Embed Size (px)
Citation preview

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
HIGH PERFORMANCE COMPUTING: MODELS, METHODS, & MEANS
SMP NODES
Prof. Thomas SterlingDepartment of Computer ScienceLouisiana State UniversityFebruary 15, 2011

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
2
Topics
• Introduction• SMP Context• Performance: Amdahl’s Law• SMP System structure• Processor core• Memory System• Chip set• South Bridge – I/O• Performance Issues• Summary – Material for the Test

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
3
Topics
• Introduction• SMP Context• Performance: Amdahl’s Law• SMP System structure• Processor core• Memory System• Chip set• South Bridge – I/O• Performance Issues• Summary – Material for the Test

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
4
Opening Remarks
• This week is about supercomputer architecture– Last time: end of cooperative computing– Today: capability computing with modern microprocessor and
multicore SMP node
• As we’ve seen, there is a diversity of HPC system types• Most common systems are either SMPs or are
ensembles of SMP nodes• “SMP” stands for: “Symmetric Multi-Processor”• System performance is strongly influenced by SMP node
performance• Understanding structure, functionality, and operation of
SMP nodes will allow effective programming

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
5
The take-away message
• Primary structure and elements that make up an SMP node
• Primary structure and elements that make up the modern multicore microprocessor component
• The factors that determine microprocessor delivered performance
• The factors that determine overall SMP sustained performance
• Amdahl’s law and how to use it• Calculating cpi• Reference: J. Hennessy & D. Patterson, “Computer Architecture A
Quantitative Approach” 3rd Edition, Morgan Kaufmann, 2003

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
6
Topics
• Introduction• SMP Context• Performance: Amdahl’s Law• SMP System structure• Processor core• Memory System• Chip set• South Bridge – I/O• Performance Issues• Summary – Material for the Test

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
7
SMP Context
• A standalone system– Incorporates everything needed for
• Processors• Memory• External I/O channels• Local disk storage• User interface
– Enterprise server and institutional computing market• Exploits economy of scale to enhance performance to cost• Substantial performance
– Target for ISVs (Independent Software Vendors)
• Shared memory multiple thread programming platform– Easier to program than distributed memory machines– Enough parallelism to fully employ system threads (processor cores)
• Building block for ensemble supercomputers– Commodity clusters– MPPs

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
8
Topics
• Introduction• SMP Context• Performance: Amdahl’s Law• SMP System structure• Processor core• Memory System• Chip set• South Bridge – I/O• Performance Issues• Summary – Material for the Test

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
9
Performance: Amdahl’s Law
Baton Rouge to Houston• from my house on East Lakeshore Dr.• to downtown Hyatt Regency• distance of 271• in air flight time: 1 hour• door to door time to drive: 4.5 hours• cruise speed of Boeing 737: 600 mph• cruise speed of BMW 528: 60 mph

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
10
Amdahl’s Law: drive or fly?
• Peak performance gain: 10X– BMW cruise approx. 60 MPH– Boeing 737 cruise approx. 600 MPH
• Time door to door– BMW
• Google estimates 4 hours 30 minutes
– Boeing 737• Time to drive to BTR from my house = 15 minutes• Wait time at BTR = 1 hour• Taxi time at BTR = 5 minutes• Continental estimates BTR to IAH 1 hour• Taxi time at IAH = 15 minutes (assuming gate available)• Time to get bags at IAH = 25 minutes• Time to get rental car = 15 minutes• Time to drive to Hyatt Regency from IAH = 45 minutes• Total time = 4.0 hours
• Sustained performance gain: 1.125X
CSC 7600 Lecture 9 : SMP Nodes Spring 2011
11
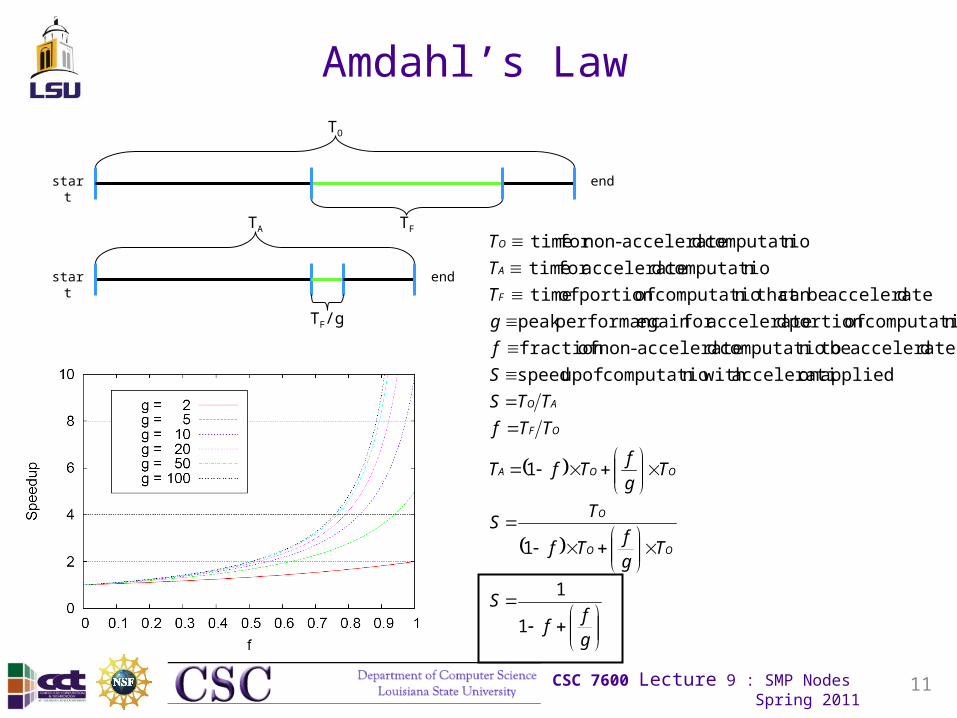
Amdahl’s Law
gf
f
S
Tgf
Tf
TS
Tg
fTfT
TTf
TTS
S
f
g
T
T
T
OO
O
OOA
OF
AO
F
A
O
1
1
1
1
appliedon acceleratin with computatio of up speed
daccelerate be n tocomputatio daccelerate-non offraction
ncomputatio ofportion dacceleratefor gain eperformancpeak
daccelerate becan n that computatio ofportion of time
ncomputatio dacceleratefor time
ncomputatio daccelerate-nonfor time
start end
TO
TF
start end
TA
TF/g

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
12
Amdahl’s Law and Parallel Computers
• Amdahl’s Law (FracX: original % to be speed up)Speedup = 1 / [(FracX/SpeedupX) + (1-FracX)]
• A portion is sequential => limits parallel speedup– Speedup <= 1/ (1-FracX)
• Ex. What fraction sequential to get 80X speedup from 100 processors? Assume either 1 processor or 100 fully used
80 = 1 / [(FracX/100) + (1-FracX)]0.8*FracX + 80*(1-FracX) = 80 - 79.2*FracX = 1FracX = (80-1)/79.2 = 0.9975• Only 0.25% sequential!
CSC 7600 Lecture 9 : SMP Nodes Spring 2011
13
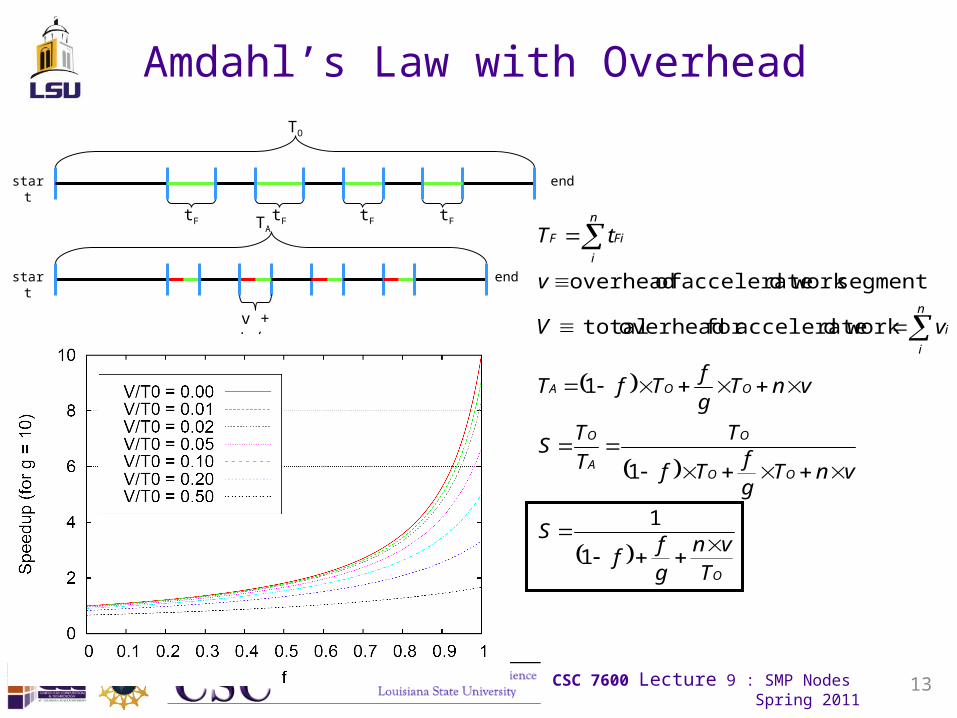
Amdahl’s Law with Overhead
O
OO
O
A
O
OOA
n
i
i
n
i
FiF
Tvn
gf
fS
vnTgf
Tf
T
T
TS
vnTg
fTfT
vV
v
tT
1
1
1
1
workdacceleratefor overhead total
segment work daccelerate of overhead
start end
TO
tF
start end
TA
v + tF/g
tF tFtF

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
14
Topics
• Introduction• SMP Context• Performance: Amdahl’s Law• SMP System structure• Processor core• Memory System• Chip set• South Bridge – I/O• Performance Issues• Summary – Material for the Test
CSC 7600 Lecture 9 : SMP Nodes Spring 2011
15
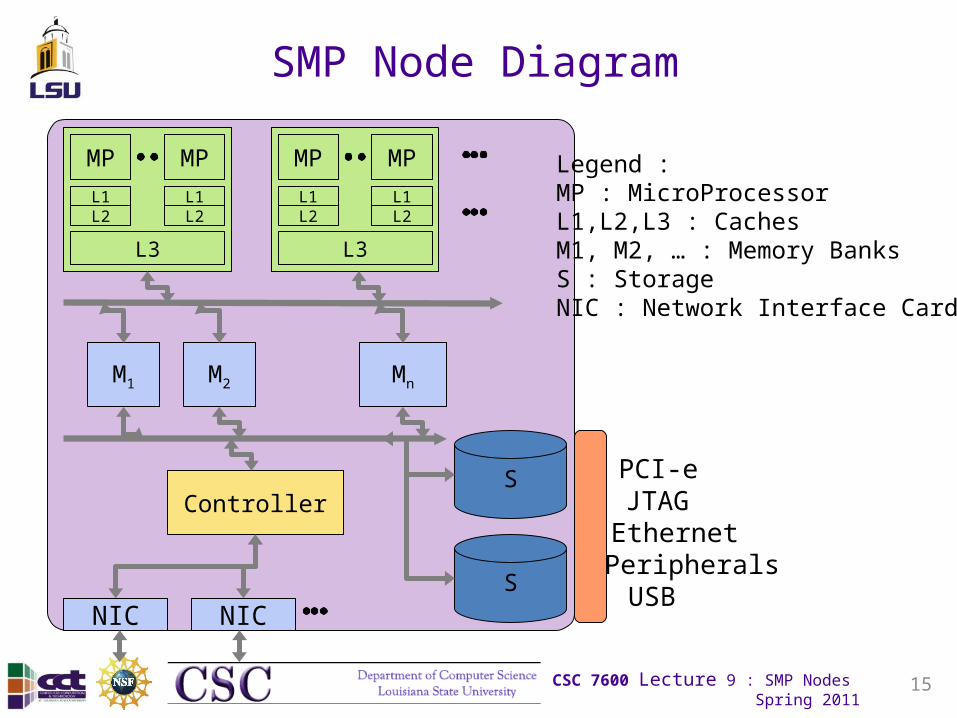
SMP Node Diagram
MPL1L2
MPL1L2
L3
MPL1L2
MPL1L2
L3
M1 M2 Mn
Controller
S
S
NIC NICUSBPeripherals
JTAG
Legend : MP : MicroProcessorL1,L2,L3 : CachesM1, M2, … : Memory BanksS : StorageNIC : Network Interface Card
Ethernet
PCI-e
CSC 7600 Lecture 9 : SMP Nodes Spring 2011
16
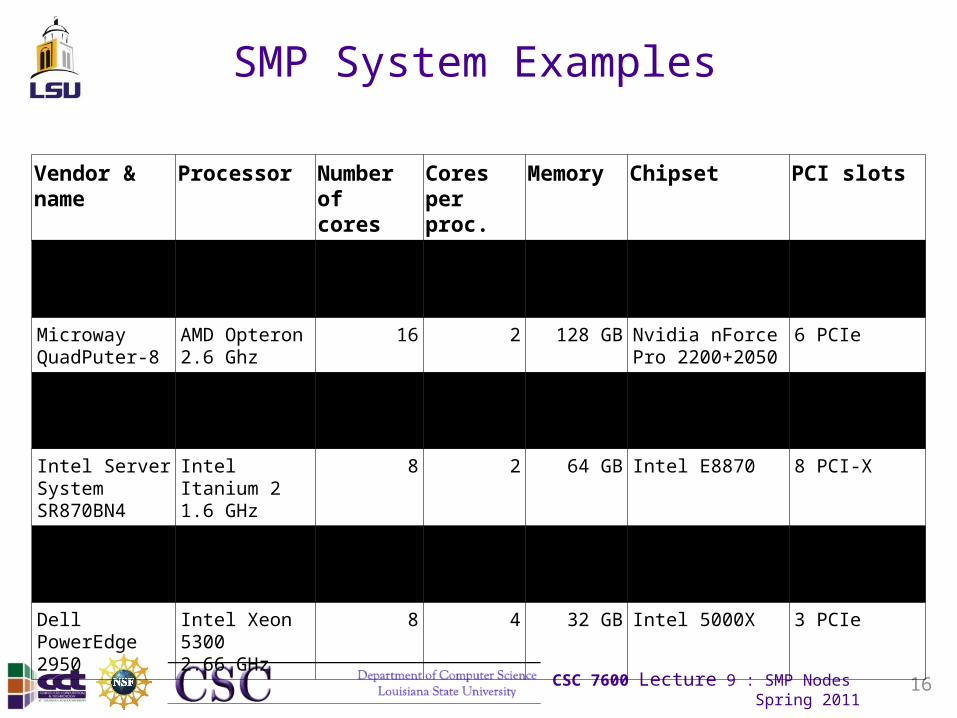
SMP System Examples
Vendor & name Processor Number of cores
Cores per proc.
Memory Chipset PCI slots
IBM eServerp5 595
IBM Power51.9 GHz
64 2 2 TB Proprietary GX+, RIO-2
≤240 PCI-X(20 standard)
Microway QuadPuter-8
AMD Opteron2.6 Ghz
16 2 128 GB Nvidia nForce Pro 2200+2050
6 PCIe
Ion M40 Intel Itanium 21.6 GHz
8 2 128 GB Hitachi CF-3e 4 PCIe2 PCI-X
Intel Server System SR870BN4
Intel Itanium 21.6 GHz
8 2 64 GB Intel E8870 8 PCI-X
HP ProliantML570 G3
Intel Xeon 70403 GHz
8 2 64 GB Intel 8500 4 PCIe6 PCI-X
Dell PowerEdge2950
Intel Xeon 53002.66 GHz
8 4 32 GB Intel 5000X 3 PCIe

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
17
Sample SMP Systems
DELL PowerEdge
HP Proliant
Intel Server System
IBM p5 595
Microway Quadputer
CSC 7600 Lecture 9 : SMP Nodes Spring 2011
18
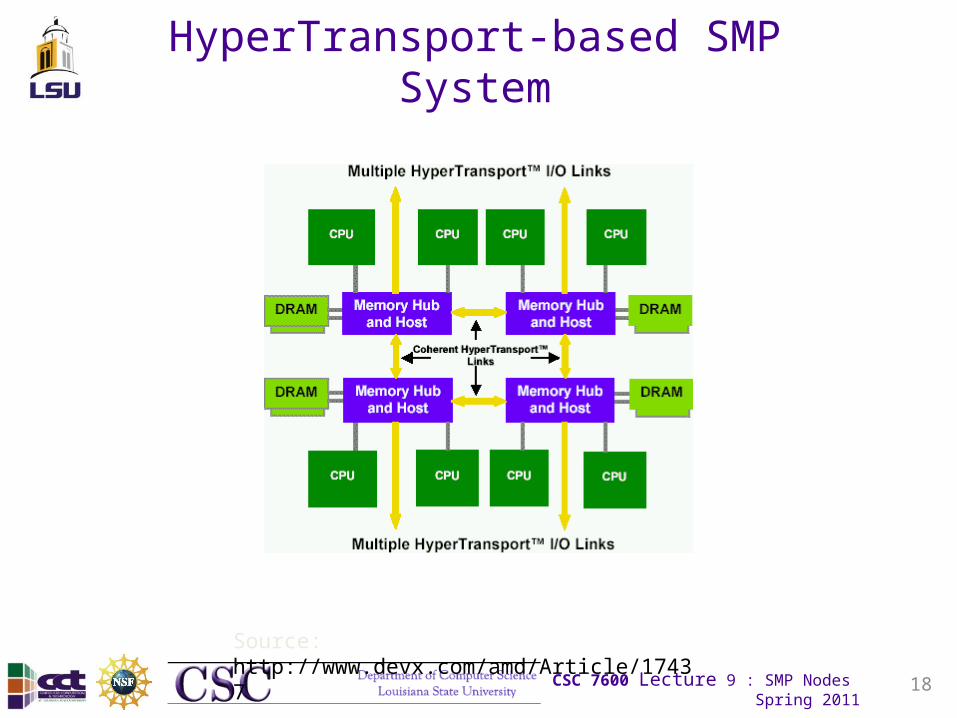
HyperTransport-based SMP System
Source: http://www.devx.com/amd/Article/17437
CSC 7600 Lecture 9 : SMP Nodes Spring 2011
19
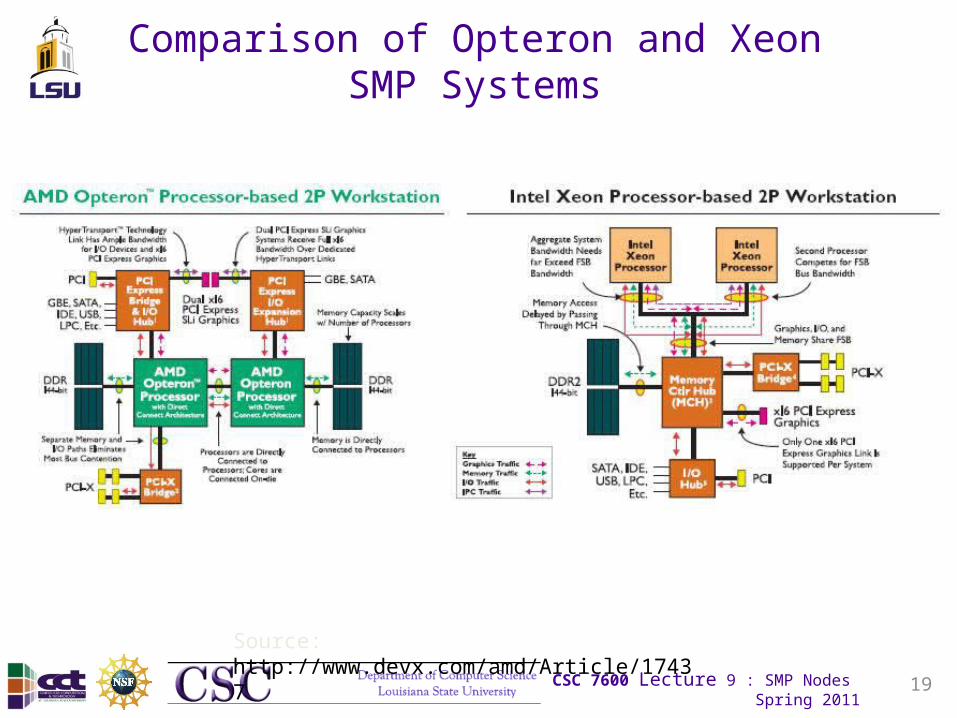
Comparison of Opteron and Xeon SMP Systems
Source: http://www.devx.com/amd/Article/17437
CSC 7600 Lecture 9 : SMP Nodes Spring 2011
20
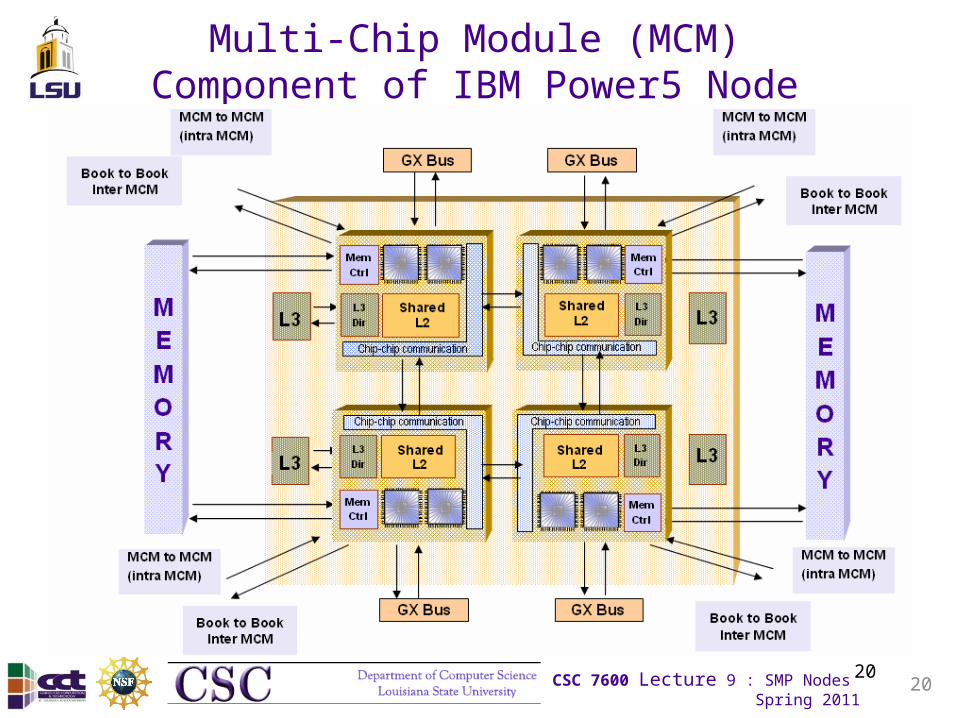
Multi-Chip Module (MCM) Component of IBM Power5 Node
20

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
21
Major Elements of an SMP Node• Processor chip
• DRAM main memory cards
• Motherboard chip set
• On-board memory network– North bridge
• On-board I/O network– South bridge
• PCI industry standard interfaces– PCI, PCI-X, PCI-express
• System Area Network controllers– e.g. Ethernet, Myrinet, Infiniband, Quadrics, Federation Switch
• System Management network – Usually Ethernet– JTAG for low level maintenance
• Internal disk and disk controller
• Peripheral interfaces

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
22
Topics
• Introduction• SMP Context• Performance: Amdahl’s Law• SMP System structure• Processor core• Memory System• Chip set• South Bridge – I/O• Performance Issues• Summary – Material for the Test
CSC 7600 Lecture 9 : SMP Nodes Spring 2011
23
FPUIA-32Control
Instr.Fetch &Decode Cache
Cache
TLB
Integer Units
IA-64 Control
Bus
Core Processor Die 4 x 1MB L3 cache
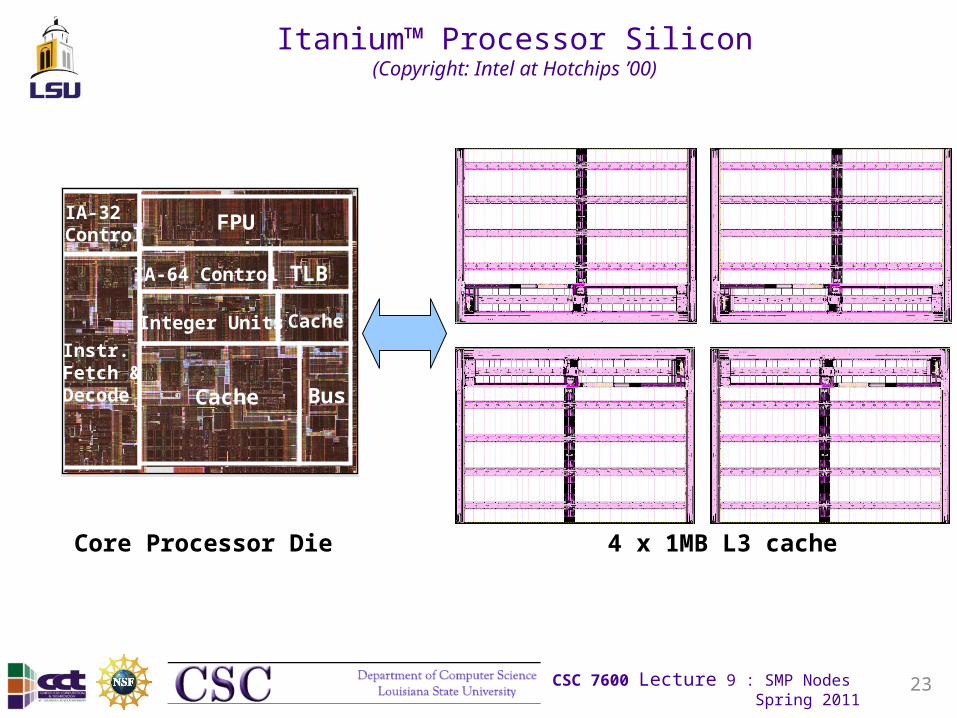
Itanium™ Processor Silicon(Copyright: Intel at Hotchips ’00)

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
24
Multicore Microprocessor Component Elements
• Multiple processor cores– One or more processors
• L1 caches– Instruction cache– Data cache
• L2 cache– Joint instruction/data cache– Dedicated to individual core processor
• L3 cache– Not all systems– Shared among multiple cores– Often off die but in same package
• Memory interface– Address translation and management (sometimes)– North bridge
• I/O interface– South bridge
CSC 7600 Lecture 9 : SMP Nodes Spring 2011
25
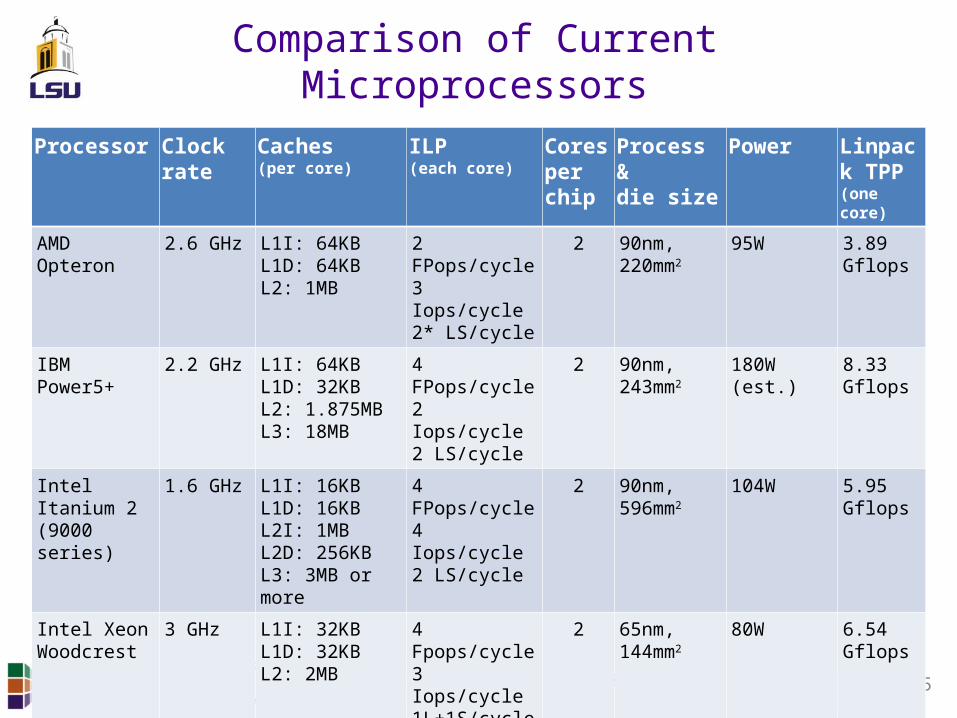
Comparison of Current Microprocessors
Processor Clock rate Caches(per core)
ILP(each core)
Cores per chip
Process &die size
Power Linpack TPP(one core)
AMD Opteron 2.6 GHz L1I: 64KBL1D: 64KBL2: 1MB
2 FPops/cycle3 Iops/cycle2* LS/cycle
2 90nm, 220mm2
95W 3.89 Gflops
IBM Power5+ 2.2 GHz L1I: 64KBL1D: 32KBL2: 1.875MBL3: 18MB
4 FPops/cycle2 Iops/cycle2 LS/cycle
2 90nm,243mm2
180W (est.) 8.33 Gflops
IntelItanium 2(9000 series)
1.6 GHz L1I: 16KBL1D: 16KBL2I: 1MBL2D: 256KBL3: 3MB or more
4 FPops/cycle4 Iops/cycle2 LS/cycle
2 90nm,596mm2
104W 5.95 Gflops
Intel Xeon Woodcrest
3 GHz L1I: 32KBL1D: 32KBL2: 2MB
4 Fpops/cycle3 Iops/cycle1L+1S/cycle
2 65nm,144mm2
80W 6.54 Gflops

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
26
Processor Core Micro Architecture
• Execution Pipeline– Stages of functionality to process issued instructions– Hazards are conflicts with continued execution– Forwarding supports closely associated operations exhibiting
precedence constraints• Out of Order Execution
– Uses reservation stations– hides some core latencies and provide fine grain asynchronous
operation supporting concurrency• Branch Prediction
– Permits computation to proceed at a conditional branch point prior to resolving predicate value
– Overlaps follow-on computation with predicate resolution– Requires roll-back or equivalent to correct false guesses– Sometimes follows both paths, and several deep

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
27
Topics
• Introduction• SMP Context• Performance: Amdahl’s Law• SMP System structure• Processor core• Memory System• Chip set• South Bridge – I/O• Performance Issues• Summary – Material for the Test
CSC 7600 Lecture 9 : SMP Nodes Spring 2011
28
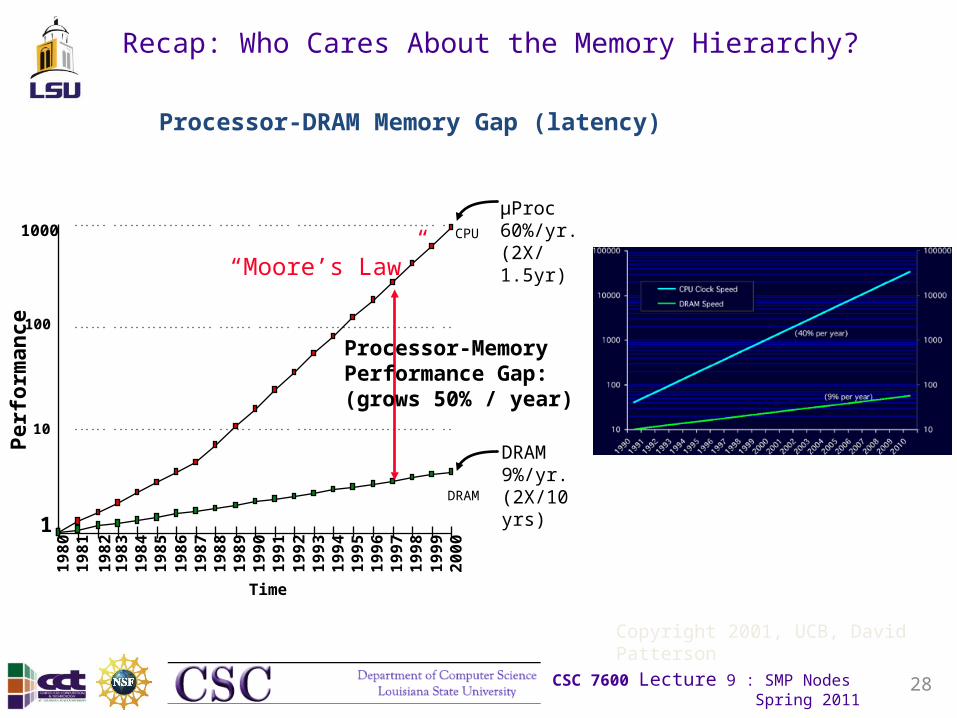
Recap: Who Cares About the Memory Hierarchy?
µProc60%/yr.(2X/1.5yr)
DRAM9%/yr.(2X/10 yrs)
1
10
100
1000
1980
1981
1983
1984
1985
1986
1987
1988
1989
1990
1991
1992
1993
1994
1995
1996
1997
1998
1999
2000
DRAM
CPU
1982
Processor-MemoryPerformance Gap:(grows 50% / year)
Perf
orm
ance
Time
“Moore’s Law”
Processor-DRAM Memory Gap (latency)
Copyright 2001, UCB, David Patterson
CSC 7600 Lecture 9 : SMP Nodes Spring 2011 29
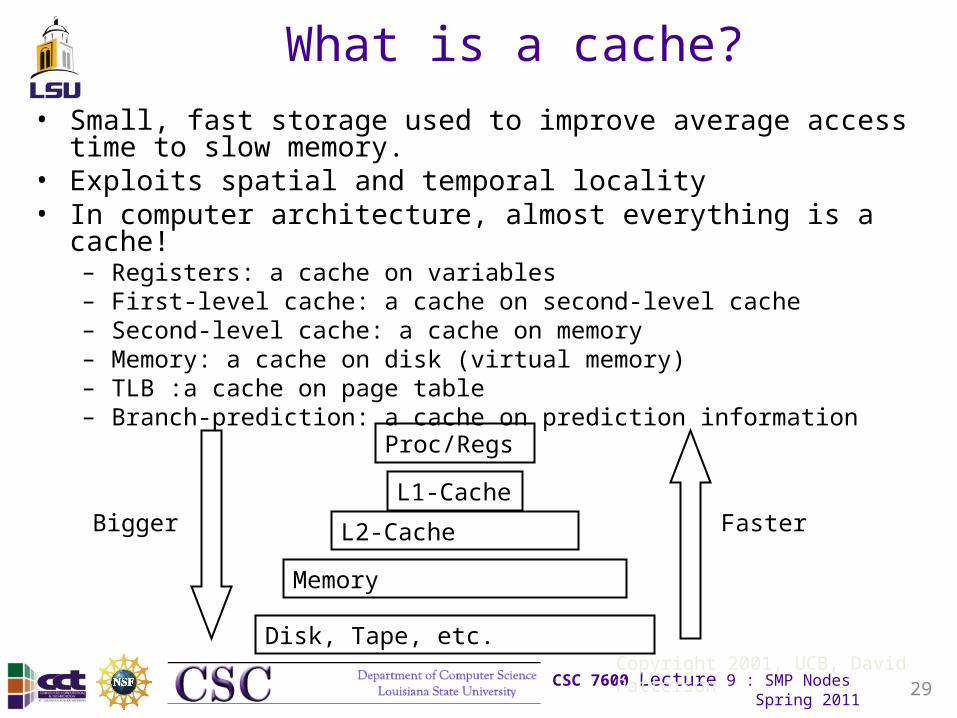
What is a cache?
• Small, fast storage used to improve average access time to slow memory.
• Exploits spatial and temporal locality• In computer architecture, almost everything is a cache!
– Registers: a cache on variables– First-level cache: a cache on second-level cache– Second-level cache: a cache on memory– Memory: a cache on disk (virtual memory)– TLB :a cache on page table– Branch-prediction: a cache on prediction information
Proc/Regs
L1-Cache
L2-Cache
Memory
Disk, Tape, etc.
Bigger Faster
Copyright 2001, UCB, David Patterson
CSC 7600 Lecture 9 : SMP Nodes Spring 2011
30
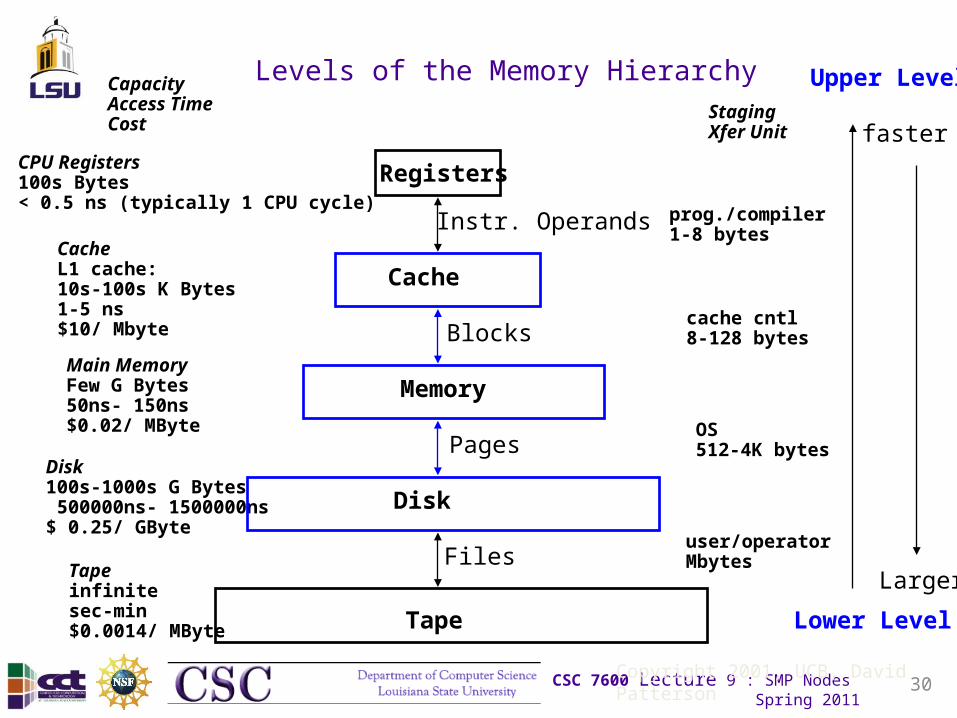
Levels of the Memory Hierarchy
CPU Registers100s Bytes< 0.5 ns (typically 1 CPU cycle)
CacheL1 cache:10s-100s K Bytes1-5 ns$10/ Mbyte
Main MemoryFew G Bytes50ns- 150ns$0.02/ MByte
Disk100s-1000s G Bytes 500000ns- 1500000ns$ 0.25/ GByte
CapacityAccess TimeCost
Tapeinfinitesec-min$0.0014/ MByte
Registers
Cache
Memory
Disk
Tape
Instr. Operands
Blocks
Pages
Files
StagingXfer Unit
prog./compiler1-8 bytes
cache cntl8-128 bytes
OS512-4K bytes
user/operatorMbytes
Upper Level
Lower Level
faster
Larger
Copyright 2001, UCB, David Patterson

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
31
Cache Measures
• Hit rate: fraction found in that level– So high that usually talk about Miss rate
• Average memory-access time = Hit time + Miss rate x Miss penalty
(ns or clocks)• Miss penalty: time to replace a block from lower level,
including time to replace in CPU– access time: time to lower level
= f(latency to lower level)– transfer time: time to transfer block
=f(BW between upper & lower levels)
Copyright 2001, UCB, David Patterson
CSC 7600 Lecture 9 : SMP Nodes Spring 2011
32
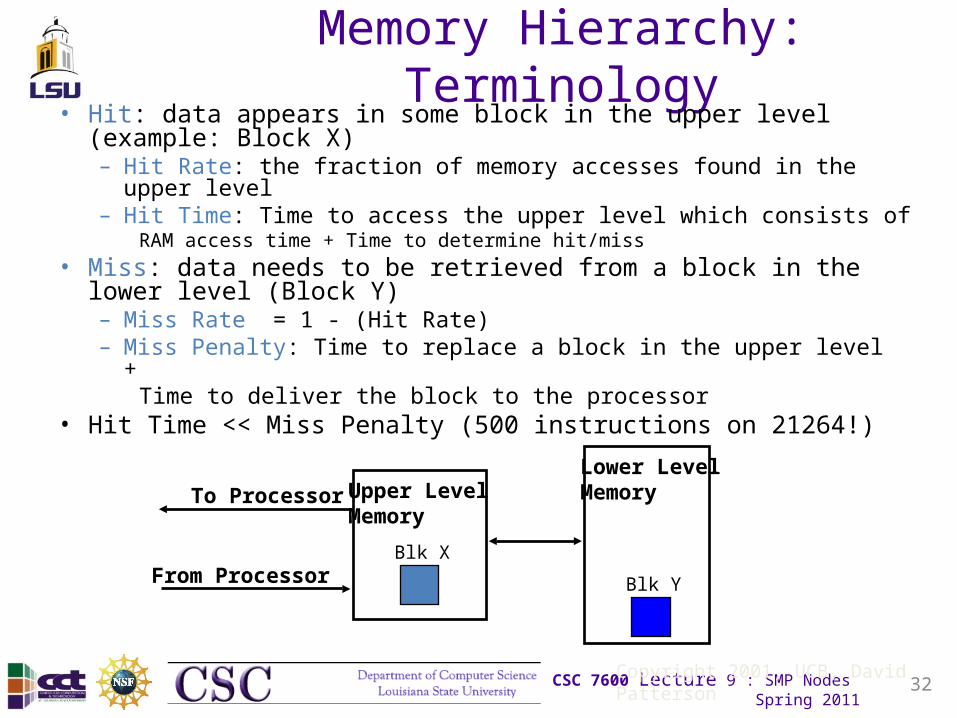
Memory Hierarchy: Terminology• Hit: data appears in some block in the upper level (example:
Block X) – Hit Rate: the fraction of memory accesses found in the upper level– Hit Time: Time to access the upper level which consists of
RAM access time + Time to determine hit/miss
• Miss: data needs to be retrieved from a block in the lower level (Block Y)– Miss Rate = 1 - (Hit Rate)– Miss Penalty: Time to replace a block in the upper level +
Time to deliver the block to the processor• Hit Time << Miss Penalty (500 instructions on 21264!)
Lower LevelMemoryUpper Level
MemoryTo Processor
From ProcessorBlk X
Blk Y
Copyright 2001, UCB, David Patterson

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
Cache Performance
33
MEMcount
MEMALU
count
ALU
MEMALUcount
cyclecount
CPII
ICPI
I
ICPI
III
TCPIIT
T = total execution timeTcycle = time for a single processor cycleIcount = total number of instructionsIALU = number of ALU instructions (e.g. register – register)IMEM = number of memory access instructions ( e.g. load, store)CPI = average cycles per instructionsCPIALU = average cycles per ALU instructions
CPIMEM = average cycles per memory instructionrmiss = cache miss raterhit = cache hit rateCPIMEM-MISS = cycles per cache missCPIMEM-HIT=cycles per cache hitMALU = instruction mix for ALU instructionsMMEM = instruction mix for memory access instruction

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
Cache Performance
34
cycleMEMMEMALUALUcount
MEMMEMALUALU
MEMALU
count
MEMMEM
count
ALUALU
TCPIMCPIMIT
CPIMCPIMCPI
MM
I
IM
I
IM
nMixInstructio
)(
)(
1
:
T = total execution timeTcycle = time for a single processor cycleIcount = total number of instructionsIALU = number of ALU instructions (e.g. register – register)IMEM = number of memory access instructions ( e.g. load, store)CPI = average cycles per instructionsCPIALU = average cycles per ALU instructions
CPIMEM = average cycles per memory instructionrmiss = cache miss raterhit = cache hit rateCPIMEM-MISS = cycles per cache missCPIMEM-HIT=cycles per cache hitMALU = instruction mix for ALU instructionsMMEM = instruction mix for memory access instruction

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
Cache Performance
35
T = total execution timeTcycle = time for a single processor cycleIcount = total number of instructionsIALU = number of ALU instructions (e.g. register – register)IMEM = number of memory access instructions ( e.g. load, store)CPI = average cycles per instructionsCPIALU = average cycles per ALU instructions
CPIMEM = average cycles per memory instructionrmiss = cache miss raterhit = cache hit rateCPIMEM-MISS = cycles per cache missCPIMEM-HIT=cycles per cache hitMALU = instruction mix for ALU instructionsMMEM = instruction mix for memory access instruction
cycleMISSMEMMISSHITMEMMEMALUALUcount
MISSMEMMISSHITMEMMEM
TCPIrCPIMCPIMIT
CPIrCPICPI

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
Cache Performance: Example
36
1
100
5.0
1
102
1010
11
HITMEM
MISSMEM
cycle
ALU
MEM
count
CPI
CPI
nsT
CPI
I
I
2.010
102
8.010
8
10
108
108
11
10
11
10
10
count
MEMMEM
count
ALUALU
MEMcountALU
I
IM
I
IM
III
sec150
105))112.0()18.0((10
11100)9.01(1
9.0
1011
A
MISSMEMAMISSHITMEMAMEM
hitA
T
CPIrCPICPI
r
sec550
105))512.0()18.0((10
51100)5.01(1
5.0
1011
B
MISSMEMBMISSHITMEMBMEM
hitB
T
CPIrCPICPI
r
CSC 7600 Lecture 9 : SMP Nodes Spring 2011
37

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
38
Topics
• Introduction• SMP Context• Performance: Amdahl’s Law• SMP System structure• Processor core• Memory System• Chip set• South Bridge – I/O• Performance Issues• Summary – Material for the Test

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
39
Motherboard Chipset
• Provides core functionality of motherboard
• Embeds low-level protocols to facilitate efficient communication between local components of computer system
• Controls the flow of data between the CPU, system memory, on-board peripheral devices, expansion interfaces and I/O susbsystem
• Also responsible for power management features, retention of non-volatile configuration data and real-time measurement
• Typically consists of:– Northbridge (Memory Controller Hub, MCH), managing traffic between the
processor, RAM, GPU, southbridge and optionally PCI Express slots– Southbridge (I/O Controller Hub, ICH), coordinating slower set of devices,
including traditional PCI bus, ISA bus, SMBus, IDE (ATA), DMA and interrupt controllers, real-time clock, BIOS memory, ACPI power management, LPC bridge (providing fan control, floppy disk, keyboard, mouse, MIDI interfaces, etc.), and optionally Ethernet, USB, IEEE1394, audio codecs and RAID interface

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
40
Major Chipset Vendors
• Intel– http://developer.intel.com/products/chipsets/index.htm
• Via– http://www.via.com.tw/en/products/chipsets
• SiS– http://www.sis.com/products/product_000001.htm
• AMD/ATI– http://ati.amd.com/products/integrated.html
• Nvidia– http://www.nvidia.com/page/mobo.html
CSC 7600 Lecture 9 : SMP Nodes Spring 2011
41
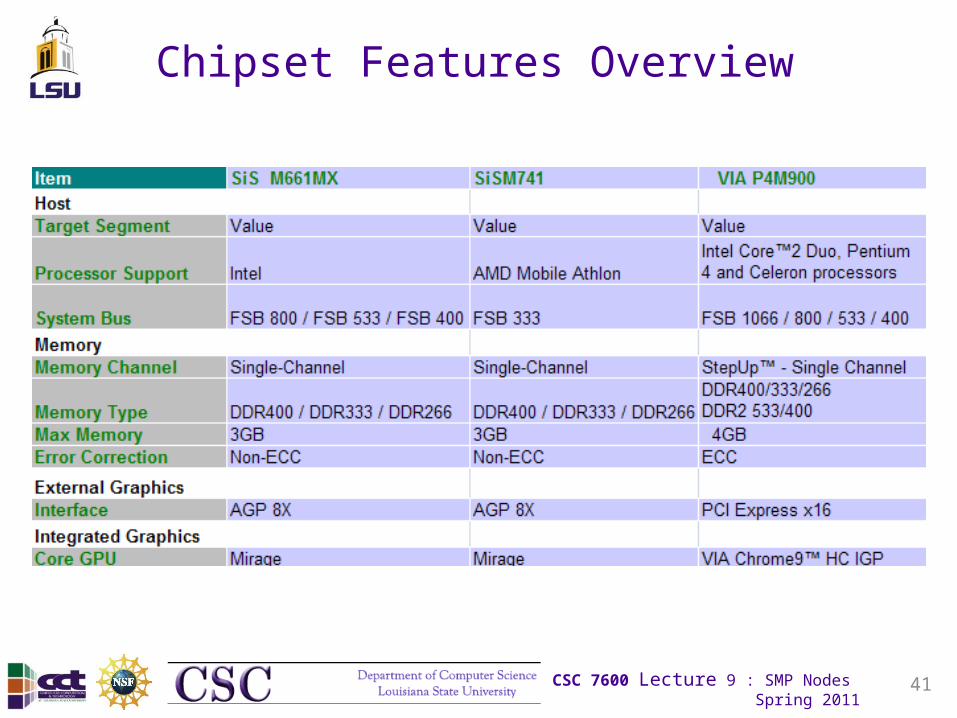
Chipset Features Overview

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
42
Motherboard
• Also referred to as main board, system board, backplane• Provides mechanical and electrical support for pluggable
components of a computer system• Constitutes the central circuitry of a computer,
distributing power and clock signals to target devices, and implementing communication backplane for data exchanges between them
• Defines expansion possibilities of a computer system through slots accommodating special purpose cards, memory modules, processor(s) and I/O ports
• Available in many form factors and with various capabilities to match particular system needs, housing capacity and cost

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
43
Motherboard Form Factors
• Refer to standardized motherboard sizes• Most popular form factor used today is ATX, evolved
from now obsolete AT (Advanced Technology) format• Examples of other common form factors:
– MicroATX, miniaturized version of ATX– WTX, large form factor designated for use in high power
workstations/servers featuring multiple processors– Mini-ITX, designed for use in thin clients– PC/104 and ETX, used in embedded systems and single
board computers– BTX (Balanced Technology Extended), introduced by Intel
as a possible successor to ATX
CSC 7600 Lecture 9 : SMP Nodes Spring 2011
44
Motherboard Manufacturers
• Abit• Albatron• Aopen• ASUS• Biostar• DFI• ECS• Epox• FIC• Foxconn• Gigabyte
• IBM• Intel• Jetway• MSI• Shuttle• Soyo• SuperMicro• Tyan• VIA

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
45
Source: http://www.motherboards.org
Populated CPU Socket

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
46
Source: http://www.motherboards.org
DIMM Memory Sockets

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
47
Motherboard on Arete

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
48
Source: http://www.tyan.com
SuperMike Motherboard: Tyan Thunder i7500 (S720)

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
49
Topics
• Introduction• SMP Context• Performance: Amdahl’s Law• SMP System structure• Processor core• Memory System• Chip set• South Bridge – I/O• Performance Issues• Summary – Material for the Test
CSC 7600 Lecture 9 : SMP Nodes Spring 2011
50
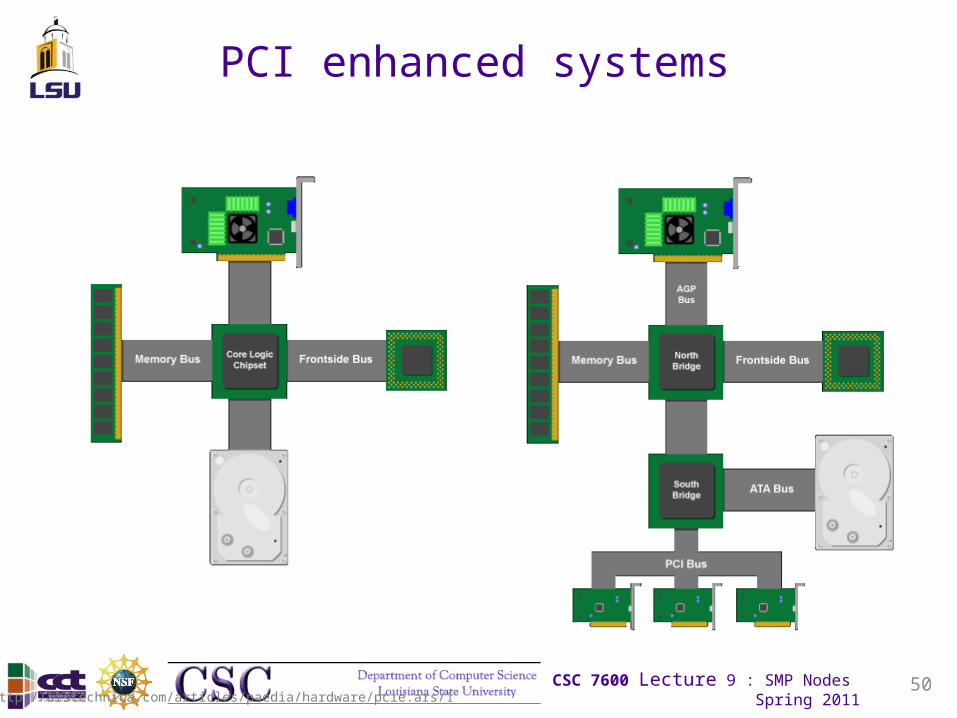
PCI enhanced systems
http://arstechnica.com/articles/paedia/hardware/pcie.ars/1

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
51
PCI-express
Lane width
Clock speed
Throughput (duplex, bits)
Throughput (duplex, bytes)
Initial expected uses
x1 2.5 GHz 5 Gbps 400 MBps Slots, Gigabit Ethernet
x2 2.5 GHz 10 Gbps 800 MBps
x4 2.5 GHz 20 Gbps 1.6 GBps Slots, 10 Gigabit Ethernet, SCSI, SAS
x8 2.5 GHz 40 Gbps 3.2 GBps
x16 2.5 GHz 80 Gbps 6.4 GBps Graphics adapters
http://www.redbooks.ibm.com/abstracts/tips0456.html

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
52
PCI-X Bus Width Clock Speed Features Bandwidth
PCI-X 66 64 Bits 66 MHz Hot Plugging, 3.3 V 533 MB/s
PCI-X 133
64 Bits 133 MHz Hot Plugging, 3.3 V 1.06 GB/s
PCI-X 266
64 Bits, optional 16 Bits only
133 MHz Double Data Rate
Hot Plugging, 3.3 & 1.5 V, ECC supported
2.13 GB/s
PCI-X 533
64 Bits, optional 16 Bits only
133 MHz Quad Data Rate
Hot Plugging, 3.3 & 1.5 V, ECC supported
4.26 GB/s
CSC 7600 Lecture 9 : SMP Nodes Spring 2011
53
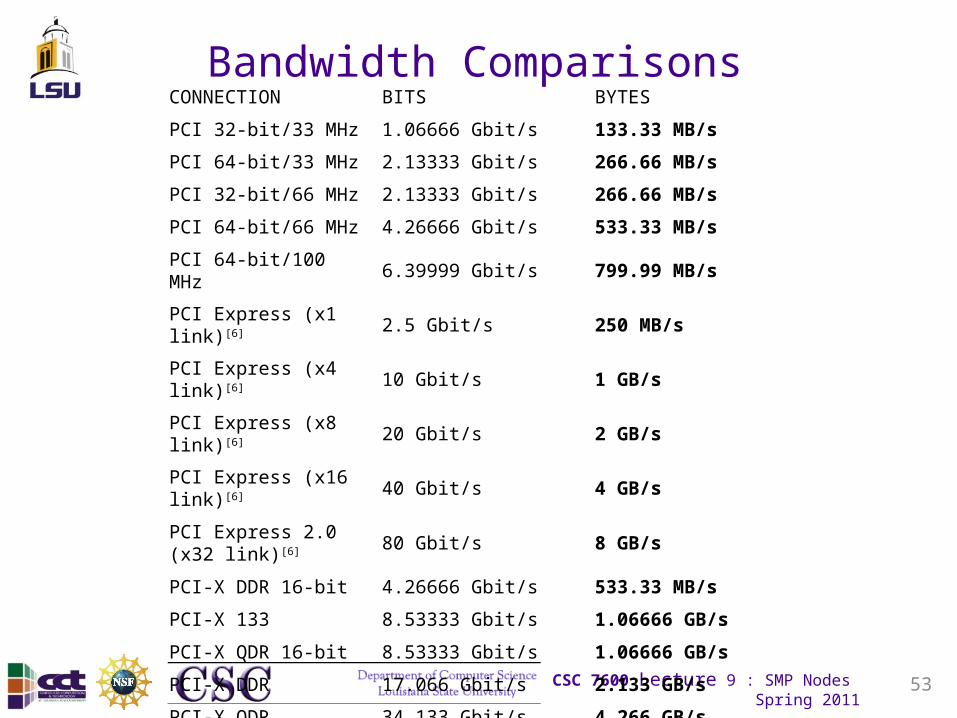
Bandwidth ComparisonsCONNECTION BITS BYTES
PCI 32-bit/33 MHz 1.06666 Gbit/s 133.33 MB/s
PCI 64-bit/33 MHz 2.13333 Gbit/s 266.66 MB/s
PCI 32-bit/66 MHz 2.13333 Gbit/s 266.66 MB/s
PCI 64-bit/66 MHz 4.26666 Gbit/s 533.33 MB/s
PCI 64-bit/100 MHz 6.39999 Gbit/s 799.99 MB/s
PCI Express (x1 link)[6] 2.5 Gbit/s 250 MB/s
PCI Express (x4 link)[6] 10 Gbit/s 1 GB/s
PCI Express (x8 link)[6] 20 Gbit/s 2 GB/s
PCI Express (x16 link)[6] 40 Gbit/s 4 GB/s
PCI Express 2.0 (x32 link)[6] 80 Gbit/s 8 GB/s
PCI-X DDR 16-bit 4.26666 Gbit/s 533.33 MB/s
PCI-X 133 8.53333 Gbit/s 1.06666 GB/s
PCI-X QDR 16-bit 8.53333 Gbit/s 1.06666 GB/s
PCI-X DDR 17.066 Gbit/s 2.133 GB/s
PCI-X QDR 34.133 Gbit/s 4.266 GB/s
AGP 8x 17.066 Gbit/s 2.133 GB/s

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
54
HyperTransport : Context
• Northbridge-Southbridge device connection facilitates communication over fast processor bus between system memory, graphics adaptor, CPU
• Southbridge operates several I/O interfaces, through the Northbridge operating over another proprietary connection
• This approach is potentially limited by the emerging bandwidth demands over inadequate I/O buses
• HyperTransport is one of the many technologies aimed at improving I/O.
• High data rates are achieved by using enhanced, low-swing, 1.2 V Low Voltage Differential Signaling (LVDS) that employs fewer pins and wires consequently reducing cost and power requirements.
• HyperTransport also helps in communication between multiple AMD Opteron CPUs
http://www.amd.com/us-en/Processors/ComputingSolutions/0,,30_288_13265_13295%5E13340,00.html

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
55
Hyper-Transport (continued)• Point-to-point parallel topology uses 2 unidirectional
links (one each for upstream and downstream)• HyperTransport technology chunks data into packets to
reduce overhead and improve efficiency of transfers. • Each HyperTransport technology link also contains 8-bit
data path that allows for insertion of a control packet in the middle of a long data packet, thus reducing latency.
• In Summary : “HyperTransport™ technology delivers the raw throughput and low latency necessary for chip-to-chip communication. It increases I/O bandwidth, cuts down the number of different system buses, reduces power consumption, provides a flexible, modular bridge architecture, and ensures compatibility with PCI. “
http://www.amd.com/us-en/Processors/ComputingSolutions/0,,30_288_13265_13295%5E13340,00.html

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
56
Topics
• Introduction• SMP Context• Performance: Amdahl’s Law• SMP System structure• Processor core• Memory System• Chip set• South Bridge – I/O• Performance Issues• Summary – Material for the Test

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
57
Performance Issues
• Cache behavior– Hit/miss rate– Replacement strategies
• Prefetching• Clock rate• ILP• Branch prediction• Memory
– Access time– Bandwidth

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
58
Topics
• Introduction• SMP Context• Performance: Amdahl’s Law• SMP System structure• Processor core• Memory System• Chip set• South Bridge – I/O• Performance Issues• Summary – Material for the Test

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
59
Summary – Material for the Test
• Please make sure that you have addressed all points outlined on slide 5
• Understand content on slide 7• Understand concepts, equations, problems on
slides 11, 12, 13• Understand content on 21, 24, 26, 29• Understand concepts on slides 32,33,34,35,36• Understand content on slides 39, 57
• Required reading material :
http://arstechnica.com/articles/paedia/hardware/pcie.ars/1

CSC 7600 Lecture 9 : SMP Nodes Spring 2011
60





























