Embed Size (px)
Citation preview

User Modeling and User-Adapted Interaction 14: 351–381, 2004.© 2004 Kluwer Academic Publishers. Printed in the Netherlands.
351
Computational Modeling and Analysis ofKnowledge Sharing in CollaborativeDistance Learning
AMY SOLLERITC-IRST, Via Sommarive 18, 38050 Povo, Trento, Italy. e-mail: [email protected]
(Received: 16 January 2004; accepted in final form 10 May 2004)
Abstract. This research aims to support collaborative distance learners by demonstratinghow a probabilistic machine learning method can be used to model and analyze onlineknowledge sharing interactions. The approach applies Hidden Markov Models and Multi-dimensional Scaling to analyze and assess sequences of coded online student interaction.These analysis techniques were used to train a system to dynamically recognize (1) whenstudents are having trouble learning the new concepts they share with each other, and (2)why they are having trouble. The results of this research may assist an instructor or intel-ligent coach in understanding and mediating situations in which groups of students collab-orate to share their knowledge.
Key words. computer-supported collaborative learning, interaction analysis, knowledge shar-ing, dialog, hidden markov models
1. Introduction
The rapid advance of distance learning and networking technology has enableduniversities and corporations to reach out and educate students across time andspace barriers. This technology supports structured, on-line learning activities,and provides facilities for assessment and collaboration. Structured collaboration,in the classroom, has proven itself a successful and uniquely powerful learningmethod (Brown and Palincsar, 1989). Most online collaborative learners, however,do not enjoy the same benefits as face-to-face learners because the technology doesnot provide constructive guidance or direction during online discussion sessions.Integrating intelligent analysis and facilitation capabilities into collaborative dis-tance learning environments may help bring the benefits of the supportive class-room closer to distance learners (Barros and Verdejo, 1999; Constantino-Gonzalez,Suthers and Escamilla de los Santos, 2003; Jermann, Soller and Muehlenbrock,2001; Muehlenbrock, 2001).
This research aims to support groups of online distance learners by demonstrat-ing a new Hidden Markov Modeling method for analyzing online knowledge shar-ing interaction. I focus on knowledge sharing interaction because students bring agreat deal of specialized knowledge and experiences to group learning situations,

352 AMY SOLLER
and how they share and assimilate this knowledge shapes the collaboration andlearning processes. The key roles of the analysis engine include (1) recognizingwhen students are having trouble learning the new concepts they share with eachother, and (2) determining why they are having trouble. This paper explains howthe analysis procedure addresses both of these issues. The procedure is intendedto assist an instructor or intelligent coach in mediating situations in which newknowledge is not effectively assimilated by the group.
In Section 2, I define knowledge sharing interaction more formally, and thenintroduce the Encouraging Positive Social Interaction while Learning On-Line(EPSILON) software and experimental method. Section 4 introduces the HiddenMarkov Modeling approach and Section 5 describes how I applied Hidden Mar-kov Models, Multidimensional Scaling, and a threshold-based clustering method,to analyze and assess sequences of coded on-line student interaction. These analy-sis techniques were used to train a system to dynamically recognize when and whystudents may be experiencing breakdowns while sharing knowledge and learningfrom each other. Section 6 summarizes and elaborates upon my results, and Sec-tion 7 discusses extensions and future research directions.
2. Supporting Knowledge Sharing Online
Imagine a group of students, who gather around a table to solve a problem andbegin to exchange the knowledge that each brings to bear on the problem. Eachgroup member brings to the table a unique pool of knowledge, grounded in hisor her individual experiences. The combination of these experiences, the ontologi-cal reconciliations of members’ understanding of them, and the group members’personalities and behaviors will determine how the collaboration proceeds, andwhether or not the group members will effectively learn from and with each other(Brown and Palincsar, 1989; Dillenbourg, 1999; Webb and Palincsar, 1996).
If we take a closer look at the interaction in such a group, we might see thatthe way in which a student shares new knowledge with the group, and the way inwhich the group responds, determines to a large extent how well this new knowl-edge is assimilated into the group, and whether or not the group members learnthe new concepts. Group members who do not effectively share the knowledge theybring to the group learning situation will have a difficult time establishing a sharedunderstanding, and co-constructing new knowledge. These difficulties ultimatelylead to poor learning outcomes (Jeong, 1998; Winquist and Larson, 1998), mak-ing research efforts to understand and support student knowledge sharing activitiesessential.
The EPSILON project is an initiative to analyze and classify episodes of knowl-edge sharing interaction, with the intention to dynamically support online learninggroups. Formally, a knowledge sharing episode is a segment of interaction (includ-ing student utterances and workspace actions) in which one student attempts topresent, explain, or illustrate new knowledge to his peers, while his peers attempt
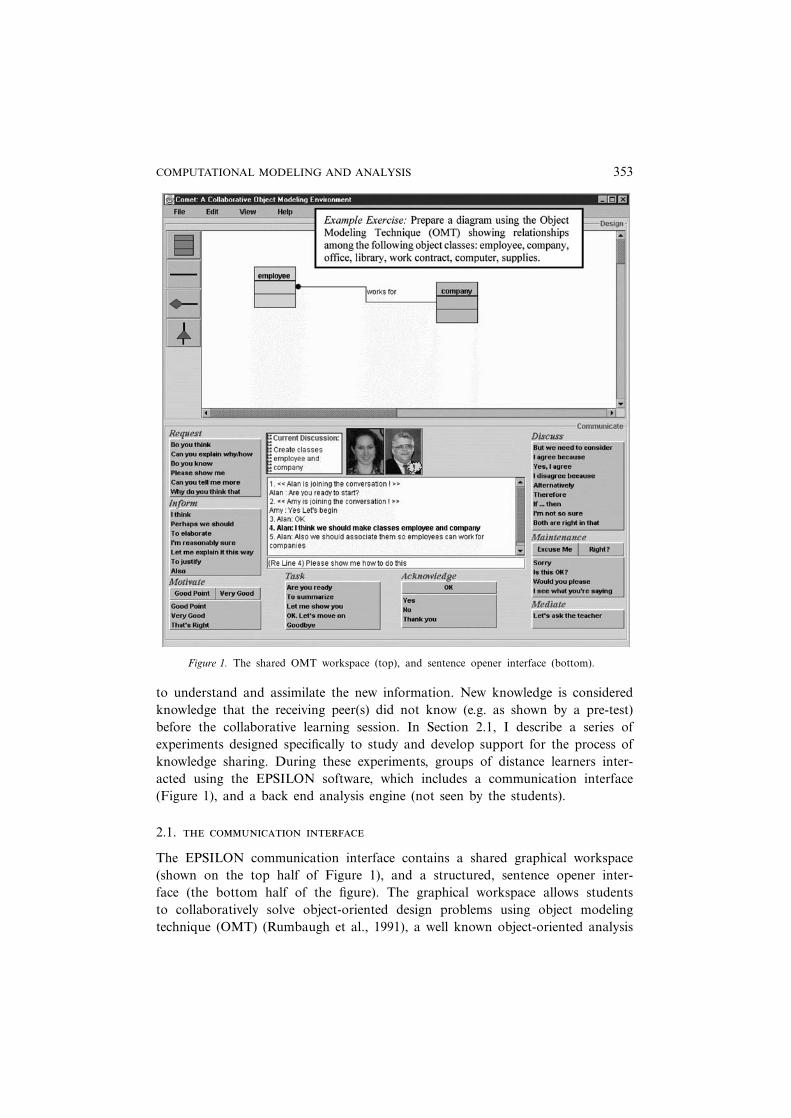
COMPUTATIONAL MODELING AND ANALYSIS 353
Figure 1. The shared OMT workspace (top), and sentence opener interface (bottom).
to understand and assimilate the new information. New knowledge is consideredknowledge that the receiving peer(s) did not know (e.g. as shown by a pre-test)before the collaborative learning session. In Section 2.1, I describe a series ofexperiments designed specifically to study and develop support for the process ofknowledge sharing. During these experiments, groups of distance learners inter-acted using the EPSILON software, which includes a communication interface(Figure 1), and a back end analysis engine (not seen by the students).
2.1. the communication interface
The EPSILON communication interface contains a shared graphical workspace(shown on the top half of Figure 1), and a structured, sentence opener inter-face (the bottom half of the figure). The graphical workspace allows studentsto collaboratively solve object-oriented design problems using object modelingtechnique (OMT) (Rumbaugh et al., 1991), a well known object-oriented analysis

354 AMY SOLLER
and design methodology. Software engineers use object-oriented analysis anddesign methodologies such as OMT to optimize their designs before implementa-tion, and to communicate design decisions. This research may be applied to simi-lar domains that involve teams of people learning to solve complex problems thatrequire inference and idea generation.
The shared OMT workspace provides a palette of buttons down the left-handside of the window that students may use to construct and link objects in differ-ent ways depending on how they are related. Objects on the shared workspace canbe selected, dragged, and modified, and changes are reflected on the workspaces ofall group members.
The EPSILON chat interface is shown on the bottom half of Figure 1. Itcontains sets of sentence openers (e.g. ‘I think’, ‘I agree because’) organizedin intuitive categories (such as Inform or Discuss) (Baker and Lund, 1997;McManus and Aiken, 1995). The sentence openers are designed to help the sys-tem identify the intentions that underlie the students’ conversational contributions(Soller, 2001). Each sentence opener is associated with a particular conversationalintention, given by a subskill and attribute. For example, the opener, ‘I think’corresponds to the subskill (or category) ‘Inform’, and the more specific attri-bute, ‘Suggest’. The categories and corresponding phrases on the interface rep-resent the conversation acts that were most often exhibited during collaborativeproblem solving in the OMT domain. They originated in 1996 from an analysisof videotaped face-to-face collaborative learning (Soller et al., 1996), and evolvedover the next five years through a series of on-line collaborative distance learningand user interface pilot studies (Soller, 2001). To contribute to the group conversa-tion in the EPSILON system, a student first selects a sentence opener. The selectedphrase appears in the text box below the group dialog window, where the studentmay type in the rest of the sentence.
The sentence opener approach was introduced by McManus and Aiken in 1995and has since shown potential in a few systems that use the phrases primarily asa mechanism for structuring the interaction. For example, Baker and Lund (1997)compared the problem solving behavior of student pairs as they communicatedthrough both a sentence opener interface and an unstructured chat interface. Theyfound that the dialogue between students who used the sentence opener interfacewas more task focused. Jermann and Schneider’s (1997) subjects could choose, foreach contribution, to type freely in a text area, or to select one of four short cutbuttons, or four sentence openers. Jermann and Schneider discovered that, in fact,it is possible to direct the group interaction by structuring the interface, as Bakerand Lund suggest. Furthermore, they found that the use of the sentence openerswas more frequent overall than that of the free text zone (58% vs. 42%). Alter-native approaches to using sentence openers include restricting the students’ nat-ural language to a formal language (Tedesco, 2003), or structuring the students’language by having them explicitly indicate the conversational intentions underly-ing their contributions (Barros and Verdejo, 1999).

COMPUTATIONAL MODELING AND ANALYSIS 355
In this research, requiring students to use a given set of sentence openersallowed the system to automatically code the dialog without having to rely on Nat-ural Language parsers. In some cases, however, students may perceive the dialog-ical constraints of the sentence openers, and use them in unexpected ways. Forexample, it is possible to use the sentence opener, ‘I think’, to say, ‘I think I dis-agree’. In order to determine to what degree the students used the openers as theywere intended, Soller (2002) had two researchers recode three of her five dialogs(selected at random). The raters were asked to assign each conversational contri-bution a tag from the coding scheme that best indicates the speaker’s intention.The new tags were then compared to the system’s codes, which describe the sen-tence openers that the students chose during the dialog. The agreement betweenthe raters and the system was high at the subskill, or category, level (κ = 0.86),and reasonable at the sentence opener level (κ = 0.66) (Carletta et al., 1997). Thissuggested that the students were, in fact, choosing appropriate sentence openers fortheir contributions.
In addition to the structured chat-style facility, the communication interfacefeatures the following awareness-oriented functionality:
– students can refer back to statements in the dialogue history by selecting theappropriate line (shown in bold in the figure);
– students may direct their comments to a particular team member by clickingon his or her picture;
– a separate agenda window (not shown) enables students to keep track of theirwork. The current discussion item from the agenda is shown in the “currentdiscussion” notepad above the discussion window;
– while students are typing a contribution, before they hit <Enter> to send theircomment to the group discussion window, a small cloud appears on their pic-tures to let their teammates know they are about to make a contribution;
– the picture of the last person to contribute to the discussion appears in a redbox.
The student action log (shown in Figure 2) is an integral part of the interface,although it is usually not seen by the students. It records information about whatwas said or done on the interface, when, and by whom. Each conversation contri-bution is coded according to the taxonomy of subskills and attributes reflected onthe interface (described in more detail in Soller, 2001), using the following format:
Line number) Date and Time : Student : Subskill : Attribute : <actual contri-bution>
Actions are logged in a similar fashion, with variables enclosed in “$” signs.As the students collaborate through the EPSILON interface, the system codes thestudent communication and actions, and sends the sequences of these codes tothe back-end analysis engine. This processing engine predicts whether or not thestudents are effectively sharing new knowledge, and provides insight into what sort

356 AMY SOLLER
Figure 2. The student action log dynamically records all student actions and conversation.
of guidance might be helpful. The coding scheme, and full experimental methodare described in Section 3.
3. Experimental Procedure
From June 2000 to April 2002, a series of experiments was run at both LRDC(University of Pittsburgh), and the MITRE Corporation in Bedford, Massachu-setts. During these studies, 12 groups of three participants each (eight groups inPittsburgh, and four groups in Bedford) were asked to solve one object-orientedanalysis and design problem using the EPSILON software.
3.1. method
The participants in each group were first asked to introduce themselves to theirteammates by answering a few personal questions. Each experiment began with ahalf hour interactive lecture on OMT basic concepts and notation, during whichthe students practiced solving realistic problems. They also participated in a halfhour hands-on software tutorial during which they were introduced to all 36 sen-tence openers on the interface. The students were then assigned to separate rooms,given individual knowledge elements (described next), and took a pre-test.
Each of the three individual knowledge elements represented a different con-ceptual element describing a key OMT concept needed for the on-line problemsolving session (for example, ‘Attributes common to a group of subclasses shouldbe attached to the superclass, because the subclasses inherit the features of thesuperclass’). Each knowledge element was explained on a sheet of paper witha worked-out example. The pre-test included one problem for each of the threeknowledge elements. It was expected that the student given knowledge element #1

COMPUTATIONAL MODELING AND ANALYSIS 357
would get only pre-test question #1 right, the student given knowledge element#2 would get only pre-test question #2 right, and likewise for the third student.To ensure that each student understood his or her unique knowledge element, anexperimenter reviewed the pre-test problem pertaining to each student’s knowledgeelement before the group began the main exercise. Students who missed the pre-test problem on their knowledge element were asked to reread their knowledge ele-ment sheet and rework the missed pre-test problem, while explaining their workout loud (Chi et al., 1989).
The participants were not told specifically that they hold different knowledgeelements, however they were reminded that their teammates may have differentbackgrounds and knowledge, and that sharing and explaining ideas, and listeningto others’ ideas is important in group learning. During the on-line sessions, whichlasted about one hour and fifteen minutes, the software automatically logged thestudents’ conversation and actions. After the problem solving session, the subjectscompleted a post-test, and filled out a questionnaire. The post-test, like the pre-test, addressed the three knowledge elements. It was expected that the members ofeffective knowledge sharing groups would perform well on all post-test questions.
3.2. data collection and pre-processing
After the problem solving sessions, the session logs were segmented by hand toextract the segments in which the students shared their unique knowledge elements.A total of 29 of these knowledge sharing episodes were manually identified, andeach was classified as either an effective knowledge sharing episode or a knowl-edge sharing breakdown. The manual segmentation procedure involved identifyingthe main topic of conversation by considering both the student dialog and work-space actions, and the initial classification was based on an examination of the preand post test scores. In the future, it should be possible to also automate the dia-log segmentation procedure, which identifies the knowledge sharing episode bound-aries (Linton et al., 2003), especially since the automated segmentation procedureneed not replicate the exact dialog boundaries that were manually identified for theanalysis presented here. The performance of the hidden markov modeling (HMM)classification procedure was shown to remain stable (and even improve slightly)when the boundaries of the knowledge sharing episodes were altered slightly.
Because the automated HMM classification procedure is a supervised machinelearning algorithm, it must first be given examples of effective knowledge sharing,and knowledge sharing breakdowns. Then, it can attempt to develop generalizedmodels from these examples that describe the characteristics of the two classes.Once these models are trained, the system can compare a new test case to thegeneralized models in order to determine which model best describes the newcase. The manual classification procedure used the following three requirements todetermine if a knowledge element was shared ‘effectively’ during a knowledge shar-ing episode (F. Linton, personal communication, May 8, 2001):

358 AMY SOLLER
(1) the individual sharing the new knowledge (the ‘sharer’) must show that sheunderstands it by correctly answering the corresponding pre and post testquestions;
(2) the concept must come up during the conversation;(3) at least one group member who did not know the concept before the col-
laborative session started (as shown by his pre-test) must show that helearned it during the session by correctly answering the corresponding post-test question.
In this paper, I focus on situations in which criteria (1) and (2) are satisfied,since these criteria are necessary for studying how new knowledge is assimilatedby collaborative learning groups. Other research has addressed how students indi-vidually acquire new knowledge (criterion 1, Gott and Lesgold, 2000), and how tomotivate students to share their ideas (criterion 2, Webb and Palincsar, 1996).
The groups produced 10 instances of effective knowledge sharing and 19instances of ineffective knowledge sharing. A sequence was considered ineffective ifthe knowledge element was discussed during the episode, but none of the receivingstudents demonstrated mastery of the concept on the post test. The 29 knowledgesharing episodes varied in length from 5 to 49 contributions, and contained bothconversational elements and OMT diagram construction actions. The top part ofFigure 3 shows an example of one such episode. The sentence openers, which indi-cate the system-coded subskills and attributes, are italicized. The bottom part ofFigure 3 shows an example of an actual sequence, based on the episode, that wasused to train the HMMs to analyze and classify new instances of knowledge shar-ing (described in Section 3.3).
In a preliminary analysis, a prototype HMM classifier was able to determine(with 100% accuracy) which of the three students played the role of knowledgesharer during the identified knowledge sharing episodes (Soller, 2002; Soller andLesgold, in press). This analysis was performed because, if successful, it wouldallow the system to assign a special set of tags to the contributions of the knowl-edge sharer. In Figure 3, for example, the tags reserved for the knowledge sharer’scontributions begin with the code “A-”. The contributions of other two studentswere arbitrarily assigned the codes “B-” and “C-”. Differentiating the roles of theknowledge sharer and recipients was thought to facilitate the system’s assessmentof the episode’s effectiveness.
3.3. questionnaire results
This section discusses the students’ responses to the questionnaires, and com-pares them to the results of the pre and post tests. The results of the question-naires are shown in Figure 4. In general, the participants felt a high degree ofengagement in the task, and felt they did learn OMT during the four hour study.A statistical analysis, however, showed that actual individual learning (as mea-

COMPUTATIONAL MODELING AND ANALYSIS 359
Student Subskill/Action Attribute Actual Contribution (Not seen by HMM) (Student C has incorrectly included the attribute $Name$ in the class $Bank$)
B Request Justification Why do you think that "name" should be added ? A Maintenance Request Attention Excuse Me A Maintenance Request Action Would you please remember that we don't need the
name in company and bank, because they inherit name from Owner?
A Edited attributes for class $Company$ - $$ B Discuss Agree Yes, I agree , Name should not be added C Maintenance Apologize Sorry A Edited attributes for class $Bank$ - $,$ C Motivate Encourage Good Point , I forgot about that.
Actual HMM Training Sequence B-Request-Justification A-Maintenance-RequestAttention A-Maintenance-RequestAction A-SuccessfulAction B-Discuss-Agree C-Maintenance-Apologize A-SuccessfulAction C-Motivate-Encourage
Figure 3. An actual logged knowledge sharing episode (above), showing system coded subskills andattributes, and its corresponding HMM training sequence (below).
sured by students’ pre and post tests) was not correlated with perceived learn-ing (as measured by the questionnaires). The pre and post tests showed thatthe subjects learned an average of 0.65 Knowledge Elements during the study,and the groups learned an average of 1.96 Knowledge Elements. Perceived learn-ing, but not actual learning, was positively influenced by the students’ degree ofengagement in the task, and their feeling of control during the study (r = 0.51and r = 0.52, respectively). As an observer, I noted that most students were veryengaged during the group exercise portion of the study, and genuinely enjoyed theexperience.
Although the questionnaire responses overall were positive, they were fairly neu-tral with respect to the sentence openers.1 This was expected because at this stageof software development, the students did not receive feedback and guidance inreturn for their efforts to communicate in a restricted language. One factor that didseem to impact students’ ability to find the sentence opener they needed was theirattitude towards chat tools in general (r = 0.52). Although students reported thatthe sentence opener tutorial was helpful, many still spent time during the problemsolving session reading through the list of sentence openers to find the one thatwas most appropriate for their contribution.
1The average from last question was 3.48 on a [0 6] scale, but was converted to a [−3 3] scale forpurposes of visual comparison.

360 AMY SOLLER
Figure 4. Averages of questionnaire responses.
4. Learning to Analyze Knowledge Sharing Interaction
The process of determining whether or not students are effectively sharing newknowledge requires an assessment of the student–student and student–computerinteraction. Studying this interaction over time should provide important insightinto the group process. But sequences of student interaction are scattered withnoise and interruptions. To complicate matters, counts of marginal statistics ofevents found in the sequences do not differentiate between effective and ineffec-tive knowledge sharing. Further analysis was run to determine if a neural networkcould be trained to distinguish between effective and ineffective knowledge shar-ing behavior. A neural network with five hidden nodes was trained by construct-ing feature vectors containing the percentage of time each group member usedeach subskill during each classified knowledge sharing episode. Since there wereeight subskill categories (see Section 2.1), and three students in each group, thisresulted in a feature vector of length 24. A cross validation study showed that thenetwork was unable to distinguish between the effective and ineffective sequencesusing this information (it achieved less than 50% accuracy). The network may haveperformed poorly because it did not take into account the progression of events inthe knowledge sharing sequences.
A look at the pairwise sequences within the knowledge sharing episodesrevealed that this ordering is important. The pairwise analysis showed that two ofthe most common transitions in the effective knowledge sharing sequences wereDiscuss–Discuss (a Discuss act followed by another Discuss act), and Discuss-Maintenance, whereas the common transitions in the ineffective sequences includedInform-Acknowledge and Inform–Inform. Although the pairwise approach providedinsight into the sorts of transitions that differ in effective and ineffective sequences,it was not able to reliably differentiate between these two cases because many of

COMPUTATIONAL MODELING AND ANALYSIS 361
0.5
0.3
0.7
0.20.1
0.10.6
0.2 0.3Office Ward CoffeeRoom
0.3
Figure 5. A Markov chain showing the probability that Hal (the robot) will enter variousrooms.
the most common pairs did not occur at all in some of the knowledge sharingsequences.
The marginal and pairwise analyses triggered the search for a more intelligentmethod that could deal with the ordered, but unpredictable and somewhat noisynature of human dialog. This is why the stochastic and sequential HMMs madethem a strong candidate for this research. HMMs were also chosen because oftheir flexibility in evaluating sequences of indefinite length, their ability to dealwith a limited amount of training data, and their recent success in speech recogni-tion tasks (Rabiner, 1989). I explain the basic procedure underlying this approachin Section 4.1.
4.1. an introduction to hidden markov modeling
Before introducing the HMM algorithm, let’s take a look at the simpler case of theMarkov chain. Markov chains are probabilistic finite state machines, used to modelprocesses that move stochastically through a series of predefined states. For exam-ple, imagine a robot whom we will call Hal, that wanders through a hospital fromroom to room performing various duties. Hal’s virtual map might include a doc-tor’s office, a ward, and the coffee room. The arcs in a Markov Chain describe theprobability of moving between states, and the sum of the probabilities on the arcsleaving a state must sum to one. So, in Figure 5, we see that if Hal is in the doc-tor’s office, there is a 20% chance that he will move to the ward, a 30% chance thathe will wander to the coffee room, and a 50% chance that he will just stay put.Markov Chains also specify that the probability of a sequence of states is the prod-uct of the probabilities along the arcs. So, if Hal is in the doctor’s office, then theprobability that he will move to the ward, and then the coffee room is (.2)(.3) =.06, or 6%.
HMMs generalize Markov Chains in that the outcome associated with passingthrough a given state is stochastically determined from a specified set of possibleoutcomes and associated probabilities. Consequently, it is not possible to determinethe state the model is in simply by observing the output (i.e. the state is “hid-den”). For example, we might estimate Hal’s location (state) by an account of the

362 AMY SOLLER
Figure 6. State transition matrix {aij }, for robot example.
messages displayed on his chest (observations). A given sequence of observationsmay be associated with more than one possible path through the HMM becauseat each state, the selection of a particular output is stochastic.
HMMs allow us to ask questions such as, “How well does a new (test) sequencematch a given model?”, or, “How can we optimize a model’s parameters to bestdescribe a given observation (training) sequence?” (Rabiner, 1989). Answering thefirst question involves computing the most likely path through the model for agiven output sequence; this can be efficiently computed by the Viterbi (1967) algo-rithm. Answering the second question requires training an HMM given sets ofexample data. This involves estimating the (initially guessed) parameters of themodel repetitively, until the most likely parameters for the training examples arediscovered. In the remainder of this section, I introduce a few of the formal con-cepts involved in answering the first question, and illustrate these concepts with asimple example. The level of detail provided here should be sufficient for under-standing the analysis that follows. For further information on HMMs, see Rabiner(1989) or Charniak (1993).
The state transition matrix for an HMM is denoted by A = {aij }, where
aij = Pr[qt+1 = Sj |qt = Si ]
The variable qt denotes the state at time t. The equation above explains that thetransition matrix describes the probabilities of the states qt+1 in the model, giventhat the previous state was qt . The transition matrix for the Hal example, describedearlier in this section, is shown in Figure 6.
An HMM differs from a Markov chain in that we might observe several differ-ent events in a particular state. For example, we might be chatting in the coffeeroom, and observe that Hal has re-entered the room but has changed the messagedisplayed on his chest (e.g. from ‘Tired’ or ‘Frustrated’ to ‘Thirsty’). Let O definean observation sequence, for example O = Tired, Tired, Thirsty, Frustrated. Theobservation symbol probability distribution describes the probabilities of each ofthe observation symbols, νk, for each of the states, at each time t. The observa-tion symbol probability distribution in state j is given by B = {bj (k)}, where
bj (k) = Pr[νk at t |qt = Sj ]

COMPUTATIONAL MODELING AND ANALYSIS 363
and V describes the set of all possible observation symbols. In this research, the112 observation symbols were given by the possible student conversational andworkspace actions, as illustrated in the example in Figure 3.
Formally, if we let π = {πi} describe the initial state distribution, where πi =Pr[q1 = si ], then an HMM (λ) can be fully described as
λ = (A, B, π)
where A = {aij } is the state transition matrix for the HMM, and B = {bj (k)} isthe observation symbol probability distribution for each state j.
We are now ready to look at the forward-backward procedure for findingthe likelihood of a given observation sequence, given an HMM. This likelihoodis denoted Pr(O|λ). Let αt (i) = Pr(O1, O2, . . . , Ot , qt = Si |λ). The variable, αt (i),is called the forward variable, and describes the probability of a partial obser-vation sequence (up until time t), given model λ. In the first step, we initial-ize αt (i):αt (i) = πibi(O1). This initializes the forward variable as the jointprobability of state Si and the initial observation O1. The second step is givenby the following equation, in which N denotes the number of states in theHMM:
αt+1(j) =[
N∑i=1
αt (i)aij
]bj (Ot+1)
The sum,N∑
i=1αt (i)aij , describes the probability of the joint event in which
O1, O2, . . . , Ot are observed, the state at time t is Si , and the state Sj isreached at time t + 1. In other words, it is the probability of being instate Sj at time t + 1, accounting for all the accompanying previous par-tial observations. Then αt+1(j) can be determined by multiplying this value bybj (Ot+1).
To find Pr(O|λ), we need only take the sum over the terminal values
Pr(O|λ) =N∑
i=1
αT (i)
The iterative training and testing algorithms for HMMs do not perform anexhaustive search of the state space. Such a search, for V possible observationsymbols, N states, and a test sequence of length T , would require O(V T *NT ) cal-culations. In the modeling and analysis of knowledge sharing interaction reportedhere, V = 112, N = 5, and T ≈ 15. An exhaustive search would require about112∗15∗515 = 5.12×1013 calculations! HMMs improve upon this by storing the bestpath for each state, at each iteration.

364 AMY SOLLER
5. Using HMMs to Assess Knowledge Sharing
5.1. modeling effective and ineffective knowledge sharing
Two 5-state HMMs were trained2 using the MATLAB HMM Toolbox.3 Thefirst was trained using only sequences of effective knowledge sharing interaction(this will be termed the effective HMM), and the second using only sequencesof ineffective knowledge sharing (the ineffective HMM). An example of a trainedHMM is shown in Figure 7. Testing the models involved running a new knowl-edge sharing sequence – one that is not used for training – through both models.The output from the effective HMM described the probability that the new testsequence was effective (as defined by the training examples), and the output fromthe ineffective HMM described the probability that the test sequence was ineffec-tive. The test sequence was then classified as effective if it had a higher path proba-bility through the effective HMM, or ineffective if its path probability through theineffective HMM was higher. Since the probabilities in these models can be quitesmall, it is common to take the log of the path probability, which results in a neg-ative number. The largest path probability is then given by the smallest absolutevalue. Procedures similar to this have been used successfully in other domains, suchas gesture recognition (Yang, Xu and Chen, 1997), and the classification of inter-national events (Schrodt, 2000).
Each of the 10 effective and 19 ineffective sequences (described in Section 3)was replicated with actors B and C swapped so that the analysis would not reflectidiosyncrasies in the labelling of participants B and C. This resulted in a totalof 58 episodes (or 29 pairs of episodes). Because of the small dataset, a modi-fied “take-2-out” 58-fold cross-validation approach was used, in which each testsequence and its B–C swapped pair was removed from the training set and testedagainst the two HMMs (representing effective and ineffective interaction) whichwere trained using the other 56 episodes.
Sixteen of the 20 effective knowledge sharing sequences were correctly classifiedby the effective HMM, and 27 of the 38 ineffective sequences were correctly classi-fied by the HMM modeling knowledge sharing breakdowns (Table I). Overall theHMM approach produced an accuracy of 74.14%, almost 25% above the baseline.The baseline comparison for this analysis is chance, or 50%, because there was a1/2 chance of arbitrarily classifying a given test sequence as effective or ineffective,and the sample size was not large enough to establish a reliable frequency baseline.
This analysis shows that HMMs are useful for identifying when students areeffectively sharing the new knowledge they bring to bear on the problem, andwhen they are experiencing knowledge sharing breakdowns. A system based onthis analysis alone could offer support and guidance about 74% of the time thestudents need it, which is better than guessing when students are having trouble,
2Before choosing the five node HMM, I experimented with 3, 4, and 6 node HMMs, obtaining sim-ilar (but not optimal) results. Performance seemed to decline with 7 or more states.3Available from Kevin Murphy at http://www.ai.mit.edu/ murphyk/Software/HMM/hmm.html.

COMPUTATIONAL MODELING AND ANALYSIS 365
1
54
32
.68
.31
.69
.32
.08
.34
.99
.44
.55
.58
17%B-Inform-Elaborate11%A-Acknowledge-Accept
15%B-Discuss-DoubtC-Acknowledge-Accept11%C-Request-InformationB-Discuss-Agree
14%B-Acknowledge-Accept13%A-Inform-Suggest
14%C-Motivate-Encourage13%B-Request-Opinion12%A-Inform-Assert11%A-Inform-Suggest
12%C-Inform-SuggestA-Request-OpinionB-Inform-Suggest
Figure 7. An example five state HMM, trained using 13 conversational sequences in which A is theknowledge sharer. Outputs for each state that exceed an 11% threshold are shown in boxes.
Table I. The number of classified knowledge sharing sequences thatbest matched each trained HMM
Effective HMM Ineffective HMM
Effective test sequences 16 4Ineffective test sequences 11 27
or basing intervention solely on students’ requests for help. The 26% error rate stillmeans that the instructor or the computer-based coach might miss the opportunityto offer advice to the group when it is needed. In this case, however, the data sug-gests that the system would probably pick up on the breakdown the next time itoccurs.
The next step is determining why students may be having trouble so that appro-priate facilitation methods can be identified and tested. The next section takes acloser look at the differences between the effective and ineffective sequences inorder understand the qualitative differences. For example, we might expect to seemore questioning and critical discussion in effective knowledge sharing episodes,and more acknowledgement in less effective episodes (Soller, 2001).
5.2. analyzing knowledge sing strategies
Understanding why a knowledge sharing episode is effective or ineffective is crit-ical to selecting a proper mediation strategy. For example, a student sharing new

366 AMY SOLLER
knowledge with his teammate may have trouble formulating sufficiently elaboratedexplanations, and may need help in using analogies or multiple representations.Or, a knowledge receiver may need encouragement to speak up and articulate whyhe does not understand a new knowledge element. In the second phase of thisresearch, I attempted to develop generalized models of effective knowledge shar-ing, and breakdowns in knowledge sharing. A system must be able to differentiatebetween these cases if it is to understand knowledge sharing interaction, and rec-ommend strategies for supporting this process. In attempting to model the variousways in which group members may fail to effectively assimilate new information,I first applied an HMM clustering approach (Juang and Rabiner, 1985; Smyth,1997). In the first step of this procedure, 20 effective, and 38 ineffective HMMswere trained (in the traditional manner) from each of the 10 paired effective, and19 paired ineffective knowledge sharing sequences. Recall from the previous sec-tion that each sequence was replicated with actors B and C swapped so that theanalysis would not introduce a bias toward the labelling of the two students whowere arbitrarily assigned the labels B and C. Each B-C swapped pair included theoriginal sequence and its paired sequence, with the B and C labels swapped.
Formally, each sequence, Sj , 1 ≤ j ≤ N , was used to train one HMM, Mi,
1 ≤ i ≤ N , i = j . For the effective case, Neff = 20, and for the ineffective case,Nineff = 38. Then, the log-likelihood of each sequence, Sj , given each of theHMMs, Mi , was calculated via the standard HMM testing procedure. This resultedin two matrices, one describing the likelihoods of the effective sequences given theeffective models, loglikeff (Sj |Mi), and one describing the likelihoods of the ineffec-tive sequences given the ineffective models, loglikineff (Sj | Mi). The format of thesematrices is shown on the right-hand side of Figure 8.
The columns of these matrices described the likelihood of each of the sequencesgiven a particular model, Mi ; hence similar HMMs should produce similar likeli-hood vectors. Given this observation, it would make sense to cluster these columnvectors to see which models were most similar. Clustering, in the traditional sense,means calculating the distance (or similarity) between vectors, and grouping similarvectors together in an iterative fashion. The data, however, did not lend itself wellto a traditional hierarchical clustering approach, because there were several outlierdata points that caused the generation of single clusters from singleton data points.One way of dealing with this problem is to represent the data in a multidimen-sional space that can easily be divided into regions describing groups of HMMs.Multidimensional Scaling (MDS) procedures were designed for this purpose (Krus-kal and Wish, 1978; Shepard, 1980).
The MDS approach was attractive for this research because each of the group-ings found in the multidimensional space might describe a particular way in whichgroup members effectively share new knowledge with each other, or experiencebreakdowns while attempting to share new knowledge with each other. The fullalgorithm to perform the MDS of HMM likelihoods is described on the left-handside of Figure 8.

COMPUTATIONAL MODELING AND ANALYSIS 367
Figure 8. An overview of the HMM and MDS procedure.
In step 4 of the algorithm, the MDS procedure was applied to the HMM log-likelihood matrices, such that loglik(Sj | Mi) → Dji , where Dji = d(LMj , LMi)
describes the Euclidean distance between the N HMM likelihood vectors in a 3dimensional space (Kruskal and Wish, 1978). The likelihood vectors were thenassigned to groups based on the closeness of the data points in the (MDS) scaledconfigurations. Figure 9 shows the left side and top views, respectively, for theeffective matrices, Dji . Figure 10 shows the top and right side views, respectively,for the ineffective matrices, Dji . In these figures, the distance from any point (withlabel i) to each of the other point in the figure, represents the relative distancefrom the model Mi to each of the other models (represented by their respectivelikelihood vectors).
The groupings are also shown in the figures. These groupings are based on thecloseness of points along all three dimensions, and therefore may not be obviousfrom looking only at one dimension. They were verified using an iterative, self-organizing data analysis technique (ISODATA) along with a maximum distancethreshold criteria (Looney, 1997). The ISODATA algorithm is similar to a k-meansclustering algorithm, except that it is able to split clusters containing feature vec-tors that exceed a maximum standard deviation threshold, σsplit, and it is also ableto lump together clusters whose centers fall within a minimum distance thresh-old, dL. The ISODATA algorithm was modified slightly, to include a maximumdistance threshold, θ , as described in step 5 of the general algorithm shown inFigure 8. The maximum distance threshold enabled the algorithm to ignore thosepoints that were too far away from any of the established clusters. The dataset thatwas analyzed was small compared to the number of different ways students may
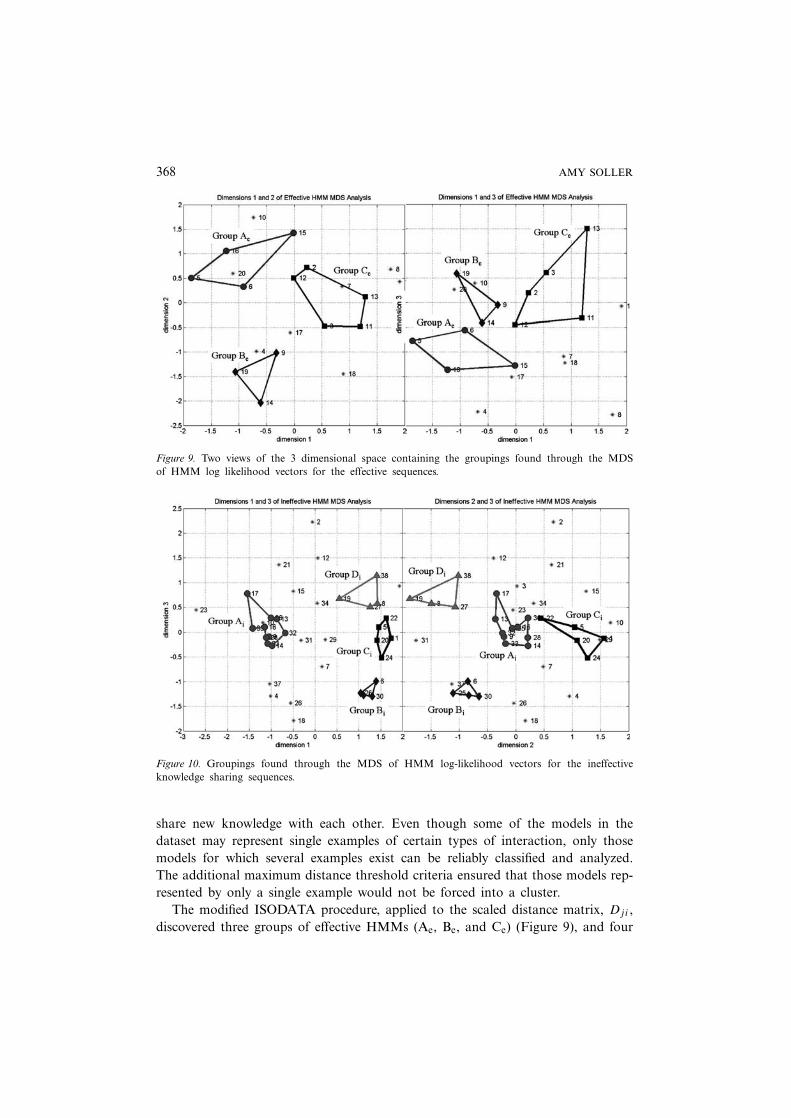
368 AMY SOLLER
Figure 9. Two views of the 3 dimensional space containing the groupings found through the MDSof HMM log likelihood vectors for the effective sequences.
Figure 10. Groupings found through the MDS of HMM log-likelihood vectors for the ineffectiveknowledge sharing sequences.
share new knowledge with each other. Even though some of the models in thedataset may represent single examples of certain types of interaction, only thosemodels for which several examples exist can be reliably classified and analyzed.The additional maximum distance threshold criteria ensured that those models rep-resented by only a single example would not be forced into a cluster.
The modified ISODATA procedure, applied to the scaled distance matrix, Dji ,discovered three groups of effective HMMs (Ae, Be, and Ce) (Figure 9), and four

COMPUTATIONAL MODELING AND ANALYSIS 369
groups of ineffective HMMs (Ai, Bi, Ci, and Di) (Figure 10). Each group of pointsshown as a collection of circles, squares, diamonds, or triangles in the figures rep-resents a set of HMMs with similar likelihood vectors, trained from a correspond-ing set of student knowledge sharing episodes. The points that are not included inany of the groupings represent those HMMs outside the maximum distance thresh-old, θ . Section 5.3 takes a look at the knowledge sharing interaction sequences,discovered by the computational procedure, so that we might better understandwhy students experience knowledge sharing breakdowns, and provide adaptive sup-port and guidance.
5.3. understanding the results of the computational procedure
Each grouping that was found through the MDS analysis and modified ISODATAprocedure, described in Section 5.2, was compared to a qualitative analysis of thestudent activity in each of the groups. The episodes were first summarized blindly,without knowledge of the groupings. Then, the summarized episodes were com-pared to the clusters that were found computationally. The next few paragraphsdescribe, as suggested by these analyses, the sort of interaction that occurs whenstudents attempt to share new knowledge with each other.
Table II shows the three generalized models that were found from the groupsof effective examples (Ae, Be, and Ce). In the first group (Ae), one of the receiv-ers (student B or C) first requests information about one of the Knowledge Ele-ments. This act is followed by an act in which the sharer (student A) provides anexplanation, and then the receiver(s) acknowledge the help. In the second group(Be), one of the receivers requests information about a Knowledge Element, thesharer provides some explanation, and then the receiver requests further clarifica-tion, after which the sharer provides further clarification. In the third group (Ce),the sharer explains or illustrates his Knowledge Element, and the receiver(s) indi-cate they understand the new information by motivating or encouraging the sharer.The knowledge sharing episode described at the beginning of this article (illus-trated in Figure 3) is an example of a sequence that was classified in group Ce.In that episode, student A explains that the attribute Name does not need to beadded to the subclasses Bank and Company, because it is inherited from the super-class Owner, and student C shows that he understands this through his encourag-ing comment, “Good Point, I forgot about that”.
Table II also shows the four generalized models that were found from the groupsof ineffective examples (Ai, Bi, Ci, and Di). In the first group (Ai), the sharer (stu-dent A) first proposes that the group discuss his Knowledge Element. The sharerthen proceeds to either explain the Knowledge Element, or give instructions to oneof the receivers (students B or C) for applying the Knowledge Element concept to theexercise. The episode closes when the receiver(s) simply acknowledges, or requestsconfirmation of his actions. In the second group (Bi), the sharer first attempts toexplain his Knowledge Element. This act is followed by only acknowledgement, and

370 AMY SOLLER
Tab
leII
.Su
mm
ariz
edde
scri
ptio
nsof
effe
ctiv
ean
din
effe
ctiv
ekn
owle
dge
shar
ing
inte
ract
ion,
base
don
the
com
puta
tion
alan
alys
is
Gro
upA
eG
roup
Be
Gro
upC
e
Gen
eral
Exp
lana
tion
sfo
rE
ach
Eff
ecti
veG
roup
1.R
ecei
ver
requ
ests
info
rmat
ion
abou
tK
E1.
Rec
eive
rre
ques
tsin
form
atio
nab
out
KE
1.Sh
arer
expl
ains
orill
ustr
ates
KE
2.Sh
arer
prov
ides
expl
anat
ion
2.Sh
arer
prov
ides
expl
anat
ion
2.R
ecei
ver
mot
ivat
es/e
ncou
rage
s3.
Rec
eive
rag
rees
3.R
ecei
ver
requ
ests
furt
her
clar
ifica
tion
4.Sh
arer
prov
ides
furt
her
clar
ifica
tion
Gro
upA
iG
roup
Bi
Gro
upC
iG
roup
Di
Gen
eral
Exp
lana
tion
sfo
rE
ach
Inef
fect
ive
Gro
up1.
Shar
erpr
opos
esK
E1.
Shar
erat
tem
pts
toex
plai
nK
E1.
Shar
erpr
opos
esK
E1.
Rec
eive
rre
ques
tsex
plan
atio
nof
KE
2.Sh
arer
expl
ains
orgi
ves
inst
ruct
ions
for
acti
on2.
Rec
eive
rac
know
ledg
es2.
Rec
eive
rdo
ubts
2.Sh
arer
expl
ains
poor
ly(n
ofu
r-th
erdi
scus
sion
)3.
Rec
eive
rac
know
ledg
esor
requ
ests
confi
rmat
ion

COMPUTATIONAL MODELING AND ANALYSIS 371
no further explanation. In the third group (Ci), the sharer proposes his Knowl-edge Element, and this act is followed by doubt on the part of the receivers.In the fourth group, one of the receivers first requests an explanation of oneof the Knowledge Elements, after which the sharer explains his Knowledge Ele-ment poorly, ending the discussion on the Knowledge Element (see Soller, 2004 forexamples of knowledge sharing breakdowns).
In general, the discussions in which students effectively shared and learnedeach other’s Knowledge Elements were marked by questioning, explanation, agree-ment, and motivation, whereas the discussions in which the students experiencedbreakdowns in knowledge sharing were marked by poor (inaccurate or incomplete)explanations, instructions for action, doubt, and acknowledgement. These elementsalone, however, do not suffice to distinguish effective from ineffective sequences.This was confirmed through a Kolmogorov–Smirnov test comparing the distribu-tion of the proportions of acts from the effective and ineffective sequences (Fisherand van Belle, 1993). The difference between the effective and ineffective distribu-tions was not significant at the 5% level (p = 0.2607).4 It appears that both thenoise (interruptions and other unpredictable events) and sequencing of the interac-tion play important roles in the characterization of knowledge sharing interaction,and a full reverse engineered explanation of the computational analysis by quali-tative means can be quite difficult.
The results of the groupings found through the clustering of the Multidimen-sional Scaled HMM Likelihoods were verified through a post-hoc modified take-2-out HMM cross validation study (similar to the take-2-out cross validation studydescribed earlier in this section). In the first step of the post-hoc cross validationstudy for the effective clusters, three generalized HMMs (MAe, MBe, and MCe)were constructed by combining the models found through the MDS HMM clus-tering procedure (Ae, Be, and Ce). The models were combined by concatenatingthe training sequences for each model, and using the concatenated set to trainthe new generalized model. For example, model MAe, which combined modelsM5, M15, M6, and M16 was constructed by training on sequences S5, S15, S6, andS16. The knowledge sharing episodes corresponding to these combined models andtheir B–C matched sequences were then used to test the models. Each sequencewas tested against each of the 3 HMMs (deleting the test sequence and its B–Cmatched sequence from the training set). This resulted in a 92.9% accuracy for theeffective sequences, and 95.8% accuracy for the ineffective sequences.5
This analysis shows that, given a sequence classified as effective or ineffective (with74.14% accuracy, from Table I), the described method is able to state why the studentsmay have been experiencing a knowledge sharing breakdown, with 96% accuracy, orwhy the knowledge sharing interaction may have been effective, with 93% accuracy (also
4For this analysis, students B and C were distinguished from the knowledge sharer (actor A), butwere not distinguished from each other.5For this post-hoc analysis, the algorithms were permitted to overtrain the models because they wereconsidered generalizations of previously determined clusters.

372 AMY SOLLER
see Soller, 2004). One caveat, however, is that the breakdown or the success must be onethat the system has seen previously, and is trained to recognize. For the current set ofeffective examples, this covers 70% of the sequences, and for the ineffective examples,this covers 63% of the sequences. A larger dataset, however, would certainly producemore examples, and hence more coverage.
The next step is to use the results of the computational procedure to provideadvice and guidance to the students. The qualitative analyses of the HMM clus-ters describes student behaviours that may lead to either knowledge sharing break-downs or success. In the case of an identified knowledge sharing breakdown, theprocedure described in this section can be used to compute the closeness betweenthe new sequence of student actions leading to the breakdown, and each knowncluster of knowledge sharing breakdowns identified through the HMM MDS clus-tering procedure. If a cluster is identified, then the nature of the cluster shoulddrive the selection of an appropriate support strategy. For example, if the sys-tem has recognized that the sharer has explained his Knowledge Element, andthe receiver has either doubted the suggestion (case Ci), or said nothing at all(case Di), there is an opportunity for the system, or instructor, to encourage thesharer to justify, clarify, or re-explain the Knowledge Element. If the receiver hasacknowledged the explanation, but the system still has evidence that the receiverdoes not understand the material, then the system might suggest that the receiverattempt to apply the new knowledge to the problem at hand. These suggestionsfollow directly from Webb’s (1992) model of student interaction. In her model,Webb describes the actions that might lead students to positive learning outcomesafter they request help from a peer. A more extensive discussion of the qualitativeanalysis with respect to Webb’s theory can be found in Soller (2004).
If the identified knowledge sharing episode has been classified as a knowledgesharing breakdown, but is not found to be in the vicinity of a known cluster, thentwo possibilities exist: some general advice could be offered based on the particu-lar knowledge element that is in question, or more tailored advice could be offeredbased on the HMM cluster closest to the target episode.
6. Discussion
A rapidly growing interest in bringing the experience of the supportive interac-tive collaborative learning classroom to distance learning students has prompteda number of CSCL researchers to work toward the development of a compre-hensive toolbox. The toolbox contains methods and strategies for understandingand computationally supporting various aspects of online collaborative learningbehavior. Some methods that these researchers have explored include finite statemachines (McManus and Aiken, 1995), fuzzy inferencing (Barros and Verdejo,1999), decision trees (Constantino-Gonzalez, Suthers and Escamilla de los Santos,2003; Goodman et al., 2004), rule learning (Katz, Aronis, and Creitz, 1999), andplan recognition (Muehlenbrock, 2001) (see Jermann, Soller, and Muehlenbrock,

COMPUTATIONAL MODELING AND ANALYSIS 373
2001, for a review of these different approaches). Missing from this toolbox werethe tools needed to model and assess complex cognitive and social processes byanalyzing naturally occurring sequences of peer dialog and actions (on computerartifacts). One such complex cognitive and social process is that of knowledgesharing and assimilation.
Knowledge sharing conversations, especially among small groups larger than 2,are dynamic, progressive, and unpredictable. This article demonstrated the pos-sibility that analyzing these conversations with a stochastic, sequential, machinelearning tool could promote a promising new CSCL research direction. Toolsthat have been used in the past, such as finite state machines and decision trees,can only account for the sorts of conversational patterns that one might predictahead of time. Computational grammars are useful for analyzing conversationsof dyads, but in groups of three or more people, there may be multiple agen-das of conversation occurring simultaneously, causing the conversation to takeon a stochastic character. HMMs are stochastic, state-based, and appear to beable to account for the seemingly random nature of conversation in groups ofthree. This research explored the notion that HMMs might be used to identifyand explain when and why students have breakdowns during knowledge sharingconversations.
The results of the post-hoc cross validation study described in Section 5.3 con-firmed that the groups found through the MDS and clustering techniques werestable. But, they did not confirm that the descriptions of these groups, from thequalitative analysis (i.e. 1. Sharer proposes KE, 2. Receiver doubts, from Table II),reflect all of the commonalities of the examples that form the basis of the groups.The accuracy of these idealized descriptions was studied by testing the generalizedHMMs with a set of coded mock test sets. These mock test sets represented, asclosely as possible, the generalized descriptions of each cluster.
The mock test sets produced only 50% accuracy (two out of four test sequenceswere classified correctly) for the ineffective models, and 66.7% accuracy (two outof three test sequences were classified correctly) for the effective models. Thereare two things we can learn from these results. First, machine learning meth-ods are notorious for producing good, but unexplainable results. This is notunusual, because in situations in which a simple explanation suffices, machinelearning techniques would not have been needed in the first place. The techniquesapplied and described in this chapter produced good results when tasked to clas-sify sequences of coded knowledge sharing interaction. Reverse-engineering thesetechniques qualitatively may help explain why they worked well; however, by itsnature, a qualitative procedure cannot explain beyond the stochastic elements ofa computational method.
Second, the mock test sets were designed to filter out all of the noise in thesequences, and include only the essential items that were perceived to be simi-lar within the groups. If the noise were in fact an essential element of the mod-els, we would expect them to perform poorly in classifying test sets that lack this

374 AMY SOLLER
essential component. This analysis supports the concept that some degree of noiseis as important in these models as it is natural in human communication. Simplestate based models or grammars that do not take some degree of randomness intoaccount may not be as effective at procedures that do account for noise.
This research looked at how we might assist a distance learning instructor bycomputationally recognizing when and why students experience breakdowns inknowledge sharing. The analysis presented in the previous section suggests that(1) a HMM approach can be used to distinguish between effective and ineffectivestudent knowledge sharing interaction, and (2) online knowledge sharing behav-ior can be assessed by analyzing sequences of conversational acts and studentactions (on a shared workspace), with limited consideration of the dialog content.Although these claims do not preclude other methods from also performing well,our research suggests that methods that do not account for the sequential and sto-chastic nature of student interaction perform less well than the HMM approach.
7. Directions for Future Research
This research has shown how a stochastic analysis of coded sequences of student inter-action, composed of conversation acts and student actions on a shared workspace, canprovide useful information about whether or not students are effectively sharing andlearning new knowledge with each other. My hope is that this research will encourageothers to pursue similar paths. Because this is a new area of research, there are manypossible paths for future work. In this section, I elaborate on four.
The first path involves improving the automated coding, or HMM, MDS, andclustering procedures with the intent to increase the accuracy of the system. Thesecond involves trying out similar machine learning procedures on similar formsof data, and comparing the results to those reported here. The third path involvesstudying how this procedure fares in analyzing aspects of collaboration other thanknowledge sharing, and the fourth involves applying the results of this analysisto provide instructional support. The following subsections should provide somedirection to assist researchers in pursuing these four paths.
7.1. improving the procedure
Research along the first path looks at improving the method described here.Although the HMMs in the first phase of this research performed well, the 25%error rate suggests that there is still room for improvement. The codes that makeup the HMM training sequences are given by the sentence openers that thestudents choose. Although the kappa analysis presented in this article showed thatstudents do generally begin their contributions with appropriate sentence open-ers, the coding scheme associates each sentence opener with only a single, primaryintention (i.e. Suggest or Justify). As such, the system is unable to capture complexintentions, such as a Discuss/Agree act that both expresses agreement and doubt.

COMPUTATIONAL MODELING AND ANALYSIS 375
One might argue that a more complicated comprehensive coding scheme that bet-ter represents the students’ complex intentions might improve the system’s accu-racy. Assigning complex intentions to utterances, however, is quite a difficult taskfor human raters, and an even more difficult task for computers. A system thatassigns secondary intentions to student contributions may even introduce addi-tional error into the training data, reducing the accuracy of the system. Furtherresearch along these lines is needed to determine the extent to which consideringonly the primary intention limits our ability to assess learning during knowledgesharing interaction.
Alternatively, the HMM approach itself might be improved upon. For example,it is possible to manipulate the number and placement of nodes and links in theHMM, changing its topology. This means that one could form hypotheses aboutvarious phases that might be present in knowledge sharing episodes (or episodesof other types of interaction), and test these hypotheses by studying the outputfrom different HMM structures (Schrodt, 2000). If, in fact, definable phases existfor learning interaction (e.g. a proposal phase, or an explanation phase), then atopology that better reflects this phase structure may increase the system’s accu-racy. Hill climbing procedures might also be used to train a system to learn theoptimal HMM topology (Freitag and McCallum, 2000).
In the second phase of this research, 58 individual HMMs were trained fromthe 58 knowledge sharing episodes before applying the MDS and clustering rou-tines. Training an HMM on only one example introduces a good deal of noiseinto the process. It may be possible to reduce the amount of noise generated beforerunning the MDS procedure by pre-processing to remove the sequence items thatdo not recur often. Although we saw in the previous section that some amountof noise is important in modeling natural human communication, more researchis needed to determine if codes that harbour less predictive power might be safelyomitted from the model.
Perhaps an obvious way to improve the accuracy of the system is to gathermore data. Data could be gathered by running more experiments, similar to theones described here, or by having students interact with the system and providefeedback. For example, the system might identify a knowledge sharing breakdown,offer advice to the students, and then ask the students to respond with an evalua-tion of the advice. The system might then integrate the student evaluations into itsmodels. Or, if the system fails to offer advice during a knowledge sharing episodethat it believes is effective, and the students are able to request help (i.e. by click-ing on a ‘HELP’ button) at the time, then the system might self-update by addingthe current knowledge sharing episode to its database.
7.2. testing and comparing similar methods
The second path worthwhile considering is that in which methods similar tothe one employed here are applied and compared. HMMs may not be the only

376 AMY SOLLER
stochastic, state-based method useful for analyzing and assessing sequences of stu-dent interaction. It seems clear that some degree of sequencing, randomness, andnoise is important; however other, similar algorithms (Roth, 1999) may performcomparably. For example, a preliminary analysis done using the data from the firstfive LRDC experimental groups showed that a genetic algorithm approach mayperform just as well as the HMM approach (A. Berfield, personal communication,April 22, 2002).
A hybrid approach could also be applied that combines HMMs with other com-putational methods for evaluating sequences of student interaction. For example,the HMM path probabilities may be used as one factor, among others obtainedstatistically, that contributes to a weighted assessment function (Walker et al.,1997) for evaluating student interaction effectiveness. Weighted combinations offactors can also serve as feature vectors in decision trees, or input layers in neuralnetworks.
In collaboration with the IMMEX laboratory at the University of California,Los Angeles, we have begun to extend the HMM approach to study studentproblem solving patterns in scientific inquiry domains. Previous research has suc-cessfully applied neural networks to identify and assess students’ problem solv-ing strategies (Stevens et al., 1999; Vendlinski and Stevens, 2002). Our preliminaryresults suggest that a hybrid approach might be used to predict whether or not stu-dents with less effective problem solving strategies are likely to change their strat-egies on the next problem set (Stevens et al., 2004). The hybrid approach involvesapplying HMMs to model the results of the Neural Network strategy assessmentover a series of problem set performances.
7.3. applying stochastic modeling to other aspects of collaboration
Knowledge sharing is just one of the many interrelated factors that influencegroup learning performance. The success of the HMM approach in analyzingknowledge sharing activities suggests that this sort of method might also beused to analyze other aspects of collaboration. But not every aspect is a goodcandidate. Supervised machine learning methods require that the variable underevaluation be measurable such that the training data can be tagged for classifica-tion. In the case of this research for example, the experiments were set up suchthat the sharing and learning of specific knowledge elements could be measuredvia pre and post tests. Good candidates might include factors such as cogni-tive conflict or student confidence. Cognitive conflict might be measured by com-paring the degree of disagreement before and after a problem solving session.Confidence, although less concrete, might be measured through questionnaires,and analyzed by modeling sequences of student interaction and problem solv-ing. The task might also be designed to include various situations intended toalter students’ confidence levels, so that the interaction can be observed in thosecontexts.

COMPUTATIONAL MODELING AND ANALYSIS 377
Applying this research to other aspects of collaboration need not mean tak-ing an HMM or similar approach. This article was intended to demonstrate notonly the utility of the HMM approach, but also the ability of a system to makeinferences about student learning from sequences of conversation acts and studentactions. Researchers interested in studying other aspects of collaboration may alsobenefit from analyzing such sequences. For example, work is now in progress at theMITRE Corporation, in Bedford, Massachusetts, to analyze coded sequences ofstudent interaction in order to assess students’ roles and interaction performance(Goodman et al., 2004). The sequences were obtained from the interface describedin this article, and consequently use the same coding scheme as this research.
7.4. providing instructional support
Once a knowledge sharing breakdown is identified, the next step is to determinehow to facilitate the group interaction through appropriate types of guidance.Research along this fourth path focuses on how to provide direction to the curric-ulum developers and instructional designers who might assist system developers inconstructing and implementing appropriate responses to student actions (for moreinformation, see Soller, 2004; Jermann, Soller and Lesgold, 2004).
The first step in providing support is determining when the students could usehelp. If the system were to offer guidance to the students each time the knowledgesharing analyzer identified a knowledge sharing breakdown, the students wouldreceive help about 74% of the time they need it. This is based on the results ofthis research showing that the knowledge sharing analyzer can correctly classify thecoded sequences about 74% of the time. Although this is not perfect, it may besufficient if we can assume that severe knowledge sharing breakdowns will proba-bly recur, at which points the system would have another opportunity to addressthem. Combining this approach with individual student modeling methods mightalso help the system detect breakdowns related to individual student impasses, andincluding a help button on the interface would enable students to obtain help whenthe system fails to detect a problem.
The next step in providing support is to determine whether or not the knowl-edge sharing episode in question matches one of the identified clusters that weredescribed in Section 5.3. If a cluster is identified, then the nature of the clustershould drive the selection of an appropriate support strategy. If no cluster is iden-tified, but the episode has been classified as a knowledge sharing breakdown, thenthe system might offer some general advice based on the particular knowledgeelement that is in question, or alert an online instructor that the learning groupis having difficulty understanding the concept.
In the development and selection of appropriate support strategies,understanding what students are doing when they succeed is just as important asunderstanding why students are failing. The data collected for this study revealedthat effective knowledge sharing patterns include situations in which the receiver

378 AMY SOLLER
probes the sharer for information, the sharer provides justification and clarifica-tion, and the receiver provides motivation and encouragement.6 In developingsupport strategies, these are some of the behaviors that we might like to encourage.
In the future, collaborative learning technology will continue to enrich distancelearning programs by connecting peers, bringing the virtual classroom to life. Dis-tance learning programs will become seamlessly integrated into our educationalsystem, and meeting the educational and social needs of evolving online learninggroups will become even more of a challenge. Efforts to leverage cross disciplin-ary research to further develop computer-based support for online groups will nodoubt benefit both instructors and students. We have just begun to construct atoolbox of methods for helping to manage, facilitate, and support various onlinecollaborative learning activities. Future research should continue to fill, examine,and augment this toolbox with new techniques. With a more complete toolbox athand, researchers may be better suited to adopt flexible and holistic views of sup-porting learning communities. This research contributed to the development of thistoolbox by introducing and testing a new tool that aids in the understanding andanalysis of a critical aspect of collaborative learning – knowledge sharing.
Acknowledgements
I am greatly indebted to Alan Lesgold for his partnership, guidance, support, andingenious insight throughout this research. Special thanks to Brad Goodman andFrank Linton at MITRE for helping to run the experiments and gather data forthis research, Patrick Jermann for his insight and motivation, and Dan Suthers,Diane Litman, Sandy Katz, and Janyce Wiebe for their collaboration and support.Thanks also to the anonymous reviewers for their detailed comments on an earlierversion of this article. This research was funded by the NetLearn project at LRDC,University of Pittsburgh.
References
Baker, M. and Lund, K.: 1997, Promoting reflective interactions in a computer-supportedcollaborative learning environment. Journal of Computer Assisted Learning 13, 175–193.
Barros, B. and Verdejo, M.F.: 1999, An approach to analyse collaboration when sharedstructured workspaces are used for carrying out group learning processes. Proceedingsof the Ninth International Conference on Artificial Intelligence in Education, Le Mans,France, pp. 449–456.
Brown, A. and Palincsar, A.: 1989, Guided, cooperative learning and individual knowledgeacquisition. In L. Resnick (ed.), Knowing, Learning, and Instruction: Essays in Honor ofRobert Glaser. Hillsdale, NJ: Lawrence Erlbaum Associates, pp. 393–451.
6This list is certainly not exhaustive, and a larger data collection would almost certainly producemore patterns.

COMPUTATIONAL MODELING AND ANALYSIS 379
Carletta, J., Isard, A., Isard, S., Kowtko, J., Doherty-Sneddon, G. and Anderson, A.: 1997,The reliability of a dialogue structure coding scheme. Computational Linguistics 23,13–32.
Charniak, E.: 1993, Statistical Language Learning. Cambridge, MA: MIT Press.Chi, M. T. H., Bassok, M., Lewis, M. W., Reimann, P. and Glaser, R.: 1989, Self-Expla-
nations: How students study and use examples in learning to solve problems. CognitiveScience 13, 145–182.
Constantino-Gonzalez, M.A., Suthers, D. and Escamilla de los Santos, J.: 2003, Coachingweb-based collaborative learning based on problem solution differences and participa-tion. International Journal of Artificial Intelligence in Education 13, 263–299.
Dillenbourg, P.: 1999, What do you mean by “Collaborative Learning”? In P. Dillenbourg(ed.), Collaborative learning: Cognitive and computational approaches. Amsterdam: Else-vier Science, pp. 1–19.
Fisher, L. and van Belle, G.: 1993, Biostatistics: A methodology for the health sciences. NewYork: John Wiley and Sons Inc.
Freitag, D. and McCallum, A.: 2000, Information extraction with HMM structures learnedby stochastic optimization. Proceedings of the AAAI 2000, Austin, Texas, pp. 584–589.
Goodman, B., Linton, F., Gaimari, R., Hitzeman, J., Ross, H. and Zarrella, J.: 2004, Usingdialog features to predict trouble during collaborative learning. Manuscript in prepara-tion.
Gott, S. and Lesgold, A.: 2000, Competence in the workplace: How cognitive performancemodels and situated instruction can accelerate skill acquisition. In R. Glaser (ed.),Advances in Instructional Psychology: Vol. 5. Educational Design and Cognitive Science.Mahwah, NJ: Lawrence Erlbaum Associates, pp. 239–327.
Jeong, H.: 1998, Knowledge Co-construction During Collaborative Learning. Doctoral Dis-sertation. University of Pittsburgh, Pittsburgh, PA.
Jermann, P. and Schneider, D.: 1997, Semi-structured interface in collaborative problemsolving. Proceedings of the First Swiss Workshop on Distributed and Parallel Systems,Lausanne, Switzerland.
Jermann, P., Soller, A. and Muehlenbrock, M.: 2001, From mirroring to guiding: A review of stateof the art technology for supporting collaborative learning. Proceedings of the First EuropeanConference on Computer-Supported Collaborative Learning, Maastricht, The Netherlands,pp. 324–331.
Jermann, P., Soller, A. and Lesgold, A.: 2004, Computer software support for CSCL. In P. Dillen-bourg (series ed.), and J. W. Strijbos, P. A. Kirschner, and R. L. Martens (vol. eds.), Computer-Supported Collaborative Learning: Vol 3. What We Know About CSCL . . . and Implementingit in Higher Education. Boston, MA: Kluwer Academic Publishers, pp. 141–166.
Juang, B. and Rabiner, L.: 1985, A probabilistic distance measure for Hidden MarkovModels. AT and T Technical Journal 64(2), 391–408.
Katz, S., Aronis, J. and Creitz, C.: 1999, Modelling pedagogical interactions with machinelearning. Proceedings of the Ninth International Conference on Artificial Intelligence inEducation, Le Mans, France, pp. 543–550.
Kruskal, J. and Wish, M.: 1978, Multidimensional scaling. Newbury Park, California: SagePublications.
Lavery, T., Franz, T., Winquist, J. and Larson, J.: 1999, The role of information exchangein predicting group accuracy on a multiple judgment task. Basic and Applied SocialPsychology 2(4), 281–289.
Linton, F. Goodman, B., Gaimari, R., Zarella, J. and Ross, H.: 2003, Student modeling foran intelligent agent in a collaborative learning environment. Proceedings of User Mod-eling 2003, Johnstown, PA, pp. 342–351.

380 AMY SOLLER
Looney, C.: 1997, Pattern Recognition Using Neural Networks. New York: Oxford Univer-sity Press.
McManus, M. and Aiken, R.: 1995, Monitoring computer-based problem solving. Journalof Artificial Intelligence in Education 6(4), 307–336.
Muehlenbrock, M.: 2001, Action-based Collaboration Analysis for Group Learning. Doc-toral Dissertation, University of Duisburg, Germany.
Perret-Clermont, A., Perret, J., and Bell, N.: 1991, The social construction of meaning andcognitive activity in elementary school children. In L. Resnick, J. Levine and S. Teas-ley (eds.), Perspectives on Socially Shared Cognition. American Psychological Society,Washington, DC, pp. 41–62.
Rabiner, L.: 1989, A tutorial on Hidden Markov Models and selected applications inspeech recognition. Proceedings of the IEEE 77(2), 257–286.
Roth, D.: 1999, Learning in natural language. Proceedings of the International Joint Con-ference on Artificial Intelligence (IJCAI ’99), Stockholm, Sweden, pp. 898–904.
Rumbaugh, J., Blaha, M., Premerlani, W., Eddy, F. and Lorensen, W.: 1991, Object-orientedmodeling and design. Englewood Cliffs, NJ: Prentice Hall.
Schrodt, P.: 2000, Pattern recognition of international crises using Hid-den Markov Models. In D. Richards (ed.), Political Complexity: Non-linear Models of Politics. Ann Arbor: University of Michigan Press,pp. 296–328.
Shepard, R.: 1980, Multidimensional Scaling, Tree-fitting, and clustering. Science 210, 90–398.
Smyth, P.: 1997, Clustering sequences with Hidden Markov Models. In M. Mozer, M. Jor-dan and T. Petsche (eds.), Proceedings of the 1996 Conference on Advances in NeuralInformation Processing Systems 9, MIT Press, pp. 648–654.
Soller, A.: 2001, Supporting social interaction in an intelligent collaborative learning sys-tem. International Journal of Artificial Intelligence in Education 12(1), 40–62.
Soller, A.: 2002, Computational Analysis of Knowledge Sharing in Collaborative DistanceLearning. Doctoral dissertation, University of Pittsburgh, Pittsburgh, PA.
Soller, A.: 2004, Understanding knowledge sharing breakdowns: A meeting of the quanti-tative and qualitative minds. Journal of Computer Assisted Learning 20.
Soller, A. and Lesgold, A.: in press, Modeling the process of knowledge sharing. In U.Hoppe and M. Ikeda (Eds.), New Technologies for Collaborative Learning. Kluwer Aca-demic Publishers.
Soller, A., Linton, F., Goodman, B. and Gaimari, R.: 1996, [Videotaped study: 3 groupsof 4–5 students each solving software system design problems using Object Mod-eling Technique during a one week course at The MITRE Institute]. Unpublishedraw data.
Stevens, R., Ikeda, J., Casillas, A., Palacio-Cayetano J. and Clyman, S.: 1999, Artifi-cial neural network-based performance assessments. Computers in Human Behavior15(1999), 295–313.
Stevens, R., Soller, A., Cooper, M., and Sprang, M.: 2004, Modeling the development ofproblem-solving skills in chemistry with a web-based tutor. Proceedings of the 7th Inter-national Conference on Intelligent Tutoring Systems (ITS 2004), Maceio, Brazil.
Tedesco, P. A.: 2003, MarCo: Building an artificial conflict mediator to support groupplanning interactions. International Journal of Artificial Intelligence in Education 13,117–155.
Vendlinski, T. and Stevens, R.: 2002, Assessing student problem-solving skills with complexcomputer-based tasks. Journal of Technology, Learning, and Assessment, 1(3), [Avail-able: http://www.jtla.org].

COMPUTATIONAL MODELING AND ANALYSIS 381
Viterbi, A.: 1967, Error bounds for convolutional codes and an asymptotically optimaldecoding algorithm. IEEE Transactions on Information Theory 13, 260–269.
Walker, M., Litman, D., Kamm, C. and Abella, A.: 1997, PARADISE: A framework forevaluating spoken dialogue agents. Proceedings of the 35th Annual Meeting of the Asso-ciation of Computational Linguistics (ACL ‘97), Madrid, Spain, pp. 271–280.
Webb, N.: 1992, Testing a theoretical model of student interaction and learning in smallgroups. In R. Hertz-Lazarowitz and N. Miller (eds.), Interaction in Cooperative Groups:The Theoretical Anatomy of Group Learning. New York: Cambridge University Press,pp. 102–119
Webb, N. and Palincsar, A.: 1996, Group processes in the classroom. In D. Berlmer andR. Calfee (eds.), Handbook of Educational Psychology. New York: Simon and SchusterMacmillan, pp. 841–873.
Winquist, J. R. and Larson, J. R.: 1998, Information pooling: When it impacts group deci-sion making. Journal of Personality and Social Psychology 74, 371–377.
Yang, J., Xu, Y. and Chen, C.: 1997, Human action learning via Hidden Markov Model.IEEE Transactions on Systems, Man, and Cybernetics – Part A: Systems and Humans27(1), 34–44.
Author’s vitae
Dr. Amy SollerITC-IRST Institute for Scientific and Technological Research, 38050 Povo Frento,Italy.Dr. Amy Soller is a postdoctorate researcher and project manager at ITC-IRST,working in the areas of user and community modeling, knowledge management,and adaptive web-based collaborative learning environments. She received her B.S.in Electrical Engineering from Boston University in 1996, and her M.S. andPh.D. degrees in Artificial Intelligence from the University of Pittsburgh, under thesupervision of Dr. Alan Lesgold. Her previous research experience includes workas a Senior Artificial Intelligence Engineer in the Advanced Instructional Environ-ments and Analytic Tools division of the MITRE Corporation. Her contributionis based on her dissertation research.





























