Embed Size (px)
Citation preview

Deep Learning for Natural Language Processing
(in 2 hours)
Eneko Agirrehttp://ixa2.si.ehu.eus/eneko
IXA NLP grouphttp://ixa.eus
@eagirre

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 2
Contents
● Introduction to Deep learning– Deep Learning ~ Learning Representations
● Text as bag of words
● Text as a sequence

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 4
Quiz
● How many of you have done– A course on linguistics– A course on computational linguistics (aka NLP)– A course on machine learning– A course on deep learning

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 5
Introduction to Deep Learning

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 6
What is deep learning
A subfield of machine learning● Supervised ML, given a dataset of
examples x with labels y
● Learn a function f(x)→y with low training error and low test error
Key manual step: design features to extract key information from x (representation)
● e.g. weather forecast (wind, temperature, humidity, pressure, precipitations … – local and nearby locations)
● e.g. sentiment of tweet (keywords like “good” “bad”, certain emojis, ...)
Source: staesthetic.wordpress.com

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 7
What is deep learning
Source: Chris Manning cs224n
x f(x)=y
Source: www.vaetas.cz
Deep? Multiple levels
Deep learning jointly learns representation and output

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 11
ImageNet Classification withDeep Convolutional Neural Networks(Krizhevsky et al. 2012)
Learning hierarchical representations for face verification with convolutional deep belief networks (Huang et al. 2012)

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 17
Brief history of NLP
● 1960s: Complex rules and first order logic. Humans build complex grammars.
● 1990s: Supervised machine learning. Humans annotate text, design laborious task-specific features, and apply ML techniques.
● 2010s: Deep learning. Learning continuous representations, get rid of task-specific features.

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 18
Why deep learning for NLP?● Technology behind current
speech processing and machine translation– Advances in the state-of-the-art on most tasks
● Focus on representation learning– Learns representations for words and word sequences fitted to the task
… including world and visual knowledge.– Naturally accounts for graded judgments about language
● Word similarity: building / house● Sentence similarity:
A pony is close to the house / There is a horse in the front yard
● End-to-end joint learning (vs. pipeline)● Transfer models accross tasks
(word embeddings, sentence encoders)

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 19
Contents
● Introduction to Deep learning– Deep Learning ~ Learning Representations
● Text as bag of words– Text Classification– Representation learning and word embeddings – Superhuman: cross-lingual word embeddings
● Text as a sequence

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 20
Classification
● Input– A document d D ∈ D – A fixed set of classes C={c1, c2, … cj}
● Output: a predicted class y C∈ D

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 23
Classification
Supervised machine learning
Learn a classifier from hand-annotated examples:● Input: A training set of n hand-labeled
documents (x1,y1) … (xm, ym)
● Output: A learned classifier f:D→C

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 24
Text Classification
● Most NLP tasks can be framed as text classification– PoS tagging, parsing, QA, MT ...
● Simple example to showcase key methods– Sentiment analysis (polarity)
– Positive or negative movie review● Full of zany characters and richly applied satire● It was pathetic● Modestly accomplished, lifted by two terrific performances.● Not NEARLY as funny as its title

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 25
Documents as Documents as feature vectors feature vectors (bag of words)(bag of words)

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 26
Feature vectors
Representation of each example (document)● Key idea for most machine learning● Example as a vector of features x
– All examples same number of features– Features: boolean, integer, real
● Pre-processing code to convert from example into feature vector– Substantial effort (e.g. tokenization)

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 27
Bag of words
Representation of each example (document)
⇒ Bag of words representation
Source: Sam Bowman

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 30
Bag of words
Classifier:● Input: vector of |V| binary features
Simple sentiment analysis: words in document 1● Output of the classifier: discrete
Simple sentiment analysis: two classes
f( ) = cit 1the 0and 0by 0...terrific 1pathetic 0funny 0...
Positive!

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 31
Classification:Classification: Softmax Softmax
(Logistic Regression) (Logistic Regression)

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 35
Softmax classification● Given: vectors of weights wc for class c
(e.g. terrific for positive class high weight)
– For each class compute wc x + b
– Add non-linearity fc = exp(wc x + b) – Normalize it to estimate probabilities:
p(y=c|x) ≈ fc / ∑c’ C∈ D fc’
● That is the softmax function:
softmax (wc x)=exp(wc x)
∑c '∈C
exp(wc ' x)

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 36
Softmax classification
● Given: vectors of weights wc for class c ’
● Output value y = argmaxc softmax(wc x)
● Task for the training algorithm: – Given labeled examples
– Find wc vectors such that the output value is not wrong for as many training examples as possible

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 38
Softmax classification
Estimating weights (parameters)● Choose parameter which
minimize error over training data
Loss function J (aka cost f. or objective f.)
Cross-entropy error on one example (xi,yi)
– We want to maximize probability of correct classi.e. minimize negative log probability of the correct class
J i(W )=−logP( yi=c∣xi)=−log(exp(W c x)
∑c '∈C
exp(W c ' x) )

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 39
Softmax classification
Estimating parameters ● Search for parameters which
minimize error over training data● Back-propagation
Stochastic gradient descent– Start with random parameters– Select K examples (mini-batch) at random– Change parameters a little bit towards minimum of loss function
for those K (derivatives!)– Continue until loss function converges (or increases)
Source: staesthetic.wordpress.com

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 41
Softmax classification
● An input layer – the feature vector
● An output layer – class probabilities
Train, given labeled data (x1,y1) … (xm, ym)
● For each example (xi,yi): – Forward: input xi, obtain predicted class ci
– If ci ≠ yi then backward: adjust parameters

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 42
Softmax classification
Source: http://cs.stanford.edu/people/karpathy/convnetjs/demo/classify2d.html
Intuition: ● Assume 2D vectors● W defines the linear
decision boundary

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 43
Going deep: Multilayer perceptron
● An input layer – just a feature vector
● One or more hidden layers, each computed on the layer below – latent features (representations)
● An output layer, based on the top hidden layer – class probabilities
● Also known as Feed Forward

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 44
Going deep: Multilayer perceptronSoftmax classification
y=softmax (W x+b)y
x W

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 45
Going deep: Multilayer perceptron
y=softmax (W 2h1+b2)
h1=f (W 1h0+b1)
h0=f (W 0 x+b0)
y
x
h1
h0
W 2
W 1
W 0

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 46
Going deep: Multilayer perceptronLayers have the same structure
Non-linear functions!
hi=f (W ihi−1+bi)
Sigmoid : σ(x)=1
1+exp(−x)
Hyperbolic : tanh (x)=1−exp(−2 x)1+exp(−2 x)
Rectified linear unit : rect (x)=max (0, x)

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 47
Going deep: Multilayer perceptronMotivation
Without non-linearities, there is no extra expresivity: a sequence of linear transformations is a linear transformation
How do we train it?
Source: http://cs.stanford.edu/people/karpathy/convnetjs/demo/classify2d.html

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 48
What about representation learning?
● Document as bag-of-words:– Each word ~ a one-hot-vector
(0 0 0 0 0 … 1 … 0 0 0)– Each document ~ summation of
words in the document(0 0 0 1 0 … 1 … 1 0 0)
● NLP has been representing words as distinct features for many years!– Is there a better alternative? Source: Sam Bowman

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 49
Representation learning
y=softmax (W 2h1+b2)
h1=f (W 1h0+b1)
h0=f (W 0 x+b0)
1
0
0
0
W 0x
(one-hot)
h0
→h0
MLP: What are we learning in W0 when we backpropagate?
W 0

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 50
Representation learning
1
0
0
0
W 0x
(one-hot)
→y=softmax (W 2h1+b2)
h1=f (W 1h0+b1)
h0=f (W 0 x+b0)
h0W 0
MLP: What are we learning in W0 when we backpropagate?

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 51
Representation learning
Back-propagation allows Neural Networks to learn representations for words while training: word embeddings!
1
0
0
0
W 0x
(one-hot)
→y=softmax (W 2h1+b2)
h1=f (W 1h0+b1)
h0=f (W 0 x+b0)
h0W 0

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 52
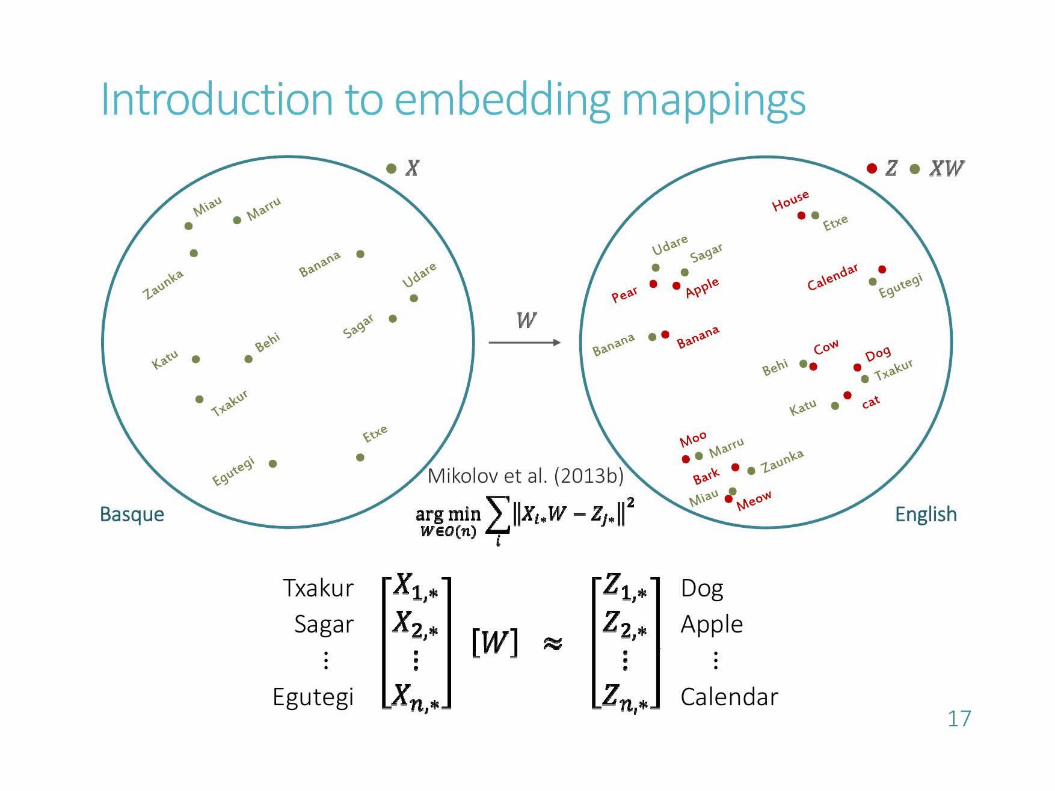
Representation learning
● Back-propagation allows Neural Networks to learn representations for words while training!– Word embeddings!
Continuous vector space instead of one-hot● Are these word embeddings useful?● Which task would be the best to learn embeddings
that can be used in other tasks?● Can we transfer this representation
from one task to the other?● Can we have all languages in one embedding space?

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 53
Representation learning Representation learning and and
word embeddings word embeddings

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 54
Word embeddings● Let’s represent words as vectors:
Similar words should have vectors which are close to each other
● If an AI has seen these two sequences
I live in CambridgeI live in Paris
● … then which one should be more plausible?
I live in TallinnI live in policeman
Cambridge
London
Tallinn
Paris
policeman
judge driver cop
WHY?

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 55
Word embeddings● Let’s represent words as vectors:
Similar words should have vectors which are close to each other
● If an AI has seen these two sequences
I live in CambridgeI live in Paris
● … then which one should be more plausible?
I live in Tallinn OKI live in policeman
Cambridge
London
Tallinn
Paris
policeman
judge driver cop
WHY?

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 59
Word embeddings
Option 1: use co-occurrence matrix PPMI ● 1A: large sparse matrix● 1B: factorize it and use low-
rank dense matrix (SVD)
●
CambridgeLondon
Tallinn
Paris
policemanjudge driver cop
Option 2: learn low-rank dense matrix directly ● 2A: MLP on particular
classification task ● 2B: find a general task
Distributional vector spaces:

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 60
Word embeddings CambridgeLondon
Tallinn
Paris
policemanjudge driver cop
… people who keep pet dogs or cats exhibit better mental and physical health …
General task with large quantities of data: guess the missing word (language models)
CBOW: given context guess middle word
SKIP-GRAM given middle word guess context
Proposed by Mikolov et al. (2013) - Word2vec
… people who keep pet dogs or cats exhibit better mental and physical health …

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 62
CBOW
Like MLP, one layer, LARGE vocabulary
… people who keep pet dogs or cats exhibit better mental and physical health …
Cross-entropy loss / Softmax expensive! Negative sampling:
JNEGw (t )=log σ(h0 i)−∑k=1
K
Ewn∼Pnoiselog σ(hon)
Source: Mikolov et al. 2013
LARGE number of classes! The vocabulary

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 63
Word embeddings
Pre-trained word embeddings can leverage texts with BILLIONS of words!!
Pre-trained word embeddings useful for: ● Word similarity● Word analogy● Other tasks like PoS tagging, NERC,
sentiment analysis, etc.● Initialize embedding layer in deep learning models
CambridgeLondon
Tallinn
Paris
policemanjudge driver cop

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 64
Word embeddings
Word similarity
CambridgeLondon
Tallinn
Paris
policemanjudge driver cop
Source: Collobert et al. 2011

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 65
Word embeddings
Word analogy:
a is to b as c is to ?
man is to king as woman is to ?
policeman
CambridgeLondon
Tallinn
Paris
judge driver cop
king
man
woman
?

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 66
Word embeddings
Word analogy:
a is to b as c is to ?
man is to king as woman is to ?
policeman
CambridgeLondon
Tallinn
Paris
judge driver cop
a−b≈c−dd≈c−a+b
king−man+woman≈queen
argmaxd∈V (cos(d , c−a+b))
king
man
womanqueen

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 68
Word embeddings
● How to use embeddings in a given task(e.g. MLP sentiment analysis):– Learn them from scratch (random init.) – Initialize using pre-trained embeddings
from some other task (e.g. word2vec)● Other embeddings:
– GloVe (Pennington et al. 2014) – Fastext (Mikolov et al. 2017)

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 70
Recap
● Deep learning: learn representations for words● Are they useful for anything?● Which task would be the best to learn
embeddings that can be used in other tasks?● Can we transfer this representation
from one task to the other?● Can we have all languages in one embedding
space?

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 71
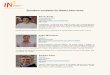
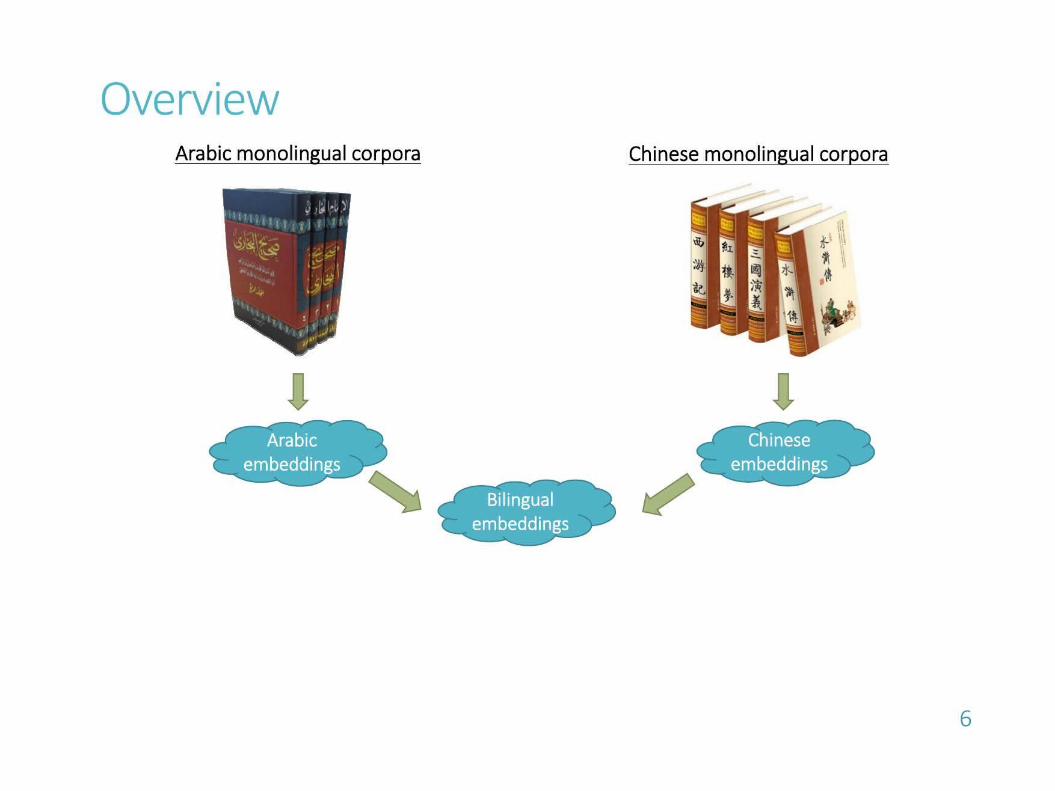
Superhuman abilities: Superhuman abilities: cross-lingual word cross-lingual word
embeddingsembeddings
http://aclweb.org/anthology/P18-1073http://aclweb.org/anthology/P18-1073














































DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 120
Contents
● Introduction to NLP– Deep Learning ~ Learning Representations
● Text as bag of words– Text Classification– Representation learning and word embeddings – Superhuman: xlingual word embeddings
● Text as a sequence: RNN– Sentence encoders– Machine Translation– Superhuman: unsupervised MT

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 121
From words to sequences● Representation for words:
one vector for each word (word embeddings)● Representation for sequences of words:
one vector for each sequence (?!) – Is it possible to represent a sentence in one
vector at all?– Let’s go back to MLP

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 122
From words to sequences
MLP: What is h0 with respect to the words in the input ?
● Add vectors of words in context (1’s in x), plus bias, apply non-linearity
h0 sentence representation
f (∑ w i+b0)

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 123
Sentence encoder
A function:input a sequence of word embeddings output a sentence representation
hidden layers
sentence representation
wi∈ℝD
w1 w2 w3
s∈ℝD'
s
sentence encoder
word embeddings

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 124
Sentence encoder
Baseline: Continuous bag of words (pre-trained embeddings)
sentence representation
w1 w2 w3
s
word embeddings
Σ
h1=f (W 1h0+b1)
h0=s

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 125
Sentence encoder
Baseline: MLP (with or without pre-trained embeddings)Encoding sequences as continous bag of words
sentence representation
f (∑ w i+b0)
s
w1 w2 w3
h1=f (W 1h0+b1)
h0=s

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 126
Problems with bag of words
● Representation is limited– repr(John loves Mary) = repr(Mary loves John)– repr(The end is weak but the film is awesome) =
repr(The end is awesome but the film is weak)● We need a more powerful representation
which takes into account word order– Sequences of tokens– Bigrams, trigrams of tokens

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 127
Sentence encoder
Concatenation
sentence representation s
w1 w2 w3
concatenate
h1=f (W 1h0+b1)
h0=s

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 128
Sentence encoder
Concatenation
It is a masterful performance but, for me, not enough to make me a fan of the film.
It is not only lovely to look at (the exquisite northern Italian countryside made me want to hop on a plane that moment), but is made even better by the subtle performance of Timothée Chalamet. "
Fantastic movie
h1=f (W 1h0+b1)
h0=s

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 129
Sentence encoder
Recurrent Neural Network (RNN)Apply a single function f recursively
hidden layers
w1 w2 w3
0 0 0 0 0 0
f f f
y
x
f

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 130
Sentence encoder: RNN
Recurrent Neural Network (RNN)
Apply a single function f recursively
keeping history (hidden) state
hidden layers
w1 w2 w3
0 0 0 0 0 0
f f f
y
x
f

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 131
Sentence encoder: RNN
Recurrent Neural Network (RNN)
Apply a single function f recursively
keeping history (hidden) state
hidden layers
w1 w2 w3
0 0 0 0 0 0
f f f
y
x
f

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 132
Sentence encoder: RNN
Recurrent Neural Network (RNN)
Apply a single function f recursively
keeping history (hidden) state
hidden layers
w1 w2 w3
0 0 0 0 0 0
f f f
y
x
f

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 133
Sentence encoder: RNN
Apply a single function f recursively.
w1 w2 w3
0 0 0 0 0 0
f f f
ht=f (ht−1 , wt)=tanh(W [ ht−1 , w t ]+b)
sentence representation
y
x
f

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 134
Sentence encoder: RNN
Varying sequence length: unroll (different graph for each input)
w1 w2 w3
0 0 0 0 0 0
f f f
sentence representation
w1 w2
0 0 0 0 0 0
f f
w3
f
w4
f
sentence representation
y
x
f

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 136
Sentence encoder: RNN
● Last hidden state is input to classifier
w1 w2 w3
0 0 0 0 0 0
f f f
g
g(ht)=softmax (U ht+c)
y
x
f

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 137
RNNs offer a lot of flexibility
MLP
Source: Fei-Fei Li & Andrej Karpathy and Justin Johnson

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 138
RNNs offer a lot of flexibility
Sentiment classification
Source: Fei-Fei Li & Andrej Karpathy and Justin Johnson

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 139
RNNs offer a lot of flexibility
Machine translation
Source: Fei-Fei Li & Andrej Karpathy and Justin Johnson

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 140
RNNs offer a lot of flexibility
Image Captioning
Source: Fei-Fei Li & Andrej Karpathy and Justin Johnson

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 141
RNNs offer a lot of flexibility
Video classification at frame level
Source: Fei-Fei Li & Andrej Karpathy and Justin Johnson

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 142
Machine TranslationMachine Translationseq2seqseq2seq

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 143
Sequence to sequence models
● For any problem that can be interpreted as a transformation from one sequence to another:– Model it as a pair of RNNs:– An encoder that reads the input sentence,
outputs nothing– A decoder whose starting hidden state is the last
hidden state of the encoder, and that generates a sentence (RNN language model)
– Give it lots of data…. Success is guaranteed (Sutskever et al. 2014)

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 144
Sequente to sequence models
● They are state-of-the-art in many problems, some of them fairly novel– Foreign sentences → translation
– Emails → simple replies (Google)
– Python functions → result
– English sentences → parsing instructions– ...

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 145
Sequence to sequence for MT
Combine two RNN: encoder and decoder
Train as regular RNN (NOTE: N classifiers)
g g
hidden layershidden layers
</s>
g
hidden layers
0 0 0 0 0 0
<s>
f f f
txakur pelikula
txakur </s>pelikula

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 146
Sequence to sequence for MT
Combine two RNN
Train as in regular RNN● Note that decoder is conditioned
on last hidden state from encoder:
g g
hidden layershidden layers
g
hidden layers
<s> txakur pelikula
txakur </s>pelikula
p(w1, ... , wm∣hencoder)≈∏t=0
m−1
y t , correct
C=hencoder
ht=tanh (W [ ht−1 , w t ,C ]+b)
y t=softmax (WS ht+ c)
J sentence=−1T∑t=1
m
log y t , correct

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 147
Sequence to sequence for MT
● Test as decoder– Compute sentence representation
</s>
0 0 0 0 0 0
f f f

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 148
Sequence to sequence for MT
● Test as conditional RLM decoder– Compute sentence representation– Generate first word
g
hidden layers
</s>
0 0 0 0 0 0
<s>
f f f
katuw t=argmax
iyt , i

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 149
Sequence to sequence for MT
● Test as conditional RLM decoder– Compute sentence representation– Generate second word
g g
hidden layershidden layers
</s>
0 0 0 0 0 0
f f f
katu
pelikula
<s>
katuw t=argmax
iyt , i

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 150
Sequence to sequence for MT
● Test as conditional RLM decoder– Compute sentence representation– Generate next word, stop if </s>
g g
hidden layershidden layers
</s>
g
hidden layers
0 0 0 0 0 0
f f f
katu pelikula
</s>pelikula
<s>
katuw t=argmax
iyt , i

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 151
Sequence to sequence for MT
● These models do not beat statistical MT● More complex RNN: LSTM● There is a huge loss of information in trying to
cram all the meaning of the input sentence in a single vector– The decoder is missing key information like
individual words in the input, word order information, length of input, etc.
– Add capability to attend to each of the tokens in the input: attention!

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 152
Re-thinking seq2seq for NMT
How can we access the necessary information at each decoding step?
g g
hidden layershidden layers
</s>
g
hidden layers
0
0
0
0
0
0
<s>
f f f
txakur pelikula
txakur </s>pelikula
h3=c= s0h0h1 h2 s1 s2 s3

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 153
Re-thinking seq2seq for NMT
Learn alignments jointly with the translation (!)(Bahdanu et al. 2015; Luong et al. 2015)
</s>
f f f
c t
α t 1+ α t 3
α t 2
0
0
0
0
0
0
st
hidden layers

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 160
Re-thinking seq2seq for NMT0
0
0
0
0
0
f f f
c t
α t 1+ α t 3
α t 2
</s>
g
hidden layers
<s>
s1
c t=∑j=1
T x
αtj h j
α tj=exp(etj)/∑k=1
T x
exp(etk)etj=a( st , h j)= stW a h j
t=1

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 161
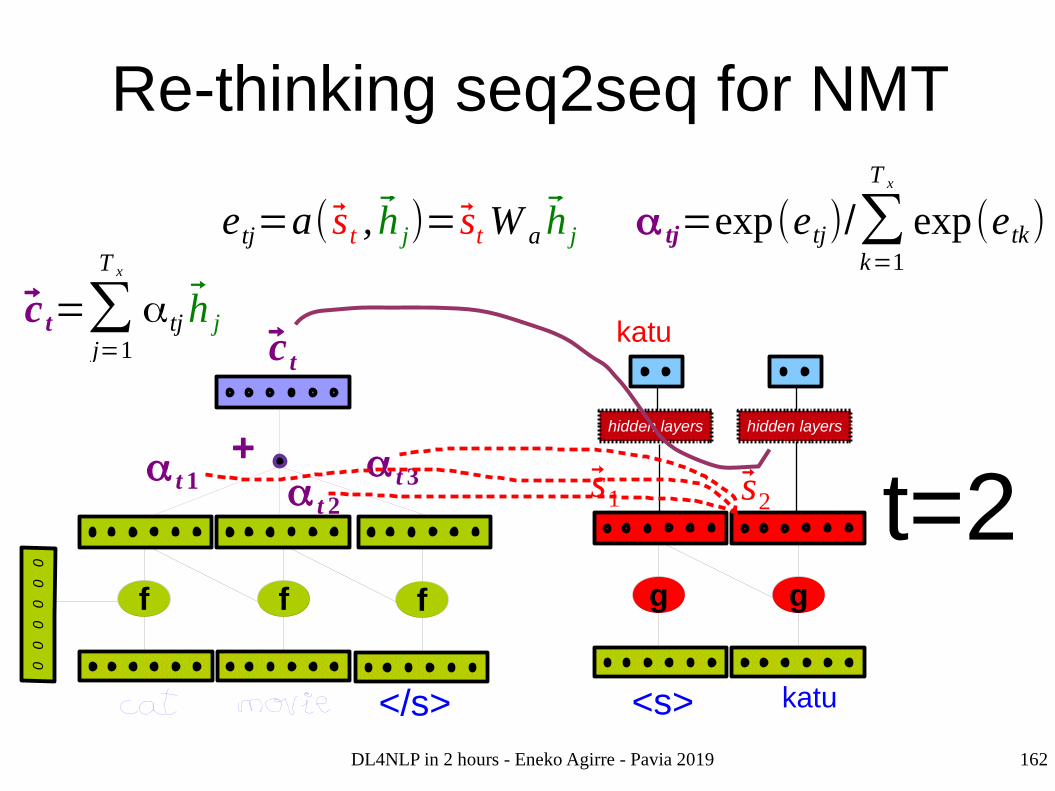
Re-thinking seq2seq for NMT0
0
0
0
0
0
f f f
c t
α t 1+ α t 3
α t 2
</s>
g
hidden layers
<s>
katu
s1
c t=∑j=1
T x
αtj h j
α tj=exp(etj)/∑k=1
T x
exp(etk)etj=a( st , h j)= stW a h j
t=1
DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 162
Re-thinking seq2seq for NMT0
0
0
0
0
0
f f f
c t
α t 1+ α t 3
α t 2
</s>
g g
hidden layershidden layers
<s> katu
katu
s1 s2
c t=∑j=1
T x
αtj h j
α tj=exp(etj)/∑k=1
T x
exp(etk)etj=a( st , h j)= stW a h j
t=2

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 163
Re-thinking seq2seq for NMT0
0
0
0
0
0
f f f
c t
α t 1+ α t 3
α t 2
</s>
g g
hidden layershidden layers
<s> katu
katu pelikula
s1 s2
c t=∑j=1
T x
αtj h j
α tj=exp(etj)/∑k=1
T x
exp(etk)etj=a( st , h j)= stW a h j
t=2

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 164
Re-thinking seq2seq for NMT0
0
0
0
0
0
f f f
c t
α t 1+ α t 3
α t 2
</s>
g g
hidden layershidden layers
g
hidden layers
<s> katu pelikula
katu </s>pelikula
s1 s2 s3
c t=∑j=1
T x
αtj h j
α tj=exp(etj)/∑k=1
T x
exp(etk)etj=a( st , h j)= stW a h j

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 166
Re-thinking seq2seq for NMT
Back to sentence representations:– Instead of last hidden state of encoder ...– Attention: keep information of all hidden states
encoder
txakur pelikula
decoder
ederra
cc0 c1 c2
c=[ c0 , c1 , c2]

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 167
Attention is all you need (!?)
Transformer (Vaswani et al. 2017) ● Extend attention to self-attention:
source (and target) with itself● Build hidden states using feed forward networks
State-of-the-art MT

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 168
Attention is all you need (!?)
Transformer (Vaswani et al. 2017)
c1
α11
+
α t 3α12
Feed forward

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 169
Attention is all you need (!?)
Transformer (Vaswani et al. 2017)
c2
α 21
+α 23
α 22
c1
Feed forward

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 170
Attention is all you need (!?)
Transformer (Vaswani et al. 2017)
c2c1 c3
α 31+α 33α 32
Feed forward

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 171
Attention is all you need (!?)
Transformer (Vaswani et al. 2017)
c2c1 c3
+
Feed forwardFeed forward
+
Feed forward
α11
+
α t 3α12
One forward pass

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 172
Recap
● Deep learning: learn representations for sentences– Encoders like RNNs (one vector plus attention) – Transformers that keep one vector per token
● Which task would be the best to learn representations that can be used in other tasks?
● Can we transfer this representation from one task to the other?
● Can we have all languages in one representation space?

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 173
Superhuman abilities: Superhuman abilities: unsupervised MTunsupervised MT
https://openreview.net/pdf?id=Sy2ogebAWhttps://openreview.net/pdf?id=Sy2ogebAW


DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 175
Unsupervised MT
● Given:– Some books in Chinese– Some other books in Arabic– A person who does not know Chinese nor Arabic
● Can a person learn to translate from Chinese to Arabic or vice versa?
● A machine can!– Leverage unsupervised cross-lingual embeddings

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 176
…
. . .
L1 embeddings
Encoder for L1
…
. . .
atte
nti
on
softmax
L2 decoder
Unsupervised MT

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 177
…
. . .
fixed cross-lingual embeddings
Shared encoder (L1/L2)
…
. . .
atten
tio
n
softmax
L1 decoder
…
. . .
atten
tio
n
softmax
L2 decoder
Unsupervised MT

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 178
Unsupervised MT Previously: cross-lingual embeddings
Steps:● Train as autoencoder:
– Given sentence in L1train shared encoder with L1 decoder
– Given sentence in L2train shared encoder with L2 decoder
● Test:– Given sentence in L1 produce
sentence in L2– Given sentence in L2 produce
sentence in L1
Fails!! Why?
…
. . .
fixed cross-lingual embeddings
Shared encoder (L1/L2)
…
. . .
atten
tio
n
softmax
L1 decoder
…
. . .
atten
tio
n
softmax
L2 decoder

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 179
Unsupervised MT
● Improvements– Denoising autoencoder: introduce noise in input– Backtranslation:
● Given sentence in L1 translate to L2 and train shared encoder with L1 decoderto recover original sentence
● It works!– Artetxe et al. (2017): The first paper (by 1 day!)
showing that it is possible to translate from one language to the other without bilingual resources

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 180
Unsupervised MT
● Significant improvements last year– NMT shared decoder– Statistical MT initialized with bilingual dictionary,
plus back-translation iterations● Results competitive with the state-of-the-art
in 2014– No bilingual resource!

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 181
Unsupervised MT
● Why does it work at all? An intuition:– Cross-lingual embedding space provides
information for k-best possible translations– NMT/SMT figures out how to best “combine”
them

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 182
Conclusions
● New research area – unsupervised Machine Translation
● Performance up, 33 BLEU En-Fr
● Plenty of margin for improvement
● Code for replicability https://github.com/artetxem/undreamt https://github.com/artetxem/monoses

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 183
References
● Mikel Artetxe, Gorka Labaka, and Eneko Agirre. 2017. Unsupervised Neural Machine Translation. In ICLR-2018.
● Mikel Artetxe, Gorka Labaka, and Eneko Agirre. 2018. Unsupervised Statistical Machine Translation. In EMNLP-2018.
● (Forthcoming)

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 184
Last wordsLast words

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 185
DL4NLP
● We have only scratched the surface of representation learning for NLP– How do learned representations match
linguistic expectations?● Exciting developments in transfer learning:
– Language generation with GPT-2– Contextual embeddings with BERT– Multilingual sentence representations
● Language understanding also requires:– Complex structure beyond sequence– Function words beyond embeddings (every,not)

DL4NLP 186
Resources
● Books!!
● Tutorials and implementations in Tensorflow (Keras) and Pytorch websites
● Stanford NLP and DL courses: https://nlp.stanford.edu/teaching/
● NYU NLP and DL courses: https://www.nyu.edu/projects/bowman/teaching.shtml
● Coursera, Udacity, Nvidia Deep Learning courses

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 187
And...
● Short 20 hour, 3 day summer course in Julyin San Sebastian (Keras) http://ixa2.si.ehu.es/deep_learning_seminar/
(pre-registration closes 15th of May!) ● Longer version in January
35 hours, 3 weeks (Tensorflow)
(to be announced)● Master and PhD opportunities

DL4NLP in 2 hours - Eneko Agirre - Pavia 2019 188
THANKS!@eagirre
Acknowledgements:
● Overall slides: Sam Bowman (NYU), Chris Manning and Richard Socher (Stanford)
● All source url’s listed in the slides