Embed Size (px)
Citation preview

Department of Computer Science Institute for System Architecture, Chair for Computer Networks
Dr.-Ing. Stephan GroßRoom: INF 3099E-Mail: [email protected]
Internet Services & Protocols
Content Distribution

2
Outline
Content Distribution & Content Networks• What is it all about?• Basic Concepts
Categories of Content Distribution• Web Caching• Content Distribution Networks• P2P Networks
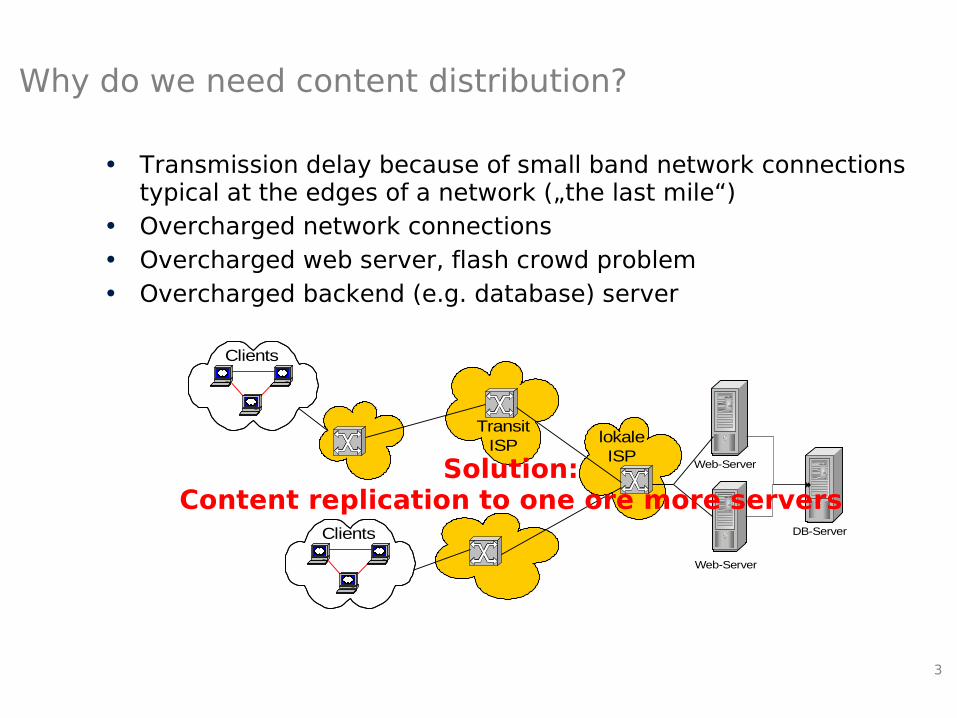
3
Why do we need content distribution?
• Transmission delay because of small band network connections typical at the edges of a network („the last mile“)
• Overcharged network connections• Overcharged web server, flash crowd problem• Overcharged backend (e.g. database) server
Web-Server
Web-Server
DB-Server
Clients
Clients
TransitISP lokale
ISPSolution:
Content replication to one ore more servers

4
Introducing Content Distribution and Content Networks
Content distribution = mechanisms for ...(1)... replicating content on multiple servers in the Internet(2)... providing requesting end systems a means to determine the servers
that can deliver the content the fastest
Content networks = new virtual overlay to the OSI stack● enable richer services that rely on underlying elements from all 7
layers of the stack.● overlay services in content networks rely on layer 7 protocols such as
HTTP or RTSP for transport
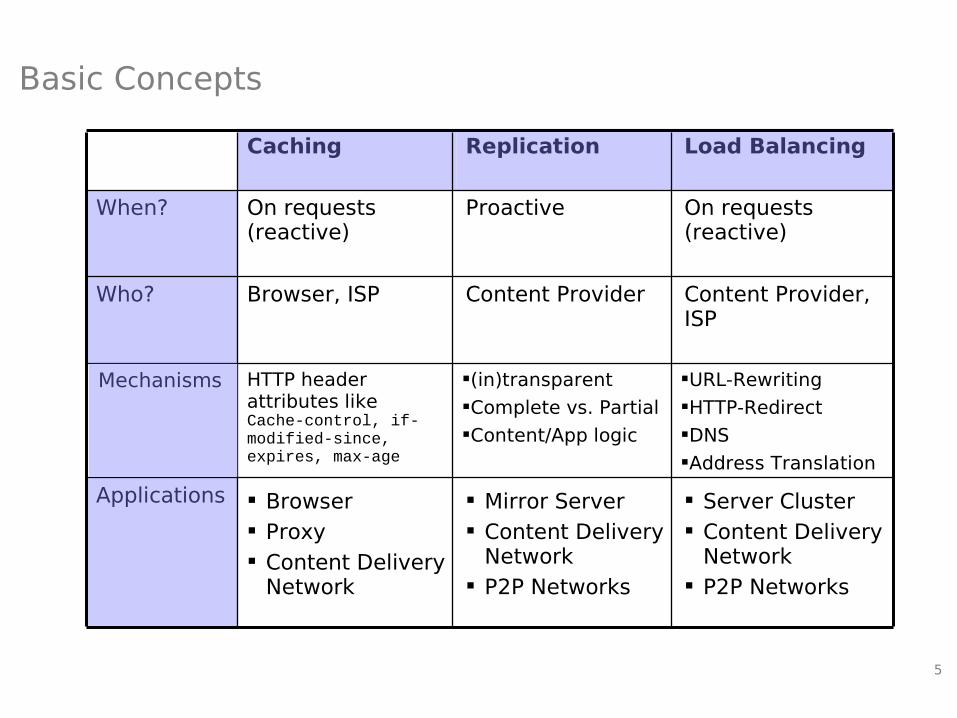
5
Basic Concepts
Server Cluster Content Delivery
Network P2P Networks
Mirror Server Content Delivery
Network P2P Networks
Browser Proxy Content Delivery
Network
Applications
Content Provider, ISP
Content ProviderBrowser, ISPWho?
On requests (reactive)
ProactiveOn requests (reactive)
When?
Load BalancingReplicationCaching
Mechanisms HTTP header attributes likeCache-control, if-modified-since, expires, max-age
(in)transparentComplete vs. PartialContent/App logic
URL-RewritingHTTP-RedirectDNSAddress Translation

Categories of Content DistributionWeb Caching

7
Web Caching Basics
● Objectiveserving the client's request without asking the server again
● User configures browserall requests are first directed to the Web cache
● Web Caching Strategy:IF (requestedObject ∈ WebCache)
THEN RETURN requestedObjectELSE BEGIN
GET requestedObject FROM OriginServerWebCache += requestedObjectRETURN requestedObject
END
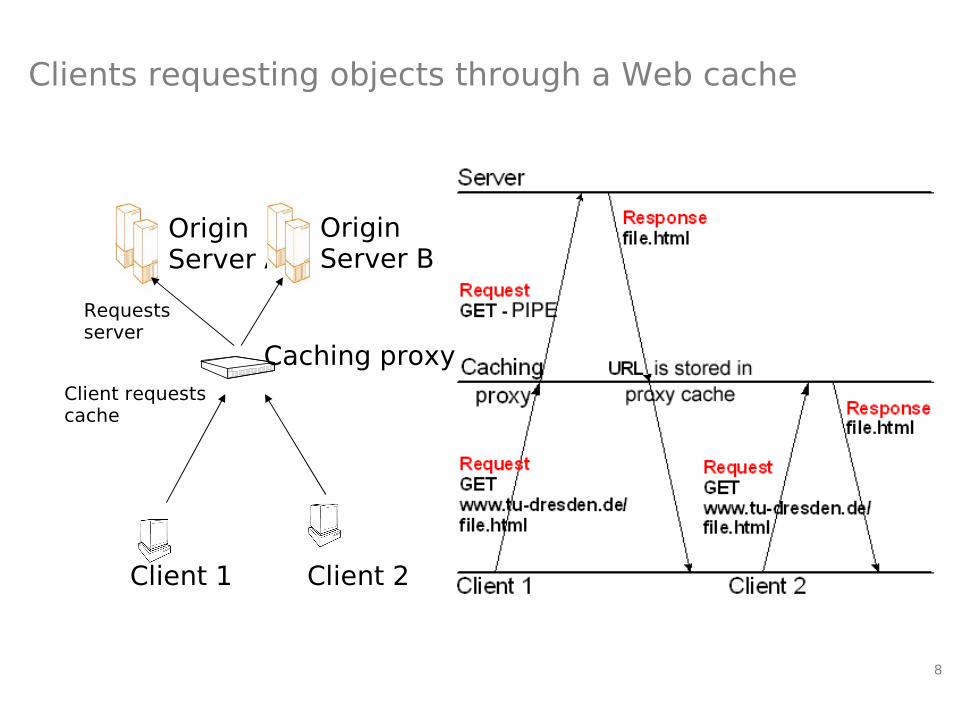
8
Clients requesting objects through a Web cache
OriginServer A
Caching proxy
OriginServer B
Client 1
Client requestscache
Requests server
Client 2

9
Web Caching Characteristics
• Cache has functions of client and server• Content is replicated on demand as a function of user
requests• Modified content is identified through heuristics • Caches are installed by independent administrative
units (institutions, companies, ISPs)
• Caching reduces delays of answers as well as the use rate of the network, and internet access point
• Weak content provider also might provide efficient information
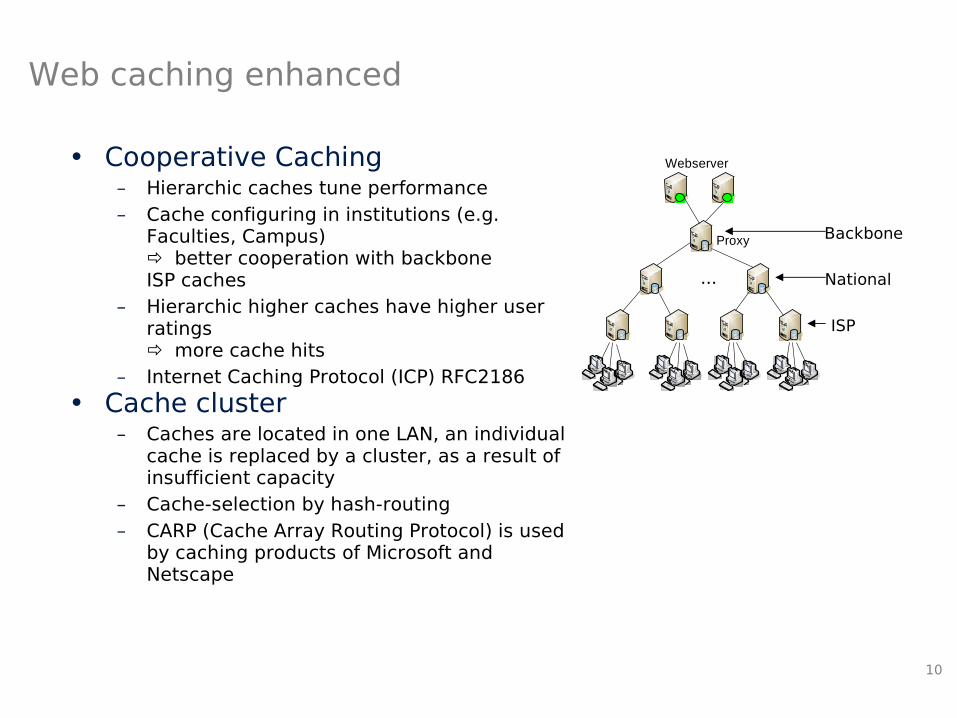
10
Web caching enhanced
• Cooperative Caching– Hierarchic caches tune performance – Cache configuring in institutions (e.g.
Faculties, Campus) better cooperation with backbone ISP caches
– Hierarchic higher caches have higher user ratings more cache hits
– Internet Caching Protocol (ICP) RFC2186
• Cache cluster– Caches are located in one LAN, an individual
cache is replaced by a cluster, as a result of insufficient capacity
– Cache-selection by hash-routing– CARP (Cache Array Routing Protocol) is used
by caching products of Microsoft and Netscape
Webserver
Proxy
...
ISP
National
Backbone

Categories of Content DistributionContent Distribution Networks
12
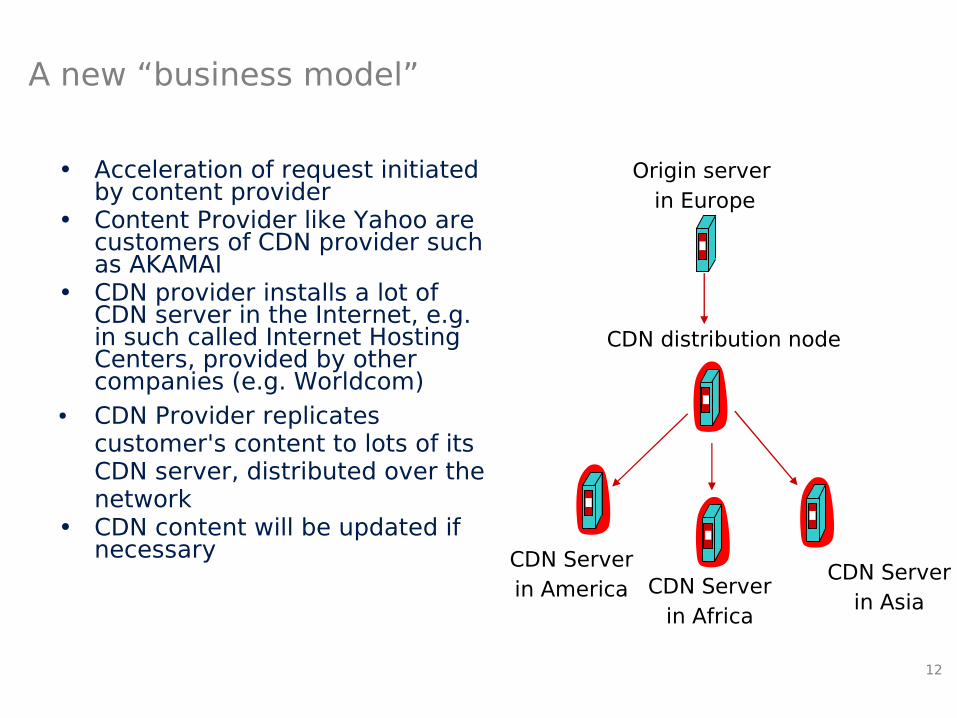
A new “business model”
• Acceleration of request initiated by content provider
• Content Provider like Yahoo are customers of CDN provider such as AKAMAI
• CDN provider installs a lot of CDN server in the Internet, e.g. in such called Internet Hosting Centers, provided by other companies (e.g. Worldcom)
● CDN Provider replicates customer's content to lots of its CDN server, distributed over the network
• CDN content will be updated if necessary
Origin server in Europe
CDN distribution node
CDN Serverin America CDN Server
in Africa
CDN Serverin Asia
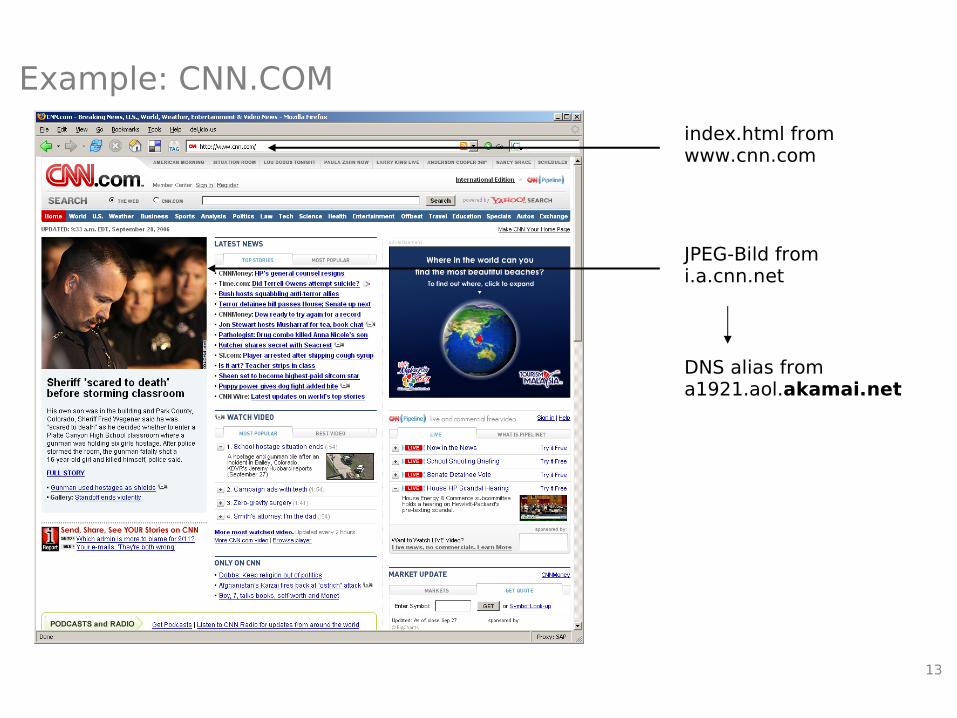
13
Example: CNN.COM
index.html from www.cnn.com
JPEG-Bild from i.a.cnn.net
DNS alias from a1921.aol.akamai.net
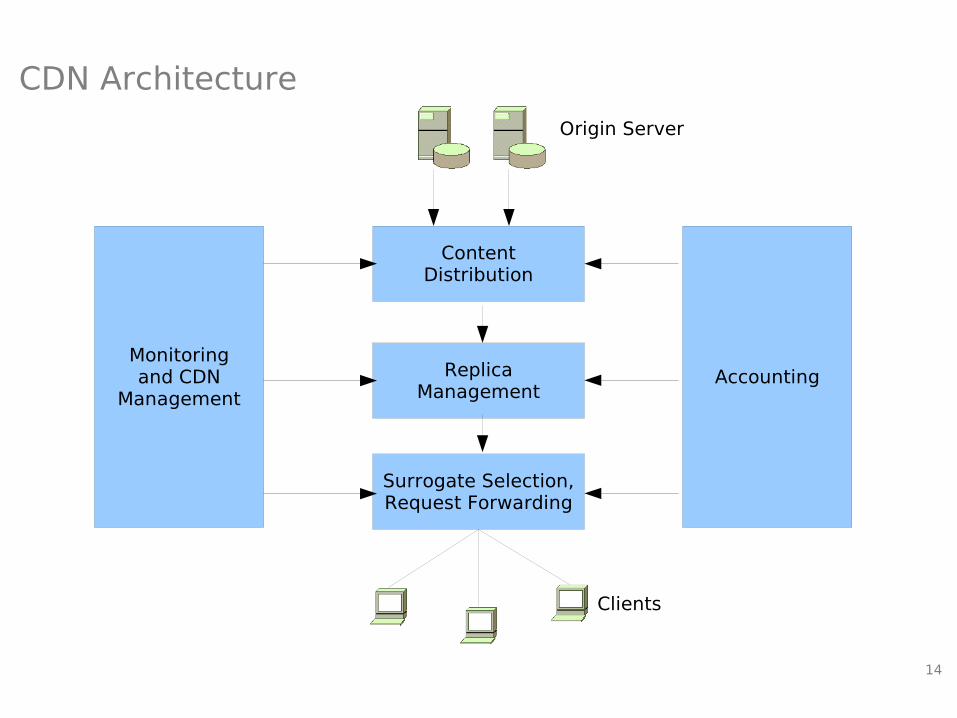
14
CDN Architecture
Monitoringand CDN
ManagementAccounting
ContentDistribution
Surrogate Selection,Request Forwarding
ReplicaManagement
Origin Server
Clients
15
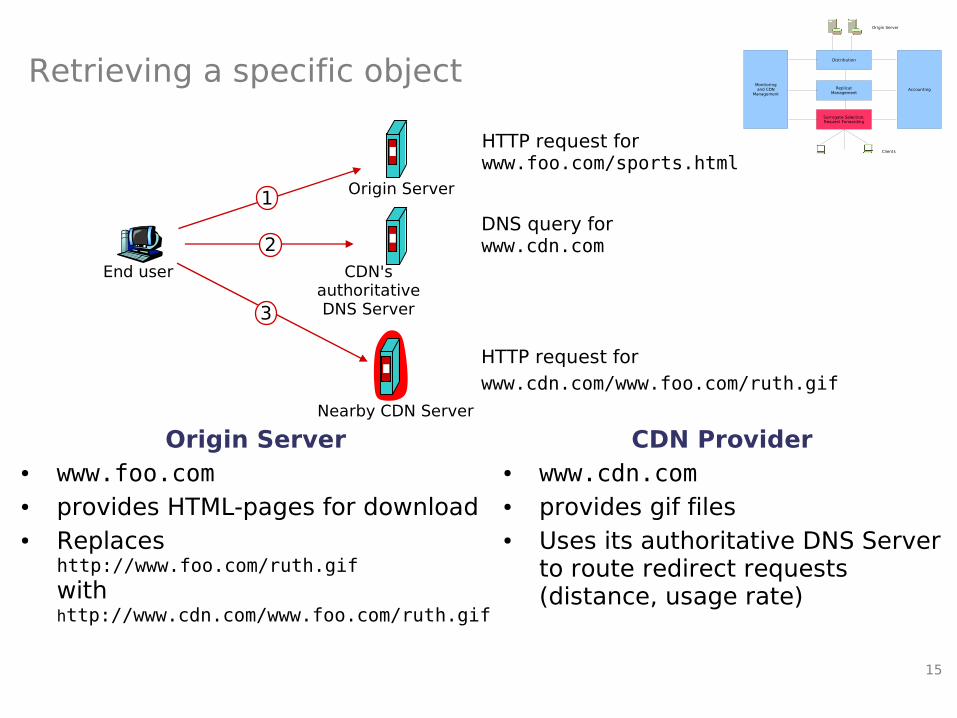
Retrieving a specific object
Origin Server● www.foo.com● provides HTML-pages for download● Replaces
http://www.foo.com/ruth.gifwithhttp://www.cdn.com/www.foo.com/ruth.gif
HTTP request forwww.foo.com/sports.html
DNS query for www.cdn.com
HTTP request for www.cdn.com/www.foo.com/ruth.gif
1
2
3
Origin Server
CDN's authoritativeDNS Server
Nearby CDN Server
CDN Provider● www.cdn.com● provides gif files ● Uses its authoritative DNS Server
to route redirect requests (distance, usage rate)
End user
Monitoringand CDN
ManagementAccounting
Distribution
Surrogate Selection,Request Forwarding
ReplicatManagement
Origin Server
Clients

16
Surrogate Selection
` Request
Set ofSurrogatesWhich Surrogate to choose
for answering the request?
Selection Criterias:• Surrogate load and availability• Round-Trip-Time and packet loss• Distance between client and surrogate
location• Requested service/object (e.g. specialised
surrogates for video streaming)• Overall network performance
Active techniques: Additional activity
(measurement) during each request Scalability problems
Passive techniques: Precalculated surrogate
selection (Routing tables)
Monitoringand CDN
ManagementAccounting
Distribution
Surrogate Selection,Request Forwarding
ReplicatManagement
Origin Server
Clients
17
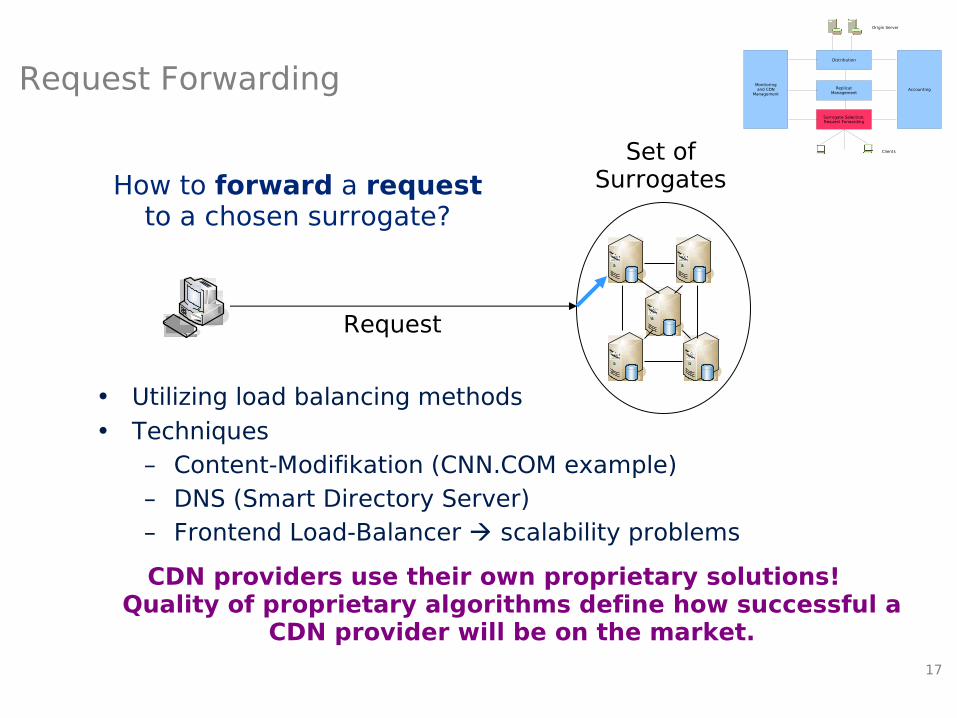
Request Forwarding
Set ofSurrogates
` Request
How to forward a requestto a chosen surrogate?
• Utilizing load balancing methods• Techniques
– Content-Modifikation (CNN.COM example)– DNS (Smart Directory Server)– Frontend Load-Balancer scalability problems
CDN providers use their own proprietary solutions!Quality of proprietary algorithms define how successful a
CDN provider will be on the market.
Monitoringand CDN
ManagementAccounting
Distribution
Surrogate Selection,Request Forwarding
ReplicatManagement
Origin Server
Clients

18
Replica Management Monitoringand CDN
ManagementAccounting
Distribution
Surrogate Selection,Request Forwarding
ReplicatManagement
Origin Server
Clients
• Problem: Where to place a surrogate?
• Criterias:– Maximize quality for all clients– Minimize investments in additional infrastructure
• Strategies:– Equally balanced load on surrogates– Direct connections to as many ISP networks as possible– Analysis of access statistics
19
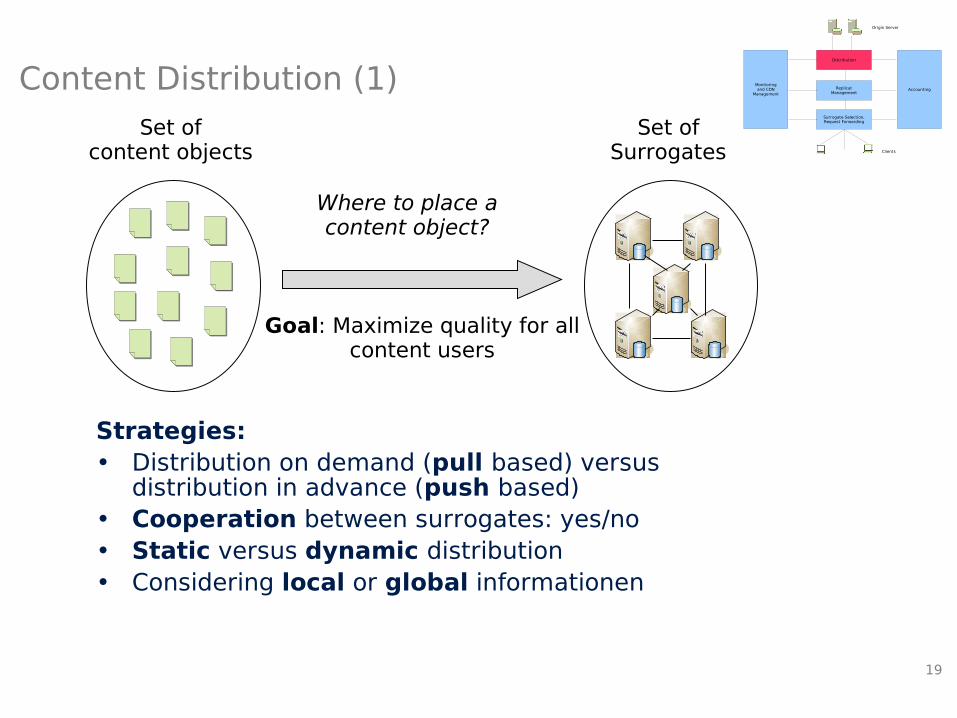
Content Distribution (1) Monitoringand CDN
ManagementAccounting
Distribution
Surrogate Selection,Request Forwarding
ReplicatManagement
Origin Server
Clients
Set ofSurrogates
Where to place acontent object?
Set ofcontent objects
Goal: Maximize quality for all content users
Strategies:• Distribution on demand (pull based) versus
distribution in advance (push based)• Cooperation between surrogates: yes/no• Static versus dynamic distribution• Considering local or global informationen

20
Content Distribution (2)
• Problem:– How to realize data consistency and data exchange
between surrogates?
• Data Consistency– Periodical Synchronization:
small time slot for inconsistencies– Change notifications:
very small time slot for inconsistencies
• Data Exchange– Unidirectional: TCP connections or specialized optimizations
(separate networks, parallel TCP connections)– Multicast: on network or application layer (overlay)– Broadcast: e.g. utilizing satellite transmissions
Monitoringand CDN
ManagementAccounting
Distribution
Surrogate Selection,Request Forwarding
ReplicatManagement
Origin Server
Clients

21
Summarizing Web Caching and CDN
Solved problems so far:• User's point of view
– Improved response delays (physical delay)– TV like quality – high fidelity (End-to-end bandwidth & packet loss)
• Content provider's point of view– Economic scaling of providing service
• Instead using big server farms for distribution of information and replication the whole network is used
• Avoiding of connection bottlenecks in local networks– Better quality for users
Both approaches still follow the traditionalclient-server paradigm!

Categories of Content DistributionP2P Networks
23
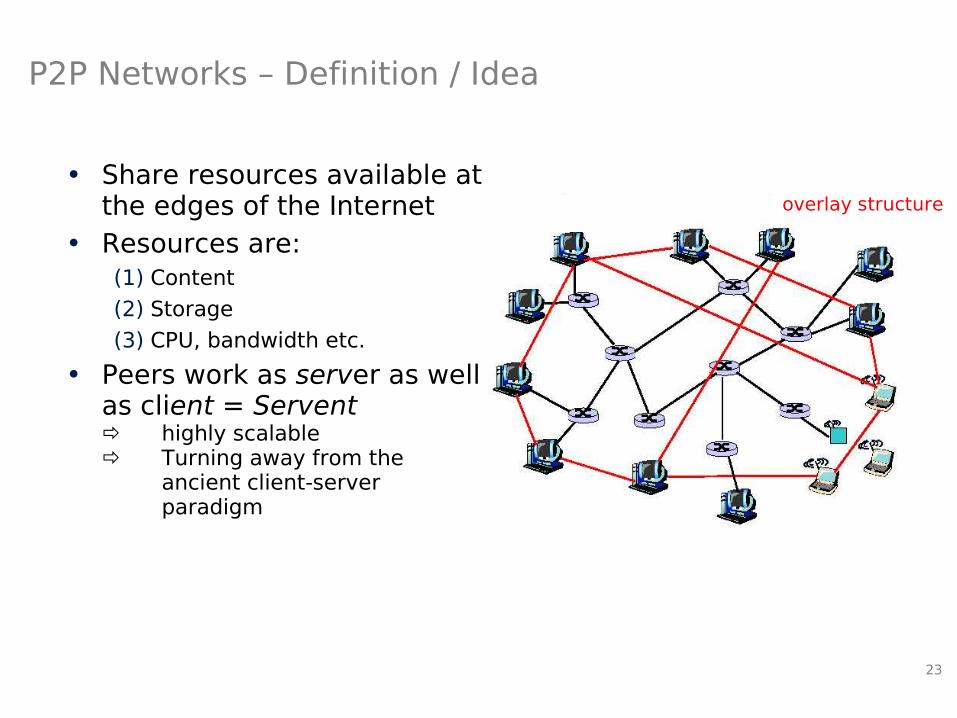
P2P Networks – Definition / Idea
• Share resources available at the edges of the Internet
• Resources are:(1) Content
(2) Storage
(3) CPU, bandwidth etc.
• Peers work as server as well as client = Servent highly scalable Turning away from the
ancient client-serverparadigm
overlay structure

24
Comparing P2P with conventional networks
Conventional Networks• Rely on specific infrastructure
offering transport services
• Centralized approach:content is stored and provided by some central server(s)
• Static network structure
P2P Networks• Form overlay structures focusing on
content allocation and distribution
• Highly decentralized approach:locate desired content at some participating peer whose address is provided to the searching peer
• P2P networks are subject to frequent changes (peers leaving/arriving)
We are focussing on technical aspects while neglecting the legal aspects of P2P networks.
25
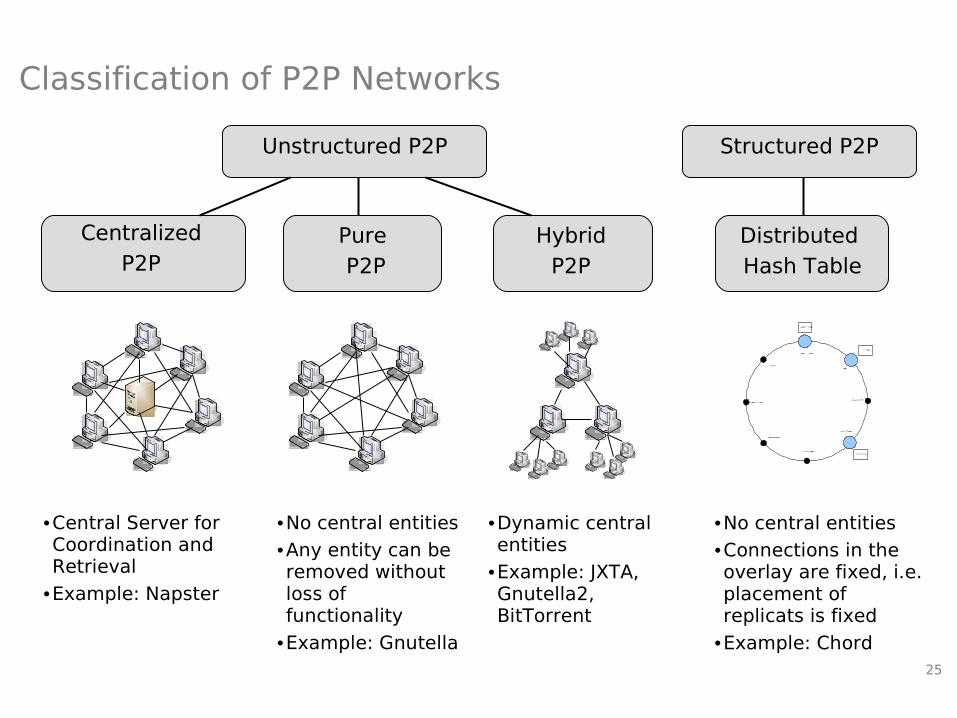
Classification of P2P Networks
Unstructured P2P Structured P2P
CentralizedP2P
Pure P2P
HybridP2P
`
`
`
`
`
`
`
`
`
`
`
`
Distributed Hash Table
`
` `
`
`
`
`
`
`
`
`
`
•Central Server for Coordination and Retrieval
•Example: Napster
•No central entities
•Any entity can be removed without loss of functionality
•Example: Gnutella
•Dynamic central entities
•Example: JXTA, Gnutella2, BitTorrent
•No central entities
•Connections in the overlay are fixed, i.e. placement of replicats is fixed
•Example: Chord
26
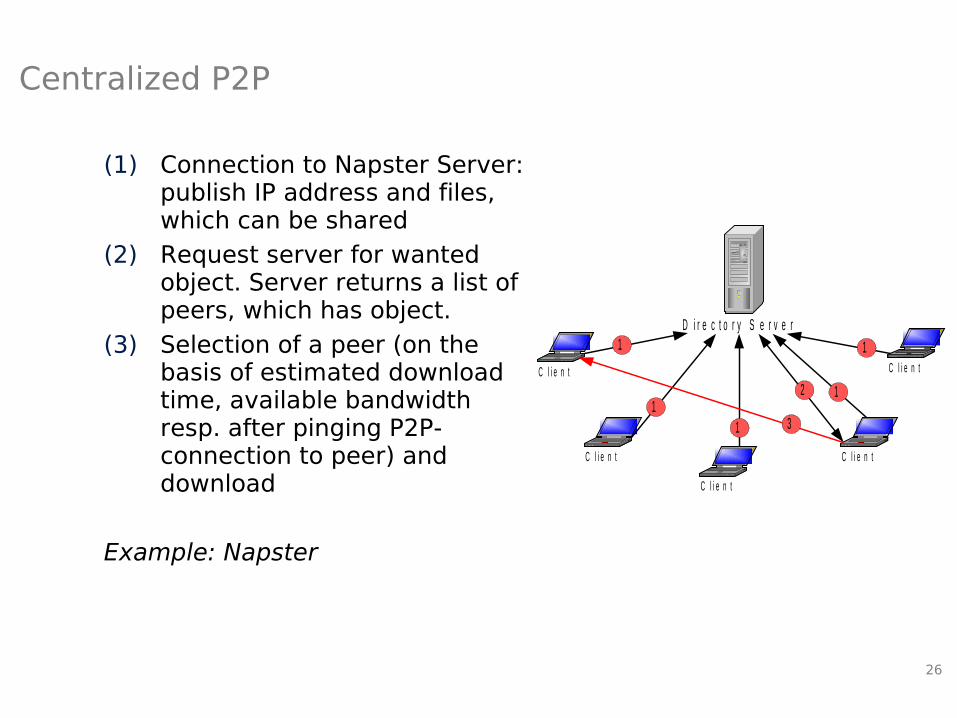
Centralized P2P
(1) Connection to Napster Server: publish IP address and files, which can be shared
(2) Request server for wanted object. Server returns a list of peers, which has object.
(3) Selection of a peer (on the basis of estimated download time, available bandwidth resp. after pinging P2P-connection to peer) and download
Example: Napster
D i r e c t o r y S e r v e r
C l i e n t C l i e n t
C l i e n t
C l i e n tC l i e n t
1
11
1
1
3
2

27
Problems of a Central Directory
• Single-Point-of-FailureIf the central directory server crashes, the entire P2P application crashes.
• Performance BottleneckIn large P2P systems with hundreds of thousands connected users, the central directory server has to cope huge amounts of data and thousands of queries per second.
• Copyright infringement and free speechLegal proceedings or censorship may result in shutting down the central directory server, thus deactivating the P2P network.
The salient drawback of using a centralized directory server is that the P2P application is only partially
decentralized.Traffic decentralized, management still
centralized

28
Decentralized or Pure P2P
• No central entities at all• Content-location directory distributed over the peers
themselves• Advantages:
– No single-point-of-failure– No performance bottleneck– No censorship possible
Examples: Gnutella, Freenet
29
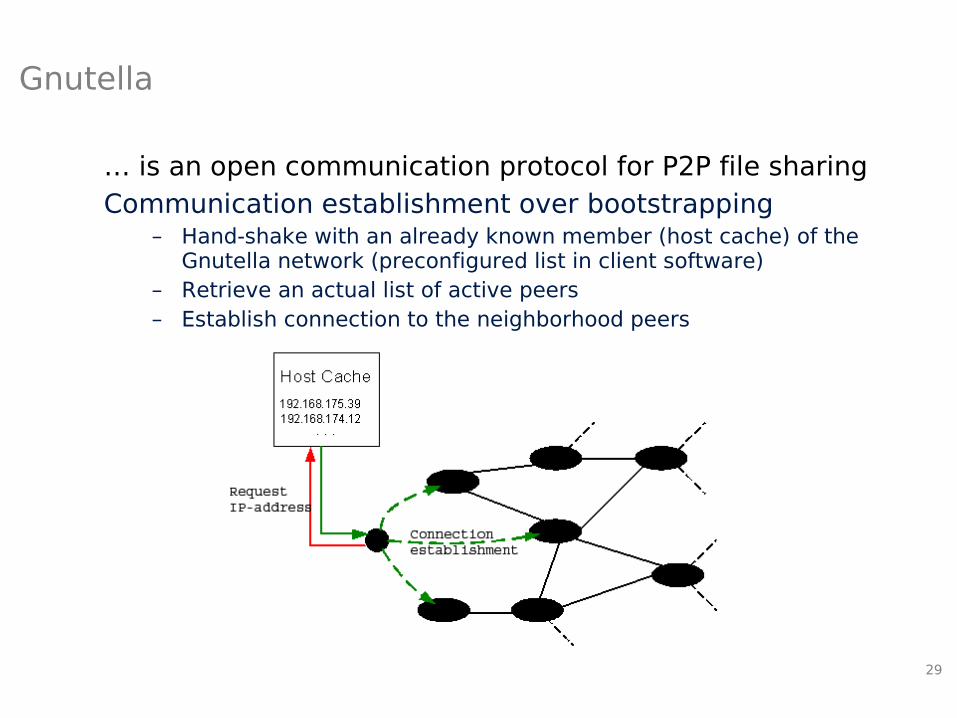
Gnutella
… is an open communication protocol for P2P file sharingCommunication establishment over bootstrapping
– Hand-shake with an already known member (host cache) of the Gnutella network (preconfigured list in client software)
– Retrieve an actual list of active peers– Establish connection to the neighborhood peers

30
Query Flooding
Discovering new peers in Gnutella• Send a broadcast ping
• Active peers answer with a pong
Locating specific content in Gnutella• Iterative search
• Send a Query msg to all neighboursIF neighbour N1 owns content THEN answer with QueryHit msg ELSE pass on Query msg to next peers
• Query msg contain TTL (max. 10 hops)
• Swarm download if more than one peer owns the requested content

31
The Problem with Query Flooding
Big overhead, few results Scalability
Kelsey Anderson: Analysis of the Traffic on the Gnutella Network. University of California, San Diego, CSE222 Final Project, March 2001

32
Hybrid P2P
Challenge: How to combine– Efficiency of centralized approach with– Robustness of decentralized approach
Solution: • Transparent separation between
– Super Nodes (SN)• build a “high-speed backbone” for the P2P network• Earn or loose their privileges due to their system ressources• Keep track of all content offered by related ordinary nodes
– Ordinary Nodes (ON)
• Content Hash = Improved identifier for content– Seamless retrieval from different peers
Intelligent two-tier architecture enhances routing performance and scalability
Examples: FastTrack, KaZaA
33
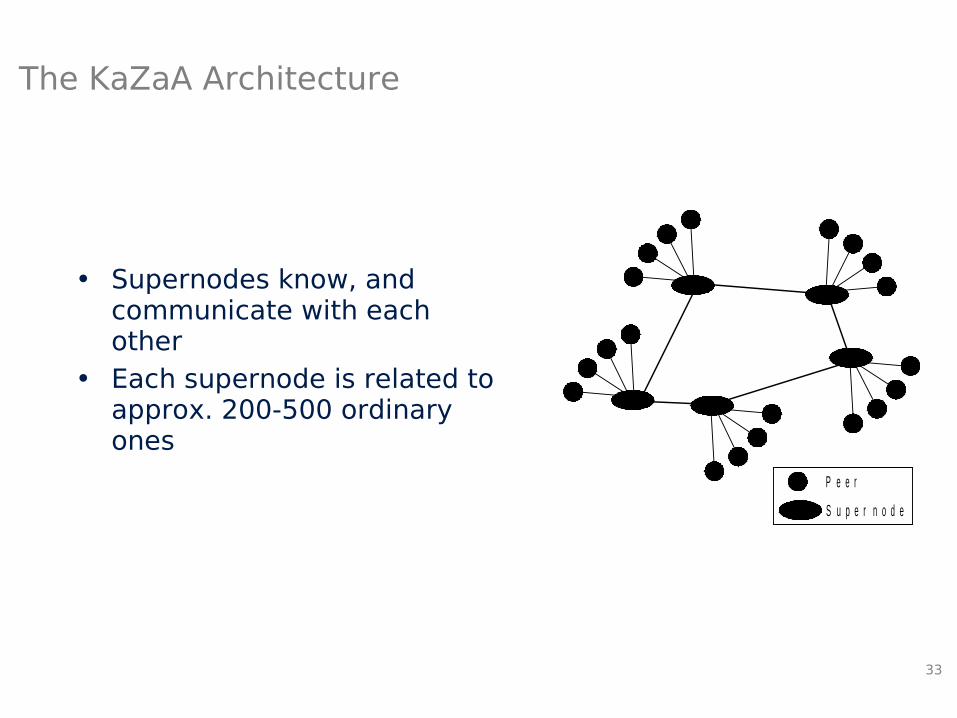
The KaZaA Architecture
• Supernodes know, and communicate with each other
• Each supernode is related to approx. 200-500 ordinary ones
P e e r
S u p e r n o d e

34
Managing the KaZaA Overlay Network
Joining the P2P network• User gets list of super nodes when downloading the software• Searching the list for operating super node, connection
establishment• Receiving an actual list of super nodes, ping to 5 of this nodes,
choose super node with lowest RTT as superior node• When super nodes leaves, peer gets new list and chooses new one
Locating and retrieving specific content• Peer sends search request to super node
– Returns list of results– else send up request to neighbouring super nodes
• Each query is only directed to a subset of all super nodes• Parallel downloads are possible due to unambiguous content
hashes
35
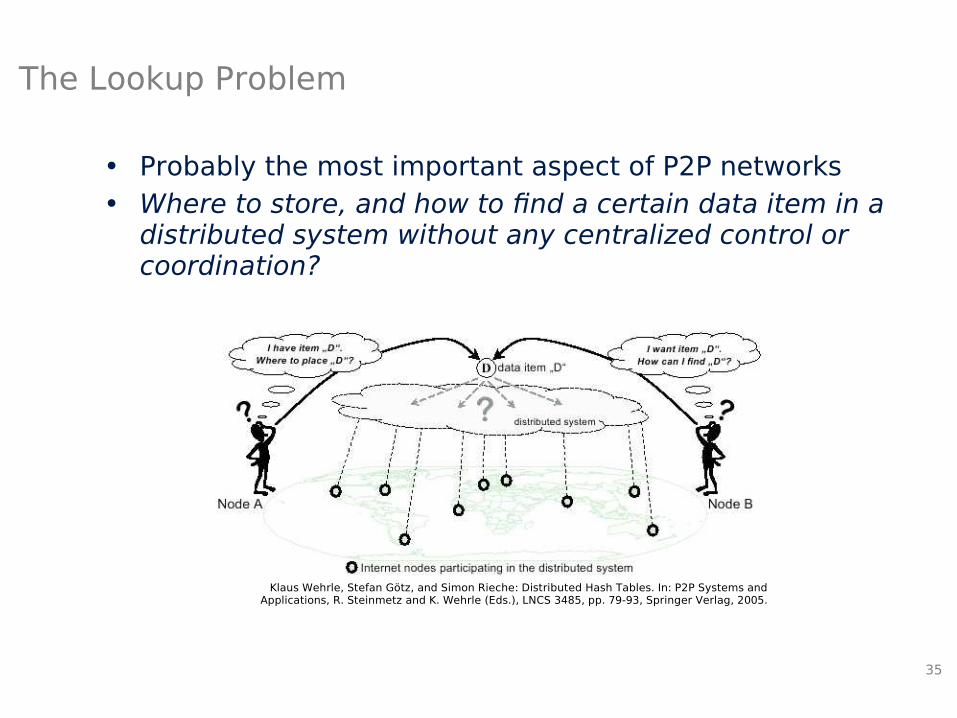
The Lookup Problem
• Probably the most important aspect of P2P networks• Where to store, and how to find a certain data item in a
distributed system without any centralized control or coordination?
Klaus Wehrle, Stefan Götz, and Simon Rieche: Distributed Hash Tables. In: P2P Systems and Applications, R. Steinmetz and K. Wehrle (Eds.), LNCS 3485, pp. 79-93, Springer Verlag, 2005.

36
Structured P2P – The Academic Approach
• In unstructured P2P networks– Content is duplicated randomly on peering nodes – Centralized approach: Relocation of content easy but does not scale well– Fully decentralized approach: Relocation of content easy but wasteful– There is no guarantee for a result when searching since the lifetime of
request messages is restricted to a limited number of hops Central servers suffer from a linear complexity for storage Flooding-based require costly breadth-first search which leads to scalability
problems in terms of communication overhead
• In structured P2P networks– Content location follows specific patterns no flooding needed– Distributed Hash Tables (DHT) = central mechanism for indexing and
searching content– Afford guaranties when searching for an object
• Examples:– Chord, Pastry, Kademlia (part of BitTorrent and eMule)– mainly differ in routing
37
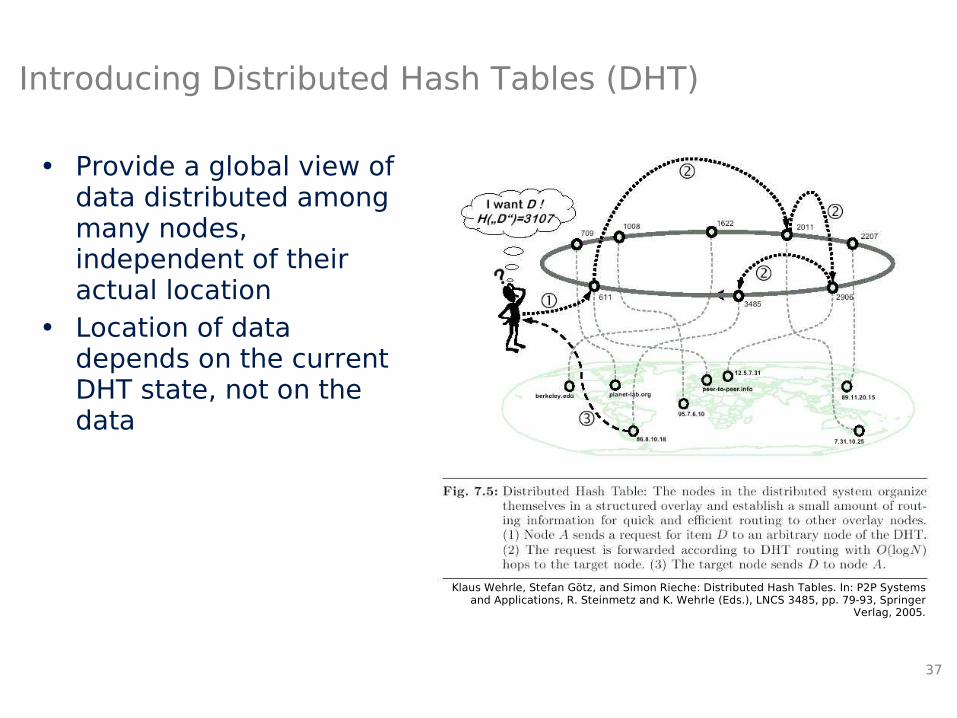
Introducing Distributed Hash Tables (DHT)
• Provide a global view of data distributed among many nodes, independent of their actual location
• Location of data depends on the current DHT state, not on the data
Klaus Wehrle, Stefan Götz, and Simon Rieche: Distributed Hash Tables. In: P2P Systems and Applications, R. Steinmetz and K. Wehrle (Eds.), LNCS 3485, pp. 79-93, Springer
Verlag, 2005.

38
Characteristics of Distributed Hash Tables
• Each DHT node manages a small number (O(log N), with N=number of nodes) of references to other nodes.
• Mapping nodes and data items into common address spaceNode-ID=DHT(Node name) and Key=DHT(Data name), respectively
• Queries are routed via a small number of nodes to the target node Data items can be located by routing via O(log N) hops
• Initial node of a lookup request may be any node of the DHT
• Equally distributing identifiers of nodes and data items Load for retrieving items should be balanced equally among all nodes
• No node plays a distinct role within the system No hot spots or bottlenecks Departure or elimination of a node has no impact on functionality Robustness against random failures and attacks
• A distributed index provides a definitive answer about results. If a data item is stored in the system, the DHT guarantees that the data is found.

39
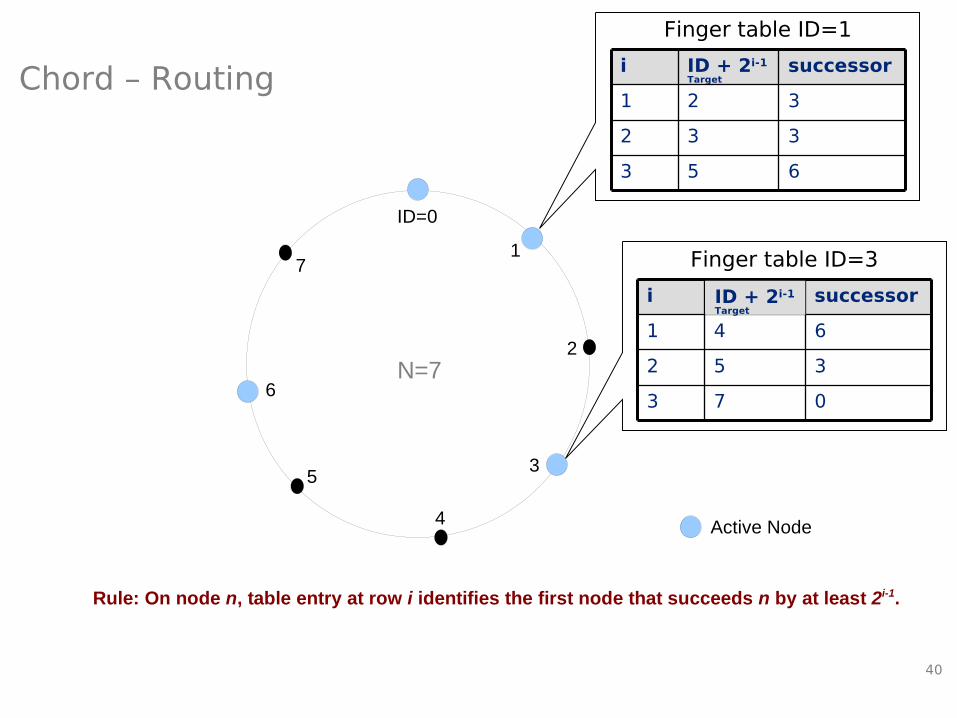
The Chord Protocol
• Routing (for N peer nodes):– Each peer stores information about O(log
2(N)) other peers
– Finger table of peer n:Entry at row i points to the first peer ss whose ID is at least 2i-1
larger than n: s = successor (n+2i-1)
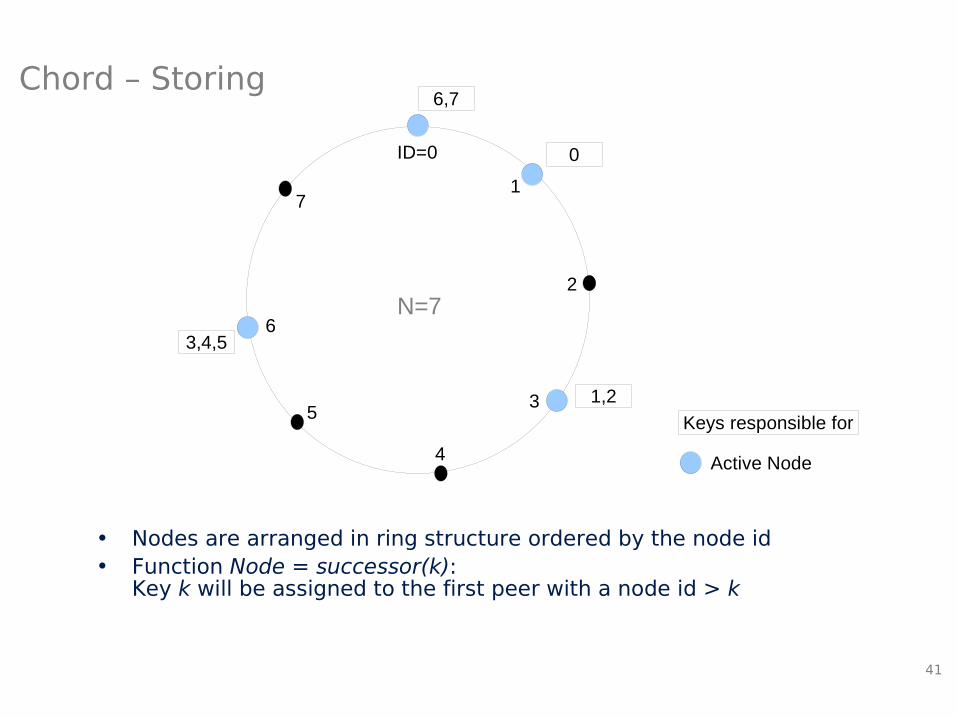
• Storing:– Data item key hosted by node with ID ≥ key– Node is responsible for all keys that precede its ID
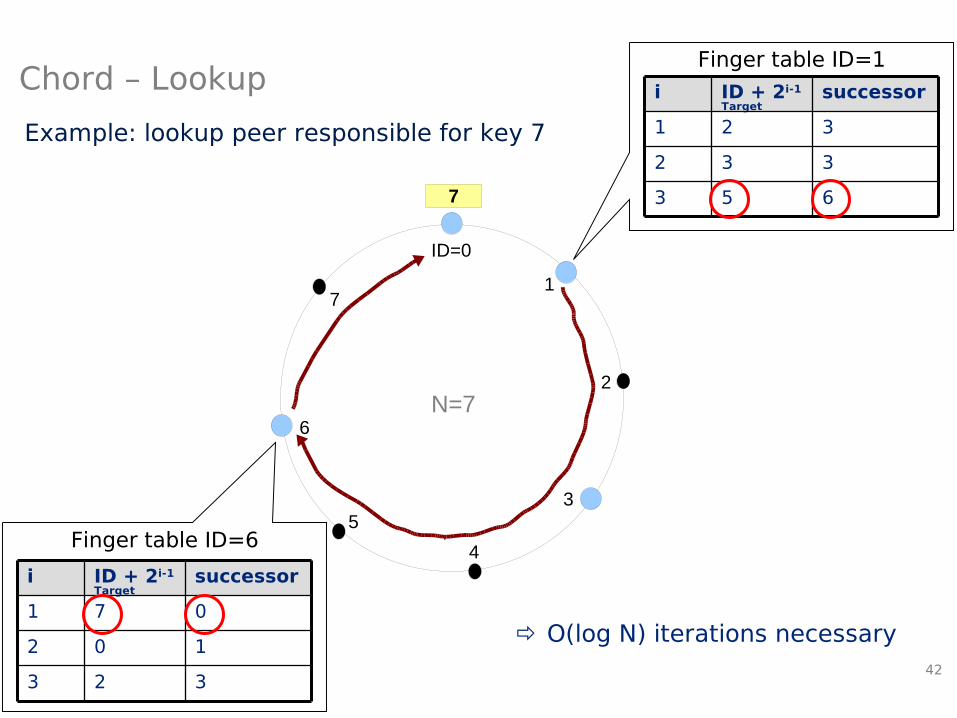
• Lookup:– Iterative: search next peer in finger table with Node-ID ≤ Key and
ask for successor(key) -> closest predecessor– Terminate, when successor(key) found
– O(log2N) iterations necessary
40
Chord – Routing
Active Node
ID=0
1
2
3
4
5
6
7
N=7
653
332
321
successorID + 2i-1
Targeti
Finger table ID=1
073
352
641
successori ID + 2i-1
Target
Finger table ID=3
Rule: On node n, table entry at row i identifies the first node that succeeds n by at least 2i-1.
41
Chord – Storing
Active Node
ID=0
1
2
3
4
5
6
7
N=7
• Nodes are arranged in ring structure ordered by the node id• Function Node = successor(k):
Key k will be assigned to the first peer with a node id > k
6,7
Keys responsible for
0
1,2
3,4,5
42
Chord – Lookup
ID=0
1
2
3
4
5
6
7
N=7
Example: lookup peer responsible for key 7
7 653
332
321
successorID + 2i-1
Targeti
Finger table ID=1
323
102
071
successorID + 2i-1
Targeti
Finger table ID=6
O(log N) iterations necessary
43
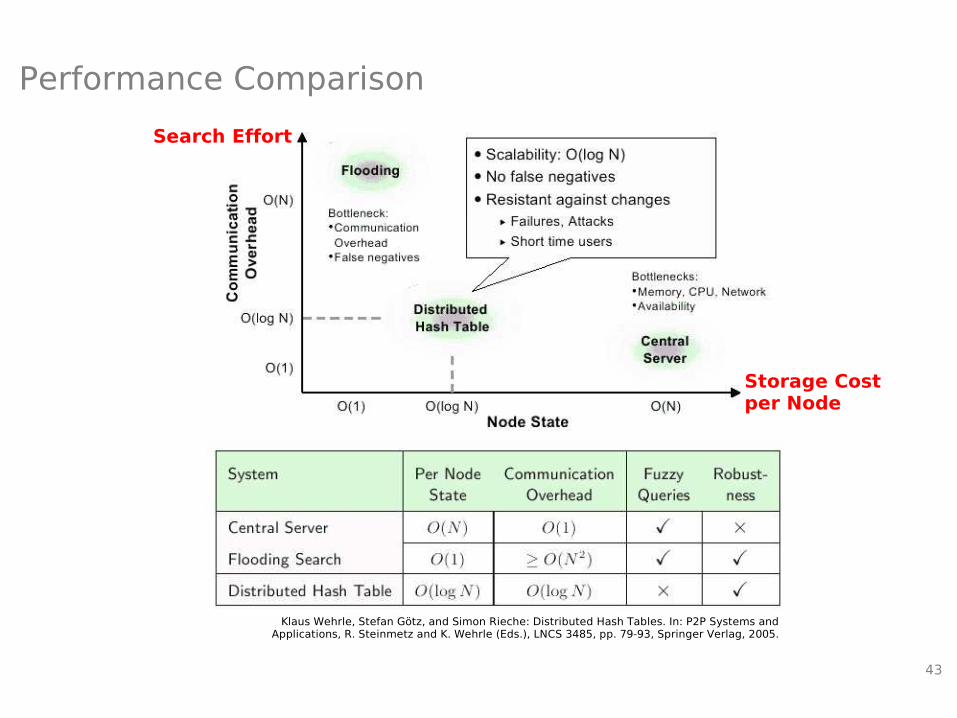
Performance Comparison
Klaus Wehrle, Stefan Götz, and Simon Rieche: Distributed Hash Tables. In: P2P Systems and Applications, R. Steinmetz and K. Wehrle (Eds.), LNCS 3485, pp. 79-93, Springer Verlag, 2005.
Search Effort
Storage Costper Node

44
Conclusion
• Motivation: Enhance service quality for content users
• Web Caching– Widely used in the Internet– Mainly locally used: User, ISP, Content Provider– Does not solve the flash crowd problem
• Content Distribution Networks– Global infrastructure for content distribution– Successful business model: AKAMAI
• P2P Networks– No infrastructure investments necessary– Widely used in the Internet, significant part of network traffic– Several techniques depending on the specific use case
Next lecture:Multimedia Applications, VoIP

















![Thomas Groß arXiv:2011.11749v1 [cs.HC] 23 Nov 2020](https://img.pdfslide.us/doc/110x75/61e1074e7b88b63e0630ab61/thomas-gro-arxiv201111749v1-cshc-23-nov-2020.jpg)











