Embed Size (px)
Citation preview

Discrimination between
Singing and Speaking Voices
Yasunori Ohishi1, Masataka Goto2, Katsunobu Itou1 and Kazuya Takeda1
1Graduate School of Information Science, Nagoya University, Japan
2National Institute of Advanced Industrial Science and Technology

Automatic discrimination system of voices
Introduction
♪ ♪
♪
Discrimination
between Singing and Speaking voices
• F0 and intensity vary widely
• Singing Formant
Not necessarily heard in an amateur’s singing voice
Possible for humans to discriminate
just by listening to an amateur's singing voice
Typical characteristics of the singing voice
What features should we extract?

Algorithms that discriminate “music” from “speech”
Instrumental sounds and the singing voice with
accompanying sounds
The characteristics of the singing voice
without accompaniments yet to be fully discussed
Early research
Frequency domain Time domain
Spectral Centroid, MFCC, etc… Zero Cross Rate, etc…
“music” category
Algorithms that discriminate “music” from “speech”
Instrumental sounds and the singing voice with
accompanying sounds
The characteristics of the singing voice
without accompaniments yet to be fully discussed
Early research
Frequency domain Time domain
Spectral Centroid, MFCC, etc… Zero Cross Rate, etc…
“music” category
Characterize the nature of the singing voice
Build a measure to discriminate the singing voice
from the speaking voice
The goal of this study is to

Quiz!!
Can you discriminate
between Singing and Speaking voices?
(Japanese voices)
Q1. Can you do it ?
(2s long)
Q2. Can you do it ?
(500ms long)
Q3. Can you do it ?
(250ms long)
0 500 1000 1500 200050
60
70
80
90
100
Segment length [ms]
Cor
rect
rat
e [%
]
Total performanceSpeaking voice performanceSinging voice performance
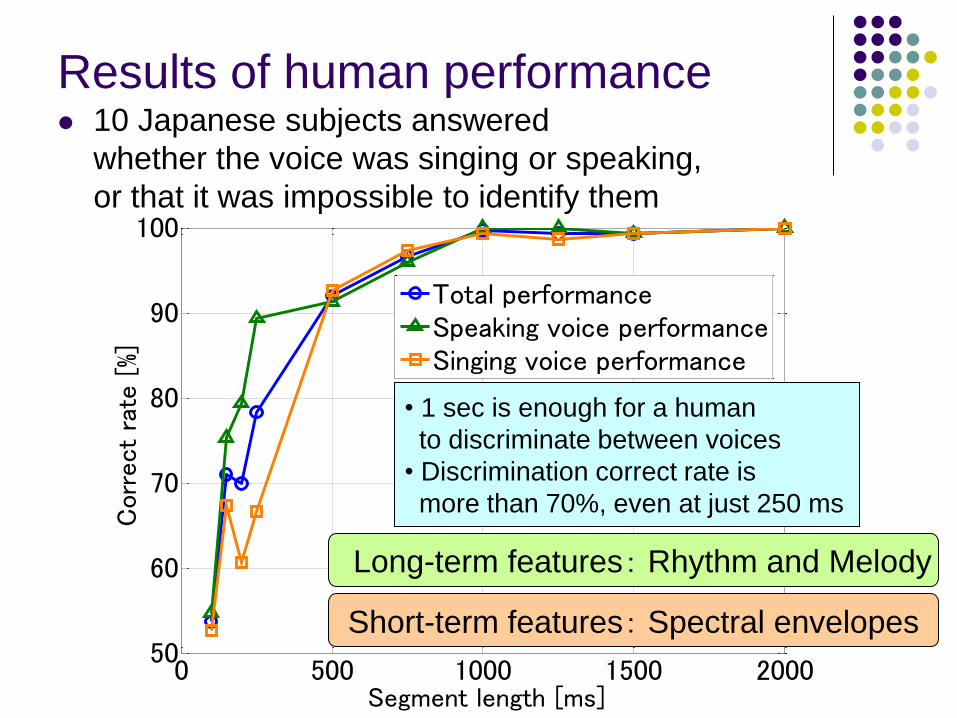
Results of human performance 10 Japanese subjects answered
whether the voice was singing or speaking,
or that it was impossible to identify them
• 1 sec is enough for a human
to discriminate between voices
• Discrimination correct rate is
more than 70%, even at just 250 ms
Long-term features: Rhythm and Melody
Short-term features: Spectral envelopes
Fre
quen
cy [
Hz]
Singing Voice Spectrogram
0 2 4 6 80
1000
2000
3000
4000
Time [sec]
Fre
quen
cy [
Hz]
Speaking Voice Spectrogram
0 1 2 30
1000
2000
3000
4000
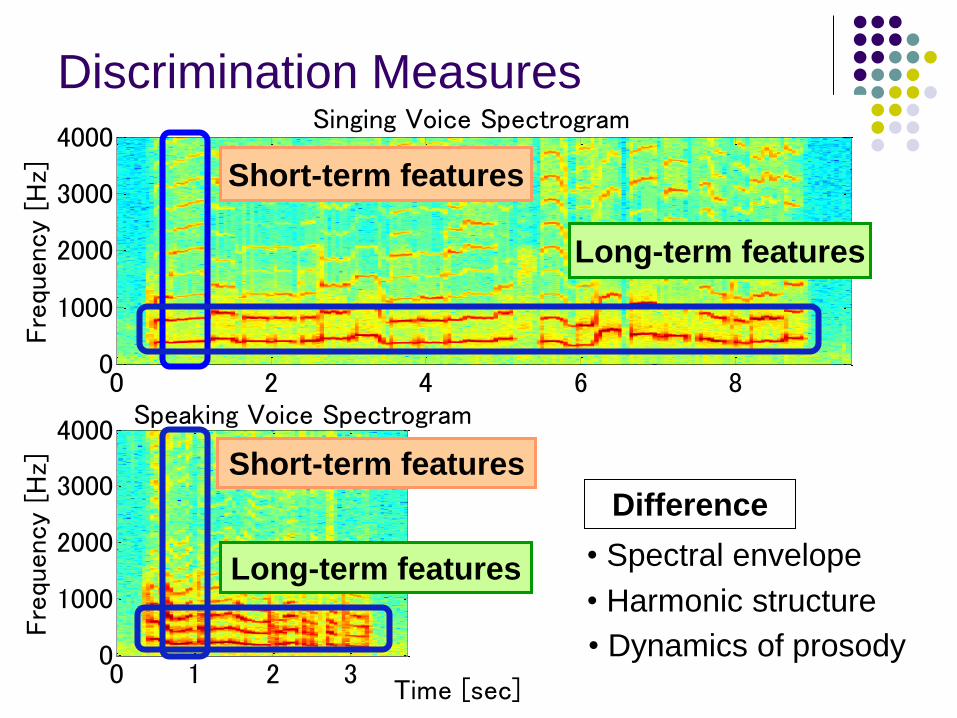
Discrimination Measures
Short-term features
Long-term features
Short-term features
Long-term features
Difference
• Spectral envelope
• Harmonic structure
• Dynamics of prosody

Short-term feature measure
The difference in the spectral envelopes
Calculating for a 100-ms hamming windowed frame every 10 ms
The difference in the vowel duration
As for the singing voice, prolonged phonemes can be observed frequently
The phoneme in the speaking voice changes one after another
Regression parameters over 5 frames
Mel-Frequency Cepstrum Coefficients (MFCCs)
DMFCCs (MFCC derivatives)
a sh i t a w a
a sh i t a w a

Long-term feature measure
F0 Extraction
A predominant-F0 estimation method (PreFEst)
Calculating the F0 value for every 10 ms
Smoothing by a median filter
The difference in the dynamics of prosody
Japanese speaking voice’s intonation
is characterized by a falling F0 contour
Singing voice is generated
under the constraint of
melodic and rhythm patterns
DF0 (five-point regression)
Singing voice
Speaking voice F0

Introducing the voice database
“AIST humming database”
75 Japanese subjects (37 males, 38 females)
Singing a chorus and “verse A” sections at an arbitrary tempo, without musical accompaniment
(25 Songs selected from
“RWC Music Database: Popular Music” )
Reading the lyrics of chorus and “verse A” sections
A total of 100 samples per subject (Singing voice: 50 samples, Speaking voice: 50 samples)

Evaluation of the Proposed Method
Training the 16-mixture GMMs
2,500 sound signals of the singing and speaking
voices of 25 subjects
Testing the proposed method
480 sound samples from 50 subjects
The maximum likelihood principle
are the GMM parameters
);(maxargˆspeak , sing
dd
fd
x
speak) sing,( , dd
Speaking voice Model
Singing voice Model
( Weight, Mean, Variance )
0 500 1000 1500 200010
20
30
40
50
60
70
80
90
100
Segment length [ms]
Cor
rect
rat
e [%
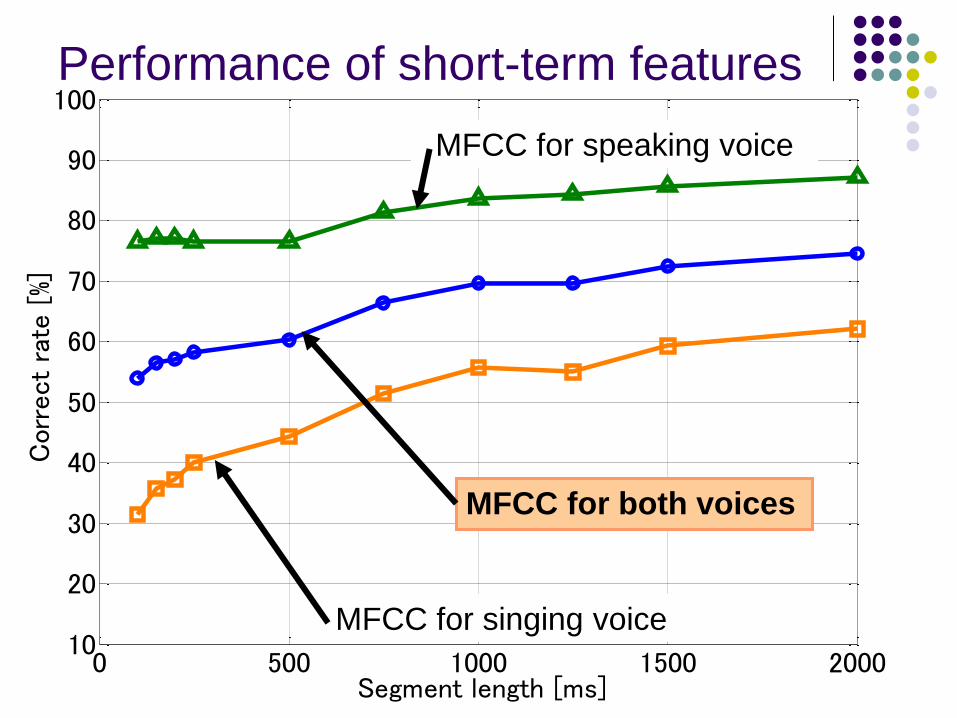
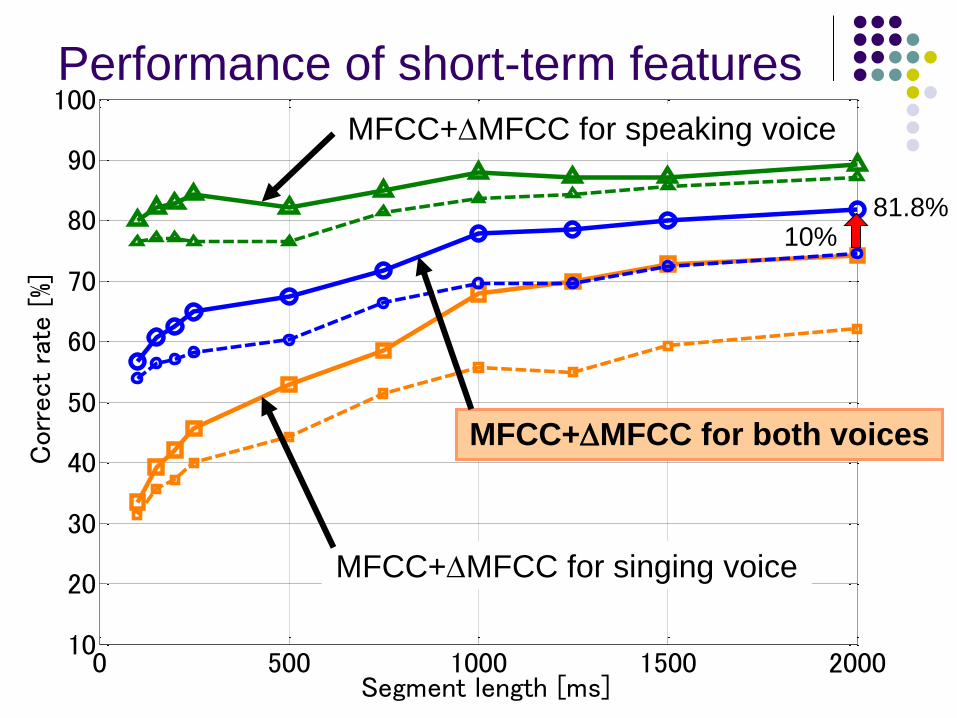
]Performance of short-term features
MFCC for speaking voice
MFCC for singing voice
MFCC for both voices
0 500 1000 1500 200010
20
30
40
50
60
70
80
90
100
Segment length [ms]
Cor
rect
rat
e [%
]Performance of short-term features
0 500 1000 1500 200010
20
30
40
50
60
70
80
90
100
Segment length [ms]
Cor
rect
rat
e [%
]
MFCC+DMFCC for speaking voice
MFCC+DMFCC for singing voice
MFCC+DMFCC for both voices
10% 81.8%
0 500 1000 1500 200010
20
30
40
50
60
70
80
90
100
Segment length [ms]
Cor
rect
rat
e [%
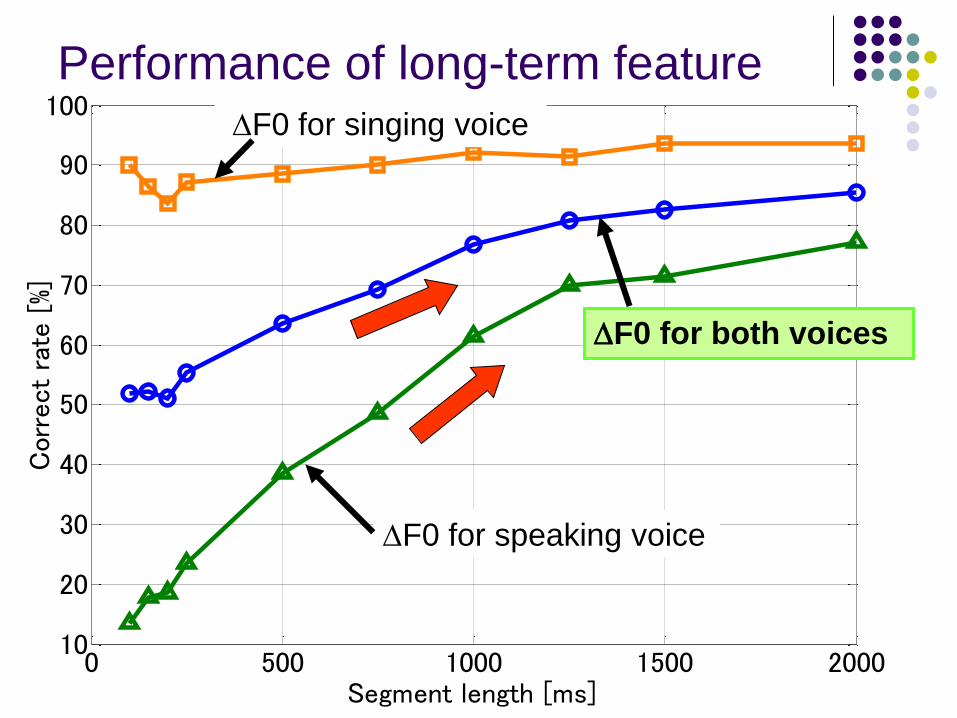
]Performance of long-term feature
DF0 for singing voice
DF0 for both voices
DF0 for speaking voice
0 500 1000 1500 200040
50
60
70
80
90
100
Segment length [ms]
Cor
rect
rat
e [%
]
0 500 1000 1500 200040
50
60
70
80
90
100
Segment length [ms]
Cor
rect
rat
e [%
]
0 500 1000 1500 200040
50
60
70
80
90
100
Segment length [ms]
Cor
rect
rat
e [%
]
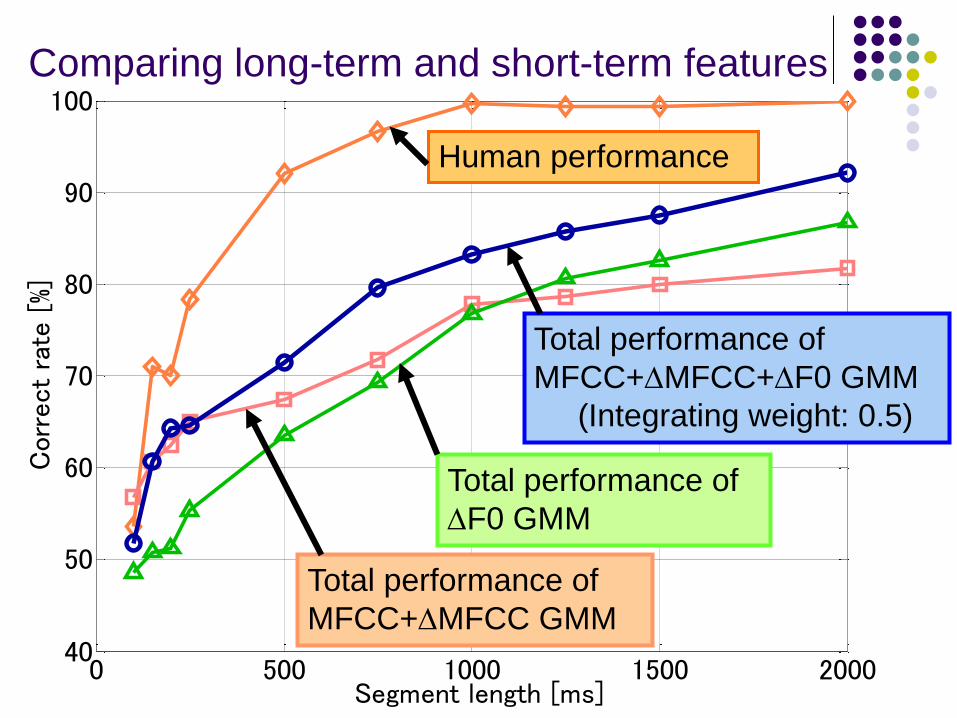
Total performance of
DF0 GMM
Total performance of
MFCC+DMFCC GMM
Comparing long-term and short-term features
Total performance of
MFCC+DMFCC+DF0 GMM
(Integrating weight: 0.5)
Human performance
Discussion
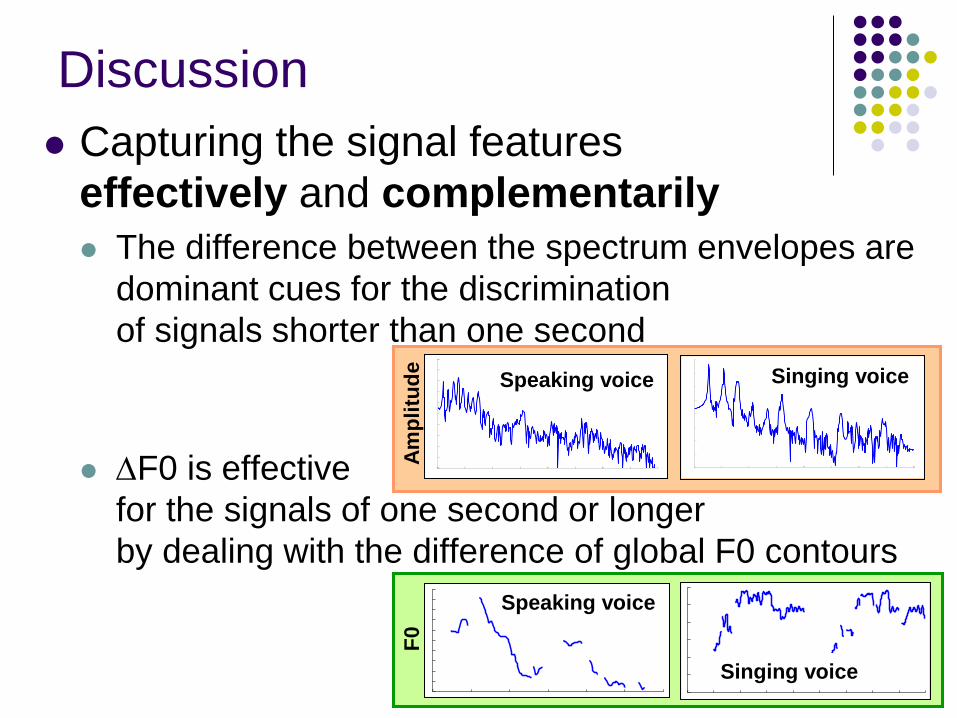
Capturing the signal features
effectively and complementarily
The difference between the spectrum envelopes are
dominant cues for the discrimination
of signals shorter than one second
DF0 is effective
for the signals of one second or longer
by dealing with the difference of global F0 contours
Singing voice
Speaking voice
F0
Speaking voice Singing voice
Am
pli
tud
e

Summary and Future work
Discrimination of singing and speaking voices by modeling two different aspects
65.0% correct rate even with 250-ms signals by MFCC
85.4% correct rate with 2-sec signals by DF0
Simple combination of the two measures
92.1% correct rate with 2-sec signals
To optimize the integration method for the two complementary measures
To extract the time domain features
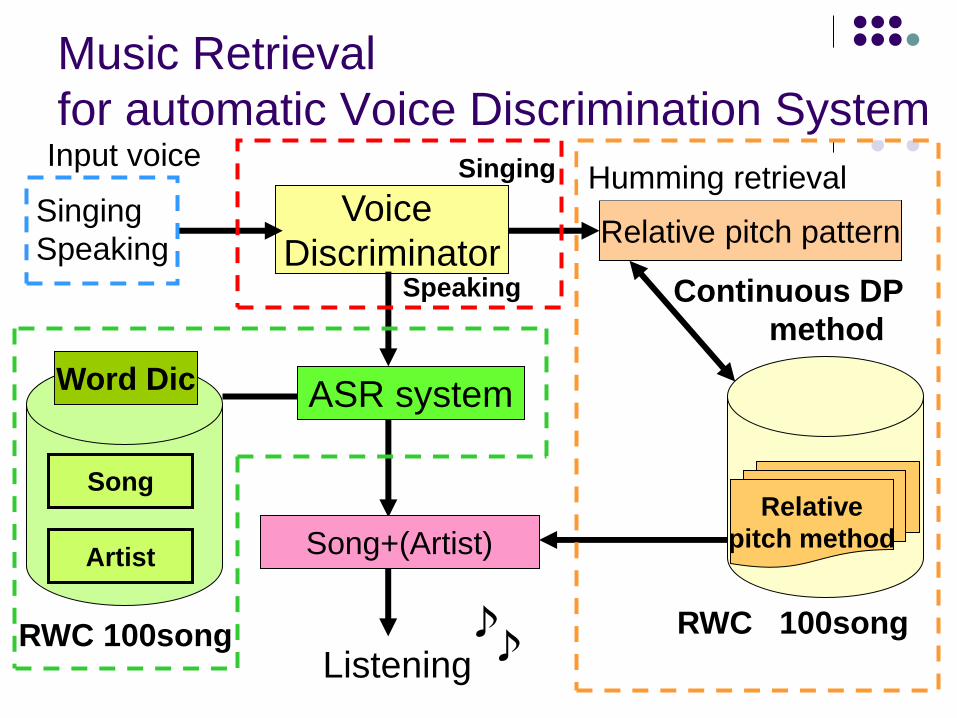
Music Retrieval
for automatic Voice Discrimination System
Voice
Discriminator
ASR system
Song
Artist
Word Dic
Song+(Artist)
Listening ♪
♪
Relative pitch pattern
RWC 100song
Relative
pitch method
Continuous DP
method
Singing
Speaking Speaking
Singing Humming retrieval Input voice
RWC 100song





























