Embed Size (px)
Citation preview

CONTEXT-AWARE AUTOMATIC OCCLUSION REMOVAL
Kumara Kahatapitiya Dumindu Tissera Ranga Rodrigo
Department of Electronic and Telecommunication EngineeringUniversity of Moratuwa, Sri Lanka
ABSTRACTOcclusion removal is an interesting application of imageenhancement, for which, existing work suggests manually-annotated or domain-specific occlusion removal. No worktries to address automatic occlusion detection and removal asa context-aware generic problem. In this paper, we present anovel methodology to identify objects that do not relate to theimage context as occlusions and remove them, reconstructingthe space occupied coherently. The proposed system detectsocclusions by considering the relation between foregroundand background object classes represented as vector embed-dings, and removes them through inpainting. We test oursystem on COCO-Stuff dataset and conduct a user study toestablish a baseline in context-aware automatic occlusionremoval.
Index Terms— Deep Learning, Context-Awareness, Oc-clusion Removal
1. INTRODUCTION
Automatically removing unrelated foreground objects froman image to “clean” it, is an intriguing and still-open area ofresearch. Images tend to loose the naturalness or the visually-pleasing nature due to the presence of such objects. For in-stance, a scene of a landscape may contain an artificial objectin the foreground, or a picturesque attraction may be crowded,making it impossible to capture its untainted beauty. Suchcomplications give rise to the requirement of automatic detec-tion and removal of undesired or unrelated objects in images.We refer to such objects as occlusions. In a general sense, thistask is challenging since the occlusions are dependent on theimage context. For instance, an occlusion in one image maybe perfectly natural in another.
The process of acquiring an occlusion-free image involvestwo subtasks: identifying unrelated things, and removingthem coherently. Image context defines which objects are un-related. Yet, due to high complexity of natural images, properinterpretation of the image context is difficult [1, 2]. Beingunrelated is usually subjective in human perception. How-ever, in a computer vision system, this should be captured ob-jectively. Object detection coupled with scene understandingand pixel generation can potentially address these subtasks.
Since Convolutional Neural Networks (CNNs) enable richfeature extraction that capture complex contextual informa-tion [3, 4, 5], and Generative Adversarial Networks (GANs)
Fig. 1: An example result of the context-aware occlusion re-moval using our system, without any post-processing. Left:input image, Right: output of the system. Notice that the peo-ple and the handbag have been removed as occlusions.
provide considerable improvements in pixel generation tasks[6, 2], we are motivated in adapting neural networks to ma-nipulate contextual information. However, we further requirea methodology of identifying unrelated objects based on theimage context. It is difficult to train an end-to-end systemto interpret the image context and remove occlusions due toa public dataset on relation — how related each object is toa certain image context — being unavailable. Thus, there isno complete system available which makes intelligent deci-sions on object relations and removes occlusions, producinga visually-pleasing and occlusion-free image.
In this paper, we propose a novel approach for occlusionremoval using an architecture which fuses both image andlanguage processing. First, we process the input image toextract background and foreground object classes separatelywith pixel-wise annotations of foreground objects. Then, ourlanguage model intuitively decides the relation of each fore-ground object to the image context; hence, it identifies occlu-sions. Finally, we mask the pixels of occlusions and feed theimage into an inpainting model which produces an occlusion-free image. This task separation allows us to tackle the is-sue of the lack of object-background relationships in datasets,since our system relies on semantic segmentations and im-age captions for training. An example result of our system isshown in Fig.1.
Contributions of this paper are as follows:
• We propose a novel system to automatically detect oc-clusions based on image context and remove them, pro-ducing a visually-pleasing occlusion-free image.
• We present the first approach which makes intelligentdecisions on the relation of objects to image context,based on foreground- and background-object detection.
arX
iv:1
905.
0271
0v1
[cs
.CV
] 7
May
201
9

2. RELATED WORKPrevious work related to context-aware occlusion removal in-cludes pre-annotated occlusion removal, occlusion removalin a specific context, and image adjustment for producingvisually-pleasing images.
Following the proposal of GANs [7], extensive researchhas been carried out in GAN-based image modeling. GAN-based inpainting is one such application, where output im-ages are conditioned on occluded input images [8, 9]. Con-ventional approaches for image inpainting, which do not usedeep network based learning approaches [10, 11], performreasonably well for homogeneous image patches, but they failin natural images. Yu et al. [2] recently proposed contex-tual attention in dilated CNN, which performs well for non-homogeneous patches. Moreover, several approaches for in-painting in a specific context, for instance, either face [12],head [13] or eye [4], and for occlusion removal in a specificcontext, for instance, rain or shadow [5, 14], have been pro-posed recently. Existing inpainting and occlusion removaltechniques provide visually-pleasing results, but require man-ually annotating occluded regions and are not generic.
Recently proposed SEGAN [15] is partially aligned withour work. It relies on a semantic segmentator and a GANto regenerate obscure content of objects in images, complet-ing their appearance. Shotton et al. [1] present a novel ap-proach for automatic semantic segmentation and visual un-derstanding of images, which involves learning a discrimi-native model of object classes, interactive semantic segmen-tation and interactive image editing. Other related work in-clude object recognition in cluttered environments [16] andocclusion-aware layer-wise modeling of images [17].
These methods of enhancing occluded images either re-construct images based on manually-annotated occluded re-gions or remove a specific type of occlusions in a particularcontext. However, none of these approaches declare occlu-sions based on image context. In other words, these do notaddress occlusion removal as a context-aware generic prob-lem. In contrast, our approach involves making intelligentdecisions on occlusions: detecting objects as occlusions de-pending on the image context, characterized by foregroundand background objects, and regenerating occluded patchescoherently. Thus, what we propose is an architecture forcontext-aware automatic occlusion removal in a generic do-main, based on a fusion of image and language processing.
3. SYSTEM ARCHITECTUREOur system consists of four interconnected sub-networks asin Fig. 2: a foreground segmentator, a background extrac-tor, a relation predictor, and an inpainter. An input imageis fed into both the foreground segmentator and the back-ground extractor. The foreground segmentator outputs pixel-wise association of foreground objects, or what we refer toas thing classes, whereas the background extractor predictsbackground objects present in the image, commonly referredto as stuff classes. These two components are followed by
Fig. 2: System Architecture
the relation predictor which utilizes both previously extractedthing and stuff classes. Relation of each thing class to theimage context is evaluated, and unrelated thing classes, i.e.,occlusions, are provided as the output of the relation predic-tor. Finally, the image inpainter network exploits the relationpredictions together with the pixel associations of the thingclasses, to mask and regenerate pixels which belong to theoccluding thing classes, generating an occlusion-free image.Following sub-sections elaborate more on the sub-networksin our proposed system.3.1. Sub-networksOur foreground segmentator is a semantic segmentation net-work based on DeepLabv3+ [18], which achieves state-of-the-art performance on the PASCAL VOC 2012 semantic im-age segmentation dataset [19] with an mIoU of 89%. Due tothe highly optimized nature of this network, we do not con-sider suggesting further improvements. Instead, we train it onthe COCO-Stuff dataset [20], which is more challenging dueto the generality of context and the higher number of classes,compared to the VOC dataset.
The background extractor is a CNN based on ResNet-101[3] model which consists of 100 convolutional layers and asingle fully-connected layer. Since the task of the backgroundextractor is to predict background classes, i.e., stuff in an im-age, this can be modeled as a multi-task classification prob-lem. Thus, when training this component, we optimize anerror which considers the summation of class-wise negativelog-likelihoods.
The relation predictor provides the intelligence on occlu-sions based on image context. The relation between objects isestimated based on vector embeddings of class labels trainedwith a language model. To this end, we adopt the model pro-posed by Mikolov et al. [21] to represent COCO labels asvectors. Training this model for our requirement is differentto the conventional requirement, where the model is trainedon a large corpus of text, essentially learning linguistic rela-tionships and syntax. What we have is image captions: fiveper image from MS COCO [22], and what we want is to learnrelations between objects as they appear in images, not lin-guistic relationships as in conventional models. Thus, weinitially create a corpus concatenating image captions as thetraining set of the dataset. Importantly, the model should notlearn the relations between any objects in separate images.Thus, we insert an end-of-paragraph (EOP) character at the

end of each set of captions corresponding to a single image.Depending on the window size used in the model, the numberof EOP characters inserted in between two sets of captionschanges. Moreover, since we require the relation between ob-ject classes, not in a linguistic sense, it is logical to modify thecorpus, removing all words except object classes. This allowsthe model to learn stronger relations between classes. There-fore, we train a separate model on this modified corpus. Tovisualize the embedding vectors of 128 dimensions in a 2Dspace, we use t-SNE algorithm [23]. We use these word em-beddings generated by the word-to-vector model trained onthe modified captions of COCO-Stuff, to predict the relationbetween objects. What we want to quantify is “how-related”each thing class in an image to its context. We objectivelycapture this measure based on both thing and stuff classes,which can be represented as
di∈Tk=
1
|Sk ∪ Tk\{i}|∑
j∈Sk∪Tk\{i}
cossim (vi , vj) ,
where Tk and Sk represent the sets of thing and stuff classesof the image k. Here, v represents an embedding vector of aclass and cossim (., .), the cosine similarity between two vec-tors. The intuition here is to capture a similarity score be-tween each embedding vector of a thing class and the remain-ing classes in an image, both thing and stuff.
We base our inpainter on a recently proposed generativeimage inpainter [2], which is attentive to contextual informa-tion of images. This follows a two-stage architecture: coarseto fine. The first stage coarsely fills the mask, which is trainedwith a spatially discounted reconstruction l1 loss. The sec-ond refines the generated pixels, which is trained with addi-tional local and global WGAN-GP [9] adversarial loss. Con-textual attention is imposed into the generation of missingpixels by implementing a special fully-convolutional encoder,which compares the similarity of patches around each gener-ated pixel and patches in unmasked region to draw contextualinformation from the region having highest weighted similar-ity. Instead of training the inpainter with simulated squaremasks, we consider generating masks of random shapes andsizes utilizing the segmentation ground truth masks of thingclasses. This provides better convergence for the network atthe task of removing thing classes based on image context.
3.2. Implementation DetailsOur system depends on image context to detect and removeocclusions. Thus, the dataset that we train our system on,should contain rich information about image context, whichis why we choose COCO-Stuff dataset. In addition to theannotations of 91 foreground classes in MS COCO, this con-tains annotations of 91 background classes called stuff. Thisdataset includes 118K training samples and 5K validationsamples. The large number of annotated images over differ-ent contexts enables better training of the system to extractcontextual information. We utilize the semantic segmenta-tions to train the foreground segmentator and the inpainter,
the stuff class labels to train the background extractor, andthe image captions to train the relation predictor.
In the foreground segmentator, we use a DeepLabv3+model pre-trained on Pascal VOC, without initializing the lastlayer to accommodate the change in the number of classes.we train the segmentator for 125K iterations on COCO-Stuff.The background extractor based on ResNet-101 is trainedfrom scratch for 50 epochs with multi-class classification lossand an input resoution of 128×128. The inpainter network istrained from scratch for 1000 epochs with random masks. Forthe relation predictor, we use the skip-gram model with a win-dow size of 3 and train for 100K iterations on the corpus ofimage captions to learn 128-dimensional word embeddings.
To compensate for the aggregation of errors, we imple-ment a few measures when interconnecting the networks1.For instance, we handle inconsistent masks by dilation, andfalse-positives which are small in area by discarding themasks less than 2% of the image. When considering theoutput of the relation predictor to identify occlusions, weconsider a similarity threshold, which is set to be 0.4. Wecompare the cosine similarity score of each thing class, nor-malized to a range of 0 to 1, and declare an occlusion whenthe similarity is less than this threshold.
4. RESULTSOur system automatically detects and removes unrelated ob-jects, i.e., occlusions in input images. Thus, to evaluate theperformance of the system, we raise two questions: whichobjects are removed by the system, and how good are the re-constructed images. Answering these evaluates the system forits utility in the application scenario. However, the evaluationof the system as a whole is challenging. This is because thereis no publicly available dataset which annotates objects notrelated to an image context, or which contains images bothwith and without such occlusions. Thus, we choose to evalu-ate the system intuitively as presented below.
4.1. Effectiveness of Word-EmbeddingsThe relation predictor is responsible for making intelligent de-cisions on occlusions in images based on word-embeddings.Thus, it is useful to evaluate the effectiveness of the trainedembedding-vectors. To qualitatively evaluate the embed-dings, we map the 128-dimensional vectors to 2-dimensionalspace using t-SNE to visualize in a graph. Fig. 4 shows themapped embedding vectors in a 2D plane, separately trainedon the original corpus of image captions and the modifiedcorpus. The embeddings on the right show more meaning-ful mapping: having strongly related objects being mappedcloser. For instance, it shows more distinction between somerelated indoor and outdoor object clusters. This is becausethe modified corpus contains only the thing and stuff classlabels, enabling a stronger relation learning between classes.
We consider the relation between each pair of classes cal-culated as a cosine similarity, to quantitatively evaluate the
1Source and trained models are available here on GitHub.

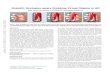
Fig. 3: Some qualitative results of our system. A variety of thing classes has been detected as occlusions based on the context.For instance, note the two sets of pictures with a dog and a vehicle as thing classes. The vehicle is detected as an occlusion inone, while the dog is detected in the other based on the context.
Fig. 4: Embedding vectors mapped into 2D space. Left:trained on the original corpus, Right: trained on the modifiedcorpus. The green and red clusters contain some related in-door objects and outdoor objects respectively, for which, theversion on right shows better distinction.
effectiveness of the embeddings, comparing against a set ofground truth values. However, such ground truth data is notavailable and, generating such in wild would not be unbiaseddue to its subjectiveness. Thus, we intuitively consider a mea-sure of relation using the count of occurrences of each objectin dataset, which can be represented as
Rab =na∩b
na∪b,
where a ∩ b denotes the set of images which consists both aand b classes, and a∪b, the set of images which consists eitherof the classes. To capture the similarity between the relationsfrom learned embeddings and counts, we evaluate their Pear-son correlation, which yields a value of 0.527. This showsthat our approach of estimating the relation has captured theco-existence of classes up to a certain extent.4.2. User StudyWe conduct two user studies to evaluate the performance ofthe complete system, involving 1245 image pairs: originaland occlusion-free reconstructed images in the validation setof COCO-Stuff. The two studies evaluate the visual-pleasingnature of the reconstructed images and a comparison betweenthe occlusions identified by the users and the system. Theformer study shows users only the occlusion-free images andallows them to choose between the options: visually-pleasingor not, whereas the latter shows users only original imagestogether with the thing class labels and allows them to recordtheir opinion on the unrelated objects in the image context.Results of these user studies are presented in Table 1.
The majority of our reconstructed images has been rated
Table 1: Preferences from the user studyVisually-pleasing Relation
Positive 992/124579.7%
Precision 39.03%
Negative 253/124520.3%
Recall 17.46%
visually-pleasing in the user study. This shows the effective-ness of the foreground segmentator and the inpainter, in accu-rately predicting the masks and reconstructing with attentionto contextual details. Although the precision and recall of theobjects that our system detected as occlusions, in comparisonwith the user preferences is not high, it establishes a baselineas the first of its kind. This shows the deviation of our learn-ing algorithm form actual human perception in some cases.In other words, in our proposed method, we consider learningrelations from scratch, based only on image captions withoutany human annotations on relation. In contrast, humans in-herit the intuition of natural relation that comes from experi-ence, which can be different to what is learned by the system.However, as shown in Fig. 3, a diverse set of objects has beendetected as occlusions based on different image contexts.
5. CONCLUSIONWe proposed a novel methodology for automatic detectionand removal of occluding unrelated objects based on imagecontext. To this end, we utilize vector embeddings of fore-ground and background objects, trained on modified imagecaptions, to capture the image context by predicting the re-lation between objects. Although our approach learns mean-ingful relations between object classes and utilizes a hand-designed algorithm to decide on occlusions, human percep-tion of it can be different. However, we establish a baselinefor context-aware automatic occlusion removal in a genericdomain, even without a publicly available dataset on relation.As future work, we hope to develop a dataset that captures hu-man annotations on object relations, which will enable end-to-end training of such networks, improving our baseline oncontext-aware occlusion removal in images.
Acknowledgments: K. Kahatapitiya was supported bythe University of Moratuwa Senate Research CommitteeGrant no. SRC/LT/2016/04 and D. Tissera, by QBITS Lab,University of Moratuwa. The authors thank the Faculty ofInformation Technology of the University of Moratuwa, SriLanka for providing computational resources.

6. REFERENCES
[1] Jamie Shotton, John Winn, Carsten Rother, and Anto-nio Criminisi, “Textonboost for Image Understanding:Multi-Class Object Recognition and Segmentation byJointly Modeling Texture, Layout, and Context,” IJCV,vol. 81, no. 1, pp. 2–23, 2009. 1, 2
[2] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu,and Thomas S. Huang, “Generative Image Inpaintingwith Contextual Attention,” in CVPR, June 2018. 1, 2,3
[3] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and JianSun, “Deep Residual Learning for Image Recognition,”in CVPR, 2016, pp. 770–778. 1, 2
[4] Brian Dolhansky and Cristian Canton Ferrer, “Eye In-Painting With Exemplar Generative Adversarial Net-works,” in CVPR, 2018, pp. 7902–7911. 1, 2
[5] Jiaying Liu, Wenhan Yang, Shuai Yang, and ZongmingGuo, “Erase or Fill? Deep Joint Recurrent Rain Re-moval and Reconstruction in Videos,” in CVPR, June2018. 1, 2
[6] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei AEfros, “Image-to-Image Translation with ConditionalAdversarial Networks,” in CVPR, 2017, pp. 1125–1134.1
[7] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza,Bing Xu, David Warde-Farley, Sherjil Ozair, AaronCourville, and Yoshua Bengio, “Generative Adversar-ial Nets,” in NeurIPS, 2014, pp. 2672–2680. 2
[8] Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue,Trevor Darrell, and Alexei A Efros, “Context Encoders:Feature Learning by Inpainting,” in CVPR, 2016, pp.2536–2544. 2
[9] Satoshi Iizuka, Edgar Simo-Serra, and HiroshiIshikawa, “Globally and Locally Consistent ImageCompletion,” ACM Transactions on Graphics, vol. 36,no. 4, pp. 107, 2017. 2, 3
[10] Coloma Ballester, Marcelo Bertalmio, Vicent Caselles,Guillermo Sapiro, and Joan Verdera, “Filling-In by JointInterpolation of Vector Fields and Gray Levels,” IEEETransactions on Image Processing, vol. 10, no. 8, pp.1200–1211, 2001. 2
[11] Alexei A Efros and William T Freeman, “Image Quilt-ing for Texture Synthesis and Transfer,” in Proceedingsof the 28th Annual Conference on Computer Graphicsand Interactive Techniques. ACM, 2001, pp. 341–346.2
[12] Yijun Li, Sifei Liu, Jimei Yang, and Ming-Hsuan Yang,“Generative Face Completion,” in CVPR, 2017, vol. 1,p. 3. 2
[13] Qianru Sun, Liqian Ma, Seong Joon Oh, Luc Van Gool,Bernt Schiele, and Mario Fritz, “Natural and EffectiveObfuscation by Head Inpainting,” in CVPR, 2018, pp.5050–5059. 2
[14] Jifeng Wang, Xiang Li, and Jian Yang, “Stacked Con-ditional Generative Adversarial Networks for JointlyLearning Shadow Detection and Shadow Removal,” inCVPR, 2018, pp. 1788–1797. 2
[15] Kiana Ehsani, Roozbeh Mottaghi, and Ali Farhadi,“SeGAN: Segmenting and Generating the Invisible,” inCVPR, 2018, pp. 6144–6153. 2
[16] Duofan Jiang, Hesheng Wang, Weidong Chen, andRuimin Wu, “A Novel Occlusion-Free Active Recogni-tion Algorithm for Objects in Clutter,” in IEEE Interna-tional Conference on Robotics and Biomimetics, 2016,pp. 1389–1394. 2
[17] Jonathan Huang and Kevin Murphy, “Efficient Infer-ence in Occlusion-Aware Generative Models of Im-ages,” arXiv preprint arXiv:1511.06362, 2015. 2
[18] Liang-Chieh Chen, Yukun Zhu, George Papandreou,Florian Schroff, and Hartwig Adam, “Encoder-Decoderwith Atrous Separable Convolution for Semantic ImageSegmentation,” in ECCV, 2018, pp. 801–818. 2
[19] Mark Everingham, Luc Van Gool, Christopher KIWilliams, John Winn, and Andrew Zisserman, “ThePASCAL Visual Object Classes (VOC) Challenge,”IJCV, vol. 88, no. 2, pp. 303–338, 2010. 2
[20] Holger Caesar, Jasper Uijlings, and Vittorio Ferrari,“COCO-Stuff: Thing and Stuff Classes in Context,”CoRR, abs/1612.03716, vol. 5, pp. 8, 2016. 2
[21] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Cor-rado, and Jeff Dean, “Distributed Representations ofWords and Phrases and their Compositionality,” inNeurIPS, 2013, pp. 3111–3119. 2
[22] Tsung-Yi Lin, Michael Maire, Serge Belongie, JamesHays, Pietro Perona, Deva Ramanan, Piotr Dollar, andC Lawrence Zitnick, “Microsoft COCO: Common Ob-jects in Context,” in ECCV. Springer, 2014, pp. 740–755. 2
[23] Laurens van der Maaten and Geoffrey Hinton, “Visual-izing Data using t-SNE,” Journal of Machine LearningResearch, vol. 9, no. Nov, pp. 2579–2605, 2008. 3