Embed Size (px)
Citation preview

Database Techniques for Linked Data Management
SIGMOD 2012
Andreas Harth1, Katja Hose2,Ralf Schenkel2,3
1Karlsruhe Instititute of Technology2Max Planck Institute for Informatics, Saarbrücken
3Saarland University, Saarbrücken

Outline for Part II
• Part II.1: Foundations– A short overview of SPARQL
• Part II.2: Rowstore Solutions• Part II.3: Columnstore Solutions• Part II.4: Other Solutions and Outlook

SPARQL
• Query language for RDF from the W3C• Main component:
– select-project-join combination of triple patterns graph pattern queries on the knowledge base

SPARQL – ExampleExample query:Find all actors from Ontario (that are in the knowledge base)
vegetarian
Albert_Einstein
physicist
Jim_Carrey
actor
Ontario
Canada
Ulm
Germany
scientist
chemist
Otto_Hahn
Frankfurt
Mike_Myers
NewmarketScarborough
Europe
isA isA isA isA isA
bornIn bornIn bornIn bornIn
locatedInlocatedIn
locatedInlocatedInlocatedInlocatedIn
isAisA
isA

Semantic Knowledge Bases from Web Sources 5
SPARQL – ExampleExample query:Find all actors from Ontario (that are in the knowledge base)
vegetarian
Jim_Carrey
actor
Ontario
Canada
Mike_Myers
NewmarketScarborough
isA isA
bornIn bornIn
locatedIn
locatedInlocatedIn
isA
actor
Ontario
?person
?loc
bornIn
locatedIn
isA
Find subgraphs of this form:
variables
constants
SELECT ?person WHERE ?person isA actor. ?person bornIn ?loc. ?loc locatedIn Ontario.

• Eliminate duplicates in results
• Return results in some order
with optional LIMIT n clause• Optional matches and filters on bounded vars
• More operators: ASK, DESCRIBE, CONSTRUCT
SPARQL – More Features
SELECT DISTINCT ?c WHERE {?person isA actor. ?person bornIn ?loc. ?loc locatedIn ?c}
SELECT ?person WHERE {?person isA actor. ?person bornIn ?loc. ?loc locatedIn Ontario} ORDER BY DESC(?person)
SELECT ?person WHERE {?person isA actor. OPTIONAL{?person bornIn ?loc}. FILTER (!BOUND(?loc))}

SPARQL: Extensions from W3C
W3C SPARQL 1.1 draft:• Aggregations (COUNT, AVG, …)• Subqueries• Negation: syntactic sugar forOPTIONAL {?x … }FILTER(!BOUND(?x))
• Regular path expressions• Updates

Why care about scalability?Rapid growth of available semantic data
> 31 billion triples in the LOD cloud, 325 sourcesDBPedia: 3.6 million entities, 1.2 billion triples

… and growing• Billion triple challenge 2008: 1B triples• Billion triple challenge 2010: 3B triples
http://km.aifb.kit.edu/projects/btc-2010/• Billion triple challenge 2011: 2B triples
http://km.aifb.kit.edu/projects/btc-2011/• War stories from
http://www.w3.org/wiki/LargeTripleStores:– BigOWLIM: 12B triples in Jun 2009 – Garlik 4store: 15B triples in Oct 2009– OpenLink Virtuoso: 15.4B+ triples – AllegroGraph: 1+ Trillion triples

Queries can be complex, tooSELECT DISTINCT ?a ?b ?lat ?long WHERE
{ ?a dbpedia:spouse ?b.
?a dbpedia:wikilink dbpediares:actor.
?b dbpedia:wikilink dbpediares:actor.
?a dbpedia:placeOfBirth ?c.
?b dbpedia:placeOfBirth ?c.
?c owl:sameAs ?c2.
?c2 pos:lat ?lat.
?c2 pos:long ?long.
}Q7 on BTC2008 in [Neumann & Weikum, 2009]

Outline for Part II
• Part II.1: Foundations– A short overview of SPARQL
• Part II.2: Rowstore Solutions• Part II.3: Columnstore Solutions• Part II.4: Other Solutions and Outlook

RDF in Row Stores• Rowstore: general relational database storing
relations as complete rows (MySQL, PostgreSQL, Oracle, DB2, SQLServer, …)
• General principles:– store triples in one giant three-attribute table(subject, predicate, object)
– convert SPARQL to equivalent SQL– The database will do the rest
• Strings often mapped to unique integer IDs• Used by many TripleStores, including 3Store,
Jena, HexaStore, RDF-3X, …
Simple extension to quadruples (with graphid):(graph,subject,predicate,object)
We consider only triples for simplicity!

Example: Triple Tableex:Katja ex:teaches ex:Databases;
ex:works_for ex:MPI_Informatics;ex:PhD_from ex:TU_Ilmenau.
ex:Andreas ex:teaches ex:Databases;ex:works_for ex:KIT;ex:PhD_from ex:DERI.
ex:Ralf ex:teaches ex:Information_Retrieval;ex:PhD_from ex:Saarland_University;ex:works_for ex:Saarland_University,
ex:MPI_Informatics.
subject predicate objectex:Katja ex:teaches ex:Databasesex:Katja ex:works_for ex:MPI_Informaticsex:Katja ex:PhD_from ex:TU_Ilmenauex:Andreas ex:teaches ex:Databasesex:Andreas ex:works_for ex:KITex:Andreas ex:PhD_from ex:DERIex:Ralf ex:teaches ex:Information_Retrievalex:Ralf ex:PhD_from ex:Saarland_Universityex:Ralf ex:works_for ex:Saarland_Universityex:Ralf ex:works_for ex:MPI_Informatics

Conversion of SPARQL to SQLGeneral approach:• One copy of the triple table for each triple pattern• Constants in patterns create constraints• Common variables across patterns create joins• FILTER conditions create constraints• OPTIONAL clauses create outer joins• UNION clauses create union expressions

SELECTFROM Triples P1, Triples P2, Triples P3
Example: Conversion to SQL QuerySELECT ?a ?b ?t WHERE{?a works_for ?u. ?b works_for ?u. ?a phd_from ?u. }OPTIONAL {?a teaches ?t}FILTER (regex(?u,“Saar“))
SELECTFROM Triples P1, Triples P2, Triples P3WHERE P1.predicate=„works_for“ AND P2.predicate=„works_for“ AND P3.predicate=„phd_from“
SELECTFROM Triples P1, Triples P2, Triples P3WHERE P1.predicate=„works_for“ AND P2.predicate=„works_for“ AND P3.predicate=„phd_from“ AND P1.object=P2.object AND P1.subject=P3.subject AND P1.object=P3.object
SELECTFROM Triples P1, Triples P2, Triples P3WHERE P1.predicate=„works_for“ AND P2.predicate=„works_for“ AND P3.predicate=„phd_from“ AND P1.object=P2.object AND P1.subject=P3.subject AND P1.object=P3.object AND REGEXP_LIKE(P1.object,“%Saar%“)
SELECT P1.subject as A, P2.subject as BFROM Triples P1, Triples P2, Triples P3WHERE P1.predicate=„works_for“ AND P2.predicate=„works_for“ AND P3.predicate=„phd_from“ AND P1.object=P2.object AND P1.subject=P3.subject AND P1.object=P3.object AND REGEXP_LIKE(P1.object,“%Saar%“)
SELECT R1.A, R1.B, R2.T FROM( SELECT P1.subject as A, P2.subject as B FROM Triples P1, Triples P2, Triples P3 WHERE P1.predicate=„works_for“ AND P2.predicate=„works_for“ AND P3.predicate=„phd_from“ AND P1.object=P2.object AND P1.subject=P3.subject AND P1.object=P3.object AND REGEXP_LIKE(P1.object,“%Saar%“) ) R1 LEFT OUTER JOIN ( SELECT P4.subject as A, P4.object as T FROM Triples P4 WHERE P4.predicate=„teaches“) AS R2) ON (R1.A=R2.A)
P1
P2
P3
P4
Filter
Projection
?u
?a,?u
?a

Is that all?No.• Which indexes should be built?
(to support evaluation of triple patterns)• How can we reduce storage space?• How can we find the best execution plan?
Existing databases need modifications:• flexible, extensible, generic storage not needed here• cannot deal with multiple self-joins of a single table• often generate bad execution plans

Dictionary for StringsMap all strings to unique integers (e.g., hashing)• Regular size, much easier to handle & compress• Map small, can be kept in main memory
<http://example.de/Katja> 194760<http://example.de/Andreas> 679375<http://example.de/Ralf> 4634
This breaks natural sorting order FILTER conditions may be more expensive!

Indexes for commonly used triple patternsPatterns with a single variable are frequentExample: Albert_Einstein invented ?x Build clustered index over (s,p,o)
Can also be used for pattern like Albert_Einstein ?p ?x
Build similar clustered indexes for all six combinations:• SPO, POS, OSP to cover all possible patterns• SOP, OPS, PSO to have all sort orders for patterns with two vars
(16,19,5356)(16,24,567)(16,24,876)(27,19,643)(27,48,10486)(50,10,10456) …
All triples in(s,p,o) order
B+ tree foreasy access
1. Lookup ids for constants:Albert_Einstein=16, invented=24
2. Lookup known prefix in index:(16,24,0)
3. Read results while prefix matches:(16,24,567), (16,24,876)come already sorted!
Triple table no longer needed, all triples in each index

Why sort order matters for joins
(16,19,5356)(16,24,567)(16,24,876)(27,19,643)(27,48,10486)(50,10,10456)
(16,33,46578)(16,56,1345)(24,16,1353)(27,18,133)(47,37,20495)(50,134,1056)
MJ
When inputs sorted by joinattribute, use Merge Join:• sequentially scan both inputs• immediately join matching triples• skip over parts without matches• allows pipelining
When inputs are unsorted/sortedby wrong attribute, use Hash Join:• build hash table from one input• scan other input, probe hash table• needs to touch every input triple• breaks pipelining
(16,19,5356)(16,24,567)(16,24,876)(27,19,643)(27,48,10486)(50,10,10456)
(27,18,133)(50,134,1056)(16,56,1345)(24,16,1353) (47,37,20495)(16,33,46578)
HJ
In general, Merge Joins are more preferrable:small memory footprint, pipelining

Even More IndexesSPARQL considers duplicates (unless removed with DISTINCT)and does not (yet) support aggregates/counting often queries with many duplicates like
SELECT ?x WHERE ?x ?y Germany.
to retrieve entities related to Germany (but counts may be important in the application!)
this materializes many identical intermediate resultsSolution:
• Precompute aggregated indexes SP,SO,PO,PS,OP,OS,S,P,OEx: SO contains, for each pair (s,o), the number of triples with subject s and object o
• Do not materialize identical bindings, but keep countsEx: ?x=Albert_Einstein:4; ?x=Angela_Merkel:10

Compression to Reduce Storage Space• Compress sequences of triples in lexicographic order
(v1;v2;v3); for SPO, v1=S, v2=P, v3=O• Step 1: compute per-attribute deltas
• Step 2: encode each delta triple separately in 1-13 bytes
(16,19,5356)(16,24,567)(16,24,676)(27,19,643)(27,48,10486)(50,10,10456)
(16,19,5356)(0,5,-4798)(0,0,109)(11,-5,-34)(0,29,9843)(23,-38,-30)
gapbit
header(7 bits)
Delta of value 2(0-4 bytes)
Delta of value 2(0-4 bytes)
Delta of value 3(0-4 bytes)
When gap=1, thedelta of value3 isincluded in header,all others are 0
Otherwise, header contains length of encoding for each of the three deltas (5*5*5=125 combinations)

Compression Effectiveness and Efficiency• Byte-level encoding almost as effectiv as bit-level
encoding techniques (Gamma, Delta, Golomb)• Much faster (10x) for decompressing• Example for Barton dataset (Neumann & Weikum 2010):
– Raw data 51 million triples, 7GB uncompressed (as N-Triples)– All 6 main indexes:
• 1.1GB size, 3.2s decompression with byte-level encoding• 1.06GB size, 42.5s decompression with Delta encoding
• Additional compression with LZ77 2x more compact,but much slower to decompress
• Compression always on page level

POS(works_for,?u,?a)
POS(pdh_from,?u,?a)
PSO(works_for,?u,?b)
Filter
Projection
?u,?a
?u
?a
MJ
MJ
Back to the Example QuerySELECT ?a ?b ?t WHERE{?a works_for ?u. ?b works_for ?u. ?a phd_from ?u. }OPTIONAL {?a teaches ?t}FILTER (regex(?u,“Saar“))
POS(works_for,?u,?a)
POS(works_for,?u,?b)
PSO(phd_from,?a,?u)
POS(teaches,?a,?t)
Filter
Projection
?u
?a,?u
?a
MJ
HJ
POS(teaches,?a,?t)
Which of the two plans is better?How many intermediate results?
1000
1000
1000
1000
100
100
50
505
2500
250
250
Core ingredients of a good query optimizer areselectivity estimators for triple patterns and joins

Selectivity Estimation for Triple PatternsHow many results will a triple pattern have?Standard databases:• per-attribute histograms• Assume independence of attributes Use aggregated indexes for exact count
Additional join statistics for blocks of triples:
too simplisticand inexact
… (16,19,5356)(16,24,567)(16,24,876)(27,19,643)(27,48,10486)(50,10,10456) …
Assume independencebetween triple patterns;additionally precompute
exact statistics for frequentpaths in the data

Outline for Part II
• Part II.1: Foundations– A short overview of SPARQL
• Part II.2: Rowstore Solutions• Part II.3: Columnstore Solutions• Part II.4: Other Solutions and Outlook

PrinciplesObservations and Assumptions:• Not too many different predicates• Triple patterns usually have fixed predicate• Need to access all triples with one predicate
Design consequence:• Use one two-attribute table for each predicate
Example Systems: SWStore, MonetDB

Example: Column Storesex:Katja ex:teaches ex:Databases;
ex:works_for ex:MPI_Informatics;ex:PhD_from ex:TU_Ilmenau.
ex:Andreas ex:teaches ex:Databases;ex:works_for ex:KIT;ex:PhD_from ex:DERI.
ex:Ralf ex:teaches ex:Information_Retrieval;ex:PhD_from ex:Saarland_University;ex:works_for ex:Saarland_University,
ex:MPI_Informatics.
subject objectex:Katja ex:TU_Ilmenauex:Andreas ex:DERIex:Ralf ex:Saarland_University
PhD_from
subject objectex:Katja ex:MPI_Informaticsex:Andreas ex:DERIex:Ralf ex:Saarland_Universityex:Ralf ex:MPI_Informatics
works_for
subject objectex:Katja ex:Databasesex:Andreas ex:Databasesex:Ralf ex:Information_Retrieval
teaches

Simplified Example: Query ConversionSELECT ?a ?b ?t WHERE{?a works_for ?u. ?b works_for ?u. ?a phd_from ?u. }
SELECT W1.subject as A, W2.subject as B FROM works_for W1, works_for W2, phd_from P3 WHERE W1.object=W2.object AND W1.subject=P3.subject AND W1.object=P3.object
So far, this is yet another relational representation of RDF.Now what are Column-Stores?
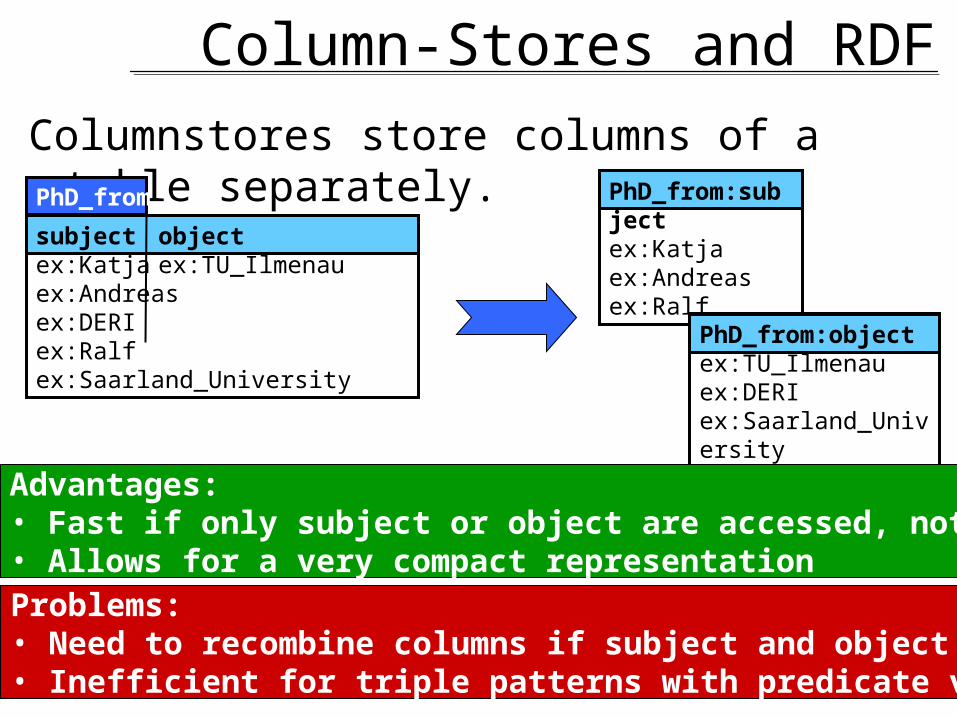
Column-Stores and RDFColumnstores store columns of a table separately.
subject objectex:Katja ex:TU_Ilmenauex:Andreas ex:DERIex:Ralf ex:Saarland_University
PhD_from PhD_from:subjectex:Katjaex:Andreasex:Ralf
PhD_from:objectex:TU_Ilmenauex:DERIex:Saarland_University
Advantages:• Fast if only subject or object are accessed, not both• Allows for a very compact representation Problems:• Need to recombine columns if subject and object are accessed• Inefficient for triple patterns with predicate variable

Compression in Column-StoresGeneral ideas: • Store subject only once• Use same order of subjects for all columns, including NULL values
when necessary
• Additional compression to get rid of NULL values
subjectex:Katjaex:Andreasex:Ralfex:Ralf
PhD_fromex:TU_Ilmenauex:DERIex:Saarland_UniversityNULL
works_forex:MPI_Informaticsex:KITex:Saarland_Universityex:MPI_Informatics
teachesex:Databasesex:Databases ex:Information_RetrievalNULL
PhD_from: bit[1110]ex:TU_Ilmenauex:DERIex:Saarland_University
Teaches: range[1-3]ex:Databasesex:Databases ex:Information_Retrieval

Outline for Part II
• Part II.1: Foundations– A short overview of SPARQL
• Part II.2: Rowstore Solutions• Part II.3: Columnstore Solutions• Part II.4: Other Solutions and Outlook
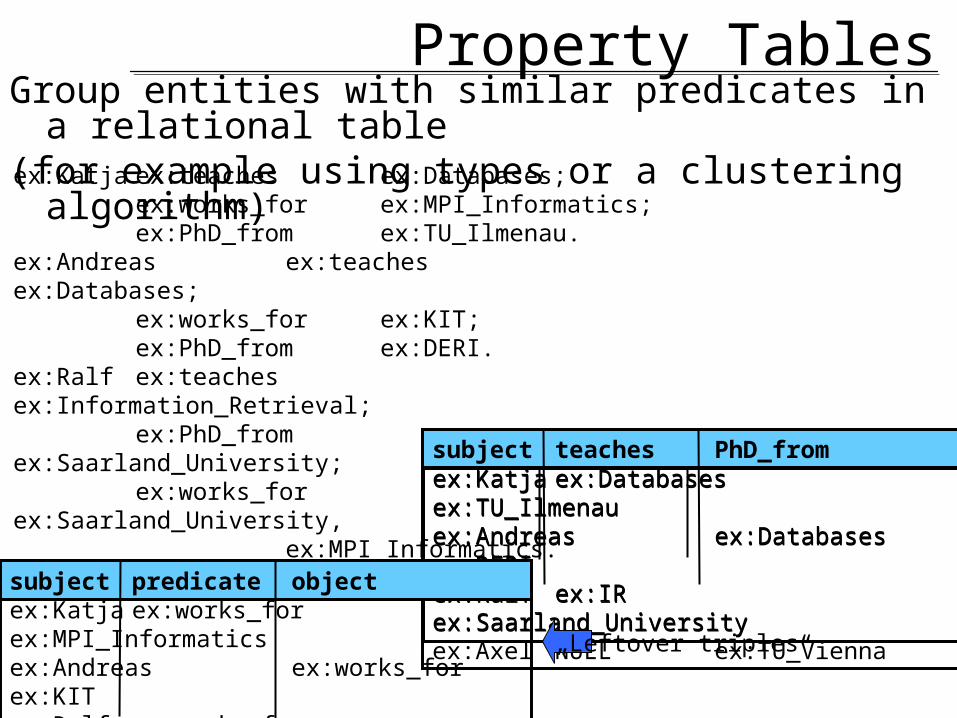
Property TablesGroup entities with similar predicates in a relational table(for example using types or a clustering algorithm)ex:Katja ex:teaches ex:Databases;
ex:works_for ex:MPI_Informatics;ex:PhD_from ex:TU_Ilmenau.
ex:Andreas ex:teaches ex:Databases;ex:works_for ex:KIT;ex:PhD_from ex:DERI.
ex:Ralf ex:teaches ex:Information_Retrieval;ex:PhD_from ex:Saarland_University;ex:works_for ex:Saarland_University,
ex:MPI_Informatics.subject teaches PhD_fromex:Katja ex:Databases ex:TU_Ilmenauex:Andreas ex:Databases ex:DERIex:Ralf ex:IR ex:Saarland_University
subject teaches PhD_fromex:Katja ex:Databases ex:TU_Ilmenauex:Andreas ex:Databases ex:DERIex:Ralf ex:IR ex:Saarland_Universityex:Axel NULL ex:TU_Vienna
subject predicate objectex:Katja ex:works_for ex:MPI_Informaticsex:Andreas ex:works_for ex:KITex:Ralf ex:works_for ex:Saarland_Universityex:Ralf ex:works_for ex:MPI_Informatics
„Leftover triples“

Property Tables: Pros and ConsAdvantages:• More in the spirit of existing relational systems• Saves many self-joins over triple tables etc.Disadvantages:• Potentially many NULL values• Multi-value attributes problematic• Query mapping depends on schema• Schema changes very expensive

Even More Systems…• Store RDF data as matrix with bit-vector
compression• Convert RDF into XML and use XML methods
(XPath, XQuery, …)• Store RDF data in graph databases• …
See proceedings for pointersSee also our tutorial at Reasoning Web 2011

Which technique is best?• Performance depends a lot on precomputation,
optimization, implementation• Comparative results on BTC 2008
(from [Neumann & Weikum, 2009]):
RDF-3XRDF-3X (2008)COLSTOREROWSTORE
RDF-3XRDF-3X (2008)COLSTOREROWSTORE

Challenges and Opportunities• SPARQL with different entailment regimes
(„query-time inference“)• Upcoming SPARQL 1.1 features (grouping,
aggregation, updates)• Ranking of results
– Efficient top-k operators– Effective scoring methods for structured queries
• Dealing with uncertain information – what is the most likely answer?– triples with probabilities
• Where is the limit for a centralized RDF store?

Backup Slides

Handling UpdatesWhat should we do when our data changes?(SPARQL 1.1 will have updates!)
Assumptions:• Queries far more frequent than updates• Updates mostly insertions, hardly any deletions• Different applications may update concurrently
Solution: Differential Indexing
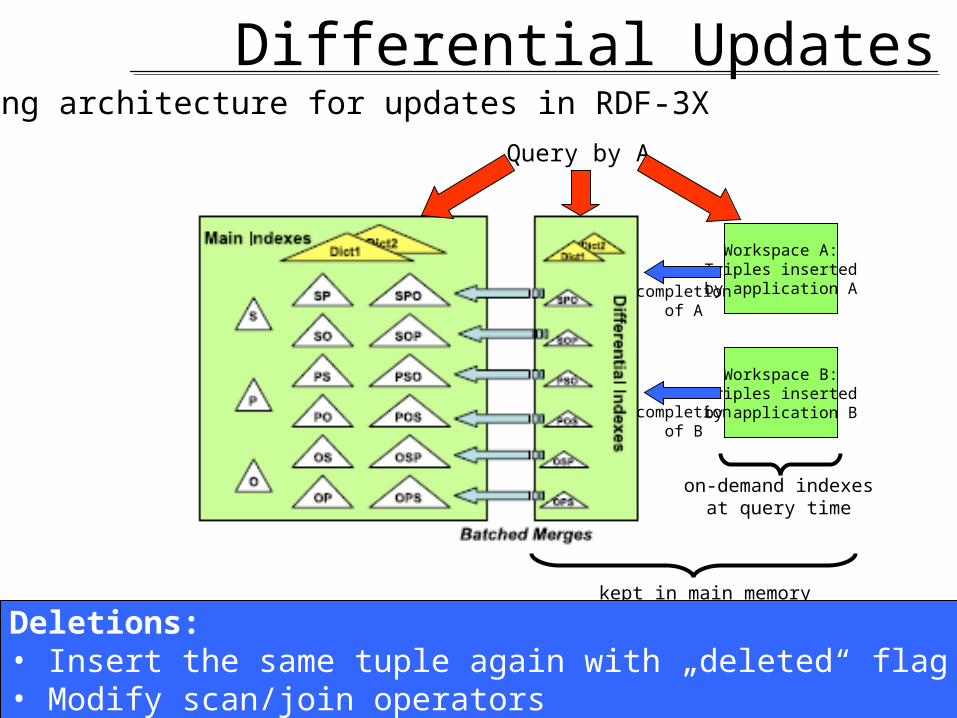
Differential Updates
Workspace A:Triples insertedby application A
Workspace B:Triples insertedby application B
on-demand indexesat query time
kept in main memory
Staging architecture for updates in RDF-3XQuery by A
completionof A
completionof B
Deletions:• Insert the same tuple again with „deleted“ flag• Modify scan/join operators







![Untitled-4 []Sethi's Lifestyle TDCP Restaurant Punjan Village Attock petroleum Chak Poorana Punjab College Sahibdad Abdul Mannan Technincal Instititute pso AL Ghani petroleum 03202440625](https://img.pdfslide.us/doc/110x75/60167932f4800074fd191fb6/untitled-4-sethis-lifestyle-tdcp-restaurant-punjan-village-attock-petroleum.jpg)





















