Embed Size (px)
Citation preview

1
Profiling and Identifying Individual Users by Their Command Line Usage and Writing Sytle
Darusalam (100111555)Supervisor Associate Prof Helen Ashman

2
Overview
• Introduction• Motivation• Literature Review • Research Question• Methodology• Result• Contribution• Future Work

3
Introduction
Profiling ->, it groups things or individuals into categories based on characteristics (N.P.Dau et al., 2000).
E.g Profiling -> user usage pattern of computer
Profiling -> user identification
It aims to identify a user in natural language (Jane Austen and William Shakespeare) and Formal language (command line history) based on the investigation of psychometric user characteristics

4
Motivation
• Previous research Biometric characteristic.• The minor thesis extends this by focusing on a
psychometric user characteristic.• Research will consider user’s writings in two
different scenarios (Natural and Formal language) and can be analyzed with n-gram in order to identify the user.

5
Literature Review • Computer science -> profiling in online social network
– Research by Ashman and Holland (on draft). They examined users to identifying Anomaly detection over user model.
– Department of electrical and computer Engineering, University of Victoria Canada outline about the use of behavioral biometrics for intrusion detection applications (Ahmed & Traore 2005).
• N-gram based analysis
– Luo et at (2010) N-gram-based malicious code feature extraction algorithm with statical language model.
– N-gram analysis based on author profile also applies in authorship attribution (Keöelj et al. 2003).

6
Research Question
The research will answer the questions
• Q1: does the use of n-gram analysis to profile users’ writing styles in social network
situations allow accurate user identification?
a. if so, does it allow both positive and negative identification?
• Q2: does the use of n-gram analysis to profile users’ command usage in their command
line histories allow accurate user identification?
a. if so, does it allow both positive and negative identification?
• Q3: if the profiling of both writing styles and command usage allow accurate user profiling, which is the most accurate?
7
Research Question Cont
Machine A Machine B
Positive Identification
Machine A Machine B
Negative Identification

8
Methodology• What is N-gram analysis ? N-gram is a language model based on collinear relation (Luo et al., 2010) & ‘N-gram is a
subset of overlapping n-sized portion of a series of letter, words, syllables, phonemes or based pairs’ (Ashman and Holland (on draft)).
• 3-gram, 5-gram, 11-gram and 15-gram is used for analysis.• Normalization Data used are percentage, Max-min and Z score • T-Test ? Method to compare the styles of two pairs of samples.
N-gram(3,5,11 & 15)
NormalizationA percentage, Max-
min & z Score
T-Test (t-Test: paired two sample for means)
Result
9
Formal language comparison
User1-history1 User1-history2
User1-history3 User1-history4
Positive Identification User2-history1 User3-history1
User5-history1User4-history1
Negative Identification

10
Natural language comparison
William Shakespeare Positive Identification
Jane Austen Positive Identification
Negative Identification
11
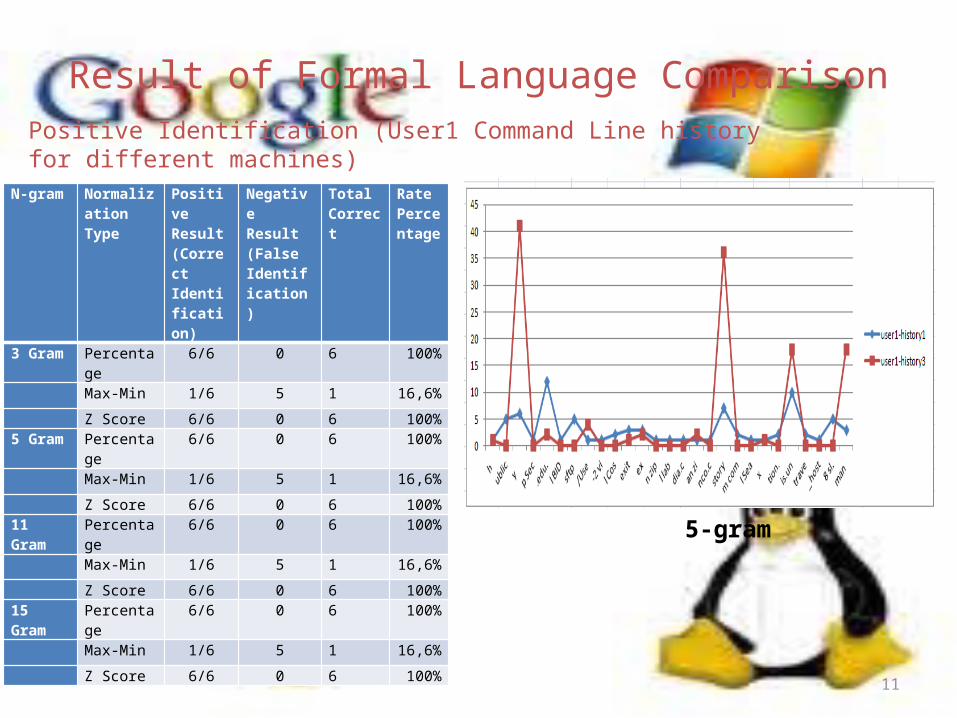
Result of Formal Language Comparison
N-gram Normalization Type
Positive Result (Correct Identification)
Negative Result (False Identification )
Total Correct
Rate Percentage
3 Gram Percentage 6/6 0 6 100%
Max-Min 1/6 5 1 16,6%
Z Score 6/6 0 6 100%5 Gram Percentage 6/6 0 6 100%
Max-Min 1/6 5 1 16,6%
Z Score 6/6 0 6 100%11 Gram Percentage 6/6 0 6 100%
Max-Min 1/6 5 1 16,6%
Z Score 6/6 0 6 100%15 Gram Percentage 6/6 0 6 100%
Max-Min 1/6 5 1 16,6%
Z Score 6/6 0 6 100%
Positive Identification (User1 Command Line history for different machines)
5-gram
12
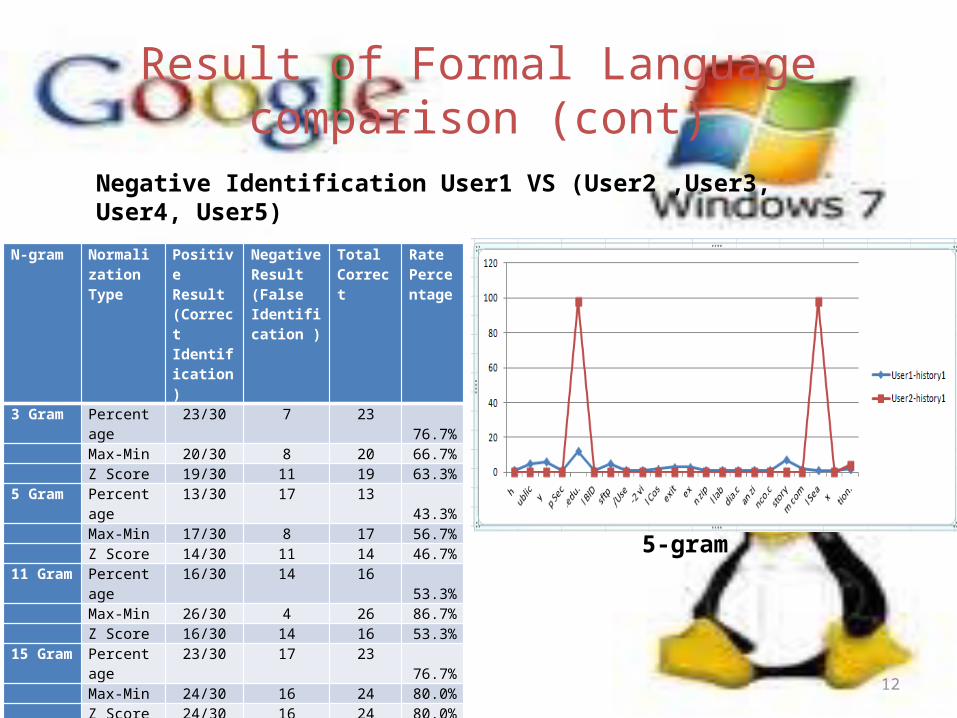
Result of Formal Language comparison (cont)
N-gram Normalization Type
Positive Result (Correct Identification)
Negative Result (False Identification )
Total Correct
Rate Percentage
3 Gram Percentage 23/30 7 23 76.7% Max-Min 20/30 8 20 66.7% Z Score 19/30 11 19 63.3%5 Gram Percentage 13/30 17 13 43.3% Max-Min 17/30 8 17 56.7% Z Score 14/30 11 14 46.7%11 Gram Percentage 16/30 14 16 53.3% Max-Min 26/30 4 26 86.7% Z Score 16/30 14 16 53.3%15 Gram Percentage 23/30 17 23 76.7% Max-Min 24/30 16 24 80.0% Z Score 24/30 16 24 80.0%
Negative Identification User1 VS (User2 ,User3, User4, User5)
5-gram
13
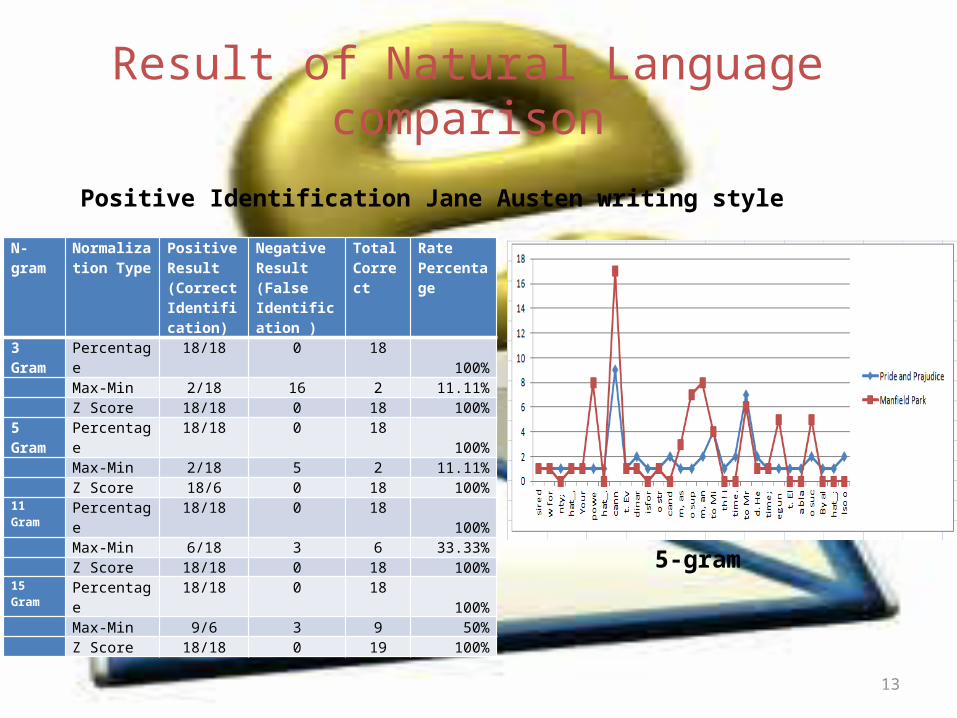
Result of Natural Language comparison
N-gram Normalization Type
Positive Result (Correct Identification)
Negative Result (False Identification )
Total Correct
Rate Percentage
3 Gram Percentage 18/18 0 18 100% Max-Min 2/18 16 2 11.11% Z Score 18/18 0 18 100%5 Gram Percentage 18/18 0 18 100% Max-Min 2/18 5 2 11.11% Z Score 18/6 0 18 100%11 Gram Percentage 18/18 0 18 100% Max-Min 6/18 3 6 33.33% Z Score 18/18 0 18 100%15 Gram Percentage 18/18 0 18 100% Max-Min 9/6 3 9 50% Z Score 18/18 0 19 100%
Positive Identification Jane Austen writing style
5-gram
14
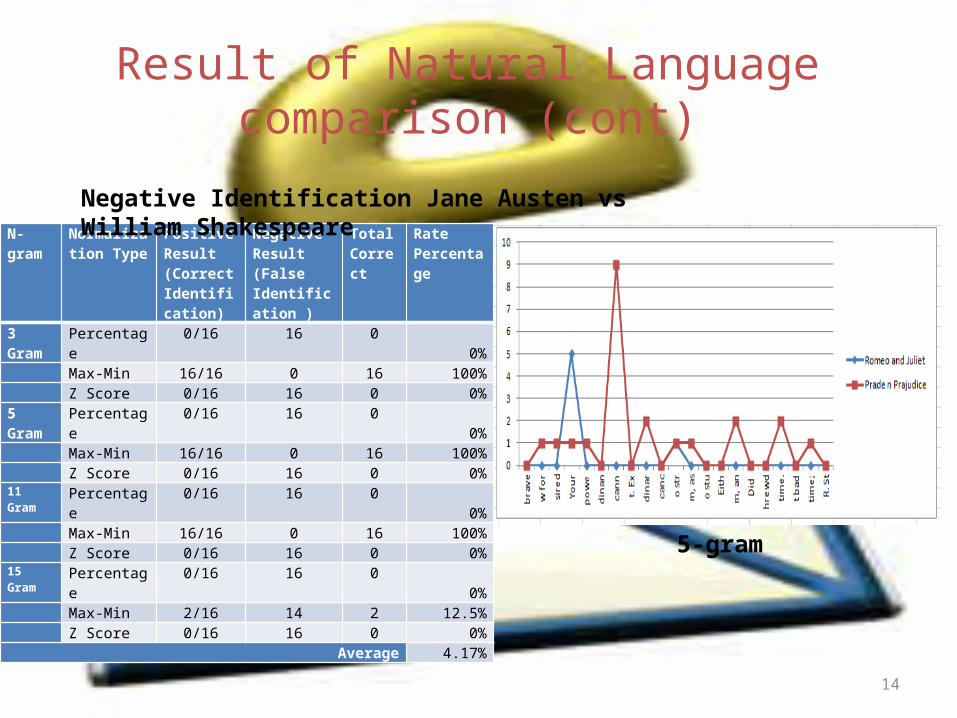
Result of Natural Language comparison (cont)
N-gram Normalization Type
Positive Result (Correct Identification)
Negative Result (False Identification )
Total Correct
Rate Percentage
3 Gram Percentage 0/16 16 0 0% Max-Min 16/16 0 16 100% Z Score 0/16 16 0 0%5 Gram Percentage 0/16 16 0 0% Max-Min 16/16 0 16 100% Z Score 0/16 16 0 0%11 Gram Percentage 0/16 16 0 0% Max-Min 16/16 0 16 100% Z Score 0/16 16 0 0%15 Gram Percentage 0/16 16 0 0% Max-Min 2/16 14 2 12.5% Z Score 0/16 16 0 0%
Average 4.17%
Negative Identification Jane Austen vs William Shakespeare
5-gram

15
Result Summary
• Formal Language1. Positive Identification Successful user identification
2. Negative Identification Successful user identification
Normalization Type Success TotalPercentage 100%Max-min 16,66%z Score 100%
Normalization Type Success TotalPercentage 62,50%Max-min 72.50%
z Score 60,83%

Result Summary cont
• Natural Language1. Positive Identification Successful user identification
2. Negative Identification Failed to identify user
• which is the most accurate? Formal Language
Normalization Type Success Total
Percentage 100%Max-min 26,38%z Score 100%
Normalization Type Success TotalPercentage 0%
Max-min 100%z Score 0%

17
Contribution
• New methods for user identification in formal language and natural language.
• It could enable intrusion detection where intruders masquerade as real users.

18
Future Work
• For formal language, trying to compare one machine divided by period of time
• Use other gram, e.g. 2,4,6,7,8,9,10,12,13, since each gram gives a different result
• User could have more than one writing style• Compare both participants in all possible
scenarios.

19
Any Question
Thank you

20
References• ALMASSIAN, N., AZMI, R. & BERENJI, S. 2009. AIDSLK: An Anomaly Based Intrusion Detection System in Linux Kernel.
Information Systems, Technology and Management, 232-243.
• ASHMAN, H. & HOLLAND, S. Profiling and identifying users with n-gram analysis on their command line histories.
• BALDUZZI, M., PLATZER, C., HOLZ, T., KIRDA, E., BALZAROTTI, D. & KRUEGEL, C. 2010. Abusing Social Networks for Automated User Profiling. In: JHA, S.,
• • OMMER, R. & KREIBICH, C. (eds.) Recent Advances in Intrusion Detection. Springer Berlin / Heidelberg.
• BHATTACHARYYA, P., GARG, A. & WU, S. F. Social Network Model Based on Keyword Categorization. Social Network Analysis and Mining, 2009. ASONAM '09. International Conference on Advances in, 20-22 July 2009 2009. 170-175.
• OYD, D. M. & ELLISON, N. B. 2008. Social network sites: Definition, history, and scholarship. Journal of Computer Mediated Communication, 13, 210-230.
• CHA, B. 2005. Host Anomaly Detection Performance Analysis Based on System Call of Neuro-Fuzzy Using Soundex Algorithm and N-gram Technique. Proceedings of the 2005 Systems Communications. IEEE Computer Society.
• DWYER, C., HILTZ, S. R. & PASSERINI, K. Trust and privacy concern within social networking sites: A comparison of Facebook and MySpace. 2007. Citeseer.
• HUBBALLI, N., BISWAS, S. & NANDI, S. Sequencegram: n-gram modeling of system calls for program based anomaly detection. Communication Systems and Networks (COMSNETS), 2011 Third International Conference on, 4-8 Jan. 2011 2011. 1-10.
• KEÖELJ, V., PENG, F., CERCONE, N. & THOMAS, C. N-gram-based author profiles for authorship attribution. 2003. Citeseer.
• KESELJ, F. P. D. S. V. & WANG, S. Language Independent Authorship Attribution using Character Level Language Models.

21
MAIA, M., ALMEIDA, J., VIRG\, \#237 & ALMEIDA, L. 2008. Identifying user behavior in online social networks. Proceedings of the 1st Workshop on Social Network Systems. Glasgow, Scotland: ACM.
MCKINNEY, S. & REEVES, D. S. 2009. User identification via process profiling: extended abstract. Proceedings of the 5th Annual Workshop on Cyber Security and Information Intelligence Research: Cyber Security and Information Intelligence Challenges and Strategies. Oak Ridge, Tennessee: ACM.
N.P.DAU, V., RAU, V. & J.TEMPLETON, S. 2000. profiling users in the UNIX OS Environment.
PANNELL, G. & ASHMAN, H. 2010. User Modelling for Exclusion and Anomaly Detection: A Behavioural Intrusion Detection System. In: DE BRA, P., KOBSA, A. &
CHIN, D. (eds.) User Modeling, Adaptation, and Personalization. Springer Berlin / Heidelberg.
RAAD, E., CHBEIR, R. & DIPANDA, A. User Profile Matching in Social Networks. Network-Based Information Systems (NBiS), 2010 13th International Conference on, 14-16 Sept. 2010 2010. 297-304.
REDDY, D. K. S. & PUJARI, A. K. 2006. N-gram analysis for computer virus detection. Journal in Computer Virology, 2, 231-239.
VOSECKY, J., DAN, H. & SHEN, V. Y. User identification across multiple social networks. Networked Digital Technologies, 2009. NDT '09. First International Conference on, 28-31 July 2009 2009. 360-365.
WEI, W., XIAOHONG, G. & XIANGLIANG, Z. Profiling program and user behaviors for anomaly intrusion detection based on non-negative matrix factorization. Decision and Control, 2004. CDC. 43rd IEEE Conference on, 14-17 Dec. 2004 2004. 99-104 Vol.1.
ZHANG, B., YIN, J., HAO, J., WANG, S. & ZHANG, D. 2007. New Malicious Code Detection Based on N-Gram Analysis and Rough Set Theory. In: WANG, Y.,
CHEUNG, Y.-M. & LIU, H. (eds.) Computational Intelligence and Security. Springer Berlin / Heidelberg.





























