Embed Size (px)
Citation preview

COMPUTER CLUSTERCourse at the University of Applied
Sciences - FH MünchenProf. Dr. Christian Vogt

Contents
TBD

Selected Literature
Gregory Pfister: In Search of Clusters, 2nd ed., Pearson 1998
Documentation for the Windows Server 2008 Failover Cluster (on the Microsoft Web Pages)
Sven Ahnert: Virtuelle Maschinen mit VMware und Microsoft, 2. Aufl., Addison-Wesley 2007 (the 3rd edition is announced for June 26, 2009).

What is a Cluster?
Wikipedia says:A computer cluster is a group of linked computers, working together closely so that in many respects they form a single computer.
Gregory Pfister says:A cluster is a type of parallel or distributed system that: consists of a collection of interconnected whole
computers, and is utilized as a single, unified computing
resource.

Features (Goals) of Clusters
High Performance Computing Load Balancing High Availability Scalability Simplified System Management Single System Image

Basic Types of Clusters
High Performance Computing (HPC) Clusters
Load Balancing Clusters (aka Server Farms)
High-Availability Clusters (aka Failover Clusters)

HPC Clusters

Load Balancing Clusters
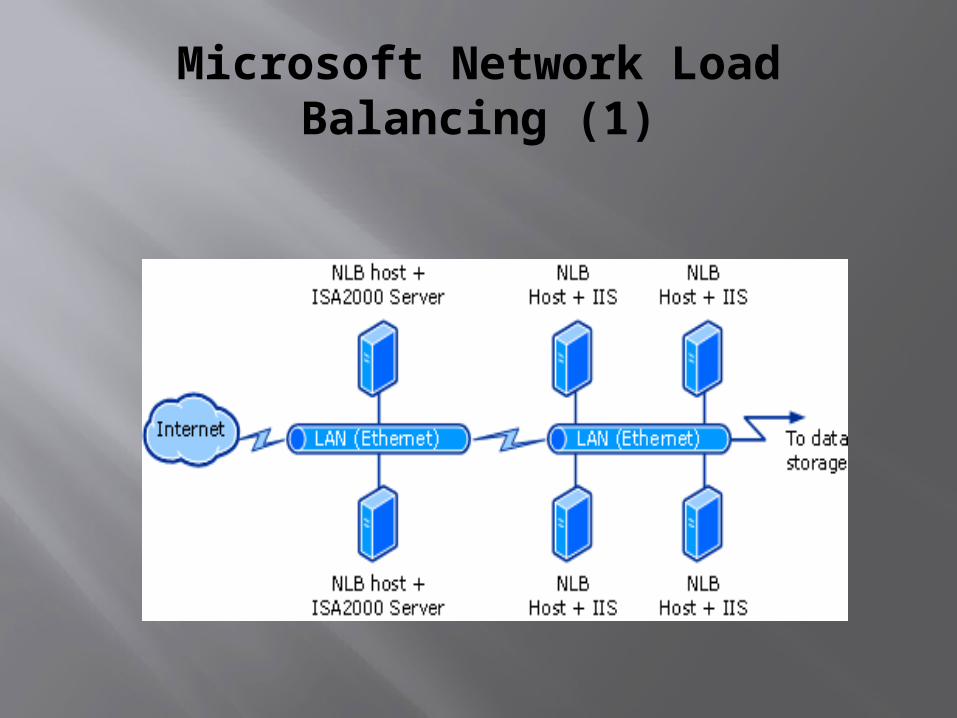
Microsoft Network Load Balancing (1)
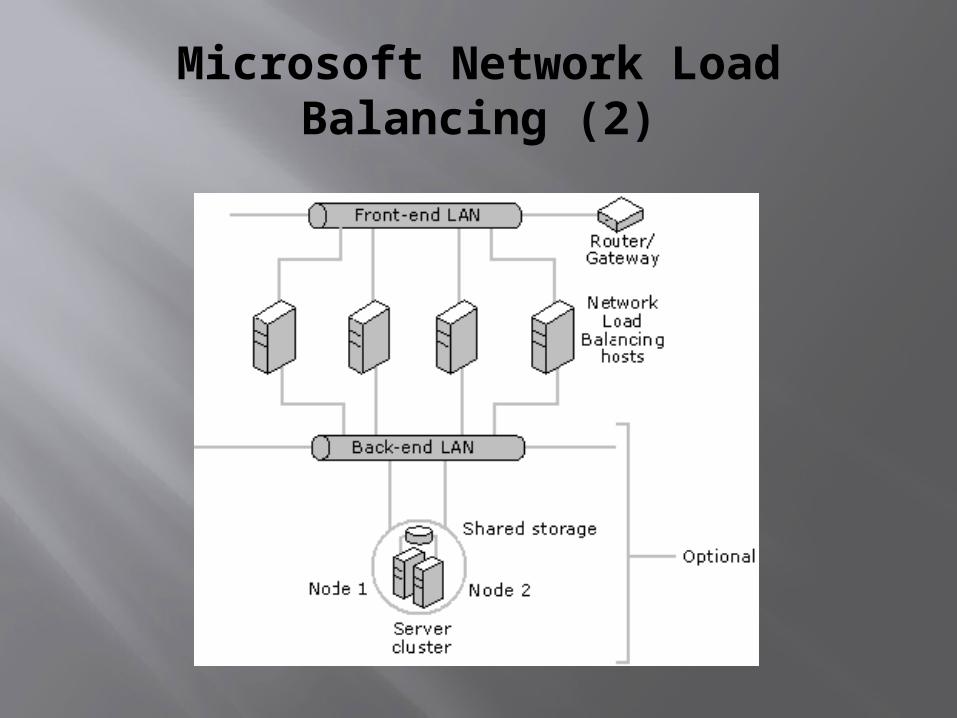
Microsoft Network Load Balancing (2)

Shared Everything Cluster

Distributed Lock Manager

Shared Nothing Cluster
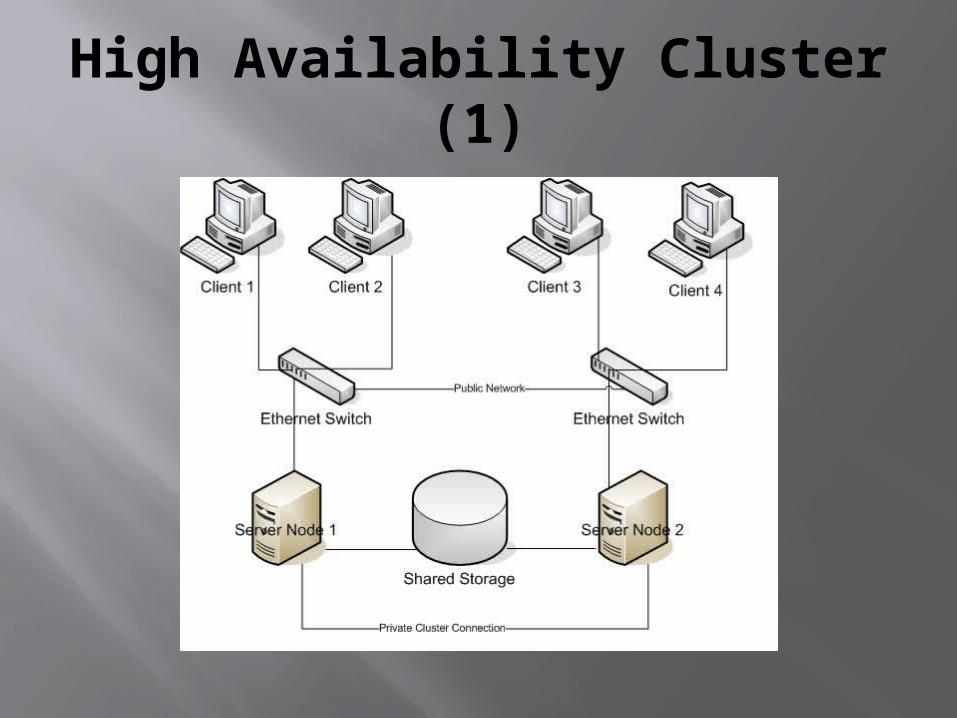
High Availability Cluster (1)
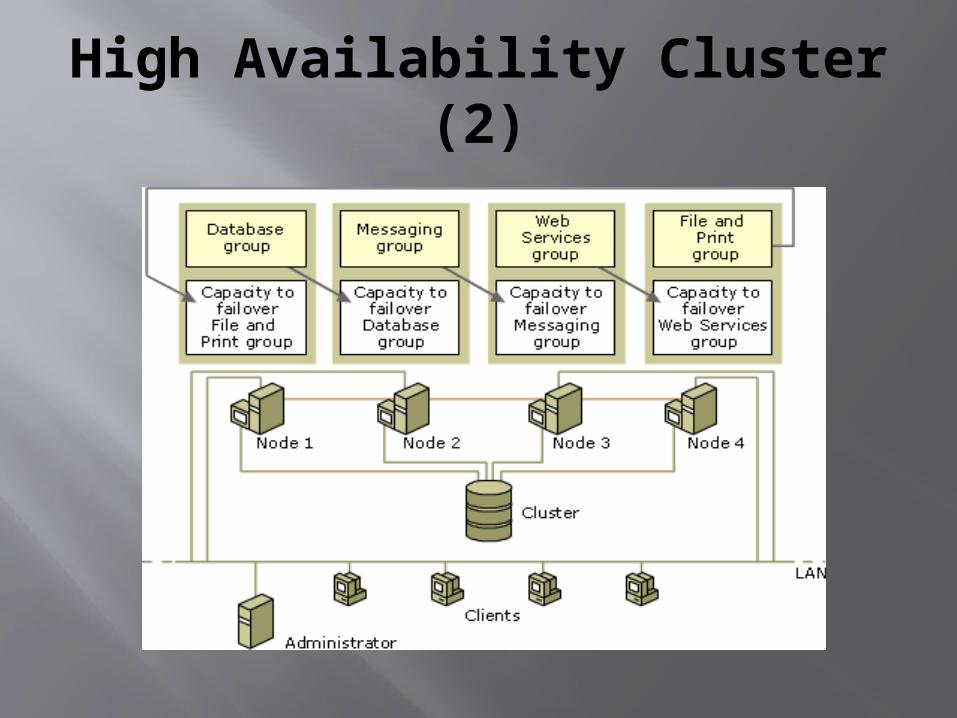
High Availability Cluster (2)

Selected HA Cluster Products (1)
VMScluster (DEC 1984, today: HP) Shared everything cluster with up to 96 nodes.
IBM HACMP (High Availability Cluster Multiprocessing, 1991) Up to 32 nodes (IBM System p with AIX or Linux).
IBM Parallel Sysplex (1994) Shared everything, up to 32 nodes (mainframes
with z/OS). Solaris Cluster, aka Sun Cluster
Up to 16 nodes.

Selected HA Cluster Products (2)
Heartbeat (HA Linux project, started in 1997) No architectural limit for the number of nodes.
Red Hat Cluster Suite Up to 128 nodes. DLM
Windows Server 2008 Failover Cluster Was: Microsoft Cluster Server (MSCS, since 1997). Up to 16 nodes on x64 (8 nodes on x86).
Oracle Real Application Cluster (RAC) Two or more computers, each running an instance of
the Oracle Database, concurrently access a single database.
Up to 100 nodes.

VMScluster

Active-Standby Cluster

Active-Active Cluster

Cluster with Virtual Machines (1)
One physical machine as hot standby for several physical machines:
physical virtual cluster
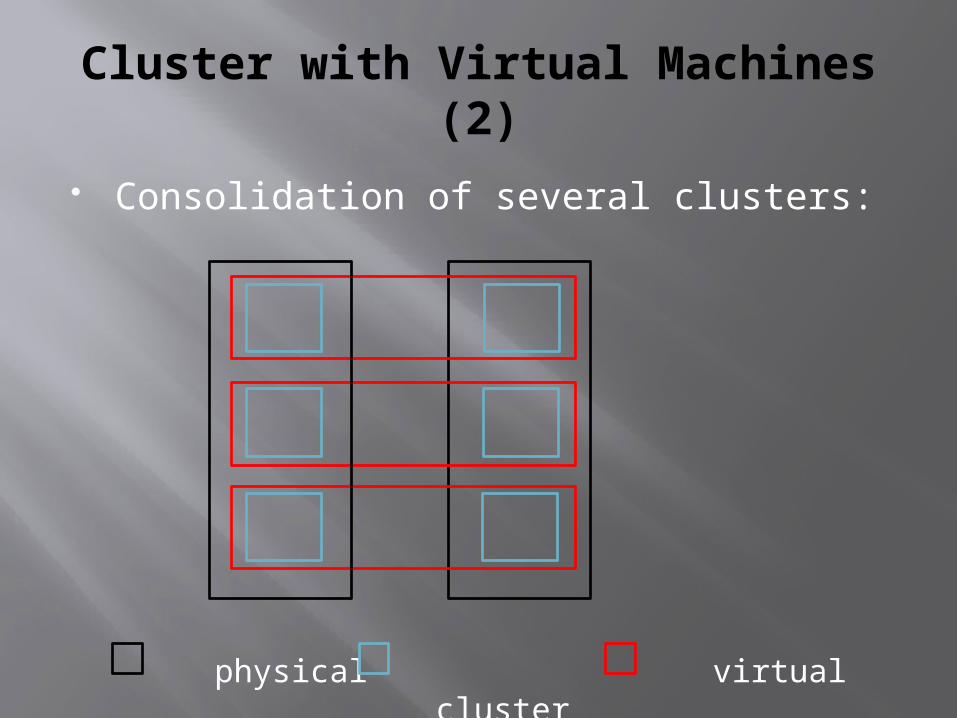
Cluster with Virtual Machines (2)
Consolidation of several clusters:
physical virtual cluster

Cluster with Virtual Machines (3)
Clustering hosts (failing over whole VMs):
physical virtual cluster

iSCSI
Internet Small Computer Systems Interface is a storage area network (SAN) protocol, carries SCSI commands over IP networks (LAN,
WAN, Internet), is an alternative to Fibre Channel (FC), using
an existing network infrastructure.
An iSCSI client is called an iSCSI Initiator.
An iSCSI server is called an iSCSI Target

iSCSI Initiator
An iSCSI initiator initiates a SCSI session, i.e. sends a SCSI command to the target.
A Hardware Initiator (host bus adapter, HBA) handles the iSCSI and TCP processing and
Ethernet interrupts independently of the CPU.
A Software Initiator runs as a memory resident device driver, uses an existing network card, leaves all protocol handling to the main CPU.

iSCSI Target
An iSCSI target waits for iSCSI initiators‘ commands, provides required input/output data transfers.
Hardware Target:A storage array (SAN) may offer its disks via the iSCSI protocol.
A Software Target: offers (parts of) the local disks to iSCSI initiators, uses an existing network card, leaves all protocol handling to the main CPU.

Logical Unit Number (LUN)
A Logical Unit Number (LUN) is the unit offered by iSCSI targets to iSCSI
initiators, represents an individually addressable SCSI device, appears to an initiator like a locally attached device, may physically reside on a non-SCSI device, and/or
be part of a RAID set, may restrict access to a single initiator, may be shared between several initiators (leaving
the handling of access conflicts to the file resp. operating system, or to some cluster software).Attention: many iSCSI target solutions do not offer this functionality.

CHAP Protocol
iSCSI optionally uses the Challenge-Hand-shake
Authen-tication Protocol (CHAP) for authentication of initiators to the target,
does not provide cryptographic protection for the data transferred.
CHAP uses a three-way handshake, bases the verification on a shared secret, which
must be known to both the initiator and the target.


Preparing a Failover Cluster
In order to build a Windows Server 2008 Failover Cluster you need to: Install the Failover Cluster Feature (in Server
Manager). Conncect networks and storage.
Public network Heartbeat network Storage network (FC or iSCSI, unless you use
SAS) Validate the hardware configuration (Cluster
Vali-dation Wizard in the Failover Cluster Management snap-in).

Preparing the Shared Storage
All disks on a shared storage bus are automatically placed in an offline state when first mapped to a cluster node. This allows storage to be simultaneously mapped to all nodes in a cluster even before the cluster is created. No longer do nodes have to be booted one at a time, disks prepared on one and then the node shut down, another node booted, the disk configuration verified, and so on.

The Cluster Validation Wizard
Run the Cluster Validation Wizard (in Failover Cluster Management). Adjust your configuration until the wizard does not
report any errors. An error-free cluster validation is a prerequisite for
obtaining Microsoft support for your cluster installation.
A full test of the Wizard consists of: System configuration Inventory Network Storage

Initial Creation of a Windows Server 2008 Failover Cluster
Use the Create Cluster Wizard (in Failover Cluster Management) to create the cluster. You will have to specify which servers are to be part of the cluster, a name for the cluster, an IP address for the cluster.
Other parameters will be chosen automatically, and can be changed later.


Fencing
(Node) Fencing is the act of forcefully disabling
a cluster node (or at least keeping it from doing disk I/O: Disk Fencing).
The decision when a node needs to be fenced is taken by the cluster software.
Some ways of how a node can be fenced are by disabling its port(s) on a Fibre Channel switch, by (remotely) powering down the node, by using the SCSI-3 Persistent Reservation.

SAN Fabric Fencing
Some Fibre Channel Switches allow programs to fence a node by disabling the switch port(s) that it is connected to.

STONITH
“Shoot the other node in the head”.
A special STONITH device (a Network Power Switch) allows a cluster node to power down other cluster nodes.
Used, for example, in Heartbeat, the Linux HA project.

SCSI-3 Persistent Reservation
Allows multiple nodes to access a SCSI device.
Blocks other nodes from accessing the device.
Supports multiple paths from host to disk. Reservations are persistent across SCSI
bus resets, and node reboots. Uses reservations, and registration. To eject another system‘s registration, a
node issues a pre-empt and abort command.

Fencing in Failover Cluster
Windows Server 2008 Failover Cluster uses SCSI-3 Persistent Reservations.
All shared storage solutions (e.g. iSCSI Targets) used in the cluster must use SCSI-3 commands, and in particular support persistent reserva-tions.(Many open source iSCSI targets do not fulfill this requirement, e.g. OpenFiler, or FreeNAS target.)
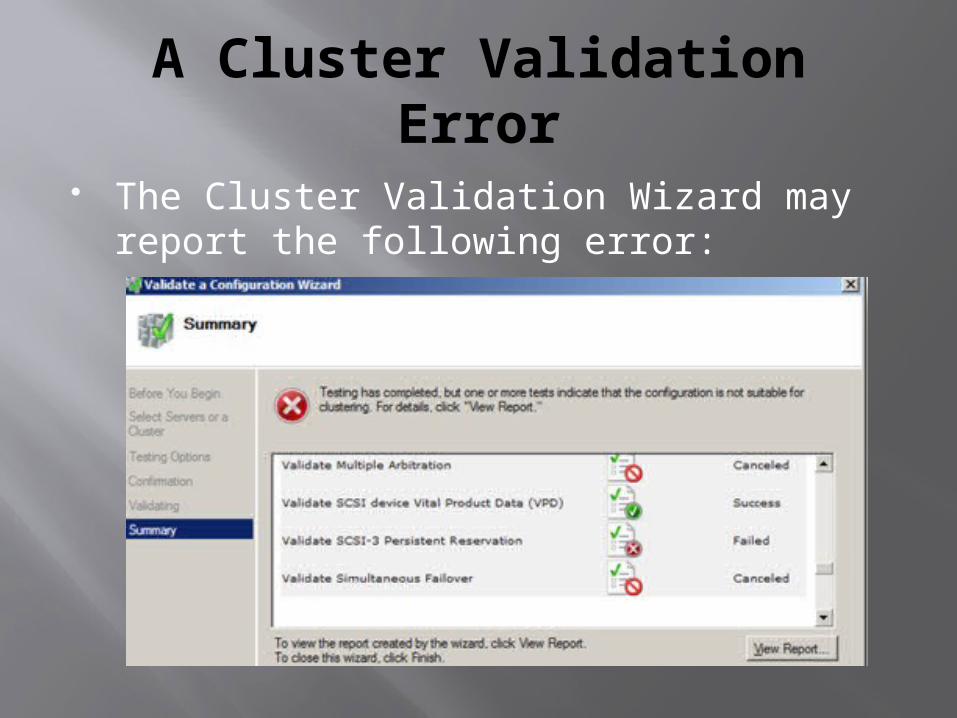
A Cluster Validation Error
The Cluster Validation Wizard may report the following error:

Cluster Partitioning (Split-Brain)
Cluster Partitioning (Split-Brain) is the situ-ation when the cluster nodes break up into groups which can communicate in their groups, and with the shared storage, but not between groups.
Cluster Partitioning can lead to serious problems, including data corruption on the shared disks.

Quorum Schemes
Cluster Partitioning can be avoided by usinga Quorum Scheme: A group of nodes is only allowed to run as a
cluster when it has quorum. Quorum consists of a majority of votes. Votes can be contributed by
Nodes Disks File Shares
each of which can provide one or more votes.
Votes in Failover Cluster
In Windows Server 2008 Failover Cluster votes can be contributed by a node, a disk (called the witness disk), a file share,
each of which provides exactly one vote.
A Witness Disk or File Share contains the cluster registry hive in the \Cluster directory.(The same information is also stored on each of the cluster nodes but may be out of date).

Quorum Schemes in Windows Server 2008 Failover Cluster (1)
Windows Server 2008 Failover Cluster can use any of four different Quorum Schemes:
Node Majority Recommended for a cluster with an odd number
of nodes.
Node and Disk Majority Recommended for a cluster with an even number
of nodes.

Quorum Schemes in Windows Server 2008 Failover Cluster (2) Node and File Share Majority
Recommended for a multi-site cluster with an even number of nodes.
No Majority: Disk Only A group of nodes may run as a cluster if they
have access to the witness disk. The witness disk is a single point of failure. Not recommended. (Only for backward
compatibility with Windows Server 2003.)


Failover Cluster Terminology
Resources Groups Services and Applications Dependencies Failover Failback Looks-Alive („Basic resource health
check“, default interval: 5 sec.) Is-Alive („Thorough resource health
check“, default interval: 1 min.)

Services and Applications
DFS Namespace Server DHCP Server Distributed Transaction Coordinator (DTC) File Server Generic Application Generic Script Generic Service Internet Storage Name Service (ISNS) Server Message Queuing Other Server Print Server Virtual Machine (Hyper-V) WINS Server

Properties of Services and Applications
General: Name Preferred Owner(s)
(Muss angegeben werden, wenn ein Failback gewünscht ist.) Failover:
Period (Default: 6 hours)Number of hours in which the Failover Threshold must not be exceeded.
Threshold (Default: 2 [?, 2 for File Server])Maximum number of times to attempt a restart or failover in the specified period. When this number is exceeded, the application is left in the failed state.
Failback: Prevent failback (Default) Allow failback
Immediately Failback between (specify range of hours of the day)

Resource Types
In addition to all services and applications mentioned before:
File Share Quorum Witness IP Address IPv6 Address IPv6 Tunnel Address MSMQ Triggers Network Name NFS Share Physical Disk Volume Shadow Copy Service Task

Properties of Resources (1)
General: Resource Name Resource Type
Dependencies Policies:
Do not restart Restart (Default)
Threshold: Maximum number of restarts in the period. Default: 1
Period: Period for restarts. Default: 15 min. Failover all resources in the service/application if restart fails?
Default: yes If restart fails, begin restarting again after ... Default: 1 hour
Pending Timeout. Default: 3 minutes

Properties of Resources (2)
Advanced Policies: Possible Owners. Basic resource health check interval /
Thorough resource health check interval Default: Use standard time period for the
resource type Use specified time period (defaults: 5 sec. / 1
min.) Run resource in separate Resource Monitor.
Default: no. Further parameters depending on the
type of the resource.

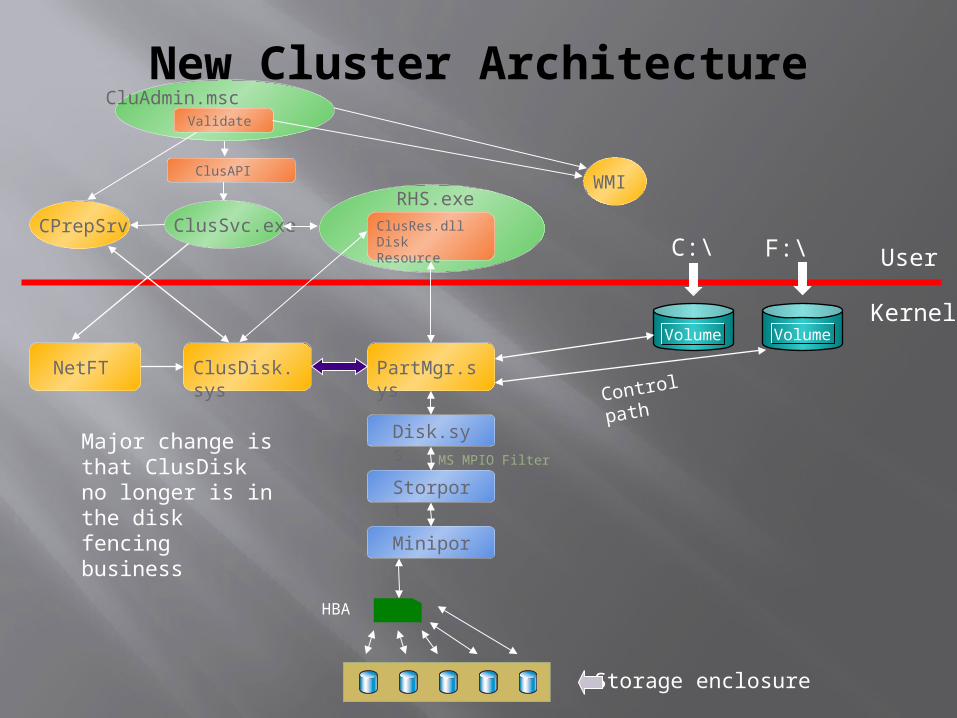
New Cluster Architecture
ClusSvc.exe ClusRes.dllDisk Resource
RHS.exe
CluAdmin.msc
HBA
Storage enclosure
User
KernelVolume
C:\
Volume
F:\
PartMgr.sys
Disk.sys
ClusDisk.sys Control pathNetFT
Storport
Miniport
Major change is that ClusDisk no longer is in the disk fencing business
MS MPIO Filter
ClusAPI
CPrepSrv
Validate
WMI
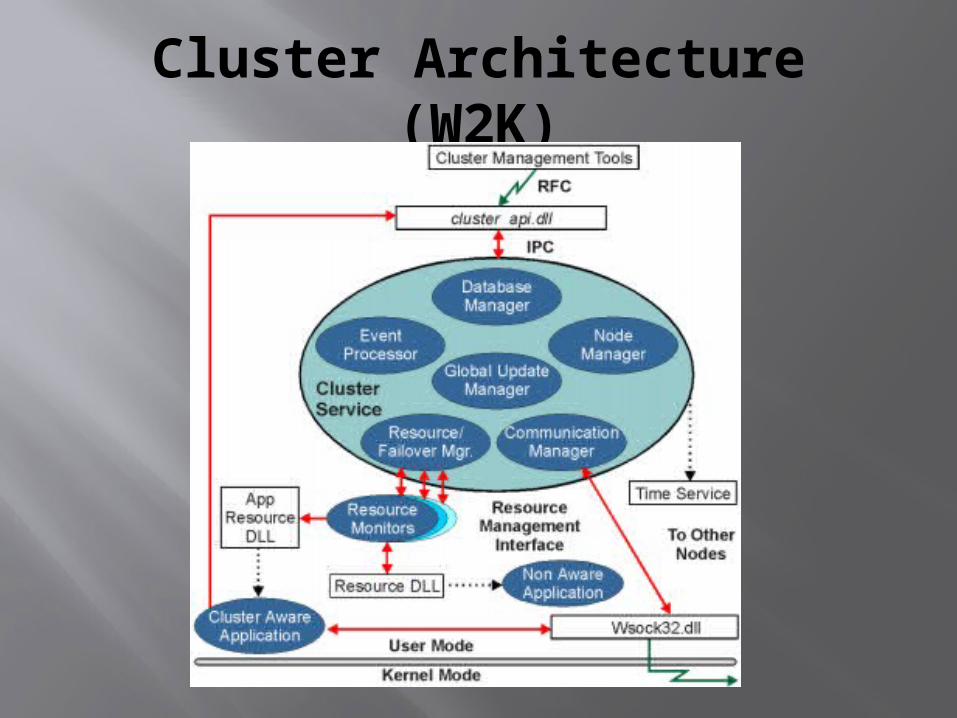
Cluster Architecture (W2K)

Cluster Service Components (1)
Database Manager Manages the configuration database contained in the
registry of each cluster node. Coordinates updates of the database. Makes sure that updates are atomic across the cluster
nodes..
Node Manager (or: Membership Manager) Maintains cluster membership. The node managers of all cluster managers communicate in
order to determine the failure of a node.
Event Processor Is responsible for communicating events to the applications,
and to other components of the cluster service.

Cluster Service Components (2)
Communication Manager Is responsible for the communication between the cluster
services on the cluster nodes, e.g. related to negotiating the entrance of a node into the cluster, information about resource states, failover and failback operations.
Global Update Manager Component for distributing update requests to all cluster
nodes.
Resource/Failover Manager: is responsible for managing the depencies between resources, starting and stopping resources, initializing failover and failback.

Resource Monitors
Resource Monitors handle the communication between the cluster service and resources.
A Resource Monitor is a separate process, using resource specific DLLs.
A Resource Monitor uses one „poller thread“ per 16 resources for performing the LooksAlive and IsAlive tests.

Routines in a Resource DLL
The resource API for writing own resource DLLs knows two types of functions: Callback routines, which can be called from the DLL:
LogEvent SetResourceStatus
Entry-point routines, which are called by the resource monitor: Startup (called once for every resource type) Open (executed when creating a new resource) Online (limit: 300 ms or asynch. in worker thread) LooksAlive (limit: 300 ms, recommended: < 50 ms) IsAlive (limit: 400 ms, recomm.: < 100 ms, or asynch.) Offline (limit: 300 ms, or asynch. in worker thread) Terminate (on error in offline or pending-timeout) Close (executed when deleting a resource) ResourceControl, and ResourceTypeControl (for „private
properties“)

Status Control for ResourcesCall
LooksAlive
RESOURCE FAILURE
Have therebeen more than
(RestartThreshold)restart attempts within
(RestartPeriod)minutes?
CallIsAlive Is
RestartActionSet to
DontRestart?
IsAliveresult
Attempt to restart the resource bycalling Online entry point
The resource isback online
The resource DLL mayindependently reportthat the resource has
failed
LooksAliveresult
No
True
True
No Response
No Response
Yes
Yes
No
False
FailSuccess
Onlineresult
Fail the resource overto a new node and
attemp restart
Have therebeen more than
(FailoverThreshold)failover attempts?
Resource remains ina failed state for
(FailoverThreshold)failover attempts?
What is theRestartAction
setting?
Online result(new node)
The resource isback online
Yes
No
Fail
DontRestart
Onlineresult
The resource remainsin a failed state
The resource is backonline (on another node)
Success
Success
RestartNoNotify
RestartNotify
Fail
False
Cluster Service
LooksAlive poll every(LooksAlivePollIntervall)
milliseconds
IsAlive poll every(IsAlivePollIntervall)
milliseconds





























