Embed Size (px)
Citation preview

Efficient Cryptographic Techniques for Securing StorageSystems
Thesis Proposal
Alina Oprea
Carnegie Mellon University, Computer Science Department
Abstract
With the advance of storage technologies to networked-attached storage, a recently emerging ar-chitecture that provides higher performance and availability than traditional direct-attached disks, newsecurity concerns arise. In these environments, clients can no longer rely only on the storage serversto provide security guarantees, since these become now easier to compromise. In consequence, clientshave to play a more proactive role in protocols designed for data protection and work together with thestorage servers to ensure the confidentiality and integrity of the data. For this purpose, traditional filesystems have been augmented with client-side cryptographic operations, leading to a number of differentcryptographic file systems solutions proposed recently.
In this thesis, we propose new approaches for three different mechanisms that are currently employedin implementations of cryptographic file systems. First, we propose novel constructions that reduce theamount of additional storage required for integrity in block storage systems. These constructions arebased on the observation that, in practice, distributions of block contents and of block access patterns arenot random. As future work, we plan to extend our constructions to provide integrity of both data andmetadata in cryptographic file systems.
Secondly, we construct efficient key management schemes for cryptographic file systems in whichthe re-encryption of a file following a user revocation is delayed until the next write to that file, a modelcalled lazy revocation. The encryption key evolves at each revocation and we devise an efficient al-gorithm to recover previous encryption keys with only logarithmic cost in the number of revocationssupported. Thirdly, we address the problem of consistency of encrypted shared file objects used to im-plement cryptographic file systems abstractly. We provide sufficient conditions for the realization of agiven level of consistency, when concurrent writes to both the file and encryption key objects are possi-ble.
We plan to integrate our three novel mechanisms in an example architecture of a cryptographic filesystem, and implement it on top of NFS using the SFS toolkit. We also plan to evaluate the amountof storage needed for integrity, the latency overhead incurred by the encryption and the integrity mech-anisms, and the throughput offered by the file system upon concurrent writes compared against thoseoffered by NFS.
1 Introduction
Networked storage solutions, such as Network-Attached Storage (NAS) and Storage Area Networks (SAN),have emerged as an alternative to direct-attached storage. These modern architectures provide remote block-level data storage services for clients, preserving the same interface as a local disk to the client file system.
1

A storage area network service is often owned and managed by an organization other than the client’s, andit may additionally store other client organizations’ data using the same physical resources. While storinglarge amounts of data on high-speed, dedicated storage-area networks simplifies storage management andstimulates information sharing, it also raises security concerns.
It is desirable that clients using a networked storage system have similar security guarantees to thoseoffered by traditional storage systems. However, the storage servers in a NAS or SAN are more exposedthan direct-attached disks. In these environments, the clients cannot rely on the storage servers for securityguarantees, and, it is thus necessary that clients secure the stored data themselves in a manner transparentto the storage servers. For this purpose, cryptographic file systems augment file systems with client-sidecryptographic operations that can be used to protect the confidentiality and integrity of stored data.
Several security mechanisms are needed to implement cryptographic file systems, in particular prim-itives for data confidentiality and integrity, access control methods to enable sharing of information, keymanagement schemes that support user revocation, and methods for guaranteeing consistency of encrypteddata, detailed below:
Data Confidentiality. In order to prevent access to stored data by unauthorized parties, data confidentialitycan be maintained using either a standard block cipher (e.g., AES) in one of the standard modes ofoperation (e.g., CBC) or a tweakable cipher [50, 33, 34]. Tweakable ciphers were designed followinga call for algorithms for block level encryption by the IEEE Security In Storage Working Group(SISW) [1]. These algorithms are length-preserving, so that block boundaries do not shift or need tobe adjusted as a result of encryption.
Data Integrity. The data stored on the storage servers is vulnerable to modification and replay attacks. Tra-ditionally, data integrity is protected using cryptographic primitives such as message-authenticationcodes (MAC) and digital signatures. More sophisticated constructions (e.g., based on Merkle trees [54])can be used to reduce the amount of additional storage needed to check the integrity of data blocks.
Access Control. An access control mechanism needs to be employed to restrict access to the informationstored to only authorized users. A natural access control method for cryptographic file systems is todistribute the appropriate cryptographic keys (e.g., encryption, MAC or signing keys) for a certain fileonly to users that have access permissions to that file. An alternative method uses capabilities [29], butassumes intelligent storage devices that can check the validity of the capabilities presented by usersbefore performing operations on data.
Key Management and User Revocation. Key management solutions in cryptographic file systems rangefrom fully centralized key distribution using a trusted key server [26] to completely decentralized keydistribution done by the file system users [45, 40]. The cryptographic keys for a file need to be updatedafter a user’s access permissions to that file are revoked. Additionally, the cryptographic informationfor that file (either an encryption of the file or some integrity information) has to be recomputed withthe new cryptographic key.
There are two revocation models, depending on when the cryptographic information for a file is up-dated. In an active revocation model, all cryptographic information is immediately recomputed aftera revocation takes place. This is expensive and might cause disruptions in the normal operation of thefile system. In the alternative model of lazy revocation, the information for each file is recomputedonly when the file is modified for the first time after a revocation [26].
Consistency of Encrypted Data. Sharing of information among clients is an important feature offered byfile systems. When multiple users are allowed concurrent access and modification of information,
2

consistency of data needs to be maintained. Many different consistency models have been definedand implemented, ranging from strong conditions such as linearizability [35] and sequential consis-tency [46], to loose consistency guarantees such as causal consistency [5] and PRAM [49].
Thesis contributions. In this thesis, we propose new approaches to three different mechanisms that can beused to improve current implementations of cryptographic file systems: data integrity, key management forcryptographic file systems adopting lazy revocation, and consistency of encrypted file objects. Our goal inthis thesis is to demonstrate that storage systems can be secured using novel provably secure cryptographicconstructions that are space-efficient and incur low performance-overhead.
To this end, we first propose space-efficient novel constructions for storage integrity that exploit the factthat distributions of block contents and of block access patterns are not random in practice [57]. To preservethe length of the encrypted blocks sent to the storage servers, clients encrypt the blocks with a tweakablecipher and keep locally some state used to check the integrity of the blocks written. The constructions usethe non-malleability property of tweakable ciphers to minimize the amount of local storage for integrity.Our preliminary results demonstrate that our constructions are space-efficient and have low performanceoverhead compared to constructions in which a hash or a MAC is stored per block. Experiments alsodemonstrate that defending against replay attacks requires more storage for integrity than a simple solutionthat defends only against modification attacks.
Secondly, we construct efficient key management schemes for systems adopting lazy revocation, calledkey-updating schemes for lazy revocation [8, 7]. Assume that the same cryptographic key is used initially fora group of files with the same access permissions and the key is modified after every revocation. We denotethe time between two revocations as a time interval. After several user revocations, the lazy revocationmodel implies that different versions of the key might be used for different files in the group. Storing anddistributing these keys becomes more difficult in such systems than in systems using active revocation.We model key-updating schemes using a center (e.g., the group owner) that initially generates some stateinformation, updated at every revocation. Upon a user request, the center uses its current local state toderive a user key and gives that to the user. From the user key of some time interval, a user must be ableto extract the key for any previous time interval efficiently. Security for key-updating schemes requires thatany polynomial-time adversary with access to the user key for a particular time interval does not obtainany information about the keys for future time intervals. The keys generated by our key-updating schemescan be used with a symmetric encryption algorithm to encrypt files for confidentiality or with a message-authentication code to authenticate files for integrity protection.
Thirdly, we address the problem of consistency of encrypted shared file objects used to implementcryptographic file systems abstractly [56]. An encrypted file object is implemented through two main com-ponents: the key object that stores the encryption key, and the file object that stores (encrypted) file contents.We emphasize that the key object and file object may be implemented via completely different protocolsand infrastructures. Our concern is the impact of the consistency of each on the consistency of the encryptedfile object that they are used to implement. More specifically, knowing the consistency of a given file accessprotocol, our goal is to find sufficient conditions for the consistency of the key distribution protocol thatensures the consistency of the encrypted file that the key object and the file object are utilized to implement.In most cryptographic file system implementations, only the owner of the file modifies the key object corre-sponding to that file. However, we consider the general, more challenging case in which more than a usercan change the content of a key object.
Lastly, we plan to implement a cryptographic file system that incorporates the three security mechanismsproposed and evaluate its performance. The cryptographic file system will be implemented on top of NFS
3

using the SFS toolkit [52]. We present a detailed design of the file system in Section 5.
2 Space-Efficient Block-Level Integrity
We address the problem of efficient integrity in encrypted storage systems with the following require-ments [57]:
Length-preserving operations Cryptographic operations on blocks are length-preserving, so that they aretransparent to the storage servers.
Space-efficiency Integrity information, used to authenticate blocks that have been written previously by aclient to the disk, is stored locally by each client. Our goal is to minimize the size of the local integrityinformation.
Performance-efficiency The update of the local integrity information done for each write operation, and theverification of each block read from the storage server should not add a high performance overhead.
Security Clients should be able to detect data modification and, possibly, replay attacks. To detect mod-ification attacks, they should consider valid only blocks previously written to disk. If replay attackdetection is required, then clients should discard versions of the block that are not the latest written todisk.
2.1 Storage Schemes
To satisfy the length-preserving requirement, blocks are encrypted individually with a tweakable encipher-ing function. A tweakable enciphering function is a length-preserving pseudorandom permutation that usesan additional parameter besides the key and message, called a tweak. The tweak can be public, but it shouldbe different for each block, so that different blocks with identical content result in different encrypted blocks.
Formally, E : K×T ×M→M is a tweakable enciphering function, forK the key space, T the tweak setandM the plaintext space. It has the property that for every K ∈ K, T ∈ T , E(K,T, ·) = ET
K(·) is a lengthpreserving permutation. A tweakable enciphering function E admits an inverse D : K × T ×M → M.Correctness requires that X = DT
K(Y ) if and only if ETK(X) = Y .
We define a storage scheme as a tuple of algorithms (Init, E, D, Write,Read, Ver) where:
1. The initialization algorithm Init() outputs a secret key k for the client that can be used in algorithmsE and D, and initializes the client state S ← ∅;
2. E is a tweakable enciphering function as above and D is its inverse.
3. The write algorithm Write(k, m, bid,S) takes as input the secret key generated by the Init algorithm,block content m, block identifier bid and the client state S. The client encrypts the block m with atweak T derived from bid under the enciphering scheme E and sends the resulting ciphertext, c =ET
k (m) and bid to the server. It also updates the client state S.
4. When performing a Read(k, bid) operation, the client gets from the server the ciphertext c of block bidwhich should be the last ciphertext written by the client with that particular block identifier. The clientdecrypts c with tweak T generated from bid and outputs the corresponding plaintext m = DT
k (c).
4

5. The verification algorithm Ver(m, bid, S) is given block content m, block identifier bid and clientstate S. It checks m’s integrity, and outputs 1 if it is valid, and 0, otherwise. Note that Ver is not akeyed function.
2.2 Notions of Integrity for Storage Schemes
We define two new notions of integrity for storage schemes, one that defends only against modification at-tacks, called int-st security, and the second that incorporates defense against replay attacks, called int-st-repsecurity. Intuitively, an int-st adversary for a storage scheme is allowed to query an encryption and a de-cryption oracle, and he wins if he tricks the client into accepting a block that the client never wrote at aparticular address. An int-st-rep adversary with access to the same oracles as an int-st adversary wins ifhe tricks the client into accepting a block different from the latest that he wrote at a particular address. Ascheme is int-st or int-st-rep secure, respectively, if the corresponding adversaries have negligible successprobabilities.
2.3 Constructions
We propose three constructions of storage schemes and analyze their security and efficiency tradeoffs.
Hash scheme HashInt. This is a very simple construction, in which the client stores in a list L pairs ofblock identifiers and hashes for all the blocks written to disk. If a block is written several times, then the listL contains only the hash of the latest block content. The storage for integrity for this scheme is linear in thenumber of blocks and the scheme provides int-st-rep security.
Scheme based on a randomness test RandInt. This construction is based on two observations. The firstone is that blocks written to disk do not look random in practice; in fact they are efficiently distinguishablefrom random blocks. And, secondly, if an adversary tries to modify ciphertexts encrypted with a tweakableenciphering scheme, the resulting plaintext looks random with very high probability. The second propertycan be derived immediately from the pseudorandomness of a tweakable cipher.
In the scheme, we use a statistical test IsRand that distinguishes efficiently uniformly chosen randomblocks from blocks that are written to disk. More explicitly, IsRand(M) returns 1 with high probability forM chosen uniformly random in the plaintext space, and 0 otherwise. The false negative rate α of the test isdefined as the probability that a uniformly random element is considered not random by the test.
The idea of the new construction is very intuitive: before encrypting a block M , the client computesIsRand(M), for IsRand a randomness test as above. If the test returns 1, then the client keeps the blockidentifier and a hash of that block for authenticity in list L. Otherwise, the client stores nothing, as the lowentropy of the block will be used to verify its integrity upon return. The block is then encrypted with a tweakequal to the block identifier and sent over to the server. When reading a ciphertext from an address, the clientfirst decrypts it to obtain a plaintext M and then computes IsRand(M). If IsRand(M) returns 1 and itshash is not stored in the hash list, then the client knows that the server has tampered with the ciphertext.Otherwise, the block is authentic.
Example of a statistical test IsRand. We give an example of a test IsRand that classifies blocks withhigh entropy as random blocks. Consider a block M divided into n parts of fixed length M = M1M2 . . . Mn
with Mi ∈ {1, 2, . . . , b}. For example, a 1024-byte block could be either divided into 1024 8-bit parts (for
5

b = 256), or alternatively into 2048 4-bit parts (for b = 16). The empirical entropy of M is defined asH = −∑b
i=1 pi log2(pi), where pi is the frequency of symbol i in the sequence M1, . . . , Mn.If we fix τ a threshold depending on n and b, then the entropy test parameterized by b and τ is defined
in Figure 1. We denote IsRand8,τ (·) by the 8-bit entropy test and IsRand4,τ (·) by the 4-bit entropy test.In our experiments, we used a threshold τ generated experimentally as follows: we generated 100,000pseudorandom 1024-byte blocks and computed, for each, its entropy. For the 8-bit test, the range of theentropy was 7.73-7.86 and for the 4-bit test, 2.55-2.64. We picked τ smaller than the minimum entropyof all the random blocks generated. This way, we ensure that uniformly random blocks have the entropygreater than τ with high probability.
Once the parameters n, b and τ of the test are chosen, we can analytically bound the false negative rateof IsRand [57]. We omit here the detailed analysis.
Write M as M = M1M2 . . .Mn with Mi ∈ {1, 2, . . . , b}Compute pi = the frequency of symbol i in M , i = 1, . . . , b
Compute H = −∑bi=1 pi log2(pi)
If H < τ , then return 0Else return 1
Figure 1: IsRandb,τ (M)
Security of the scheme. The int-st-security of the scheme is based on the pseudorandomness of thetweakable cipher used for encrypting blocks, the collision resistance of the hash function used to hash blockcontents and the false negative rate α of test IsRand. A complete security proof of the construction is givenin [57]. The scheme is not int-st-rep secure, as clients accept blocks that look non-random, even if they arenot the latest written to a certain location.
Scheme secure against replay attacks RepInt. This construction stems from the observation that theblock access distribution in practice is not uniformly random, in fact it follows a Zipf-like distribution.More specifically, there are few blocks that are written more than once, with the majority of the blocksbeing written just once. Briefly, the solution we propose to defend replay attacks is to keep a counter foreach block that is written more than once. The counter denotes the number of writes to a particular block.We also keep a flag (one bit for each block) that is initially set to 0 for all blocks and becomes 1 when theblock is written first. We do not need to store counters for blocks that are written once or not written at all, asthe counter could be inferred in these cases from the flags. We then compute the tweak as a function of theblock identifier and the counter, so that if a block is written more than once, it is encrypted every time witha different tweak. After computing the tweak as indicated, the scheme proceeds as the previous scheme: ateach Write operation, a hash of the block written is stored in a list L if it has high entropy. A message isconsidered valid if either it has low entropy or its hash is stored in L. The intuition for the correctness of thisscheme is that decryptions of the same ciphertext using the same key, but different tweaks, are independent.Thus, if the server replies with an older version of an encrypted block, the client uses a different tweak fordecrypting it than the one with which it was originally encrypted. Then, the chance that it still yields alow-entropy plaintext is small.
6
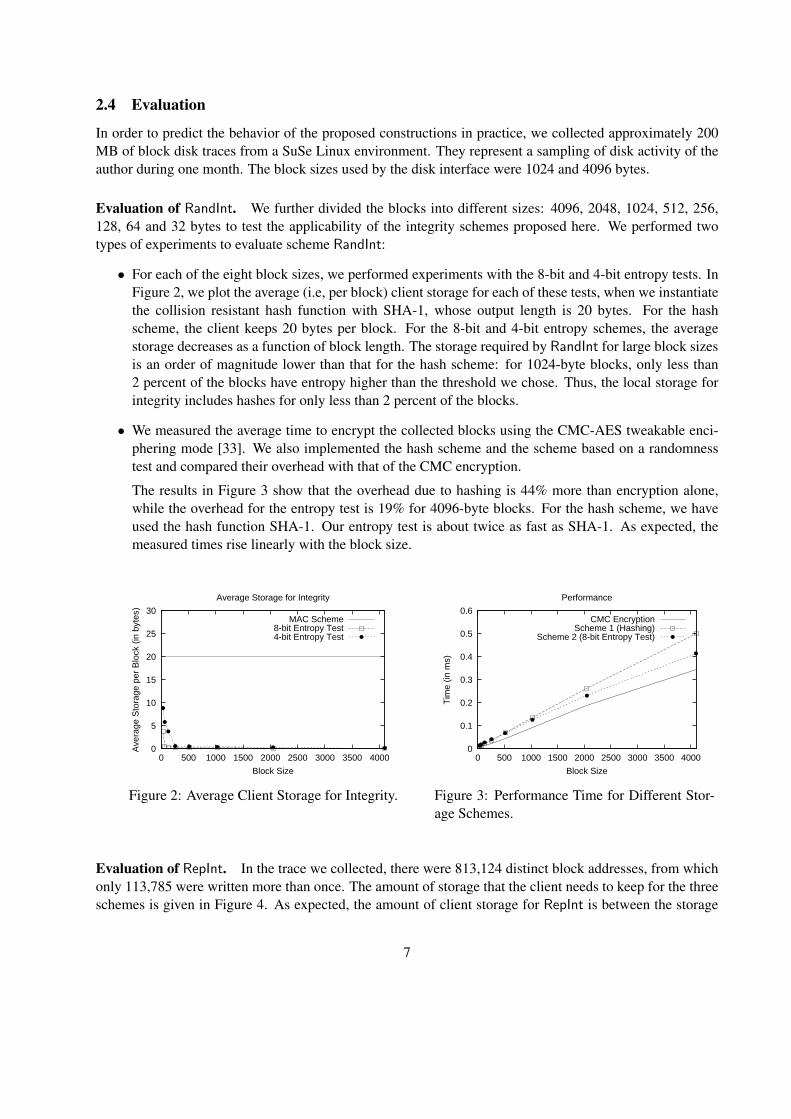
2.4 Evaluation
In order to predict the behavior of the proposed constructions in practice, we collected approximately 200MB of block disk traces from a SuSe Linux environment. They represent a sampling of disk activity of theauthor during one month. The block sizes used by the disk interface were 1024 and 4096 bytes.
Evaluation of RandInt. We further divided the blocks into different sizes: 4096, 2048, 1024, 512, 256,128, 64 and 32 bytes to test the applicability of the integrity schemes proposed here. We performed twotypes of experiments to evaluate scheme RandInt:
• For each of the eight block sizes, we performed experiments with the 8-bit and 4-bit entropy tests. InFigure 2, we plot the average (i.e, per block) client storage for each of these tests, when we instantiatethe collision resistant hash function with SHA-1, whose output length is 20 bytes. For the hashscheme, the client keeps 20 bytes per block. For the 8-bit and 4-bit entropy schemes, the averagestorage decreases as a function of block length. The storage required by RandInt for large block sizesis an order of magnitude lower than that for the hash scheme: for 1024-byte blocks, only less than2 percent of the blocks have entropy higher than the threshold we chose. Thus, the local storage forintegrity includes hashes for only less than 2 percent of the blocks.
• We measured the average time to encrypt the collected blocks using the CMC-AES tweakable enci-phering mode [33]. We also implemented the hash scheme and the scheme based on a randomnesstest and compared their overhead with that of the CMC encryption.
The results in Figure 3 show that the overhead due to hashing is 44% more than encryption alone,while the overhead for the entropy test is 19% for 4096-byte blocks. For the hash scheme, we haveused the hash function SHA-1. Our entropy test is about twice as fast as SHA-1. As expected, themeasured times rise linearly with the block size.
0
5
10
15
20
25
30
0 500 1000 1500 2000 2500 3000 3500 4000
Ave
rage
Sto
rage
per
Blo
ck (
in b
ytes
)
Block Size
Average Storage for Integrity
MAC Scheme8-bit Entropy Test4-bit Entropy Test
Figure 2: Average Client Storage for Integrity.
0
0.1
0.2
0.3
0.4
0.5
0.6
0 500 1000 1500 2000 2500 3000 3500 4000
Tim
e (in
ms)
Block Size
Performance
CMC EncryptionScheme 1 (Hashing)
Scheme 2 (8-bit Entropy Test)
Figure 3: Performance Time for Different Stor-age Schemes.
Evaluation of RepInt. In the trace we collected, there were 813,124 distinct block addresses, from whichonly 113,785 were written more than once. The amount of storage that the client needs to keep for the threeschemes is given in Figure 4. As expected, the amount of client storage for RepInt is between the storage
7

required by schemes HashInt and RandInt. Of course, the client storage increases with the lifetime of thesystem, as more blocks are overwritten. One solution to prevent the indefinite expansion of client state is toperiodically change the encryption key, re-encrypt all the data under the new key, recompute all the integrityinformation and reset all the block flags.
Storage for HashInt Storage for RandInt Storage for RepInt16.262 MB 0.022 MB 0.351 MB
Figure 4: Client Storage for the Three Schemes for One-Month Traces.
2.5 Related Work
Integrity in cryptographic file systems. The existing cryptographic file systems demonstrate that there isa tradeoff between the amount of server-side storage of integrity information and the access time to read andwrite individual file blocks. The most common integrity method, developed in TCFS [18], ECFS [14] (bothextensions of CFS [15]), NASD [30] and SNAD [55], is to store a hash or a keyed hash for each block on theserver. This construction results in a linear storage for integrity in the number of blocks at the storage serverand constant access time. Cepheus [26] and SUNDR [48] construct for each file a Merkle hash tree mappedon the i-node tree of the file. The storage server needs to store only the authenticated root of the hash tree, atthe expense of increasing the time to check the integrity of a block and update a block content. The accesstime depends on the file size, as the hash tree is not balanced. Sirius [31] stores a digital signature for eachfile, so the whole file needs to be read in order to check the integrity of a single block in the file.
Authenticated encryption. Another area related to our work is that of authenticated encryption (e.g., [11,41, 44], a cryptographic primitive that provides privacy and message authenticity at the same time. Thetraditional approach for constructing authenticated encryption is by generic composition, i.e., the combi-nation of a secure encryption scheme and an unforgeable message authentication code (MAC). However,Bellare and Namprempre [11] analyze the security of the composition and provide proofs that some of thewidely believed secure compositions are actually insecure. The authenticated encryption method used inboth SSL and SSH is proved to be insecure by Krawczyk [44] and Bellare et al. [9], respectively. Bellare etal. [9] and Kohno et al. [42] supply new definitions for integrity that protect against replay and out-of-orderdelivery attacks for network protocols. While we also define integrity against replay attacks for encryptedstorage systems, our definitions are particularly tailored to the storage scenario, and are thus different fromthe network case.
3 Key Management for Cryptographic File Systems with Lazy Revocation
We consider the problem of efficient key management in cryptographic file systems that allow shared accessto files and that adopt the lazy revocation model. In such systems, the cryptographic keys associated with agroup of files are generated and distributed by an entity we call center. The center might be a trusted entityif a centralized key distribution solution is used. Alternatively, the center might be one of the users, e.g. theowner of the files, in a decentralized key distribution protocol. The center distributes the group keys to allusers that have access rights to the group of files it manages. A user revocation triggers the change of thegroup keys. In a lazy revocation model, the update of the cryptographic information for a file after a user
8

revocation is delayed until the first write to that file. This implies that users might need to use older versionsof the group key for performing cryptographic operations on files.
3.1 Problem Definition
In our model, we divide time into intervals, not necessarily of fixed length, and each time interval is associ-ated with a new key that can be used in a symmetric-key cryptographic algorithm. In a key-updating scheme,the center generates initial state information that is updated at each time interval, and from which the centercan derive a user key. The user key for interval t permits a user to derive the keys of previous time intervals(ki for i ≤ t), but it should not give any information about keys of future time intervals (ki for i > t).
We formalize key-updating schemes in the following definition. For simplicity, we assume that all thekeys are bit strings of length κ, for κ a security parameter. The number of time intervals and the securityparameter are given as input to the initialization algorithm.
Definition 1 (Key-Updating Schemes). A key-updating scheme consists of four deterministic polynomialtime algorithms KU = (Init, Update, Derive, Extract) with the following properties:
- The initialization algorithm, Init, takes as input the security parameter 1κ, the number of time inter-vals T and a random seed s ∈ {0, 1}l(κ) for a polynomial l(κ), and outputs a bit string S0, called theinitial center state.
- The key update algorithm, Update, takes as input the current time interval t, the current center state St,and outputs the center state St+1 for the next time interval.
- The user key derivation algorithm, Derive, is given as input a time interval t and the center state St,and outputs the user key Mt. The user key can be used to derive all keys ki for 1 ≤ i ≤ t.
- The key extraction algorithm, Extract, is executed by the user and takes as input a time interval t, theuser key Mt for interval t as received from the center, and a target time interval i with 1 ≤ i ≤ t. Thealgorithm outputs the key ki for interval i.
Security of key-updating schemes for lazy revocation. The definition of security for key-updating schemesrequires that a polynomial-time adversary with access to the user key for a time interval t is not able to deriveany information about the keys for the next time interval. More specifically, the adversary receives the userkey for consecutive time intervals until he decides to output stop at a time interval t. Then, the adversary ischallenged with a key which is either the correct key generated in the key-updating scheme in time intervalt + 1 or a randomly generated key from the key space. The adversary wins if he can distinguish in which ofthe two experiments he participates. The key-updating scheme is secure if any polynomial-time adversaryhas a negligible probability of success.
3.2 Constructions
We briefly describe three constructions of key-updating schemes with different complexity and communi-cation tradeoffs. The first two constructions are based on previously proposed methods, that become securein our model after some subtle modifications. Additionally, we propose a third construction that is moreefficient than the known schemes. It uses a binary tree to derive the user keys and is also provably secure inour model.
9

B1 = G1(B2) · · · BT−1 = G1(BT ) BT = G1(BT+1) BT+1 = s0
k1 = G2(B2) · · · kT−1 = G2(BT ) kT = G2(BT+1)
Figure 5: The chaining construction. The user key for interval t is Mt = (Bt, kt).
s0 s1 = f−1(s0) · · · st = f−1(st−1) · · ·k1 = h(s1) · · · kt = h(st) · · ·
Figure 6: The trapdoor construction. The user key for interval t is Mt = (st, f).
Chaining construction (CKU). In this construction the user keys and keys are generated iteratively froma random seed using a pseudorandom generator G : {0, 1}κ → {0, 1}2κ. We write G(s) = G1(s)‖G2(s)with |G1(s)| = |G2(s)| = κ for s ∈ {0, 1}κ. The derivation of the keys and user keys of the chainingconstruction, called CKU, are described in Figure 5. In the initialization algorithm, a random seed s0 oflength κ is chosen, and this is stored in the center state. In the Update algorithm, the state for time t + 1 isidentical to the state for time t. The user key Mt = (Bt, kt) is derived from seed s0 from T − t + 1 iterativeapplications of the pseudorandom generator G. Given the user key for time interval t, the key for intervali ≤ t is extracted by t− i applications of G.
Trapdoor permutation construction (TDKU). In this construction, the center picks an initial randomstate s0 that is updated at each time interval by applying the inverse of a trapdoor permutation f . Thetrapdoor is known only to the center, but a user, given the state at a certain moment (consisting of the state atthat interval and the trapdoor permutation f ), can apply the permutation iteratively to generate all previousstates. The key kt for a time interval is generated by applying a hash function h, modeled as a randomoracle, to the current state. The derivation of the keys and user keys of the trapdoor construction, calledTDKU, are described in Figure 6. This construction has the advantage that knowledge of the total numberof time intervals is not needed in advance; on the other hand, its security can only be proved in the randomoracle model.
Tree construction (TreeKU). The tree-based key-updating scheme, called TreeKU, generates keys usinga complete binary tree with T nodes, assuming w.l.o.g. that T = 2d − 1 for some d ∈ Z. Each node in thetree is associated with a time interval between 1 and T , a unique label in {0, 1}∗, a tree-key in {0, 1}κ andan external key in {0, 1}κ such that:
1. Time intervals are assigned to tree nodes using post-order tree traversal, i.e., a node corresponds tointerval i if it is the i-th node in the post-order traversal of the tree. We refer to the node associatedwith interval t as node t.
2. The nodes of the tree are labeled as follows: the root of the tree is labeled by the empty string ε, andthe left and right children of a node with label ` are labeled by `‖0 and by `‖1, respectively.
3. The tree-key for the root node is chosen at random. The tree-keys for the two children of an internalnode in the tree are derived from the tree-key of the parent node using a pseudorandom generatorG : {0, 1}κ → {0, 1}2κ. For an input s ∈ {0, 1}κ, we write G(s) = G1(s)‖G2(s) with |G1(s)| =|G2(s)| = κ. If the tree-key for the internal node with label ` is denoted u`, then the tree-keys for itsleft and right children are u`‖0 = G1(u`) and u`‖1 = G2(u`), respectively. This implies that once thetree-key for a node is revealed, then the tree-keys of its children can be computed, but knowing the
10

uε
0 1
00 01 10 11
G2(uε)
u1
=
G1(u0)
u00
=
G2(u0)
u01
=
G2(u1)
u11
=
G1(uε)
u0
=
G1(u1)
u10
=
Figure 7: Deriving tree keys for T = 7. uε is a random value.
Time interval 1 2 3 4 5 6 7Tree key u00 u01 u0 u10 u11 u1 uε
User key u00 u00 u0 u0 u0 u0 uε
u01 u10 u10 u1
u11
Key Fu00(1) Fu01(1) Fu0(1) Fu10(1) Fu11(1) Fu1(1) Fuε(1)
Figure 8: The keys for scheme TreeKU.
tree-keys of both children of a node does not reveal any information about the tree-key of the node.An example of deriving the tree keys for T = 7 is given in Figure 7.
4. The external key of a node t is the key kt output by the scheme to the application for interval t. Fora node t with label ` and tree-key u`, the external key kt is obtained by computing Fu`
(1), for F apseudorandom function on bits.
The center state at each time interval contains the label/tree-key pairs for all the nodes on the path from theroot to the current node and the same information for their left siblings if any. The user key Mt consists ofthe label/tree-key pairs for the left siblings (if any) of all nodes on the path from the root to the parent of nodet and the label/tree-key pair of node t. The different keys for scheme TreeKU for the example constructedare given in Figure 8. To extract a key ki given the user key Mt with i ≤ t, a user finds the maximumpredecessor of node i in post-order traversal whose label/tree-key pair is included in the user tree-key Mt.Then it computes the tree-keys for all nodes on the path from that predecessor to node i, and applies thepseudorandom function F to derive the key for node i.
3.3 Comparison of the Constructions
We analyze the complexity of the cryptographic operations in the Update, Derive and Extract algorithms andthe space complexities of the center state and the user keys for all three proposed constructions. We specifywhat kind of operations we measure and distinguish public-key operations (PK op.) from pseudorandomgenerator applications (PRG op.) because PK operations are typically much more expensive than PRGapplications. The space complexities are measured in bits. The detailed analysis is in Figure 9.
11

CKU TDKU TreeKU
Update(t, St) time 0 1 PK op. O(log T ) PRG op.∗
Derive(t, St) time T − t PRG op. 0 0Extract(t,Mt, i) time t− i PRG op. t− i PK op. O(log T ) PRG op.Center state size κ poly(κ) O(κ log T )User key size κ κ O(κ log T )
Figure 9: Worst-case time and space complexities of the constructions. ∗Note: the amortized complexity ofUpdate(t, St) in the binary tree scheme is constant.
The chaining scheme CKU has efficient Update and Extract algorithms, but the complexity of the user-key derivation algorithm is linear in the number of time intervals. On the other hand, the trapdoor permu-tation scheme TDKU has efficient user-key derivation, but the complexity of the Update algorithm is oneapplication of the trapdoor permutation inverse and that of the Extract(t,Mt, i) algorithm is t−i applicationsof the trapdoor permutation. The tree-based scheme TreeKU balances the tradeoffs between the complex-ity of the three algorithms: the cost of Derive algorithm is constant and that of the Update and Extractalgorithms is logarithmic in the number of time intervals in the worst-case, at the expense of increasing thecenter-state and user-key sizes to O(κ log T ). Moreover, the amortized cost of the Update algorithm in thebinary tree construction is constant.
3.4 Composition of Key-Updating Schemes
Let KU1 and KU2 be two secure key-updating schemes using the same security parameter κ with T1 and T2
time intervals, respectively. We combine the two schemes into a secure key-updating scheme KU, which iseither the additive or multiplicative composition of the two schemes with T = T1 +T2 and T = T1 ·T2 timeintervals, respectively. The composition methods can be used for constructing key-updating schemes with alarge number of time intervals.
The additive composition of two key-updating schemes uses the keys generated by the first scheme forthe first T1 time intervals and the keys generated by the second scheme for the subsequent T2 time intervals.The user key for the first T1 intervals in KU is the same as that of scheme KU1 for the same interval. For aninterval t greater than T1, the user key includes both the user key for interval t−T1 of scheme KU2, and theuser key for interval T1 of scheme KU1.
The idea behind the multiplicative composition operation is to use every key of the first scheme to seedan instance of the second scheme. Thus, for each one of the T1 time intervals of the first scheme, we generatean instance of the second scheme with T2 time intervals. We denote a time interval t for 1 ≤ t ≤ T1 · T2
of scheme KU as a pair t = <i, j>, where i and j are such that t = (i − 1)T2 + j for 1 ≤ i ≤ T1 and1 ≤ j ≤ T2. The user key for a time interval t = <i, j> includes both the user key for time interval i− 1 ofscheme KU1 and the user key for time interval j of scheme KU2. A user receiving M<i,j> can extract thekey for any time interval <m, n> ≤ <i, j> by first extracting the key K for time interval m of KU1 (thisstep needs to be performed only if m < i), then using K to derive the initial state of the m-th instance ofthe scheme KU2, and finally, deriving the key k<m,n>.
We present [8] the detailed composition methods and proofs that the constructed scheme KU is a securekey-updating scheme, assuming that the initial schemes KU1 and KU2 are secure.
12

3.5 Related Work
Key management in cryptographic file systems. The first cryptographic file systems (CFS [15, 16]and TCFS [18]) include simple key management schemes, not suitable for sharing large amounts of data.Cepheus [26] considers data sharing and uses a trusted key server for distributing cryptographic keys.Cepheus introduces the idea of lazy revocation, and implements it by storing all previous cryptographickeys for a filegroup on the trusted server. Plutus [40] also adopts lazy revocation and introduces a sophis-ticated scheme for the derivation of previous cryptographic keys from the latest keys, called key rotation.The key rotation in Plutus uses the RSA trapdoor permutation for the derivation of both the signing andthe encryption keys. Independent of our work, Fu et al. [27] have proposed key regression, a model similarto key-updating schemes for lazy revocation. However, the tree construction we propose, TreeKU, is moreefficient than their constructions.
In file systems such as Farsite [3], SNAD [55], SiRiUS [31] and the EFS file system for Windows [19, 20]the file data is protected by a unique file encryption key and/or a unique file signature key. The meta-datainformation for a file includes an encryption under the public key of each user with access rights to the fileof these file keys. While this scheme simplifies key management, it requires additional space on the storageservers proportional to the number of users accessing a file. To our knowledge, neither of these file systemsaddresses the problem of efficient revocation of users.
Time-evolving cryptography. Time-evolving cryptography protects a cryptographic primitive against keyexposure by dividing the time into intervals and using a different secret key for every time interval. Forwardand backward-secure [6] primitives protect past and future uses of the secret key, respectively. The notion ofkey-updating schemes that we define is backward-secure, in the sense that it maintains security in the timeintervals following a key exposure.
There exist many efficient constructions of forward-secure signatures [10, 2, 38] and several genericconstructions [43, 51]. Bellare and Yee [12] analyze forward-secure private-key cryptographic primitives(forward-secure pseudorandom generators, message authentication codes and symmetric encryption) andCanetti, Halevi and Katz [17] construct the first forward-secure public-key encryption scheme. Forwardsecurity has been combined with backward security in models that protect both the past and future timeintervals, called key-insulated [22, 23] and intrusion-resilient models [39, 21]. A survey of forward-securecryptography is given by Itkis [37].
4 Consistency of Encrypted File Objects
Consistency for a file system that supports data sharing specifies the semantics of multiple users accessingfiles simultaneously. An ideal model of consistency would respect the real-time ordering of file operations,i.e., a read would return the last written version of that file. This intuition is captured in the model ofconsistency known as linearizability [35], though in practice, such ideal consistency models can have highperformance penalties. It is well known that there is a tradeoff between performance and consistency.As such, numerous consistency conditions weaker than linearizability, and that can be implemented moreefficiently in various contexts, have been explored. Sequential consistency [46], causal consistency [5],PRAM consistency [49] and more recently, fork consistency [53], are several examples.
Here we address the problem of consistency for encrypted file objects used to implement a cryptographicfile system. An encrypted file object can be constructed from a file object and a key object that holds theencryption key for the file. Given a file object that satisfies a generic consistency property, our goal is to
13

find sufficient conditions for the key and file objects that guarantee that the encrypted file object preservesthe consistency of the file object.
4.1 Types of Consistency Conditions
In a concurrent system, some processes perform invocation and response operations on a set of sharedobjects. A particular sequence of invocations and responses on a set of shared objects is called history. Aconsistency condition consists of a set of histories with certain properties. Intuitively, the fact that a historysatisfies a consistency condition gives some guarantees about the order in which the concurrent operationsfrom the history are viewed by each process. The sequence of operations seen by a process is called theserialization for that process.
We consider here only objects that accept read and write operations, which in the literature are calledregisters. There exist several types of consistency conditions, which can be categorized into three classes,described below.
Sequential conditions. These conditions guarantee that there exists a legal total ordering of the operationsin a history, called serialization, such that each process views the operations in that order. An ordering ofoperations is legal if the result of a read operation returns the value written by the most recent write operationbefore that read. Examples of conditions from this class are sequential consistency and linearizability.
Sequential consistency requires that the total order of operations respects the local order of operationsdone by each process. In addition, linearizability requires that the total order respects the real-time order:if an operation is invoked after the response of a second operation, then the first operation needs to succeedthe second in the total order.
Examples of a sequential consistent and a linearizable history are given in Figures 10 and 11, respec-tively. We denote by Write(X, v) the operation that writes value v to object X and by v ← Read(X) the op-eration that reads value v from object X . The history from Figure 10 admits the total ordering Write(X, 2);Write(X, 1); 1 ← Read(X), which does not respect the real-time ordering among the two write operations.This history is sequentially consistent, but not linearizable. The history from Figure 11 admits the totalordering Write(X, 1); Write(X, 2); Write(X, 3); 3 ← Read(X), which respects the real-time ordering.
p1 : Write(X,1) 1←Read(X)
p2 : Write(X,2)
Figure 10: Sequential consistent history.
p1 : Write(X,1) 3←Read(X)
p2 : Write(X,2) Write(X,3)
Figure 11: Linearizable history.
Conditions with eventual propagation. A history satisfies eventual propagation [25] if, intuitively, allthe write operations done by the processes in the system are eventually seen by all processes. However, theorder in which processes see the operations might be different.
This class generalizes the class of sequential conditions. Examples of conditions that satisfy eventualpropagation, but are not sequential, include causal consistency and PRAM consistency. PRAM consistencyrequires that the order in which each process sees the operations respects local order, whereas the strongercausal consistency demands that the sequence of operations seen by each process respects the causal or-der [5]. Two operations are ordered by the causal order if either: (a) they are ordered by the local order; (b)
14

the first operation writes a value to an object and the second operation reads that value from the object; (c)there is a chain of operations starting with the first and ending with the second such that any two consecutiveoperations from the chain satisfy (a) or (b).
Examples of causal and PRAM consistent histories are given in Figure 12 and 13, respectively. Thehistory from Figure 12 does not admit a sequential ordering of its operations, but it admits a serialization foreach process that respects the causal order. The serialization for process p1 is Write(X, 1); Write(X, 2); 2 ←Read(X) and that for process p2 is Write(X, 2); Write(X, 1); 1 ← Read(X). The history from Figure 13is not causally consistent, but only PRAM consistent. The following serializations for each process respectsthe local order: Write(X, 1); Write(X, 2); Write(Y, 1) for p1, Write(X, 1); Write(X, 2); 2 ← Read(X);Write(Y, 1) for p2 and Write(Y, 1); 1 ← Read(Y ); Write(X, 1); 1 ← Read(X); Write(X, 2) for p3.
p1 : Write(X,1) 2←Read(X)
p2 : Write(X,2) 1←Read(X)
Figure 12: Causal consistent history.
p1 : Write(X,1) Write(X,2)
p2 : 2←Read(X) Write(Y,1)
p3 : 1←Read(Y ) 1←Read(X)
Figure 13: PRAM consistent history.
Forking conditions. To model encrypted file systems over untrusted storage, we need to consider consis-tency conditions that might not satisfy the eventual propagation property. In a model with potentially faultystorage, it might be the case that a process only views a subset of the writes of the other processes, besidesthe operations it performs. A forking condition demands that the serializations for each process can be ar-ranged into a forking tree. Intuitively, arranging the serializations in a tree means that any two serializationsmight have a common prefix of identical operations, but once they diverge, they do not contain both thesame operation. Thus, the operations that belong to a subset of serializations must be ordered the same inall those serializations. In addition, each serialization needs to respect a given consistency condition.
We give an example of a history in Figure 14 that is not linearizable, but that accepts a forking treeshown in Figure 15. Processes p1 and p2 do not see any operations performed by process p3. Process p3
sees only the writes on object X done by p1 and p2, respectively, but no other operations done by p1 or p2.Each path in the forking tree from the root to a leaf corresponds to a serialization for a process. Each branchin the tree respects the real-time ordering relation.
In analyzing generically the consistency of encrypted file objects, we restrict ourselves to these three classesof conditions. One of our contribution is to construct generalizations of existing conditions and divide theminto these classes. We give formal definitions for each class in our manuscript [56].
4.2 Definition of Consistency for Encrypted File Objects
Given a consistency condition C for a file object that belongs to one of the three classes described, wedefine a corresponding condition Cenc for an encrypted file object. Intuitively, an encrypted file object isCenc-consistent if there is an arrangement (i.e., order of operations) of key and file operations such that themost recent key write operation before each file operation seen by each client is the write of the key usedto encrypt or decrypt that file. In addition, the order of operations should respect legality for file and key
15

p1 : Write(X,1) 2←Read(X) Write(Y,1) 1←Read(Y )
p2 : Write(X,2) Write(Y,2)
p3 : Write(X,3) 3←Read(X)
Figure 14: Forking history.
Write(X, 1)
Write(X, 2)
2← Read(X) Write(X, 3)
3← Read(X)
Write(Y, 1) Write(Y, 2)
1← Read(Y )
p1
p2
p3
Figure 15: A forking tree for the history.
histories, and the desired consistency C of the file access protocol. The formal definition is given in ourpaper [56].
4.3 Deadlock-Freedom is a Sufficient Condition for Consistency
We consider a history H of read and write operations on a file object F and key object K. We assumethat H restricted to key operations, denoted H|K, satisfies consistency condition C1 and H restricted to fileoperations, denoted H|F, satisfies consistency condition C2.
A history is deadlock-free if, intuitively, it prevents a situation in which a client who reads the latest keyfrom the key object and the latest (encrypted) file contents from the file object is not able to decrypt thecontents with the key (i.e., the file is encrypted with a different key). In this case, the read of the encryptedfile fails, as would all subsequent file read operations, a situation called deadlock.
We give an example in Figure 16 of a history that leads to deadlocks for sequential consistent keyoperations and causal consistent file operations. Here c1 and c2 are file values encrypted with key valuesk1 and k2, respectively. In any sequential consistent serialization of the key operations, k1 is written beforek2. Write(F, c1) depends causally on Write(F, c2), and, thus, in any causal consistent serialization of fileoperations, c2 is written before c1. A client reading the latest value of the key and file objects after all thewrite operations have been executed gets key value k2 and file value c1. The client has reached a deadlockin this case.
p1 : Write(K,k1) Write(K,k2)
p2 : k2←Read(K) Write(F,c2)
p3 : c2←Read(F) k1←Read(K) Write(F,c1)
Figure 16: A history that leads to deadlocks.
Definition of deadlock-free histories. We consider here the particular case in which there is only onewriter for the key object, as in most cryptographic file system implementations. Usually, the file ownerchanges and distributes the encryption key for the file. In this case, we can use increasing sequence numbers
16

for key write operations. A history H of operations on a key object K and file object F is deadlock-free withrespect to conditions C1 and C2 if, intuitively, in any ordering of the file operations in H that respects therestrictions given by condition C2, the encryption keys used in the file write operations have non-decreasingsequence numbers.
Main result. We investigated the connection between deadlock-free and consistent histories of encryptedfile objects. Our main result establishes that if a history H restricted to key operations satisfies consis-tency C1, H restricted to file operations satisfies consistency C2, and, in addition, H is deadlock-free withrespect to C1 and C2, then H is Cenc
2 -consistent. The result is subject to several restrictions on the conditionsC1 and C2, detailed in [56].
Our main result demonstrates that, in order to construct consistent encrypted file objects, it is enough toorder the file write operations in increasing order of the encryption keys sequence numbers, while preservingthe desired consistency for the file operations. We generalized our result to the case in which multipleprocesses can concurrently write the key object. More details are given in our manuscript [56].
4.4 Related Work
Consistency in cryptographic file systems. SUNDR [48] provides consistency guarantees (i.e., fork con-sistency [53]) in a model with a Byzantine storage server and benign clients. A misbehaving server mightconceal users’ operations from each other and break the total order among operations, with the effect thatusers get divided into groups that will never see the same system state again. Thus, SUNDR does not preventreplay (or rollback) attacks done by the untrusted storage server. However, it guarantees weaker consistency,i.e., if two users view different versions of the file system at some moment, then they can never have thesame view again, resulting in a definitive fork of their views. In addition, if users communicate using anout-of-band channel, they can detect the rollback attack.
SUNDR only protects data integrity, but not the confidentiality of the data. In contrast, we study theconsistency of encrypted file systems and generalize the notion of fork consistency to a larger class ofconditions.
Consistency of distributed objects. Different applications have different consistency and performancerequirements. For this reason, many different consistency conditions have been defined and implemented,ranging from strong conditions such as linearizability [35], sequential consistency [46], and timed consis-tency [59] to loose consistency guarantees such as causal consistency [5], PRAM [49], coherence [32, 28],and processor consistency [32, 28, 4] and optimistic protocols such as weak consistency [24], entry consis-tency [13], release consistency [47].
We generalize a subset of the existing consistency conditions by defining two classes of generic con-sistency conditions. One of the classes contains only conditions that satisfy eventual propagation [25], i.e.,every process sees all the writes done by all the other processes, and in addition, the serialization for eachprocess respects a given partial order on the operations. Different properties of generic consistency con-ditions that satisfy eventual propagation have been analyzed in previous work, such as locality [60] (i.e.,whether the consistency of operations on several individual objects is preserved in the history that containsall the operations on the given objects) and composability [25] (i.e., whether different consistency conditionscan be combined into a stronger, more restrictive one). Our second class extends fork consistency [53], andis thus appropriate for a model where the shared storage is untrusted and potentially faulty.
17

Figure 17: Proposed architecture.
5 Cryptographic File System Design
We describe a cryptographic file system design consisting of several parties: an untrusted storage serverStSrv, a trusted server TrSrv and users of the file system. The trusted server is responsible for holding someintegrity information that can be used to authenticate each file block, distribute the encryption keys for filesupon user request, restricting access to files only to authorized users, and ordering the write operations onfiles.
In the following, we detail how our design addresses each of the security mechanisms described inthe introduction, using the techniques from Sections 2, 3, and 4. We emphasize that our techniques aregeneral and flexible, and, as such, they can be used in a variety of cryptographic file system architectures.In Figure 17 we give an example of such an architecture. We plan to implement a similar architecture to theone presented here on top of the NFS file system using the SFS toolkit [52].
5.1 Data Confidentiality and Integrity
Each file is divided into blocks of fixed length, each encrypted individually with a tweakable cipher. Thetweak used for encryption and decryption is the concatenation of the block offset in the file and a counterdenoting the total number of writes to that block. The integrity information for a block with content b,denoted IntInf(b), contains this counter. The hash of the block is included into IntInf(b) only if IsRand(b) =1, for a particular test IsRand, in which case we call the block “random”.
We include into a file i-node the integrity information for authenticating individual blocks of the file.For each file f , we could build two hash trees: CtrTree(f) authenticating the counters for all blocks andRandTree(f) authenticating only the random blocks. We can include in the i-node of each file the roots ofthese two hash trees.
For authenticating directories, we could recursively build a hash tree FSTree on top of the i-node treeof the file system. Internal nodes in FSTree are hashes of directory i-nodes and the leaves of the hash
18

tree are hashes of file i-nodes. The directory i-node is modified to contain a hash for all the i-nodes of itssubdirectories and files. In our design, we choose to store the root of FSTree in the trusted server TrSrv andthe rest of FSTree on the storage server StSrv. Upon a write operation, the root of FSTree stored by TrSrvand the hash tree FSTree stored by StSrv need to be updated. When reading a block in a file, a user gets thelatest integrity information from TrSrv and checks that the block read from StSrv is authentic by reading theappropriate entries in FSTree from StSrv.
We will investigate to what extent it is possible to reduce the size of FSTree. One idea is to encrypt thei-node entries for files and directories, and use our efficient integrity method instead of hashing file i-nodeswhen building the tree FSTree.
5.2 Key Management and User Revocation
We encrypt each block in a file initially with the same file encryption key, and we use the block offset as atweak. Upon a user revocation, the file key needs to be changed and distributed to the users that have accesspermissions on the file. The owner of the file generates and sends the file encryption keys to TrSrv. Weadopt the model of lazy revocation, so different blocks might be encrypted with different versions of thekey. The file owner generates the encryption key for the file he owns using a key-updating scheme. When auser with read or write access needs a key for encrypting or decrypting a block in the file, he contacts TrSrvand gets the latest user key. From the user key, he can efficiently extract the version of the key needed. Weplan to implement the tree key-updating scheme TreeKU.
In order to decrypt a file block, users need to know which version of the key is used to encrypt thatblock. For that, we need to store the latest time interval for any file (which equals the number of revocationsto that file) and the key identifier which is used to encrypt each file block. Similarly to authenticating thecounters for each block, we could store in the i-node of a file the latest time interval and the root of the hashtree KeyTree built over key identifiers for each block in the file.
5.3 Access Control
In previous work [31, 40], the differentiation of readers and writers is done using digital signatures forintegrity, and distributing different keys to readers and writers. Readers of a file get only the signatureverification key and writers receive the signing key. Here we propose a solution without the use of public-key cryptography, inspired by the NASD access control method [29].
Both readers and writers are given the symmetric encryption key for a file. The integrity information ismanaged by the trusted server TrSrv, who also maintains the access control lists for all files. Before a writeoperation, the user authenticates to TrSrv and, if he has write permissions on the file, he gets a capability.The capability is verified by the storage server StSrv before executing the write operation.
Assume that user U wants to write the block with offset n in file f . TrSrv maintains a counter that keepstrack of the total number of write operations in the file system. If this counter is equal to t at the momentU sends the Write request, then the write capability given to U is cap(t, f, n, U) = MACkST
(t, f, n, U),for kST a symmetric key that TrSrv and StSrv share and MAC a secure message-authentication code. Al-ternatively, TrSrv could sign the capability, but our goal is to avoid the use of public-key cryptography. Toguarantee freshness of the capabilities, TrSrv and StSrv need to have synchronized clocks and the capabili-ties should include the time when they were issued, as well.
19

5.4 Sequential Consistency
To obtain a sequential consistent encrypted file system, our main result described in Section 4 guarantees thatit is enough to order sequentially the write operations in increasing order of their encryption key sequencenumber. In our design, we use the trusted server TrSrv to order the write operations. For that, TrSrvmaintains a counter Top denoting the total number of writes done by all users. When a user U performs awrite operation, he contacts TrSrv and gets a timestamp t = Top. U presents the timestamp to the storageserver StSrv, which only performs a write operation if its timestamp is higher than the timestamp of theprevious write operation to that address. If StSrv does no respect the order imposed by TrSrv, then thiscan be detected later upon a read operation. A stale version of a block will not match the latest integrityinformation stored by TrSrv for that block.
5.5 User Operations on Files
Users that have access permissions for a certain file could perform either a Read or a Write operation ona block of the file. In addition, file owners can create the file, delete the file and grant or revoke accesspermissions to that file. A revocation of either a read or write access permission triggers the change of theencryption key for the file.
5.6 Evaluation Metrics
We plan to evaluate our prototype with respect to several metrics:
• The amount of storage for integrity that needs to be stored on StSrv and TrSrv. The storage forintegrity is defined as the amount of storage in addition to the file system data and metadata that isnecessary to check the integrity of each file block individually.
• The latency overhead introduced by encryption and our integrity method compared to the NFS proto-col.
• The throughput, i.e., number of operations per time unit, offered by the system when there are con-current writes.
Latency and throughput are standard measures used to evaluate file system performance [36, 58]. Ourgoal is to demonstrate through experiments that our system needs lower storage for integrity than previ-ous cryptographic file systems, introduces a low latency overhead and achieves a reasonable decrease inthroughput compared to NFS.
6 Proposed Timeline
We propose the following timeline:
Finish consistency paper November 2005Implementation of cryptographic file system November 2005 - May 2006
Evaluation of prototype May 2006 - August 2006Thesis writing August 2006 - December 2006
Time permitting, there are several ideas that we can explore further in the cryptographic file system imple-mentation:
20

Randomness test for compressed data. It is common that users compress files before storing them re-motely. The entropy test that we have designed classifies the majority of blocks from a compressedfile as random. Therefore, a hash needs to be stored for these blocks. We could devise a random-ness test that can differentiate compressed data (using the gzip algorithm, for example) from randomblocks. Such a test will be useful to reduce the amount of storage for integrity even further. However,a theoretical analysis similar to that for the entropy test might be complicated.
Reduce size of FSTree As described in Section 5.1, we will think about reducing the size of the hash treeFSTree used for the integrity of the file system. We might be able to reuse the ideas from Section 2for that.
Different consistency conditions. In our initial prototype, we plan to implement a sequential consistentfile system. We could further implement weaker consistency conditions (e.g., PRAM or causal con-sistency), for which it is not necessary to contact the trusted server for each block write operation.This involves design of new protocols for each consistency condition that we implement, as to ourknowledge, there do not exist protocols for an architecture similar to that described here that provideconsistency guarantees considered here.
Another interesting extension is to store all the integrity information on the storage server StSrv anduse digital signatures to authenticate it, similarly to SUNDR [48]. In such an architecture, we cannotguarantee a consistency condition that satisfies eventual propagation, but only a forking consistencycondition. As we generalized the notion of fork consistency [53] to weaker forking conditions, wecould design more efficient fork consistent protocols than those used by the SUNDR file system. Wecould evaluate the performance overhead of a fork consistent protocol compared to the sequentialconsistent protocol described here. We expect the overhead to be substantial due to the use of digitalsignatures.
References
[1] “IEEE security in storage working group. http://siswg.org.”
[2] M. Abdalla and L. Reyzin, “A new forward-secure digital signature scheme,” in Proc. Asiacrypt 2000,vol. 1976 of Lecture Notes in Computer Science, pp. 116–129, Springer-Verlag, 2000.
[3] A. Adya, W. J. Bolosky, M. Castro, G. Cermak, R. Chaiken, J. R. Douceur, J. Howell, J. R. Lorch,M. Theimer, and R. P. Wattenhofer, “FARSITE: Federated, available, and reliable storage for an in-completely trusted environment,” in Proc. 5th Symposium on Operating System Design and Implemen-tation (OSDI), Usenix, 2002.
[4] M. Ahamad, R. Bazzi, R. John, P. Kohli, and G. Neiger, “The power of processor consistency,” Tech-nical Report GIT-CC-92/34, Georgia Institute of Technology, 1992.
[5] M. Ahamad, G. Neiger, J. Burns, P. Kohli, and P. Hutto, “Causal memory: Definitions, implementationand programming,” Distributed Computing, vol. 1, no. 9, pp. 37–49, 1995.
[6] R. Anderson, “Two remarks on public-key cryptology,” Technical Report UCAM-CL-TR-549, Uni-versity of Cambridge, 2002.
21

[7] M. Backes, C. Cachin, and A. Oprea, “Lazy revocation in cryptographic file systems,” Research ReportRZ 3628, IBM Research, Aug. 2005.
[8] M. Backes, C. Cachin, and A. Oprea, “Secure key-updating for lazy revocation,” Technical Report RZ3627, IBM Research, Aug. 2005.
[9] M. Bellare, T. Kohno, and C. Namprempre, “Authenticated encryption in SSH: Provably fixing theSSH binary packet protocol,” in Proc. 9th ACM Conference on Computer and Communication Security(CCS), pp. 1–11, 2002.
[10] M. Bellare and S. Miner, “A forward-secure digital signature scheme,” in Proc. Crypto 1999, vol. 1666of Lecture Notes in Computer Science, pp. 431–448, Springer-Verlag, 1999.
[11] M. Bellare and C. Namprempre, “Authenticated encryption: Relations among notions and analysis ofthe generic composition paradigm,” in Proc. Asiacrypt 2000, vol. 1976 of Lecture Notes in ComputerScience, pp. 531–545, Springer-Verlag, 2000.
[12] M. Bellare and B. Yee, “Forward-security in private-key cryptography,” in Proc. CT-RSA 2003,vol. 2612 of Lecture Notes in Computer Science, pp. 1–18, Springer-Verlag, 2003.
[13] B. Bershad, M. Zekauskas, and W. Sawdon, “The Midway distributed shared-memory system,” inProc. IEEE COMPCON Conference, pp. 528–537, IEEE, 1993.
[14] D. Bindel, M. Chew, and C. Wells, “Extended cryptographic file system,” 1999. manuscript.
[15] M. Blaze, “A cryptographic file system for Unix,” in Proc. First ACM Conference on Computer andCommunication Security (CCS), pp. 9–16, 1993.
[16] M. Blaze, “Key management in an encrypting file system,” in Proc. Summer 1994 USENIX TechnicalConference, pp. 28–35, 1994.
[17] R. Canetti, S. Halevi, and J. Katz, “A forward-secure public-key encryption scheme,” in Proc. Euro-crypt 2003, vol. 2656 of Lecture Notes in Computer Science, pp. 255–271, Springer-Verlag, 2003.
[18] G. Cattaneo, L. Catuogno, A. D. Sorbo, and P. Persiano, “The design and implementation of a transpar-ent cryptographic file system for Unix,” in Proc. USENIX Annual Technical Conference 2001, FreenixTrack, pp. 199–212, 2001.
[19] M. Corporation, “Encrypting file system for Windows 2000,” 1999. White paper.
[20] M. Corporation, “Encrypting file system for Windows XP and Windows Server 2003,” 2002. Whitepaper.
[21] Y. Dodis, M. Franklin, J. Katz, A. Miyaji, and M. Yung, “Intrusion-resilient public-key encryption,”in Proc. CT-RSA 2003, vol. 2612 of Lecture Notes in Computer Science, pp. 19–32, Springer-Verlag,2003.
[22] Y. Dodis, J. Katz, S. Xu, and M. Yung, “Key insulated public-key cryptosystems,” in Proc. Eurocrypt2002, vol. 2332 of Lecture Notes in Computer Science, pp. 65–82, Springer-Verlag, 2002.
22

[23] Y. Dodis, J. Katz, and M. Yung, “Strong key-insulated signature schemes,” in Proc. Workshop of PublicKey Cryptography (PKC), vol. 2567 of Lecture Notes in Computer Science, pp. 130–144, Springer-Verlag, 2002.
[24] M. Dubois, C. Scheurich, and F. Briggs, “Synchronization, coherence and event ordering in multipro-cessors,” IEEE Computer, vol. 21, no. 2, pp. 9–21, 1988.
[25] R. Friedman, R. Vitenberg, and G. Chockler, “On the composability of consistency conditions,” Infor-mation Processing Letters, vol. 86, pp. 169–176, 2002.
[26] K. Fu, “Group sharing and random access in cryptographic storage file systems,” Master’s thesis,Massachusetts Institute of Technology, 1999.
[27] K. Fu, S. Kamara, and T. Kohno, “Key regression: Enabling efficient key distribution for secure dis-tributed storage,” 2005. Cryptology ePrint Archive Report 2005/303.
[28] K. Gharachorloo, D. Lenoski, J. Laudon, P. Gibbons, A. Gupta, and J.Hennessy, “Memory consistencyand event ordering in scalable shared-memory multiprocessors,” in Proc. 17th Annual InternationalSymposium on Computer Architecture, pp. 15–26, 1990.
[29] H. Gobioff, G. Gibson, and D. Tygar, “Security of network-attached storage devices,” Technical ReportCMU-CS-97-118, CMU, 1997.
[30] H. Gobioff, D. Nagle, and G. Gibson, “Integrity and performance in network-attached storage,” Tech-nical Report CMU-CS-98-182, CMU, 1998.
[31] E. Goh, H. Shacham, N. Modadugu, and D. Boneh, “SiRiUS: Securing remote untrusted storage,” inProc. Network and Distributed Systems Security (NDSS) Symposium 2003, pp. 131–145, ISOC, 2003.
[32] J. Goodman, “Cache consistency and sequential consistency,” Technical Report 61, SCI Committee,1989.
[33] S. Halevi and P. Rogaway, “A tweakable enciphering mode,” in Proc. Crypto 2003, vol. 2729 of LectureNotes in Computer Science, pp. 482–499, Springer-Verlag, 2003.
[34] S. Halevi and P. Rogaway, “A parallelizable enciphering mode,” in Proc. The RSA conference - Cryp-tographer’s track (RSA-CT), vol. 2964 of Lecture Notes in Computer Science, pp. 292–304, Springer-Verlag, 2004.
[35] M. Herlihy and J. Wing, “Linearizability: A corretness condition for concurrent objects,” ACM Trans-actions on Programming Languages and Systems, vol. 12, no. 3, pp. 463–492, 1990.
[36] J. Howard, M. L. Kazar, S. G. Menees, D. A. Nichols, M. Satyanarayanan, R. N. Sidebotham, and M. J.West, “Scale and performance in a distributed file system,” ACM Transactions on Computer Systems,vol. 6, no. 1, pp. 51–81, 1988.
[37] G. Itkis, “Forward security, adaptive cryptography: Time evolution.” Survey, available from http://www.cs.bu.edu/fac/itkis/pap/forward-secure-survey.pdf.
[38] G. Itkis and L. Reyzin, “Forward-secure signatures with optimal signing and verifying,” in Proc.Crypto 2001, vol. 2139 of Lecture Notes in Computer Science, pp. 332–354, Springer-Verlag, 2001.
23

[39] G. Itkis and L. Reyzin, “SiBIR: Signer-base intrusion-resilient signatures,” in Proc. Crypto 2002,vol. 2442 of Lecture Notes in Computer Science, pp. 499–514, Springer-Verlag, 2002.
[40] M. Kallahalla, E. Riedel, R. Swaminathan, Q. Wang, and K. Fu, “Plutus: Scalable secure file sharingon untrusted storage,” in Proc. Second USENIX Conference on File and Storage Technologies (FAST),2003.
[41] J. Katz and M. Yung, “Unforgeable encryption and chosen ciphertext secure modes of operation,” inProc. FSE 2000, vol. 1978 of Lecture Notes in Computer Science, pp. 284–299, Springer-Verlag, 2001.
[42] T. Kohno, A. Palacio, and J. Black, “Building secure cryptographic transforms, or how to encrypt andMAC,” 2003. Cryptology ePrint Archive Report 2005/177.
[43] H. Krawczyk, “Simple forward-secure signatures from any signature scheme,” in Proc. 7th ACM Con-ference on Computer and Communication Security (CCS), pp. 108–115, 2000.
[44] H. Krawczyk, “The order of encryption and authentication for protecting communications (or: Howsecure is SSL?,” in Proc. Crypto 2001, vol. 2139 of Lecture Notes in Computer Science, pp. 310–331,Springer-Verlag, 2001.
[45] J. Kubiatowicz, D. Bindel, Y. Chen, S. Czerwinski, P. Eaton, D. Geels, R. Gummadi, S. Rhea,H. Weatherspoon, W. Weimer, C. Wells, and B. Zhao, “Oceanstore: An architecture for global-scalepersistent storage,” in Proc. 9th International Conference on Architectural Support for ProgrammingLanguages and Operating Systems (ASPLOS), pp. 190–201, ACM, 2000.
[46] L. Lamport, “How to make a multiprocessor computer that correctly executes multiprocess programs,”IEEE Transactions on Computers, vol. 28, no. 9, pp. 690–691, 1979.
[47] D. Lenoski, J. Laudon, K. Gharachorloo, W. D. Weber, A. Gupta, J. Hennessy, M. Horowitz, and M. S.Lam, “The Stanford Dash multiprocessor,” IEEE Computer, vol. 25, no. 3, pp. 63–79, 1992.
[48] J. Li, M. Krohn, D. Mazieres, and D. Shasha, “Secure untrusted data repository,” in Proc. 6th Sympo-sium on Operating System Design and Implementation (OSDI), pp. 121–136, Usenix, 2004.
[49] R. Lipton and J. Sandberg, “Pram: A scalable shared memory,” Technical Report CS-TR-180-88,Princeton University, Department of Computer Science, 1988.
[50] M. Liskov, R. Rivest, and D. Wagner, “Tweakable block ciphers,” in Proc. Crypto 2002, vol. 2442 ofLecture Notes in Computer Science, pp. 31–46, Springer-Verlag, 2002.
[51] T. Malkin, D. Micciancio, and S. Miner, “Efficient generic forward-secure signatures with an un-bounded number of time periods,” in Proc. Eurocrypt 2002, vol. 2332 of Lecture Notes in ComputerScience, pp. 400–417, Springer-Verlag, 2002.
[52] D. Mazieres, “A toolkit for user-level file systems,” in Proc. USENIX Annual Technical Conference,pp. 261–274, USENIX, 2001.
[53] D. Mazieres and D. Shasha, “Building secure file systems out of byzantine storage,” in Proc. 21st ACMSymposium on Principles of Distributed Computing (PODC), pp. 108–117, ACM, 2002.
24

[54] R. Merkle, “A certified digital signature,” in Proc. Crypto 1989, vol. 435 of Lecture Notes in ComputerScience, pp. 218–238, Springer-Verlag, 1989.
[55] E. Miller, D. Long, W. Freeman, and B. Reed, “Strong security for distributed file systems,” in Proc.the First USENIX Conference on File and Storage Technologies (FAST), 2002.
[56] A. Oprea and M. K. Reiter, “On consistency of encrypted file objects,” 2005. Manuscript.
[57] A. Oprea, M. K. Reiter, and K. Yang, “Space-efficient block storage integrity,” in Proc. Network andDistributed System Security Symposium (NDSS), ISOC, 2005.
[58] B. Pawlowski, C. Juszczak, P. Staubach, C. Smith, D. Lebel, and D. Hitz, “Nfs version 3 - design andimplementation,” in Proc. USENIX Technical Conference, pp. 137–152, 1994.
[59] F. J. Torres-Rojas, M. Ahamad, and M. Raynal, “Timed consistency for shared distributed objects,”in Proc. 18th ACM Symposium on Principles of Distributed Computing (PODC), pp. 163–172, ACM,1999.
[60] R. Vitenberg and R. Friedman, “On the locality of consistency conditions,” in Proc. 17th InternationalSymposium on Distributed Computing (DISC)), pp. 92–105, 2003.
25





























