Embed Size (px)
Citation preview

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
cours OROC–SC–FP (1/5)
Filtrage Bayesienet Approximation Particulaire
Francois Le GlandINRIA Rennes et IRMAR
http://www.irisa.fr/aspi/legland/ensta/
22 et 29 septembre 2017
1 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Presentationcourte biographieorganisation pratique du cours
Introduction au filtrage
Estimation bayesienne
Systemes lineaires gaussiens
Extensions
Systemes non–lineaires / non–gaussiens
2 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Francois Le Gland
◮ telephone : 02 99 84 73 62 / 06 95 02 13 16
◮ e–mail : francois.le [email protected]
formation
◮ ingenieur Ecole Centrale Paris (1978)
◮ DEA de Probabilites a Paris 6 (1979)
◮ these en Mathematiques Appliquees a Paris Dauphine (1981)
carriere professionnelle : chercheur a l’INRIA (directeur de recherchedepuis 1991)
◮ a Rocquencourt jusqu’en 1983
◮ a Sophia Antipolis de 1983 a 1993
◮ a Rennes depuis 1993
membre de l’IRMAR depuis 2012
3 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
responsable de l’equipe
ASPI : Applications Statistiques des Systemes de Particules enInteraction
http://www.irisa.fr/aspi/
themes
◮ filtrage particulaire, et applications en
• localisation, navigation et poursuite• assimilation de donnees sequentielle
◮ inference statistique des modeles de Markov caches
◮ simulation d’evenements rares, et extensions en
• simulation moleculaire• optimisation globale
◮ analyse mathematique des methodes particulaires
4 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
contrats industriels
◮ avec France Telecom R&D, sur la localisation de terminaux mobiles
◮ avec Thales, sur la navigation par correlation de terrain
◮ avec DGA / Techniques Navales, sur l’optimisation dupositionnement et de l’activation de capteurs
◮ avec Naval Group (ex-DCNS), sur le pistage TBD multi–cible
projets ANR
◮ FIL, sur la fusion de donnees pour la localisation
◮ PREVASSEMBLE, sur les methodes d’ensemble pour l’assimilationde donnees et la prevision
projets europeens
◮ HYBRIDGE et iFLY, sur les methodes de Monte Carloconditionnelles pour l’evaluation de risque en trafic aerien
collaboration avec ONERA
5 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Organisation pratique du cours
a chaque seance (sauf aujourd’hui)
◮ cours magistral
◮ seance de TP MATLAB en salle informatique
• par binome• rapport ecrit + code source MATLAB, a rendre pour la seance
suivante• en cas de difficulte, e–mail a francois.le [email protected]
support de cours
◮ polycopie (aspects theoriques)
◮ planches presentees en cours magistral
◮ enonce des TP MATLAB
ressources : articles a telecharger, archives, etc.
http://www.irisa.fr/aspi/legland/ensta/
6 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
controle des connaissances
◮ TP MATLAB (29 septembre, 13 et 27 octobre)
◮ examen final (20 octobre)
liste des TP proposes cette annee
◮ recalage altimetrique de navigation inertielle
◮ suivi visuel par histogramme de couleur
◮ navigation en environnement interieur
autres TP proposes les annees precedentes
◮ assimilation de donnees sequentielle pour le modele de Lorenz
◮ poursuite d’une cible furtive (track–before–detect)
◮ valorisation d’options europeennes dans le modele de Black–Scholes
◮ evaluation du risque de collision
7 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
cours 1 (aujourd’hui)
introduction au filtrage, estimation bayesienne, cas gaussiensystemes lineaires gaussiens : filtre de Kalmansystemes non lineaires / non gaussiens : exemples en localisation,navigation et poursuite
cours 2methodes de Monte Carlo : simulation selon une distribution deGibbs–Boltzmann, simulation selon un melange fini
cours 3filtre bayesien optimal : representation probabiliste vs. equationrecurrentedistributions de Feynman–Kac (distributions de Gibbs–Boltzmanntrajectorielles)approximation particulaire
8 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
cours 4methodes de branchement multi–niveaux : calcul de probabilites dedepassement de niveau (statique), simulation d’evenements rares
cours 5theoremes limites pour les approximations particulaires : convergencedans Lp, theoreme central limite
9 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Presentation
Introduction au filtragenecessite / utilite d’un modele a prioriexploitation du modele a priori
Estimation bayesienne
Systemes lineaires gaussiens
Extensions
Systemes non–lineaires / non–gaussiens
10 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Cadre general
il s’agit d’estimer, si possible de maniere recursive, l’etat Xn d’un systeme(par exemple, position et vitesse d’un mobile) au vu d’observationsbruitees Y0:n = (Y0 · · ·Yn) reliees a l’etat par une relation du genre
Yk = hk(Xk) + Vk
nombreuses applications en localisation, navigation et poursuite demobiles
◮ poursuite de cible (avion, missile, drone, batiment de surface,sous–marin)
◮ suivi d’objets dans des sequences video
◮ navigation en environnement interieur (robot mobile, pieton)
◮ navigation inertielle, recalage avec un modele numerique de terrain
◮ navigation de terminaux mobiles, recalage avec une carte decouverture
11 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
il s’agit dans ce cas de determiner position et vitesse d’un mobile, enutilisant comme observations des mesures partielles issues de capteurs
(i) mesures directes
• distance par rapport a une ou plusieurs stations• angle par rapport a une direction de reference• proximite par rapport a une ou plusieurs stations• altitude par rapport a un niveau de reference ou par rapport au relief
(ii) mesures indirectes, combinees avec une base de mesuresgeo–referencees, disponibles par exemple sous la forme d’une cartenumerique
• altitude du relief + modele numerique de terrain• attenuation de la puissance du signal recu + carte de couverture
exemples (en fin de seance)
12 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Necessite d’un modele a priorisans information supplementaire, observer
Yk = hk(Xk) + Vk
pose un nouveau probleme d’estimation a chaque nouvel instant (pasd’accumulation des observations) + dans chacun de ces problemesd’estimation separement, la dimension m de l’etat cache est (souvent)plus grande que la dimension d de l’observation
estimer l’etat cache Xk au vu de la seule observation Yk et meme sansbruit d’observation Vk , est un probleme mal–pose
◮ la relation possede plus d’inconnues que d’equations
◮ meme dans le cas favorable ou m = d , la relation non–lineaire peutposseder plusieurs solutions distinctes
◮ la suite reconstituee peut etre globalement peu pertinente (en tantque suite), meme si separement chacune des estimations marginalesest pertinente (incoherence temporelle)
13 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
approche variationnelle pour lever l’indetermination ou l’incoherencetemporelle : introduire des informations supplementaires sur la suitecachee, sous la forme de fonctions de cout portant sur l’etat initial et surles transitions entre deux etats successifs
par exemple, le critere a minimiser par rapport a la suitex0:n = (x0, x1, · · · , xn)
J(x0:n) = c0(x0) +
n∑
k=1
ck(xk−1, xk) +
n∑
k=0
dk(xk)
combine des fonctions de cout qui representent◮ une information a priori sur la suite recherchee◮ un terme d’attache aux donnees, par exemple de la forme
dk(x) =12 |Yk − hk(x)|
2
avec l’interpretation que la suite recherchee doit verifier a chaqueinstant l’equation d’observation en un sens approche
ou qui peuvent juste representer une contrainte (ou une propriete) que lasuite recherchee devrait verifier (ou posseder)
14 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
typiquement, l’information a priori est representee par
c0(x) =12 |x − µ|2 et ck(x , x
′) = 12 |x
′ − fk(x)|2
avec l’interpretation que
◮ l’etat initial x0 recherche doit etre proche de µ
◮ et que la transition (xk−1, xk) recherchee doit verifier l’equationxk = fk(xk−1) en un sens approche
cette regularisation (du point de vue de l’optimisation) peut s’interpretercomme l’ajout d’une information a priori (du point de vue de l’estimationstatistique)
15 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
plus generalement, si l’information a priori est representee par
c0(x) = − log p0(x) et ck(x , x′) = − log pk(x
′ | x)
alors minimiser le critere
J(x0:n) = − log p0(x0)−n∑
k=1
log pk(xk | xk−1) +
n∑
k=0
dk(xk)
revient a maximiser (estimateur MAP (maximum a posteriori))
exp{−J(x0:n)} = p0(x0)n∏
k=1
pk(xk | xk−1)
︸ ︷︷ ︸p0:n(x0:n)
exp{−n∑
k=0
dk(xk)}
ou p0:n(x0:n) represente la densite de probabilite conjointe des etatssuccessifs (X0,X1, · · · ,Xn) de la chaıne de Markov caracterisee par
◮ la densite de probabilite initiale p0(x0)
◮ et les densites de probabilite de transition pk(xk | xk−1)
16 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
approche statistique avec un point de vue pragmatique : au lieu derechercher un maximum de la densite a posteriori, on choisitd’echantillonner cette densite, ce qui permet par exemple de calculer desesperances (ou des integrales) du type
∫
E
· · ·
∫
E
f (x0:n) exp{−J(x0:n)} dx0:n
=
∫
E
· · ·
∫
E
f (x0:n) exp{−n∑
k=0
dk(xk)} p0:n(x0:n) dx0:n
= E[f (X0:n) exp{−n∑
k=0
dk(Xk)} ]
on verra comment resoudre ce probleme de maniere approchee, ensimulant des echantillons de variables aleatoires distribuees(approximativement) selon la distribution de Gibbs–Boltzmanntrajectorielle definie ci–dessus
lien entre les deux approches : methode asymptotique de Laplace17 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
resume : necessite / utilite d’un modele a priori
◮ pour completer l’information apportee par les observations
◮ pour faire le lien entre des observations recues a des instantsdifferents (compte tenu que le mobile s’est en principe deplace entreces instants)
ce modele peut etre rustique ou grossier , et il est souvent bruite (onaccepte l’idee que le modele est necessairement faux, et on essaye dequantifier, de maniere statistique, l’erreur de modelisation)
il suffit en pratique de savoir simuler a chaque pas de temps des v.a.independantes selon le modele propose : comme ce modele est bruite(aleatoire) des simulations differentes proposeront des etats possiblesdifferents
effet desire : permettre l’exploration rationnelle de l’espace d’etat pourproposer des solutions realistes, qui seront ensuite confirmees, renforceesou au contraire abandonnees : il suffira pour cela de savoir evaluer lafonction de vraisemblance en chacune des solutions proposees
18 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Modeles
modele (du plus simple au plus general)modele d’etat (espace d’etat continu R
m)
◮ lineaire, bruits gaussiens
◮ non–lineaire, bruits gaussiens
◮ modele d’etat general : non–lineaire, bruits non–gaussiens
modele de Markov cache (HMM), et extensions
◮ modele de Markov cache (etat cache markovien, observationsindependantes / markoviennes conditionnellement aux etats caches)
◮ chaıne de Markov partiellement observee (etats caches etobservations conjointement markoviens)
19 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
espace d’etat general
◮ fini, denombrable
◮ espace euclidien, variete
◮ hybride continu / discret
◮ avec contraintes
◮ graphe (collection de nœuds et d’aretes)
20 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Exploitation du modele a priori
approche bayesienne, fusion d’information : loi a posteriori obtenue encombinant
◮ loi a priori (modele d’etat)
◮ vraisemblance (adequation entre mesures et etats)
mise en œuvre recursive grace a la propriete de Markov
principe general : a l’aide de la formule de Bayes, la loi conditionnelle deX0:n sachant Y0:n s’exprime a partir de
◮ la loi de X0:n
◮ la loi conditionnelle de Y0:n sachant X0:n, souvent facile a evaluerpar exemple dans le modele additif
Yk = hk(Xk) + Vk
21 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
en principe, la loi conditionnelle de Xn sachant Y0:n s’obtient facilementpar marginalisation
en pratique, cette loi conditionnelle n’a d’expression explicite que danscertains cas particuliers
◮ chaıne de Markov a espace d’etat fini
◮ modele lineaire gaussien
d’ou l’interet pour les methodes de simulation de type Monte Carlo dansle cas general : le filtrage particulaire offre une maniere numeriquementefficace de mettre en œuvre les methodes bayesiennes
22 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Presentation
Introduction au filtrage
Estimation bayesienneestimation bayesienneborne de Cramer–Rao a posterioricadre gaussien
Systemes lineaires gaussiens
Extensions
Systemes non–lineaires / non–gaussiens
23 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Estimation bayesienne
soit Z = (X ,Y ) a valeurs dans E × F (par exemple E = Rm, F = R
d ) deloi jointe connue (pas necessairement donnee par une densite p(x , y))
objectif : exploiter au mieux l’observation de Y pour ameliorer laconnaissance de la composante cachee X
un estimateur ψ de la statistique φ = φ(X ) a valeurs dans Rp est uneapplication definie sur F , a valeurs dans Rp
mesure de l’ecart entre ψ(Y ) et φ(X ) : erreur quadratique moyenne
E|ψ(Y )− φ(X )|2
trace de la matrice de correlation de l’erreur d’estimation
E[ (ψ(Y )− φ(X )) (ψ(Y )− φ(X ))∗ ]
symetrique semi–definie positive, de dimension p × p
24 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
estimateur MMSE (minimum mean square error) : estimateur φ tel que
E[ (φ(Y )−φ(X )) (φ(Y )−φ(X ))∗ ] ≤ E[ (ψ(Y )−φ(X )) (ψ(Y )−φ(X ))∗ ]
pour tout autre estimateur ψ, au sens des matrices symetriquesa fortiori
E|φ(Y )− φ(X )|2 ≤ E|ψ(Y )− φ(X )|2
pour tout autre estimateur ψ
Proposition l’estimateur MMSE de la statistique φ = φ(X ) au vu del’observation Y est la moyenne conditionnelle de φ(X ) sachant Y
φ(Y ) = E[φ(X ) | Y ] =
∫
E
φ(x) P[X ∈ dx | Y ]
25 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Preuve pour un estimateur ψ quelconque, la decomposition
ψ(Y )− φ(X ) = ψ(Y )− φ(Y ) + φ(Y )− φ(X )
entraıne
E[ (ψ(Y )− φ(X )) (ψ(Y )− φ(X ))∗ ]
= E[ (ψ(Y )− φ(Y )) (ψ(Y )− φ(Y ))∗ ]
+ E[ (φ(Y )− φ(X )) (φ(Y )− φ(X ))∗ ]
+ E[ (ψ(Y )− φ(Y )) (φ(Y )− φ(X ))∗ ] + (· · · )∗
si les deux produits croises sont nuls, alors
E[ (ψ(Y )−φ(X )) (ψ(Y )−φ(X ))∗ ] ≥ E[ (φ(Y )−φ(X )) (φ(Y )−φ(X ))∗ ]
au sens des matrices symetriques, avec egalite pour ψ(Y ) = φ(Y )
26 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
il reste a verifier que
E[ (φ(Y )− φ(X )) (ψ(Y )− φ(Y ))∗ ]
= E[E[φ(Y )− φ(X ) | Y ] (ψ(Y )− φ(Y ))∗ ]
= E[ (φ(Y )− E[φ(X ) | Y ]) (ψ(Y )− φ(Y ))∗ ] = 0
par definition deφ(Y ) = E[φ(X ) | Y ] �
pros : solution universelle (la loi conditionnelle de X sachant Y permet deconstruire l’estimateur MMSE de n’importe quelle statistique φ = φ(X ))cons : solution infini–dimensionnelle (distribution ou densite deprobabilite)
27 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Borne de Cramer–Rao a posterioril’erreur quadratique moyenne associee a l’estimateur bayesien fournit uneborne inferieure, atteinte (par l’estimateur bayesien) mais souvent difficilea evaluer
la borne de Cramer–Rao a posteriori (differente de la borne parametrique)est plus facilement calculable mais pas necessairement atteinte
hypothese : la loi jointe de Z = (X ,Y ) possede une densite (assezreguliere) sur Rm × F
P[X ∈ dx ,Y ∈ dy ] = p(x , y) dx λ(dy)
obtenue souvent grace a la factorisation (formule de Bayes)
p(x , y) = p(y | x) p(x) = p(x | y) p(y)
et cette densite verifie∫
Rm
∫
F
∂2
∂x2p(x , y) λ(dy) dx =
∫
Rm
p′′(x) dx = 0
28 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
on definit le biais de l’estimateur ψ comme
b(ψ, x) = E[ψ(Y ) | X = x ]− φ(x) =
∫
F
(ψ(y)− φ(x)) p(y | x) λ(dy)
Theoreme si la matrice d’information de Fisher
J = −E[∂2
∂x2log p(X ,Y )] matrice de dimension m ×m
est inversible, alors
E[ (ψ(Y )− φ(X )) (ψ(Y )− φ(X ))∗ ] ≥ M J−1 M∗
avecM = E[φ′(X )] matrice de dimension p ×m
pour tout estimateur ψ tel que∫
Rm
(b(ψ, x) p(x))′ dx = 0
29 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Preuve par definition
b(ψ, x) p(x) =
∫
F
(ψ(y)− φ(x)) p(x , y) λ(dy)
et la matrice jacobienne (de dimension p ×m) associee verifie
(b(ψ, x) p(x))′
= −φ′(x)
∫
F
p(x , y) λ(dy) +
∫
F
(ψ(y)− φ(x))∂
∂xp(x , y) λ(dy)
= −φ′(x) p(x) +
∫
F
(ψ(y)− φ(x))∂
∂xlog p(x , y) p(x , y) λ(dy)
en integrant par rapport a la variable x ∈ Rm et avec l’hypothese, il vient
−
∫
Rm
φ′(x) p(x) dx +
∫
Rm
∫
F
(ψ(y)− φ(x))∂
∂xlog p(x , y) p(x , y) λ(dy) dx
= −E[φ′(X )] + E[ (ψ(Y )− φ(X ))∂
∂xlog p(X ,Y ) ] = 0
30 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
c’est–a–dire que
E[ (ψ(Y )− φ(X ))∂
∂xlog p(X ,Y ) ] = M
d’autre part, il resulte de l’identite
∂2
∂x2log p(x , y) =
1
p(x , y)
∂2
∂x2p(x , y)− (
∂
∂xlog p(x , y))∗
∂
∂xlog p(x , y)
entre matrices de dimension m ×m, que
E[ (∂
∂xlog p(X ,Y ))∗
∂
∂xlog p(X ,Y ) ]
=
∫
Rm
∫
F
∂2
∂x2p(x , y) λ(dy) dx − E[
∂2
∂x2log p(X ,Y ) ]
et par hypothese
E[ (∂
∂xlog p(X ,Y ))∗
∂
∂xlog p(X ,Y ) ] = J
31 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
on introduit ensuite le vecteur aleatoire (de dimension p +m)
ψ(Y )− φ(X )
(∂
∂xlog p(X ,Y ))∗
et sa matrice de covariance
(C MM∗ J
)
compte tenu que cette matrice est symetrique semi–definie positive, onverifie que pour tout vecteur u ∈ R
p
0 ≤
(u∗ −(J−1 M∗ u)∗
) (C MM∗ J
) (u
−J−1 M∗ u
)
=
(u∗ −(J−1 M∗ u)∗
) ((C −M J−1 M∗) u
0
)
= u∗ (C −M J−1 M∗) u
c’est–a–dire que le complement de Schur ∆ = C −M J−1 M∗ estegalement une matrice symetrique semi–definie positive, d’ou
C ≥ M J−1 M∗�
32 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Utilisation pratiquepour evaluer a l’avance la performance d’un estimateur donne ψ(Y ) de lavariable cachee X au vu de l’observation Y , on realise N simulationsindependantes
(X j ,Y j) pour tout j = 1 · · ·N
pour avoir une idee de la performance, on evalue empiriquement lamatrice de correlation des erreurs d’estimation
E[ (ψ(Y )− X ) (ψ(Y )− X )∗ ] ≈1
N
N∑
j=1
(ψ(Y j)− X j) (ψ(Y j)− X j)∗
et pour avoir une idee de la marge d’amelioration possible, on compareavec la borne J−1
pour calculer la matrice d’information de Fisher J intervenant dans laborne, on evalue empiriquement la matrice
−J = E[∂2
∂x2log p(X ,Y )] ≈
1
N
N∑
j=1
∂2
∂x2log p(X j ,Y j)
33 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
borne calculable a l’avance, pas de connaissance necessaire de la “vraie”valeur (qui n’existe d’ailleurs pas dans le cadre bayesien)moyenne sur toutes les realisations possibles
de l’observation et de la composante cachee conjointement
par contraste, dans la borne de Cramer–Rao parametrique (vs. borne deCramer–Rao a posteriori) il n’y a pas de loi a priori sur la composantecachee θ
Theoreme si la matrice d’information de Fisher
J(θ) = −E[∂2
∂θ2log p(Y | θ) | θ] matrice de dimension m ×m
est inversible, alors
E[ (ψ(Y )− φ(θ)) (ψ(Y )− φ(θ))∗ | θ] ≥ φ′(θ) J−1(θ) (φ′(θ))∗
pour tout estimateur ψ sans biais de θ, c–a–d tel que E[ψ(Y ) | θ] = φ(θ)
34 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
decomposition ”loi jointe” = ”loi conditionnelle” × ”loi marginale”
p(x , y) = p(x | y) p(y) = p(y | x) p(x)
d’ou les expressions equivalentes suivantes
J = −E[∂2
∂x2log p(X ,Y )]
= −E[∂2
∂x2log p(X | Y )]
= −E[∂2
∂x2log p(Y | X ) ]− E[
∂2
∂x2log p(X )]
= E[−E[∂2
∂x2log p(Y | X ) | X ]
︸ ︷︷ ︸J(X )
]− E[∂2
∂x2log p(X )]
pour la matrice d’information de Fisher
35 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Exemple soit X et V deux vecteurs aleatoires gaussiens independants demoyenne X et 0, de matrice de covariance QX et QV , et on poseY = h(X ) + Vsi QX et QV sont inversibles, alors
p(y | x) ∝ exp{− 12 (y − h(x))∗ Q−1
V (y − h(x))}
p(x) ∝ exp{− 12 (x − X )∗ Q−1
X (x − X )}
d’ou
− log p(x , y) = 12 (y−h(x))∗ Q−1
V (y−h(x))+ 12 (x−X )∗ Q−1
X (x−X )+cste
−∂2
∂x2log p(x , y) = (h′(x))∗ Q−1
V h′(x)− (y − h(x))∗ Q−1V h′′(x) + Q−1
X
et la matrice d’information de Fisher
J = −E[∂2
∂x2log p(X ,Y )] = E[(h′(X ))∗ Q−1
V h′(X )]−E[V ∗ Q−1V h′′(X )]︸ ︷︷ ︸0
+Q−1X
36 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
dans le cas particulier ou h(x) = H x
J = H∗ Q−1V H+Q−1
X et J−1 = QX−QX H∗ (H QX H∗+QV )−1 H QX
repose sur le lemme d’inversion matricielle suivant
Lemme soit Q et R deux matrices symetriques definies positives, dedimension m et d respectivement, et soit H une matrice d ×m, alors
(H∗ R−1 H + Q−1)−1 = Q − Q H∗ (H Q H∗ + R)−1 H Q
Remarque cette formule d’inversion permet de remplacer l’inversion de lamatrice (H∗ R−1 H + Q−1) de dimension m, par l’inversion de la matrice(H Q H∗ + R) de dimension d , avec en general d ≤ m
37 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Preuve on remarque d’abord que
H Q H∗ + R ≥ R et H∗ R−1 H + Q−1 ≥ Q−1
au sens des matrices symetriques, ce qui prouve que les matrices
(H Q H∗ + R) et (H∗ R−1 H + Q−1)
sont inversibles
38 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
on verifie alors que
[Q − Q H∗ (H Q H∗ + R)−1 H Q ] [H∗ R−1 H + Q−1]
= Q H∗ R−1 H + I
− Q H∗ (H Q H∗ + R)−1 (H Q H∗ + R − R)R−1 H
− Q H∗ (H Q H∗ + R)−1 H
= Q H∗ R−1 H + I
− Q H∗ R−1 H + Q H∗ (H Q H∗ + R)−1 H
− Q H∗ (H Q H∗ + R)−1 H
= I �
39 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Cadre gaussien
estimateur MMSE dans le cas gaussiensoit Z = (X ,Y ) vecteur aleatoire gaussien a valeurs dans Rm × R
d de
moyenne Z = (X , Y ), de matrice de covariance QZ =
(QX QXY
QYX QY
)
Proposition la loi conditionnelle de X sachant Y est gaussienne, demoyenne X (Y ) et de matrice de covariance R (ne dependant pas de Y ),et si la matrice de covariance QY est inversible, alors
X (Y ) = X + QXY Q−1Y (Y − Y )
et0 ≤ R = QX − QXY Q−1
Y QYX ≤ QX
complement de Schur de la matrice QY dans la matrice–bloc QZ
40 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Remarque on verifie que0 ≤ R ≤ QX
au sens des matrices symetriques, c’est–a–dire que l’utilisation del’information supplementaire (Y = y), permet de reduire l’incertitude quel’on a sur le vecteur aleatoire Xla majoration R ≤ QX est evidente, et la minoration R ≥ 0 resulte del’identite
0 ≤
(u∗ −(Q−1
Y QYX u)∗)
QX QXY
QYX QY
u
−Q−1Y QYX u
=
(u∗ −(Q−1
Y QYX u)∗)
(QX − QXY Q−1Y QYX ) u
0
= u∗ R u
pour tout vecteur u ∈ Rm, ce qui permet de conclure que R ≥ 0
41 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Remarque la matrice R ne depend pas de y , et peut donc etre calculeeavant meme de disposer de la valeur y prise par l’observation Y
Remarque soit X = X (Y ) l’estimateur MMSE de X sachant Ycompte tenu que
X = X + QXY Q−1Y (Y − Y )
depend de facon affine du vecteur aleatoire Y , on en deduit que(X , X ,Y ) est un vecteur aleatoire gaussien, comme transformation affinedu vecteur aleatoire gaussien Z = (X ,Y )
42 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Remarque si Y = (Y ′,Y ′′) ou les composantes Y ′ et Y ′′ sontindependantes
Z =
X
Y ′
Y ′′
et QZ =
QX QXY ′ QXY ′′
QY ′X QY ′ 0QY ′′X 0 QY ′′
et si les matrices QY ′ et QY ′′ sont inversibles, alors la distribution deprobabilite conditionnelle du vecteur aleatoire X sachant Y = y , avecy = (y ′, y ′′), est une distribution de probabilite gaussienne de moyenne
X (y) = X + QXY Q−1Y (y − Y )
= X +
(QXY ′ QXY ′′
) (QY ′ 00 QY ′′
)−1 (
y ′ − Y ′
y ′′ − Y ′′
)
= X + QXY ′ Q−1Y ′ (y
′ − Y ′) + QXY ′′ Q−1Y ′′ (y
′′ − Y ′′)
43 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
et de matrice de covariance
R = QX − QXY Q−1Y QYX
= QX −
(QXY ′ QXY ′′
) (QY ′ 00 QY ′′
)−1 (
QY ′X
QY ′′X
)
= QX − QXY ′ Q−1Y ′ QY ′X − QXY ′′ Q−1
Y ′′ QY ′′X
44 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Preuve de la Proposition on pose Ξ = X − QXY Q−1Y Y , et on verifie que
le vecteur aleatoire (Ξ,Y ) est gaussien, comme transformation affine duvecteur aleatoire gaussien Z = (X ,Y )on verifie que
Ξ = E[Ξ] = X − QXY Q−1Y Y
et par difference
Ξ− Ξ = (X − X )− QXY Q−1Y (Y − Y )
45 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
on en deduit facilement la matrice de covariance
QΞ = E[(Ξ− Ξ) (Ξ− Ξ)∗]
= E[((X − X )− QXY Q−1Y (Y − Y )) ((X − X )− QXY Q−1
Y (Y − Y ))∗]
= E[(X − X ) (X − X )∗]− E[(X − X ) (Y − Y )∗] Q−1Y QYX
− QXY Q−1Y E[(Y − Y ) (X − X )∗]
+ QXY Q−1Y E[(Y − Y ) (Y − Y )∗] Q−1
Y QYX
= QX − QXY Q−1Y QYX = R
et la matrice de correlation
QΞY = E[(Ξ− Ξ) (Y − Y )∗]
= E[((X − X )− QXY Q−1Y (Y − Y )) (Y − Y )∗]
= E[(X − X ) (Y − Y )∗]− QXY Q−1Y E[(Y − Y ) (Y − Y )∗] = 0
46 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
en particulier, les vecteurs aleatoires gaussiens Ξ et Y sont decorreles,donc independants
il suffit alors d’exprimer la fonction caracteristique de la distribution deprobabilite conditionnelle du vecteur aleatoire X = Ξ+ QXY Q−1
Y Ysachant Y , soit
E[ exp{i u∗X} | Y ] = E[ exp{i u∗(Ξ + QXY Q−1Y Y )} | Y ]
= exp{i u∗ QXY Q−1Y Y } E[ exp{i u∗Ξ} ]
= exp{i u∗ QXY Q−1Y Y } exp{i u∗(X − QXY Q−1
Y Y )− 12 u
∗ R u}
= exp{i u∗(X + QXY Q−1Y (Y − Y ))− 1
2 u∗ R u}
= exp{i u∗X (Y )− 12 u
∗ R u}
on reconnait la fonction caracteristique d’un vecteur aleatoire gaussien demoyenne X (Y ) et de matrice de covariance R �
47 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Exemple soit X et V deux vecteurs aleatoires gaussiens independants demoyenne X et 0, de matrice de covariance QX et QV , et on poseY = H X + Valors Z = (X ,Y ) vecteur aleatoire gaussien a valeurs dans Rm × R
d demoyenne Z = (X ,H X ), de matrice de covariance
QZ =
(QX QX H∗
H QX H QX H∗ + QV
)
si QV est inversible, alors a fortiori H QX H∗ + QV est inversible, et
X (Y ) = X + QX H∗ (H QX H∗ + QV )−1 (Y − H X )
et0 ≤ R = QX − QX H∗ (H QX H∗ + QV )
−1 H QX ≤ QX
complement de Schur de la matrice H QX H∗ + QV dans la matrice–blocQZ
si de plus QX est inversible, alors (lemme d’inversion matricielle)
R = (H∗ Q−1X H + Q−1
V )−1 = J−1
48 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
la moyenne conditionnelle X (Y ) est l’estimateur MMSE de X sachant Y ,donc pour tout estimateur ψ on a
E[ (ψ(Y )− X ) (ψ(Y )− X )∗ ] ≥ E[ (X (Y )− X ) (X (Y )− X )∗ ] = R ≥ J−1
i.e. la borne de Cramer–Rao a posteriori J−1 est atteinte dans le casgaussien
Remarque autre demonstration de J−1 = R
p(x | y) ∝ exp{− 12 (x − X (y))∗ R−1 (x − X (y))}
d’ou− log p(x | y) = 1
2 (x − X (y))∗ R−1 (x − X (y)) + cste
−∂2
∂x2log p(x | y) = R−1
et la matrice d’information de Fisher
J = −E[∂2
∂x2log p(X | Y )] = R−1
49 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Presentation
Introduction au filtrage
Estimation bayesienne
Systemes lineaires gaussienssystemes lineaires gaussiensfiltre de Kalmanlisseur de Kalman
Extensions
Systemes non–lineaires / non–gaussiens
50 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Systemes lineaires gaussiens
suite d’etats caches {Xk} a valeurs dans Rm, verifiant
Xk = Fk Xk−1 + fk +Wk
et suite d’observations {Yk} a valeurs dans Rd , verifiant
Yk = Hk Xk + hk + Vk
hypotheses :
◮ etat initial X0 gaussien, de moyenne X0 et de matrice de covarianceQX
0
◮ bruit d’etat {Wk} blanc gaussien, de matrice de covariance QWk
◮ bruit d’observation {Vk} blanc gaussien, de matrice de covarianceQV
k
◮ suites {Wk} et {Vk} et etat initial X0 mutuellement independants
51 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
interpretation du modele a priori
Xk = Fk Xk−1 + fk +Wk
en terme de propagation des incertitudes
◮ meme si l’etat Xk−1 = x est connu exactement a l’instant (k − 1),on peut seulement dire que l’etat Xk a l’instant k est incertain, etdistribue comme un vecteur aleatoire gaussien, de moyenne Fk x + fket de matrice de covariance QW
k
◮ si l’etat Xk−1 est incertain a l’instant (k − 1), et distribue comme unvecteur aleatoire gaussien, de moyenne Xk−1 et de matrice decovariance QX
k−1, alors cette incertitude se propage a l’instant k :meme en absence de bruit, l’etat Xk a l’instant k est incertain, etdistribue comme un vecteur aleatoire gaussien, de moyenneFk Xk−1 + fk et de matrice de covariance Fk Q
Xk−1 F
∗
k
52 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Proposition la suite {Zk = (Xk ,Yk)} est un processus aleatoire gaussien
Preuve pour tout instant n, le vecteur aleatoire (Z0,Z1, · · · ,Zn) peuts’exprimer comme transformation affine du vecteur aleatoire(X0,W1, · · · ,Wn,V0,V1, · · · ,Vn) qui par hypothese est un vecteuraleatoire gaussien, donc le vecteur aleatoire (Z0,Z1, · · · ,Zn) est gaussien,comme transformation affine d’un vecteur aleatoire gaussien
53 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Resume on rappelle qu’il s’agit d’estimer le vecteur aleatoire Xk a partirde Y0:k = (Y0, · · · ,Yk), de facon optimale et recursive, dans le modele
Xk = Fk Xk−1 + fk +Wk
Yk = Hk Xk + hk + Vk
si on adopte le critere MMSE, alors il s’agit de calculer la distribution deprobabilite conditionnelle du vecteur aleatoire Xk sachant Y0:k , et commele cadre est gaussien, il suffit de calculer la moyenne et la matrice decovariance deterministe
Xk = E[Xk | Y0:k ] et Pk = E[(Xk − Xk) (Xk − Xk)∗]
on definit egalement les quantites suivantes
X−
k = E[Xk | Y0:k−1] et P−
k = E[(Xk − X−
k ) (Xk − X−
k )∗]
54 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
en revanche, le calcul direct a partir des formules de conditionnementdans les vecteurs aleatoires gaussiens est
◮ de taille croissante
◮ non recursif
55 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Filtre de Kalmansupposons connue la distribution de probabilite conditionnelle du vecteuraleatoire Xk−1 sachant Y0:k−1 : pour calculer la distribution deprobabilite conditionnelle du vecteur aleatoire Xk sachant Y0:k , onprocede en deux etapes
◮ dans l’etape de prediction, on calcule la distribution de probabiliteconditionnelle du vecteur aleatoire Xk sachant les observationspassees Y0:k−1, ce qui est facile a partir de l’equation d’etat
◮ dans l’etape de correction, on utilise la nouvelle observation Yk , etparticulierement la composante de l’observation Yk qui apporte uneinformation nouvelle par rapport aux observations passees Y0:k−1,c–a–d
Ik = Yk − E[Yk | Y0:k−1]
d’apres l’equation d’observation, on a
E[Yk | Y0:k−1] = Hk E[Xk | Y0:k−1]+hk+E[Vk | Y0:k−1] = Hk X−
k +hk
ou on a utilise l’independance de Vk et de Y0:k−1
56 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Remarque par definition, toute fonction des variables (Y0, · · · ,Yk−1,Yk)peut s’exprimer en fonction des variables (Y0, · · · ,Yk−1, Ik), etreciproquementon en deduit que (Y0:k−1, Ik) contient exactement la meme informationque Y0:k
Lemme la suite {Ik} est un processus gaussien, appele processusd’innovationen particulier a l’instant k , le vecteur aleatoire Ik est gaussien, demoyenne nulle et de matrice de covariance
Q Ik = Hk P
−
k H∗
k + QVk
et independant de Y0:k−1
plus generalement, le v.a. (Xk − X−
k , Ik) est gaussien, de moyenne nulleet de matrice de covariance
(P−
k P−
k H∗
k
Hk P−
k Hk P−
k H∗
k + QVk
)
et independant de Y0:k−157 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Preuve d’apres la theorie du conditionnement dans les v.a. gaussiens,l’observation predite E[Yk | Y0:k−1] depend de facon affine desobservations passees (Y0,Y1, · · · ,Yk−1), et donc l’innovation Ik dependde facon affine des observations (Y0,Y1, · · · ,Yk)
on en deduit que le v.a. (I0, I1, · · · , Ik) est gaussien, commetransformation affine du v.a. gaussien (Y0,Y1, · · · ,Yk)
toujours d’apres la theorie du conditionnement dans les v.a. gaussiens,l’etat predit X−
k = E[Xk | Y0:k−1] depend de facon affine des observationspassees (Y0,Y1, · · · ,Yk−1)
on en deduit que le v.a. (Y0,Y1, · · · ,Yk−1,Xk − X−
k , Ik) est gaussien —
et en particulier le v.a. (Xk − X−
k , Ik) est gaussien — commetransformation affine d’un v.a. gaussien, et compte tenu que
E[Xk − X−
k | Y0:k−1] = 0 et E[Ik | Y0:k−1] = 0
par definition, le v.a. (Xk − X−
k , Ik) est independant de Y0:k−1
58 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
d’apres l’equation d’observation, on a
Ik = Yk − (Hk X−
k + hk) = Hk (Xk − X−
k ) + Vk
et on en deduit que
Q Ik = E[Ik I
∗
k ]
= E[(Hk (Xk − X−
k ) + Vk) (Hk (Xk − X−
k ) + Vk)∗]
= Hk E[(Xk − X−
k ) (Xk − X−
k )∗] H∗
k + E[Vk V∗
k ]
+ E[Vk (Xk − X−
k )∗] H∗
k + Hk E[(Xk − X−
k )V ∗
k ]
= Hk P−
k H∗
k + QVk
ou on a utilise dans la derniere egalite, l’independance de (Xk − X−
k ) et
de Vk , donc E[(Xk − X−
k )V ∗
k ] = 0
59 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
on a egalement
E[(Xk − X−
k ) I ∗k ] = E[(Xk − X−
k ) (Hk (Xk − X−
k ) + Vk)∗]
= E[(Xk − X−
k ) (Xk − X−
k )∗] H∗
k + E[(Xk − X−
k )V ∗
k ]
= P−
k H∗
k
ou on a utilise dans la derniere egalite, l’independance de (Xk − X−
k ) et
de Vk , donc E[(Xk − X−
k )V ∗
k ] = 0 �
60 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Theoreme [Filtre de Kalman] on suppose que la matrice de covarianceQV
k est inversible, pour tout instant k
alors les suites {Xk} et {Pk} sont definies par les equations suivantes
X−
k = Fk Xk−1 + fk
P−
k = Fk Pk−1 F∗
k + QWk
et
Xk = X−
k + Kk [Yk − (Hk X−
k + hk)]
Pk = [I − Kk Hk ] P−
k
ou la matriceKk = P−
k H∗
k [Hk P−
k H∗
k + QVk ]−1
est appelee gain de Kalman, avec les initialisations
X−
0 = X0 = E[X0] et P−
0 = QX0 = cov(X0)
61 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Remarque la suite {Pk} ne depend pas des observations : elle peut doncetre pre–calculee
Remarque si les coefficients Fk et fk dans l’equation d’etat et lescoefficients Hk et hk dans l’equation d’observation dependent desobservations passees Y0:k−1, alors la suite {Zk = (Xk ,Yk)} n’est plusgaussienne, mais conditionnellement a Y0:k−1 le couple (Xk ,Yk) estgaussienon dit que la suite {Xk} est conditionnellement gaussienne, et on verifieque la distribution de probabilite conditionnelle du v.a. Xk sachant Y0:k
est gaussienne, de moyenne Xk et de matrice de covariance Pk donneesencore par les equations du Theoreme
62 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Preuve on procede en plusieurs etapes, en s’appuyant sur la theorie duconditionnement dans les v.a. gaussiens
◮ initialisation expression de X0 et P0 en fonction de X−
0 et P−
0
le v.a. (X0,Y0) est gaussien, de moyenne et de matrice de covariancedonnees par
X−
0
H0 X−
0 + h0
et
(P−
0 P−
0 H∗
0
H0 P−
0 H0 P−
0 H∗
0 + QV0
)
respectivementon en deduit que la distribution de probabilite conditionnelle du v.a. X0
sachant Y0 est gaussienne, de moyenne
X0 = X−
0 + P−
0 H∗
0 [H0 P−
0 H∗
0 + QV0 ]−1 [Y0 − (H0 X
−
0 + h0)]
et de matrice de covariance deterministe
P0 = P−
0 − P−
0 H∗
0 [H0 P−
0 H∗
0 + QV0 ]−1 H0 P
−
0
63 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
◮ etape de prediction expression de X−
k et P−
k en fonction de Xk−1 etPk−1
le v.a. (Xk ,Y0, · · · ,Yk−1) est gaussien, de sorte que la distribution deprobabilite conditionnelle du v.a. Xk sachant Y0:k−1 est gaussienne, de
moyenne X−
k et de matrice de covariance deterministe P−
k
d’apres l’equation d’etat
Xk = Fk Xk−1 + fk +Wk
on a
X−
k = E[Xk | Y0:k−1] = Fk E[Xk−1 | Y0:k−1] + fk + E[Wk | Y0:k−1]
= Fk Xk−1 + fk
compte tenu que Wk et Y0:k−1 sont independantspar difference
Xk − X−
k = Fk (Xk−1 − Xk−1) +Wk
64 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
on en deduit que
P−
k = E[(Xk − X−
k ) (Xk − X−
k )∗]
= E[(Fk (Xk−1 − Xk−1) +Wk) (Fk (Xk−1 − Xk−1) +Wk)∗]
= Fk E[(Xk−1 − Xk−1) (Xk−1 − Xk−1)∗] F ∗
k + E[Wk W∗
k ]
+ E[Wk (Xk−1 − Xk−1)∗] F ∗
k + Fk E[(Xk−1 − Xk−1)W∗
k ]
= Fk Pk−1 F∗
k + QWk
ou on a utilise dans la derniere egalite, l’independance de (Xk−1 − Xk−1)
et de Wk , donc E[(Xk−1 − Xk−1)W∗
k ] = 0
65 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
◮ etape de correction expression de Xk et Pk en fonction de X−
k et P−
k
le v.a. (Xk ,Y0, · · · ,Yk) est gaussien, de sorte que la distribution deprobabilite conditionnelle du v.a. Xk sachant Y0:k est gaussienne, demoyenne Xk et de matrice de covariance deterministe Pk
compte tenu de l’independance entre Ik et Y0:k−1, on a
Xk = E[Xk | Y0:k ]
= X−
k + E[Xk − X−
k | Y0:k ]
= X−
k + E[Xk − X−
k | Y0:k−1, Ik ]
= X−
k + E[Xk − X−
k | Ik ]
par difference
Xk − Xk = (Xk − X−
k )− (Xk − X−
k ) = (Xk − X−
k )− E[Xk − X−
k | Ik ]
66 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
de sorte que
Pk = E[ (Xk − Xk) (Xk − Xk)∗ ]
= E[ ((Xk − X−
k )− E[Xk − X−
k | Ik ]) ((Xk − X−
k )− E[Xk − X−
k | Ik ])∗ ]
il suffit donc de calculer la moyenne conditionnelle et la matrice decovariance conditionnelle du v.a. (Xk − X−
k ) sachant Ik , or le v.a.
(Xk − X−
k , Ik) est gaussien, de moyenne nulle et de matrice de covariance(
P−
k P−
k H∗
k
Hk P−
k Hk P−
k H∗
k + QVk
)
si la matrice QVk est inversible, alors a fortiori la matrice
Q Ik = Hk P
−
k H∗
k + QVk est inversible, et on en deduit que
Xk = X−
k + P−
k H∗
k [Hk P−
k H∗
k + QVk ]−1 Ik
etPk = P−
k − P−
k H∗
k [Hk P−
k H∗
k + QVk ]−1 Hk P
−
k �
67 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Lisseur de Kalman
il s’agit estimer l’etat cache Xk pour un instant k , intermediaire entrel’instant initial 0 et l’instant final n, au vu de toutes les observationsY0:n = (Y0, · · · ,Yn)si on adopte le critere MMSE, alors il s’agit de calculer la distribution deprobabilite conditionnelle du vecteur aleatoire Xk sachant Y0:n, et commele cadre est gaussien, il suffit de calculer la moyenne et la matrice decovariance deterministe
X nk = E[Xk | Y0:n] et Pn
k = E[(Xk − X nk ) (Xk − X n
k )∗]
clairement, X nn = Xn et Pn
n = Pn pour k = n
68 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Theoreme [Lisseur de Kalman] on suppose que les matrices de covarianceQV
k et QWk sont inversibles, pour tout instant k
alors {X nk } et {Pn
k } sont definis par les equations retrogrades suivantes
X nk−1 = Xk−1 + Lk (X n
k − X−
k )
Pnk−1 = Pk−1 − Lk (P−
k − Pnk ) L
∗
k
avec la matrice de gain
Lk = Pk−1 F∗
k (P−
k )−1
et avec les initialisations
X nn = Xn et Pn
n = Pn
Remarque si la matrice de covariance QWk est inversible, alors a fortiori la
matrice de covariance P−
k = Fk Pk−1 F∗
k + QWk est inversible
69 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Preuve on remarque que le v.a. Yk = Hk Xk + hk + Vk peut s’exprimercomme transformation affine du v.a. (Xk ,Vk), et donc a fortiori comme
transformation affine du v.a. (Y0:k−1,Xk − X−
k ,Vk)
de meme, le v.a. Yk+p = Hk+p Xk+p + hk+p + Vk+p peut s’exprimercomme transformation affine du v.a. (Xk+p,Vk+p), et par transitivitecomme transformation affine du v.a. (Xk ,Wk+1, · · · ,Wk+p,Vk+p), etdonc a fortiori comme transformation affine du v.a.(Y0:k−1,Xk − X−
k ,Wk+1, · · · ,Wk+p,Vk+p)
on en deduit que le v.a. Y0:n = (Y0:k−1,Yk , · · · ,Yn) peut s’exprimer
comme transformation affine du v.a. (Y0:k−1,Xk − X−
k ,Zk+1:n) ouZk+1:n = (Wk+1, · · · ,Wn,Vk ,Vk+1, · · · ,Vn) par definition
et on verifie que les v.a. Y0:k−1, Xk − X−
k et Zk+1:n sont mutuellementindependants
70 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
il en resulte que
Unk−1 = E[Xk−1 | Y0:k−1,Xk − X−
k ,Zk+1:n]
= Xk−1 + E[Xk−1 − Xk−1 | Y0:k−1,Xk − X−
k ,Zk+1:n]
= Xk−1 + E[Xk−1 − Xk−1 | Y0:k−1] + E[Xk−1 − Xk−1 | Xk − X−
k ]
+ E[Xk−1 − Xk−1 | Zk+1:n]
= Xk−1 + E[Xk−1 − Xk−1 | Xk − X−
k ]
compte tenu que E[Xk−1 − Xk−1 | Y0:k−1] = 0 par definition, et ou on a
utilise dans la derniere egalite le fait que (Xk−1 − Xk−1) est independant
de Zk+1:n, donc E[Xk−1 − Xk−1 | Zk+1:n] = 0par difference
Xk−1 − Unk−1 = (Xk−1 − Xk−1)− (Un
k−1 − Xk−1)
= (Xk−1 − Xk−1)− E[Xk−1 − Xk−1 | Xk − X−
k ]
71 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
de sorte que
E[(Xk−1 − Unk−1) (Xk−1 − Un
k−1)∗]
= E[ ((Xk−1 − Xk−1)− E[Xk−1 − Xk−1 | Xk − X−
k ])
((Xk−1 − Xk−1)− E[Xk−1 − Xk−1 | Xk − X−
k ])∗ ]
il suffit donc de calculer la moyenne conditionnelle et la matrice decovariance conditionnelle du v.a. (Xk−1 − Xk−1) sachant (Xk − X−
k )
d’apres la theorie du conditionnement dans les v.a. gaussiens, l’etatestime Xk−1 = E[Xk−1 | Y0:k−1] et l’etat predit X
−
k = E[Xk | Y0:k−1]dependent de facon affine des observations passees (Y0, · · · ,Yk−1), de
sorte que le v.a. (Xk−1 − Xk−1,Xk − X−
k ) depend de facon affine du v.a.(Y0, · · · ,Yk−1,Xk−1,Xk)
on en deduit que le v.a. (Xk−1 − Xk−1,Xk − X−
k ) est gaussien, commetransformation affine d’un v.a. gaussien
72 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
par difference
Xk − X−
k = Fk (Xk−1 − Xk−1) + Gk Wk
de sorte que
E[(Xk−1 − Xk−1) (Xk − X−
k )∗]
= E[(Xk−1 − Xk−1) (Fk (Xk−1 − Xk−1) + Gk Wk)∗]
= E[(Xk−1 − Xk−1) (Xk−1 − Xk−1)∗] F ∗
k + E[(Xk−1 − Xk−1)W∗
k ] Gk
= Pk−1 F∗
k
dans cette derniere egalite, on a utilise le fait que (Xk−1 − Xk−1) et Wk
sont independants, donc E[(Xk−1 − Xk−1)W∗
k ] = 0
on en deduit que le v.a. gaussien (Xk−1 − Xk−1,Xk − X−
k ) est demoyenne nulle et de matrice de covariance
(Pk−1 Pk−1 F
∗
k
Fk Pk−1 P−
k
)
73 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
par hypothese, la matrice P−
k est inversible, et on en deduit que
Unk−1 = Xk−1 + Pk−1 F
∗
k (P−
k )−1 (Xk − X−
k ) = Xk−1 + Lk (Xk − X−
k )
et
E[(Xk−1 − Unk−1) (Xk−1 − Un
k−1)∗] = Pk−1 − Pk−1 F
∗
k (P−
k )−1 Fk Pk−1
= Pk−1 − Lk P−
k L∗k
on rappelle que (Y0:k−1,Xk − X−
k ,Zk+1:n) contient davantaged’information que Y0:n, de sorte que
X nk−1 = E[Xk−1 | Y0:n] = E[Un
k−1 | Y0:n] = Xk−1 + Lk (X nk − X−
k )
par difference
Xk−1 − X nk−1 = (Xk−1 − Un
k−1) + (Unk−1 − X n
k−1)
etUnk−1 − X n
k−1 = Lk (Xk − X nk )
74 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
de sorte que
Pnk−1 = E[ (Xk−1 − X n
k−1) (Xk−1 − X nk−1)
∗ ]
= E[ ((Xk−1 − Unk−1) + (Un
k−1 − X nk−1)) ((Xk−1 − Un
k−1) + (Unk−1 − X n
k−1))∗ ]
= E[ (Xk−1 − Unk−1) (Xk−1 − Un
k−1)∗ ] + E[ (Un
k−1 − X nk−1) (U
nk−1 − X n
k−1)∗ ]
+ E[ (Unk−1 − X n
k−1) (Xk−1 − Unk−1)
∗ ]
+ E[ (Xk−1 − Unk−1) (U
nk−1 − X n
k−1)∗ ]
= (Pk−1 − Lk P−
k L∗k) + Lk Pnk L
∗
k
dans cette derniere egalite, on a utilise le fait que
◮ (Unk−1 − X n
k−1) depend de (Y0:k−1,Xk − X−
k ,Zk+1:n)
◮ et E[Xk−1 − Unk−1 | Y0:k−1,Xk − X−
k ,Zk+1:n] = 0 par definition
donc E[ (Xk−1 − Unk−1) (U
nk−1 − X n
k−1)∗ ] = 0 �
75 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Presentation
Introduction au filtrage
Estimation bayesienne
Systemes lineaires gaussiens
Extensionsborne de Cramer–Rao a posteriorifiltre de Kalman etendu (linearisation)
Systemes non–lineaires / non–gaussiens
76 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Borne de Cramer–Rao a posteriori
suite d’etats caches {Xk} a valeurs dans Rm, verifiant
Xk = bk(Xk−1) + σk(Xk−1)Wk
et suite d’observations {Yk} a valeurs dans Rd , verifiant
Yk = hk(Xk) + Vk
hypotheses :
◮ etat initial X0 pas necessairement gaussien
◮ bruit d’etat {Wk} blanc gaussien, de matrice de covariance QWk
◮ bruit d’observation {Vk} blanc gaussien, de matrice de covarianceQV
k
◮ suites {Wk} et {Vk} et etat initial X0 mutuellement independants
◮ fonctions bk , σk et hk derivables
77 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
si les matrices de covariance Σk(x) = σk(x)QWk (σk(x))
∗ sont inversiblespour tout x ∈ R
m, alors il existe des densites de transition definies par
P[Xk ∈ dx ′ | Xk−1 = x ] = pk(x′ | x) dx ′
et si les matrices de covariance QVk sont inversibles, alors il existe des
densites d’emission definies par
P[Yk ∈ dy | Xk = x ] = qk(y | x) dy
clairement
pk(x′ | x) =
1√det(2πΣk(x))
exp{− 12 (x
′−bk(x))∗ (Σk(x))
−1 (x ′−bk(x))}
et
qk(y | x) =1√
det(2πQVk )
exp{− 12 (y − hk(x))
∗ (QVk )−1 (y − hk(x))}
78 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Theoreme pour tout estimateur ψ(Y0:n) de l’etat cache Xn a partir desobservations Y0:n, l’erreur quadratique moyenne est minoree par
E[ (ψ(Y0:n)− Xn) (ψ(Y0:n)− Xn)∗ ] ≥ J−1
n
et la matrice d’information de Fisher Jn peut se calculer de la faconrecursive suivante
Jk = D+k − D∗
k (Jk−1 + D−
k )−1 Dk
avec
D−
k = −E[∂2
∂x2k−1
log pk(Xk | Xk−1) ]
Dk = −E[∂2
∂xk−1 ∂xklog pk(Xk | Xk−1) ]
D+k = −E[
∂2
∂x2klog pk(Xk | Xk−1) ]− E[
∂2
∂x2klog qk(Yk | Xk) ]
79 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Remarque dans le cas particulier ou les coefficients σk(x) = I nedependent pas de x ∈ R
m, et si les matrices de covariance QWk et QV
k
sont inversibles, alors
D−
k = E[ (b′k(Xk−1))∗ (QW
k )−1 b′k(Xk−1) ]
Dk = −E[ (b′k(Xk−1))∗ ] (QW
k )−1
D+k = (QW
k )−1 + E[ (h′k(Xk))∗ (QV
k )−1 h′k(Xk) ]
80 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Utilisation pratique
pour evaluer a l’avance la performance d’un estimateur donne ψ(Y0:n) del’etat cache Xn au vu des observations Y0:n = (Y0, · · · ,Yn), on realise Msimulations independantes
X jn et Y j
0:n = (Y j0 , · · · ,Y
jn) pour tout j = 1 · · ·M
on evalue empiriquement l’erreur quadratique moyenne
E[ (ψ(Y0:n)− Xn) (ψ(Y0:n)− Xn)∗ ]
≈1
M
M∑
j=1
(ψ(Y j0:n)− X j
n) (ψ(Yj0:n)− X j
n)∗
pour avoir une idee de la performance, et on compare avec la borne J−1n
pour avoir une idee de la marge d’amelioration possible
81 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Calcul numerique approchepour calculer la matrice d’information de Fisher Jn intervenant dans laborne, on realise M simulations independantes
X j0:n = (X j
0, · · · ,Xjn) pour tout j = 1 · · ·M
on evalue empiriquement, pour tout instant k = 1 · · · n, les matrices
D−
k = E[ (b′k(Xk−1))∗ (QW
k )−1 b′k(Xk−1) ]
≈1
M
M∑
j=1
(b′k(Xjk−1))
∗ (QWk )−1 b′k(X
jk−1)
Dk = −E[ (b′k(Xk−1))∗ ] (QW
k )−1
≈ −1
M
M∑
j=1
(b′k(Xjk−1))
∗ (QWk )−1
82 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
et
D+k = (QW
k )−1 + E[ (h′k(Xk))∗ (QV
k )−1 h′k(Xk) ]
≈ (QWk )−1 +
1
M
M∑
j=1
(h′k(Xjk))
∗ (QVk )−1 h′k(X
jk)
et on calcule recursivement
Jk = D+k − D∗
k (Jk−1 + D−
k )−1 Dk
en utilisant les approximations empiriques des matrices D−
k , Dk et D+k
83 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Filtre de Kalman etendu (linearisation)
suite d’etats caches {Xk} a valeurs dans Rm, verifiant
Xk = bk(Xk−1) + σk(Xk−1)Wk
et suite d’observations {Yk} a valeurs dans Rd , verifiant
Yk = hk(Xk) + Vk
hypotheses :
◮ etat initial X0 pas necessairement gaussien
◮ bruit d’etat {Wk} blanc gaussien, de matrice de covariance QWk
◮ bruit d’observation {Vk} blanc gaussien, de matrice de covarianceQV
k
◮ suites {Wk} et {Vk} et etat initial X0 mutuellement independants
◮ fonctions bk et hk derivables
84 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
idee : lineariser les fonctions bk et σk autour de Xk−1, c’est–a–dire
bk(x) ≃ bk(Xk−1) + b′k(Xk−1) (x − Xk−1) et σk(x) ≃ σk(Xk−1)
et lineariser la fonction hk autour de X−
k , c’est–a–dire
hk(x) ≃ hk(X−
k ) + h′k(X−
k ) (x − X−
k )
on introduit le systeme conditionnellement lineaire gaussien
Xk = Fk Xk−1 + fk + Gk Wk
Yk = Hk Xk + hk + Vk
avec
Fk = b′k(Xk−1) , fk = −b′k(Xk−1) Xk−1+bk(Xk−1) et Gk = σk(Xk−1)
et avec
Hk = h′k(X−
k ) et hk = −h′k(X−
k ) X−
k + hk(X−
k )
on remarque que
Fk Xk−1 + fk = bk(Xk−1) et Hk X−
k + hk = hk(X−
k )85 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
on applique alors exactement le filtre de Kalman a ce nouveau systeme,d’ou l’algorithme sous–optimal suivant
X−
k = bk(Xk−1)
P−
k = b′k(Xk−1)Pk−1 (b′
k(Xk−1))∗ + σk(Xk−1)Q
Wk (σk(Xk−1))
∗
et
Xk = X−
k + Kk [Yk − hk(X−
k )]
Pk = [I − Kk h′
k(X−
k )] P−
k
avec la matrice de gain
Kk = P−
k (h′k(X−
k ))∗ [h′k(X−
k )P−
k (h′k(X−
k ))∗ + QVk ]−1
on choisit l’initialisation X−
0 et P−
0 de telle sorte que N (X−
0 ,P−
0 ) soitune bonne approximation de la distribution de probabilite du vecteuraleatoire X0
86 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Presentation
Introduction au filtrage
Estimation bayesienne
Systemes lineaires gaussiens
Extensions
Systemes non–lineaires / non–gaussienssystemes non–lineaires / non–gaussiensfiltrage particulaire in a nutshellexemples en localisation, navigation et poursuite
87 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Systemes non–lineaires / non–gaussiensevolution de l’etat cache
Xk = fk(Xk−1,Wk) avec Wk ∼ pk(dw)
il suffit de savoir simuler
X0 ∼ µ0(dx) et Wk ∼ pk(dw)
relation entre observation et etat cache
Yk = hk(Xk) + Vk avec Vk ∼ qk(v) dv
il suffit de connaıtre / savoir evaluer la fonction de vraisemblance
gk(x′) = qk(Yk − hk(x
′))
coherence entre un etat possible et l’observation reelle, e.g.
gk(x′) ∝ exp{− 1
2 |Yk − hk(x′)|2}
88 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
objectif : estimer recursivement l’etat cache Xk
au vu des observations Y0:k = (Y0 · · ·Yk)il s’agira d’approcher numeriquement le filtre bayesien
µk(dx) = P[Xk ∈ dx | Y0:k ]
ou plus generalement une distribution de Feynman–Kac
89 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Filtrage particulaire in a nutshell
approximation numerique du filtre bayesien
µk(dx) = P[Xk ∈ dx | Y0:k ]
par la distribution empirique ponderee
µNk =
N∑
i=1
w ik δξik
avec
N∑
i=1
w ik = 1
associee a un systeme de N particules, caracterise par
◮ les positions (ξ1k · · · ξNk )
◮ et les poids positifs (w1k · · ·w
Nk )
il suffit de decrire comment poids et positions evoluent d’un pas de tempsa l’autre
90 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
algorithme SIR (sampling with importance resampling) : version de base
◮ reechantillonnage (selection) : independamment pour touti = 1 · · ·Non choisit un individu ξ i
k−1 au sein de la population (ξ1k−1, · · · , ξNk−1)
en fonction des poids (w1k−1, · · · ,w
Nk−1)
◮ prediction (mutation) : independamment pour tout i = 1 · · ·N
ξik = fk(ξik−1,W
ik) avec W i
k ∼ pk(dw)
◮ correction (ponderation) : pour tout i = 1 · · ·N
w ik = qk(Yk − hk(ξ
ik)) /
[ N∑
j=1
qk(Yk − hk(ξjk))]
91 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
si on n’effectue pas de reechantillonnagealgorithme SIS (sequential importance sampling)
◮ prediction : independamment pour tout i = 1 · · ·N
ξik = fk(ξik−1,W
ik) avec W i
k ∼ pk(dw)
◮ correction : pour tout i = 1 · · ·N
w ik = w i
k−1 qk(Yk − hk(ξik)) /
[ N∑
j=1
w jk−1 qk(Yk − hk(ξ
jk))]
utilisation differente des poids dans SIR et dans SIS
92 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
1er exemple : recalage altimetrique de navigation inertielledemo originale due a Fabien Campillo (INRIA, Montpellier)financement : DGA, programme d’etude amont NCT (nouveaux conceptspour la navigation par correlation de terrain), coordination ThalesCommunications
◮ mesures inertielles• acceleration lineaire et vitesse angulaire de l’avion (centrale inertielle)
→ par double integration : estimation inertielle de position et vitessede l’avion
◮ modele a priori pour l’evolution de l’erreur d’estimation inertielle
◮ mesures altimetriques bruitees de l’altitude de l’avion• par rapport au niveau de la mer (baro–altimetre)• au–dessus du relief (radio–altimetre)
→ par difference : mesure bruitee de la hauteur du relief a laverticale de l’avion
◮ correlation avec une carte numerique (MNT, modele numerique deterrain) donnant la hauteur du relief en toute position horizontale
93 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
0 10 20 30 40 50 60 70 80 90 1005600
5700
5800
5900
6000
6100
6200
6300
6400
6500
6600
Figure : Trajectoire reelle et trajectoire estimee par integration des mesuresinertielles seules — Profil du relief survole et mesures altimetriques bruitees
94 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
mesures inertielles bruitees : acceleration de l’avion dans le planhorizontal
aINS
k = ak + w INS
k
trajectoire estimee par integration des mesures inertielle seules
r INS
k = r INS
k−1 +∆k vINS
k−1 et v INS
k = v INS
k−1 +∆k aINS
k
variable d’etat Xk = (δrk , δvk) : correction a apporter a l’estimationinertielle de la position et de la vitesse dans le plan horizontal, i.e.
δrk = rk − r INS
k et δvk = vk − v INS
k
modele d’etat : par difference (ou par linearisation, dans un modele plusrealiste)
δrk = rk−1 +∆k vk−1 − (r INS
k−1 +∆k vINS
k−1) = δrk−1 +∆k δvk−1
δvk = vk−1 +∆k ak − (v INS
k−1 +∆k aINS
k ) = δvk−1 −∆k wINS
k
i.e. (δrkδvk
)=
(δrk−1 +∆k δvk−1
δvk−1
)−∆k
(0
w INS
k
)
95 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
observation Yk : hauteur du relief a la verticale de l’avion, obtenue pardifference
◮ entre l’altitude de l’avion mesuree par rapport au niveau de la mer
zBAR
k = zk + wBAR
k
◮ et l’altitude de l’avion mesuree au–dessus du relief
zALT
k = (zk − hk(Xk)) + wALT
k
i.e.
Yk = zBAR
k − zALT
k = hk(Xk) + Vk avec Vk = wBAR
k − wALT
k
relation hk(x) avec l’etat cache x = (δr , δv) : altitude du relief (lu sur lacarte numerique) a la position r INS
k + δr dans le plan horizontalponderation (fonction de vraisemblance) : ecart entre la hauteur du reliefmesuree a la verticale de l’avion, et la hauteur du relief lue sur la cartenumerique
gk(x) ∝ qk(Yk − hk(x))
demo (mise en œuvre au 1er TP)96 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
2eme exemple : suivi visuel par histogramme de couleurdemo due a Elise Arnaud (UJF et INRIA, Grenoble)source : Patrick Perez, Carine Hue, Jako Vermaak and Marc Gangnet,Color-based probabilistic tracking , European Conference on ComputerVision (ECCV’02)l’utilisateur selectionne une zone dans la premiere image de la sequenceobjectif : suivre automatiquement cette meme zone sur l’ensemble de lasequence
. . .initialisation image 2 image 3 image 10
Figure : Suivi d’un visage dans une sequence de 10 images
hypothese : l’histogramme de couleur de la zone a suivre est constant lelong de la sequence
99 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
la zone initiale est caracterisee par un histogramme de couleur(histogramme de reference), construit avec les Nb couleurs les plusrepresentees dans cette zone
nombre normalise q∗(n) de pixels de la zone initiale dont lacouleur est la couleur n = 1, · · · ,Nb
Figure : Zone initiale et histogramme de couleur associe, avec Nb = 64
100 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
pour evaluer la pertinence d’une zone–test dans la k–eme image de lasequence, caracterisee par la position (exprimee en pixels) de son centrex , on calcule son histogramme de couleur
nombre normalise qk(x , n) de pixels de la zone–test centree a laposition x dans la k–eme image de la sequence, dont la couleurest la couleur n = 1 · · ·Nb
et on definit une mesure de distance (distance de Hellinger) entre lesdeux histogrammes de couleur normalises
D(q∗, qk(x)) = 1−Nb∑
n=1
√q∗(n) qk(x , n) =
12
Nb∑
n=1
(√q∗(n)−
√qk(x , n))
2
101 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
variable d’etat Xk = rk : position du centre de la zone suivie dans lak–eme imagemodele d’etat : marche aleatoire simple
rk = rk−1 +Wk
observation Yk : k–eme image de la sequenceponderation : ecart entre l’histogramme de la zone–test et l’histogrammede reference
gk(x) ∝ exp{−λD(q∗, qk(x))}
demo (mise en œuvre au 2eme TP)
102 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
3eme exemple : navigation en environnement interieurfinancement : ANR, projet FIL (fusion d’information pour la localisation),programme Telecommunications, coordination Thales Alenia Space
◮ mesures de navigation (PNS, pedestrian navigation system)
• distance parcourue et changement de direction entre deux instantssuccessifs
→ par integration : estimation PNS de position et orientation del’utilisateur
◮ modele de deplacement a priori pour l’utilisateur, i.e. evolution deposition et orientation, a partir des mesures PNS incrementales
◮ mesures bruitees de
• distance entre un utilisateur et une balise de ranging de positionconnue et de portee limitee
◮ detection (ou non–detection) par une balise de proximite
◮ map–matching : contraintes de deplacement dues a la presenced’obstacles, disponibles a partir d’un plan du batiment
107 / 114
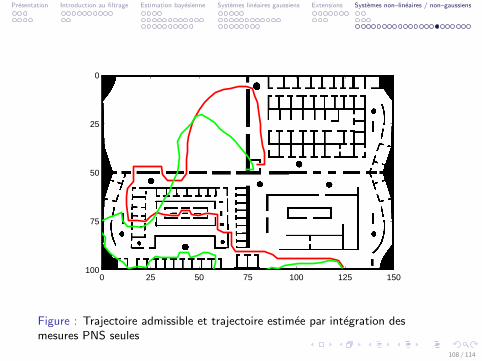
Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
0 25 50 75 100 125 150
0
25
50
75
100
Figure : Trajectoire admissible et trajectoire estimee par integration desmesures PNS seules
108 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
0 25 50 75 100 125 150
0
25
50
75
100
Figure : Balises de ranging a portee limitee
109 / 114
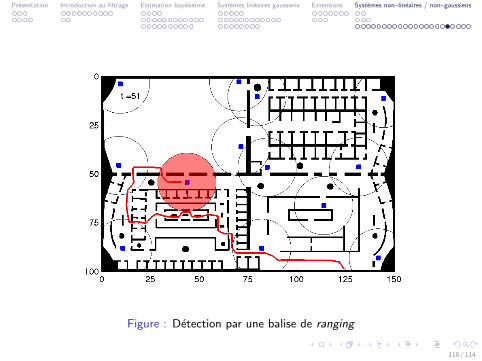
Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
Figure : Detection par une balise de ranging
110 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
mesures PNS incrementales bruitee : distance parcourue et changementde direction entre deux instants successifs
dPNS
k = dk + wwalk
k et αPNS
k = αk + w turn
k
trajectoire estimee par integration des mesures PNS seules
rPNS
k = rPNS
k−1 + u(θPNS
k−1 ) dPNS
k et θPNS
k = θPNS
k−1 + αPNS
k
variable d’etat Xk = (rk , θk) : position et orientation de l’utilisateurmodele d’etat : mise a jour incrementale a l’aide des mesures PNS
rk = rk−1+u(θk−1) (dPNS
k − wwalk
k )︸ ︷︷ ︸dk
et θk = θk−1+(αPNS
k − w turn
k )︸ ︷︷ ︸αk
i.e.(
rkθk
)=
(rk−1 + u(θk−1) d
PNS
k
θk−1 + αPNS
k
)−
(u(θk−1) 0
0 1
) (wwalk
k
w turn
k
)
111 / 114

Presentation Introduction au filtrage Estimation bayesienne Systemes lineaires gaussiens Extensions Systemes non–lineaires / non–gaussiens
observation Yk : distance a une balise active situee a la position a et deportee R
Yk = h(Xk) + Vk
relation h(x) avec l’etat cache x = (r , θ) : distance |r − a| a la baliseponderation (fonction de vraisemblance) : ecart entre la distance mesureea la balise, et la distance reelle a la balise
gk(x) ∝ qk(Yk − h(x))
si l’utilisateur est / n’est pas detecte par la balise, alors
gk(x) ∝ 1{h(x) ≤ R} ou bien gk(x) ∝ 1{h(x) ≥ R}
demo (mise en œuvre au 3eme TP)
112 / 114





























