states, and PπSA =∫S′ dPπSAS′ as the marginal distribution of states and the
actions following the policy π.
4. MethodsOur goal is to construct the embedding representation of theobservation and action (discrete or continuous) for complexdynamical systems that does not rely on generative decodingof the full observation, but still provides a useful predictivesignal that can be used for exploration. This requires arepresentation where functionally similar states are closetogether, and functionally distinct states are far apart. Weapproach this objective from the standpoint of maximizingmutual information under several criteria.
4.1. Mutual information maximizing state and actionembedding representations
In this subsection, we introduce the desiderata for our ob-jective and discuss the variational divergence lower boundfor efficient computation of the objective. We denote theembedding function of states φα : S → Rd and actionsψβ : A → Rd with parameters α and β (i.e. neural net-works) respectively. We seek to learn the embedding func-tion of states (φα) and actions (ψβ) satisfying the followingtwo criteria:
1. Given the embedding representation of states and theactions [φα(s);ψβ(a)], the uncertainty of the embed-ding representation of the corresponding next statesφα(s′) should be minimal and vice versa.
2. Given the embedding representation of states and thecorresponding next states [φα(s);φα(s′)], the uncer-tainty of the embedding representation of the corre-sponding actions ψβ(a) should also be minimal andvice versa.
Intuitively, the first criterion translates to maximizing themutual information between [φα(s);ψβ(a)], and φα(s′)
which we define as IS(α, β) in Equation (1). And thesecond criterion translates to maximizing the mutual in-formation between [φα(s);φα(s′)] and ψβ(a) defined asIA(α, β) in Equation (2).
maximizeα,β
IS(α, β) := I([φα(s);ψβ(a)];φα(s′))
= DKL (PπSAS′ ‖ PπSA ⊗ PπS′) (1)
maximizeα,β
IA(α, β) := I([φα(s);φα(s′)];ψβ(a))
= DKL (PπSAS′ ‖ PπSS′ ⊗ PπA) (2)
Mutual information is not bounded from above and maximiz-ing mutual information is notoriously difficult to compute inhigh dimensional settings. Motivated by (Hjelm et al., 2018;Belghazi et al., 2018), we compute the variational diver-gence lower bound of mutual information (Nowozin et al.,2016). Concretely, variational divergence (f-divergence) rep-resentation is a tight estimator for the mutual information oftwo random variables X and Z, derived as in Equation (3).
I(X;Z) = DKL(PXZ ‖ PX ⊗ PZ) (3)≥ supω∈Ω
EPXZTω(x, z)− logEPX⊗PZ exp(Tω(x, z)),
where Tω : X × Z → R is a differentiable transform withparameter ω. Furthermore, for better numerical stability, weutilize a different measure between the joint and marginalsthan the KL-divergence. In particular, we employ Jensen-Shannon divergence (JSD) (Hjelm et al., 2018) which isbounded both from below and above by 0 and log(4) 1.
Theorem 1. The lower bound of mutual information usingJensen-Shannon divergence is
I(JSD)(X;Z) ≥ supω∈Ω
EPXZ [−sp (−Tω(x, z))]
− EPX⊗PZ [sp (Tω(x, z))] + log(4)
Proof.
I(JSD)(X;Z) = DJSD(PXZ ‖ PX ⊗ PZ)
≥ supω∈Ω
EPXZ [Sω(x, z)]− EPX⊗PZ [JSD∗ (Sω(x, z))]
= supω∈Ω
EPXZ [−sp (−Tω(x, z))]
− EPX⊗PZ [sp (Tω(x, z))] + log(4),
where the inequality in the second line holds from thedefinition of f -divergence (Nowozin et al., 2016). Inthe third line, we substituted Sω(x, z) = log(2) −log(1 + exp(−Tω(x, z))) and Fenchel conjugate of Jensen-Shannon divergence, JSD∗(t) = − log(2− exp(t)).
1In (Nowozin et al., 2016), the authors derive the lower boundof DJSD = DKL(P ||M) +DKL(Q||M), instead of DJSD =12(DKL(P ||M) +DKL(Q||M)), where M = 1
2(P +Q).

EMI: Exploration with Mutual Information
CONV CONV
CONCAT
fc
-sp
sp
+
fc fc
-sp
sp
+
concat
concat
concat
concat
concat
CONVCONV
CONV I(JSD)S
I(JSD)A
concat
1
atl+b m2
c
s0tl+b m2
c
(s0tl+b m2
c)
(atl+b m2
c)
FCfc
fc
FCfc
fc
FCfc
fcFCfc
fc
FCfc
fcFCfc
fc
atl
stl
s0tl
(atl)
(stl)
(s0tl)
TwS((stl
), (atl),(s0tl+b m
2c))
TwS((stl
), (atl),(s0tl
))
TwA((stl
), (atl),(s0tl
))
TwA((stl
), (atl+b m2
c),(s0tl))
Figure 2: Computational architecture for estimating I (JSD)S and I (JSD)
A for image-based observations.
From Theorem 1, we have,maximize
α,βI(JSD)S (α, β)
≥ maximizeα,β
supωS∈ΩS
EPπSAS′
[−sp
(−TωS (φα(s), ψβ(a), φα(s
′)))]
− EPπSA⊗Pπ
S′
[sp(TωS (φα(s), ψβ(a), φα(s
′)))]
+ log 4, (4)
maximizeα,β
I(JSD)A (α, β)
≥ maximizeα,β
supωA∈ΩA
EPπSAS′
[−sp
(−TωA (φα(s), ψβ(a), φα(s
′)))]
− EPπSS′⊗Pπ
A
[sp(TωA (φα(s), ψβ(a), φα(s
′)))]
+ log 4, (5)
where sp(z) = log(1 + exp(z)). The expectations in Equa-tion (4) and Equation (5) are approximated using the em-pirical samples trajectories τ . Note, the samples s′ ∼ PπS′
and a ∼ PπA from the marginals are obtained by dropping(s, a) and (s, s′) in samples (s, a, s′) and (s, a, s′) fromPπSAS′ . Figure 2 illustrates the computational architecturefor estimating the lower bounds on IS and IA.
4.2. Embedding the linear dynamics model with theerror model
Since the embedding representation space is learned, it isnatural to impose a topology on it (Kohonen, 1983). InEMI, we impose a simple and convenient topology wheretransitions are linear since this spares us from having to alsorepresent a complex dynamical model. This allows us tooffload most of the modeling burden onto the embeddingfunction itself, which in turn provides us with a useful andinformative measure of surprise when visiting novel states.Once the embedding representations are learned, this lineardynamics model allows us to measure surprise in terms ofthe residual error under the model or measure diversity interms of the similarity in the embedding space. Section 4.3discusses the intrinsic reward computation procedure inmore detail.
Concretely, we seek to learn the representation of statesφ(s) and the actions ψ(a) such that the representation ofthe corresponding next state φ(s′) follow linear dynamicsi.e. φ(s′) = φ(s) + ψ(a). Intuitively, we would like thenonlinear aspects of the dynamics to be offloaded to the neu-ral networks φ(·), ψ(·) so that in the Rd embedding space,the dynamics become linear. Regardless of the expressivityof the neural networks, however, there always exists irre-ducible error under the linear dynamic model. For example,the state transition which leads the agent from one room toanother in Atari environments (i.e. Venture, Montezuma’srevenge, etc.) or the transition leading the agent in thesame position under certain actions (i.e. Agent bumpinginto a wall when navigating a maze) would be extremelychallenging to explain under the linear dynamics model.
To this end, we introduce the error model Sγ : S×A → Rd,which is another neural network taking the state and actionas input, estimating the irreducible error under the linearmodel. Motivated by the work of Candès et al. (2011),we seek to minimize Frobenius norm of the error term sothat the error term contributes on sparingly unexplainableoccasions. Equation (6) shows the embedding learningproblem under linear dynamics with modeled errors.
minimizeα,β,γ
‖Sγ‖2,0︸ ︷︷ ︸error minimization
subject to Φ′α = Φα + Ψβ + Sγ︸ ︷︷ ︸embedding linear dynamics
, (6)
where we used the matrix notation for compactness.Φα,Ψβ , Sγ denotes the matrices of respective embeddingrepresentations stacked columns wise. Relaxing the matrix‖ · ‖2,0 norm with Frobenius norm, Equation (7) shows ourfinal learning objective.

EMI: Exploration with Mutual Information
minimizeα,β,γ
‖Φ′α − (Φα + Ψβ + Sγ) ‖2F+ λerror‖Sγ‖2F + λinfoLinfo, (7)
where Linfo denotes the following mutual information term.
Linfo = infωS∈ΩS
EPπSAS′ sp (−TωS (φα(s), ψβ(a), φα(s′)))
+ EPπSA⊗PπS′ sp(TωS (φα(s), ψβ(a), φα(s′))
)+ infωA∈ΩA
EPπSAS′ sp (−TωA(φα(s), ψβ(a), φα(s′)))
+ EPπSS′⊗PπA sp (TωA(φα(s), ψβ(a), φα(s′)))
λerror, λinfo are hyperparameters which control the relativecontributions of the linear dynamics error and the mutualinformation term. In practice, for image-based experi-ments, we found the optimization process to be more sta-ble when we further regularize the distribution of actionembedding representation to follow a predefined prior dis-tribution. Concretely, we regularize the action embeddingdistribution to follow a standard normal distribution viaDKL(Pπψ ‖ N (0, I)) similar to VAEs (Kingma & Welling,2013). Intuitively, this has the effect of grounding the dis-tribution of action embedding representation (and conse-quently the state embedding representation) across differentiterations of the learning process.
Note, regularizing the distribution of state instead of actionembeddings renders the optimization process much moreunstable. This is because the distribution of states are muchmore likely to be skewed than the distribution of actions,especially during the initial stage of optimization, so theGaussian approximation becomes much less accurate incontrast to the distribution of actions. In Section 5.5, wecompare the state and action embeddings as regularizationtargets in terms of the quality of the learned embeddingfunctions.
4.3. Intrinsic reward augmentation
We consider a formulation based on the prediction errorunder the linear dynamics model as shown in Equation (8).This formulation incorporates the error term and makes surewe differentiate the irreducible error that does not contributeas the novelty.
re(st, at, s′t) = ‖φ(st) + ψ(at) + S(st, at)− φ(s′t)‖2
(8)
Algorithm 1 shows the complete procedure in detail. Thechoice of different intrinsic reward formulation and the com-putation of Linfo are fully described in supplementary Sec-tion 2 and 3.
Algorithm 1 Exploration with mutual information state andaction embeddings (EMI)
initialize α, β, γ, ωA, ωSfor i = 1, . . . , MAXITER do
Collect samples (st, at, s′t)nt=1 with policy πθCompute prediction error intrinsic rewardsre(st, at, s′t)nt=1 following Equation (8)for j = 1, . . . , OPTITER do
for k = 1, . . . , b nmc doSample a minibatch (stl , atl , s′tl)ml=1
Update α, β, γ, ωA, ωS using the Adam updaterule to minimize Equation (7)
end forend forAugment the intrinsic rewards with environment re-ward renv as r = renv + ηre and update the policynetwork πθ using any RL method
end for
5. ExperimentsWe compare the experimental performance of EMI to recentprior works on both low-dimensional locomotion tasks withcontinuous control from rllab benchmark (Duan et al., 2016)and the complex vision-based tasks with discrete controlfrom the Arcade Learning Environment (Bellemare et al.,2013). For the locomotion tasks, we chose SwimmerGatherand SparseHalfCheetah environments for direct comparisonagainst the prior work of (Fu et al., 2017). SwimmerGatheris a hierarchical task where a two-link robot needs to reachgreen pellets, which give positive rewards, instead of redpellets, which give negative rewards. SparseHalfCheetah isa challenging locomotion task where a cheetah-like robotdoes not receive any rewards until it moves 5 units in onedirection.
For vision-based tasks, we selected Freeway, Frostbite, Ven-ture, Montezuma’s Revenge, Gravitar, and Solaris for com-parison with recent prior works (Pathak et al., 2017; Fuet al., 2017; Burda et al., 2018). These six Atari environ-ments feature very sparse reward feedback and often containmany moving distractor objects which can be challengingfor the methods that rely on explicit decoding of the fullobservations (Oh et al., 2015). Table 1 shows the overallperformance of EMI compared to the baseline methods inall tasks.
5.1. Implementation Details
We compare all exploration methods using the same RL pro-cedure, in order to provide a fair comparison. Specifically,we use TRPO (Schulman et al., 2015), a policy gradientmethod that can be applied to both continuous and discreteaction spaces. Although the absolute performance on eachtask depends strongly on the choice of RL algorithm, com-
EMI: Exploration with Mutual Information
1
2
3
4
5
1 2 3
4 5
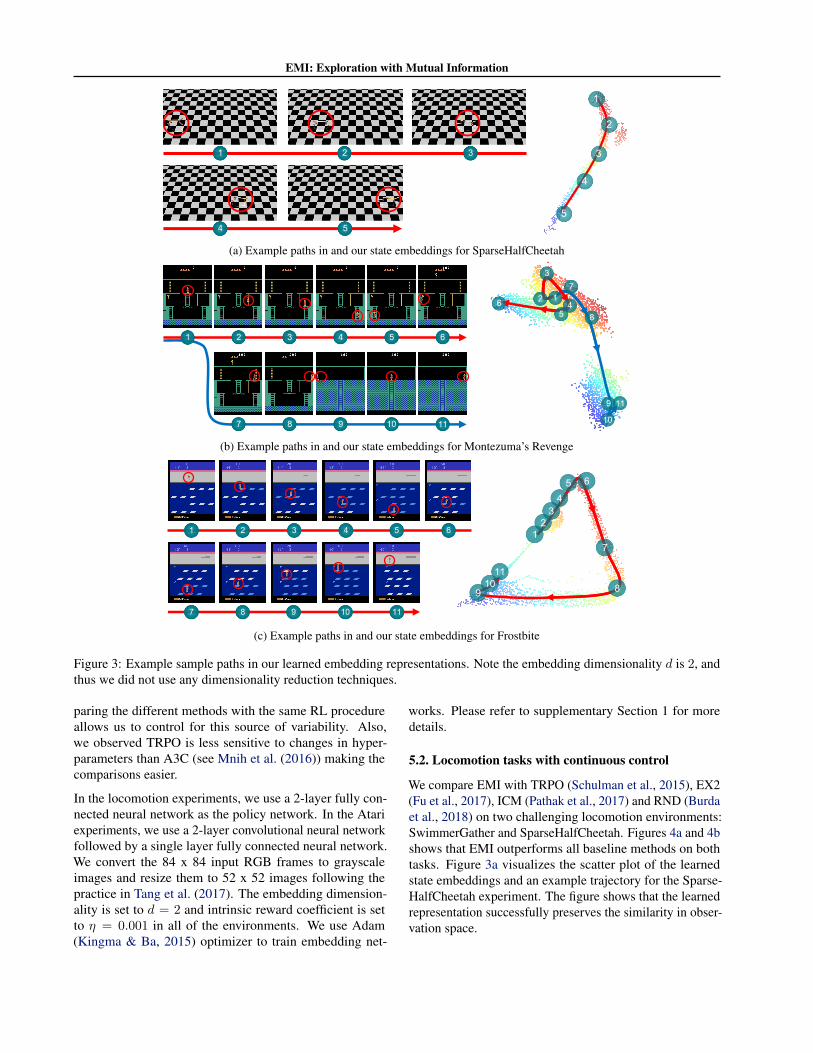
(a) Example paths in and our state embeddings for SparseHalfCheetah
12
3
45
6
7
9
10
8
11
1 2 4 6
7 9 11
3 5
8 10
(b) Example paths in and our state embeddings for Montezuma’s Revenge
12345 6
7
891011
1 2 3 4 5 6
7 8 9 10 11
(c) Example paths in and our state embeddings for Frostbite
Figure 3: Example sample paths in our learned embedding representations. Note the embedding dimensionality d is 2, andthus we did not use any dimensionality reduction techniques.
paring the different methods with the same RL procedureallows us to control for this source of variability. Also,we observed TRPO is less sensitive to changes in hyper-parameters than A3C (see Mnih et al. (2016)) making thecomparisons easier.
In the locomotion experiments, we use a 2-layer fully con-nected neural network as the policy network. In the Atariexperiments, we use a 2-layer convolutional neural networkfollowed by a single layer fully connected neural network.We convert the 84 x 84 input RGB frames to grayscaleimages and resize them to 52 x 52 images following thepractice in Tang et al. (2017). The embedding dimension-ality is set to d = 2 and intrinsic reward coefficient is setto η = 0.001 in all of the environments. We use Adam(Kingma & Ba, 2015) optimizer to train embedding net-
works. Please refer to supplementary Section 1 for moredetails.
5.2. Locomotion tasks with continuous control
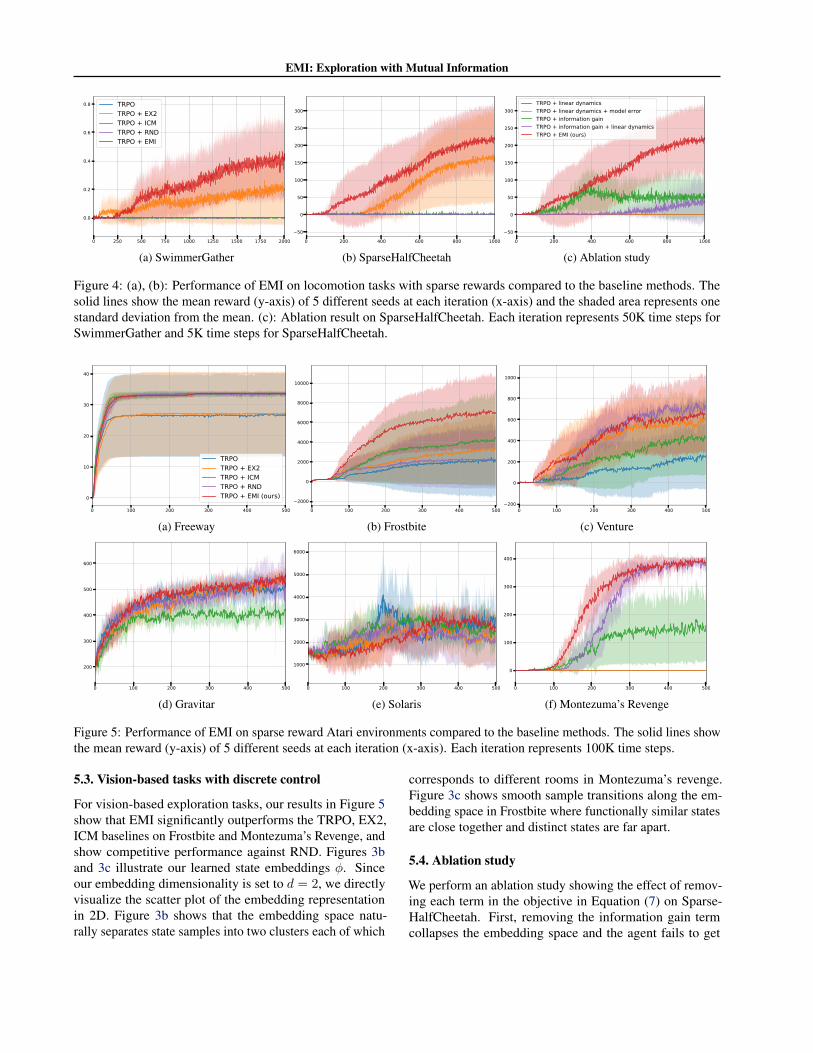
We compare EMI with TRPO (Schulman et al., 2015), EX2(Fu et al., 2017), ICM (Pathak et al., 2017) and RND (Burdaet al., 2018) on two challenging locomotion environments:SwimmerGather and SparseHalfCheetah. Figures 4a and 4bshows that EMI outperforms all baseline methods on bothtasks. Figure 3a visualizes the scatter plot of the learnedstate embeddings and an example trajectory for the Sparse-HalfCheetah experiment. The figure shows that the learnedrepresentation successfully preserves the similarity in obser-vation space.
EMI: Exploration with Mutual Information
0 250 500 750 1000 1250 1500 1750 2000
0.0
0.2
0.4
0.6
0.8 TRPOTRPO + EX2TRPO + ICMTRPO + RNDTRPO + EMI
(a) SwimmerGather
0 200 400 600 800 1000−50
0
50
100
150
200
250
300
(b) SparseHalfCheetah
0 200 400 600 800 1000−50
0
50
100
150
200
250
300TRPO + linear dynamicsTRPO + linear dynamics + model errorTRPO + information gainTRPO + information gain + linear dynamicsTRPO + EMI (ours)
(c) Ablation study
Figure 4: (a), (b): Performance of EMI on locomotion tasks with sparse rewards compared to the baseline methods. Thesolid lines show the mean reward (y-axis) of 5 different seeds at each iteration (x-axis) and the shaded area represents onestandard deviation from the mean. (c): Ablation result on SparseHalfCheetah. Each iteration represents 50K time steps forSwimmerGather and 5K time steps for SparseHalfCheetah.
0 100 200 300 400 500
0
10
20
30
40
TRPOTRPO + EX2TRPO + ICMTRPO + RNDTRPO + EMI (ours)
(a) Freeway
0 100 200 300 400 500−2000
0
2000
4000
6000
8000
10000
(b) Frostbite
0 100 200 300 400 500−200
0
200
400
600
800
1000
(c) Venture
0 100 200 300 400 500
200
300
400
500
600
(d) Gravitar
0 100 200 300 400 500
1000
2000
3000
4000
5000
6000
(e) Solaris
0 100 200 300 400 500
0
100
200
300
400
(f) Montezuma’s Revenge
Figure 5: Performance of EMI on sparse reward Atari environments compared to the baseline methods. The solid lines showthe mean reward (y-axis) of 5 different seeds at each iteration (x-axis). Each iteration represents 100K time steps.
5.3. Vision-based tasks with discrete control
For vision-based exploration tasks, our results in Figure 5show that EMI significantly outperforms the TRPO, EX2,ICM baselines on Frostbite and Montezuma’s Revenge, andshow competitive performance against RND. Figures 3band 3c illustrate our learned state embeddings φ. Sinceour embedding dimensionality is set to d = 2, we directlyvisualize the scatter plot of the embedding representationin 2D. Figure 3b shows that the embedding space natu-rally separates state samples into two clusters each of which
corresponds to different rooms in Montezuma’s revenge.Figure 3c shows smooth sample transitions along the em-bedding space in Frostbite where functionally similar statesare close together and distinct states are far apart.
5.4. Ablation study
We perform an ablation study showing the effect of remov-ing each term in the objective in Equation (7) on Sparse-HalfCheetah. First, removing the information gain termcollapses the embedding space and the agent fails to get
EMI: Exploration with Mutual Information
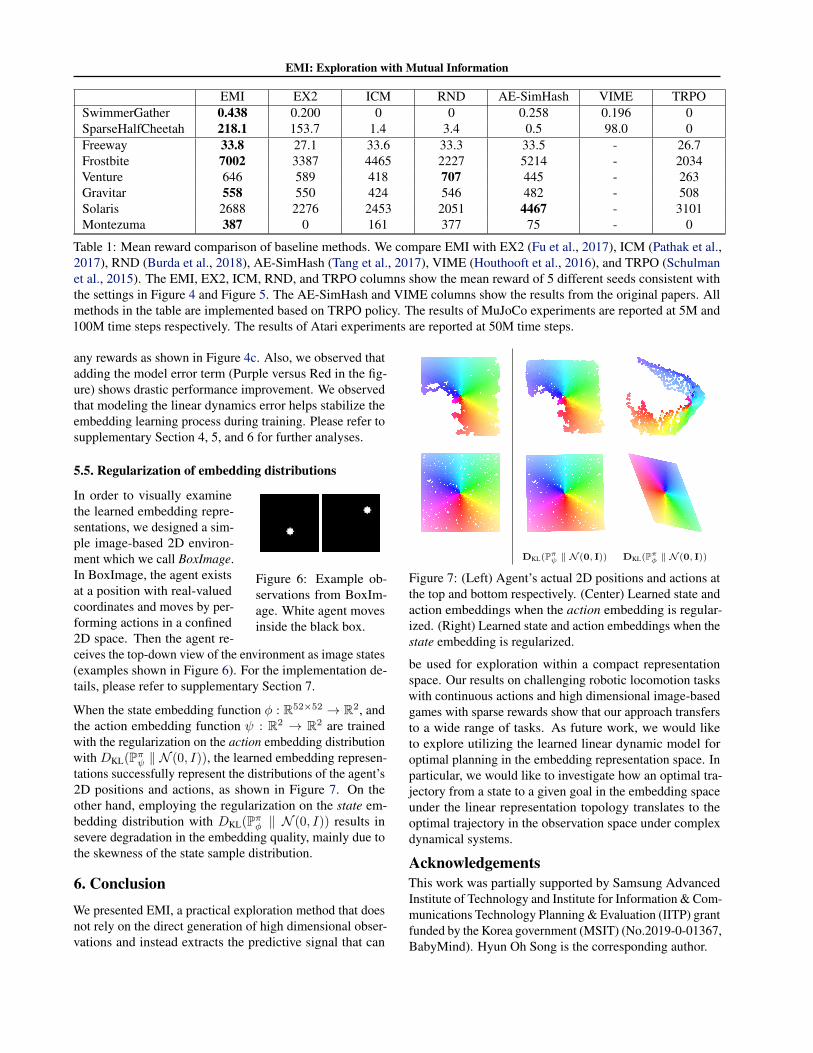
EMI EX2 ICM RND AE-SimHash VIME TRPOSwimmerGather 0.438 0.200 0 0 0.258 0.196 0SparseHalfCheetah 218.1 153.7 1.4 3.4 0.5 98.0 0Freeway 33.8 27.1 33.6 33.3 33.5 - 26.7Frostbite 7002 3387 4465 2227 5214 - 2034Venture 646 589 418 707 445 - 263Gravitar 558 550 424 546 482 - 508Solaris 2688 2276 2453 2051 4467 - 3101Montezuma 387 0 161 377 75 - 0
Table 1: Mean reward comparison of baseline methods. We compare EMI with EX2 (Fu et al., 2017), ICM (Pathak et al.,2017), RND (Burda et al., 2018), AE-SimHash (Tang et al., 2017), VIME (Houthooft et al., 2016), and TRPO (Schulmanet al., 2015). The EMI, EX2, ICM, RND, and TRPO columns show the mean reward of 5 different seeds consistent withthe settings in Figure 4 and Figure 5. The AE-SimHash and VIME columns show the results from the original papers. Allmethods in the table are implemented based on TRPO policy. The results of MuJoCo experiments are reported at 5M and100M time steps respectively. The results of Atari experiments are reported at 50M time steps.
any rewards as shown in Figure 4c. Also, we observed thatadding the model error term (Purple versus Red in the fig-ure) shows drastic performance improvement. We observedthat modeling the linear dynamics error helps stabilize theembedding learning process during training. Please refer tosupplementary Section 4, 5, and 6 for further analyses.
5.5. Regularization of embedding distributions
Figure 6: Example ob-servations from BoxIm-age. White agent movesinside the black box.
In order to visually examinethe learned embedding repre-sentations, we designed a sim-ple image-based 2D environ-ment which we call BoxImage.In BoxImage, the agent existsat a position with real-valuedcoordinates and moves by per-forming actions in a confined2D space. Then the agent re-ceives the top-down view of the environment as image states(examples shown in Figure 6). For the implementation de-tails, please refer to supplementary Section 7.
When the state embedding function φ : R52×52 → R2, andthe action embedding function ψ : R2 → R2 are trainedwith the regularization on the action embedding distributionwith DKL(Pπψ ‖ N (0, I)), the learned embedding represen-tations successfully represent the distributions of the agent’s2D positions and actions, as shown in Figure 7. On theother hand, employing the regularization on the state em-bedding distribution with DKL(Pπφ ‖ N (0, I)) results insevere degradation in the embedding quality, mainly due tothe skewness of the state sample distribution.
6. ConclusionWe presented EMI, a practical exploration method that doesnot rely on the direct generation of high dimensional obser-vations and instead extracts the predictive signal that can
DKL(Pπψ ‖ N (0, I)) DKL(Pπφ ‖ N (0, I))
Figure 7: (Left) Agent’s actual 2D positions and actions atthe top and bottom respectively. (Center) Learned state andaction embeddings when the action embedding is regular-ized. (Right) Learned state and action embeddings when thestate embedding is regularized.
be used for exploration within a compact representationspace. Our results on challenging robotic locomotion taskswith continuous actions and high dimensional image-basedgames with sparse rewards show that our approach transfersto a wide range of tasks. As future work, we would liketo explore utilizing the learned linear dynamic model foroptimal planning in the embedding representation space. Inparticular, we would like to investigate how an optimal tra-jectory from a state to a given goal in the embedding spaceunder the linear representation topology translates to theoptimal trajectory in the observation space under complexdynamical systems.
AcknowledgementsThis work was partially supported by Samsung AdvancedInstitute of Technology and Institute for Information & Com-munications Technology Planning & Evaluation (IITP) grantfunded by the Korea government (MSIT) (No.2019-0-01367,BabyMind). Hyun Oh Song is the corresponding author.

EMI: Exploration with Mutual Information
ReferencesBelghazi, I., Rajeswar, S., Baratin, A., Hjelm, R. D., and
Courville, A. Mutual information neural estimation. InInternational Conference on Machine Learning, volume2018, 2018.
Bellemare, M., Veness, J., and Talvitie, E. Skip contexttree switching. In International Conference on MachineLearning, pp. 1458–1466, 2014.
Bellemare, M., Srinivasan, S., Ostrovski, G., Schaul, T.,Saxton, D., and Munos, R. Unifying count-based explo-ration and intrinsic motivation. In Advances in NeuralInformation Processing Systems, pp. 1471–1479, 2016.
Bellemare, M. G., Naddaf, Y., Veness, J., and Bowling, M.The arcade learning environment: An evaluation plat-form for general agents. Journal of Artificial IntelligenceResearch, 47:253–279, 2013.
Burda, Y., Edwards, H., Storkey, A., and Klimov, O. Ex-ploration by random network distillation. arXiv preprintarXiv:1810.12894, 2018.
Candès, E. J., Li, X., Ma, Y., and Wright, J. Robust principalcomponent analysis? Journal of the ACM (JACM), 58(3):11, 2011.
Chen, X., Duan, Y., Houthooft, R., Schulman, J., Sutskever,I., and Abbeel, P. Infogan: Interpretable representationlearning by information maximizing generative adversar-ial nets. In Advances in neural information processingsystems, pp. 2172–2180, 2016.
Donsker, M. D. and Varadhan, S. S. Asymptotic evaluationof certain markov process expectations for large time. iv.Communications on Pure and Applied Mathematics, 36(2):183–212, 1983.
Duan, Y., Chen, X., Houthooft, R., Schulman, J., andAbbeel, P. Benchmarking deep reinforcement learningfor continuous control. In International Conference onMachine Learning, pp. 1329–1338, 2016.
Fu, J., Co-Reyes, J., and Levine, S. Ex2: Exploration withexemplar models for deep reinforcement learning. InAdvances in Neural Information Processing Systems, pp.2577–2587, 2017.
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B.,Warde-Farley, D., Ozair, S., Courville, A., and Bengio,Y. Generative adversarial nets. In Advances in neuralinformation processing systems, pp. 2672–2680, 2014.
Hjelm, R. D., Fedorov, A., Lavoie-Marchildon, S., Gre-wal, K., Trischler, A., and Bengio, Y. Learning deeprepresentations by mutual information estimation andmaximization. arXiv preprint arXiv:1808.06670, 2018.
Houthooft, R., Chen, X., Duan, Y., Schulman, J., De Turck,F., and Abbeel, P. Vime: Variational information maxi-mizing exploration. In Advances in Neural InformationProcessing Systems, pp. 1109–1117, 2016.
Kingma, D. P. and Ba, J. L. Adam: A method for stochasticoptimization. In Proceedings of the 3rd InternationalConference on Learning Representations (ICLR), 2015.
Kingma, D. P. and Welling, M. Auto-encoding variationalbayes. arXiv preprint arXiv:1312.6114, 2013.
Kohonen, T. Representation of information in spatial mapswhich are produced by self-organization. In Synergeticsof the Brain, pp. 264–273. Springer, 1983.
Kohonen, T. and Somervuo, P. Self-organizing maps ofsymbol strings. Neurocomputing, 21(1-3):19–30, 1998.
Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness,J., Bellemare, M. G., Graves, A., Riedmiller, M., Fidje-land, A. K., Ostrovski, G., et al. Human-level controlthrough deep reinforcement learning. Nature, 518(7540):529, 2015.
Mnih, V., Badia, A. P., Mirza, M., Graves, A., Lillicrap,T., Harley, T., Silver, D., and Kavukcuoglu, K. Asyn-chronous methods for deep reinforcement learning. InInternational conference on machine learning, pp. 1928–1937, 2016.
Mohamed, S. and Rezende, D. J. Variational informationmaximisation for intrinsically motivated reinforcementlearning. In Advances in neural information processingsystems, pp. 2125–2133, 2015.
Nachum, O., Gu, S., Lee, H., and Levine, S. Near-optimalrepresentation learning for hierarchical reinforcementlearning. arXiv preprint arXiv:1810.01257, 2018.
Nowozin, S., Cseke, B., and Tomioka, R. f-gan: Traininggenerative neural samplers using variational divergenceminimization. In Advances in Neural Information Pro-cessing Systems, pp. 271–279, 2016.
Oh, J., Guo, X., Lee, H., Lewis, R. L., and Singh, S. Action-conditional video prediction using deep networks in atarigames. In Advances in neural information processingsystems, pp. 2863–2871, 2015.
Oord, A. v. d., Li, Y., and Vinyals, O. Representation learn-ing with contrastive predictive coding. arXiv preprintarXiv:1807.03748, 2018.
Ostrovski, G., Bellemare, M. G., Oord, A. v. d., and Munos,R. Count-based exploration with neural density models.arXiv preprint arXiv:1703.01310, 2017.

EMI: Exploration with Mutual Information
Pathak, D., Agrawal, P., Efros, A. A., and Darrell, T.Curiosity-driven exploration by self-supervised predic-tion. In International Conference on Machine Learning,volume 2017, 2017.
Schulman, J., Levine, S., Abbeel, P., Jordan, M., and Moritz,P. Trust region policy optimization. In InternationalConference on Machine Learning, volume 2015, 2015.
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., andKlimov, O. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017.
Stadie, B. C., Levine, S., and Abbeel, P. Incentivizing ex-ploration in reinforcement learning with deep predictivemodels. arXiv preprint arXiv:1507.00814, 2015.
Tang, H., Houthooft, R., Foote, D., Stooke, A., Chen, X.,Duan, Y., Schulman, J., DeTurck, F., and Abbeel, P. #exploration: A study of count-based exploration for deepreinforcement learning. In Advances in Neural Informa-tion Processing Systems, pp. 2753–2762, 2017.
Thomas, V., Pondard, J., Bengio, E., Sarfati, M., Beaudoin,P., Meurs, M.-J., Pineau, J., Precup, D., and Bengio,Y. Independently controllable factors. arXiv preprintarXiv:1708.01289, 2017.
van den Oord, A., Kalchbrenner, N., Espeholt, L., Vinyals,O., Graves, A., et al. Conditional image generation withpixelcnn decoders. In Advances in Neural InformationProcessing Systems, pp. 4790–4798, 2016.





























