Embed Size (px)
Citation preview

Efficient and Numerically Stable
Sparse Learning
Sihong Xie1, Wei Fan2, Olivier Verscheure2, and Jiangtao
Ren3
1University of Illinois at Chicago, USA2 IBM T.J. Watson Research Center, New York, USA
3 Sun Yat-Sen University, Guangzhou, China
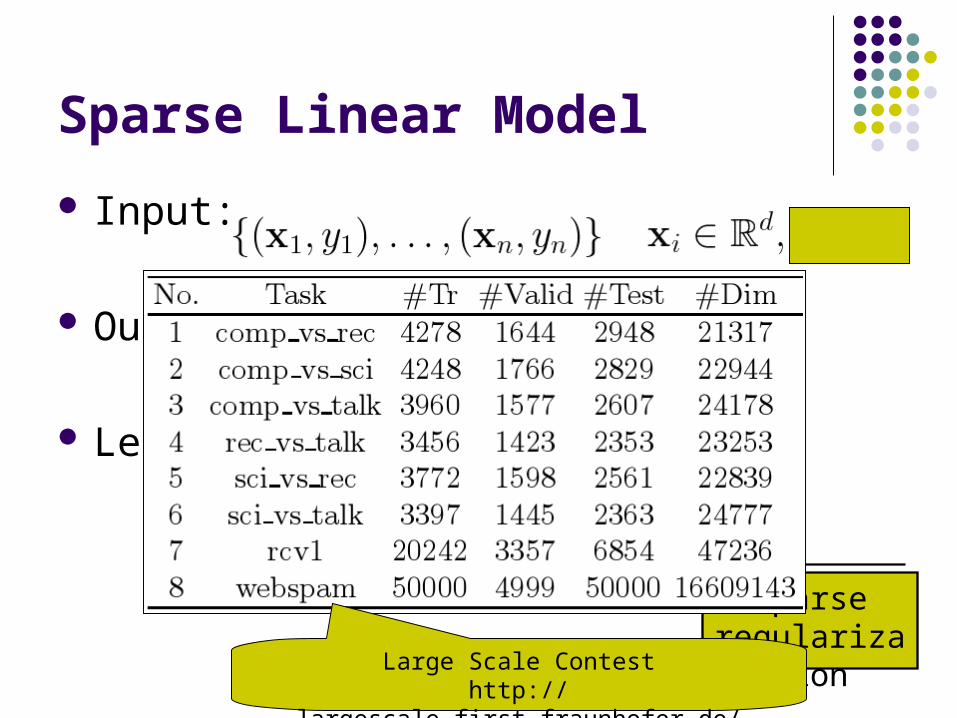
Sparse Linear Model
Input:
Output: sparse linear model
Learning formulation
Sparse regularization
Large Scale Contesthttp://largescale.first.fraunhofer.de/instructions/

Objectives Sparsity
Accuracy
Numerical Stability limited precision friendly
Scalability Large scale training data (rows and columns)

Outline
“Numerical un-stability” of two popular approaches
Propose sparse linear model online numerically stable parallelizable good sparcity – don’t take features unless
necesseary Experiments results

Stability in Sparse learning
•Numerical Problems of Direct Iterative Methods
Numerical Problems of Mirror Descent
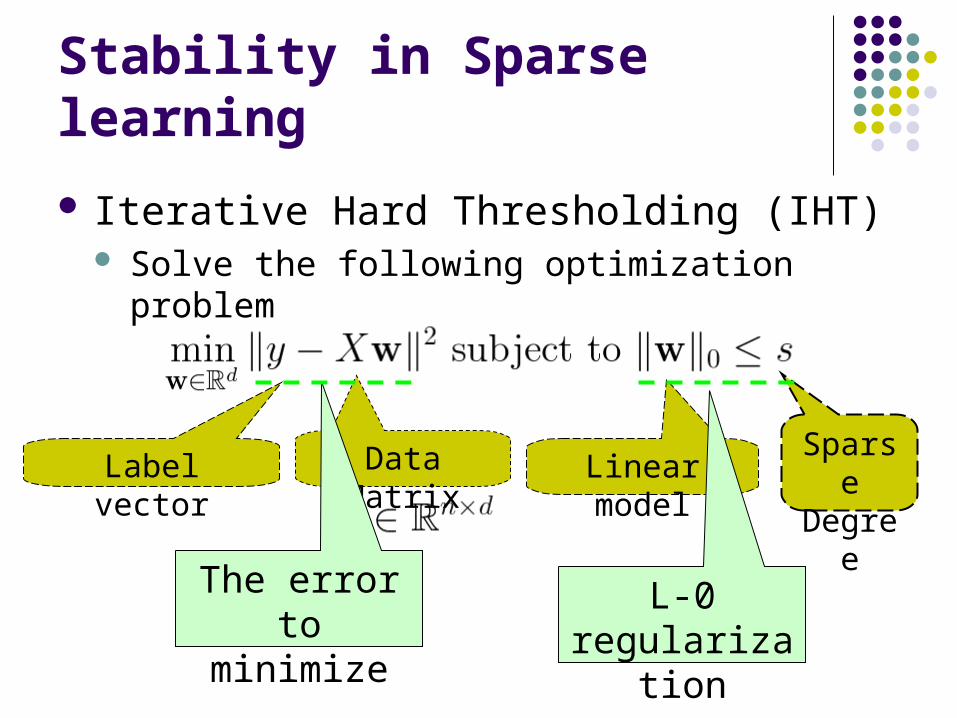
Stability in Sparse learning
Iterative Hard Thresholding (IHT) Solve the following optimization problem
Linear modelLabel vector Data Matrix Sparse Degree
The errorto minimize
L-0 regularization
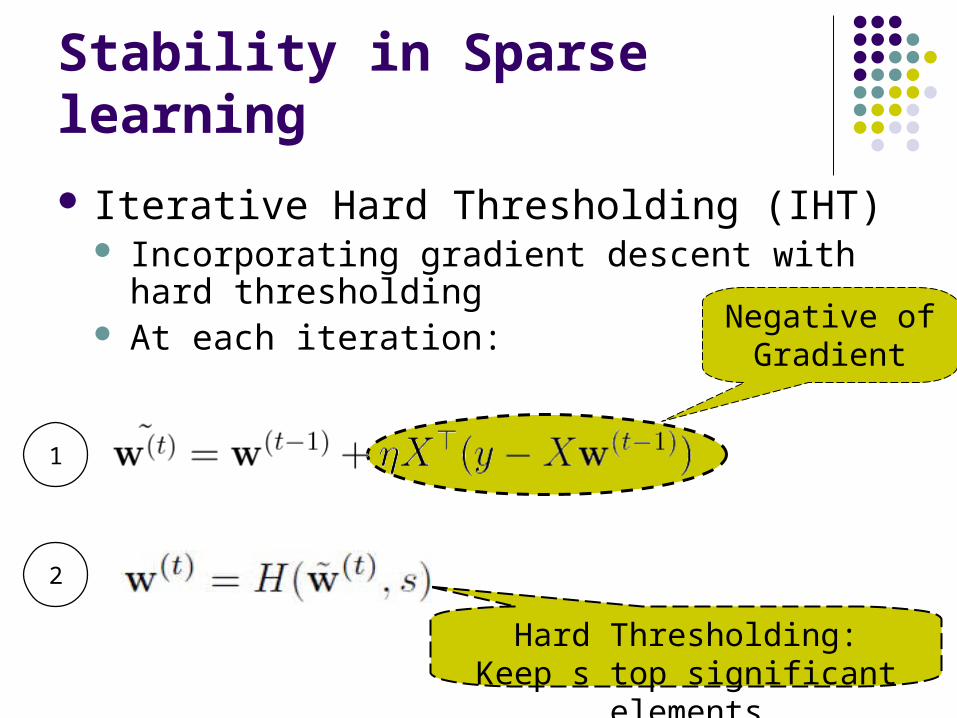
Stability in Sparse learning
Iterative Hard Thresholding (IHT) Incorporating gradient descent with hard
thresholding At each iteration:
Hard Thresholding:Keep s top significant elements
Negative ofGradient
1
2
Iterative Hard Thresholding (IHT) Advantages: Simple and scalable
Stability in Sparse learning
Convergence of IHT

Stability in Sparse learning
For IHT algorithm to converge, the iteration matrix should have its spectral radius less than 1
Spectral radius
•Iterative Hard Thresholding (IHT)
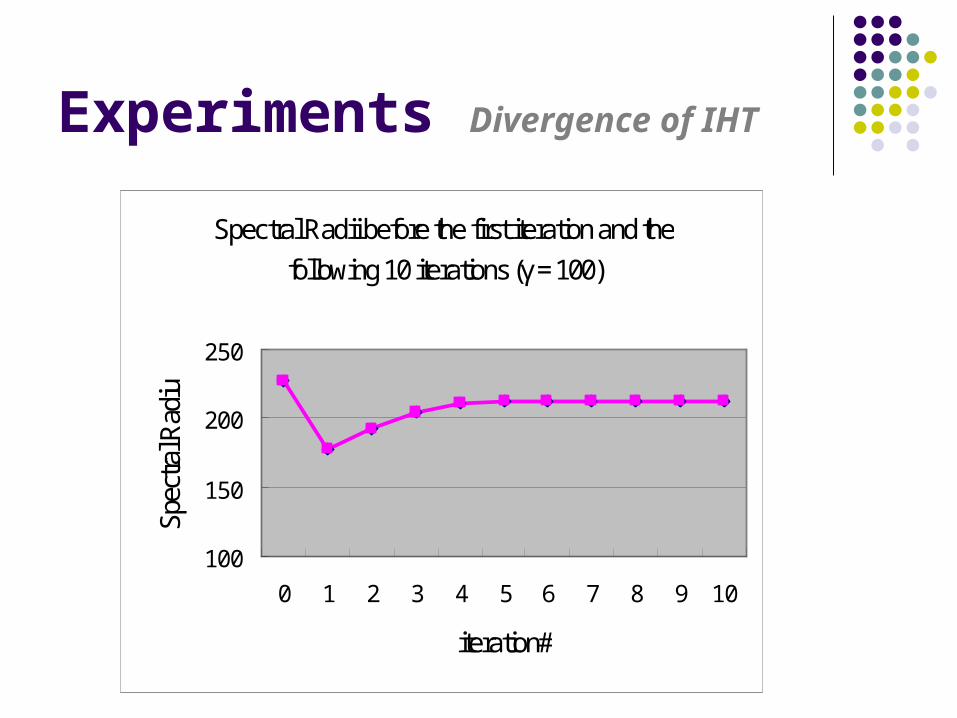
Experiments Divergence of IHT
Spectral Radii before the first iteration and thefollowing 10 iterations (γ = 100)
100
150
200
250
0 1 2 3 4 5 6 7 8 9 10
iteration#
Spec
tral R
adiu
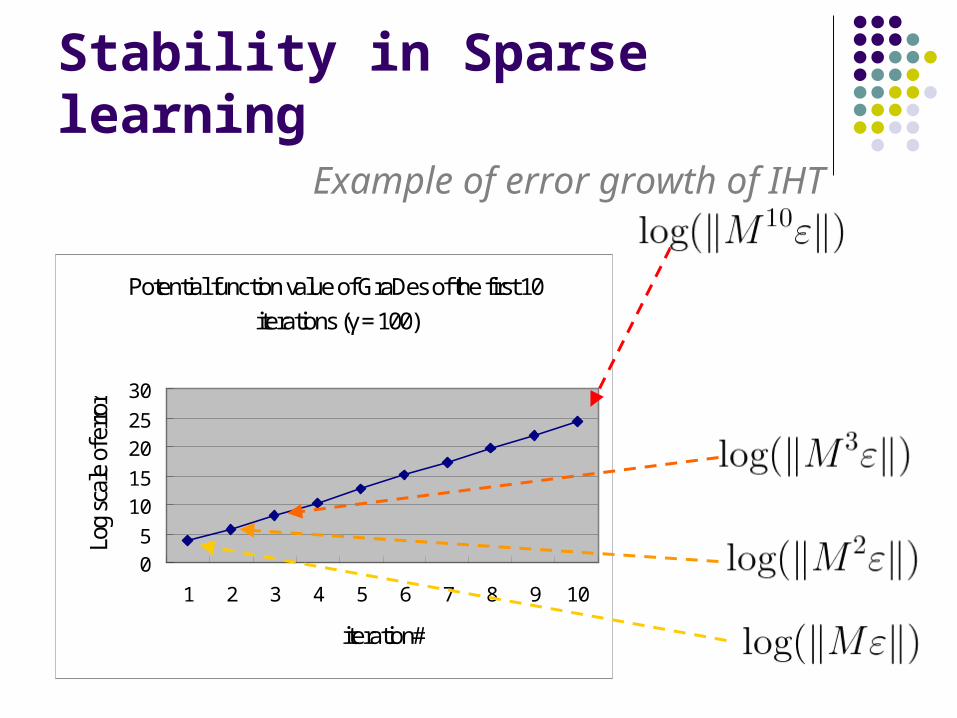
Stability in Sparse learning
Potential function value of GraDes of the first 10iterations (γ = 100)
05
1015
2025
30
1 2 3 4 5 6 7 8 9 10
iteration#
Log
scal
e of
erro
r
Example of error growth of IHT

Stability in Sparse learning
Numerical Problems of Mirror Descent
•Numerical Problems of Direct Iterative Methods
Numerical Problems of Mirror Descent

Stability in Sparse learning
Mirror Descent Algorithm (MDA) Solve the L-1 regularized formulation
Maintain two vectors: primal and dual
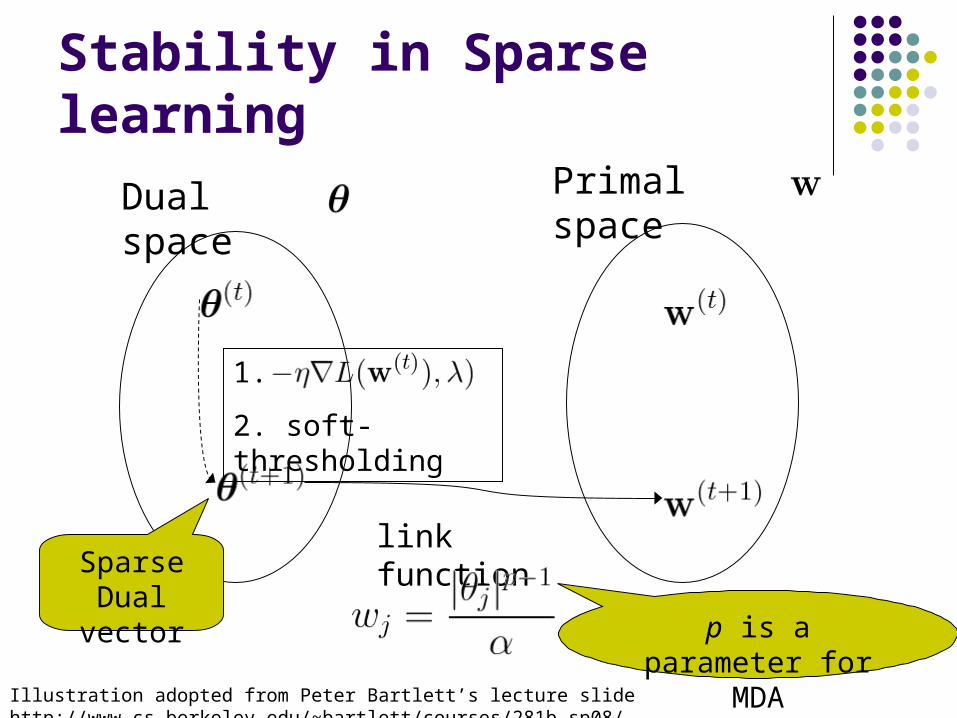
Stability in Sparse learning
Dual space Primal space
Illustration adopted from Peter Bartlett’s lecture slide http://www.cs.berkeley.edu/~bartlett/courses/281b-sp08/
link function
1.
2. soft-thresholding
SparseDual vector
p is a parameter for MDA

Stability in Sparse learning
MDA link function
Floating number system
significant digits base exponent×
Example: A computer with only 4 significant digits 0.1 + 0.00001 = 0.1
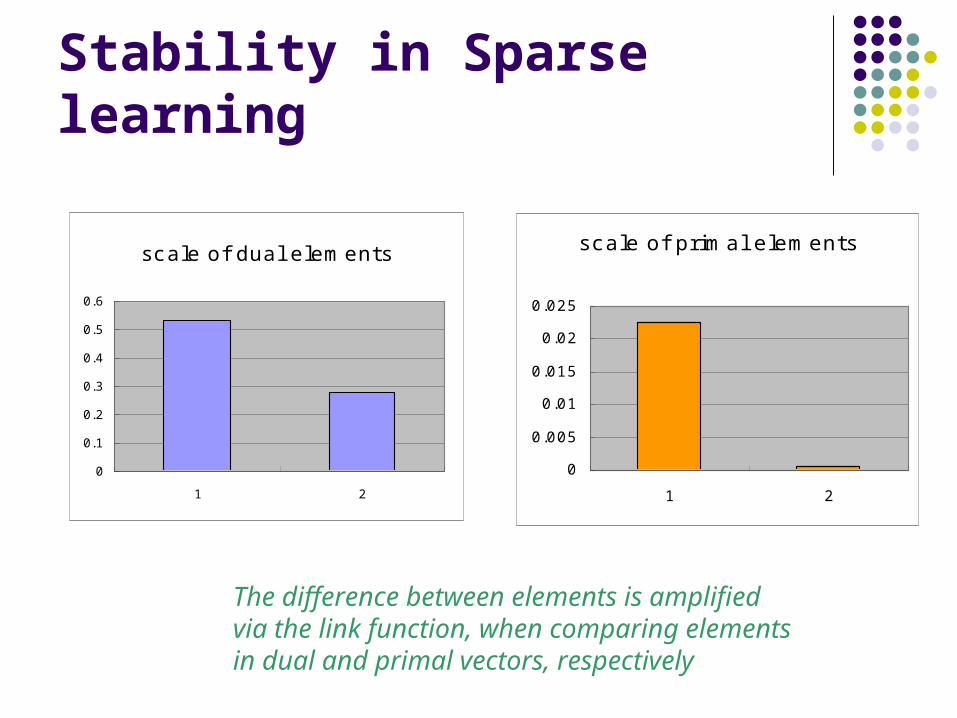
Stability in Sparse learning
scale of dual elements
0
0.1
0.2
0.3
0.4
0.5
0.6
1 2
scale of primal elements
0
0.005
0.01
0.015
0.02
0.025
1 2
The difference between elements is amplified via the link function, when comparing elements in dual and primal vectors, respectively

Experiments Numerical problem of MDA
Experimental settings Train models with 40%
density. Parameter p is set to 2ln(d)
(p=33) and 0.5 ln(d) respectively [ST2009]
selectedunsed
[ST2009] Shai S. Shwartz and Ambuj Tewari. Stochastic methods for ℓ1 regularized loss minimization. In ICML, pages 929–936. ACM, 2009.

Performance Criteria Percentage of elements that are
truncated during prediction Dynamical range
Experiments Numerical problem of MDA

Objectives of a Simple Approach
Numerically Stable Computationally efficient
Online, parallelizable Accurate models with higher sparsity
Costly to obtain too many features (e.g. medical diagnostics)
For an excellent theoretical treatment of trading off between accuracy and sparsity see
S. Shalev-Shwartz, N. Srebro, and T. Zhang. Trading accuracy for sparsity. Technical report, TTIC, May 2009.
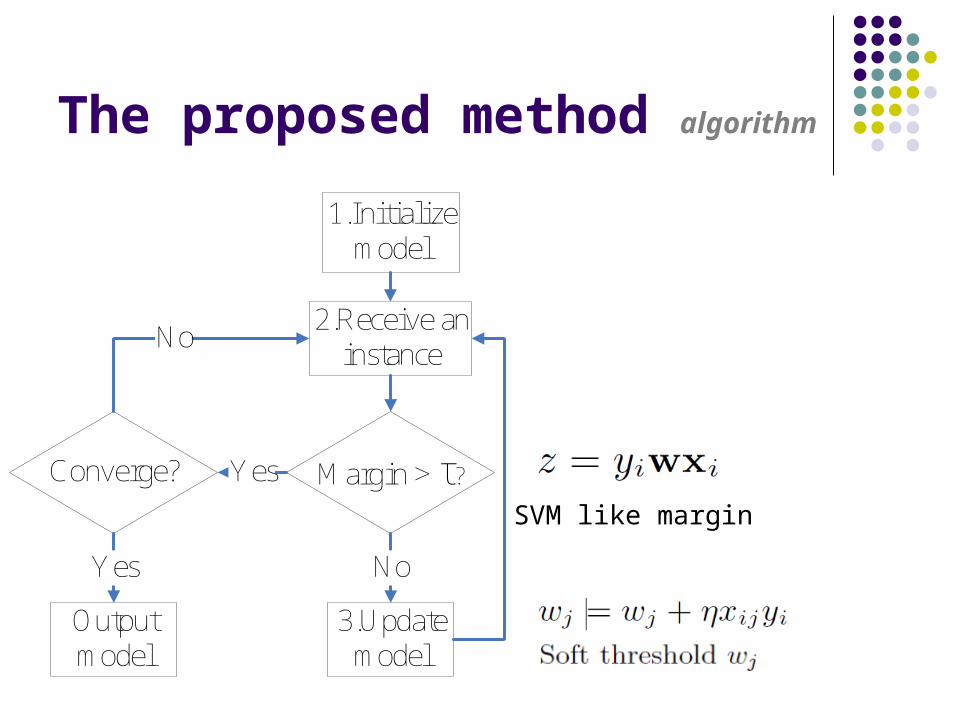
The proposed method algorithm
1.Initialize model
2.Receive an instance
3.Update model
Margin > τ?Yes
No
Converge?
Output model
Yes
No
SVM like margin

Numerical Stability and Scalability Considerations
numerical stability Less conditions on data matrix such as spectral
radius and no change of scales
Less precision demanding (works under limited precision, theorem 1) Under mild conditions, the proposed method
converges even for a large number of iterations proportional to
Machine precision

Numerical Stability and Scalability Considerations
Online fashion: one example at a time Parallelization for intensive data access
Data can be distributed to computers, where parts of the inner product can be obtained.
Small network communication (only parts of inner product and signals to update model)

The proposed method properties
Soft-thresholding L1-regularization for sparse model
Perceptron: avoids updates when the current features are able to predict well – sparcity
Convergence under soft-thresholding and limited precision (Lemma 2 and Theorem 1) – numerical stability
Generalization error bound (Theorem 3)
Don’t complicate the model when
unnecessary
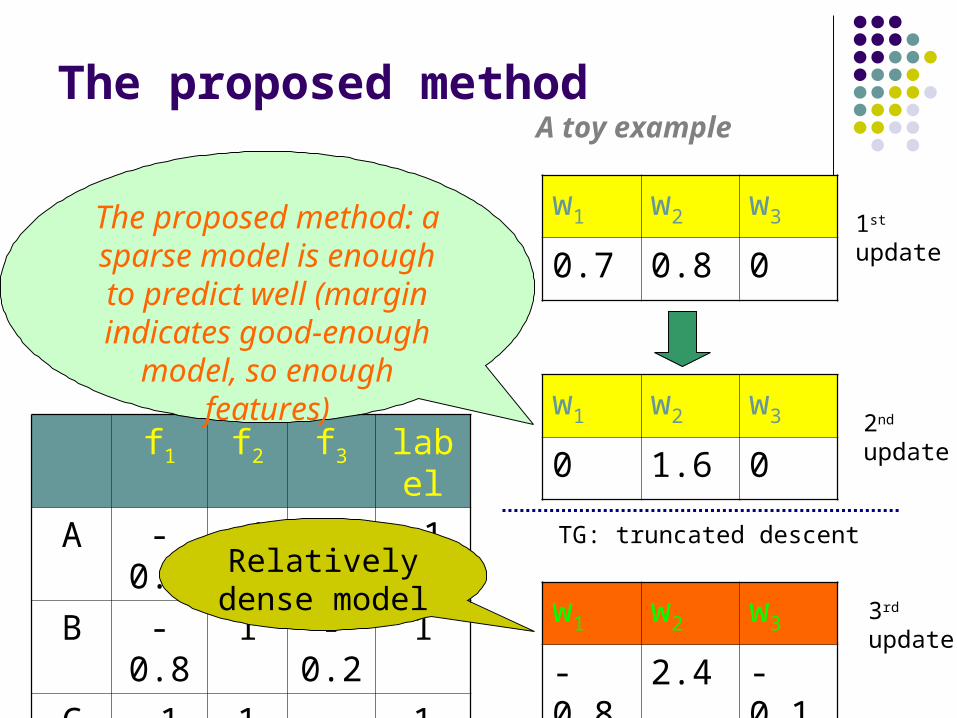
The proposed method A toy example
f1 f2 f3 label
A -0.9 -1 0.2 -1
B -0.8 1 -0.2 1
C -1 1 -0.3 1
w1 w2 w3
0 1.6 0
w1 w2 w3
-0.8 2.4 -0.1
w1 w2 w3
0.7 0.8 0
Relatively dense model
The proposed method: a sparse model is enough to predict well (margin indicates good-enough
model, so enough features)
TG: truncated descent
1st
update
2nd
update
3rd
update

Experiments Overall comparison The proposed algorithm + 3 baseline sparse
learning algorithms (all with logistic loss function) SMIDAS (MDA based [ST2009]): p = 0.5log(d)
(cannot run with bigger p due to numerical problem)
TG (Truncated Gradient [LLZ2009]) SCD (Stochastic Coordinate Descent [ST2009])
[ST2009] Shai Shalev-Shwartz and Ambuj Tewari, Stochastic methods for l1 regularized loss minimization. Proceedings of the 26th International Conference on Machine Learning,pages 929-936, 2009.[LLZ2009] John Langford, Lihong Li, and Tong Zhang. Sparse online learning via truncatedgradient. Journal of Machine Learning Research, 10:777–801, 2009.

Experiments Overall comparison
Accuracy under the same model density First 7 datasets: maximum 40% of features Webspam: select maximum 0.1% of features Stop running the program when maximum
percentage of features are selected
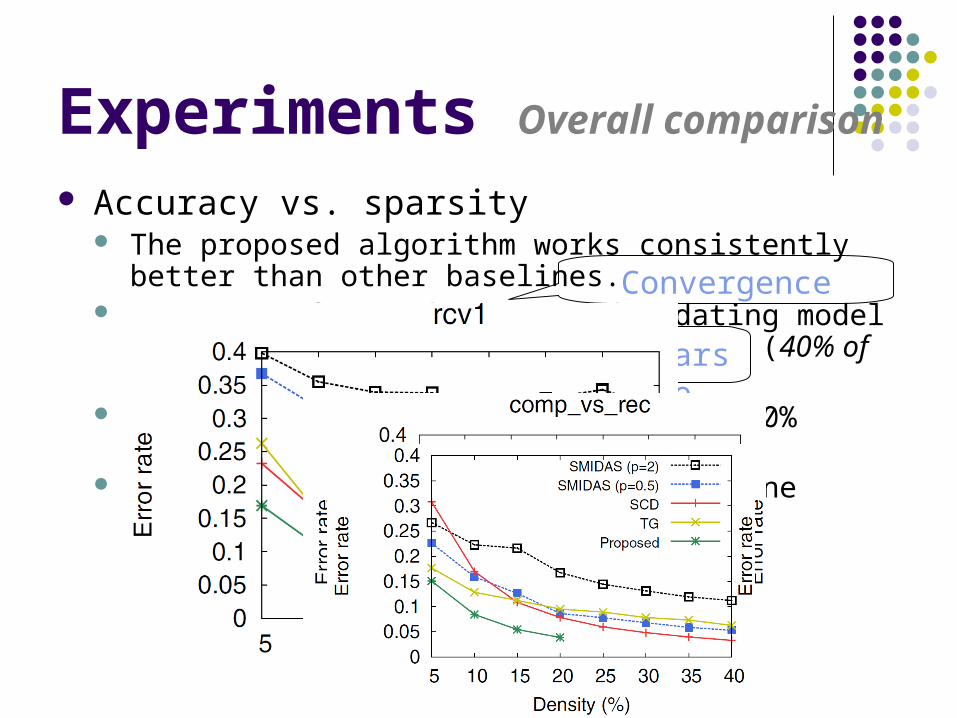
Experiments Overall comparison
Accuracy vs. sparsity The proposed algorithm works consistently better than
other baselines. On 5 out of 8 tasks, stopped updating model before
reaching the maximum density (40% of features) On task 1, outperforms others with 10% features On task 3, ties with the best baseline using 20% features
Sparse
Convergence

Conclusion Numerical Stability of Sparse Learning
Gradient Descent using matrix iteration may diverge without the spectral radius assumption.
When dimensionality is high, MDA produces many infinitesimal elements.
Trading off Sparsity and Accuracy Other methods (TG, SCD) are unable to train accurate
models with high sparsity. Proposed approach is numerically stable, online
parallelizable and converges. Controlled by margin L-1 regularization and soft threshold
Experimental codes are available www.weifan.info













![Visibility of individual packet loss on H.264 encoded ...tysong/files/MMCN09-QoE.pdf · Verscheure et al [9] studied the impact of bit rate, data loss and their combined impact on](https://img.pdfslide.us/doc/110x75/5ababaed7f8b9ad1768be16b/visibility-of-individual-packet-loss-on-h264-encoded-tysongfilesmmcn09-qoepdfverscheure.jpg)
















