Embed Size (px)
Citation preview

Database servers on chip multiprocessors: limitations and opportunitiesN. HardavellasI. PandisR. Johnson
N. MancherilA. AilamakiB. Falsafi
Benjamin ReillySeptember 27, 2011
Tuesday, 27 September, 11

The fattened cache (and CPU)
Cache capacity = Cache latency
More data on hand, but higher cost to retrieve it
CPUs show similar trend in development: continually larger, and more complex
Tuesday, 27 September, 11

OVERVIEW
•Motivation
• Experiment design
• Results and observations
•What now?
• Summary and discussion
Tuesday, 27 September, 11

Dividing the CMPs
CMPs?Chip multiprocessors: several cores sharing on-chip resources (caches)
Vary in:•# of cores•# of hardware threads (“contexts”)•Execution order•Pipeline depth
Tuesday, 27 September, 11

The ‘Fat Camp’ (FC)
Key characteristics•Few, but powerful cores•Few (1-2) hardware contexts•OoO –– Out-of-Order execution•ILP –– Instruction-level parallelism
Core 0 Core 1Thread Context
Tuesday, 27 September, 11
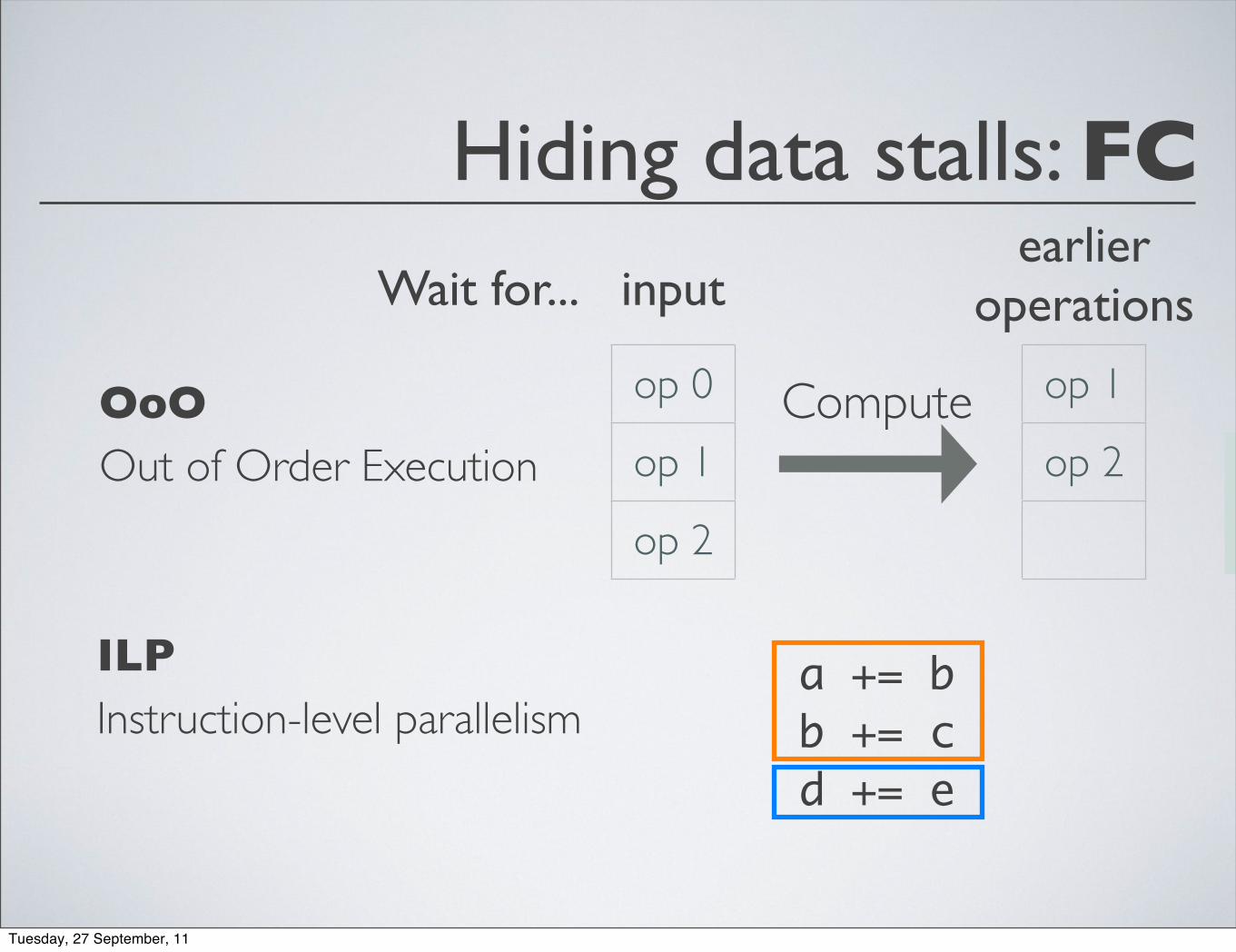
Hiding data stalls: FC
OoOOut of Order Execution
ILPInstruction-level parallelism
op 0
op 1
op 2
Wait for... input
Compute op 1
op 2
earlier operations
a += bb += cd += e
Tuesday, 27 September, 11

The ‘Lean Camp’ (LC)
Key characteristics•Many, but weaker cores•Several (4+) hardware contexts•In-order execution (simpler)
Core 0
Core 1 Core 5
Core 2
Core 3
Core 4
Core 7
Core 6
Tuesday, 27 September, 11

Core 0Core 0Core 0Core 0Core 0Core 0Core 0Core 0Core 0Core 0
Hiding data stalls: LCHardware contexts interleaved in round-robin fashion, skipping contexts that are in data stalls.
Running
Idle (runnable)
Stalled (non-runnable)
Tuesday, 27 September, 11

(Un)saturated workloads
Workloads•DSS•OLTP
Number of requests• Saturated: work always available for each
hardware context•Unsaturated: work not always available
Tuesday, 27 September, 11
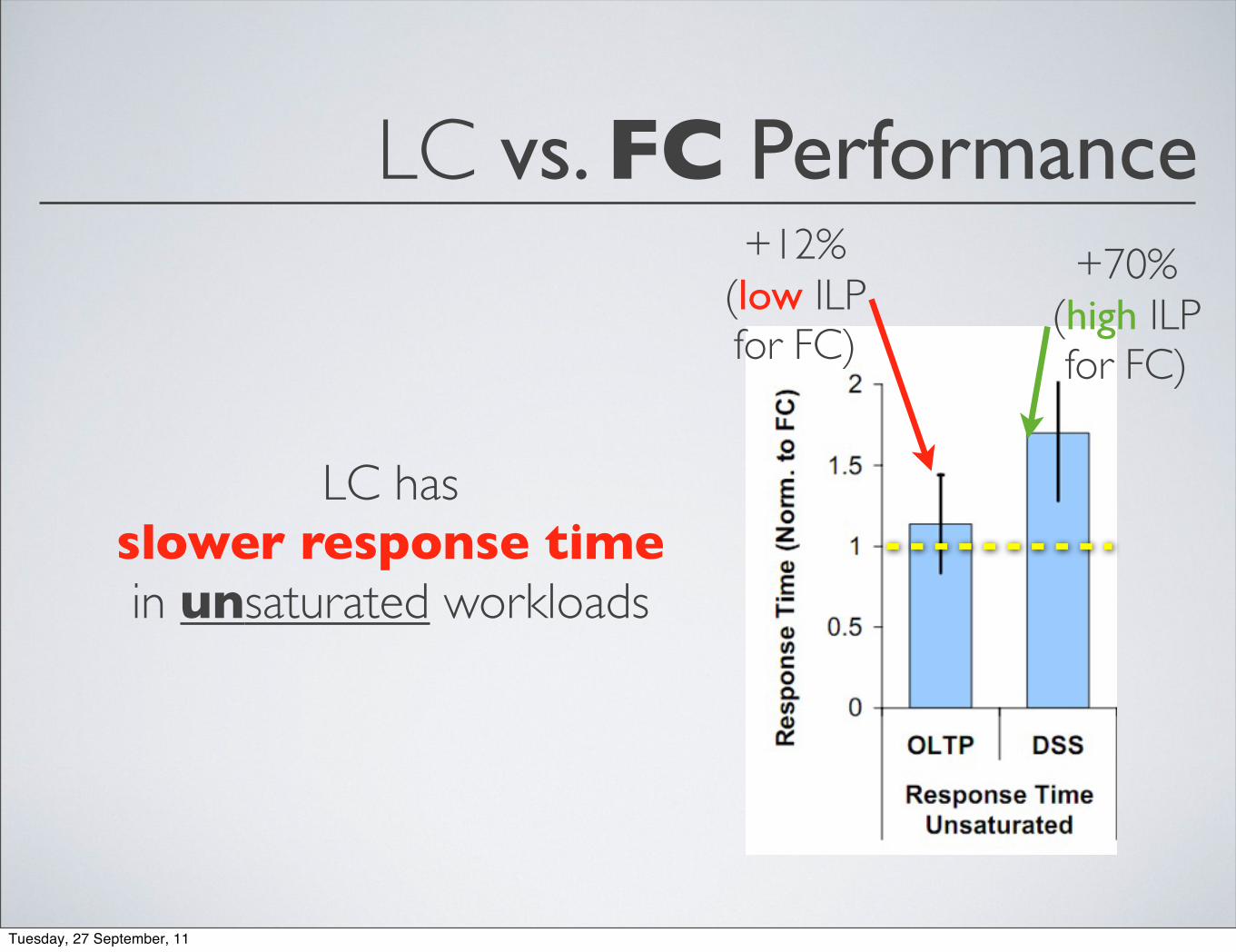
LC vs. FC Performance
LC has slower response timein unsaturated workloads
+12%(low ILP for FC)
+70%(high ILP for FC)
Tuesday, 27 September, 11
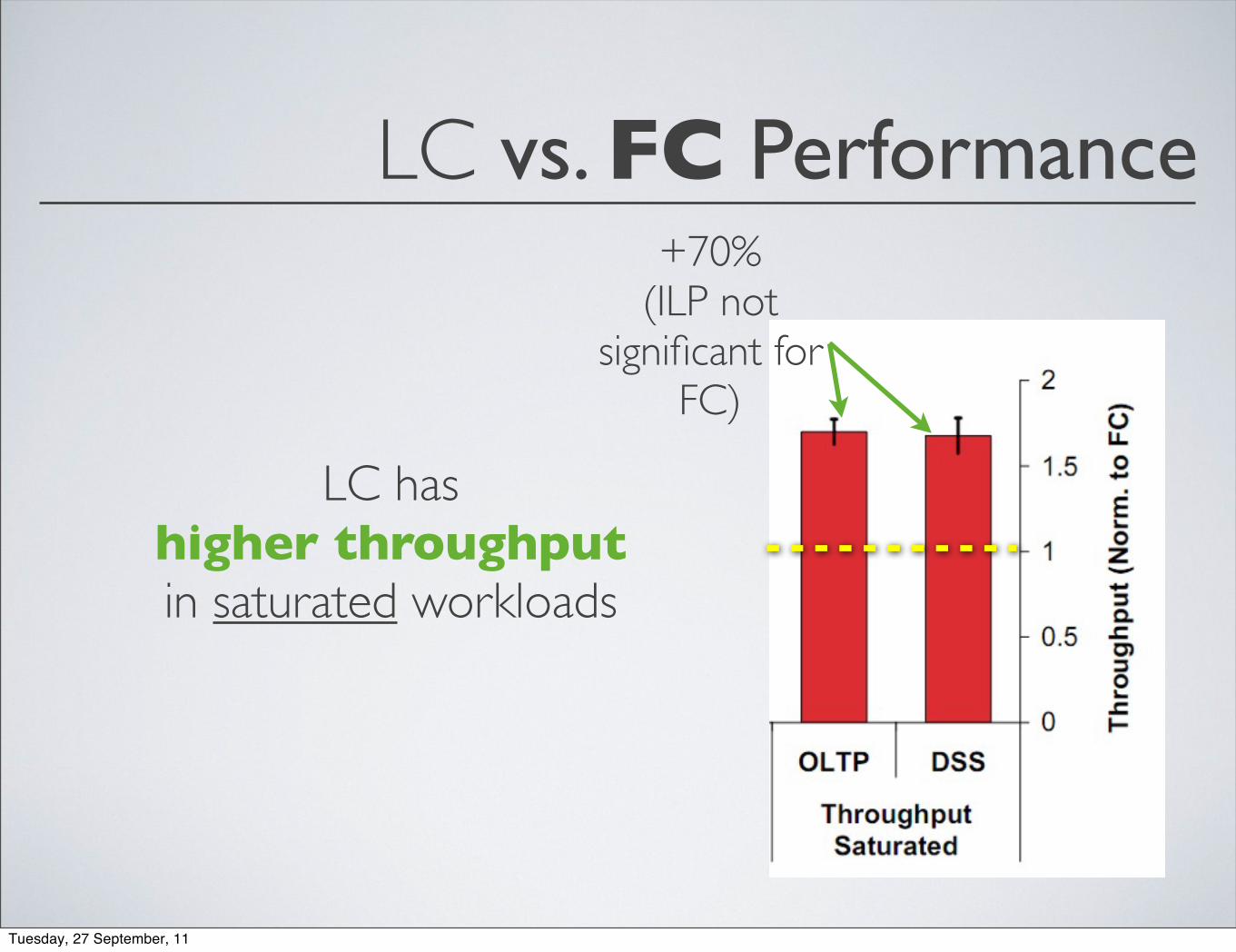
LC vs. FC Performance
LC has higher throughputin saturated workloads
+70%(ILP not
significant for FC)
Tuesday, 27 September, 11
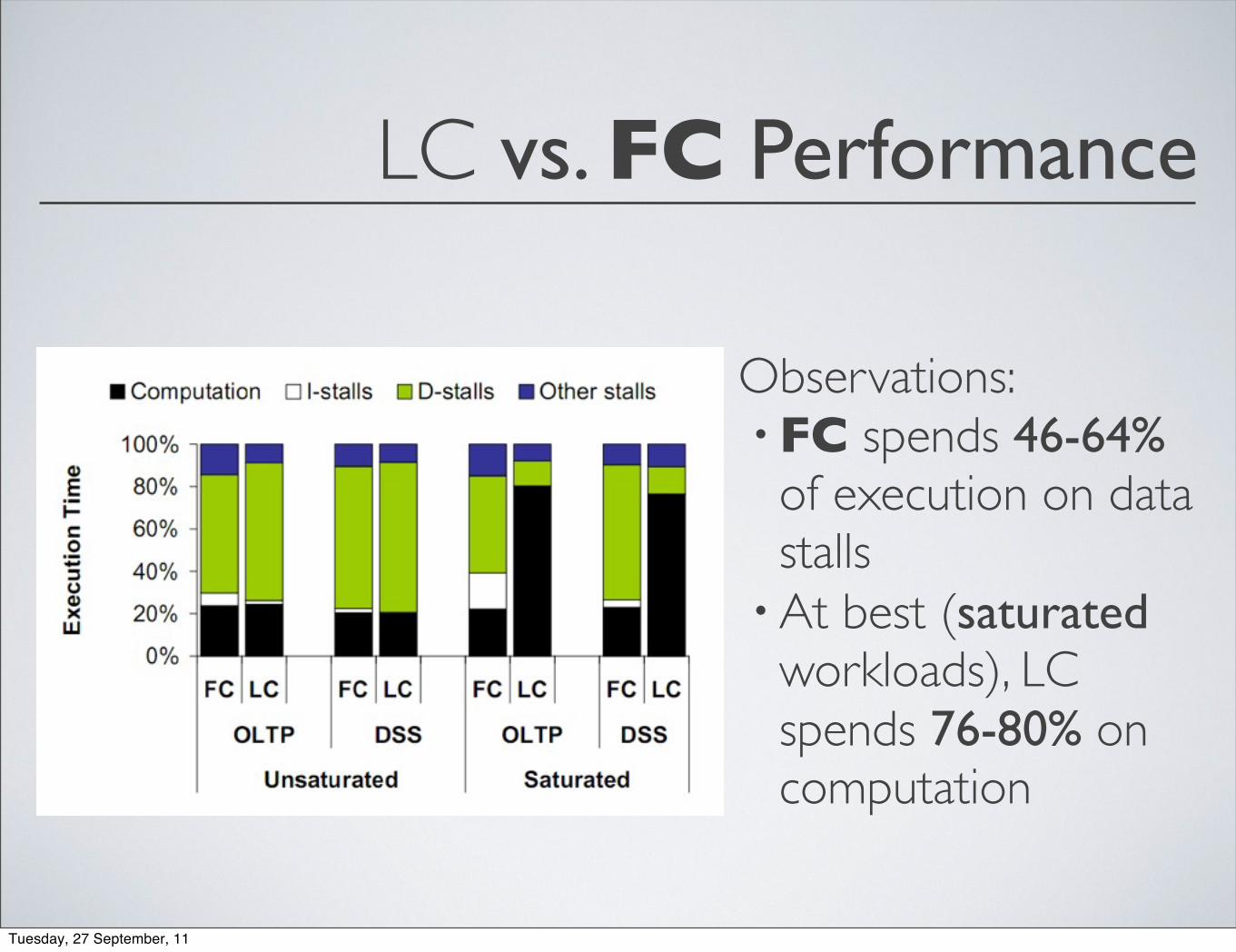
LC vs. FC Performance
Observations:•FC spends 46-64% of execution on data stalls•At best (saturated workloads), LC spends 76-80% on computation
Tuesday, 27 September, 11
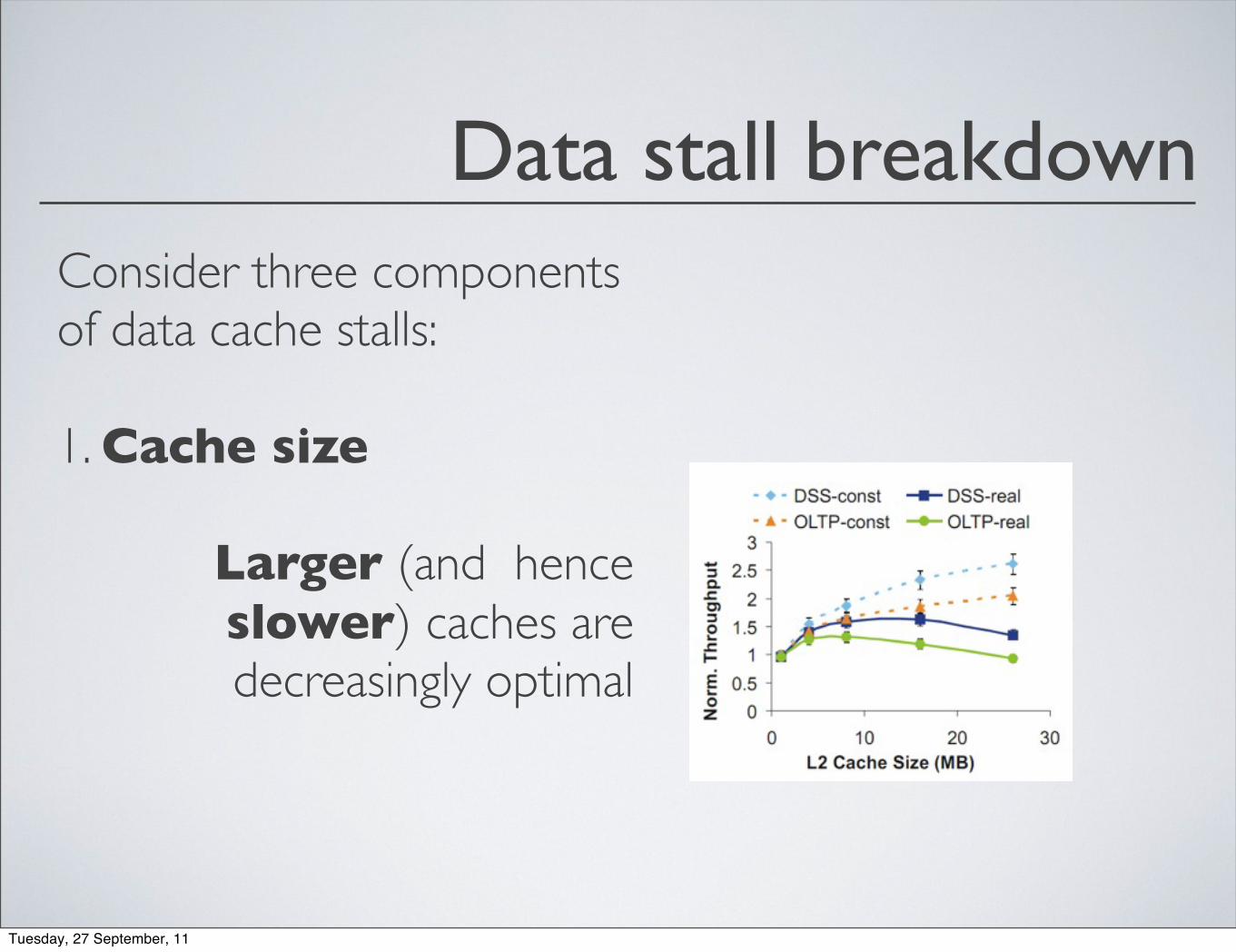
Data stall breakdown
Larger (and hence slower) caches are decreasingly optimal
Consider three components of data cache stalls:
1. Cache size
Tuesday, 27 September, 11
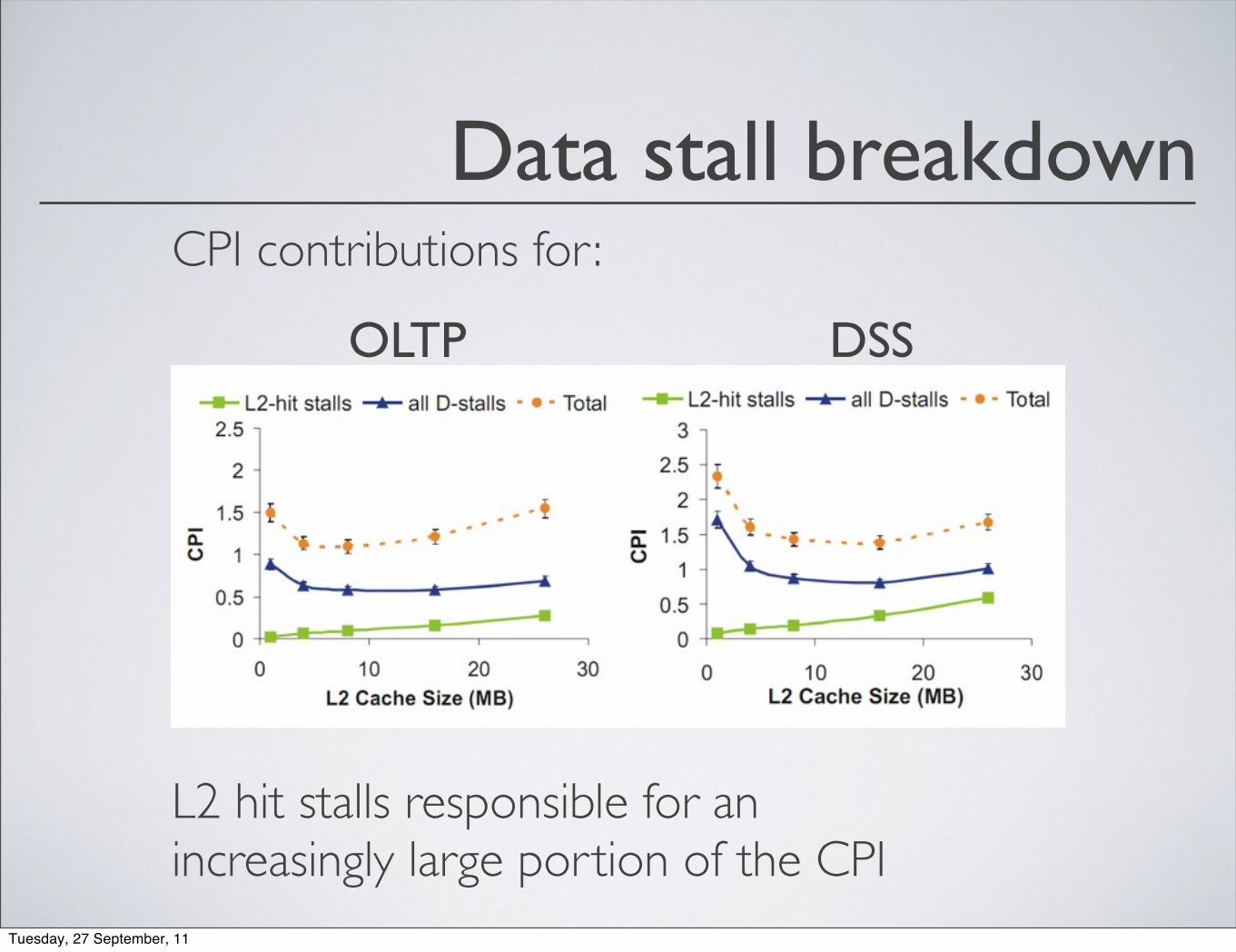
Data stall breakdownCPI contributions for :
OLTP DSS
L2 hit stalls responsible for an increasingly large portion of the CPI
Tuesday, 27 September, 11

Data stall breakdown
2. Per-chip core integration
SMP CMP
Processing 4x 1-core 1x 4-core
L2 cache(s) 4MB / CPU16 MB shared
Fewer cores per chip = fewer L2 hits
Tuesday, 27 September, 11
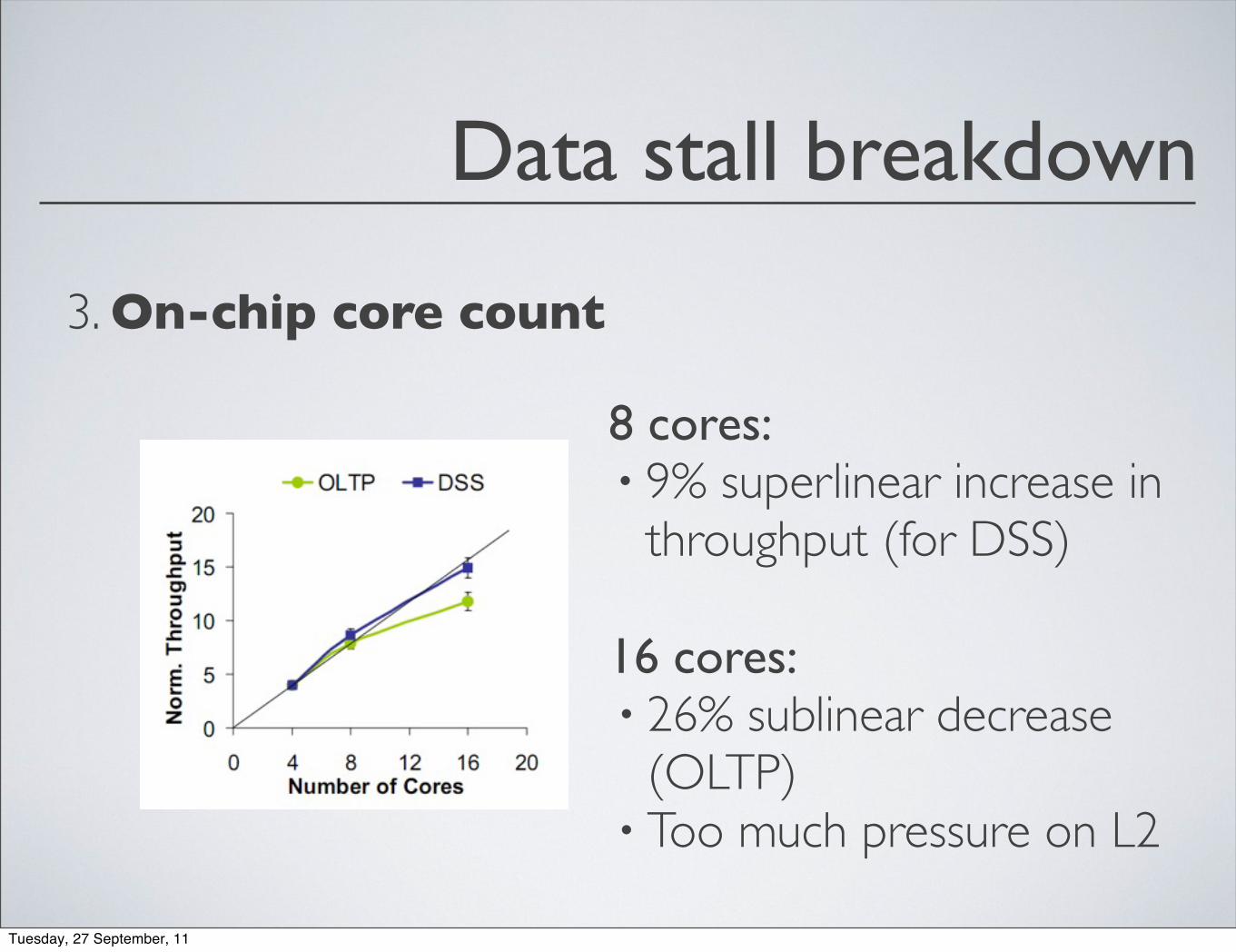
Data stall breakdown
3. On-chip core count
8 cores:• 9% superlinear increase in
throughput (for DSS)
16 cores:• 26% sublinear decrease
(OLTP)• Too much pressure on L2
Tuesday, 27 September, 11

How do we apply this?
1. Increase parallelism
• Divide!(more threads ⇒ more saturation)
• Pipeline/OLP (producer-consumer pairs)
• Partition input (not ideal; static and complex)
Tuesday, 27 September, 11

How do we apply this?
2. Improve data locality
• Reduce data stalls to help with unsaturated workloads
• Halt producers in favour of consumers
• Use cache-friendly algorithms
3.Use staged DBs
• Partition work by groups of relational operators
Tuesday, 27 September, 11

Summary & Discussion
1. LC typically performs better than FC
• LC is best under saturated workloads.
• Is there room for FC CMPs in DB applications?
2. L2 hits are a bottleneck
• Why were DBs ignored in HW design?
• How can we avoid incurring the cost of an L2 hit?
Tuesday, 27 September, 11





























