Embed Size (px)
Citation preview

Constituency Parsing
Fall 2019
COS 484: Natural Language Processing
(Some slides adapted from Chris Manning, Mike Collins)

Overview
• Constituency structure vs dependency structure • Context-free grammar (CFG) • Probabilistic context-free grammar (PCFG) • The CKY algorithm • Evaluation • Lexicalized PCFGs
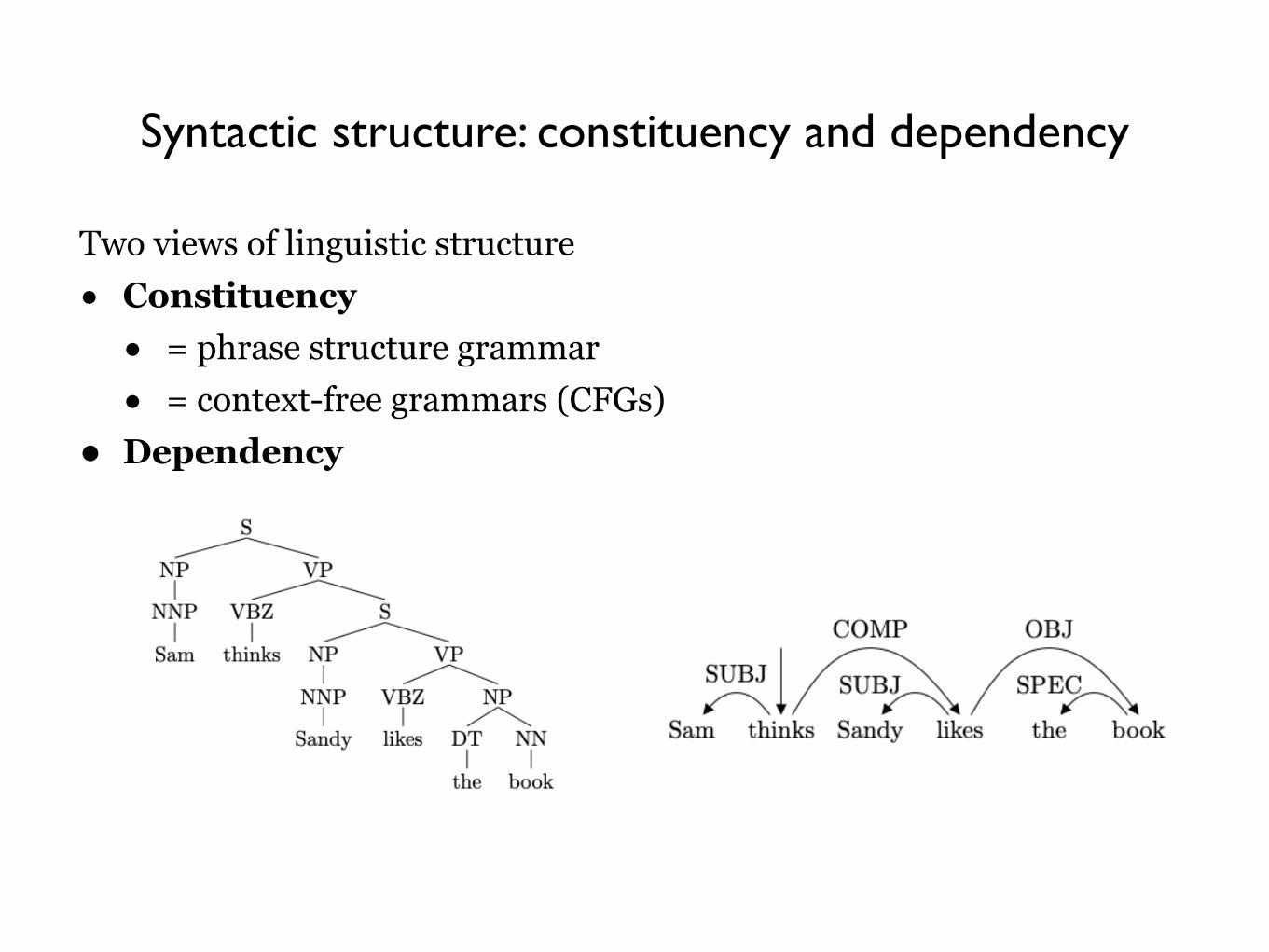
Syntactic structure: constituency and dependency
Two views of linguistic structure • Constituency
• = phrase structure grammar • = context-free grammars (CFGs)
• Dependency

Constituency structure
• Phrase structure organizes words into nested constituents
• Starting units: words
the, cuddly, cat, by, the, door
• Words combine into phrases
the cuddly cat, by the door
are given a category: part-of-speech tags
Det, Adj, N, P, Det, N
NP Det Adj N→
with categories
PP P NP→
recursively
NP NP PP→
• Phrases can combine into bigger phrasesthe cuddly cat by the door

Dependency structure
• Dependency structure shows which words depend on (modify or are arguments of) which other words.
Satellites spot whales from space
Satellites spot whales from space❌
This Thursday
nsubj
nmod
dobj case

Why do we need sentence structure?
• We need to understand sentence structure in order to be able to interpret language correctly
• Human communicate complex ideas by composing words together into bigger units
• We need to know what is connected to what
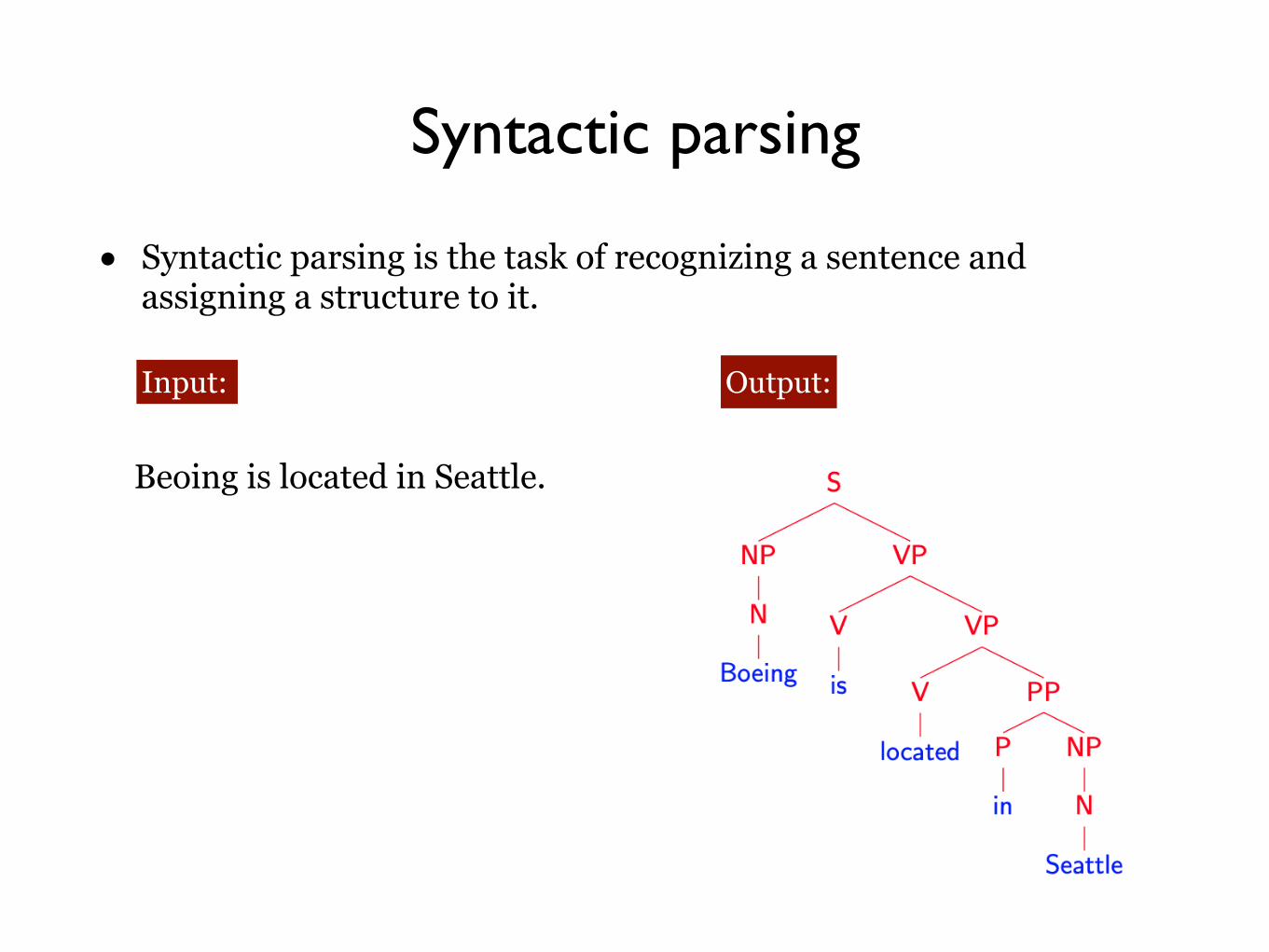
Syntactic parsing
• Syntactic parsing is the task of recognizing a sentence and assigning a structure to it.
Input: Output:
Beoing is located in Seattle.
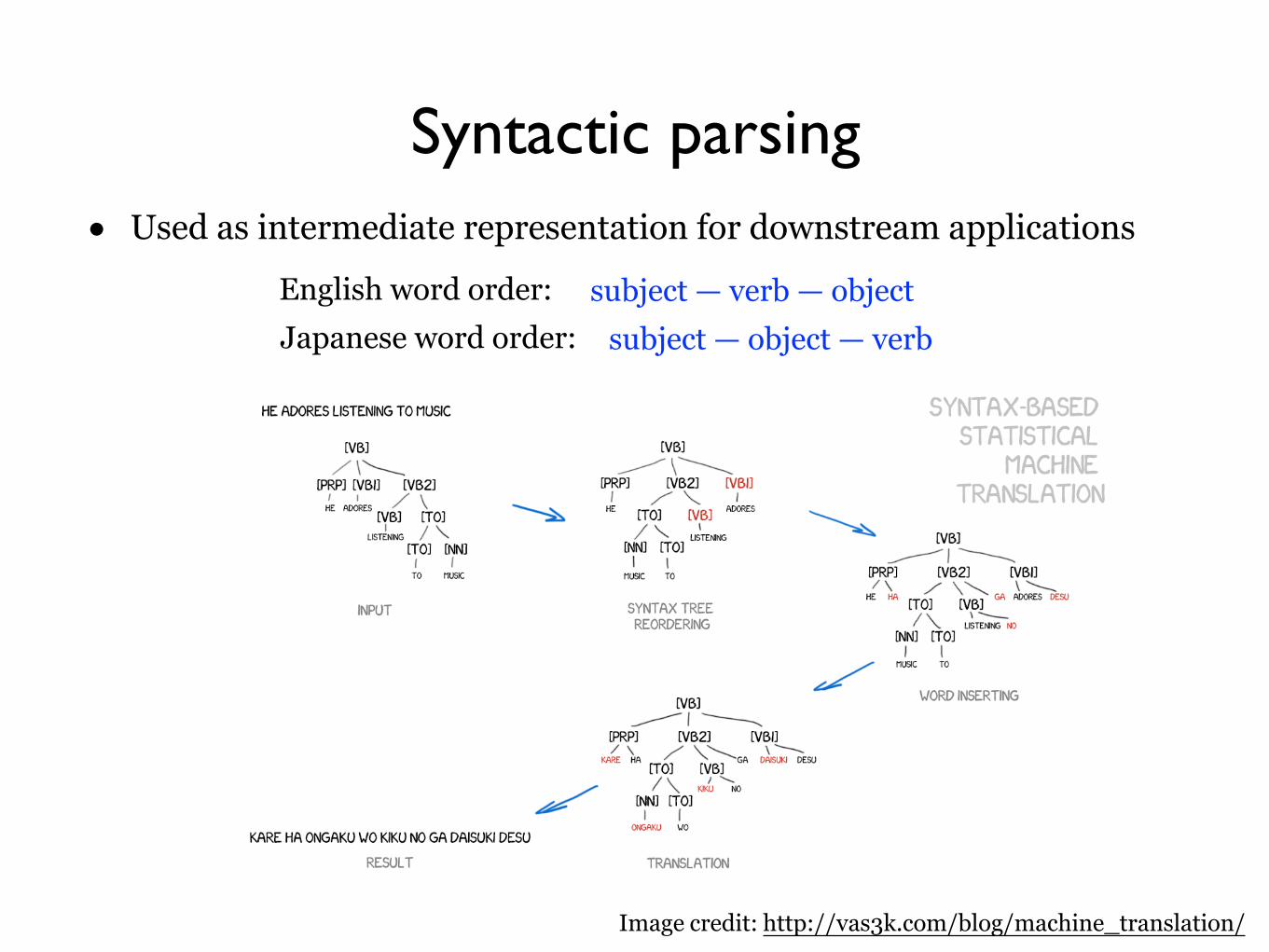
Syntactic parsing• Used as intermediate representation for downstream applications
Image credit: http://vas3k.com/blog/machine_translation/
English word order: subject — verb — objectJapanese word order: subject — object — verb
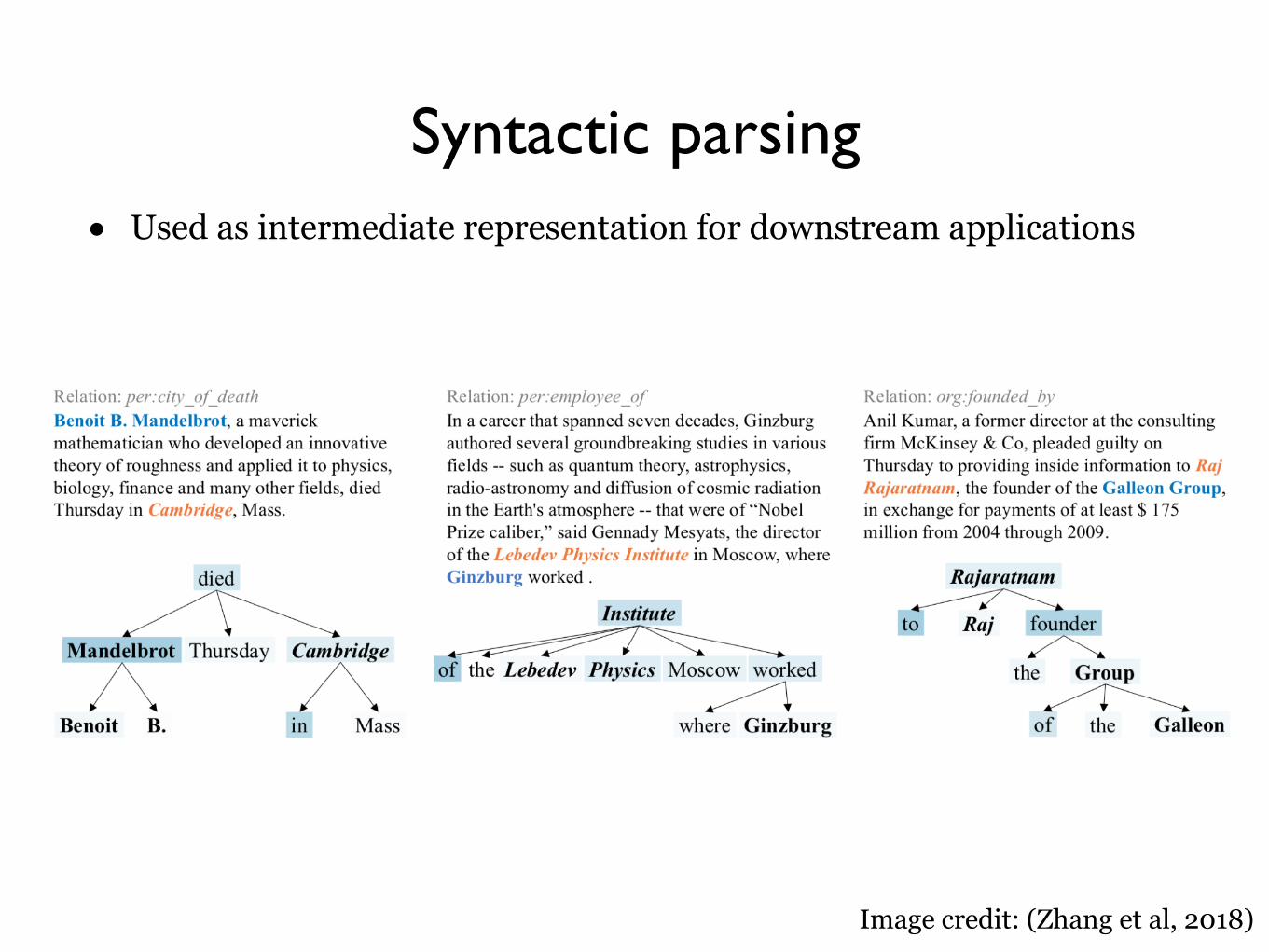
Syntactic parsing• Used as intermediate representation for downstream applications
Image credit: (Zhang et al, 2018)

Context-free grammars
• The most widely used formal system for modeling constituency structure in English and other natural languages
• A context free grammar where
• is a set of non-terminal symbols
• is a set of terminal symbols
• is a set of rules of the form for ,
• is a distinguished start symbol
G = (N, Σ, R, S)NΣR X → Y1Y2…Yn n ≥ 1X ∈ N, Yi ∈ (N ∪ Σ)S ∈ N

A Context-Free Grammar for English
Grammar Lexicon
S:sentence, VP:verb phrase, NP: noun phrase, PP:prepositional phrase, DT:determiner, Vi:intransitive verb, Vt:transitive verb, NN: noun, IN:preposition

(Left-most) Derivations
• Given a CFG , a left-most derivation is a sequence of strings , where
Gs1, s2, …, sn
• s1 = S
• : all possible strings made up of words from sn ∈ Σ* Σ
• Each for is derived from by picking the left-most non-terminal in and replacing it by some where
si i = 2,…, n si−1X si−1 β X → β ∈ R
• : yield of the derivationsn

(Left-most) Derivations• Ss1 =
• NP VPs2 =
• DT NN VPs3 =
• the NN VPs4 =
• the man VPs5 =
• the man Vis6 =
A derivation can be represented as a parse tree!
• A string is in the language defined by the CFG if there is at least one derivation whose yield is
s ∈ Σ*s
• The set of possible derivations may be finite or infinite
• the man sleepss7 =
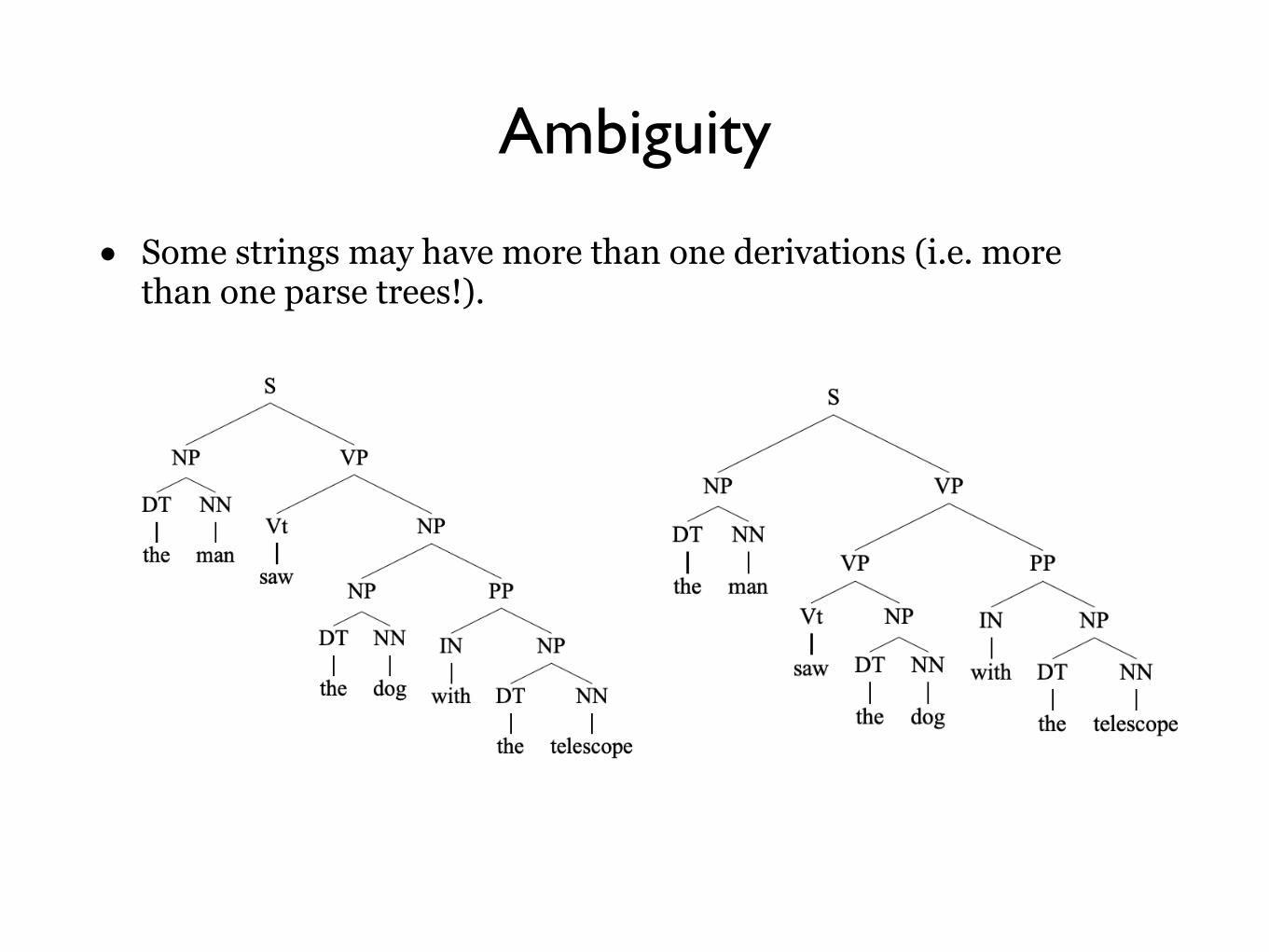
Ambiguity
• Some strings may have more than one derivations (i.e. more than one parse trees!).

“Classical” NLP Parsing
• In fact, sentences can have a very large number of possible parses
The board approved [its acquisition] [by Royal Trustco Ltd.] [of Toronto] [for $27 a share] [at its monthly meeting].
((ab)c)d (a(bc))d (ab)(cd) a((bc)d) a(b(cd))
Catalan number: Cn =1
n + 1 (2nn )
• It is also difficult to construct a grammar with enough coverage • A less constrained grammar can parse more sentences but
result in more parses for even simple sentences • There is no way to choose the right parse!

Statistical parsing
• Learning from data: treebanks
• Adding probabilities to the rules: probabilistic CFGs (PCFGs)
Treebanks: a collection of sentences paired with their parse trees
The Penn Treebank Project (Marcus et al, 1993)

Treebanks
• Standard setup (WSJ portion of Penn Treebank): • 40,000 sentences for training • 1,700 for development • 2,400 for testing
• Why building a treebank instead of a grammar?
• Broad coverage
• Frequencies and distributional information
• A way to evaluate systems

Probabilistic context-free grammars (PCFGs)
• A probabilistic context-free grammar (PCFG) consists of:
• A context-free grammar: G = (N, Σ, R, S)
• For each rule , there is a parameter . For any ,
α → β ∈ R q(α → β) ≥ 0X ∈ N
∑α→β:α=X
q(α → β) = 1

Probabilistic context-free grammars (PCFGs)For any derivation (parse tree) containing rules:
, the probability of the parse is:α1 → β1, α2 → β2, …, αl → βll
∏i=1
q(αi → βi)
P(t) = q(S → NP VP) × q(NP → DT NN) × q(DT → the)
× q(NN → man) × q(VP → Vi) × q(Vi → sleeps)
= 1.0 × 0.3 × 1.0 × 0.7 × 0.4 × 1.0 = 0.084
Why do we want ?∑α→β:α=X
q(α → β) = 1

Deriving a PCFG from a treebank
• Training data: a set of parse trees t1, t2, …, tm
• A PCFG :
• is the set of all non-terminals seen in the trees
• is the set of all words seen in the trees
• is taken to be S.
• is taken to be the set of all rules seen in the trees
(N, Σ, S, R, q)NΣSR α → β
• The maximum-likelihood parameter estimates are:
qML(α → β) =Count(α → β)
Count(α)
If we have seen the rule 105 times, and the the non-terminal 1000 times,
VP → Vt NPVP q(VP → Vt NP) = 0.105

Parsing with PCFGs
• Given a sentence and a PCFG, how to find the highest scoring parse tree for ?
ss
• The CKY algorithm: applies to a PCFG in Chomsky normal form (CNF)
• Chomsky Normal Form (CNF): all the rules take one of the two following forms:
• where
• where X → Y1Y2 X ∈ N, Y1 ∈ N, Y2 ∈ NX → Y X ∈ N, Y ∈ Σ
• It is possible to convert any PCFG into an equivalent grammar in CNF! • However, the trees will look differently; It is possible to do “reverse
transformation”
argmaxt∈𝒯(s)P(t)
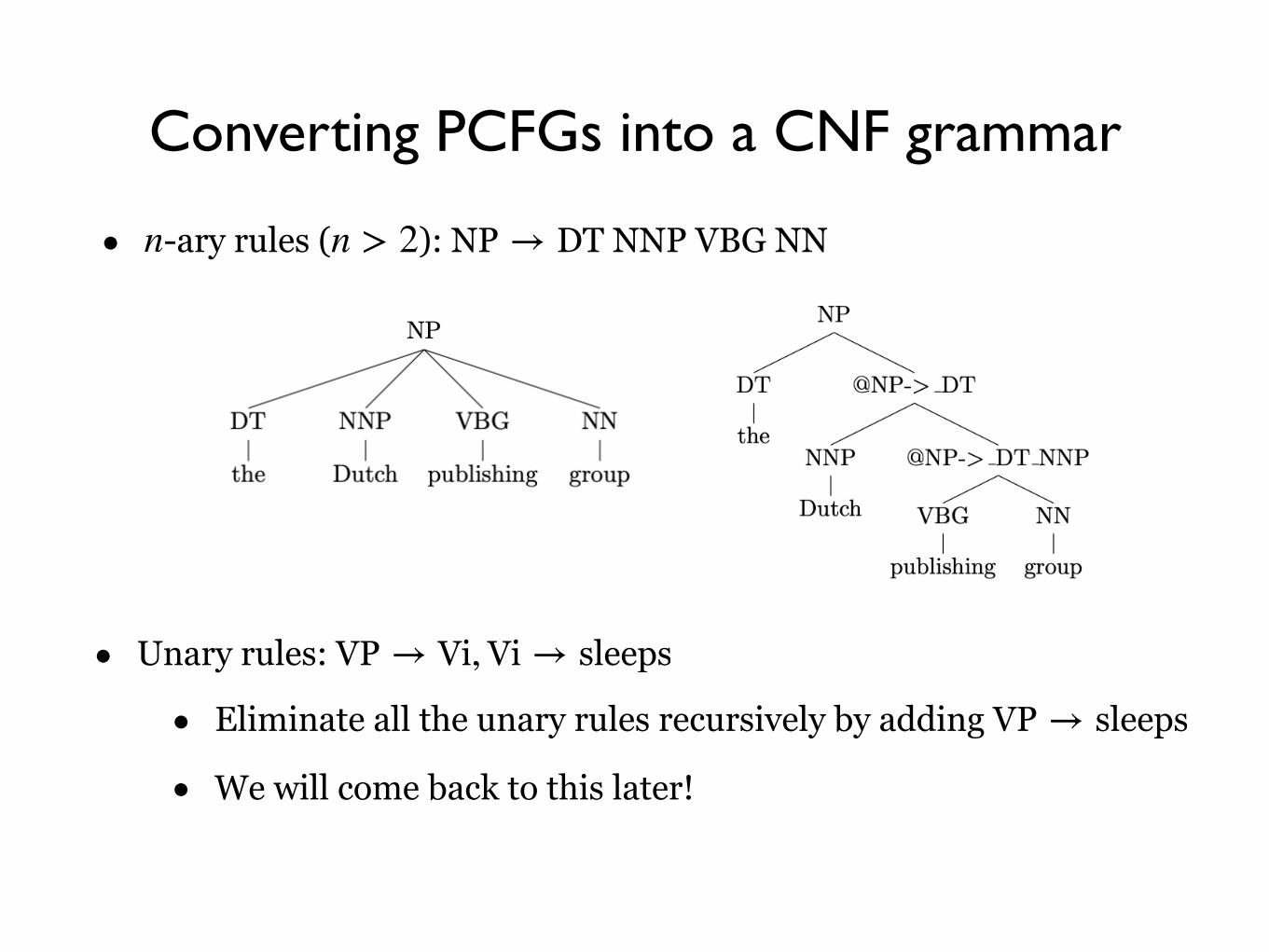
Converting PCFGs into a CNF grammar
• -ary rules ( ): n n > 2 NP → DT NNP VBG NN
• Unary rules: VP → Vi, Vi → sleeps
• Eliminate all the unary rules recursively by adding VP → sleeps
• We will come back to this later!

The CKY algorithm
• Dynamic programming
• Given a sentence , denote as the highest score for any parse tree that dominates words and has non-terminal as its root.
x1, x2, …, xn π(i, j, X)xi, …, xj
X ∈ N
• Output: π(1,n, S)
• Initially, for , i = 1,2,…, n
π(i, i, X) = {q(X → xi) if X → xi ∈ R0 otherwise
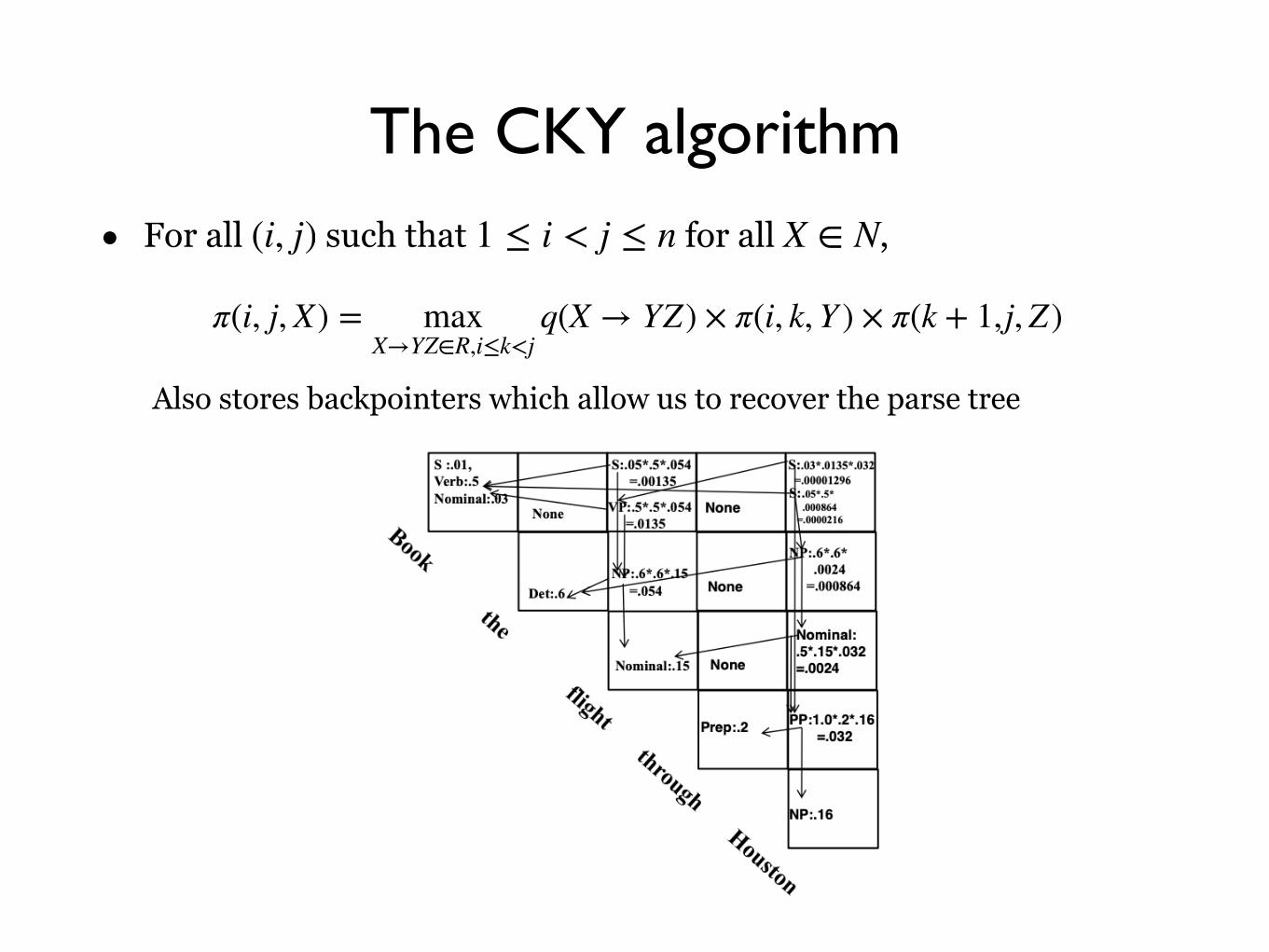
The CKY algorithm
• For all such that for all , (i, j) 1 ≤ i < j ≤ n X ∈ N
π(i, j, X) = maxX→YZ∈R,i≤k<j
q(X → YZ) × π(i, k, Y ) × π(k + 1,j, Z)
Also stores backpointers which allow us to recover the parse tree

The CKY algorithm
Running time?
O(n3 |R | )

CKY with unary rules
• In practice, we also allow unary rules:
where X → Y X, Y ∈ N
conversion to/from the normal form is easier
How does this change CKY?
π(i, j, X) = maxX→Y∈R
q(X → Y ) × π(i, j, Y )
• Compute unary closure: if there is a rule chain , add X → Y1, Y1 → Y2, …, Yk → Y
q(X → Y ) = q(X → Y1) × ⋯ × q(Yk → Y )
• Update unary rule once after the binary rules
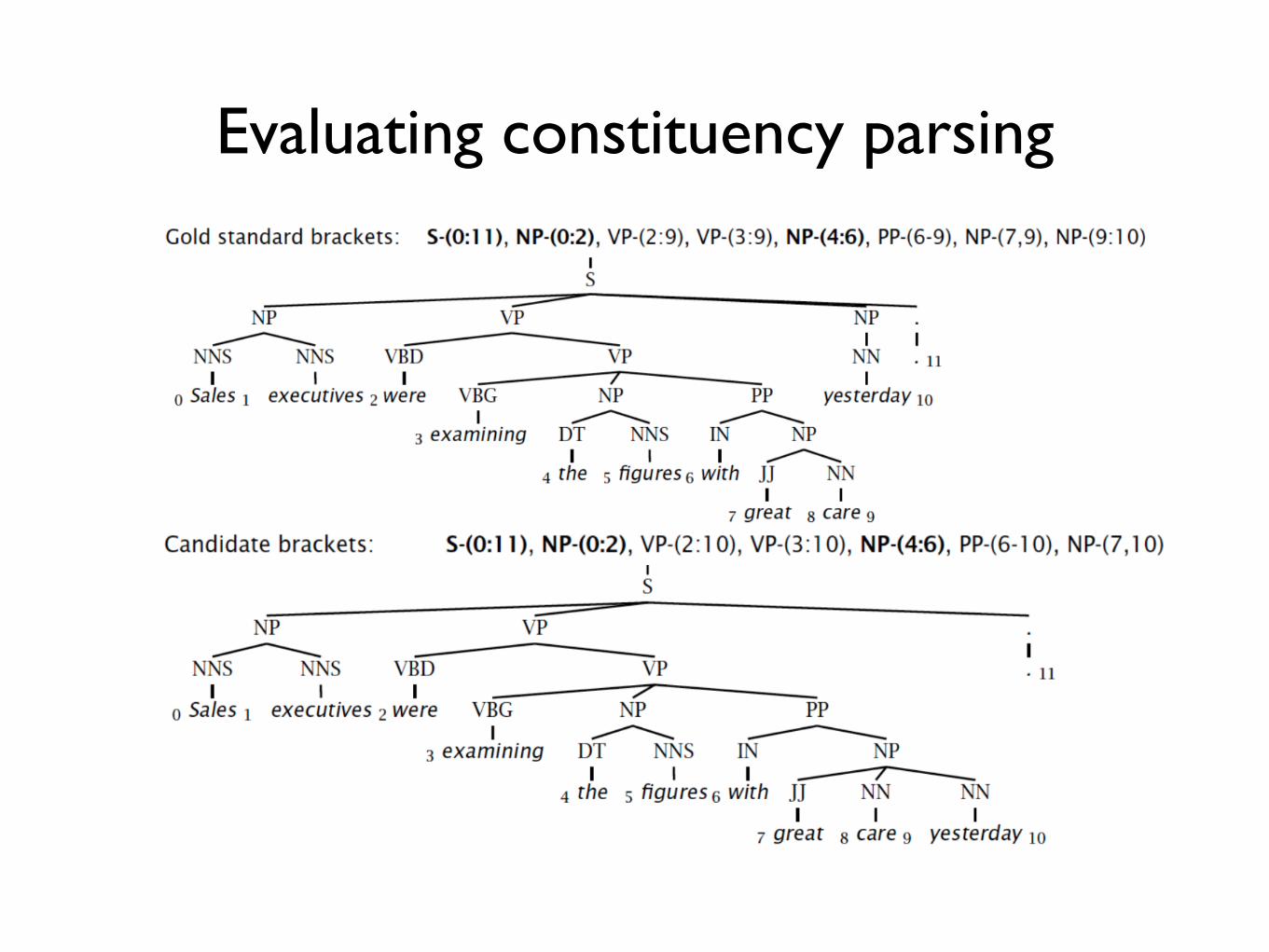
Evaluating constituency parsing

Evaluating constituency parsing
• Recall: (# correct constituents in candidate) / (# constituents in gold tree)
• Precision: (# correct constituents in candidate) / (# constituents in candidate)
• Labeled precision/recall require getting the non-terminal label correct
• F1 = (2 * precision * recall) / (precision + recall)
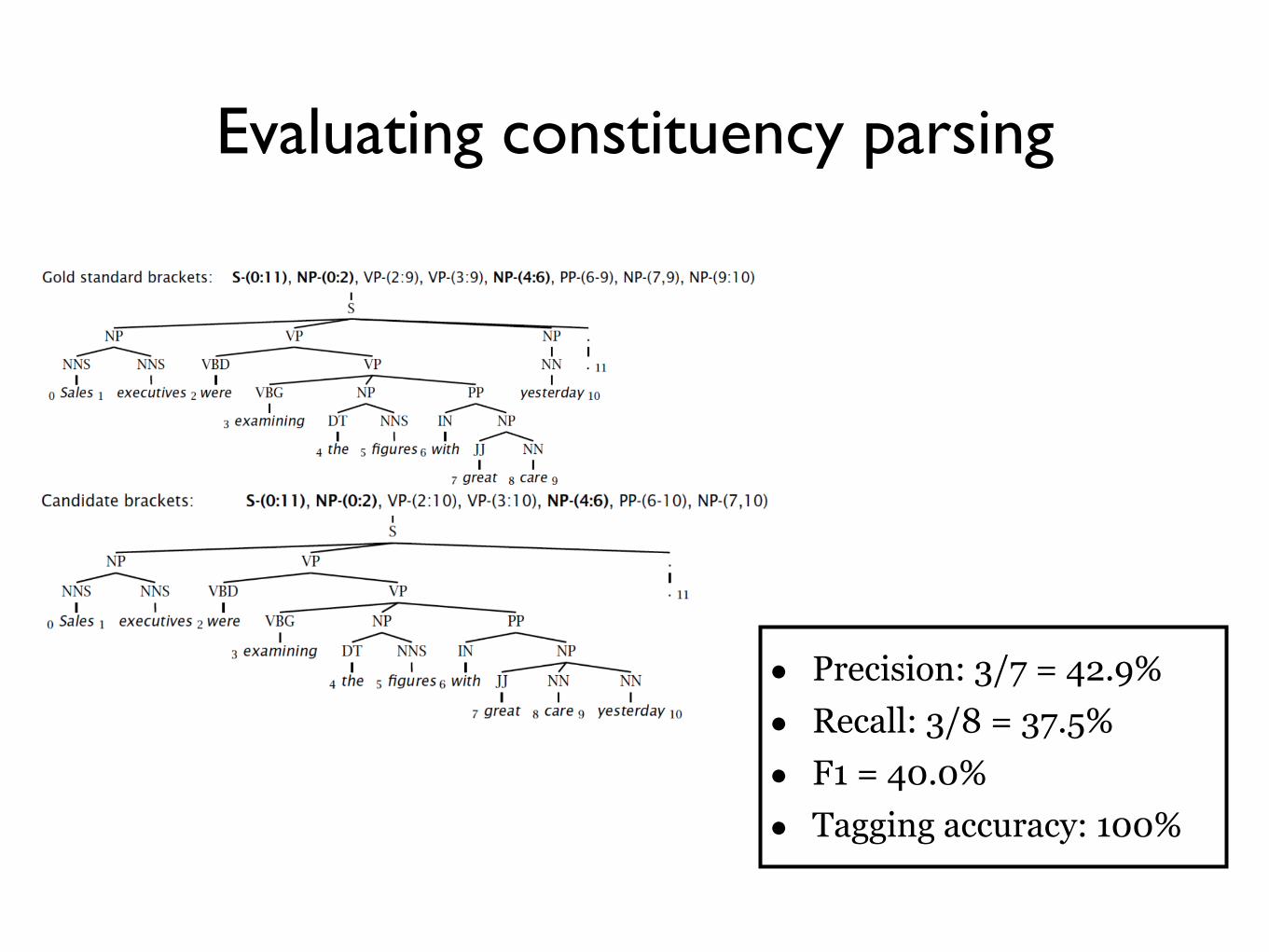
Evaluating constituency parsing
• Precision: 3/7 = 42.9% • Recall: 3/8 = 37.5% • F1 = 40.0% • Tagging accuracy: 100%

Weaknesses of PCFGs
• Lack of sensitivity to lexical information (words)
The only difference between these two parses: vs q(VP → VP PP) q(NP → NP PP)
… without looking at the words!
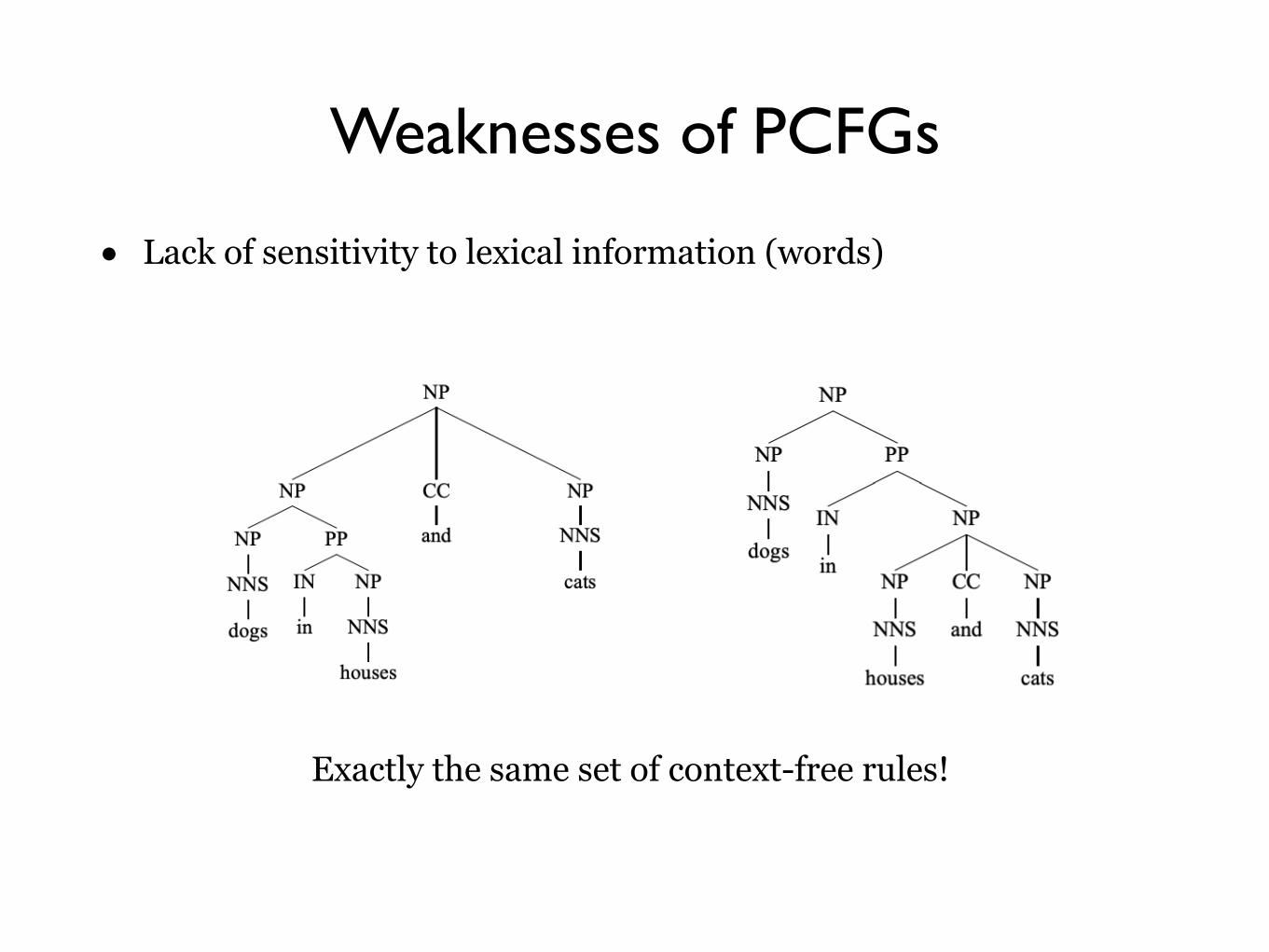
Weaknesses of PCFGs
• Lack of sensitivity to lexical information (words)
Exactly the same set of context-free rules!
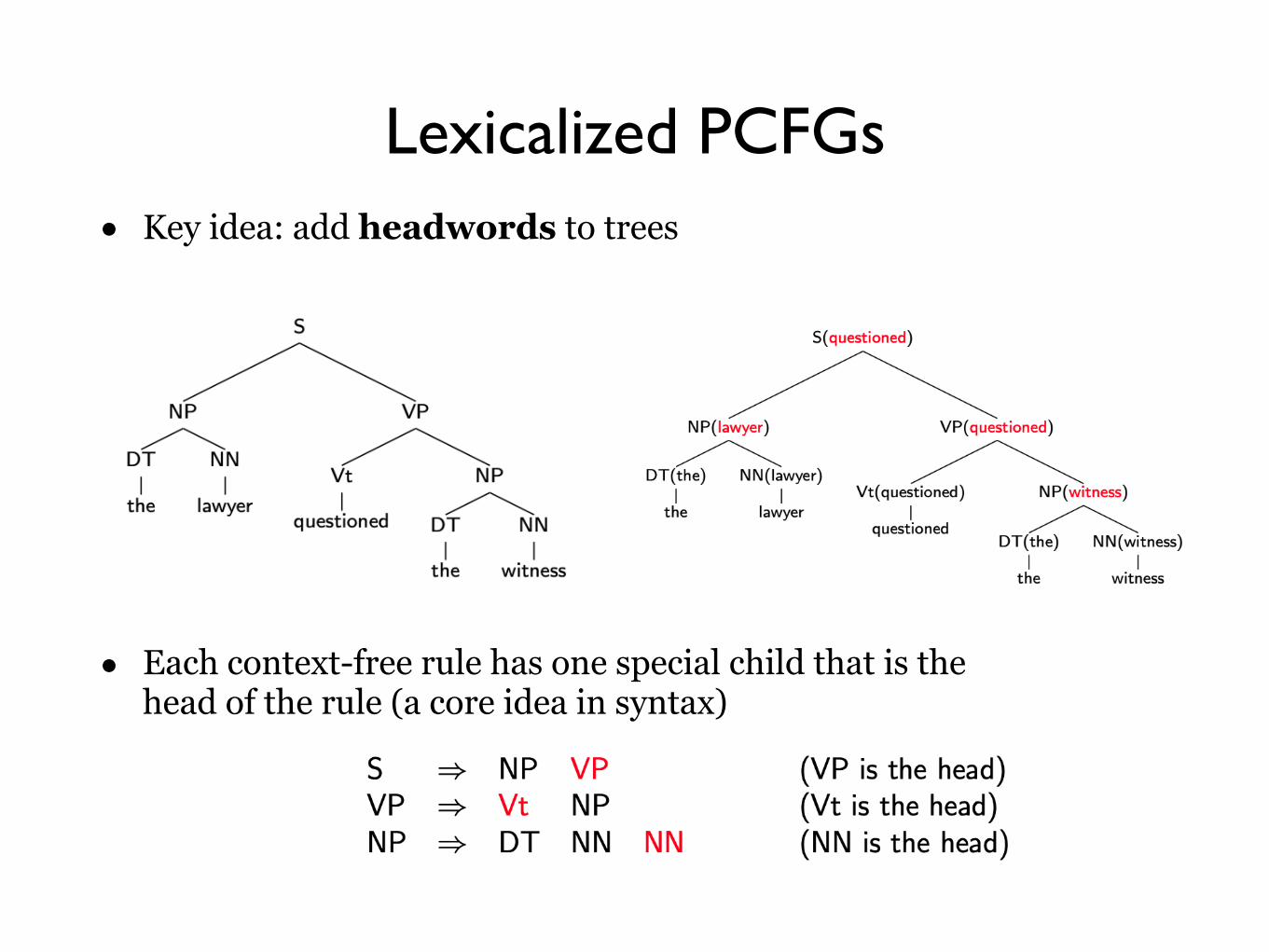
Lexicalized PCFGs• Key idea: add headwords to trees
• Each context-free rule has one special child that is the head of the rule (a core idea in syntax)
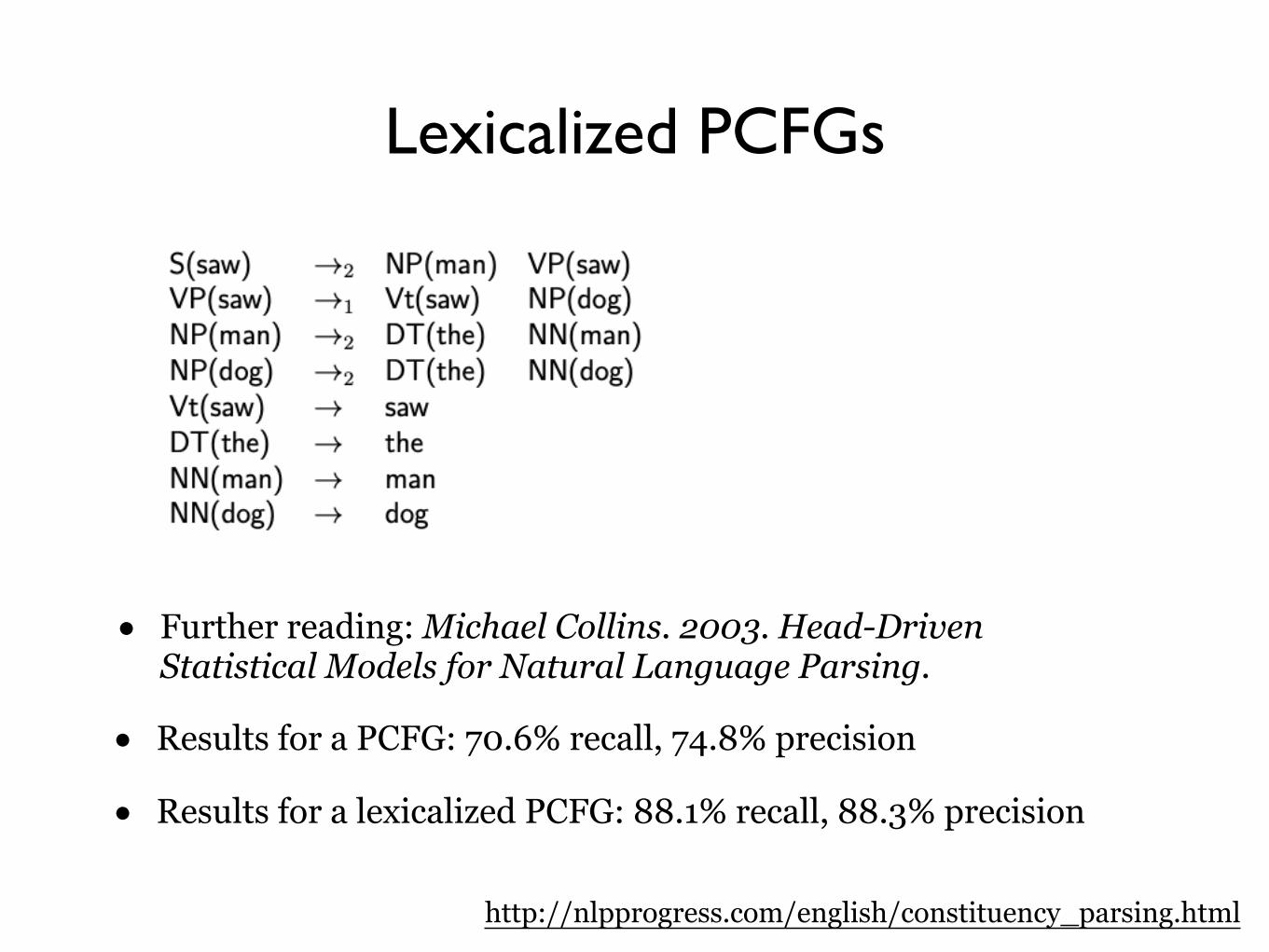
Lexicalized PCFGs
• Further reading: Michael Collins. 2003. Head-Driven Statistical Models for Natural Language Parsing.
• Results for a PCFG: 70.6% recall, 74.8% precision
• Results for a lexicalized PCFG: 88.1% recall, 88.3% precision
http://nlpprogress.com/english/constituency_parsing.html









![Bare-Bones Dependency Parsing - Uppsala Universitystp.lingfil.uu.se/~nivre/docs/BareBones.pdf · I Parsing methods for bare-bones dependency parsing I Chart parsing ... Eisner 2000]:](https://img.pdfslide.us/doc/110x75/5b1dbccd7f8b9a397f8b5558/bare-bones-dependency-parsing-uppsala-nivredocsbarebonespdf-i-parsing-methods.jpg)



















