Embed Size (px)
Citation preview

ThisprojecthasreceivedfundingfromtheEuropeanUnion’sHorizon2020researchandinnovationprogramundergrantagreementNo688191.
D5.2–FIELDTRIALSANDEVALUATIONV1
ProjectNumber 688191
ProjectAcronym STREAMLINE
Nature D:DemonstratorDisseminationLevel Public
WorkPackage WP5DueDeliveryDate 30thNovember2016ActualDeliveryDate 30thNovember2016LeadBeneficiary Rovio
Authors
JorgeTeixeira(ALB)VâniaGonçalves(NMusic)FilipeCorreira(NMusic)PhilippeRigaux(IMR)HenriHeiskanen(Rovio)ArtemGarmash(Rovio)KatjaKivilahti(Rovio)JuhoAutio(Rovio)BjörnHovstadius(SICS–projectcoordinator)

D5.2–FIELDTRIALSANDEVALUATIONV1
2
ExecutiveSummarySTREAMLINEaimstoimproveApacheFlinkframeworkintermsofonlinestreamlearning,dataminingandfusingdataat-restanddatain-motion.Weutilisetheframeworkonfourmajorsectors:telco,music,gamesandwebcontent.Withafocusonpredictivecontextualisationandcross-sectordatafusion,theplatformshouldbesuitablefornon-technicalusers,providingeasytousequerylanguage.ThispublicreportistheseconddeliverableoftheSTREAMLINEworkpackage5(IndustrialApplicationsandEvaluation).Thefocusofthisworkpackageisonthedesign,integration,implementationandevaluationoftherealworldindustrialapplicationsdeployedbythefourindustrialpartners.ThisdocumentreportsthefirstiterationofthefieldtrialsandevaluationcarriedonoutintaskT5.4oftheworkplan.Fourdifferentreal-worldusecasesaredescribedinthisdocument:areal-timeprofilingandrecommendationapplicationbyAlticeLabs(ALB),areal-timeprofilingandrecommendationsystemforusersandcontentcuratorsbyNMusic,areal-timeprofilingpipelineandarecommendationsystembyRovio,andaretailproductsclassificationandmonitoringbyInternetMemoryResearch(IMR).

D5.2–FIELDTRIALSANDEVALUATIONV1
3
TableofContents1 Introduction................................................................................................................................10
2 AlticeLabs...................................................................................................................................11
2.1 KPI1:RateofRecommendations..........................................................................................11
2.1.1 Currentsystem...............................................................................................................................112.1.2 BaselineandTargetmeasures........................................................................................................12
2.2 KPI2:CustomersRejection....................................................................................................12
2.2.1 Currentsystem...............................................................................................................................122.2.2 BaselineandTargetmeasures........................................................................................................12
2.3 KPI3:CustomersEngagement...............................................................................................12
2.3.1 Currentsystem...............................................................................................................................122.3.2 BaselineandTargetmeasures........................................................................................................12
2.4 KPI4:RecommendationSuccessRate...................................................................................13
2.4.1 Currentsystem...............................................................................................................................132.4.2 BaselineandTargetmeasures........................................................................................................13
2.5 KPI5:RelativeShare..............................................................................................................13
2.5.1 Currentsystem...............................................................................................................................132.5.2 BaselineandTargetmeasures........................................................................................................13
2.6 Results...................................................................................................................................13
2.7 SolutionDescription..............................................................................................................14
2.7.1 GlobalArchitectureOverview........................................................................................................142.7.2 DeploymentandOperationsMaintenance....................................................................................152.7.3 Dataingestion:MessageBrokerSystems.......................................................................................152.7.4 Deployment,configurationandautomation..................................................................................17
3 NMusic........................................................................................................................................20
3.1 KPI1:Numberofusersthatconsumerecommendedcontentperday................................20
3.1.1 Currentsystem...............................................................................................................................213.1.2 BaselineandTargetmeasures........................................................................................................21
3.2 KPI2:Numberofrecommendationsconsumedmorethan50%oftheirlength..................21
3.2.1 Currentsystem...............................................................................................................................21

D5.2–FIELDTRIALSANDEVALUATIONV1
4
3.2.2 BaselineandTargetmeasures........................................................................................................21
3.3 KPI3:Shareofsessiontimespentconsumingrecommendedcontent................................21
3.3.1 Currentsystem...............................................................................................................................223.3.2 BaselineandTargetmeasures........................................................................................................22
3.4 KPI4:Timelinessofrecommendations.................................................................................22
3.4.1 Currentsystem...............................................................................................................................223.4.2 BaselineandTargetmeasures........................................................................................................22
3.5 KPI5:Timespentcuratingcontent.......................................................................................22
3.5.1 Currentsystem...............................................................................................................................223.5.2 BaselineandTargetmeasures........................................................................................................22
3.6 KPI6:Quantityofcuratedcontent........................................................................................23
3.6.1 Currentsystem...............................................................................................................................233.6.2 BaselineandTargetmeasures........................................................................................................23
3.7 Results...................................................................................................................................23
3.8 SolutionDescription..............................................................................................................23
3.8.1 BuildingandInstallingtheAnonymizerservice..............................................................................233.8.2 OperatingtheAnonymizerservice.................................................................................................24
4 Rovio...........................................................................................................................................25
4.1 KPI1:ServiceUptimePercentage.........................................................................................25
4.1.1 BaselineandTargetmeasures........................................................................................................264.1.2 Results............................................................................................................................................26
4.2 KPI2:Real-timedashboardvisits..........................................................................................29
4.2.1 BaselineandTargetmeasures........................................................................................................304.2.2 Results............................................................................................................................................30
4.3 SolutionDescription..............................................................................................................31
4.3.1 BuildingFlinkJobsprojects.............................................................................................................324.3.2 DeployingFlinkJobsusingcommandline.......................................................................................324.3.3 AzkabanWorkflowManager..........................................................................................................334.3.4 FlinkStreamingJobPlugin..............................................................................................................354.3.5 OmniataStreamingJob..................................................................................................................354.3.6 ConfigurableStreamingAggregationJob.......................................................................................39

D5.2–FIELDTRIALSANDEVALUATIONV1
5
4.3.7 NagiosMonitoring..........................................................................................................................46
5 InternetMemoryResearch........................................................................................................48
5.1 KPI1:Model’spredictionprecision.......................................................................................48
5.1.1 Currentsystem...............................................................................................................................485.1.2 BaselineandTargetmeasures........................................................................................................48
5.2 KPI2:Start-overTrainingNecessity.......................................................................................49
5.2.1 Currentsystem...............................................................................................................................495.2.2 BaselineandTargetmeasures........................................................................................................49
5.3 KPI3:Trainingphasetime.....................................................................................................49
5.3.1 Currentsystem...............................................................................................................................495.3.2 BaselineandTargetmeasures........................................................................................................49
5.4 KPI4:Documentintraininglatency......................................................................................50
5.4.1 Currentsystem...............................................................................................................................505.4.2 BaselineandTargetmeasures........................................................................................................50
6 GapAnalysis...............................................................................................................................51
7 Conclusion..................................................................................................................................53

D5.2–FIELDTRIALSANDEVALUATIONV1
6
ListofFiguresFigure2.1:ALBGlobalarchitecture..................................................................................................14
Figure2.2:SAPOBrokerdashboard.................................................................................................17
Figure4.1:ServicestatebreakdownofOmniataFlinkstream.........................................................27
Figure4.2:OmniataFlinkstreameventhistogram..........................................................................28
Figure4.3:FlinkstreamserviceuptimefrombeginningofOctober................................................29
Figure4.4:Real-timedashboarddailyvisits.....................................................................................30
Figure4.5:Batchdashboarddailyvisits...........................................................................................30
Figure4.6:Roviobigdatapipelinearchitecture...............................................................................31
Figure4.7:Rovioreal-timepipeline.................................................................................................32
Figure4.8:Examplestreamingjobconfiguration.............................................................................35
Figure4.9:Omniatastreamlingjobhighlevelarchitecture.............................................................36
Figure4.10:TopologyofOmniatastreamingjob.............................................................................36
Figure4.11:Omniatadashboard......................................................................................................38
Figure4.12:DAGofFlinkcustomaggregationjob...........................................................................42
Figure4.13:Grafanadashboardexample........................................................................................43
Figure4.14:Grafanadashboardexample........................................................................................43
Figure4.15:Grafanadashboardeditor............................................................................................44
Figure4.16:KafkaoffsetmonitoringUI............................................................................................45
Figure4.17:Kafkaoffsetlagovertime.............................................................................................45
Figure4.18:NagiosmonitoringdashboardwithFlinkstreamsservicemonitor..............................46

D5.2–FIELDTRIALSANDEVALUATIONV1
7
ListofTablesTable2.1:SAPOBrokercomparedtoSAPObrokerandApackeKafka.............................................17
Table2.2:ComparisonofAnsibleandChef......................................................................................19
Table4.1:Real-timevsBatchdashboardvisits................................................................................30
Table4.2:Jobconfigurationparameters..........................................................................................35
Table4.3:ImportanteventfieldsforOmniatastreaming................................................................37

D5.2–FIELDTRIALSANDEVALUATIONV1
8
ListofListingsListing2.1:Ansibleexamplecommands...........................................................................................18
Listing2.2:Ansibleplaybookexample..............................................................................................18
Listing2.3:Ansiblehostsexample....................................................................................................19
Listing3.1:InstallingbuilddependenciesofAnonymizer................................................................24
Listing3.2:BuildingAnonymizerslim-jars........................................................................................24
Listing3.3:RunningAnonymizerservice..........................................................................................24
Listing3.4:CheckingoftheAnonymizerlogs...................................................................................24
Listing3.5:Kafkacattool...................................................................................................................24
Listing4.1:BuildingRovioFlinkprojectswithMaven......................................................................32
Listing4.2:StartingFlinkjobsfromcommandline..........................................................................33
Listing4.3:FlinkjobsinAzkabanscheduler......................................................................................33
Listing4.4:Examplebatchjobconfiguration...................................................................................34
Listing4.5:Exampleanalyticseventfrompaymentservice.............................................................37
Listing4.6:Omniatajobconfiguration.............................................................................................38
Listing4.7:ExampleOmniataAPIcall...............................................................................................38
Listing4.8:Flinkaggregationjobconfigurationexample.................................................................41

D5.2–FIELDTRIALSANDEVALUATIONV1
9
ListofAbbreviationsandAcronymsALS AlternatingLeastSquaresAPI ApplicationProgrammingInterfaceAWS AmazonWebServicesDAG DirectedAcyclicGraphEMR ElasticMapReduceEPG ElectronicProgramGuidesGUID GlobalUniqueIdentifierHD HighDefinitionHDFS HadoopDistributedFileSystemHTML HypertextMarkupLanguageID IdentifierIMDB InternetMovieDatabaseIPTV InternetProtocolTelevisionJDBC JavaDatabaseConnectivityJSON JavaScriptObjectNotionKPI KeyPerformanceIndicatorOMDB OpenMovieDatabaseQA QualityAssuranceQoS QualityofServiceREST RepresentationalStateTransferS3 AmazonSimpleStorageServiceSLA Service-LevelAgreementTB TerabyteUTC CoordinatedUniversalTimeVoD VideoonDemand

D5.2–FIELDTRIALSANDEVALUATIONV1
10
1 IntroductionSTREAMLINE aims to improveApache Flink framework in termsof online stream learning, datamining and fusing streamandnon-streamdata, and apply it to fourmajor sectors: telco (ALB),media content (NMusic), games (Rovio) andweb content (IMR). Use cases of each partner aredescribed in more detail in document “D5.1 - Design and Implementation v1”. This documentdescribes the results of “Prototype” stage of STREAMLINE development cycle. Each partnerprovides a set of KPIs that have been used to measure the performance of STREAMLINEcomponents in a prototype deployment.We also provide solution descriptions aswell as high-levelgapanalysistogettechnicalinsightoneachusecase.

D5.2–FIELDTRIALSANDEVALUATIONV1
11
2 AlticeLabsALB use case aims to provide targeted and contextualized recommended content to IPTVcustomers, by connecting very high throughputs of at-rest and in-motion data streams intoSTREAMLINE Flink framework, which ultimately will allow for new services, performanceimprovements, cost reduction and business growth. ALB use cases are summarised in the nextparagraphs.
UseCase1:Real-timeAnalyticsandPrediction
AnalyticsareanessentialpartofIPTVbusiness,asthemostimportantindicatorsandactionsarecalculated and retrieved from this data. Providing real-time analytics on both TV services andapplicationsaroundIPTVrepresentacrucialnextsteptoimprovedcustomerexperience.
UseCase2:Real-timeProfiling
Profiling is important forbothusersandclientsaswellas forTVchannelsandprograms.Users’profiles are the mechanisms that allow a thoughtful characterization of clients, typically in anautomaticmanner.Theseprofilesareimportanttoallowdetailedandtargetedrecommendationsforcustomers.
Regarding programs/channels profiles, although with different goals, the mechanisms to buildthem are similar. From the business perspective, these profiles allow a broad set of actionsrangingfromtargetcampaignsofspecificproductsorservicestoreal-timecharacterizationofTVcontent
UseCase3:Real-timeRecommendation
By providing quick and short lists of targeted recommended programs, fullscreen lists ofcategorizedrecommendationsorevenrelatedprogramsandchannels,theoverallgoal isalwaysto improve customer satisfaction and engagement by recommending, on a real-time basis, thebestandmostsuitablecontentaccordingtotheusers’preferencesandtheat-the-timeavailablecontentoptions.
2.1 KPI1:RateofRecommendations
ThisKPImeasurestherateofrecommendationsprovidedtocustomers.Thisismeasuredusingthenumberofrecommendationseachcustomerreceivesunderaparticularscenario.ThegoalofthisKPI istoevaluatethecapabilityofthesystemtoproviderecommendationstocustomers,anditdoesnottakeintoaccount,atthisstage,forthequalityoftherecommendations.ThisKPIcanbemappedintoatypicalevaluationmetricdefinedasrecall.
2.1.1 Currentsystem
ALBcurrentIPTVcontentrecommendationsystemdoesnotprovideautomaticrecommendations,butrathereditorial (manually)chosenones.For instance,popularTVprogramsorSoccergamesaretypicallydisplayedincustomerssettopboxesarerecommendations.

D5.2–FIELDTRIALSANDEVALUATIONV1
12
2.1.2 BaselineandTargetmeasures
At this stage it is not possible to define a baseline as ALB do not have a fully automaticrecommendationsystem.Nevertheless,weexpectSTREAMLINEtobeabletoprovideaminimumof5to10personalizedrecommendationstoeachcustomersbasedonhishistoricalandreal-timeactivitytogetherwiththeTVcontentavailability.ThisisthusconsideredasthetargetmeasureforKPI1.
2.2 KPI2:CustomersRejection
ThisKPImeasurestherateofrejectedrecommendationsprovidedtocustomers.Thisismeasuredby the number of times each customer premeditatedly removes a particular recommendedcontentorcategory.ThisKPIiscalculatedfromtheprecisionoftherecommendationsystem.
2.2.1 Currentsystem
As mentioned in previous KPIs, ALB current IPTV content recommendation system does notprovideautomatic recommendations, but rather editorial (manually) chosenones. For instance,popular TV programs or Soccer games are typically displayed in customers’ set top boxes arerecommendations.
2.2.2 BaselineandTargetmeasures
Althoughatthisstageitisnotpossibleneithertodefineabaselineortargetmeasures,asALBdonothavea fullyautomaticrecommendationsysteminproduction, it isexpectedthatthis targetmeasureislowandgetslowerasthesystemevolvestopilotandproductionphases..
2.3 KPI3:CustomersEngagement
ThisKPImeasurestheengagementofrecommendationsoncustomers.Thisismeasuredbasedonthenumberofrecommendationsthateachcustomerfollowed.Wheneveracustomerreceivesarecommendation,eitherbecausehespecificallylookedforbynavigatingthroughthesettopboxmenuorbecauseitshowedinthescreen,it isassumedthattherecommendationhasapositiveimpactinthecustomer–andthusimprovesengagement–ifthecustomerselectsorwatchthatparticularrecommendedcontent.
2.3.1 Currentsystem
Once again, asmentioned in previous KPIs, ALB current IPTV content recommendation systemdoesnotprovideautomaticrecommendations,butrathereditorial(manually)chosenones.
2.3.2 BaselineandTargetmeasures
Atthisstageitisnotpossibleneithertodefineabaselinenortargetmeasures,asALBdonothavea fully automatic recommendation system in production. Nevertheless, as opposed to definedtargetmeasuresforKPI2(customersrejection),thistargetmeasureisexpectedtoincreaseastherecommendationsystemevolvestofromprototypetopilotandlastlytoproduction.

D5.2–FIELDTRIALSANDEVALUATIONV1
13
2.4 KPI4:RecommendationSuccessRate
This KPI is a combinationof Customers Engagement, Rate of Recommendations andCustomersRejection KPIs previously described that aims to assign a success rate to the recommendationsprovided to the customers’ under context constrains such as a particular time frame or set ofcustomers’.
2.4.1 Currentsystem
ALBcurrentIPTVcontentrecommendationsystemdoesnotprovideautomaticrecommendations,butrathereditorial(manually)chosenones.
2.4.2 BaselineandTargetmeasures
Althoughwithoutarecommendationsysteminproductionortestsitisnotpossibletodefinedabaseline,itisexpectedthatwithSTREAMLINEitwillbepossibletoachieveaminimumof50%ofsuccessrate.
2.5 KPI5:RelativeShareTheshare,asanindicator,measurestheaudienceofaparticularTVprogram.ItisoneofthemostcommonperformanceindicatorsforTVproviders,andisextremelyimportanttounderstandthepopularityofTVprogramsandchannels.
ThisKPImeasurestheimpactthattherecommendationenginehasontheprogramshare.ThisKPIistestedusingA/Btests,anditismeasuredthroughtheratiobetweentheshareofeachprogramwatchedbycustomerswithoutrecommendationversuscustomerswhichprogramwaspreviouslyrecommendedbySTREAMLINEframework.
2.5.1 Currentsystem
Once again, asmentioned in previous KPIs, ALB current IPTV content recommendation systemdoesnotprovideautomaticrecommendations,butrathereditorial(manually)chosenones.
2.5.2 BaselineandTargetmeasures
Itisnotpossibletodefinedabaselineatthisstage,neitherasingletargetmeasure,fortwomainreasons:First, the impacton theshareofaprogram/channelvariesa lot, for instance,with thepopularityoftheprogram/channel itselfandthetimeofthedayit isscreened.Andsecond,thisimpact isalsostronglycorrelatedwiththeRecommendationSuccessRateKPI,asahighsuccessrecommendationrateisexpectedtoariseahigherimpactontheshare.
2.6 ResultsALB use cases are strongly dependent on Machine Learning to be able to provide the users’profiling and TV content recommendations. At this stage Flink does not provide a streamingmachinelearningalgorithmcapableofachievingthesegoals.ALB,incollaborationwithSZTAKI,iscurrentlytestingiALSasoneapproachforreal-timerecommendations.
D5.2–FIELDTRIALSANDEVALUATIONV1
14
2.7 SolutionDescription
2.7.1 GlobalArchitectureOverview
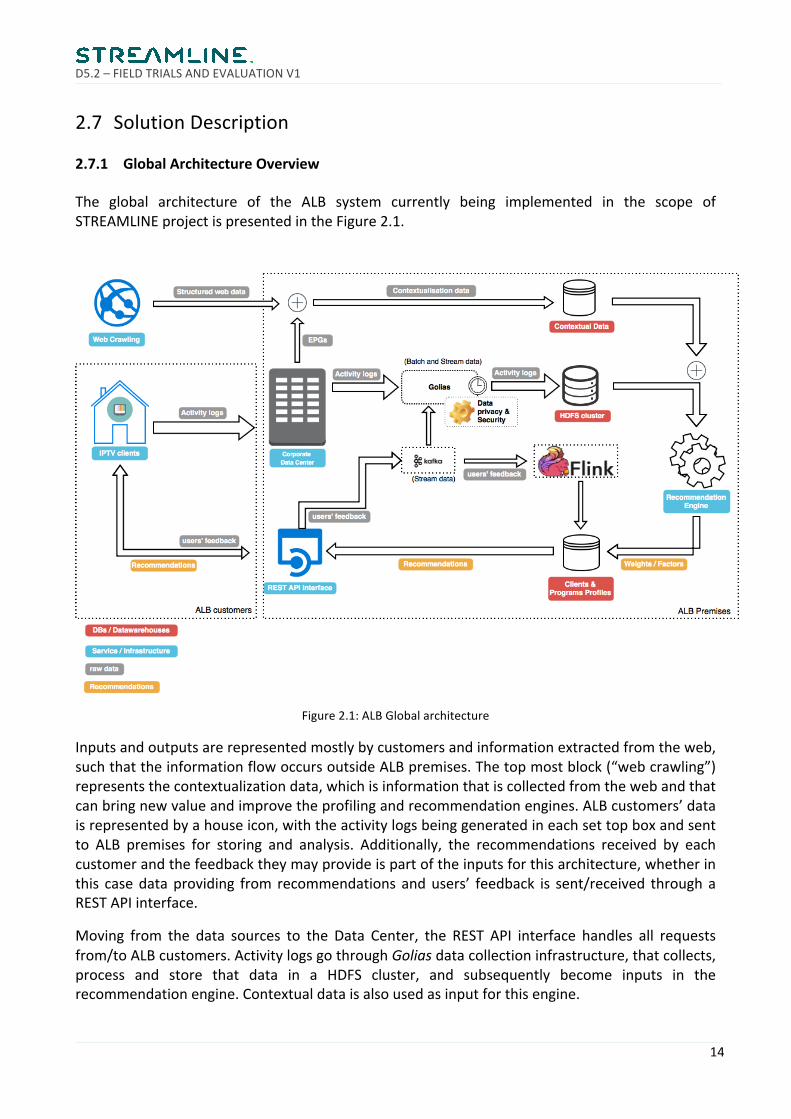
The global architecture of the ALB system currently being implemented in the scope ofSTREAMLINEprojectispresentedintheFigure2.1.
Figure2.1:ALBGlobalarchitecture
Inputsandoutputsarerepresentedmostlybycustomersandinformationextractedfromtheweb,suchthattheinformationflowoccursoutsideALBpremises.Thetopmostblock(“webcrawling”)representsthecontextualizationdata,whichisinformationthatiscollectedfromthewebandthatcanbringnewvalueandimprovetheprofilingandrecommendationengines.ALBcustomers’dataisrepresentedbyahouseicon,withtheactivitylogsbeinggeneratedineachsettopboxandsentto ALB premises for storing and analysis. Additionally, the recommendations received by eachcustomerandthefeedbacktheymayprovideispartoftheinputsforthisarchitecture,whetherinthis casedataproviding from recommendations andusers’ feedback is sent/received throughaRESTAPIinterface.
Moving from the data sources to the Data Center, the REST API interface handles all requestsfrom/toALBcustomers.ActivitylogsgothroughGoliasdatacollectioninfrastructure,thatcollects,process and store that data in a HDFS cluster, and subsequently become inputs in therecommendationengine.Contextualdataisalsousedasinputforthisengine.

D5.2–FIELDTRIALSANDEVALUATIONV1
15
The final step toprovide real-time recommendation to customers’ is toaggregate the rankings,weightsandfactorsobtainedbytherecommendationengineforeachprogramwithbothhistoricand real-timecustomers’ feedback collectedandprocessedbyApacheFlink. This information isthenprocessedandstoredinafastdistributeddatabase(definedinthearchitecturediagramas“Clients & Programs Profiles”), which can be accessed directly from the REST API interface toprovideresponsestoallcustomers’requests.
2.7.2 DeploymentandOperationsMaintenance
The cost of debugging live software and services, together with the customers’ potential un-satisfactioncausedbydowntimeordegradedQoSisnow-a-daystoohightoworththerisk.ALBisparticularlycarefulwithdeploymentandmaintenanceoperationsaroundservicesandsoftware,andthe integrationofApacheFlinkandSTREAMLINEarchitecture in its infrastructuretakes intoaccount three different aspects: (i) data ingestion; (ii) data processing pipeline; and (iii)deployment. Data ingestion is one of the first layers of STREAMLINE architecture and boththroughputandstabilitymustbeconfidentlyassured:ALBisprogressivelyadaptingitscurrentin-housemessagingsolution(SAPOBroker)toKakfacluster.Forthedataprocessingpipeline,ALBistestingthecapabilitiesofApacheNifitohostallthedataprocessingpipelineconcerningitsuse-cases. And finally, deployment, configuration and automation of all the software on largedistributedsystemsinhandledusingAnsible,oneofthemoststablesolutionsavailable,togetherwithChef.
Inthefollowingsub-sectionswewillpresentdetailedinformationandcomparativestudiesofeachof the three key aspects of the STREAMLINE infrastructure concerning operations andmaintenance.
2.7.3 Dataingestion:MessageBrokerSystemsMessage Broker Systems are typically used in software infrastructures as a network layer thathandles communication – based on formally defined messages – between applications. Thesebrokersareresponsibleformessagevalidation,transformationandroutingandaimtominimizethemutualawarenessthatapplicationsshouldhaveofeachotherinordertobeabletoexchangemessages.Examplesofactionsthatmightbetakenbymessagebrokersystems include(i) routemessages to one or more of many destinations; (ii) transform messages to an alternativerepresentation;(iii)respondtoeventsorerrorsandmanyothers.
Now-a-daysALBmessagebrokersystemusedinthescopeof(IP)TVcontentandanalyticsisbasedon SAPO Broker (https://github.com/sapo/sapo-broker), but due to several integration andarchitecturaldecisionsandlimitations,thissystemisbeingprogressivelyreplacedbyKafka.Thisisanother important step for operations in the scope of STREAMLINE project, as Apache FlinktypicallyincludesKafkaasthepreferabledatastreamsingestionsystem.
2.7.3.1 SAPOBroker
SAPOBrokerisafullyin-housedevelopmentforadistributedmessagingframework.Amongmanyfeatures, it provides minimal administration overhead, Publish-Subscribe and Point-to-Pointmessagingandguaranteeddeliveryandwildcardsubscriptions.SAPObrokerhasanevent-drivenarchitectureand isconsideredasamessageorientedmiddlewarebyprovidingboth“queueing”
D5.2–FIELDTRIALSANDEVALUATIONV1
16
and“handling”mechanismsformessages.Italsoincludesadistributednetworkofvirtualbrokers–interbrokers–thataimtoactasasinglebroker.
2.7.3.2 ApacheKafka
Kafkaisadistributedstreamingplatformwiththreekeycapabilities:(i)publishingandsubscribingto streams of records. In this respect it is similar to amessage queue or enterprisemessagingsystem;(ii)storingstreamsofrecordsinafault-tolerantway;(iii)processingstreamsofrecordsastheyoccur.AndKafka isgood for twobroadclassesofapplication: tobuild real-timestreamingdata pipelines that reliably get data between systems or applications and to build real-timestreaming applications that transformor react to the streamsof data.Additionally, it runs as aclusterononeormoreservers.
BycombiningSAPOBrokerandApacheKafka,thegoal istokeepoperationalandmaintainwithloweffortaverylargesystemcurrentlyresponsibleforseveralcriticalservicesatALB,butalsotoprogressively replace it byApacheKafka, a state-of-the-artmessaging systemmore suitable forALBneeds.
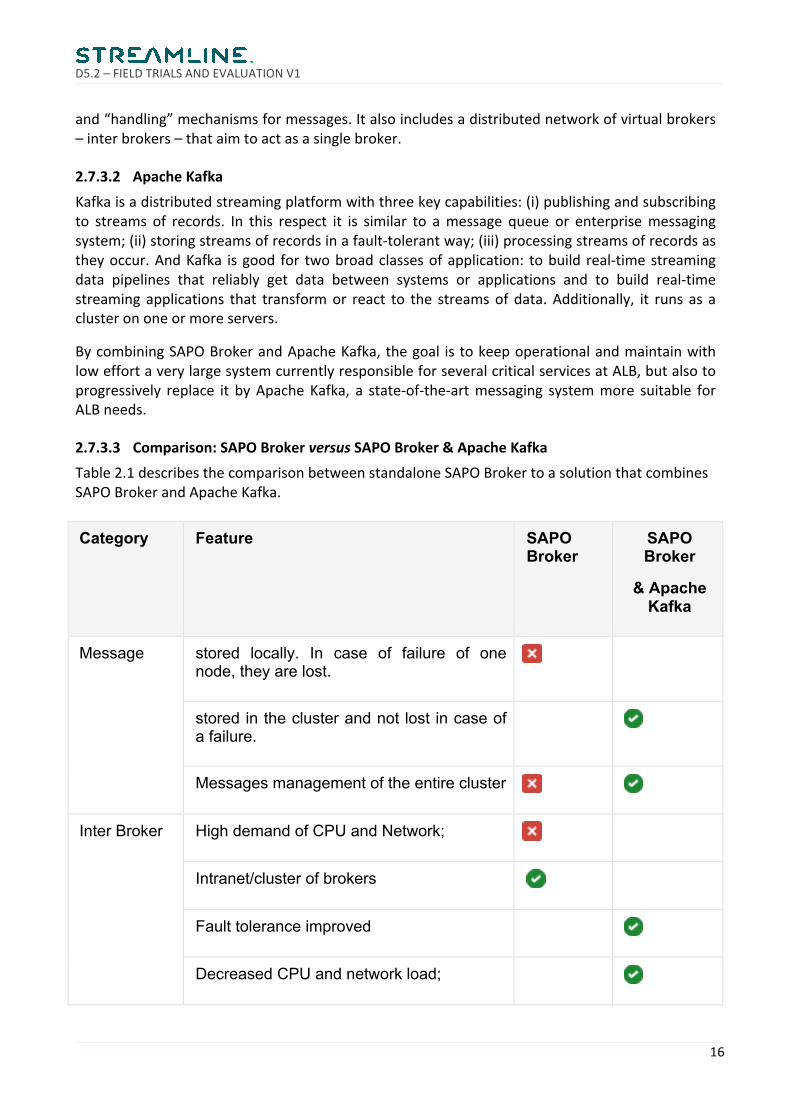
2.7.3.3 Comparison:SAPOBrokerversusSAPOBroker&ApacheKafkaTable2.1describesthecomparisonbetweenstandaloneSAPOBrokertoasolutionthatcombinesSAPOBrokerandApacheKafka.
Category Feature SAPO Broker
SAPO Broker
& Apache Kafka
Message stored locally. In case of failure of one node, they are lost.
stored in the cluster and not lost in case of a failure.
Messages management of the entire cluster
Inter Broker High demand of CPU and Network;
Intranet/cluster of brokers
Fault tolerance improved
Decreased CPU and network load;

D5.2–FIELDTRIALSANDEVALUATIONV1
17
New apps can consume messages without affecting inter broker flow
Failure resilience
Loss of messages if failure of one instance
Live rolling upgrade
Table2.1:SAPOBrokercomparedtoSAPObrokerandApackeKafka
2.7.3.4 SAPOBroker&ApacheKafkaDashboardsThe current integration of SAPO Broker with Apache Kafka provides web-based dashboards tomonitorandexploretheagents,topicsandqueuescurrentlyintheproductionenvironment.Thisinfrastructure issharedamongothercriticalservicesatALB,andoneofthoseservicesconcernswiththeactivitylogsofIPTVcustomers.TheFigure2.2presentsthedashboardofSAPOBroker&ApacheKafka,with real-timestatisticsof themost relevant indicators suchas inputandoutputrates,queuedmessagesanderrorrates.
Figure2.2:SAPOBrokerdashboard
2.7.4 Deployment,configurationandautomationTheconfigurationanddeploymentoflargedistributedsystemsonbothvirtualizedplatformsandbare-metal hosts is a critical task at ALB. It is crucial that this process if fully automate andreplicable, based onmature and solid software tools. Ansible and Chef, alongwith Puppet arecurrentlythereferencesforsuchtasks.AfteralongandexhaustivecomparisonbetweenAnsible

D5.2–FIELDTRIALSANDEVALUATIONV1
18
and Chef, ALB opted for Ansible. Ansible is thus the currently software tool adopted andsupportedforconfigurationanddeploymentonourpremises.
2.7.4.1 AnsibleAnsibleaimstoprovidesimplelarge-scaleorchestrationofsystemsinalightweightpackageoverSSH rather than an all-encompassing solution. One can think of Ansible as a higher-level,idempotentversionofbashscriptsthatiseasiertorapidlydevelopandmanage,especiallygiventhe language choice of YAML. This configuration and deployment software tool has onemajoradvantage: it isnotmandatorythe installationofagentsonallmanagedmachines,as itusesanSSHcommunicationprotocol.Additionally,itcanbeeasilyintegratedinalmostanyprogramminglanguageandhassupport to JSON. Its’ typicalarchitecture iscomposedbyacentral server (theansibleadminconsole)andseveralclientsmanagedbythiscentralserver.ThecontrolisgatheredbySSHcommunicationbetweenthecentralserverandtheclients.
One of the key features of Ansible are the playbooks - these are the configuration fileswheretherearedefineddifferentplaysof commandsondifferenthosts,organisedusingYAMLsyntaxbuiltfromtasks,rolesandhosts.
# to specify single actions on specific machines, use ‘ansible’ command
>> ansible 10.112.76.90 -m raw -a "yum -y install python-simplejson" –k
# to execute playbooks, use ‘ansible-playbook’ command
>> ansible-playbook install-pdsngtools.yml
Listing2.1:Ansibleexamplecommands
Withplaybooksit’spossibletodefine,foreachparticularhost/machinespecifiedinthehostsfile,variablestouseinthe“play”,taskstoperformoneachhost,rolesfordifferentservicesandhosts,shellcommands,humanreadablenamesforthetasks,amongmanyothers.
---
- hosts: data-collector
sudo: yes
tasks:
- name: Install redhat-rpm-config (Dependence)
yum: name=redhat-rpm-config state=latest
- name: Configure Apache Flink.
copy: src=../files/usr/local/flink/conf/flink-conf.yaml dest=/usr/local/flink/conf/flink-conf.yaml owner=root group=root mode=0644
Listing2.2:Ansibleplaybookexample
[data-collector]
10.112.76.90 ansible_ssh_user=admin ansible_ssh_pass=xxxxx
D5.2–FIELDTRIALSANDEVALUATIONV1
19
10.112.76.91 ansible_ssh_user=root ansible_ssh_pass=xxxxx
10.112.76.92 ansible_ssh_user=root ansible_ssh_pass=xxxxx
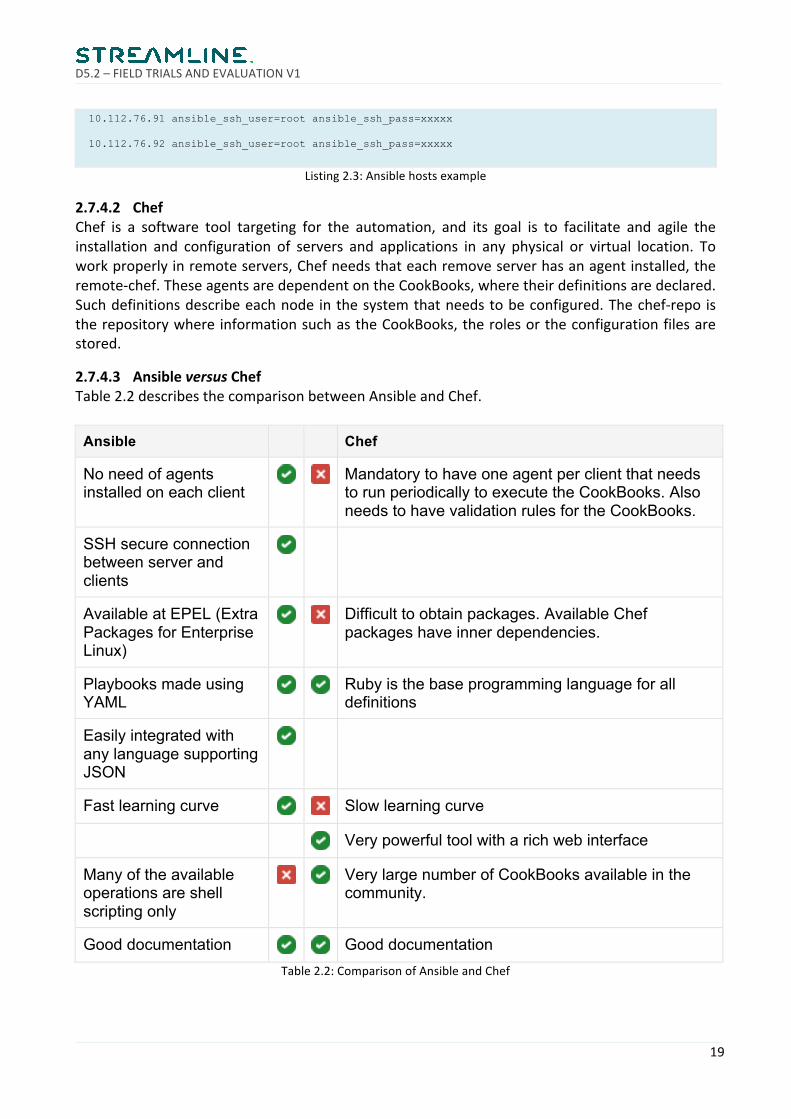
Listing2.3:Ansiblehostsexample
2.7.4.2 ChefChef is a software tool targeting for the automation, and its goal is to facilitate and agile theinstallation and configuration of servers and applications in any physical or virtual location. Toworkproperlyinremoteservers,Chefneedsthateachremoveserverhasanagentinstalled,theremote-chef.TheseagentsaredependentontheCookBooks,wheretheirdefinitionsaredeclared.Suchdefinitionsdescribeeachnode inthesystemthatneedstobeconfigured.Thechef-repo istherepositorywhereinformationsuchastheCookBooks,therolesortheconfigurationfilesarestored.
2.7.4.3 AnsibleversusChefTable2.2describesthecomparisonbetweenAnsibleandChef.
Ansible
Chef
No need of agents installed on each client
Mandatory to have one agent per client that needs to run periodically to execute the CookBooks. Also needs to have validation rules for the CookBooks.
SSH secure connection between server and clients
Available at EPEL (Extra Packages for Enterprise Linux)
Difficult to obtain packages. Available Chef packages have inner dependencies.
Playbooks made using YAML
Ruby is the base programming language for all definitions
Easily integrated with any language supporting JSON
Fast learning curve
Slow learning curve
Very powerful tool with a rich web interface
Many of the available operations are shell scripting only
Very large number of CookBooks available in the community.
Good documentation
Good documentation Table2.2:ComparisonofAnsibleandChef

D5.2–FIELDTRIALSANDEVALUATIONV1
20
3 NMusic
NMusic’susecasesintendtoleverageonSTREAMLINEandFlink’sreal-timefunctionalitiestobuildautomatedrecommendationsbenefittingfromabiggerknowledgebaseofeventsandautomaticcross-checkingandvalidationofnewinformationfromanumberofsources.Inaddition,NMusicexpects toadd thecapacity topropose fasterandmoreup-to-date recommendationsbasedonreal-time events,while delivering an improved and personalised user experience. NMusic’s usecasesaresummarisedinthenextparagraphs.
UseCase1:RecommendationsforcontentconsumersProviderecommendationsofmusictracks,videosandpodcastepisodes.Theserecommendationsarebasedonusers’activity(plays,likes,etc.),users’context(athome,atwork,traveling,etc.),externalactivity(newmusicevents,ornews)andcatalogueactivity(newalbumreleases,newvideos,newartists).ThisusecasehasNMusicastheindustrialpartnerandSztakiastheacademicpartner.
UseCase2:Recommendationsforcontentcurators(editorialteam)Providerecommendationstothecurators,tosupporttheminthecreationofeditorialcontent(e.g.,thematicplaylists,highlights,etc).Theserecommendationsaretobebasedontheactivityofcontentconsumers,theactivityoftheeditorialcontentcurators,andtheactivityofthirdparties(news,concerts).ThisusecasehasNMusicastheindustrialpartnerandSztakiastheacademicpartner.
UseCase3:MusiccontextualdataProvidedataaboutmusicnewsandeventshappeninginPortugaltocontentconsumers.ThisdatashallbeextractedfromtheWeb,andprovideddirectlytotheusers’ofNMusic’sapps,asdetailedintheuserstoriesbelow.Itshallalsobeusedtomakecontentdemandpredictionsandcontentrecommendations,asexplainedinUseCase4.ThisusecasehasNMusicandIMRasindustrialpartners.
UseCase4:Insightsintouserbehaviourforcontentcurators(editorialteam)Providecontentdemandpredictionsandcontentrecommendations,tobeusedbytheeditorialteamtofeedintoeditorialplaylists,channelsandhighlights.ThisusecasehasNMusicandIMRasindustrialpartners.NMusicshallprovidedataaboutitsusers’activity,andIMRshallnormalizethisdataandidentifysignificantpatterns.
ThegoalsoftheseusecaseswillbeassessedusingtheKPIsdescribedinthefollowingsections.
3.1 KPI1:NumberofusersthatconsumerecommendedcontentperdayEnd-usersofNMusic’sappscanchoosetosearch forcontent for themselvesor toconsumetherecommendations proposed by the apps. In the latter case, they are offered a list of differentrecommended contents, which they may choose to consume sequentially or may simply picksomethinginparticularthatcallstheirattention.
This KPI is about increasing the number of users that find recommended content appealingenoughtobeconsumed.

D5.2–FIELDTRIALSANDEVALUATIONV1
21
3.1.1 Currentsystem
NMusic’splatformalreadyprovidescontentrecommendations,butitdoesnottrackhowtheuserreachedthecontentthatsheisconsuming(e.g.,whetheritwasrecommendedorotherwise).Thestreamingplatformwillneedtobeextendedtocollectthisinformation.
3.1.2 BaselineandTargetmeasures
Toestablishabaseline, it isfirstneededtoputinplacethemechanismthatwillrecordhowtheusersreachthecontentsthattheychoosetoconsume.Thiswillallowtoestablishabaseline,andallowtoposteriorlycomparethenumberofusersthatconsumerecommendedcontenteachday;usingtheoldandusingthenewrecommendationengines.
WeexpectthenumberofusersthatconsumecontentthatwasrecommendedusingSTREAMLINEtoincreaseby50%,whencomparedwiththecurrentconsumptionofrecommendedcontent.
3.2 KPI2:Numberofrecommendationsconsumedmorethan50%oftheirlength
Eventhoughanend-usermaychoosetoconsumerecommendedcontent,shemayquicklyrealisethatitisnotonethatsheenjoys,andthuspickssomethingelsetoconsume.
ThisKPI isaboutincreasingthetimespentbytheuserconsumingrecommendedcontent,asweexpectittohaveacorrelationwiththequalityoftherecommendations.
3.2.1 Currentsystem
NMusic’splatformalreadycollectsthetimespentconsumingcontent,andwillbeextendedtoalsocollectwhichofthesecontentswereconsumedbecausetheywererecommended.
3.2.2 BaselineandTargetmeasures
Toestablishabaseline, it isfirstneededtoputinplacethemechanismthatwillrecordhowtheusersreachthecontentsthattheychoosetoconsume.Thiswillallowtoestablishabaseline,andallowtoposteriorlycomparethenumberofrecommendationsconsumedmorethan50%oftheirlength;usingtheoldandusingthenewrecommendationengines.
Weexpectthenumberofrecommendationsthatareconsumedmorethan50%oftheirlengthtoincreasesignificantly.
3.3 KPI3:ShareofsessiontimespentconsumingrecommendedcontentIfanend-user increases theuseof thestreamingplatform ingeneral, itwillbenatural that theconsumptionofrecommendedcontentalsoincreases.Itmaythereforenotbeclearifanincreasein recommended content consumption is due to an improvement in the recommendationsthemselves.
This KPI is about assessing if the time spentby theend-user consuming recommended contentincreasesinrelationtothetimespentconsumingnon-recommendedcontent.

D5.2–FIELDTRIALSANDEVALUATIONV1
22
3.3.1 Currentsystem
NMusic’splatformalreadycollectsthetimespentconsumingcontent,andwillbeextendedtoalsocollectwhichofthesecontentswereconsumedbecausetheywerepartofarecommendation.
3.3.2 BaselineandTargetmeasures
Toestablishabaseline, it isfirstneededtoputinplacethemechanismthatwillrecordhowtheusersreachthecontentsthattheychoosetoconsume.Thiswillallowtoestablishabaseline,andallow toposteriorly compare theshareof session time spent consuming recommendedcontent;usingtheoldandusingthenewrecommendationengines.
We expect an increase by 100% in the share of session time used for consumption ofrecommendedcontent.
3.4 KPI4:TimelinessofrecommendationsThe recommendationsproducedbyNMusic’s platformare currently generatedonceaday, andthereforedonotadapttousers’differentbehavioursandcontextsthroughouttheday.
ThisKPIisaboutmakingrecommendationsthataremoretimelytotheusers’currentcontext.
3.4.1 Currentsystem
Therecommendationsenginethat ispartofNMusic’splatformproducesrecommendationsonlyonceaday,andwillbereplacedbythenewenginebasedonSTREAMLINE(andonApacheFlink).
3.4.2 BaselineandTargetmeasures
The generation of recommendations should change from a daily batch to real timerecommendations.
3.5 KPI5:TimespentcuratingcontentThecurationofeditorialplaylistsandhighlightsisatime-intensiveprocessthatiscurrentlydonebasedontheexpertiseofNMusic’seditorialteam.
ThisKPIisaboutreducingthetimeneededtodocurationworkbyprovidingauxiliarytoolstotheeditorialteam,i.e.byrecommendingcontentforthecuratedsections.
3.5.1 Currentsystem
The editorial team is able to create, edit and delete editorial playlists and highlights, usingNMusic’seditorialbackoffice.Thetimespentperformingthesetaskswillbecollectedwithinthebackoffice, to allow to assess thedifference in the time spent performing these tasks once theeditorialteamgainsaccesstotheeditorialrecommendations.
3.5.2 BaselineandTargetmeasures
Toestablishabaseline,it isfirstneededtoputinplacethemechanismthatwillrecordthetimespent by the editorial team. This will allow to establish a baseline, and allow to posteriorlycomparethequantityofcuratedcontent;usingthepreviousversionofthebackofficeandthenewversionthatprovidescontentcurationrecommendations.

D5.2–FIELDTRIALSANDEVALUATIONV1
23
Thetimespentdoingcurationworkshouldreducesignificantly(e.g.,consideringa95%confidencelevel)oncetheeditorialrecommendationsaremadeavailable.
3.6 KPI6:QuantityofcuratedcontentThecurationofeditorialplaylistsandhighlightsisatime-intensiveprocessthatiscurrentlydonebasedontheexpertiseofNMusic’seditorialteam.
ThisKPI isabout increasingthenumberofcuratedplaylistsandhighlights,byprovidingauxiliarytoolstotheeditorialteam.
3.6.1 Currentsystem
The editorial team is able to create, edit and delete editorial playlists and highlights, usingNMusic’s editorial backoffice. The amount of these changeswill need to be trackedwithin thebackoffice,toallowtoassessthedifferenceinthenumberofcuratedcontentsoncetheeditorialteamgainsaccesstotheeditorialrecommendations.
3.6.2 BaselineandTargetmeasures
Toestablishabaseline,itisfirstneededtoputinplacethemechanismthatwillrecordthenumberofoperationsperformedbytheeditorialteam.Thiswillallowtoposteriorlycomparethequantityofcuratedcontent;usingthepreviousversionofthebackofficeandthenewversionthatprovidescontentcurationrecommendations.
The number of curated editorial playlists and highlights should increase significantly once theeditorialrecommendationsaremadeavailable.
3.7 ResultsThemechanismstofullycollectthebaselinedatashouldbeinplacebyapril2017,therefore,thereisn’tyetenoughdatatoassesstheKPIsdescribedintheprevioussections.
3.8 SolutionDescriptionNMusic’s Anonymizer service was developed specifically to provide anonymized data to itsStreamlinepartners.ItreadsreportedusertransactionsfromaKafkatopic,anonymizesthembyremovinganyinformationthatmayallowtodirectlyorindirectlyidentifyauser,andpublishestheanonymized transaction to another Kafka topic. This service poses a few requirements on itsinstallationandoperation.
3.8.1 BuildingandInstallingtheAnonymizerservice
Installing the build dependencies, namely SBT, as detailed in the official documentation isdescribedinListing3.1.
sudo apt-get install apt-transport-https echo "deb https://dl.bintray.com/sbt/debian /" | sudo tee -a /etc/apt/sources.list.d/sbt.list sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 642AC823 sudo apt-get update sudo apt-get install sbt

D5.2–FIELDTRIALSANDEVALUATIONV1
24
Listing3.1:InstallingbuilddependenciesofAnonymizer
Building into slim-jars and collect all the files into thetarget/pack directory is described inListing3.2.sbt pack
Listing3.2:BuildingAnonymizerslim-jars
RunningtheserviceisdescribedinListing3.3.
cd target/pack/ mkdir log bin/trans_anonymizer &>> log/trans_anonymizer.log & bin/grouped_trans_anonymizer &>> log/grouped_trans_anonymizer.log &
Listing3.3:RunningAnonymizerservice
3.8.2 OperatingtheAnonymizerservice
Toaassess iftheserviceisrunningasexpectedyoucancheckthelogsforanywarningorerrormessagesand/orverifythatitisproducingtheexpectedanonymizeddatatotheKafkatopics.
CheckingofthelogsisdescribedintheListing3.4.
tail -f log/trans_anonymizer.log Tail -f log/grouped_trans_anonymizer.log
Listing3.4:CheckingoftheAnonymizerlogs
TocheckthattheexpectedanonymizeddataisbeingproducedyoucanusethekafkacattoolasdescribedinListing3.5.
kafkacat -C -b localhost -t user.activity.tracktransactions.anonymized-incoming -p 0 -o -2000 -e kafkacat -C -b localhost -t user.activity.tracktransactions.grouped.anonymized-incoming -p 0 -o -2000 -e
Listing3.5:Kafkacattool

D5.2–FIELDTRIALSANDEVALUATIONV1
25
4 RovioRovio’sbigdatapipeline collectsdata fromgameclients, servicesandexternal systems.Data isaggregatedandanalysedtoproduceuserprofileswithfeaturessuchasregistrationdate,lastseentimestamp, average session length, churn score, ads shown and money spent. Profiles areprocessed further to produce KPIs like daily new and returning users, retention, total in-apppurchaseandadsrevenue,conversionrateandaveragerevenueperuser.Userprofilesarealsoused for service targetingpurposes; for examplewemaydisable interstitial ads from spenders,targetin-apppurchasecampaignsforhookedplayersthathavenotyetconvertedtospenders,orsimplifythelevelsforplayerslikelytochurn.Rovio’sgoalistoutiliseSTREAMLINEtoimprovethedeliverytimeandself-servicecapabilitiesofplayerprofilingandgamesbusinessreporting.Rovio’susecasesaresummarisedinthenextparagraphs.
Usecase1:Real-timeprofilingandKPI’s
Thepurposeofthereal-timeprofilingandKPI’susecaseistobuildthefoundationforreal-timeanalyticsandthenrolloutreal-timedashboardsandprofilesfordifferentgamesandservices.ScopeofthepilotistointroduceApacheFlinktoourtechnologystackanduseOmniatareal-timeserverforserverintegrationasafirststeptoprovidereal-timestreaminganalyticsforgameprojects.Thisapproachallowsustoconcentrateontheintegrationofthereal-timeplatformandtoolstoourstack,butstillofferimmediatevalueforbothinternalandexternalgameteams.Duringsecondhalfof2016werunapilotforthesystemwhereagameintechnicalsoftlaunchwasusingthissysteminparallelwiththelegacybatchsystem. Secondstepforthereal-timeprofilingandKPI’susecaseistoprovideaninternallydevelopedtoolforRovioteamstocreatecustomreportingpipelinesfortheirgamesandservices.DataisstreamedfromKafkatoaFlinkclusterthatjoins,filtersandaggregatesthedatabeforewritingthedataintotimeseriesdatabase.Implementationofthissystemstartedinsecondhalfof2016andweplantostartpilotingthesystembeforetheendoftheyear. Usecase2:Recommendationsystem
Purpose of the recommendation system use case was to provide real-time recommendationengine for a gaming service.Unfortunatelydue toorganisational changes theownershipof thissystemchangedanditwasthendecidedthatApacheFlinkwillnotbeutilisedinthefinalsolution.ForthisreasontheRoviorecommendationsystemusecasewasdiscontinuedintheSTREAMLINEprojectinthesummerandnopilotwasexecutedforthesystem.
ThegoalsoftheseusecaseswillbeassessedusingtheKPIsdescribedinthefollowingsections.
4.1 KPI1:ServiceUptimePercentageRovio Games are developed and operated globally. It is therefore required that all servicesincludinganalyticsprovidehighservicelevelwith24/7support.
ThisKPIisaboutmeasuringtheservicelevelofApacheFlinkbasedfeaturesusingservicelife-timeuptimepercentage. Service life-time uptimepercentage is calculated by subtracting from100%thepercentageofminuteswhensystemwasnotinstate“OK”forreasonsotherthanscheduled

D5.2–FIELDTRIALSANDEVALUATIONV1
26
maintenance.Servicelife-timebeginsfromAugustwhenservicewasconsideredfeaturecomplete.ThisdataisretrievedfromNagiosmonitoringsystem.
4.1.1 BaselineandTargetmeasures
Rovio did not have comparative real-time analytics platform in use prior to Apache Flink andcurrentlywedonotsystematicallymeasureservice levelacrossall theRovioservices.However,the best practise is to target Monthly Uptime Percentage of 99,95% provided by most of theAmazonWebServices.WeusethisastargetservicelevelforApacheFlinkfeatures.
4.1.2 Results
ThedatafromNagiosmonitoringsystemsuggeststhatservice-uptimewas99,59%withscheduledmaintenancebreaksincluded.

D5.2–FIELDTRIALSANDEVALUATIONV1
27
Figure4.1:ServicestatebreakdownofOmniataFlinkstream
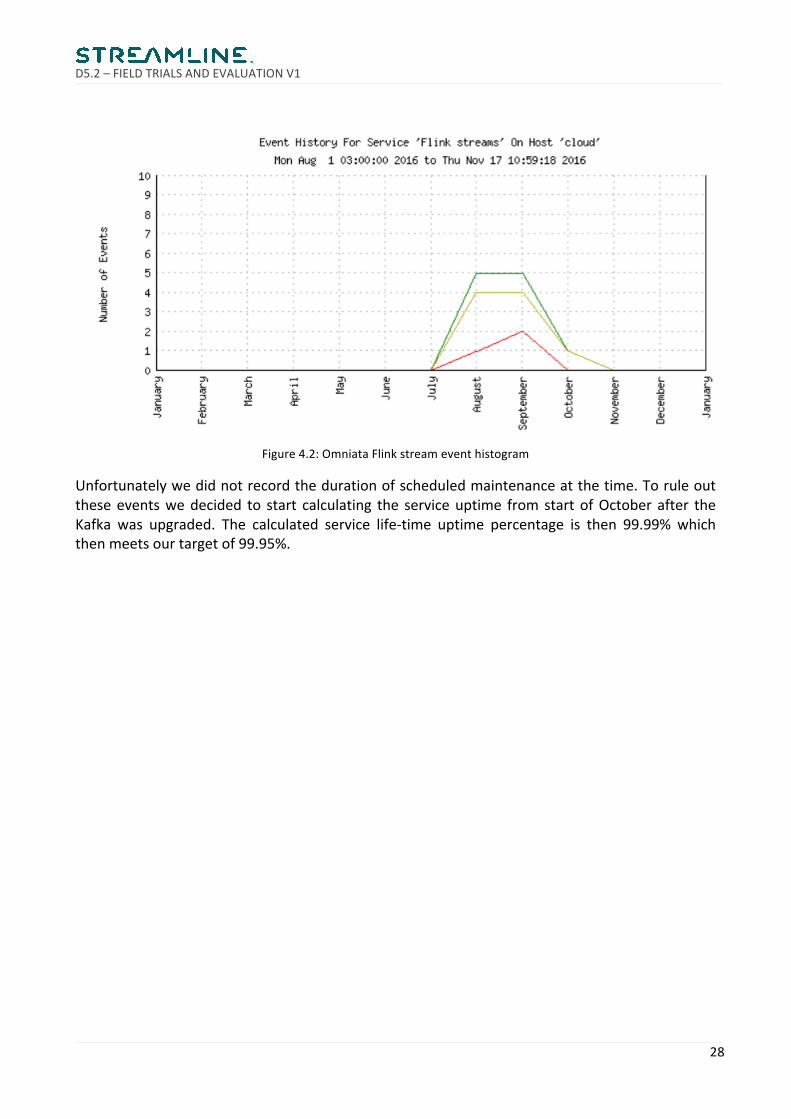
When looking at the event histogram we can see that the notifications are from August andSeptember.AtthistimewedidKafkaupgradesthataffectedtheFlinkmonitoringsystemaswell.
D5.2–FIELDTRIALSANDEVALUATIONV1
28
Figure4.2:OmniataFlinkstreameventhistogram
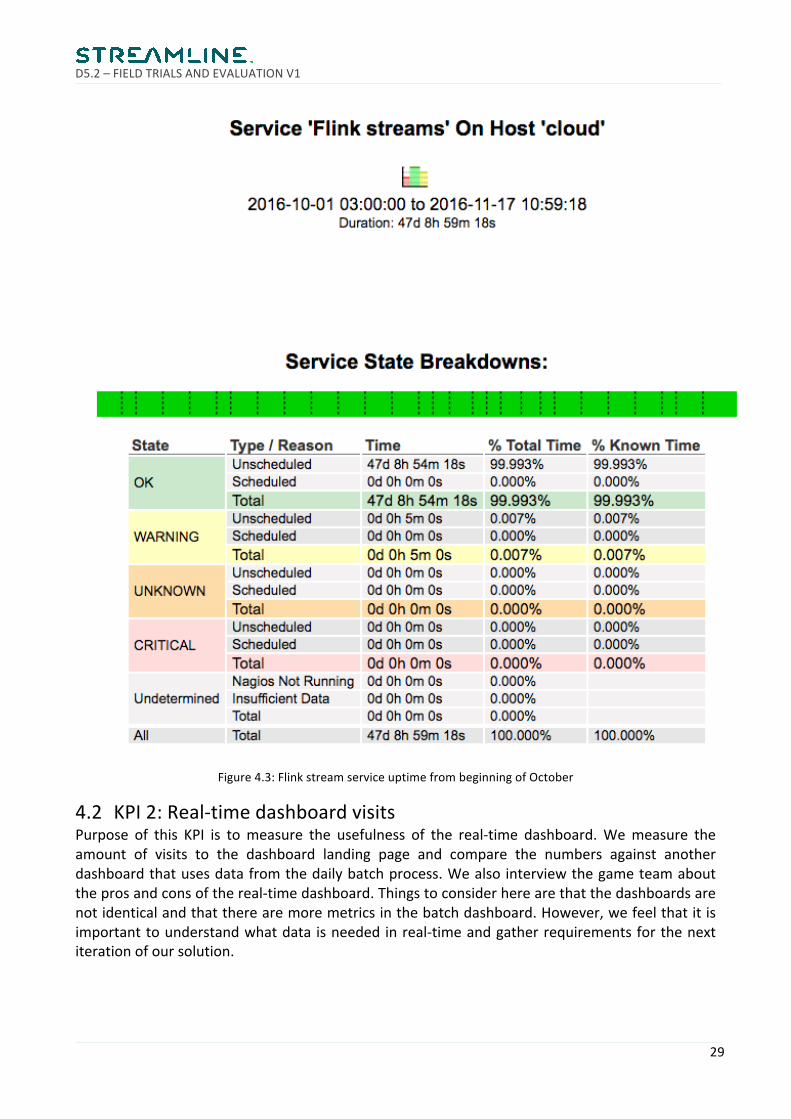
Unfortunatelywedidnotrecordthedurationofscheduledmaintenanceatthetime.Toruleouttheseeventswedecided to start calculating the serviceuptime fromstartofOctober after theKafka was upgraded. The calculated service life-time uptime percentage is then 99.99% whichthenmeetsourtargetof99.95%.
D5.2–FIELDTRIALSANDEVALUATIONV1
29
Figure4.3:FlinkstreamserviceuptimefrombeginningofOctober
4.2 KPI2:Real-timedashboardvisitsPurpose of this KPI is tomeasure the usefulness of the real-time dashboard.Wemeasure theamount of visits to the dashboard landing page and compare the numbers against anotherdashboardthatusesdatafromthedailybatchprocess.Wealso interviewthegameteamabouttheprosandconsofthereal-timedashboard.Thingstoconsiderherearethatthedashboardsarenotidenticalandthattherearemoremetricsinthebatchdashboard.However,wefeelthatitisimportanttounderstandwhatdata isneededinreal-timeandgatherrequirementsforthenextiterationofoursolution.
D5.2–FIELDTRIALSANDEVALUATIONV1
30
4.2.1 BaselineandTargetmeasures
Duringagame’stechnicalsoftlaunch,producersandanalystsfollowgamemetricsdaily.Targetistogetat leastonepagevisitperdayandtheamountoftotalpagevisitsshouldbenolessthan50%ofthenumberofbatchdashboardvisits.
4.2.2 Results
WhencomparingthepageviewdatafromstartofAugust,wecanseethatreal-timedashboardvisitswerelessthan20%ofthebatchvisits,whichisbelowtarget(20%<50%).
Dashboard Total page views since August 2016
Real-time 55
Batch 331
Table4.1:Real-timevsBatchdashboardvisits
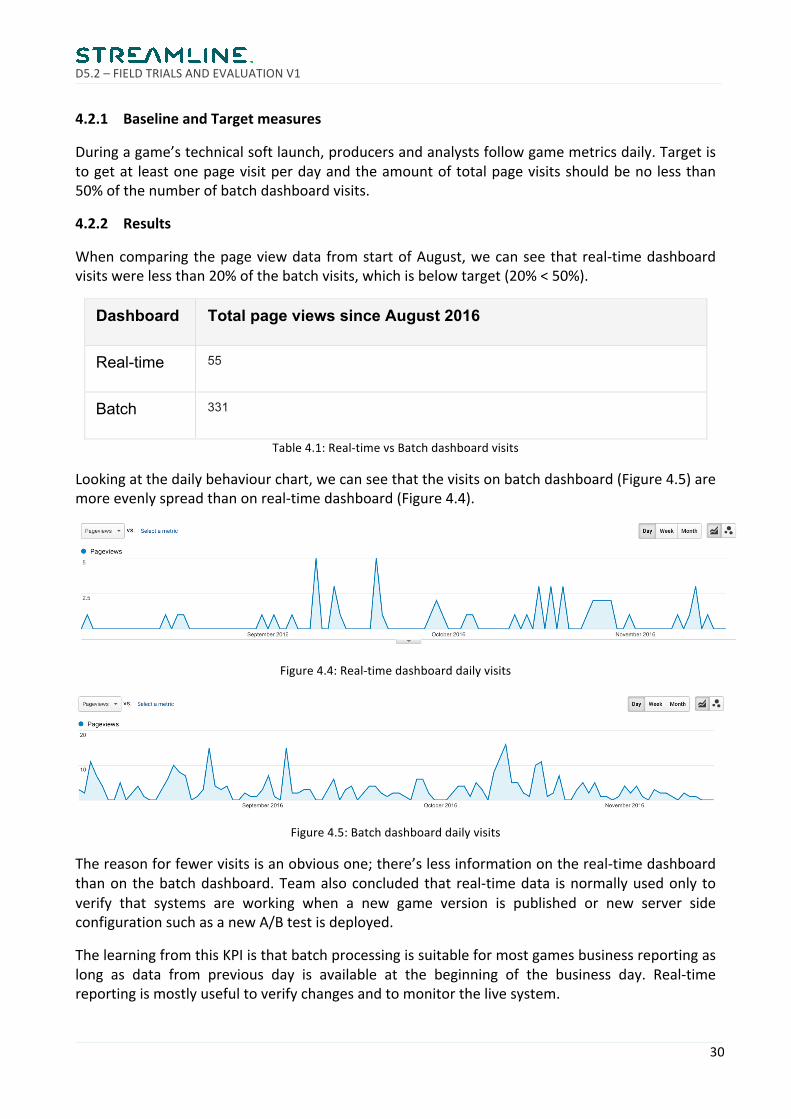
Lookingatthedailybehaviourchart,wecanseethatthevisitsonbatchdashboard(Figure4.5)aremoreevenlyspreadthanonreal-timedashboard(Figure4.4).
Figure4.4:Real-timedashboarddailyvisits
Figure4.5:Batchdashboarddailyvisits
Thereasonforfewervisitsisanobviousone;there’slessinformationonthereal-timedashboardthanonthebatchdashboard.Teamalsoconcludedthat real-timedata isnormallyusedonly toverify that systems are working when a new game version is published or new server sideconfigurationsuchasanewA/Btestisdeployed.
ThelearningfromthisKPIisthatbatchprocessingissuitableformostgamesbusinessreportingaslong as data from previous day is available at the beginning of the business day. Real-timereportingismostlyusefultoverifychangesandtomonitorthelivesystem.
D5.2–FIELDTRIALSANDEVALUATIONV1
31
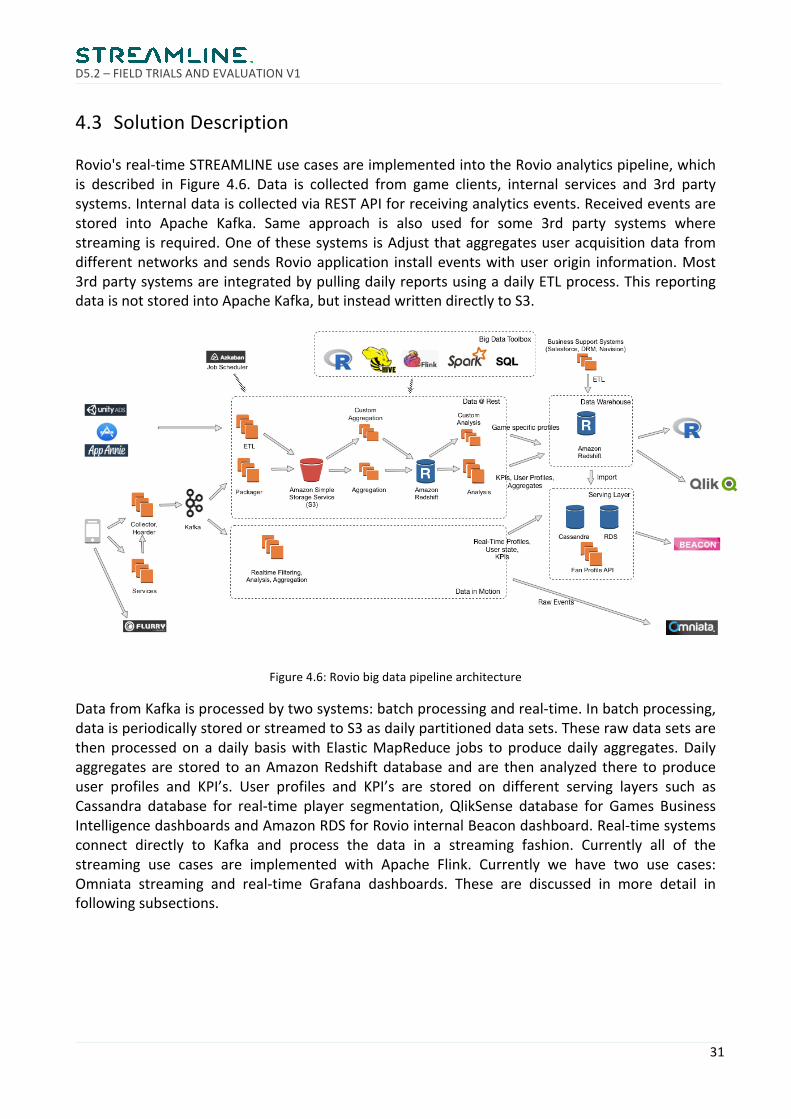
4.3 SolutionDescriptionRovio'sreal-timeSTREAMLINEusecasesareimplementedintotheRovioanalyticspipeline,whichis described in Figure 4.6. Data is collected from game clients, internal services and 3rd partysystems.InternaldataiscollectedviaRESTAPIforreceivinganalyticsevents.Receivedeventsarestored into Apache Kafka. Same approach is also used for some 3rd party systems wherestreamingisrequired.OneofthesesystemsisAdjustthataggregatesuseracquisitiondatafromdifferentnetworksandsendsRovioapplication installeventswithuserorigin information.Most3rdpartysystemsareintegratedbypullingdailyreportsusingadailyETLprocess.ThisreportingdataisnotstoredintoApacheKafka,butinsteadwrittendirectlytoS3.
Figure4.6:Roviobigdatapipelinearchitecture
DatafromKafkaisprocessedbytwosystems:batchprocessingandreal-time.Inbatchprocessing,dataisperiodicallystoredorstreamedtoS3asdailypartitioneddatasets.TheserawdatasetsarethenprocessedonadailybasiswithElasticMapReduce jobs toproducedaily aggregates.Dailyaggregatesare stored toanAmazonRedshiftdatabaseandare thenanalyzed there toproduceuser profiles and KPI’s. User profiles and KPI’s are stored on different serving layers such asCassandra database for real-time player segmentation, QlikSense database for Games BusinessIntelligencedashboardsandAmazonRDSforRoviointernalBeacondashboard.Real-timesystemsconnect directly to Kafka and process the data in a streaming fashion. Currently all of thestreaming use cases are implemented with Apache Flink. Currently we have two use cases:Omniata streaming and real-time Grafana dashboards. These are discussed in more detail infollowingsubsections.

D5.2–FIELDTRIALSANDEVALUATIONV1
32
Figure4.7:Rovioreal-timepipeline
AllanalyticsjobsarescheduledusingAzkabanworkflowmanager.WealsocurrentlyuseAzkabantostartandmonitorApacheFlinkstreams.Analyticsjobs,servicesanddatasourcesaremonitoredwithNagios servermonitoring software.Additionally,wehaveahigher level ofmonitoring andserviceorchestrationsystem inRovio.Most importantly, in thecontextofSTREAMLINE,wecanuseTeamCitycontinuousintegrationsystemtodeployFlinkstreamsautomaticallytotest,stagingandproductionenvironmentswheneverwemergepullrequestsinourGitHubrepositories.
4.3.1 BuildingFlinkJobsprojects
All Apache Flink streams and batch jobs are stored in a GitHub repository named FlinkJobs.Projectsarebuiltwithmaven.TobuildaprojectgointotheprojectfolderandrunthecommanddescribedinListing4.1.
mvn clean package
Listing4.1:BuildingRovioFlinkprojectswithMaven
Thiswillcreateanuber-jarsuitableforsubmittingtoApacheFlink. JobsaresubmittedeitherbyusingacommandlinetoolorAzkaban.
4.3.2 DeployingFlinkJobsusingcommandline
Tostartthejobsfromcommandlinerunthefollowing:
$ aws s3 cp s3://ds-analytics-emrjobs-cloud/flink/omniata-stream/scripts/launch-flink-cluster-cloud.sh ./
$ chmod u+x launch-flink-cluster-cloud.sh
$ ./launch-flink-cluster-cloud.sh
D5.2–FIELDTRIALSANDEVALUATIONV1
33
# wait/check that the job starts
$ listactive | grep omniata-abisland-stream
# Flink UI to check that records are processed
$ python flink-ui.py `listactive | grep omniata-abisland-stream | cut -d " " -f1` | grep FlinkUI
Listing4.2:StartingFlinkjobsfromcommandline
The command line utility described above is currently used for Omniata stream only. ThepreferredwaytolaunchFlinkjobsistoschedulethemthroughAzkaban.
4.3.3 AzkabanWorkflowManager
Processing of analytics pipeline jobs and streams is orchestratedwith Azkaban scheduler. FlinkAzkaban Plugins are used to schedule Flink batch jobs and start/stop Flink streams in AmazonElasticMapReduceclusters.
Listing4.3:FlinkjobsinAzkabanscheduler
4.3.3.1 FlinkBatchJobPluginFlink batch job plugin is used to run an Apache Flink batch job on an EMR cluster. Listing 4.4describestheexamplejobconfiguration.
type=flinkbatchname=ProfilerDNUInitialization#-cisusedtospecifythemainclassunlessthejarhasitdefinedbyitselfstep.1.options.-c=com.rovio.ds.DNURuleInitiatestep.1.jar=/home/hadoop/flink-jobs/profiler-ab-testing-1.0.0-SNAPSHOT.jarstep.1.args.--input_data_path=s3n\://ds-analytics-raw-${rovio.env}/hoarder/topic=audit.supermoon/processdate*/step.1.args.--path_s3=s3\://ds-analytics-aggregate-${rovio.env}/profiler/ab-testing/
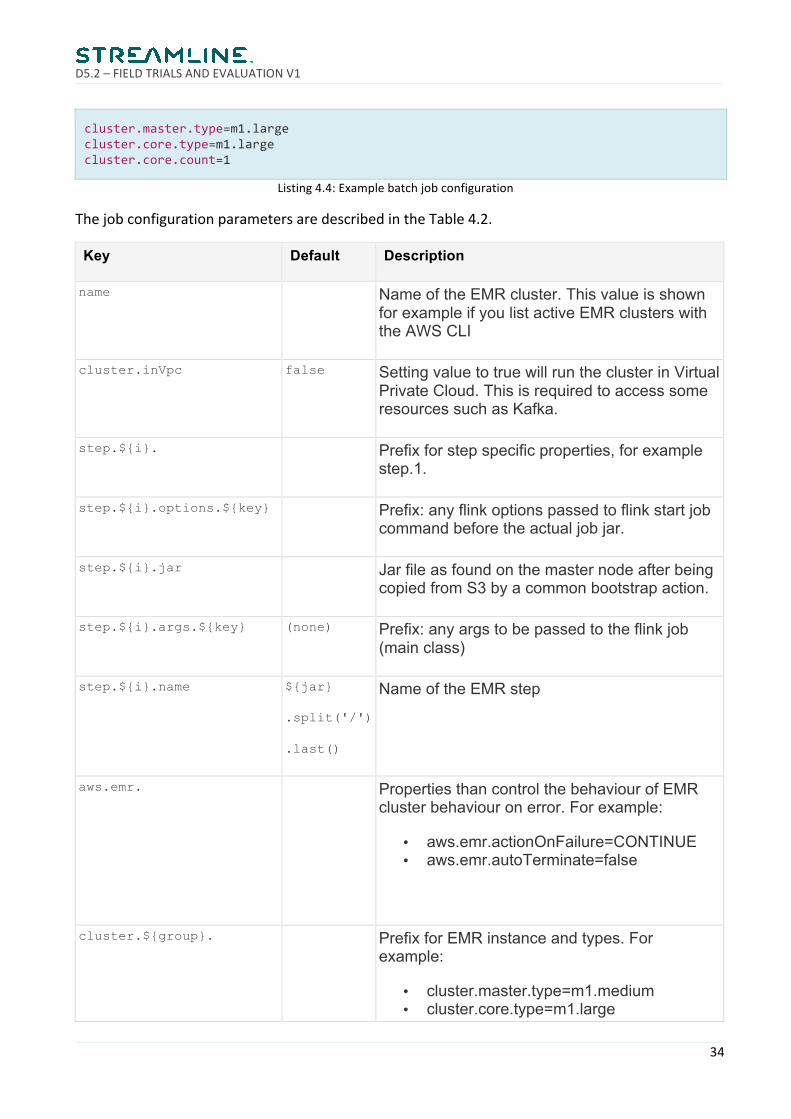
D5.2–FIELDTRIALSANDEVALUATIONV1
34
cluster.master.type=m1.largecluster.core.type=m1.largecluster.core.count=1
Listing4.4:Examplebatchjobconfiguration
ThejobconfigurationparametersaredescribedintheTable4.2.
Key Default Description
name Name of the EMR cluster. This value is shown for example if you list active EMR clusters with the AWS CLI
cluster.inVpc false Setting value to true will run the cluster in Virtual Private Cloud. This is required to access some resources such as Kafka.
step.${i}. Prefix for step specific properties, for example step.1.
step.${i}.options.${key} Prefix: any flink options passed to flink start job command before the actual job jar.
step.${i}.jar Jar file as found on the master node after being copied from S3 by a common bootstrap action.
step.${i}.args.${key} (none) Prefix: any args to be passed to the flink job (main class)
step.${i}.name ${jar}
.split('/')
.last()
Name of the EMR step
aws.emr. Properties than control the behaviour of EMR cluster behaviour on error. For example:
• aws.emr.actionOnFailure=CONTINUE • aws.emr.autoTerminate=false
cluster.${group}. Prefix for EMR instance and types. For example:
• cluster.master.type=m1.medium • cluster.core.type=m1.large

D5.2–FIELDTRIALSANDEVALUATIONV1
35
• cluster.core.count=1
Table4.2:Jobconfigurationparameters
4.3.4 FlinkStreamingJobPlugin
Flink Streaming job type can be used to run a Flink stream in an EMR cluster. The supportedproperties are the same as for Flink batch job type. The only difference is that the job typeparameteris“flinkstream”.Belowisanexampleconfigurationforstreamingjob.
type=flinkstreamname=flink-aggregate-wallet_purchase#Optional:thisishowflinkloggingcanbecustomized.#`shellScript`isjustexecutedontheshell,notsubmittedtoflinkstep.1.name=Copylog4j.propertiesstep.1.shellScript=file\:///bin/cpstep.1.args=/home/hadoop/flink-jobs/custom-aggregate-stream/${rovio.env}/log4j.properties,\/home/hadoop/flink-1.0.0/conf/log4j.properties#Actualflinkstreamjob.Thisislaunchedwith`flink/binrun`.step.2.jar=/home/hadoop/flink-jobs/custom-aggregate-stream/custom-aggregate-stream-1.0.0-SNAPSHOT.jarstep.2.args.--commonConf=/home/hadoop/flink-jobs/custom-aggregate-stream/common-${rovio.env}.jsonstep.2.args.--jobConf=/home/hadoop/flink-jobs/custom-aggregate-stream/job-wallet_purchase.json#ifneedtoaccesskafkaclustercluster.inVpc=truecluster.master.type=m1.largecluster.core.type=m1.largecluster.core.count=1
Figure4.8:Examplestreamingjobconfiguration
4.3.5 OmniataStreamingJob
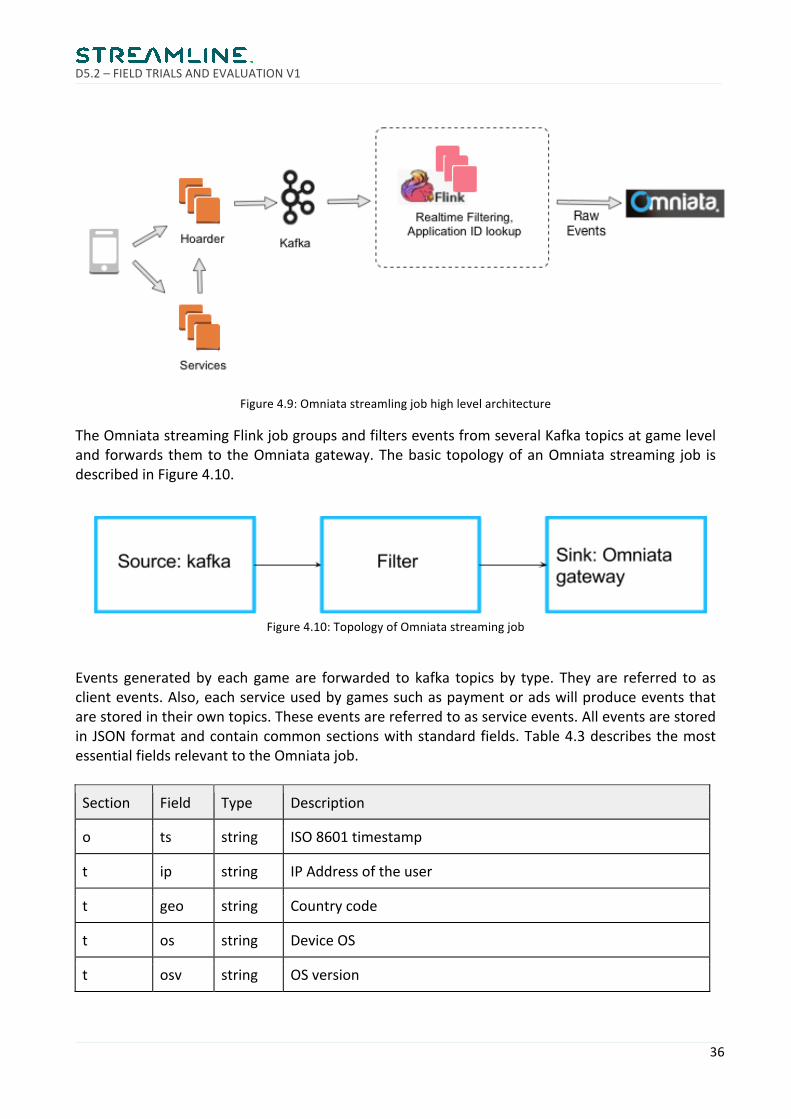
Omniata streaming system is the pilot use case for the Rovio real-time profiling pipeline. ItintegratesRoviodatapipelinetotheOmniataserverandtotheserverAPI.ThissystemisbasedonApacheFlinkandisdeployedtoanAWSEMRclusteralongsidethebatchprocessingpipeline.ThehighlevelarchitectureofOmniatastreamingisdescribedinFigure4.9.
D5.2–FIELDTRIALSANDEVALUATIONV1
36
Figure4.9:Omniatastreamlingjobhighlevelarchitecture
TheOmniatastreamingFlinkjobgroupsandfilterseventsfromseveralKafkatopicsatgameleveland forwards themto theOmniatagateway.Thebasic topologyofanOmniatastreaming job isdescribedinFigure4.10.
Figure4.10:TopologyofOmniatastreamingjob
Events generatedby each gameare forwarded to kafka topics by type. They are referred to asclientevents.Also,eachserviceusedbygamessuchaspaymentoradswillproduceeventsthatarestoredintheirowntopics.Theseeventsarereferredtoasserviceevents.AlleventsarestoredinJSONformatandcontaincommonsectionswithstandardfields.Table4.3describesthemostessentialfieldsrelevanttotheOmniatajob.
Section Field Type Description
o ts string ISO8601timestamp
t ip string IPAddressoftheuser
t geo string Countrycode
t os string DeviceOS
t osv string OSversion

D5.2–FIELDTRIALSANDEVALUATIONV1
37
t eots string Eventoccurrencetimestamp
s aid1 string DeviceID
s aid2 string UserID
s cid string GameID
s cver string Gameversion
s dcid string Distributionchannel,e.g.AppleorGooglePlay
m t string Eventtype Table4.3:ImportanteventfieldsforOmniatastreaming
Themessage section (m) contains any custom fields specific to the event type. For example, apaymenteventcouldhavethecontentdescribedinListing4.5. { "m": { "productId": "coinpack1", "providerOrderId": "75a8629d-584e-4b15-a186-650730a78bbc", "clientBundleId": "com.rovio.bestgameever", "duplicate": "false", "receiptCreated": "2015-03-04T19:58:49.579+0000", "t": "purchase", "provider": "GooglePlay", "price": "0.99", "voucherId": "66026871-fbb9-4b00-be96-d9dc67c20f9e", "receiptId": "90e25db6-d795-4de8-a45a-a2db2c5c8bb0", "status": "Purchased" } }
Listing4.5:Exampleanalyticseventfrompaymentservice
Jobconfiguration issupplied inaJSONfilethatcontainscommonKafkaconfiguration,per-gamefiltersandOmniataapplicationkey.Listing4.6describestheexamplejobconfiguration. { "sinksPerKafkaSource": 2, "kafka": { "bootstrap.servers": "kafka8v-01:9092,kafka8v-02:9092", "group.id": "omniata-stream-cloud" }, "commonTopics": [ "audit.wallet", "audit.session" ], "topics": [ { "topic": "angrybirds_62829967", "omniataAppKey": "abcdef", "filters": [ { "field": "s.cid", "include": [ "angrybirds_62829967"
D5.2–FIELDTRIALSANDEVALUATIONV1
38
] } ] } ] }
Listing4.6:Omniatajobconfiguration
TheOmniataapplicationkeyispreconfiguredfromOmniatadashboardsandeachgamemayhaveseveral app IDs for eachapp store.Additionally, data canbe filteredbasedongameversion todisabletestbuilds,orcountrytobuildregionspecificdashboards.ExampleOmniatadashboardisshowninFigure4.11.
Figure4.11:Omniatadashboard
Eventsare representedasmaps inside the job. TheOmniatagateway is implementedas Flink’ssinkwhichusesHttpClient tosendrequests.TheOmniataRESTAPIacceptsonlyoneeventatatime and requires some mandatory parameters like uid and event type. Two event types aremappedtoOmniatastandardeventstoenablepredefineddashboards:om_loadandom_revenue.Listing4.7describestheexampleOmniataAPIcall. GET https://example.analyzer.omniata.com/event ?api_key=ae4398de &uid=e439da31f399c23a &om_event_type=om_revenue &total=2.99 ¤cy_code=EUR &om_platform=ios
Listing4.7:ExampleOmniataAPIcall
Flinkaccumulatorsareusedtoprovideusefulmetricsformonitoringpurposeslikethenumberofsent events per game and the number of dropped events due to missing mandatory fields ormisconfiguration.

D5.2–FIELDTRIALSANDEVALUATIONV1
39
4.3.6 ConfigurableStreamingAggregationJob
InConfigurableStreamingAggregationusecaseweimplementagenericApacheFlinkjobwheretheaggregationrulesaredefinedinadeclarativemanner.
The input is analytics events in JSON. Users can refer to arbitrary JSON fields in theirconfigurations, so the aggregation jobs don't have to depend on any pre-defined schema. ThedeclarativeconfigurationdefineswhatKafkatopicstoread,whichfieldstogroupby,windowsize,andpairsofaggregatefunctionandJSONfield.Additionalfilterscanbedefined.
The job writes to InfluxDB, a time-series database. InfluxDB doesn't require creating a tableschemainadvance.TheFlinkjobcancreatenewmeasurementtypesbyjustsendingthedatain.Grafanadiscoversnewmeasurementsandtheirfieldsautomatically.Real-time(near)dashboardsarecreatedusingthetoolsofferedbyGrafana'swebUI.
4.3.6.1 SupportedaggregationfeaturesThesetoffeaturesisratherlimited,ifcomparedtotheexpressivityoffull-blownSQLsyntax.WelookforwardtoremovingourcustomcodeinfavourofFlinkSQL,whenGroupWindowsinStreamSQLbecomesavailable.
Ouraggregatejobimplementsthefollowingfeatures:
• Aggregate functions: count, distinctCount (implemented with HyperLogLog), min, max,sum,avg
• Filters:equal,regex,and,or,not(specifiedasinverse=trueonanyotherfilter)• Timewindow:valueandanytimeunitofjava.util.concurrent.TimeUnit• Measurement: the name of target "table" in InfluxDB (ie. measurement). Configuration
mustalsoincludethealiasesforInfluxDBdatapointtags(thefieldstogroupby)andfields(aggregatedvalues).
Multiple measurements can be produced by a single instance of the job. Measurements aredefinedasalistinthejobconfiguration.DifferentmeasurementsmayshareKafkatopicsastheirinput.TheKafkastream issplitafter reading fromKafka, ie.eachtopic isonlyreadoncebytheFlinkjobevenifdifferentmeasurementsrequireit.
4.3.6.2 ConfigurationexampleTheconfigurationdescribedinListing4.8producesthreedifferentmeasurements:
• active_session,ads_campaigns&wallet_purchase• Eachmeasurementproducesoneormoreaggregatedfields
{ "kafka":{ "group.id":"aggregate-all_server_measurements_combined" }, "parallelism":8, "measurements":[ { "name":"active_session", "topics":[ "audit.session", "audit.identity", "audit.wallet"

D5.2–FIELDTRIALSANDEVALUATIONV1
40
], "tags":{ "s.cid":"app_id", "s.dcid":"distribution_channel", "s.cver":"client_version" }, "fields":[ { "function":"distinctCount", "source":"s.aid1", "target":"unique_users" }, { "function":"count", "source":"*", "target":"event_count" } ], "windowSize":{ "value":60, "unit":"seconds" } }, { "name":"ads_campaigns", "topics":[ "audit.ads" ], "tags":{ "s.cid":"app_id", "m.campaign":"campaign", "m.zone":"placement", "m.networkName":"network", "t.geo":"country" }, "fields":[ { "function":"count", "source":"*", "target":"impressions" } ], "windowSize":{ "value":60, "unit":"seconds" }, "filters":[ { "field":"m.t", "type":"equal", "value":"ads.impression.1" } ] }, { "name":"wallet_purchase", "topics":[ "audit.wallet" ], "tags":{ "s.cid":"app_id", "s.dcid":"distribution_channel" }, "fields":[ { "function":"sum", "source":"m.price", "target":"revenue" }, { "function":"count",

D5.2–FIELDTRIALSANDEVALUATIONV1
41
"source":"m.price", "target":"purchases" } ], "windowSize":{ "value":60, "unit":"seconds" }, "filters":[ { "type":"or", "filters":[ { "type":"and", "filters":[ { "field":"s.cid", "type":"equal", "value":"special_game" }, { "field":"m.status", "type":"equal", "value":"Purchased" } ] }, { "type":"and", "filters":[ { "field":"m.t", "type":"equal", "value":"purchase" }, { "field":"m.duplicate", "type":"equal", "value":"false" }, ] } ] } ] } ] }
Listing4.8:Flinkaggregationjobconfigurationexample
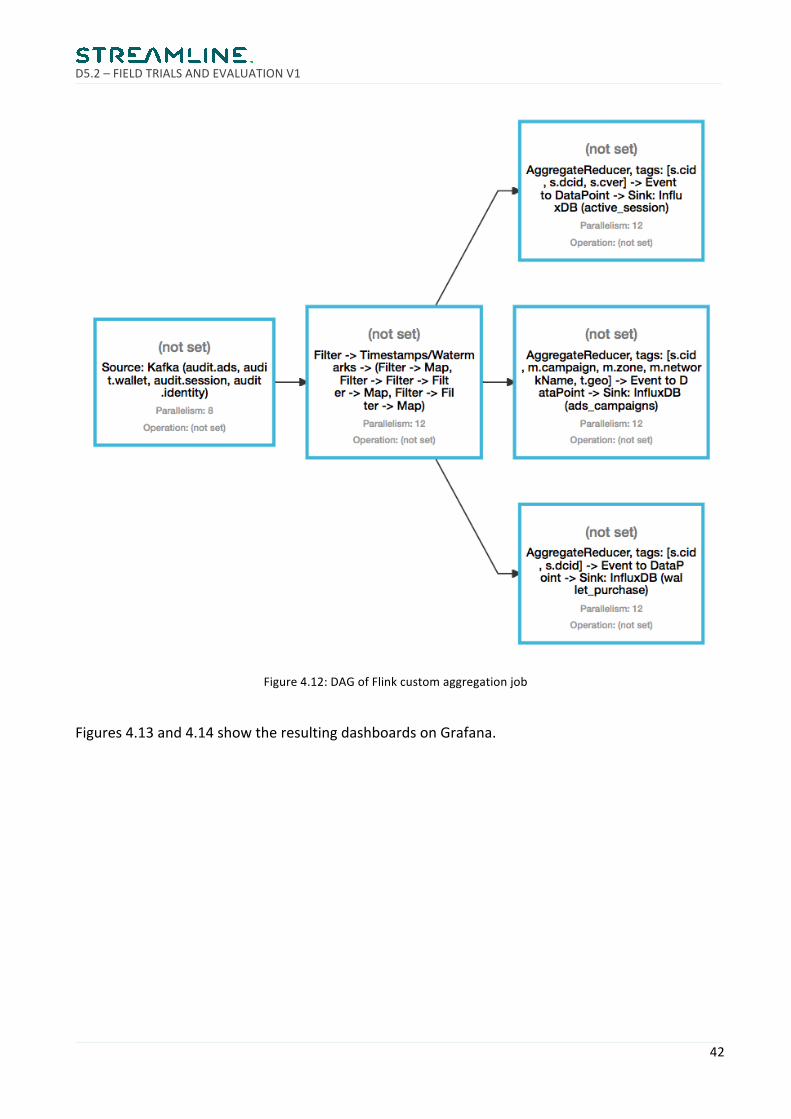
TheresultingFlinkJobDAGisdescribedinFigure4.12.
D5.2–FIELDTRIALSANDEVALUATIONV1
42
Figure4.12:DAGofFlinkcustomaggregationjob
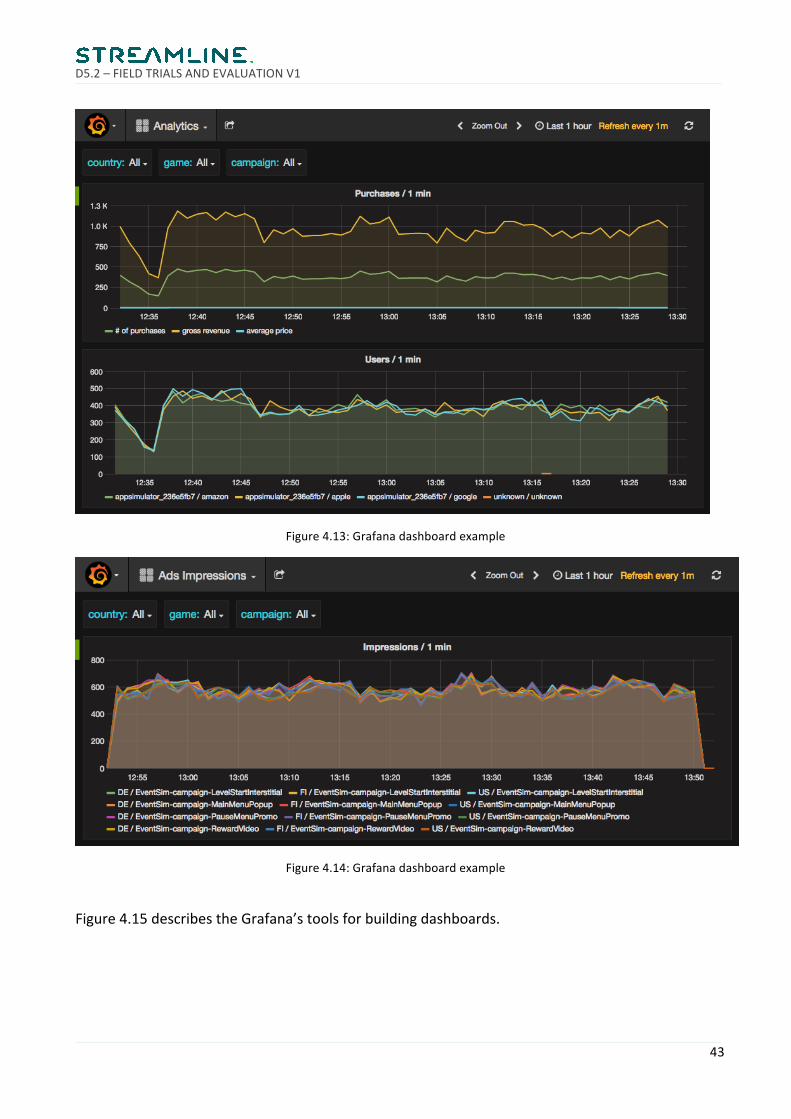
Figures4.13and4.14showtheresultingdashboardsonGrafana.
D5.2–FIELDTRIALSANDEVALUATIONV1
43
Figure4.13:Grafanadashboardexample
Figure4.14:Grafanadashboardexample
Figure4.15describestheGrafana’stoolsforbuildingdashboards.

D5.2–FIELDTRIALSANDEVALUATIONV1
44
Figure4.15:Grafanadashboardeditor
4.3.6.3 MonitoringRovio monitors the data quality by having a Flink accumulator for invalid events. Currentlytimestampistheonlymandatoryfield.Wefallbacktothevalue'unknown'ifanyoftherequestedJSONfieldsisnotfound
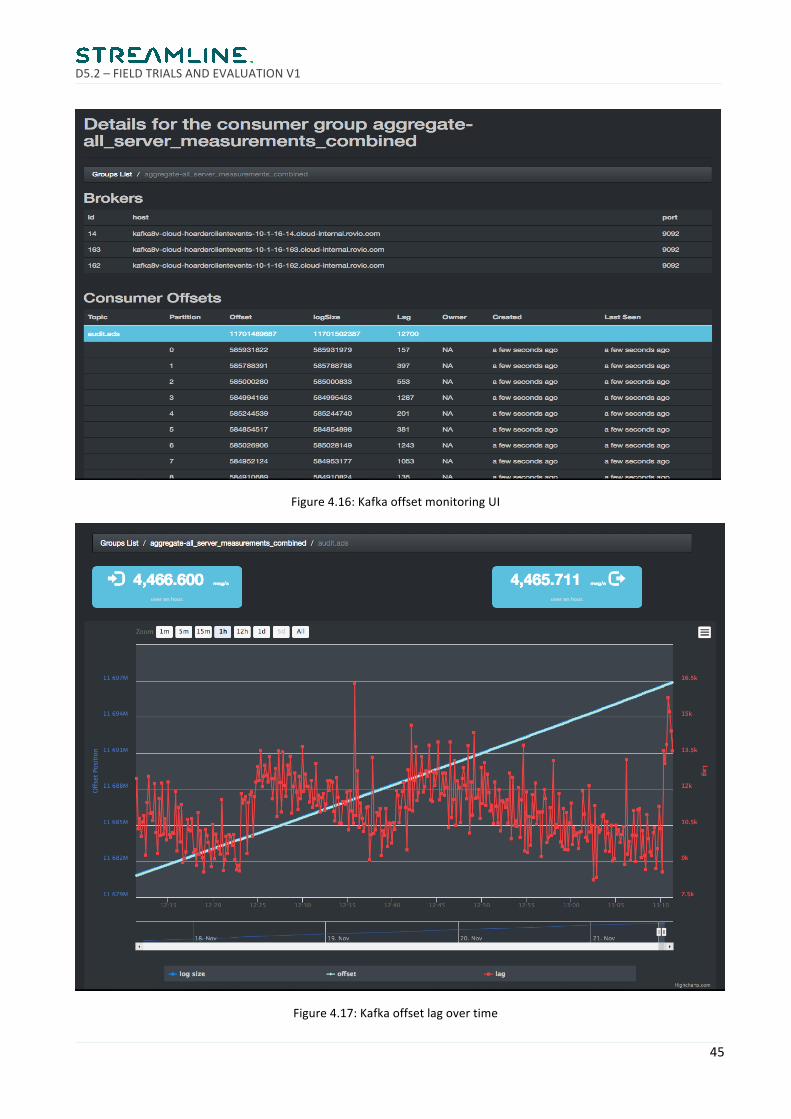
Kafkaconsumeroffsetsareusedtomonitorjobhealthandlag. Forthisweusethe"KafkaOffsetMonitor" (https://github.com/quantifind/KafkaOffsetMonitor). See Figures 4.16 and 4.17 forexamplescreenshotsoftheOffsetMonitorUI.
D5.2–FIELDTRIALSANDEVALUATIONV1
45
Figure4.16:KafkaoffsetmonitoringUI
Figure4.17:Kafkaoffsetlagovertime

D5.2–FIELDTRIALSANDEVALUATIONV1
46
4.3.6.4 Flink/HadoopenvironmentWebuildanuberjaroftheFlinkjobthatcanbelaunchedwithAzkabanonAmazonEMR,runningflinkonHadoop/YARN.WehadadependencyconflictbetweenInfluxDBclientlibraryandHadoopthatmadethe jobfail.Tofixtheconflictwe includedamodifiedversionofGuava inthe job jarusingthemaven-shade-plugin.
4.3.7 NagiosMonitoring
Tokeeptrackof long-runningFlinkstreamjobs,wewroteaNagiosscripttocheckthestatusofFlink jobsusingFlink’smonitoringRESTAPI.ThescriptenumeratesEMRclustersandselectstheoneswhereFlinkisrunning.ThenthemonitoringAPIisusedtocheckjobstatusandthedynamicsofread-bytesandwrite-bytesmetrics.
Figure4.18:NagiosmonitoringdashboardwithFlinkstreamsservicemonitor

D5.2–FIELDTRIALSANDEVALUATIONV1
47
Nagios monitoring is configured to send alerts to Rovio 24/7 cloud support in case of criticalserviceissues.

D5.2–FIELDTRIALSANDEVALUATIONV1
48
5 InternetMemoryResearch
Internet memory collects product information online using its crawling-scraping technology. Inordertoorganizethecollecteddataitusesacategorizationmodeltopredictthecategoryofeachcrawledproduct.Thismodel istrainedonabasisofasetofproductsthatcomesfromasimilardatastream.Thestreamofproductsfortrainingcomesfromperiodicrecrawlesofagivensetofsites.Currently,theworkflowistoperiodicallyretrainthemodelfromscratchonthebasisoftheprevious database plus the current increment. This task is very time consuming as during theprocessthepreviousiterationofthemodeliscompletelydisregarded.
AsStreamlineprojectdealswithsimultaneousprocessingdatainmotionanddataatrest,whichisverywellalignedwiththeoptimizationswewouldliketostudyinourcategorizationworkflow.Wewouldliketostudy,withtheacademicpartnersSztakiandTUBerlin,thepossibleoptimizationsbyintroducing incremental training phase to our categorizationworkflow. This optimizationwouldleverage last trained categorizationmodel as data in-rest together with the stream of trainingdata.
UseCase1:Productcategorization-parallelizationoftraining
Currently IMR is using a complex workflow, only parts of which are successfully parallelized -namelydatacleaningandpreprocessingbutnotthetrainingitself.Fromtheeffortinthisusecasewehopetoachieveparallelizationoftraining,whichisnowimplementedasacentralizedpythonworkflow.Asyoucanimaginethisphaseisverytimeconsuming.
UseCase2:Productcategorization-parallelincrementaltrainingPutinplaceincrementaltrainingphase.IncomparisonwiththeUseCase1,thatassumesparallelizationofthetrainingphase,wherethetrainingstartsalwaysoverthefulldataset,thisusecasefocusesonincrementaltraining.Thisshoulddiminishthelatencybetweenappearanceofadocumentinatrainingsettoitsusageintraining.Inotherwords,thiswouldallowustoretrainonlyrelevantpartsofthemodel,morefrequently.
For brevity, wewill call themodel produced using current centralized algorithm as centralizedmodel,theoneproducedusingparallelalgorithmasparallelmodelandtheoneusingincrementaltrainingasincrementalmodel.
5.1 KPI1:Model’spredictionprecisionUsingagroundtruthdataset,everytimethemodeliscreateditsprecisionisassessed.
5.1.1 Currentsystem
Currentlywhenmodelistraineditsprecisionisassessedonagroundtruthdatasetthatisnotpartofthetrainingset.
5.1.2 BaselineandTargetmeasures
Thegroundtruthisestablishedusingadatasetwhosedocumentsarenotpresentinthetrainingset. For Use Cases 1 and 2 the comparisons between the centralized, parallel and incrementalmodels will be used to determine the possible deteriorations of precisions using variousapproaches.Ideally,theprecisionshouldnotdeteriorateasafunctionofthealgorithmused.

D5.2–FIELDTRIALSANDEVALUATIONV1
49
Giventhatthecurrentprecisionis83.3%,wewouldnotexpecttodowngradetheprecisionbelow80%asthepricetopayforincreasedscalability.
5.2 KPI2:Start-overTrainingNecessityUsing theprecisionmeasurecomparison for thecentralized (orparallel)and incrementalmodelwedetectpossibledeteriorationinthequalityofthepredictionoftheincrementalmodel.Ifthedeteriorationsurpassesagiventhreshold,theinputmodelforincrementaltrainingwillhavetobereplacedwithfreshparallelmodel.
This KPI is tomeasure how often this pricey operation of incrementalmodel reset has to takeplace.
5.2.1 Currentsystem
Currently,themodelisrebuiltfromafulltrainingsetonceamonth.
5.2.2 BaselineandTargetmeasures
AssumingthattheFlinksolutionbringsalinearboosttothemodelconstruction(seetheexpectedimprovements of other KPIs), we do not want to downgrade the periodicity of a full rebuildperiodicity,i.e.,itshouldremainatleastonemonth.
5.3 KPI3:TrainingphasetimeCurrently,thetrainingphaseisacentralizedprocessthatrunsononeserverduetoincapabilityofparallelizationofthealgorithm.UsingthisKPIwewouldliketomeasurethetimeittakestotrainthemodelgivenacertaintrainingsetagainstthecentralizedtrainingalgorithm.
5.3.1 Currentsystem
Currently, we are using a python implementation of the categorization training algorithm. Themodelisrebuiltfromafulltrainingsetonceamonth,andthemodelconstructiontimeisbetween4and5hours.Thetrainingsetconsistsof~14Mlabelledproducts.
ThisalgorithmshouldbereplacedbyitsequivalentimplementationinFlink.
5.3.2 BaselineandTargetmeasures
Thebaselineisestablishedasafunctionofsizeofthetrainingsetandnumberofservers.Nowthenumberofserversissetto1becausewedonothavethetrainingalgorithmparallelized.
The parallelized construction should scale linearly with the number of nodes assigned to thesystem,andwithrespecttothetrainingsetsize.Namely,takingasabaselinethecurrentbuildingcostsgivenabove;weexpectthat
1. Theconstructiontimeshouldbeoftheorderof4/Nhours,where4isthecurrentbuildingtime,andNthenumberofnodes,assumingafixedtrainingsetof14Mproducts.
2. The construction time should of the order of 4*M/14hours,whereM is the size of thetrainingset,andM/14representstheratioofthissizewithrespecttothecurrentsettings(14Mproducts),assumingasinglenode.

D5.2–FIELDTRIALSANDEVALUATIONV1
50
5.4 KPI4:DocumentintraininglatencyEverytimeweacquireadocumentthatwasnotusedfortraining,wewouldlikeourmodeltobeawareofthisdocumentassoonaspossible.Currently,astheprocessoftrainingiscentralized,thetraining is not triggered every time we acquire a unseen document. In Use Case 1, we wouldobservetrainingthemodelmoreoftenthusdiminishingthelatency.InUseCase2,wewouldliketodiminishthelatencyunderthelevelacquiredusingparalleltraining.
5.4.1 Currentsystem
Currently,thecentralizedmodelisretrainedeveryXdays,sothelatencyismeasuredinnumberofdays.
5.4.2 BaselineandTargetmeasures
Thebaselineforcomparingthelatencybetweencentralizedandparalleltrainingisestablishedasthe period between the centralized trainings. The baseline between parallel and incrementaltrainingneedstobeestablished,astheimplementationofbothincrementalandparalleltrainingalgorithmneedstobedevelopedanddeployed.
The most interesting measure for IMR will be the mean time between the acquisition of thetraining document and its usage in training - applicable on the incremental training. Thusevaluatingtheyieldoftheincrementaltraining-whichshouldbeordersofmagnitudelowerthanlatencymeasuredforeithercentralizedorparalleltrainingalgorithms.

D5.2–FIELDTRIALSANDEVALUATIONV1
51
6 GapAnalysisThis chapter describesmissing Apache Flink features and other technical issues each industrialpartnerencounteredduringtheirusecaseimplementationanddeployment.
RoviousecaseshighlightedfollowingdeficienciesinApacheFlink:
• Copyingamodelbetweenjobswasnotdocumentedand itdoesnothaveawelldefinedAPI
• Streamingmachinelearningwasnotavailableontimefortherecommendationsystemusecase
• Streaming SQL does not yet support aggregations and joins which required us toimplement our own generic aggregation flow using json based data processingconfigurations
• Featuressuchascountdistinctnotsupportedoutofthebox,butrequirecustomuniquecheckingusingout-of-corestatebackend
• Documentation about log configuration is incomplete or outdated. It seems that whenrunningjobsonacluster,theonlywaytochangelogconfigurationistomodifythelog4jconfigurationinFlinkinstallationdirectory.Thismeansit’simpossibletoconfigureloggingseparatelyonajoblevel.
• SNAPSHOTversionsarepublished forFlink java libraries,butnoFlinkdistribution (tgz) isavailable.ItwouldbeeasiertotrynewestFlinkfeaturesiftherewasnoneedtobuildFlinkfromsourcebyyourself.
IMRusecaseidentifiedthefollowingexpectationsfromtheforthcomingFlinkMLfunctionalities:
• Parallelization of the classification model construction. We currently use a centralizedimplementation (in Python) of the Passive/Aggressive classification method. Having ascalableconstructionmethodavailableasaFlinkprocesswouldconstituteamajorbenefitforus,sincethesizeofthetrainingdatasetisduetogrowcontinuouslyinthefuture.
• Incremental trainingwould also be an asset, andwould avoid to rebuild themodel toooften.
• Various knobs to control both the parallel and incremental construction are alsoexpected.Whileweaimatavoidingafrequentrebuildofthemodelfromthefulltrainingset,theprecisionshouldremainatanacceptablelevel(say,above80%).Thisconstitutesatrade-offthatshouldbecontrolledbyseveralparameters,suchastheamountoftrainingdata,acontinuousprecisionevaluation,ortheperiodicityoffullrebuild.
ALBusecasesidentifiedthefollowinggapsinFlinkthat,iffulfilled,willgreatlyimprovebothusersandcustomers:
• At this stage is not yet available a streaming machine learning algorithm suitable forprofiling(UC2)andrecommendations(UC3).
• The streaming SQL language available in Flink does not support, at this stage, dataaggregation (e.g.: group by) or joins, does directly impacting of the analytics use case(UC1).
• HyperLogLog is an algorithm used for the count-distinct problem, approximating thenumberofdistinctelements(cardinality),whichisabletoestimatecardinalitiesof>10^9

D5.2–FIELDTRIALSANDEVALUATIONV1
52
with a typical accuracy of 2%. This approach is currently in production at ALB and is anextremelyvaluableassettobeincludedinnearfuturereleasesofFlink.
• AtthisstageFlinkdoesnotprovidepackagingforRedHat/CentOS,whichwouldbeaniceto have for ALB, as it would be directly included in the operations and maintenanceprocedures.

D5.2–FIELDTRIALSANDEVALUATIONV1
53
7 ConclusionThepresentdocumentreportsthefirst iterationoftheFieldTrialsandEvaluationcarriedout intaskT5.4ofSTREAMLINEworkplan.SubsequentreportsonDesignandImplementationactivitieswill be reported in deliverables D5.3 (M21) and D5.5 (M33), and Field Trials and EvaluationactivitieswillbereportedindeliverablesD5.4(M24)andD5.6(M36).
During the firstyearof theSTREAMLINEprojectNMusichasput intoplacea fewchanges to itsmusic streaming platform,which allow to provide to third parties data about the activity of itsusers. Apache Kafka is now a cornerstone of the NMusic’s platform architecture, supportingasynchronouscommunicationbetweensomeoftheservices,andasthemeansofprovidingdatato theSTREAMLINEpartners.TheAnonymizer servicewasdevelopedusingApacheFlink,andconsumes user activity produced by the platform’s services and republishes anonymized andaggregatedversionsofthisdatafortheconsumptionoftheSTREAMLINEpartners.
During the first year of STREAMLINE project, Rovio was able to develop three Flink basedprototype systems: Recommendation System, Omniata Streaming System and ConfigurableStreaming Aggregation System. Out of these three, Omniata Streaming System was used inproductionduringagame’s technical soft launch.The resultswerepromising.TheApacheFlinkbasedservicewasstableandRoviowasabletoimplementrequiredfeaturesefficiently.Infuturedevelopment, Rovio plans to focus on operational reporting and anomaly detection, aswell asplayerprofilingandpotentiallyusingmachinelearningforplayersegmentation.
DuringthefirstyearofSTREAMLINEproject,ALBfocuswasontheadaptationandintegrationofcurrent technological blocks to a combined batch and stream approach, allows following Flinkphilosophy. This lead to the development of theData Collection Framework, the integration ofKafka into thecurrentmessaging systemand,at this stage,preliminary testswith iALSmachinelearningalgorithmforreal-timerecommendations.
During the first year of the project, IMR experimented several algorithms for productclassification, including tests on the preliminary phases (data cleaning, feature extraction) thatimpacttheresultsoftheclassifier.WealsoinparallelinstalledaFlinkclusterinourdatacenter.Atthispointwefoundasatisfyingapproach,basedonthepassive-aggressiveclassificationalgorithmproposed in paper “Online Passive-Aggressive Algorithms”(http://jmlr.csail.mit.edu/papers/volume7/crammer06a/crammer06a.pdf), and we work activelywithourpartnerstotransposethisapproachinFlink,withseveralexpectedmajorimprovements:(1)processingofproductsinstreams,andnotinbatches,(2)parallelconstructionoftheclassifier,and(3)incrementalupdateoftheclassifier.





























