Embed Size (px)
Citation preview

Effect of Frequency and Idiomaticity onSecond Language ReadingComprehension
RON MARTINEZUniversity of NottinghamNottingham England
VICTORIA A MURPHYUniversity of OxfordOxford England
A number of studies claim that knowledge of 5000ndash8000 of the mostfrequent words should provide at least 95 coverage of mostunsimplified texts in English arguably enough to guess or ignoremost unknown words while reading (Hirsh amp Nation 1992 Hu ampNation 2000 Laufer 1991 Nation 2006) However perhaps hidden inthat 95 figure are other kinds of wordsmdashmultiword expressionsmdashnotaccounted for by current estimates based on frequency lists Suchexpressions are often composed of highly frequent words andtherefore it is possible that such items may go unnoticed by learnersreading in the second language To test this assertion a two-part testwas taken by 101 adult Brazilian learners of English One partcontained short texts composed of the top 2000 words in Englishthe second part contained the exact same words however thearrangement of these same words constituted multiword expressions(eg large and by R by and large) Tests of reading comprehensionindicated that learnersrsquo comprehension not only decreased signifi-cantly when multiword expressions were present in text but studentsalso tended to overestimate how much they understood as a function ofexpressions that either went unnoticed or were misunderstooddoi 105054tq2011247708
M uch research into second language (L2) learning points to readingas an important source for linguistic development in the target
language (eg Elley amp Mangubhai 1983 Krashen 1993 Nation 1997)However unlike native speakers who can usually understand close to 100of nonspecialized texts (Carver 1994) readers processing text in a foreignlanguage are often faced with a comparatively laborious and cumbersomejob that at times might seem more like an unpleasant guessing game In
TESOL QUARTERLY Vol 45 No 2 June 2011 267
much of the literature to date researchers have suggested that by passingcertain vocabulary lsquolsquothresholdsrsquorsquo (Nation 2001 p 144) L2 readersrsquocomprehension of texts in the target language will naturally increaseAlthough the preceding claim is undoubtedly true to a degree there issome question as to what exactly constitutes vocabulary
When most language students and teachers hear vocabulary they thinkwords (Hill 2000) However studies of large bodies of naturally occurringtextual data or corpora have shown that some words commonly occur withother words and these combinations actually form unitary and distinctmeanings (Nattinger amp DeCarrico 1992 Pawley amp Syder 1983 Sinclair1991) Such multiword expressions are increasingly being viewed byresearchers as a central part of the mental lexicon and even languageacquisition itself (Ellis 2008 Wray 2002) Therein lies the current chasmbetween research into the relationship between vocabulary and readingcomprehension and research into vocabulary Clearly vocabulary is morethan individual words but individual words are all that is mentioned incurrent research on vocabulary thresholds
A possible reason for the aforementioned dichotomy is the fact thatword coverage estimates (how many words are known in a text) are basedon lists of the most common orthographic words alone This monolexicaltendency in word lists is merely a reflection of current technologicallimitations There is simply no easy way to automatically extract frequencylists that are inclusive of meaningful multiword lexical items Nonethelessthis convenient exclusion has also meant that little research to date hasoccurred into what effects such expressions might have on readingcomprehension as it is often simply assumed that idiomatic expressionsare fairly rare in language and still fewer are the ones which cannot bedecoded through context or other semantic clues (Grant amp Bauer 2004)However it is argued throughout the present article that not only aremultiword expressions much more common than popularly assumed butthey are also difficult for readers to both accurately identify and decodemdasheven when they only contain very common words
As supporting evidence for the above assertions we describe andpresent data from a study that put to test multiword expressions and thepossible effects they have on reading comprehension
RELATIONSHIP BETWEEN THE NUMBER OF WORDSKNOWN AND READING COMPREHENSION
According to informed estimates (eg Goulden Nation amp Read1990) the average educated native speaker of English possesses a
1 According to Nation (2001) a word family consists of lsquolsquoa headword its inflected forms andits closely derived formsrsquorsquo (p 8)
268 TESOL QUARTERLY
receptive knowledge of around 20000-word families1mdasha number whichmay seem daunting to a learner of the language Perhaps for that reasona number of researchers (eg Hirsh amp Nation 1992 Hu amp Nation 2000Laufer 1989b) have endeavored to answer the following question Howmany words are really necessary in order to comprehend most texts Theanswer to that question is of interest to a wide range of parties fromdevelopers of English as a foreign language textbooks to writers ofgraded readers to practicing classroom teachers and their students(Nation amp Waring 1997) After all to be able to put a concrete numberon the words one needs to know to function in the target language is tobe able to set teaching goals divide proficiency levels and see aproverbial light at the end of the L2 learning tunnel
However the answer to that question has also proved somewhatcomplex requiring identifying not so much how many words one needsto know in absolute terms but rather how many words a learner needs toknow in order to understand a text in spite of unknown vocabulary Basingtheir assertions mostly on the assumption that pleasurable reading occursonly when a reader knows almost all the words in a text Hirsh and Nation(1992) stipulated the ideal percentage of words known in an unsimplifiedtext at around 98 which the authors claimed could be reached with aknowledge of 5000-word families However one limitation of the Hirsh andNation study was that the texts used were novels written for teenagers andadolescents To determine whether the same word family figure wouldapply to authentic texts designed for general (ie adult native speaker)consumption Nation (2006) conducted a new analysis of fiction andnonfiction text (eg novels and newspapers) The trialing showed that if98 coverage of a text is needed for unassisted comprehension then an8000- to 9000-word family vocabulary is needed Therefore assuming the98 figure is valid (as supported by Hu amp Nation 2000 and most recentlySchmitt Jiang amp Grabe 2011) a learner requires a knowledge of at least8000-word families in order to adequately comprehend most unsimplifiedfiction and nonfiction text
Word Counts and Their Limitations
The estimates of how many words a reader needs to know in order toread unsimplified text may actually be somewhat misleading withoutcritical examination of the underlying constructs The main problem liesin the compilation of word frequency lists themselves including whatconstitutes a word (cf Gardner 2007)
As mentioned earlier current research suggests that 8000ndash9000 wordscan provide around 98 coverage of most texts (Nation 2006) However
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 269
Nationrsquos recommendations are for an lsquolsquo8000ndash9000 word-family vocabu-laryrsquorsquo (p 79) which does not necessarily mean knowing 8000 words
From the point of view of reading a word family consists of a base word andall its derived and inflected forms that can be understood by a learnerwithout having to learn each form separately [ ] The important principlebehind the idea of a word family is that once the base word or even a derivedword is known the recognition of other members of the family requires littleor no extra effort (Bauer amp Nation 1993 p 253)
In the lists that Nation and other researchers have used to calculate wordknowledge (eg Nation 2006 West 1953) a word can include a base formand over 80 derivational affixes (Nation 2006 p 66) resulting in lsquolsquosomelarge word families especially among the high-frequency wordsrsquorsquo (Nation2006) but there may be an issue of overconflation of forms Consider forexample the semantic distance between the following pairs of words nameR namely price R priceless fish R fishy puzzle R puzzling Each of thepreceding pairs would be grouped into the same respective word family butit is unlikely that a learner of English would require lsquolsquolittle or no extraeffortrsquorsquo (Bauer amp Nation 1993 p 253) to derive the meaning of a word likefishy from fish2 It is therefore conceivable that a number of those 8000- to9000-word families do not have the psycholinguistic validity that issometimes assumed and some of the 30000 (or so) separate wordssubsumed in those families would in fact need to be learned separately
Similar to the semantic distance between fish and fishy there is oftenan equal or greater disparity of meaning when a word is juxtaposed withanother or more words and a new expression forms (Moon 1997 Wray2002) For example the words fine good and perfect each have meaninghowever those meanings do not remain in the expressions finely tunedfor good and perfect stranger
Nation (2006) recognized this limitation of current word lists howeverhe did not consider it a problem Nation based this assertion on theassumption that most learners will be able to guess the meaning ofmultiword expressions that have some element of transparency and sincethe number of lsquolsquotruly opaquersquorsquo phrases in English is relatively small for thepurposes of reading they are lsquolsquonot a major issuersquorsquo (p 66) However it isdebatable just how lsquolsquosmallrsquorsquo in number those opaque expressions are andmuch like the previously discussed derived word forms that are actuallysemantically dissimilar just how easy it is for a learner of English toaccurately guess the meaning of more lsquolsquotransparentrsquorsquo expressions
2 According to the Cambridge Advanced Learnerrsquos Dictionary (Walter Woodford amp Good2008) which is informed by the one-billion-word Cambridge International Corpus thefirst sense of fishy is lsquolsquodishonest or falsersquorsquo (p 537) and not lsquolsquosmelling of fishrsquorsquo
270 TESOL QUARTERLY
Martinez and Schmitt (2010) for example sought to compile a list of themost common expressions derived from the British National Corpus3
(BNC) Their main criteria for selection was frequency and relativenoncompositionality in other words the items chosen for selection neededto possess semantic and grammatical properties that could pose decodingproblems for learners when reading Their exhaustive search rendered over500 multiword expressions that were frequent enough to be included in alist of the top 5000 words in Englishmdashor over 10 of the entire frequencylist A sample of the list is provided in Table 1
As an example of how taking word frequency into account alonepotentially leads to very misleading estimates of text comprehensibilityconsider the following text taken from The Economist
But over the past few months competing 3G smartphones with touch screensand a host of features have been coming thick and fast to the American marketAnd waiting in the wings are any number of open-source smartphones basedon the nifty Linux operating system Apple will need to pull out all the stops ifthe iPhone is not to be swept aside by the flood of do-it-all smartphonesheading for Americarsquos shores (lsquolsquoThe iPhonersquos second comingrsquorsquo 2008)
The above paragraph contains a number of expressions which are partlyor totally opaque including the following seven
- over the past- a host of- thick and fast- waiting in the wings- any number of- pull out all the stops- swept aside
3 A 100-million word corpus predominantly composed of written English (The BritishNational Corpus 2007)
TABLE 1
Highly Frequent Idioms With Words From Beginner EFL Textbooks for Comparison
Frequency (BNC) Idioms Frequency (BNC) Words (for comparison)
18041 as well as 466 steak14650 at all 455 niece12762 in order to 400 receptionist10556 take place 387 lettuce7138 for instance 385 gym4584 and so on 377 carrot4578 be about to 341 snack3684 at once 337 earrings2676 in spite of 302 dessert1995 in effect 291 refrigerator
Note EFL 5 English as a foreign language BNC 5 British National Corpus
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 271
Current text word coverage calculations ignore such expressionsAccording to software commonly used to analyze the word familyfrequency distribution of text (VocabProfile [Cobb nd]) the sameEconomist paragraph is broken down as shown in Table 2
So if comprehension of a text were based on word coverage alonecurrent methods of text analysis (Table 2) suggest that a learner with avocabulary of at least the top 2000 words in English should be able tounderstand 9552 of the lexis in the Economist text (64 of the 67 words[tokens] counted) by some estimates (eg Laufer 1989b) enough foradequate comprehension If that same learner also knew just two wordsin the text on the Academic Word List (Coxhead 2000)mdashfeatures andsourcemdashshe would understand an additional 299 affording thatlearner a knowledge of 9851mdashtheoretically approximating nativelikelevels of comprehension (Carver 1994 p 432) However a closer lookat the breakdown in Table 2 shows that words like pull out all the andstops were all considered as separate and very common words when inreality they form one noncompositional expression pull out all the stopsIn fact all of the seven expressions have mistakenly been fragmentedand categorized as pertaining to the top 2000 words Thereforeassuming that a learner who knows only the 2000 most common wordsin English would not understand those expressions without the help of adictionary and if we reconduct the analysis taking those sevenexpressions into account (constituting 23 words) the total number ofwords fitting into the top 2000 goes down to 41 (64 minus 23) and that9552 figure actually drops from adequate comprehension down to6119 (41 4 67 5 06119)mdashwell below acceptable levels of readingcomprehension (Hu amp Nation 2000)
TABLE 2
Word Frequency Breakdown of The Economist text (Not Including Proper Nouns)
Frequency Words (67 tokens 54 types) Text coverage
0ndash1000 a all and any are based be been but by comingdo fast few for have heading if in is it marketmonths need not number of on open operatingout over past pull shores stops system the totouch waiting will with
8358
1001ndash2000 aside competing flood host screens swept thickwings
1194
Academic Word List(AWL)
features source 299
Off list Nifty 149Words in top 2000 9552+ AWL words 299Total text coverage 9851
272 TESOL QUARTERLY
RELATIONSHIP BETWEEN FORMULAIC LANGUAGE ANDREADING COMPREHENSION
Considering the relative wealth of research and literature on L2reading comprehension and separately multiword expressions inEnglish there is a surprising dearth of information regarding the roleif any formulaic language plays in the comprehension of texts in aforeign language The relatively few studies that do exist (eg Cooper1999 Liontas 2002) seem to confirm that it is especially the moresemantically opaque idioms that pose interpretability problems for L2readers and as these more core idioms are relatively rare (Grant ampNation 2006) Nation (2006) could be right in attenuating theirsignificance in reading comprehension
Nevertheless as discussed earlier there is evidence that a significantnumber of relatively opaque expressions occur frequently in texts inEnglish One commonly cited estimate (Erman amp Warren 2000) is thatsomewhat more than one-half (55) of any text will consist of formulaiclanguage (p 50) Naturally the opacity of those expressions will lie onwhat Lewis (1993 p 98) called a lsquolsquospectrum of idiomaticityrsquorsquo (Figure 1) akind of continuum of compositionality
Furthermore even when an expression does not meet the criteria ofcore or nonmatching idiom the relative ease or difficulty with which alearner will unpack its meaning is less inherent to the item itself andmore a learner-dependent variable Just as knowing fish may or may nottranslate into understanding fishy knowing perfect does not necessarilymean understanding perfect stranger
What is more although previous studies (Cooper 1999 Liontas2002) have found that in textual context more transparent idioms weremore easily understood than their opaque counterparts it should alsobe noted that the participants in those studies were aware that they werebeing tested specifically on their ability to correctly interpret idioms Inother words what cannot be known from most existing studies on idiominterpretation is how well the participants would have been able toidentify and understand the idioms in the first place had they not beenaware of their presence in the text
FIGURE 1 A spectrum of idiomaticity (compositionality)
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 273
A notable exception is Bishop (2004) who investigated thedifferential look-up behavior of participants who read texts thatcontained unknown words and unknown multiword expressions synon-ymous with those words Bishop confirmed that even though both wordsand multiword expressions were unknown readers looked up themeaning of words significantly more often He concludes that learnerslsquolsquodo not notice unknown formulaic sequences as readily as unknownwordsrsquorsquo (p 18)
Therefore idiomatic language in text irrespective of composition-ality might most usefully be classified as what Laufer (1989a) calledlsquolsquodeceptively transparentrsquorsquo (p 11) Laufer found that many Englishlearners misanalyze words like infallible as in+fall+ible (ie lsquolsquocannot fallrsquorsquo)and nevertheless as never+less (ie lsquolsquoalways morersquorsquo p 12) Likewisemdashalthough they were not part of her studymdashshe found that idioms like hitand miss were being read and interpreted word for word These lexicalitems that lsquolsquolearners think they know but they do notrsquorsquo (Laufer 1989ap 11) can impede reading comprehension in ways not accounted for inlists of common word families Nation (2006) seemed to assume thatmultiword expressions that have some element of transparency howeversmall will be reasonably interpretable through guessing However theLaufer (1989a) study may provide evidence to the contrary
But an attempt to guess (regardless of whether it is successful or not)presupposes awareness on the part of the learner that he is facing anunknown word If such an awareness is not there no attempt is made to inferthe missing meaning This is precisely the case with deceptively transparentwords The learner thinks he knows and then assigns the wrong meaning tothem [ ] (p 16)
Substitute lsquolsquoidiomrsquorsquo for lsquolsquowordrsquorsquo abovemdashnot an unreasonable conceptualstretchmdashand it becomes clear that multiword expressions just maypresent a larger problem for reading comprehension than accounted forin the current literature
In fact such lsquolsquodeceptionrsquorsquo seems even more likely to occur withmultiword expressions because such a large number of them arecomposed of very common words a learner would assume he or sheknows (Spottl amp McCarthy 2003 p 145 Stubbs amp Barth 2003 p 71)Moreover there is evidence that learners are reluctant to revisehypotheses formed regarding lexical items when reading even whenthe context does not support those hypotheses (Haynes 1993 Pigada ampSchmitt 2006)
274 TESOL QUARTERLY
Summary and Research Questions
In summary the following has been argued thus faramp Current estimates of how many words one needs to know in order to
comprehend most texts may be inaccurate due to overinclusion of derivedword forms and a total exclusion of multiword units of vocabulary
amp Contrary to some research there is evidence in corpus data that thenumber of frequently occurring noncompositional multiwordexpressions in English is higher than previously believed
amp Even when an expression is partly or even fully compositional thereis no way of knowing how accurately an L2 reader will interpret (oreven identify) that item
amp The claim that special attention to the 2000ndash3000 most commonwords in English is pedagogically sound since they provide around80 of text coverage (eg OrsquoKeeffe McCarthy amp Carter 2007Read 2004 p 148 Staelighr 2008) deserves closer scrutiny becausethose words are often merely tips of phraseological icebergs
It is therefore clear that there is a need for further investigation into howcommon words and the multiword units they form can affect readingcomprehension when reading in English as a foreign language To thatend we conducted a study to answer the following research questions
1 Are two texts written with the exact same high-frequency wordsunderstood equally well by L2 learners when one of the texts is moreidiomatic than the other
2 Can the presence of multiword expressions in a text lead L2 learners tobelieve they have understood that text better than they actually have
METHOD
Participants
Brazilian adult learners of English (n 5 101) all native speakers ofBrazilian Portuguese were selected to participate in the study Thesample ranged in age from 18 to 64 years (M 5 2576 SD 5 931) andconsisted of 43 men and 58 women representing seven different regionsof Brazil
All participants in the study had had a minimum of 80 hr of tuition inEnglish prior to the start of the research and had been tested aspossessing intermediate or higher levels of proficiency Howeverbecause all participants attended private language schools the actualinstruments by which their proficiency was assessed varied widely
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 275
Regardless uniformity in proficiency was not of prime importance in thestudy because the research questions are concerned with a significantchange in the paired samples within the same group
The Test
To write the eight texts (four texts in each test) a corpus of words wascarefully chosen from the list of the 2000 most frequent words in the BNCThe reading comprehension of each text was tested by seven true or falseitems totaling 28 per test part or 56 overall The test when administeredappears as one but is actually in two parts (Test 1 and Test 2) each partcontaining the exact same words with some words in Test 2 formingmultiword expressions Great care was taken to ensure that the texts areotherwise equal There is no visual difference between the two parts andthe texts are of almost uniform length in both parts (Table 3 and Figure 2)In addition care was taken not to include any extra cultural references inany of the texts and the comprehension task itself did not change acrossthe test parts The texts are stated to have come from peoplersquos descriptionof themselves in lsquolsquoFriendsbookrsquorsquo (intentionally similar to Facebook) On thewhole therefore it could be said that the style of the text is personal andinformal
The vast majority of the words are in the top 1000 withapproximately 985 of the words occurring in the BNC top 2000(Table 3) These results were in turn compared with the General ServiceList (West 1953) using software developed by Heatley and Nation(Range 1994) and another package using the same corpus created byCobb (nd) The results were practically identical in all cases (Range985 VocabProfile 98494)
Another key feature of the test is the rating scale which requires the testtaker to circle what she believes is his or her comprehension of each textfrom 5 to 1005 This self-reported comprehension is designed to helpanswer the second research question of whether the presence ofmultiword expressions in a text can lead L2 learners to believe they have
TABLE 3
Summary of Test 1 and Test 2 Text Data
Total wordcount
Total clausecount T-unit count
Top 1000words coverage
Top 1001ndash2000 words
coverage
Test 1 416 56 45 957373 27650Test 2 412 54 42 957373 27650
Note Data measured using vocabulary profiler (Cobb nd) A T-unit or a minimal terminableunit is lsquolsquoone main clause plus any subordinate clausersquorsquo (Hunt 1968 p 4)
276 TESOL QUARTERLY
understood that text better than they actually have Testing whatcomprehenders believe they understoodmdashcompared to what they actuallyunderstoodmdashby comparing test scores to self-assessment of comprehen-sion via a rating scale is often referred to as lsquolsquocomprehension calibrationrsquorsquoand is a method that has been used extensively in psychological research(eg Bransford amp Johnson 1972 Glenberg Wilkinson amp Epstein 1982Maki amp McGuire 2002 Moore Lin-Agler amp Zabrucky 2005) butsomewhat less so in applied linguistics (cf Brantmeier 2006 Jung 2003Morrison 2004 Oh 2001 Sarac amp Tarhan 2009)
Finally participants were asked to record their start and finish timesfor each part of the test
Procedure
Following an initial field test an item analysis was conducted toestablish the facility value6 of the test items and a discrimination indexfor both test parts to discern whether the test was discriminatingbetween stronger and weaker participants Items that were found to haveexceptionally high or low scores were carefully analyzed and the wordingof both test items and reading texts adjusted accordingly
Finally as advocated in Schmitt Schmitt and Clapham (2001) oneimportant requirement of an L2 test of reading comprehension is that itbe answerable by native or nativelike speakers of the language (p 65)To that end a smaller group of native speakers (n 5 8) was also tested asan additional check of the testrsquos validity That group produced a mean
FIGURE 2 Side-by-side comparison of matched texts from the two test parts (full version ofthe test available on request)
4 These are vocabulary profilers that essentially use word frequency lists to break all thewords in a text down into those that occur for example in the top 1000 second 1000third 1000 and so on
5 lsquolsquo0rsquorsquo would be virtually impossible because learners would be familiar with most words inthe texts if not all
6 A test itemrsquos facility value is calculated by dividing the number of participants whoanswered that item correctly by the total number of participants (Hughes 2003)
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 277
score of 28 in Test 1 (the maximum score) and 2775 in Test 2 showingthat both test parts posed very little difficulty for people for whomEnglish is a first language
The students received the two parts of the test in alternating order(ie counterbalanced) to control for any effect of taking Test 1 beforeTest 2 (and vice versa) because by counterbalancing one is able toinclude a variable order into an analysis and identify the extent towhich order affects performance on the dependent measures
RESULTS
All the scores and self-reported comprehension measures wererecorded in a statistical analysis software program (SPSS) Eachparticipantrsquos test results were transcribed into the software item by item(ie correct and incorrect) text by text (eg Text A Text B etc numbercorrect out of 7 for each) and test by test (ie Test 1 and Test 2 numbercorrect out of 28 possible for each) Also recorded were each participantrsquosself-reported comprehension assessments (a rating scale from 5 to 100)as they pertained to each text as well as which version (Test 1 or Test 2first) of the instrument each candidate had received To assess the effectof counterbalancing a repeated measures analysis of variance (ANOVA)was conducted with one within-subjects factor (TEST) with two levels(Test 1 score Test 2 score) and one between-subjects factor (VERSION)with two levels (Test 1 first Test 2 first) This analysis revealed a robustmain effect of test (F (199) 5 59338 p 0001 g2 5 086) and a discreteeffect of version (F (199) 5 405 p 5 0047 g2 5 004) but importantlythere was no significant Test 6 Version interaction (F (199) 5 281 p 5
0097 g2 5 002) illustrating that participantsrsquo scores did not vary as afunction of which version of the test they were completing
Comprehension of Test 1 versus Test 2
The central tendencies from both tests are presented in Table 4As predicted participantsrsquo scores were significantly lower on Test 2
relative to Test 1 (t(100) 5 2410 p 0001) with a strong effect size(g2 5 0828)7 confirming that even when two sets of texts contain theexact same words and even if those words are very commoncomprehension of those texts will not be the same when one containsidiomaticity
7 Confidence intervals at 95 for all t-tests
278 TESOL QUARTERLY
Self-Reported Comprehension of Test 1 versus Test 2
A t-test was also performed on the difference between whatparticipants believed they understood (ie their reported comprehen-sion) and what they actually understood in both Tests 1 and 2 (Table 5)Mean reported comprehension (MRC) was arrived at by calculating themeans of all the self-reported comprehension percentages (5ndash100)and the mean actual comprehension (MAC) is the mean of the score oneach text divided by seven (the maximum score)
MAC was lower than MRC in both Test 1(MRC M 5 08738 SD 013MAC M 5 08603 SD 5 009) and Test 2 (MRC M 5 06029 SD 019MAC M 5 05258 SD 5 014) however the difference between MRCand MAC was statistically reliable in Test 2 only where the test wascomposed of multiword expressions (t(100) 5 395 p 0001 g2 5
007)8 These data therefore appear to support a positive answer to thesecond research questionmdashthat learners may believe they understandmore than they actually do by virtue of their simply understanding theindividual words in a text
Variation in the Data
MRC versus MAC
Naturally there were some individual differences in the test resultsTable 6 shows that roughly one-half of all participants (n 5 50)overestimated their comprehension in both tests (indicated by MRC
TABLE 4
Descriptive Statistics (Tests 1 and 2)
Mean Median Mode Minimum Maximum SD
Test 1a 2409 2500 2500 1800 2800 244Test 2b 1476 1500 1500 600 2500 393
Note SD 5 standard deviation aTexts composed of common words however with little or noopaque phraseology bTexts composed of common words which comprise collocations andidiomatic language
TABLE 5
Reported Versus Actual Comprehension
Test 1 Test 2
Mean reported comprehension (MRC) 8738 6029Mean actual comprehension (MAC) 8603 5258
8 By comparison the results of the paired sample t-test for the Test 1 MRC-MAC means weret(100) 5 104 p 5 0302 g2 5 0005
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 279
greater than MAC) On the surface this might suggest that those 50participants did not overestimate their comprehension in Test 2 as aresult of its relative noncompositionality but rather as a generaltendency regardless of idiomaticity However when MAC is subtractedfrom MRC for that group and the difference compared across the teststhe difference is twice as large in Test 2 (t(49) 5 492 p 0001 g2 5
0108) This difference is even more evident in the same analysis of Test2 alone Isolating the results of that test there was a total of 70participants (over 69 of the entire sample) whose MRC was greaterthan their MAC The difference between MRC minus MAC for thesubgroup of 70 participants reveals that their overestimation of theircomprehension in Test 2 was four times greater than in Test 1 (t(69) 5
770 p 0001 g2 5 0228) Further among that group of 70 whoseTest 2 MRC was greater than their MAC 20 students either under-estimated or actually accurately guessed their comprehension in Test 1but significantly overestimated their comprehension in Test 2 (t(19) 5
849 p 0001 g2 5 0264) Only 30 participants in the present studyactually underestimated their comprehension on Test 2
Variation in Time Spent on the Tests
All candidates were also asked to record their start and finishing timesof each test (Table 7) It is not surprising that on average participantsspent more time on the texts which contained idiomatic expressionsHowever this trend was not uniform among the participants and thetime data may help provide some insight into just how aware someparticipants were of the presence of idiomaticity in the texts Thispossibility is explored further in the Discussion
TABLE 6
Trend of Increase in MRC-MAC Discrepancy Across Test Parts
NMRC minus MAC
(Test 1)MRC minus MAC
(Test 2)
Students with MRC MAC (bothtest parts)
50 009 019
Students with MRC MAC (Test 2) 70 004 017Students with MRC MAC (Test 2only)
20 2010 014
Students with MRC MAC (Test 2) 31a 2005 2015
Note MRC 5 mean reported comprehension MAC 5 mean actual comprehension aOnly oneparticipant in this group had MRC 5 MAC
280 TESOL QUARTERLY
DISCUSSION
To reiterate the present study sought to address the followingresearch questions
1 Are two texts written with the exact same high-frequency wordsunderstood equally well by L2 learners when one of the texts is moreidiomatic than the other
2 Can the presence of multiword expressions in a text lead L2 learners tobelieve they have understood that text better than they actually have
A group of 101 adult Brazilian learners of English was tested using twoseparate measures of reading comprehension (one with idiomaticlanguage and one without) and the results of the two tests were thencompared Although verbal reports would provide even greater insightthe resultant data from this study do seem to support a positive answer tothe first research question Participants achieved significantly lowerscores on the comprehension measure which assessed their under-standing of texts that contain multiword expressions It should bereiterated that this result was obtained in spite of both tests being writtenwith the exact same high-frequency words
Likewise through participantsrsquo self-reported comprehension thereseems to be evidence that the presence of multiword expressions in atext can lead L2 readers to overestimate their assessment of how muchthey have actually understood suggesting a positive answer to the secondresearch question
Although it seems apparent that participantsrsquo reading comprehensionin the present study was adversely affected by idiomaticity this sectionexplores and possibly explains variation in comprehension of the testsand further discusses evidence that multiword expressions negativelyaffected participantsrsquo comprehension
On the Stronger and Weaker Performance in the Tests
There are at least three important revelations emerging from theMRC-MAC data analysis presented in Table 6 First nearly two thirds of
TABLE 7
Time It Took Participants to Take Tests
N Mean time (minutes) SD
Time it took to take Test 1 91a 1085 436Time it took to take Test 2 91 1465 377
Note SD 5 standard deviation aSome participants (n 5 10) forgot to write in the time or left itincomplete
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 281
all participants believed they understood more than they actually did inTest 2 Second the data show that over 28 of those students (n 5 20)did not overestimate their comprehension in Test 1 providing evidencethat whereas they were apparently able to gauge their comprehensionfairly accurately when the texts were relatively devoid of idiomaticitythey were significantly less able to do so when relative noncomposition-ality was present Finally the MRC-MAC data presented so far indicatethat although not all participants tended to overestimate theircomprehension in Test 2 those who did (again the majority of cases)generally did so by a much larger margin Put simply it would seem thatnot only are many learners misunderstanding idiomaticity in text butthey may be doing so more than they (or researchers) realize
Further Evidence of Idiomaticity Negatively AffectingComprehension
The mean difference between MRC and MAC for the 70 students whooverestimated their comprehension in Test 2 (Table 6) was 017 For thesake of argument one could establish an MRC-MAC difference above020 as a cutoff for apparently marked lack of awareness of the extentof idiomaticity in Test 29 comparatively speaking This in turn wouldmean that there were 30 participants who ostensibly demonstrated aparticularly high overestimation of how much of Test 2 they had actuallyunderstood A sample of just the top 10 is provided in Table 8
Table 8 shows not only how different those participantsrsquo MRC wasfrom their Test 2 it also lists the same figures for Test 1 for comparison
9 A t-test reveals that the mean is in fact statistically significant even at the 003 differencelevel (t 5 653 p 5 003)
TABLE 8
Partial List of Participants With Exceptionally High Overestimation of Test 2 Comprehension(Difference 020)
ParticipantMRCTest 1
MACTest 1 Difference
MRCTest 2
MACTest 2 Difference
118 100 089 011 094 032 0626 075 068 007 081 028 05392 081 089 2008 075 025 05090 100 089 011 081 039 042115 100 089 011 087 050 03722 100 096 003 094 057 03780 094 068 026 069 032 03759 094 089 005 069 036 03321 100 093 007 087 057 03050 087 078 009 069 039 029
282 TESOL QUARTERLY
Whereas for Test 1 those 30 participantsrsquo assessment of readingcomprehension was usually only slightly overestimated10 (and in oneinstance even underestimated) the same participants in Test 2 had amarkedly overinflated conception of how much they had understood
Although not intended as a principal source of data for our analysisthe start and finish times recorded by participants on the tests in a fewinstances helped confirm the above assertions11 Table 7 shows thatthere was a significant difference between how long participants spenttaking each test (t 5 852 p 0001) However there were a number ofparticipants (n 5 26) who reported actually spending either the same orless time on Test 2 On the surface at least this fact would indicate thatthose 26 participants did not notice much difference between the testsOf course in reality that datum alone does not provide such evidencebecause that time may simply reflect a number of other confoundingvariables including affective (eg simply giving up) or even social (egthe need to leave early to meet a friend) and for that reason also was notconsidered to be a reliable source of data from those participantsHowever as a complementary source when triangulated with the othervariables some of the data analyzed earlier in the current study areoccasionally fortified further still with the time data (Table 9)
The data in Table 9 in many ways tie together the elements discussedin the analysis thus far in the present study A much lower score in Test 2than in Test 1 (columns B and C) an increase in the mean MRC-MACdifference across the tests (columns H and K) a relatively moderatedecrease in MRC in Test 2 vis-a-vis Test 1 (columns F and I) a markeddifference between MRC and MAC in Test 2 (column K) and theoccasional lack of increase (in Table 9 participants 118 80 59 and 50)in time it took to take Test 2 (columns D and E) These findings ontheir own in combination and especially in concert provide evidencethat (1) the students in Table 9 did not seem to appreciate the fullextent of the idiomaticity in Test 2 and (2) they appeared to think thatthey understood more than they actually did in Test 2
Perhaps most important 98 of all participants (n 5 99) scoredsignificantly lower on Test 2 (mean difference of 953 points out of 28SD 5 363) which shows that learners are generally unable to guess themeaning of idiomatic language even in the (largely inconsistent)instances in which they become aware of its presence
11 It should be noted that because 10 of the participantsrsquo time data were left incomplete afull group analysis could not be carried out thus the time data are only included asauxiliary information
10 As can be seen in Table 8 in fact only one participantmdashnumber 80mdashactually had anMRC-MAC difference in Test 1 that was also 020 Those of the other 29 participantswere all lower
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 283
For example the first participant in Tables 8 and 9 (number 118)who consistently overrated his own comprehension relative to his actualcomprehension answered for Text A of Test 2 as shown in Figure 3
On the basis of the responses it is likely that participant 118associated itrsquos about time with lsquolsquohas a problem with timersquorsquo Irsquom a little over thehill with lsquolsquohe probably lives in an area with hillsrsquorsquo and lsquolsquohe lives on the hill
TABLE 9
Triangulated Data Showing Negative Effect of Idiomaticity on Comprehension
A B C D E F G H I J K
Score Time Test 1 Test 2
Partic-ipant Test 1 Test 2 Test 1 Test 2 MRC MAC
Differ-ence MRC MAC
Differ-ence
118 25 9 2000 1800 100 089 11 094 032 0626 19 8 Missing Missing 075 068 007 081 028 05392 25 8 900 1100 081 089 2008 075 025 05090 25 11 900 1500 100 089 011 081 039 042115 25 14 1300 1500 100 089 011 087 050 03722 27 16 Missing Missing 100 096 003 094 057 03780 19 9 1000 1000 094 068 026 069 032 03759 25 10 1500 1400 094 089 005 069 036 03321 26 16 Missing Missing 100 093 007 087 057 03050 22 11 2000 1200 088 079 009 069 039 030
12 Of the 24 multiword expressions targeted for assessment of comprehension in Test 2 onlyfour were core idioms
FIGURE 3 Sample answer to Text A of Test 2
284 TESOL QUARTERLY
but not on top of itrsquorsquomdasha literal reading of those expressions His 100self-assessment is an indication that his answers were not guesses butinstead based on confidence that he had understood all the individualwords in the text The same answering dynamic occurred time and timeagain in Test 2
Returning therefore to the issues raised in the introduction thepresent research appears to provide evidence that idiomsmdashopaque orotherwise12mdashcan in fact cause major problems for L2 learners of Englishwhen reading In general the participants in our study were lesssuccessful at guessing the meaning of idioms than those in previousidiom-centered research such as Cooper (1999) and Liontas (2002)Because the learners in our study were not alerted to the presence ofidiomaticity in the text prior to reading this study may more accuratelyreflect what takes place in more naturally occurring L2 reading Finallythe difficulties that the participants encountered occurred in textscomposed purely of very common words showing that word frequencyalone is not necessarily a good measure of text coverage Lauferrsquos(1989a) hypothesis that much lexis in text can be deceptivelytransparent is confirmed in the present research extended to multiwordexpressions
Limitations of the Research
Although the research presented here does provide some significantevidence that the presence of idiomaticity in a text can negatively affectthe comprehension of that text by an L2 reader little is known about thestrategies the test takers employed Even though metacognition wasoutside the scope of examination of the present study such informationis highly relevant and future research should include protocols such asthose included in previous research on idioms (eg Liontas 20032007) which may provide crucial qualitative data regarding theindividual differences and behavior of the participants themselvesOverall future work in this area should consider making use of differentmeasures of self-assessment in order to explore the limitations of themethodology used in the present study
Also a question can be asked concerning the relative density ofmultiword expressions in each text In other words what is not known ison average how many such items a reader can expect to encounter Theratio of idioms to orthographic words in the texts tested in the presentstudy is very likely higher than averagemdashbut how much higher is as yetunknown Likewise the passages themselves were relatively short so it isunknown whether or not texts of greater length (and thereforecontextualization) would render the same or similar results
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 285
CONCLUSION
The present study provides some empirical evidence that a focus onword in L2 pedagogy may be detrimental to learnersrsquo development ofreading comprehension in the target language In most casesparticipants overestimated how much they had understood the textstested when those texts contained multiword expressions of varyingdegrees of compositionality comprised of very common individualwords Even when participants showed evidence of awareness of apresence of idiomaticity in the texts they generally were not very good atguessing the meaning of expressions Although Grant and Nation(2006) could be right that the teaching of individual idioms may not belsquolsquodeserving of class timersquorsquo (p 5) it is clear that at the very least raisinglearnersrsquo consciousness as to their prevalence and frequently deceptivetransparency in text certainly is
Concomitantly the present research serves to demonstrate theincompleteness of current lists of common words which now informimportant pedagogical instruments such as vocabulary tests gradedreaders and course syllabuses Under current methods as illustrated inthe Table 2 analysis of the Economist paragraph a text measured againstthe word lists now commonly in use can be mistakenly analyzed as beingeasily understood when in fact once multiword expressions are takeninto account the actual text coverage of easily understood words is farless Existing estimates of how many words one needs to know in order toadequately process naturally occurring texts (Hu amp Nation 2000Nation 2006) may need to be revisited to determine how many wordsand multiword expressions one needs to know
In practice research shows that learners will continue to believe theyunderstand items that they actually do not even after repeatedexposures to that same item (Bensoussan amp Laufer 1984 Haynes1993 Pigada amp Schmitt 2006) Language teachers and relatedprofessionals such as textbook writers need to consider ways tocontinuously help learners notice the gap between what they think theyknow and understand and what they actually do (Laufer 1997) Oneway this can be achieved has already been thoroughly discussed in thepresent paper devise texts (and tests) designed to lead readers down anidiomatic garden path Norbert Schmitt (as cited in Weir 2005) made asimilar recommendation
Perhaps the best and most valid type of vocabulary test is a reading passagewith comprehension questions but with the items requiring a full under-standing of particular words or phrases in the text This would mimic the realworld task of reading for comprehension and also the loss of comprehensionwhen key vocabulary is not known (p 123)
286 TESOL QUARTERLY
Therefore a further implication this research has for L2 pedagogy is themore careful design of the reading component of proficiency tests suchas IELTS (International English Language Testing System) and Test ofEnglish as a Foreign Language to be more strategic regarding the amountand kind of phraseology contained in the texts Proficiency was not thecentral focus of our study and future research could adopt a similarmethodology but with the inclusion of proficiency measures ofparticipants in order to explore how various types of expressions (egnoncompositional figurative imageable etc) may differentially affectpreidentified proficiency levels
Thus in order to be more methodical about such things as theinclusion of formulaic language in L2 tests and reading input in generalan important preliminary step will be to establish (a) what type offormulaic sequences are good discriminators of proficiency thresholdlevels and (b) which expressions of that identified type are mostcommon In other words what will be usefulmdashand is indeed nowbeginning to emerge (Martinez amp Schmitt 2010 Shin amp Nation 2008Simpson-Vlach amp Ellis 2010)mdashare lists of formulaic sequences that servea function similar to that of the General Service List not to revolutionizecurrent language pedagogy but to more finely tune it
THE AUTHORS
Ron Martinez is currently pursuing a doctorate at the University of NottinghamNottingham England on the topic of inclusion of phraseology in languageassessment He specializes in second language materials development
Victoria Murphy is a lecturer in Applied Linguistics and Second LanguageAcquisition at the University of Oxford Oxford England Her research interestsinclude the lexical development of first language or second language learners andthe cognitive processes that underlie language acquisition
REFERENCES
Bauer L amp Nation P (1993) Word families International Journal of Lexicography 6253ndash279 doi101093ijl64253
Bensoussan M amp Laufer B (1984) Lexical guessing in context in EFL readingcomprehension Journal of Research in Reading 7 15ndash32 doi101111j1467-98171984tb00252x
Bishop H (2004) Noticing formulaic sequences A problem of measuring thesubjective LSO Working Papers in Linguistics 4 15ndash19
Bransford D B amp Johnson M K (1972) Contextual prerequisites for under-standing Some investigations of comprehension and recall Journal of VerbalLearning and Verbal Behavior 11 717ndash726 doi101016S0022-5371(72)80006-9
Brantmeier C (2006) Advanced L2 learners and reading placement Self-assessment CBT and subsequent performance System 34 15ndash35 doi101016jsystem200508004
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 287
Carver R P (1994) Percentage of unknown vocabulary words in text as a functionof the relative difficulty of the text Implications for instruction Journal of ReadingBehavior 26 413ndash437
Cobb T (nd) Web VocabProfile [Online program] Retrieved from httpwwwlextutorcavp [an adaption of A Heatley amp P Nation Range (1994)]
Cooper T C (1999) Processing of idioms by L2 learners of English TESOLQuarterly 33 233ndash262 doi1023073587719
Coxhead A (2000) A new academic word list TESOL Quarterly 34 213ndash238doi1023073587951
Elley W amp Mangubhai F (1983) The impact of reading on second languagelearning Reading Research Quarterly 19 53ndash67 doi102307747337
Ellis N C (2008) Phraseology The periphery and the heart of language In FMeunier amp S Granger (Eds) Phraseology in language learning and teaching (pp 1ndash13) Amsterdam The Netherlands John Benjamins
Erman B amp Warren B (2000) The idiom principle and the open choice principleText 20 29ndash62
Gardner D (2007) Validating the construct of Word in applied corpus-basedvocabulary research A critical survey Applied Linguistics 28 241ndash265doi101093applinamm010
Glenberg A M Wilkinson A C amp Epstein W (1982) The illusion of knowingFailure in the self-assessment of comprehension Memory and Cognition 10 597ndash602 doi103758BF03202442
Goulden R Nation P amp Read J (1990) How large can a receptive vocabulary beApplied Linguistics 11 341ndash363 doi101093applin114341
Grant L amp Bauer L (2004) Criteria for re-defining idioms Are we barking up thewrong tree Applied Linguistics 25 38ndash61 doi101093applin25138
Grant L amp Nation P (2006) How many idioms are there in English ITL -International Journal of Applied Linguistics 151 1ndash14 doi102143ITL15102015219
Haynes M (1993) Patterns and perils of guessing in second language reading In THuckin M Haynes amp J Coady (Eds) Second language reading and vocabularylearning (pp 46ndash64) Norwood NJ Ablex Publishing Corporation
Heatley A amp Nation P (1994) Range [Computer program] Wellington NewZealand Victoria University of Wellington Retrieved from httpwwwvuwacnzlals
Hill J (2000) Revising priorities From grammatical failure to collocational successIn M Lewis (Ed) Teaching collocation Further developments in the Lexical Approach(pp 47ndash69) Hove England LTP
Hirsh D amp Nation P (1992) What vocabulary size is needed to read unsimplifiedtexts for pleasure Reading in a Foreign Language 8 689ndash696
Hu H M amp Nation P (2000) Unknown vocabulary density and readingcomprehension Reading in a Foreign Language 13 403ndash429
Hughes A (2003) Testing for language teachers Cambridge England CambridgeUniversity Press
Hunt K (1968) An instrument to measure syntactic maturity Tallahassee FL USDepartment of Health Education and Welfare
Jung E H (2003) The effects of organization markers on ESL learnersrsquo textunderstanding TESOL Quarterly 37 749ndash759 doi1023073588223
Krashen S (1993) The power of reading Insights from research Englewood COLibraries Unlimited
Laufer B (1989a) A factor of difficulty in vocabulary learning Deceptivetransparency AILA Review 6 10ndash20
288 TESOL QUARTERLY
Laufer B (1989b) What percentage of lexis is essential for comprehension In CLauren amp M Nordman (Eds) Special language From humans thinking to thinkingmachines (pp 316ndash323) London England Multilingual Matters
Laufer B (1991) How much lexis is necessary for reading comprehension In P JL Arnaud amp H Bejoint (Eds) Vocabulary and applied linguistics (pp 126ndash132)Oxford England Macmillan
Laufer B (1997) The lexical plight in second language reading Words you donrsquotknow words you think you know and words you canrsquot guess In J Coady amp THuckin (Eds) Second language vocabulary acquisition (pp 20ndash34) CambridgeEngland Cambridge University Press
Lewis M (1993) The Lexical Approach The state of ELT and a way forward HoveEngland LTP
Liontas J I (2002) Context and idiom understanding in second languagesEUROSLA Yearbook 2 155ndash185
Liontas J I (2003) Killing two birds with one stone Understanding Spanish VPidioms in and out of context Hispania 86 289ndash301 doi10230720062862
Liontas J I (2007) The eye never sees what the brain understands Making sense ofidioms in second languages Lingua et Linguistica 1) 25ndash44
Maki R H amp McGuire M J (2002) Metacognition for text Findings andimplications for education In T Schwarz amp L Bennett (Eds) Appliedmetacognition (pp 39ndash67) Cambridge England Cambridge University Press
Martinez R amp Schmitt N (2010) A phrasal expressions listManuscript submitted forpublication
Moon R (1997) Vocabulary connections Multi-word items in English In NSchmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 40ndash63) Cambridge England Cambridge University Press
Moore D Lin-Agler L M amp Zabrucky K M (2005) A source of metacomprehen-sion inaccuracy Reading Psychology 26 251ndash265 doi10108002702710590962578
Morrison L (2004) Comprehension monitoring in first and second languagereading The Canadian Modern Language Review 61 77ndash106
Nation I S P (2001) Learning vocabulary in another language Cambridge EnglandCambridge University Press
Nation I S P (2006) How large a vocabulary is needed for reading and listeningThe Canadian Modern Language Review 63 59ndash82
Nation I S P amp Waring R (1997) Vocabulary size text coverage and word lists InN Schmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 6ndash19) Cambridge England Cambridge University Press
Nation P (1997) The language learning benefits of extensive reading LanguageTeacher 21 13ndash16
Nattinger J R amp DeCarrico J S (1992) Lexical phrases and language teachingOxford England Oxford University Press
Oh S Y (2001) Two types of input modification and EFL reading comprehensionSimplification versus elaboration TESOL Quarterly 35 69ndash96 doi1023073587860
OrsquoKeeffe A McCarthy M amp Carter R (2007) From corpus to classroom Language useand language teaching Cambridge England Cambridge University Press
Pawley A amp Syder F H (1983) Two puzzles for linguistic theory Nativelikeselection and nativelike fluency In J C Richards amp R Schmidt (Eds) Languageand communication (pp 191ndash226) New York NY Longman
Pigada M amp Schmitt N (2006) Vocabulary acquisition from extensive reading Acase study Reading in a Foreign Language 18 1ndash28
Read J (2004) Research in teaching vocabulary Annual Review of Applied Linguistics24 146ndash161 doi101017S0267190504000078
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 289
Sarac S amp Tarhan B (2009) Calibration of comprehension and performance inL2 reading International Electronic Journal of Elementary Education 2 167ndash179
Schmitt N Jiang N amp Grabe W (2011) The percentage of words known in a textand reading comprehension Modern Language Journal 95(1) 26ndash43
Schmitt N Schmitt D amp Clapham C (2001) Developing and exploring thebehaviour of two new versions of the Vocabulary Levels Test Language Testing 1855ndash88
Shin D amp Nation I S P (2008) Beyond single words The most frequentcollocations in spoken English ELT Journal 62 339ndash348 doi101093eltccm091
Simpson-Vlach R amp Ellis N C (2010) An academic formulas list New methods inphraseology research Applied Linguistics 31(4) 487ndash512
Sinclair J (1991) Corpus concordance collocation Oxford England OxfordUniversity Press
Spottl C amp McCarthy M (2003) Formulaic utterances in the multi-lingual contextIn J Cenoz B Hufeisen ampU Jessner (Eds) The multilingual lexicon (pp 133ndash151) Dordrecht The Netherlands Kluwer
Staelighr L S (2008) Vocabulary size and the skills of listening reading and writingLanguage Learning Journal 36 139ndash152 doi10108009571730802389975
Stubbs M amp Barth I (2003) Using recurrent phrases as text-type descriminators Aquantitative method and some findings Functions of Language 10 61ndash104doi101075fol10104stu
The British National Corpus (2007) The British National Corpus(version 3 BNC XMLed) [CD-ROM] Distributed by Oxford University Computing Services on behalfof the BNC Consortium
The iPhonersquos second coming (2008 July) The Economist Retrieved from httpwwweconomistcomscience-technologydisplaystorycfmstory_id5E1_TTSDDJTG
Walter E Woodford K amp Good M (Eds) (2008) Cambridge advanced learnerrsquosdictionary (3rd ed) Cambridge England Cambridge University Press
Weir C J (2005) Language testing and validation An evidence-based approachNew York NY Palgrave Macmillan
West M (1953) A general service list of English words London England LongmanWray A (2002) Formulaic language and the lexicon Cambridge England Cambridge
University Press
290 TESOL QUARTERLY

much of the literature to date researchers have suggested that by passingcertain vocabulary lsquolsquothresholdsrsquorsquo (Nation 2001 p 144) L2 readersrsquocomprehension of texts in the target language will naturally increaseAlthough the preceding claim is undoubtedly true to a degree there issome question as to what exactly constitutes vocabulary
When most language students and teachers hear vocabulary they thinkwords (Hill 2000) However studies of large bodies of naturally occurringtextual data or corpora have shown that some words commonly occur withother words and these combinations actually form unitary and distinctmeanings (Nattinger amp DeCarrico 1992 Pawley amp Syder 1983 Sinclair1991) Such multiword expressions are increasingly being viewed byresearchers as a central part of the mental lexicon and even languageacquisition itself (Ellis 2008 Wray 2002) Therein lies the current chasmbetween research into the relationship between vocabulary and readingcomprehension and research into vocabulary Clearly vocabulary is morethan individual words but individual words are all that is mentioned incurrent research on vocabulary thresholds
A possible reason for the aforementioned dichotomy is the fact thatword coverage estimates (how many words are known in a text) are basedon lists of the most common orthographic words alone This monolexicaltendency in word lists is merely a reflection of current technologicallimitations There is simply no easy way to automatically extract frequencylists that are inclusive of meaningful multiword lexical items Nonethelessthis convenient exclusion has also meant that little research to date hasoccurred into what effects such expressions might have on readingcomprehension as it is often simply assumed that idiomatic expressionsare fairly rare in language and still fewer are the ones which cannot bedecoded through context or other semantic clues (Grant amp Bauer 2004)However it is argued throughout the present article that not only aremultiword expressions much more common than popularly assumed butthey are also difficult for readers to both accurately identify and decodemdasheven when they only contain very common words
As supporting evidence for the above assertions we describe andpresent data from a study that put to test multiword expressions and thepossible effects they have on reading comprehension
RELATIONSHIP BETWEEN THE NUMBER OF WORDSKNOWN AND READING COMPREHENSION
According to informed estimates (eg Goulden Nation amp Read1990) the average educated native speaker of English possesses a
1 According to Nation (2001) a word family consists of lsquolsquoa headword its inflected forms andits closely derived formsrsquorsquo (p 8)
268 TESOL QUARTERLY
receptive knowledge of around 20000-word families1mdasha number whichmay seem daunting to a learner of the language Perhaps for that reasona number of researchers (eg Hirsh amp Nation 1992 Hu amp Nation 2000Laufer 1989b) have endeavored to answer the following question Howmany words are really necessary in order to comprehend most texts Theanswer to that question is of interest to a wide range of parties fromdevelopers of English as a foreign language textbooks to writers ofgraded readers to practicing classroom teachers and their students(Nation amp Waring 1997) After all to be able to put a concrete numberon the words one needs to know to function in the target language is tobe able to set teaching goals divide proficiency levels and see aproverbial light at the end of the L2 learning tunnel
However the answer to that question has also proved somewhatcomplex requiring identifying not so much how many words one needsto know in absolute terms but rather how many words a learner needs toknow in order to understand a text in spite of unknown vocabulary Basingtheir assertions mostly on the assumption that pleasurable reading occursonly when a reader knows almost all the words in a text Hirsh and Nation(1992) stipulated the ideal percentage of words known in an unsimplifiedtext at around 98 which the authors claimed could be reached with aknowledge of 5000-word families However one limitation of the Hirsh andNation study was that the texts used were novels written for teenagers andadolescents To determine whether the same word family figure wouldapply to authentic texts designed for general (ie adult native speaker)consumption Nation (2006) conducted a new analysis of fiction andnonfiction text (eg novels and newspapers) The trialing showed that if98 coverage of a text is needed for unassisted comprehension then an8000- to 9000-word family vocabulary is needed Therefore assuming the98 figure is valid (as supported by Hu amp Nation 2000 and most recentlySchmitt Jiang amp Grabe 2011) a learner requires a knowledge of at least8000-word families in order to adequately comprehend most unsimplifiedfiction and nonfiction text
Word Counts and Their Limitations
The estimates of how many words a reader needs to know in order toread unsimplified text may actually be somewhat misleading withoutcritical examination of the underlying constructs The main problem liesin the compilation of word frequency lists themselves including whatconstitutes a word (cf Gardner 2007)
As mentioned earlier current research suggests that 8000ndash9000 wordscan provide around 98 coverage of most texts (Nation 2006) However
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 269
Nationrsquos recommendations are for an lsquolsquo8000ndash9000 word-family vocabu-laryrsquorsquo (p 79) which does not necessarily mean knowing 8000 words
From the point of view of reading a word family consists of a base word andall its derived and inflected forms that can be understood by a learnerwithout having to learn each form separately [ ] The important principlebehind the idea of a word family is that once the base word or even a derivedword is known the recognition of other members of the family requires littleor no extra effort (Bauer amp Nation 1993 p 253)
In the lists that Nation and other researchers have used to calculate wordknowledge (eg Nation 2006 West 1953) a word can include a base formand over 80 derivational affixes (Nation 2006 p 66) resulting in lsquolsquosomelarge word families especially among the high-frequency wordsrsquorsquo (Nation2006) but there may be an issue of overconflation of forms Consider forexample the semantic distance between the following pairs of words nameR namely price R priceless fish R fishy puzzle R puzzling Each of thepreceding pairs would be grouped into the same respective word family butit is unlikely that a learner of English would require lsquolsquolittle or no extraeffortrsquorsquo (Bauer amp Nation 1993 p 253) to derive the meaning of a word likefishy from fish2 It is therefore conceivable that a number of those 8000- to9000-word families do not have the psycholinguistic validity that issometimes assumed and some of the 30000 (or so) separate wordssubsumed in those families would in fact need to be learned separately
Similar to the semantic distance between fish and fishy there is oftenan equal or greater disparity of meaning when a word is juxtaposed withanother or more words and a new expression forms (Moon 1997 Wray2002) For example the words fine good and perfect each have meaninghowever those meanings do not remain in the expressions finely tunedfor good and perfect stranger
Nation (2006) recognized this limitation of current word lists howeverhe did not consider it a problem Nation based this assertion on theassumption that most learners will be able to guess the meaning ofmultiword expressions that have some element of transparency and sincethe number of lsquolsquotruly opaquersquorsquo phrases in English is relatively small for thepurposes of reading they are lsquolsquonot a major issuersquorsquo (p 66) However it isdebatable just how lsquolsquosmallrsquorsquo in number those opaque expressions are andmuch like the previously discussed derived word forms that are actuallysemantically dissimilar just how easy it is for a learner of English toaccurately guess the meaning of more lsquolsquotransparentrsquorsquo expressions
2 According to the Cambridge Advanced Learnerrsquos Dictionary (Walter Woodford amp Good2008) which is informed by the one-billion-word Cambridge International Corpus thefirst sense of fishy is lsquolsquodishonest or falsersquorsquo (p 537) and not lsquolsquosmelling of fishrsquorsquo
270 TESOL QUARTERLY
Martinez and Schmitt (2010) for example sought to compile a list of themost common expressions derived from the British National Corpus3
(BNC) Their main criteria for selection was frequency and relativenoncompositionality in other words the items chosen for selection neededto possess semantic and grammatical properties that could pose decodingproblems for learners when reading Their exhaustive search rendered over500 multiword expressions that were frequent enough to be included in alist of the top 5000 words in Englishmdashor over 10 of the entire frequencylist A sample of the list is provided in Table 1
As an example of how taking word frequency into account alonepotentially leads to very misleading estimates of text comprehensibilityconsider the following text taken from The Economist
But over the past few months competing 3G smartphones with touch screensand a host of features have been coming thick and fast to the American marketAnd waiting in the wings are any number of open-source smartphones basedon the nifty Linux operating system Apple will need to pull out all the stops ifthe iPhone is not to be swept aside by the flood of do-it-all smartphonesheading for Americarsquos shores (lsquolsquoThe iPhonersquos second comingrsquorsquo 2008)
The above paragraph contains a number of expressions which are partlyor totally opaque including the following seven
- over the past- a host of- thick and fast- waiting in the wings- any number of- pull out all the stops- swept aside
3 A 100-million word corpus predominantly composed of written English (The BritishNational Corpus 2007)
TABLE 1
Highly Frequent Idioms With Words From Beginner EFL Textbooks for Comparison
Frequency (BNC) Idioms Frequency (BNC) Words (for comparison)
18041 as well as 466 steak14650 at all 455 niece12762 in order to 400 receptionist10556 take place 387 lettuce7138 for instance 385 gym4584 and so on 377 carrot4578 be about to 341 snack3684 at once 337 earrings2676 in spite of 302 dessert1995 in effect 291 refrigerator
Note EFL 5 English as a foreign language BNC 5 British National Corpus
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 271
Current text word coverage calculations ignore such expressionsAccording to software commonly used to analyze the word familyfrequency distribution of text (VocabProfile [Cobb nd]) the sameEconomist paragraph is broken down as shown in Table 2
So if comprehension of a text were based on word coverage alonecurrent methods of text analysis (Table 2) suggest that a learner with avocabulary of at least the top 2000 words in English should be able tounderstand 9552 of the lexis in the Economist text (64 of the 67 words[tokens] counted) by some estimates (eg Laufer 1989b) enough foradequate comprehension If that same learner also knew just two wordsin the text on the Academic Word List (Coxhead 2000)mdashfeatures andsourcemdashshe would understand an additional 299 affording thatlearner a knowledge of 9851mdashtheoretically approximating nativelikelevels of comprehension (Carver 1994 p 432) However a closer lookat the breakdown in Table 2 shows that words like pull out all the andstops were all considered as separate and very common words when inreality they form one noncompositional expression pull out all the stopsIn fact all of the seven expressions have mistakenly been fragmentedand categorized as pertaining to the top 2000 words Thereforeassuming that a learner who knows only the 2000 most common wordsin English would not understand those expressions without the help of adictionary and if we reconduct the analysis taking those sevenexpressions into account (constituting 23 words) the total number ofwords fitting into the top 2000 goes down to 41 (64 minus 23) and that9552 figure actually drops from adequate comprehension down to6119 (41 4 67 5 06119)mdashwell below acceptable levels of readingcomprehension (Hu amp Nation 2000)
TABLE 2
Word Frequency Breakdown of The Economist text (Not Including Proper Nouns)
Frequency Words (67 tokens 54 types) Text coverage
0ndash1000 a all and any are based be been but by comingdo fast few for have heading if in is it marketmonths need not number of on open operatingout over past pull shores stops system the totouch waiting will with
8358
1001ndash2000 aside competing flood host screens swept thickwings
1194
Academic Word List(AWL)
features source 299
Off list Nifty 149Words in top 2000 9552+ AWL words 299Total text coverage 9851
272 TESOL QUARTERLY
RELATIONSHIP BETWEEN FORMULAIC LANGUAGE ANDREADING COMPREHENSION
Considering the relative wealth of research and literature on L2reading comprehension and separately multiword expressions inEnglish there is a surprising dearth of information regarding the roleif any formulaic language plays in the comprehension of texts in aforeign language The relatively few studies that do exist (eg Cooper1999 Liontas 2002) seem to confirm that it is especially the moresemantically opaque idioms that pose interpretability problems for L2readers and as these more core idioms are relatively rare (Grant ampNation 2006) Nation (2006) could be right in attenuating theirsignificance in reading comprehension
Nevertheless as discussed earlier there is evidence that a significantnumber of relatively opaque expressions occur frequently in texts inEnglish One commonly cited estimate (Erman amp Warren 2000) is thatsomewhat more than one-half (55) of any text will consist of formulaiclanguage (p 50) Naturally the opacity of those expressions will lie onwhat Lewis (1993 p 98) called a lsquolsquospectrum of idiomaticityrsquorsquo (Figure 1) akind of continuum of compositionality
Furthermore even when an expression does not meet the criteria ofcore or nonmatching idiom the relative ease or difficulty with which alearner will unpack its meaning is less inherent to the item itself andmore a learner-dependent variable Just as knowing fish may or may nottranslate into understanding fishy knowing perfect does not necessarilymean understanding perfect stranger
What is more although previous studies (Cooper 1999 Liontas2002) have found that in textual context more transparent idioms weremore easily understood than their opaque counterparts it should alsobe noted that the participants in those studies were aware that they werebeing tested specifically on their ability to correctly interpret idioms Inother words what cannot be known from most existing studies on idiominterpretation is how well the participants would have been able toidentify and understand the idioms in the first place had they not beenaware of their presence in the text
FIGURE 1 A spectrum of idiomaticity (compositionality)
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 273
A notable exception is Bishop (2004) who investigated thedifferential look-up behavior of participants who read texts thatcontained unknown words and unknown multiword expressions synon-ymous with those words Bishop confirmed that even though both wordsand multiword expressions were unknown readers looked up themeaning of words significantly more often He concludes that learnerslsquolsquodo not notice unknown formulaic sequences as readily as unknownwordsrsquorsquo (p 18)
Therefore idiomatic language in text irrespective of composition-ality might most usefully be classified as what Laufer (1989a) calledlsquolsquodeceptively transparentrsquorsquo (p 11) Laufer found that many Englishlearners misanalyze words like infallible as in+fall+ible (ie lsquolsquocannot fallrsquorsquo)and nevertheless as never+less (ie lsquolsquoalways morersquorsquo p 12) Likewisemdashalthough they were not part of her studymdashshe found that idioms like hitand miss were being read and interpreted word for word These lexicalitems that lsquolsquolearners think they know but they do notrsquorsquo (Laufer 1989ap 11) can impede reading comprehension in ways not accounted for inlists of common word families Nation (2006) seemed to assume thatmultiword expressions that have some element of transparency howeversmall will be reasonably interpretable through guessing However theLaufer (1989a) study may provide evidence to the contrary
But an attempt to guess (regardless of whether it is successful or not)presupposes awareness on the part of the learner that he is facing anunknown word If such an awareness is not there no attempt is made to inferthe missing meaning This is precisely the case with deceptively transparentwords The learner thinks he knows and then assigns the wrong meaning tothem [ ] (p 16)
Substitute lsquolsquoidiomrsquorsquo for lsquolsquowordrsquorsquo abovemdashnot an unreasonable conceptualstretchmdashand it becomes clear that multiword expressions just maypresent a larger problem for reading comprehension than accounted forin the current literature
In fact such lsquolsquodeceptionrsquorsquo seems even more likely to occur withmultiword expressions because such a large number of them arecomposed of very common words a learner would assume he or sheknows (Spottl amp McCarthy 2003 p 145 Stubbs amp Barth 2003 p 71)Moreover there is evidence that learners are reluctant to revisehypotheses formed regarding lexical items when reading even whenthe context does not support those hypotheses (Haynes 1993 Pigada ampSchmitt 2006)
274 TESOL QUARTERLY
Summary and Research Questions
In summary the following has been argued thus faramp Current estimates of how many words one needs to know in order to
comprehend most texts may be inaccurate due to overinclusion of derivedword forms and a total exclusion of multiword units of vocabulary
amp Contrary to some research there is evidence in corpus data that thenumber of frequently occurring noncompositional multiwordexpressions in English is higher than previously believed
amp Even when an expression is partly or even fully compositional thereis no way of knowing how accurately an L2 reader will interpret (oreven identify) that item
amp The claim that special attention to the 2000ndash3000 most commonwords in English is pedagogically sound since they provide around80 of text coverage (eg OrsquoKeeffe McCarthy amp Carter 2007Read 2004 p 148 Staelighr 2008) deserves closer scrutiny becausethose words are often merely tips of phraseological icebergs
It is therefore clear that there is a need for further investigation into howcommon words and the multiword units they form can affect readingcomprehension when reading in English as a foreign language To thatend we conducted a study to answer the following research questions
1 Are two texts written with the exact same high-frequency wordsunderstood equally well by L2 learners when one of the texts is moreidiomatic than the other
2 Can the presence of multiword expressions in a text lead L2 learners tobelieve they have understood that text better than they actually have
METHOD
Participants
Brazilian adult learners of English (n 5 101) all native speakers ofBrazilian Portuguese were selected to participate in the study Thesample ranged in age from 18 to 64 years (M 5 2576 SD 5 931) andconsisted of 43 men and 58 women representing seven different regionsof Brazil
All participants in the study had had a minimum of 80 hr of tuition inEnglish prior to the start of the research and had been tested aspossessing intermediate or higher levels of proficiency Howeverbecause all participants attended private language schools the actualinstruments by which their proficiency was assessed varied widely
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 275
Regardless uniformity in proficiency was not of prime importance in thestudy because the research questions are concerned with a significantchange in the paired samples within the same group
The Test
To write the eight texts (four texts in each test) a corpus of words wascarefully chosen from the list of the 2000 most frequent words in the BNCThe reading comprehension of each text was tested by seven true or falseitems totaling 28 per test part or 56 overall The test when administeredappears as one but is actually in two parts (Test 1 and Test 2) each partcontaining the exact same words with some words in Test 2 formingmultiword expressions Great care was taken to ensure that the texts areotherwise equal There is no visual difference between the two parts andthe texts are of almost uniform length in both parts (Table 3 and Figure 2)In addition care was taken not to include any extra cultural references inany of the texts and the comprehension task itself did not change acrossthe test parts The texts are stated to have come from peoplersquos descriptionof themselves in lsquolsquoFriendsbookrsquorsquo (intentionally similar to Facebook) On thewhole therefore it could be said that the style of the text is personal andinformal
The vast majority of the words are in the top 1000 withapproximately 985 of the words occurring in the BNC top 2000(Table 3) These results were in turn compared with the General ServiceList (West 1953) using software developed by Heatley and Nation(Range 1994) and another package using the same corpus created byCobb (nd) The results were practically identical in all cases (Range985 VocabProfile 98494)
Another key feature of the test is the rating scale which requires the testtaker to circle what she believes is his or her comprehension of each textfrom 5 to 1005 This self-reported comprehension is designed to helpanswer the second research question of whether the presence ofmultiword expressions in a text can lead L2 learners to believe they have
TABLE 3
Summary of Test 1 and Test 2 Text Data
Total wordcount
Total clausecount T-unit count
Top 1000words coverage
Top 1001ndash2000 words
coverage
Test 1 416 56 45 957373 27650Test 2 412 54 42 957373 27650
Note Data measured using vocabulary profiler (Cobb nd) A T-unit or a minimal terminableunit is lsquolsquoone main clause plus any subordinate clausersquorsquo (Hunt 1968 p 4)
276 TESOL QUARTERLY
understood that text better than they actually have Testing whatcomprehenders believe they understoodmdashcompared to what they actuallyunderstoodmdashby comparing test scores to self-assessment of comprehen-sion via a rating scale is often referred to as lsquolsquocomprehension calibrationrsquorsquoand is a method that has been used extensively in psychological research(eg Bransford amp Johnson 1972 Glenberg Wilkinson amp Epstein 1982Maki amp McGuire 2002 Moore Lin-Agler amp Zabrucky 2005) butsomewhat less so in applied linguistics (cf Brantmeier 2006 Jung 2003Morrison 2004 Oh 2001 Sarac amp Tarhan 2009)
Finally participants were asked to record their start and finish timesfor each part of the test
Procedure
Following an initial field test an item analysis was conducted toestablish the facility value6 of the test items and a discrimination indexfor both test parts to discern whether the test was discriminatingbetween stronger and weaker participants Items that were found to haveexceptionally high or low scores were carefully analyzed and the wordingof both test items and reading texts adjusted accordingly
Finally as advocated in Schmitt Schmitt and Clapham (2001) oneimportant requirement of an L2 test of reading comprehension is that itbe answerable by native or nativelike speakers of the language (p 65)To that end a smaller group of native speakers (n 5 8) was also tested asan additional check of the testrsquos validity That group produced a mean
FIGURE 2 Side-by-side comparison of matched texts from the two test parts (full version ofthe test available on request)
4 These are vocabulary profilers that essentially use word frequency lists to break all thewords in a text down into those that occur for example in the top 1000 second 1000third 1000 and so on
5 lsquolsquo0rsquorsquo would be virtually impossible because learners would be familiar with most words inthe texts if not all
6 A test itemrsquos facility value is calculated by dividing the number of participants whoanswered that item correctly by the total number of participants (Hughes 2003)
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 277
score of 28 in Test 1 (the maximum score) and 2775 in Test 2 showingthat both test parts posed very little difficulty for people for whomEnglish is a first language
The students received the two parts of the test in alternating order(ie counterbalanced) to control for any effect of taking Test 1 beforeTest 2 (and vice versa) because by counterbalancing one is able toinclude a variable order into an analysis and identify the extent towhich order affects performance on the dependent measures
RESULTS
All the scores and self-reported comprehension measures wererecorded in a statistical analysis software program (SPSS) Eachparticipantrsquos test results were transcribed into the software item by item(ie correct and incorrect) text by text (eg Text A Text B etc numbercorrect out of 7 for each) and test by test (ie Test 1 and Test 2 numbercorrect out of 28 possible for each) Also recorded were each participantrsquosself-reported comprehension assessments (a rating scale from 5 to 100)as they pertained to each text as well as which version (Test 1 or Test 2first) of the instrument each candidate had received To assess the effectof counterbalancing a repeated measures analysis of variance (ANOVA)was conducted with one within-subjects factor (TEST) with two levels(Test 1 score Test 2 score) and one between-subjects factor (VERSION)with two levels (Test 1 first Test 2 first) This analysis revealed a robustmain effect of test (F (199) 5 59338 p 0001 g2 5 086) and a discreteeffect of version (F (199) 5 405 p 5 0047 g2 5 004) but importantlythere was no significant Test 6 Version interaction (F (199) 5 281 p 5
0097 g2 5 002) illustrating that participantsrsquo scores did not vary as afunction of which version of the test they were completing
Comprehension of Test 1 versus Test 2
The central tendencies from both tests are presented in Table 4As predicted participantsrsquo scores were significantly lower on Test 2
relative to Test 1 (t(100) 5 2410 p 0001) with a strong effect size(g2 5 0828)7 confirming that even when two sets of texts contain theexact same words and even if those words are very commoncomprehension of those texts will not be the same when one containsidiomaticity
7 Confidence intervals at 95 for all t-tests
278 TESOL QUARTERLY
Self-Reported Comprehension of Test 1 versus Test 2
A t-test was also performed on the difference between whatparticipants believed they understood (ie their reported comprehen-sion) and what they actually understood in both Tests 1 and 2 (Table 5)Mean reported comprehension (MRC) was arrived at by calculating themeans of all the self-reported comprehension percentages (5ndash100)and the mean actual comprehension (MAC) is the mean of the score oneach text divided by seven (the maximum score)
MAC was lower than MRC in both Test 1(MRC M 5 08738 SD 013MAC M 5 08603 SD 5 009) and Test 2 (MRC M 5 06029 SD 019MAC M 5 05258 SD 5 014) however the difference between MRCand MAC was statistically reliable in Test 2 only where the test wascomposed of multiword expressions (t(100) 5 395 p 0001 g2 5
007)8 These data therefore appear to support a positive answer to thesecond research questionmdashthat learners may believe they understandmore than they actually do by virtue of their simply understanding theindividual words in a text
Variation in the Data
MRC versus MAC
Naturally there were some individual differences in the test resultsTable 6 shows that roughly one-half of all participants (n 5 50)overestimated their comprehension in both tests (indicated by MRC
TABLE 4
Descriptive Statistics (Tests 1 and 2)
Mean Median Mode Minimum Maximum SD
Test 1a 2409 2500 2500 1800 2800 244Test 2b 1476 1500 1500 600 2500 393
Note SD 5 standard deviation aTexts composed of common words however with little or noopaque phraseology bTexts composed of common words which comprise collocations andidiomatic language
TABLE 5
Reported Versus Actual Comprehension
Test 1 Test 2
Mean reported comprehension (MRC) 8738 6029Mean actual comprehension (MAC) 8603 5258
8 By comparison the results of the paired sample t-test for the Test 1 MRC-MAC means weret(100) 5 104 p 5 0302 g2 5 0005
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 279
greater than MAC) On the surface this might suggest that those 50participants did not overestimate their comprehension in Test 2 as aresult of its relative noncompositionality but rather as a generaltendency regardless of idiomaticity However when MAC is subtractedfrom MRC for that group and the difference compared across the teststhe difference is twice as large in Test 2 (t(49) 5 492 p 0001 g2 5
0108) This difference is even more evident in the same analysis of Test2 alone Isolating the results of that test there was a total of 70participants (over 69 of the entire sample) whose MRC was greaterthan their MAC The difference between MRC minus MAC for thesubgroup of 70 participants reveals that their overestimation of theircomprehension in Test 2 was four times greater than in Test 1 (t(69) 5
770 p 0001 g2 5 0228) Further among that group of 70 whoseTest 2 MRC was greater than their MAC 20 students either under-estimated or actually accurately guessed their comprehension in Test 1but significantly overestimated their comprehension in Test 2 (t(19) 5
849 p 0001 g2 5 0264) Only 30 participants in the present studyactually underestimated their comprehension on Test 2
Variation in Time Spent on the Tests
All candidates were also asked to record their start and finishing timesof each test (Table 7) It is not surprising that on average participantsspent more time on the texts which contained idiomatic expressionsHowever this trend was not uniform among the participants and thetime data may help provide some insight into just how aware someparticipants were of the presence of idiomaticity in the texts Thispossibility is explored further in the Discussion
TABLE 6
Trend of Increase in MRC-MAC Discrepancy Across Test Parts
NMRC minus MAC
(Test 1)MRC minus MAC
(Test 2)
Students with MRC MAC (bothtest parts)
50 009 019
Students with MRC MAC (Test 2) 70 004 017Students with MRC MAC (Test 2only)
20 2010 014
Students with MRC MAC (Test 2) 31a 2005 2015
Note MRC 5 mean reported comprehension MAC 5 mean actual comprehension aOnly oneparticipant in this group had MRC 5 MAC
280 TESOL QUARTERLY
DISCUSSION
To reiterate the present study sought to address the followingresearch questions
1 Are two texts written with the exact same high-frequency wordsunderstood equally well by L2 learners when one of the texts is moreidiomatic than the other
2 Can the presence of multiword expressions in a text lead L2 learners tobelieve they have understood that text better than they actually have
A group of 101 adult Brazilian learners of English was tested using twoseparate measures of reading comprehension (one with idiomaticlanguage and one without) and the results of the two tests were thencompared Although verbal reports would provide even greater insightthe resultant data from this study do seem to support a positive answer tothe first research question Participants achieved significantly lowerscores on the comprehension measure which assessed their under-standing of texts that contain multiword expressions It should bereiterated that this result was obtained in spite of both tests being writtenwith the exact same high-frequency words
Likewise through participantsrsquo self-reported comprehension thereseems to be evidence that the presence of multiword expressions in atext can lead L2 readers to overestimate their assessment of how muchthey have actually understood suggesting a positive answer to the secondresearch question
Although it seems apparent that participantsrsquo reading comprehensionin the present study was adversely affected by idiomaticity this sectionexplores and possibly explains variation in comprehension of the testsand further discusses evidence that multiword expressions negativelyaffected participantsrsquo comprehension
On the Stronger and Weaker Performance in the Tests
There are at least three important revelations emerging from theMRC-MAC data analysis presented in Table 6 First nearly two thirds of
TABLE 7
Time It Took Participants to Take Tests
N Mean time (minutes) SD
Time it took to take Test 1 91a 1085 436Time it took to take Test 2 91 1465 377
Note SD 5 standard deviation aSome participants (n 5 10) forgot to write in the time or left itincomplete
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 281
all participants believed they understood more than they actually did inTest 2 Second the data show that over 28 of those students (n 5 20)did not overestimate their comprehension in Test 1 providing evidencethat whereas they were apparently able to gauge their comprehensionfairly accurately when the texts were relatively devoid of idiomaticitythey were significantly less able to do so when relative noncomposition-ality was present Finally the MRC-MAC data presented so far indicatethat although not all participants tended to overestimate theircomprehension in Test 2 those who did (again the majority of cases)generally did so by a much larger margin Put simply it would seem thatnot only are many learners misunderstanding idiomaticity in text butthey may be doing so more than they (or researchers) realize
Further Evidence of Idiomaticity Negatively AffectingComprehension
The mean difference between MRC and MAC for the 70 students whooverestimated their comprehension in Test 2 (Table 6) was 017 For thesake of argument one could establish an MRC-MAC difference above020 as a cutoff for apparently marked lack of awareness of the extentof idiomaticity in Test 29 comparatively speaking This in turn wouldmean that there were 30 participants who ostensibly demonstrated aparticularly high overestimation of how much of Test 2 they had actuallyunderstood A sample of just the top 10 is provided in Table 8
Table 8 shows not only how different those participantsrsquo MRC wasfrom their Test 2 it also lists the same figures for Test 1 for comparison
9 A t-test reveals that the mean is in fact statistically significant even at the 003 differencelevel (t 5 653 p 5 003)
TABLE 8
Partial List of Participants With Exceptionally High Overestimation of Test 2 Comprehension(Difference 020)
ParticipantMRCTest 1
MACTest 1 Difference
MRCTest 2
MACTest 2 Difference
118 100 089 011 094 032 0626 075 068 007 081 028 05392 081 089 2008 075 025 05090 100 089 011 081 039 042115 100 089 011 087 050 03722 100 096 003 094 057 03780 094 068 026 069 032 03759 094 089 005 069 036 03321 100 093 007 087 057 03050 087 078 009 069 039 029
282 TESOL QUARTERLY
Whereas for Test 1 those 30 participantsrsquo assessment of readingcomprehension was usually only slightly overestimated10 (and in oneinstance even underestimated) the same participants in Test 2 had amarkedly overinflated conception of how much they had understood
Although not intended as a principal source of data for our analysisthe start and finish times recorded by participants on the tests in a fewinstances helped confirm the above assertions11 Table 7 shows thatthere was a significant difference between how long participants spenttaking each test (t 5 852 p 0001) However there were a number ofparticipants (n 5 26) who reported actually spending either the same orless time on Test 2 On the surface at least this fact would indicate thatthose 26 participants did not notice much difference between the testsOf course in reality that datum alone does not provide such evidencebecause that time may simply reflect a number of other confoundingvariables including affective (eg simply giving up) or even social (egthe need to leave early to meet a friend) and for that reason also was notconsidered to be a reliable source of data from those participantsHowever as a complementary source when triangulated with the othervariables some of the data analyzed earlier in the current study areoccasionally fortified further still with the time data (Table 9)
The data in Table 9 in many ways tie together the elements discussedin the analysis thus far in the present study A much lower score in Test 2than in Test 1 (columns B and C) an increase in the mean MRC-MACdifference across the tests (columns H and K) a relatively moderatedecrease in MRC in Test 2 vis-a-vis Test 1 (columns F and I) a markeddifference between MRC and MAC in Test 2 (column K) and theoccasional lack of increase (in Table 9 participants 118 80 59 and 50)in time it took to take Test 2 (columns D and E) These findings ontheir own in combination and especially in concert provide evidencethat (1) the students in Table 9 did not seem to appreciate the fullextent of the idiomaticity in Test 2 and (2) they appeared to think thatthey understood more than they actually did in Test 2
Perhaps most important 98 of all participants (n 5 99) scoredsignificantly lower on Test 2 (mean difference of 953 points out of 28SD 5 363) which shows that learners are generally unable to guess themeaning of idiomatic language even in the (largely inconsistent)instances in which they become aware of its presence
11 It should be noted that because 10 of the participantsrsquo time data were left incomplete afull group analysis could not be carried out thus the time data are only included asauxiliary information
10 As can be seen in Table 8 in fact only one participantmdashnumber 80mdashactually had anMRC-MAC difference in Test 1 that was also 020 Those of the other 29 participantswere all lower
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 283
For example the first participant in Tables 8 and 9 (number 118)who consistently overrated his own comprehension relative to his actualcomprehension answered for Text A of Test 2 as shown in Figure 3
On the basis of the responses it is likely that participant 118associated itrsquos about time with lsquolsquohas a problem with timersquorsquo Irsquom a little over thehill with lsquolsquohe probably lives in an area with hillsrsquorsquo and lsquolsquohe lives on the hill
TABLE 9
Triangulated Data Showing Negative Effect of Idiomaticity on Comprehension
A B C D E F G H I J K
Score Time Test 1 Test 2
Partic-ipant Test 1 Test 2 Test 1 Test 2 MRC MAC
Differ-ence MRC MAC
Differ-ence
118 25 9 2000 1800 100 089 11 094 032 0626 19 8 Missing Missing 075 068 007 081 028 05392 25 8 900 1100 081 089 2008 075 025 05090 25 11 900 1500 100 089 011 081 039 042115 25 14 1300 1500 100 089 011 087 050 03722 27 16 Missing Missing 100 096 003 094 057 03780 19 9 1000 1000 094 068 026 069 032 03759 25 10 1500 1400 094 089 005 069 036 03321 26 16 Missing Missing 100 093 007 087 057 03050 22 11 2000 1200 088 079 009 069 039 030
12 Of the 24 multiword expressions targeted for assessment of comprehension in Test 2 onlyfour were core idioms
FIGURE 3 Sample answer to Text A of Test 2
284 TESOL QUARTERLY
but not on top of itrsquorsquomdasha literal reading of those expressions His 100self-assessment is an indication that his answers were not guesses butinstead based on confidence that he had understood all the individualwords in the text The same answering dynamic occurred time and timeagain in Test 2
Returning therefore to the issues raised in the introduction thepresent research appears to provide evidence that idiomsmdashopaque orotherwise12mdashcan in fact cause major problems for L2 learners of Englishwhen reading In general the participants in our study were lesssuccessful at guessing the meaning of idioms than those in previousidiom-centered research such as Cooper (1999) and Liontas (2002)Because the learners in our study were not alerted to the presence ofidiomaticity in the text prior to reading this study may more accuratelyreflect what takes place in more naturally occurring L2 reading Finallythe difficulties that the participants encountered occurred in textscomposed purely of very common words showing that word frequencyalone is not necessarily a good measure of text coverage Lauferrsquos(1989a) hypothesis that much lexis in text can be deceptivelytransparent is confirmed in the present research extended to multiwordexpressions
Limitations of the Research
Although the research presented here does provide some significantevidence that the presence of idiomaticity in a text can negatively affectthe comprehension of that text by an L2 reader little is known about thestrategies the test takers employed Even though metacognition wasoutside the scope of examination of the present study such informationis highly relevant and future research should include protocols such asthose included in previous research on idioms (eg Liontas 20032007) which may provide crucial qualitative data regarding theindividual differences and behavior of the participants themselvesOverall future work in this area should consider making use of differentmeasures of self-assessment in order to explore the limitations of themethodology used in the present study
Also a question can be asked concerning the relative density ofmultiword expressions in each text In other words what is not known ison average how many such items a reader can expect to encounter Theratio of idioms to orthographic words in the texts tested in the presentstudy is very likely higher than averagemdashbut how much higher is as yetunknown Likewise the passages themselves were relatively short so it isunknown whether or not texts of greater length (and thereforecontextualization) would render the same or similar results
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 285
CONCLUSION
The present study provides some empirical evidence that a focus onword in L2 pedagogy may be detrimental to learnersrsquo development ofreading comprehension in the target language In most casesparticipants overestimated how much they had understood the textstested when those texts contained multiword expressions of varyingdegrees of compositionality comprised of very common individualwords Even when participants showed evidence of awareness of apresence of idiomaticity in the texts they generally were not very good atguessing the meaning of expressions Although Grant and Nation(2006) could be right that the teaching of individual idioms may not belsquolsquodeserving of class timersquorsquo (p 5) it is clear that at the very least raisinglearnersrsquo consciousness as to their prevalence and frequently deceptivetransparency in text certainly is
Concomitantly the present research serves to demonstrate theincompleteness of current lists of common words which now informimportant pedagogical instruments such as vocabulary tests gradedreaders and course syllabuses Under current methods as illustrated inthe Table 2 analysis of the Economist paragraph a text measured againstthe word lists now commonly in use can be mistakenly analyzed as beingeasily understood when in fact once multiword expressions are takeninto account the actual text coverage of easily understood words is farless Existing estimates of how many words one needs to know in order toadequately process naturally occurring texts (Hu amp Nation 2000Nation 2006) may need to be revisited to determine how many wordsand multiword expressions one needs to know
In practice research shows that learners will continue to believe theyunderstand items that they actually do not even after repeatedexposures to that same item (Bensoussan amp Laufer 1984 Haynes1993 Pigada amp Schmitt 2006) Language teachers and relatedprofessionals such as textbook writers need to consider ways tocontinuously help learners notice the gap between what they think theyknow and understand and what they actually do (Laufer 1997) Oneway this can be achieved has already been thoroughly discussed in thepresent paper devise texts (and tests) designed to lead readers down anidiomatic garden path Norbert Schmitt (as cited in Weir 2005) made asimilar recommendation
Perhaps the best and most valid type of vocabulary test is a reading passagewith comprehension questions but with the items requiring a full under-standing of particular words or phrases in the text This would mimic the realworld task of reading for comprehension and also the loss of comprehensionwhen key vocabulary is not known (p 123)
286 TESOL QUARTERLY
Therefore a further implication this research has for L2 pedagogy is themore careful design of the reading component of proficiency tests suchas IELTS (International English Language Testing System) and Test ofEnglish as a Foreign Language to be more strategic regarding the amountand kind of phraseology contained in the texts Proficiency was not thecentral focus of our study and future research could adopt a similarmethodology but with the inclusion of proficiency measures ofparticipants in order to explore how various types of expressions (egnoncompositional figurative imageable etc) may differentially affectpreidentified proficiency levels
Thus in order to be more methodical about such things as theinclusion of formulaic language in L2 tests and reading input in generalan important preliminary step will be to establish (a) what type offormulaic sequences are good discriminators of proficiency thresholdlevels and (b) which expressions of that identified type are mostcommon In other words what will be usefulmdashand is indeed nowbeginning to emerge (Martinez amp Schmitt 2010 Shin amp Nation 2008Simpson-Vlach amp Ellis 2010)mdashare lists of formulaic sequences that servea function similar to that of the General Service List not to revolutionizecurrent language pedagogy but to more finely tune it
THE AUTHORS
Ron Martinez is currently pursuing a doctorate at the University of NottinghamNottingham England on the topic of inclusion of phraseology in languageassessment He specializes in second language materials development
Victoria Murphy is a lecturer in Applied Linguistics and Second LanguageAcquisition at the University of Oxford Oxford England Her research interestsinclude the lexical development of first language or second language learners andthe cognitive processes that underlie language acquisition
REFERENCES
Bauer L amp Nation P (1993) Word families International Journal of Lexicography 6253ndash279 doi101093ijl64253
Bensoussan M amp Laufer B (1984) Lexical guessing in context in EFL readingcomprehension Journal of Research in Reading 7 15ndash32 doi101111j1467-98171984tb00252x
Bishop H (2004) Noticing formulaic sequences A problem of measuring thesubjective LSO Working Papers in Linguistics 4 15ndash19
Bransford D B amp Johnson M K (1972) Contextual prerequisites for under-standing Some investigations of comprehension and recall Journal of VerbalLearning and Verbal Behavior 11 717ndash726 doi101016S0022-5371(72)80006-9
Brantmeier C (2006) Advanced L2 learners and reading placement Self-assessment CBT and subsequent performance System 34 15ndash35 doi101016jsystem200508004
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 287
Carver R P (1994) Percentage of unknown vocabulary words in text as a functionof the relative difficulty of the text Implications for instruction Journal of ReadingBehavior 26 413ndash437
Cobb T (nd) Web VocabProfile [Online program] Retrieved from httpwwwlextutorcavp [an adaption of A Heatley amp P Nation Range (1994)]
Cooper T C (1999) Processing of idioms by L2 learners of English TESOLQuarterly 33 233ndash262 doi1023073587719
Coxhead A (2000) A new academic word list TESOL Quarterly 34 213ndash238doi1023073587951
Elley W amp Mangubhai F (1983) The impact of reading on second languagelearning Reading Research Quarterly 19 53ndash67 doi102307747337
Ellis N C (2008) Phraseology The periphery and the heart of language In FMeunier amp S Granger (Eds) Phraseology in language learning and teaching (pp 1ndash13) Amsterdam The Netherlands John Benjamins
Erman B amp Warren B (2000) The idiom principle and the open choice principleText 20 29ndash62
Gardner D (2007) Validating the construct of Word in applied corpus-basedvocabulary research A critical survey Applied Linguistics 28 241ndash265doi101093applinamm010
Glenberg A M Wilkinson A C amp Epstein W (1982) The illusion of knowingFailure in the self-assessment of comprehension Memory and Cognition 10 597ndash602 doi103758BF03202442
Goulden R Nation P amp Read J (1990) How large can a receptive vocabulary beApplied Linguistics 11 341ndash363 doi101093applin114341
Grant L amp Bauer L (2004) Criteria for re-defining idioms Are we barking up thewrong tree Applied Linguistics 25 38ndash61 doi101093applin25138
Grant L amp Nation P (2006) How many idioms are there in English ITL -International Journal of Applied Linguistics 151 1ndash14 doi102143ITL15102015219
Haynes M (1993) Patterns and perils of guessing in second language reading In THuckin M Haynes amp J Coady (Eds) Second language reading and vocabularylearning (pp 46ndash64) Norwood NJ Ablex Publishing Corporation
Heatley A amp Nation P (1994) Range [Computer program] Wellington NewZealand Victoria University of Wellington Retrieved from httpwwwvuwacnzlals
Hill J (2000) Revising priorities From grammatical failure to collocational successIn M Lewis (Ed) Teaching collocation Further developments in the Lexical Approach(pp 47ndash69) Hove England LTP
Hirsh D amp Nation P (1992) What vocabulary size is needed to read unsimplifiedtexts for pleasure Reading in a Foreign Language 8 689ndash696
Hu H M amp Nation P (2000) Unknown vocabulary density and readingcomprehension Reading in a Foreign Language 13 403ndash429
Hughes A (2003) Testing for language teachers Cambridge England CambridgeUniversity Press
Hunt K (1968) An instrument to measure syntactic maturity Tallahassee FL USDepartment of Health Education and Welfare
Jung E H (2003) The effects of organization markers on ESL learnersrsquo textunderstanding TESOL Quarterly 37 749ndash759 doi1023073588223
Krashen S (1993) The power of reading Insights from research Englewood COLibraries Unlimited
Laufer B (1989a) A factor of difficulty in vocabulary learning Deceptivetransparency AILA Review 6 10ndash20
288 TESOL QUARTERLY
Laufer B (1989b) What percentage of lexis is essential for comprehension In CLauren amp M Nordman (Eds) Special language From humans thinking to thinkingmachines (pp 316ndash323) London England Multilingual Matters
Laufer B (1991) How much lexis is necessary for reading comprehension In P JL Arnaud amp H Bejoint (Eds) Vocabulary and applied linguistics (pp 126ndash132)Oxford England Macmillan
Laufer B (1997) The lexical plight in second language reading Words you donrsquotknow words you think you know and words you canrsquot guess In J Coady amp THuckin (Eds) Second language vocabulary acquisition (pp 20ndash34) CambridgeEngland Cambridge University Press
Lewis M (1993) The Lexical Approach The state of ELT and a way forward HoveEngland LTP
Liontas J I (2002) Context and idiom understanding in second languagesEUROSLA Yearbook 2 155ndash185
Liontas J I (2003) Killing two birds with one stone Understanding Spanish VPidioms in and out of context Hispania 86 289ndash301 doi10230720062862
Liontas J I (2007) The eye never sees what the brain understands Making sense ofidioms in second languages Lingua et Linguistica 1) 25ndash44
Maki R H amp McGuire M J (2002) Metacognition for text Findings andimplications for education In T Schwarz amp L Bennett (Eds) Appliedmetacognition (pp 39ndash67) Cambridge England Cambridge University Press
Martinez R amp Schmitt N (2010) A phrasal expressions listManuscript submitted forpublication
Moon R (1997) Vocabulary connections Multi-word items in English In NSchmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 40ndash63) Cambridge England Cambridge University Press
Moore D Lin-Agler L M amp Zabrucky K M (2005) A source of metacomprehen-sion inaccuracy Reading Psychology 26 251ndash265 doi10108002702710590962578
Morrison L (2004) Comprehension monitoring in first and second languagereading The Canadian Modern Language Review 61 77ndash106
Nation I S P (2001) Learning vocabulary in another language Cambridge EnglandCambridge University Press
Nation I S P (2006) How large a vocabulary is needed for reading and listeningThe Canadian Modern Language Review 63 59ndash82
Nation I S P amp Waring R (1997) Vocabulary size text coverage and word lists InN Schmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 6ndash19) Cambridge England Cambridge University Press
Nation P (1997) The language learning benefits of extensive reading LanguageTeacher 21 13ndash16
Nattinger J R amp DeCarrico J S (1992) Lexical phrases and language teachingOxford England Oxford University Press
Oh S Y (2001) Two types of input modification and EFL reading comprehensionSimplification versus elaboration TESOL Quarterly 35 69ndash96 doi1023073587860
OrsquoKeeffe A McCarthy M amp Carter R (2007) From corpus to classroom Language useand language teaching Cambridge England Cambridge University Press
Pawley A amp Syder F H (1983) Two puzzles for linguistic theory Nativelikeselection and nativelike fluency In J C Richards amp R Schmidt (Eds) Languageand communication (pp 191ndash226) New York NY Longman
Pigada M amp Schmitt N (2006) Vocabulary acquisition from extensive reading Acase study Reading in a Foreign Language 18 1ndash28
Read J (2004) Research in teaching vocabulary Annual Review of Applied Linguistics24 146ndash161 doi101017S0267190504000078
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 289
Sarac S amp Tarhan B (2009) Calibration of comprehension and performance inL2 reading International Electronic Journal of Elementary Education 2 167ndash179
Schmitt N Jiang N amp Grabe W (2011) The percentage of words known in a textand reading comprehension Modern Language Journal 95(1) 26ndash43
Schmitt N Schmitt D amp Clapham C (2001) Developing and exploring thebehaviour of two new versions of the Vocabulary Levels Test Language Testing 1855ndash88
Shin D amp Nation I S P (2008) Beyond single words The most frequentcollocations in spoken English ELT Journal 62 339ndash348 doi101093eltccm091
Simpson-Vlach R amp Ellis N C (2010) An academic formulas list New methods inphraseology research Applied Linguistics 31(4) 487ndash512
Sinclair J (1991) Corpus concordance collocation Oxford England OxfordUniversity Press
Spottl C amp McCarthy M (2003) Formulaic utterances in the multi-lingual contextIn J Cenoz B Hufeisen ampU Jessner (Eds) The multilingual lexicon (pp 133ndash151) Dordrecht The Netherlands Kluwer
Staelighr L S (2008) Vocabulary size and the skills of listening reading and writingLanguage Learning Journal 36 139ndash152 doi10108009571730802389975
Stubbs M amp Barth I (2003) Using recurrent phrases as text-type descriminators Aquantitative method and some findings Functions of Language 10 61ndash104doi101075fol10104stu
The British National Corpus (2007) The British National Corpus(version 3 BNC XMLed) [CD-ROM] Distributed by Oxford University Computing Services on behalfof the BNC Consortium
The iPhonersquos second coming (2008 July) The Economist Retrieved from httpwwweconomistcomscience-technologydisplaystorycfmstory_id5E1_TTSDDJTG
Walter E Woodford K amp Good M (Eds) (2008) Cambridge advanced learnerrsquosdictionary (3rd ed) Cambridge England Cambridge University Press
Weir C J (2005) Language testing and validation An evidence-based approachNew York NY Palgrave Macmillan
West M (1953) A general service list of English words London England LongmanWray A (2002) Formulaic language and the lexicon Cambridge England Cambridge
University Press
290 TESOL QUARTERLY

receptive knowledge of around 20000-word families1mdasha number whichmay seem daunting to a learner of the language Perhaps for that reasona number of researchers (eg Hirsh amp Nation 1992 Hu amp Nation 2000Laufer 1989b) have endeavored to answer the following question Howmany words are really necessary in order to comprehend most texts Theanswer to that question is of interest to a wide range of parties fromdevelopers of English as a foreign language textbooks to writers ofgraded readers to practicing classroom teachers and their students(Nation amp Waring 1997) After all to be able to put a concrete numberon the words one needs to know to function in the target language is tobe able to set teaching goals divide proficiency levels and see aproverbial light at the end of the L2 learning tunnel
However the answer to that question has also proved somewhatcomplex requiring identifying not so much how many words one needsto know in absolute terms but rather how many words a learner needs toknow in order to understand a text in spite of unknown vocabulary Basingtheir assertions mostly on the assumption that pleasurable reading occursonly when a reader knows almost all the words in a text Hirsh and Nation(1992) stipulated the ideal percentage of words known in an unsimplifiedtext at around 98 which the authors claimed could be reached with aknowledge of 5000-word families However one limitation of the Hirsh andNation study was that the texts used were novels written for teenagers andadolescents To determine whether the same word family figure wouldapply to authentic texts designed for general (ie adult native speaker)consumption Nation (2006) conducted a new analysis of fiction andnonfiction text (eg novels and newspapers) The trialing showed that if98 coverage of a text is needed for unassisted comprehension then an8000- to 9000-word family vocabulary is needed Therefore assuming the98 figure is valid (as supported by Hu amp Nation 2000 and most recentlySchmitt Jiang amp Grabe 2011) a learner requires a knowledge of at least8000-word families in order to adequately comprehend most unsimplifiedfiction and nonfiction text
Word Counts and Their Limitations
The estimates of how many words a reader needs to know in order toread unsimplified text may actually be somewhat misleading withoutcritical examination of the underlying constructs The main problem liesin the compilation of word frequency lists themselves including whatconstitutes a word (cf Gardner 2007)
As mentioned earlier current research suggests that 8000ndash9000 wordscan provide around 98 coverage of most texts (Nation 2006) However
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 269
Nationrsquos recommendations are for an lsquolsquo8000ndash9000 word-family vocabu-laryrsquorsquo (p 79) which does not necessarily mean knowing 8000 words
From the point of view of reading a word family consists of a base word andall its derived and inflected forms that can be understood by a learnerwithout having to learn each form separately [ ] The important principlebehind the idea of a word family is that once the base word or even a derivedword is known the recognition of other members of the family requires littleor no extra effort (Bauer amp Nation 1993 p 253)
In the lists that Nation and other researchers have used to calculate wordknowledge (eg Nation 2006 West 1953) a word can include a base formand over 80 derivational affixes (Nation 2006 p 66) resulting in lsquolsquosomelarge word families especially among the high-frequency wordsrsquorsquo (Nation2006) but there may be an issue of overconflation of forms Consider forexample the semantic distance between the following pairs of words nameR namely price R priceless fish R fishy puzzle R puzzling Each of thepreceding pairs would be grouped into the same respective word family butit is unlikely that a learner of English would require lsquolsquolittle or no extraeffortrsquorsquo (Bauer amp Nation 1993 p 253) to derive the meaning of a word likefishy from fish2 It is therefore conceivable that a number of those 8000- to9000-word families do not have the psycholinguistic validity that issometimes assumed and some of the 30000 (or so) separate wordssubsumed in those families would in fact need to be learned separately
Similar to the semantic distance between fish and fishy there is oftenan equal or greater disparity of meaning when a word is juxtaposed withanother or more words and a new expression forms (Moon 1997 Wray2002) For example the words fine good and perfect each have meaninghowever those meanings do not remain in the expressions finely tunedfor good and perfect stranger
Nation (2006) recognized this limitation of current word lists howeverhe did not consider it a problem Nation based this assertion on theassumption that most learners will be able to guess the meaning ofmultiword expressions that have some element of transparency and sincethe number of lsquolsquotruly opaquersquorsquo phrases in English is relatively small for thepurposes of reading they are lsquolsquonot a major issuersquorsquo (p 66) However it isdebatable just how lsquolsquosmallrsquorsquo in number those opaque expressions are andmuch like the previously discussed derived word forms that are actuallysemantically dissimilar just how easy it is for a learner of English toaccurately guess the meaning of more lsquolsquotransparentrsquorsquo expressions
2 According to the Cambridge Advanced Learnerrsquos Dictionary (Walter Woodford amp Good2008) which is informed by the one-billion-word Cambridge International Corpus thefirst sense of fishy is lsquolsquodishonest or falsersquorsquo (p 537) and not lsquolsquosmelling of fishrsquorsquo
270 TESOL QUARTERLY
Martinez and Schmitt (2010) for example sought to compile a list of themost common expressions derived from the British National Corpus3
(BNC) Their main criteria for selection was frequency and relativenoncompositionality in other words the items chosen for selection neededto possess semantic and grammatical properties that could pose decodingproblems for learners when reading Their exhaustive search rendered over500 multiword expressions that were frequent enough to be included in alist of the top 5000 words in Englishmdashor over 10 of the entire frequencylist A sample of the list is provided in Table 1
As an example of how taking word frequency into account alonepotentially leads to very misleading estimates of text comprehensibilityconsider the following text taken from The Economist
But over the past few months competing 3G smartphones with touch screensand a host of features have been coming thick and fast to the American marketAnd waiting in the wings are any number of open-source smartphones basedon the nifty Linux operating system Apple will need to pull out all the stops ifthe iPhone is not to be swept aside by the flood of do-it-all smartphonesheading for Americarsquos shores (lsquolsquoThe iPhonersquos second comingrsquorsquo 2008)
The above paragraph contains a number of expressions which are partlyor totally opaque including the following seven
- over the past- a host of- thick and fast- waiting in the wings- any number of- pull out all the stops- swept aside
3 A 100-million word corpus predominantly composed of written English (The BritishNational Corpus 2007)
TABLE 1
Highly Frequent Idioms With Words From Beginner EFL Textbooks for Comparison
Frequency (BNC) Idioms Frequency (BNC) Words (for comparison)
18041 as well as 466 steak14650 at all 455 niece12762 in order to 400 receptionist10556 take place 387 lettuce7138 for instance 385 gym4584 and so on 377 carrot4578 be about to 341 snack3684 at once 337 earrings2676 in spite of 302 dessert1995 in effect 291 refrigerator
Note EFL 5 English as a foreign language BNC 5 British National Corpus
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 271
Current text word coverage calculations ignore such expressionsAccording to software commonly used to analyze the word familyfrequency distribution of text (VocabProfile [Cobb nd]) the sameEconomist paragraph is broken down as shown in Table 2
So if comprehension of a text were based on word coverage alonecurrent methods of text analysis (Table 2) suggest that a learner with avocabulary of at least the top 2000 words in English should be able tounderstand 9552 of the lexis in the Economist text (64 of the 67 words[tokens] counted) by some estimates (eg Laufer 1989b) enough foradequate comprehension If that same learner also knew just two wordsin the text on the Academic Word List (Coxhead 2000)mdashfeatures andsourcemdashshe would understand an additional 299 affording thatlearner a knowledge of 9851mdashtheoretically approximating nativelikelevels of comprehension (Carver 1994 p 432) However a closer lookat the breakdown in Table 2 shows that words like pull out all the andstops were all considered as separate and very common words when inreality they form one noncompositional expression pull out all the stopsIn fact all of the seven expressions have mistakenly been fragmentedand categorized as pertaining to the top 2000 words Thereforeassuming that a learner who knows only the 2000 most common wordsin English would not understand those expressions without the help of adictionary and if we reconduct the analysis taking those sevenexpressions into account (constituting 23 words) the total number ofwords fitting into the top 2000 goes down to 41 (64 minus 23) and that9552 figure actually drops from adequate comprehension down to6119 (41 4 67 5 06119)mdashwell below acceptable levels of readingcomprehension (Hu amp Nation 2000)
TABLE 2
Word Frequency Breakdown of The Economist text (Not Including Proper Nouns)
Frequency Words (67 tokens 54 types) Text coverage
0ndash1000 a all and any are based be been but by comingdo fast few for have heading if in is it marketmonths need not number of on open operatingout over past pull shores stops system the totouch waiting will with
8358
1001ndash2000 aside competing flood host screens swept thickwings
1194
Academic Word List(AWL)
features source 299
Off list Nifty 149Words in top 2000 9552+ AWL words 299Total text coverage 9851
272 TESOL QUARTERLY
RELATIONSHIP BETWEEN FORMULAIC LANGUAGE ANDREADING COMPREHENSION
Considering the relative wealth of research and literature on L2reading comprehension and separately multiword expressions inEnglish there is a surprising dearth of information regarding the roleif any formulaic language plays in the comprehension of texts in aforeign language The relatively few studies that do exist (eg Cooper1999 Liontas 2002) seem to confirm that it is especially the moresemantically opaque idioms that pose interpretability problems for L2readers and as these more core idioms are relatively rare (Grant ampNation 2006) Nation (2006) could be right in attenuating theirsignificance in reading comprehension
Nevertheless as discussed earlier there is evidence that a significantnumber of relatively opaque expressions occur frequently in texts inEnglish One commonly cited estimate (Erman amp Warren 2000) is thatsomewhat more than one-half (55) of any text will consist of formulaiclanguage (p 50) Naturally the opacity of those expressions will lie onwhat Lewis (1993 p 98) called a lsquolsquospectrum of idiomaticityrsquorsquo (Figure 1) akind of continuum of compositionality
Furthermore even when an expression does not meet the criteria ofcore or nonmatching idiom the relative ease or difficulty with which alearner will unpack its meaning is less inherent to the item itself andmore a learner-dependent variable Just as knowing fish may or may nottranslate into understanding fishy knowing perfect does not necessarilymean understanding perfect stranger
What is more although previous studies (Cooper 1999 Liontas2002) have found that in textual context more transparent idioms weremore easily understood than their opaque counterparts it should alsobe noted that the participants in those studies were aware that they werebeing tested specifically on their ability to correctly interpret idioms Inother words what cannot be known from most existing studies on idiominterpretation is how well the participants would have been able toidentify and understand the idioms in the first place had they not beenaware of their presence in the text
FIGURE 1 A spectrum of idiomaticity (compositionality)
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 273
A notable exception is Bishop (2004) who investigated thedifferential look-up behavior of participants who read texts thatcontained unknown words and unknown multiword expressions synon-ymous with those words Bishop confirmed that even though both wordsand multiword expressions were unknown readers looked up themeaning of words significantly more often He concludes that learnerslsquolsquodo not notice unknown formulaic sequences as readily as unknownwordsrsquorsquo (p 18)
Therefore idiomatic language in text irrespective of composition-ality might most usefully be classified as what Laufer (1989a) calledlsquolsquodeceptively transparentrsquorsquo (p 11) Laufer found that many Englishlearners misanalyze words like infallible as in+fall+ible (ie lsquolsquocannot fallrsquorsquo)and nevertheless as never+less (ie lsquolsquoalways morersquorsquo p 12) Likewisemdashalthough they were not part of her studymdashshe found that idioms like hitand miss were being read and interpreted word for word These lexicalitems that lsquolsquolearners think they know but they do notrsquorsquo (Laufer 1989ap 11) can impede reading comprehension in ways not accounted for inlists of common word families Nation (2006) seemed to assume thatmultiword expressions that have some element of transparency howeversmall will be reasonably interpretable through guessing However theLaufer (1989a) study may provide evidence to the contrary
But an attempt to guess (regardless of whether it is successful or not)presupposes awareness on the part of the learner that he is facing anunknown word If such an awareness is not there no attempt is made to inferthe missing meaning This is precisely the case with deceptively transparentwords The learner thinks he knows and then assigns the wrong meaning tothem [ ] (p 16)
Substitute lsquolsquoidiomrsquorsquo for lsquolsquowordrsquorsquo abovemdashnot an unreasonable conceptualstretchmdashand it becomes clear that multiword expressions just maypresent a larger problem for reading comprehension than accounted forin the current literature
In fact such lsquolsquodeceptionrsquorsquo seems even more likely to occur withmultiword expressions because such a large number of them arecomposed of very common words a learner would assume he or sheknows (Spottl amp McCarthy 2003 p 145 Stubbs amp Barth 2003 p 71)Moreover there is evidence that learners are reluctant to revisehypotheses formed regarding lexical items when reading even whenthe context does not support those hypotheses (Haynes 1993 Pigada ampSchmitt 2006)
274 TESOL QUARTERLY
Summary and Research Questions
In summary the following has been argued thus faramp Current estimates of how many words one needs to know in order to
comprehend most texts may be inaccurate due to overinclusion of derivedword forms and a total exclusion of multiword units of vocabulary
amp Contrary to some research there is evidence in corpus data that thenumber of frequently occurring noncompositional multiwordexpressions in English is higher than previously believed
amp Even when an expression is partly or even fully compositional thereis no way of knowing how accurately an L2 reader will interpret (oreven identify) that item
amp The claim that special attention to the 2000ndash3000 most commonwords in English is pedagogically sound since they provide around80 of text coverage (eg OrsquoKeeffe McCarthy amp Carter 2007Read 2004 p 148 Staelighr 2008) deserves closer scrutiny becausethose words are often merely tips of phraseological icebergs
It is therefore clear that there is a need for further investigation into howcommon words and the multiword units they form can affect readingcomprehension when reading in English as a foreign language To thatend we conducted a study to answer the following research questions
1 Are two texts written with the exact same high-frequency wordsunderstood equally well by L2 learners when one of the texts is moreidiomatic than the other
2 Can the presence of multiword expressions in a text lead L2 learners tobelieve they have understood that text better than they actually have
METHOD
Participants
Brazilian adult learners of English (n 5 101) all native speakers ofBrazilian Portuguese were selected to participate in the study Thesample ranged in age from 18 to 64 years (M 5 2576 SD 5 931) andconsisted of 43 men and 58 women representing seven different regionsof Brazil
All participants in the study had had a minimum of 80 hr of tuition inEnglish prior to the start of the research and had been tested aspossessing intermediate or higher levels of proficiency Howeverbecause all participants attended private language schools the actualinstruments by which their proficiency was assessed varied widely
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 275
Regardless uniformity in proficiency was not of prime importance in thestudy because the research questions are concerned with a significantchange in the paired samples within the same group
The Test
To write the eight texts (four texts in each test) a corpus of words wascarefully chosen from the list of the 2000 most frequent words in the BNCThe reading comprehension of each text was tested by seven true or falseitems totaling 28 per test part or 56 overall The test when administeredappears as one but is actually in two parts (Test 1 and Test 2) each partcontaining the exact same words with some words in Test 2 formingmultiword expressions Great care was taken to ensure that the texts areotherwise equal There is no visual difference between the two parts andthe texts are of almost uniform length in both parts (Table 3 and Figure 2)In addition care was taken not to include any extra cultural references inany of the texts and the comprehension task itself did not change acrossthe test parts The texts are stated to have come from peoplersquos descriptionof themselves in lsquolsquoFriendsbookrsquorsquo (intentionally similar to Facebook) On thewhole therefore it could be said that the style of the text is personal andinformal
The vast majority of the words are in the top 1000 withapproximately 985 of the words occurring in the BNC top 2000(Table 3) These results were in turn compared with the General ServiceList (West 1953) using software developed by Heatley and Nation(Range 1994) and another package using the same corpus created byCobb (nd) The results were practically identical in all cases (Range985 VocabProfile 98494)
Another key feature of the test is the rating scale which requires the testtaker to circle what she believes is his or her comprehension of each textfrom 5 to 1005 This self-reported comprehension is designed to helpanswer the second research question of whether the presence ofmultiword expressions in a text can lead L2 learners to believe they have
TABLE 3
Summary of Test 1 and Test 2 Text Data
Total wordcount
Total clausecount T-unit count
Top 1000words coverage
Top 1001ndash2000 words
coverage
Test 1 416 56 45 957373 27650Test 2 412 54 42 957373 27650
Note Data measured using vocabulary profiler (Cobb nd) A T-unit or a minimal terminableunit is lsquolsquoone main clause plus any subordinate clausersquorsquo (Hunt 1968 p 4)
276 TESOL QUARTERLY
understood that text better than they actually have Testing whatcomprehenders believe they understoodmdashcompared to what they actuallyunderstoodmdashby comparing test scores to self-assessment of comprehen-sion via a rating scale is often referred to as lsquolsquocomprehension calibrationrsquorsquoand is a method that has been used extensively in psychological research(eg Bransford amp Johnson 1972 Glenberg Wilkinson amp Epstein 1982Maki amp McGuire 2002 Moore Lin-Agler amp Zabrucky 2005) butsomewhat less so in applied linguistics (cf Brantmeier 2006 Jung 2003Morrison 2004 Oh 2001 Sarac amp Tarhan 2009)
Finally participants were asked to record their start and finish timesfor each part of the test
Procedure
Following an initial field test an item analysis was conducted toestablish the facility value6 of the test items and a discrimination indexfor both test parts to discern whether the test was discriminatingbetween stronger and weaker participants Items that were found to haveexceptionally high or low scores were carefully analyzed and the wordingof both test items and reading texts adjusted accordingly
Finally as advocated in Schmitt Schmitt and Clapham (2001) oneimportant requirement of an L2 test of reading comprehension is that itbe answerable by native or nativelike speakers of the language (p 65)To that end a smaller group of native speakers (n 5 8) was also tested asan additional check of the testrsquos validity That group produced a mean
FIGURE 2 Side-by-side comparison of matched texts from the two test parts (full version ofthe test available on request)
4 These are vocabulary profilers that essentially use word frequency lists to break all thewords in a text down into those that occur for example in the top 1000 second 1000third 1000 and so on
5 lsquolsquo0rsquorsquo would be virtually impossible because learners would be familiar with most words inthe texts if not all
6 A test itemrsquos facility value is calculated by dividing the number of participants whoanswered that item correctly by the total number of participants (Hughes 2003)
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 277
score of 28 in Test 1 (the maximum score) and 2775 in Test 2 showingthat both test parts posed very little difficulty for people for whomEnglish is a first language
The students received the two parts of the test in alternating order(ie counterbalanced) to control for any effect of taking Test 1 beforeTest 2 (and vice versa) because by counterbalancing one is able toinclude a variable order into an analysis and identify the extent towhich order affects performance on the dependent measures
RESULTS
All the scores and self-reported comprehension measures wererecorded in a statistical analysis software program (SPSS) Eachparticipantrsquos test results were transcribed into the software item by item(ie correct and incorrect) text by text (eg Text A Text B etc numbercorrect out of 7 for each) and test by test (ie Test 1 and Test 2 numbercorrect out of 28 possible for each) Also recorded were each participantrsquosself-reported comprehension assessments (a rating scale from 5 to 100)as they pertained to each text as well as which version (Test 1 or Test 2first) of the instrument each candidate had received To assess the effectof counterbalancing a repeated measures analysis of variance (ANOVA)was conducted with one within-subjects factor (TEST) with two levels(Test 1 score Test 2 score) and one between-subjects factor (VERSION)with two levels (Test 1 first Test 2 first) This analysis revealed a robustmain effect of test (F (199) 5 59338 p 0001 g2 5 086) and a discreteeffect of version (F (199) 5 405 p 5 0047 g2 5 004) but importantlythere was no significant Test 6 Version interaction (F (199) 5 281 p 5
0097 g2 5 002) illustrating that participantsrsquo scores did not vary as afunction of which version of the test they were completing
Comprehension of Test 1 versus Test 2
The central tendencies from both tests are presented in Table 4As predicted participantsrsquo scores were significantly lower on Test 2
relative to Test 1 (t(100) 5 2410 p 0001) with a strong effect size(g2 5 0828)7 confirming that even when two sets of texts contain theexact same words and even if those words are very commoncomprehension of those texts will not be the same when one containsidiomaticity
7 Confidence intervals at 95 for all t-tests
278 TESOL QUARTERLY
Self-Reported Comprehension of Test 1 versus Test 2
A t-test was also performed on the difference between whatparticipants believed they understood (ie their reported comprehen-sion) and what they actually understood in both Tests 1 and 2 (Table 5)Mean reported comprehension (MRC) was arrived at by calculating themeans of all the self-reported comprehension percentages (5ndash100)and the mean actual comprehension (MAC) is the mean of the score oneach text divided by seven (the maximum score)
MAC was lower than MRC in both Test 1(MRC M 5 08738 SD 013MAC M 5 08603 SD 5 009) and Test 2 (MRC M 5 06029 SD 019MAC M 5 05258 SD 5 014) however the difference between MRCand MAC was statistically reliable in Test 2 only where the test wascomposed of multiword expressions (t(100) 5 395 p 0001 g2 5
007)8 These data therefore appear to support a positive answer to thesecond research questionmdashthat learners may believe they understandmore than they actually do by virtue of their simply understanding theindividual words in a text
Variation in the Data
MRC versus MAC
Naturally there were some individual differences in the test resultsTable 6 shows that roughly one-half of all participants (n 5 50)overestimated their comprehension in both tests (indicated by MRC
TABLE 4
Descriptive Statistics (Tests 1 and 2)
Mean Median Mode Minimum Maximum SD
Test 1a 2409 2500 2500 1800 2800 244Test 2b 1476 1500 1500 600 2500 393
Note SD 5 standard deviation aTexts composed of common words however with little or noopaque phraseology bTexts composed of common words which comprise collocations andidiomatic language
TABLE 5
Reported Versus Actual Comprehension
Test 1 Test 2
Mean reported comprehension (MRC) 8738 6029Mean actual comprehension (MAC) 8603 5258
8 By comparison the results of the paired sample t-test for the Test 1 MRC-MAC means weret(100) 5 104 p 5 0302 g2 5 0005
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 279
greater than MAC) On the surface this might suggest that those 50participants did not overestimate their comprehension in Test 2 as aresult of its relative noncompositionality but rather as a generaltendency regardless of idiomaticity However when MAC is subtractedfrom MRC for that group and the difference compared across the teststhe difference is twice as large in Test 2 (t(49) 5 492 p 0001 g2 5
0108) This difference is even more evident in the same analysis of Test2 alone Isolating the results of that test there was a total of 70participants (over 69 of the entire sample) whose MRC was greaterthan their MAC The difference between MRC minus MAC for thesubgroup of 70 participants reveals that their overestimation of theircomprehension in Test 2 was four times greater than in Test 1 (t(69) 5
770 p 0001 g2 5 0228) Further among that group of 70 whoseTest 2 MRC was greater than their MAC 20 students either under-estimated or actually accurately guessed their comprehension in Test 1but significantly overestimated their comprehension in Test 2 (t(19) 5
849 p 0001 g2 5 0264) Only 30 participants in the present studyactually underestimated their comprehension on Test 2
Variation in Time Spent on the Tests
All candidates were also asked to record their start and finishing timesof each test (Table 7) It is not surprising that on average participantsspent more time on the texts which contained idiomatic expressionsHowever this trend was not uniform among the participants and thetime data may help provide some insight into just how aware someparticipants were of the presence of idiomaticity in the texts Thispossibility is explored further in the Discussion
TABLE 6
Trend of Increase in MRC-MAC Discrepancy Across Test Parts
NMRC minus MAC
(Test 1)MRC minus MAC
(Test 2)
Students with MRC MAC (bothtest parts)
50 009 019
Students with MRC MAC (Test 2) 70 004 017Students with MRC MAC (Test 2only)
20 2010 014
Students with MRC MAC (Test 2) 31a 2005 2015
Note MRC 5 mean reported comprehension MAC 5 mean actual comprehension aOnly oneparticipant in this group had MRC 5 MAC
280 TESOL QUARTERLY
DISCUSSION
To reiterate the present study sought to address the followingresearch questions
1 Are two texts written with the exact same high-frequency wordsunderstood equally well by L2 learners when one of the texts is moreidiomatic than the other
2 Can the presence of multiword expressions in a text lead L2 learners tobelieve they have understood that text better than they actually have
A group of 101 adult Brazilian learners of English was tested using twoseparate measures of reading comprehension (one with idiomaticlanguage and one without) and the results of the two tests were thencompared Although verbal reports would provide even greater insightthe resultant data from this study do seem to support a positive answer tothe first research question Participants achieved significantly lowerscores on the comprehension measure which assessed their under-standing of texts that contain multiword expressions It should bereiterated that this result was obtained in spite of both tests being writtenwith the exact same high-frequency words
Likewise through participantsrsquo self-reported comprehension thereseems to be evidence that the presence of multiword expressions in atext can lead L2 readers to overestimate their assessment of how muchthey have actually understood suggesting a positive answer to the secondresearch question
Although it seems apparent that participantsrsquo reading comprehensionin the present study was adversely affected by idiomaticity this sectionexplores and possibly explains variation in comprehension of the testsand further discusses evidence that multiword expressions negativelyaffected participantsrsquo comprehension
On the Stronger and Weaker Performance in the Tests
There are at least three important revelations emerging from theMRC-MAC data analysis presented in Table 6 First nearly two thirds of
TABLE 7
Time It Took Participants to Take Tests
N Mean time (minutes) SD
Time it took to take Test 1 91a 1085 436Time it took to take Test 2 91 1465 377
Note SD 5 standard deviation aSome participants (n 5 10) forgot to write in the time or left itincomplete
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 281
all participants believed they understood more than they actually did inTest 2 Second the data show that over 28 of those students (n 5 20)did not overestimate their comprehension in Test 1 providing evidencethat whereas they were apparently able to gauge their comprehensionfairly accurately when the texts were relatively devoid of idiomaticitythey were significantly less able to do so when relative noncomposition-ality was present Finally the MRC-MAC data presented so far indicatethat although not all participants tended to overestimate theircomprehension in Test 2 those who did (again the majority of cases)generally did so by a much larger margin Put simply it would seem thatnot only are many learners misunderstanding idiomaticity in text butthey may be doing so more than they (or researchers) realize
Further Evidence of Idiomaticity Negatively AffectingComprehension
The mean difference between MRC and MAC for the 70 students whooverestimated their comprehension in Test 2 (Table 6) was 017 For thesake of argument one could establish an MRC-MAC difference above020 as a cutoff for apparently marked lack of awareness of the extentof idiomaticity in Test 29 comparatively speaking This in turn wouldmean that there were 30 participants who ostensibly demonstrated aparticularly high overestimation of how much of Test 2 they had actuallyunderstood A sample of just the top 10 is provided in Table 8
Table 8 shows not only how different those participantsrsquo MRC wasfrom their Test 2 it also lists the same figures for Test 1 for comparison
9 A t-test reveals that the mean is in fact statistically significant even at the 003 differencelevel (t 5 653 p 5 003)
TABLE 8
Partial List of Participants With Exceptionally High Overestimation of Test 2 Comprehension(Difference 020)
ParticipantMRCTest 1
MACTest 1 Difference
MRCTest 2
MACTest 2 Difference
118 100 089 011 094 032 0626 075 068 007 081 028 05392 081 089 2008 075 025 05090 100 089 011 081 039 042115 100 089 011 087 050 03722 100 096 003 094 057 03780 094 068 026 069 032 03759 094 089 005 069 036 03321 100 093 007 087 057 03050 087 078 009 069 039 029
282 TESOL QUARTERLY
Whereas for Test 1 those 30 participantsrsquo assessment of readingcomprehension was usually only slightly overestimated10 (and in oneinstance even underestimated) the same participants in Test 2 had amarkedly overinflated conception of how much they had understood
Although not intended as a principal source of data for our analysisthe start and finish times recorded by participants on the tests in a fewinstances helped confirm the above assertions11 Table 7 shows thatthere was a significant difference between how long participants spenttaking each test (t 5 852 p 0001) However there were a number ofparticipants (n 5 26) who reported actually spending either the same orless time on Test 2 On the surface at least this fact would indicate thatthose 26 participants did not notice much difference between the testsOf course in reality that datum alone does not provide such evidencebecause that time may simply reflect a number of other confoundingvariables including affective (eg simply giving up) or even social (egthe need to leave early to meet a friend) and for that reason also was notconsidered to be a reliable source of data from those participantsHowever as a complementary source when triangulated with the othervariables some of the data analyzed earlier in the current study areoccasionally fortified further still with the time data (Table 9)
The data in Table 9 in many ways tie together the elements discussedin the analysis thus far in the present study A much lower score in Test 2than in Test 1 (columns B and C) an increase in the mean MRC-MACdifference across the tests (columns H and K) a relatively moderatedecrease in MRC in Test 2 vis-a-vis Test 1 (columns F and I) a markeddifference between MRC and MAC in Test 2 (column K) and theoccasional lack of increase (in Table 9 participants 118 80 59 and 50)in time it took to take Test 2 (columns D and E) These findings ontheir own in combination and especially in concert provide evidencethat (1) the students in Table 9 did not seem to appreciate the fullextent of the idiomaticity in Test 2 and (2) they appeared to think thatthey understood more than they actually did in Test 2
Perhaps most important 98 of all participants (n 5 99) scoredsignificantly lower on Test 2 (mean difference of 953 points out of 28SD 5 363) which shows that learners are generally unable to guess themeaning of idiomatic language even in the (largely inconsistent)instances in which they become aware of its presence
11 It should be noted that because 10 of the participantsrsquo time data were left incomplete afull group analysis could not be carried out thus the time data are only included asauxiliary information
10 As can be seen in Table 8 in fact only one participantmdashnumber 80mdashactually had anMRC-MAC difference in Test 1 that was also 020 Those of the other 29 participantswere all lower
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 283
For example the first participant in Tables 8 and 9 (number 118)who consistently overrated his own comprehension relative to his actualcomprehension answered for Text A of Test 2 as shown in Figure 3
On the basis of the responses it is likely that participant 118associated itrsquos about time with lsquolsquohas a problem with timersquorsquo Irsquom a little over thehill with lsquolsquohe probably lives in an area with hillsrsquorsquo and lsquolsquohe lives on the hill
TABLE 9
Triangulated Data Showing Negative Effect of Idiomaticity on Comprehension
A B C D E F G H I J K
Score Time Test 1 Test 2
Partic-ipant Test 1 Test 2 Test 1 Test 2 MRC MAC
Differ-ence MRC MAC
Differ-ence
118 25 9 2000 1800 100 089 11 094 032 0626 19 8 Missing Missing 075 068 007 081 028 05392 25 8 900 1100 081 089 2008 075 025 05090 25 11 900 1500 100 089 011 081 039 042115 25 14 1300 1500 100 089 011 087 050 03722 27 16 Missing Missing 100 096 003 094 057 03780 19 9 1000 1000 094 068 026 069 032 03759 25 10 1500 1400 094 089 005 069 036 03321 26 16 Missing Missing 100 093 007 087 057 03050 22 11 2000 1200 088 079 009 069 039 030
12 Of the 24 multiword expressions targeted for assessment of comprehension in Test 2 onlyfour were core idioms
FIGURE 3 Sample answer to Text A of Test 2
284 TESOL QUARTERLY
but not on top of itrsquorsquomdasha literal reading of those expressions His 100self-assessment is an indication that his answers were not guesses butinstead based on confidence that he had understood all the individualwords in the text The same answering dynamic occurred time and timeagain in Test 2
Returning therefore to the issues raised in the introduction thepresent research appears to provide evidence that idiomsmdashopaque orotherwise12mdashcan in fact cause major problems for L2 learners of Englishwhen reading In general the participants in our study were lesssuccessful at guessing the meaning of idioms than those in previousidiom-centered research such as Cooper (1999) and Liontas (2002)Because the learners in our study were not alerted to the presence ofidiomaticity in the text prior to reading this study may more accuratelyreflect what takes place in more naturally occurring L2 reading Finallythe difficulties that the participants encountered occurred in textscomposed purely of very common words showing that word frequencyalone is not necessarily a good measure of text coverage Lauferrsquos(1989a) hypothesis that much lexis in text can be deceptivelytransparent is confirmed in the present research extended to multiwordexpressions
Limitations of the Research
Although the research presented here does provide some significantevidence that the presence of idiomaticity in a text can negatively affectthe comprehension of that text by an L2 reader little is known about thestrategies the test takers employed Even though metacognition wasoutside the scope of examination of the present study such informationis highly relevant and future research should include protocols such asthose included in previous research on idioms (eg Liontas 20032007) which may provide crucial qualitative data regarding theindividual differences and behavior of the participants themselvesOverall future work in this area should consider making use of differentmeasures of self-assessment in order to explore the limitations of themethodology used in the present study
Also a question can be asked concerning the relative density ofmultiword expressions in each text In other words what is not known ison average how many such items a reader can expect to encounter Theratio of idioms to orthographic words in the texts tested in the presentstudy is very likely higher than averagemdashbut how much higher is as yetunknown Likewise the passages themselves were relatively short so it isunknown whether or not texts of greater length (and thereforecontextualization) would render the same or similar results
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 285
CONCLUSION
The present study provides some empirical evidence that a focus onword in L2 pedagogy may be detrimental to learnersrsquo development ofreading comprehension in the target language In most casesparticipants overestimated how much they had understood the textstested when those texts contained multiword expressions of varyingdegrees of compositionality comprised of very common individualwords Even when participants showed evidence of awareness of apresence of idiomaticity in the texts they generally were not very good atguessing the meaning of expressions Although Grant and Nation(2006) could be right that the teaching of individual idioms may not belsquolsquodeserving of class timersquorsquo (p 5) it is clear that at the very least raisinglearnersrsquo consciousness as to their prevalence and frequently deceptivetransparency in text certainly is
Concomitantly the present research serves to demonstrate theincompleteness of current lists of common words which now informimportant pedagogical instruments such as vocabulary tests gradedreaders and course syllabuses Under current methods as illustrated inthe Table 2 analysis of the Economist paragraph a text measured againstthe word lists now commonly in use can be mistakenly analyzed as beingeasily understood when in fact once multiword expressions are takeninto account the actual text coverage of easily understood words is farless Existing estimates of how many words one needs to know in order toadequately process naturally occurring texts (Hu amp Nation 2000Nation 2006) may need to be revisited to determine how many wordsand multiword expressions one needs to know
In practice research shows that learners will continue to believe theyunderstand items that they actually do not even after repeatedexposures to that same item (Bensoussan amp Laufer 1984 Haynes1993 Pigada amp Schmitt 2006) Language teachers and relatedprofessionals such as textbook writers need to consider ways tocontinuously help learners notice the gap between what they think theyknow and understand and what they actually do (Laufer 1997) Oneway this can be achieved has already been thoroughly discussed in thepresent paper devise texts (and tests) designed to lead readers down anidiomatic garden path Norbert Schmitt (as cited in Weir 2005) made asimilar recommendation
Perhaps the best and most valid type of vocabulary test is a reading passagewith comprehension questions but with the items requiring a full under-standing of particular words or phrases in the text This would mimic the realworld task of reading for comprehension and also the loss of comprehensionwhen key vocabulary is not known (p 123)
286 TESOL QUARTERLY
Therefore a further implication this research has for L2 pedagogy is themore careful design of the reading component of proficiency tests suchas IELTS (International English Language Testing System) and Test ofEnglish as a Foreign Language to be more strategic regarding the amountand kind of phraseology contained in the texts Proficiency was not thecentral focus of our study and future research could adopt a similarmethodology but with the inclusion of proficiency measures ofparticipants in order to explore how various types of expressions (egnoncompositional figurative imageable etc) may differentially affectpreidentified proficiency levels
Thus in order to be more methodical about such things as theinclusion of formulaic language in L2 tests and reading input in generalan important preliminary step will be to establish (a) what type offormulaic sequences are good discriminators of proficiency thresholdlevels and (b) which expressions of that identified type are mostcommon In other words what will be usefulmdashand is indeed nowbeginning to emerge (Martinez amp Schmitt 2010 Shin amp Nation 2008Simpson-Vlach amp Ellis 2010)mdashare lists of formulaic sequences that servea function similar to that of the General Service List not to revolutionizecurrent language pedagogy but to more finely tune it
THE AUTHORS
Ron Martinez is currently pursuing a doctorate at the University of NottinghamNottingham England on the topic of inclusion of phraseology in languageassessment He specializes in second language materials development
Victoria Murphy is a lecturer in Applied Linguistics and Second LanguageAcquisition at the University of Oxford Oxford England Her research interestsinclude the lexical development of first language or second language learners andthe cognitive processes that underlie language acquisition
REFERENCES
Bauer L amp Nation P (1993) Word families International Journal of Lexicography 6253ndash279 doi101093ijl64253
Bensoussan M amp Laufer B (1984) Lexical guessing in context in EFL readingcomprehension Journal of Research in Reading 7 15ndash32 doi101111j1467-98171984tb00252x
Bishop H (2004) Noticing formulaic sequences A problem of measuring thesubjective LSO Working Papers in Linguistics 4 15ndash19
Bransford D B amp Johnson M K (1972) Contextual prerequisites for under-standing Some investigations of comprehension and recall Journal of VerbalLearning and Verbal Behavior 11 717ndash726 doi101016S0022-5371(72)80006-9
Brantmeier C (2006) Advanced L2 learners and reading placement Self-assessment CBT and subsequent performance System 34 15ndash35 doi101016jsystem200508004
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 287
Carver R P (1994) Percentage of unknown vocabulary words in text as a functionof the relative difficulty of the text Implications for instruction Journal of ReadingBehavior 26 413ndash437
Cobb T (nd) Web VocabProfile [Online program] Retrieved from httpwwwlextutorcavp [an adaption of A Heatley amp P Nation Range (1994)]
Cooper T C (1999) Processing of idioms by L2 learners of English TESOLQuarterly 33 233ndash262 doi1023073587719
Coxhead A (2000) A new academic word list TESOL Quarterly 34 213ndash238doi1023073587951
Elley W amp Mangubhai F (1983) The impact of reading on second languagelearning Reading Research Quarterly 19 53ndash67 doi102307747337
Ellis N C (2008) Phraseology The periphery and the heart of language In FMeunier amp S Granger (Eds) Phraseology in language learning and teaching (pp 1ndash13) Amsterdam The Netherlands John Benjamins
Erman B amp Warren B (2000) The idiom principle and the open choice principleText 20 29ndash62
Gardner D (2007) Validating the construct of Word in applied corpus-basedvocabulary research A critical survey Applied Linguistics 28 241ndash265doi101093applinamm010
Glenberg A M Wilkinson A C amp Epstein W (1982) The illusion of knowingFailure in the self-assessment of comprehension Memory and Cognition 10 597ndash602 doi103758BF03202442
Goulden R Nation P amp Read J (1990) How large can a receptive vocabulary beApplied Linguistics 11 341ndash363 doi101093applin114341
Grant L amp Bauer L (2004) Criteria for re-defining idioms Are we barking up thewrong tree Applied Linguistics 25 38ndash61 doi101093applin25138
Grant L amp Nation P (2006) How many idioms are there in English ITL -International Journal of Applied Linguistics 151 1ndash14 doi102143ITL15102015219
Haynes M (1993) Patterns and perils of guessing in second language reading In THuckin M Haynes amp J Coady (Eds) Second language reading and vocabularylearning (pp 46ndash64) Norwood NJ Ablex Publishing Corporation
Heatley A amp Nation P (1994) Range [Computer program] Wellington NewZealand Victoria University of Wellington Retrieved from httpwwwvuwacnzlals
Hill J (2000) Revising priorities From grammatical failure to collocational successIn M Lewis (Ed) Teaching collocation Further developments in the Lexical Approach(pp 47ndash69) Hove England LTP
Hirsh D amp Nation P (1992) What vocabulary size is needed to read unsimplifiedtexts for pleasure Reading in a Foreign Language 8 689ndash696
Hu H M amp Nation P (2000) Unknown vocabulary density and readingcomprehension Reading in a Foreign Language 13 403ndash429
Hughes A (2003) Testing for language teachers Cambridge England CambridgeUniversity Press
Hunt K (1968) An instrument to measure syntactic maturity Tallahassee FL USDepartment of Health Education and Welfare
Jung E H (2003) The effects of organization markers on ESL learnersrsquo textunderstanding TESOL Quarterly 37 749ndash759 doi1023073588223
Krashen S (1993) The power of reading Insights from research Englewood COLibraries Unlimited
Laufer B (1989a) A factor of difficulty in vocabulary learning Deceptivetransparency AILA Review 6 10ndash20
288 TESOL QUARTERLY
Laufer B (1989b) What percentage of lexis is essential for comprehension In CLauren amp M Nordman (Eds) Special language From humans thinking to thinkingmachines (pp 316ndash323) London England Multilingual Matters
Laufer B (1991) How much lexis is necessary for reading comprehension In P JL Arnaud amp H Bejoint (Eds) Vocabulary and applied linguistics (pp 126ndash132)Oxford England Macmillan
Laufer B (1997) The lexical plight in second language reading Words you donrsquotknow words you think you know and words you canrsquot guess In J Coady amp THuckin (Eds) Second language vocabulary acquisition (pp 20ndash34) CambridgeEngland Cambridge University Press
Lewis M (1993) The Lexical Approach The state of ELT and a way forward HoveEngland LTP
Liontas J I (2002) Context and idiom understanding in second languagesEUROSLA Yearbook 2 155ndash185
Liontas J I (2003) Killing two birds with one stone Understanding Spanish VPidioms in and out of context Hispania 86 289ndash301 doi10230720062862
Liontas J I (2007) The eye never sees what the brain understands Making sense ofidioms in second languages Lingua et Linguistica 1) 25ndash44
Maki R H amp McGuire M J (2002) Metacognition for text Findings andimplications for education In T Schwarz amp L Bennett (Eds) Appliedmetacognition (pp 39ndash67) Cambridge England Cambridge University Press
Martinez R amp Schmitt N (2010) A phrasal expressions listManuscript submitted forpublication
Moon R (1997) Vocabulary connections Multi-word items in English In NSchmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 40ndash63) Cambridge England Cambridge University Press
Moore D Lin-Agler L M amp Zabrucky K M (2005) A source of metacomprehen-sion inaccuracy Reading Psychology 26 251ndash265 doi10108002702710590962578
Morrison L (2004) Comprehension monitoring in first and second languagereading The Canadian Modern Language Review 61 77ndash106
Nation I S P (2001) Learning vocabulary in another language Cambridge EnglandCambridge University Press
Nation I S P (2006) How large a vocabulary is needed for reading and listeningThe Canadian Modern Language Review 63 59ndash82
Nation I S P amp Waring R (1997) Vocabulary size text coverage and word lists InN Schmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 6ndash19) Cambridge England Cambridge University Press
Nation P (1997) The language learning benefits of extensive reading LanguageTeacher 21 13ndash16
Nattinger J R amp DeCarrico J S (1992) Lexical phrases and language teachingOxford England Oxford University Press
Oh S Y (2001) Two types of input modification and EFL reading comprehensionSimplification versus elaboration TESOL Quarterly 35 69ndash96 doi1023073587860
OrsquoKeeffe A McCarthy M amp Carter R (2007) From corpus to classroom Language useand language teaching Cambridge England Cambridge University Press
Pawley A amp Syder F H (1983) Two puzzles for linguistic theory Nativelikeselection and nativelike fluency In J C Richards amp R Schmidt (Eds) Languageand communication (pp 191ndash226) New York NY Longman
Pigada M amp Schmitt N (2006) Vocabulary acquisition from extensive reading Acase study Reading in a Foreign Language 18 1ndash28
Read J (2004) Research in teaching vocabulary Annual Review of Applied Linguistics24 146ndash161 doi101017S0267190504000078
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 289
Sarac S amp Tarhan B (2009) Calibration of comprehension and performance inL2 reading International Electronic Journal of Elementary Education 2 167ndash179
Schmitt N Jiang N amp Grabe W (2011) The percentage of words known in a textand reading comprehension Modern Language Journal 95(1) 26ndash43
Schmitt N Schmitt D amp Clapham C (2001) Developing and exploring thebehaviour of two new versions of the Vocabulary Levels Test Language Testing 1855ndash88
Shin D amp Nation I S P (2008) Beyond single words The most frequentcollocations in spoken English ELT Journal 62 339ndash348 doi101093eltccm091
Simpson-Vlach R amp Ellis N C (2010) An academic formulas list New methods inphraseology research Applied Linguistics 31(4) 487ndash512
Sinclair J (1991) Corpus concordance collocation Oxford England OxfordUniversity Press
Spottl C amp McCarthy M (2003) Formulaic utterances in the multi-lingual contextIn J Cenoz B Hufeisen ampU Jessner (Eds) The multilingual lexicon (pp 133ndash151) Dordrecht The Netherlands Kluwer
Staelighr L S (2008) Vocabulary size and the skills of listening reading and writingLanguage Learning Journal 36 139ndash152 doi10108009571730802389975
Stubbs M amp Barth I (2003) Using recurrent phrases as text-type descriminators Aquantitative method and some findings Functions of Language 10 61ndash104doi101075fol10104stu
The British National Corpus (2007) The British National Corpus(version 3 BNC XMLed) [CD-ROM] Distributed by Oxford University Computing Services on behalfof the BNC Consortium
The iPhonersquos second coming (2008 July) The Economist Retrieved from httpwwweconomistcomscience-technologydisplaystorycfmstory_id5E1_TTSDDJTG
Walter E Woodford K amp Good M (Eds) (2008) Cambridge advanced learnerrsquosdictionary (3rd ed) Cambridge England Cambridge University Press
Weir C J (2005) Language testing and validation An evidence-based approachNew York NY Palgrave Macmillan
West M (1953) A general service list of English words London England LongmanWray A (2002) Formulaic language and the lexicon Cambridge England Cambridge
University Press
290 TESOL QUARTERLY

Nationrsquos recommendations are for an lsquolsquo8000ndash9000 word-family vocabu-laryrsquorsquo (p 79) which does not necessarily mean knowing 8000 words
From the point of view of reading a word family consists of a base word andall its derived and inflected forms that can be understood by a learnerwithout having to learn each form separately [ ] The important principlebehind the idea of a word family is that once the base word or even a derivedword is known the recognition of other members of the family requires littleor no extra effort (Bauer amp Nation 1993 p 253)
In the lists that Nation and other researchers have used to calculate wordknowledge (eg Nation 2006 West 1953) a word can include a base formand over 80 derivational affixes (Nation 2006 p 66) resulting in lsquolsquosomelarge word families especially among the high-frequency wordsrsquorsquo (Nation2006) but there may be an issue of overconflation of forms Consider forexample the semantic distance between the following pairs of words nameR namely price R priceless fish R fishy puzzle R puzzling Each of thepreceding pairs would be grouped into the same respective word family butit is unlikely that a learner of English would require lsquolsquolittle or no extraeffortrsquorsquo (Bauer amp Nation 1993 p 253) to derive the meaning of a word likefishy from fish2 It is therefore conceivable that a number of those 8000- to9000-word families do not have the psycholinguistic validity that issometimes assumed and some of the 30000 (or so) separate wordssubsumed in those families would in fact need to be learned separately
Similar to the semantic distance between fish and fishy there is oftenan equal or greater disparity of meaning when a word is juxtaposed withanother or more words and a new expression forms (Moon 1997 Wray2002) For example the words fine good and perfect each have meaninghowever those meanings do not remain in the expressions finely tunedfor good and perfect stranger
Nation (2006) recognized this limitation of current word lists howeverhe did not consider it a problem Nation based this assertion on theassumption that most learners will be able to guess the meaning ofmultiword expressions that have some element of transparency and sincethe number of lsquolsquotruly opaquersquorsquo phrases in English is relatively small for thepurposes of reading they are lsquolsquonot a major issuersquorsquo (p 66) However it isdebatable just how lsquolsquosmallrsquorsquo in number those opaque expressions are andmuch like the previously discussed derived word forms that are actuallysemantically dissimilar just how easy it is for a learner of English toaccurately guess the meaning of more lsquolsquotransparentrsquorsquo expressions
2 According to the Cambridge Advanced Learnerrsquos Dictionary (Walter Woodford amp Good2008) which is informed by the one-billion-word Cambridge International Corpus thefirst sense of fishy is lsquolsquodishonest or falsersquorsquo (p 537) and not lsquolsquosmelling of fishrsquorsquo
270 TESOL QUARTERLY
Martinez and Schmitt (2010) for example sought to compile a list of themost common expressions derived from the British National Corpus3
(BNC) Their main criteria for selection was frequency and relativenoncompositionality in other words the items chosen for selection neededto possess semantic and grammatical properties that could pose decodingproblems for learners when reading Their exhaustive search rendered over500 multiword expressions that were frequent enough to be included in alist of the top 5000 words in Englishmdashor over 10 of the entire frequencylist A sample of the list is provided in Table 1
As an example of how taking word frequency into account alonepotentially leads to very misleading estimates of text comprehensibilityconsider the following text taken from The Economist
But over the past few months competing 3G smartphones with touch screensand a host of features have been coming thick and fast to the American marketAnd waiting in the wings are any number of open-source smartphones basedon the nifty Linux operating system Apple will need to pull out all the stops ifthe iPhone is not to be swept aside by the flood of do-it-all smartphonesheading for Americarsquos shores (lsquolsquoThe iPhonersquos second comingrsquorsquo 2008)
The above paragraph contains a number of expressions which are partlyor totally opaque including the following seven
- over the past- a host of- thick and fast- waiting in the wings- any number of- pull out all the stops- swept aside
3 A 100-million word corpus predominantly composed of written English (The BritishNational Corpus 2007)
TABLE 1
Highly Frequent Idioms With Words From Beginner EFL Textbooks for Comparison
Frequency (BNC) Idioms Frequency (BNC) Words (for comparison)
18041 as well as 466 steak14650 at all 455 niece12762 in order to 400 receptionist10556 take place 387 lettuce7138 for instance 385 gym4584 and so on 377 carrot4578 be about to 341 snack3684 at once 337 earrings2676 in spite of 302 dessert1995 in effect 291 refrigerator
Note EFL 5 English as a foreign language BNC 5 British National Corpus
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 271
Current text word coverage calculations ignore such expressionsAccording to software commonly used to analyze the word familyfrequency distribution of text (VocabProfile [Cobb nd]) the sameEconomist paragraph is broken down as shown in Table 2
So if comprehension of a text were based on word coverage alonecurrent methods of text analysis (Table 2) suggest that a learner with avocabulary of at least the top 2000 words in English should be able tounderstand 9552 of the lexis in the Economist text (64 of the 67 words[tokens] counted) by some estimates (eg Laufer 1989b) enough foradequate comprehension If that same learner also knew just two wordsin the text on the Academic Word List (Coxhead 2000)mdashfeatures andsourcemdashshe would understand an additional 299 affording thatlearner a knowledge of 9851mdashtheoretically approximating nativelikelevels of comprehension (Carver 1994 p 432) However a closer lookat the breakdown in Table 2 shows that words like pull out all the andstops were all considered as separate and very common words when inreality they form one noncompositional expression pull out all the stopsIn fact all of the seven expressions have mistakenly been fragmentedand categorized as pertaining to the top 2000 words Thereforeassuming that a learner who knows only the 2000 most common wordsin English would not understand those expressions without the help of adictionary and if we reconduct the analysis taking those sevenexpressions into account (constituting 23 words) the total number ofwords fitting into the top 2000 goes down to 41 (64 minus 23) and that9552 figure actually drops from adequate comprehension down to6119 (41 4 67 5 06119)mdashwell below acceptable levels of readingcomprehension (Hu amp Nation 2000)
TABLE 2
Word Frequency Breakdown of The Economist text (Not Including Proper Nouns)
Frequency Words (67 tokens 54 types) Text coverage
0ndash1000 a all and any are based be been but by comingdo fast few for have heading if in is it marketmonths need not number of on open operatingout over past pull shores stops system the totouch waiting will with
8358
1001ndash2000 aside competing flood host screens swept thickwings
1194
Academic Word List(AWL)
features source 299
Off list Nifty 149Words in top 2000 9552+ AWL words 299Total text coverage 9851
272 TESOL QUARTERLY
RELATIONSHIP BETWEEN FORMULAIC LANGUAGE ANDREADING COMPREHENSION
Considering the relative wealth of research and literature on L2reading comprehension and separately multiword expressions inEnglish there is a surprising dearth of information regarding the roleif any formulaic language plays in the comprehension of texts in aforeign language The relatively few studies that do exist (eg Cooper1999 Liontas 2002) seem to confirm that it is especially the moresemantically opaque idioms that pose interpretability problems for L2readers and as these more core idioms are relatively rare (Grant ampNation 2006) Nation (2006) could be right in attenuating theirsignificance in reading comprehension
Nevertheless as discussed earlier there is evidence that a significantnumber of relatively opaque expressions occur frequently in texts inEnglish One commonly cited estimate (Erman amp Warren 2000) is thatsomewhat more than one-half (55) of any text will consist of formulaiclanguage (p 50) Naturally the opacity of those expressions will lie onwhat Lewis (1993 p 98) called a lsquolsquospectrum of idiomaticityrsquorsquo (Figure 1) akind of continuum of compositionality
Furthermore even when an expression does not meet the criteria ofcore or nonmatching idiom the relative ease or difficulty with which alearner will unpack its meaning is less inherent to the item itself andmore a learner-dependent variable Just as knowing fish may or may nottranslate into understanding fishy knowing perfect does not necessarilymean understanding perfect stranger
What is more although previous studies (Cooper 1999 Liontas2002) have found that in textual context more transparent idioms weremore easily understood than their opaque counterparts it should alsobe noted that the participants in those studies were aware that they werebeing tested specifically on their ability to correctly interpret idioms Inother words what cannot be known from most existing studies on idiominterpretation is how well the participants would have been able toidentify and understand the idioms in the first place had they not beenaware of their presence in the text
FIGURE 1 A spectrum of idiomaticity (compositionality)
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 273
A notable exception is Bishop (2004) who investigated thedifferential look-up behavior of participants who read texts thatcontained unknown words and unknown multiword expressions synon-ymous with those words Bishop confirmed that even though both wordsand multiword expressions were unknown readers looked up themeaning of words significantly more often He concludes that learnerslsquolsquodo not notice unknown formulaic sequences as readily as unknownwordsrsquorsquo (p 18)
Therefore idiomatic language in text irrespective of composition-ality might most usefully be classified as what Laufer (1989a) calledlsquolsquodeceptively transparentrsquorsquo (p 11) Laufer found that many Englishlearners misanalyze words like infallible as in+fall+ible (ie lsquolsquocannot fallrsquorsquo)and nevertheless as never+less (ie lsquolsquoalways morersquorsquo p 12) Likewisemdashalthough they were not part of her studymdashshe found that idioms like hitand miss were being read and interpreted word for word These lexicalitems that lsquolsquolearners think they know but they do notrsquorsquo (Laufer 1989ap 11) can impede reading comprehension in ways not accounted for inlists of common word families Nation (2006) seemed to assume thatmultiword expressions that have some element of transparency howeversmall will be reasonably interpretable through guessing However theLaufer (1989a) study may provide evidence to the contrary
But an attempt to guess (regardless of whether it is successful or not)presupposes awareness on the part of the learner that he is facing anunknown word If such an awareness is not there no attempt is made to inferthe missing meaning This is precisely the case with deceptively transparentwords The learner thinks he knows and then assigns the wrong meaning tothem [ ] (p 16)
Substitute lsquolsquoidiomrsquorsquo for lsquolsquowordrsquorsquo abovemdashnot an unreasonable conceptualstretchmdashand it becomes clear that multiword expressions just maypresent a larger problem for reading comprehension than accounted forin the current literature
In fact such lsquolsquodeceptionrsquorsquo seems even more likely to occur withmultiword expressions because such a large number of them arecomposed of very common words a learner would assume he or sheknows (Spottl amp McCarthy 2003 p 145 Stubbs amp Barth 2003 p 71)Moreover there is evidence that learners are reluctant to revisehypotheses formed regarding lexical items when reading even whenthe context does not support those hypotheses (Haynes 1993 Pigada ampSchmitt 2006)
274 TESOL QUARTERLY
Summary and Research Questions
In summary the following has been argued thus faramp Current estimates of how many words one needs to know in order to
comprehend most texts may be inaccurate due to overinclusion of derivedword forms and a total exclusion of multiword units of vocabulary
amp Contrary to some research there is evidence in corpus data that thenumber of frequently occurring noncompositional multiwordexpressions in English is higher than previously believed
amp Even when an expression is partly or even fully compositional thereis no way of knowing how accurately an L2 reader will interpret (oreven identify) that item
amp The claim that special attention to the 2000ndash3000 most commonwords in English is pedagogically sound since they provide around80 of text coverage (eg OrsquoKeeffe McCarthy amp Carter 2007Read 2004 p 148 Staelighr 2008) deserves closer scrutiny becausethose words are often merely tips of phraseological icebergs
It is therefore clear that there is a need for further investigation into howcommon words and the multiword units they form can affect readingcomprehension when reading in English as a foreign language To thatend we conducted a study to answer the following research questions
1 Are two texts written with the exact same high-frequency wordsunderstood equally well by L2 learners when one of the texts is moreidiomatic than the other
2 Can the presence of multiword expressions in a text lead L2 learners tobelieve they have understood that text better than they actually have
METHOD
Participants
Brazilian adult learners of English (n 5 101) all native speakers ofBrazilian Portuguese were selected to participate in the study Thesample ranged in age from 18 to 64 years (M 5 2576 SD 5 931) andconsisted of 43 men and 58 women representing seven different regionsof Brazil
All participants in the study had had a minimum of 80 hr of tuition inEnglish prior to the start of the research and had been tested aspossessing intermediate or higher levels of proficiency Howeverbecause all participants attended private language schools the actualinstruments by which their proficiency was assessed varied widely
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 275
Regardless uniformity in proficiency was not of prime importance in thestudy because the research questions are concerned with a significantchange in the paired samples within the same group
The Test
To write the eight texts (four texts in each test) a corpus of words wascarefully chosen from the list of the 2000 most frequent words in the BNCThe reading comprehension of each text was tested by seven true or falseitems totaling 28 per test part or 56 overall The test when administeredappears as one but is actually in two parts (Test 1 and Test 2) each partcontaining the exact same words with some words in Test 2 formingmultiword expressions Great care was taken to ensure that the texts areotherwise equal There is no visual difference between the two parts andthe texts are of almost uniform length in both parts (Table 3 and Figure 2)In addition care was taken not to include any extra cultural references inany of the texts and the comprehension task itself did not change acrossthe test parts The texts are stated to have come from peoplersquos descriptionof themselves in lsquolsquoFriendsbookrsquorsquo (intentionally similar to Facebook) On thewhole therefore it could be said that the style of the text is personal andinformal
The vast majority of the words are in the top 1000 withapproximately 985 of the words occurring in the BNC top 2000(Table 3) These results were in turn compared with the General ServiceList (West 1953) using software developed by Heatley and Nation(Range 1994) and another package using the same corpus created byCobb (nd) The results were practically identical in all cases (Range985 VocabProfile 98494)
Another key feature of the test is the rating scale which requires the testtaker to circle what she believes is his or her comprehension of each textfrom 5 to 1005 This self-reported comprehension is designed to helpanswer the second research question of whether the presence ofmultiword expressions in a text can lead L2 learners to believe they have
TABLE 3
Summary of Test 1 and Test 2 Text Data
Total wordcount
Total clausecount T-unit count
Top 1000words coverage
Top 1001ndash2000 words
coverage
Test 1 416 56 45 957373 27650Test 2 412 54 42 957373 27650
Note Data measured using vocabulary profiler (Cobb nd) A T-unit or a minimal terminableunit is lsquolsquoone main clause plus any subordinate clausersquorsquo (Hunt 1968 p 4)
276 TESOL QUARTERLY
understood that text better than they actually have Testing whatcomprehenders believe they understoodmdashcompared to what they actuallyunderstoodmdashby comparing test scores to self-assessment of comprehen-sion via a rating scale is often referred to as lsquolsquocomprehension calibrationrsquorsquoand is a method that has been used extensively in psychological research(eg Bransford amp Johnson 1972 Glenberg Wilkinson amp Epstein 1982Maki amp McGuire 2002 Moore Lin-Agler amp Zabrucky 2005) butsomewhat less so in applied linguistics (cf Brantmeier 2006 Jung 2003Morrison 2004 Oh 2001 Sarac amp Tarhan 2009)
Finally participants were asked to record their start and finish timesfor each part of the test
Procedure
Following an initial field test an item analysis was conducted toestablish the facility value6 of the test items and a discrimination indexfor both test parts to discern whether the test was discriminatingbetween stronger and weaker participants Items that were found to haveexceptionally high or low scores were carefully analyzed and the wordingof both test items and reading texts adjusted accordingly
Finally as advocated in Schmitt Schmitt and Clapham (2001) oneimportant requirement of an L2 test of reading comprehension is that itbe answerable by native or nativelike speakers of the language (p 65)To that end a smaller group of native speakers (n 5 8) was also tested asan additional check of the testrsquos validity That group produced a mean
FIGURE 2 Side-by-side comparison of matched texts from the two test parts (full version ofthe test available on request)
4 These are vocabulary profilers that essentially use word frequency lists to break all thewords in a text down into those that occur for example in the top 1000 second 1000third 1000 and so on
5 lsquolsquo0rsquorsquo would be virtually impossible because learners would be familiar with most words inthe texts if not all
6 A test itemrsquos facility value is calculated by dividing the number of participants whoanswered that item correctly by the total number of participants (Hughes 2003)
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 277
score of 28 in Test 1 (the maximum score) and 2775 in Test 2 showingthat both test parts posed very little difficulty for people for whomEnglish is a first language
The students received the two parts of the test in alternating order(ie counterbalanced) to control for any effect of taking Test 1 beforeTest 2 (and vice versa) because by counterbalancing one is able toinclude a variable order into an analysis and identify the extent towhich order affects performance on the dependent measures
RESULTS
All the scores and self-reported comprehension measures wererecorded in a statistical analysis software program (SPSS) Eachparticipantrsquos test results were transcribed into the software item by item(ie correct and incorrect) text by text (eg Text A Text B etc numbercorrect out of 7 for each) and test by test (ie Test 1 and Test 2 numbercorrect out of 28 possible for each) Also recorded were each participantrsquosself-reported comprehension assessments (a rating scale from 5 to 100)as they pertained to each text as well as which version (Test 1 or Test 2first) of the instrument each candidate had received To assess the effectof counterbalancing a repeated measures analysis of variance (ANOVA)was conducted with one within-subjects factor (TEST) with two levels(Test 1 score Test 2 score) and one between-subjects factor (VERSION)with two levels (Test 1 first Test 2 first) This analysis revealed a robustmain effect of test (F (199) 5 59338 p 0001 g2 5 086) and a discreteeffect of version (F (199) 5 405 p 5 0047 g2 5 004) but importantlythere was no significant Test 6 Version interaction (F (199) 5 281 p 5
0097 g2 5 002) illustrating that participantsrsquo scores did not vary as afunction of which version of the test they were completing
Comprehension of Test 1 versus Test 2
The central tendencies from both tests are presented in Table 4As predicted participantsrsquo scores were significantly lower on Test 2
relative to Test 1 (t(100) 5 2410 p 0001) with a strong effect size(g2 5 0828)7 confirming that even when two sets of texts contain theexact same words and even if those words are very commoncomprehension of those texts will not be the same when one containsidiomaticity
7 Confidence intervals at 95 for all t-tests
278 TESOL QUARTERLY
Self-Reported Comprehension of Test 1 versus Test 2
A t-test was also performed on the difference between whatparticipants believed they understood (ie their reported comprehen-sion) and what they actually understood in both Tests 1 and 2 (Table 5)Mean reported comprehension (MRC) was arrived at by calculating themeans of all the self-reported comprehension percentages (5ndash100)and the mean actual comprehension (MAC) is the mean of the score oneach text divided by seven (the maximum score)
MAC was lower than MRC in both Test 1(MRC M 5 08738 SD 013MAC M 5 08603 SD 5 009) and Test 2 (MRC M 5 06029 SD 019MAC M 5 05258 SD 5 014) however the difference between MRCand MAC was statistically reliable in Test 2 only where the test wascomposed of multiword expressions (t(100) 5 395 p 0001 g2 5
007)8 These data therefore appear to support a positive answer to thesecond research questionmdashthat learners may believe they understandmore than they actually do by virtue of their simply understanding theindividual words in a text
Variation in the Data
MRC versus MAC
Naturally there were some individual differences in the test resultsTable 6 shows that roughly one-half of all participants (n 5 50)overestimated their comprehension in both tests (indicated by MRC
TABLE 4
Descriptive Statistics (Tests 1 and 2)
Mean Median Mode Minimum Maximum SD
Test 1a 2409 2500 2500 1800 2800 244Test 2b 1476 1500 1500 600 2500 393
Note SD 5 standard deviation aTexts composed of common words however with little or noopaque phraseology bTexts composed of common words which comprise collocations andidiomatic language
TABLE 5
Reported Versus Actual Comprehension
Test 1 Test 2
Mean reported comprehension (MRC) 8738 6029Mean actual comprehension (MAC) 8603 5258
8 By comparison the results of the paired sample t-test for the Test 1 MRC-MAC means weret(100) 5 104 p 5 0302 g2 5 0005
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 279
greater than MAC) On the surface this might suggest that those 50participants did not overestimate their comprehension in Test 2 as aresult of its relative noncompositionality but rather as a generaltendency regardless of idiomaticity However when MAC is subtractedfrom MRC for that group and the difference compared across the teststhe difference is twice as large in Test 2 (t(49) 5 492 p 0001 g2 5
0108) This difference is even more evident in the same analysis of Test2 alone Isolating the results of that test there was a total of 70participants (over 69 of the entire sample) whose MRC was greaterthan their MAC The difference between MRC minus MAC for thesubgroup of 70 participants reveals that their overestimation of theircomprehension in Test 2 was four times greater than in Test 1 (t(69) 5
770 p 0001 g2 5 0228) Further among that group of 70 whoseTest 2 MRC was greater than their MAC 20 students either under-estimated or actually accurately guessed their comprehension in Test 1but significantly overestimated their comprehension in Test 2 (t(19) 5
849 p 0001 g2 5 0264) Only 30 participants in the present studyactually underestimated their comprehension on Test 2
Variation in Time Spent on the Tests
All candidates were also asked to record their start and finishing timesof each test (Table 7) It is not surprising that on average participantsspent more time on the texts which contained idiomatic expressionsHowever this trend was not uniform among the participants and thetime data may help provide some insight into just how aware someparticipants were of the presence of idiomaticity in the texts Thispossibility is explored further in the Discussion
TABLE 6
Trend of Increase in MRC-MAC Discrepancy Across Test Parts
NMRC minus MAC
(Test 1)MRC minus MAC
(Test 2)
Students with MRC MAC (bothtest parts)
50 009 019
Students with MRC MAC (Test 2) 70 004 017Students with MRC MAC (Test 2only)
20 2010 014
Students with MRC MAC (Test 2) 31a 2005 2015
Note MRC 5 mean reported comprehension MAC 5 mean actual comprehension aOnly oneparticipant in this group had MRC 5 MAC
280 TESOL QUARTERLY
DISCUSSION
To reiterate the present study sought to address the followingresearch questions
1 Are two texts written with the exact same high-frequency wordsunderstood equally well by L2 learners when one of the texts is moreidiomatic than the other
2 Can the presence of multiword expressions in a text lead L2 learners tobelieve they have understood that text better than they actually have
A group of 101 adult Brazilian learners of English was tested using twoseparate measures of reading comprehension (one with idiomaticlanguage and one without) and the results of the two tests were thencompared Although verbal reports would provide even greater insightthe resultant data from this study do seem to support a positive answer tothe first research question Participants achieved significantly lowerscores on the comprehension measure which assessed their under-standing of texts that contain multiword expressions It should bereiterated that this result was obtained in spite of both tests being writtenwith the exact same high-frequency words
Likewise through participantsrsquo self-reported comprehension thereseems to be evidence that the presence of multiword expressions in atext can lead L2 readers to overestimate their assessment of how muchthey have actually understood suggesting a positive answer to the secondresearch question
Although it seems apparent that participantsrsquo reading comprehensionin the present study was adversely affected by idiomaticity this sectionexplores and possibly explains variation in comprehension of the testsand further discusses evidence that multiword expressions negativelyaffected participantsrsquo comprehension
On the Stronger and Weaker Performance in the Tests
There are at least three important revelations emerging from theMRC-MAC data analysis presented in Table 6 First nearly two thirds of
TABLE 7
Time It Took Participants to Take Tests
N Mean time (minutes) SD
Time it took to take Test 1 91a 1085 436Time it took to take Test 2 91 1465 377
Note SD 5 standard deviation aSome participants (n 5 10) forgot to write in the time or left itincomplete
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 281
all participants believed they understood more than they actually did inTest 2 Second the data show that over 28 of those students (n 5 20)did not overestimate their comprehension in Test 1 providing evidencethat whereas they were apparently able to gauge their comprehensionfairly accurately when the texts were relatively devoid of idiomaticitythey were significantly less able to do so when relative noncomposition-ality was present Finally the MRC-MAC data presented so far indicatethat although not all participants tended to overestimate theircomprehension in Test 2 those who did (again the majority of cases)generally did so by a much larger margin Put simply it would seem thatnot only are many learners misunderstanding idiomaticity in text butthey may be doing so more than they (or researchers) realize
Further Evidence of Idiomaticity Negatively AffectingComprehension
The mean difference between MRC and MAC for the 70 students whooverestimated their comprehension in Test 2 (Table 6) was 017 For thesake of argument one could establish an MRC-MAC difference above020 as a cutoff for apparently marked lack of awareness of the extentof idiomaticity in Test 29 comparatively speaking This in turn wouldmean that there were 30 participants who ostensibly demonstrated aparticularly high overestimation of how much of Test 2 they had actuallyunderstood A sample of just the top 10 is provided in Table 8
Table 8 shows not only how different those participantsrsquo MRC wasfrom their Test 2 it also lists the same figures for Test 1 for comparison
9 A t-test reveals that the mean is in fact statistically significant even at the 003 differencelevel (t 5 653 p 5 003)
TABLE 8
Partial List of Participants With Exceptionally High Overestimation of Test 2 Comprehension(Difference 020)
ParticipantMRCTest 1
MACTest 1 Difference
MRCTest 2
MACTest 2 Difference
118 100 089 011 094 032 0626 075 068 007 081 028 05392 081 089 2008 075 025 05090 100 089 011 081 039 042115 100 089 011 087 050 03722 100 096 003 094 057 03780 094 068 026 069 032 03759 094 089 005 069 036 03321 100 093 007 087 057 03050 087 078 009 069 039 029
282 TESOL QUARTERLY
Whereas for Test 1 those 30 participantsrsquo assessment of readingcomprehension was usually only slightly overestimated10 (and in oneinstance even underestimated) the same participants in Test 2 had amarkedly overinflated conception of how much they had understood
Although not intended as a principal source of data for our analysisthe start and finish times recorded by participants on the tests in a fewinstances helped confirm the above assertions11 Table 7 shows thatthere was a significant difference between how long participants spenttaking each test (t 5 852 p 0001) However there were a number ofparticipants (n 5 26) who reported actually spending either the same orless time on Test 2 On the surface at least this fact would indicate thatthose 26 participants did not notice much difference between the testsOf course in reality that datum alone does not provide such evidencebecause that time may simply reflect a number of other confoundingvariables including affective (eg simply giving up) or even social (egthe need to leave early to meet a friend) and for that reason also was notconsidered to be a reliable source of data from those participantsHowever as a complementary source when triangulated with the othervariables some of the data analyzed earlier in the current study areoccasionally fortified further still with the time data (Table 9)
The data in Table 9 in many ways tie together the elements discussedin the analysis thus far in the present study A much lower score in Test 2than in Test 1 (columns B and C) an increase in the mean MRC-MACdifference across the tests (columns H and K) a relatively moderatedecrease in MRC in Test 2 vis-a-vis Test 1 (columns F and I) a markeddifference between MRC and MAC in Test 2 (column K) and theoccasional lack of increase (in Table 9 participants 118 80 59 and 50)in time it took to take Test 2 (columns D and E) These findings ontheir own in combination and especially in concert provide evidencethat (1) the students in Table 9 did not seem to appreciate the fullextent of the idiomaticity in Test 2 and (2) they appeared to think thatthey understood more than they actually did in Test 2
Perhaps most important 98 of all participants (n 5 99) scoredsignificantly lower on Test 2 (mean difference of 953 points out of 28SD 5 363) which shows that learners are generally unable to guess themeaning of idiomatic language even in the (largely inconsistent)instances in which they become aware of its presence
11 It should be noted that because 10 of the participantsrsquo time data were left incomplete afull group analysis could not be carried out thus the time data are only included asauxiliary information
10 As can be seen in Table 8 in fact only one participantmdashnumber 80mdashactually had anMRC-MAC difference in Test 1 that was also 020 Those of the other 29 participantswere all lower
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 283
For example the first participant in Tables 8 and 9 (number 118)who consistently overrated his own comprehension relative to his actualcomprehension answered for Text A of Test 2 as shown in Figure 3
On the basis of the responses it is likely that participant 118associated itrsquos about time with lsquolsquohas a problem with timersquorsquo Irsquom a little over thehill with lsquolsquohe probably lives in an area with hillsrsquorsquo and lsquolsquohe lives on the hill
TABLE 9
Triangulated Data Showing Negative Effect of Idiomaticity on Comprehension
A B C D E F G H I J K
Score Time Test 1 Test 2
Partic-ipant Test 1 Test 2 Test 1 Test 2 MRC MAC
Differ-ence MRC MAC
Differ-ence
118 25 9 2000 1800 100 089 11 094 032 0626 19 8 Missing Missing 075 068 007 081 028 05392 25 8 900 1100 081 089 2008 075 025 05090 25 11 900 1500 100 089 011 081 039 042115 25 14 1300 1500 100 089 011 087 050 03722 27 16 Missing Missing 100 096 003 094 057 03780 19 9 1000 1000 094 068 026 069 032 03759 25 10 1500 1400 094 089 005 069 036 03321 26 16 Missing Missing 100 093 007 087 057 03050 22 11 2000 1200 088 079 009 069 039 030
12 Of the 24 multiword expressions targeted for assessment of comprehension in Test 2 onlyfour were core idioms
FIGURE 3 Sample answer to Text A of Test 2
284 TESOL QUARTERLY
but not on top of itrsquorsquomdasha literal reading of those expressions His 100self-assessment is an indication that his answers were not guesses butinstead based on confidence that he had understood all the individualwords in the text The same answering dynamic occurred time and timeagain in Test 2
Returning therefore to the issues raised in the introduction thepresent research appears to provide evidence that idiomsmdashopaque orotherwise12mdashcan in fact cause major problems for L2 learners of Englishwhen reading In general the participants in our study were lesssuccessful at guessing the meaning of idioms than those in previousidiom-centered research such as Cooper (1999) and Liontas (2002)Because the learners in our study were not alerted to the presence ofidiomaticity in the text prior to reading this study may more accuratelyreflect what takes place in more naturally occurring L2 reading Finallythe difficulties that the participants encountered occurred in textscomposed purely of very common words showing that word frequencyalone is not necessarily a good measure of text coverage Lauferrsquos(1989a) hypothesis that much lexis in text can be deceptivelytransparent is confirmed in the present research extended to multiwordexpressions
Limitations of the Research
Although the research presented here does provide some significantevidence that the presence of idiomaticity in a text can negatively affectthe comprehension of that text by an L2 reader little is known about thestrategies the test takers employed Even though metacognition wasoutside the scope of examination of the present study such informationis highly relevant and future research should include protocols such asthose included in previous research on idioms (eg Liontas 20032007) which may provide crucial qualitative data regarding theindividual differences and behavior of the participants themselvesOverall future work in this area should consider making use of differentmeasures of self-assessment in order to explore the limitations of themethodology used in the present study
Also a question can be asked concerning the relative density ofmultiword expressions in each text In other words what is not known ison average how many such items a reader can expect to encounter Theratio of idioms to orthographic words in the texts tested in the presentstudy is very likely higher than averagemdashbut how much higher is as yetunknown Likewise the passages themselves were relatively short so it isunknown whether or not texts of greater length (and thereforecontextualization) would render the same or similar results
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 285
CONCLUSION
The present study provides some empirical evidence that a focus onword in L2 pedagogy may be detrimental to learnersrsquo development ofreading comprehension in the target language In most casesparticipants overestimated how much they had understood the textstested when those texts contained multiword expressions of varyingdegrees of compositionality comprised of very common individualwords Even when participants showed evidence of awareness of apresence of idiomaticity in the texts they generally were not very good atguessing the meaning of expressions Although Grant and Nation(2006) could be right that the teaching of individual idioms may not belsquolsquodeserving of class timersquorsquo (p 5) it is clear that at the very least raisinglearnersrsquo consciousness as to their prevalence and frequently deceptivetransparency in text certainly is
Concomitantly the present research serves to demonstrate theincompleteness of current lists of common words which now informimportant pedagogical instruments such as vocabulary tests gradedreaders and course syllabuses Under current methods as illustrated inthe Table 2 analysis of the Economist paragraph a text measured againstthe word lists now commonly in use can be mistakenly analyzed as beingeasily understood when in fact once multiword expressions are takeninto account the actual text coverage of easily understood words is farless Existing estimates of how many words one needs to know in order toadequately process naturally occurring texts (Hu amp Nation 2000Nation 2006) may need to be revisited to determine how many wordsand multiword expressions one needs to know
In practice research shows that learners will continue to believe theyunderstand items that they actually do not even after repeatedexposures to that same item (Bensoussan amp Laufer 1984 Haynes1993 Pigada amp Schmitt 2006) Language teachers and relatedprofessionals such as textbook writers need to consider ways tocontinuously help learners notice the gap between what they think theyknow and understand and what they actually do (Laufer 1997) Oneway this can be achieved has already been thoroughly discussed in thepresent paper devise texts (and tests) designed to lead readers down anidiomatic garden path Norbert Schmitt (as cited in Weir 2005) made asimilar recommendation
Perhaps the best and most valid type of vocabulary test is a reading passagewith comprehension questions but with the items requiring a full under-standing of particular words or phrases in the text This would mimic the realworld task of reading for comprehension and also the loss of comprehensionwhen key vocabulary is not known (p 123)
286 TESOL QUARTERLY
Therefore a further implication this research has for L2 pedagogy is themore careful design of the reading component of proficiency tests suchas IELTS (International English Language Testing System) and Test ofEnglish as a Foreign Language to be more strategic regarding the amountand kind of phraseology contained in the texts Proficiency was not thecentral focus of our study and future research could adopt a similarmethodology but with the inclusion of proficiency measures ofparticipants in order to explore how various types of expressions (egnoncompositional figurative imageable etc) may differentially affectpreidentified proficiency levels
Thus in order to be more methodical about such things as theinclusion of formulaic language in L2 tests and reading input in generalan important preliminary step will be to establish (a) what type offormulaic sequences are good discriminators of proficiency thresholdlevels and (b) which expressions of that identified type are mostcommon In other words what will be usefulmdashand is indeed nowbeginning to emerge (Martinez amp Schmitt 2010 Shin amp Nation 2008Simpson-Vlach amp Ellis 2010)mdashare lists of formulaic sequences that servea function similar to that of the General Service List not to revolutionizecurrent language pedagogy but to more finely tune it
THE AUTHORS
Ron Martinez is currently pursuing a doctorate at the University of NottinghamNottingham England on the topic of inclusion of phraseology in languageassessment He specializes in second language materials development
Victoria Murphy is a lecturer in Applied Linguistics and Second LanguageAcquisition at the University of Oxford Oxford England Her research interestsinclude the lexical development of first language or second language learners andthe cognitive processes that underlie language acquisition
REFERENCES
Bauer L amp Nation P (1993) Word families International Journal of Lexicography 6253ndash279 doi101093ijl64253
Bensoussan M amp Laufer B (1984) Lexical guessing in context in EFL readingcomprehension Journal of Research in Reading 7 15ndash32 doi101111j1467-98171984tb00252x
Bishop H (2004) Noticing formulaic sequences A problem of measuring thesubjective LSO Working Papers in Linguistics 4 15ndash19
Bransford D B amp Johnson M K (1972) Contextual prerequisites for under-standing Some investigations of comprehension and recall Journal of VerbalLearning and Verbal Behavior 11 717ndash726 doi101016S0022-5371(72)80006-9
Brantmeier C (2006) Advanced L2 learners and reading placement Self-assessment CBT and subsequent performance System 34 15ndash35 doi101016jsystem200508004
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 287
Carver R P (1994) Percentage of unknown vocabulary words in text as a functionof the relative difficulty of the text Implications for instruction Journal of ReadingBehavior 26 413ndash437
Cobb T (nd) Web VocabProfile [Online program] Retrieved from httpwwwlextutorcavp [an adaption of A Heatley amp P Nation Range (1994)]
Cooper T C (1999) Processing of idioms by L2 learners of English TESOLQuarterly 33 233ndash262 doi1023073587719
Coxhead A (2000) A new academic word list TESOL Quarterly 34 213ndash238doi1023073587951
Elley W amp Mangubhai F (1983) The impact of reading on second languagelearning Reading Research Quarterly 19 53ndash67 doi102307747337
Ellis N C (2008) Phraseology The periphery and the heart of language In FMeunier amp S Granger (Eds) Phraseology in language learning and teaching (pp 1ndash13) Amsterdam The Netherlands John Benjamins
Erman B amp Warren B (2000) The idiom principle and the open choice principleText 20 29ndash62
Gardner D (2007) Validating the construct of Word in applied corpus-basedvocabulary research A critical survey Applied Linguistics 28 241ndash265doi101093applinamm010
Glenberg A M Wilkinson A C amp Epstein W (1982) The illusion of knowingFailure in the self-assessment of comprehension Memory and Cognition 10 597ndash602 doi103758BF03202442
Goulden R Nation P amp Read J (1990) How large can a receptive vocabulary beApplied Linguistics 11 341ndash363 doi101093applin114341
Grant L amp Bauer L (2004) Criteria for re-defining idioms Are we barking up thewrong tree Applied Linguistics 25 38ndash61 doi101093applin25138
Grant L amp Nation P (2006) How many idioms are there in English ITL -International Journal of Applied Linguistics 151 1ndash14 doi102143ITL15102015219
Haynes M (1993) Patterns and perils of guessing in second language reading In THuckin M Haynes amp J Coady (Eds) Second language reading and vocabularylearning (pp 46ndash64) Norwood NJ Ablex Publishing Corporation
Heatley A amp Nation P (1994) Range [Computer program] Wellington NewZealand Victoria University of Wellington Retrieved from httpwwwvuwacnzlals
Hill J (2000) Revising priorities From grammatical failure to collocational successIn M Lewis (Ed) Teaching collocation Further developments in the Lexical Approach(pp 47ndash69) Hove England LTP
Hirsh D amp Nation P (1992) What vocabulary size is needed to read unsimplifiedtexts for pleasure Reading in a Foreign Language 8 689ndash696
Hu H M amp Nation P (2000) Unknown vocabulary density and readingcomprehension Reading in a Foreign Language 13 403ndash429
Hughes A (2003) Testing for language teachers Cambridge England CambridgeUniversity Press
Hunt K (1968) An instrument to measure syntactic maturity Tallahassee FL USDepartment of Health Education and Welfare
Jung E H (2003) The effects of organization markers on ESL learnersrsquo textunderstanding TESOL Quarterly 37 749ndash759 doi1023073588223
Krashen S (1993) The power of reading Insights from research Englewood COLibraries Unlimited
Laufer B (1989a) A factor of difficulty in vocabulary learning Deceptivetransparency AILA Review 6 10ndash20
288 TESOL QUARTERLY
Laufer B (1989b) What percentage of lexis is essential for comprehension In CLauren amp M Nordman (Eds) Special language From humans thinking to thinkingmachines (pp 316ndash323) London England Multilingual Matters
Laufer B (1991) How much lexis is necessary for reading comprehension In P JL Arnaud amp H Bejoint (Eds) Vocabulary and applied linguistics (pp 126ndash132)Oxford England Macmillan
Laufer B (1997) The lexical plight in second language reading Words you donrsquotknow words you think you know and words you canrsquot guess In J Coady amp THuckin (Eds) Second language vocabulary acquisition (pp 20ndash34) CambridgeEngland Cambridge University Press
Lewis M (1993) The Lexical Approach The state of ELT and a way forward HoveEngland LTP
Liontas J I (2002) Context and idiom understanding in second languagesEUROSLA Yearbook 2 155ndash185
Liontas J I (2003) Killing two birds with one stone Understanding Spanish VPidioms in and out of context Hispania 86 289ndash301 doi10230720062862
Liontas J I (2007) The eye never sees what the brain understands Making sense ofidioms in second languages Lingua et Linguistica 1) 25ndash44
Maki R H amp McGuire M J (2002) Metacognition for text Findings andimplications for education In T Schwarz amp L Bennett (Eds) Appliedmetacognition (pp 39ndash67) Cambridge England Cambridge University Press
Martinez R amp Schmitt N (2010) A phrasal expressions listManuscript submitted forpublication
Moon R (1997) Vocabulary connections Multi-word items in English In NSchmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 40ndash63) Cambridge England Cambridge University Press
Moore D Lin-Agler L M amp Zabrucky K M (2005) A source of metacomprehen-sion inaccuracy Reading Psychology 26 251ndash265 doi10108002702710590962578
Morrison L (2004) Comprehension monitoring in first and second languagereading The Canadian Modern Language Review 61 77ndash106
Nation I S P (2001) Learning vocabulary in another language Cambridge EnglandCambridge University Press
Nation I S P (2006) How large a vocabulary is needed for reading and listeningThe Canadian Modern Language Review 63 59ndash82
Nation I S P amp Waring R (1997) Vocabulary size text coverage and word lists InN Schmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 6ndash19) Cambridge England Cambridge University Press
Nation P (1997) The language learning benefits of extensive reading LanguageTeacher 21 13ndash16
Nattinger J R amp DeCarrico J S (1992) Lexical phrases and language teachingOxford England Oxford University Press
Oh S Y (2001) Two types of input modification and EFL reading comprehensionSimplification versus elaboration TESOL Quarterly 35 69ndash96 doi1023073587860
OrsquoKeeffe A McCarthy M amp Carter R (2007) From corpus to classroom Language useand language teaching Cambridge England Cambridge University Press
Pawley A amp Syder F H (1983) Two puzzles for linguistic theory Nativelikeselection and nativelike fluency In J C Richards amp R Schmidt (Eds) Languageand communication (pp 191ndash226) New York NY Longman
Pigada M amp Schmitt N (2006) Vocabulary acquisition from extensive reading Acase study Reading in a Foreign Language 18 1ndash28
Read J (2004) Research in teaching vocabulary Annual Review of Applied Linguistics24 146ndash161 doi101017S0267190504000078
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 289
Sarac S amp Tarhan B (2009) Calibration of comprehension and performance inL2 reading International Electronic Journal of Elementary Education 2 167ndash179
Schmitt N Jiang N amp Grabe W (2011) The percentage of words known in a textand reading comprehension Modern Language Journal 95(1) 26ndash43
Schmitt N Schmitt D amp Clapham C (2001) Developing and exploring thebehaviour of two new versions of the Vocabulary Levels Test Language Testing 1855ndash88
Shin D amp Nation I S P (2008) Beyond single words The most frequentcollocations in spoken English ELT Journal 62 339ndash348 doi101093eltccm091
Simpson-Vlach R amp Ellis N C (2010) An academic formulas list New methods inphraseology research Applied Linguistics 31(4) 487ndash512
Sinclair J (1991) Corpus concordance collocation Oxford England OxfordUniversity Press
Spottl C amp McCarthy M (2003) Formulaic utterances in the multi-lingual contextIn J Cenoz B Hufeisen ampU Jessner (Eds) The multilingual lexicon (pp 133ndash151) Dordrecht The Netherlands Kluwer
Staelighr L S (2008) Vocabulary size and the skills of listening reading and writingLanguage Learning Journal 36 139ndash152 doi10108009571730802389975
Stubbs M amp Barth I (2003) Using recurrent phrases as text-type descriminators Aquantitative method and some findings Functions of Language 10 61ndash104doi101075fol10104stu
The British National Corpus (2007) The British National Corpus(version 3 BNC XMLed) [CD-ROM] Distributed by Oxford University Computing Services on behalfof the BNC Consortium
The iPhonersquos second coming (2008 July) The Economist Retrieved from httpwwweconomistcomscience-technologydisplaystorycfmstory_id5E1_TTSDDJTG
Walter E Woodford K amp Good M (Eds) (2008) Cambridge advanced learnerrsquosdictionary (3rd ed) Cambridge England Cambridge University Press
Weir C J (2005) Language testing and validation An evidence-based approachNew York NY Palgrave Macmillan
West M (1953) A general service list of English words London England LongmanWray A (2002) Formulaic language and the lexicon Cambridge England Cambridge
University Press
290 TESOL QUARTERLY
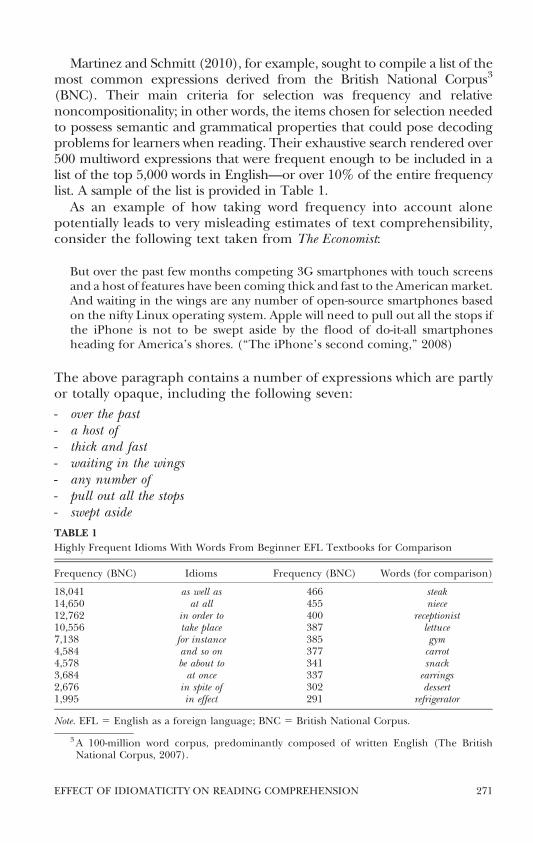
Martinez and Schmitt (2010) for example sought to compile a list of themost common expressions derived from the British National Corpus3
(BNC) Their main criteria for selection was frequency and relativenoncompositionality in other words the items chosen for selection neededto possess semantic and grammatical properties that could pose decodingproblems for learners when reading Their exhaustive search rendered over500 multiword expressions that were frequent enough to be included in alist of the top 5000 words in Englishmdashor over 10 of the entire frequencylist A sample of the list is provided in Table 1
As an example of how taking word frequency into account alonepotentially leads to very misleading estimates of text comprehensibilityconsider the following text taken from The Economist
But over the past few months competing 3G smartphones with touch screensand a host of features have been coming thick and fast to the American marketAnd waiting in the wings are any number of open-source smartphones basedon the nifty Linux operating system Apple will need to pull out all the stops ifthe iPhone is not to be swept aside by the flood of do-it-all smartphonesheading for Americarsquos shores (lsquolsquoThe iPhonersquos second comingrsquorsquo 2008)
The above paragraph contains a number of expressions which are partlyor totally opaque including the following seven
- over the past- a host of- thick and fast- waiting in the wings- any number of- pull out all the stops- swept aside
3 A 100-million word corpus predominantly composed of written English (The BritishNational Corpus 2007)
TABLE 1
Highly Frequent Idioms With Words From Beginner EFL Textbooks for Comparison
Frequency (BNC) Idioms Frequency (BNC) Words (for comparison)
18041 as well as 466 steak14650 at all 455 niece12762 in order to 400 receptionist10556 take place 387 lettuce7138 for instance 385 gym4584 and so on 377 carrot4578 be about to 341 snack3684 at once 337 earrings2676 in spite of 302 dessert1995 in effect 291 refrigerator
Note EFL 5 English as a foreign language BNC 5 British National Corpus
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 271
Current text word coverage calculations ignore such expressionsAccording to software commonly used to analyze the word familyfrequency distribution of text (VocabProfile [Cobb nd]) the sameEconomist paragraph is broken down as shown in Table 2
So if comprehension of a text were based on word coverage alonecurrent methods of text analysis (Table 2) suggest that a learner with avocabulary of at least the top 2000 words in English should be able tounderstand 9552 of the lexis in the Economist text (64 of the 67 words[tokens] counted) by some estimates (eg Laufer 1989b) enough foradequate comprehension If that same learner also knew just two wordsin the text on the Academic Word List (Coxhead 2000)mdashfeatures andsourcemdashshe would understand an additional 299 affording thatlearner a knowledge of 9851mdashtheoretically approximating nativelikelevels of comprehension (Carver 1994 p 432) However a closer lookat the breakdown in Table 2 shows that words like pull out all the andstops were all considered as separate and very common words when inreality they form one noncompositional expression pull out all the stopsIn fact all of the seven expressions have mistakenly been fragmentedand categorized as pertaining to the top 2000 words Thereforeassuming that a learner who knows only the 2000 most common wordsin English would not understand those expressions without the help of adictionary and if we reconduct the analysis taking those sevenexpressions into account (constituting 23 words) the total number ofwords fitting into the top 2000 goes down to 41 (64 minus 23) and that9552 figure actually drops from adequate comprehension down to6119 (41 4 67 5 06119)mdashwell below acceptable levels of readingcomprehension (Hu amp Nation 2000)
TABLE 2
Word Frequency Breakdown of The Economist text (Not Including Proper Nouns)
Frequency Words (67 tokens 54 types) Text coverage
0ndash1000 a all and any are based be been but by comingdo fast few for have heading if in is it marketmonths need not number of on open operatingout over past pull shores stops system the totouch waiting will with
8358
1001ndash2000 aside competing flood host screens swept thickwings
1194
Academic Word List(AWL)
features source 299
Off list Nifty 149Words in top 2000 9552+ AWL words 299Total text coverage 9851
272 TESOL QUARTERLY
RELATIONSHIP BETWEEN FORMULAIC LANGUAGE ANDREADING COMPREHENSION
Considering the relative wealth of research and literature on L2reading comprehension and separately multiword expressions inEnglish there is a surprising dearth of information regarding the roleif any formulaic language plays in the comprehension of texts in aforeign language The relatively few studies that do exist (eg Cooper1999 Liontas 2002) seem to confirm that it is especially the moresemantically opaque idioms that pose interpretability problems for L2readers and as these more core idioms are relatively rare (Grant ampNation 2006) Nation (2006) could be right in attenuating theirsignificance in reading comprehension
Nevertheless as discussed earlier there is evidence that a significantnumber of relatively opaque expressions occur frequently in texts inEnglish One commonly cited estimate (Erman amp Warren 2000) is thatsomewhat more than one-half (55) of any text will consist of formulaiclanguage (p 50) Naturally the opacity of those expressions will lie onwhat Lewis (1993 p 98) called a lsquolsquospectrum of idiomaticityrsquorsquo (Figure 1) akind of continuum of compositionality
Furthermore even when an expression does not meet the criteria ofcore or nonmatching idiom the relative ease or difficulty with which alearner will unpack its meaning is less inherent to the item itself andmore a learner-dependent variable Just as knowing fish may or may nottranslate into understanding fishy knowing perfect does not necessarilymean understanding perfect stranger
What is more although previous studies (Cooper 1999 Liontas2002) have found that in textual context more transparent idioms weremore easily understood than their opaque counterparts it should alsobe noted that the participants in those studies were aware that they werebeing tested specifically on their ability to correctly interpret idioms Inother words what cannot be known from most existing studies on idiominterpretation is how well the participants would have been able toidentify and understand the idioms in the first place had they not beenaware of their presence in the text
FIGURE 1 A spectrum of idiomaticity (compositionality)
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 273
A notable exception is Bishop (2004) who investigated thedifferential look-up behavior of participants who read texts thatcontained unknown words and unknown multiword expressions synon-ymous with those words Bishop confirmed that even though both wordsand multiword expressions were unknown readers looked up themeaning of words significantly more often He concludes that learnerslsquolsquodo not notice unknown formulaic sequences as readily as unknownwordsrsquorsquo (p 18)
Therefore idiomatic language in text irrespective of composition-ality might most usefully be classified as what Laufer (1989a) calledlsquolsquodeceptively transparentrsquorsquo (p 11) Laufer found that many Englishlearners misanalyze words like infallible as in+fall+ible (ie lsquolsquocannot fallrsquorsquo)and nevertheless as never+less (ie lsquolsquoalways morersquorsquo p 12) Likewisemdashalthough they were not part of her studymdashshe found that idioms like hitand miss were being read and interpreted word for word These lexicalitems that lsquolsquolearners think they know but they do notrsquorsquo (Laufer 1989ap 11) can impede reading comprehension in ways not accounted for inlists of common word families Nation (2006) seemed to assume thatmultiword expressions that have some element of transparency howeversmall will be reasonably interpretable through guessing However theLaufer (1989a) study may provide evidence to the contrary
But an attempt to guess (regardless of whether it is successful or not)presupposes awareness on the part of the learner that he is facing anunknown word If such an awareness is not there no attempt is made to inferthe missing meaning This is precisely the case with deceptively transparentwords The learner thinks he knows and then assigns the wrong meaning tothem [ ] (p 16)
Substitute lsquolsquoidiomrsquorsquo for lsquolsquowordrsquorsquo abovemdashnot an unreasonable conceptualstretchmdashand it becomes clear that multiword expressions just maypresent a larger problem for reading comprehension than accounted forin the current literature
In fact such lsquolsquodeceptionrsquorsquo seems even more likely to occur withmultiword expressions because such a large number of them arecomposed of very common words a learner would assume he or sheknows (Spottl amp McCarthy 2003 p 145 Stubbs amp Barth 2003 p 71)Moreover there is evidence that learners are reluctant to revisehypotheses formed regarding lexical items when reading even whenthe context does not support those hypotheses (Haynes 1993 Pigada ampSchmitt 2006)
274 TESOL QUARTERLY
Summary and Research Questions
In summary the following has been argued thus faramp Current estimates of how many words one needs to know in order to
comprehend most texts may be inaccurate due to overinclusion of derivedword forms and a total exclusion of multiword units of vocabulary
amp Contrary to some research there is evidence in corpus data that thenumber of frequently occurring noncompositional multiwordexpressions in English is higher than previously believed
amp Even when an expression is partly or even fully compositional thereis no way of knowing how accurately an L2 reader will interpret (oreven identify) that item
amp The claim that special attention to the 2000ndash3000 most commonwords in English is pedagogically sound since they provide around80 of text coverage (eg OrsquoKeeffe McCarthy amp Carter 2007Read 2004 p 148 Staelighr 2008) deserves closer scrutiny becausethose words are often merely tips of phraseological icebergs
It is therefore clear that there is a need for further investigation into howcommon words and the multiword units they form can affect readingcomprehension when reading in English as a foreign language To thatend we conducted a study to answer the following research questions
1 Are two texts written with the exact same high-frequency wordsunderstood equally well by L2 learners when one of the texts is moreidiomatic than the other
2 Can the presence of multiword expressions in a text lead L2 learners tobelieve they have understood that text better than they actually have
METHOD
Participants
Brazilian adult learners of English (n 5 101) all native speakers ofBrazilian Portuguese were selected to participate in the study Thesample ranged in age from 18 to 64 years (M 5 2576 SD 5 931) andconsisted of 43 men and 58 women representing seven different regionsof Brazil
All participants in the study had had a minimum of 80 hr of tuition inEnglish prior to the start of the research and had been tested aspossessing intermediate or higher levels of proficiency Howeverbecause all participants attended private language schools the actualinstruments by which their proficiency was assessed varied widely
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 275
Regardless uniformity in proficiency was not of prime importance in thestudy because the research questions are concerned with a significantchange in the paired samples within the same group
The Test
To write the eight texts (four texts in each test) a corpus of words wascarefully chosen from the list of the 2000 most frequent words in the BNCThe reading comprehension of each text was tested by seven true or falseitems totaling 28 per test part or 56 overall The test when administeredappears as one but is actually in two parts (Test 1 and Test 2) each partcontaining the exact same words with some words in Test 2 formingmultiword expressions Great care was taken to ensure that the texts areotherwise equal There is no visual difference between the two parts andthe texts are of almost uniform length in both parts (Table 3 and Figure 2)In addition care was taken not to include any extra cultural references inany of the texts and the comprehension task itself did not change acrossthe test parts The texts are stated to have come from peoplersquos descriptionof themselves in lsquolsquoFriendsbookrsquorsquo (intentionally similar to Facebook) On thewhole therefore it could be said that the style of the text is personal andinformal
The vast majority of the words are in the top 1000 withapproximately 985 of the words occurring in the BNC top 2000(Table 3) These results were in turn compared with the General ServiceList (West 1953) using software developed by Heatley and Nation(Range 1994) and another package using the same corpus created byCobb (nd) The results were practically identical in all cases (Range985 VocabProfile 98494)
Another key feature of the test is the rating scale which requires the testtaker to circle what she believes is his or her comprehension of each textfrom 5 to 1005 This self-reported comprehension is designed to helpanswer the second research question of whether the presence ofmultiword expressions in a text can lead L2 learners to believe they have
TABLE 3
Summary of Test 1 and Test 2 Text Data
Total wordcount
Total clausecount T-unit count
Top 1000words coverage
Top 1001ndash2000 words
coverage
Test 1 416 56 45 957373 27650Test 2 412 54 42 957373 27650
Note Data measured using vocabulary profiler (Cobb nd) A T-unit or a minimal terminableunit is lsquolsquoone main clause plus any subordinate clausersquorsquo (Hunt 1968 p 4)
276 TESOL QUARTERLY
understood that text better than they actually have Testing whatcomprehenders believe they understoodmdashcompared to what they actuallyunderstoodmdashby comparing test scores to self-assessment of comprehen-sion via a rating scale is often referred to as lsquolsquocomprehension calibrationrsquorsquoand is a method that has been used extensively in psychological research(eg Bransford amp Johnson 1972 Glenberg Wilkinson amp Epstein 1982Maki amp McGuire 2002 Moore Lin-Agler amp Zabrucky 2005) butsomewhat less so in applied linguistics (cf Brantmeier 2006 Jung 2003Morrison 2004 Oh 2001 Sarac amp Tarhan 2009)
Finally participants were asked to record their start and finish timesfor each part of the test
Procedure
Following an initial field test an item analysis was conducted toestablish the facility value6 of the test items and a discrimination indexfor both test parts to discern whether the test was discriminatingbetween stronger and weaker participants Items that were found to haveexceptionally high or low scores were carefully analyzed and the wordingof both test items and reading texts adjusted accordingly
Finally as advocated in Schmitt Schmitt and Clapham (2001) oneimportant requirement of an L2 test of reading comprehension is that itbe answerable by native or nativelike speakers of the language (p 65)To that end a smaller group of native speakers (n 5 8) was also tested asan additional check of the testrsquos validity That group produced a mean
FIGURE 2 Side-by-side comparison of matched texts from the two test parts (full version ofthe test available on request)
4 These are vocabulary profilers that essentially use word frequency lists to break all thewords in a text down into those that occur for example in the top 1000 second 1000third 1000 and so on
5 lsquolsquo0rsquorsquo would be virtually impossible because learners would be familiar with most words inthe texts if not all
6 A test itemrsquos facility value is calculated by dividing the number of participants whoanswered that item correctly by the total number of participants (Hughes 2003)
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 277
score of 28 in Test 1 (the maximum score) and 2775 in Test 2 showingthat both test parts posed very little difficulty for people for whomEnglish is a first language
The students received the two parts of the test in alternating order(ie counterbalanced) to control for any effect of taking Test 1 beforeTest 2 (and vice versa) because by counterbalancing one is able toinclude a variable order into an analysis and identify the extent towhich order affects performance on the dependent measures
RESULTS
All the scores and self-reported comprehension measures wererecorded in a statistical analysis software program (SPSS) Eachparticipantrsquos test results were transcribed into the software item by item(ie correct and incorrect) text by text (eg Text A Text B etc numbercorrect out of 7 for each) and test by test (ie Test 1 and Test 2 numbercorrect out of 28 possible for each) Also recorded were each participantrsquosself-reported comprehension assessments (a rating scale from 5 to 100)as they pertained to each text as well as which version (Test 1 or Test 2first) of the instrument each candidate had received To assess the effectof counterbalancing a repeated measures analysis of variance (ANOVA)was conducted with one within-subjects factor (TEST) with two levels(Test 1 score Test 2 score) and one between-subjects factor (VERSION)with two levels (Test 1 first Test 2 first) This analysis revealed a robustmain effect of test (F (199) 5 59338 p 0001 g2 5 086) and a discreteeffect of version (F (199) 5 405 p 5 0047 g2 5 004) but importantlythere was no significant Test 6 Version interaction (F (199) 5 281 p 5
0097 g2 5 002) illustrating that participantsrsquo scores did not vary as afunction of which version of the test they were completing
Comprehension of Test 1 versus Test 2
The central tendencies from both tests are presented in Table 4As predicted participantsrsquo scores were significantly lower on Test 2
relative to Test 1 (t(100) 5 2410 p 0001) with a strong effect size(g2 5 0828)7 confirming that even when two sets of texts contain theexact same words and even if those words are very commoncomprehension of those texts will not be the same when one containsidiomaticity
7 Confidence intervals at 95 for all t-tests
278 TESOL QUARTERLY
Self-Reported Comprehension of Test 1 versus Test 2
A t-test was also performed on the difference between whatparticipants believed they understood (ie their reported comprehen-sion) and what they actually understood in both Tests 1 and 2 (Table 5)Mean reported comprehension (MRC) was arrived at by calculating themeans of all the self-reported comprehension percentages (5ndash100)and the mean actual comprehension (MAC) is the mean of the score oneach text divided by seven (the maximum score)
MAC was lower than MRC in both Test 1(MRC M 5 08738 SD 013MAC M 5 08603 SD 5 009) and Test 2 (MRC M 5 06029 SD 019MAC M 5 05258 SD 5 014) however the difference between MRCand MAC was statistically reliable in Test 2 only where the test wascomposed of multiword expressions (t(100) 5 395 p 0001 g2 5
007)8 These data therefore appear to support a positive answer to thesecond research questionmdashthat learners may believe they understandmore than they actually do by virtue of their simply understanding theindividual words in a text
Variation in the Data
MRC versus MAC
Naturally there were some individual differences in the test resultsTable 6 shows that roughly one-half of all participants (n 5 50)overestimated their comprehension in both tests (indicated by MRC
TABLE 4
Descriptive Statistics (Tests 1 and 2)
Mean Median Mode Minimum Maximum SD
Test 1a 2409 2500 2500 1800 2800 244Test 2b 1476 1500 1500 600 2500 393
Note SD 5 standard deviation aTexts composed of common words however with little or noopaque phraseology bTexts composed of common words which comprise collocations andidiomatic language
TABLE 5
Reported Versus Actual Comprehension
Test 1 Test 2
Mean reported comprehension (MRC) 8738 6029Mean actual comprehension (MAC) 8603 5258
8 By comparison the results of the paired sample t-test for the Test 1 MRC-MAC means weret(100) 5 104 p 5 0302 g2 5 0005
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 279
greater than MAC) On the surface this might suggest that those 50participants did not overestimate their comprehension in Test 2 as aresult of its relative noncompositionality but rather as a generaltendency regardless of idiomaticity However when MAC is subtractedfrom MRC for that group and the difference compared across the teststhe difference is twice as large in Test 2 (t(49) 5 492 p 0001 g2 5
0108) This difference is even more evident in the same analysis of Test2 alone Isolating the results of that test there was a total of 70participants (over 69 of the entire sample) whose MRC was greaterthan their MAC The difference between MRC minus MAC for thesubgroup of 70 participants reveals that their overestimation of theircomprehension in Test 2 was four times greater than in Test 1 (t(69) 5
770 p 0001 g2 5 0228) Further among that group of 70 whoseTest 2 MRC was greater than their MAC 20 students either under-estimated or actually accurately guessed their comprehension in Test 1but significantly overestimated their comprehension in Test 2 (t(19) 5
849 p 0001 g2 5 0264) Only 30 participants in the present studyactually underestimated their comprehension on Test 2
Variation in Time Spent on the Tests
All candidates were also asked to record their start and finishing timesof each test (Table 7) It is not surprising that on average participantsspent more time on the texts which contained idiomatic expressionsHowever this trend was not uniform among the participants and thetime data may help provide some insight into just how aware someparticipants were of the presence of idiomaticity in the texts Thispossibility is explored further in the Discussion
TABLE 6
Trend of Increase in MRC-MAC Discrepancy Across Test Parts
NMRC minus MAC
(Test 1)MRC minus MAC
(Test 2)
Students with MRC MAC (bothtest parts)
50 009 019
Students with MRC MAC (Test 2) 70 004 017Students with MRC MAC (Test 2only)
20 2010 014
Students with MRC MAC (Test 2) 31a 2005 2015
Note MRC 5 mean reported comprehension MAC 5 mean actual comprehension aOnly oneparticipant in this group had MRC 5 MAC
280 TESOL QUARTERLY
DISCUSSION
To reiterate the present study sought to address the followingresearch questions
1 Are two texts written with the exact same high-frequency wordsunderstood equally well by L2 learners when one of the texts is moreidiomatic than the other
2 Can the presence of multiword expressions in a text lead L2 learners tobelieve they have understood that text better than they actually have
A group of 101 adult Brazilian learners of English was tested using twoseparate measures of reading comprehension (one with idiomaticlanguage and one without) and the results of the two tests were thencompared Although verbal reports would provide even greater insightthe resultant data from this study do seem to support a positive answer tothe first research question Participants achieved significantly lowerscores on the comprehension measure which assessed their under-standing of texts that contain multiword expressions It should bereiterated that this result was obtained in spite of both tests being writtenwith the exact same high-frequency words
Likewise through participantsrsquo self-reported comprehension thereseems to be evidence that the presence of multiword expressions in atext can lead L2 readers to overestimate their assessment of how muchthey have actually understood suggesting a positive answer to the secondresearch question
Although it seems apparent that participantsrsquo reading comprehensionin the present study was adversely affected by idiomaticity this sectionexplores and possibly explains variation in comprehension of the testsand further discusses evidence that multiword expressions negativelyaffected participantsrsquo comprehension
On the Stronger and Weaker Performance in the Tests
There are at least three important revelations emerging from theMRC-MAC data analysis presented in Table 6 First nearly two thirds of
TABLE 7
Time It Took Participants to Take Tests
N Mean time (minutes) SD
Time it took to take Test 1 91a 1085 436Time it took to take Test 2 91 1465 377
Note SD 5 standard deviation aSome participants (n 5 10) forgot to write in the time or left itincomplete
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 281
all participants believed they understood more than they actually did inTest 2 Second the data show that over 28 of those students (n 5 20)did not overestimate their comprehension in Test 1 providing evidencethat whereas they were apparently able to gauge their comprehensionfairly accurately when the texts were relatively devoid of idiomaticitythey were significantly less able to do so when relative noncomposition-ality was present Finally the MRC-MAC data presented so far indicatethat although not all participants tended to overestimate theircomprehension in Test 2 those who did (again the majority of cases)generally did so by a much larger margin Put simply it would seem thatnot only are many learners misunderstanding idiomaticity in text butthey may be doing so more than they (or researchers) realize
Further Evidence of Idiomaticity Negatively AffectingComprehension
The mean difference between MRC and MAC for the 70 students whooverestimated their comprehension in Test 2 (Table 6) was 017 For thesake of argument one could establish an MRC-MAC difference above020 as a cutoff for apparently marked lack of awareness of the extentof idiomaticity in Test 29 comparatively speaking This in turn wouldmean that there were 30 participants who ostensibly demonstrated aparticularly high overestimation of how much of Test 2 they had actuallyunderstood A sample of just the top 10 is provided in Table 8
Table 8 shows not only how different those participantsrsquo MRC wasfrom their Test 2 it also lists the same figures for Test 1 for comparison
9 A t-test reveals that the mean is in fact statistically significant even at the 003 differencelevel (t 5 653 p 5 003)
TABLE 8
Partial List of Participants With Exceptionally High Overestimation of Test 2 Comprehension(Difference 020)
ParticipantMRCTest 1
MACTest 1 Difference
MRCTest 2
MACTest 2 Difference
118 100 089 011 094 032 0626 075 068 007 081 028 05392 081 089 2008 075 025 05090 100 089 011 081 039 042115 100 089 011 087 050 03722 100 096 003 094 057 03780 094 068 026 069 032 03759 094 089 005 069 036 03321 100 093 007 087 057 03050 087 078 009 069 039 029
282 TESOL QUARTERLY
Whereas for Test 1 those 30 participantsrsquo assessment of readingcomprehension was usually only slightly overestimated10 (and in oneinstance even underestimated) the same participants in Test 2 had amarkedly overinflated conception of how much they had understood
Although not intended as a principal source of data for our analysisthe start and finish times recorded by participants on the tests in a fewinstances helped confirm the above assertions11 Table 7 shows thatthere was a significant difference between how long participants spenttaking each test (t 5 852 p 0001) However there were a number ofparticipants (n 5 26) who reported actually spending either the same orless time on Test 2 On the surface at least this fact would indicate thatthose 26 participants did not notice much difference between the testsOf course in reality that datum alone does not provide such evidencebecause that time may simply reflect a number of other confoundingvariables including affective (eg simply giving up) or even social (egthe need to leave early to meet a friend) and for that reason also was notconsidered to be a reliable source of data from those participantsHowever as a complementary source when triangulated with the othervariables some of the data analyzed earlier in the current study areoccasionally fortified further still with the time data (Table 9)
The data in Table 9 in many ways tie together the elements discussedin the analysis thus far in the present study A much lower score in Test 2than in Test 1 (columns B and C) an increase in the mean MRC-MACdifference across the tests (columns H and K) a relatively moderatedecrease in MRC in Test 2 vis-a-vis Test 1 (columns F and I) a markeddifference between MRC and MAC in Test 2 (column K) and theoccasional lack of increase (in Table 9 participants 118 80 59 and 50)in time it took to take Test 2 (columns D and E) These findings ontheir own in combination and especially in concert provide evidencethat (1) the students in Table 9 did not seem to appreciate the fullextent of the idiomaticity in Test 2 and (2) they appeared to think thatthey understood more than they actually did in Test 2
Perhaps most important 98 of all participants (n 5 99) scoredsignificantly lower on Test 2 (mean difference of 953 points out of 28SD 5 363) which shows that learners are generally unable to guess themeaning of idiomatic language even in the (largely inconsistent)instances in which they become aware of its presence
11 It should be noted that because 10 of the participantsrsquo time data were left incomplete afull group analysis could not be carried out thus the time data are only included asauxiliary information
10 As can be seen in Table 8 in fact only one participantmdashnumber 80mdashactually had anMRC-MAC difference in Test 1 that was also 020 Those of the other 29 participantswere all lower
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 283
For example the first participant in Tables 8 and 9 (number 118)who consistently overrated his own comprehension relative to his actualcomprehension answered for Text A of Test 2 as shown in Figure 3
On the basis of the responses it is likely that participant 118associated itrsquos about time with lsquolsquohas a problem with timersquorsquo Irsquom a little over thehill with lsquolsquohe probably lives in an area with hillsrsquorsquo and lsquolsquohe lives on the hill
TABLE 9
Triangulated Data Showing Negative Effect of Idiomaticity on Comprehension
A B C D E F G H I J K
Score Time Test 1 Test 2
Partic-ipant Test 1 Test 2 Test 1 Test 2 MRC MAC
Differ-ence MRC MAC
Differ-ence
118 25 9 2000 1800 100 089 11 094 032 0626 19 8 Missing Missing 075 068 007 081 028 05392 25 8 900 1100 081 089 2008 075 025 05090 25 11 900 1500 100 089 011 081 039 042115 25 14 1300 1500 100 089 011 087 050 03722 27 16 Missing Missing 100 096 003 094 057 03780 19 9 1000 1000 094 068 026 069 032 03759 25 10 1500 1400 094 089 005 069 036 03321 26 16 Missing Missing 100 093 007 087 057 03050 22 11 2000 1200 088 079 009 069 039 030
12 Of the 24 multiword expressions targeted for assessment of comprehension in Test 2 onlyfour were core idioms
FIGURE 3 Sample answer to Text A of Test 2
284 TESOL QUARTERLY
but not on top of itrsquorsquomdasha literal reading of those expressions His 100self-assessment is an indication that his answers were not guesses butinstead based on confidence that he had understood all the individualwords in the text The same answering dynamic occurred time and timeagain in Test 2
Returning therefore to the issues raised in the introduction thepresent research appears to provide evidence that idiomsmdashopaque orotherwise12mdashcan in fact cause major problems for L2 learners of Englishwhen reading In general the participants in our study were lesssuccessful at guessing the meaning of idioms than those in previousidiom-centered research such as Cooper (1999) and Liontas (2002)Because the learners in our study were not alerted to the presence ofidiomaticity in the text prior to reading this study may more accuratelyreflect what takes place in more naturally occurring L2 reading Finallythe difficulties that the participants encountered occurred in textscomposed purely of very common words showing that word frequencyalone is not necessarily a good measure of text coverage Lauferrsquos(1989a) hypothesis that much lexis in text can be deceptivelytransparent is confirmed in the present research extended to multiwordexpressions
Limitations of the Research
Although the research presented here does provide some significantevidence that the presence of idiomaticity in a text can negatively affectthe comprehension of that text by an L2 reader little is known about thestrategies the test takers employed Even though metacognition wasoutside the scope of examination of the present study such informationis highly relevant and future research should include protocols such asthose included in previous research on idioms (eg Liontas 20032007) which may provide crucial qualitative data regarding theindividual differences and behavior of the participants themselvesOverall future work in this area should consider making use of differentmeasures of self-assessment in order to explore the limitations of themethodology used in the present study
Also a question can be asked concerning the relative density ofmultiword expressions in each text In other words what is not known ison average how many such items a reader can expect to encounter Theratio of idioms to orthographic words in the texts tested in the presentstudy is very likely higher than averagemdashbut how much higher is as yetunknown Likewise the passages themselves were relatively short so it isunknown whether or not texts of greater length (and thereforecontextualization) would render the same or similar results
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 285
CONCLUSION
The present study provides some empirical evidence that a focus onword in L2 pedagogy may be detrimental to learnersrsquo development ofreading comprehension in the target language In most casesparticipants overestimated how much they had understood the textstested when those texts contained multiword expressions of varyingdegrees of compositionality comprised of very common individualwords Even when participants showed evidence of awareness of apresence of idiomaticity in the texts they generally were not very good atguessing the meaning of expressions Although Grant and Nation(2006) could be right that the teaching of individual idioms may not belsquolsquodeserving of class timersquorsquo (p 5) it is clear that at the very least raisinglearnersrsquo consciousness as to their prevalence and frequently deceptivetransparency in text certainly is
Concomitantly the present research serves to demonstrate theincompleteness of current lists of common words which now informimportant pedagogical instruments such as vocabulary tests gradedreaders and course syllabuses Under current methods as illustrated inthe Table 2 analysis of the Economist paragraph a text measured againstthe word lists now commonly in use can be mistakenly analyzed as beingeasily understood when in fact once multiword expressions are takeninto account the actual text coverage of easily understood words is farless Existing estimates of how many words one needs to know in order toadequately process naturally occurring texts (Hu amp Nation 2000Nation 2006) may need to be revisited to determine how many wordsand multiword expressions one needs to know
In practice research shows that learners will continue to believe theyunderstand items that they actually do not even after repeatedexposures to that same item (Bensoussan amp Laufer 1984 Haynes1993 Pigada amp Schmitt 2006) Language teachers and relatedprofessionals such as textbook writers need to consider ways tocontinuously help learners notice the gap between what they think theyknow and understand and what they actually do (Laufer 1997) Oneway this can be achieved has already been thoroughly discussed in thepresent paper devise texts (and tests) designed to lead readers down anidiomatic garden path Norbert Schmitt (as cited in Weir 2005) made asimilar recommendation
Perhaps the best and most valid type of vocabulary test is a reading passagewith comprehension questions but with the items requiring a full under-standing of particular words or phrases in the text This would mimic the realworld task of reading for comprehension and also the loss of comprehensionwhen key vocabulary is not known (p 123)
286 TESOL QUARTERLY
Therefore a further implication this research has for L2 pedagogy is themore careful design of the reading component of proficiency tests suchas IELTS (International English Language Testing System) and Test ofEnglish as a Foreign Language to be more strategic regarding the amountand kind of phraseology contained in the texts Proficiency was not thecentral focus of our study and future research could adopt a similarmethodology but with the inclusion of proficiency measures ofparticipants in order to explore how various types of expressions (egnoncompositional figurative imageable etc) may differentially affectpreidentified proficiency levels
Thus in order to be more methodical about such things as theinclusion of formulaic language in L2 tests and reading input in generalan important preliminary step will be to establish (a) what type offormulaic sequences are good discriminators of proficiency thresholdlevels and (b) which expressions of that identified type are mostcommon In other words what will be usefulmdashand is indeed nowbeginning to emerge (Martinez amp Schmitt 2010 Shin amp Nation 2008Simpson-Vlach amp Ellis 2010)mdashare lists of formulaic sequences that servea function similar to that of the General Service List not to revolutionizecurrent language pedagogy but to more finely tune it
THE AUTHORS
Ron Martinez is currently pursuing a doctorate at the University of NottinghamNottingham England on the topic of inclusion of phraseology in languageassessment He specializes in second language materials development
Victoria Murphy is a lecturer in Applied Linguistics and Second LanguageAcquisition at the University of Oxford Oxford England Her research interestsinclude the lexical development of first language or second language learners andthe cognitive processes that underlie language acquisition
REFERENCES
Bauer L amp Nation P (1993) Word families International Journal of Lexicography 6253ndash279 doi101093ijl64253
Bensoussan M amp Laufer B (1984) Lexical guessing in context in EFL readingcomprehension Journal of Research in Reading 7 15ndash32 doi101111j1467-98171984tb00252x
Bishop H (2004) Noticing formulaic sequences A problem of measuring thesubjective LSO Working Papers in Linguistics 4 15ndash19
Bransford D B amp Johnson M K (1972) Contextual prerequisites for under-standing Some investigations of comprehension and recall Journal of VerbalLearning and Verbal Behavior 11 717ndash726 doi101016S0022-5371(72)80006-9
Brantmeier C (2006) Advanced L2 learners and reading placement Self-assessment CBT and subsequent performance System 34 15ndash35 doi101016jsystem200508004
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 287
Carver R P (1994) Percentage of unknown vocabulary words in text as a functionof the relative difficulty of the text Implications for instruction Journal of ReadingBehavior 26 413ndash437
Cobb T (nd) Web VocabProfile [Online program] Retrieved from httpwwwlextutorcavp [an adaption of A Heatley amp P Nation Range (1994)]
Cooper T C (1999) Processing of idioms by L2 learners of English TESOLQuarterly 33 233ndash262 doi1023073587719
Coxhead A (2000) A new academic word list TESOL Quarterly 34 213ndash238doi1023073587951
Elley W amp Mangubhai F (1983) The impact of reading on second languagelearning Reading Research Quarterly 19 53ndash67 doi102307747337
Ellis N C (2008) Phraseology The periphery and the heart of language In FMeunier amp S Granger (Eds) Phraseology in language learning and teaching (pp 1ndash13) Amsterdam The Netherlands John Benjamins
Erman B amp Warren B (2000) The idiom principle and the open choice principleText 20 29ndash62
Gardner D (2007) Validating the construct of Word in applied corpus-basedvocabulary research A critical survey Applied Linguistics 28 241ndash265doi101093applinamm010
Glenberg A M Wilkinson A C amp Epstein W (1982) The illusion of knowingFailure in the self-assessment of comprehension Memory and Cognition 10 597ndash602 doi103758BF03202442
Goulden R Nation P amp Read J (1990) How large can a receptive vocabulary beApplied Linguistics 11 341ndash363 doi101093applin114341
Grant L amp Bauer L (2004) Criteria for re-defining idioms Are we barking up thewrong tree Applied Linguistics 25 38ndash61 doi101093applin25138
Grant L amp Nation P (2006) How many idioms are there in English ITL -International Journal of Applied Linguistics 151 1ndash14 doi102143ITL15102015219
Haynes M (1993) Patterns and perils of guessing in second language reading In THuckin M Haynes amp J Coady (Eds) Second language reading and vocabularylearning (pp 46ndash64) Norwood NJ Ablex Publishing Corporation
Heatley A amp Nation P (1994) Range [Computer program] Wellington NewZealand Victoria University of Wellington Retrieved from httpwwwvuwacnzlals
Hill J (2000) Revising priorities From grammatical failure to collocational successIn M Lewis (Ed) Teaching collocation Further developments in the Lexical Approach(pp 47ndash69) Hove England LTP
Hirsh D amp Nation P (1992) What vocabulary size is needed to read unsimplifiedtexts for pleasure Reading in a Foreign Language 8 689ndash696
Hu H M amp Nation P (2000) Unknown vocabulary density and readingcomprehension Reading in a Foreign Language 13 403ndash429
Hughes A (2003) Testing for language teachers Cambridge England CambridgeUniversity Press
Hunt K (1968) An instrument to measure syntactic maturity Tallahassee FL USDepartment of Health Education and Welfare
Jung E H (2003) The effects of organization markers on ESL learnersrsquo textunderstanding TESOL Quarterly 37 749ndash759 doi1023073588223
Krashen S (1993) The power of reading Insights from research Englewood COLibraries Unlimited
Laufer B (1989a) A factor of difficulty in vocabulary learning Deceptivetransparency AILA Review 6 10ndash20
288 TESOL QUARTERLY
Laufer B (1989b) What percentage of lexis is essential for comprehension In CLauren amp M Nordman (Eds) Special language From humans thinking to thinkingmachines (pp 316ndash323) London England Multilingual Matters
Laufer B (1991) How much lexis is necessary for reading comprehension In P JL Arnaud amp H Bejoint (Eds) Vocabulary and applied linguistics (pp 126ndash132)Oxford England Macmillan
Laufer B (1997) The lexical plight in second language reading Words you donrsquotknow words you think you know and words you canrsquot guess In J Coady amp THuckin (Eds) Second language vocabulary acquisition (pp 20ndash34) CambridgeEngland Cambridge University Press
Lewis M (1993) The Lexical Approach The state of ELT and a way forward HoveEngland LTP
Liontas J I (2002) Context and idiom understanding in second languagesEUROSLA Yearbook 2 155ndash185
Liontas J I (2003) Killing two birds with one stone Understanding Spanish VPidioms in and out of context Hispania 86 289ndash301 doi10230720062862
Liontas J I (2007) The eye never sees what the brain understands Making sense ofidioms in second languages Lingua et Linguistica 1) 25ndash44
Maki R H amp McGuire M J (2002) Metacognition for text Findings andimplications for education In T Schwarz amp L Bennett (Eds) Appliedmetacognition (pp 39ndash67) Cambridge England Cambridge University Press
Martinez R amp Schmitt N (2010) A phrasal expressions listManuscript submitted forpublication
Moon R (1997) Vocabulary connections Multi-word items in English In NSchmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 40ndash63) Cambridge England Cambridge University Press
Moore D Lin-Agler L M amp Zabrucky K M (2005) A source of metacomprehen-sion inaccuracy Reading Psychology 26 251ndash265 doi10108002702710590962578
Morrison L (2004) Comprehension monitoring in first and second languagereading The Canadian Modern Language Review 61 77ndash106
Nation I S P (2001) Learning vocabulary in another language Cambridge EnglandCambridge University Press
Nation I S P (2006) How large a vocabulary is needed for reading and listeningThe Canadian Modern Language Review 63 59ndash82
Nation I S P amp Waring R (1997) Vocabulary size text coverage and word lists InN Schmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 6ndash19) Cambridge England Cambridge University Press
Nation P (1997) The language learning benefits of extensive reading LanguageTeacher 21 13ndash16
Nattinger J R amp DeCarrico J S (1992) Lexical phrases and language teachingOxford England Oxford University Press
Oh S Y (2001) Two types of input modification and EFL reading comprehensionSimplification versus elaboration TESOL Quarterly 35 69ndash96 doi1023073587860
OrsquoKeeffe A McCarthy M amp Carter R (2007) From corpus to classroom Language useand language teaching Cambridge England Cambridge University Press
Pawley A amp Syder F H (1983) Two puzzles for linguistic theory Nativelikeselection and nativelike fluency In J C Richards amp R Schmidt (Eds) Languageand communication (pp 191ndash226) New York NY Longman
Pigada M amp Schmitt N (2006) Vocabulary acquisition from extensive reading Acase study Reading in a Foreign Language 18 1ndash28
Read J (2004) Research in teaching vocabulary Annual Review of Applied Linguistics24 146ndash161 doi101017S0267190504000078
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 289
Sarac S amp Tarhan B (2009) Calibration of comprehension and performance inL2 reading International Electronic Journal of Elementary Education 2 167ndash179
Schmitt N Jiang N amp Grabe W (2011) The percentage of words known in a textand reading comprehension Modern Language Journal 95(1) 26ndash43
Schmitt N Schmitt D amp Clapham C (2001) Developing and exploring thebehaviour of two new versions of the Vocabulary Levels Test Language Testing 1855ndash88
Shin D amp Nation I S P (2008) Beyond single words The most frequentcollocations in spoken English ELT Journal 62 339ndash348 doi101093eltccm091
Simpson-Vlach R amp Ellis N C (2010) An academic formulas list New methods inphraseology research Applied Linguistics 31(4) 487ndash512
Sinclair J (1991) Corpus concordance collocation Oxford England OxfordUniversity Press
Spottl C amp McCarthy M (2003) Formulaic utterances in the multi-lingual contextIn J Cenoz B Hufeisen ampU Jessner (Eds) The multilingual lexicon (pp 133ndash151) Dordrecht The Netherlands Kluwer
Staelighr L S (2008) Vocabulary size and the skills of listening reading and writingLanguage Learning Journal 36 139ndash152 doi10108009571730802389975
Stubbs M amp Barth I (2003) Using recurrent phrases as text-type descriminators Aquantitative method and some findings Functions of Language 10 61ndash104doi101075fol10104stu
The British National Corpus (2007) The British National Corpus(version 3 BNC XMLed) [CD-ROM] Distributed by Oxford University Computing Services on behalfof the BNC Consortium
The iPhonersquos second coming (2008 July) The Economist Retrieved from httpwwweconomistcomscience-technologydisplaystorycfmstory_id5E1_TTSDDJTG
Walter E Woodford K amp Good M (Eds) (2008) Cambridge advanced learnerrsquosdictionary (3rd ed) Cambridge England Cambridge University Press
Weir C J (2005) Language testing and validation An evidence-based approachNew York NY Palgrave Macmillan
West M (1953) A general service list of English words London England LongmanWray A (2002) Formulaic language and the lexicon Cambridge England Cambridge
University Press
290 TESOL QUARTERLY

Current text word coverage calculations ignore such expressionsAccording to software commonly used to analyze the word familyfrequency distribution of text (VocabProfile [Cobb nd]) the sameEconomist paragraph is broken down as shown in Table 2
So if comprehension of a text were based on word coverage alonecurrent methods of text analysis (Table 2) suggest that a learner with avocabulary of at least the top 2000 words in English should be able tounderstand 9552 of the lexis in the Economist text (64 of the 67 words[tokens] counted) by some estimates (eg Laufer 1989b) enough foradequate comprehension If that same learner also knew just two wordsin the text on the Academic Word List (Coxhead 2000)mdashfeatures andsourcemdashshe would understand an additional 299 affording thatlearner a knowledge of 9851mdashtheoretically approximating nativelikelevels of comprehension (Carver 1994 p 432) However a closer lookat the breakdown in Table 2 shows that words like pull out all the andstops were all considered as separate and very common words when inreality they form one noncompositional expression pull out all the stopsIn fact all of the seven expressions have mistakenly been fragmentedand categorized as pertaining to the top 2000 words Thereforeassuming that a learner who knows only the 2000 most common wordsin English would not understand those expressions without the help of adictionary and if we reconduct the analysis taking those sevenexpressions into account (constituting 23 words) the total number ofwords fitting into the top 2000 goes down to 41 (64 minus 23) and that9552 figure actually drops from adequate comprehension down to6119 (41 4 67 5 06119)mdashwell below acceptable levels of readingcomprehension (Hu amp Nation 2000)
TABLE 2
Word Frequency Breakdown of The Economist text (Not Including Proper Nouns)
Frequency Words (67 tokens 54 types) Text coverage
0ndash1000 a all and any are based be been but by comingdo fast few for have heading if in is it marketmonths need not number of on open operatingout over past pull shores stops system the totouch waiting will with
8358
1001ndash2000 aside competing flood host screens swept thickwings
1194
Academic Word List(AWL)
features source 299
Off list Nifty 149Words in top 2000 9552+ AWL words 299Total text coverage 9851
272 TESOL QUARTERLY
RELATIONSHIP BETWEEN FORMULAIC LANGUAGE ANDREADING COMPREHENSION
Considering the relative wealth of research and literature on L2reading comprehension and separately multiword expressions inEnglish there is a surprising dearth of information regarding the roleif any formulaic language plays in the comprehension of texts in aforeign language The relatively few studies that do exist (eg Cooper1999 Liontas 2002) seem to confirm that it is especially the moresemantically opaque idioms that pose interpretability problems for L2readers and as these more core idioms are relatively rare (Grant ampNation 2006) Nation (2006) could be right in attenuating theirsignificance in reading comprehension
Nevertheless as discussed earlier there is evidence that a significantnumber of relatively opaque expressions occur frequently in texts inEnglish One commonly cited estimate (Erman amp Warren 2000) is thatsomewhat more than one-half (55) of any text will consist of formulaiclanguage (p 50) Naturally the opacity of those expressions will lie onwhat Lewis (1993 p 98) called a lsquolsquospectrum of idiomaticityrsquorsquo (Figure 1) akind of continuum of compositionality
Furthermore even when an expression does not meet the criteria ofcore or nonmatching idiom the relative ease or difficulty with which alearner will unpack its meaning is less inherent to the item itself andmore a learner-dependent variable Just as knowing fish may or may nottranslate into understanding fishy knowing perfect does not necessarilymean understanding perfect stranger
What is more although previous studies (Cooper 1999 Liontas2002) have found that in textual context more transparent idioms weremore easily understood than their opaque counterparts it should alsobe noted that the participants in those studies were aware that they werebeing tested specifically on their ability to correctly interpret idioms Inother words what cannot be known from most existing studies on idiominterpretation is how well the participants would have been able toidentify and understand the idioms in the first place had they not beenaware of their presence in the text
FIGURE 1 A spectrum of idiomaticity (compositionality)
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 273
A notable exception is Bishop (2004) who investigated thedifferential look-up behavior of participants who read texts thatcontained unknown words and unknown multiword expressions synon-ymous with those words Bishop confirmed that even though both wordsand multiword expressions were unknown readers looked up themeaning of words significantly more often He concludes that learnerslsquolsquodo not notice unknown formulaic sequences as readily as unknownwordsrsquorsquo (p 18)
Therefore idiomatic language in text irrespective of composition-ality might most usefully be classified as what Laufer (1989a) calledlsquolsquodeceptively transparentrsquorsquo (p 11) Laufer found that many Englishlearners misanalyze words like infallible as in+fall+ible (ie lsquolsquocannot fallrsquorsquo)and nevertheless as never+less (ie lsquolsquoalways morersquorsquo p 12) Likewisemdashalthough they were not part of her studymdashshe found that idioms like hitand miss were being read and interpreted word for word These lexicalitems that lsquolsquolearners think they know but they do notrsquorsquo (Laufer 1989ap 11) can impede reading comprehension in ways not accounted for inlists of common word families Nation (2006) seemed to assume thatmultiword expressions that have some element of transparency howeversmall will be reasonably interpretable through guessing However theLaufer (1989a) study may provide evidence to the contrary
But an attempt to guess (regardless of whether it is successful or not)presupposes awareness on the part of the learner that he is facing anunknown word If such an awareness is not there no attempt is made to inferthe missing meaning This is precisely the case with deceptively transparentwords The learner thinks he knows and then assigns the wrong meaning tothem [ ] (p 16)
Substitute lsquolsquoidiomrsquorsquo for lsquolsquowordrsquorsquo abovemdashnot an unreasonable conceptualstretchmdashand it becomes clear that multiword expressions just maypresent a larger problem for reading comprehension than accounted forin the current literature
In fact such lsquolsquodeceptionrsquorsquo seems even more likely to occur withmultiword expressions because such a large number of them arecomposed of very common words a learner would assume he or sheknows (Spottl amp McCarthy 2003 p 145 Stubbs amp Barth 2003 p 71)Moreover there is evidence that learners are reluctant to revisehypotheses formed regarding lexical items when reading even whenthe context does not support those hypotheses (Haynes 1993 Pigada ampSchmitt 2006)
274 TESOL QUARTERLY
Summary and Research Questions
In summary the following has been argued thus faramp Current estimates of how many words one needs to know in order to
comprehend most texts may be inaccurate due to overinclusion of derivedword forms and a total exclusion of multiword units of vocabulary
amp Contrary to some research there is evidence in corpus data that thenumber of frequently occurring noncompositional multiwordexpressions in English is higher than previously believed
amp Even when an expression is partly or even fully compositional thereis no way of knowing how accurately an L2 reader will interpret (oreven identify) that item
amp The claim that special attention to the 2000ndash3000 most commonwords in English is pedagogically sound since they provide around80 of text coverage (eg OrsquoKeeffe McCarthy amp Carter 2007Read 2004 p 148 Staelighr 2008) deserves closer scrutiny becausethose words are often merely tips of phraseological icebergs
It is therefore clear that there is a need for further investigation into howcommon words and the multiword units they form can affect readingcomprehension when reading in English as a foreign language To thatend we conducted a study to answer the following research questions
1 Are two texts written with the exact same high-frequency wordsunderstood equally well by L2 learners when one of the texts is moreidiomatic than the other
2 Can the presence of multiword expressions in a text lead L2 learners tobelieve they have understood that text better than they actually have
METHOD
Participants
Brazilian adult learners of English (n 5 101) all native speakers ofBrazilian Portuguese were selected to participate in the study Thesample ranged in age from 18 to 64 years (M 5 2576 SD 5 931) andconsisted of 43 men and 58 women representing seven different regionsof Brazil
All participants in the study had had a minimum of 80 hr of tuition inEnglish prior to the start of the research and had been tested aspossessing intermediate or higher levels of proficiency Howeverbecause all participants attended private language schools the actualinstruments by which their proficiency was assessed varied widely
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 275
Regardless uniformity in proficiency was not of prime importance in thestudy because the research questions are concerned with a significantchange in the paired samples within the same group
The Test
To write the eight texts (four texts in each test) a corpus of words wascarefully chosen from the list of the 2000 most frequent words in the BNCThe reading comprehension of each text was tested by seven true or falseitems totaling 28 per test part or 56 overall The test when administeredappears as one but is actually in two parts (Test 1 and Test 2) each partcontaining the exact same words with some words in Test 2 formingmultiword expressions Great care was taken to ensure that the texts areotherwise equal There is no visual difference between the two parts andthe texts are of almost uniform length in both parts (Table 3 and Figure 2)In addition care was taken not to include any extra cultural references inany of the texts and the comprehension task itself did not change acrossthe test parts The texts are stated to have come from peoplersquos descriptionof themselves in lsquolsquoFriendsbookrsquorsquo (intentionally similar to Facebook) On thewhole therefore it could be said that the style of the text is personal andinformal
The vast majority of the words are in the top 1000 withapproximately 985 of the words occurring in the BNC top 2000(Table 3) These results were in turn compared with the General ServiceList (West 1953) using software developed by Heatley and Nation(Range 1994) and another package using the same corpus created byCobb (nd) The results were practically identical in all cases (Range985 VocabProfile 98494)
Another key feature of the test is the rating scale which requires the testtaker to circle what she believes is his or her comprehension of each textfrom 5 to 1005 This self-reported comprehension is designed to helpanswer the second research question of whether the presence ofmultiword expressions in a text can lead L2 learners to believe they have
TABLE 3
Summary of Test 1 and Test 2 Text Data
Total wordcount
Total clausecount T-unit count
Top 1000words coverage
Top 1001ndash2000 words
coverage
Test 1 416 56 45 957373 27650Test 2 412 54 42 957373 27650
Note Data measured using vocabulary profiler (Cobb nd) A T-unit or a minimal terminableunit is lsquolsquoone main clause plus any subordinate clausersquorsquo (Hunt 1968 p 4)
276 TESOL QUARTERLY
understood that text better than they actually have Testing whatcomprehenders believe they understoodmdashcompared to what they actuallyunderstoodmdashby comparing test scores to self-assessment of comprehen-sion via a rating scale is often referred to as lsquolsquocomprehension calibrationrsquorsquoand is a method that has been used extensively in psychological research(eg Bransford amp Johnson 1972 Glenberg Wilkinson amp Epstein 1982Maki amp McGuire 2002 Moore Lin-Agler amp Zabrucky 2005) butsomewhat less so in applied linguistics (cf Brantmeier 2006 Jung 2003Morrison 2004 Oh 2001 Sarac amp Tarhan 2009)
Finally participants were asked to record their start and finish timesfor each part of the test
Procedure
Following an initial field test an item analysis was conducted toestablish the facility value6 of the test items and a discrimination indexfor both test parts to discern whether the test was discriminatingbetween stronger and weaker participants Items that were found to haveexceptionally high or low scores were carefully analyzed and the wordingof both test items and reading texts adjusted accordingly
Finally as advocated in Schmitt Schmitt and Clapham (2001) oneimportant requirement of an L2 test of reading comprehension is that itbe answerable by native or nativelike speakers of the language (p 65)To that end a smaller group of native speakers (n 5 8) was also tested asan additional check of the testrsquos validity That group produced a mean
FIGURE 2 Side-by-side comparison of matched texts from the two test parts (full version ofthe test available on request)
4 These are vocabulary profilers that essentially use word frequency lists to break all thewords in a text down into those that occur for example in the top 1000 second 1000third 1000 and so on
5 lsquolsquo0rsquorsquo would be virtually impossible because learners would be familiar with most words inthe texts if not all
6 A test itemrsquos facility value is calculated by dividing the number of participants whoanswered that item correctly by the total number of participants (Hughes 2003)
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 277
score of 28 in Test 1 (the maximum score) and 2775 in Test 2 showingthat both test parts posed very little difficulty for people for whomEnglish is a first language
The students received the two parts of the test in alternating order(ie counterbalanced) to control for any effect of taking Test 1 beforeTest 2 (and vice versa) because by counterbalancing one is able toinclude a variable order into an analysis and identify the extent towhich order affects performance on the dependent measures
RESULTS
All the scores and self-reported comprehension measures wererecorded in a statistical analysis software program (SPSS) Eachparticipantrsquos test results were transcribed into the software item by item(ie correct and incorrect) text by text (eg Text A Text B etc numbercorrect out of 7 for each) and test by test (ie Test 1 and Test 2 numbercorrect out of 28 possible for each) Also recorded were each participantrsquosself-reported comprehension assessments (a rating scale from 5 to 100)as they pertained to each text as well as which version (Test 1 or Test 2first) of the instrument each candidate had received To assess the effectof counterbalancing a repeated measures analysis of variance (ANOVA)was conducted with one within-subjects factor (TEST) with two levels(Test 1 score Test 2 score) and one between-subjects factor (VERSION)with two levels (Test 1 first Test 2 first) This analysis revealed a robustmain effect of test (F (199) 5 59338 p 0001 g2 5 086) and a discreteeffect of version (F (199) 5 405 p 5 0047 g2 5 004) but importantlythere was no significant Test 6 Version interaction (F (199) 5 281 p 5
0097 g2 5 002) illustrating that participantsrsquo scores did not vary as afunction of which version of the test they were completing
Comprehension of Test 1 versus Test 2
The central tendencies from both tests are presented in Table 4As predicted participantsrsquo scores were significantly lower on Test 2
relative to Test 1 (t(100) 5 2410 p 0001) with a strong effect size(g2 5 0828)7 confirming that even when two sets of texts contain theexact same words and even if those words are very commoncomprehension of those texts will not be the same when one containsidiomaticity
7 Confidence intervals at 95 for all t-tests
278 TESOL QUARTERLY
Self-Reported Comprehension of Test 1 versus Test 2
A t-test was also performed on the difference between whatparticipants believed they understood (ie their reported comprehen-sion) and what they actually understood in both Tests 1 and 2 (Table 5)Mean reported comprehension (MRC) was arrived at by calculating themeans of all the self-reported comprehension percentages (5ndash100)and the mean actual comprehension (MAC) is the mean of the score oneach text divided by seven (the maximum score)
MAC was lower than MRC in both Test 1(MRC M 5 08738 SD 013MAC M 5 08603 SD 5 009) and Test 2 (MRC M 5 06029 SD 019MAC M 5 05258 SD 5 014) however the difference between MRCand MAC was statistically reliable in Test 2 only where the test wascomposed of multiword expressions (t(100) 5 395 p 0001 g2 5
007)8 These data therefore appear to support a positive answer to thesecond research questionmdashthat learners may believe they understandmore than they actually do by virtue of their simply understanding theindividual words in a text
Variation in the Data
MRC versus MAC
Naturally there were some individual differences in the test resultsTable 6 shows that roughly one-half of all participants (n 5 50)overestimated their comprehension in both tests (indicated by MRC
TABLE 4
Descriptive Statistics (Tests 1 and 2)
Mean Median Mode Minimum Maximum SD
Test 1a 2409 2500 2500 1800 2800 244Test 2b 1476 1500 1500 600 2500 393
Note SD 5 standard deviation aTexts composed of common words however with little or noopaque phraseology bTexts composed of common words which comprise collocations andidiomatic language
TABLE 5
Reported Versus Actual Comprehension
Test 1 Test 2
Mean reported comprehension (MRC) 8738 6029Mean actual comprehension (MAC) 8603 5258
8 By comparison the results of the paired sample t-test for the Test 1 MRC-MAC means weret(100) 5 104 p 5 0302 g2 5 0005
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 279
greater than MAC) On the surface this might suggest that those 50participants did not overestimate their comprehension in Test 2 as aresult of its relative noncompositionality but rather as a generaltendency regardless of idiomaticity However when MAC is subtractedfrom MRC for that group and the difference compared across the teststhe difference is twice as large in Test 2 (t(49) 5 492 p 0001 g2 5
0108) This difference is even more evident in the same analysis of Test2 alone Isolating the results of that test there was a total of 70participants (over 69 of the entire sample) whose MRC was greaterthan their MAC The difference between MRC minus MAC for thesubgroup of 70 participants reveals that their overestimation of theircomprehension in Test 2 was four times greater than in Test 1 (t(69) 5
770 p 0001 g2 5 0228) Further among that group of 70 whoseTest 2 MRC was greater than their MAC 20 students either under-estimated or actually accurately guessed their comprehension in Test 1but significantly overestimated their comprehension in Test 2 (t(19) 5
849 p 0001 g2 5 0264) Only 30 participants in the present studyactually underestimated their comprehension on Test 2
Variation in Time Spent on the Tests
All candidates were also asked to record their start and finishing timesof each test (Table 7) It is not surprising that on average participantsspent more time on the texts which contained idiomatic expressionsHowever this trend was not uniform among the participants and thetime data may help provide some insight into just how aware someparticipants were of the presence of idiomaticity in the texts Thispossibility is explored further in the Discussion
TABLE 6
Trend of Increase in MRC-MAC Discrepancy Across Test Parts
NMRC minus MAC
(Test 1)MRC minus MAC
(Test 2)
Students with MRC MAC (bothtest parts)
50 009 019
Students with MRC MAC (Test 2) 70 004 017Students with MRC MAC (Test 2only)
20 2010 014
Students with MRC MAC (Test 2) 31a 2005 2015
Note MRC 5 mean reported comprehension MAC 5 mean actual comprehension aOnly oneparticipant in this group had MRC 5 MAC
280 TESOL QUARTERLY
DISCUSSION
To reiterate the present study sought to address the followingresearch questions
1 Are two texts written with the exact same high-frequency wordsunderstood equally well by L2 learners when one of the texts is moreidiomatic than the other
2 Can the presence of multiword expressions in a text lead L2 learners tobelieve they have understood that text better than they actually have
A group of 101 adult Brazilian learners of English was tested using twoseparate measures of reading comprehension (one with idiomaticlanguage and one without) and the results of the two tests were thencompared Although verbal reports would provide even greater insightthe resultant data from this study do seem to support a positive answer tothe first research question Participants achieved significantly lowerscores on the comprehension measure which assessed their under-standing of texts that contain multiword expressions It should bereiterated that this result was obtained in spite of both tests being writtenwith the exact same high-frequency words
Likewise through participantsrsquo self-reported comprehension thereseems to be evidence that the presence of multiword expressions in atext can lead L2 readers to overestimate their assessment of how muchthey have actually understood suggesting a positive answer to the secondresearch question
Although it seems apparent that participantsrsquo reading comprehensionin the present study was adversely affected by idiomaticity this sectionexplores and possibly explains variation in comprehension of the testsand further discusses evidence that multiword expressions negativelyaffected participantsrsquo comprehension
On the Stronger and Weaker Performance in the Tests
There are at least three important revelations emerging from theMRC-MAC data analysis presented in Table 6 First nearly two thirds of
TABLE 7
Time It Took Participants to Take Tests
N Mean time (minutes) SD
Time it took to take Test 1 91a 1085 436Time it took to take Test 2 91 1465 377
Note SD 5 standard deviation aSome participants (n 5 10) forgot to write in the time or left itincomplete
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 281
all participants believed they understood more than they actually did inTest 2 Second the data show that over 28 of those students (n 5 20)did not overestimate their comprehension in Test 1 providing evidencethat whereas they were apparently able to gauge their comprehensionfairly accurately when the texts were relatively devoid of idiomaticitythey were significantly less able to do so when relative noncomposition-ality was present Finally the MRC-MAC data presented so far indicatethat although not all participants tended to overestimate theircomprehension in Test 2 those who did (again the majority of cases)generally did so by a much larger margin Put simply it would seem thatnot only are many learners misunderstanding idiomaticity in text butthey may be doing so more than they (or researchers) realize
Further Evidence of Idiomaticity Negatively AffectingComprehension
The mean difference between MRC and MAC for the 70 students whooverestimated their comprehension in Test 2 (Table 6) was 017 For thesake of argument one could establish an MRC-MAC difference above020 as a cutoff for apparently marked lack of awareness of the extentof idiomaticity in Test 29 comparatively speaking This in turn wouldmean that there were 30 participants who ostensibly demonstrated aparticularly high overestimation of how much of Test 2 they had actuallyunderstood A sample of just the top 10 is provided in Table 8
Table 8 shows not only how different those participantsrsquo MRC wasfrom their Test 2 it also lists the same figures for Test 1 for comparison
9 A t-test reveals that the mean is in fact statistically significant even at the 003 differencelevel (t 5 653 p 5 003)
TABLE 8
Partial List of Participants With Exceptionally High Overestimation of Test 2 Comprehension(Difference 020)
ParticipantMRCTest 1
MACTest 1 Difference
MRCTest 2
MACTest 2 Difference
118 100 089 011 094 032 0626 075 068 007 081 028 05392 081 089 2008 075 025 05090 100 089 011 081 039 042115 100 089 011 087 050 03722 100 096 003 094 057 03780 094 068 026 069 032 03759 094 089 005 069 036 03321 100 093 007 087 057 03050 087 078 009 069 039 029
282 TESOL QUARTERLY
Whereas for Test 1 those 30 participantsrsquo assessment of readingcomprehension was usually only slightly overestimated10 (and in oneinstance even underestimated) the same participants in Test 2 had amarkedly overinflated conception of how much they had understood
Although not intended as a principal source of data for our analysisthe start and finish times recorded by participants on the tests in a fewinstances helped confirm the above assertions11 Table 7 shows thatthere was a significant difference between how long participants spenttaking each test (t 5 852 p 0001) However there were a number ofparticipants (n 5 26) who reported actually spending either the same orless time on Test 2 On the surface at least this fact would indicate thatthose 26 participants did not notice much difference between the testsOf course in reality that datum alone does not provide such evidencebecause that time may simply reflect a number of other confoundingvariables including affective (eg simply giving up) or even social (egthe need to leave early to meet a friend) and for that reason also was notconsidered to be a reliable source of data from those participantsHowever as a complementary source when triangulated with the othervariables some of the data analyzed earlier in the current study areoccasionally fortified further still with the time data (Table 9)
The data in Table 9 in many ways tie together the elements discussedin the analysis thus far in the present study A much lower score in Test 2than in Test 1 (columns B and C) an increase in the mean MRC-MACdifference across the tests (columns H and K) a relatively moderatedecrease in MRC in Test 2 vis-a-vis Test 1 (columns F and I) a markeddifference between MRC and MAC in Test 2 (column K) and theoccasional lack of increase (in Table 9 participants 118 80 59 and 50)in time it took to take Test 2 (columns D and E) These findings ontheir own in combination and especially in concert provide evidencethat (1) the students in Table 9 did not seem to appreciate the fullextent of the idiomaticity in Test 2 and (2) they appeared to think thatthey understood more than they actually did in Test 2
Perhaps most important 98 of all participants (n 5 99) scoredsignificantly lower on Test 2 (mean difference of 953 points out of 28SD 5 363) which shows that learners are generally unable to guess themeaning of idiomatic language even in the (largely inconsistent)instances in which they become aware of its presence
11 It should be noted that because 10 of the participantsrsquo time data were left incomplete afull group analysis could not be carried out thus the time data are only included asauxiliary information
10 As can be seen in Table 8 in fact only one participantmdashnumber 80mdashactually had anMRC-MAC difference in Test 1 that was also 020 Those of the other 29 participantswere all lower
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 283
For example the first participant in Tables 8 and 9 (number 118)who consistently overrated his own comprehension relative to his actualcomprehension answered for Text A of Test 2 as shown in Figure 3
On the basis of the responses it is likely that participant 118associated itrsquos about time with lsquolsquohas a problem with timersquorsquo Irsquom a little over thehill with lsquolsquohe probably lives in an area with hillsrsquorsquo and lsquolsquohe lives on the hill
TABLE 9
Triangulated Data Showing Negative Effect of Idiomaticity on Comprehension
A B C D E F G H I J K
Score Time Test 1 Test 2
Partic-ipant Test 1 Test 2 Test 1 Test 2 MRC MAC
Differ-ence MRC MAC
Differ-ence
118 25 9 2000 1800 100 089 11 094 032 0626 19 8 Missing Missing 075 068 007 081 028 05392 25 8 900 1100 081 089 2008 075 025 05090 25 11 900 1500 100 089 011 081 039 042115 25 14 1300 1500 100 089 011 087 050 03722 27 16 Missing Missing 100 096 003 094 057 03780 19 9 1000 1000 094 068 026 069 032 03759 25 10 1500 1400 094 089 005 069 036 03321 26 16 Missing Missing 100 093 007 087 057 03050 22 11 2000 1200 088 079 009 069 039 030
12 Of the 24 multiword expressions targeted for assessment of comprehension in Test 2 onlyfour were core idioms
FIGURE 3 Sample answer to Text A of Test 2
284 TESOL QUARTERLY
but not on top of itrsquorsquomdasha literal reading of those expressions His 100self-assessment is an indication that his answers were not guesses butinstead based on confidence that he had understood all the individualwords in the text The same answering dynamic occurred time and timeagain in Test 2
Returning therefore to the issues raised in the introduction thepresent research appears to provide evidence that idiomsmdashopaque orotherwise12mdashcan in fact cause major problems for L2 learners of Englishwhen reading In general the participants in our study were lesssuccessful at guessing the meaning of idioms than those in previousidiom-centered research such as Cooper (1999) and Liontas (2002)Because the learners in our study were not alerted to the presence ofidiomaticity in the text prior to reading this study may more accuratelyreflect what takes place in more naturally occurring L2 reading Finallythe difficulties that the participants encountered occurred in textscomposed purely of very common words showing that word frequencyalone is not necessarily a good measure of text coverage Lauferrsquos(1989a) hypothesis that much lexis in text can be deceptivelytransparent is confirmed in the present research extended to multiwordexpressions
Limitations of the Research
Although the research presented here does provide some significantevidence that the presence of idiomaticity in a text can negatively affectthe comprehension of that text by an L2 reader little is known about thestrategies the test takers employed Even though metacognition wasoutside the scope of examination of the present study such informationis highly relevant and future research should include protocols such asthose included in previous research on idioms (eg Liontas 20032007) which may provide crucial qualitative data regarding theindividual differences and behavior of the participants themselvesOverall future work in this area should consider making use of differentmeasures of self-assessment in order to explore the limitations of themethodology used in the present study
Also a question can be asked concerning the relative density ofmultiword expressions in each text In other words what is not known ison average how many such items a reader can expect to encounter Theratio of idioms to orthographic words in the texts tested in the presentstudy is very likely higher than averagemdashbut how much higher is as yetunknown Likewise the passages themselves were relatively short so it isunknown whether or not texts of greater length (and thereforecontextualization) would render the same or similar results
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 285
CONCLUSION
The present study provides some empirical evidence that a focus onword in L2 pedagogy may be detrimental to learnersrsquo development ofreading comprehension in the target language In most casesparticipants overestimated how much they had understood the textstested when those texts contained multiword expressions of varyingdegrees of compositionality comprised of very common individualwords Even when participants showed evidence of awareness of apresence of idiomaticity in the texts they generally were not very good atguessing the meaning of expressions Although Grant and Nation(2006) could be right that the teaching of individual idioms may not belsquolsquodeserving of class timersquorsquo (p 5) it is clear that at the very least raisinglearnersrsquo consciousness as to their prevalence and frequently deceptivetransparency in text certainly is
Concomitantly the present research serves to demonstrate theincompleteness of current lists of common words which now informimportant pedagogical instruments such as vocabulary tests gradedreaders and course syllabuses Under current methods as illustrated inthe Table 2 analysis of the Economist paragraph a text measured againstthe word lists now commonly in use can be mistakenly analyzed as beingeasily understood when in fact once multiword expressions are takeninto account the actual text coverage of easily understood words is farless Existing estimates of how many words one needs to know in order toadequately process naturally occurring texts (Hu amp Nation 2000Nation 2006) may need to be revisited to determine how many wordsand multiword expressions one needs to know
In practice research shows that learners will continue to believe theyunderstand items that they actually do not even after repeatedexposures to that same item (Bensoussan amp Laufer 1984 Haynes1993 Pigada amp Schmitt 2006) Language teachers and relatedprofessionals such as textbook writers need to consider ways tocontinuously help learners notice the gap between what they think theyknow and understand and what they actually do (Laufer 1997) Oneway this can be achieved has already been thoroughly discussed in thepresent paper devise texts (and tests) designed to lead readers down anidiomatic garden path Norbert Schmitt (as cited in Weir 2005) made asimilar recommendation
Perhaps the best and most valid type of vocabulary test is a reading passagewith comprehension questions but with the items requiring a full under-standing of particular words or phrases in the text This would mimic the realworld task of reading for comprehension and also the loss of comprehensionwhen key vocabulary is not known (p 123)
286 TESOL QUARTERLY
Therefore a further implication this research has for L2 pedagogy is themore careful design of the reading component of proficiency tests suchas IELTS (International English Language Testing System) and Test ofEnglish as a Foreign Language to be more strategic regarding the amountand kind of phraseology contained in the texts Proficiency was not thecentral focus of our study and future research could adopt a similarmethodology but with the inclusion of proficiency measures ofparticipants in order to explore how various types of expressions (egnoncompositional figurative imageable etc) may differentially affectpreidentified proficiency levels
Thus in order to be more methodical about such things as theinclusion of formulaic language in L2 tests and reading input in generalan important preliminary step will be to establish (a) what type offormulaic sequences are good discriminators of proficiency thresholdlevels and (b) which expressions of that identified type are mostcommon In other words what will be usefulmdashand is indeed nowbeginning to emerge (Martinez amp Schmitt 2010 Shin amp Nation 2008Simpson-Vlach amp Ellis 2010)mdashare lists of formulaic sequences that servea function similar to that of the General Service List not to revolutionizecurrent language pedagogy but to more finely tune it
THE AUTHORS
Ron Martinez is currently pursuing a doctorate at the University of NottinghamNottingham England on the topic of inclusion of phraseology in languageassessment He specializes in second language materials development
Victoria Murphy is a lecturer in Applied Linguistics and Second LanguageAcquisition at the University of Oxford Oxford England Her research interestsinclude the lexical development of first language or second language learners andthe cognitive processes that underlie language acquisition
REFERENCES
Bauer L amp Nation P (1993) Word families International Journal of Lexicography 6253ndash279 doi101093ijl64253
Bensoussan M amp Laufer B (1984) Lexical guessing in context in EFL readingcomprehension Journal of Research in Reading 7 15ndash32 doi101111j1467-98171984tb00252x
Bishop H (2004) Noticing formulaic sequences A problem of measuring thesubjective LSO Working Papers in Linguistics 4 15ndash19
Bransford D B amp Johnson M K (1972) Contextual prerequisites for under-standing Some investigations of comprehension and recall Journal of VerbalLearning and Verbal Behavior 11 717ndash726 doi101016S0022-5371(72)80006-9
Brantmeier C (2006) Advanced L2 learners and reading placement Self-assessment CBT and subsequent performance System 34 15ndash35 doi101016jsystem200508004
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 287
Carver R P (1994) Percentage of unknown vocabulary words in text as a functionof the relative difficulty of the text Implications for instruction Journal of ReadingBehavior 26 413ndash437
Cobb T (nd) Web VocabProfile [Online program] Retrieved from httpwwwlextutorcavp [an adaption of A Heatley amp P Nation Range (1994)]
Cooper T C (1999) Processing of idioms by L2 learners of English TESOLQuarterly 33 233ndash262 doi1023073587719
Coxhead A (2000) A new academic word list TESOL Quarterly 34 213ndash238doi1023073587951
Elley W amp Mangubhai F (1983) The impact of reading on second languagelearning Reading Research Quarterly 19 53ndash67 doi102307747337
Ellis N C (2008) Phraseology The periphery and the heart of language In FMeunier amp S Granger (Eds) Phraseology in language learning and teaching (pp 1ndash13) Amsterdam The Netherlands John Benjamins
Erman B amp Warren B (2000) The idiom principle and the open choice principleText 20 29ndash62
Gardner D (2007) Validating the construct of Word in applied corpus-basedvocabulary research A critical survey Applied Linguistics 28 241ndash265doi101093applinamm010
Glenberg A M Wilkinson A C amp Epstein W (1982) The illusion of knowingFailure in the self-assessment of comprehension Memory and Cognition 10 597ndash602 doi103758BF03202442
Goulden R Nation P amp Read J (1990) How large can a receptive vocabulary beApplied Linguistics 11 341ndash363 doi101093applin114341
Grant L amp Bauer L (2004) Criteria for re-defining idioms Are we barking up thewrong tree Applied Linguistics 25 38ndash61 doi101093applin25138
Grant L amp Nation P (2006) How many idioms are there in English ITL -International Journal of Applied Linguistics 151 1ndash14 doi102143ITL15102015219
Haynes M (1993) Patterns and perils of guessing in second language reading In THuckin M Haynes amp J Coady (Eds) Second language reading and vocabularylearning (pp 46ndash64) Norwood NJ Ablex Publishing Corporation
Heatley A amp Nation P (1994) Range [Computer program] Wellington NewZealand Victoria University of Wellington Retrieved from httpwwwvuwacnzlals
Hill J (2000) Revising priorities From grammatical failure to collocational successIn M Lewis (Ed) Teaching collocation Further developments in the Lexical Approach(pp 47ndash69) Hove England LTP
Hirsh D amp Nation P (1992) What vocabulary size is needed to read unsimplifiedtexts for pleasure Reading in a Foreign Language 8 689ndash696
Hu H M amp Nation P (2000) Unknown vocabulary density and readingcomprehension Reading in a Foreign Language 13 403ndash429
Hughes A (2003) Testing for language teachers Cambridge England CambridgeUniversity Press
Hunt K (1968) An instrument to measure syntactic maturity Tallahassee FL USDepartment of Health Education and Welfare
Jung E H (2003) The effects of organization markers on ESL learnersrsquo textunderstanding TESOL Quarterly 37 749ndash759 doi1023073588223
Krashen S (1993) The power of reading Insights from research Englewood COLibraries Unlimited
Laufer B (1989a) A factor of difficulty in vocabulary learning Deceptivetransparency AILA Review 6 10ndash20
288 TESOL QUARTERLY
Laufer B (1989b) What percentage of lexis is essential for comprehension In CLauren amp M Nordman (Eds) Special language From humans thinking to thinkingmachines (pp 316ndash323) London England Multilingual Matters
Laufer B (1991) How much lexis is necessary for reading comprehension In P JL Arnaud amp H Bejoint (Eds) Vocabulary and applied linguistics (pp 126ndash132)Oxford England Macmillan
Laufer B (1997) The lexical plight in second language reading Words you donrsquotknow words you think you know and words you canrsquot guess In J Coady amp THuckin (Eds) Second language vocabulary acquisition (pp 20ndash34) CambridgeEngland Cambridge University Press
Lewis M (1993) The Lexical Approach The state of ELT and a way forward HoveEngland LTP
Liontas J I (2002) Context and idiom understanding in second languagesEUROSLA Yearbook 2 155ndash185
Liontas J I (2003) Killing two birds with one stone Understanding Spanish VPidioms in and out of context Hispania 86 289ndash301 doi10230720062862
Liontas J I (2007) The eye never sees what the brain understands Making sense ofidioms in second languages Lingua et Linguistica 1) 25ndash44
Maki R H amp McGuire M J (2002) Metacognition for text Findings andimplications for education In T Schwarz amp L Bennett (Eds) Appliedmetacognition (pp 39ndash67) Cambridge England Cambridge University Press
Martinez R amp Schmitt N (2010) A phrasal expressions listManuscript submitted forpublication
Moon R (1997) Vocabulary connections Multi-word items in English In NSchmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 40ndash63) Cambridge England Cambridge University Press
Moore D Lin-Agler L M amp Zabrucky K M (2005) A source of metacomprehen-sion inaccuracy Reading Psychology 26 251ndash265 doi10108002702710590962578
Morrison L (2004) Comprehension monitoring in first and second languagereading The Canadian Modern Language Review 61 77ndash106
Nation I S P (2001) Learning vocabulary in another language Cambridge EnglandCambridge University Press
Nation I S P (2006) How large a vocabulary is needed for reading and listeningThe Canadian Modern Language Review 63 59ndash82
Nation I S P amp Waring R (1997) Vocabulary size text coverage and word lists InN Schmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 6ndash19) Cambridge England Cambridge University Press
Nation P (1997) The language learning benefits of extensive reading LanguageTeacher 21 13ndash16
Nattinger J R amp DeCarrico J S (1992) Lexical phrases and language teachingOxford England Oxford University Press
Oh S Y (2001) Two types of input modification and EFL reading comprehensionSimplification versus elaboration TESOL Quarterly 35 69ndash96 doi1023073587860
OrsquoKeeffe A McCarthy M amp Carter R (2007) From corpus to classroom Language useand language teaching Cambridge England Cambridge University Press
Pawley A amp Syder F H (1983) Two puzzles for linguistic theory Nativelikeselection and nativelike fluency In J C Richards amp R Schmidt (Eds) Languageand communication (pp 191ndash226) New York NY Longman
Pigada M amp Schmitt N (2006) Vocabulary acquisition from extensive reading Acase study Reading in a Foreign Language 18 1ndash28
Read J (2004) Research in teaching vocabulary Annual Review of Applied Linguistics24 146ndash161 doi101017S0267190504000078
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 289
Sarac S amp Tarhan B (2009) Calibration of comprehension and performance inL2 reading International Electronic Journal of Elementary Education 2 167ndash179
Schmitt N Jiang N amp Grabe W (2011) The percentage of words known in a textand reading comprehension Modern Language Journal 95(1) 26ndash43
Schmitt N Schmitt D amp Clapham C (2001) Developing and exploring thebehaviour of two new versions of the Vocabulary Levels Test Language Testing 1855ndash88
Shin D amp Nation I S P (2008) Beyond single words The most frequentcollocations in spoken English ELT Journal 62 339ndash348 doi101093eltccm091
Simpson-Vlach R amp Ellis N C (2010) An academic formulas list New methods inphraseology research Applied Linguistics 31(4) 487ndash512
Sinclair J (1991) Corpus concordance collocation Oxford England OxfordUniversity Press
Spottl C amp McCarthy M (2003) Formulaic utterances in the multi-lingual contextIn J Cenoz B Hufeisen ampU Jessner (Eds) The multilingual lexicon (pp 133ndash151) Dordrecht The Netherlands Kluwer
Staelighr L S (2008) Vocabulary size and the skills of listening reading and writingLanguage Learning Journal 36 139ndash152 doi10108009571730802389975
Stubbs M amp Barth I (2003) Using recurrent phrases as text-type descriminators Aquantitative method and some findings Functions of Language 10 61ndash104doi101075fol10104stu
The British National Corpus (2007) The British National Corpus(version 3 BNC XMLed) [CD-ROM] Distributed by Oxford University Computing Services on behalfof the BNC Consortium
The iPhonersquos second coming (2008 July) The Economist Retrieved from httpwwweconomistcomscience-technologydisplaystorycfmstory_id5E1_TTSDDJTG
Walter E Woodford K amp Good M (Eds) (2008) Cambridge advanced learnerrsquosdictionary (3rd ed) Cambridge England Cambridge University Press
Weir C J (2005) Language testing and validation An evidence-based approachNew York NY Palgrave Macmillan
West M (1953) A general service list of English words London England LongmanWray A (2002) Formulaic language and the lexicon Cambridge England Cambridge
University Press
290 TESOL QUARTERLY

RELATIONSHIP BETWEEN FORMULAIC LANGUAGE ANDREADING COMPREHENSION
Considering the relative wealth of research and literature on L2reading comprehension and separately multiword expressions inEnglish there is a surprising dearth of information regarding the roleif any formulaic language plays in the comprehension of texts in aforeign language The relatively few studies that do exist (eg Cooper1999 Liontas 2002) seem to confirm that it is especially the moresemantically opaque idioms that pose interpretability problems for L2readers and as these more core idioms are relatively rare (Grant ampNation 2006) Nation (2006) could be right in attenuating theirsignificance in reading comprehension
Nevertheless as discussed earlier there is evidence that a significantnumber of relatively opaque expressions occur frequently in texts inEnglish One commonly cited estimate (Erman amp Warren 2000) is thatsomewhat more than one-half (55) of any text will consist of formulaiclanguage (p 50) Naturally the opacity of those expressions will lie onwhat Lewis (1993 p 98) called a lsquolsquospectrum of idiomaticityrsquorsquo (Figure 1) akind of continuum of compositionality
Furthermore even when an expression does not meet the criteria ofcore or nonmatching idiom the relative ease or difficulty with which alearner will unpack its meaning is less inherent to the item itself andmore a learner-dependent variable Just as knowing fish may or may nottranslate into understanding fishy knowing perfect does not necessarilymean understanding perfect stranger
What is more although previous studies (Cooper 1999 Liontas2002) have found that in textual context more transparent idioms weremore easily understood than their opaque counterparts it should alsobe noted that the participants in those studies were aware that they werebeing tested specifically on their ability to correctly interpret idioms Inother words what cannot be known from most existing studies on idiominterpretation is how well the participants would have been able toidentify and understand the idioms in the first place had they not beenaware of their presence in the text
FIGURE 1 A spectrum of idiomaticity (compositionality)
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 273
A notable exception is Bishop (2004) who investigated thedifferential look-up behavior of participants who read texts thatcontained unknown words and unknown multiword expressions synon-ymous with those words Bishop confirmed that even though both wordsand multiword expressions were unknown readers looked up themeaning of words significantly more often He concludes that learnerslsquolsquodo not notice unknown formulaic sequences as readily as unknownwordsrsquorsquo (p 18)
Therefore idiomatic language in text irrespective of composition-ality might most usefully be classified as what Laufer (1989a) calledlsquolsquodeceptively transparentrsquorsquo (p 11) Laufer found that many Englishlearners misanalyze words like infallible as in+fall+ible (ie lsquolsquocannot fallrsquorsquo)and nevertheless as never+less (ie lsquolsquoalways morersquorsquo p 12) Likewisemdashalthough they were not part of her studymdashshe found that idioms like hitand miss were being read and interpreted word for word These lexicalitems that lsquolsquolearners think they know but they do notrsquorsquo (Laufer 1989ap 11) can impede reading comprehension in ways not accounted for inlists of common word families Nation (2006) seemed to assume thatmultiword expressions that have some element of transparency howeversmall will be reasonably interpretable through guessing However theLaufer (1989a) study may provide evidence to the contrary
But an attempt to guess (regardless of whether it is successful or not)presupposes awareness on the part of the learner that he is facing anunknown word If such an awareness is not there no attempt is made to inferthe missing meaning This is precisely the case with deceptively transparentwords The learner thinks he knows and then assigns the wrong meaning tothem [ ] (p 16)
Substitute lsquolsquoidiomrsquorsquo for lsquolsquowordrsquorsquo abovemdashnot an unreasonable conceptualstretchmdashand it becomes clear that multiword expressions just maypresent a larger problem for reading comprehension than accounted forin the current literature
In fact such lsquolsquodeceptionrsquorsquo seems even more likely to occur withmultiword expressions because such a large number of them arecomposed of very common words a learner would assume he or sheknows (Spottl amp McCarthy 2003 p 145 Stubbs amp Barth 2003 p 71)Moreover there is evidence that learners are reluctant to revisehypotheses formed regarding lexical items when reading even whenthe context does not support those hypotheses (Haynes 1993 Pigada ampSchmitt 2006)
274 TESOL QUARTERLY
Summary and Research Questions
In summary the following has been argued thus faramp Current estimates of how many words one needs to know in order to
comprehend most texts may be inaccurate due to overinclusion of derivedword forms and a total exclusion of multiword units of vocabulary
amp Contrary to some research there is evidence in corpus data that thenumber of frequently occurring noncompositional multiwordexpressions in English is higher than previously believed
amp Even when an expression is partly or even fully compositional thereis no way of knowing how accurately an L2 reader will interpret (oreven identify) that item
amp The claim that special attention to the 2000ndash3000 most commonwords in English is pedagogically sound since they provide around80 of text coverage (eg OrsquoKeeffe McCarthy amp Carter 2007Read 2004 p 148 Staelighr 2008) deserves closer scrutiny becausethose words are often merely tips of phraseological icebergs
It is therefore clear that there is a need for further investigation into howcommon words and the multiword units they form can affect readingcomprehension when reading in English as a foreign language To thatend we conducted a study to answer the following research questions
1 Are two texts written with the exact same high-frequency wordsunderstood equally well by L2 learners when one of the texts is moreidiomatic than the other
2 Can the presence of multiword expressions in a text lead L2 learners tobelieve they have understood that text better than they actually have
METHOD
Participants
Brazilian adult learners of English (n 5 101) all native speakers ofBrazilian Portuguese were selected to participate in the study Thesample ranged in age from 18 to 64 years (M 5 2576 SD 5 931) andconsisted of 43 men and 58 women representing seven different regionsof Brazil
All participants in the study had had a minimum of 80 hr of tuition inEnglish prior to the start of the research and had been tested aspossessing intermediate or higher levels of proficiency Howeverbecause all participants attended private language schools the actualinstruments by which their proficiency was assessed varied widely
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 275
Regardless uniformity in proficiency was not of prime importance in thestudy because the research questions are concerned with a significantchange in the paired samples within the same group
The Test
To write the eight texts (four texts in each test) a corpus of words wascarefully chosen from the list of the 2000 most frequent words in the BNCThe reading comprehension of each text was tested by seven true or falseitems totaling 28 per test part or 56 overall The test when administeredappears as one but is actually in two parts (Test 1 and Test 2) each partcontaining the exact same words with some words in Test 2 formingmultiword expressions Great care was taken to ensure that the texts areotherwise equal There is no visual difference between the two parts andthe texts are of almost uniform length in both parts (Table 3 and Figure 2)In addition care was taken not to include any extra cultural references inany of the texts and the comprehension task itself did not change acrossthe test parts The texts are stated to have come from peoplersquos descriptionof themselves in lsquolsquoFriendsbookrsquorsquo (intentionally similar to Facebook) On thewhole therefore it could be said that the style of the text is personal andinformal
The vast majority of the words are in the top 1000 withapproximately 985 of the words occurring in the BNC top 2000(Table 3) These results were in turn compared with the General ServiceList (West 1953) using software developed by Heatley and Nation(Range 1994) and another package using the same corpus created byCobb (nd) The results were practically identical in all cases (Range985 VocabProfile 98494)
Another key feature of the test is the rating scale which requires the testtaker to circle what she believes is his or her comprehension of each textfrom 5 to 1005 This self-reported comprehension is designed to helpanswer the second research question of whether the presence ofmultiword expressions in a text can lead L2 learners to believe they have
TABLE 3
Summary of Test 1 and Test 2 Text Data
Total wordcount
Total clausecount T-unit count
Top 1000words coverage
Top 1001ndash2000 words
coverage
Test 1 416 56 45 957373 27650Test 2 412 54 42 957373 27650
Note Data measured using vocabulary profiler (Cobb nd) A T-unit or a minimal terminableunit is lsquolsquoone main clause plus any subordinate clausersquorsquo (Hunt 1968 p 4)
276 TESOL QUARTERLY
understood that text better than they actually have Testing whatcomprehenders believe they understoodmdashcompared to what they actuallyunderstoodmdashby comparing test scores to self-assessment of comprehen-sion via a rating scale is often referred to as lsquolsquocomprehension calibrationrsquorsquoand is a method that has been used extensively in psychological research(eg Bransford amp Johnson 1972 Glenberg Wilkinson amp Epstein 1982Maki amp McGuire 2002 Moore Lin-Agler amp Zabrucky 2005) butsomewhat less so in applied linguistics (cf Brantmeier 2006 Jung 2003Morrison 2004 Oh 2001 Sarac amp Tarhan 2009)
Finally participants were asked to record their start and finish timesfor each part of the test
Procedure
Following an initial field test an item analysis was conducted toestablish the facility value6 of the test items and a discrimination indexfor both test parts to discern whether the test was discriminatingbetween stronger and weaker participants Items that were found to haveexceptionally high or low scores were carefully analyzed and the wordingof both test items and reading texts adjusted accordingly
Finally as advocated in Schmitt Schmitt and Clapham (2001) oneimportant requirement of an L2 test of reading comprehension is that itbe answerable by native or nativelike speakers of the language (p 65)To that end a smaller group of native speakers (n 5 8) was also tested asan additional check of the testrsquos validity That group produced a mean
FIGURE 2 Side-by-side comparison of matched texts from the two test parts (full version ofthe test available on request)
4 These are vocabulary profilers that essentially use word frequency lists to break all thewords in a text down into those that occur for example in the top 1000 second 1000third 1000 and so on
5 lsquolsquo0rsquorsquo would be virtually impossible because learners would be familiar with most words inthe texts if not all
6 A test itemrsquos facility value is calculated by dividing the number of participants whoanswered that item correctly by the total number of participants (Hughes 2003)
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 277
score of 28 in Test 1 (the maximum score) and 2775 in Test 2 showingthat both test parts posed very little difficulty for people for whomEnglish is a first language
The students received the two parts of the test in alternating order(ie counterbalanced) to control for any effect of taking Test 1 beforeTest 2 (and vice versa) because by counterbalancing one is able toinclude a variable order into an analysis and identify the extent towhich order affects performance on the dependent measures
RESULTS
All the scores and self-reported comprehension measures wererecorded in a statistical analysis software program (SPSS) Eachparticipantrsquos test results were transcribed into the software item by item(ie correct and incorrect) text by text (eg Text A Text B etc numbercorrect out of 7 for each) and test by test (ie Test 1 and Test 2 numbercorrect out of 28 possible for each) Also recorded were each participantrsquosself-reported comprehension assessments (a rating scale from 5 to 100)as they pertained to each text as well as which version (Test 1 or Test 2first) of the instrument each candidate had received To assess the effectof counterbalancing a repeated measures analysis of variance (ANOVA)was conducted with one within-subjects factor (TEST) with two levels(Test 1 score Test 2 score) and one between-subjects factor (VERSION)with two levels (Test 1 first Test 2 first) This analysis revealed a robustmain effect of test (F (199) 5 59338 p 0001 g2 5 086) and a discreteeffect of version (F (199) 5 405 p 5 0047 g2 5 004) but importantlythere was no significant Test 6 Version interaction (F (199) 5 281 p 5
0097 g2 5 002) illustrating that participantsrsquo scores did not vary as afunction of which version of the test they were completing
Comprehension of Test 1 versus Test 2
The central tendencies from both tests are presented in Table 4As predicted participantsrsquo scores were significantly lower on Test 2
relative to Test 1 (t(100) 5 2410 p 0001) with a strong effect size(g2 5 0828)7 confirming that even when two sets of texts contain theexact same words and even if those words are very commoncomprehension of those texts will not be the same when one containsidiomaticity
7 Confidence intervals at 95 for all t-tests
278 TESOL QUARTERLY
Self-Reported Comprehension of Test 1 versus Test 2
A t-test was also performed on the difference between whatparticipants believed they understood (ie their reported comprehen-sion) and what they actually understood in both Tests 1 and 2 (Table 5)Mean reported comprehension (MRC) was arrived at by calculating themeans of all the self-reported comprehension percentages (5ndash100)and the mean actual comprehension (MAC) is the mean of the score oneach text divided by seven (the maximum score)
MAC was lower than MRC in both Test 1(MRC M 5 08738 SD 013MAC M 5 08603 SD 5 009) and Test 2 (MRC M 5 06029 SD 019MAC M 5 05258 SD 5 014) however the difference between MRCand MAC was statistically reliable in Test 2 only where the test wascomposed of multiword expressions (t(100) 5 395 p 0001 g2 5
007)8 These data therefore appear to support a positive answer to thesecond research questionmdashthat learners may believe they understandmore than they actually do by virtue of their simply understanding theindividual words in a text
Variation in the Data
MRC versus MAC
Naturally there were some individual differences in the test resultsTable 6 shows that roughly one-half of all participants (n 5 50)overestimated their comprehension in both tests (indicated by MRC
TABLE 4
Descriptive Statistics (Tests 1 and 2)
Mean Median Mode Minimum Maximum SD
Test 1a 2409 2500 2500 1800 2800 244Test 2b 1476 1500 1500 600 2500 393
Note SD 5 standard deviation aTexts composed of common words however with little or noopaque phraseology bTexts composed of common words which comprise collocations andidiomatic language
TABLE 5
Reported Versus Actual Comprehension
Test 1 Test 2
Mean reported comprehension (MRC) 8738 6029Mean actual comprehension (MAC) 8603 5258
8 By comparison the results of the paired sample t-test for the Test 1 MRC-MAC means weret(100) 5 104 p 5 0302 g2 5 0005
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 279
greater than MAC) On the surface this might suggest that those 50participants did not overestimate their comprehension in Test 2 as aresult of its relative noncompositionality but rather as a generaltendency regardless of idiomaticity However when MAC is subtractedfrom MRC for that group and the difference compared across the teststhe difference is twice as large in Test 2 (t(49) 5 492 p 0001 g2 5
0108) This difference is even more evident in the same analysis of Test2 alone Isolating the results of that test there was a total of 70participants (over 69 of the entire sample) whose MRC was greaterthan their MAC The difference between MRC minus MAC for thesubgroup of 70 participants reveals that their overestimation of theircomprehension in Test 2 was four times greater than in Test 1 (t(69) 5
770 p 0001 g2 5 0228) Further among that group of 70 whoseTest 2 MRC was greater than their MAC 20 students either under-estimated or actually accurately guessed their comprehension in Test 1but significantly overestimated their comprehension in Test 2 (t(19) 5
849 p 0001 g2 5 0264) Only 30 participants in the present studyactually underestimated their comprehension on Test 2
Variation in Time Spent on the Tests
All candidates were also asked to record their start and finishing timesof each test (Table 7) It is not surprising that on average participantsspent more time on the texts which contained idiomatic expressionsHowever this trend was not uniform among the participants and thetime data may help provide some insight into just how aware someparticipants were of the presence of idiomaticity in the texts Thispossibility is explored further in the Discussion
TABLE 6
Trend of Increase in MRC-MAC Discrepancy Across Test Parts
NMRC minus MAC
(Test 1)MRC minus MAC
(Test 2)
Students with MRC MAC (bothtest parts)
50 009 019
Students with MRC MAC (Test 2) 70 004 017Students with MRC MAC (Test 2only)
20 2010 014
Students with MRC MAC (Test 2) 31a 2005 2015
Note MRC 5 mean reported comprehension MAC 5 mean actual comprehension aOnly oneparticipant in this group had MRC 5 MAC
280 TESOL QUARTERLY
DISCUSSION
To reiterate the present study sought to address the followingresearch questions
1 Are two texts written with the exact same high-frequency wordsunderstood equally well by L2 learners when one of the texts is moreidiomatic than the other
2 Can the presence of multiword expressions in a text lead L2 learners tobelieve they have understood that text better than they actually have
A group of 101 adult Brazilian learners of English was tested using twoseparate measures of reading comprehension (one with idiomaticlanguage and one without) and the results of the two tests were thencompared Although verbal reports would provide even greater insightthe resultant data from this study do seem to support a positive answer tothe first research question Participants achieved significantly lowerscores on the comprehension measure which assessed their under-standing of texts that contain multiword expressions It should bereiterated that this result was obtained in spite of both tests being writtenwith the exact same high-frequency words
Likewise through participantsrsquo self-reported comprehension thereseems to be evidence that the presence of multiword expressions in atext can lead L2 readers to overestimate their assessment of how muchthey have actually understood suggesting a positive answer to the secondresearch question
Although it seems apparent that participantsrsquo reading comprehensionin the present study was adversely affected by idiomaticity this sectionexplores and possibly explains variation in comprehension of the testsand further discusses evidence that multiword expressions negativelyaffected participantsrsquo comprehension
On the Stronger and Weaker Performance in the Tests
There are at least three important revelations emerging from theMRC-MAC data analysis presented in Table 6 First nearly two thirds of
TABLE 7
Time It Took Participants to Take Tests
N Mean time (minutes) SD
Time it took to take Test 1 91a 1085 436Time it took to take Test 2 91 1465 377
Note SD 5 standard deviation aSome participants (n 5 10) forgot to write in the time or left itincomplete
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 281
all participants believed they understood more than they actually did inTest 2 Second the data show that over 28 of those students (n 5 20)did not overestimate their comprehension in Test 1 providing evidencethat whereas they were apparently able to gauge their comprehensionfairly accurately when the texts were relatively devoid of idiomaticitythey were significantly less able to do so when relative noncomposition-ality was present Finally the MRC-MAC data presented so far indicatethat although not all participants tended to overestimate theircomprehension in Test 2 those who did (again the majority of cases)generally did so by a much larger margin Put simply it would seem thatnot only are many learners misunderstanding idiomaticity in text butthey may be doing so more than they (or researchers) realize
Further Evidence of Idiomaticity Negatively AffectingComprehension
The mean difference between MRC and MAC for the 70 students whooverestimated their comprehension in Test 2 (Table 6) was 017 For thesake of argument one could establish an MRC-MAC difference above020 as a cutoff for apparently marked lack of awareness of the extentof idiomaticity in Test 29 comparatively speaking This in turn wouldmean that there were 30 participants who ostensibly demonstrated aparticularly high overestimation of how much of Test 2 they had actuallyunderstood A sample of just the top 10 is provided in Table 8
Table 8 shows not only how different those participantsrsquo MRC wasfrom their Test 2 it also lists the same figures for Test 1 for comparison
9 A t-test reveals that the mean is in fact statistically significant even at the 003 differencelevel (t 5 653 p 5 003)
TABLE 8
Partial List of Participants With Exceptionally High Overestimation of Test 2 Comprehension(Difference 020)
ParticipantMRCTest 1
MACTest 1 Difference
MRCTest 2
MACTest 2 Difference
118 100 089 011 094 032 0626 075 068 007 081 028 05392 081 089 2008 075 025 05090 100 089 011 081 039 042115 100 089 011 087 050 03722 100 096 003 094 057 03780 094 068 026 069 032 03759 094 089 005 069 036 03321 100 093 007 087 057 03050 087 078 009 069 039 029
282 TESOL QUARTERLY
Whereas for Test 1 those 30 participantsrsquo assessment of readingcomprehension was usually only slightly overestimated10 (and in oneinstance even underestimated) the same participants in Test 2 had amarkedly overinflated conception of how much they had understood
Although not intended as a principal source of data for our analysisthe start and finish times recorded by participants on the tests in a fewinstances helped confirm the above assertions11 Table 7 shows thatthere was a significant difference between how long participants spenttaking each test (t 5 852 p 0001) However there were a number ofparticipants (n 5 26) who reported actually spending either the same orless time on Test 2 On the surface at least this fact would indicate thatthose 26 participants did not notice much difference between the testsOf course in reality that datum alone does not provide such evidencebecause that time may simply reflect a number of other confoundingvariables including affective (eg simply giving up) or even social (egthe need to leave early to meet a friend) and for that reason also was notconsidered to be a reliable source of data from those participantsHowever as a complementary source when triangulated with the othervariables some of the data analyzed earlier in the current study areoccasionally fortified further still with the time data (Table 9)
The data in Table 9 in many ways tie together the elements discussedin the analysis thus far in the present study A much lower score in Test 2than in Test 1 (columns B and C) an increase in the mean MRC-MACdifference across the tests (columns H and K) a relatively moderatedecrease in MRC in Test 2 vis-a-vis Test 1 (columns F and I) a markeddifference between MRC and MAC in Test 2 (column K) and theoccasional lack of increase (in Table 9 participants 118 80 59 and 50)in time it took to take Test 2 (columns D and E) These findings ontheir own in combination and especially in concert provide evidencethat (1) the students in Table 9 did not seem to appreciate the fullextent of the idiomaticity in Test 2 and (2) they appeared to think thatthey understood more than they actually did in Test 2
Perhaps most important 98 of all participants (n 5 99) scoredsignificantly lower on Test 2 (mean difference of 953 points out of 28SD 5 363) which shows that learners are generally unable to guess themeaning of idiomatic language even in the (largely inconsistent)instances in which they become aware of its presence
11 It should be noted that because 10 of the participantsrsquo time data were left incomplete afull group analysis could not be carried out thus the time data are only included asauxiliary information
10 As can be seen in Table 8 in fact only one participantmdashnumber 80mdashactually had anMRC-MAC difference in Test 1 that was also 020 Those of the other 29 participantswere all lower
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 283
For example the first participant in Tables 8 and 9 (number 118)who consistently overrated his own comprehension relative to his actualcomprehension answered for Text A of Test 2 as shown in Figure 3
On the basis of the responses it is likely that participant 118associated itrsquos about time with lsquolsquohas a problem with timersquorsquo Irsquom a little over thehill with lsquolsquohe probably lives in an area with hillsrsquorsquo and lsquolsquohe lives on the hill
TABLE 9
Triangulated Data Showing Negative Effect of Idiomaticity on Comprehension
A B C D E F G H I J K
Score Time Test 1 Test 2
Partic-ipant Test 1 Test 2 Test 1 Test 2 MRC MAC
Differ-ence MRC MAC
Differ-ence
118 25 9 2000 1800 100 089 11 094 032 0626 19 8 Missing Missing 075 068 007 081 028 05392 25 8 900 1100 081 089 2008 075 025 05090 25 11 900 1500 100 089 011 081 039 042115 25 14 1300 1500 100 089 011 087 050 03722 27 16 Missing Missing 100 096 003 094 057 03780 19 9 1000 1000 094 068 026 069 032 03759 25 10 1500 1400 094 089 005 069 036 03321 26 16 Missing Missing 100 093 007 087 057 03050 22 11 2000 1200 088 079 009 069 039 030
12 Of the 24 multiword expressions targeted for assessment of comprehension in Test 2 onlyfour were core idioms
FIGURE 3 Sample answer to Text A of Test 2
284 TESOL QUARTERLY
but not on top of itrsquorsquomdasha literal reading of those expressions His 100self-assessment is an indication that his answers were not guesses butinstead based on confidence that he had understood all the individualwords in the text The same answering dynamic occurred time and timeagain in Test 2
Returning therefore to the issues raised in the introduction thepresent research appears to provide evidence that idiomsmdashopaque orotherwise12mdashcan in fact cause major problems for L2 learners of Englishwhen reading In general the participants in our study were lesssuccessful at guessing the meaning of idioms than those in previousidiom-centered research such as Cooper (1999) and Liontas (2002)Because the learners in our study were not alerted to the presence ofidiomaticity in the text prior to reading this study may more accuratelyreflect what takes place in more naturally occurring L2 reading Finallythe difficulties that the participants encountered occurred in textscomposed purely of very common words showing that word frequencyalone is not necessarily a good measure of text coverage Lauferrsquos(1989a) hypothesis that much lexis in text can be deceptivelytransparent is confirmed in the present research extended to multiwordexpressions
Limitations of the Research
Although the research presented here does provide some significantevidence that the presence of idiomaticity in a text can negatively affectthe comprehension of that text by an L2 reader little is known about thestrategies the test takers employed Even though metacognition wasoutside the scope of examination of the present study such informationis highly relevant and future research should include protocols such asthose included in previous research on idioms (eg Liontas 20032007) which may provide crucial qualitative data regarding theindividual differences and behavior of the participants themselvesOverall future work in this area should consider making use of differentmeasures of self-assessment in order to explore the limitations of themethodology used in the present study
Also a question can be asked concerning the relative density ofmultiword expressions in each text In other words what is not known ison average how many such items a reader can expect to encounter Theratio of idioms to orthographic words in the texts tested in the presentstudy is very likely higher than averagemdashbut how much higher is as yetunknown Likewise the passages themselves were relatively short so it isunknown whether or not texts of greater length (and thereforecontextualization) would render the same or similar results
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 285
CONCLUSION
The present study provides some empirical evidence that a focus onword in L2 pedagogy may be detrimental to learnersrsquo development ofreading comprehension in the target language In most casesparticipants overestimated how much they had understood the textstested when those texts contained multiword expressions of varyingdegrees of compositionality comprised of very common individualwords Even when participants showed evidence of awareness of apresence of idiomaticity in the texts they generally were not very good atguessing the meaning of expressions Although Grant and Nation(2006) could be right that the teaching of individual idioms may not belsquolsquodeserving of class timersquorsquo (p 5) it is clear that at the very least raisinglearnersrsquo consciousness as to their prevalence and frequently deceptivetransparency in text certainly is
Concomitantly the present research serves to demonstrate theincompleteness of current lists of common words which now informimportant pedagogical instruments such as vocabulary tests gradedreaders and course syllabuses Under current methods as illustrated inthe Table 2 analysis of the Economist paragraph a text measured againstthe word lists now commonly in use can be mistakenly analyzed as beingeasily understood when in fact once multiword expressions are takeninto account the actual text coverage of easily understood words is farless Existing estimates of how many words one needs to know in order toadequately process naturally occurring texts (Hu amp Nation 2000Nation 2006) may need to be revisited to determine how many wordsand multiword expressions one needs to know
In practice research shows that learners will continue to believe theyunderstand items that they actually do not even after repeatedexposures to that same item (Bensoussan amp Laufer 1984 Haynes1993 Pigada amp Schmitt 2006) Language teachers and relatedprofessionals such as textbook writers need to consider ways tocontinuously help learners notice the gap between what they think theyknow and understand and what they actually do (Laufer 1997) Oneway this can be achieved has already been thoroughly discussed in thepresent paper devise texts (and tests) designed to lead readers down anidiomatic garden path Norbert Schmitt (as cited in Weir 2005) made asimilar recommendation
Perhaps the best and most valid type of vocabulary test is a reading passagewith comprehension questions but with the items requiring a full under-standing of particular words or phrases in the text This would mimic the realworld task of reading for comprehension and also the loss of comprehensionwhen key vocabulary is not known (p 123)
286 TESOL QUARTERLY
Therefore a further implication this research has for L2 pedagogy is themore careful design of the reading component of proficiency tests suchas IELTS (International English Language Testing System) and Test ofEnglish as a Foreign Language to be more strategic regarding the amountand kind of phraseology contained in the texts Proficiency was not thecentral focus of our study and future research could adopt a similarmethodology but with the inclusion of proficiency measures ofparticipants in order to explore how various types of expressions (egnoncompositional figurative imageable etc) may differentially affectpreidentified proficiency levels
Thus in order to be more methodical about such things as theinclusion of formulaic language in L2 tests and reading input in generalan important preliminary step will be to establish (a) what type offormulaic sequences are good discriminators of proficiency thresholdlevels and (b) which expressions of that identified type are mostcommon In other words what will be usefulmdashand is indeed nowbeginning to emerge (Martinez amp Schmitt 2010 Shin amp Nation 2008Simpson-Vlach amp Ellis 2010)mdashare lists of formulaic sequences that servea function similar to that of the General Service List not to revolutionizecurrent language pedagogy but to more finely tune it
THE AUTHORS
Ron Martinez is currently pursuing a doctorate at the University of NottinghamNottingham England on the topic of inclusion of phraseology in languageassessment He specializes in second language materials development
Victoria Murphy is a lecturer in Applied Linguistics and Second LanguageAcquisition at the University of Oxford Oxford England Her research interestsinclude the lexical development of first language or second language learners andthe cognitive processes that underlie language acquisition
REFERENCES
Bauer L amp Nation P (1993) Word families International Journal of Lexicography 6253ndash279 doi101093ijl64253
Bensoussan M amp Laufer B (1984) Lexical guessing in context in EFL readingcomprehension Journal of Research in Reading 7 15ndash32 doi101111j1467-98171984tb00252x
Bishop H (2004) Noticing formulaic sequences A problem of measuring thesubjective LSO Working Papers in Linguistics 4 15ndash19
Bransford D B amp Johnson M K (1972) Contextual prerequisites for under-standing Some investigations of comprehension and recall Journal of VerbalLearning and Verbal Behavior 11 717ndash726 doi101016S0022-5371(72)80006-9
Brantmeier C (2006) Advanced L2 learners and reading placement Self-assessment CBT and subsequent performance System 34 15ndash35 doi101016jsystem200508004
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 287
Carver R P (1994) Percentage of unknown vocabulary words in text as a functionof the relative difficulty of the text Implications for instruction Journal of ReadingBehavior 26 413ndash437
Cobb T (nd) Web VocabProfile [Online program] Retrieved from httpwwwlextutorcavp [an adaption of A Heatley amp P Nation Range (1994)]
Cooper T C (1999) Processing of idioms by L2 learners of English TESOLQuarterly 33 233ndash262 doi1023073587719
Coxhead A (2000) A new academic word list TESOL Quarterly 34 213ndash238doi1023073587951
Elley W amp Mangubhai F (1983) The impact of reading on second languagelearning Reading Research Quarterly 19 53ndash67 doi102307747337
Ellis N C (2008) Phraseology The periphery and the heart of language In FMeunier amp S Granger (Eds) Phraseology in language learning and teaching (pp 1ndash13) Amsterdam The Netherlands John Benjamins
Erman B amp Warren B (2000) The idiom principle and the open choice principleText 20 29ndash62
Gardner D (2007) Validating the construct of Word in applied corpus-basedvocabulary research A critical survey Applied Linguistics 28 241ndash265doi101093applinamm010
Glenberg A M Wilkinson A C amp Epstein W (1982) The illusion of knowingFailure in the self-assessment of comprehension Memory and Cognition 10 597ndash602 doi103758BF03202442
Goulden R Nation P amp Read J (1990) How large can a receptive vocabulary beApplied Linguistics 11 341ndash363 doi101093applin114341
Grant L amp Bauer L (2004) Criteria for re-defining idioms Are we barking up thewrong tree Applied Linguistics 25 38ndash61 doi101093applin25138
Grant L amp Nation P (2006) How many idioms are there in English ITL -International Journal of Applied Linguistics 151 1ndash14 doi102143ITL15102015219
Haynes M (1993) Patterns and perils of guessing in second language reading In THuckin M Haynes amp J Coady (Eds) Second language reading and vocabularylearning (pp 46ndash64) Norwood NJ Ablex Publishing Corporation
Heatley A amp Nation P (1994) Range [Computer program] Wellington NewZealand Victoria University of Wellington Retrieved from httpwwwvuwacnzlals
Hill J (2000) Revising priorities From grammatical failure to collocational successIn M Lewis (Ed) Teaching collocation Further developments in the Lexical Approach(pp 47ndash69) Hove England LTP
Hirsh D amp Nation P (1992) What vocabulary size is needed to read unsimplifiedtexts for pleasure Reading in a Foreign Language 8 689ndash696
Hu H M amp Nation P (2000) Unknown vocabulary density and readingcomprehension Reading in a Foreign Language 13 403ndash429
Hughes A (2003) Testing for language teachers Cambridge England CambridgeUniversity Press
Hunt K (1968) An instrument to measure syntactic maturity Tallahassee FL USDepartment of Health Education and Welfare
Jung E H (2003) The effects of organization markers on ESL learnersrsquo textunderstanding TESOL Quarterly 37 749ndash759 doi1023073588223
Krashen S (1993) The power of reading Insights from research Englewood COLibraries Unlimited
Laufer B (1989a) A factor of difficulty in vocabulary learning Deceptivetransparency AILA Review 6 10ndash20
288 TESOL QUARTERLY
Laufer B (1989b) What percentage of lexis is essential for comprehension In CLauren amp M Nordman (Eds) Special language From humans thinking to thinkingmachines (pp 316ndash323) London England Multilingual Matters
Laufer B (1991) How much lexis is necessary for reading comprehension In P JL Arnaud amp H Bejoint (Eds) Vocabulary and applied linguistics (pp 126ndash132)Oxford England Macmillan
Laufer B (1997) The lexical plight in second language reading Words you donrsquotknow words you think you know and words you canrsquot guess In J Coady amp THuckin (Eds) Second language vocabulary acquisition (pp 20ndash34) CambridgeEngland Cambridge University Press
Lewis M (1993) The Lexical Approach The state of ELT and a way forward HoveEngland LTP
Liontas J I (2002) Context and idiom understanding in second languagesEUROSLA Yearbook 2 155ndash185
Liontas J I (2003) Killing two birds with one stone Understanding Spanish VPidioms in and out of context Hispania 86 289ndash301 doi10230720062862
Liontas J I (2007) The eye never sees what the brain understands Making sense ofidioms in second languages Lingua et Linguistica 1) 25ndash44
Maki R H amp McGuire M J (2002) Metacognition for text Findings andimplications for education In T Schwarz amp L Bennett (Eds) Appliedmetacognition (pp 39ndash67) Cambridge England Cambridge University Press
Martinez R amp Schmitt N (2010) A phrasal expressions listManuscript submitted forpublication
Moon R (1997) Vocabulary connections Multi-word items in English In NSchmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 40ndash63) Cambridge England Cambridge University Press
Moore D Lin-Agler L M amp Zabrucky K M (2005) A source of metacomprehen-sion inaccuracy Reading Psychology 26 251ndash265 doi10108002702710590962578
Morrison L (2004) Comprehension monitoring in first and second languagereading The Canadian Modern Language Review 61 77ndash106
Nation I S P (2001) Learning vocabulary in another language Cambridge EnglandCambridge University Press
Nation I S P (2006) How large a vocabulary is needed for reading and listeningThe Canadian Modern Language Review 63 59ndash82
Nation I S P amp Waring R (1997) Vocabulary size text coverage and word lists InN Schmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 6ndash19) Cambridge England Cambridge University Press
Nation P (1997) The language learning benefits of extensive reading LanguageTeacher 21 13ndash16
Nattinger J R amp DeCarrico J S (1992) Lexical phrases and language teachingOxford England Oxford University Press
Oh S Y (2001) Two types of input modification and EFL reading comprehensionSimplification versus elaboration TESOL Quarterly 35 69ndash96 doi1023073587860
OrsquoKeeffe A McCarthy M amp Carter R (2007) From corpus to classroom Language useand language teaching Cambridge England Cambridge University Press
Pawley A amp Syder F H (1983) Two puzzles for linguistic theory Nativelikeselection and nativelike fluency In J C Richards amp R Schmidt (Eds) Languageand communication (pp 191ndash226) New York NY Longman
Pigada M amp Schmitt N (2006) Vocabulary acquisition from extensive reading Acase study Reading in a Foreign Language 18 1ndash28
Read J (2004) Research in teaching vocabulary Annual Review of Applied Linguistics24 146ndash161 doi101017S0267190504000078
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 289
Sarac S amp Tarhan B (2009) Calibration of comprehension and performance inL2 reading International Electronic Journal of Elementary Education 2 167ndash179
Schmitt N Jiang N amp Grabe W (2011) The percentage of words known in a textand reading comprehension Modern Language Journal 95(1) 26ndash43
Schmitt N Schmitt D amp Clapham C (2001) Developing and exploring thebehaviour of two new versions of the Vocabulary Levels Test Language Testing 1855ndash88
Shin D amp Nation I S P (2008) Beyond single words The most frequentcollocations in spoken English ELT Journal 62 339ndash348 doi101093eltccm091
Simpson-Vlach R amp Ellis N C (2010) An academic formulas list New methods inphraseology research Applied Linguistics 31(4) 487ndash512
Sinclair J (1991) Corpus concordance collocation Oxford England OxfordUniversity Press
Spottl C amp McCarthy M (2003) Formulaic utterances in the multi-lingual contextIn J Cenoz B Hufeisen ampU Jessner (Eds) The multilingual lexicon (pp 133ndash151) Dordrecht The Netherlands Kluwer
Staelighr L S (2008) Vocabulary size and the skills of listening reading and writingLanguage Learning Journal 36 139ndash152 doi10108009571730802389975
Stubbs M amp Barth I (2003) Using recurrent phrases as text-type descriminators Aquantitative method and some findings Functions of Language 10 61ndash104doi101075fol10104stu
The British National Corpus (2007) The British National Corpus(version 3 BNC XMLed) [CD-ROM] Distributed by Oxford University Computing Services on behalfof the BNC Consortium
The iPhonersquos second coming (2008 July) The Economist Retrieved from httpwwweconomistcomscience-technologydisplaystorycfmstory_id5E1_TTSDDJTG
Walter E Woodford K amp Good M (Eds) (2008) Cambridge advanced learnerrsquosdictionary (3rd ed) Cambridge England Cambridge University Press
Weir C J (2005) Language testing and validation An evidence-based approachNew York NY Palgrave Macmillan
West M (1953) A general service list of English words London England LongmanWray A (2002) Formulaic language and the lexicon Cambridge England Cambridge
University Press
290 TESOL QUARTERLY

A notable exception is Bishop (2004) who investigated thedifferential look-up behavior of participants who read texts thatcontained unknown words and unknown multiword expressions synon-ymous with those words Bishop confirmed that even though both wordsand multiword expressions were unknown readers looked up themeaning of words significantly more often He concludes that learnerslsquolsquodo not notice unknown formulaic sequences as readily as unknownwordsrsquorsquo (p 18)
Therefore idiomatic language in text irrespective of composition-ality might most usefully be classified as what Laufer (1989a) calledlsquolsquodeceptively transparentrsquorsquo (p 11) Laufer found that many Englishlearners misanalyze words like infallible as in+fall+ible (ie lsquolsquocannot fallrsquorsquo)and nevertheless as never+less (ie lsquolsquoalways morersquorsquo p 12) Likewisemdashalthough they were not part of her studymdashshe found that idioms like hitand miss were being read and interpreted word for word These lexicalitems that lsquolsquolearners think they know but they do notrsquorsquo (Laufer 1989ap 11) can impede reading comprehension in ways not accounted for inlists of common word families Nation (2006) seemed to assume thatmultiword expressions that have some element of transparency howeversmall will be reasonably interpretable through guessing However theLaufer (1989a) study may provide evidence to the contrary
But an attempt to guess (regardless of whether it is successful or not)presupposes awareness on the part of the learner that he is facing anunknown word If such an awareness is not there no attempt is made to inferthe missing meaning This is precisely the case with deceptively transparentwords The learner thinks he knows and then assigns the wrong meaning tothem [ ] (p 16)
Substitute lsquolsquoidiomrsquorsquo for lsquolsquowordrsquorsquo abovemdashnot an unreasonable conceptualstretchmdashand it becomes clear that multiword expressions just maypresent a larger problem for reading comprehension than accounted forin the current literature
In fact such lsquolsquodeceptionrsquorsquo seems even more likely to occur withmultiword expressions because such a large number of them arecomposed of very common words a learner would assume he or sheknows (Spottl amp McCarthy 2003 p 145 Stubbs amp Barth 2003 p 71)Moreover there is evidence that learners are reluctant to revisehypotheses formed regarding lexical items when reading even whenthe context does not support those hypotheses (Haynes 1993 Pigada ampSchmitt 2006)
274 TESOL QUARTERLY
Summary and Research Questions
In summary the following has been argued thus faramp Current estimates of how many words one needs to know in order to
comprehend most texts may be inaccurate due to overinclusion of derivedword forms and a total exclusion of multiword units of vocabulary
amp Contrary to some research there is evidence in corpus data that thenumber of frequently occurring noncompositional multiwordexpressions in English is higher than previously believed
amp Even when an expression is partly or even fully compositional thereis no way of knowing how accurately an L2 reader will interpret (oreven identify) that item
amp The claim that special attention to the 2000ndash3000 most commonwords in English is pedagogically sound since they provide around80 of text coverage (eg OrsquoKeeffe McCarthy amp Carter 2007Read 2004 p 148 Staelighr 2008) deserves closer scrutiny becausethose words are often merely tips of phraseological icebergs
It is therefore clear that there is a need for further investigation into howcommon words and the multiword units they form can affect readingcomprehension when reading in English as a foreign language To thatend we conducted a study to answer the following research questions
1 Are two texts written with the exact same high-frequency wordsunderstood equally well by L2 learners when one of the texts is moreidiomatic than the other
2 Can the presence of multiword expressions in a text lead L2 learners tobelieve they have understood that text better than they actually have
METHOD
Participants
Brazilian adult learners of English (n 5 101) all native speakers ofBrazilian Portuguese were selected to participate in the study Thesample ranged in age from 18 to 64 years (M 5 2576 SD 5 931) andconsisted of 43 men and 58 women representing seven different regionsof Brazil
All participants in the study had had a minimum of 80 hr of tuition inEnglish prior to the start of the research and had been tested aspossessing intermediate or higher levels of proficiency Howeverbecause all participants attended private language schools the actualinstruments by which their proficiency was assessed varied widely
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 275
Regardless uniformity in proficiency was not of prime importance in thestudy because the research questions are concerned with a significantchange in the paired samples within the same group
The Test
To write the eight texts (four texts in each test) a corpus of words wascarefully chosen from the list of the 2000 most frequent words in the BNCThe reading comprehension of each text was tested by seven true or falseitems totaling 28 per test part or 56 overall The test when administeredappears as one but is actually in two parts (Test 1 and Test 2) each partcontaining the exact same words with some words in Test 2 formingmultiword expressions Great care was taken to ensure that the texts areotherwise equal There is no visual difference between the two parts andthe texts are of almost uniform length in both parts (Table 3 and Figure 2)In addition care was taken not to include any extra cultural references inany of the texts and the comprehension task itself did not change acrossthe test parts The texts are stated to have come from peoplersquos descriptionof themselves in lsquolsquoFriendsbookrsquorsquo (intentionally similar to Facebook) On thewhole therefore it could be said that the style of the text is personal andinformal
The vast majority of the words are in the top 1000 withapproximately 985 of the words occurring in the BNC top 2000(Table 3) These results were in turn compared with the General ServiceList (West 1953) using software developed by Heatley and Nation(Range 1994) and another package using the same corpus created byCobb (nd) The results were practically identical in all cases (Range985 VocabProfile 98494)
Another key feature of the test is the rating scale which requires the testtaker to circle what she believes is his or her comprehension of each textfrom 5 to 1005 This self-reported comprehension is designed to helpanswer the second research question of whether the presence ofmultiword expressions in a text can lead L2 learners to believe they have
TABLE 3
Summary of Test 1 and Test 2 Text Data
Total wordcount
Total clausecount T-unit count
Top 1000words coverage
Top 1001ndash2000 words
coverage
Test 1 416 56 45 957373 27650Test 2 412 54 42 957373 27650
Note Data measured using vocabulary profiler (Cobb nd) A T-unit or a minimal terminableunit is lsquolsquoone main clause plus any subordinate clausersquorsquo (Hunt 1968 p 4)
276 TESOL QUARTERLY
understood that text better than they actually have Testing whatcomprehenders believe they understoodmdashcompared to what they actuallyunderstoodmdashby comparing test scores to self-assessment of comprehen-sion via a rating scale is often referred to as lsquolsquocomprehension calibrationrsquorsquoand is a method that has been used extensively in psychological research(eg Bransford amp Johnson 1972 Glenberg Wilkinson amp Epstein 1982Maki amp McGuire 2002 Moore Lin-Agler amp Zabrucky 2005) butsomewhat less so in applied linguistics (cf Brantmeier 2006 Jung 2003Morrison 2004 Oh 2001 Sarac amp Tarhan 2009)
Finally participants were asked to record their start and finish timesfor each part of the test
Procedure
Following an initial field test an item analysis was conducted toestablish the facility value6 of the test items and a discrimination indexfor both test parts to discern whether the test was discriminatingbetween stronger and weaker participants Items that were found to haveexceptionally high or low scores were carefully analyzed and the wordingof both test items and reading texts adjusted accordingly
Finally as advocated in Schmitt Schmitt and Clapham (2001) oneimportant requirement of an L2 test of reading comprehension is that itbe answerable by native or nativelike speakers of the language (p 65)To that end a smaller group of native speakers (n 5 8) was also tested asan additional check of the testrsquos validity That group produced a mean
FIGURE 2 Side-by-side comparison of matched texts from the two test parts (full version ofthe test available on request)
4 These are vocabulary profilers that essentially use word frequency lists to break all thewords in a text down into those that occur for example in the top 1000 second 1000third 1000 and so on
5 lsquolsquo0rsquorsquo would be virtually impossible because learners would be familiar with most words inthe texts if not all
6 A test itemrsquos facility value is calculated by dividing the number of participants whoanswered that item correctly by the total number of participants (Hughes 2003)
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 277
score of 28 in Test 1 (the maximum score) and 2775 in Test 2 showingthat both test parts posed very little difficulty for people for whomEnglish is a first language
The students received the two parts of the test in alternating order(ie counterbalanced) to control for any effect of taking Test 1 beforeTest 2 (and vice versa) because by counterbalancing one is able toinclude a variable order into an analysis and identify the extent towhich order affects performance on the dependent measures
RESULTS
All the scores and self-reported comprehension measures wererecorded in a statistical analysis software program (SPSS) Eachparticipantrsquos test results were transcribed into the software item by item(ie correct and incorrect) text by text (eg Text A Text B etc numbercorrect out of 7 for each) and test by test (ie Test 1 and Test 2 numbercorrect out of 28 possible for each) Also recorded were each participantrsquosself-reported comprehension assessments (a rating scale from 5 to 100)as they pertained to each text as well as which version (Test 1 or Test 2first) of the instrument each candidate had received To assess the effectof counterbalancing a repeated measures analysis of variance (ANOVA)was conducted with one within-subjects factor (TEST) with two levels(Test 1 score Test 2 score) and one between-subjects factor (VERSION)with two levels (Test 1 first Test 2 first) This analysis revealed a robustmain effect of test (F (199) 5 59338 p 0001 g2 5 086) and a discreteeffect of version (F (199) 5 405 p 5 0047 g2 5 004) but importantlythere was no significant Test 6 Version interaction (F (199) 5 281 p 5
0097 g2 5 002) illustrating that participantsrsquo scores did not vary as afunction of which version of the test they were completing
Comprehension of Test 1 versus Test 2
The central tendencies from both tests are presented in Table 4As predicted participantsrsquo scores were significantly lower on Test 2
relative to Test 1 (t(100) 5 2410 p 0001) with a strong effect size(g2 5 0828)7 confirming that even when two sets of texts contain theexact same words and even if those words are very commoncomprehension of those texts will not be the same when one containsidiomaticity
7 Confidence intervals at 95 for all t-tests
278 TESOL QUARTERLY
Self-Reported Comprehension of Test 1 versus Test 2
A t-test was also performed on the difference between whatparticipants believed they understood (ie their reported comprehen-sion) and what they actually understood in both Tests 1 and 2 (Table 5)Mean reported comprehension (MRC) was arrived at by calculating themeans of all the self-reported comprehension percentages (5ndash100)and the mean actual comprehension (MAC) is the mean of the score oneach text divided by seven (the maximum score)
MAC was lower than MRC in both Test 1(MRC M 5 08738 SD 013MAC M 5 08603 SD 5 009) and Test 2 (MRC M 5 06029 SD 019MAC M 5 05258 SD 5 014) however the difference between MRCand MAC was statistically reliable in Test 2 only where the test wascomposed of multiword expressions (t(100) 5 395 p 0001 g2 5
007)8 These data therefore appear to support a positive answer to thesecond research questionmdashthat learners may believe they understandmore than they actually do by virtue of their simply understanding theindividual words in a text
Variation in the Data
MRC versus MAC
Naturally there were some individual differences in the test resultsTable 6 shows that roughly one-half of all participants (n 5 50)overestimated their comprehension in both tests (indicated by MRC
TABLE 4
Descriptive Statistics (Tests 1 and 2)
Mean Median Mode Minimum Maximum SD
Test 1a 2409 2500 2500 1800 2800 244Test 2b 1476 1500 1500 600 2500 393
Note SD 5 standard deviation aTexts composed of common words however with little or noopaque phraseology bTexts composed of common words which comprise collocations andidiomatic language
TABLE 5
Reported Versus Actual Comprehension
Test 1 Test 2
Mean reported comprehension (MRC) 8738 6029Mean actual comprehension (MAC) 8603 5258
8 By comparison the results of the paired sample t-test for the Test 1 MRC-MAC means weret(100) 5 104 p 5 0302 g2 5 0005
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 279
greater than MAC) On the surface this might suggest that those 50participants did not overestimate their comprehension in Test 2 as aresult of its relative noncompositionality but rather as a generaltendency regardless of idiomaticity However when MAC is subtractedfrom MRC for that group and the difference compared across the teststhe difference is twice as large in Test 2 (t(49) 5 492 p 0001 g2 5
0108) This difference is even more evident in the same analysis of Test2 alone Isolating the results of that test there was a total of 70participants (over 69 of the entire sample) whose MRC was greaterthan their MAC The difference between MRC minus MAC for thesubgroup of 70 participants reveals that their overestimation of theircomprehension in Test 2 was four times greater than in Test 1 (t(69) 5
770 p 0001 g2 5 0228) Further among that group of 70 whoseTest 2 MRC was greater than their MAC 20 students either under-estimated or actually accurately guessed their comprehension in Test 1but significantly overestimated their comprehension in Test 2 (t(19) 5
849 p 0001 g2 5 0264) Only 30 participants in the present studyactually underestimated their comprehension on Test 2
Variation in Time Spent on the Tests
All candidates were also asked to record their start and finishing timesof each test (Table 7) It is not surprising that on average participantsspent more time on the texts which contained idiomatic expressionsHowever this trend was not uniform among the participants and thetime data may help provide some insight into just how aware someparticipants were of the presence of idiomaticity in the texts Thispossibility is explored further in the Discussion
TABLE 6
Trend of Increase in MRC-MAC Discrepancy Across Test Parts
NMRC minus MAC
(Test 1)MRC minus MAC
(Test 2)
Students with MRC MAC (bothtest parts)
50 009 019
Students with MRC MAC (Test 2) 70 004 017Students with MRC MAC (Test 2only)
20 2010 014
Students with MRC MAC (Test 2) 31a 2005 2015
Note MRC 5 mean reported comprehension MAC 5 mean actual comprehension aOnly oneparticipant in this group had MRC 5 MAC
280 TESOL QUARTERLY
DISCUSSION
To reiterate the present study sought to address the followingresearch questions
1 Are two texts written with the exact same high-frequency wordsunderstood equally well by L2 learners when one of the texts is moreidiomatic than the other
2 Can the presence of multiword expressions in a text lead L2 learners tobelieve they have understood that text better than they actually have
A group of 101 adult Brazilian learners of English was tested using twoseparate measures of reading comprehension (one with idiomaticlanguage and one without) and the results of the two tests were thencompared Although verbal reports would provide even greater insightthe resultant data from this study do seem to support a positive answer tothe first research question Participants achieved significantly lowerscores on the comprehension measure which assessed their under-standing of texts that contain multiword expressions It should bereiterated that this result was obtained in spite of both tests being writtenwith the exact same high-frequency words
Likewise through participantsrsquo self-reported comprehension thereseems to be evidence that the presence of multiword expressions in atext can lead L2 readers to overestimate their assessment of how muchthey have actually understood suggesting a positive answer to the secondresearch question
Although it seems apparent that participantsrsquo reading comprehensionin the present study was adversely affected by idiomaticity this sectionexplores and possibly explains variation in comprehension of the testsand further discusses evidence that multiword expressions negativelyaffected participantsrsquo comprehension
On the Stronger and Weaker Performance in the Tests
There are at least three important revelations emerging from theMRC-MAC data analysis presented in Table 6 First nearly two thirds of
TABLE 7
Time It Took Participants to Take Tests
N Mean time (minutes) SD
Time it took to take Test 1 91a 1085 436Time it took to take Test 2 91 1465 377
Note SD 5 standard deviation aSome participants (n 5 10) forgot to write in the time or left itincomplete
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 281
all participants believed they understood more than they actually did inTest 2 Second the data show that over 28 of those students (n 5 20)did not overestimate their comprehension in Test 1 providing evidencethat whereas they were apparently able to gauge their comprehensionfairly accurately when the texts were relatively devoid of idiomaticitythey were significantly less able to do so when relative noncomposition-ality was present Finally the MRC-MAC data presented so far indicatethat although not all participants tended to overestimate theircomprehension in Test 2 those who did (again the majority of cases)generally did so by a much larger margin Put simply it would seem thatnot only are many learners misunderstanding idiomaticity in text butthey may be doing so more than they (or researchers) realize
Further Evidence of Idiomaticity Negatively AffectingComprehension
The mean difference between MRC and MAC for the 70 students whooverestimated their comprehension in Test 2 (Table 6) was 017 For thesake of argument one could establish an MRC-MAC difference above020 as a cutoff for apparently marked lack of awareness of the extentof idiomaticity in Test 29 comparatively speaking This in turn wouldmean that there were 30 participants who ostensibly demonstrated aparticularly high overestimation of how much of Test 2 they had actuallyunderstood A sample of just the top 10 is provided in Table 8
Table 8 shows not only how different those participantsrsquo MRC wasfrom their Test 2 it also lists the same figures for Test 1 for comparison
9 A t-test reveals that the mean is in fact statistically significant even at the 003 differencelevel (t 5 653 p 5 003)
TABLE 8
Partial List of Participants With Exceptionally High Overestimation of Test 2 Comprehension(Difference 020)
ParticipantMRCTest 1
MACTest 1 Difference
MRCTest 2
MACTest 2 Difference
118 100 089 011 094 032 0626 075 068 007 081 028 05392 081 089 2008 075 025 05090 100 089 011 081 039 042115 100 089 011 087 050 03722 100 096 003 094 057 03780 094 068 026 069 032 03759 094 089 005 069 036 03321 100 093 007 087 057 03050 087 078 009 069 039 029
282 TESOL QUARTERLY
Whereas for Test 1 those 30 participantsrsquo assessment of readingcomprehension was usually only slightly overestimated10 (and in oneinstance even underestimated) the same participants in Test 2 had amarkedly overinflated conception of how much they had understood
Although not intended as a principal source of data for our analysisthe start and finish times recorded by participants on the tests in a fewinstances helped confirm the above assertions11 Table 7 shows thatthere was a significant difference between how long participants spenttaking each test (t 5 852 p 0001) However there were a number ofparticipants (n 5 26) who reported actually spending either the same orless time on Test 2 On the surface at least this fact would indicate thatthose 26 participants did not notice much difference between the testsOf course in reality that datum alone does not provide such evidencebecause that time may simply reflect a number of other confoundingvariables including affective (eg simply giving up) or even social (egthe need to leave early to meet a friend) and for that reason also was notconsidered to be a reliable source of data from those participantsHowever as a complementary source when triangulated with the othervariables some of the data analyzed earlier in the current study areoccasionally fortified further still with the time data (Table 9)
The data in Table 9 in many ways tie together the elements discussedin the analysis thus far in the present study A much lower score in Test 2than in Test 1 (columns B and C) an increase in the mean MRC-MACdifference across the tests (columns H and K) a relatively moderatedecrease in MRC in Test 2 vis-a-vis Test 1 (columns F and I) a markeddifference between MRC and MAC in Test 2 (column K) and theoccasional lack of increase (in Table 9 participants 118 80 59 and 50)in time it took to take Test 2 (columns D and E) These findings ontheir own in combination and especially in concert provide evidencethat (1) the students in Table 9 did not seem to appreciate the fullextent of the idiomaticity in Test 2 and (2) they appeared to think thatthey understood more than they actually did in Test 2
Perhaps most important 98 of all participants (n 5 99) scoredsignificantly lower on Test 2 (mean difference of 953 points out of 28SD 5 363) which shows that learners are generally unable to guess themeaning of idiomatic language even in the (largely inconsistent)instances in which they become aware of its presence
11 It should be noted that because 10 of the participantsrsquo time data were left incomplete afull group analysis could not be carried out thus the time data are only included asauxiliary information
10 As can be seen in Table 8 in fact only one participantmdashnumber 80mdashactually had anMRC-MAC difference in Test 1 that was also 020 Those of the other 29 participantswere all lower
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 283
For example the first participant in Tables 8 and 9 (number 118)who consistently overrated his own comprehension relative to his actualcomprehension answered for Text A of Test 2 as shown in Figure 3
On the basis of the responses it is likely that participant 118associated itrsquos about time with lsquolsquohas a problem with timersquorsquo Irsquom a little over thehill with lsquolsquohe probably lives in an area with hillsrsquorsquo and lsquolsquohe lives on the hill
TABLE 9
Triangulated Data Showing Negative Effect of Idiomaticity on Comprehension
A B C D E F G H I J K
Score Time Test 1 Test 2
Partic-ipant Test 1 Test 2 Test 1 Test 2 MRC MAC
Differ-ence MRC MAC
Differ-ence
118 25 9 2000 1800 100 089 11 094 032 0626 19 8 Missing Missing 075 068 007 081 028 05392 25 8 900 1100 081 089 2008 075 025 05090 25 11 900 1500 100 089 011 081 039 042115 25 14 1300 1500 100 089 011 087 050 03722 27 16 Missing Missing 100 096 003 094 057 03780 19 9 1000 1000 094 068 026 069 032 03759 25 10 1500 1400 094 089 005 069 036 03321 26 16 Missing Missing 100 093 007 087 057 03050 22 11 2000 1200 088 079 009 069 039 030
12 Of the 24 multiword expressions targeted for assessment of comprehension in Test 2 onlyfour were core idioms
FIGURE 3 Sample answer to Text A of Test 2
284 TESOL QUARTERLY
but not on top of itrsquorsquomdasha literal reading of those expressions His 100self-assessment is an indication that his answers were not guesses butinstead based on confidence that he had understood all the individualwords in the text The same answering dynamic occurred time and timeagain in Test 2
Returning therefore to the issues raised in the introduction thepresent research appears to provide evidence that idiomsmdashopaque orotherwise12mdashcan in fact cause major problems for L2 learners of Englishwhen reading In general the participants in our study were lesssuccessful at guessing the meaning of idioms than those in previousidiom-centered research such as Cooper (1999) and Liontas (2002)Because the learners in our study were not alerted to the presence ofidiomaticity in the text prior to reading this study may more accuratelyreflect what takes place in more naturally occurring L2 reading Finallythe difficulties that the participants encountered occurred in textscomposed purely of very common words showing that word frequencyalone is not necessarily a good measure of text coverage Lauferrsquos(1989a) hypothesis that much lexis in text can be deceptivelytransparent is confirmed in the present research extended to multiwordexpressions
Limitations of the Research
Although the research presented here does provide some significantevidence that the presence of idiomaticity in a text can negatively affectthe comprehension of that text by an L2 reader little is known about thestrategies the test takers employed Even though metacognition wasoutside the scope of examination of the present study such informationis highly relevant and future research should include protocols such asthose included in previous research on idioms (eg Liontas 20032007) which may provide crucial qualitative data regarding theindividual differences and behavior of the participants themselvesOverall future work in this area should consider making use of differentmeasures of self-assessment in order to explore the limitations of themethodology used in the present study
Also a question can be asked concerning the relative density ofmultiword expressions in each text In other words what is not known ison average how many such items a reader can expect to encounter Theratio of idioms to orthographic words in the texts tested in the presentstudy is very likely higher than averagemdashbut how much higher is as yetunknown Likewise the passages themselves were relatively short so it isunknown whether or not texts of greater length (and thereforecontextualization) would render the same or similar results
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 285
CONCLUSION
The present study provides some empirical evidence that a focus onword in L2 pedagogy may be detrimental to learnersrsquo development ofreading comprehension in the target language In most casesparticipants overestimated how much they had understood the textstested when those texts contained multiword expressions of varyingdegrees of compositionality comprised of very common individualwords Even when participants showed evidence of awareness of apresence of idiomaticity in the texts they generally were not very good atguessing the meaning of expressions Although Grant and Nation(2006) could be right that the teaching of individual idioms may not belsquolsquodeserving of class timersquorsquo (p 5) it is clear that at the very least raisinglearnersrsquo consciousness as to their prevalence and frequently deceptivetransparency in text certainly is
Concomitantly the present research serves to demonstrate theincompleteness of current lists of common words which now informimportant pedagogical instruments such as vocabulary tests gradedreaders and course syllabuses Under current methods as illustrated inthe Table 2 analysis of the Economist paragraph a text measured againstthe word lists now commonly in use can be mistakenly analyzed as beingeasily understood when in fact once multiword expressions are takeninto account the actual text coverage of easily understood words is farless Existing estimates of how many words one needs to know in order toadequately process naturally occurring texts (Hu amp Nation 2000Nation 2006) may need to be revisited to determine how many wordsand multiword expressions one needs to know
In practice research shows that learners will continue to believe theyunderstand items that they actually do not even after repeatedexposures to that same item (Bensoussan amp Laufer 1984 Haynes1993 Pigada amp Schmitt 2006) Language teachers and relatedprofessionals such as textbook writers need to consider ways tocontinuously help learners notice the gap between what they think theyknow and understand and what they actually do (Laufer 1997) Oneway this can be achieved has already been thoroughly discussed in thepresent paper devise texts (and tests) designed to lead readers down anidiomatic garden path Norbert Schmitt (as cited in Weir 2005) made asimilar recommendation
Perhaps the best and most valid type of vocabulary test is a reading passagewith comprehension questions but with the items requiring a full under-standing of particular words or phrases in the text This would mimic the realworld task of reading for comprehension and also the loss of comprehensionwhen key vocabulary is not known (p 123)
286 TESOL QUARTERLY
Therefore a further implication this research has for L2 pedagogy is themore careful design of the reading component of proficiency tests suchas IELTS (International English Language Testing System) and Test ofEnglish as a Foreign Language to be more strategic regarding the amountand kind of phraseology contained in the texts Proficiency was not thecentral focus of our study and future research could adopt a similarmethodology but with the inclusion of proficiency measures ofparticipants in order to explore how various types of expressions (egnoncompositional figurative imageable etc) may differentially affectpreidentified proficiency levels
Thus in order to be more methodical about such things as theinclusion of formulaic language in L2 tests and reading input in generalan important preliminary step will be to establish (a) what type offormulaic sequences are good discriminators of proficiency thresholdlevels and (b) which expressions of that identified type are mostcommon In other words what will be usefulmdashand is indeed nowbeginning to emerge (Martinez amp Schmitt 2010 Shin amp Nation 2008Simpson-Vlach amp Ellis 2010)mdashare lists of formulaic sequences that servea function similar to that of the General Service List not to revolutionizecurrent language pedagogy but to more finely tune it
THE AUTHORS
Ron Martinez is currently pursuing a doctorate at the University of NottinghamNottingham England on the topic of inclusion of phraseology in languageassessment He specializes in second language materials development
Victoria Murphy is a lecturer in Applied Linguistics and Second LanguageAcquisition at the University of Oxford Oxford England Her research interestsinclude the lexical development of first language or second language learners andthe cognitive processes that underlie language acquisition
REFERENCES
Bauer L amp Nation P (1993) Word families International Journal of Lexicography 6253ndash279 doi101093ijl64253
Bensoussan M amp Laufer B (1984) Lexical guessing in context in EFL readingcomprehension Journal of Research in Reading 7 15ndash32 doi101111j1467-98171984tb00252x
Bishop H (2004) Noticing formulaic sequences A problem of measuring thesubjective LSO Working Papers in Linguistics 4 15ndash19
Bransford D B amp Johnson M K (1972) Contextual prerequisites for under-standing Some investigations of comprehension and recall Journal of VerbalLearning and Verbal Behavior 11 717ndash726 doi101016S0022-5371(72)80006-9
Brantmeier C (2006) Advanced L2 learners and reading placement Self-assessment CBT and subsequent performance System 34 15ndash35 doi101016jsystem200508004
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 287
Carver R P (1994) Percentage of unknown vocabulary words in text as a functionof the relative difficulty of the text Implications for instruction Journal of ReadingBehavior 26 413ndash437
Cobb T (nd) Web VocabProfile [Online program] Retrieved from httpwwwlextutorcavp [an adaption of A Heatley amp P Nation Range (1994)]
Cooper T C (1999) Processing of idioms by L2 learners of English TESOLQuarterly 33 233ndash262 doi1023073587719
Coxhead A (2000) A new academic word list TESOL Quarterly 34 213ndash238doi1023073587951
Elley W amp Mangubhai F (1983) The impact of reading on second languagelearning Reading Research Quarterly 19 53ndash67 doi102307747337
Ellis N C (2008) Phraseology The periphery and the heart of language In FMeunier amp S Granger (Eds) Phraseology in language learning and teaching (pp 1ndash13) Amsterdam The Netherlands John Benjamins
Erman B amp Warren B (2000) The idiom principle and the open choice principleText 20 29ndash62
Gardner D (2007) Validating the construct of Word in applied corpus-basedvocabulary research A critical survey Applied Linguistics 28 241ndash265doi101093applinamm010
Glenberg A M Wilkinson A C amp Epstein W (1982) The illusion of knowingFailure in the self-assessment of comprehension Memory and Cognition 10 597ndash602 doi103758BF03202442
Goulden R Nation P amp Read J (1990) How large can a receptive vocabulary beApplied Linguistics 11 341ndash363 doi101093applin114341
Grant L amp Bauer L (2004) Criteria for re-defining idioms Are we barking up thewrong tree Applied Linguistics 25 38ndash61 doi101093applin25138
Grant L amp Nation P (2006) How many idioms are there in English ITL -International Journal of Applied Linguistics 151 1ndash14 doi102143ITL15102015219
Haynes M (1993) Patterns and perils of guessing in second language reading In THuckin M Haynes amp J Coady (Eds) Second language reading and vocabularylearning (pp 46ndash64) Norwood NJ Ablex Publishing Corporation
Heatley A amp Nation P (1994) Range [Computer program] Wellington NewZealand Victoria University of Wellington Retrieved from httpwwwvuwacnzlals
Hill J (2000) Revising priorities From grammatical failure to collocational successIn M Lewis (Ed) Teaching collocation Further developments in the Lexical Approach(pp 47ndash69) Hove England LTP
Hirsh D amp Nation P (1992) What vocabulary size is needed to read unsimplifiedtexts for pleasure Reading in a Foreign Language 8 689ndash696
Hu H M amp Nation P (2000) Unknown vocabulary density and readingcomprehension Reading in a Foreign Language 13 403ndash429
Hughes A (2003) Testing for language teachers Cambridge England CambridgeUniversity Press
Hunt K (1968) An instrument to measure syntactic maturity Tallahassee FL USDepartment of Health Education and Welfare
Jung E H (2003) The effects of organization markers on ESL learnersrsquo textunderstanding TESOL Quarterly 37 749ndash759 doi1023073588223
Krashen S (1993) The power of reading Insights from research Englewood COLibraries Unlimited
Laufer B (1989a) A factor of difficulty in vocabulary learning Deceptivetransparency AILA Review 6 10ndash20
288 TESOL QUARTERLY
Laufer B (1989b) What percentage of lexis is essential for comprehension In CLauren amp M Nordman (Eds) Special language From humans thinking to thinkingmachines (pp 316ndash323) London England Multilingual Matters
Laufer B (1991) How much lexis is necessary for reading comprehension In P JL Arnaud amp H Bejoint (Eds) Vocabulary and applied linguistics (pp 126ndash132)Oxford England Macmillan
Laufer B (1997) The lexical plight in second language reading Words you donrsquotknow words you think you know and words you canrsquot guess In J Coady amp THuckin (Eds) Second language vocabulary acquisition (pp 20ndash34) CambridgeEngland Cambridge University Press
Lewis M (1993) The Lexical Approach The state of ELT and a way forward HoveEngland LTP
Liontas J I (2002) Context and idiom understanding in second languagesEUROSLA Yearbook 2 155ndash185
Liontas J I (2003) Killing two birds with one stone Understanding Spanish VPidioms in and out of context Hispania 86 289ndash301 doi10230720062862
Liontas J I (2007) The eye never sees what the brain understands Making sense ofidioms in second languages Lingua et Linguistica 1) 25ndash44
Maki R H amp McGuire M J (2002) Metacognition for text Findings andimplications for education In T Schwarz amp L Bennett (Eds) Appliedmetacognition (pp 39ndash67) Cambridge England Cambridge University Press
Martinez R amp Schmitt N (2010) A phrasal expressions listManuscript submitted forpublication
Moon R (1997) Vocabulary connections Multi-word items in English In NSchmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 40ndash63) Cambridge England Cambridge University Press
Moore D Lin-Agler L M amp Zabrucky K M (2005) A source of metacomprehen-sion inaccuracy Reading Psychology 26 251ndash265 doi10108002702710590962578
Morrison L (2004) Comprehension monitoring in first and second languagereading The Canadian Modern Language Review 61 77ndash106
Nation I S P (2001) Learning vocabulary in another language Cambridge EnglandCambridge University Press
Nation I S P (2006) How large a vocabulary is needed for reading and listeningThe Canadian Modern Language Review 63 59ndash82
Nation I S P amp Waring R (1997) Vocabulary size text coverage and word lists InN Schmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 6ndash19) Cambridge England Cambridge University Press
Nation P (1997) The language learning benefits of extensive reading LanguageTeacher 21 13ndash16
Nattinger J R amp DeCarrico J S (1992) Lexical phrases and language teachingOxford England Oxford University Press
Oh S Y (2001) Two types of input modification and EFL reading comprehensionSimplification versus elaboration TESOL Quarterly 35 69ndash96 doi1023073587860
OrsquoKeeffe A McCarthy M amp Carter R (2007) From corpus to classroom Language useand language teaching Cambridge England Cambridge University Press
Pawley A amp Syder F H (1983) Two puzzles for linguistic theory Nativelikeselection and nativelike fluency In J C Richards amp R Schmidt (Eds) Languageand communication (pp 191ndash226) New York NY Longman
Pigada M amp Schmitt N (2006) Vocabulary acquisition from extensive reading Acase study Reading in a Foreign Language 18 1ndash28
Read J (2004) Research in teaching vocabulary Annual Review of Applied Linguistics24 146ndash161 doi101017S0267190504000078
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 289
Sarac S amp Tarhan B (2009) Calibration of comprehension and performance inL2 reading International Electronic Journal of Elementary Education 2 167ndash179
Schmitt N Jiang N amp Grabe W (2011) The percentage of words known in a textand reading comprehension Modern Language Journal 95(1) 26ndash43
Schmitt N Schmitt D amp Clapham C (2001) Developing and exploring thebehaviour of two new versions of the Vocabulary Levels Test Language Testing 1855ndash88
Shin D amp Nation I S P (2008) Beyond single words The most frequentcollocations in spoken English ELT Journal 62 339ndash348 doi101093eltccm091
Simpson-Vlach R amp Ellis N C (2010) An academic formulas list New methods inphraseology research Applied Linguistics 31(4) 487ndash512
Sinclair J (1991) Corpus concordance collocation Oxford England OxfordUniversity Press
Spottl C amp McCarthy M (2003) Formulaic utterances in the multi-lingual contextIn J Cenoz B Hufeisen ampU Jessner (Eds) The multilingual lexicon (pp 133ndash151) Dordrecht The Netherlands Kluwer
Staelighr L S (2008) Vocabulary size and the skills of listening reading and writingLanguage Learning Journal 36 139ndash152 doi10108009571730802389975
Stubbs M amp Barth I (2003) Using recurrent phrases as text-type descriminators Aquantitative method and some findings Functions of Language 10 61ndash104doi101075fol10104stu
The British National Corpus (2007) The British National Corpus(version 3 BNC XMLed) [CD-ROM] Distributed by Oxford University Computing Services on behalfof the BNC Consortium
The iPhonersquos second coming (2008 July) The Economist Retrieved from httpwwweconomistcomscience-technologydisplaystorycfmstory_id5E1_TTSDDJTG
Walter E Woodford K amp Good M (Eds) (2008) Cambridge advanced learnerrsquosdictionary (3rd ed) Cambridge England Cambridge University Press
Weir C J (2005) Language testing and validation An evidence-based approachNew York NY Palgrave Macmillan
West M (1953) A general service list of English words London England LongmanWray A (2002) Formulaic language and the lexicon Cambridge England Cambridge
University Press
290 TESOL QUARTERLY

Summary and Research Questions
In summary the following has been argued thus faramp Current estimates of how many words one needs to know in order to
comprehend most texts may be inaccurate due to overinclusion of derivedword forms and a total exclusion of multiword units of vocabulary
amp Contrary to some research there is evidence in corpus data that thenumber of frequently occurring noncompositional multiwordexpressions in English is higher than previously believed
amp Even when an expression is partly or even fully compositional thereis no way of knowing how accurately an L2 reader will interpret (oreven identify) that item
amp The claim that special attention to the 2000ndash3000 most commonwords in English is pedagogically sound since they provide around80 of text coverage (eg OrsquoKeeffe McCarthy amp Carter 2007Read 2004 p 148 Staelighr 2008) deserves closer scrutiny becausethose words are often merely tips of phraseological icebergs
It is therefore clear that there is a need for further investigation into howcommon words and the multiword units they form can affect readingcomprehension when reading in English as a foreign language To thatend we conducted a study to answer the following research questions
1 Are two texts written with the exact same high-frequency wordsunderstood equally well by L2 learners when one of the texts is moreidiomatic than the other
2 Can the presence of multiword expressions in a text lead L2 learners tobelieve they have understood that text better than they actually have
METHOD
Participants
Brazilian adult learners of English (n 5 101) all native speakers ofBrazilian Portuguese were selected to participate in the study Thesample ranged in age from 18 to 64 years (M 5 2576 SD 5 931) andconsisted of 43 men and 58 women representing seven different regionsof Brazil
All participants in the study had had a minimum of 80 hr of tuition inEnglish prior to the start of the research and had been tested aspossessing intermediate or higher levels of proficiency Howeverbecause all participants attended private language schools the actualinstruments by which their proficiency was assessed varied widely
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 275
Regardless uniformity in proficiency was not of prime importance in thestudy because the research questions are concerned with a significantchange in the paired samples within the same group
The Test
To write the eight texts (four texts in each test) a corpus of words wascarefully chosen from the list of the 2000 most frequent words in the BNCThe reading comprehension of each text was tested by seven true or falseitems totaling 28 per test part or 56 overall The test when administeredappears as one but is actually in two parts (Test 1 and Test 2) each partcontaining the exact same words with some words in Test 2 formingmultiword expressions Great care was taken to ensure that the texts areotherwise equal There is no visual difference between the two parts andthe texts are of almost uniform length in both parts (Table 3 and Figure 2)In addition care was taken not to include any extra cultural references inany of the texts and the comprehension task itself did not change acrossthe test parts The texts are stated to have come from peoplersquos descriptionof themselves in lsquolsquoFriendsbookrsquorsquo (intentionally similar to Facebook) On thewhole therefore it could be said that the style of the text is personal andinformal
The vast majority of the words are in the top 1000 withapproximately 985 of the words occurring in the BNC top 2000(Table 3) These results were in turn compared with the General ServiceList (West 1953) using software developed by Heatley and Nation(Range 1994) and another package using the same corpus created byCobb (nd) The results were practically identical in all cases (Range985 VocabProfile 98494)
Another key feature of the test is the rating scale which requires the testtaker to circle what she believes is his or her comprehension of each textfrom 5 to 1005 This self-reported comprehension is designed to helpanswer the second research question of whether the presence ofmultiword expressions in a text can lead L2 learners to believe they have
TABLE 3
Summary of Test 1 and Test 2 Text Data
Total wordcount
Total clausecount T-unit count
Top 1000words coverage
Top 1001ndash2000 words
coverage
Test 1 416 56 45 957373 27650Test 2 412 54 42 957373 27650
Note Data measured using vocabulary profiler (Cobb nd) A T-unit or a minimal terminableunit is lsquolsquoone main clause plus any subordinate clausersquorsquo (Hunt 1968 p 4)
276 TESOL QUARTERLY
understood that text better than they actually have Testing whatcomprehenders believe they understoodmdashcompared to what they actuallyunderstoodmdashby comparing test scores to self-assessment of comprehen-sion via a rating scale is often referred to as lsquolsquocomprehension calibrationrsquorsquoand is a method that has been used extensively in psychological research(eg Bransford amp Johnson 1972 Glenberg Wilkinson amp Epstein 1982Maki amp McGuire 2002 Moore Lin-Agler amp Zabrucky 2005) butsomewhat less so in applied linguistics (cf Brantmeier 2006 Jung 2003Morrison 2004 Oh 2001 Sarac amp Tarhan 2009)
Finally participants were asked to record their start and finish timesfor each part of the test
Procedure
Following an initial field test an item analysis was conducted toestablish the facility value6 of the test items and a discrimination indexfor both test parts to discern whether the test was discriminatingbetween stronger and weaker participants Items that were found to haveexceptionally high or low scores were carefully analyzed and the wordingof both test items and reading texts adjusted accordingly
Finally as advocated in Schmitt Schmitt and Clapham (2001) oneimportant requirement of an L2 test of reading comprehension is that itbe answerable by native or nativelike speakers of the language (p 65)To that end a smaller group of native speakers (n 5 8) was also tested asan additional check of the testrsquos validity That group produced a mean
FIGURE 2 Side-by-side comparison of matched texts from the two test parts (full version ofthe test available on request)
4 These are vocabulary profilers that essentially use word frequency lists to break all thewords in a text down into those that occur for example in the top 1000 second 1000third 1000 and so on
5 lsquolsquo0rsquorsquo would be virtually impossible because learners would be familiar with most words inthe texts if not all
6 A test itemrsquos facility value is calculated by dividing the number of participants whoanswered that item correctly by the total number of participants (Hughes 2003)
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 277
score of 28 in Test 1 (the maximum score) and 2775 in Test 2 showingthat both test parts posed very little difficulty for people for whomEnglish is a first language
The students received the two parts of the test in alternating order(ie counterbalanced) to control for any effect of taking Test 1 beforeTest 2 (and vice versa) because by counterbalancing one is able toinclude a variable order into an analysis and identify the extent towhich order affects performance on the dependent measures
RESULTS
All the scores and self-reported comprehension measures wererecorded in a statistical analysis software program (SPSS) Eachparticipantrsquos test results were transcribed into the software item by item(ie correct and incorrect) text by text (eg Text A Text B etc numbercorrect out of 7 for each) and test by test (ie Test 1 and Test 2 numbercorrect out of 28 possible for each) Also recorded were each participantrsquosself-reported comprehension assessments (a rating scale from 5 to 100)as they pertained to each text as well as which version (Test 1 or Test 2first) of the instrument each candidate had received To assess the effectof counterbalancing a repeated measures analysis of variance (ANOVA)was conducted with one within-subjects factor (TEST) with two levels(Test 1 score Test 2 score) and one between-subjects factor (VERSION)with two levels (Test 1 first Test 2 first) This analysis revealed a robustmain effect of test (F (199) 5 59338 p 0001 g2 5 086) and a discreteeffect of version (F (199) 5 405 p 5 0047 g2 5 004) but importantlythere was no significant Test 6 Version interaction (F (199) 5 281 p 5
0097 g2 5 002) illustrating that participantsrsquo scores did not vary as afunction of which version of the test they were completing
Comprehension of Test 1 versus Test 2
The central tendencies from both tests are presented in Table 4As predicted participantsrsquo scores were significantly lower on Test 2
relative to Test 1 (t(100) 5 2410 p 0001) with a strong effect size(g2 5 0828)7 confirming that even when two sets of texts contain theexact same words and even if those words are very commoncomprehension of those texts will not be the same when one containsidiomaticity
7 Confidence intervals at 95 for all t-tests
278 TESOL QUARTERLY
Self-Reported Comprehension of Test 1 versus Test 2
A t-test was also performed on the difference between whatparticipants believed they understood (ie their reported comprehen-sion) and what they actually understood in both Tests 1 and 2 (Table 5)Mean reported comprehension (MRC) was arrived at by calculating themeans of all the self-reported comprehension percentages (5ndash100)and the mean actual comprehension (MAC) is the mean of the score oneach text divided by seven (the maximum score)
MAC was lower than MRC in both Test 1(MRC M 5 08738 SD 013MAC M 5 08603 SD 5 009) and Test 2 (MRC M 5 06029 SD 019MAC M 5 05258 SD 5 014) however the difference between MRCand MAC was statistically reliable in Test 2 only where the test wascomposed of multiword expressions (t(100) 5 395 p 0001 g2 5
007)8 These data therefore appear to support a positive answer to thesecond research questionmdashthat learners may believe they understandmore than they actually do by virtue of their simply understanding theindividual words in a text
Variation in the Data
MRC versus MAC
Naturally there were some individual differences in the test resultsTable 6 shows that roughly one-half of all participants (n 5 50)overestimated their comprehension in both tests (indicated by MRC
TABLE 4
Descriptive Statistics (Tests 1 and 2)
Mean Median Mode Minimum Maximum SD
Test 1a 2409 2500 2500 1800 2800 244Test 2b 1476 1500 1500 600 2500 393
Note SD 5 standard deviation aTexts composed of common words however with little or noopaque phraseology bTexts composed of common words which comprise collocations andidiomatic language
TABLE 5
Reported Versus Actual Comprehension
Test 1 Test 2
Mean reported comprehension (MRC) 8738 6029Mean actual comprehension (MAC) 8603 5258
8 By comparison the results of the paired sample t-test for the Test 1 MRC-MAC means weret(100) 5 104 p 5 0302 g2 5 0005
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 279
greater than MAC) On the surface this might suggest that those 50participants did not overestimate their comprehension in Test 2 as aresult of its relative noncompositionality but rather as a generaltendency regardless of idiomaticity However when MAC is subtractedfrom MRC for that group and the difference compared across the teststhe difference is twice as large in Test 2 (t(49) 5 492 p 0001 g2 5
0108) This difference is even more evident in the same analysis of Test2 alone Isolating the results of that test there was a total of 70participants (over 69 of the entire sample) whose MRC was greaterthan their MAC The difference between MRC minus MAC for thesubgroup of 70 participants reveals that their overestimation of theircomprehension in Test 2 was four times greater than in Test 1 (t(69) 5
770 p 0001 g2 5 0228) Further among that group of 70 whoseTest 2 MRC was greater than their MAC 20 students either under-estimated or actually accurately guessed their comprehension in Test 1but significantly overestimated their comprehension in Test 2 (t(19) 5
849 p 0001 g2 5 0264) Only 30 participants in the present studyactually underestimated their comprehension on Test 2
Variation in Time Spent on the Tests
All candidates were also asked to record their start and finishing timesof each test (Table 7) It is not surprising that on average participantsspent more time on the texts which contained idiomatic expressionsHowever this trend was not uniform among the participants and thetime data may help provide some insight into just how aware someparticipants were of the presence of idiomaticity in the texts Thispossibility is explored further in the Discussion
TABLE 6
Trend of Increase in MRC-MAC Discrepancy Across Test Parts
NMRC minus MAC
(Test 1)MRC minus MAC
(Test 2)
Students with MRC MAC (bothtest parts)
50 009 019
Students with MRC MAC (Test 2) 70 004 017Students with MRC MAC (Test 2only)
20 2010 014
Students with MRC MAC (Test 2) 31a 2005 2015
Note MRC 5 mean reported comprehension MAC 5 mean actual comprehension aOnly oneparticipant in this group had MRC 5 MAC
280 TESOL QUARTERLY
DISCUSSION
To reiterate the present study sought to address the followingresearch questions
1 Are two texts written with the exact same high-frequency wordsunderstood equally well by L2 learners when one of the texts is moreidiomatic than the other
2 Can the presence of multiword expressions in a text lead L2 learners tobelieve they have understood that text better than they actually have
A group of 101 adult Brazilian learners of English was tested using twoseparate measures of reading comprehension (one with idiomaticlanguage and one without) and the results of the two tests were thencompared Although verbal reports would provide even greater insightthe resultant data from this study do seem to support a positive answer tothe first research question Participants achieved significantly lowerscores on the comprehension measure which assessed their under-standing of texts that contain multiword expressions It should bereiterated that this result was obtained in spite of both tests being writtenwith the exact same high-frequency words
Likewise through participantsrsquo self-reported comprehension thereseems to be evidence that the presence of multiword expressions in atext can lead L2 readers to overestimate their assessment of how muchthey have actually understood suggesting a positive answer to the secondresearch question
Although it seems apparent that participantsrsquo reading comprehensionin the present study was adversely affected by idiomaticity this sectionexplores and possibly explains variation in comprehension of the testsand further discusses evidence that multiword expressions negativelyaffected participantsrsquo comprehension
On the Stronger and Weaker Performance in the Tests
There are at least three important revelations emerging from theMRC-MAC data analysis presented in Table 6 First nearly two thirds of
TABLE 7
Time It Took Participants to Take Tests
N Mean time (minutes) SD
Time it took to take Test 1 91a 1085 436Time it took to take Test 2 91 1465 377
Note SD 5 standard deviation aSome participants (n 5 10) forgot to write in the time or left itincomplete
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 281
all participants believed they understood more than they actually did inTest 2 Second the data show that over 28 of those students (n 5 20)did not overestimate their comprehension in Test 1 providing evidencethat whereas they were apparently able to gauge their comprehensionfairly accurately when the texts were relatively devoid of idiomaticitythey were significantly less able to do so when relative noncomposition-ality was present Finally the MRC-MAC data presented so far indicatethat although not all participants tended to overestimate theircomprehension in Test 2 those who did (again the majority of cases)generally did so by a much larger margin Put simply it would seem thatnot only are many learners misunderstanding idiomaticity in text butthey may be doing so more than they (or researchers) realize
Further Evidence of Idiomaticity Negatively AffectingComprehension
The mean difference between MRC and MAC for the 70 students whooverestimated their comprehension in Test 2 (Table 6) was 017 For thesake of argument one could establish an MRC-MAC difference above020 as a cutoff for apparently marked lack of awareness of the extentof idiomaticity in Test 29 comparatively speaking This in turn wouldmean that there were 30 participants who ostensibly demonstrated aparticularly high overestimation of how much of Test 2 they had actuallyunderstood A sample of just the top 10 is provided in Table 8
Table 8 shows not only how different those participantsrsquo MRC wasfrom their Test 2 it also lists the same figures for Test 1 for comparison
9 A t-test reveals that the mean is in fact statistically significant even at the 003 differencelevel (t 5 653 p 5 003)
TABLE 8
Partial List of Participants With Exceptionally High Overestimation of Test 2 Comprehension(Difference 020)
ParticipantMRCTest 1
MACTest 1 Difference
MRCTest 2
MACTest 2 Difference
118 100 089 011 094 032 0626 075 068 007 081 028 05392 081 089 2008 075 025 05090 100 089 011 081 039 042115 100 089 011 087 050 03722 100 096 003 094 057 03780 094 068 026 069 032 03759 094 089 005 069 036 03321 100 093 007 087 057 03050 087 078 009 069 039 029
282 TESOL QUARTERLY
Whereas for Test 1 those 30 participantsrsquo assessment of readingcomprehension was usually only slightly overestimated10 (and in oneinstance even underestimated) the same participants in Test 2 had amarkedly overinflated conception of how much they had understood
Although not intended as a principal source of data for our analysisthe start and finish times recorded by participants on the tests in a fewinstances helped confirm the above assertions11 Table 7 shows thatthere was a significant difference between how long participants spenttaking each test (t 5 852 p 0001) However there were a number ofparticipants (n 5 26) who reported actually spending either the same orless time on Test 2 On the surface at least this fact would indicate thatthose 26 participants did not notice much difference between the testsOf course in reality that datum alone does not provide such evidencebecause that time may simply reflect a number of other confoundingvariables including affective (eg simply giving up) or even social (egthe need to leave early to meet a friend) and for that reason also was notconsidered to be a reliable source of data from those participantsHowever as a complementary source when triangulated with the othervariables some of the data analyzed earlier in the current study areoccasionally fortified further still with the time data (Table 9)
The data in Table 9 in many ways tie together the elements discussedin the analysis thus far in the present study A much lower score in Test 2than in Test 1 (columns B and C) an increase in the mean MRC-MACdifference across the tests (columns H and K) a relatively moderatedecrease in MRC in Test 2 vis-a-vis Test 1 (columns F and I) a markeddifference between MRC and MAC in Test 2 (column K) and theoccasional lack of increase (in Table 9 participants 118 80 59 and 50)in time it took to take Test 2 (columns D and E) These findings ontheir own in combination and especially in concert provide evidencethat (1) the students in Table 9 did not seem to appreciate the fullextent of the idiomaticity in Test 2 and (2) they appeared to think thatthey understood more than they actually did in Test 2
Perhaps most important 98 of all participants (n 5 99) scoredsignificantly lower on Test 2 (mean difference of 953 points out of 28SD 5 363) which shows that learners are generally unable to guess themeaning of idiomatic language even in the (largely inconsistent)instances in which they become aware of its presence
11 It should be noted that because 10 of the participantsrsquo time data were left incomplete afull group analysis could not be carried out thus the time data are only included asauxiliary information
10 As can be seen in Table 8 in fact only one participantmdashnumber 80mdashactually had anMRC-MAC difference in Test 1 that was also 020 Those of the other 29 participantswere all lower
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 283
For example the first participant in Tables 8 and 9 (number 118)who consistently overrated his own comprehension relative to his actualcomprehension answered for Text A of Test 2 as shown in Figure 3
On the basis of the responses it is likely that participant 118associated itrsquos about time with lsquolsquohas a problem with timersquorsquo Irsquom a little over thehill with lsquolsquohe probably lives in an area with hillsrsquorsquo and lsquolsquohe lives on the hill
TABLE 9
Triangulated Data Showing Negative Effect of Idiomaticity on Comprehension
A B C D E F G H I J K
Score Time Test 1 Test 2
Partic-ipant Test 1 Test 2 Test 1 Test 2 MRC MAC
Differ-ence MRC MAC
Differ-ence
118 25 9 2000 1800 100 089 11 094 032 0626 19 8 Missing Missing 075 068 007 081 028 05392 25 8 900 1100 081 089 2008 075 025 05090 25 11 900 1500 100 089 011 081 039 042115 25 14 1300 1500 100 089 011 087 050 03722 27 16 Missing Missing 100 096 003 094 057 03780 19 9 1000 1000 094 068 026 069 032 03759 25 10 1500 1400 094 089 005 069 036 03321 26 16 Missing Missing 100 093 007 087 057 03050 22 11 2000 1200 088 079 009 069 039 030
12 Of the 24 multiword expressions targeted for assessment of comprehension in Test 2 onlyfour were core idioms
FIGURE 3 Sample answer to Text A of Test 2
284 TESOL QUARTERLY
but not on top of itrsquorsquomdasha literal reading of those expressions His 100self-assessment is an indication that his answers were not guesses butinstead based on confidence that he had understood all the individualwords in the text The same answering dynamic occurred time and timeagain in Test 2
Returning therefore to the issues raised in the introduction thepresent research appears to provide evidence that idiomsmdashopaque orotherwise12mdashcan in fact cause major problems for L2 learners of Englishwhen reading In general the participants in our study were lesssuccessful at guessing the meaning of idioms than those in previousidiom-centered research such as Cooper (1999) and Liontas (2002)Because the learners in our study were not alerted to the presence ofidiomaticity in the text prior to reading this study may more accuratelyreflect what takes place in more naturally occurring L2 reading Finallythe difficulties that the participants encountered occurred in textscomposed purely of very common words showing that word frequencyalone is not necessarily a good measure of text coverage Lauferrsquos(1989a) hypothesis that much lexis in text can be deceptivelytransparent is confirmed in the present research extended to multiwordexpressions
Limitations of the Research
Although the research presented here does provide some significantevidence that the presence of idiomaticity in a text can negatively affectthe comprehension of that text by an L2 reader little is known about thestrategies the test takers employed Even though metacognition wasoutside the scope of examination of the present study such informationis highly relevant and future research should include protocols such asthose included in previous research on idioms (eg Liontas 20032007) which may provide crucial qualitative data regarding theindividual differences and behavior of the participants themselvesOverall future work in this area should consider making use of differentmeasures of self-assessment in order to explore the limitations of themethodology used in the present study
Also a question can be asked concerning the relative density ofmultiword expressions in each text In other words what is not known ison average how many such items a reader can expect to encounter Theratio of idioms to orthographic words in the texts tested in the presentstudy is very likely higher than averagemdashbut how much higher is as yetunknown Likewise the passages themselves were relatively short so it isunknown whether or not texts of greater length (and thereforecontextualization) would render the same or similar results
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 285
CONCLUSION
The present study provides some empirical evidence that a focus onword in L2 pedagogy may be detrimental to learnersrsquo development ofreading comprehension in the target language In most casesparticipants overestimated how much they had understood the textstested when those texts contained multiword expressions of varyingdegrees of compositionality comprised of very common individualwords Even when participants showed evidence of awareness of apresence of idiomaticity in the texts they generally were not very good atguessing the meaning of expressions Although Grant and Nation(2006) could be right that the teaching of individual idioms may not belsquolsquodeserving of class timersquorsquo (p 5) it is clear that at the very least raisinglearnersrsquo consciousness as to their prevalence and frequently deceptivetransparency in text certainly is
Concomitantly the present research serves to demonstrate theincompleteness of current lists of common words which now informimportant pedagogical instruments such as vocabulary tests gradedreaders and course syllabuses Under current methods as illustrated inthe Table 2 analysis of the Economist paragraph a text measured againstthe word lists now commonly in use can be mistakenly analyzed as beingeasily understood when in fact once multiword expressions are takeninto account the actual text coverage of easily understood words is farless Existing estimates of how many words one needs to know in order toadequately process naturally occurring texts (Hu amp Nation 2000Nation 2006) may need to be revisited to determine how many wordsand multiword expressions one needs to know
In practice research shows that learners will continue to believe theyunderstand items that they actually do not even after repeatedexposures to that same item (Bensoussan amp Laufer 1984 Haynes1993 Pigada amp Schmitt 2006) Language teachers and relatedprofessionals such as textbook writers need to consider ways tocontinuously help learners notice the gap between what they think theyknow and understand and what they actually do (Laufer 1997) Oneway this can be achieved has already been thoroughly discussed in thepresent paper devise texts (and tests) designed to lead readers down anidiomatic garden path Norbert Schmitt (as cited in Weir 2005) made asimilar recommendation
Perhaps the best and most valid type of vocabulary test is a reading passagewith comprehension questions but with the items requiring a full under-standing of particular words or phrases in the text This would mimic the realworld task of reading for comprehension and also the loss of comprehensionwhen key vocabulary is not known (p 123)
286 TESOL QUARTERLY
Therefore a further implication this research has for L2 pedagogy is themore careful design of the reading component of proficiency tests suchas IELTS (International English Language Testing System) and Test ofEnglish as a Foreign Language to be more strategic regarding the amountand kind of phraseology contained in the texts Proficiency was not thecentral focus of our study and future research could adopt a similarmethodology but with the inclusion of proficiency measures ofparticipants in order to explore how various types of expressions (egnoncompositional figurative imageable etc) may differentially affectpreidentified proficiency levels
Thus in order to be more methodical about such things as theinclusion of formulaic language in L2 tests and reading input in generalan important preliminary step will be to establish (a) what type offormulaic sequences are good discriminators of proficiency thresholdlevels and (b) which expressions of that identified type are mostcommon In other words what will be usefulmdashand is indeed nowbeginning to emerge (Martinez amp Schmitt 2010 Shin amp Nation 2008Simpson-Vlach amp Ellis 2010)mdashare lists of formulaic sequences that servea function similar to that of the General Service List not to revolutionizecurrent language pedagogy but to more finely tune it
THE AUTHORS
Ron Martinez is currently pursuing a doctorate at the University of NottinghamNottingham England on the topic of inclusion of phraseology in languageassessment He specializes in second language materials development
Victoria Murphy is a lecturer in Applied Linguistics and Second LanguageAcquisition at the University of Oxford Oxford England Her research interestsinclude the lexical development of first language or second language learners andthe cognitive processes that underlie language acquisition
REFERENCES
Bauer L amp Nation P (1993) Word families International Journal of Lexicography 6253ndash279 doi101093ijl64253
Bensoussan M amp Laufer B (1984) Lexical guessing in context in EFL readingcomprehension Journal of Research in Reading 7 15ndash32 doi101111j1467-98171984tb00252x
Bishop H (2004) Noticing formulaic sequences A problem of measuring thesubjective LSO Working Papers in Linguistics 4 15ndash19
Bransford D B amp Johnson M K (1972) Contextual prerequisites for under-standing Some investigations of comprehension and recall Journal of VerbalLearning and Verbal Behavior 11 717ndash726 doi101016S0022-5371(72)80006-9
Brantmeier C (2006) Advanced L2 learners and reading placement Self-assessment CBT and subsequent performance System 34 15ndash35 doi101016jsystem200508004
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 287
Carver R P (1994) Percentage of unknown vocabulary words in text as a functionof the relative difficulty of the text Implications for instruction Journal of ReadingBehavior 26 413ndash437
Cobb T (nd) Web VocabProfile [Online program] Retrieved from httpwwwlextutorcavp [an adaption of A Heatley amp P Nation Range (1994)]
Cooper T C (1999) Processing of idioms by L2 learners of English TESOLQuarterly 33 233ndash262 doi1023073587719
Coxhead A (2000) A new academic word list TESOL Quarterly 34 213ndash238doi1023073587951
Elley W amp Mangubhai F (1983) The impact of reading on second languagelearning Reading Research Quarterly 19 53ndash67 doi102307747337
Ellis N C (2008) Phraseology The periphery and the heart of language In FMeunier amp S Granger (Eds) Phraseology in language learning and teaching (pp 1ndash13) Amsterdam The Netherlands John Benjamins
Erman B amp Warren B (2000) The idiom principle and the open choice principleText 20 29ndash62
Gardner D (2007) Validating the construct of Word in applied corpus-basedvocabulary research A critical survey Applied Linguistics 28 241ndash265doi101093applinamm010
Glenberg A M Wilkinson A C amp Epstein W (1982) The illusion of knowingFailure in the self-assessment of comprehension Memory and Cognition 10 597ndash602 doi103758BF03202442
Goulden R Nation P amp Read J (1990) How large can a receptive vocabulary beApplied Linguistics 11 341ndash363 doi101093applin114341
Grant L amp Bauer L (2004) Criteria for re-defining idioms Are we barking up thewrong tree Applied Linguistics 25 38ndash61 doi101093applin25138
Grant L amp Nation P (2006) How many idioms are there in English ITL -International Journal of Applied Linguistics 151 1ndash14 doi102143ITL15102015219
Haynes M (1993) Patterns and perils of guessing in second language reading In THuckin M Haynes amp J Coady (Eds) Second language reading and vocabularylearning (pp 46ndash64) Norwood NJ Ablex Publishing Corporation
Heatley A amp Nation P (1994) Range [Computer program] Wellington NewZealand Victoria University of Wellington Retrieved from httpwwwvuwacnzlals
Hill J (2000) Revising priorities From grammatical failure to collocational successIn M Lewis (Ed) Teaching collocation Further developments in the Lexical Approach(pp 47ndash69) Hove England LTP
Hirsh D amp Nation P (1992) What vocabulary size is needed to read unsimplifiedtexts for pleasure Reading in a Foreign Language 8 689ndash696
Hu H M amp Nation P (2000) Unknown vocabulary density and readingcomprehension Reading in a Foreign Language 13 403ndash429
Hughes A (2003) Testing for language teachers Cambridge England CambridgeUniversity Press
Hunt K (1968) An instrument to measure syntactic maturity Tallahassee FL USDepartment of Health Education and Welfare
Jung E H (2003) The effects of organization markers on ESL learnersrsquo textunderstanding TESOL Quarterly 37 749ndash759 doi1023073588223
Krashen S (1993) The power of reading Insights from research Englewood COLibraries Unlimited
Laufer B (1989a) A factor of difficulty in vocabulary learning Deceptivetransparency AILA Review 6 10ndash20
288 TESOL QUARTERLY
Laufer B (1989b) What percentage of lexis is essential for comprehension In CLauren amp M Nordman (Eds) Special language From humans thinking to thinkingmachines (pp 316ndash323) London England Multilingual Matters
Laufer B (1991) How much lexis is necessary for reading comprehension In P JL Arnaud amp H Bejoint (Eds) Vocabulary and applied linguistics (pp 126ndash132)Oxford England Macmillan
Laufer B (1997) The lexical plight in second language reading Words you donrsquotknow words you think you know and words you canrsquot guess In J Coady amp THuckin (Eds) Second language vocabulary acquisition (pp 20ndash34) CambridgeEngland Cambridge University Press
Lewis M (1993) The Lexical Approach The state of ELT and a way forward HoveEngland LTP
Liontas J I (2002) Context and idiom understanding in second languagesEUROSLA Yearbook 2 155ndash185
Liontas J I (2003) Killing two birds with one stone Understanding Spanish VPidioms in and out of context Hispania 86 289ndash301 doi10230720062862
Liontas J I (2007) The eye never sees what the brain understands Making sense ofidioms in second languages Lingua et Linguistica 1) 25ndash44
Maki R H amp McGuire M J (2002) Metacognition for text Findings andimplications for education In T Schwarz amp L Bennett (Eds) Appliedmetacognition (pp 39ndash67) Cambridge England Cambridge University Press
Martinez R amp Schmitt N (2010) A phrasal expressions listManuscript submitted forpublication
Moon R (1997) Vocabulary connections Multi-word items in English In NSchmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 40ndash63) Cambridge England Cambridge University Press
Moore D Lin-Agler L M amp Zabrucky K M (2005) A source of metacomprehen-sion inaccuracy Reading Psychology 26 251ndash265 doi10108002702710590962578
Morrison L (2004) Comprehension monitoring in first and second languagereading The Canadian Modern Language Review 61 77ndash106
Nation I S P (2001) Learning vocabulary in another language Cambridge EnglandCambridge University Press
Nation I S P (2006) How large a vocabulary is needed for reading and listeningThe Canadian Modern Language Review 63 59ndash82
Nation I S P amp Waring R (1997) Vocabulary size text coverage and word lists InN Schmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 6ndash19) Cambridge England Cambridge University Press
Nation P (1997) The language learning benefits of extensive reading LanguageTeacher 21 13ndash16
Nattinger J R amp DeCarrico J S (1992) Lexical phrases and language teachingOxford England Oxford University Press
Oh S Y (2001) Two types of input modification and EFL reading comprehensionSimplification versus elaboration TESOL Quarterly 35 69ndash96 doi1023073587860
OrsquoKeeffe A McCarthy M amp Carter R (2007) From corpus to classroom Language useand language teaching Cambridge England Cambridge University Press
Pawley A amp Syder F H (1983) Two puzzles for linguistic theory Nativelikeselection and nativelike fluency In J C Richards amp R Schmidt (Eds) Languageand communication (pp 191ndash226) New York NY Longman
Pigada M amp Schmitt N (2006) Vocabulary acquisition from extensive reading Acase study Reading in a Foreign Language 18 1ndash28
Read J (2004) Research in teaching vocabulary Annual Review of Applied Linguistics24 146ndash161 doi101017S0267190504000078
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 289
Sarac S amp Tarhan B (2009) Calibration of comprehension and performance inL2 reading International Electronic Journal of Elementary Education 2 167ndash179
Schmitt N Jiang N amp Grabe W (2011) The percentage of words known in a textand reading comprehension Modern Language Journal 95(1) 26ndash43
Schmitt N Schmitt D amp Clapham C (2001) Developing and exploring thebehaviour of two new versions of the Vocabulary Levels Test Language Testing 1855ndash88
Shin D amp Nation I S P (2008) Beyond single words The most frequentcollocations in spoken English ELT Journal 62 339ndash348 doi101093eltccm091
Simpson-Vlach R amp Ellis N C (2010) An academic formulas list New methods inphraseology research Applied Linguistics 31(4) 487ndash512
Sinclair J (1991) Corpus concordance collocation Oxford England OxfordUniversity Press
Spottl C amp McCarthy M (2003) Formulaic utterances in the multi-lingual contextIn J Cenoz B Hufeisen ampU Jessner (Eds) The multilingual lexicon (pp 133ndash151) Dordrecht The Netherlands Kluwer
Staelighr L S (2008) Vocabulary size and the skills of listening reading and writingLanguage Learning Journal 36 139ndash152 doi10108009571730802389975
Stubbs M amp Barth I (2003) Using recurrent phrases as text-type descriminators Aquantitative method and some findings Functions of Language 10 61ndash104doi101075fol10104stu
The British National Corpus (2007) The British National Corpus(version 3 BNC XMLed) [CD-ROM] Distributed by Oxford University Computing Services on behalfof the BNC Consortium
The iPhonersquos second coming (2008 July) The Economist Retrieved from httpwwweconomistcomscience-technologydisplaystorycfmstory_id5E1_TTSDDJTG
Walter E Woodford K amp Good M (Eds) (2008) Cambridge advanced learnerrsquosdictionary (3rd ed) Cambridge England Cambridge University Press
Weir C J (2005) Language testing and validation An evidence-based approachNew York NY Palgrave Macmillan
West M (1953) A general service list of English words London England LongmanWray A (2002) Formulaic language and the lexicon Cambridge England Cambridge
University Press
290 TESOL QUARTERLY

Regardless uniformity in proficiency was not of prime importance in thestudy because the research questions are concerned with a significantchange in the paired samples within the same group
The Test
To write the eight texts (four texts in each test) a corpus of words wascarefully chosen from the list of the 2000 most frequent words in the BNCThe reading comprehension of each text was tested by seven true or falseitems totaling 28 per test part or 56 overall The test when administeredappears as one but is actually in two parts (Test 1 and Test 2) each partcontaining the exact same words with some words in Test 2 formingmultiword expressions Great care was taken to ensure that the texts areotherwise equal There is no visual difference between the two parts andthe texts are of almost uniform length in both parts (Table 3 and Figure 2)In addition care was taken not to include any extra cultural references inany of the texts and the comprehension task itself did not change acrossthe test parts The texts are stated to have come from peoplersquos descriptionof themselves in lsquolsquoFriendsbookrsquorsquo (intentionally similar to Facebook) On thewhole therefore it could be said that the style of the text is personal andinformal
The vast majority of the words are in the top 1000 withapproximately 985 of the words occurring in the BNC top 2000(Table 3) These results were in turn compared with the General ServiceList (West 1953) using software developed by Heatley and Nation(Range 1994) and another package using the same corpus created byCobb (nd) The results were practically identical in all cases (Range985 VocabProfile 98494)
Another key feature of the test is the rating scale which requires the testtaker to circle what she believes is his or her comprehension of each textfrom 5 to 1005 This self-reported comprehension is designed to helpanswer the second research question of whether the presence ofmultiword expressions in a text can lead L2 learners to believe they have
TABLE 3
Summary of Test 1 and Test 2 Text Data
Total wordcount
Total clausecount T-unit count
Top 1000words coverage
Top 1001ndash2000 words
coverage
Test 1 416 56 45 957373 27650Test 2 412 54 42 957373 27650
Note Data measured using vocabulary profiler (Cobb nd) A T-unit or a minimal terminableunit is lsquolsquoone main clause plus any subordinate clausersquorsquo (Hunt 1968 p 4)
276 TESOL QUARTERLY
understood that text better than they actually have Testing whatcomprehenders believe they understoodmdashcompared to what they actuallyunderstoodmdashby comparing test scores to self-assessment of comprehen-sion via a rating scale is often referred to as lsquolsquocomprehension calibrationrsquorsquoand is a method that has been used extensively in psychological research(eg Bransford amp Johnson 1972 Glenberg Wilkinson amp Epstein 1982Maki amp McGuire 2002 Moore Lin-Agler amp Zabrucky 2005) butsomewhat less so in applied linguistics (cf Brantmeier 2006 Jung 2003Morrison 2004 Oh 2001 Sarac amp Tarhan 2009)
Finally participants were asked to record their start and finish timesfor each part of the test
Procedure
Following an initial field test an item analysis was conducted toestablish the facility value6 of the test items and a discrimination indexfor both test parts to discern whether the test was discriminatingbetween stronger and weaker participants Items that were found to haveexceptionally high or low scores were carefully analyzed and the wordingof both test items and reading texts adjusted accordingly
Finally as advocated in Schmitt Schmitt and Clapham (2001) oneimportant requirement of an L2 test of reading comprehension is that itbe answerable by native or nativelike speakers of the language (p 65)To that end a smaller group of native speakers (n 5 8) was also tested asan additional check of the testrsquos validity That group produced a mean
FIGURE 2 Side-by-side comparison of matched texts from the two test parts (full version ofthe test available on request)
4 These are vocabulary profilers that essentially use word frequency lists to break all thewords in a text down into those that occur for example in the top 1000 second 1000third 1000 and so on
5 lsquolsquo0rsquorsquo would be virtually impossible because learners would be familiar with most words inthe texts if not all
6 A test itemrsquos facility value is calculated by dividing the number of participants whoanswered that item correctly by the total number of participants (Hughes 2003)
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 277
score of 28 in Test 1 (the maximum score) and 2775 in Test 2 showingthat both test parts posed very little difficulty for people for whomEnglish is a first language
The students received the two parts of the test in alternating order(ie counterbalanced) to control for any effect of taking Test 1 beforeTest 2 (and vice versa) because by counterbalancing one is able toinclude a variable order into an analysis and identify the extent towhich order affects performance on the dependent measures
RESULTS
All the scores and self-reported comprehension measures wererecorded in a statistical analysis software program (SPSS) Eachparticipantrsquos test results were transcribed into the software item by item(ie correct and incorrect) text by text (eg Text A Text B etc numbercorrect out of 7 for each) and test by test (ie Test 1 and Test 2 numbercorrect out of 28 possible for each) Also recorded were each participantrsquosself-reported comprehension assessments (a rating scale from 5 to 100)as they pertained to each text as well as which version (Test 1 or Test 2first) of the instrument each candidate had received To assess the effectof counterbalancing a repeated measures analysis of variance (ANOVA)was conducted with one within-subjects factor (TEST) with two levels(Test 1 score Test 2 score) and one between-subjects factor (VERSION)with two levels (Test 1 first Test 2 first) This analysis revealed a robustmain effect of test (F (199) 5 59338 p 0001 g2 5 086) and a discreteeffect of version (F (199) 5 405 p 5 0047 g2 5 004) but importantlythere was no significant Test 6 Version interaction (F (199) 5 281 p 5
0097 g2 5 002) illustrating that participantsrsquo scores did not vary as afunction of which version of the test they were completing
Comprehension of Test 1 versus Test 2
The central tendencies from both tests are presented in Table 4As predicted participantsrsquo scores were significantly lower on Test 2
relative to Test 1 (t(100) 5 2410 p 0001) with a strong effect size(g2 5 0828)7 confirming that even when two sets of texts contain theexact same words and even if those words are very commoncomprehension of those texts will not be the same when one containsidiomaticity
7 Confidence intervals at 95 for all t-tests
278 TESOL QUARTERLY
Self-Reported Comprehension of Test 1 versus Test 2
A t-test was also performed on the difference between whatparticipants believed they understood (ie their reported comprehen-sion) and what they actually understood in both Tests 1 and 2 (Table 5)Mean reported comprehension (MRC) was arrived at by calculating themeans of all the self-reported comprehension percentages (5ndash100)and the mean actual comprehension (MAC) is the mean of the score oneach text divided by seven (the maximum score)
MAC was lower than MRC in both Test 1(MRC M 5 08738 SD 013MAC M 5 08603 SD 5 009) and Test 2 (MRC M 5 06029 SD 019MAC M 5 05258 SD 5 014) however the difference between MRCand MAC was statistically reliable in Test 2 only where the test wascomposed of multiword expressions (t(100) 5 395 p 0001 g2 5
007)8 These data therefore appear to support a positive answer to thesecond research questionmdashthat learners may believe they understandmore than they actually do by virtue of their simply understanding theindividual words in a text
Variation in the Data
MRC versus MAC
Naturally there were some individual differences in the test resultsTable 6 shows that roughly one-half of all participants (n 5 50)overestimated their comprehension in both tests (indicated by MRC
TABLE 4
Descriptive Statistics (Tests 1 and 2)
Mean Median Mode Minimum Maximum SD
Test 1a 2409 2500 2500 1800 2800 244Test 2b 1476 1500 1500 600 2500 393
Note SD 5 standard deviation aTexts composed of common words however with little or noopaque phraseology bTexts composed of common words which comprise collocations andidiomatic language
TABLE 5
Reported Versus Actual Comprehension
Test 1 Test 2
Mean reported comprehension (MRC) 8738 6029Mean actual comprehension (MAC) 8603 5258
8 By comparison the results of the paired sample t-test for the Test 1 MRC-MAC means weret(100) 5 104 p 5 0302 g2 5 0005
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 279
greater than MAC) On the surface this might suggest that those 50participants did not overestimate their comprehension in Test 2 as aresult of its relative noncompositionality but rather as a generaltendency regardless of idiomaticity However when MAC is subtractedfrom MRC for that group and the difference compared across the teststhe difference is twice as large in Test 2 (t(49) 5 492 p 0001 g2 5
0108) This difference is even more evident in the same analysis of Test2 alone Isolating the results of that test there was a total of 70participants (over 69 of the entire sample) whose MRC was greaterthan their MAC The difference between MRC minus MAC for thesubgroup of 70 participants reveals that their overestimation of theircomprehension in Test 2 was four times greater than in Test 1 (t(69) 5
770 p 0001 g2 5 0228) Further among that group of 70 whoseTest 2 MRC was greater than their MAC 20 students either under-estimated or actually accurately guessed their comprehension in Test 1but significantly overestimated their comprehension in Test 2 (t(19) 5
849 p 0001 g2 5 0264) Only 30 participants in the present studyactually underestimated their comprehension on Test 2
Variation in Time Spent on the Tests
All candidates were also asked to record their start and finishing timesof each test (Table 7) It is not surprising that on average participantsspent more time on the texts which contained idiomatic expressionsHowever this trend was not uniform among the participants and thetime data may help provide some insight into just how aware someparticipants were of the presence of idiomaticity in the texts Thispossibility is explored further in the Discussion
TABLE 6
Trend of Increase in MRC-MAC Discrepancy Across Test Parts
NMRC minus MAC
(Test 1)MRC minus MAC
(Test 2)
Students with MRC MAC (bothtest parts)
50 009 019
Students with MRC MAC (Test 2) 70 004 017Students with MRC MAC (Test 2only)
20 2010 014
Students with MRC MAC (Test 2) 31a 2005 2015
Note MRC 5 mean reported comprehension MAC 5 mean actual comprehension aOnly oneparticipant in this group had MRC 5 MAC
280 TESOL QUARTERLY
DISCUSSION
To reiterate the present study sought to address the followingresearch questions
1 Are two texts written with the exact same high-frequency wordsunderstood equally well by L2 learners when one of the texts is moreidiomatic than the other
2 Can the presence of multiword expressions in a text lead L2 learners tobelieve they have understood that text better than they actually have
A group of 101 adult Brazilian learners of English was tested using twoseparate measures of reading comprehension (one with idiomaticlanguage and one without) and the results of the two tests were thencompared Although verbal reports would provide even greater insightthe resultant data from this study do seem to support a positive answer tothe first research question Participants achieved significantly lowerscores on the comprehension measure which assessed their under-standing of texts that contain multiword expressions It should bereiterated that this result was obtained in spite of both tests being writtenwith the exact same high-frequency words
Likewise through participantsrsquo self-reported comprehension thereseems to be evidence that the presence of multiword expressions in atext can lead L2 readers to overestimate their assessment of how muchthey have actually understood suggesting a positive answer to the secondresearch question
Although it seems apparent that participantsrsquo reading comprehensionin the present study was adversely affected by idiomaticity this sectionexplores and possibly explains variation in comprehension of the testsand further discusses evidence that multiword expressions negativelyaffected participantsrsquo comprehension
On the Stronger and Weaker Performance in the Tests
There are at least three important revelations emerging from theMRC-MAC data analysis presented in Table 6 First nearly two thirds of
TABLE 7
Time It Took Participants to Take Tests
N Mean time (minutes) SD
Time it took to take Test 1 91a 1085 436Time it took to take Test 2 91 1465 377
Note SD 5 standard deviation aSome participants (n 5 10) forgot to write in the time or left itincomplete
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 281
all participants believed they understood more than they actually did inTest 2 Second the data show that over 28 of those students (n 5 20)did not overestimate their comprehension in Test 1 providing evidencethat whereas they were apparently able to gauge their comprehensionfairly accurately when the texts were relatively devoid of idiomaticitythey were significantly less able to do so when relative noncomposition-ality was present Finally the MRC-MAC data presented so far indicatethat although not all participants tended to overestimate theircomprehension in Test 2 those who did (again the majority of cases)generally did so by a much larger margin Put simply it would seem thatnot only are many learners misunderstanding idiomaticity in text butthey may be doing so more than they (or researchers) realize
Further Evidence of Idiomaticity Negatively AffectingComprehension
The mean difference between MRC and MAC for the 70 students whooverestimated their comprehension in Test 2 (Table 6) was 017 For thesake of argument one could establish an MRC-MAC difference above020 as a cutoff for apparently marked lack of awareness of the extentof idiomaticity in Test 29 comparatively speaking This in turn wouldmean that there were 30 participants who ostensibly demonstrated aparticularly high overestimation of how much of Test 2 they had actuallyunderstood A sample of just the top 10 is provided in Table 8
Table 8 shows not only how different those participantsrsquo MRC wasfrom their Test 2 it also lists the same figures for Test 1 for comparison
9 A t-test reveals that the mean is in fact statistically significant even at the 003 differencelevel (t 5 653 p 5 003)
TABLE 8
Partial List of Participants With Exceptionally High Overestimation of Test 2 Comprehension(Difference 020)
ParticipantMRCTest 1
MACTest 1 Difference
MRCTest 2
MACTest 2 Difference
118 100 089 011 094 032 0626 075 068 007 081 028 05392 081 089 2008 075 025 05090 100 089 011 081 039 042115 100 089 011 087 050 03722 100 096 003 094 057 03780 094 068 026 069 032 03759 094 089 005 069 036 03321 100 093 007 087 057 03050 087 078 009 069 039 029
282 TESOL QUARTERLY
Whereas for Test 1 those 30 participantsrsquo assessment of readingcomprehension was usually only slightly overestimated10 (and in oneinstance even underestimated) the same participants in Test 2 had amarkedly overinflated conception of how much they had understood
Although not intended as a principal source of data for our analysisthe start and finish times recorded by participants on the tests in a fewinstances helped confirm the above assertions11 Table 7 shows thatthere was a significant difference between how long participants spenttaking each test (t 5 852 p 0001) However there were a number ofparticipants (n 5 26) who reported actually spending either the same orless time on Test 2 On the surface at least this fact would indicate thatthose 26 participants did not notice much difference between the testsOf course in reality that datum alone does not provide such evidencebecause that time may simply reflect a number of other confoundingvariables including affective (eg simply giving up) or even social (egthe need to leave early to meet a friend) and for that reason also was notconsidered to be a reliable source of data from those participantsHowever as a complementary source when triangulated with the othervariables some of the data analyzed earlier in the current study areoccasionally fortified further still with the time data (Table 9)
The data in Table 9 in many ways tie together the elements discussedin the analysis thus far in the present study A much lower score in Test 2than in Test 1 (columns B and C) an increase in the mean MRC-MACdifference across the tests (columns H and K) a relatively moderatedecrease in MRC in Test 2 vis-a-vis Test 1 (columns F and I) a markeddifference between MRC and MAC in Test 2 (column K) and theoccasional lack of increase (in Table 9 participants 118 80 59 and 50)in time it took to take Test 2 (columns D and E) These findings ontheir own in combination and especially in concert provide evidencethat (1) the students in Table 9 did not seem to appreciate the fullextent of the idiomaticity in Test 2 and (2) they appeared to think thatthey understood more than they actually did in Test 2
Perhaps most important 98 of all participants (n 5 99) scoredsignificantly lower on Test 2 (mean difference of 953 points out of 28SD 5 363) which shows that learners are generally unable to guess themeaning of idiomatic language even in the (largely inconsistent)instances in which they become aware of its presence
11 It should be noted that because 10 of the participantsrsquo time data were left incomplete afull group analysis could not be carried out thus the time data are only included asauxiliary information
10 As can be seen in Table 8 in fact only one participantmdashnumber 80mdashactually had anMRC-MAC difference in Test 1 that was also 020 Those of the other 29 participantswere all lower
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 283
For example the first participant in Tables 8 and 9 (number 118)who consistently overrated his own comprehension relative to his actualcomprehension answered for Text A of Test 2 as shown in Figure 3
On the basis of the responses it is likely that participant 118associated itrsquos about time with lsquolsquohas a problem with timersquorsquo Irsquom a little over thehill with lsquolsquohe probably lives in an area with hillsrsquorsquo and lsquolsquohe lives on the hill
TABLE 9
Triangulated Data Showing Negative Effect of Idiomaticity on Comprehension
A B C D E F G H I J K
Score Time Test 1 Test 2
Partic-ipant Test 1 Test 2 Test 1 Test 2 MRC MAC
Differ-ence MRC MAC
Differ-ence
118 25 9 2000 1800 100 089 11 094 032 0626 19 8 Missing Missing 075 068 007 081 028 05392 25 8 900 1100 081 089 2008 075 025 05090 25 11 900 1500 100 089 011 081 039 042115 25 14 1300 1500 100 089 011 087 050 03722 27 16 Missing Missing 100 096 003 094 057 03780 19 9 1000 1000 094 068 026 069 032 03759 25 10 1500 1400 094 089 005 069 036 03321 26 16 Missing Missing 100 093 007 087 057 03050 22 11 2000 1200 088 079 009 069 039 030
12 Of the 24 multiword expressions targeted for assessment of comprehension in Test 2 onlyfour were core idioms
FIGURE 3 Sample answer to Text A of Test 2
284 TESOL QUARTERLY
but not on top of itrsquorsquomdasha literal reading of those expressions His 100self-assessment is an indication that his answers were not guesses butinstead based on confidence that he had understood all the individualwords in the text The same answering dynamic occurred time and timeagain in Test 2
Returning therefore to the issues raised in the introduction thepresent research appears to provide evidence that idiomsmdashopaque orotherwise12mdashcan in fact cause major problems for L2 learners of Englishwhen reading In general the participants in our study were lesssuccessful at guessing the meaning of idioms than those in previousidiom-centered research such as Cooper (1999) and Liontas (2002)Because the learners in our study were not alerted to the presence ofidiomaticity in the text prior to reading this study may more accuratelyreflect what takes place in more naturally occurring L2 reading Finallythe difficulties that the participants encountered occurred in textscomposed purely of very common words showing that word frequencyalone is not necessarily a good measure of text coverage Lauferrsquos(1989a) hypothesis that much lexis in text can be deceptivelytransparent is confirmed in the present research extended to multiwordexpressions
Limitations of the Research
Although the research presented here does provide some significantevidence that the presence of idiomaticity in a text can negatively affectthe comprehension of that text by an L2 reader little is known about thestrategies the test takers employed Even though metacognition wasoutside the scope of examination of the present study such informationis highly relevant and future research should include protocols such asthose included in previous research on idioms (eg Liontas 20032007) which may provide crucial qualitative data regarding theindividual differences and behavior of the participants themselvesOverall future work in this area should consider making use of differentmeasures of self-assessment in order to explore the limitations of themethodology used in the present study
Also a question can be asked concerning the relative density ofmultiword expressions in each text In other words what is not known ison average how many such items a reader can expect to encounter Theratio of idioms to orthographic words in the texts tested in the presentstudy is very likely higher than averagemdashbut how much higher is as yetunknown Likewise the passages themselves were relatively short so it isunknown whether or not texts of greater length (and thereforecontextualization) would render the same or similar results
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 285
CONCLUSION
The present study provides some empirical evidence that a focus onword in L2 pedagogy may be detrimental to learnersrsquo development ofreading comprehension in the target language In most casesparticipants overestimated how much they had understood the textstested when those texts contained multiword expressions of varyingdegrees of compositionality comprised of very common individualwords Even when participants showed evidence of awareness of apresence of idiomaticity in the texts they generally were not very good atguessing the meaning of expressions Although Grant and Nation(2006) could be right that the teaching of individual idioms may not belsquolsquodeserving of class timersquorsquo (p 5) it is clear that at the very least raisinglearnersrsquo consciousness as to their prevalence and frequently deceptivetransparency in text certainly is
Concomitantly the present research serves to demonstrate theincompleteness of current lists of common words which now informimportant pedagogical instruments such as vocabulary tests gradedreaders and course syllabuses Under current methods as illustrated inthe Table 2 analysis of the Economist paragraph a text measured againstthe word lists now commonly in use can be mistakenly analyzed as beingeasily understood when in fact once multiword expressions are takeninto account the actual text coverage of easily understood words is farless Existing estimates of how many words one needs to know in order toadequately process naturally occurring texts (Hu amp Nation 2000Nation 2006) may need to be revisited to determine how many wordsand multiword expressions one needs to know
In practice research shows that learners will continue to believe theyunderstand items that they actually do not even after repeatedexposures to that same item (Bensoussan amp Laufer 1984 Haynes1993 Pigada amp Schmitt 2006) Language teachers and relatedprofessionals such as textbook writers need to consider ways tocontinuously help learners notice the gap between what they think theyknow and understand and what they actually do (Laufer 1997) Oneway this can be achieved has already been thoroughly discussed in thepresent paper devise texts (and tests) designed to lead readers down anidiomatic garden path Norbert Schmitt (as cited in Weir 2005) made asimilar recommendation
Perhaps the best and most valid type of vocabulary test is a reading passagewith comprehension questions but with the items requiring a full under-standing of particular words or phrases in the text This would mimic the realworld task of reading for comprehension and also the loss of comprehensionwhen key vocabulary is not known (p 123)
286 TESOL QUARTERLY
Therefore a further implication this research has for L2 pedagogy is themore careful design of the reading component of proficiency tests suchas IELTS (International English Language Testing System) and Test ofEnglish as a Foreign Language to be more strategic regarding the amountand kind of phraseology contained in the texts Proficiency was not thecentral focus of our study and future research could adopt a similarmethodology but with the inclusion of proficiency measures ofparticipants in order to explore how various types of expressions (egnoncompositional figurative imageable etc) may differentially affectpreidentified proficiency levels
Thus in order to be more methodical about such things as theinclusion of formulaic language in L2 tests and reading input in generalan important preliminary step will be to establish (a) what type offormulaic sequences are good discriminators of proficiency thresholdlevels and (b) which expressions of that identified type are mostcommon In other words what will be usefulmdashand is indeed nowbeginning to emerge (Martinez amp Schmitt 2010 Shin amp Nation 2008Simpson-Vlach amp Ellis 2010)mdashare lists of formulaic sequences that servea function similar to that of the General Service List not to revolutionizecurrent language pedagogy but to more finely tune it
THE AUTHORS
Ron Martinez is currently pursuing a doctorate at the University of NottinghamNottingham England on the topic of inclusion of phraseology in languageassessment He specializes in second language materials development
Victoria Murphy is a lecturer in Applied Linguistics and Second LanguageAcquisition at the University of Oxford Oxford England Her research interestsinclude the lexical development of first language or second language learners andthe cognitive processes that underlie language acquisition
REFERENCES
Bauer L amp Nation P (1993) Word families International Journal of Lexicography 6253ndash279 doi101093ijl64253
Bensoussan M amp Laufer B (1984) Lexical guessing in context in EFL readingcomprehension Journal of Research in Reading 7 15ndash32 doi101111j1467-98171984tb00252x
Bishop H (2004) Noticing formulaic sequences A problem of measuring thesubjective LSO Working Papers in Linguistics 4 15ndash19
Bransford D B amp Johnson M K (1972) Contextual prerequisites for under-standing Some investigations of comprehension and recall Journal of VerbalLearning and Verbal Behavior 11 717ndash726 doi101016S0022-5371(72)80006-9
Brantmeier C (2006) Advanced L2 learners and reading placement Self-assessment CBT and subsequent performance System 34 15ndash35 doi101016jsystem200508004
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 287
Carver R P (1994) Percentage of unknown vocabulary words in text as a functionof the relative difficulty of the text Implications for instruction Journal of ReadingBehavior 26 413ndash437
Cobb T (nd) Web VocabProfile [Online program] Retrieved from httpwwwlextutorcavp [an adaption of A Heatley amp P Nation Range (1994)]
Cooper T C (1999) Processing of idioms by L2 learners of English TESOLQuarterly 33 233ndash262 doi1023073587719
Coxhead A (2000) A new academic word list TESOL Quarterly 34 213ndash238doi1023073587951
Elley W amp Mangubhai F (1983) The impact of reading on second languagelearning Reading Research Quarterly 19 53ndash67 doi102307747337
Ellis N C (2008) Phraseology The periphery and the heart of language In FMeunier amp S Granger (Eds) Phraseology in language learning and teaching (pp 1ndash13) Amsterdam The Netherlands John Benjamins
Erman B amp Warren B (2000) The idiom principle and the open choice principleText 20 29ndash62
Gardner D (2007) Validating the construct of Word in applied corpus-basedvocabulary research A critical survey Applied Linguistics 28 241ndash265doi101093applinamm010
Glenberg A M Wilkinson A C amp Epstein W (1982) The illusion of knowingFailure in the self-assessment of comprehension Memory and Cognition 10 597ndash602 doi103758BF03202442
Goulden R Nation P amp Read J (1990) How large can a receptive vocabulary beApplied Linguistics 11 341ndash363 doi101093applin114341
Grant L amp Bauer L (2004) Criteria for re-defining idioms Are we barking up thewrong tree Applied Linguistics 25 38ndash61 doi101093applin25138
Grant L amp Nation P (2006) How many idioms are there in English ITL -International Journal of Applied Linguistics 151 1ndash14 doi102143ITL15102015219
Haynes M (1993) Patterns and perils of guessing in second language reading In THuckin M Haynes amp J Coady (Eds) Second language reading and vocabularylearning (pp 46ndash64) Norwood NJ Ablex Publishing Corporation
Heatley A amp Nation P (1994) Range [Computer program] Wellington NewZealand Victoria University of Wellington Retrieved from httpwwwvuwacnzlals
Hill J (2000) Revising priorities From grammatical failure to collocational successIn M Lewis (Ed) Teaching collocation Further developments in the Lexical Approach(pp 47ndash69) Hove England LTP
Hirsh D amp Nation P (1992) What vocabulary size is needed to read unsimplifiedtexts for pleasure Reading in a Foreign Language 8 689ndash696
Hu H M amp Nation P (2000) Unknown vocabulary density and readingcomprehension Reading in a Foreign Language 13 403ndash429
Hughes A (2003) Testing for language teachers Cambridge England CambridgeUniversity Press
Hunt K (1968) An instrument to measure syntactic maturity Tallahassee FL USDepartment of Health Education and Welfare
Jung E H (2003) The effects of organization markers on ESL learnersrsquo textunderstanding TESOL Quarterly 37 749ndash759 doi1023073588223
Krashen S (1993) The power of reading Insights from research Englewood COLibraries Unlimited
Laufer B (1989a) A factor of difficulty in vocabulary learning Deceptivetransparency AILA Review 6 10ndash20
288 TESOL QUARTERLY
Laufer B (1989b) What percentage of lexis is essential for comprehension In CLauren amp M Nordman (Eds) Special language From humans thinking to thinkingmachines (pp 316ndash323) London England Multilingual Matters
Laufer B (1991) How much lexis is necessary for reading comprehension In P JL Arnaud amp H Bejoint (Eds) Vocabulary and applied linguistics (pp 126ndash132)Oxford England Macmillan
Laufer B (1997) The lexical plight in second language reading Words you donrsquotknow words you think you know and words you canrsquot guess In J Coady amp THuckin (Eds) Second language vocabulary acquisition (pp 20ndash34) CambridgeEngland Cambridge University Press
Lewis M (1993) The Lexical Approach The state of ELT and a way forward HoveEngland LTP
Liontas J I (2002) Context and idiom understanding in second languagesEUROSLA Yearbook 2 155ndash185
Liontas J I (2003) Killing two birds with one stone Understanding Spanish VPidioms in and out of context Hispania 86 289ndash301 doi10230720062862
Liontas J I (2007) The eye never sees what the brain understands Making sense ofidioms in second languages Lingua et Linguistica 1) 25ndash44
Maki R H amp McGuire M J (2002) Metacognition for text Findings andimplications for education In T Schwarz amp L Bennett (Eds) Appliedmetacognition (pp 39ndash67) Cambridge England Cambridge University Press
Martinez R amp Schmitt N (2010) A phrasal expressions listManuscript submitted forpublication
Moon R (1997) Vocabulary connections Multi-word items in English In NSchmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 40ndash63) Cambridge England Cambridge University Press
Moore D Lin-Agler L M amp Zabrucky K M (2005) A source of metacomprehen-sion inaccuracy Reading Psychology 26 251ndash265 doi10108002702710590962578
Morrison L (2004) Comprehension monitoring in first and second languagereading The Canadian Modern Language Review 61 77ndash106
Nation I S P (2001) Learning vocabulary in another language Cambridge EnglandCambridge University Press
Nation I S P (2006) How large a vocabulary is needed for reading and listeningThe Canadian Modern Language Review 63 59ndash82
Nation I S P amp Waring R (1997) Vocabulary size text coverage and word lists InN Schmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 6ndash19) Cambridge England Cambridge University Press
Nation P (1997) The language learning benefits of extensive reading LanguageTeacher 21 13ndash16
Nattinger J R amp DeCarrico J S (1992) Lexical phrases and language teachingOxford England Oxford University Press
Oh S Y (2001) Two types of input modification and EFL reading comprehensionSimplification versus elaboration TESOL Quarterly 35 69ndash96 doi1023073587860
OrsquoKeeffe A McCarthy M amp Carter R (2007) From corpus to classroom Language useand language teaching Cambridge England Cambridge University Press
Pawley A amp Syder F H (1983) Two puzzles for linguistic theory Nativelikeselection and nativelike fluency In J C Richards amp R Schmidt (Eds) Languageand communication (pp 191ndash226) New York NY Longman
Pigada M amp Schmitt N (2006) Vocabulary acquisition from extensive reading Acase study Reading in a Foreign Language 18 1ndash28
Read J (2004) Research in teaching vocabulary Annual Review of Applied Linguistics24 146ndash161 doi101017S0267190504000078
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 289
Sarac S amp Tarhan B (2009) Calibration of comprehension and performance inL2 reading International Electronic Journal of Elementary Education 2 167ndash179
Schmitt N Jiang N amp Grabe W (2011) The percentage of words known in a textand reading comprehension Modern Language Journal 95(1) 26ndash43
Schmitt N Schmitt D amp Clapham C (2001) Developing and exploring thebehaviour of two new versions of the Vocabulary Levels Test Language Testing 1855ndash88
Shin D amp Nation I S P (2008) Beyond single words The most frequentcollocations in spoken English ELT Journal 62 339ndash348 doi101093eltccm091
Simpson-Vlach R amp Ellis N C (2010) An academic formulas list New methods inphraseology research Applied Linguistics 31(4) 487ndash512
Sinclair J (1991) Corpus concordance collocation Oxford England OxfordUniversity Press
Spottl C amp McCarthy M (2003) Formulaic utterances in the multi-lingual contextIn J Cenoz B Hufeisen ampU Jessner (Eds) The multilingual lexicon (pp 133ndash151) Dordrecht The Netherlands Kluwer
Staelighr L S (2008) Vocabulary size and the skills of listening reading and writingLanguage Learning Journal 36 139ndash152 doi10108009571730802389975
Stubbs M amp Barth I (2003) Using recurrent phrases as text-type descriminators Aquantitative method and some findings Functions of Language 10 61ndash104doi101075fol10104stu
The British National Corpus (2007) The British National Corpus(version 3 BNC XMLed) [CD-ROM] Distributed by Oxford University Computing Services on behalfof the BNC Consortium
The iPhonersquos second coming (2008 July) The Economist Retrieved from httpwwweconomistcomscience-technologydisplaystorycfmstory_id5E1_TTSDDJTG
Walter E Woodford K amp Good M (Eds) (2008) Cambridge advanced learnerrsquosdictionary (3rd ed) Cambridge England Cambridge University Press
Weir C J (2005) Language testing and validation An evidence-based approachNew York NY Palgrave Macmillan
West M (1953) A general service list of English words London England LongmanWray A (2002) Formulaic language and the lexicon Cambridge England Cambridge
University Press
290 TESOL QUARTERLY

understood that text better than they actually have Testing whatcomprehenders believe they understoodmdashcompared to what they actuallyunderstoodmdashby comparing test scores to self-assessment of comprehen-sion via a rating scale is often referred to as lsquolsquocomprehension calibrationrsquorsquoand is a method that has been used extensively in psychological research(eg Bransford amp Johnson 1972 Glenberg Wilkinson amp Epstein 1982Maki amp McGuire 2002 Moore Lin-Agler amp Zabrucky 2005) butsomewhat less so in applied linguistics (cf Brantmeier 2006 Jung 2003Morrison 2004 Oh 2001 Sarac amp Tarhan 2009)
Finally participants were asked to record their start and finish timesfor each part of the test
Procedure
Following an initial field test an item analysis was conducted toestablish the facility value6 of the test items and a discrimination indexfor both test parts to discern whether the test was discriminatingbetween stronger and weaker participants Items that were found to haveexceptionally high or low scores were carefully analyzed and the wordingof both test items and reading texts adjusted accordingly
Finally as advocated in Schmitt Schmitt and Clapham (2001) oneimportant requirement of an L2 test of reading comprehension is that itbe answerable by native or nativelike speakers of the language (p 65)To that end a smaller group of native speakers (n 5 8) was also tested asan additional check of the testrsquos validity That group produced a mean
FIGURE 2 Side-by-side comparison of matched texts from the two test parts (full version ofthe test available on request)
4 These are vocabulary profilers that essentially use word frequency lists to break all thewords in a text down into those that occur for example in the top 1000 second 1000third 1000 and so on
5 lsquolsquo0rsquorsquo would be virtually impossible because learners would be familiar with most words inthe texts if not all
6 A test itemrsquos facility value is calculated by dividing the number of participants whoanswered that item correctly by the total number of participants (Hughes 2003)
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 277
score of 28 in Test 1 (the maximum score) and 2775 in Test 2 showingthat both test parts posed very little difficulty for people for whomEnglish is a first language
The students received the two parts of the test in alternating order(ie counterbalanced) to control for any effect of taking Test 1 beforeTest 2 (and vice versa) because by counterbalancing one is able toinclude a variable order into an analysis and identify the extent towhich order affects performance on the dependent measures
RESULTS
All the scores and self-reported comprehension measures wererecorded in a statistical analysis software program (SPSS) Eachparticipantrsquos test results were transcribed into the software item by item(ie correct and incorrect) text by text (eg Text A Text B etc numbercorrect out of 7 for each) and test by test (ie Test 1 and Test 2 numbercorrect out of 28 possible for each) Also recorded were each participantrsquosself-reported comprehension assessments (a rating scale from 5 to 100)as they pertained to each text as well as which version (Test 1 or Test 2first) of the instrument each candidate had received To assess the effectof counterbalancing a repeated measures analysis of variance (ANOVA)was conducted with one within-subjects factor (TEST) with two levels(Test 1 score Test 2 score) and one between-subjects factor (VERSION)with two levels (Test 1 first Test 2 first) This analysis revealed a robustmain effect of test (F (199) 5 59338 p 0001 g2 5 086) and a discreteeffect of version (F (199) 5 405 p 5 0047 g2 5 004) but importantlythere was no significant Test 6 Version interaction (F (199) 5 281 p 5
0097 g2 5 002) illustrating that participantsrsquo scores did not vary as afunction of which version of the test they were completing
Comprehension of Test 1 versus Test 2
The central tendencies from both tests are presented in Table 4As predicted participantsrsquo scores were significantly lower on Test 2
relative to Test 1 (t(100) 5 2410 p 0001) with a strong effect size(g2 5 0828)7 confirming that even when two sets of texts contain theexact same words and even if those words are very commoncomprehension of those texts will not be the same when one containsidiomaticity
7 Confidence intervals at 95 for all t-tests
278 TESOL QUARTERLY
Self-Reported Comprehension of Test 1 versus Test 2
A t-test was also performed on the difference between whatparticipants believed they understood (ie their reported comprehen-sion) and what they actually understood in both Tests 1 and 2 (Table 5)Mean reported comprehension (MRC) was arrived at by calculating themeans of all the self-reported comprehension percentages (5ndash100)and the mean actual comprehension (MAC) is the mean of the score oneach text divided by seven (the maximum score)
MAC was lower than MRC in both Test 1(MRC M 5 08738 SD 013MAC M 5 08603 SD 5 009) and Test 2 (MRC M 5 06029 SD 019MAC M 5 05258 SD 5 014) however the difference between MRCand MAC was statistically reliable in Test 2 only where the test wascomposed of multiword expressions (t(100) 5 395 p 0001 g2 5
007)8 These data therefore appear to support a positive answer to thesecond research questionmdashthat learners may believe they understandmore than they actually do by virtue of their simply understanding theindividual words in a text
Variation in the Data
MRC versus MAC
Naturally there were some individual differences in the test resultsTable 6 shows that roughly one-half of all participants (n 5 50)overestimated their comprehension in both tests (indicated by MRC
TABLE 4
Descriptive Statistics (Tests 1 and 2)
Mean Median Mode Minimum Maximum SD
Test 1a 2409 2500 2500 1800 2800 244Test 2b 1476 1500 1500 600 2500 393
Note SD 5 standard deviation aTexts composed of common words however with little or noopaque phraseology bTexts composed of common words which comprise collocations andidiomatic language
TABLE 5
Reported Versus Actual Comprehension
Test 1 Test 2
Mean reported comprehension (MRC) 8738 6029Mean actual comprehension (MAC) 8603 5258
8 By comparison the results of the paired sample t-test for the Test 1 MRC-MAC means weret(100) 5 104 p 5 0302 g2 5 0005
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 279
greater than MAC) On the surface this might suggest that those 50participants did not overestimate their comprehension in Test 2 as aresult of its relative noncompositionality but rather as a generaltendency regardless of idiomaticity However when MAC is subtractedfrom MRC for that group and the difference compared across the teststhe difference is twice as large in Test 2 (t(49) 5 492 p 0001 g2 5
0108) This difference is even more evident in the same analysis of Test2 alone Isolating the results of that test there was a total of 70participants (over 69 of the entire sample) whose MRC was greaterthan their MAC The difference between MRC minus MAC for thesubgroup of 70 participants reveals that their overestimation of theircomprehension in Test 2 was four times greater than in Test 1 (t(69) 5
770 p 0001 g2 5 0228) Further among that group of 70 whoseTest 2 MRC was greater than their MAC 20 students either under-estimated or actually accurately guessed their comprehension in Test 1but significantly overestimated their comprehension in Test 2 (t(19) 5
849 p 0001 g2 5 0264) Only 30 participants in the present studyactually underestimated their comprehension on Test 2
Variation in Time Spent on the Tests
All candidates were also asked to record their start and finishing timesof each test (Table 7) It is not surprising that on average participantsspent more time on the texts which contained idiomatic expressionsHowever this trend was not uniform among the participants and thetime data may help provide some insight into just how aware someparticipants were of the presence of idiomaticity in the texts Thispossibility is explored further in the Discussion
TABLE 6
Trend of Increase in MRC-MAC Discrepancy Across Test Parts
NMRC minus MAC
(Test 1)MRC minus MAC
(Test 2)
Students with MRC MAC (bothtest parts)
50 009 019
Students with MRC MAC (Test 2) 70 004 017Students with MRC MAC (Test 2only)
20 2010 014
Students with MRC MAC (Test 2) 31a 2005 2015
Note MRC 5 mean reported comprehension MAC 5 mean actual comprehension aOnly oneparticipant in this group had MRC 5 MAC
280 TESOL QUARTERLY
DISCUSSION
To reiterate the present study sought to address the followingresearch questions
1 Are two texts written with the exact same high-frequency wordsunderstood equally well by L2 learners when one of the texts is moreidiomatic than the other
2 Can the presence of multiword expressions in a text lead L2 learners tobelieve they have understood that text better than they actually have
A group of 101 adult Brazilian learners of English was tested using twoseparate measures of reading comprehension (one with idiomaticlanguage and one without) and the results of the two tests were thencompared Although verbal reports would provide even greater insightthe resultant data from this study do seem to support a positive answer tothe first research question Participants achieved significantly lowerscores on the comprehension measure which assessed their under-standing of texts that contain multiword expressions It should bereiterated that this result was obtained in spite of both tests being writtenwith the exact same high-frequency words
Likewise through participantsrsquo self-reported comprehension thereseems to be evidence that the presence of multiword expressions in atext can lead L2 readers to overestimate their assessment of how muchthey have actually understood suggesting a positive answer to the secondresearch question
Although it seems apparent that participantsrsquo reading comprehensionin the present study was adversely affected by idiomaticity this sectionexplores and possibly explains variation in comprehension of the testsand further discusses evidence that multiword expressions negativelyaffected participantsrsquo comprehension
On the Stronger and Weaker Performance in the Tests
There are at least three important revelations emerging from theMRC-MAC data analysis presented in Table 6 First nearly two thirds of
TABLE 7
Time It Took Participants to Take Tests
N Mean time (minutes) SD
Time it took to take Test 1 91a 1085 436Time it took to take Test 2 91 1465 377
Note SD 5 standard deviation aSome participants (n 5 10) forgot to write in the time or left itincomplete
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 281
all participants believed they understood more than they actually did inTest 2 Second the data show that over 28 of those students (n 5 20)did not overestimate their comprehension in Test 1 providing evidencethat whereas they were apparently able to gauge their comprehensionfairly accurately when the texts were relatively devoid of idiomaticitythey were significantly less able to do so when relative noncomposition-ality was present Finally the MRC-MAC data presented so far indicatethat although not all participants tended to overestimate theircomprehension in Test 2 those who did (again the majority of cases)generally did so by a much larger margin Put simply it would seem thatnot only are many learners misunderstanding idiomaticity in text butthey may be doing so more than they (or researchers) realize
Further Evidence of Idiomaticity Negatively AffectingComprehension
The mean difference between MRC and MAC for the 70 students whooverestimated their comprehension in Test 2 (Table 6) was 017 For thesake of argument one could establish an MRC-MAC difference above020 as a cutoff for apparently marked lack of awareness of the extentof idiomaticity in Test 29 comparatively speaking This in turn wouldmean that there were 30 participants who ostensibly demonstrated aparticularly high overestimation of how much of Test 2 they had actuallyunderstood A sample of just the top 10 is provided in Table 8
Table 8 shows not only how different those participantsrsquo MRC wasfrom their Test 2 it also lists the same figures for Test 1 for comparison
9 A t-test reveals that the mean is in fact statistically significant even at the 003 differencelevel (t 5 653 p 5 003)
TABLE 8
Partial List of Participants With Exceptionally High Overestimation of Test 2 Comprehension(Difference 020)
ParticipantMRCTest 1
MACTest 1 Difference
MRCTest 2
MACTest 2 Difference
118 100 089 011 094 032 0626 075 068 007 081 028 05392 081 089 2008 075 025 05090 100 089 011 081 039 042115 100 089 011 087 050 03722 100 096 003 094 057 03780 094 068 026 069 032 03759 094 089 005 069 036 03321 100 093 007 087 057 03050 087 078 009 069 039 029
282 TESOL QUARTERLY
Whereas for Test 1 those 30 participantsrsquo assessment of readingcomprehension was usually only slightly overestimated10 (and in oneinstance even underestimated) the same participants in Test 2 had amarkedly overinflated conception of how much they had understood
Although not intended as a principal source of data for our analysisthe start and finish times recorded by participants on the tests in a fewinstances helped confirm the above assertions11 Table 7 shows thatthere was a significant difference between how long participants spenttaking each test (t 5 852 p 0001) However there were a number ofparticipants (n 5 26) who reported actually spending either the same orless time on Test 2 On the surface at least this fact would indicate thatthose 26 participants did not notice much difference between the testsOf course in reality that datum alone does not provide such evidencebecause that time may simply reflect a number of other confoundingvariables including affective (eg simply giving up) or even social (egthe need to leave early to meet a friend) and for that reason also was notconsidered to be a reliable source of data from those participantsHowever as a complementary source when triangulated with the othervariables some of the data analyzed earlier in the current study areoccasionally fortified further still with the time data (Table 9)
The data in Table 9 in many ways tie together the elements discussedin the analysis thus far in the present study A much lower score in Test 2than in Test 1 (columns B and C) an increase in the mean MRC-MACdifference across the tests (columns H and K) a relatively moderatedecrease in MRC in Test 2 vis-a-vis Test 1 (columns F and I) a markeddifference between MRC and MAC in Test 2 (column K) and theoccasional lack of increase (in Table 9 participants 118 80 59 and 50)in time it took to take Test 2 (columns D and E) These findings ontheir own in combination and especially in concert provide evidencethat (1) the students in Table 9 did not seem to appreciate the fullextent of the idiomaticity in Test 2 and (2) they appeared to think thatthey understood more than they actually did in Test 2
Perhaps most important 98 of all participants (n 5 99) scoredsignificantly lower on Test 2 (mean difference of 953 points out of 28SD 5 363) which shows that learners are generally unable to guess themeaning of idiomatic language even in the (largely inconsistent)instances in which they become aware of its presence
11 It should be noted that because 10 of the participantsrsquo time data were left incomplete afull group analysis could not be carried out thus the time data are only included asauxiliary information
10 As can be seen in Table 8 in fact only one participantmdashnumber 80mdashactually had anMRC-MAC difference in Test 1 that was also 020 Those of the other 29 participantswere all lower
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 283
For example the first participant in Tables 8 and 9 (number 118)who consistently overrated his own comprehension relative to his actualcomprehension answered for Text A of Test 2 as shown in Figure 3
On the basis of the responses it is likely that participant 118associated itrsquos about time with lsquolsquohas a problem with timersquorsquo Irsquom a little over thehill with lsquolsquohe probably lives in an area with hillsrsquorsquo and lsquolsquohe lives on the hill
TABLE 9
Triangulated Data Showing Negative Effect of Idiomaticity on Comprehension
A B C D E F G H I J K
Score Time Test 1 Test 2
Partic-ipant Test 1 Test 2 Test 1 Test 2 MRC MAC
Differ-ence MRC MAC
Differ-ence
118 25 9 2000 1800 100 089 11 094 032 0626 19 8 Missing Missing 075 068 007 081 028 05392 25 8 900 1100 081 089 2008 075 025 05090 25 11 900 1500 100 089 011 081 039 042115 25 14 1300 1500 100 089 011 087 050 03722 27 16 Missing Missing 100 096 003 094 057 03780 19 9 1000 1000 094 068 026 069 032 03759 25 10 1500 1400 094 089 005 069 036 03321 26 16 Missing Missing 100 093 007 087 057 03050 22 11 2000 1200 088 079 009 069 039 030
12 Of the 24 multiword expressions targeted for assessment of comprehension in Test 2 onlyfour were core idioms
FIGURE 3 Sample answer to Text A of Test 2
284 TESOL QUARTERLY
but not on top of itrsquorsquomdasha literal reading of those expressions His 100self-assessment is an indication that his answers were not guesses butinstead based on confidence that he had understood all the individualwords in the text The same answering dynamic occurred time and timeagain in Test 2
Returning therefore to the issues raised in the introduction thepresent research appears to provide evidence that idiomsmdashopaque orotherwise12mdashcan in fact cause major problems for L2 learners of Englishwhen reading In general the participants in our study were lesssuccessful at guessing the meaning of idioms than those in previousidiom-centered research such as Cooper (1999) and Liontas (2002)Because the learners in our study were not alerted to the presence ofidiomaticity in the text prior to reading this study may more accuratelyreflect what takes place in more naturally occurring L2 reading Finallythe difficulties that the participants encountered occurred in textscomposed purely of very common words showing that word frequencyalone is not necessarily a good measure of text coverage Lauferrsquos(1989a) hypothesis that much lexis in text can be deceptivelytransparent is confirmed in the present research extended to multiwordexpressions
Limitations of the Research
Although the research presented here does provide some significantevidence that the presence of idiomaticity in a text can negatively affectthe comprehension of that text by an L2 reader little is known about thestrategies the test takers employed Even though metacognition wasoutside the scope of examination of the present study such informationis highly relevant and future research should include protocols such asthose included in previous research on idioms (eg Liontas 20032007) which may provide crucial qualitative data regarding theindividual differences and behavior of the participants themselvesOverall future work in this area should consider making use of differentmeasures of self-assessment in order to explore the limitations of themethodology used in the present study
Also a question can be asked concerning the relative density ofmultiword expressions in each text In other words what is not known ison average how many such items a reader can expect to encounter Theratio of idioms to orthographic words in the texts tested in the presentstudy is very likely higher than averagemdashbut how much higher is as yetunknown Likewise the passages themselves were relatively short so it isunknown whether or not texts of greater length (and thereforecontextualization) would render the same or similar results
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 285
CONCLUSION
The present study provides some empirical evidence that a focus onword in L2 pedagogy may be detrimental to learnersrsquo development ofreading comprehension in the target language In most casesparticipants overestimated how much they had understood the textstested when those texts contained multiword expressions of varyingdegrees of compositionality comprised of very common individualwords Even when participants showed evidence of awareness of apresence of idiomaticity in the texts they generally were not very good atguessing the meaning of expressions Although Grant and Nation(2006) could be right that the teaching of individual idioms may not belsquolsquodeserving of class timersquorsquo (p 5) it is clear that at the very least raisinglearnersrsquo consciousness as to their prevalence and frequently deceptivetransparency in text certainly is
Concomitantly the present research serves to demonstrate theincompleteness of current lists of common words which now informimportant pedagogical instruments such as vocabulary tests gradedreaders and course syllabuses Under current methods as illustrated inthe Table 2 analysis of the Economist paragraph a text measured againstthe word lists now commonly in use can be mistakenly analyzed as beingeasily understood when in fact once multiword expressions are takeninto account the actual text coverage of easily understood words is farless Existing estimates of how many words one needs to know in order toadequately process naturally occurring texts (Hu amp Nation 2000Nation 2006) may need to be revisited to determine how many wordsand multiword expressions one needs to know
In practice research shows that learners will continue to believe theyunderstand items that they actually do not even after repeatedexposures to that same item (Bensoussan amp Laufer 1984 Haynes1993 Pigada amp Schmitt 2006) Language teachers and relatedprofessionals such as textbook writers need to consider ways tocontinuously help learners notice the gap between what they think theyknow and understand and what they actually do (Laufer 1997) Oneway this can be achieved has already been thoroughly discussed in thepresent paper devise texts (and tests) designed to lead readers down anidiomatic garden path Norbert Schmitt (as cited in Weir 2005) made asimilar recommendation
Perhaps the best and most valid type of vocabulary test is a reading passagewith comprehension questions but with the items requiring a full under-standing of particular words or phrases in the text This would mimic the realworld task of reading for comprehension and also the loss of comprehensionwhen key vocabulary is not known (p 123)
286 TESOL QUARTERLY
Therefore a further implication this research has for L2 pedagogy is themore careful design of the reading component of proficiency tests suchas IELTS (International English Language Testing System) and Test ofEnglish as a Foreign Language to be more strategic regarding the amountand kind of phraseology contained in the texts Proficiency was not thecentral focus of our study and future research could adopt a similarmethodology but with the inclusion of proficiency measures ofparticipants in order to explore how various types of expressions (egnoncompositional figurative imageable etc) may differentially affectpreidentified proficiency levels
Thus in order to be more methodical about such things as theinclusion of formulaic language in L2 tests and reading input in generalan important preliminary step will be to establish (a) what type offormulaic sequences are good discriminators of proficiency thresholdlevels and (b) which expressions of that identified type are mostcommon In other words what will be usefulmdashand is indeed nowbeginning to emerge (Martinez amp Schmitt 2010 Shin amp Nation 2008Simpson-Vlach amp Ellis 2010)mdashare lists of formulaic sequences that servea function similar to that of the General Service List not to revolutionizecurrent language pedagogy but to more finely tune it
THE AUTHORS
Ron Martinez is currently pursuing a doctorate at the University of NottinghamNottingham England on the topic of inclusion of phraseology in languageassessment He specializes in second language materials development
Victoria Murphy is a lecturer in Applied Linguistics and Second LanguageAcquisition at the University of Oxford Oxford England Her research interestsinclude the lexical development of first language or second language learners andthe cognitive processes that underlie language acquisition
REFERENCES
Bauer L amp Nation P (1993) Word families International Journal of Lexicography 6253ndash279 doi101093ijl64253
Bensoussan M amp Laufer B (1984) Lexical guessing in context in EFL readingcomprehension Journal of Research in Reading 7 15ndash32 doi101111j1467-98171984tb00252x
Bishop H (2004) Noticing formulaic sequences A problem of measuring thesubjective LSO Working Papers in Linguistics 4 15ndash19
Bransford D B amp Johnson M K (1972) Contextual prerequisites for under-standing Some investigations of comprehension and recall Journal of VerbalLearning and Verbal Behavior 11 717ndash726 doi101016S0022-5371(72)80006-9
Brantmeier C (2006) Advanced L2 learners and reading placement Self-assessment CBT and subsequent performance System 34 15ndash35 doi101016jsystem200508004
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 287
Carver R P (1994) Percentage of unknown vocabulary words in text as a functionof the relative difficulty of the text Implications for instruction Journal of ReadingBehavior 26 413ndash437
Cobb T (nd) Web VocabProfile [Online program] Retrieved from httpwwwlextutorcavp [an adaption of A Heatley amp P Nation Range (1994)]
Cooper T C (1999) Processing of idioms by L2 learners of English TESOLQuarterly 33 233ndash262 doi1023073587719
Coxhead A (2000) A new academic word list TESOL Quarterly 34 213ndash238doi1023073587951
Elley W amp Mangubhai F (1983) The impact of reading on second languagelearning Reading Research Quarterly 19 53ndash67 doi102307747337
Ellis N C (2008) Phraseology The periphery and the heart of language In FMeunier amp S Granger (Eds) Phraseology in language learning and teaching (pp 1ndash13) Amsterdam The Netherlands John Benjamins
Erman B amp Warren B (2000) The idiom principle and the open choice principleText 20 29ndash62
Gardner D (2007) Validating the construct of Word in applied corpus-basedvocabulary research A critical survey Applied Linguistics 28 241ndash265doi101093applinamm010
Glenberg A M Wilkinson A C amp Epstein W (1982) The illusion of knowingFailure in the self-assessment of comprehension Memory and Cognition 10 597ndash602 doi103758BF03202442
Goulden R Nation P amp Read J (1990) How large can a receptive vocabulary beApplied Linguistics 11 341ndash363 doi101093applin114341
Grant L amp Bauer L (2004) Criteria for re-defining idioms Are we barking up thewrong tree Applied Linguistics 25 38ndash61 doi101093applin25138
Grant L amp Nation P (2006) How many idioms are there in English ITL -International Journal of Applied Linguistics 151 1ndash14 doi102143ITL15102015219
Haynes M (1993) Patterns and perils of guessing in second language reading In THuckin M Haynes amp J Coady (Eds) Second language reading and vocabularylearning (pp 46ndash64) Norwood NJ Ablex Publishing Corporation
Heatley A amp Nation P (1994) Range [Computer program] Wellington NewZealand Victoria University of Wellington Retrieved from httpwwwvuwacnzlals
Hill J (2000) Revising priorities From grammatical failure to collocational successIn M Lewis (Ed) Teaching collocation Further developments in the Lexical Approach(pp 47ndash69) Hove England LTP
Hirsh D amp Nation P (1992) What vocabulary size is needed to read unsimplifiedtexts for pleasure Reading in a Foreign Language 8 689ndash696
Hu H M amp Nation P (2000) Unknown vocabulary density and readingcomprehension Reading in a Foreign Language 13 403ndash429
Hughes A (2003) Testing for language teachers Cambridge England CambridgeUniversity Press
Hunt K (1968) An instrument to measure syntactic maturity Tallahassee FL USDepartment of Health Education and Welfare
Jung E H (2003) The effects of organization markers on ESL learnersrsquo textunderstanding TESOL Quarterly 37 749ndash759 doi1023073588223
Krashen S (1993) The power of reading Insights from research Englewood COLibraries Unlimited
Laufer B (1989a) A factor of difficulty in vocabulary learning Deceptivetransparency AILA Review 6 10ndash20
288 TESOL QUARTERLY
Laufer B (1989b) What percentage of lexis is essential for comprehension In CLauren amp M Nordman (Eds) Special language From humans thinking to thinkingmachines (pp 316ndash323) London England Multilingual Matters
Laufer B (1991) How much lexis is necessary for reading comprehension In P JL Arnaud amp H Bejoint (Eds) Vocabulary and applied linguistics (pp 126ndash132)Oxford England Macmillan
Laufer B (1997) The lexical plight in second language reading Words you donrsquotknow words you think you know and words you canrsquot guess In J Coady amp THuckin (Eds) Second language vocabulary acquisition (pp 20ndash34) CambridgeEngland Cambridge University Press
Lewis M (1993) The Lexical Approach The state of ELT and a way forward HoveEngland LTP
Liontas J I (2002) Context and idiom understanding in second languagesEUROSLA Yearbook 2 155ndash185
Liontas J I (2003) Killing two birds with one stone Understanding Spanish VPidioms in and out of context Hispania 86 289ndash301 doi10230720062862
Liontas J I (2007) The eye never sees what the brain understands Making sense ofidioms in second languages Lingua et Linguistica 1) 25ndash44
Maki R H amp McGuire M J (2002) Metacognition for text Findings andimplications for education In T Schwarz amp L Bennett (Eds) Appliedmetacognition (pp 39ndash67) Cambridge England Cambridge University Press
Martinez R amp Schmitt N (2010) A phrasal expressions listManuscript submitted forpublication
Moon R (1997) Vocabulary connections Multi-word items in English In NSchmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 40ndash63) Cambridge England Cambridge University Press
Moore D Lin-Agler L M amp Zabrucky K M (2005) A source of metacomprehen-sion inaccuracy Reading Psychology 26 251ndash265 doi10108002702710590962578
Morrison L (2004) Comprehension monitoring in first and second languagereading The Canadian Modern Language Review 61 77ndash106
Nation I S P (2001) Learning vocabulary in another language Cambridge EnglandCambridge University Press
Nation I S P (2006) How large a vocabulary is needed for reading and listeningThe Canadian Modern Language Review 63 59ndash82
Nation I S P amp Waring R (1997) Vocabulary size text coverage and word lists InN Schmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 6ndash19) Cambridge England Cambridge University Press
Nation P (1997) The language learning benefits of extensive reading LanguageTeacher 21 13ndash16
Nattinger J R amp DeCarrico J S (1992) Lexical phrases and language teachingOxford England Oxford University Press
Oh S Y (2001) Two types of input modification and EFL reading comprehensionSimplification versus elaboration TESOL Quarterly 35 69ndash96 doi1023073587860
OrsquoKeeffe A McCarthy M amp Carter R (2007) From corpus to classroom Language useand language teaching Cambridge England Cambridge University Press
Pawley A amp Syder F H (1983) Two puzzles for linguistic theory Nativelikeselection and nativelike fluency In J C Richards amp R Schmidt (Eds) Languageand communication (pp 191ndash226) New York NY Longman
Pigada M amp Schmitt N (2006) Vocabulary acquisition from extensive reading Acase study Reading in a Foreign Language 18 1ndash28
Read J (2004) Research in teaching vocabulary Annual Review of Applied Linguistics24 146ndash161 doi101017S0267190504000078
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 289
Sarac S amp Tarhan B (2009) Calibration of comprehension and performance inL2 reading International Electronic Journal of Elementary Education 2 167ndash179
Schmitt N Jiang N amp Grabe W (2011) The percentage of words known in a textand reading comprehension Modern Language Journal 95(1) 26ndash43
Schmitt N Schmitt D amp Clapham C (2001) Developing and exploring thebehaviour of two new versions of the Vocabulary Levels Test Language Testing 1855ndash88
Shin D amp Nation I S P (2008) Beyond single words The most frequentcollocations in spoken English ELT Journal 62 339ndash348 doi101093eltccm091
Simpson-Vlach R amp Ellis N C (2010) An academic formulas list New methods inphraseology research Applied Linguistics 31(4) 487ndash512
Sinclair J (1991) Corpus concordance collocation Oxford England OxfordUniversity Press
Spottl C amp McCarthy M (2003) Formulaic utterances in the multi-lingual contextIn J Cenoz B Hufeisen ampU Jessner (Eds) The multilingual lexicon (pp 133ndash151) Dordrecht The Netherlands Kluwer
Staelighr L S (2008) Vocabulary size and the skills of listening reading and writingLanguage Learning Journal 36 139ndash152 doi10108009571730802389975
Stubbs M amp Barth I (2003) Using recurrent phrases as text-type descriminators Aquantitative method and some findings Functions of Language 10 61ndash104doi101075fol10104stu
The British National Corpus (2007) The British National Corpus(version 3 BNC XMLed) [CD-ROM] Distributed by Oxford University Computing Services on behalfof the BNC Consortium
The iPhonersquos second coming (2008 July) The Economist Retrieved from httpwwweconomistcomscience-technologydisplaystorycfmstory_id5E1_TTSDDJTG
Walter E Woodford K amp Good M (Eds) (2008) Cambridge advanced learnerrsquosdictionary (3rd ed) Cambridge England Cambridge University Press
Weir C J (2005) Language testing and validation An evidence-based approachNew York NY Palgrave Macmillan
West M (1953) A general service list of English words London England LongmanWray A (2002) Formulaic language and the lexicon Cambridge England Cambridge
University Press
290 TESOL QUARTERLY

score of 28 in Test 1 (the maximum score) and 2775 in Test 2 showingthat both test parts posed very little difficulty for people for whomEnglish is a first language
The students received the two parts of the test in alternating order(ie counterbalanced) to control for any effect of taking Test 1 beforeTest 2 (and vice versa) because by counterbalancing one is able toinclude a variable order into an analysis and identify the extent towhich order affects performance on the dependent measures
RESULTS
All the scores and self-reported comprehension measures wererecorded in a statistical analysis software program (SPSS) Eachparticipantrsquos test results were transcribed into the software item by item(ie correct and incorrect) text by text (eg Text A Text B etc numbercorrect out of 7 for each) and test by test (ie Test 1 and Test 2 numbercorrect out of 28 possible for each) Also recorded were each participantrsquosself-reported comprehension assessments (a rating scale from 5 to 100)as they pertained to each text as well as which version (Test 1 or Test 2first) of the instrument each candidate had received To assess the effectof counterbalancing a repeated measures analysis of variance (ANOVA)was conducted with one within-subjects factor (TEST) with two levels(Test 1 score Test 2 score) and one between-subjects factor (VERSION)with two levels (Test 1 first Test 2 first) This analysis revealed a robustmain effect of test (F (199) 5 59338 p 0001 g2 5 086) and a discreteeffect of version (F (199) 5 405 p 5 0047 g2 5 004) but importantlythere was no significant Test 6 Version interaction (F (199) 5 281 p 5
0097 g2 5 002) illustrating that participantsrsquo scores did not vary as afunction of which version of the test they were completing
Comprehension of Test 1 versus Test 2
The central tendencies from both tests are presented in Table 4As predicted participantsrsquo scores were significantly lower on Test 2
relative to Test 1 (t(100) 5 2410 p 0001) with a strong effect size(g2 5 0828)7 confirming that even when two sets of texts contain theexact same words and even if those words are very commoncomprehension of those texts will not be the same when one containsidiomaticity
7 Confidence intervals at 95 for all t-tests
278 TESOL QUARTERLY
Self-Reported Comprehension of Test 1 versus Test 2
A t-test was also performed on the difference between whatparticipants believed they understood (ie their reported comprehen-sion) and what they actually understood in both Tests 1 and 2 (Table 5)Mean reported comprehension (MRC) was arrived at by calculating themeans of all the self-reported comprehension percentages (5ndash100)and the mean actual comprehension (MAC) is the mean of the score oneach text divided by seven (the maximum score)
MAC was lower than MRC in both Test 1(MRC M 5 08738 SD 013MAC M 5 08603 SD 5 009) and Test 2 (MRC M 5 06029 SD 019MAC M 5 05258 SD 5 014) however the difference between MRCand MAC was statistically reliable in Test 2 only where the test wascomposed of multiword expressions (t(100) 5 395 p 0001 g2 5
007)8 These data therefore appear to support a positive answer to thesecond research questionmdashthat learners may believe they understandmore than they actually do by virtue of their simply understanding theindividual words in a text
Variation in the Data
MRC versus MAC
Naturally there were some individual differences in the test resultsTable 6 shows that roughly one-half of all participants (n 5 50)overestimated their comprehension in both tests (indicated by MRC
TABLE 4
Descriptive Statistics (Tests 1 and 2)
Mean Median Mode Minimum Maximum SD
Test 1a 2409 2500 2500 1800 2800 244Test 2b 1476 1500 1500 600 2500 393
Note SD 5 standard deviation aTexts composed of common words however with little or noopaque phraseology bTexts composed of common words which comprise collocations andidiomatic language
TABLE 5
Reported Versus Actual Comprehension
Test 1 Test 2
Mean reported comprehension (MRC) 8738 6029Mean actual comprehension (MAC) 8603 5258
8 By comparison the results of the paired sample t-test for the Test 1 MRC-MAC means weret(100) 5 104 p 5 0302 g2 5 0005
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 279
greater than MAC) On the surface this might suggest that those 50participants did not overestimate their comprehension in Test 2 as aresult of its relative noncompositionality but rather as a generaltendency regardless of idiomaticity However when MAC is subtractedfrom MRC for that group and the difference compared across the teststhe difference is twice as large in Test 2 (t(49) 5 492 p 0001 g2 5
0108) This difference is even more evident in the same analysis of Test2 alone Isolating the results of that test there was a total of 70participants (over 69 of the entire sample) whose MRC was greaterthan their MAC The difference between MRC minus MAC for thesubgroup of 70 participants reveals that their overestimation of theircomprehension in Test 2 was four times greater than in Test 1 (t(69) 5
770 p 0001 g2 5 0228) Further among that group of 70 whoseTest 2 MRC was greater than their MAC 20 students either under-estimated or actually accurately guessed their comprehension in Test 1but significantly overestimated their comprehension in Test 2 (t(19) 5
849 p 0001 g2 5 0264) Only 30 participants in the present studyactually underestimated their comprehension on Test 2
Variation in Time Spent on the Tests
All candidates were also asked to record their start and finishing timesof each test (Table 7) It is not surprising that on average participantsspent more time on the texts which contained idiomatic expressionsHowever this trend was not uniform among the participants and thetime data may help provide some insight into just how aware someparticipants were of the presence of idiomaticity in the texts Thispossibility is explored further in the Discussion
TABLE 6
Trend of Increase in MRC-MAC Discrepancy Across Test Parts
NMRC minus MAC
(Test 1)MRC minus MAC
(Test 2)
Students with MRC MAC (bothtest parts)
50 009 019
Students with MRC MAC (Test 2) 70 004 017Students with MRC MAC (Test 2only)
20 2010 014
Students with MRC MAC (Test 2) 31a 2005 2015
Note MRC 5 mean reported comprehension MAC 5 mean actual comprehension aOnly oneparticipant in this group had MRC 5 MAC
280 TESOL QUARTERLY
DISCUSSION
To reiterate the present study sought to address the followingresearch questions
1 Are two texts written with the exact same high-frequency wordsunderstood equally well by L2 learners when one of the texts is moreidiomatic than the other
2 Can the presence of multiword expressions in a text lead L2 learners tobelieve they have understood that text better than they actually have
A group of 101 adult Brazilian learners of English was tested using twoseparate measures of reading comprehension (one with idiomaticlanguage and one without) and the results of the two tests were thencompared Although verbal reports would provide even greater insightthe resultant data from this study do seem to support a positive answer tothe first research question Participants achieved significantly lowerscores on the comprehension measure which assessed their under-standing of texts that contain multiword expressions It should bereiterated that this result was obtained in spite of both tests being writtenwith the exact same high-frequency words
Likewise through participantsrsquo self-reported comprehension thereseems to be evidence that the presence of multiword expressions in atext can lead L2 readers to overestimate their assessment of how muchthey have actually understood suggesting a positive answer to the secondresearch question
Although it seems apparent that participantsrsquo reading comprehensionin the present study was adversely affected by idiomaticity this sectionexplores and possibly explains variation in comprehension of the testsand further discusses evidence that multiword expressions negativelyaffected participantsrsquo comprehension
On the Stronger and Weaker Performance in the Tests
There are at least three important revelations emerging from theMRC-MAC data analysis presented in Table 6 First nearly two thirds of
TABLE 7
Time It Took Participants to Take Tests
N Mean time (minutes) SD
Time it took to take Test 1 91a 1085 436Time it took to take Test 2 91 1465 377
Note SD 5 standard deviation aSome participants (n 5 10) forgot to write in the time or left itincomplete
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 281
all participants believed they understood more than they actually did inTest 2 Second the data show that over 28 of those students (n 5 20)did not overestimate their comprehension in Test 1 providing evidencethat whereas they were apparently able to gauge their comprehensionfairly accurately when the texts were relatively devoid of idiomaticitythey were significantly less able to do so when relative noncomposition-ality was present Finally the MRC-MAC data presented so far indicatethat although not all participants tended to overestimate theircomprehension in Test 2 those who did (again the majority of cases)generally did so by a much larger margin Put simply it would seem thatnot only are many learners misunderstanding idiomaticity in text butthey may be doing so more than they (or researchers) realize
Further Evidence of Idiomaticity Negatively AffectingComprehension
The mean difference between MRC and MAC for the 70 students whooverestimated their comprehension in Test 2 (Table 6) was 017 For thesake of argument one could establish an MRC-MAC difference above020 as a cutoff for apparently marked lack of awareness of the extentof idiomaticity in Test 29 comparatively speaking This in turn wouldmean that there were 30 participants who ostensibly demonstrated aparticularly high overestimation of how much of Test 2 they had actuallyunderstood A sample of just the top 10 is provided in Table 8
Table 8 shows not only how different those participantsrsquo MRC wasfrom their Test 2 it also lists the same figures for Test 1 for comparison
9 A t-test reveals that the mean is in fact statistically significant even at the 003 differencelevel (t 5 653 p 5 003)
TABLE 8
Partial List of Participants With Exceptionally High Overestimation of Test 2 Comprehension(Difference 020)
ParticipantMRCTest 1
MACTest 1 Difference
MRCTest 2
MACTest 2 Difference
118 100 089 011 094 032 0626 075 068 007 081 028 05392 081 089 2008 075 025 05090 100 089 011 081 039 042115 100 089 011 087 050 03722 100 096 003 094 057 03780 094 068 026 069 032 03759 094 089 005 069 036 03321 100 093 007 087 057 03050 087 078 009 069 039 029
282 TESOL QUARTERLY
Whereas for Test 1 those 30 participantsrsquo assessment of readingcomprehension was usually only slightly overestimated10 (and in oneinstance even underestimated) the same participants in Test 2 had amarkedly overinflated conception of how much they had understood
Although not intended as a principal source of data for our analysisthe start and finish times recorded by participants on the tests in a fewinstances helped confirm the above assertions11 Table 7 shows thatthere was a significant difference between how long participants spenttaking each test (t 5 852 p 0001) However there were a number ofparticipants (n 5 26) who reported actually spending either the same orless time on Test 2 On the surface at least this fact would indicate thatthose 26 participants did not notice much difference between the testsOf course in reality that datum alone does not provide such evidencebecause that time may simply reflect a number of other confoundingvariables including affective (eg simply giving up) or even social (egthe need to leave early to meet a friend) and for that reason also was notconsidered to be a reliable source of data from those participantsHowever as a complementary source when triangulated with the othervariables some of the data analyzed earlier in the current study areoccasionally fortified further still with the time data (Table 9)
The data in Table 9 in many ways tie together the elements discussedin the analysis thus far in the present study A much lower score in Test 2than in Test 1 (columns B and C) an increase in the mean MRC-MACdifference across the tests (columns H and K) a relatively moderatedecrease in MRC in Test 2 vis-a-vis Test 1 (columns F and I) a markeddifference between MRC and MAC in Test 2 (column K) and theoccasional lack of increase (in Table 9 participants 118 80 59 and 50)in time it took to take Test 2 (columns D and E) These findings ontheir own in combination and especially in concert provide evidencethat (1) the students in Table 9 did not seem to appreciate the fullextent of the idiomaticity in Test 2 and (2) they appeared to think thatthey understood more than they actually did in Test 2
Perhaps most important 98 of all participants (n 5 99) scoredsignificantly lower on Test 2 (mean difference of 953 points out of 28SD 5 363) which shows that learners are generally unable to guess themeaning of idiomatic language even in the (largely inconsistent)instances in which they become aware of its presence
11 It should be noted that because 10 of the participantsrsquo time data were left incomplete afull group analysis could not be carried out thus the time data are only included asauxiliary information
10 As can be seen in Table 8 in fact only one participantmdashnumber 80mdashactually had anMRC-MAC difference in Test 1 that was also 020 Those of the other 29 participantswere all lower
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 283
For example the first participant in Tables 8 and 9 (number 118)who consistently overrated his own comprehension relative to his actualcomprehension answered for Text A of Test 2 as shown in Figure 3
On the basis of the responses it is likely that participant 118associated itrsquos about time with lsquolsquohas a problem with timersquorsquo Irsquom a little over thehill with lsquolsquohe probably lives in an area with hillsrsquorsquo and lsquolsquohe lives on the hill
TABLE 9
Triangulated Data Showing Negative Effect of Idiomaticity on Comprehension
A B C D E F G H I J K
Score Time Test 1 Test 2
Partic-ipant Test 1 Test 2 Test 1 Test 2 MRC MAC
Differ-ence MRC MAC
Differ-ence
118 25 9 2000 1800 100 089 11 094 032 0626 19 8 Missing Missing 075 068 007 081 028 05392 25 8 900 1100 081 089 2008 075 025 05090 25 11 900 1500 100 089 011 081 039 042115 25 14 1300 1500 100 089 011 087 050 03722 27 16 Missing Missing 100 096 003 094 057 03780 19 9 1000 1000 094 068 026 069 032 03759 25 10 1500 1400 094 089 005 069 036 03321 26 16 Missing Missing 100 093 007 087 057 03050 22 11 2000 1200 088 079 009 069 039 030
12 Of the 24 multiword expressions targeted for assessment of comprehension in Test 2 onlyfour were core idioms
FIGURE 3 Sample answer to Text A of Test 2
284 TESOL QUARTERLY
but not on top of itrsquorsquomdasha literal reading of those expressions His 100self-assessment is an indication that his answers were not guesses butinstead based on confidence that he had understood all the individualwords in the text The same answering dynamic occurred time and timeagain in Test 2
Returning therefore to the issues raised in the introduction thepresent research appears to provide evidence that idiomsmdashopaque orotherwise12mdashcan in fact cause major problems for L2 learners of Englishwhen reading In general the participants in our study were lesssuccessful at guessing the meaning of idioms than those in previousidiom-centered research such as Cooper (1999) and Liontas (2002)Because the learners in our study were not alerted to the presence ofidiomaticity in the text prior to reading this study may more accuratelyreflect what takes place in more naturally occurring L2 reading Finallythe difficulties that the participants encountered occurred in textscomposed purely of very common words showing that word frequencyalone is not necessarily a good measure of text coverage Lauferrsquos(1989a) hypothesis that much lexis in text can be deceptivelytransparent is confirmed in the present research extended to multiwordexpressions
Limitations of the Research
Although the research presented here does provide some significantevidence that the presence of idiomaticity in a text can negatively affectthe comprehension of that text by an L2 reader little is known about thestrategies the test takers employed Even though metacognition wasoutside the scope of examination of the present study such informationis highly relevant and future research should include protocols such asthose included in previous research on idioms (eg Liontas 20032007) which may provide crucial qualitative data regarding theindividual differences and behavior of the participants themselvesOverall future work in this area should consider making use of differentmeasures of self-assessment in order to explore the limitations of themethodology used in the present study
Also a question can be asked concerning the relative density ofmultiword expressions in each text In other words what is not known ison average how many such items a reader can expect to encounter Theratio of idioms to orthographic words in the texts tested in the presentstudy is very likely higher than averagemdashbut how much higher is as yetunknown Likewise the passages themselves were relatively short so it isunknown whether or not texts of greater length (and thereforecontextualization) would render the same or similar results
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 285
CONCLUSION
The present study provides some empirical evidence that a focus onword in L2 pedagogy may be detrimental to learnersrsquo development ofreading comprehension in the target language In most casesparticipants overestimated how much they had understood the textstested when those texts contained multiword expressions of varyingdegrees of compositionality comprised of very common individualwords Even when participants showed evidence of awareness of apresence of idiomaticity in the texts they generally were not very good atguessing the meaning of expressions Although Grant and Nation(2006) could be right that the teaching of individual idioms may not belsquolsquodeserving of class timersquorsquo (p 5) it is clear that at the very least raisinglearnersrsquo consciousness as to their prevalence and frequently deceptivetransparency in text certainly is
Concomitantly the present research serves to demonstrate theincompleteness of current lists of common words which now informimportant pedagogical instruments such as vocabulary tests gradedreaders and course syllabuses Under current methods as illustrated inthe Table 2 analysis of the Economist paragraph a text measured againstthe word lists now commonly in use can be mistakenly analyzed as beingeasily understood when in fact once multiword expressions are takeninto account the actual text coverage of easily understood words is farless Existing estimates of how many words one needs to know in order toadequately process naturally occurring texts (Hu amp Nation 2000Nation 2006) may need to be revisited to determine how many wordsand multiword expressions one needs to know
In practice research shows that learners will continue to believe theyunderstand items that they actually do not even after repeatedexposures to that same item (Bensoussan amp Laufer 1984 Haynes1993 Pigada amp Schmitt 2006) Language teachers and relatedprofessionals such as textbook writers need to consider ways tocontinuously help learners notice the gap between what they think theyknow and understand and what they actually do (Laufer 1997) Oneway this can be achieved has already been thoroughly discussed in thepresent paper devise texts (and tests) designed to lead readers down anidiomatic garden path Norbert Schmitt (as cited in Weir 2005) made asimilar recommendation
Perhaps the best and most valid type of vocabulary test is a reading passagewith comprehension questions but with the items requiring a full under-standing of particular words or phrases in the text This would mimic the realworld task of reading for comprehension and also the loss of comprehensionwhen key vocabulary is not known (p 123)
286 TESOL QUARTERLY
Therefore a further implication this research has for L2 pedagogy is themore careful design of the reading component of proficiency tests suchas IELTS (International English Language Testing System) and Test ofEnglish as a Foreign Language to be more strategic regarding the amountand kind of phraseology contained in the texts Proficiency was not thecentral focus of our study and future research could adopt a similarmethodology but with the inclusion of proficiency measures ofparticipants in order to explore how various types of expressions (egnoncompositional figurative imageable etc) may differentially affectpreidentified proficiency levels
Thus in order to be more methodical about such things as theinclusion of formulaic language in L2 tests and reading input in generalan important preliminary step will be to establish (a) what type offormulaic sequences are good discriminators of proficiency thresholdlevels and (b) which expressions of that identified type are mostcommon In other words what will be usefulmdashand is indeed nowbeginning to emerge (Martinez amp Schmitt 2010 Shin amp Nation 2008Simpson-Vlach amp Ellis 2010)mdashare lists of formulaic sequences that servea function similar to that of the General Service List not to revolutionizecurrent language pedagogy but to more finely tune it
THE AUTHORS
Ron Martinez is currently pursuing a doctorate at the University of NottinghamNottingham England on the topic of inclusion of phraseology in languageassessment He specializes in second language materials development
Victoria Murphy is a lecturer in Applied Linguistics and Second LanguageAcquisition at the University of Oxford Oxford England Her research interestsinclude the lexical development of first language or second language learners andthe cognitive processes that underlie language acquisition
REFERENCES
Bauer L amp Nation P (1993) Word families International Journal of Lexicography 6253ndash279 doi101093ijl64253
Bensoussan M amp Laufer B (1984) Lexical guessing in context in EFL readingcomprehension Journal of Research in Reading 7 15ndash32 doi101111j1467-98171984tb00252x
Bishop H (2004) Noticing formulaic sequences A problem of measuring thesubjective LSO Working Papers in Linguistics 4 15ndash19
Bransford D B amp Johnson M K (1972) Contextual prerequisites for under-standing Some investigations of comprehension and recall Journal of VerbalLearning and Verbal Behavior 11 717ndash726 doi101016S0022-5371(72)80006-9
Brantmeier C (2006) Advanced L2 learners and reading placement Self-assessment CBT and subsequent performance System 34 15ndash35 doi101016jsystem200508004
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 287
Carver R P (1994) Percentage of unknown vocabulary words in text as a functionof the relative difficulty of the text Implications for instruction Journal of ReadingBehavior 26 413ndash437
Cobb T (nd) Web VocabProfile [Online program] Retrieved from httpwwwlextutorcavp [an adaption of A Heatley amp P Nation Range (1994)]
Cooper T C (1999) Processing of idioms by L2 learners of English TESOLQuarterly 33 233ndash262 doi1023073587719
Coxhead A (2000) A new academic word list TESOL Quarterly 34 213ndash238doi1023073587951
Elley W amp Mangubhai F (1983) The impact of reading on second languagelearning Reading Research Quarterly 19 53ndash67 doi102307747337
Ellis N C (2008) Phraseology The periphery and the heart of language In FMeunier amp S Granger (Eds) Phraseology in language learning and teaching (pp 1ndash13) Amsterdam The Netherlands John Benjamins
Erman B amp Warren B (2000) The idiom principle and the open choice principleText 20 29ndash62
Gardner D (2007) Validating the construct of Word in applied corpus-basedvocabulary research A critical survey Applied Linguistics 28 241ndash265doi101093applinamm010
Glenberg A M Wilkinson A C amp Epstein W (1982) The illusion of knowingFailure in the self-assessment of comprehension Memory and Cognition 10 597ndash602 doi103758BF03202442
Goulden R Nation P amp Read J (1990) How large can a receptive vocabulary beApplied Linguistics 11 341ndash363 doi101093applin114341
Grant L amp Bauer L (2004) Criteria for re-defining idioms Are we barking up thewrong tree Applied Linguistics 25 38ndash61 doi101093applin25138
Grant L amp Nation P (2006) How many idioms are there in English ITL -International Journal of Applied Linguistics 151 1ndash14 doi102143ITL15102015219
Haynes M (1993) Patterns and perils of guessing in second language reading In THuckin M Haynes amp J Coady (Eds) Second language reading and vocabularylearning (pp 46ndash64) Norwood NJ Ablex Publishing Corporation
Heatley A amp Nation P (1994) Range [Computer program] Wellington NewZealand Victoria University of Wellington Retrieved from httpwwwvuwacnzlals
Hill J (2000) Revising priorities From grammatical failure to collocational successIn M Lewis (Ed) Teaching collocation Further developments in the Lexical Approach(pp 47ndash69) Hove England LTP
Hirsh D amp Nation P (1992) What vocabulary size is needed to read unsimplifiedtexts for pleasure Reading in a Foreign Language 8 689ndash696
Hu H M amp Nation P (2000) Unknown vocabulary density and readingcomprehension Reading in a Foreign Language 13 403ndash429
Hughes A (2003) Testing for language teachers Cambridge England CambridgeUniversity Press
Hunt K (1968) An instrument to measure syntactic maturity Tallahassee FL USDepartment of Health Education and Welfare
Jung E H (2003) The effects of organization markers on ESL learnersrsquo textunderstanding TESOL Quarterly 37 749ndash759 doi1023073588223
Krashen S (1993) The power of reading Insights from research Englewood COLibraries Unlimited
Laufer B (1989a) A factor of difficulty in vocabulary learning Deceptivetransparency AILA Review 6 10ndash20
288 TESOL QUARTERLY
Laufer B (1989b) What percentage of lexis is essential for comprehension In CLauren amp M Nordman (Eds) Special language From humans thinking to thinkingmachines (pp 316ndash323) London England Multilingual Matters
Laufer B (1991) How much lexis is necessary for reading comprehension In P JL Arnaud amp H Bejoint (Eds) Vocabulary and applied linguistics (pp 126ndash132)Oxford England Macmillan
Laufer B (1997) The lexical plight in second language reading Words you donrsquotknow words you think you know and words you canrsquot guess In J Coady amp THuckin (Eds) Second language vocabulary acquisition (pp 20ndash34) CambridgeEngland Cambridge University Press
Lewis M (1993) The Lexical Approach The state of ELT and a way forward HoveEngland LTP
Liontas J I (2002) Context and idiom understanding in second languagesEUROSLA Yearbook 2 155ndash185
Liontas J I (2003) Killing two birds with one stone Understanding Spanish VPidioms in and out of context Hispania 86 289ndash301 doi10230720062862
Liontas J I (2007) The eye never sees what the brain understands Making sense ofidioms in second languages Lingua et Linguistica 1) 25ndash44
Maki R H amp McGuire M J (2002) Metacognition for text Findings andimplications for education In T Schwarz amp L Bennett (Eds) Appliedmetacognition (pp 39ndash67) Cambridge England Cambridge University Press
Martinez R amp Schmitt N (2010) A phrasal expressions listManuscript submitted forpublication
Moon R (1997) Vocabulary connections Multi-word items in English In NSchmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 40ndash63) Cambridge England Cambridge University Press
Moore D Lin-Agler L M amp Zabrucky K M (2005) A source of metacomprehen-sion inaccuracy Reading Psychology 26 251ndash265 doi10108002702710590962578
Morrison L (2004) Comprehension monitoring in first and second languagereading The Canadian Modern Language Review 61 77ndash106
Nation I S P (2001) Learning vocabulary in another language Cambridge EnglandCambridge University Press
Nation I S P (2006) How large a vocabulary is needed for reading and listeningThe Canadian Modern Language Review 63 59ndash82
Nation I S P amp Waring R (1997) Vocabulary size text coverage and word lists InN Schmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 6ndash19) Cambridge England Cambridge University Press
Nation P (1997) The language learning benefits of extensive reading LanguageTeacher 21 13ndash16
Nattinger J R amp DeCarrico J S (1992) Lexical phrases and language teachingOxford England Oxford University Press
Oh S Y (2001) Two types of input modification and EFL reading comprehensionSimplification versus elaboration TESOL Quarterly 35 69ndash96 doi1023073587860
OrsquoKeeffe A McCarthy M amp Carter R (2007) From corpus to classroom Language useand language teaching Cambridge England Cambridge University Press
Pawley A amp Syder F H (1983) Two puzzles for linguistic theory Nativelikeselection and nativelike fluency In J C Richards amp R Schmidt (Eds) Languageand communication (pp 191ndash226) New York NY Longman
Pigada M amp Schmitt N (2006) Vocabulary acquisition from extensive reading Acase study Reading in a Foreign Language 18 1ndash28
Read J (2004) Research in teaching vocabulary Annual Review of Applied Linguistics24 146ndash161 doi101017S0267190504000078
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 289
Sarac S amp Tarhan B (2009) Calibration of comprehension and performance inL2 reading International Electronic Journal of Elementary Education 2 167ndash179
Schmitt N Jiang N amp Grabe W (2011) The percentage of words known in a textand reading comprehension Modern Language Journal 95(1) 26ndash43
Schmitt N Schmitt D amp Clapham C (2001) Developing and exploring thebehaviour of two new versions of the Vocabulary Levels Test Language Testing 1855ndash88
Shin D amp Nation I S P (2008) Beyond single words The most frequentcollocations in spoken English ELT Journal 62 339ndash348 doi101093eltccm091
Simpson-Vlach R amp Ellis N C (2010) An academic formulas list New methods inphraseology research Applied Linguistics 31(4) 487ndash512
Sinclair J (1991) Corpus concordance collocation Oxford England OxfordUniversity Press
Spottl C amp McCarthy M (2003) Formulaic utterances in the multi-lingual contextIn J Cenoz B Hufeisen ampU Jessner (Eds) The multilingual lexicon (pp 133ndash151) Dordrecht The Netherlands Kluwer
Staelighr L S (2008) Vocabulary size and the skills of listening reading and writingLanguage Learning Journal 36 139ndash152 doi10108009571730802389975
Stubbs M amp Barth I (2003) Using recurrent phrases as text-type descriminators Aquantitative method and some findings Functions of Language 10 61ndash104doi101075fol10104stu
The British National Corpus (2007) The British National Corpus(version 3 BNC XMLed) [CD-ROM] Distributed by Oxford University Computing Services on behalfof the BNC Consortium
The iPhonersquos second coming (2008 July) The Economist Retrieved from httpwwweconomistcomscience-technologydisplaystorycfmstory_id5E1_TTSDDJTG
Walter E Woodford K amp Good M (Eds) (2008) Cambridge advanced learnerrsquosdictionary (3rd ed) Cambridge England Cambridge University Press
Weir C J (2005) Language testing and validation An evidence-based approachNew York NY Palgrave Macmillan
West M (1953) A general service list of English words London England LongmanWray A (2002) Formulaic language and the lexicon Cambridge England Cambridge
University Press
290 TESOL QUARTERLY

Self-Reported Comprehension of Test 1 versus Test 2
A t-test was also performed on the difference between whatparticipants believed they understood (ie their reported comprehen-sion) and what they actually understood in both Tests 1 and 2 (Table 5)Mean reported comprehension (MRC) was arrived at by calculating themeans of all the self-reported comprehension percentages (5ndash100)and the mean actual comprehension (MAC) is the mean of the score oneach text divided by seven (the maximum score)
MAC was lower than MRC in both Test 1(MRC M 5 08738 SD 013MAC M 5 08603 SD 5 009) and Test 2 (MRC M 5 06029 SD 019MAC M 5 05258 SD 5 014) however the difference between MRCand MAC was statistically reliable in Test 2 only where the test wascomposed of multiword expressions (t(100) 5 395 p 0001 g2 5
007)8 These data therefore appear to support a positive answer to thesecond research questionmdashthat learners may believe they understandmore than they actually do by virtue of their simply understanding theindividual words in a text
Variation in the Data
MRC versus MAC
Naturally there were some individual differences in the test resultsTable 6 shows that roughly one-half of all participants (n 5 50)overestimated their comprehension in both tests (indicated by MRC
TABLE 4
Descriptive Statistics (Tests 1 and 2)
Mean Median Mode Minimum Maximum SD
Test 1a 2409 2500 2500 1800 2800 244Test 2b 1476 1500 1500 600 2500 393
Note SD 5 standard deviation aTexts composed of common words however with little or noopaque phraseology bTexts composed of common words which comprise collocations andidiomatic language
TABLE 5
Reported Versus Actual Comprehension
Test 1 Test 2
Mean reported comprehension (MRC) 8738 6029Mean actual comprehension (MAC) 8603 5258
8 By comparison the results of the paired sample t-test for the Test 1 MRC-MAC means weret(100) 5 104 p 5 0302 g2 5 0005
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 279
greater than MAC) On the surface this might suggest that those 50participants did not overestimate their comprehension in Test 2 as aresult of its relative noncompositionality but rather as a generaltendency regardless of idiomaticity However when MAC is subtractedfrom MRC for that group and the difference compared across the teststhe difference is twice as large in Test 2 (t(49) 5 492 p 0001 g2 5
0108) This difference is even more evident in the same analysis of Test2 alone Isolating the results of that test there was a total of 70participants (over 69 of the entire sample) whose MRC was greaterthan their MAC The difference between MRC minus MAC for thesubgroup of 70 participants reveals that their overestimation of theircomprehension in Test 2 was four times greater than in Test 1 (t(69) 5
770 p 0001 g2 5 0228) Further among that group of 70 whoseTest 2 MRC was greater than their MAC 20 students either under-estimated or actually accurately guessed their comprehension in Test 1but significantly overestimated their comprehension in Test 2 (t(19) 5
849 p 0001 g2 5 0264) Only 30 participants in the present studyactually underestimated their comprehension on Test 2
Variation in Time Spent on the Tests
All candidates were also asked to record their start and finishing timesof each test (Table 7) It is not surprising that on average participantsspent more time on the texts which contained idiomatic expressionsHowever this trend was not uniform among the participants and thetime data may help provide some insight into just how aware someparticipants were of the presence of idiomaticity in the texts Thispossibility is explored further in the Discussion
TABLE 6
Trend of Increase in MRC-MAC Discrepancy Across Test Parts
NMRC minus MAC
(Test 1)MRC minus MAC
(Test 2)
Students with MRC MAC (bothtest parts)
50 009 019
Students with MRC MAC (Test 2) 70 004 017Students with MRC MAC (Test 2only)
20 2010 014
Students with MRC MAC (Test 2) 31a 2005 2015
Note MRC 5 mean reported comprehension MAC 5 mean actual comprehension aOnly oneparticipant in this group had MRC 5 MAC
280 TESOL QUARTERLY
DISCUSSION
To reiterate the present study sought to address the followingresearch questions
1 Are two texts written with the exact same high-frequency wordsunderstood equally well by L2 learners when one of the texts is moreidiomatic than the other
2 Can the presence of multiword expressions in a text lead L2 learners tobelieve they have understood that text better than they actually have
A group of 101 adult Brazilian learners of English was tested using twoseparate measures of reading comprehension (one with idiomaticlanguage and one without) and the results of the two tests were thencompared Although verbal reports would provide even greater insightthe resultant data from this study do seem to support a positive answer tothe first research question Participants achieved significantly lowerscores on the comprehension measure which assessed their under-standing of texts that contain multiword expressions It should bereiterated that this result was obtained in spite of both tests being writtenwith the exact same high-frequency words
Likewise through participantsrsquo self-reported comprehension thereseems to be evidence that the presence of multiword expressions in atext can lead L2 readers to overestimate their assessment of how muchthey have actually understood suggesting a positive answer to the secondresearch question
Although it seems apparent that participantsrsquo reading comprehensionin the present study was adversely affected by idiomaticity this sectionexplores and possibly explains variation in comprehension of the testsand further discusses evidence that multiword expressions negativelyaffected participantsrsquo comprehension
On the Stronger and Weaker Performance in the Tests
There are at least three important revelations emerging from theMRC-MAC data analysis presented in Table 6 First nearly two thirds of
TABLE 7
Time It Took Participants to Take Tests
N Mean time (minutes) SD
Time it took to take Test 1 91a 1085 436Time it took to take Test 2 91 1465 377
Note SD 5 standard deviation aSome participants (n 5 10) forgot to write in the time or left itincomplete
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 281
all participants believed they understood more than they actually did inTest 2 Second the data show that over 28 of those students (n 5 20)did not overestimate their comprehension in Test 1 providing evidencethat whereas they were apparently able to gauge their comprehensionfairly accurately when the texts were relatively devoid of idiomaticitythey were significantly less able to do so when relative noncomposition-ality was present Finally the MRC-MAC data presented so far indicatethat although not all participants tended to overestimate theircomprehension in Test 2 those who did (again the majority of cases)generally did so by a much larger margin Put simply it would seem thatnot only are many learners misunderstanding idiomaticity in text butthey may be doing so more than they (or researchers) realize
Further Evidence of Idiomaticity Negatively AffectingComprehension
The mean difference between MRC and MAC for the 70 students whooverestimated their comprehension in Test 2 (Table 6) was 017 For thesake of argument one could establish an MRC-MAC difference above020 as a cutoff for apparently marked lack of awareness of the extentof idiomaticity in Test 29 comparatively speaking This in turn wouldmean that there were 30 participants who ostensibly demonstrated aparticularly high overestimation of how much of Test 2 they had actuallyunderstood A sample of just the top 10 is provided in Table 8
Table 8 shows not only how different those participantsrsquo MRC wasfrom their Test 2 it also lists the same figures for Test 1 for comparison
9 A t-test reveals that the mean is in fact statistically significant even at the 003 differencelevel (t 5 653 p 5 003)
TABLE 8
Partial List of Participants With Exceptionally High Overestimation of Test 2 Comprehension(Difference 020)
ParticipantMRCTest 1
MACTest 1 Difference
MRCTest 2
MACTest 2 Difference
118 100 089 011 094 032 0626 075 068 007 081 028 05392 081 089 2008 075 025 05090 100 089 011 081 039 042115 100 089 011 087 050 03722 100 096 003 094 057 03780 094 068 026 069 032 03759 094 089 005 069 036 03321 100 093 007 087 057 03050 087 078 009 069 039 029
282 TESOL QUARTERLY
Whereas for Test 1 those 30 participantsrsquo assessment of readingcomprehension was usually only slightly overestimated10 (and in oneinstance even underestimated) the same participants in Test 2 had amarkedly overinflated conception of how much they had understood
Although not intended as a principal source of data for our analysisthe start and finish times recorded by participants on the tests in a fewinstances helped confirm the above assertions11 Table 7 shows thatthere was a significant difference between how long participants spenttaking each test (t 5 852 p 0001) However there were a number ofparticipants (n 5 26) who reported actually spending either the same orless time on Test 2 On the surface at least this fact would indicate thatthose 26 participants did not notice much difference between the testsOf course in reality that datum alone does not provide such evidencebecause that time may simply reflect a number of other confoundingvariables including affective (eg simply giving up) or even social (egthe need to leave early to meet a friend) and for that reason also was notconsidered to be a reliable source of data from those participantsHowever as a complementary source when triangulated with the othervariables some of the data analyzed earlier in the current study areoccasionally fortified further still with the time data (Table 9)
The data in Table 9 in many ways tie together the elements discussedin the analysis thus far in the present study A much lower score in Test 2than in Test 1 (columns B and C) an increase in the mean MRC-MACdifference across the tests (columns H and K) a relatively moderatedecrease in MRC in Test 2 vis-a-vis Test 1 (columns F and I) a markeddifference between MRC and MAC in Test 2 (column K) and theoccasional lack of increase (in Table 9 participants 118 80 59 and 50)in time it took to take Test 2 (columns D and E) These findings ontheir own in combination and especially in concert provide evidencethat (1) the students in Table 9 did not seem to appreciate the fullextent of the idiomaticity in Test 2 and (2) they appeared to think thatthey understood more than they actually did in Test 2
Perhaps most important 98 of all participants (n 5 99) scoredsignificantly lower on Test 2 (mean difference of 953 points out of 28SD 5 363) which shows that learners are generally unable to guess themeaning of idiomatic language even in the (largely inconsistent)instances in which they become aware of its presence
11 It should be noted that because 10 of the participantsrsquo time data were left incomplete afull group analysis could not be carried out thus the time data are only included asauxiliary information
10 As can be seen in Table 8 in fact only one participantmdashnumber 80mdashactually had anMRC-MAC difference in Test 1 that was also 020 Those of the other 29 participantswere all lower
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 283
For example the first participant in Tables 8 and 9 (number 118)who consistently overrated his own comprehension relative to his actualcomprehension answered for Text A of Test 2 as shown in Figure 3
On the basis of the responses it is likely that participant 118associated itrsquos about time with lsquolsquohas a problem with timersquorsquo Irsquom a little over thehill with lsquolsquohe probably lives in an area with hillsrsquorsquo and lsquolsquohe lives on the hill
TABLE 9
Triangulated Data Showing Negative Effect of Idiomaticity on Comprehension
A B C D E F G H I J K
Score Time Test 1 Test 2
Partic-ipant Test 1 Test 2 Test 1 Test 2 MRC MAC
Differ-ence MRC MAC
Differ-ence
118 25 9 2000 1800 100 089 11 094 032 0626 19 8 Missing Missing 075 068 007 081 028 05392 25 8 900 1100 081 089 2008 075 025 05090 25 11 900 1500 100 089 011 081 039 042115 25 14 1300 1500 100 089 011 087 050 03722 27 16 Missing Missing 100 096 003 094 057 03780 19 9 1000 1000 094 068 026 069 032 03759 25 10 1500 1400 094 089 005 069 036 03321 26 16 Missing Missing 100 093 007 087 057 03050 22 11 2000 1200 088 079 009 069 039 030
12 Of the 24 multiword expressions targeted for assessment of comprehension in Test 2 onlyfour were core idioms
FIGURE 3 Sample answer to Text A of Test 2
284 TESOL QUARTERLY
but not on top of itrsquorsquomdasha literal reading of those expressions His 100self-assessment is an indication that his answers were not guesses butinstead based on confidence that he had understood all the individualwords in the text The same answering dynamic occurred time and timeagain in Test 2
Returning therefore to the issues raised in the introduction thepresent research appears to provide evidence that idiomsmdashopaque orotherwise12mdashcan in fact cause major problems for L2 learners of Englishwhen reading In general the participants in our study were lesssuccessful at guessing the meaning of idioms than those in previousidiom-centered research such as Cooper (1999) and Liontas (2002)Because the learners in our study were not alerted to the presence ofidiomaticity in the text prior to reading this study may more accuratelyreflect what takes place in more naturally occurring L2 reading Finallythe difficulties that the participants encountered occurred in textscomposed purely of very common words showing that word frequencyalone is not necessarily a good measure of text coverage Lauferrsquos(1989a) hypothesis that much lexis in text can be deceptivelytransparent is confirmed in the present research extended to multiwordexpressions
Limitations of the Research
Although the research presented here does provide some significantevidence that the presence of idiomaticity in a text can negatively affectthe comprehension of that text by an L2 reader little is known about thestrategies the test takers employed Even though metacognition wasoutside the scope of examination of the present study such informationis highly relevant and future research should include protocols such asthose included in previous research on idioms (eg Liontas 20032007) which may provide crucial qualitative data regarding theindividual differences and behavior of the participants themselvesOverall future work in this area should consider making use of differentmeasures of self-assessment in order to explore the limitations of themethodology used in the present study
Also a question can be asked concerning the relative density ofmultiword expressions in each text In other words what is not known ison average how many such items a reader can expect to encounter Theratio of idioms to orthographic words in the texts tested in the presentstudy is very likely higher than averagemdashbut how much higher is as yetunknown Likewise the passages themselves were relatively short so it isunknown whether or not texts of greater length (and thereforecontextualization) would render the same or similar results
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 285
CONCLUSION
The present study provides some empirical evidence that a focus onword in L2 pedagogy may be detrimental to learnersrsquo development ofreading comprehension in the target language In most casesparticipants overestimated how much they had understood the textstested when those texts contained multiword expressions of varyingdegrees of compositionality comprised of very common individualwords Even when participants showed evidence of awareness of apresence of idiomaticity in the texts they generally were not very good atguessing the meaning of expressions Although Grant and Nation(2006) could be right that the teaching of individual idioms may not belsquolsquodeserving of class timersquorsquo (p 5) it is clear that at the very least raisinglearnersrsquo consciousness as to their prevalence and frequently deceptivetransparency in text certainly is
Concomitantly the present research serves to demonstrate theincompleteness of current lists of common words which now informimportant pedagogical instruments such as vocabulary tests gradedreaders and course syllabuses Under current methods as illustrated inthe Table 2 analysis of the Economist paragraph a text measured againstthe word lists now commonly in use can be mistakenly analyzed as beingeasily understood when in fact once multiword expressions are takeninto account the actual text coverage of easily understood words is farless Existing estimates of how many words one needs to know in order toadequately process naturally occurring texts (Hu amp Nation 2000Nation 2006) may need to be revisited to determine how many wordsand multiword expressions one needs to know
In practice research shows that learners will continue to believe theyunderstand items that they actually do not even after repeatedexposures to that same item (Bensoussan amp Laufer 1984 Haynes1993 Pigada amp Schmitt 2006) Language teachers and relatedprofessionals such as textbook writers need to consider ways tocontinuously help learners notice the gap between what they think theyknow and understand and what they actually do (Laufer 1997) Oneway this can be achieved has already been thoroughly discussed in thepresent paper devise texts (and tests) designed to lead readers down anidiomatic garden path Norbert Schmitt (as cited in Weir 2005) made asimilar recommendation
Perhaps the best and most valid type of vocabulary test is a reading passagewith comprehension questions but with the items requiring a full under-standing of particular words or phrases in the text This would mimic the realworld task of reading for comprehension and also the loss of comprehensionwhen key vocabulary is not known (p 123)
286 TESOL QUARTERLY
Therefore a further implication this research has for L2 pedagogy is themore careful design of the reading component of proficiency tests suchas IELTS (International English Language Testing System) and Test ofEnglish as a Foreign Language to be more strategic regarding the amountand kind of phraseology contained in the texts Proficiency was not thecentral focus of our study and future research could adopt a similarmethodology but with the inclusion of proficiency measures ofparticipants in order to explore how various types of expressions (egnoncompositional figurative imageable etc) may differentially affectpreidentified proficiency levels
Thus in order to be more methodical about such things as theinclusion of formulaic language in L2 tests and reading input in generalan important preliminary step will be to establish (a) what type offormulaic sequences are good discriminators of proficiency thresholdlevels and (b) which expressions of that identified type are mostcommon In other words what will be usefulmdashand is indeed nowbeginning to emerge (Martinez amp Schmitt 2010 Shin amp Nation 2008Simpson-Vlach amp Ellis 2010)mdashare lists of formulaic sequences that servea function similar to that of the General Service List not to revolutionizecurrent language pedagogy but to more finely tune it
THE AUTHORS
Ron Martinez is currently pursuing a doctorate at the University of NottinghamNottingham England on the topic of inclusion of phraseology in languageassessment He specializes in second language materials development
Victoria Murphy is a lecturer in Applied Linguistics and Second LanguageAcquisition at the University of Oxford Oxford England Her research interestsinclude the lexical development of first language or second language learners andthe cognitive processes that underlie language acquisition
REFERENCES
Bauer L amp Nation P (1993) Word families International Journal of Lexicography 6253ndash279 doi101093ijl64253
Bensoussan M amp Laufer B (1984) Lexical guessing in context in EFL readingcomprehension Journal of Research in Reading 7 15ndash32 doi101111j1467-98171984tb00252x
Bishop H (2004) Noticing formulaic sequences A problem of measuring thesubjective LSO Working Papers in Linguistics 4 15ndash19
Bransford D B amp Johnson M K (1972) Contextual prerequisites for under-standing Some investigations of comprehension and recall Journal of VerbalLearning and Verbal Behavior 11 717ndash726 doi101016S0022-5371(72)80006-9
Brantmeier C (2006) Advanced L2 learners and reading placement Self-assessment CBT and subsequent performance System 34 15ndash35 doi101016jsystem200508004
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 287
Carver R P (1994) Percentage of unknown vocabulary words in text as a functionof the relative difficulty of the text Implications for instruction Journal of ReadingBehavior 26 413ndash437
Cobb T (nd) Web VocabProfile [Online program] Retrieved from httpwwwlextutorcavp [an adaption of A Heatley amp P Nation Range (1994)]
Cooper T C (1999) Processing of idioms by L2 learners of English TESOLQuarterly 33 233ndash262 doi1023073587719
Coxhead A (2000) A new academic word list TESOL Quarterly 34 213ndash238doi1023073587951
Elley W amp Mangubhai F (1983) The impact of reading on second languagelearning Reading Research Quarterly 19 53ndash67 doi102307747337
Ellis N C (2008) Phraseology The periphery and the heart of language In FMeunier amp S Granger (Eds) Phraseology in language learning and teaching (pp 1ndash13) Amsterdam The Netherlands John Benjamins
Erman B amp Warren B (2000) The idiom principle and the open choice principleText 20 29ndash62
Gardner D (2007) Validating the construct of Word in applied corpus-basedvocabulary research A critical survey Applied Linguistics 28 241ndash265doi101093applinamm010
Glenberg A M Wilkinson A C amp Epstein W (1982) The illusion of knowingFailure in the self-assessment of comprehension Memory and Cognition 10 597ndash602 doi103758BF03202442
Goulden R Nation P amp Read J (1990) How large can a receptive vocabulary beApplied Linguistics 11 341ndash363 doi101093applin114341
Grant L amp Bauer L (2004) Criteria for re-defining idioms Are we barking up thewrong tree Applied Linguistics 25 38ndash61 doi101093applin25138
Grant L amp Nation P (2006) How many idioms are there in English ITL -International Journal of Applied Linguistics 151 1ndash14 doi102143ITL15102015219
Haynes M (1993) Patterns and perils of guessing in second language reading In THuckin M Haynes amp J Coady (Eds) Second language reading and vocabularylearning (pp 46ndash64) Norwood NJ Ablex Publishing Corporation
Heatley A amp Nation P (1994) Range [Computer program] Wellington NewZealand Victoria University of Wellington Retrieved from httpwwwvuwacnzlals
Hill J (2000) Revising priorities From grammatical failure to collocational successIn M Lewis (Ed) Teaching collocation Further developments in the Lexical Approach(pp 47ndash69) Hove England LTP
Hirsh D amp Nation P (1992) What vocabulary size is needed to read unsimplifiedtexts for pleasure Reading in a Foreign Language 8 689ndash696
Hu H M amp Nation P (2000) Unknown vocabulary density and readingcomprehension Reading in a Foreign Language 13 403ndash429
Hughes A (2003) Testing for language teachers Cambridge England CambridgeUniversity Press
Hunt K (1968) An instrument to measure syntactic maturity Tallahassee FL USDepartment of Health Education and Welfare
Jung E H (2003) The effects of organization markers on ESL learnersrsquo textunderstanding TESOL Quarterly 37 749ndash759 doi1023073588223
Krashen S (1993) The power of reading Insights from research Englewood COLibraries Unlimited
Laufer B (1989a) A factor of difficulty in vocabulary learning Deceptivetransparency AILA Review 6 10ndash20
288 TESOL QUARTERLY
Laufer B (1989b) What percentage of lexis is essential for comprehension In CLauren amp M Nordman (Eds) Special language From humans thinking to thinkingmachines (pp 316ndash323) London England Multilingual Matters
Laufer B (1991) How much lexis is necessary for reading comprehension In P JL Arnaud amp H Bejoint (Eds) Vocabulary and applied linguistics (pp 126ndash132)Oxford England Macmillan
Laufer B (1997) The lexical plight in second language reading Words you donrsquotknow words you think you know and words you canrsquot guess In J Coady amp THuckin (Eds) Second language vocabulary acquisition (pp 20ndash34) CambridgeEngland Cambridge University Press
Lewis M (1993) The Lexical Approach The state of ELT and a way forward HoveEngland LTP
Liontas J I (2002) Context and idiom understanding in second languagesEUROSLA Yearbook 2 155ndash185
Liontas J I (2003) Killing two birds with one stone Understanding Spanish VPidioms in and out of context Hispania 86 289ndash301 doi10230720062862
Liontas J I (2007) The eye never sees what the brain understands Making sense ofidioms in second languages Lingua et Linguistica 1) 25ndash44
Maki R H amp McGuire M J (2002) Metacognition for text Findings andimplications for education In T Schwarz amp L Bennett (Eds) Appliedmetacognition (pp 39ndash67) Cambridge England Cambridge University Press
Martinez R amp Schmitt N (2010) A phrasal expressions listManuscript submitted forpublication
Moon R (1997) Vocabulary connections Multi-word items in English In NSchmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 40ndash63) Cambridge England Cambridge University Press
Moore D Lin-Agler L M amp Zabrucky K M (2005) A source of metacomprehen-sion inaccuracy Reading Psychology 26 251ndash265 doi10108002702710590962578
Morrison L (2004) Comprehension monitoring in first and second languagereading The Canadian Modern Language Review 61 77ndash106
Nation I S P (2001) Learning vocabulary in another language Cambridge EnglandCambridge University Press
Nation I S P (2006) How large a vocabulary is needed for reading and listeningThe Canadian Modern Language Review 63 59ndash82
Nation I S P amp Waring R (1997) Vocabulary size text coverage and word lists InN Schmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 6ndash19) Cambridge England Cambridge University Press
Nation P (1997) The language learning benefits of extensive reading LanguageTeacher 21 13ndash16
Nattinger J R amp DeCarrico J S (1992) Lexical phrases and language teachingOxford England Oxford University Press
Oh S Y (2001) Two types of input modification and EFL reading comprehensionSimplification versus elaboration TESOL Quarterly 35 69ndash96 doi1023073587860
OrsquoKeeffe A McCarthy M amp Carter R (2007) From corpus to classroom Language useand language teaching Cambridge England Cambridge University Press
Pawley A amp Syder F H (1983) Two puzzles for linguistic theory Nativelikeselection and nativelike fluency In J C Richards amp R Schmidt (Eds) Languageand communication (pp 191ndash226) New York NY Longman
Pigada M amp Schmitt N (2006) Vocabulary acquisition from extensive reading Acase study Reading in a Foreign Language 18 1ndash28
Read J (2004) Research in teaching vocabulary Annual Review of Applied Linguistics24 146ndash161 doi101017S0267190504000078
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 289
Sarac S amp Tarhan B (2009) Calibration of comprehension and performance inL2 reading International Electronic Journal of Elementary Education 2 167ndash179
Schmitt N Jiang N amp Grabe W (2011) The percentage of words known in a textand reading comprehension Modern Language Journal 95(1) 26ndash43
Schmitt N Schmitt D amp Clapham C (2001) Developing and exploring thebehaviour of two new versions of the Vocabulary Levels Test Language Testing 1855ndash88
Shin D amp Nation I S P (2008) Beyond single words The most frequentcollocations in spoken English ELT Journal 62 339ndash348 doi101093eltccm091
Simpson-Vlach R amp Ellis N C (2010) An academic formulas list New methods inphraseology research Applied Linguistics 31(4) 487ndash512
Sinclair J (1991) Corpus concordance collocation Oxford England OxfordUniversity Press
Spottl C amp McCarthy M (2003) Formulaic utterances in the multi-lingual contextIn J Cenoz B Hufeisen ampU Jessner (Eds) The multilingual lexicon (pp 133ndash151) Dordrecht The Netherlands Kluwer
Staelighr L S (2008) Vocabulary size and the skills of listening reading and writingLanguage Learning Journal 36 139ndash152 doi10108009571730802389975
Stubbs M amp Barth I (2003) Using recurrent phrases as text-type descriminators Aquantitative method and some findings Functions of Language 10 61ndash104doi101075fol10104stu
The British National Corpus (2007) The British National Corpus(version 3 BNC XMLed) [CD-ROM] Distributed by Oxford University Computing Services on behalfof the BNC Consortium
The iPhonersquos second coming (2008 July) The Economist Retrieved from httpwwweconomistcomscience-technologydisplaystorycfmstory_id5E1_TTSDDJTG
Walter E Woodford K amp Good M (Eds) (2008) Cambridge advanced learnerrsquosdictionary (3rd ed) Cambridge England Cambridge University Press
Weir C J (2005) Language testing and validation An evidence-based approachNew York NY Palgrave Macmillan
West M (1953) A general service list of English words London England LongmanWray A (2002) Formulaic language and the lexicon Cambridge England Cambridge
University Press
290 TESOL QUARTERLY

greater than MAC) On the surface this might suggest that those 50participants did not overestimate their comprehension in Test 2 as aresult of its relative noncompositionality but rather as a generaltendency regardless of idiomaticity However when MAC is subtractedfrom MRC for that group and the difference compared across the teststhe difference is twice as large in Test 2 (t(49) 5 492 p 0001 g2 5
0108) This difference is even more evident in the same analysis of Test2 alone Isolating the results of that test there was a total of 70participants (over 69 of the entire sample) whose MRC was greaterthan their MAC The difference between MRC minus MAC for thesubgroup of 70 participants reveals that their overestimation of theircomprehension in Test 2 was four times greater than in Test 1 (t(69) 5
770 p 0001 g2 5 0228) Further among that group of 70 whoseTest 2 MRC was greater than their MAC 20 students either under-estimated or actually accurately guessed their comprehension in Test 1but significantly overestimated their comprehension in Test 2 (t(19) 5
849 p 0001 g2 5 0264) Only 30 participants in the present studyactually underestimated their comprehension on Test 2
Variation in Time Spent on the Tests
All candidates were also asked to record their start and finishing timesof each test (Table 7) It is not surprising that on average participantsspent more time on the texts which contained idiomatic expressionsHowever this trend was not uniform among the participants and thetime data may help provide some insight into just how aware someparticipants were of the presence of idiomaticity in the texts Thispossibility is explored further in the Discussion
TABLE 6
Trend of Increase in MRC-MAC Discrepancy Across Test Parts
NMRC minus MAC
(Test 1)MRC minus MAC
(Test 2)
Students with MRC MAC (bothtest parts)
50 009 019
Students with MRC MAC (Test 2) 70 004 017Students with MRC MAC (Test 2only)
20 2010 014
Students with MRC MAC (Test 2) 31a 2005 2015
Note MRC 5 mean reported comprehension MAC 5 mean actual comprehension aOnly oneparticipant in this group had MRC 5 MAC
280 TESOL QUARTERLY
DISCUSSION
To reiterate the present study sought to address the followingresearch questions
1 Are two texts written with the exact same high-frequency wordsunderstood equally well by L2 learners when one of the texts is moreidiomatic than the other
2 Can the presence of multiword expressions in a text lead L2 learners tobelieve they have understood that text better than they actually have
A group of 101 adult Brazilian learners of English was tested using twoseparate measures of reading comprehension (one with idiomaticlanguage and one without) and the results of the two tests were thencompared Although verbal reports would provide even greater insightthe resultant data from this study do seem to support a positive answer tothe first research question Participants achieved significantly lowerscores on the comprehension measure which assessed their under-standing of texts that contain multiword expressions It should bereiterated that this result was obtained in spite of both tests being writtenwith the exact same high-frequency words
Likewise through participantsrsquo self-reported comprehension thereseems to be evidence that the presence of multiword expressions in atext can lead L2 readers to overestimate their assessment of how muchthey have actually understood suggesting a positive answer to the secondresearch question
Although it seems apparent that participantsrsquo reading comprehensionin the present study was adversely affected by idiomaticity this sectionexplores and possibly explains variation in comprehension of the testsand further discusses evidence that multiword expressions negativelyaffected participantsrsquo comprehension
On the Stronger and Weaker Performance in the Tests
There are at least three important revelations emerging from theMRC-MAC data analysis presented in Table 6 First nearly two thirds of
TABLE 7
Time It Took Participants to Take Tests
N Mean time (minutes) SD
Time it took to take Test 1 91a 1085 436Time it took to take Test 2 91 1465 377
Note SD 5 standard deviation aSome participants (n 5 10) forgot to write in the time or left itincomplete
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 281
all participants believed they understood more than they actually did inTest 2 Second the data show that over 28 of those students (n 5 20)did not overestimate their comprehension in Test 1 providing evidencethat whereas they were apparently able to gauge their comprehensionfairly accurately when the texts were relatively devoid of idiomaticitythey were significantly less able to do so when relative noncomposition-ality was present Finally the MRC-MAC data presented so far indicatethat although not all participants tended to overestimate theircomprehension in Test 2 those who did (again the majority of cases)generally did so by a much larger margin Put simply it would seem thatnot only are many learners misunderstanding idiomaticity in text butthey may be doing so more than they (or researchers) realize
Further Evidence of Idiomaticity Negatively AffectingComprehension
The mean difference between MRC and MAC for the 70 students whooverestimated their comprehension in Test 2 (Table 6) was 017 For thesake of argument one could establish an MRC-MAC difference above020 as a cutoff for apparently marked lack of awareness of the extentof idiomaticity in Test 29 comparatively speaking This in turn wouldmean that there were 30 participants who ostensibly demonstrated aparticularly high overestimation of how much of Test 2 they had actuallyunderstood A sample of just the top 10 is provided in Table 8
Table 8 shows not only how different those participantsrsquo MRC wasfrom their Test 2 it also lists the same figures for Test 1 for comparison
9 A t-test reveals that the mean is in fact statistically significant even at the 003 differencelevel (t 5 653 p 5 003)
TABLE 8
Partial List of Participants With Exceptionally High Overestimation of Test 2 Comprehension(Difference 020)
ParticipantMRCTest 1
MACTest 1 Difference
MRCTest 2
MACTest 2 Difference
118 100 089 011 094 032 0626 075 068 007 081 028 05392 081 089 2008 075 025 05090 100 089 011 081 039 042115 100 089 011 087 050 03722 100 096 003 094 057 03780 094 068 026 069 032 03759 094 089 005 069 036 03321 100 093 007 087 057 03050 087 078 009 069 039 029
282 TESOL QUARTERLY
Whereas for Test 1 those 30 participantsrsquo assessment of readingcomprehension was usually only slightly overestimated10 (and in oneinstance even underestimated) the same participants in Test 2 had amarkedly overinflated conception of how much they had understood
Although not intended as a principal source of data for our analysisthe start and finish times recorded by participants on the tests in a fewinstances helped confirm the above assertions11 Table 7 shows thatthere was a significant difference between how long participants spenttaking each test (t 5 852 p 0001) However there were a number ofparticipants (n 5 26) who reported actually spending either the same orless time on Test 2 On the surface at least this fact would indicate thatthose 26 participants did not notice much difference between the testsOf course in reality that datum alone does not provide such evidencebecause that time may simply reflect a number of other confoundingvariables including affective (eg simply giving up) or even social (egthe need to leave early to meet a friend) and for that reason also was notconsidered to be a reliable source of data from those participantsHowever as a complementary source when triangulated with the othervariables some of the data analyzed earlier in the current study areoccasionally fortified further still with the time data (Table 9)
The data in Table 9 in many ways tie together the elements discussedin the analysis thus far in the present study A much lower score in Test 2than in Test 1 (columns B and C) an increase in the mean MRC-MACdifference across the tests (columns H and K) a relatively moderatedecrease in MRC in Test 2 vis-a-vis Test 1 (columns F and I) a markeddifference between MRC and MAC in Test 2 (column K) and theoccasional lack of increase (in Table 9 participants 118 80 59 and 50)in time it took to take Test 2 (columns D and E) These findings ontheir own in combination and especially in concert provide evidencethat (1) the students in Table 9 did not seem to appreciate the fullextent of the idiomaticity in Test 2 and (2) they appeared to think thatthey understood more than they actually did in Test 2
Perhaps most important 98 of all participants (n 5 99) scoredsignificantly lower on Test 2 (mean difference of 953 points out of 28SD 5 363) which shows that learners are generally unable to guess themeaning of idiomatic language even in the (largely inconsistent)instances in which they become aware of its presence
11 It should be noted that because 10 of the participantsrsquo time data were left incomplete afull group analysis could not be carried out thus the time data are only included asauxiliary information
10 As can be seen in Table 8 in fact only one participantmdashnumber 80mdashactually had anMRC-MAC difference in Test 1 that was also 020 Those of the other 29 participantswere all lower
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 283
For example the first participant in Tables 8 and 9 (number 118)who consistently overrated his own comprehension relative to his actualcomprehension answered for Text A of Test 2 as shown in Figure 3
On the basis of the responses it is likely that participant 118associated itrsquos about time with lsquolsquohas a problem with timersquorsquo Irsquom a little over thehill with lsquolsquohe probably lives in an area with hillsrsquorsquo and lsquolsquohe lives on the hill
TABLE 9
Triangulated Data Showing Negative Effect of Idiomaticity on Comprehension
A B C D E F G H I J K
Score Time Test 1 Test 2
Partic-ipant Test 1 Test 2 Test 1 Test 2 MRC MAC
Differ-ence MRC MAC
Differ-ence
118 25 9 2000 1800 100 089 11 094 032 0626 19 8 Missing Missing 075 068 007 081 028 05392 25 8 900 1100 081 089 2008 075 025 05090 25 11 900 1500 100 089 011 081 039 042115 25 14 1300 1500 100 089 011 087 050 03722 27 16 Missing Missing 100 096 003 094 057 03780 19 9 1000 1000 094 068 026 069 032 03759 25 10 1500 1400 094 089 005 069 036 03321 26 16 Missing Missing 100 093 007 087 057 03050 22 11 2000 1200 088 079 009 069 039 030
12 Of the 24 multiword expressions targeted for assessment of comprehension in Test 2 onlyfour were core idioms
FIGURE 3 Sample answer to Text A of Test 2
284 TESOL QUARTERLY
but not on top of itrsquorsquomdasha literal reading of those expressions His 100self-assessment is an indication that his answers were not guesses butinstead based on confidence that he had understood all the individualwords in the text The same answering dynamic occurred time and timeagain in Test 2
Returning therefore to the issues raised in the introduction thepresent research appears to provide evidence that idiomsmdashopaque orotherwise12mdashcan in fact cause major problems for L2 learners of Englishwhen reading In general the participants in our study were lesssuccessful at guessing the meaning of idioms than those in previousidiom-centered research such as Cooper (1999) and Liontas (2002)Because the learners in our study were not alerted to the presence ofidiomaticity in the text prior to reading this study may more accuratelyreflect what takes place in more naturally occurring L2 reading Finallythe difficulties that the participants encountered occurred in textscomposed purely of very common words showing that word frequencyalone is not necessarily a good measure of text coverage Lauferrsquos(1989a) hypothesis that much lexis in text can be deceptivelytransparent is confirmed in the present research extended to multiwordexpressions
Limitations of the Research
Although the research presented here does provide some significantevidence that the presence of idiomaticity in a text can negatively affectthe comprehension of that text by an L2 reader little is known about thestrategies the test takers employed Even though metacognition wasoutside the scope of examination of the present study such informationis highly relevant and future research should include protocols such asthose included in previous research on idioms (eg Liontas 20032007) which may provide crucial qualitative data regarding theindividual differences and behavior of the participants themselvesOverall future work in this area should consider making use of differentmeasures of self-assessment in order to explore the limitations of themethodology used in the present study
Also a question can be asked concerning the relative density ofmultiword expressions in each text In other words what is not known ison average how many such items a reader can expect to encounter Theratio of idioms to orthographic words in the texts tested in the presentstudy is very likely higher than averagemdashbut how much higher is as yetunknown Likewise the passages themselves were relatively short so it isunknown whether or not texts of greater length (and thereforecontextualization) would render the same or similar results
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 285
CONCLUSION
The present study provides some empirical evidence that a focus onword in L2 pedagogy may be detrimental to learnersrsquo development ofreading comprehension in the target language In most casesparticipants overestimated how much they had understood the textstested when those texts contained multiword expressions of varyingdegrees of compositionality comprised of very common individualwords Even when participants showed evidence of awareness of apresence of idiomaticity in the texts they generally were not very good atguessing the meaning of expressions Although Grant and Nation(2006) could be right that the teaching of individual idioms may not belsquolsquodeserving of class timersquorsquo (p 5) it is clear that at the very least raisinglearnersrsquo consciousness as to their prevalence and frequently deceptivetransparency in text certainly is
Concomitantly the present research serves to demonstrate theincompleteness of current lists of common words which now informimportant pedagogical instruments such as vocabulary tests gradedreaders and course syllabuses Under current methods as illustrated inthe Table 2 analysis of the Economist paragraph a text measured againstthe word lists now commonly in use can be mistakenly analyzed as beingeasily understood when in fact once multiword expressions are takeninto account the actual text coverage of easily understood words is farless Existing estimates of how many words one needs to know in order toadequately process naturally occurring texts (Hu amp Nation 2000Nation 2006) may need to be revisited to determine how many wordsand multiword expressions one needs to know
In practice research shows that learners will continue to believe theyunderstand items that they actually do not even after repeatedexposures to that same item (Bensoussan amp Laufer 1984 Haynes1993 Pigada amp Schmitt 2006) Language teachers and relatedprofessionals such as textbook writers need to consider ways tocontinuously help learners notice the gap between what they think theyknow and understand and what they actually do (Laufer 1997) Oneway this can be achieved has already been thoroughly discussed in thepresent paper devise texts (and tests) designed to lead readers down anidiomatic garden path Norbert Schmitt (as cited in Weir 2005) made asimilar recommendation
Perhaps the best and most valid type of vocabulary test is a reading passagewith comprehension questions but with the items requiring a full under-standing of particular words or phrases in the text This would mimic the realworld task of reading for comprehension and also the loss of comprehensionwhen key vocabulary is not known (p 123)
286 TESOL QUARTERLY
Therefore a further implication this research has for L2 pedagogy is themore careful design of the reading component of proficiency tests suchas IELTS (International English Language Testing System) and Test ofEnglish as a Foreign Language to be more strategic regarding the amountand kind of phraseology contained in the texts Proficiency was not thecentral focus of our study and future research could adopt a similarmethodology but with the inclusion of proficiency measures ofparticipants in order to explore how various types of expressions (egnoncompositional figurative imageable etc) may differentially affectpreidentified proficiency levels
Thus in order to be more methodical about such things as theinclusion of formulaic language in L2 tests and reading input in generalan important preliminary step will be to establish (a) what type offormulaic sequences are good discriminators of proficiency thresholdlevels and (b) which expressions of that identified type are mostcommon In other words what will be usefulmdashand is indeed nowbeginning to emerge (Martinez amp Schmitt 2010 Shin amp Nation 2008Simpson-Vlach amp Ellis 2010)mdashare lists of formulaic sequences that servea function similar to that of the General Service List not to revolutionizecurrent language pedagogy but to more finely tune it
THE AUTHORS
Ron Martinez is currently pursuing a doctorate at the University of NottinghamNottingham England on the topic of inclusion of phraseology in languageassessment He specializes in second language materials development
Victoria Murphy is a lecturer in Applied Linguistics and Second LanguageAcquisition at the University of Oxford Oxford England Her research interestsinclude the lexical development of first language or second language learners andthe cognitive processes that underlie language acquisition
REFERENCES
Bauer L amp Nation P (1993) Word families International Journal of Lexicography 6253ndash279 doi101093ijl64253
Bensoussan M amp Laufer B (1984) Lexical guessing in context in EFL readingcomprehension Journal of Research in Reading 7 15ndash32 doi101111j1467-98171984tb00252x
Bishop H (2004) Noticing formulaic sequences A problem of measuring thesubjective LSO Working Papers in Linguistics 4 15ndash19
Bransford D B amp Johnson M K (1972) Contextual prerequisites for under-standing Some investigations of comprehension and recall Journal of VerbalLearning and Verbal Behavior 11 717ndash726 doi101016S0022-5371(72)80006-9
Brantmeier C (2006) Advanced L2 learners and reading placement Self-assessment CBT and subsequent performance System 34 15ndash35 doi101016jsystem200508004
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 287
Carver R P (1994) Percentage of unknown vocabulary words in text as a functionof the relative difficulty of the text Implications for instruction Journal of ReadingBehavior 26 413ndash437
Cobb T (nd) Web VocabProfile [Online program] Retrieved from httpwwwlextutorcavp [an adaption of A Heatley amp P Nation Range (1994)]
Cooper T C (1999) Processing of idioms by L2 learners of English TESOLQuarterly 33 233ndash262 doi1023073587719
Coxhead A (2000) A new academic word list TESOL Quarterly 34 213ndash238doi1023073587951
Elley W amp Mangubhai F (1983) The impact of reading on second languagelearning Reading Research Quarterly 19 53ndash67 doi102307747337
Ellis N C (2008) Phraseology The periphery and the heart of language In FMeunier amp S Granger (Eds) Phraseology in language learning and teaching (pp 1ndash13) Amsterdam The Netherlands John Benjamins
Erman B amp Warren B (2000) The idiom principle and the open choice principleText 20 29ndash62
Gardner D (2007) Validating the construct of Word in applied corpus-basedvocabulary research A critical survey Applied Linguistics 28 241ndash265doi101093applinamm010
Glenberg A M Wilkinson A C amp Epstein W (1982) The illusion of knowingFailure in the self-assessment of comprehension Memory and Cognition 10 597ndash602 doi103758BF03202442
Goulden R Nation P amp Read J (1990) How large can a receptive vocabulary beApplied Linguistics 11 341ndash363 doi101093applin114341
Grant L amp Bauer L (2004) Criteria for re-defining idioms Are we barking up thewrong tree Applied Linguistics 25 38ndash61 doi101093applin25138
Grant L amp Nation P (2006) How many idioms are there in English ITL -International Journal of Applied Linguistics 151 1ndash14 doi102143ITL15102015219
Haynes M (1993) Patterns and perils of guessing in second language reading In THuckin M Haynes amp J Coady (Eds) Second language reading and vocabularylearning (pp 46ndash64) Norwood NJ Ablex Publishing Corporation
Heatley A amp Nation P (1994) Range [Computer program] Wellington NewZealand Victoria University of Wellington Retrieved from httpwwwvuwacnzlals
Hill J (2000) Revising priorities From grammatical failure to collocational successIn M Lewis (Ed) Teaching collocation Further developments in the Lexical Approach(pp 47ndash69) Hove England LTP
Hirsh D amp Nation P (1992) What vocabulary size is needed to read unsimplifiedtexts for pleasure Reading in a Foreign Language 8 689ndash696
Hu H M amp Nation P (2000) Unknown vocabulary density and readingcomprehension Reading in a Foreign Language 13 403ndash429
Hughes A (2003) Testing for language teachers Cambridge England CambridgeUniversity Press
Hunt K (1968) An instrument to measure syntactic maturity Tallahassee FL USDepartment of Health Education and Welfare
Jung E H (2003) The effects of organization markers on ESL learnersrsquo textunderstanding TESOL Quarterly 37 749ndash759 doi1023073588223
Krashen S (1993) The power of reading Insights from research Englewood COLibraries Unlimited
Laufer B (1989a) A factor of difficulty in vocabulary learning Deceptivetransparency AILA Review 6 10ndash20
288 TESOL QUARTERLY
Laufer B (1989b) What percentage of lexis is essential for comprehension In CLauren amp M Nordman (Eds) Special language From humans thinking to thinkingmachines (pp 316ndash323) London England Multilingual Matters
Laufer B (1991) How much lexis is necessary for reading comprehension In P JL Arnaud amp H Bejoint (Eds) Vocabulary and applied linguistics (pp 126ndash132)Oxford England Macmillan
Laufer B (1997) The lexical plight in second language reading Words you donrsquotknow words you think you know and words you canrsquot guess In J Coady amp THuckin (Eds) Second language vocabulary acquisition (pp 20ndash34) CambridgeEngland Cambridge University Press
Lewis M (1993) The Lexical Approach The state of ELT and a way forward HoveEngland LTP
Liontas J I (2002) Context and idiom understanding in second languagesEUROSLA Yearbook 2 155ndash185
Liontas J I (2003) Killing two birds with one stone Understanding Spanish VPidioms in and out of context Hispania 86 289ndash301 doi10230720062862
Liontas J I (2007) The eye never sees what the brain understands Making sense ofidioms in second languages Lingua et Linguistica 1) 25ndash44
Maki R H amp McGuire M J (2002) Metacognition for text Findings andimplications for education In T Schwarz amp L Bennett (Eds) Appliedmetacognition (pp 39ndash67) Cambridge England Cambridge University Press
Martinez R amp Schmitt N (2010) A phrasal expressions listManuscript submitted forpublication
Moon R (1997) Vocabulary connections Multi-word items in English In NSchmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 40ndash63) Cambridge England Cambridge University Press
Moore D Lin-Agler L M amp Zabrucky K M (2005) A source of metacomprehen-sion inaccuracy Reading Psychology 26 251ndash265 doi10108002702710590962578
Morrison L (2004) Comprehension monitoring in first and second languagereading The Canadian Modern Language Review 61 77ndash106
Nation I S P (2001) Learning vocabulary in another language Cambridge EnglandCambridge University Press
Nation I S P (2006) How large a vocabulary is needed for reading and listeningThe Canadian Modern Language Review 63 59ndash82
Nation I S P amp Waring R (1997) Vocabulary size text coverage and word lists InN Schmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 6ndash19) Cambridge England Cambridge University Press
Nation P (1997) The language learning benefits of extensive reading LanguageTeacher 21 13ndash16
Nattinger J R amp DeCarrico J S (1992) Lexical phrases and language teachingOxford England Oxford University Press
Oh S Y (2001) Two types of input modification and EFL reading comprehensionSimplification versus elaboration TESOL Quarterly 35 69ndash96 doi1023073587860
OrsquoKeeffe A McCarthy M amp Carter R (2007) From corpus to classroom Language useand language teaching Cambridge England Cambridge University Press
Pawley A amp Syder F H (1983) Two puzzles for linguistic theory Nativelikeselection and nativelike fluency In J C Richards amp R Schmidt (Eds) Languageand communication (pp 191ndash226) New York NY Longman
Pigada M amp Schmitt N (2006) Vocabulary acquisition from extensive reading Acase study Reading in a Foreign Language 18 1ndash28
Read J (2004) Research in teaching vocabulary Annual Review of Applied Linguistics24 146ndash161 doi101017S0267190504000078
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 289
Sarac S amp Tarhan B (2009) Calibration of comprehension and performance inL2 reading International Electronic Journal of Elementary Education 2 167ndash179
Schmitt N Jiang N amp Grabe W (2011) The percentage of words known in a textand reading comprehension Modern Language Journal 95(1) 26ndash43
Schmitt N Schmitt D amp Clapham C (2001) Developing and exploring thebehaviour of two new versions of the Vocabulary Levels Test Language Testing 1855ndash88
Shin D amp Nation I S P (2008) Beyond single words The most frequentcollocations in spoken English ELT Journal 62 339ndash348 doi101093eltccm091
Simpson-Vlach R amp Ellis N C (2010) An academic formulas list New methods inphraseology research Applied Linguistics 31(4) 487ndash512
Sinclair J (1991) Corpus concordance collocation Oxford England OxfordUniversity Press
Spottl C amp McCarthy M (2003) Formulaic utterances in the multi-lingual contextIn J Cenoz B Hufeisen ampU Jessner (Eds) The multilingual lexicon (pp 133ndash151) Dordrecht The Netherlands Kluwer
Staelighr L S (2008) Vocabulary size and the skills of listening reading and writingLanguage Learning Journal 36 139ndash152 doi10108009571730802389975
Stubbs M amp Barth I (2003) Using recurrent phrases as text-type descriminators Aquantitative method and some findings Functions of Language 10 61ndash104doi101075fol10104stu
The British National Corpus (2007) The British National Corpus(version 3 BNC XMLed) [CD-ROM] Distributed by Oxford University Computing Services on behalfof the BNC Consortium
The iPhonersquos second coming (2008 July) The Economist Retrieved from httpwwweconomistcomscience-technologydisplaystorycfmstory_id5E1_TTSDDJTG
Walter E Woodford K amp Good M (Eds) (2008) Cambridge advanced learnerrsquosdictionary (3rd ed) Cambridge England Cambridge University Press
Weir C J (2005) Language testing and validation An evidence-based approachNew York NY Palgrave Macmillan
West M (1953) A general service list of English words London England LongmanWray A (2002) Formulaic language and the lexicon Cambridge England Cambridge
University Press
290 TESOL QUARTERLY

DISCUSSION
To reiterate the present study sought to address the followingresearch questions
1 Are two texts written with the exact same high-frequency wordsunderstood equally well by L2 learners when one of the texts is moreidiomatic than the other
2 Can the presence of multiword expressions in a text lead L2 learners tobelieve they have understood that text better than they actually have
A group of 101 adult Brazilian learners of English was tested using twoseparate measures of reading comprehension (one with idiomaticlanguage and one without) and the results of the two tests were thencompared Although verbal reports would provide even greater insightthe resultant data from this study do seem to support a positive answer tothe first research question Participants achieved significantly lowerscores on the comprehension measure which assessed their under-standing of texts that contain multiword expressions It should bereiterated that this result was obtained in spite of both tests being writtenwith the exact same high-frequency words
Likewise through participantsrsquo self-reported comprehension thereseems to be evidence that the presence of multiword expressions in atext can lead L2 readers to overestimate their assessment of how muchthey have actually understood suggesting a positive answer to the secondresearch question
Although it seems apparent that participantsrsquo reading comprehensionin the present study was adversely affected by idiomaticity this sectionexplores and possibly explains variation in comprehension of the testsand further discusses evidence that multiword expressions negativelyaffected participantsrsquo comprehension
On the Stronger and Weaker Performance in the Tests
There are at least three important revelations emerging from theMRC-MAC data analysis presented in Table 6 First nearly two thirds of
TABLE 7
Time It Took Participants to Take Tests
N Mean time (minutes) SD
Time it took to take Test 1 91a 1085 436Time it took to take Test 2 91 1465 377
Note SD 5 standard deviation aSome participants (n 5 10) forgot to write in the time or left itincomplete
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 281
all participants believed they understood more than they actually did inTest 2 Second the data show that over 28 of those students (n 5 20)did not overestimate their comprehension in Test 1 providing evidencethat whereas they were apparently able to gauge their comprehensionfairly accurately when the texts were relatively devoid of idiomaticitythey were significantly less able to do so when relative noncomposition-ality was present Finally the MRC-MAC data presented so far indicatethat although not all participants tended to overestimate theircomprehension in Test 2 those who did (again the majority of cases)generally did so by a much larger margin Put simply it would seem thatnot only are many learners misunderstanding idiomaticity in text butthey may be doing so more than they (or researchers) realize
Further Evidence of Idiomaticity Negatively AffectingComprehension
The mean difference between MRC and MAC for the 70 students whooverestimated their comprehension in Test 2 (Table 6) was 017 For thesake of argument one could establish an MRC-MAC difference above020 as a cutoff for apparently marked lack of awareness of the extentof idiomaticity in Test 29 comparatively speaking This in turn wouldmean that there were 30 participants who ostensibly demonstrated aparticularly high overestimation of how much of Test 2 they had actuallyunderstood A sample of just the top 10 is provided in Table 8
Table 8 shows not only how different those participantsrsquo MRC wasfrom their Test 2 it also lists the same figures for Test 1 for comparison
9 A t-test reveals that the mean is in fact statistically significant even at the 003 differencelevel (t 5 653 p 5 003)
TABLE 8
Partial List of Participants With Exceptionally High Overestimation of Test 2 Comprehension(Difference 020)
ParticipantMRCTest 1
MACTest 1 Difference
MRCTest 2
MACTest 2 Difference
118 100 089 011 094 032 0626 075 068 007 081 028 05392 081 089 2008 075 025 05090 100 089 011 081 039 042115 100 089 011 087 050 03722 100 096 003 094 057 03780 094 068 026 069 032 03759 094 089 005 069 036 03321 100 093 007 087 057 03050 087 078 009 069 039 029
282 TESOL QUARTERLY
Whereas for Test 1 those 30 participantsrsquo assessment of readingcomprehension was usually only slightly overestimated10 (and in oneinstance even underestimated) the same participants in Test 2 had amarkedly overinflated conception of how much they had understood
Although not intended as a principal source of data for our analysisthe start and finish times recorded by participants on the tests in a fewinstances helped confirm the above assertions11 Table 7 shows thatthere was a significant difference between how long participants spenttaking each test (t 5 852 p 0001) However there were a number ofparticipants (n 5 26) who reported actually spending either the same orless time on Test 2 On the surface at least this fact would indicate thatthose 26 participants did not notice much difference between the testsOf course in reality that datum alone does not provide such evidencebecause that time may simply reflect a number of other confoundingvariables including affective (eg simply giving up) or even social (egthe need to leave early to meet a friend) and for that reason also was notconsidered to be a reliable source of data from those participantsHowever as a complementary source when triangulated with the othervariables some of the data analyzed earlier in the current study areoccasionally fortified further still with the time data (Table 9)
The data in Table 9 in many ways tie together the elements discussedin the analysis thus far in the present study A much lower score in Test 2than in Test 1 (columns B and C) an increase in the mean MRC-MACdifference across the tests (columns H and K) a relatively moderatedecrease in MRC in Test 2 vis-a-vis Test 1 (columns F and I) a markeddifference between MRC and MAC in Test 2 (column K) and theoccasional lack of increase (in Table 9 participants 118 80 59 and 50)in time it took to take Test 2 (columns D and E) These findings ontheir own in combination and especially in concert provide evidencethat (1) the students in Table 9 did not seem to appreciate the fullextent of the idiomaticity in Test 2 and (2) they appeared to think thatthey understood more than they actually did in Test 2
Perhaps most important 98 of all participants (n 5 99) scoredsignificantly lower on Test 2 (mean difference of 953 points out of 28SD 5 363) which shows that learners are generally unable to guess themeaning of idiomatic language even in the (largely inconsistent)instances in which they become aware of its presence
11 It should be noted that because 10 of the participantsrsquo time data were left incomplete afull group analysis could not be carried out thus the time data are only included asauxiliary information
10 As can be seen in Table 8 in fact only one participantmdashnumber 80mdashactually had anMRC-MAC difference in Test 1 that was also 020 Those of the other 29 participantswere all lower
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 283
For example the first participant in Tables 8 and 9 (number 118)who consistently overrated his own comprehension relative to his actualcomprehension answered for Text A of Test 2 as shown in Figure 3
On the basis of the responses it is likely that participant 118associated itrsquos about time with lsquolsquohas a problem with timersquorsquo Irsquom a little over thehill with lsquolsquohe probably lives in an area with hillsrsquorsquo and lsquolsquohe lives on the hill
TABLE 9
Triangulated Data Showing Negative Effect of Idiomaticity on Comprehension
A B C D E F G H I J K
Score Time Test 1 Test 2
Partic-ipant Test 1 Test 2 Test 1 Test 2 MRC MAC
Differ-ence MRC MAC
Differ-ence
118 25 9 2000 1800 100 089 11 094 032 0626 19 8 Missing Missing 075 068 007 081 028 05392 25 8 900 1100 081 089 2008 075 025 05090 25 11 900 1500 100 089 011 081 039 042115 25 14 1300 1500 100 089 011 087 050 03722 27 16 Missing Missing 100 096 003 094 057 03780 19 9 1000 1000 094 068 026 069 032 03759 25 10 1500 1400 094 089 005 069 036 03321 26 16 Missing Missing 100 093 007 087 057 03050 22 11 2000 1200 088 079 009 069 039 030
12 Of the 24 multiword expressions targeted for assessment of comprehension in Test 2 onlyfour were core idioms
FIGURE 3 Sample answer to Text A of Test 2
284 TESOL QUARTERLY
but not on top of itrsquorsquomdasha literal reading of those expressions His 100self-assessment is an indication that his answers were not guesses butinstead based on confidence that he had understood all the individualwords in the text The same answering dynamic occurred time and timeagain in Test 2
Returning therefore to the issues raised in the introduction thepresent research appears to provide evidence that idiomsmdashopaque orotherwise12mdashcan in fact cause major problems for L2 learners of Englishwhen reading In general the participants in our study were lesssuccessful at guessing the meaning of idioms than those in previousidiom-centered research such as Cooper (1999) and Liontas (2002)Because the learners in our study were not alerted to the presence ofidiomaticity in the text prior to reading this study may more accuratelyreflect what takes place in more naturally occurring L2 reading Finallythe difficulties that the participants encountered occurred in textscomposed purely of very common words showing that word frequencyalone is not necessarily a good measure of text coverage Lauferrsquos(1989a) hypothesis that much lexis in text can be deceptivelytransparent is confirmed in the present research extended to multiwordexpressions
Limitations of the Research
Although the research presented here does provide some significantevidence that the presence of idiomaticity in a text can negatively affectthe comprehension of that text by an L2 reader little is known about thestrategies the test takers employed Even though metacognition wasoutside the scope of examination of the present study such informationis highly relevant and future research should include protocols such asthose included in previous research on idioms (eg Liontas 20032007) which may provide crucial qualitative data regarding theindividual differences and behavior of the participants themselvesOverall future work in this area should consider making use of differentmeasures of self-assessment in order to explore the limitations of themethodology used in the present study
Also a question can be asked concerning the relative density ofmultiword expressions in each text In other words what is not known ison average how many such items a reader can expect to encounter Theratio of idioms to orthographic words in the texts tested in the presentstudy is very likely higher than averagemdashbut how much higher is as yetunknown Likewise the passages themselves were relatively short so it isunknown whether or not texts of greater length (and thereforecontextualization) would render the same or similar results
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 285
CONCLUSION
The present study provides some empirical evidence that a focus onword in L2 pedagogy may be detrimental to learnersrsquo development ofreading comprehension in the target language In most casesparticipants overestimated how much they had understood the textstested when those texts contained multiword expressions of varyingdegrees of compositionality comprised of very common individualwords Even when participants showed evidence of awareness of apresence of idiomaticity in the texts they generally were not very good atguessing the meaning of expressions Although Grant and Nation(2006) could be right that the teaching of individual idioms may not belsquolsquodeserving of class timersquorsquo (p 5) it is clear that at the very least raisinglearnersrsquo consciousness as to their prevalence and frequently deceptivetransparency in text certainly is
Concomitantly the present research serves to demonstrate theincompleteness of current lists of common words which now informimportant pedagogical instruments such as vocabulary tests gradedreaders and course syllabuses Under current methods as illustrated inthe Table 2 analysis of the Economist paragraph a text measured againstthe word lists now commonly in use can be mistakenly analyzed as beingeasily understood when in fact once multiword expressions are takeninto account the actual text coverage of easily understood words is farless Existing estimates of how many words one needs to know in order toadequately process naturally occurring texts (Hu amp Nation 2000Nation 2006) may need to be revisited to determine how many wordsand multiword expressions one needs to know
In practice research shows that learners will continue to believe theyunderstand items that they actually do not even after repeatedexposures to that same item (Bensoussan amp Laufer 1984 Haynes1993 Pigada amp Schmitt 2006) Language teachers and relatedprofessionals such as textbook writers need to consider ways tocontinuously help learners notice the gap between what they think theyknow and understand and what they actually do (Laufer 1997) Oneway this can be achieved has already been thoroughly discussed in thepresent paper devise texts (and tests) designed to lead readers down anidiomatic garden path Norbert Schmitt (as cited in Weir 2005) made asimilar recommendation
Perhaps the best and most valid type of vocabulary test is a reading passagewith comprehension questions but with the items requiring a full under-standing of particular words or phrases in the text This would mimic the realworld task of reading for comprehension and also the loss of comprehensionwhen key vocabulary is not known (p 123)
286 TESOL QUARTERLY
Therefore a further implication this research has for L2 pedagogy is themore careful design of the reading component of proficiency tests suchas IELTS (International English Language Testing System) and Test ofEnglish as a Foreign Language to be more strategic regarding the amountand kind of phraseology contained in the texts Proficiency was not thecentral focus of our study and future research could adopt a similarmethodology but with the inclusion of proficiency measures ofparticipants in order to explore how various types of expressions (egnoncompositional figurative imageable etc) may differentially affectpreidentified proficiency levels
Thus in order to be more methodical about such things as theinclusion of formulaic language in L2 tests and reading input in generalan important preliminary step will be to establish (a) what type offormulaic sequences are good discriminators of proficiency thresholdlevels and (b) which expressions of that identified type are mostcommon In other words what will be usefulmdashand is indeed nowbeginning to emerge (Martinez amp Schmitt 2010 Shin amp Nation 2008Simpson-Vlach amp Ellis 2010)mdashare lists of formulaic sequences that servea function similar to that of the General Service List not to revolutionizecurrent language pedagogy but to more finely tune it
THE AUTHORS
Ron Martinez is currently pursuing a doctorate at the University of NottinghamNottingham England on the topic of inclusion of phraseology in languageassessment He specializes in second language materials development
Victoria Murphy is a lecturer in Applied Linguistics and Second LanguageAcquisition at the University of Oxford Oxford England Her research interestsinclude the lexical development of first language or second language learners andthe cognitive processes that underlie language acquisition
REFERENCES
Bauer L amp Nation P (1993) Word families International Journal of Lexicography 6253ndash279 doi101093ijl64253
Bensoussan M amp Laufer B (1984) Lexical guessing in context in EFL readingcomprehension Journal of Research in Reading 7 15ndash32 doi101111j1467-98171984tb00252x
Bishop H (2004) Noticing formulaic sequences A problem of measuring thesubjective LSO Working Papers in Linguistics 4 15ndash19
Bransford D B amp Johnson M K (1972) Contextual prerequisites for under-standing Some investigations of comprehension and recall Journal of VerbalLearning and Verbal Behavior 11 717ndash726 doi101016S0022-5371(72)80006-9
Brantmeier C (2006) Advanced L2 learners and reading placement Self-assessment CBT and subsequent performance System 34 15ndash35 doi101016jsystem200508004
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 287
Carver R P (1994) Percentage of unknown vocabulary words in text as a functionof the relative difficulty of the text Implications for instruction Journal of ReadingBehavior 26 413ndash437
Cobb T (nd) Web VocabProfile [Online program] Retrieved from httpwwwlextutorcavp [an adaption of A Heatley amp P Nation Range (1994)]
Cooper T C (1999) Processing of idioms by L2 learners of English TESOLQuarterly 33 233ndash262 doi1023073587719
Coxhead A (2000) A new academic word list TESOL Quarterly 34 213ndash238doi1023073587951
Elley W amp Mangubhai F (1983) The impact of reading on second languagelearning Reading Research Quarterly 19 53ndash67 doi102307747337
Ellis N C (2008) Phraseology The periphery and the heart of language In FMeunier amp S Granger (Eds) Phraseology in language learning and teaching (pp 1ndash13) Amsterdam The Netherlands John Benjamins
Erman B amp Warren B (2000) The idiom principle and the open choice principleText 20 29ndash62
Gardner D (2007) Validating the construct of Word in applied corpus-basedvocabulary research A critical survey Applied Linguistics 28 241ndash265doi101093applinamm010
Glenberg A M Wilkinson A C amp Epstein W (1982) The illusion of knowingFailure in the self-assessment of comprehension Memory and Cognition 10 597ndash602 doi103758BF03202442
Goulden R Nation P amp Read J (1990) How large can a receptive vocabulary beApplied Linguistics 11 341ndash363 doi101093applin114341
Grant L amp Bauer L (2004) Criteria for re-defining idioms Are we barking up thewrong tree Applied Linguistics 25 38ndash61 doi101093applin25138
Grant L amp Nation P (2006) How many idioms are there in English ITL -International Journal of Applied Linguistics 151 1ndash14 doi102143ITL15102015219
Haynes M (1993) Patterns and perils of guessing in second language reading In THuckin M Haynes amp J Coady (Eds) Second language reading and vocabularylearning (pp 46ndash64) Norwood NJ Ablex Publishing Corporation
Heatley A amp Nation P (1994) Range [Computer program] Wellington NewZealand Victoria University of Wellington Retrieved from httpwwwvuwacnzlals
Hill J (2000) Revising priorities From grammatical failure to collocational successIn M Lewis (Ed) Teaching collocation Further developments in the Lexical Approach(pp 47ndash69) Hove England LTP
Hirsh D amp Nation P (1992) What vocabulary size is needed to read unsimplifiedtexts for pleasure Reading in a Foreign Language 8 689ndash696
Hu H M amp Nation P (2000) Unknown vocabulary density and readingcomprehension Reading in a Foreign Language 13 403ndash429
Hughes A (2003) Testing for language teachers Cambridge England CambridgeUniversity Press
Hunt K (1968) An instrument to measure syntactic maturity Tallahassee FL USDepartment of Health Education and Welfare
Jung E H (2003) The effects of organization markers on ESL learnersrsquo textunderstanding TESOL Quarterly 37 749ndash759 doi1023073588223
Krashen S (1993) The power of reading Insights from research Englewood COLibraries Unlimited
Laufer B (1989a) A factor of difficulty in vocabulary learning Deceptivetransparency AILA Review 6 10ndash20
288 TESOL QUARTERLY
Laufer B (1989b) What percentage of lexis is essential for comprehension In CLauren amp M Nordman (Eds) Special language From humans thinking to thinkingmachines (pp 316ndash323) London England Multilingual Matters
Laufer B (1991) How much lexis is necessary for reading comprehension In P JL Arnaud amp H Bejoint (Eds) Vocabulary and applied linguistics (pp 126ndash132)Oxford England Macmillan
Laufer B (1997) The lexical plight in second language reading Words you donrsquotknow words you think you know and words you canrsquot guess In J Coady amp THuckin (Eds) Second language vocabulary acquisition (pp 20ndash34) CambridgeEngland Cambridge University Press
Lewis M (1993) The Lexical Approach The state of ELT and a way forward HoveEngland LTP
Liontas J I (2002) Context and idiom understanding in second languagesEUROSLA Yearbook 2 155ndash185
Liontas J I (2003) Killing two birds with one stone Understanding Spanish VPidioms in and out of context Hispania 86 289ndash301 doi10230720062862
Liontas J I (2007) The eye never sees what the brain understands Making sense ofidioms in second languages Lingua et Linguistica 1) 25ndash44
Maki R H amp McGuire M J (2002) Metacognition for text Findings andimplications for education In T Schwarz amp L Bennett (Eds) Appliedmetacognition (pp 39ndash67) Cambridge England Cambridge University Press
Martinez R amp Schmitt N (2010) A phrasal expressions listManuscript submitted forpublication
Moon R (1997) Vocabulary connections Multi-word items in English In NSchmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 40ndash63) Cambridge England Cambridge University Press
Moore D Lin-Agler L M amp Zabrucky K M (2005) A source of metacomprehen-sion inaccuracy Reading Psychology 26 251ndash265 doi10108002702710590962578
Morrison L (2004) Comprehension monitoring in first and second languagereading The Canadian Modern Language Review 61 77ndash106
Nation I S P (2001) Learning vocabulary in another language Cambridge EnglandCambridge University Press
Nation I S P (2006) How large a vocabulary is needed for reading and listeningThe Canadian Modern Language Review 63 59ndash82
Nation I S P amp Waring R (1997) Vocabulary size text coverage and word lists InN Schmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 6ndash19) Cambridge England Cambridge University Press
Nation P (1997) The language learning benefits of extensive reading LanguageTeacher 21 13ndash16
Nattinger J R amp DeCarrico J S (1992) Lexical phrases and language teachingOxford England Oxford University Press
Oh S Y (2001) Two types of input modification and EFL reading comprehensionSimplification versus elaboration TESOL Quarterly 35 69ndash96 doi1023073587860
OrsquoKeeffe A McCarthy M amp Carter R (2007) From corpus to classroom Language useand language teaching Cambridge England Cambridge University Press
Pawley A amp Syder F H (1983) Two puzzles for linguistic theory Nativelikeselection and nativelike fluency In J C Richards amp R Schmidt (Eds) Languageand communication (pp 191ndash226) New York NY Longman
Pigada M amp Schmitt N (2006) Vocabulary acquisition from extensive reading Acase study Reading in a Foreign Language 18 1ndash28
Read J (2004) Research in teaching vocabulary Annual Review of Applied Linguistics24 146ndash161 doi101017S0267190504000078
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 289
Sarac S amp Tarhan B (2009) Calibration of comprehension and performance inL2 reading International Electronic Journal of Elementary Education 2 167ndash179
Schmitt N Jiang N amp Grabe W (2011) The percentage of words known in a textand reading comprehension Modern Language Journal 95(1) 26ndash43
Schmitt N Schmitt D amp Clapham C (2001) Developing and exploring thebehaviour of two new versions of the Vocabulary Levels Test Language Testing 1855ndash88
Shin D amp Nation I S P (2008) Beyond single words The most frequentcollocations in spoken English ELT Journal 62 339ndash348 doi101093eltccm091
Simpson-Vlach R amp Ellis N C (2010) An academic formulas list New methods inphraseology research Applied Linguistics 31(4) 487ndash512
Sinclair J (1991) Corpus concordance collocation Oxford England OxfordUniversity Press
Spottl C amp McCarthy M (2003) Formulaic utterances in the multi-lingual contextIn J Cenoz B Hufeisen ampU Jessner (Eds) The multilingual lexicon (pp 133ndash151) Dordrecht The Netherlands Kluwer
Staelighr L S (2008) Vocabulary size and the skills of listening reading and writingLanguage Learning Journal 36 139ndash152 doi10108009571730802389975
Stubbs M amp Barth I (2003) Using recurrent phrases as text-type descriminators Aquantitative method and some findings Functions of Language 10 61ndash104doi101075fol10104stu
The British National Corpus (2007) The British National Corpus(version 3 BNC XMLed) [CD-ROM] Distributed by Oxford University Computing Services on behalfof the BNC Consortium
The iPhonersquos second coming (2008 July) The Economist Retrieved from httpwwweconomistcomscience-technologydisplaystorycfmstory_id5E1_TTSDDJTG
Walter E Woodford K amp Good M (Eds) (2008) Cambridge advanced learnerrsquosdictionary (3rd ed) Cambridge England Cambridge University Press
Weir C J (2005) Language testing and validation An evidence-based approachNew York NY Palgrave Macmillan
West M (1953) A general service list of English words London England LongmanWray A (2002) Formulaic language and the lexicon Cambridge England Cambridge
University Press
290 TESOL QUARTERLY
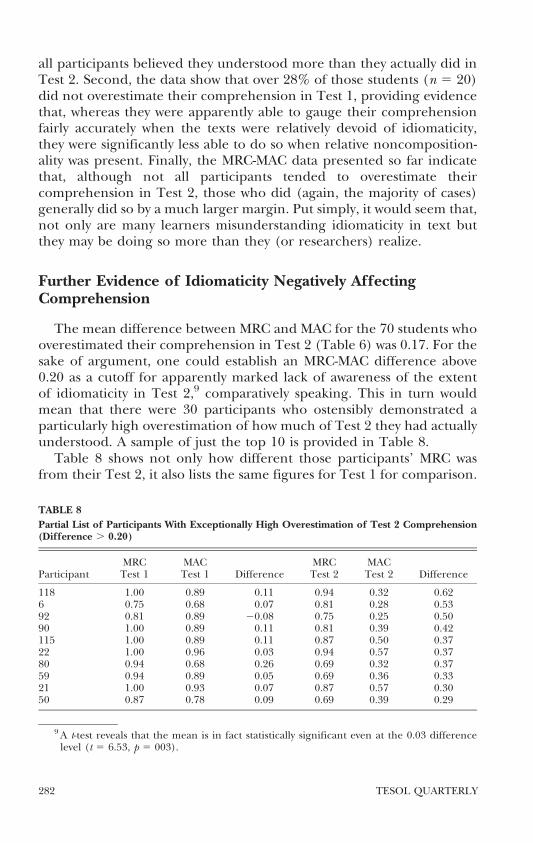
all participants believed they understood more than they actually did inTest 2 Second the data show that over 28 of those students (n 5 20)did not overestimate their comprehension in Test 1 providing evidencethat whereas they were apparently able to gauge their comprehensionfairly accurately when the texts were relatively devoid of idiomaticitythey were significantly less able to do so when relative noncomposition-ality was present Finally the MRC-MAC data presented so far indicatethat although not all participants tended to overestimate theircomprehension in Test 2 those who did (again the majority of cases)generally did so by a much larger margin Put simply it would seem thatnot only are many learners misunderstanding idiomaticity in text butthey may be doing so more than they (or researchers) realize
Further Evidence of Idiomaticity Negatively AffectingComprehension
The mean difference between MRC and MAC for the 70 students whooverestimated their comprehension in Test 2 (Table 6) was 017 For thesake of argument one could establish an MRC-MAC difference above020 as a cutoff for apparently marked lack of awareness of the extentof idiomaticity in Test 29 comparatively speaking This in turn wouldmean that there were 30 participants who ostensibly demonstrated aparticularly high overestimation of how much of Test 2 they had actuallyunderstood A sample of just the top 10 is provided in Table 8
Table 8 shows not only how different those participantsrsquo MRC wasfrom their Test 2 it also lists the same figures for Test 1 for comparison
9 A t-test reveals that the mean is in fact statistically significant even at the 003 differencelevel (t 5 653 p 5 003)
TABLE 8
Partial List of Participants With Exceptionally High Overestimation of Test 2 Comprehension(Difference 020)
ParticipantMRCTest 1
MACTest 1 Difference
MRCTest 2
MACTest 2 Difference
118 100 089 011 094 032 0626 075 068 007 081 028 05392 081 089 2008 075 025 05090 100 089 011 081 039 042115 100 089 011 087 050 03722 100 096 003 094 057 03780 094 068 026 069 032 03759 094 089 005 069 036 03321 100 093 007 087 057 03050 087 078 009 069 039 029
282 TESOL QUARTERLY
Whereas for Test 1 those 30 participantsrsquo assessment of readingcomprehension was usually only slightly overestimated10 (and in oneinstance even underestimated) the same participants in Test 2 had amarkedly overinflated conception of how much they had understood
Although not intended as a principal source of data for our analysisthe start and finish times recorded by participants on the tests in a fewinstances helped confirm the above assertions11 Table 7 shows thatthere was a significant difference between how long participants spenttaking each test (t 5 852 p 0001) However there were a number ofparticipants (n 5 26) who reported actually spending either the same orless time on Test 2 On the surface at least this fact would indicate thatthose 26 participants did not notice much difference between the testsOf course in reality that datum alone does not provide such evidencebecause that time may simply reflect a number of other confoundingvariables including affective (eg simply giving up) or even social (egthe need to leave early to meet a friend) and for that reason also was notconsidered to be a reliable source of data from those participantsHowever as a complementary source when triangulated with the othervariables some of the data analyzed earlier in the current study areoccasionally fortified further still with the time data (Table 9)
The data in Table 9 in many ways tie together the elements discussedin the analysis thus far in the present study A much lower score in Test 2than in Test 1 (columns B and C) an increase in the mean MRC-MACdifference across the tests (columns H and K) a relatively moderatedecrease in MRC in Test 2 vis-a-vis Test 1 (columns F and I) a markeddifference between MRC and MAC in Test 2 (column K) and theoccasional lack of increase (in Table 9 participants 118 80 59 and 50)in time it took to take Test 2 (columns D and E) These findings ontheir own in combination and especially in concert provide evidencethat (1) the students in Table 9 did not seem to appreciate the fullextent of the idiomaticity in Test 2 and (2) they appeared to think thatthey understood more than they actually did in Test 2
Perhaps most important 98 of all participants (n 5 99) scoredsignificantly lower on Test 2 (mean difference of 953 points out of 28SD 5 363) which shows that learners are generally unable to guess themeaning of idiomatic language even in the (largely inconsistent)instances in which they become aware of its presence
11 It should be noted that because 10 of the participantsrsquo time data were left incomplete afull group analysis could not be carried out thus the time data are only included asauxiliary information
10 As can be seen in Table 8 in fact only one participantmdashnumber 80mdashactually had anMRC-MAC difference in Test 1 that was also 020 Those of the other 29 participantswere all lower
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 283
For example the first participant in Tables 8 and 9 (number 118)who consistently overrated his own comprehension relative to his actualcomprehension answered for Text A of Test 2 as shown in Figure 3
On the basis of the responses it is likely that participant 118associated itrsquos about time with lsquolsquohas a problem with timersquorsquo Irsquom a little over thehill with lsquolsquohe probably lives in an area with hillsrsquorsquo and lsquolsquohe lives on the hill
TABLE 9
Triangulated Data Showing Negative Effect of Idiomaticity on Comprehension
A B C D E F G H I J K
Score Time Test 1 Test 2
Partic-ipant Test 1 Test 2 Test 1 Test 2 MRC MAC
Differ-ence MRC MAC
Differ-ence
118 25 9 2000 1800 100 089 11 094 032 0626 19 8 Missing Missing 075 068 007 081 028 05392 25 8 900 1100 081 089 2008 075 025 05090 25 11 900 1500 100 089 011 081 039 042115 25 14 1300 1500 100 089 011 087 050 03722 27 16 Missing Missing 100 096 003 094 057 03780 19 9 1000 1000 094 068 026 069 032 03759 25 10 1500 1400 094 089 005 069 036 03321 26 16 Missing Missing 100 093 007 087 057 03050 22 11 2000 1200 088 079 009 069 039 030
12 Of the 24 multiword expressions targeted for assessment of comprehension in Test 2 onlyfour were core idioms
FIGURE 3 Sample answer to Text A of Test 2
284 TESOL QUARTERLY
but not on top of itrsquorsquomdasha literal reading of those expressions His 100self-assessment is an indication that his answers were not guesses butinstead based on confidence that he had understood all the individualwords in the text The same answering dynamic occurred time and timeagain in Test 2
Returning therefore to the issues raised in the introduction thepresent research appears to provide evidence that idiomsmdashopaque orotherwise12mdashcan in fact cause major problems for L2 learners of Englishwhen reading In general the participants in our study were lesssuccessful at guessing the meaning of idioms than those in previousidiom-centered research such as Cooper (1999) and Liontas (2002)Because the learners in our study were not alerted to the presence ofidiomaticity in the text prior to reading this study may more accuratelyreflect what takes place in more naturally occurring L2 reading Finallythe difficulties that the participants encountered occurred in textscomposed purely of very common words showing that word frequencyalone is not necessarily a good measure of text coverage Lauferrsquos(1989a) hypothesis that much lexis in text can be deceptivelytransparent is confirmed in the present research extended to multiwordexpressions
Limitations of the Research
Although the research presented here does provide some significantevidence that the presence of idiomaticity in a text can negatively affectthe comprehension of that text by an L2 reader little is known about thestrategies the test takers employed Even though metacognition wasoutside the scope of examination of the present study such informationis highly relevant and future research should include protocols such asthose included in previous research on idioms (eg Liontas 20032007) which may provide crucial qualitative data regarding theindividual differences and behavior of the participants themselvesOverall future work in this area should consider making use of differentmeasures of self-assessment in order to explore the limitations of themethodology used in the present study
Also a question can be asked concerning the relative density ofmultiword expressions in each text In other words what is not known ison average how many such items a reader can expect to encounter Theratio of idioms to orthographic words in the texts tested in the presentstudy is very likely higher than averagemdashbut how much higher is as yetunknown Likewise the passages themselves were relatively short so it isunknown whether or not texts of greater length (and thereforecontextualization) would render the same or similar results
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 285
CONCLUSION
The present study provides some empirical evidence that a focus onword in L2 pedagogy may be detrimental to learnersrsquo development ofreading comprehension in the target language In most casesparticipants overestimated how much they had understood the textstested when those texts contained multiword expressions of varyingdegrees of compositionality comprised of very common individualwords Even when participants showed evidence of awareness of apresence of idiomaticity in the texts they generally were not very good atguessing the meaning of expressions Although Grant and Nation(2006) could be right that the teaching of individual idioms may not belsquolsquodeserving of class timersquorsquo (p 5) it is clear that at the very least raisinglearnersrsquo consciousness as to their prevalence and frequently deceptivetransparency in text certainly is
Concomitantly the present research serves to demonstrate theincompleteness of current lists of common words which now informimportant pedagogical instruments such as vocabulary tests gradedreaders and course syllabuses Under current methods as illustrated inthe Table 2 analysis of the Economist paragraph a text measured againstthe word lists now commonly in use can be mistakenly analyzed as beingeasily understood when in fact once multiword expressions are takeninto account the actual text coverage of easily understood words is farless Existing estimates of how many words one needs to know in order toadequately process naturally occurring texts (Hu amp Nation 2000Nation 2006) may need to be revisited to determine how many wordsand multiword expressions one needs to know
In practice research shows that learners will continue to believe theyunderstand items that they actually do not even after repeatedexposures to that same item (Bensoussan amp Laufer 1984 Haynes1993 Pigada amp Schmitt 2006) Language teachers and relatedprofessionals such as textbook writers need to consider ways tocontinuously help learners notice the gap between what they think theyknow and understand and what they actually do (Laufer 1997) Oneway this can be achieved has already been thoroughly discussed in thepresent paper devise texts (and tests) designed to lead readers down anidiomatic garden path Norbert Schmitt (as cited in Weir 2005) made asimilar recommendation
Perhaps the best and most valid type of vocabulary test is a reading passagewith comprehension questions but with the items requiring a full under-standing of particular words or phrases in the text This would mimic the realworld task of reading for comprehension and also the loss of comprehensionwhen key vocabulary is not known (p 123)
286 TESOL QUARTERLY
Therefore a further implication this research has for L2 pedagogy is themore careful design of the reading component of proficiency tests suchas IELTS (International English Language Testing System) and Test ofEnglish as a Foreign Language to be more strategic regarding the amountand kind of phraseology contained in the texts Proficiency was not thecentral focus of our study and future research could adopt a similarmethodology but with the inclusion of proficiency measures ofparticipants in order to explore how various types of expressions (egnoncompositional figurative imageable etc) may differentially affectpreidentified proficiency levels
Thus in order to be more methodical about such things as theinclusion of formulaic language in L2 tests and reading input in generalan important preliminary step will be to establish (a) what type offormulaic sequences are good discriminators of proficiency thresholdlevels and (b) which expressions of that identified type are mostcommon In other words what will be usefulmdashand is indeed nowbeginning to emerge (Martinez amp Schmitt 2010 Shin amp Nation 2008Simpson-Vlach amp Ellis 2010)mdashare lists of formulaic sequences that servea function similar to that of the General Service List not to revolutionizecurrent language pedagogy but to more finely tune it
THE AUTHORS
Ron Martinez is currently pursuing a doctorate at the University of NottinghamNottingham England on the topic of inclusion of phraseology in languageassessment He specializes in second language materials development
Victoria Murphy is a lecturer in Applied Linguistics and Second LanguageAcquisition at the University of Oxford Oxford England Her research interestsinclude the lexical development of first language or second language learners andthe cognitive processes that underlie language acquisition
REFERENCES
Bauer L amp Nation P (1993) Word families International Journal of Lexicography 6253ndash279 doi101093ijl64253
Bensoussan M amp Laufer B (1984) Lexical guessing in context in EFL readingcomprehension Journal of Research in Reading 7 15ndash32 doi101111j1467-98171984tb00252x
Bishop H (2004) Noticing formulaic sequences A problem of measuring thesubjective LSO Working Papers in Linguistics 4 15ndash19
Bransford D B amp Johnson M K (1972) Contextual prerequisites for under-standing Some investigations of comprehension and recall Journal of VerbalLearning and Verbal Behavior 11 717ndash726 doi101016S0022-5371(72)80006-9
Brantmeier C (2006) Advanced L2 learners and reading placement Self-assessment CBT and subsequent performance System 34 15ndash35 doi101016jsystem200508004
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 287
Carver R P (1994) Percentage of unknown vocabulary words in text as a functionof the relative difficulty of the text Implications for instruction Journal of ReadingBehavior 26 413ndash437
Cobb T (nd) Web VocabProfile [Online program] Retrieved from httpwwwlextutorcavp [an adaption of A Heatley amp P Nation Range (1994)]
Cooper T C (1999) Processing of idioms by L2 learners of English TESOLQuarterly 33 233ndash262 doi1023073587719
Coxhead A (2000) A new academic word list TESOL Quarterly 34 213ndash238doi1023073587951
Elley W amp Mangubhai F (1983) The impact of reading on second languagelearning Reading Research Quarterly 19 53ndash67 doi102307747337
Ellis N C (2008) Phraseology The periphery and the heart of language In FMeunier amp S Granger (Eds) Phraseology in language learning and teaching (pp 1ndash13) Amsterdam The Netherlands John Benjamins
Erman B amp Warren B (2000) The idiom principle and the open choice principleText 20 29ndash62
Gardner D (2007) Validating the construct of Word in applied corpus-basedvocabulary research A critical survey Applied Linguistics 28 241ndash265doi101093applinamm010
Glenberg A M Wilkinson A C amp Epstein W (1982) The illusion of knowingFailure in the self-assessment of comprehension Memory and Cognition 10 597ndash602 doi103758BF03202442
Goulden R Nation P amp Read J (1990) How large can a receptive vocabulary beApplied Linguistics 11 341ndash363 doi101093applin114341
Grant L amp Bauer L (2004) Criteria for re-defining idioms Are we barking up thewrong tree Applied Linguistics 25 38ndash61 doi101093applin25138
Grant L amp Nation P (2006) How many idioms are there in English ITL -International Journal of Applied Linguistics 151 1ndash14 doi102143ITL15102015219
Haynes M (1993) Patterns and perils of guessing in second language reading In THuckin M Haynes amp J Coady (Eds) Second language reading and vocabularylearning (pp 46ndash64) Norwood NJ Ablex Publishing Corporation
Heatley A amp Nation P (1994) Range [Computer program] Wellington NewZealand Victoria University of Wellington Retrieved from httpwwwvuwacnzlals
Hill J (2000) Revising priorities From grammatical failure to collocational successIn M Lewis (Ed) Teaching collocation Further developments in the Lexical Approach(pp 47ndash69) Hove England LTP
Hirsh D amp Nation P (1992) What vocabulary size is needed to read unsimplifiedtexts for pleasure Reading in a Foreign Language 8 689ndash696
Hu H M amp Nation P (2000) Unknown vocabulary density and readingcomprehension Reading in a Foreign Language 13 403ndash429
Hughes A (2003) Testing for language teachers Cambridge England CambridgeUniversity Press
Hunt K (1968) An instrument to measure syntactic maturity Tallahassee FL USDepartment of Health Education and Welfare
Jung E H (2003) The effects of organization markers on ESL learnersrsquo textunderstanding TESOL Quarterly 37 749ndash759 doi1023073588223
Krashen S (1993) The power of reading Insights from research Englewood COLibraries Unlimited
Laufer B (1989a) A factor of difficulty in vocabulary learning Deceptivetransparency AILA Review 6 10ndash20
288 TESOL QUARTERLY
Laufer B (1989b) What percentage of lexis is essential for comprehension In CLauren amp M Nordman (Eds) Special language From humans thinking to thinkingmachines (pp 316ndash323) London England Multilingual Matters
Laufer B (1991) How much lexis is necessary for reading comprehension In P JL Arnaud amp H Bejoint (Eds) Vocabulary and applied linguistics (pp 126ndash132)Oxford England Macmillan
Laufer B (1997) The lexical plight in second language reading Words you donrsquotknow words you think you know and words you canrsquot guess In J Coady amp THuckin (Eds) Second language vocabulary acquisition (pp 20ndash34) CambridgeEngland Cambridge University Press
Lewis M (1993) The Lexical Approach The state of ELT and a way forward HoveEngland LTP
Liontas J I (2002) Context and idiom understanding in second languagesEUROSLA Yearbook 2 155ndash185
Liontas J I (2003) Killing two birds with one stone Understanding Spanish VPidioms in and out of context Hispania 86 289ndash301 doi10230720062862
Liontas J I (2007) The eye never sees what the brain understands Making sense ofidioms in second languages Lingua et Linguistica 1) 25ndash44
Maki R H amp McGuire M J (2002) Metacognition for text Findings andimplications for education In T Schwarz amp L Bennett (Eds) Appliedmetacognition (pp 39ndash67) Cambridge England Cambridge University Press
Martinez R amp Schmitt N (2010) A phrasal expressions listManuscript submitted forpublication
Moon R (1997) Vocabulary connections Multi-word items in English In NSchmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 40ndash63) Cambridge England Cambridge University Press
Moore D Lin-Agler L M amp Zabrucky K M (2005) A source of metacomprehen-sion inaccuracy Reading Psychology 26 251ndash265 doi10108002702710590962578
Morrison L (2004) Comprehension monitoring in first and second languagereading The Canadian Modern Language Review 61 77ndash106
Nation I S P (2001) Learning vocabulary in another language Cambridge EnglandCambridge University Press
Nation I S P (2006) How large a vocabulary is needed for reading and listeningThe Canadian Modern Language Review 63 59ndash82
Nation I S P amp Waring R (1997) Vocabulary size text coverage and word lists InN Schmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 6ndash19) Cambridge England Cambridge University Press
Nation P (1997) The language learning benefits of extensive reading LanguageTeacher 21 13ndash16
Nattinger J R amp DeCarrico J S (1992) Lexical phrases and language teachingOxford England Oxford University Press
Oh S Y (2001) Two types of input modification and EFL reading comprehensionSimplification versus elaboration TESOL Quarterly 35 69ndash96 doi1023073587860
OrsquoKeeffe A McCarthy M amp Carter R (2007) From corpus to classroom Language useand language teaching Cambridge England Cambridge University Press
Pawley A amp Syder F H (1983) Two puzzles for linguistic theory Nativelikeselection and nativelike fluency In J C Richards amp R Schmidt (Eds) Languageand communication (pp 191ndash226) New York NY Longman
Pigada M amp Schmitt N (2006) Vocabulary acquisition from extensive reading Acase study Reading in a Foreign Language 18 1ndash28
Read J (2004) Research in teaching vocabulary Annual Review of Applied Linguistics24 146ndash161 doi101017S0267190504000078
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 289
Sarac S amp Tarhan B (2009) Calibration of comprehension and performance inL2 reading International Electronic Journal of Elementary Education 2 167ndash179
Schmitt N Jiang N amp Grabe W (2011) The percentage of words known in a textand reading comprehension Modern Language Journal 95(1) 26ndash43
Schmitt N Schmitt D amp Clapham C (2001) Developing and exploring thebehaviour of two new versions of the Vocabulary Levels Test Language Testing 1855ndash88
Shin D amp Nation I S P (2008) Beyond single words The most frequentcollocations in spoken English ELT Journal 62 339ndash348 doi101093eltccm091
Simpson-Vlach R amp Ellis N C (2010) An academic formulas list New methods inphraseology research Applied Linguistics 31(4) 487ndash512
Sinclair J (1991) Corpus concordance collocation Oxford England OxfordUniversity Press
Spottl C amp McCarthy M (2003) Formulaic utterances in the multi-lingual contextIn J Cenoz B Hufeisen ampU Jessner (Eds) The multilingual lexicon (pp 133ndash151) Dordrecht The Netherlands Kluwer
Staelighr L S (2008) Vocabulary size and the skills of listening reading and writingLanguage Learning Journal 36 139ndash152 doi10108009571730802389975
Stubbs M amp Barth I (2003) Using recurrent phrases as text-type descriminators Aquantitative method and some findings Functions of Language 10 61ndash104doi101075fol10104stu
The British National Corpus (2007) The British National Corpus(version 3 BNC XMLed) [CD-ROM] Distributed by Oxford University Computing Services on behalfof the BNC Consortium
The iPhonersquos second coming (2008 July) The Economist Retrieved from httpwwweconomistcomscience-technologydisplaystorycfmstory_id5E1_TTSDDJTG
Walter E Woodford K amp Good M (Eds) (2008) Cambridge advanced learnerrsquosdictionary (3rd ed) Cambridge England Cambridge University Press
Weir C J (2005) Language testing and validation An evidence-based approachNew York NY Palgrave Macmillan
West M (1953) A general service list of English words London England LongmanWray A (2002) Formulaic language and the lexicon Cambridge England Cambridge
University Press
290 TESOL QUARTERLY

Whereas for Test 1 those 30 participantsrsquo assessment of readingcomprehension was usually only slightly overestimated10 (and in oneinstance even underestimated) the same participants in Test 2 had amarkedly overinflated conception of how much they had understood
Although not intended as a principal source of data for our analysisthe start and finish times recorded by participants on the tests in a fewinstances helped confirm the above assertions11 Table 7 shows thatthere was a significant difference between how long participants spenttaking each test (t 5 852 p 0001) However there were a number ofparticipants (n 5 26) who reported actually spending either the same orless time on Test 2 On the surface at least this fact would indicate thatthose 26 participants did not notice much difference between the testsOf course in reality that datum alone does not provide such evidencebecause that time may simply reflect a number of other confoundingvariables including affective (eg simply giving up) or even social (egthe need to leave early to meet a friend) and for that reason also was notconsidered to be a reliable source of data from those participantsHowever as a complementary source when triangulated with the othervariables some of the data analyzed earlier in the current study areoccasionally fortified further still with the time data (Table 9)
The data in Table 9 in many ways tie together the elements discussedin the analysis thus far in the present study A much lower score in Test 2than in Test 1 (columns B and C) an increase in the mean MRC-MACdifference across the tests (columns H and K) a relatively moderatedecrease in MRC in Test 2 vis-a-vis Test 1 (columns F and I) a markeddifference between MRC and MAC in Test 2 (column K) and theoccasional lack of increase (in Table 9 participants 118 80 59 and 50)in time it took to take Test 2 (columns D and E) These findings ontheir own in combination and especially in concert provide evidencethat (1) the students in Table 9 did not seem to appreciate the fullextent of the idiomaticity in Test 2 and (2) they appeared to think thatthey understood more than they actually did in Test 2
Perhaps most important 98 of all participants (n 5 99) scoredsignificantly lower on Test 2 (mean difference of 953 points out of 28SD 5 363) which shows that learners are generally unable to guess themeaning of idiomatic language even in the (largely inconsistent)instances in which they become aware of its presence
11 It should be noted that because 10 of the participantsrsquo time data were left incomplete afull group analysis could not be carried out thus the time data are only included asauxiliary information
10 As can be seen in Table 8 in fact only one participantmdashnumber 80mdashactually had anMRC-MAC difference in Test 1 that was also 020 Those of the other 29 participantswere all lower
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 283
For example the first participant in Tables 8 and 9 (number 118)who consistently overrated his own comprehension relative to his actualcomprehension answered for Text A of Test 2 as shown in Figure 3
On the basis of the responses it is likely that participant 118associated itrsquos about time with lsquolsquohas a problem with timersquorsquo Irsquom a little over thehill with lsquolsquohe probably lives in an area with hillsrsquorsquo and lsquolsquohe lives on the hill
TABLE 9
Triangulated Data Showing Negative Effect of Idiomaticity on Comprehension
A B C D E F G H I J K
Score Time Test 1 Test 2
Partic-ipant Test 1 Test 2 Test 1 Test 2 MRC MAC
Differ-ence MRC MAC
Differ-ence
118 25 9 2000 1800 100 089 11 094 032 0626 19 8 Missing Missing 075 068 007 081 028 05392 25 8 900 1100 081 089 2008 075 025 05090 25 11 900 1500 100 089 011 081 039 042115 25 14 1300 1500 100 089 011 087 050 03722 27 16 Missing Missing 100 096 003 094 057 03780 19 9 1000 1000 094 068 026 069 032 03759 25 10 1500 1400 094 089 005 069 036 03321 26 16 Missing Missing 100 093 007 087 057 03050 22 11 2000 1200 088 079 009 069 039 030
12 Of the 24 multiword expressions targeted for assessment of comprehension in Test 2 onlyfour were core idioms
FIGURE 3 Sample answer to Text A of Test 2
284 TESOL QUARTERLY
but not on top of itrsquorsquomdasha literal reading of those expressions His 100self-assessment is an indication that his answers were not guesses butinstead based on confidence that he had understood all the individualwords in the text The same answering dynamic occurred time and timeagain in Test 2
Returning therefore to the issues raised in the introduction thepresent research appears to provide evidence that idiomsmdashopaque orotherwise12mdashcan in fact cause major problems for L2 learners of Englishwhen reading In general the participants in our study were lesssuccessful at guessing the meaning of idioms than those in previousidiom-centered research such as Cooper (1999) and Liontas (2002)Because the learners in our study were not alerted to the presence ofidiomaticity in the text prior to reading this study may more accuratelyreflect what takes place in more naturally occurring L2 reading Finallythe difficulties that the participants encountered occurred in textscomposed purely of very common words showing that word frequencyalone is not necessarily a good measure of text coverage Lauferrsquos(1989a) hypothesis that much lexis in text can be deceptivelytransparent is confirmed in the present research extended to multiwordexpressions
Limitations of the Research
Although the research presented here does provide some significantevidence that the presence of idiomaticity in a text can negatively affectthe comprehension of that text by an L2 reader little is known about thestrategies the test takers employed Even though metacognition wasoutside the scope of examination of the present study such informationis highly relevant and future research should include protocols such asthose included in previous research on idioms (eg Liontas 20032007) which may provide crucial qualitative data regarding theindividual differences and behavior of the participants themselvesOverall future work in this area should consider making use of differentmeasures of self-assessment in order to explore the limitations of themethodology used in the present study
Also a question can be asked concerning the relative density ofmultiword expressions in each text In other words what is not known ison average how many such items a reader can expect to encounter Theratio of idioms to orthographic words in the texts tested in the presentstudy is very likely higher than averagemdashbut how much higher is as yetunknown Likewise the passages themselves were relatively short so it isunknown whether or not texts of greater length (and thereforecontextualization) would render the same or similar results
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 285
CONCLUSION
The present study provides some empirical evidence that a focus onword in L2 pedagogy may be detrimental to learnersrsquo development ofreading comprehension in the target language In most casesparticipants overestimated how much they had understood the textstested when those texts contained multiword expressions of varyingdegrees of compositionality comprised of very common individualwords Even when participants showed evidence of awareness of apresence of idiomaticity in the texts they generally were not very good atguessing the meaning of expressions Although Grant and Nation(2006) could be right that the teaching of individual idioms may not belsquolsquodeserving of class timersquorsquo (p 5) it is clear that at the very least raisinglearnersrsquo consciousness as to their prevalence and frequently deceptivetransparency in text certainly is
Concomitantly the present research serves to demonstrate theincompleteness of current lists of common words which now informimportant pedagogical instruments such as vocabulary tests gradedreaders and course syllabuses Under current methods as illustrated inthe Table 2 analysis of the Economist paragraph a text measured againstthe word lists now commonly in use can be mistakenly analyzed as beingeasily understood when in fact once multiword expressions are takeninto account the actual text coverage of easily understood words is farless Existing estimates of how many words one needs to know in order toadequately process naturally occurring texts (Hu amp Nation 2000Nation 2006) may need to be revisited to determine how many wordsand multiword expressions one needs to know
In practice research shows that learners will continue to believe theyunderstand items that they actually do not even after repeatedexposures to that same item (Bensoussan amp Laufer 1984 Haynes1993 Pigada amp Schmitt 2006) Language teachers and relatedprofessionals such as textbook writers need to consider ways tocontinuously help learners notice the gap between what they think theyknow and understand and what they actually do (Laufer 1997) Oneway this can be achieved has already been thoroughly discussed in thepresent paper devise texts (and tests) designed to lead readers down anidiomatic garden path Norbert Schmitt (as cited in Weir 2005) made asimilar recommendation
Perhaps the best and most valid type of vocabulary test is a reading passagewith comprehension questions but with the items requiring a full under-standing of particular words or phrases in the text This would mimic the realworld task of reading for comprehension and also the loss of comprehensionwhen key vocabulary is not known (p 123)
286 TESOL QUARTERLY
Therefore a further implication this research has for L2 pedagogy is themore careful design of the reading component of proficiency tests suchas IELTS (International English Language Testing System) and Test ofEnglish as a Foreign Language to be more strategic regarding the amountand kind of phraseology contained in the texts Proficiency was not thecentral focus of our study and future research could adopt a similarmethodology but with the inclusion of proficiency measures ofparticipants in order to explore how various types of expressions (egnoncompositional figurative imageable etc) may differentially affectpreidentified proficiency levels
Thus in order to be more methodical about such things as theinclusion of formulaic language in L2 tests and reading input in generalan important preliminary step will be to establish (a) what type offormulaic sequences are good discriminators of proficiency thresholdlevels and (b) which expressions of that identified type are mostcommon In other words what will be usefulmdashand is indeed nowbeginning to emerge (Martinez amp Schmitt 2010 Shin amp Nation 2008Simpson-Vlach amp Ellis 2010)mdashare lists of formulaic sequences that servea function similar to that of the General Service List not to revolutionizecurrent language pedagogy but to more finely tune it
THE AUTHORS
Ron Martinez is currently pursuing a doctorate at the University of NottinghamNottingham England on the topic of inclusion of phraseology in languageassessment He specializes in second language materials development
Victoria Murphy is a lecturer in Applied Linguistics and Second LanguageAcquisition at the University of Oxford Oxford England Her research interestsinclude the lexical development of first language or second language learners andthe cognitive processes that underlie language acquisition
REFERENCES
Bauer L amp Nation P (1993) Word families International Journal of Lexicography 6253ndash279 doi101093ijl64253
Bensoussan M amp Laufer B (1984) Lexical guessing in context in EFL readingcomprehension Journal of Research in Reading 7 15ndash32 doi101111j1467-98171984tb00252x
Bishop H (2004) Noticing formulaic sequences A problem of measuring thesubjective LSO Working Papers in Linguistics 4 15ndash19
Bransford D B amp Johnson M K (1972) Contextual prerequisites for under-standing Some investigations of comprehension and recall Journal of VerbalLearning and Verbal Behavior 11 717ndash726 doi101016S0022-5371(72)80006-9
Brantmeier C (2006) Advanced L2 learners and reading placement Self-assessment CBT and subsequent performance System 34 15ndash35 doi101016jsystem200508004
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 287
Carver R P (1994) Percentage of unknown vocabulary words in text as a functionof the relative difficulty of the text Implications for instruction Journal of ReadingBehavior 26 413ndash437
Cobb T (nd) Web VocabProfile [Online program] Retrieved from httpwwwlextutorcavp [an adaption of A Heatley amp P Nation Range (1994)]
Cooper T C (1999) Processing of idioms by L2 learners of English TESOLQuarterly 33 233ndash262 doi1023073587719
Coxhead A (2000) A new academic word list TESOL Quarterly 34 213ndash238doi1023073587951
Elley W amp Mangubhai F (1983) The impact of reading on second languagelearning Reading Research Quarterly 19 53ndash67 doi102307747337
Ellis N C (2008) Phraseology The periphery and the heart of language In FMeunier amp S Granger (Eds) Phraseology in language learning and teaching (pp 1ndash13) Amsterdam The Netherlands John Benjamins
Erman B amp Warren B (2000) The idiom principle and the open choice principleText 20 29ndash62
Gardner D (2007) Validating the construct of Word in applied corpus-basedvocabulary research A critical survey Applied Linguistics 28 241ndash265doi101093applinamm010
Glenberg A M Wilkinson A C amp Epstein W (1982) The illusion of knowingFailure in the self-assessment of comprehension Memory and Cognition 10 597ndash602 doi103758BF03202442
Goulden R Nation P amp Read J (1990) How large can a receptive vocabulary beApplied Linguistics 11 341ndash363 doi101093applin114341
Grant L amp Bauer L (2004) Criteria for re-defining idioms Are we barking up thewrong tree Applied Linguistics 25 38ndash61 doi101093applin25138
Grant L amp Nation P (2006) How many idioms are there in English ITL -International Journal of Applied Linguistics 151 1ndash14 doi102143ITL15102015219
Haynes M (1993) Patterns and perils of guessing in second language reading In THuckin M Haynes amp J Coady (Eds) Second language reading and vocabularylearning (pp 46ndash64) Norwood NJ Ablex Publishing Corporation
Heatley A amp Nation P (1994) Range [Computer program] Wellington NewZealand Victoria University of Wellington Retrieved from httpwwwvuwacnzlals
Hill J (2000) Revising priorities From grammatical failure to collocational successIn M Lewis (Ed) Teaching collocation Further developments in the Lexical Approach(pp 47ndash69) Hove England LTP
Hirsh D amp Nation P (1992) What vocabulary size is needed to read unsimplifiedtexts for pleasure Reading in a Foreign Language 8 689ndash696
Hu H M amp Nation P (2000) Unknown vocabulary density and readingcomprehension Reading in a Foreign Language 13 403ndash429
Hughes A (2003) Testing for language teachers Cambridge England CambridgeUniversity Press
Hunt K (1968) An instrument to measure syntactic maturity Tallahassee FL USDepartment of Health Education and Welfare
Jung E H (2003) The effects of organization markers on ESL learnersrsquo textunderstanding TESOL Quarterly 37 749ndash759 doi1023073588223
Krashen S (1993) The power of reading Insights from research Englewood COLibraries Unlimited
Laufer B (1989a) A factor of difficulty in vocabulary learning Deceptivetransparency AILA Review 6 10ndash20
288 TESOL QUARTERLY
Laufer B (1989b) What percentage of lexis is essential for comprehension In CLauren amp M Nordman (Eds) Special language From humans thinking to thinkingmachines (pp 316ndash323) London England Multilingual Matters
Laufer B (1991) How much lexis is necessary for reading comprehension In P JL Arnaud amp H Bejoint (Eds) Vocabulary and applied linguistics (pp 126ndash132)Oxford England Macmillan
Laufer B (1997) The lexical plight in second language reading Words you donrsquotknow words you think you know and words you canrsquot guess In J Coady amp THuckin (Eds) Second language vocabulary acquisition (pp 20ndash34) CambridgeEngland Cambridge University Press
Lewis M (1993) The Lexical Approach The state of ELT and a way forward HoveEngland LTP
Liontas J I (2002) Context and idiom understanding in second languagesEUROSLA Yearbook 2 155ndash185
Liontas J I (2003) Killing two birds with one stone Understanding Spanish VPidioms in and out of context Hispania 86 289ndash301 doi10230720062862
Liontas J I (2007) The eye never sees what the brain understands Making sense ofidioms in second languages Lingua et Linguistica 1) 25ndash44
Maki R H amp McGuire M J (2002) Metacognition for text Findings andimplications for education In T Schwarz amp L Bennett (Eds) Appliedmetacognition (pp 39ndash67) Cambridge England Cambridge University Press
Martinez R amp Schmitt N (2010) A phrasal expressions listManuscript submitted forpublication
Moon R (1997) Vocabulary connections Multi-word items in English In NSchmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 40ndash63) Cambridge England Cambridge University Press
Moore D Lin-Agler L M amp Zabrucky K M (2005) A source of metacomprehen-sion inaccuracy Reading Psychology 26 251ndash265 doi10108002702710590962578
Morrison L (2004) Comprehension monitoring in first and second languagereading The Canadian Modern Language Review 61 77ndash106
Nation I S P (2001) Learning vocabulary in another language Cambridge EnglandCambridge University Press
Nation I S P (2006) How large a vocabulary is needed for reading and listeningThe Canadian Modern Language Review 63 59ndash82
Nation I S P amp Waring R (1997) Vocabulary size text coverage and word lists InN Schmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 6ndash19) Cambridge England Cambridge University Press
Nation P (1997) The language learning benefits of extensive reading LanguageTeacher 21 13ndash16
Nattinger J R amp DeCarrico J S (1992) Lexical phrases and language teachingOxford England Oxford University Press
Oh S Y (2001) Two types of input modification and EFL reading comprehensionSimplification versus elaboration TESOL Quarterly 35 69ndash96 doi1023073587860
OrsquoKeeffe A McCarthy M amp Carter R (2007) From corpus to classroom Language useand language teaching Cambridge England Cambridge University Press
Pawley A amp Syder F H (1983) Two puzzles for linguistic theory Nativelikeselection and nativelike fluency In J C Richards amp R Schmidt (Eds) Languageand communication (pp 191ndash226) New York NY Longman
Pigada M amp Schmitt N (2006) Vocabulary acquisition from extensive reading Acase study Reading in a Foreign Language 18 1ndash28
Read J (2004) Research in teaching vocabulary Annual Review of Applied Linguistics24 146ndash161 doi101017S0267190504000078
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 289
Sarac S amp Tarhan B (2009) Calibration of comprehension and performance inL2 reading International Electronic Journal of Elementary Education 2 167ndash179
Schmitt N Jiang N amp Grabe W (2011) The percentage of words known in a textand reading comprehension Modern Language Journal 95(1) 26ndash43
Schmitt N Schmitt D amp Clapham C (2001) Developing and exploring thebehaviour of two new versions of the Vocabulary Levels Test Language Testing 1855ndash88
Shin D amp Nation I S P (2008) Beyond single words The most frequentcollocations in spoken English ELT Journal 62 339ndash348 doi101093eltccm091
Simpson-Vlach R amp Ellis N C (2010) An academic formulas list New methods inphraseology research Applied Linguistics 31(4) 487ndash512
Sinclair J (1991) Corpus concordance collocation Oxford England OxfordUniversity Press
Spottl C amp McCarthy M (2003) Formulaic utterances in the multi-lingual contextIn J Cenoz B Hufeisen ampU Jessner (Eds) The multilingual lexicon (pp 133ndash151) Dordrecht The Netherlands Kluwer
Staelighr L S (2008) Vocabulary size and the skills of listening reading and writingLanguage Learning Journal 36 139ndash152 doi10108009571730802389975
Stubbs M amp Barth I (2003) Using recurrent phrases as text-type descriminators Aquantitative method and some findings Functions of Language 10 61ndash104doi101075fol10104stu
The British National Corpus (2007) The British National Corpus(version 3 BNC XMLed) [CD-ROM] Distributed by Oxford University Computing Services on behalfof the BNC Consortium
The iPhonersquos second coming (2008 July) The Economist Retrieved from httpwwweconomistcomscience-technologydisplaystorycfmstory_id5E1_TTSDDJTG
Walter E Woodford K amp Good M (Eds) (2008) Cambridge advanced learnerrsquosdictionary (3rd ed) Cambridge England Cambridge University Press
Weir C J (2005) Language testing and validation An evidence-based approachNew York NY Palgrave Macmillan
West M (1953) A general service list of English words London England LongmanWray A (2002) Formulaic language and the lexicon Cambridge England Cambridge
University Press
290 TESOL QUARTERLY

For example the first participant in Tables 8 and 9 (number 118)who consistently overrated his own comprehension relative to his actualcomprehension answered for Text A of Test 2 as shown in Figure 3
On the basis of the responses it is likely that participant 118associated itrsquos about time with lsquolsquohas a problem with timersquorsquo Irsquom a little over thehill with lsquolsquohe probably lives in an area with hillsrsquorsquo and lsquolsquohe lives on the hill
TABLE 9
Triangulated Data Showing Negative Effect of Idiomaticity on Comprehension
A B C D E F G H I J K
Score Time Test 1 Test 2
Partic-ipant Test 1 Test 2 Test 1 Test 2 MRC MAC
Differ-ence MRC MAC
Differ-ence
118 25 9 2000 1800 100 089 11 094 032 0626 19 8 Missing Missing 075 068 007 081 028 05392 25 8 900 1100 081 089 2008 075 025 05090 25 11 900 1500 100 089 011 081 039 042115 25 14 1300 1500 100 089 011 087 050 03722 27 16 Missing Missing 100 096 003 094 057 03780 19 9 1000 1000 094 068 026 069 032 03759 25 10 1500 1400 094 089 005 069 036 03321 26 16 Missing Missing 100 093 007 087 057 03050 22 11 2000 1200 088 079 009 069 039 030
12 Of the 24 multiword expressions targeted for assessment of comprehension in Test 2 onlyfour were core idioms
FIGURE 3 Sample answer to Text A of Test 2
284 TESOL QUARTERLY
but not on top of itrsquorsquomdasha literal reading of those expressions His 100self-assessment is an indication that his answers were not guesses butinstead based on confidence that he had understood all the individualwords in the text The same answering dynamic occurred time and timeagain in Test 2
Returning therefore to the issues raised in the introduction thepresent research appears to provide evidence that idiomsmdashopaque orotherwise12mdashcan in fact cause major problems for L2 learners of Englishwhen reading In general the participants in our study were lesssuccessful at guessing the meaning of idioms than those in previousidiom-centered research such as Cooper (1999) and Liontas (2002)Because the learners in our study were not alerted to the presence ofidiomaticity in the text prior to reading this study may more accuratelyreflect what takes place in more naturally occurring L2 reading Finallythe difficulties that the participants encountered occurred in textscomposed purely of very common words showing that word frequencyalone is not necessarily a good measure of text coverage Lauferrsquos(1989a) hypothesis that much lexis in text can be deceptivelytransparent is confirmed in the present research extended to multiwordexpressions
Limitations of the Research
Although the research presented here does provide some significantevidence that the presence of idiomaticity in a text can negatively affectthe comprehension of that text by an L2 reader little is known about thestrategies the test takers employed Even though metacognition wasoutside the scope of examination of the present study such informationis highly relevant and future research should include protocols such asthose included in previous research on idioms (eg Liontas 20032007) which may provide crucial qualitative data regarding theindividual differences and behavior of the participants themselvesOverall future work in this area should consider making use of differentmeasures of self-assessment in order to explore the limitations of themethodology used in the present study
Also a question can be asked concerning the relative density ofmultiword expressions in each text In other words what is not known ison average how many such items a reader can expect to encounter Theratio of idioms to orthographic words in the texts tested in the presentstudy is very likely higher than averagemdashbut how much higher is as yetunknown Likewise the passages themselves were relatively short so it isunknown whether or not texts of greater length (and thereforecontextualization) would render the same or similar results
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 285
CONCLUSION
The present study provides some empirical evidence that a focus onword in L2 pedagogy may be detrimental to learnersrsquo development ofreading comprehension in the target language In most casesparticipants overestimated how much they had understood the textstested when those texts contained multiword expressions of varyingdegrees of compositionality comprised of very common individualwords Even when participants showed evidence of awareness of apresence of idiomaticity in the texts they generally were not very good atguessing the meaning of expressions Although Grant and Nation(2006) could be right that the teaching of individual idioms may not belsquolsquodeserving of class timersquorsquo (p 5) it is clear that at the very least raisinglearnersrsquo consciousness as to their prevalence and frequently deceptivetransparency in text certainly is
Concomitantly the present research serves to demonstrate theincompleteness of current lists of common words which now informimportant pedagogical instruments such as vocabulary tests gradedreaders and course syllabuses Under current methods as illustrated inthe Table 2 analysis of the Economist paragraph a text measured againstthe word lists now commonly in use can be mistakenly analyzed as beingeasily understood when in fact once multiword expressions are takeninto account the actual text coverage of easily understood words is farless Existing estimates of how many words one needs to know in order toadequately process naturally occurring texts (Hu amp Nation 2000Nation 2006) may need to be revisited to determine how many wordsand multiword expressions one needs to know
In practice research shows that learners will continue to believe theyunderstand items that they actually do not even after repeatedexposures to that same item (Bensoussan amp Laufer 1984 Haynes1993 Pigada amp Schmitt 2006) Language teachers and relatedprofessionals such as textbook writers need to consider ways tocontinuously help learners notice the gap between what they think theyknow and understand and what they actually do (Laufer 1997) Oneway this can be achieved has already been thoroughly discussed in thepresent paper devise texts (and tests) designed to lead readers down anidiomatic garden path Norbert Schmitt (as cited in Weir 2005) made asimilar recommendation
Perhaps the best and most valid type of vocabulary test is a reading passagewith comprehension questions but with the items requiring a full under-standing of particular words or phrases in the text This would mimic the realworld task of reading for comprehension and also the loss of comprehensionwhen key vocabulary is not known (p 123)
286 TESOL QUARTERLY
Therefore a further implication this research has for L2 pedagogy is themore careful design of the reading component of proficiency tests suchas IELTS (International English Language Testing System) and Test ofEnglish as a Foreign Language to be more strategic regarding the amountand kind of phraseology contained in the texts Proficiency was not thecentral focus of our study and future research could adopt a similarmethodology but with the inclusion of proficiency measures ofparticipants in order to explore how various types of expressions (egnoncompositional figurative imageable etc) may differentially affectpreidentified proficiency levels
Thus in order to be more methodical about such things as theinclusion of formulaic language in L2 tests and reading input in generalan important preliminary step will be to establish (a) what type offormulaic sequences are good discriminators of proficiency thresholdlevels and (b) which expressions of that identified type are mostcommon In other words what will be usefulmdashand is indeed nowbeginning to emerge (Martinez amp Schmitt 2010 Shin amp Nation 2008Simpson-Vlach amp Ellis 2010)mdashare lists of formulaic sequences that servea function similar to that of the General Service List not to revolutionizecurrent language pedagogy but to more finely tune it
THE AUTHORS
Ron Martinez is currently pursuing a doctorate at the University of NottinghamNottingham England on the topic of inclusion of phraseology in languageassessment He specializes in second language materials development
Victoria Murphy is a lecturer in Applied Linguistics and Second LanguageAcquisition at the University of Oxford Oxford England Her research interestsinclude the lexical development of first language or second language learners andthe cognitive processes that underlie language acquisition
REFERENCES
Bauer L amp Nation P (1993) Word families International Journal of Lexicography 6253ndash279 doi101093ijl64253
Bensoussan M amp Laufer B (1984) Lexical guessing in context in EFL readingcomprehension Journal of Research in Reading 7 15ndash32 doi101111j1467-98171984tb00252x
Bishop H (2004) Noticing formulaic sequences A problem of measuring thesubjective LSO Working Papers in Linguistics 4 15ndash19
Bransford D B amp Johnson M K (1972) Contextual prerequisites for under-standing Some investigations of comprehension and recall Journal of VerbalLearning and Verbal Behavior 11 717ndash726 doi101016S0022-5371(72)80006-9
Brantmeier C (2006) Advanced L2 learners and reading placement Self-assessment CBT and subsequent performance System 34 15ndash35 doi101016jsystem200508004
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 287
Carver R P (1994) Percentage of unknown vocabulary words in text as a functionof the relative difficulty of the text Implications for instruction Journal of ReadingBehavior 26 413ndash437
Cobb T (nd) Web VocabProfile [Online program] Retrieved from httpwwwlextutorcavp [an adaption of A Heatley amp P Nation Range (1994)]
Cooper T C (1999) Processing of idioms by L2 learners of English TESOLQuarterly 33 233ndash262 doi1023073587719
Coxhead A (2000) A new academic word list TESOL Quarterly 34 213ndash238doi1023073587951
Elley W amp Mangubhai F (1983) The impact of reading on second languagelearning Reading Research Quarterly 19 53ndash67 doi102307747337
Ellis N C (2008) Phraseology The periphery and the heart of language In FMeunier amp S Granger (Eds) Phraseology in language learning and teaching (pp 1ndash13) Amsterdam The Netherlands John Benjamins
Erman B amp Warren B (2000) The idiom principle and the open choice principleText 20 29ndash62
Gardner D (2007) Validating the construct of Word in applied corpus-basedvocabulary research A critical survey Applied Linguistics 28 241ndash265doi101093applinamm010
Glenberg A M Wilkinson A C amp Epstein W (1982) The illusion of knowingFailure in the self-assessment of comprehension Memory and Cognition 10 597ndash602 doi103758BF03202442
Goulden R Nation P amp Read J (1990) How large can a receptive vocabulary beApplied Linguistics 11 341ndash363 doi101093applin114341
Grant L amp Bauer L (2004) Criteria for re-defining idioms Are we barking up thewrong tree Applied Linguistics 25 38ndash61 doi101093applin25138
Grant L amp Nation P (2006) How many idioms are there in English ITL -International Journal of Applied Linguistics 151 1ndash14 doi102143ITL15102015219
Haynes M (1993) Patterns and perils of guessing in second language reading In THuckin M Haynes amp J Coady (Eds) Second language reading and vocabularylearning (pp 46ndash64) Norwood NJ Ablex Publishing Corporation
Heatley A amp Nation P (1994) Range [Computer program] Wellington NewZealand Victoria University of Wellington Retrieved from httpwwwvuwacnzlals
Hill J (2000) Revising priorities From grammatical failure to collocational successIn M Lewis (Ed) Teaching collocation Further developments in the Lexical Approach(pp 47ndash69) Hove England LTP
Hirsh D amp Nation P (1992) What vocabulary size is needed to read unsimplifiedtexts for pleasure Reading in a Foreign Language 8 689ndash696
Hu H M amp Nation P (2000) Unknown vocabulary density and readingcomprehension Reading in a Foreign Language 13 403ndash429
Hughes A (2003) Testing for language teachers Cambridge England CambridgeUniversity Press
Hunt K (1968) An instrument to measure syntactic maturity Tallahassee FL USDepartment of Health Education and Welfare
Jung E H (2003) The effects of organization markers on ESL learnersrsquo textunderstanding TESOL Quarterly 37 749ndash759 doi1023073588223
Krashen S (1993) The power of reading Insights from research Englewood COLibraries Unlimited
Laufer B (1989a) A factor of difficulty in vocabulary learning Deceptivetransparency AILA Review 6 10ndash20
288 TESOL QUARTERLY
Laufer B (1989b) What percentage of lexis is essential for comprehension In CLauren amp M Nordman (Eds) Special language From humans thinking to thinkingmachines (pp 316ndash323) London England Multilingual Matters
Laufer B (1991) How much lexis is necessary for reading comprehension In P JL Arnaud amp H Bejoint (Eds) Vocabulary and applied linguistics (pp 126ndash132)Oxford England Macmillan
Laufer B (1997) The lexical plight in second language reading Words you donrsquotknow words you think you know and words you canrsquot guess In J Coady amp THuckin (Eds) Second language vocabulary acquisition (pp 20ndash34) CambridgeEngland Cambridge University Press
Lewis M (1993) The Lexical Approach The state of ELT and a way forward HoveEngland LTP
Liontas J I (2002) Context and idiom understanding in second languagesEUROSLA Yearbook 2 155ndash185
Liontas J I (2003) Killing two birds with one stone Understanding Spanish VPidioms in and out of context Hispania 86 289ndash301 doi10230720062862
Liontas J I (2007) The eye never sees what the brain understands Making sense ofidioms in second languages Lingua et Linguistica 1) 25ndash44
Maki R H amp McGuire M J (2002) Metacognition for text Findings andimplications for education In T Schwarz amp L Bennett (Eds) Appliedmetacognition (pp 39ndash67) Cambridge England Cambridge University Press
Martinez R amp Schmitt N (2010) A phrasal expressions listManuscript submitted forpublication
Moon R (1997) Vocabulary connections Multi-word items in English In NSchmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 40ndash63) Cambridge England Cambridge University Press
Moore D Lin-Agler L M amp Zabrucky K M (2005) A source of metacomprehen-sion inaccuracy Reading Psychology 26 251ndash265 doi10108002702710590962578
Morrison L (2004) Comprehension monitoring in first and second languagereading The Canadian Modern Language Review 61 77ndash106
Nation I S P (2001) Learning vocabulary in another language Cambridge EnglandCambridge University Press
Nation I S P (2006) How large a vocabulary is needed for reading and listeningThe Canadian Modern Language Review 63 59ndash82
Nation I S P amp Waring R (1997) Vocabulary size text coverage and word lists InN Schmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 6ndash19) Cambridge England Cambridge University Press
Nation P (1997) The language learning benefits of extensive reading LanguageTeacher 21 13ndash16
Nattinger J R amp DeCarrico J S (1992) Lexical phrases and language teachingOxford England Oxford University Press
Oh S Y (2001) Two types of input modification and EFL reading comprehensionSimplification versus elaboration TESOL Quarterly 35 69ndash96 doi1023073587860
OrsquoKeeffe A McCarthy M amp Carter R (2007) From corpus to classroom Language useand language teaching Cambridge England Cambridge University Press
Pawley A amp Syder F H (1983) Two puzzles for linguistic theory Nativelikeselection and nativelike fluency In J C Richards amp R Schmidt (Eds) Languageand communication (pp 191ndash226) New York NY Longman
Pigada M amp Schmitt N (2006) Vocabulary acquisition from extensive reading Acase study Reading in a Foreign Language 18 1ndash28
Read J (2004) Research in teaching vocabulary Annual Review of Applied Linguistics24 146ndash161 doi101017S0267190504000078
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 289
Sarac S amp Tarhan B (2009) Calibration of comprehension and performance inL2 reading International Electronic Journal of Elementary Education 2 167ndash179
Schmitt N Jiang N amp Grabe W (2011) The percentage of words known in a textand reading comprehension Modern Language Journal 95(1) 26ndash43
Schmitt N Schmitt D amp Clapham C (2001) Developing and exploring thebehaviour of two new versions of the Vocabulary Levels Test Language Testing 1855ndash88
Shin D amp Nation I S P (2008) Beyond single words The most frequentcollocations in spoken English ELT Journal 62 339ndash348 doi101093eltccm091
Simpson-Vlach R amp Ellis N C (2010) An academic formulas list New methods inphraseology research Applied Linguistics 31(4) 487ndash512
Sinclair J (1991) Corpus concordance collocation Oxford England OxfordUniversity Press
Spottl C amp McCarthy M (2003) Formulaic utterances in the multi-lingual contextIn J Cenoz B Hufeisen ampU Jessner (Eds) The multilingual lexicon (pp 133ndash151) Dordrecht The Netherlands Kluwer
Staelighr L S (2008) Vocabulary size and the skills of listening reading and writingLanguage Learning Journal 36 139ndash152 doi10108009571730802389975
Stubbs M amp Barth I (2003) Using recurrent phrases as text-type descriminators Aquantitative method and some findings Functions of Language 10 61ndash104doi101075fol10104stu
The British National Corpus (2007) The British National Corpus(version 3 BNC XMLed) [CD-ROM] Distributed by Oxford University Computing Services on behalfof the BNC Consortium
The iPhonersquos second coming (2008 July) The Economist Retrieved from httpwwweconomistcomscience-technologydisplaystorycfmstory_id5E1_TTSDDJTG
Walter E Woodford K amp Good M (Eds) (2008) Cambridge advanced learnerrsquosdictionary (3rd ed) Cambridge England Cambridge University Press
Weir C J (2005) Language testing and validation An evidence-based approachNew York NY Palgrave Macmillan
West M (1953) A general service list of English words London England LongmanWray A (2002) Formulaic language and the lexicon Cambridge England Cambridge
University Press
290 TESOL QUARTERLY

but not on top of itrsquorsquomdasha literal reading of those expressions His 100self-assessment is an indication that his answers were not guesses butinstead based on confidence that he had understood all the individualwords in the text The same answering dynamic occurred time and timeagain in Test 2
Returning therefore to the issues raised in the introduction thepresent research appears to provide evidence that idiomsmdashopaque orotherwise12mdashcan in fact cause major problems for L2 learners of Englishwhen reading In general the participants in our study were lesssuccessful at guessing the meaning of idioms than those in previousidiom-centered research such as Cooper (1999) and Liontas (2002)Because the learners in our study were not alerted to the presence ofidiomaticity in the text prior to reading this study may more accuratelyreflect what takes place in more naturally occurring L2 reading Finallythe difficulties that the participants encountered occurred in textscomposed purely of very common words showing that word frequencyalone is not necessarily a good measure of text coverage Lauferrsquos(1989a) hypothesis that much lexis in text can be deceptivelytransparent is confirmed in the present research extended to multiwordexpressions
Limitations of the Research
Although the research presented here does provide some significantevidence that the presence of idiomaticity in a text can negatively affectthe comprehension of that text by an L2 reader little is known about thestrategies the test takers employed Even though metacognition wasoutside the scope of examination of the present study such informationis highly relevant and future research should include protocols such asthose included in previous research on idioms (eg Liontas 20032007) which may provide crucial qualitative data regarding theindividual differences and behavior of the participants themselvesOverall future work in this area should consider making use of differentmeasures of self-assessment in order to explore the limitations of themethodology used in the present study
Also a question can be asked concerning the relative density ofmultiword expressions in each text In other words what is not known ison average how many such items a reader can expect to encounter Theratio of idioms to orthographic words in the texts tested in the presentstudy is very likely higher than averagemdashbut how much higher is as yetunknown Likewise the passages themselves were relatively short so it isunknown whether or not texts of greater length (and thereforecontextualization) would render the same or similar results
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 285
CONCLUSION
The present study provides some empirical evidence that a focus onword in L2 pedagogy may be detrimental to learnersrsquo development ofreading comprehension in the target language In most casesparticipants overestimated how much they had understood the textstested when those texts contained multiword expressions of varyingdegrees of compositionality comprised of very common individualwords Even when participants showed evidence of awareness of apresence of idiomaticity in the texts they generally were not very good atguessing the meaning of expressions Although Grant and Nation(2006) could be right that the teaching of individual idioms may not belsquolsquodeserving of class timersquorsquo (p 5) it is clear that at the very least raisinglearnersrsquo consciousness as to their prevalence and frequently deceptivetransparency in text certainly is
Concomitantly the present research serves to demonstrate theincompleteness of current lists of common words which now informimportant pedagogical instruments such as vocabulary tests gradedreaders and course syllabuses Under current methods as illustrated inthe Table 2 analysis of the Economist paragraph a text measured againstthe word lists now commonly in use can be mistakenly analyzed as beingeasily understood when in fact once multiword expressions are takeninto account the actual text coverage of easily understood words is farless Existing estimates of how many words one needs to know in order toadequately process naturally occurring texts (Hu amp Nation 2000Nation 2006) may need to be revisited to determine how many wordsand multiword expressions one needs to know
In practice research shows that learners will continue to believe theyunderstand items that they actually do not even after repeatedexposures to that same item (Bensoussan amp Laufer 1984 Haynes1993 Pigada amp Schmitt 2006) Language teachers and relatedprofessionals such as textbook writers need to consider ways tocontinuously help learners notice the gap between what they think theyknow and understand and what they actually do (Laufer 1997) Oneway this can be achieved has already been thoroughly discussed in thepresent paper devise texts (and tests) designed to lead readers down anidiomatic garden path Norbert Schmitt (as cited in Weir 2005) made asimilar recommendation
Perhaps the best and most valid type of vocabulary test is a reading passagewith comprehension questions but with the items requiring a full under-standing of particular words or phrases in the text This would mimic the realworld task of reading for comprehension and also the loss of comprehensionwhen key vocabulary is not known (p 123)
286 TESOL QUARTERLY
Therefore a further implication this research has for L2 pedagogy is themore careful design of the reading component of proficiency tests suchas IELTS (International English Language Testing System) and Test ofEnglish as a Foreign Language to be more strategic regarding the amountand kind of phraseology contained in the texts Proficiency was not thecentral focus of our study and future research could adopt a similarmethodology but with the inclusion of proficiency measures ofparticipants in order to explore how various types of expressions (egnoncompositional figurative imageable etc) may differentially affectpreidentified proficiency levels
Thus in order to be more methodical about such things as theinclusion of formulaic language in L2 tests and reading input in generalan important preliminary step will be to establish (a) what type offormulaic sequences are good discriminators of proficiency thresholdlevels and (b) which expressions of that identified type are mostcommon In other words what will be usefulmdashand is indeed nowbeginning to emerge (Martinez amp Schmitt 2010 Shin amp Nation 2008Simpson-Vlach amp Ellis 2010)mdashare lists of formulaic sequences that servea function similar to that of the General Service List not to revolutionizecurrent language pedagogy but to more finely tune it
THE AUTHORS
Ron Martinez is currently pursuing a doctorate at the University of NottinghamNottingham England on the topic of inclusion of phraseology in languageassessment He specializes in second language materials development
Victoria Murphy is a lecturer in Applied Linguistics and Second LanguageAcquisition at the University of Oxford Oxford England Her research interestsinclude the lexical development of first language or second language learners andthe cognitive processes that underlie language acquisition
REFERENCES
Bauer L amp Nation P (1993) Word families International Journal of Lexicography 6253ndash279 doi101093ijl64253
Bensoussan M amp Laufer B (1984) Lexical guessing in context in EFL readingcomprehension Journal of Research in Reading 7 15ndash32 doi101111j1467-98171984tb00252x
Bishop H (2004) Noticing formulaic sequences A problem of measuring thesubjective LSO Working Papers in Linguistics 4 15ndash19
Bransford D B amp Johnson M K (1972) Contextual prerequisites for under-standing Some investigations of comprehension and recall Journal of VerbalLearning and Verbal Behavior 11 717ndash726 doi101016S0022-5371(72)80006-9
Brantmeier C (2006) Advanced L2 learners and reading placement Self-assessment CBT and subsequent performance System 34 15ndash35 doi101016jsystem200508004
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 287
Carver R P (1994) Percentage of unknown vocabulary words in text as a functionof the relative difficulty of the text Implications for instruction Journal of ReadingBehavior 26 413ndash437
Cobb T (nd) Web VocabProfile [Online program] Retrieved from httpwwwlextutorcavp [an adaption of A Heatley amp P Nation Range (1994)]
Cooper T C (1999) Processing of idioms by L2 learners of English TESOLQuarterly 33 233ndash262 doi1023073587719
Coxhead A (2000) A new academic word list TESOL Quarterly 34 213ndash238doi1023073587951
Elley W amp Mangubhai F (1983) The impact of reading on second languagelearning Reading Research Quarterly 19 53ndash67 doi102307747337
Ellis N C (2008) Phraseology The periphery and the heart of language In FMeunier amp S Granger (Eds) Phraseology in language learning and teaching (pp 1ndash13) Amsterdam The Netherlands John Benjamins
Erman B amp Warren B (2000) The idiom principle and the open choice principleText 20 29ndash62
Gardner D (2007) Validating the construct of Word in applied corpus-basedvocabulary research A critical survey Applied Linguistics 28 241ndash265doi101093applinamm010
Glenberg A M Wilkinson A C amp Epstein W (1982) The illusion of knowingFailure in the self-assessment of comprehension Memory and Cognition 10 597ndash602 doi103758BF03202442
Goulden R Nation P amp Read J (1990) How large can a receptive vocabulary beApplied Linguistics 11 341ndash363 doi101093applin114341
Grant L amp Bauer L (2004) Criteria for re-defining idioms Are we barking up thewrong tree Applied Linguistics 25 38ndash61 doi101093applin25138
Grant L amp Nation P (2006) How many idioms are there in English ITL -International Journal of Applied Linguistics 151 1ndash14 doi102143ITL15102015219
Haynes M (1993) Patterns and perils of guessing in second language reading In THuckin M Haynes amp J Coady (Eds) Second language reading and vocabularylearning (pp 46ndash64) Norwood NJ Ablex Publishing Corporation
Heatley A amp Nation P (1994) Range [Computer program] Wellington NewZealand Victoria University of Wellington Retrieved from httpwwwvuwacnzlals
Hill J (2000) Revising priorities From grammatical failure to collocational successIn M Lewis (Ed) Teaching collocation Further developments in the Lexical Approach(pp 47ndash69) Hove England LTP
Hirsh D amp Nation P (1992) What vocabulary size is needed to read unsimplifiedtexts for pleasure Reading in a Foreign Language 8 689ndash696
Hu H M amp Nation P (2000) Unknown vocabulary density and readingcomprehension Reading in a Foreign Language 13 403ndash429
Hughes A (2003) Testing for language teachers Cambridge England CambridgeUniversity Press
Hunt K (1968) An instrument to measure syntactic maturity Tallahassee FL USDepartment of Health Education and Welfare
Jung E H (2003) The effects of organization markers on ESL learnersrsquo textunderstanding TESOL Quarterly 37 749ndash759 doi1023073588223
Krashen S (1993) The power of reading Insights from research Englewood COLibraries Unlimited
Laufer B (1989a) A factor of difficulty in vocabulary learning Deceptivetransparency AILA Review 6 10ndash20
288 TESOL QUARTERLY
Laufer B (1989b) What percentage of lexis is essential for comprehension In CLauren amp M Nordman (Eds) Special language From humans thinking to thinkingmachines (pp 316ndash323) London England Multilingual Matters
Laufer B (1991) How much lexis is necessary for reading comprehension In P JL Arnaud amp H Bejoint (Eds) Vocabulary and applied linguistics (pp 126ndash132)Oxford England Macmillan
Laufer B (1997) The lexical plight in second language reading Words you donrsquotknow words you think you know and words you canrsquot guess In J Coady amp THuckin (Eds) Second language vocabulary acquisition (pp 20ndash34) CambridgeEngland Cambridge University Press
Lewis M (1993) The Lexical Approach The state of ELT and a way forward HoveEngland LTP
Liontas J I (2002) Context and idiom understanding in second languagesEUROSLA Yearbook 2 155ndash185
Liontas J I (2003) Killing two birds with one stone Understanding Spanish VPidioms in and out of context Hispania 86 289ndash301 doi10230720062862
Liontas J I (2007) The eye never sees what the brain understands Making sense ofidioms in second languages Lingua et Linguistica 1) 25ndash44
Maki R H amp McGuire M J (2002) Metacognition for text Findings andimplications for education In T Schwarz amp L Bennett (Eds) Appliedmetacognition (pp 39ndash67) Cambridge England Cambridge University Press
Martinez R amp Schmitt N (2010) A phrasal expressions listManuscript submitted forpublication
Moon R (1997) Vocabulary connections Multi-word items in English In NSchmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 40ndash63) Cambridge England Cambridge University Press
Moore D Lin-Agler L M amp Zabrucky K M (2005) A source of metacomprehen-sion inaccuracy Reading Psychology 26 251ndash265 doi10108002702710590962578
Morrison L (2004) Comprehension monitoring in first and second languagereading The Canadian Modern Language Review 61 77ndash106
Nation I S P (2001) Learning vocabulary in another language Cambridge EnglandCambridge University Press
Nation I S P (2006) How large a vocabulary is needed for reading and listeningThe Canadian Modern Language Review 63 59ndash82
Nation I S P amp Waring R (1997) Vocabulary size text coverage and word lists InN Schmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 6ndash19) Cambridge England Cambridge University Press
Nation P (1997) The language learning benefits of extensive reading LanguageTeacher 21 13ndash16
Nattinger J R amp DeCarrico J S (1992) Lexical phrases and language teachingOxford England Oxford University Press
Oh S Y (2001) Two types of input modification and EFL reading comprehensionSimplification versus elaboration TESOL Quarterly 35 69ndash96 doi1023073587860
OrsquoKeeffe A McCarthy M amp Carter R (2007) From corpus to classroom Language useand language teaching Cambridge England Cambridge University Press
Pawley A amp Syder F H (1983) Two puzzles for linguistic theory Nativelikeselection and nativelike fluency In J C Richards amp R Schmidt (Eds) Languageand communication (pp 191ndash226) New York NY Longman
Pigada M amp Schmitt N (2006) Vocabulary acquisition from extensive reading Acase study Reading in a Foreign Language 18 1ndash28
Read J (2004) Research in teaching vocabulary Annual Review of Applied Linguistics24 146ndash161 doi101017S0267190504000078
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 289
Sarac S amp Tarhan B (2009) Calibration of comprehension and performance inL2 reading International Electronic Journal of Elementary Education 2 167ndash179
Schmitt N Jiang N amp Grabe W (2011) The percentage of words known in a textand reading comprehension Modern Language Journal 95(1) 26ndash43
Schmitt N Schmitt D amp Clapham C (2001) Developing and exploring thebehaviour of two new versions of the Vocabulary Levels Test Language Testing 1855ndash88
Shin D amp Nation I S P (2008) Beyond single words The most frequentcollocations in spoken English ELT Journal 62 339ndash348 doi101093eltccm091
Simpson-Vlach R amp Ellis N C (2010) An academic formulas list New methods inphraseology research Applied Linguistics 31(4) 487ndash512
Sinclair J (1991) Corpus concordance collocation Oxford England OxfordUniversity Press
Spottl C amp McCarthy M (2003) Formulaic utterances in the multi-lingual contextIn J Cenoz B Hufeisen ampU Jessner (Eds) The multilingual lexicon (pp 133ndash151) Dordrecht The Netherlands Kluwer
Staelighr L S (2008) Vocabulary size and the skills of listening reading and writingLanguage Learning Journal 36 139ndash152 doi10108009571730802389975
Stubbs M amp Barth I (2003) Using recurrent phrases as text-type descriminators Aquantitative method and some findings Functions of Language 10 61ndash104doi101075fol10104stu
The British National Corpus (2007) The British National Corpus(version 3 BNC XMLed) [CD-ROM] Distributed by Oxford University Computing Services on behalfof the BNC Consortium
The iPhonersquos second coming (2008 July) The Economist Retrieved from httpwwweconomistcomscience-technologydisplaystorycfmstory_id5E1_TTSDDJTG
Walter E Woodford K amp Good M (Eds) (2008) Cambridge advanced learnerrsquosdictionary (3rd ed) Cambridge England Cambridge University Press
Weir C J (2005) Language testing and validation An evidence-based approachNew York NY Palgrave Macmillan
West M (1953) A general service list of English words London England LongmanWray A (2002) Formulaic language and the lexicon Cambridge England Cambridge
University Press
290 TESOL QUARTERLY

CONCLUSION
The present study provides some empirical evidence that a focus onword in L2 pedagogy may be detrimental to learnersrsquo development ofreading comprehension in the target language In most casesparticipants overestimated how much they had understood the textstested when those texts contained multiword expressions of varyingdegrees of compositionality comprised of very common individualwords Even when participants showed evidence of awareness of apresence of idiomaticity in the texts they generally were not very good atguessing the meaning of expressions Although Grant and Nation(2006) could be right that the teaching of individual idioms may not belsquolsquodeserving of class timersquorsquo (p 5) it is clear that at the very least raisinglearnersrsquo consciousness as to their prevalence and frequently deceptivetransparency in text certainly is
Concomitantly the present research serves to demonstrate theincompleteness of current lists of common words which now informimportant pedagogical instruments such as vocabulary tests gradedreaders and course syllabuses Under current methods as illustrated inthe Table 2 analysis of the Economist paragraph a text measured againstthe word lists now commonly in use can be mistakenly analyzed as beingeasily understood when in fact once multiword expressions are takeninto account the actual text coverage of easily understood words is farless Existing estimates of how many words one needs to know in order toadequately process naturally occurring texts (Hu amp Nation 2000Nation 2006) may need to be revisited to determine how many wordsand multiword expressions one needs to know
In practice research shows that learners will continue to believe theyunderstand items that they actually do not even after repeatedexposures to that same item (Bensoussan amp Laufer 1984 Haynes1993 Pigada amp Schmitt 2006) Language teachers and relatedprofessionals such as textbook writers need to consider ways tocontinuously help learners notice the gap between what they think theyknow and understand and what they actually do (Laufer 1997) Oneway this can be achieved has already been thoroughly discussed in thepresent paper devise texts (and tests) designed to lead readers down anidiomatic garden path Norbert Schmitt (as cited in Weir 2005) made asimilar recommendation
Perhaps the best and most valid type of vocabulary test is a reading passagewith comprehension questions but with the items requiring a full under-standing of particular words or phrases in the text This would mimic the realworld task of reading for comprehension and also the loss of comprehensionwhen key vocabulary is not known (p 123)
286 TESOL QUARTERLY
Therefore a further implication this research has for L2 pedagogy is themore careful design of the reading component of proficiency tests suchas IELTS (International English Language Testing System) and Test ofEnglish as a Foreign Language to be more strategic regarding the amountand kind of phraseology contained in the texts Proficiency was not thecentral focus of our study and future research could adopt a similarmethodology but with the inclusion of proficiency measures ofparticipants in order to explore how various types of expressions (egnoncompositional figurative imageable etc) may differentially affectpreidentified proficiency levels
Thus in order to be more methodical about such things as theinclusion of formulaic language in L2 tests and reading input in generalan important preliminary step will be to establish (a) what type offormulaic sequences are good discriminators of proficiency thresholdlevels and (b) which expressions of that identified type are mostcommon In other words what will be usefulmdashand is indeed nowbeginning to emerge (Martinez amp Schmitt 2010 Shin amp Nation 2008Simpson-Vlach amp Ellis 2010)mdashare lists of formulaic sequences that servea function similar to that of the General Service List not to revolutionizecurrent language pedagogy but to more finely tune it
THE AUTHORS
Ron Martinez is currently pursuing a doctorate at the University of NottinghamNottingham England on the topic of inclusion of phraseology in languageassessment He specializes in second language materials development
Victoria Murphy is a lecturer in Applied Linguistics and Second LanguageAcquisition at the University of Oxford Oxford England Her research interestsinclude the lexical development of first language or second language learners andthe cognitive processes that underlie language acquisition
REFERENCES
Bauer L amp Nation P (1993) Word families International Journal of Lexicography 6253ndash279 doi101093ijl64253
Bensoussan M amp Laufer B (1984) Lexical guessing in context in EFL readingcomprehension Journal of Research in Reading 7 15ndash32 doi101111j1467-98171984tb00252x
Bishop H (2004) Noticing formulaic sequences A problem of measuring thesubjective LSO Working Papers in Linguistics 4 15ndash19
Bransford D B amp Johnson M K (1972) Contextual prerequisites for under-standing Some investigations of comprehension and recall Journal of VerbalLearning and Verbal Behavior 11 717ndash726 doi101016S0022-5371(72)80006-9
Brantmeier C (2006) Advanced L2 learners and reading placement Self-assessment CBT and subsequent performance System 34 15ndash35 doi101016jsystem200508004
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 287
Carver R P (1994) Percentage of unknown vocabulary words in text as a functionof the relative difficulty of the text Implications for instruction Journal of ReadingBehavior 26 413ndash437
Cobb T (nd) Web VocabProfile [Online program] Retrieved from httpwwwlextutorcavp [an adaption of A Heatley amp P Nation Range (1994)]
Cooper T C (1999) Processing of idioms by L2 learners of English TESOLQuarterly 33 233ndash262 doi1023073587719
Coxhead A (2000) A new academic word list TESOL Quarterly 34 213ndash238doi1023073587951
Elley W amp Mangubhai F (1983) The impact of reading on second languagelearning Reading Research Quarterly 19 53ndash67 doi102307747337
Ellis N C (2008) Phraseology The periphery and the heart of language In FMeunier amp S Granger (Eds) Phraseology in language learning and teaching (pp 1ndash13) Amsterdam The Netherlands John Benjamins
Erman B amp Warren B (2000) The idiom principle and the open choice principleText 20 29ndash62
Gardner D (2007) Validating the construct of Word in applied corpus-basedvocabulary research A critical survey Applied Linguistics 28 241ndash265doi101093applinamm010
Glenberg A M Wilkinson A C amp Epstein W (1982) The illusion of knowingFailure in the self-assessment of comprehension Memory and Cognition 10 597ndash602 doi103758BF03202442
Goulden R Nation P amp Read J (1990) How large can a receptive vocabulary beApplied Linguistics 11 341ndash363 doi101093applin114341
Grant L amp Bauer L (2004) Criteria for re-defining idioms Are we barking up thewrong tree Applied Linguistics 25 38ndash61 doi101093applin25138
Grant L amp Nation P (2006) How many idioms are there in English ITL -International Journal of Applied Linguistics 151 1ndash14 doi102143ITL15102015219
Haynes M (1993) Patterns and perils of guessing in second language reading In THuckin M Haynes amp J Coady (Eds) Second language reading and vocabularylearning (pp 46ndash64) Norwood NJ Ablex Publishing Corporation
Heatley A amp Nation P (1994) Range [Computer program] Wellington NewZealand Victoria University of Wellington Retrieved from httpwwwvuwacnzlals
Hill J (2000) Revising priorities From grammatical failure to collocational successIn M Lewis (Ed) Teaching collocation Further developments in the Lexical Approach(pp 47ndash69) Hove England LTP
Hirsh D amp Nation P (1992) What vocabulary size is needed to read unsimplifiedtexts for pleasure Reading in a Foreign Language 8 689ndash696
Hu H M amp Nation P (2000) Unknown vocabulary density and readingcomprehension Reading in a Foreign Language 13 403ndash429
Hughes A (2003) Testing for language teachers Cambridge England CambridgeUniversity Press
Hunt K (1968) An instrument to measure syntactic maturity Tallahassee FL USDepartment of Health Education and Welfare
Jung E H (2003) The effects of organization markers on ESL learnersrsquo textunderstanding TESOL Quarterly 37 749ndash759 doi1023073588223
Krashen S (1993) The power of reading Insights from research Englewood COLibraries Unlimited
Laufer B (1989a) A factor of difficulty in vocabulary learning Deceptivetransparency AILA Review 6 10ndash20
288 TESOL QUARTERLY
Laufer B (1989b) What percentage of lexis is essential for comprehension In CLauren amp M Nordman (Eds) Special language From humans thinking to thinkingmachines (pp 316ndash323) London England Multilingual Matters
Laufer B (1991) How much lexis is necessary for reading comprehension In P JL Arnaud amp H Bejoint (Eds) Vocabulary and applied linguistics (pp 126ndash132)Oxford England Macmillan
Laufer B (1997) The lexical plight in second language reading Words you donrsquotknow words you think you know and words you canrsquot guess In J Coady amp THuckin (Eds) Second language vocabulary acquisition (pp 20ndash34) CambridgeEngland Cambridge University Press
Lewis M (1993) The Lexical Approach The state of ELT and a way forward HoveEngland LTP
Liontas J I (2002) Context and idiom understanding in second languagesEUROSLA Yearbook 2 155ndash185
Liontas J I (2003) Killing two birds with one stone Understanding Spanish VPidioms in and out of context Hispania 86 289ndash301 doi10230720062862
Liontas J I (2007) The eye never sees what the brain understands Making sense ofidioms in second languages Lingua et Linguistica 1) 25ndash44
Maki R H amp McGuire M J (2002) Metacognition for text Findings andimplications for education In T Schwarz amp L Bennett (Eds) Appliedmetacognition (pp 39ndash67) Cambridge England Cambridge University Press
Martinez R amp Schmitt N (2010) A phrasal expressions listManuscript submitted forpublication
Moon R (1997) Vocabulary connections Multi-word items in English In NSchmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 40ndash63) Cambridge England Cambridge University Press
Moore D Lin-Agler L M amp Zabrucky K M (2005) A source of metacomprehen-sion inaccuracy Reading Psychology 26 251ndash265 doi10108002702710590962578
Morrison L (2004) Comprehension monitoring in first and second languagereading The Canadian Modern Language Review 61 77ndash106
Nation I S P (2001) Learning vocabulary in another language Cambridge EnglandCambridge University Press
Nation I S P (2006) How large a vocabulary is needed for reading and listeningThe Canadian Modern Language Review 63 59ndash82
Nation I S P amp Waring R (1997) Vocabulary size text coverage and word lists InN Schmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 6ndash19) Cambridge England Cambridge University Press
Nation P (1997) The language learning benefits of extensive reading LanguageTeacher 21 13ndash16
Nattinger J R amp DeCarrico J S (1992) Lexical phrases and language teachingOxford England Oxford University Press
Oh S Y (2001) Two types of input modification and EFL reading comprehensionSimplification versus elaboration TESOL Quarterly 35 69ndash96 doi1023073587860
OrsquoKeeffe A McCarthy M amp Carter R (2007) From corpus to classroom Language useand language teaching Cambridge England Cambridge University Press
Pawley A amp Syder F H (1983) Two puzzles for linguistic theory Nativelikeselection and nativelike fluency In J C Richards amp R Schmidt (Eds) Languageand communication (pp 191ndash226) New York NY Longman
Pigada M amp Schmitt N (2006) Vocabulary acquisition from extensive reading Acase study Reading in a Foreign Language 18 1ndash28
Read J (2004) Research in teaching vocabulary Annual Review of Applied Linguistics24 146ndash161 doi101017S0267190504000078
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 289
Sarac S amp Tarhan B (2009) Calibration of comprehension and performance inL2 reading International Electronic Journal of Elementary Education 2 167ndash179
Schmitt N Jiang N amp Grabe W (2011) The percentage of words known in a textand reading comprehension Modern Language Journal 95(1) 26ndash43
Schmitt N Schmitt D amp Clapham C (2001) Developing and exploring thebehaviour of two new versions of the Vocabulary Levels Test Language Testing 1855ndash88
Shin D amp Nation I S P (2008) Beyond single words The most frequentcollocations in spoken English ELT Journal 62 339ndash348 doi101093eltccm091
Simpson-Vlach R amp Ellis N C (2010) An academic formulas list New methods inphraseology research Applied Linguistics 31(4) 487ndash512
Sinclair J (1991) Corpus concordance collocation Oxford England OxfordUniversity Press
Spottl C amp McCarthy M (2003) Formulaic utterances in the multi-lingual contextIn J Cenoz B Hufeisen ampU Jessner (Eds) The multilingual lexicon (pp 133ndash151) Dordrecht The Netherlands Kluwer
Staelighr L S (2008) Vocabulary size and the skills of listening reading and writingLanguage Learning Journal 36 139ndash152 doi10108009571730802389975
Stubbs M amp Barth I (2003) Using recurrent phrases as text-type descriminators Aquantitative method and some findings Functions of Language 10 61ndash104doi101075fol10104stu
The British National Corpus (2007) The British National Corpus(version 3 BNC XMLed) [CD-ROM] Distributed by Oxford University Computing Services on behalfof the BNC Consortium
The iPhonersquos second coming (2008 July) The Economist Retrieved from httpwwweconomistcomscience-technologydisplaystorycfmstory_id5E1_TTSDDJTG
Walter E Woodford K amp Good M (Eds) (2008) Cambridge advanced learnerrsquosdictionary (3rd ed) Cambridge England Cambridge University Press
Weir C J (2005) Language testing and validation An evidence-based approachNew York NY Palgrave Macmillan
West M (1953) A general service list of English words London England LongmanWray A (2002) Formulaic language and the lexicon Cambridge England Cambridge
University Press
290 TESOL QUARTERLY

Therefore a further implication this research has for L2 pedagogy is themore careful design of the reading component of proficiency tests suchas IELTS (International English Language Testing System) and Test ofEnglish as a Foreign Language to be more strategic regarding the amountand kind of phraseology contained in the texts Proficiency was not thecentral focus of our study and future research could adopt a similarmethodology but with the inclusion of proficiency measures ofparticipants in order to explore how various types of expressions (egnoncompositional figurative imageable etc) may differentially affectpreidentified proficiency levels
Thus in order to be more methodical about such things as theinclusion of formulaic language in L2 tests and reading input in generalan important preliminary step will be to establish (a) what type offormulaic sequences are good discriminators of proficiency thresholdlevels and (b) which expressions of that identified type are mostcommon In other words what will be usefulmdashand is indeed nowbeginning to emerge (Martinez amp Schmitt 2010 Shin amp Nation 2008Simpson-Vlach amp Ellis 2010)mdashare lists of formulaic sequences that servea function similar to that of the General Service List not to revolutionizecurrent language pedagogy but to more finely tune it
THE AUTHORS
Ron Martinez is currently pursuing a doctorate at the University of NottinghamNottingham England on the topic of inclusion of phraseology in languageassessment He specializes in second language materials development
Victoria Murphy is a lecturer in Applied Linguistics and Second LanguageAcquisition at the University of Oxford Oxford England Her research interestsinclude the lexical development of first language or second language learners andthe cognitive processes that underlie language acquisition
REFERENCES
Bauer L amp Nation P (1993) Word families International Journal of Lexicography 6253ndash279 doi101093ijl64253
Bensoussan M amp Laufer B (1984) Lexical guessing in context in EFL readingcomprehension Journal of Research in Reading 7 15ndash32 doi101111j1467-98171984tb00252x
Bishop H (2004) Noticing formulaic sequences A problem of measuring thesubjective LSO Working Papers in Linguistics 4 15ndash19
Bransford D B amp Johnson M K (1972) Contextual prerequisites for under-standing Some investigations of comprehension and recall Journal of VerbalLearning and Verbal Behavior 11 717ndash726 doi101016S0022-5371(72)80006-9
Brantmeier C (2006) Advanced L2 learners and reading placement Self-assessment CBT and subsequent performance System 34 15ndash35 doi101016jsystem200508004
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 287
Carver R P (1994) Percentage of unknown vocabulary words in text as a functionof the relative difficulty of the text Implications for instruction Journal of ReadingBehavior 26 413ndash437
Cobb T (nd) Web VocabProfile [Online program] Retrieved from httpwwwlextutorcavp [an adaption of A Heatley amp P Nation Range (1994)]
Cooper T C (1999) Processing of idioms by L2 learners of English TESOLQuarterly 33 233ndash262 doi1023073587719
Coxhead A (2000) A new academic word list TESOL Quarterly 34 213ndash238doi1023073587951
Elley W amp Mangubhai F (1983) The impact of reading on second languagelearning Reading Research Quarterly 19 53ndash67 doi102307747337
Ellis N C (2008) Phraseology The periphery and the heart of language In FMeunier amp S Granger (Eds) Phraseology in language learning and teaching (pp 1ndash13) Amsterdam The Netherlands John Benjamins
Erman B amp Warren B (2000) The idiom principle and the open choice principleText 20 29ndash62
Gardner D (2007) Validating the construct of Word in applied corpus-basedvocabulary research A critical survey Applied Linguistics 28 241ndash265doi101093applinamm010
Glenberg A M Wilkinson A C amp Epstein W (1982) The illusion of knowingFailure in the self-assessment of comprehension Memory and Cognition 10 597ndash602 doi103758BF03202442
Goulden R Nation P amp Read J (1990) How large can a receptive vocabulary beApplied Linguistics 11 341ndash363 doi101093applin114341
Grant L amp Bauer L (2004) Criteria for re-defining idioms Are we barking up thewrong tree Applied Linguistics 25 38ndash61 doi101093applin25138
Grant L amp Nation P (2006) How many idioms are there in English ITL -International Journal of Applied Linguistics 151 1ndash14 doi102143ITL15102015219
Haynes M (1993) Patterns and perils of guessing in second language reading In THuckin M Haynes amp J Coady (Eds) Second language reading and vocabularylearning (pp 46ndash64) Norwood NJ Ablex Publishing Corporation
Heatley A amp Nation P (1994) Range [Computer program] Wellington NewZealand Victoria University of Wellington Retrieved from httpwwwvuwacnzlals
Hill J (2000) Revising priorities From grammatical failure to collocational successIn M Lewis (Ed) Teaching collocation Further developments in the Lexical Approach(pp 47ndash69) Hove England LTP
Hirsh D amp Nation P (1992) What vocabulary size is needed to read unsimplifiedtexts for pleasure Reading in a Foreign Language 8 689ndash696
Hu H M amp Nation P (2000) Unknown vocabulary density and readingcomprehension Reading in a Foreign Language 13 403ndash429
Hughes A (2003) Testing for language teachers Cambridge England CambridgeUniversity Press
Hunt K (1968) An instrument to measure syntactic maturity Tallahassee FL USDepartment of Health Education and Welfare
Jung E H (2003) The effects of organization markers on ESL learnersrsquo textunderstanding TESOL Quarterly 37 749ndash759 doi1023073588223
Krashen S (1993) The power of reading Insights from research Englewood COLibraries Unlimited
Laufer B (1989a) A factor of difficulty in vocabulary learning Deceptivetransparency AILA Review 6 10ndash20
288 TESOL QUARTERLY
Laufer B (1989b) What percentage of lexis is essential for comprehension In CLauren amp M Nordman (Eds) Special language From humans thinking to thinkingmachines (pp 316ndash323) London England Multilingual Matters
Laufer B (1991) How much lexis is necessary for reading comprehension In P JL Arnaud amp H Bejoint (Eds) Vocabulary and applied linguistics (pp 126ndash132)Oxford England Macmillan
Laufer B (1997) The lexical plight in second language reading Words you donrsquotknow words you think you know and words you canrsquot guess In J Coady amp THuckin (Eds) Second language vocabulary acquisition (pp 20ndash34) CambridgeEngland Cambridge University Press
Lewis M (1993) The Lexical Approach The state of ELT and a way forward HoveEngland LTP
Liontas J I (2002) Context and idiom understanding in second languagesEUROSLA Yearbook 2 155ndash185
Liontas J I (2003) Killing two birds with one stone Understanding Spanish VPidioms in and out of context Hispania 86 289ndash301 doi10230720062862
Liontas J I (2007) The eye never sees what the brain understands Making sense ofidioms in second languages Lingua et Linguistica 1) 25ndash44
Maki R H amp McGuire M J (2002) Metacognition for text Findings andimplications for education In T Schwarz amp L Bennett (Eds) Appliedmetacognition (pp 39ndash67) Cambridge England Cambridge University Press
Martinez R amp Schmitt N (2010) A phrasal expressions listManuscript submitted forpublication
Moon R (1997) Vocabulary connections Multi-word items in English In NSchmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 40ndash63) Cambridge England Cambridge University Press
Moore D Lin-Agler L M amp Zabrucky K M (2005) A source of metacomprehen-sion inaccuracy Reading Psychology 26 251ndash265 doi10108002702710590962578
Morrison L (2004) Comprehension monitoring in first and second languagereading The Canadian Modern Language Review 61 77ndash106
Nation I S P (2001) Learning vocabulary in another language Cambridge EnglandCambridge University Press
Nation I S P (2006) How large a vocabulary is needed for reading and listeningThe Canadian Modern Language Review 63 59ndash82
Nation I S P amp Waring R (1997) Vocabulary size text coverage and word lists InN Schmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 6ndash19) Cambridge England Cambridge University Press
Nation P (1997) The language learning benefits of extensive reading LanguageTeacher 21 13ndash16
Nattinger J R amp DeCarrico J S (1992) Lexical phrases and language teachingOxford England Oxford University Press
Oh S Y (2001) Two types of input modification and EFL reading comprehensionSimplification versus elaboration TESOL Quarterly 35 69ndash96 doi1023073587860
OrsquoKeeffe A McCarthy M amp Carter R (2007) From corpus to classroom Language useand language teaching Cambridge England Cambridge University Press
Pawley A amp Syder F H (1983) Two puzzles for linguistic theory Nativelikeselection and nativelike fluency In J C Richards amp R Schmidt (Eds) Languageand communication (pp 191ndash226) New York NY Longman
Pigada M amp Schmitt N (2006) Vocabulary acquisition from extensive reading Acase study Reading in a Foreign Language 18 1ndash28
Read J (2004) Research in teaching vocabulary Annual Review of Applied Linguistics24 146ndash161 doi101017S0267190504000078
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 289
Sarac S amp Tarhan B (2009) Calibration of comprehension and performance inL2 reading International Electronic Journal of Elementary Education 2 167ndash179
Schmitt N Jiang N amp Grabe W (2011) The percentage of words known in a textand reading comprehension Modern Language Journal 95(1) 26ndash43
Schmitt N Schmitt D amp Clapham C (2001) Developing and exploring thebehaviour of two new versions of the Vocabulary Levels Test Language Testing 1855ndash88
Shin D amp Nation I S P (2008) Beyond single words The most frequentcollocations in spoken English ELT Journal 62 339ndash348 doi101093eltccm091
Simpson-Vlach R amp Ellis N C (2010) An academic formulas list New methods inphraseology research Applied Linguistics 31(4) 487ndash512
Sinclair J (1991) Corpus concordance collocation Oxford England OxfordUniversity Press
Spottl C amp McCarthy M (2003) Formulaic utterances in the multi-lingual contextIn J Cenoz B Hufeisen ampU Jessner (Eds) The multilingual lexicon (pp 133ndash151) Dordrecht The Netherlands Kluwer
Staelighr L S (2008) Vocabulary size and the skills of listening reading and writingLanguage Learning Journal 36 139ndash152 doi10108009571730802389975
Stubbs M amp Barth I (2003) Using recurrent phrases as text-type descriminators Aquantitative method and some findings Functions of Language 10 61ndash104doi101075fol10104stu
The British National Corpus (2007) The British National Corpus(version 3 BNC XMLed) [CD-ROM] Distributed by Oxford University Computing Services on behalfof the BNC Consortium
The iPhonersquos second coming (2008 July) The Economist Retrieved from httpwwweconomistcomscience-technologydisplaystorycfmstory_id5E1_TTSDDJTG
Walter E Woodford K amp Good M (Eds) (2008) Cambridge advanced learnerrsquosdictionary (3rd ed) Cambridge England Cambridge University Press
Weir C J (2005) Language testing and validation An evidence-based approachNew York NY Palgrave Macmillan
West M (1953) A general service list of English words London England LongmanWray A (2002) Formulaic language and the lexicon Cambridge England Cambridge
University Press
290 TESOL QUARTERLY

Carver R P (1994) Percentage of unknown vocabulary words in text as a functionof the relative difficulty of the text Implications for instruction Journal of ReadingBehavior 26 413ndash437
Cobb T (nd) Web VocabProfile [Online program] Retrieved from httpwwwlextutorcavp [an adaption of A Heatley amp P Nation Range (1994)]
Cooper T C (1999) Processing of idioms by L2 learners of English TESOLQuarterly 33 233ndash262 doi1023073587719
Coxhead A (2000) A new academic word list TESOL Quarterly 34 213ndash238doi1023073587951
Elley W amp Mangubhai F (1983) The impact of reading on second languagelearning Reading Research Quarterly 19 53ndash67 doi102307747337
Ellis N C (2008) Phraseology The periphery and the heart of language In FMeunier amp S Granger (Eds) Phraseology in language learning and teaching (pp 1ndash13) Amsterdam The Netherlands John Benjamins
Erman B amp Warren B (2000) The idiom principle and the open choice principleText 20 29ndash62
Gardner D (2007) Validating the construct of Word in applied corpus-basedvocabulary research A critical survey Applied Linguistics 28 241ndash265doi101093applinamm010
Glenberg A M Wilkinson A C amp Epstein W (1982) The illusion of knowingFailure in the self-assessment of comprehension Memory and Cognition 10 597ndash602 doi103758BF03202442
Goulden R Nation P amp Read J (1990) How large can a receptive vocabulary beApplied Linguistics 11 341ndash363 doi101093applin114341
Grant L amp Bauer L (2004) Criteria for re-defining idioms Are we barking up thewrong tree Applied Linguistics 25 38ndash61 doi101093applin25138
Grant L amp Nation P (2006) How many idioms are there in English ITL -International Journal of Applied Linguistics 151 1ndash14 doi102143ITL15102015219
Haynes M (1993) Patterns and perils of guessing in second language reading In THuckin M Haynes amp J Coady (Eds) Second language reading and vocabularylearning (pp 46ndash64) Norwood NJ Ablex Publishing Corporation
Heatley A amp Nation P (1994) Range [Computer program] Wellington NewZealand Victoria University of Wellington Retrieved from httpwwwvuwacnzlals
Hill J (2000) Revising priorities From grammatical failure to collocational successIn M Lewis (Ed) Teaching collocation Further developments in the Lexical Approach(pp 47ndash69) Hove England LTP
Hirsh D amp Nation P (1992) What vocabulary size is needed to read unsimplifiedtexts for pleasure Reading in a Foreign Language 8 689ndash696
Hu H M amp Nation P (2000) Unknown vocabulary density and readingcomprehension Reading in a Foreign Language 13 403ndash429
Hughes A (2003) Testing for language teachers Cambridge England CambridgeUniversity Press
Hunt K (1968) An instrument to measure syntactic maturity Tallahassee FL USDepartment of Health Education and Welfare
Jung E H (2003) The effects of organization markers on ESL learnersrsquo textunderstanding TESOL Quarterly 37 749ndash759 doi1023073588223
Krashen S (1993) The power of reading Insights from research Englewood COLibraries Unlimited
Laufer B (1989a) A factor of difficulty in vocabulary learning Deceptivetransparency AILA Review 6 10ndash20
288 TESOL QUARTERLY
Laufer B (1989b) What percentage of lexis is essential for comprehension In CLauren amp M Nordman (Eds) Special language From humans thinking to thinkingmachines (pp 316ndash323) London England Multilingual Matters
Laufer B (1991) How much lexis is necessary for reading comprehension In P JL Arnaud amp H Bejoint (Eds) Vocabulary and applied linguistics (pp 126ndash132)Oxford England Macmillan
Laufer B (1997) The lexical plight in second language reading Words you donrsquotknow words you think you know and words you canrsquot guess In J Coady amp THuckin (Eds) Second language vocabulary acquisition (pp 20ndash34) CambridgeEngland Cambridge University Press
Lewis M (1993) The Lexical Approach The state of ELT and a way forward HoveEngland LTP
Liontas J I (2002) Context and idiom understanding in second languagesEUROSLA Yearbook 2 155ndash185
Liontas J I (2003) Killing two birds with one stone Understanding Spanish VPidioms in and out of context Hispania 86 289ndash301 doi10230720062862
Liontas J I (2007) The eye never sees what the brain understands Making sense ofidioms in second languages Lingua et Linguistica 1) 25ndash44
Maki R H amp McGuire M J (2002) Metacognition for text Findings andimplications for education In T Schwarz amp L Bennett (Eds) Appliedmetacognition (pp 39ndash67) Cambridge England Cambridge University Press
Martinez R amp Schmitt N (2010) A phrasal expressions listManuscript submitted forpublication
Moon R (1997) Vocabulary connections Multi-word items in English In NSchmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 40ndash63) Cambridge England Cambridge University Press
Moore D Lin-Agler L M amp Zabrucky K M (2005) A source of metacomprehen-sion inaccuracy Reading Psychology 26 251ndash265 doi10108002702710590962578
Morrison L (2004) Comprehension monitoring in first and second languagereading The Canadian Modern Language Review 61 77ndash106
Nation I S P (2001) Learning vocabulary in another language Cambridge EnglandCambridge University Press
Nation I S P (2006) How large a vocabulary is needed for reading and listeningThe Canadian Modern Language Review 63 59ndash82
Nation I S P amp Waring R (1997) Vocabulary size text coverage and word lists InN Schmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 6ndash19) Cambridge England Cambridge University Press
Nation P (1997) The language learning benefits of extensive reading LanguageTeacher 21 13ndash16
Nattinger J R amp DeCarrico J S (1992) Lexical phrases and language teachingOxford England Oxford University Press
Oh S Y (2001) Two types of input modification and EFL reading comprehensionSimplification versus elaboration TESOL Quarterly 35 69ndash96 doi1023073587860
OrsquoKeeffe A McCarthy M amp Carter R (2007) From corpus to classroom Language useand language teaching Cambridge England Cambridge University Press
Pawley A amp Syder F H (1983) Two puzzles for linguistic theory Nativelikeselection and nativelike fluency In J C Richards amp R Schmidt (Eds) Languageand communication (pp 191ndash226) New York NY Longman
Pigada M amp Schmitt N (2006) Vocabulary acquisition from extensive reading Acase study Reading in a Foreign Language 18 1ndash28
Read J (2004) Research in teaching vocabulary Annual Review of Applied Linguistics24 146ndash161 doi101017S0267190504000078
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 289
Sarac S amp Tarhan B (2009) Calibration of comprehension and performance inL2 reading International Electronic Journal of Elementary Education 2 167ndash179
Schmitt N Jiang N amp Grabe W (2011) The percentage of words known in a textand reading comprehension Modern Language Journal 95(1) 26ndash43
Schmitt N Schmitt D amp Clapham C (2001) Developing and exploring thebehaviour of two new versions of the Vocabulary Levels Test Language Testing 1855ndash88
Shin D amp Nation I S P (2008) Beyond single words The most frequentcollocations in spoken English ELT Journal 62 339ndash348 doi101093eltccm091
Simpson-Vlach R amp Ellis N C (2010) An academic formulas list New methods inphraseology research Applied Linguistics 31(4) 487ndash512
Sinclair J (1991) Corpus concordance collocation Oxford England OxfordUniversity Press
Spottl C amp McCarthy M (2003) Formulaic utterances in the multi-lingual contextIn J Cenoz B Hufeisen ampU Jessner (Eds) The multilingual lexicon (pp 133ndash151) Dordrecht The Netherlands Kluwer
Staelighr L S (2008) Vocabulary size and the skills of listening reading and writingLanguage Learning Journal 36 139ndash152 doi10108009571730802389975
Stubbs M amp Barth I (2003) Using recurrent phrases as text-type descriminators Aquantitative method and some findings Functions of Language 10 61ndash104doi101075fol10104stu
The British National Corpus (2007) The British National Corpus(version 3 BNC XMLed) [CD-ROM] Distributed by Oxford University Computing Services on behalfof the BNC Consortium
The iPhonersquos second coming (2008 July) The Economist Retrieved from httpwwweconomistcomscience-technologydisplaystorycfmstory_id5E1_TTSDDJTG
Walter E Woodford K amp Good M (Eds) (2008) Cambridge advanced learnerrsquosdictionary (3rd ed) Cambridge England Cambridge University Press
Weir C J (2005) Language testing and validation An evidence-based approachNew York NY Palgrave Macmillan
West M (1953) A general service list of English words London England LongmanWray A (2002) Formulaic language and the lexicon Cambridge England Cambridge
University Press
290 TESOL QUARTERLY

Laufer B (1989b) What percentage of lexis is essential for comprehension In CLauren amp M Nordman (Eds) Special language From humans thinking to thinkingmachines (pp 316ndash323) London England Multilingual Matters
Laufer B (1991) How much lexis is necessary for reading comprehension In P JL Arnaud amp H Bejoint (Eds) Vocabulary and applied linguistics (pp 126ndash132)Oxford England Macmillan
Laufer B (1997) The lexical plight in second language reading Words you donrsquotknow words you think you know and words you canrsquot guess In J Coady amp THuckin (Eds) Second language vocabulary acquisition (pp 20ndash34) CambridgeEngland Cambridge University Press
Lewis M (1993) The Lexical Approach The state of ELT and a way forward HoveEngland LTP
Liontas J I (2002) Context and idiom understanding in second languagesEUROSLA Yearbook 2 155ndash185
Liontas J I (2003) Killing two birds with one stone Understanding Spanish VPidioms in and out of context Hispania 86 289ndash301 doi10230720062862
Liontas J I (2007) The eye never sees what the brain understands Making sense ofidioms in second languages Lingua et Linguistica 1) 25ndash44
Maki R H amp McGuire M J (2002) Metacognition for text Findings andimplications for education In T Schwarz amp L Bennett (Eds) Appliedmetacognition (pp 39ndash67) Cambridge England Cambridge University Press
Martinez R amp Schmitt N (2010) A phrasal expressions listManuscript submitted forpublication
Moon R (1997) Vocabulary connections Multi-word items in English In NSchmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 40ndash63) Cambridge England Cambridge University Press
Moore D Lin-Agler L M amp Zabrucky K M (2005) A source of metacomprehen-sion inaccuracy Reading Psychology 26 251ndash265 doi10108002702710590962578
Morrison L (2004) Comprehension monitoring in first and second languagereading The Canadian Modern Language Review 61 77ndash106
Nation I S P (2001) Learning vocabulary in another language Cambridge EnglandCambridge University Press
Nation I S P (2006) How large a vocabulary is needed for reading and listeningThe Canadian Modern Language Review 63 59ndash82
Nation I S P amp Waring R (1997) Vocabulary size text coverage and word lists InN Schmitt amp M McCarthy (Eds) Vocabulary Description acquisition and pedagogy(pp 6ndash19) Cambridge England Cambridge University Press
Nation P (1997) The language learning benefits of extensive reading LanguageTeacher 21 13ndash16
Nattinger J R amp DeCarrico J S (1992) Lexical phrases and language teachingOxford England Oxford University Press
Oh S Y (2001) Two types of input modification and EFL reading comprehensionSimplification versus elaboration TESOL Quarterly 35 69ndash96 doi1023073587860
OrsquoKeeffe A McCarthy M amp Carter R (2007) From corpus to classroom Language useand language teaching Cambridge England Cambridge University Press
Pawley A amp Syder F H (1983) Two puzzles for linguistic theory Nativelikeselection and nativelike fluency In J C Richards amp R Schmidt (Eds) Languageand communication (pp 191ndash226) New York NY Longman
Pigada M amp Schmitt N (2006) Vocabulary acquisition from extensive reading Acase study Reading in a Foreign Language 18 1ndash28
Read J (2004) Research in teaching vocabulary Annual Review of Applied Linguistics24 146ndash161 doi101017S0267190504000078
EFFECT OF IDIOMATICITY ON READING COMPREHENSION 289
Sarac S amp Tarhan B (2009) Calibration of comprehension and performance inL2 reading International Electronic Journal of Elementary Education 2 167ndash179
Schmitt N Jiang N amp Grabe W (2011) The percentage of words known in a textand reading comprehension Modern Language Journal 95(1) 26ndash43
Schmitt N Schmitt D amp Clapham C (2001) Developing and exploring thebehaviour of two new versions of the Vocabulary Levels Test Language Testing 1855ndash88
Shin D amp Nation I S P (2008) Beyond single words The most frequentcollocations in spoken English ELT Journal 62 339ndash348 doi101093eltccm091
Simpson-Vlach R amp Ellis N C (2010) An academic formulas list New methods inphraseology research Applied Linguistics 31(4) 487ndash512
Sinclair J (1991) Corpus concordance collocation Oxford England OxfordUniversity Press
Spottl C amp McCarthy M (2003) Formulaic utterances in the multi-lingual contextIn J Cenoz B Hufeisen ampU Jessner (Eds) The multilingual lexicon (pp 133ndash151) Dordrecht The Netherlands Kluwer
Staelighr L S (2008) Vocabulary size and the skills of listening reading and writingLanguage Learning Journal 36 139ndash152 doi10108009571730802389975
Stubbs M amp Barth I (2003) Using recurrent phrases as text-type descriminators Aquantitative method and some findings Functions of Language 10 61ndash104doi101075fol10104stu
The British National Corpus (2007) The British National Corpus(version 3 BNC XMLed) [CD-ROM] Distributed by Oxford University Computing Services on behalfof the BNC Consortium
The iPhonersquos second coming (2008 July) The Economist Retrieved from httpwwweconomistcomscience-technologydisplaystorycfmstory_id5E1_TTSDDJTG
Walter E Woodford K amp Good M (Eds) (2008) Cambridge advanced learnerrsquosdictionary (3rd ed) Cambridge England Cambridge University Press
Weir C J (2005) Language testing and validation An evidence-based approachNew York NY Palgrave Macmillan
West M (1953) A general service list of English words London England LongmanWray A (2002) Formulaic language and the lexicon Cambridge England Cambridge
University Press
290 TESOL QUARTERLY

Sarac S amp Tarhan B (2009) Calibration of comprehension and performance inL2 reading International Electronic Journal of Elementary Education 2 167ndash179
Schmitt N Jiang N amp Grabe W (2011) The percentage of words known in a textand reading comprehension Modern Language Journal 95(1) 26ndash43
Schmitt N Schmitt D amp Clapham C (2001) Developing and exploring thebehaviour of two new versions of the Vocabulary Levels Test Language Testing 1855ndash88
Shin D amp Nation I S P (2008) Beyond single words The most frequentcollocations in spoken English ELT Journal 62 339ndash348 doi101093eltccm091
Simpson-Vlach R amp Ellis N C (2010) An academic formulas list New methods inphraseology research Applied Linguistics 31(4) 487ndash512
Sinclair J (1991) Corpus concordance collocation Oxford England OxfordUniversity Press
Spottl C amp McCarthy M (2003) Formulaic utterances in the multi-lingual contextIn J Cenoz B Hufeisen ampU Jessner (Eds) The multilingual lexicon (pp 133ndash151) Dordrecht The Netherlands Kluwer
Staelighr L S (2008) Vocabulary size and the skills of listening reading and writingLanguage Learning Journal 36 139ndash152 doi10108009571730802389975
Stubbs M amp Barth I (2003) Using recurrent phrases as text-type descriminators Aquantitative method and some findings Functions of Language 10 61ndash104doi101075fol10104stu
The British National Corpus (2007) The British National Corpus(version 3 BNC XMLed) [CD-ROM] Distributed by Oxford University Computing Services on behalfof the BNC Consortium
The iPhonersquos second coming (2008 July) The Economist Retrieved from httpwwweconomistcomscience-technologydisplaystorycfmstory_id5E1_TTSDDJTG
Walter E Woodford K amp Good M (Eds) (2008) Cambridge advanced learnerrsquosdictionary (3rd ed) Cambridge England Cambridge University Press
Weir C J (2005) Language testing and validation An evidence-based approachNew York NY Palgrave Macmillan
West M (1953) A general service list of English words London England LongmanWray A (2002) Formulaic language and the lexicon Cambridge England Cambridge
University Press
290 TESOL QUARTERLY





























