Embed Size (px)
Citation preview

Corpus-based Natural Language Generation
Srinivas Bangalore
AT&T Labs-Research
Joint work with Owen Rambow and John Chen

Overview• Background• FERGUS – trainable surface realizer
– SuperTags – linguistic model underlying FERGUS– Statistical components of FERGUS
• Experiments and Evaluation• Evaluation Metrics • Experiments on quality and quantity of training
data

Output Generation
Generation System
Multimodal
Speech
Text
Tables Propositions,CommunicativeGoals, ??
Interaction Controller
Interactive System
• Process of converting a system-internal representation to an human interpretable form.

Natural Language Generation (NLG)
• Definition– Input: Set of communicative goals– Output: Sequence of words
• Example (in the context of a dialog system)– Input
• Implicit-confirm(orig-city:NEWARK), Implicit-confirm(dest-city:SEATTLE), Request(depart-date)
– Output• Flying from Newark to Seattle. What date would
you like to leave?• Alternative: You are flying from Newark. What
date would you like to leave? You are flying to Seattle.

Template-based Generation• Language generation is achieved by manipulating
text strings– Example: “FLYING TO dest-city, LEAVING FROM
orig-city, AND WHAT DATE DID YOU WANT TO LEAVE?”
• Number of templates grows quickly– No syntactic generalization; different templates for
singular and plural versions
• Not much variation in output– No planning of text; simple concatenation of strings
• Maintainability – Complex to assemble and change with large number of
templates

NL-based Generation
• Language generation is achieved in three steps (Reiter 1994)– Text planning
• Transform communicative goals into sequence of elementary communicative goals
– Sentence planning• Choose linguistic resources to express the
elementary communicative goals
– Surface realization• Produce surface word order according to the
grammar of the language.

Corpus-based NLG• Most NLG systems are hand-crafted• Recent research on statistical models for NLG
components – Surface Realizer: Langkilde and Knight 1998, Bangalore and Rambow
2000, Ratnaparkhi 2000
– Sentence Planner: Walker et.al 2001
• Statistical translation models can be seen as incorporating statistical NLG.
• Our Approach: Combine linguistic models with statistical models derived from annotated corpora

A Dialogue System with NLG
CommunicativeGoals
Text String/Lattice
Prosody-Annotated Text String
Semantic (?)Representation

Overview• Background• FERGUS – trainable surface realizer
– SuperTags – linguistic model underlying FERGUS– Statistical components of FERGUS
• Experiments and Evaluation• Evaluation Metrics • Experiments on quality and quantity of training
data

FERGUS Surface Realizer
• FERGUS: Flexible Empirical/Rationalist Generation Using Syntax
• Input: Underspecified dependency tree
• Output: Sequence of wordscontrol
poachers now
the underground
tradepoachers now control the underground trade

Linguistic Model : SuperTags• Elementary objects of linguistic analysis (based on
Tree-Adjoining Grammar)
– Grammatical function– Subcategorization frame (active valency)– Passive valency with direction of modification– Realization of arguments (passive, wh-movement,
relative clause)
S
NP
VP
V
NP
control
S
NP
VP
V
NP
control
S
NP
VP
NP
PP
P
VP*
with
S
VP
V
NP
control
S*

SuperTagging for Analysis (1)
Poachers now control the underground trade
NP
N
poachers
N
NN
tradeS
NP
VP
V
NP
N
poachers
e
::
S
SAdv
now
VP
VPAdv
now
VP
AdvVP
now
::
S
S
VP
V
NP
control
S
NP
VP
V
NP
control
S
NP
VP
V
NP
control e
S
NP
NPDet
the
NP
NP
N
trade
N
NN
poachers
S
NP
VP
V
NP
N
trade
e
N
NAdj
underground
S
NP
VP
V
NP
Adj
underground
e
S
NP
VP
V
NP
Adj
underground
e
S
NP
e
:

SuperTagging for Analysis (2)
Poachers now control the underground trade
poachers
nowcontrol
the underground
trade

SuperTagging for Analysis (3)
• Trigram Model for SuperTag disambiguation
• Probabilities estimated from annotated corpora
N
iiiii sssPswPSP1
21 ),|(*)|(maxarg)(
Emit Probability Contextual Probability

Dependency Analysis
• SuperTagging results in an “almost” parse
• Dependency requirements of each supertag can be used to form a dependency tree
poachers now
control
the underground
trade
arg0 arg1
mod mod
mod

Treatment of Adjuncts
• Adjunct supertags specify– category of node at which to adjoin– direction of modification
VP
NP
PP
P
VP*
with
S
NP
PP
P
S*
with

Treatment of Adjuncts• Collapse all adjunct () trees identical except for
adjunction category and/or direction into a -tree
• Like argument trees, -trees only specify active valency, not passive valency
• Passive valency recorded in separate -table
• Similar approach in TAG chosen by McDonald (1985) and D-Tree Substitution Grammar (Rambow et.al 1995).
??
NP
PP
P
with

FERGUS System Architecture
Output:word string
Tree Model
semi-specified
TAG derivation
tree
word lattice
Tree Chooser
UnravelerLP
Chooser
Input: underspecife
d dependency
tree
TAGLanguage
Model

Corpus Description• Dependency tree annotated with
– Part-of-speech
– Morphological information
– Syntactic information (“SuperTag”)
– Grammatical functions
– Sense tags (derived from WordNet)
onLC482ninthA_NXNCDninth
ninthLC15Nov.B_NnNNPNov.
defaultLC150onB_vxPnxINon
saidwillLC604default_INFA_nx0VVBdefault
defaulttheLC256U.S.A_NXNNNPU.S.
-LC70say_PASTB_nx0Vs1VBDsaid
saidtheLC453TreasuryA_NXNNNPTreasury
Head Word
Function words
Dep. Lexclass
Dep. Morph
Dep. STAGDep.
POS
Dep.
Word

Input Representation
• Dependency Tree – Semi-specified: any feature can be specified
• Role information
• Function words
poachers now
control
the underground
trade

Tree ChooserModel 1:• Given a dependency tree assign the appropriate
supertag to each node• Probability of daughter supertag:• Choose most probable supertag compatible with
mother supertag
),,|( dmmd llssP
poachers now
control
the underground
tradepoachers now
control
the underground
trade

Tree Chooser (2)Model 2:
• Given a dependency tree assign the appropriate supertag to each node
• Probability of mother supertag:
• Treelet is modeled as a set of independent mother-daughter links.
• Choose most probable supertag compatible with grandmother supertag
)(*)|(maxargs
TPs
TsP
poachers now
control
the underground
tradepoachers now
control
the underground
trade

Representing Supertag as a String
• A supertag can be uniquely represented as a string.
S
NP
VP
V
NP
S NP NP VP V V NP NP VP SL R LL R R RL L L
0 1 2 3 4 5 6 7 8 9

Unraveler• Dependency tree + supertags = semi-specified derivation tree
– Argument positions need not be fixed in input
– Adjunction sites of -trees not specified
• Given a semi-specified derivation tree, produce a word lattice
• XTAG grammar specifies possible positions of daughters in mother supertag.
poachers now
control
the underground
trade
poachersnow
control
the underground
trade
0,3,8,9

Unraveler (2)• Tree associated with supertag represented as string
(=frontier)
• Bottom-up word lattice construction
• Lattice is determinized and minimized
poachersnow
control
the underground
trade
0,3,8,9
now
poachersnow
poachers
control
control
the
the
underground
underground
trade
trade
now

Linear Precedence Chooser• Given a word lattice produce the most likely string• A stochastic n-gram model is
– Used to rank the likelihood of the strings in the lattice
– Represented as a weighted finite-state automaton
– Composed with the word lattice
• Retrieves the best path through the composed lattice
Bestpath (Lattice o LanguageModel)

Overview• Background• FERGUS – trainable surface realizer
– SuperTags – linguistic model underlying FERGUS– Statistical components of FERGUS
• Experiments and Evaluation• Evaluation Metrics • Experiments on quality and quantity of training
data

Experiment Setup
Baseline Model
TM-LM
TM-XTAG TM-XTAG-LM
RandomDependencyStructure
TrueDependencyStructure
No SuperTags SuperTags
Beta Trees Gamma Trees

Experiment Setup• Baseline Model
– Random dependency tree structure
– Compute distribution of daughter to left (right) of mother
• TM-LM Model– Annotated dependency tree structure for computing
left(right) distribution
• TM-XTAG Model– Annotated derivation tree structure (without gamma trees)
– Compute distribution of a daughter supertag given mother information
• TM-XTAG-LM Model– Annotated derivation tree structure with gamma trees

Evaluation Metric
• Complex issue
• Metric – Objective and automatic– Without human intervention– Quick turnaround
• These metrics not designed to compare realizers (but …)

Two String-based Evaluation Metrics• String edit distance between reference string
(length in words: R) and result string– Substitution (S)– Insertions (I)– Deletions (D)– Moves = pairs of deletions and insertions (M)– Remaining insertions (I’) and deletions (D’)
• Example: poachers now control the underground trade
trade poachers the underground control now
i . d d . . s i
Simple String Accuracy = 1- (I+D+S)/RGeneration String Accuracy = 1 – (M+I’+D’+S)/R

Experiments and Evaluation
• Training corpus: One million words of WSJ corpus
• Test corpus:– 100 randomly chosen sentences– Average sentence length 16.7 words
0.7240.589TM-XTAG-LM (=FERGUS)
0.6840.550TM-XTAG
0.6680.529TM-LM
0.5620.412Baseline
Generation String Accuracy
Simple String Accuracy
Model

Two Tree-based Evaluation Metrics
• Not all moves equally bad: moves which permute nodes in tree better than moves which “scramble” tree (projectivity)
• Simple Tree Accuracy: calculate S, D, I on each treelet
• Generation Tree Accuracy: calculate S, M, I’, D’ on each treelet
• Example: There was estimate for phase the second no cost
estimate
there was no cost for
phase
the second
estimate
there was no costfor
phase
the second
estimate
there was no costfor
phase
second the

Measuring Performance Using Evaluation Metrics
• Baseline: randomly assigned dependency structure, learn position of dependent to head
• Training corpus: One million words of WSJ corpus
• Test corpus
– 100 randomly chosen sentences
– average sentence length 16.7 words
Tree model
Simple String Acc
Generation String Acc
Simple Tree Acc
Generation Tree Acc
Baseline LR model
0.41 0.56 0.41 0.63
FERGUS 0.58 0.72 0.66 0.76

Overview• Background• FERGUS – trainable surface realizer
– SuperTags – linguistic model underlying FERGUS– Statistical components of FERGUS
• Experiments and Evaluation• Evaluation Metrics • Experiments on quality and quantity of training
data

Experimental Validation
• Problem: how are these metrics motivated?
• Solution (following Walker et.al. 1997)– Perform experiments to elicit human
judgements on sentences– Relate human judgements to metrics

Experimental Setup• Web-based
• Human subjects read short paragraph from WSJ and three or five variants of last sentence constructed by hand
• Humans judge:
– Understandability: How easy is this sentence to understand?
– Quality: How well-written is this sentence?
• Values: 1-7; 3 values have qualitative labels
• Ten subjects; each subject made a total of 24 judgements
• Data normalized by subtracting mean for each subject and dividing by standard deviation; then each variant averaged over subjects

Results of Experimental Validation• Strong correlations between normalized
understanding and quality judgements
• The two tree-based metrics correlate with both understandability and quality.
• The string-based metrics do not correlate with either understandability or quality.
Correlation with
Simple String Acc
Generation String Acc
Simple Tree Acc
Generation Tree Acc
Norm. und. 0.08 0.23 0.51 0.48
Norm. qual. 0.16 0.33 0.45 0.42

Experimental Validation: Finding Linear Models
• Other goal of the experiment: find better metrics• Series of linear regressions
– Dependent measures: normalized understanding and quality
– Independent measures: different combinations of :• the four metrics• sentence length• the “problem variables (S,I,D,M,I’,D’)
• Can improve on explanatory power of original four metrics
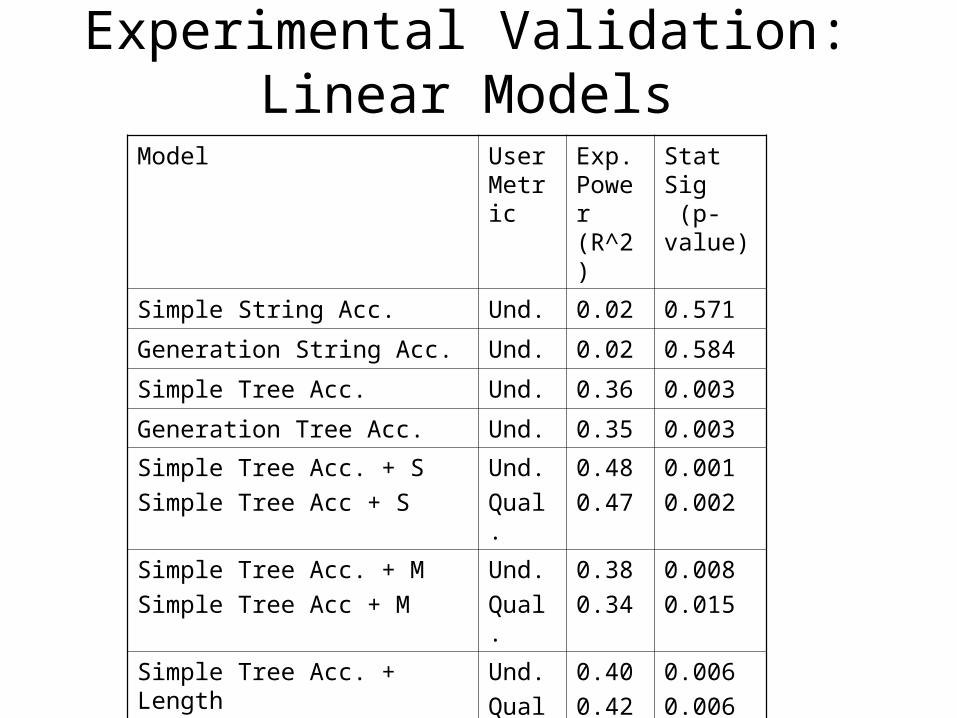
Experimental Validation: Linear Models
Model User Metric
Exp. Power (R^2)
Stat Sig (p-value)
Simple String Acc. Und. 0.02 0.571
Generation String Acc. Und. 0.02 0.584
Simple Tree Acc. Und. 0.36 0.003
Generation Tree Acc. Und. 0.35 0.003
Simple Tree Acc. + S
Simple Tree Acc + S
Und.
Qual.
0.48
0.47
0.001
0.002
Simple Tree Acc. + M
Simple Tree Acc + M
Und.
Qual.
0.38
0.34
0.008
0.015
Simple Tree Acc. + Length
Simple Tree Acc + Length
Und.
Qual.
0.40
0.42
0.006
0.006
Simple Tree Acc. + S + Length
Simple Tree Acc + S + Length
Und.
Qual.
0.51
0.53
0.003
0.002

Experimental Validation:Model of Understanding
Normalized Understanding = 1.4728*simple tree accuracy – 0.1015*substitutions – 0.0228*length – 0.2127
R2 = 0.5126
-1.3
-0.3
0.7
1.7
-1.1 -0.6 -0.1 0.4
1.478*Simple Tree Accuracy - 0.1015*S - 0.0228*length - 0.2127
Nor
mal
ized
un
der
stan
din
g

Experimental Validation: Model of Quality
Normalized Quality = 1.2134*simple tree accuracy – 0.0839*substitutions –0.0280*length – 0.0689
R2 = 0.5332
-1.3
-0.3
0.7
1.7
-1.1 -0.6 -0.1 0.4
1.2134*Simple Tree Accuracy - 0.0839*Substitutions - 0.0280*length - 0.0689
Nor
mal
ized
Qu
alit
y

Two New Metrics• Don’t want length to be included in the metrics• Understandability Accuracy = (1.3147*simple tree
accuracy – 0.1039*substitutions – 0.4458)/0.8689• Quality Accuracy = (1.0192*simple tree accuracy
– 0.0869*substitutions – 0.3553) /0.6639• Scores using new metrics:
Tree ModelUnderstandability Accuracy
Quality Accuracy
Baseline -0.08 -0.12
FERGUS 0.44 0.42

Summary
• FERGUS combines a linguistic model and a statistical model for surface realization.
• Tree model combined with linear model outperforms either of them alone.
• Four evaluation metrics introduced and validated.
• Created two new metrics which better correlate with human judgments.

Overview• Background• FERGUS – trainable surface realizer
– SuperTags – linguistic model underlying FERGUS– Statistical components of FERGUS
• Experiments and Evaluation• Evaluation Metrics • Experiments on quality and quantity of training
data

Motivation: What are the effects of quality and quantity on resulting model?
• Corpus quality– Manually-checked treebank: (English) Penn Treebank
(Marcus, et.al. 93)– Parsed, not manually-checked treebank: BLLIP
Treebank (Charniak 2000)
• Grammar quality– Hand-crafted grammar (XTAG) (XTAG-Group 2001)– Auto-extracted grammar (Chen, Vijay-Shanker 2000)
• Corpus size– Small ( < 1M words) or Large ( > 1M words)

Treebanks
• Penn Treebank (Marcus, et.al. 93)– Approximately 1,000,000 words– Hand-checked, bracketed text– WSJ news articles
• BLLIP Treebank (Charniak 2000)– Approximately 40,000,000 words– Automatically parsed, non hand checked text– WSJ news and newswire

Automatically extracted grammars
• Given a bracketed sentence, derive a set of TAG trees out of which it is composed (Chen, Vijay-Shanker 2000) (cf. Xia 99, Chiang 2000)– Head percolation table (Magerman 95)– Distinguishing complements from adjuncts (Chen,
Vijay-Shanker 2000, Collins 97)
NP-SBJ
S-TPC-4
NNS
Sales
VP
VBD
dipped
ADVP-MNR
RB
slightly
NP-C
S-TPC-4
NNS
Sales
VP
VBD
dipped
ADVP-A
RB
slightly
NP
NNS
Sales
VP
VBD
dipped
NP
S
ADVP
RB
slightly
S
S

Experiment: Quality of annotated corpus and grammar
• Questions– Hand-written grammar versus automatically extracted
grammar?
– Hand-checked treebank versus parsed, unchecked treebank?
• Invariant: Training data size– 1M words of TM corpus, 1M words of LM corpus
• Variables:– Treebank: PTB or BLLIP
– Grammar: XTAG or Auto-extracted grammar

Results of experiment on quality of annotated corpus (1)
• Invariant: Automatically extracted grammar• Treebank comparion
– Grammar size (tree frames)• Auto-extract (PTB) 3063• Auto-extract (BLLIP) 3763
– Generation results• Auto-extract (PTB) 0.749• Auto-extract (BLLIP) 0.727
• As expected, better quality annotated corpus results in better model accuracy

Results of experiment on quality of grammar (2)
• Invariant: Penn Treebank• Grammar comparison
– Grammar size (tree frames)• XTAG (PTB) 444• Auto-extract (PTB) 3063
– Generation results• XTAG (PTB) 0.742• Auto-extract (PTB) 0.749
• Surprisingly, automatically extracted grammar’s model yields comparable results to hand-crafted grammar’s model

Experiment: small corpora
• Purpose:– To investigate effect of resource size with limited
amounts of data ( < 1M words)
• Invariants:– Penn Treebank only (no BLLIP)
– Auto-extract grammars only (no XTAG)
• Variables:– Size of TM corpus
– Size of LM corpus

Results of experiment on small corpora (1)
• Varying LM– More LM,
better acc
• Varying TM– TM size must
be at least 1/10 LM size
– Leveling off of accuracy when TM at 500K words
0.43
0.48
0.53
0.58
0.63
0.68
0.73
0K 5K 10K 50K 100K 500K 1M
TM
Strin
g Ac
cura
cy
5K LM 10K LM 100K LM 1M LM

Result of experiment on small corpora (2)
• Increasing LM has greater effect than increasing TM– Example:
• 5K TM 5K LM - 0.50• 5K TM 1M LM – 0.64• 1M TM 5K LM - 0.60
• But given fixed size LM, more TM generally improves performance– Example
• 1M TM 1M LM – 0.75

Experiment: Large corpora
• Purpose:– To investigate the effects of resource size with large
amounts of data ( > 1M words)
• Invariants:– BLLIP only (parsed, unchecked)
– Auto-extracted grammars only (no XTAG)
• Variables:– Size of TM
– Size of LM

Results of experiment on large corpora
• Increasing LM also increases performance
• 10M of BLLIP yields better accuracy than 1M of PTB
• Increasing size of TM increases performance– Best result obtained: 0.791
0.67
0.69
0.71
0.73
0.75
0.77
0.79
0.81
0M 1M 10M 20M 30M 40M
TM
Str
ing
Acc
urac
y
1M LM 2M LM

Summary• Not only linear language model, but also tree model
is important in stochastic generation using FERGUS– Caveat: TM corpus at least 1/10 the size of LM corpus
• Auto extracted grammar– Results in linguistically plausible grammar for generation– Can perform as well as hand-crafted grammar
• Output of high performance parser can substitute for hand-checked treebank– Large corpus size compensates for low-quality annotation– Training on 10M BLLIP gives better results than 1M
PTB


Output Generation• An interactive system needs to convey its
information state to the user.• Generation: Process of converting a
system-internal representation to an human interpretable form.
• Input: Communicative goals, Propositions, ??• Output:
• Speech
• Text• Tables
• Multimodal and Multimedia

Results of experiment on large corpora
• Increasing LM also increases performance
• 10M of BLLIP yields better accuracy than 1M of PTB
• Increasing size of TM increases performance– Best result obtained: 0.791
0.30.35
0.40.45
0.50.55
0.60.65
0.7
0M 1M 10M 20M 30M 40M
TM
Und
erst
anda
bilit
y
1M LM 2M LM

Coling slides

Natural Language Generation
Typical components of generation system:• Text Planning:
– Transform communicative goal into sequence (or structure) of elementary communicative goals.
• Sentence Planning:– Choose linguistic resources to achieve elementary
communicative goals.
• Realization:– Produce surface output.

Stochastic Models in Realization
• Our system performs – (some) lexical choice,
– (some) syntactic choice,
– morphology and
– linearization
• Useful if:– Need to generate wide variety of texts (MT)
– Need to quickly customize generator to new domains or genres.

Stochastic Models in Generation: Recent Approaches
• Langkilde and Knight (INLG 1998, NAACL 200)• Features:
– Generation from “semantic” interlingua for MT.– Hand-coded rules overgenerate possible realizations for
interlingua elements– Rule output composed into a lattice– Linear Language Model (bigram) chhoses best path
through lattice
• Problem:– No guarantee of grammaticality, e.g., subject-verb
agreement.

Stochastic Models in Generation: Recent Approaches (2)
• Ratnaparkhi (NAACL 2000)Features:
– Generation of NPs in restricted domain (air travel) of type flights in the evening to New York
– Semantics represented as list of attribute-value pairs– Maximum entropy model trained on dependency tree and
attribute sets
Problems:– No guarantee of grammaticality– Developed and tested on very narrow domain– Subjective evaluation by only two subjects (including
author)

Stochastic Models in Generation: Recent Approaches (3)
• Oh & Rudnicky: n-gram language models for specific dialog acts
• Systemic-functional generation with hand-chosen probabilities (Fawcett 1992).
• Stochastic Machine Translation approaches can be seen as incorporating stochastic models for generation

Stochastic Models in Generation: Our Approach
• Corpus-based learning to refine syntactic and lexical choice; generate surface string
• Use of stochastic tree model and linear language model
• Use of pre-existing hand crafted grammar: XTAG.

Corpus Description• Dependency tree annotated with
– Part-of-speech
– Morphological information
– Syntactic information (“SuperTag”)
– Grammatical functions
– Sense tags (derived from WordNet)
Dep.
Word
Dep.
POS
Dep. STAG Dep. Morph Dep Lexclass
Function words
Head Word
Treasury NNP A_NXN Treasury LC453 the said
said VBD B_nx0Vs1 say_PAST_STR
LC70 -
U.S. NNP A_NXN U.S. LC256 the default
default VB A_nx0V default_INF LC604 will said
on IN B_vxPnx on LC150 default
Nov. NNP B_Nn Nov. LC15 ninth
ninth CD A_NXN ninth LC482 on

Input Representation
• Dependency Tree – Semi-specified: any feature can be specified
• Role information
• Function words
poachers now
control
the underground
trade

Tree ChooserModel 1:• Given a dependency tree assign the appropriate
supertag to each node• Probability of daughter supertag:• Choose most probable supertag compatible with
mother supertag
),,|( dmmd llssP
poachers now
control
the underground
tradepoachers now
control
the underground
trade

Tree Chooser (2)Model 2:
• Given a dependency tree assign the appropriate supertag to each node
• Probability of mother supertag:
• Treelet is modeled as a set of independent mother-daughter links.
• Choose most probable supertag compatible with grandmother supertag
)(*)|(maxargs
TPs
TsP
poachers now
control
the underground
tradepoachers now
control
the underground
trade

Treatment of Adjuncts
• Adjunct supertags specify– category of node at which to adjoin– direction of modification
NP
NP
PP
P
NP
with
S
NP
PP
P
S
with

Treatment of Adjuncts• Collapse all adjunct () trees identical except for
adjunction category and/or direction into a -tree
• Like argument trees, -trees only specify active valency, not passive valency
• Passive valency recorded in separate -table
• Similar approach in TAG chosen by McDonald (1985) and D-Tree Substitution Grammar (Rambow et.al 1995).
??
NP
PP
P
with

Unraveler• Dependency tree + supertags = semi-specified derivation tree
– Argument positions need not be fixed in input
– Adjunction sites of -trees not specified
• Given a semi-specified derivation tree, produce a word lattice
• XTAG grammar specifies possible positions of daughters in mother supertag.
poachers now
control
the underground
trade
poachersnow
control
the underground
trade
0,3,8,9

Unraveler (2)• Tree associated with supertag represented as string
(=frontier)
• Bottom-up word lattice construction
• Lattice is determinized and minimized
poachersnow
control
the underground
trade
0,3,8,9
now
poachersnow
poachers
control
control
the
the
underground
underground
trade
trade
now

Linear Precedence Chooser• Given a word lattice produce the most likely string• A stochastic n-gram model is
– Used to rank the likelihood of the strings in the lattice
– Represented as a weighted finite-state automaton
– Composed with the word lattice
• Retrieves the best path through the composed lattice
Bestpath (Lattice o LanguageModel)

Experiment Setup
Baseline Model
TM-LM
TM-XTAG TM-XTAG-LM
RandomDependencyStructure
TrueDependencyStructure
No SuperTags SuperTags
Beta Trees Gamma Trees

Experiment Setup• Baseline Model
– Random dependency tree structure
– Compute distribution of daughter to left (right) of mother
• TM-LM Model– Annotated dependency tree structure for computing
left(right) distribution
• TM-XTAG Model– Annotated derivation tree structure (without gamma trees)
– Compute distribution of a daughter supertag given mother information
• TM-XTAG-LM Model– Annotated derivation tree structure with gamma trees

Evaluation Metric
• Complex issue
• Metric – Objective and automatic– Without human intervention– Quick turnaround
• These metrics not designed to compare realizers (but …)

Two String-based Evaluation Metrics• String edit distance between reference string
(length in words: R) and result string– Substitution (S)– Insertions (I)– Deletions (D)– Moves = pairs of deletions and insertions (M)– Remaining insertions (I’) and deletions (D’)
• Example: poachers now control the underground trade
trade poachers the underground control now
i . d d . . s i
Simple String Accuracy = 1- (I+D+S)/RGeneration String Accuracy = 1 – (M+I’+D’+S)/R

Experiments and Evaluation
• Training corpus: One million words of WSJ corpus
• Test corpus:– 100 randomly chosen sentences– Average sentence length 16.7 words
ModelSimple String Accuracy
Generation String Accuracy
Baseline 0.412 0.562
TM-LM 0.529 0.668
TM-XTAG 0.550 0.684
TM-XTAG-LM (=FERGUS)
0.589 0.724

INLG slides on evaluation

Two Tree-based Evaluation Metrics
• Not all moves equally bad: moves which permute nodes in tree better than moves which “scramble” tree (projectivity)
• Simple Tree Accuracy: calculate S, D, I on each treelet
• Generation Tree Accuracy: calculate S, M, I’, D’ on each treelet
• Example: There was estimate for phase the second no costestimate
there was no cost for
phase
thesecond
estimate
there was no
cost
for
phase
thesecond

Measuring Performance Using Evaluation Metrics
• Baseline: randomly assigned dependency structure, learn position of dependent to head
• Training corpus: One million words of WSJ corpus
• Test corpus
– 100 randomly chosen sentences
– average sentence length 16.7 words
0.7240.589TM-XTAG-LM (=FERGUS)
0.5620.412Baseline LR Model
Generation String Accuracy
Simple String Accuracy
Model

Experimental Validation
• Problem: how are these metrics motivated?
• Solution (following Walker et.al. 1997)– Perform experiments to elicit human
judgements on sentences– Relate human judgements to metrics

Experimental Setup• Web-based
• Human subjects read short paragraph from WSJ and three or five variants of last sentence constructed by hand
• Humans judge:
– Understnadability: How easy is this sentence to understand?
– Qulaity: How well-written is this sentence?
• Values: 1-7; 3 values have qualitative labels
• Ten subjects; each subject made a total of 24 judgements
• Data normalized by subtracting mean for each subject and dividing by standard deviation; then each variant averaged over subjects

Results of Experimental Validation
• Strong correlations between normalized understanding and quality judgements
• The two tree-based metrics correlate with both understandability and quality.
• The string-based metrics do not correlate with either understandability or quality.
• Table HERE

Experimental Validation: Finding Linear Models
• Other goal of the experiment: find better metrics• Series of linear regressions
– Dependent measures: normalized understanding and quality
– Independent measures: different combinations of :• the four metrics• sentence length• the “problem variables (S,I,D,M,I’,D’)
• Can improve on explanatory power of original four metrics

Impact of Quality and Quantity of Corpora on Stochastic
Generation
EMNLP 2001 slides

Statistical Approaches to Generation
• Motivation– Wide-coverage
– Generation system needs to be created quickly
• Recent explosion in interest– Knight and Hatzivassiloglou 1995
– Langkilde and Knight 1998
– Bangalore and Rambow 2000
– Ratnaparkhi 2000
– Uchimoto, et.al. 2000

Motivation: What are the effects of quality and quantity on
resulting model?• Corpus quality
– Manually-checked treebank: (English) Penn Treebank (Marcus, et.al. 93)
– Parsed, not manually-checked treebank: BLLIP Treebank (Charniak 2000)
• Grammar quality– Hand-crafted grammar (XTAG) (XTAG-Group 2001)– Auto-extracted grammar (Chen, Vijay-Shanker 2000)
• Corpus size– Small ( < 1M words) or Large ( > 1M words)

Outline
• Tree Adjoining Grammar (TAG)• FERGUS generation system• Description of alternative system components
– Penn Treebank and BLLIP Treebank– XTAG grammar and Automatically extracted grammar
• Experiments– Evaluation metrics– Quality of corpus and grammar– Small corpora– Large corpora

Tree-Adjoining Grammar (TAG)
• A TAG (Schabes 90) is a set of lexicalized trees– Localize dependencies– Factor recursion
S
VP
V
eats
NP
NP
S
VP
V
eats
NP
N
yesterday
VP
VP
• Lexicalized trees versus tree frames (supertags)S
VP
V
eats
NP
NPS
VP
V NP
NPLexicalized tree Tree frame(supertag)

FERGUS Generation System
• FERGUS: Flexible Empirical/Rationalist Generation Using Syntax (Bangalore and Rambow 2000)– Input: Underspecified dependency tree– Output: Sequence of words
poachers now
control
the underground
trade Poachers now control theunderground trade

FERGUS system architecture
Semi-specified
TAGDerivation
Tree
WordLattice
Input: Underspecified Dependency Tree
Output: String
TAG LanguageModel
TreeChooser
UnravelerLP
Chooser
TreeModel

Tree chooser
• Goal: Use statistical model to select a supertag for each word in dependency tree
poachers now
control
the underground
trade
poachers now
control
the underground
trade
VP
V
NP
S
NPVP
V
NP
S
NP
NP
S
VP
V
NP
S
S*
Example: Some choices for “control” - Subcat frame - Realization of arguments - passive, wh-movement, rel-cl

Unraveler
• Semi-specified derivation tree– Def: dependency tree
plus supertags– Free parameters
• Argument positions• Precise location of
adjunction
• Goal of unraveler– From semi-specified
derivation tree to word lattice
• Example
poachers now
control
the underground
trade
now
poachers
theunderground
now
controlpoachers
trade
… …
control …
……

LP chooser
• Goal: Produce most likely string given word lattice• Means: Stochastic trigram language model
– Represented as finite state automaton– Procedure
• Compose with word lattice• Rank likelihood of strings in lattice• Retrieve best path through composed lattice

Treebanks
• Penn Treebank (Marcus, et.al. 93)– Approximately 1,000,000 words– Hand-checked, bracketed text– WSJ news articles
• BLLIP Treebank (Charniak 2000)– Approximately 40,000,000 words– Automatically parsed, non hand checked text– WSJ news and newswire

XTAG Grammar
• Hand-crafted TAG (XTAG-Group 2001)– English language– 1000 tree frames
• Heuristic mapping of treebank bracketings to XTAG

Automatically extracted grammars
• Given a bracketed sentence, derive a set of TAG trees out of which it is composed (Chen, Vijay-Shanker 2000) (cf. Xia 99, Chiang 2000)– Head percolation table (Magerman 95)– Distinguishing complements from adjuncts (Chen,
Vijay-Shanker 2000, Collins 97)
NP-SBJ
S-TPC-4
NNS
Sales
VP
VBD
dipped
ADVP-MNR
RB
slightly
NP-C
S-TPC-4
NNS
Sales
VP
VBD
dipped
ADVP-A
RB
slightly
NP
NNS
Sales
VP
VBD
dipped
NP
S
ADVP
RB
slightly
S
S

Outline
• Tree-Adjoining Grammar (TAG)• FERGUS generation system• Description of alternative system components
– Penn Treebank and BLLIP Treebank– XTAG grammar and Automatically extracted grammar
• Experiments– Evaluation metrics– Quality of corpus and grammar– Small corpora– Large corpora

Evaluation metrics
• Complexity of issue of evaluation (Bangalore, Rambow, Whittaker 2000)
• Evaluation metric used here: String edit distance– String accuracy = 1 - (M + I’ + D’ + S) / R
• S: Substitutions, I: Insertions, D: Deletions• M: Moves (Pairs of deletions and insertions)• Remaining insertions (I’) and deletions (D’)
• Example– poachers now control the underground trade– trade poachers the underground control now– I . D D . S S I

Experiment: Quality of annotated corpus and grammar• Questions
– Hand-written grammar versus automatically extracted grammar?
– Hand-checked treebank versus parsed, unchecked treebank?
• Invariant: Training data size– 1M words of TM corpus, 1M words of LM corpus
• Variables:– Treebank: PTB or BLLIP
– Grammar: XTAG or Auto-extracted grammar

Results of experiment on quality of annotated corpus (1)
• Invariant: Automatically extracted grammar• Treebank comparion
– Grammar size (tree frames)• Auto-extract (PTB) 3063• Auto-extract (BLLIP) 3763
– Generation results• Auto-extract (PTB) 0.749• Auto-extract (BLLIP) 0.727
• As expected, better quality annotated corpus results in better model accuracy

Results of experiment on quality of grammar (2)
• Invariant: Penn Treebank• Grammar comparison
– Grammar size (tree frames)• XTAG (PTB) 444• Auto-extract (PTB) 3063
– Generation results• XTAG (PTB) 0.742• Auto-extract (PTB) 0.749
• Surprisingly, automatically extracted grammar’s model yields comparable results to hand-crafted grammar’s model

Experiment: small corpora
• Purpose:– To investigate effect of resource size with limited
amounts of data ( < 1M words)
• Invariants:– Penn Treebank only (no BLLIP)
– Auto-extract grammars only (no XTAG)
• Variables:– Size of TM corpus
– Size of LM corpus

Results of experiment on small corpora (1)
• Varying LM– More LM,
better acc
• Varying TM– TM size must
be at least 1/10 LM size
– Leveling off of accuracy when TM at 500K words
0.43
0.48
0.53
0.58
0.63
0.68
0.73
0K 5K 10K 50K 100K 500K 1M
TM
Strin
g Ac
cura
cy
5K LM 10K LM 100K LM 1M LM

Results of experiment on small corpora (1)
• Varying LM– More LM,
better acc
• Varying TM– TM size must
be at least 1/10 LM size
– Leveling off of accuracy when TM at 500K words
-0.2-0.15
-0.1-0.05
00.05
0.10.15
0.20.25
0.30.35
0.40.45
0.5
0K 5K 10K 50K 100K 500K 1000K
TM
Unde
rsta
ndab
ility
5K LM 10K LM 100K LM 1M LM

Result of experiment on small corpora (2)
• Increasing LM has greater effect than increasing TM– Example:
• 5K TM 5K LM - 0.50• 5K TM 1M LM – 0.64• 1M TM 5K LM - 0.60
• But given fixed size LM, more TM generally improves performance– Example
• 1M TM 1M LM – 0.75

Experiment: Large corpora
• Purpose:– To investigate the effects of resource size with large
amounts of data ( > 1M words)
• Invariants:– BLLIP only (parsed, unchecked)
– Auto-extracted grammars only (no XTAG)
• Variables:– Size of TM
– Size of LM
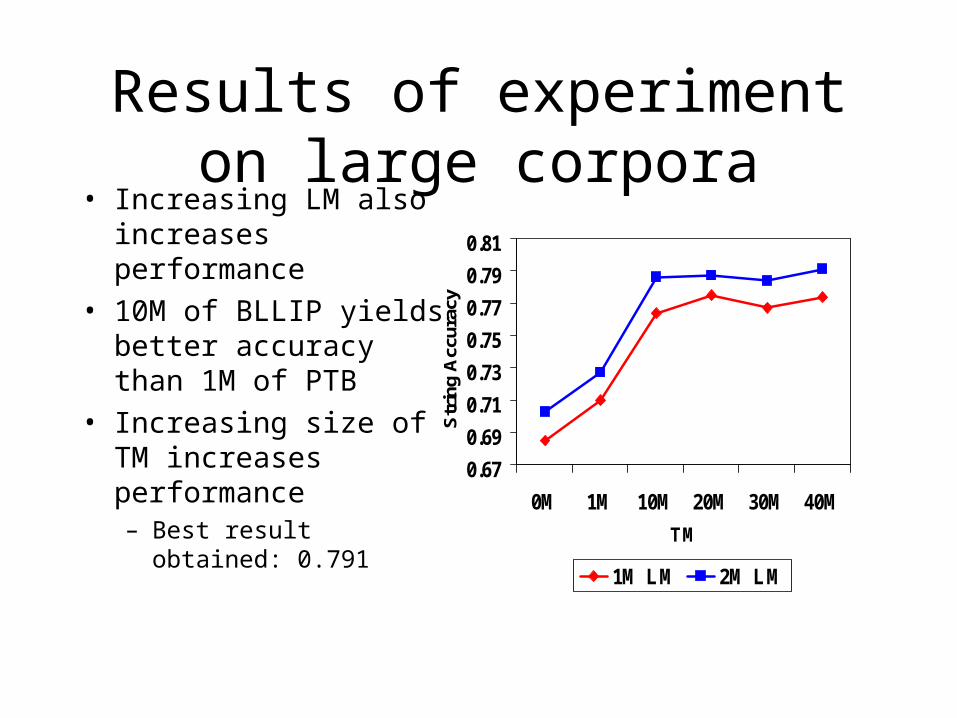
Results of experiment on large corpora
• Increasing LM also increases performance
• 10M of BLLIP yields better accuracy than 1M of PTB
• Increasing size of TM increases performance– Best result obtained: 0.791
0.67
0.69
0.71
0.73
0.75
0.77
0.79
0.81
0M 1M 10M 20M 30M 40M
TM
Str
ing
Acc
urac
y
1M LM 2M LM

Summary• Not only linear language model, but also tree model
is important in stochastic generation using FERGUS– Caveat: TM corpus at least 1/10 the size of LM corpus
• Auto extracted grammar– Results in linguistically plausible grammar for generation– Can perform as well as hand-crafted grammar
• Output of high performance parser can substitute for hand-checked treebank– Large corpus size compensates for low-quality annotation– Training on 10M BLLIP gives better results than 1M
PTB

Towards Automatic Generation of Natural Language Generation
Systems
John Chen
Joint work with
Srinivas Bangalore
Owen Rambow

Natural Language Generation
• Definition– Input: Set of communicative goals
– Output: Sequence of words
• Example– Input
• Implicit-confirm(orig-city:NEWARK), Implicit-confirm(dest-city:DALLAS), Request(depart-date)
– Output• Flying from Newark to Dallas. What date would you like to leave?
• Alternative: You are flying from Newark. What date would you like to leave? You are flying to Dallas.

Importance of Automatic Generation in NLG Systems
• Alternative: Handwritten templates– Example: “FLYING TO dest-city, LEAVING FROM orig-city, AND WHAT DATE DID YOU WANT TO LEAVE?”
• Problems with alternative– Porting to new domains– Complexity with a complicated domain– Maintenance issues

Architecture of Communicator Generation System
SPoT
Sentence Planner
Imp-confirm(NEWARK)
Imp-confirm(DALLAS)
Request(depart-date)
Flying from Newark to Dallas. What date would you like to leave?
/fl/ /ih/ /ng/ /f/ /r/ /uh/ …
TTS
FERGUS
Surface GeneratorImp-confirm(NEWARK)
Request(depart-date)Soft-merge-general
Period
Imp-confirm(DALLAS)
DM
Dialog Manager

SPoT: Sentence Planner, Trainable (Walker, Rambow, Rogati 2001)
• Input: Text plan (communicative goals)– Example: Implicit-confirm(orig-city:NEWARK),
Implicit-confirm(dest-city:DALLAS), Request(depart-date)
• Output: Ranked sentence plans
Imp-confirm(NEWARK) Imp-confirm(DALLAS)
Request(depart-date)Soft-merge-general
Period
Imp-confirm(NEWARK)
Imp-confirm(DALLAS)
Request(depart-date)
Period
Period
Flying from Newark to Dallas. What date would you like to leave?
You are flying from Newark. What date would you like to leave? You are flying to Dallas.
4.5 2.7

SPoT Architecture
• Stages– SPG: Sentence plan generator
• Generate a set of candidate sentence plans– SPR: Sentence plan ranker
• Rank sentence plans using RankBoost (Freund, Schapire)• Training data are sets of sentence plans ranked by human
judges
• Result– 5% difference in mean rankings between best sentence
plans chosen by SPoT and by human judges

Porting SPoT to a New Domain
• Problem– Training requires human judges to rank sentence plans
• Domain-dependent vs. Domain-independent features
• Experiment (Walker, Rambow)– Train using domain-independent features only
– Model trained on only domain-independent features is as good as model trained on both kinds of features

FERGUS Surface Realizer (Bangalore, Rambow 2000)
• FERGUS: Flexible Empirical/Rationalist Generation Using Syntax
• Input: Underspecified dependency tree
• Output: Sequence of wordscontrol
poachers now
the underground
tradepoachers now control the underground trade

Tree-Adjoining Grammar (TAG)
• A TAG (Schabes 90) is a set of lexicalized trees– Localize dependencies– Factor recursion
• Lexicalized trees versus tree frames (supertags)
S
NP
VP
V
NP
S
VP
V
NP
eats eats
VP
VP* V
yesterday
S
NP
VP
V
NP
eats
S
NP
VP
V
NPLexicalized tree
Tree frame(supertag)

FERGUS System Architecture
Output:word string
Tree Model
semi-specified
TAG derivation
tree
word lattice
Tree Chooser
UnravelerLP
Chooser
Input: underspecife
d dependency
tree
TAGLanguage
Model

Tree Chooser
• Purpose: Statistical model selects a supertag for each word in dependency tree
control
poachers now
the underground
trade
control
poachers now
the underground
trade
S
NP
VP
V
NP
S
NP
VP
V
NP
S
NP S
S*
VP
V
NP
Example: Choices for “control” - Subcat frame - Realization of arguments - passive, wh-move, rel-cl
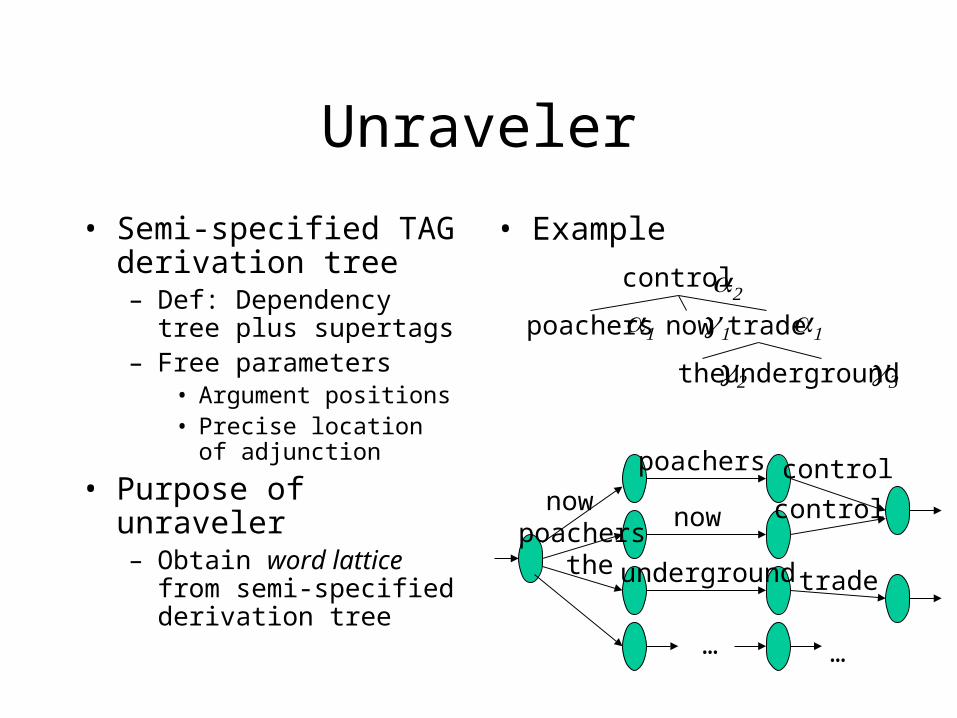
Unraveler
• Semi-specified TAG derivation tree– Def: Dependency tree plus
supertags– Free parameters
• Argument positions• Precise location of
adjunction
• Purpose of unraveler– Obtain word lattice from
semi-specified derivation tree
• Example
control
poachers now
theunderground
trade
nowpoachers
the
poachers
now
control
control
underground trade
… …

LP Chooser
• Purpose: Produce most likely string given word lattice
• Means: Stochastic trigram language model– Represented as a finite state automaton– Procedure
• Compose with word lattice
• Rank likelihood of strings in lattice
• Retrieve best path through composed lattice

Issues in Training FERGUS
• FERGUS requires– Hand-written TAG grammar for target domain data– Hand-treebanked target domain sentences– Raw unannotated target domain sentences
Tree Model
Tree Chooser
UnravelerLP
Chooser
TAGLanguage
Model

Issues in Training FERGUS
• Outline– Recent work
• Porting FERGUS to Communicator domain• Integration of FERGUS with SPoT
– Previous work (Bangalore, Chen, Rambow 2001)
• Parsed treebank instead of hand-checked treebank• Auto-extracted grammar instead of handwritten
grammar

Treebanks
• Penn Treebank (Marcus, et al. 1993)– Approximately 1,000,000 words– Hand-checked, bracketed text– WSJ news articles
• BLLIP Treebank (Charniak 2000)– Approximately 40,000,000 words– Automatically parsed, non hand checked text– WSJ news and newswire

XTAG Grammar
• Hand-crafted TAG (XTAG-Group 2001)– English language– Approximately 1000 tree frames
• Heuristic mapping of treebank bracketings to XTAG

Automatically Extracted Grammars
• Given a bracketed sentence, derive a set of TAG trees out of which it is composed (Chen, Vijay-Shanker 2000) (cf. Xia 1999, Chiang 2000)– Head percolation table (Magerman 1995)– Distinguishing complements from adjuncts (Chen, Vijay-Shanker
2000, Collins 1997)
S
VBD
VP
NNS
NP-SBJ ADVP-MNR
RB
Sales dipped slightly
S
VBD
VP
NNS
NP-C ADVP-A
RB
Sales dipped slightly
NNS
NP
Sales
S
VBD
VPNP
dipped
VP* ADVP
RB
slightly
VP

Evaluation metrics
• Complexity of evaluation issue (Bangalore, Rambow, Whittaker 2000)
• String edit distance is current evaluation metric
– Range: -1.0 <= acc <= 1.0
• Example– poachers now control the underground trade– trade poachers the underground control now– I . D D S I
R
SDIMacc
''1
S:substitutions, I:insertions, D:deletions, M:moves (pairs of deletions and insertions), R: remaining insertions and deletions

Experiment: Quality of Annotated Corpus and Grammar
• How FERGUS performance is affected by– Handwritten grammar versus automatically extracted grammar
• PTB
• BLLIP
– Handchecked treebank versus parsed, unchecked treebank• XTAG
• Automatically extracted grammar
• Invariant: training data size– 1M words of TM corpus, 1M words of LM corpus

• Invariant: Automatically extracted grammar• Treebank comparison
• As expected, better quality annotated corpus results in better model accuracy
Result of Experiment on Quality of Annotated Corpus
Grammar size
Generation Results
PTB 3063 0.749
BLLIP 3763 0.727

Results of Experiment on Quality of Grammar
• Invariant: Penn Treebank• Grammar comparison
• Surprisingly, automatically extracted grammar’s model yields comparable results to hand-crafted grammar’s model
Grammar size
Generation Results
XTAG 444 0.742
Auto-extract 3063 0.749

Conclusions About Using Automatically Generated Training
Data• Output of high performance parser can
substitute for hand-checked treebank
• Auto extracted grammar can perform as well as hand-crafted grammar

Problems in Porting FERGUS to a New Domain--Communicator
• Training the tree model– No TAG grammar explicitly written for target domain– Little or no hand-treebanked target domain data
• Training the language model– No target corpus (human-human interaction often
different)– Small corpora (problem of hand-transcription)

Questions about Porting FERGUS to the Communicator Domain
• Can out-of-domain data used instead of in-domain data?
• Substitute parsed data for hand-treebanked data for TM?
• Effect of using small in-domain corpus for LM?

Two Kinds of Training Data
• “Out of domain” data (PTB)– Penn Treebank WSJ
• Approximately 1,000,000 words• Hand-annotated for syntax
• “In-domain” data (HH)– Human-human dialogs (from CMU)
• 13,000 words• Automatically annotated for syntax by a partial
dependency parser trained on WSJ

Test Data
• Template-based data– Approximately 2200 words– Based on Communicator templates
• Slots filled in via a probability model

XTAG-Based FERGUS Results
• Small, in domain LM helps
• Small in-domain TM helps
• Using both LM and TM together helps even more
• Comparable results to matched WSJ training and test data (0.74)
OUT TM
IN TM
OUT LM
0.68 0.72
IN LM
0.72 0.76
String Accuracies

Extracted Grammar-Based FERGUS Results
• Small, in domain LM doesn’t hurt
• IN TM column requires full, not partial, parser
• Comparable results to matched WSJ training and test data (0.75)
OUT TM
IN TM
OUT LM
0.73
IN LM
0.72
String Accuracies

Interpolating LM’s
• Problem: HH LM is small
• Idea: Weighted interpolation of HH LM with large, out-of domain LM (WSJ)

How to weight interpolated LM’s
• Experiment– Alternate weighting HH-LM, WSJ-LM more
• Results
– WSJ only: 0.71, HH only: 0.71
• Analysis– Interpolated LM never better than non-interpolated
0.1HH+WSJ
0.2HH+WSJ
0.4HH+WSJ
HH+
0.4WSJ
HH+
0.2WSJ
HH+
0.1WSJ
0. 71 0. 71 0.71 0.69 0.69 0.69

Conclusions About Training Fergus’s TM in the Communicator
Domain• No TAG grammar explicitly written for target
domain– Viable alternatives
• Hand-written, out-of-domain TAG grammar
• Automatically extracted TAG grammar
• Little or no hand-treebanked target domain data– Viable alternatives
• Out-of-domain treebanked data
• Automatically parsed “in-domain” data

Conclusions About Training Fergus’s LM in the Communicator
Domain• Problems
– No target corpus (human-human interaction often different)– Small corpora (problem of hand-transcription)
• Findings– Small HH corpus is viable alternative to large completely out-
of-domain corpus (WSJ)• Similar accuracies• Better accuracy if TM is also HH based
– Interpolation of (small) HH with (large) WSJ does not result in better accuracies

Integration of SPoT with FERGUS
• Results so far– Possible that SPoT is easily transferrable to a
new domain– FERGUS seems to be easily transferred to a
new domain
• Questions– Can SPoT and FERGUS work together?– If so, can they be ported together to the
Communicator domain with good results?

Can SPoT and FERGUS work together?
• SPoT Output– Deep syntactic tree
• FERGUS Input, in previous experiments– Surface syntactic dependency tree

Addition of Rule-based Component to FERGUS
• Purpose– Convert deep syntax to surface syntax tree
• Adds linguistic knowledge to input tree– Example: what in what day is a determiner, not an NP
Output:word string
semi-specified
TAG derivation
tree
word lattice
Tree Chooser
UnravelerLP
Chooser
underspecifed dependency
tree
Rule-Based Component
Deep-syntax
tree

Quality of Integrated SPoT and FERGUS
• Train– TM: either HH or WSJ– LM: HH
• Test– SPoT test data (2,200 words)
• Results– HH TM: 0.86– WSJ TM: 0.88
• Analysis– High quality results– It seems that TM’s effect on output quality diminishes because of
addition of Rule-based component (cf. 0.76/0.72)

Integrating FERGUS with Communicator
• Pre-integration– Sentence template
• “FLYING TO dest-city, LEAVING FROM orig-city, AND WHAT DATE DID YOU WANT TO LEAVE?”
• Post-integration– Dependency trees with templatesFLYING
TO dest-city ,

Variations on How FERGUS Can Be Integrated With Communicator
• FERGUS Off-line– Pre-compile surface strings from set of all possible
templated dependency trees– Good for small domain, and if slot fillers don’t matter
• FERGUS On-line (currently implemented)– On-the-fly conversion of templated dependency trees to
surface strings– Required for large domain– Results show that FERGUS is fast enough to use this
way in a dialog system (avg. response time: 0.28 sec)

Conclusion: Automatic Generation of Natural Language Generation
Systems Seems Realizable• SPoT seems portable
– It performs as well using only domain-independent features as using both these and also domain-dependent features.
• Encouraging results for FERGUS– Possible to use out-of-domain data for adequate results– Qualities of in-domain data resources
• Don’t need hand-crafted grammar• Don’t need large amount of in-domain data• Can use automatically parsed in-domain data

Conclusions about integrating FERGUS with SPoT and
Communicator• Integrating FERGUS with SPoT
– Necessity of adding Rule-based component to FERGUS
– High resulting accuracy
– Diminishing effect of TM on output quality
• Integrating FERGUS with Communicator– On-line integration has been implemented
– Fast response time
– Adequate results

Future Work (1)
• Experiments with different resources– Hand-checked HH parsed corpus
• Different kinds of automatically extracted grammars from this corpus
• Hand-checked HH versus parsed HH
– Parsed HH (not dependency-parsed)• Different kinds of automatically extracted grammars
from this corpus
• Interpolation of TM instead of LM

Future Work (2)
• FERGUS Output to Prosody-marker input





























