Embed Size (px)
Citation preview

CS60021:ScalableDataMining
MapReduceSourangshuBha=acharya

Mo?va?on:GoogleExample• 20+billionwebpagesx20KB=400+TB• 1computerreads30-35MB/secfromdisk
– ~4monthstoreadtheweb• ~1,000harddrivestostoretheweb• Takesevenmoretodosomethingusefulwiththedata!
• Today,astandardarchitectureforsuchproblemsisemerging:– ClusterofcommodityLinuxnodes– Commoditynetwork(ethernet)toconnectthem
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,h=p://
www.mmds.org2
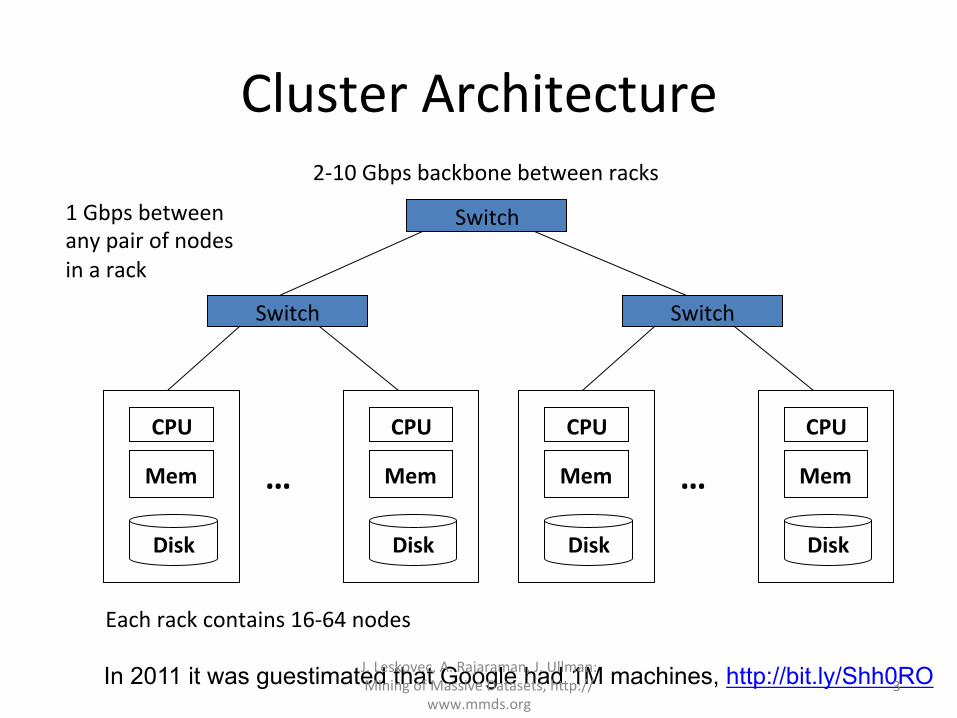
ClusterArchitecture
Mem
Disk
CPU
Mem
Disk
CPU
…
Switch
Eachrackcontains16-64nodes
Mem
Disk
CPU
Mem
Disk
CPU
…
Switch
Switch1Gbpsbetweenanypairofnodesinarack
2-10Gbpsbackbonebetweenracks
In 2011 it was guestimated that Google had 1M machines, http://bit.ly/Shh0RO J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,h=p://
www.mmds.org3

Large-scaleCompu?ng• Large-scalecompuAngfordataminingproblemsoncommodityhardware
• Challenges:– HowdoyoudistributecomputaAon?– Howcanwemakeiteasytowritedistributedprograms?
– Machinesfail:• Oneservermaystayup3years(1,000days)• Ifyouhave1,000servers,expecttoloose1/day• Peoplees?matedGooglehad~1Mmachinesin2011
– 1,000machinesfaileveryday!J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,h=p://
www.mmds.org4

BigDataChallengesq Scalability:processingshouldscalewithincreaseindata.q FaultTolerance:func?oninpresenceofhardwarefailureq CostEffec?ve:shouldrunoncommodityhardwareq Easeofuse:programsshouldbesmallq Flexibility:abletoprocessunstructureddata
q Solu?on:MapReduce!

IdeaandSolu?on• Issue:CopyingdataoveranetworktakesAme• Idea:
– Bringcomputa?onclosetothedata– Storefilesmul?ple?mesforreliability
• Map-reduceaddressestheseproblems– Elegantwaytoworkwithbigdata– StorageInfrastructure–Filesystem
• Google:GFS.Hadoop:HDFS– Programmingmodel
• Map-Reduce J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,h=p://
www.mmds.org6

StorageInfrastructure
• Problem:– Ifnodesfail,howtostoredatapersistently?
• Answer:– DistributedFileSystem:
• Providesglobalfilenamespace• GoogleGFS;HadoopHDFS;
• TypicalusagepaKern– Hugefiles(100sofGBtoTB)– Dataisrarelyupdatedinplace– Readsandappendsarecommon
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,h=p://
www.mmds.org7

WhatisHadoop?q Ascalablefault-tolerantdistributedsystemfordatastorage
andprocessing.q CoreHadoop:
q HadoopDistributedFileSystem(HDFS)q HadoopYARN:JobSchedulingandClusterResourceManagementq HadoopMapReduce:Frameworkfordistributeddataprocessing.
q OpenSourcesystemwithlargecommunitysupport.h=ps://hadoop.apache.org/
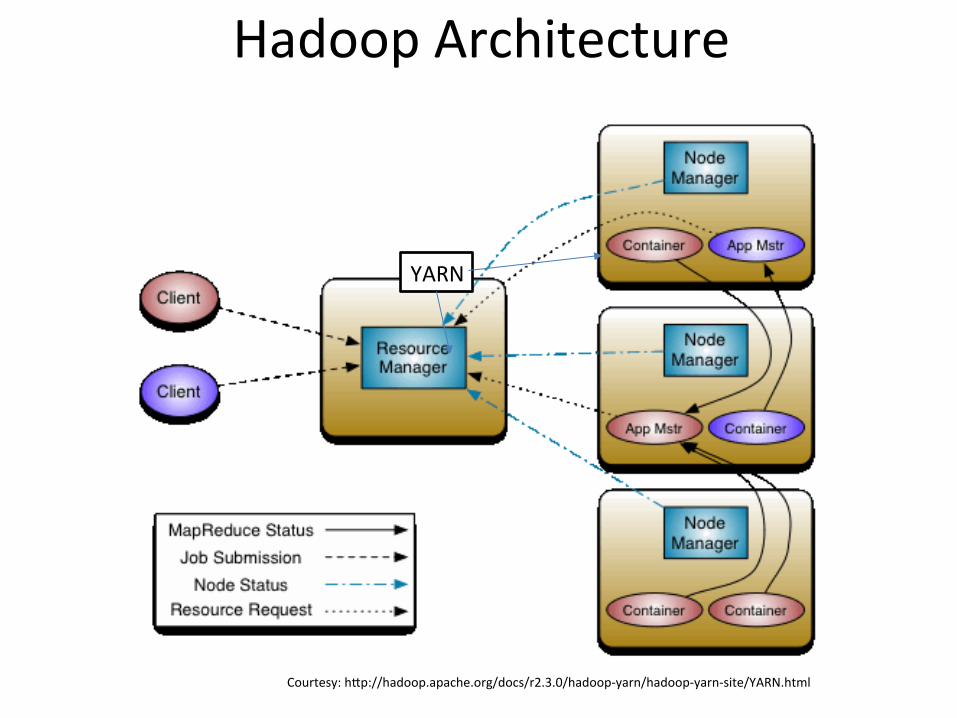
HadoopArchitecture
YARN
Courtesy:h=p://hadoop.apache.org/docs/r2.3.0/hadoop-yarn/hadoop-yarn-site/YARN.html

HDFS

HDFSq Assump?ons
q Hardwarefailureisthenorm.q Streamingdataaccess.q Writeonce,readmany?mes.q Highthroughput,notlowlatency.q Largedatasets.
q Characteris?cs:q Performsbestwithmodestnumberoflargefilesq Op?mizedforstreamingreadsq Layerontopofna?vefilesystem.

HDFSq Dataisorganizedintofileanddirectories.q Filesaredividedintoblocksanddistributedtonodes.q Blockplacementisknownatthe?meofread
q Computa?onmovedtosamenode.
q Replica?onisusedfor:q Speedq Faulttoleranceq Selfhealing.

Goals of HDFS • Very Large Distributed File System
– 10K nodes, 100 million files, 10 PB • Assumes Commodity Hardware
– Files are replicated to handle hardware failure – Detect failures and recovers from them
• Optimized for Batch Processing – Data locations exposed so that computations can move to where data resides – Provides very high aggregate bandwidth
• User Space, runs on heterogeneous OS

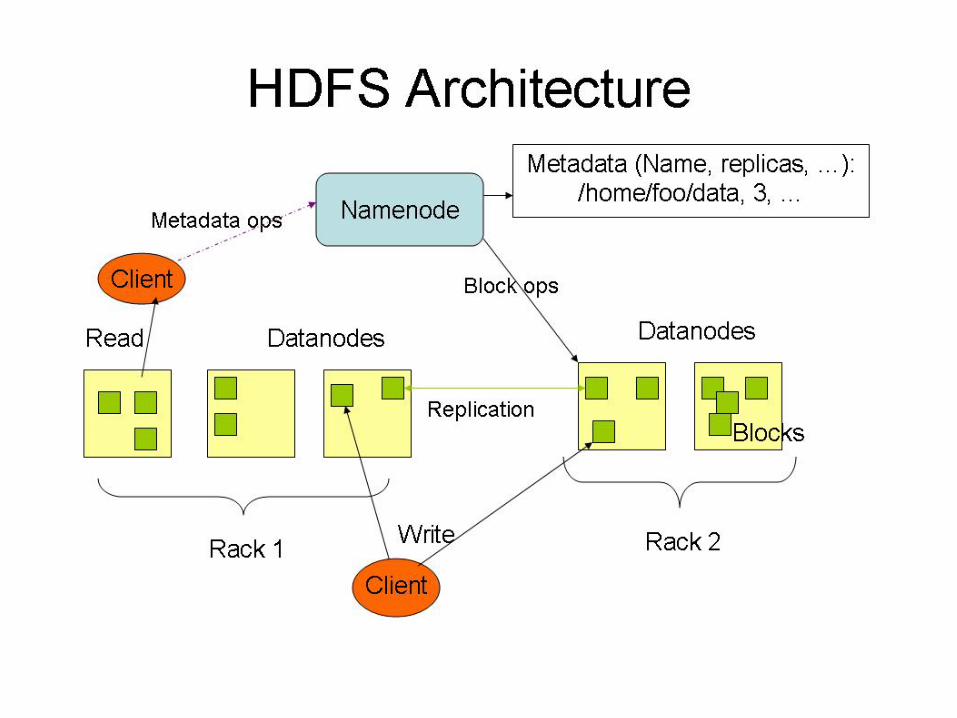
Distributed File System • Single Namespace for entire cluster • Data Coherency
– Write-once-read-many access model – Client can only append to existing files
• Files are broken up into blocks – Typically 128 MB block size – Each block replicated on multiple DataNodes
• Intelligent Client – Client can find location of blocks – Client accesses data directly from DataNode

NameNode Metadata • Meta-data in Memory
– The entire metadata is in main memory – No demand paging of meta-data
• Types of Metadata – List of files – List of Blocks for each file – List of DataNodes for each block – File attributes, e.g creation time, replication factor
• A Transaction Log – Records file creations, file deletions. etc

DataNode • A Block Server
– Stores data in the local file system (e.g. ext3) – Stores meta-data of a block (e.g. CRC) – Serves data and meta-data to Clients
• Block Report – Periodically sends a report of all existing blocks to the NameNode
• Facilitates Pipelining of Data – Forwards data to other specified DataNodes
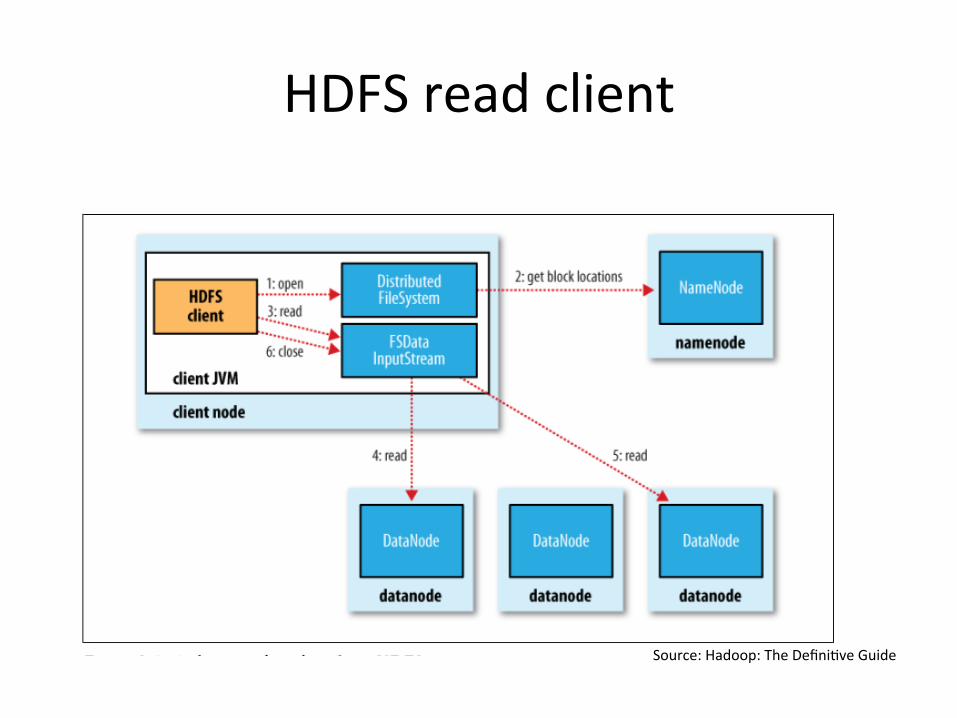
HDFSreadclient
Source:Hadoop:TheDefini?veGuide
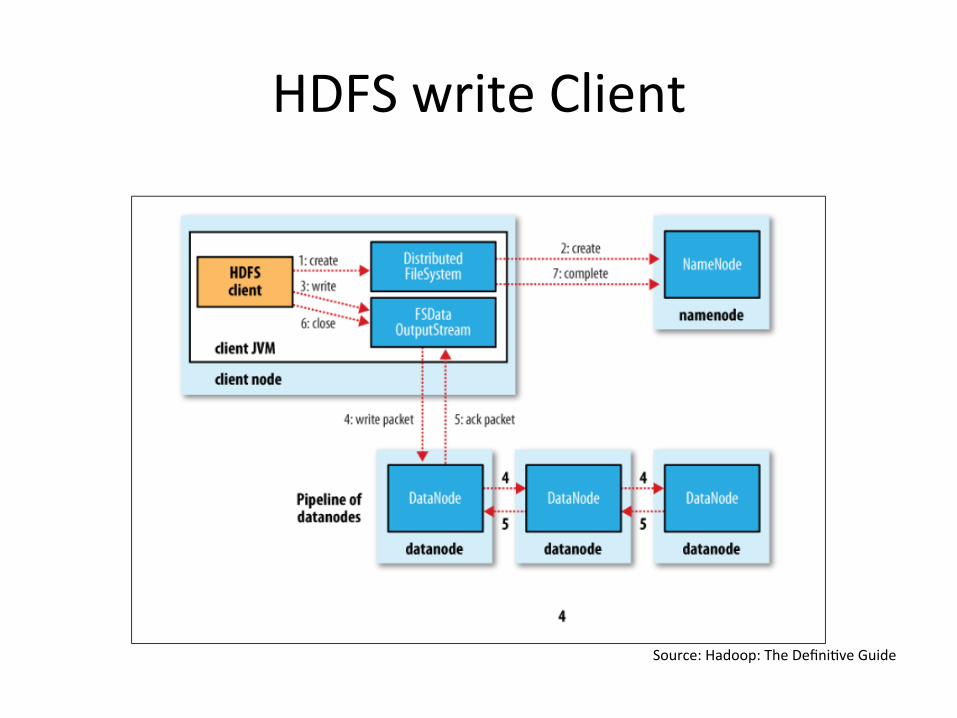
HDFSwriteClient
Source:Hadoop:TheDefini?veGuide

Block Placement • Current Strategy
-- One replica on local node -- Second replica on a remote rack -- Third replica on same remote rack -- Additional replicas are randomly placed
• Clients read from nearest replica • Would like to make this policy pluggable

NameNode Failure • A single point of failure • Transaction Log stored in multiple directories
– A directory on the local file system – A directory on a remote file system (NFS/CIFS)
• Need to develop a real HA solution

Data Pipelining • Client retrieves a list of DataNodes on which to place
replicas of a block • Client writes block to the first DataNode • The first DataNode forwards the data to the next
DataNode in the Pipeline • When all replicas are written, the Client moves on to
write the next block in file

MAPREDUCE

WhatisMapReduce?q Methodfordistribu?ngataskacrossmul?pleservers.q ProposedbyDeanandGhemawat,2004.q Consistsoftwodevelopercreatedphases:
q Mapq Reduce
q InbetweenMapandReduceistheShuffleandSortphase.q Userisresponsibleforcas?ngtheproblemintomap–reduce
framework.q Mul?plemap-reducejobscanbe“chained”.

ProgrammingModel:MapReduce
Warm-uptask:• Wehaveahugetextdocument
• Countthenumberof?meseachdis?nctwordappearsinthefile
• SampleapplicaAon:– AnalyzewebserverlogstofindpopularURLs
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,h=p://
www.mmds.org25

Task:WordCount
Case1:– Filetoolargeformemory,butall<word,count>pairsfitinmemory
Case2:• Countoccurrencesofwords:
– words(doc.txt) | sort | uniq -c • wherewordstakesafileandoutputsthewordsinit,oneperaline
• Case2capturestheessenceofMapReduce– Greatthingisthatitisnaturallyparallelizable
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,h=p://
www.mmds.org26

MapReduce:Overview• Sequen?allyreadalotofdata• Map:
– Extractsomethingyoucareabout
• Groupbykey:SortandShuffle• Reduce:
– Aggregate,summarize,filterortransform
• Writetheresult
Outlinestaysthesame,MapandReducechangetofittheproblem
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,h=p://
www.mmds.org27
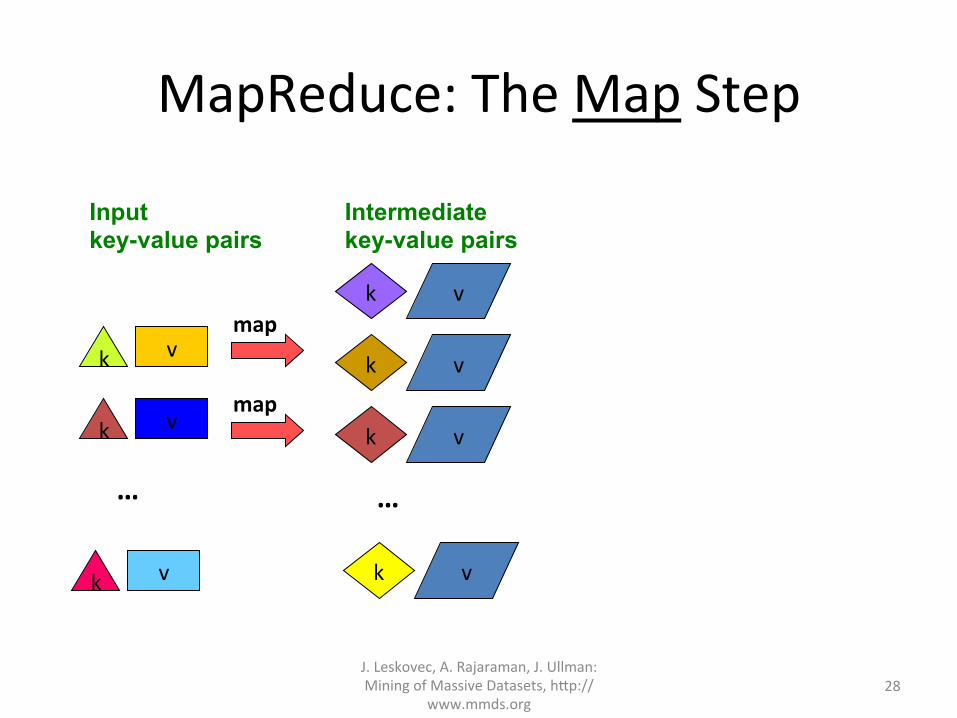
MapReduce:TheMapStep
vk
k v
k v
mapvk
vk
…
k vmap
Input key-value pairs
Intermediate key-value pairs
…
k v
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,h=p://
www.mmds.org28
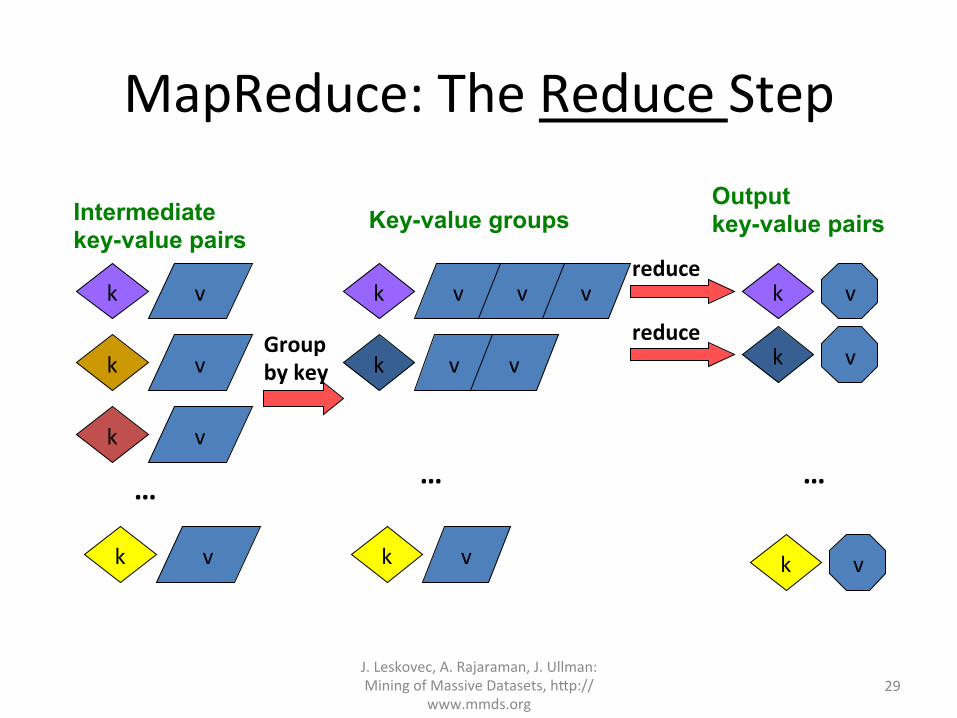
MapReduce:TheReduceStep
k v
…
k v
k v
k v
Intermediate key-value pairs
Groupbykey
reduce
reduce
k v
k v
k v
…
k v
…
k v
k v v
v v
Key-value groups Output key-value pairs
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,h=p://
www.mmds.org29

MoreSpecifically• Input:asetofkey-valuepairs• Programmerspecifiestwomethods:
– Map(k, v) → <k’, v’>* • Takesakey-valuepairandoutputsasetofkey-valuepairs
– E.g.,keyisthefilename,valueisasinglelineinthefile
• ThereisoneMapcallforevery(k,v)pair
– Reduce(k’, <v’>*) → <k’, v’’>* • Allvaluesv’withsamekeyk’arereducedtogetherandprocessedinv’order
• ThereisoneReducefunc?oncallperuniquekeyk’
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,h=p://
www.mmds.org30
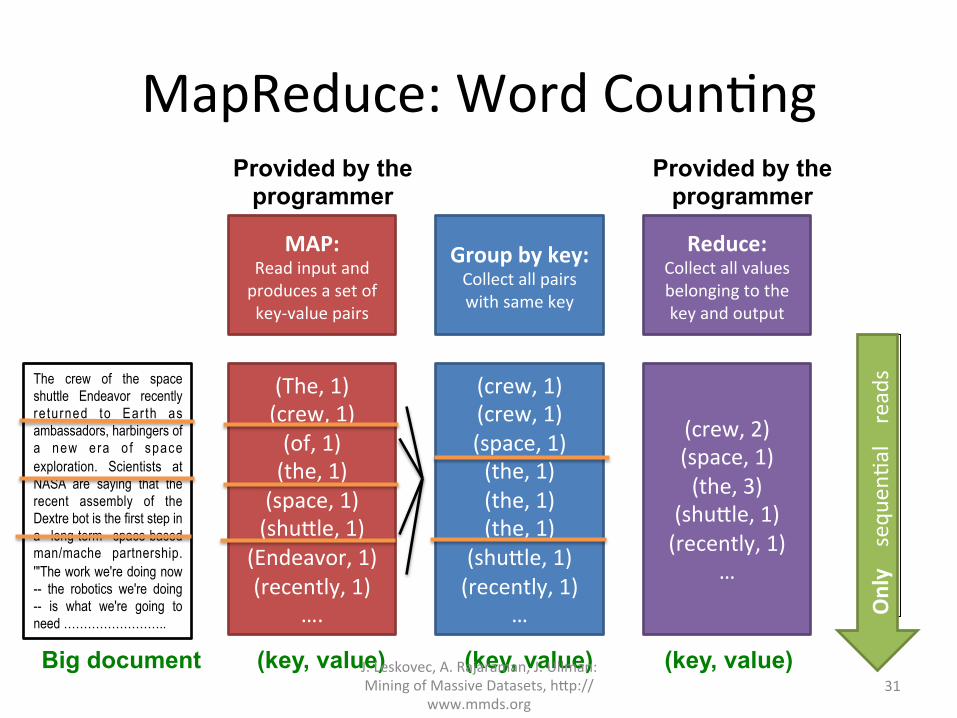
MapReduce:WordCoun?ng
The crew of the space shuttle Endeavor recently re turned to Ear th as ambassadors, harbingers of a new era o f space exploration. Scientists at NASA are saying that the recent assembly of the Dextre bot is the first step in a long-term space-based man/mache partnership. '"The work we're doing now -- the robotics we're doing -- is what we're going to need ……………………..
Big document
(The,1)(crew,1)(of,1)(the,1)(space,1)(shu=le,1)
(Endeavor,1)(recently,1)
….
(crew,1)(crew,1)(space,1)(the,1)(the,1)(the,1)
(shu=le,1)(recently,1)
…
(crew,2)(space,1)(the,3)
(shu=le,1)(recently,1)
…
MAP:Readinputandproducesasetofkey-valuepairs
Groupbykey:Collectallpairswithsamekey
Reduce:Collectallvaluesbelongingtothekeyandoutput
(key, value)
Provided by the programmer
Provided by the programmer
(key, value) (key, value)
Sequ
en?a
llyre
adth
edata
Onlysequ
en?a
lreads
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,h=p://
www.mmds.org31

WordCountUsingMapReduce
map(key, value): // key: document name; value: text of the document for each word w in value:
emit(w, 1)
reduce(key, values): // key: a word; value: an iterator over counts result = 0 for each count v in values: result += v emit(key, result)
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,h=p://
www.mmds.org32

MapPhaseq Userwritesthemappermethod.q Inputisanunstructuredrecord:
q E.g.ArowofRDBMStable,q Alineofatextfile,etc
q Outputisasetofrecordsoftheform:<key,value>q Bothkeyandvaluecanbeanything,e.g.text,number,etc.q E.g.forrowofRDBMStable:<columnid,value>q Lineoftextfile:<word,count>

Shuffle/Sortphaseq Shufflephaseensuresthatallthemapperoutputrecordswith
thesamekeyvalue,goestothesamereducer.q Sortensuresthatamongtherecordsreceivedateach
reducer,recordswithsamekeyarrivestogether.

Reducephaseq Reducerisauserdefinedfunc?onwhichprocessesmapper
outputrecordswithsomeofthekeysoutputbymapper.q Inputisoftheform<key,value>
q Allrecordshavingsamekeyarrivetogether.
q Outputisasetofrecordsoftheform<key,value>q Keyisnotimportant
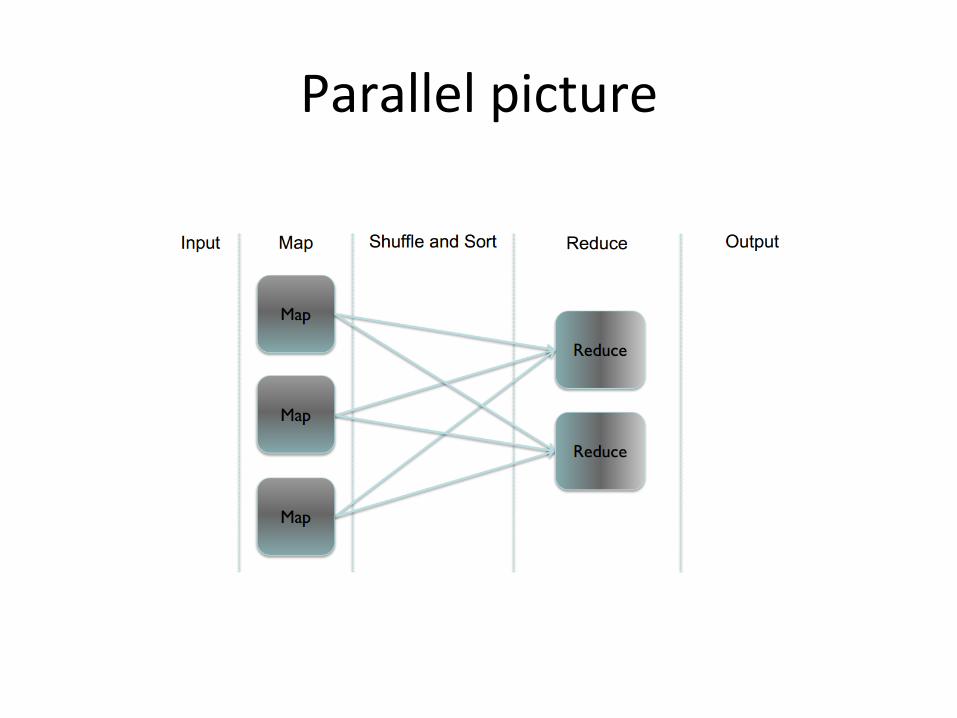
Parallelpicture

Example
• WordCount:Countthetotalno.ofoccurrencesofeachword
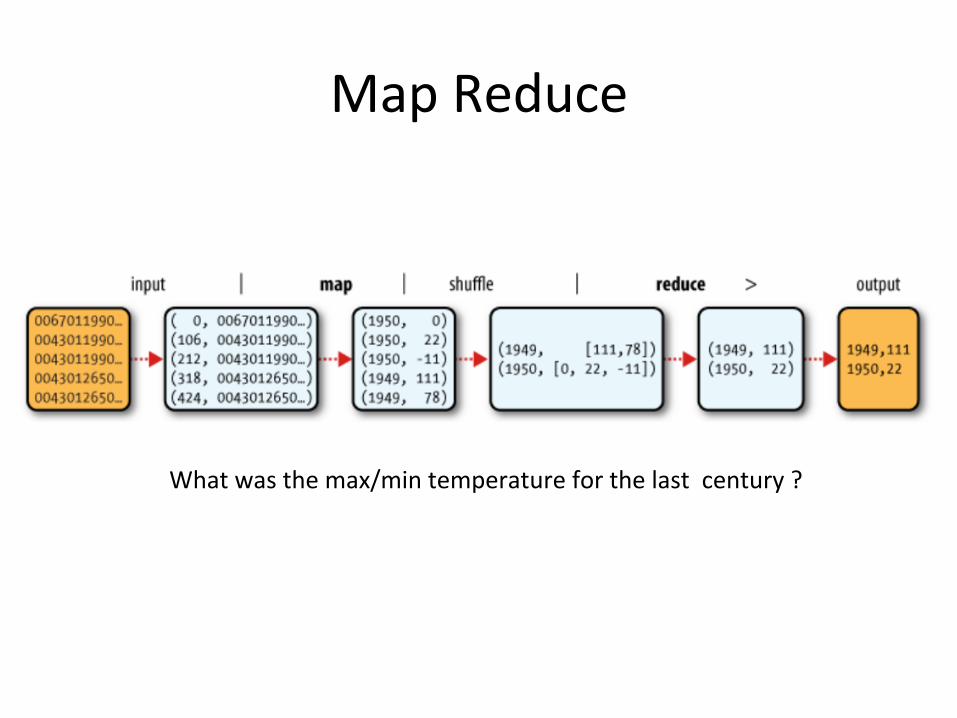
MapReduce
Whatwasthemax/mintemperatureforthelastcentury?

HadoopMapReduceq Provides:
q Automa?cparalleliza?onandDistribu?onq FaultToleranceq MethodsforinterfacingwithHDFSforcoloca?onofcomputa?onand
storageofoutput.q StatusandMonitoringtoolsq APIinJavaq Abilitytodefinethemapperandreducerinmanylanguagesthrough
Hadoopstreaming.
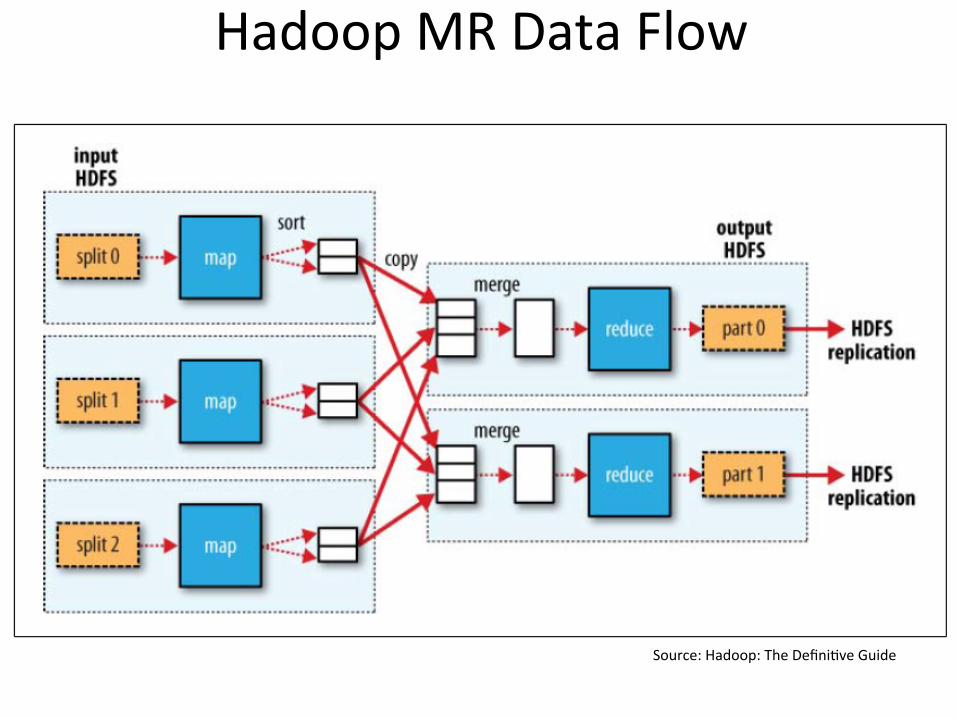
HadoopMRDataFlow
Source:Hadoop:TheDefini?veGuide
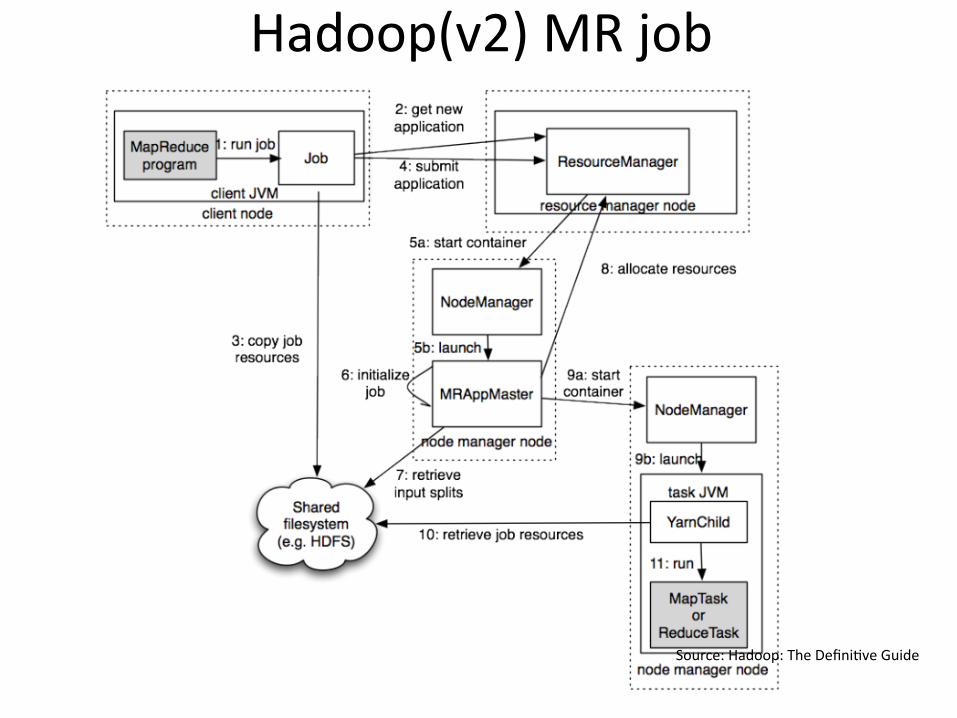
Hadoop(v2)MRjob
Source:Hadoop:TheDefini?veGuide
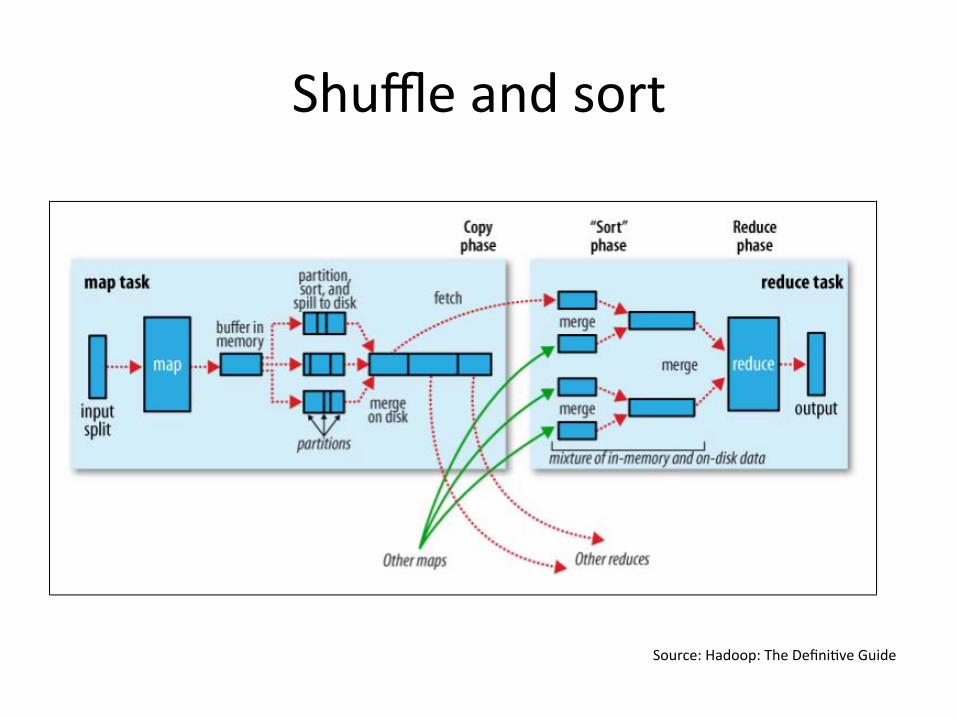
Shuffleandsort
Source:Hadoop:TheDefini?veGuide

DataFlow
• Inputandfinaloutputarestoredonadistributedfilesystem(FS):– Schedulertriestoschedulemaptasks“close”tophysicalstorageloca?onofinputdata
• IntermediateresultsarestoredonlocalFSofMapandReduceworkers
• OutputisoVeninputtoanotherMapReducetaskJ.Leskovec,A.Rajaraman,J.Ullman:
MiningofMassiveDatasets,h=p://www.mmds.org
43

Coordina?on:Master
• MasternodetakescareofcoordinaAon:– Taskstatus:(idle,in-progress,completed)– Idletasksgetscheduledasworkersbecomeavailable– Whenamaptaskcompletes,itsendsthemastertheloca?onandsizesofitsRintermediatefiles,oneforeachreducer
– Masterpushesthisinfotoreducers
• Masterpingsworkersperiodicallytodetectfailures
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,h=p://
www.mmds.org44

Faulttolerance
q Comesfromscalabilityandcosteffec?venessq HDFS:
q Replica?onq MapReduce
q Restar?ngfailedtasks:mapandreduceq Wri?ngmapoutputtoFSq Minimizesre-computa?on

DealingwithFailures
• Mapworkerfailure– Maptaskscompletedorin-progressatworkerareresettoidle
– Reduceworkersareno?fiedwhentaskisrescheduledonanotherworker
• Reduceworkerfailure– Onlyin-progresstasksareresettoidle– Reducetaskisrestarted
• Masterfailure– MapReducetaskisabortedandclientisno?fied
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,h=p://
www.mmds.org46

Failures
q Taskfailureq Taskhasfailed–reporterrortonodemanager,appmaster,client.
q Tasknotresponsive,JVMfailure–Nodemanagerrestartstasks.
q Applica?onMasterfailureq Applica?onmastersendsheartbeatstoresourcemanager.q Ifnotreceived,theresourcemanagerretrivesjobhistoryoftheruntasks.
q Nodemanagerfailure

HowmanyMapandReducejobs?
• Mmaptasks,Rreducetasks• Ruleofathumb:
– MakeMmuchlargerthanthenumberofnodesinthecluster
– OneDFSchunkpermapiscommon– Improvesdynamicloadbalancingandspeedsuprecoveryfromworkerfailures
• UsuallyRissmallerthanM– BecauseoutputisspreadacrossRfiles
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,h=p://
www.mmds.org48
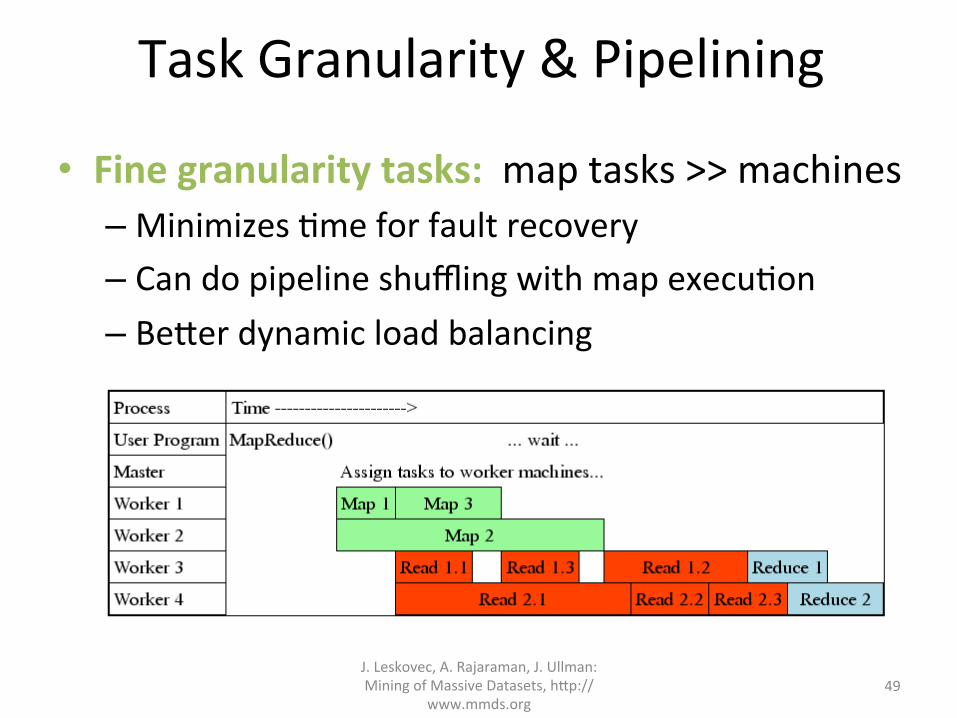
TaskGranularity&Pipelining
• Finegranularitytasks:maptasks>>machines– Minimizes?meforfaultrecovery– Candopipelineshufflingwithmapexecu?on– Be=erdynamicloadbalancing
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,h=p://
www.mmds.org49

Refinements:BackupTasks• Problem
– Slowworkerssignificantlylengthenthejobcomple?on?me:
• Otherjobsonthemachine• Baddisks• Weirdthings
• SoluAon– Nearendofphase,spawnbackupcopiesoftasks
• Whicheveronefinishesfirst“wins”• Effect
– Drama?callyshortensjobcomple?on?me
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,h=p://
www.mmds.org50
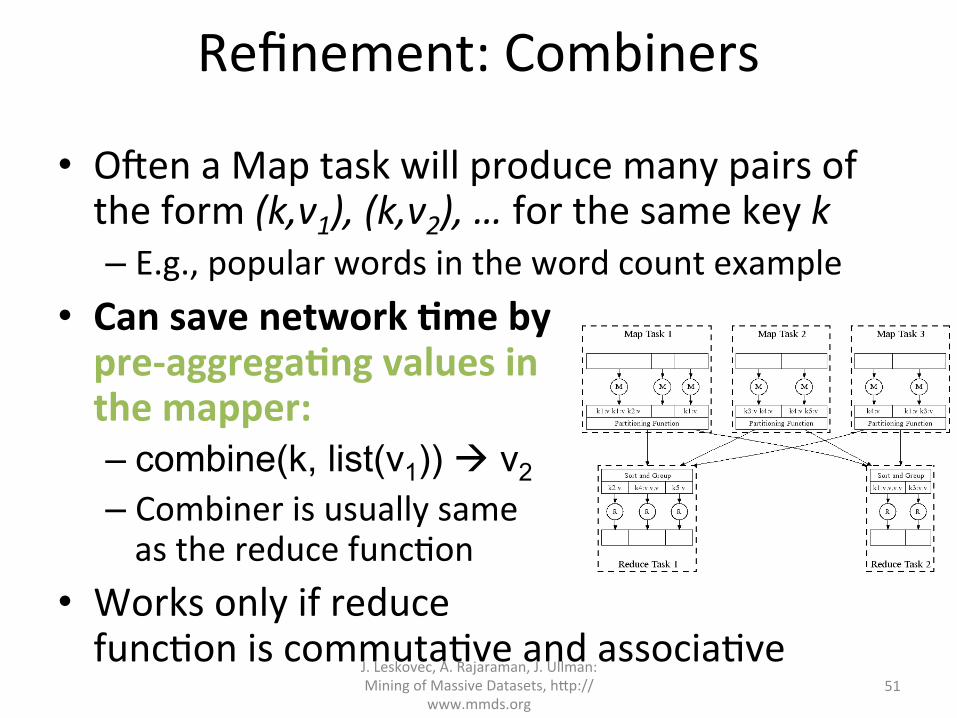
Refinement:Combiners
• OvenaMaptaskwillproducemanypairsoftheform(k,v1),(k,v2),…forthesamekeyk– E.g.,popularwordsinthewordcountexample
• CansavenetworkAmebypre-aggregaAngvaluesinthemapper:– combine(k, list(v1)) à v2 – Combinerisusuallysameasthereducefunc?on
• Worksonlyifreducefunc?oniscommuta?veandassocia?ve
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,h=p://
www.mmds.org51
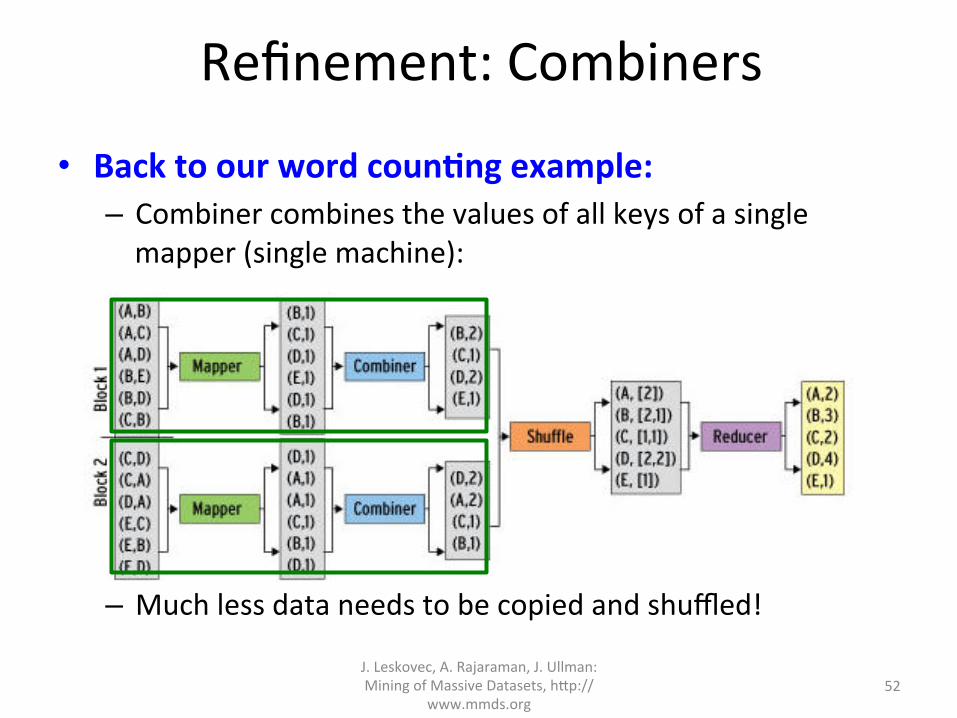
Refinement:Combiners
• BacktoourwordcounAngexample:– Combinercombinesthevaluesofallkeysofasinglemapper(singlemachine):
– Muchlessdataneedstobecopiedandshuffled!
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,h=p://
www.mmds.org52

Refinement:Par??onFunc?on
• WanttocontrolhowkeysgetparAAoned– Inputstomaptasksarecreatedbycon?guoussplitsofinputfile
– Reduceneedstoensurethatrecordswiththesameintermediatekeyendupatthesameworker
• SystemusesadefaultparAAonfuncAon:– hash(key) mod R
• SomeAmesusefultooverridethehashfuncAon:– E.g.,hash(hostname(URL)) mod RensuresURLsfromahostendupinthesameoutputfile
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,h=p://
www.mmds.org53
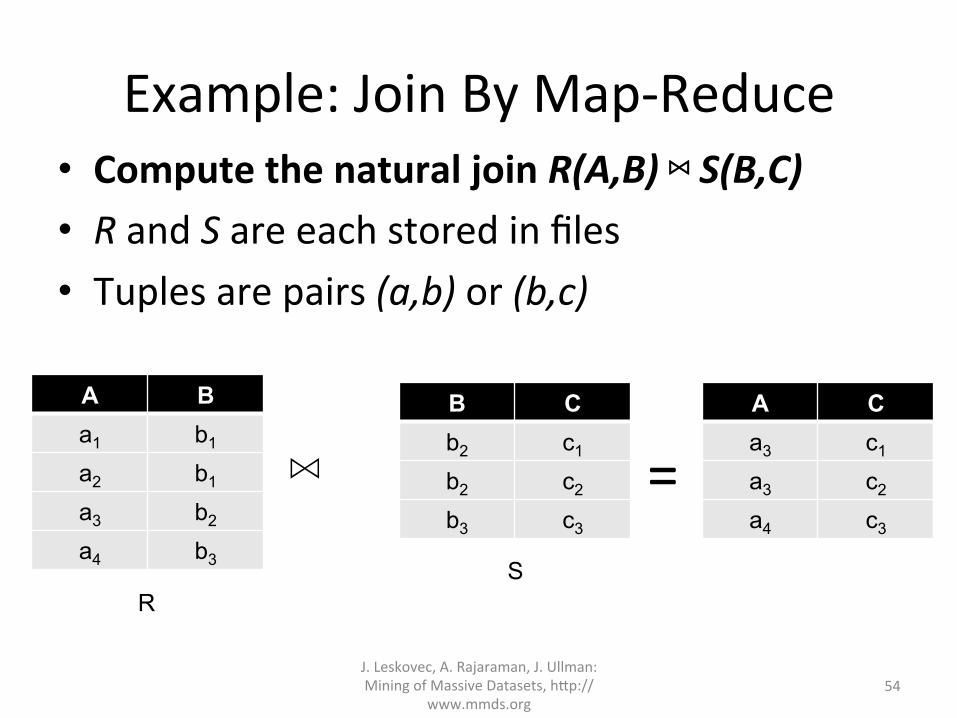
Example:JoinByMap-Reduce• ComputethenaturaljoinR(A,B)⋈S(B,C)• RandSareeachstoredinfiles• Tuplesarepairs(a,b)or(b,c)
J.Leskovec,A.Rajaraman,J.Ullman:MiningofMassiveDatasets,h=p://
www.mmds.org54
A B a1 b1
a2 b1
a3 b2
a4 b3
B C b2 c1
b2 c2
b3 c3
⋈A C a3 c1
a3 c2
a4 c3
=
R S
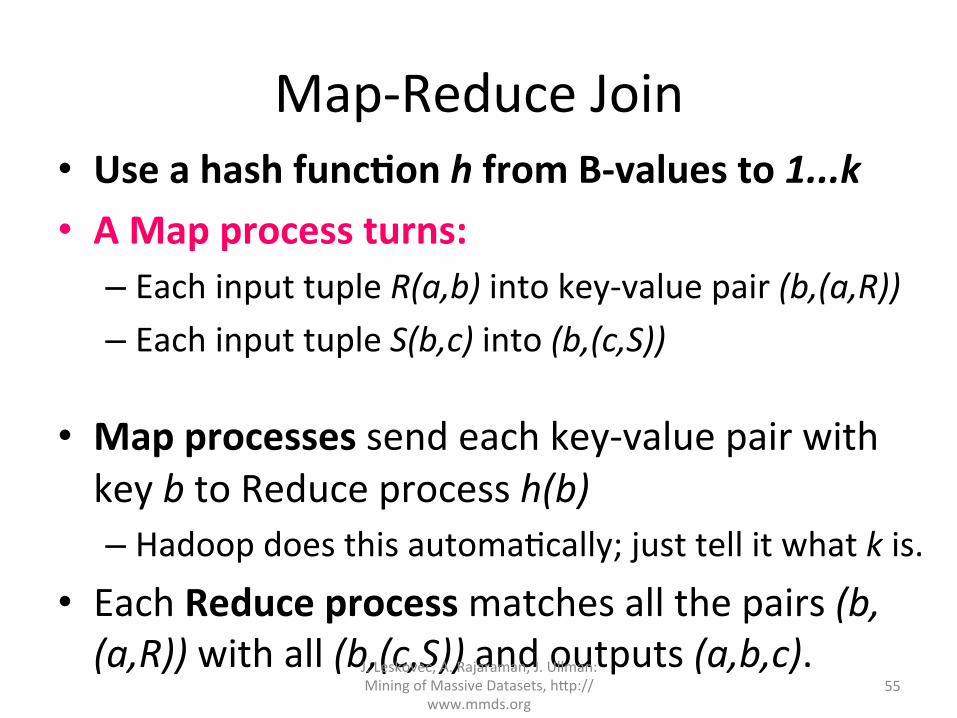
Map-ReduceJoin• UseahashfuncAonhfromB-valuesto1...k• AMapprocessturns:
– EachinputtupleR(a,b)intokey-valuepair(b,(a,R))– EachinputtupleS(b,c)into(b,(c,S))
• Mapprocessessendeachkey-valuepairwithkeybtoReduceprocessh(b)– Hadoopdoesthisautoma?cally;justtellitwhatkis.
• EachReduceprocessmatchesallthepairs(b,(a,R))withall(b,(c,S))andoutputs(a,b,c).J.Leskovec,A.Rajaraman,J.Ullman:
MiningofMassiveDatasets,h=p://www.mmds.org
55





























