Embed Size (px)
Citation preview

Robin Lievrouw
Collective Learning in Swarm Robotics
Academic year 2017-2018Faculty of Engineering and ArchitectureChair: Prof. dr. ir. Bart DhoedtDepartment of Information Technology
Master of Science in Information Engineering TechnologyMaster's dissertation submitted in order to obtain the academic degree of
Counsellor: Dr. Yara KhalufSupervisors: Prof. dr. ir. Pieter Simoens, Dr. Yara Khaluf


Word of thanks
First and foremost, I would like to thank my supervisor dr. Yara Khaluf for always beingavailable for help during my thesis, giving me meaningful feedback while always being veryfriendly.Secondly, I would like to thank Prof. dr. ir. Pieter Simoens as well, for giving me the opportunityto write my thesis about the very interesting field of swarm robotics and also giving me insightfulfeedback.Finally, I would like to thank my parents for supporting me during this thesis as well as thankmy good friends in Ghent for all the good times that were had.

Abstract
Robot swarms are the artificial equivalent of natural swarms of animals. Examples of this arecolonies of ants or shoals of fish. Swarm robotics, a field of study that deals with decentralizedcoordination of a lot of small, autonomous robots, takes a lot of inspiration from natural swarmsto develop collective behaviors such as foraging or aggregation. In this thesis, the focus lies ondeveloping a homogeneous robotic swarm that learns the rewards associated with its actionsthrough two learning approaches based on reinforcement learning, with the ultimate goal ofmaximizing the swarms collective lifetime. The two proposed approaches are validated in a sim-ulated experiment using the ARGoS simulator and the effects of certain factors on the learningprocess are researched.


Collectief leren in Zwerm-RoboticaRobin Lievrouw
Promotor(s): Prof. dr. ir. Pieter Simoens, Dr. Yara Khaluf
Abstract— In dit artikel worden twee leermethodes voorgesteld engevalideerd om een robotzwerm de associaties tussen beloning en straf telaten aanleren in een onbekende omgeving met gebruik van de ARGoS sim-ulator. Het doel van de leertechnieken is om de collectieve levensduur vande zwerm te gaan maximaliseren, waarbij verscheidene factoren die eeninvloed hebben op het leerproces worden onderzocht.
Kernwoorden— conditionering - robotzwermen - collectief leren - trialand error
I. INLEIDING
ZWE rm-robotica is een relatief nieuw veld van studie waar-bij het gaat om de coordinatie van meerdere kleine een-
voudige robots. Deze coordinatie gebeurd op een gedecen-traliseerde, zelforganiserende manier waarbij er inspiratie wordtgenomen van natuurlijk voorkomende zwermen zoals scholenvan vissen en mierenkolonies.
Elke robot zijn levensduur is afhankelijk van zijn batterij,waarbij zo efficient mogelijk opereren noodzakelijk is om dielevensduur te maximaliseren. Een van de grootste sterktes vaneen zwerm komt uit de hoeveelheid individuen die tegelijk oper-eren. Het is dus wenselijk dat elk individu van een zwerm evenlang en zo lang mogelijk leeft. Dit zodanig dat de populatieg-rootte constant blijft over de tijd.
Om de collectieve levensduur van de zwerm zolang mo-gelijk te maken is het dus noodzakelijk dat elk individu energie-efficiente strategieen gaat aanleren door kennis te vergaren endeze kennis te gaan omzetten in een bepaald gedrag.
In dit artikel worden twee leermethodes ontwikkeld waar-bij men naast , traditionele conditionering, het leren door be-loning en straf, ook leren door goedkeuring van anderen gaattoepassen op een robotzwerm die zich in een onbekende omgev-ing bevindt. Hierbij is het de bedoeling dat de robots leren omhun energieniveau zo gelijk mogelijk te houden over de gehelezwerm om zo de collectieve levensduur te maximaliseren. Detwee ontwikkelde methodes worden gevalideerd door gebruik temaken van een gesimuleerd experiment in de ARGoS simulator,waarbij de invloed van verscheidene factoren op het leerproceswordt onderzocht. De effectiviteit van beide technieken wordtonderzocht door een vergelijking te stellen tussen de verdelingvan de energieniveaus voor en na het uitvoeren van het experi-ment.
II. LITERATUUR
A. Collectieve Robotsystemen
Collectieve robotsystemen zijn systemen waarbij er gewerktwordt met meerdere robots tegelijk, wat bepaalde voordelen enook nadelen met zich meebrengt. Een van die voordelen isbijvoorbeeld het feit dat bepaalde taken die onmogelijk warenvoor een enkele robot, nu wel mogelijk zijn voor meerdere,waarbij men kan rekenen op een grotere parallelliteit. De robu-ustheid van het systeem wordt ook bevorderd. Een belangrijk
nadeel dan, is de complexiteit die gepaard gaat met het con-troleren van zo’n collectief systeem, als ook de interferentie dietussen robots kan ontstaan.
Zwermsystemen dan, zijn een bijzonder geval van zo’n col-lectief systeem, waarbij bepaalde eigenschappen mee gepaardgaan. De autonomie van elke individu of robot is hier een eerstevan. Ook worden de robots op een gedecentraliseerde maniergecontroleerd en dit door lokale interacties met elkaar en deomgeving te gaan uitvoeren waarbij de som van al de individuelegedragen leidt tot een collectief gedrag van de zwerm. Nog eeneigenschap van zwermsystemen is de eenvoud van elk individu,waarbij sensoren en communicatie lokaal zijn.
B. Ontwerpmethodes voor robotzwermen
Voor het ontwerpen van robotzwermen bestaan er verschil-lende methodes, waarbij de meeste vallen onder twee cate-gorieen, gedragsgebaseerd of automatisch.Gedragsgebaseerde methodes starten met het ontwikkelen vanhet individueel gedrag van elke robot waarbij men aanpassingenblijft uitvoeren op een trial and error manier tot het gewenstecollectieve gedrag van de zwerm zich voordoet.In de automatische categorie, wordt het gedrag niet ontwikkelddoor mensen, maar wordt het zelf automatisch gegenereerd. Hi-erbij zijn er twee subcategorieen, namelijk evolutionaire robot-ica en reinforcement learning of conditionering.Bij evolutionaire robotica worden de principes van evolutie inde natuur zoals de wet van de sterkste en natuurlijke selectietoegepast om zo gewenst robotgedrag te gaan genereren.Bij conditionering echter, gaat men gedragen gaan aanleren doormiddel van beloning en straf.
C. Collectief Beslissen en leren
Het maken van een collectieve beslissing is een subveld vancollectief gedrag waarbij het gaat om een keuze van een groepindividuen, die na gemaakt te zijn, niet meer aan een enkeleindividu kan gelinkt worden. Collectieve beslissingen zijn eenbelangrijk aspect voor zwerm-robotica omdat het een noodzake-lijk component is bij vele toepassingen [3]. Groepsbeslissingenhebben ook een aantal voordelen over individuele beslissingen.Een der van is bijvoorbeeld het argument van de ”wisdom of thecrowds”, waarbij het gebruikmaken van meerdere meningen ineen groepsbeslissing leidt tot een beter geınformeerde besliss-ing.
Een nadeel dan aan collectieve beslissingen is afkomstig vanhet complexe effect dat de ordening en mobiliteit [4] van de zw-erm kan hebben op de dynamica van zo’n groepsbeslissing, wathet soms moeilijk maakt om theoretische modellen voor groeps-beslissingen effectief te gaan implementeren.

D. Reinforcement Learning
Reinforcement learning of conditionering is een leertechniekwaarbij een individu de associaties gaat leren tussen zijn actiesen de beloning of straf daarvoor. Bij conditionering gaat mendie associaties leren door te gaan interageren met zijn omgevingwaardoor men kennis verkrijgt, die men dan exploiteert om een”policy” te gaan aanleren. Die policy definieert het eigenlijkegedrag van een individu, waarbij men weet in welke situatie menwelke actie moet uitvoeren om zoveel mogelijk beloning te gaanverkrijgen. Door bepaalde acties te straffen en andere te belonenkan men dan een gewenst gedrag gaan genereren.
III. ONDERZOEK
In dit artikel, zijn er twee leermethodes ontwikkeld die ge-bruikt worden om een robotzwerm zijn collectieve levensduur tegaan maximaliseren. Bij beide methodes wordt er op een manierbeloning en straf uitgedeeld voor elke actie die uitgevoerd wordtom zo de robots een bepaald gedrag te gaan aanleren die collec-tief leidt tot een betere uitkomst.
Wat volgt is een korte theoretische uitleg over beide meth-odes, gevolgd door wat uitleg over de gekozen robotsimulatoren robot.
A. Toepassen van conditionering
In de eerste methode wordt een traditionele techniek van con-ditionering toegepast waarbij robots de relatie tussen beloningen hun acties gaan leren door te gaan interageren met hunomgeving. Deze ervaringen gebruiken ze dan om hun gedragte gaan vormen naar maximalisatie van het beloningssignaal.Door bepaalde acties te gaan belonen en anderen te gaan straf-fen, kunnen we bepaald gedrag gaan aanleren aan de robots.Deze methode heeft wel een belangrijke toevoeging wat leidt toteen collectief leren in plaats van individueel. De ervaringen dieelke robot namelijk opdoet in zijn omgeving, worden gedeeldmet zijn dichte buren, om zo kennis sneller te gaan verspreidenin de zwerm en dus een versnellend effect te hebben op het leer-proces.
B. Zwerm laten leren door herhaalde stemmingen
De tweede methode werkt gelijkaardig met de eerste, waar-bij het grote verschil zit in het beloningsmechanisme. Daarwaar voordien de beloning uit de omgeving voortkwam, is zenu afkomstig vanuit de zwerm zelf. Hierbij zijn het de bu-ren van een robot zijn die een bepaalde actie goed of slechtkeuren. Als men dan een meerderheid van robots heeft die eenvoorkeur hebben voor bepaald gewenst gedrag, kan je de gehelezwerm een bepaald gedrag gaan aanleren, omdat nu ook weerelke robot streeft naar het maximaliseren van zijn verkregen be-loning. Als een actie meer goedkeuringen dan afkeuringen kri-jgt, wordt deze dus beloont en andersom gestraft. Bij een ex ae-quo of wanneer er geen goed- of afkeuringen worden vernomen,is er ook geen beloning of straf.
C. Simulatie met ARGoS
Onderzoekers in robotica kiezen vaak voor simulaties van ex-perimenten in plaats van het werken met echte robots om ver-scheidene redenen. Kost is hier een van de grootste factoren,
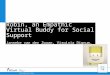
naast het feit dat het uitvoeren van echte experimenten ook veeltijd in beslag neemt. Het gebruik van simulators, die accuraatgenoeg zijn tegenover de echte wereld, vormt hierdoor een heelaantrekkelijk alternatief. Voor zwerm-robotica is de ARGoS(Autonomous Robots Go Swarming) simulator een aantrekke-lijke, open-source simulator met hoge nauwkeurigheid, flexi-biliteit en performantie. Waar andere simulators falen om dezedrie eigenschappen te kunnen combineren [2] zoals Stage ofGazebo, is ARGoS de eerste die dit wel kan. Het is dan ookde keuze geworden als robotsimulator voor dit werk.ARGoS heeft verschillende robots beschikbaar ter simulatie enhier is er gekozen voor de foot-bot, een bepaalde configuratievan het modulaire marXbot robotplatform. De foot-bot is eenkleine, mobiele robot die beschikt over verschillende sensorenen modules. Op figuur 1 kan je de foot-bot zien met zijn sen-soren en features.
Fig. 1. Overzicht van de foot-bot zijn sensoren en modules
D. Experiment
In het gesimuleerde experiment wordt dus een zwerm vanfoot-bots losgelaten in een arena van 10 vierkante meter. Elkerobot start het experiment met een eigen energieniveau, die lin-eair met de tijd leegloopt. Hierbij kan dit niveau niet onder nulgaan, maar blijft de robot wel functioneren bij een leeg energien-iveau. De waarde die elke robot krijgt als startwaarde voor zijnenergieniveau is willekeurig genomen uit een normale verdelingmet een grote spreiding. (Gemiddelde = 500, Standaarddeviatie= 250)
De arena heeft verschillende energievlekken op de grond,die elke foot-bot kan consumeren om zo bijkomende energiete verkrijgen. Hierbij gebruikt de foot-bot zijn grondsensorom veranderingen in grijswaardes op de grond op te merken.In de arena moet de foot-bot op verschillende tijdstippenkeuzes maken, waarin telkens moet gekozen worden tusseneen egoıstische actie en een cooperatieve actie. Een voorbeeldvan zo’n keuze is bijvoorbeeld wanneer een foot-bot zo’n en-ergievlek detecteert. Hij moet dan de keuze maken tussen hetconsumeren van de energie(egoıstisch) of cooperatief op zoekgaan naar de foot-bot die deze energievlek het meest nodig heeft(het laagste energieniveau heeft). Hierbij kiest de foot-bot voorde actie die gemiddeld het meest beloning oplevert.

Het doel van het experiment is om het energieniveau over degehele zwerm ongeveer gelijk te maken of uniformeren, zodanigdat men de collectieve levensduur van het gehele zwerm gaatmaximaliseren. Van dit doel, heeft elk individu van de zwermnatuurlijk geen weet. Hierbij heeft elke foot-bot als individueeldoel wel, om beloning te gaan maximaliseren. Om ervoor tezorgen dat het collectief doel bereikt wordt, gaan we dus gebruikmaken van de twee voorgestelde methodes.
Fig. 2. Screenshot van experiment setting
IV. RESULTATEN
A. Eerste methode
Voor de eerste leermethode te onderzoeken werd het experi-ment opgesteld met een populatiegrootte van 80 foot-bots en meteen duur van 10000 simulatiestappen of 1000 seconden. Hier-bij startten de foot-bots het experiment met een voorkeur vooregoıstische acties.
In figuur 3 kan men het verschil zien tussen de energieniveau-verdeling over de gehele zwerm voor en na afloop van het exper-iment. Het energieniveau is duidelijk veel meer uniform over degehele zwerm dan bij de start, waarbij er bovendien geen enkelefoot-bot is die een energie niveau van nul heeft. Ook de proba-biliteiten voor de verschillende acties zijn door de leertechniekgevormd naar cooperatief gedrag.
Het experiment is initieel geconfigureerd met energievlekkendie opnieuw te voorschijn komen na consumptie en daarom kri-jgen de foot-bots eigenlijk oneindig veel kansen om uit hunomgeving te leren. Als men het aantal consumpties over degehele zwerm echter limiteert door de vlekken te laten verd-wijnen, hebben de foot-bots maar een eindig aantal kansen omte leren. Het experiment uitvoeren met een limiet van 100 con-sumpties leidde tot een onderbreking in het leerproces, waarbijhet belang van de communicatie van ervaringen wordt onder-streept. Door die communicatie worden de weinige ervaringengedeeld met anderen, wat leidt tot meer kennis doorheen de zw-erm. 100 consumpties bleek niet voldoende om doorheen degehele zwerm cooperatief gedrag te vormen.
Een andere toevoeging aan het experiment was het introduc-eren van een scenario waarbij de foot-bots, na aanleren vancooperatief gedrag, toch terugvielen op hun egoıstische keuzes.
Fig. 3. Energieniveauverdeling bij start en afloop experiment
Dit gebeurd wanneer de foot-bots weten dat hun energieniveaubinnen een bepaalde tijd lager dan een drempelwaarde gaat za-kken en ze voorspellen dit aan de hand van hun instroom vanenergie, door consumpties, te vergelijken met de uitstroom. Hi-erdoor gaan ze hun aangeleerd gedrag gaan negeren en kiezenze voor hun individuele overlevingskansen zo groot mogelijk temaken door alle gedetecteerde energievlekken onmiddellijk teconsumeren. In figuur 4 kan men deze overgang zien over detijd, waarbij het experiment dubbel zo lang is uitgevoerd. Defiguur toont hierbij de evolutie van het gedrag over de gehelezwerm bij het detecteren van een energievlek. De figuur betreftweer de keuze over consumptie van een energievlek bij detectie.De blauwe lijn indiceert een cooperatieve keuze, de rode eenegoıstische.
Fig. 4. Probabiliteiten voor keuze over consumptie van energievlekken bij de-tectie doorheen de tijd

Vanaf simulatiestap 4000 wordt het aantal beschikbare en-ergievlekken in de arena sterk verminderd, wat leidt tot eenuithongering van energie doorheen het zwerm, waardoor na ver-loop van tijd elke foot-bot kiest voor het overlevingsmecha-nisme.
B. Tweede methode
Het experiment werd hier uitgevoerd met 100 foot-bots, waar-bij 70 % van de foot-bots een voorkeur heeft voor cooperatiefgedrag en 30 % voor egoıstisch gedrag. Deze meerderheidvan foot-bots is voldoende om er voor te zorgen dat na ver-loop van tijd, de gehele zwerm leert om zich te gedragen opdezelfde manier. Hierbij gebeurd dit proces natuurlijk tragerdan bij de eerste methode omdat er nog een minderheid van 30% vasthoudt aan egoıstische acties bij het begin van het experi-ment. In figuur 5 kan je de energieverdeling zien van de zwermna afloop van het experiment, waarbij er verschillende mogeli-jke functies gefit worden tegen de data. De Cauchyverdelingpast hierbij het best volgens bepaalde criteria.
Fig. 5. Energieniveauverdeling bij start en afloop experiment
Dit experiment werd ook uitgevoerd voor verschillende pop-ulatiegroottes, waarbij het op viel dat er een toename was inde snelheid van het leerproces bij grotere populaties. Dit komtomdat er meer foot-bots zijn die tegelijk de omgeving aan hetverkennen zijn, wat leidt tot meer simultane interacties. Dit,gekoppeld aan het feit dat er een grotere participatie is bij elkestemming over een actie, leidt tot een sneller leerproces. Eengrotere populatie kan ook nadelig uitvallen vanaf een bepaaldegrootte. Doordat de arena maar beperkt plaats heeft, zorgenhele grote zwermen van robots voor veel interferentie doordatde robots elkaar constant moeten ontwijken. De foot-bots kun-nen de arena niet vrij verkennen door deze hinder, waardoor hetleerproces vertraagd.
Het experiment werd ook uitgevoerd met verschillendegroottes van meerder- of minderheden aan cooperatieve foot-bots. Waarbij bij een minderheid, dit duidelijk zorgt voorslechte resultaten op de spreiding van de energieniveaus door-dat egoıstisch gedrag over de tijd de overhand neemt.
Daar waar voorheen het experiment werd uitgevoerd met eenuniforme verdeling van de foot-bots van beide ”gemeenschap-pen”, egoıstisch en cooperatief, werd het effect onderzocht vaneen slechte verdeling, waarbij de twee gemeenschappen gesplit
starten in het experiment. Dit zorgt voor een vertraging in hetleerproces, omdat beide gemeenschappen elkaars acties goed-keurden, omdat er een afwezigheid van andere meningen is. Defoot-bots mengen zich echter snel, waarna het effectieve leer-proces op gang komt.
V. CONCLUSIE
In dit artikel zijn twee leermethodes, die ontwikkeld engevalideerd zijn met de ARGoS simulator, toegepast op eenrobotzwerm van foot-bots die de taak krijgt om zijn collectievelevensduur te gaan maximaliseren in een onbekende omgeving.De foot-bots doen dit door hun energieniveau zoveel mogelijkuniform te maken doorheen de zwerm en dat gedrag leren zeaan door middel van leren.
De eerste voorgestelde methode is een variant van rein-forcement learning waarbij de communicatie van ervaringen istoegevoegd, met een positief effect op het leerproces als gevolg.Dit blijkt een effectieve methode te zijn, aangezien na afloopvan het experiment we goede resultaten zien op vlak van sprei-ding van het energieniveau. Hierbij zagen we het effect van eengelimiteerd aantal leermogelijkheden op het leerproces en intro-duceerden we een scenario waarin persoonlijke overleving terugde overhand op geleerde kennis krag.
De tweede methode is gelijkaardig aan de eerste, maar daarwaarbij bij de ene methode de beloningen uitgingen van deomgeving, komen ze hier vanuit de zwerm zelf. De methodebleek effectief om de zwerm geheel cooperatief gedrag te gaanaanleren bij een startende meerderheid van 70% cooperatievefoot-bots. Hierbij zijn er verschillende factoren gevonden en on-derzocht die een invloed hebben op het leerproces werden zoalspopulatiegrootte en ruimtelijke ordening van beide, egoıstischeen cooperatieve, gemeenschappen.
REFERENCES
[1] Brambilla Manuele ,Ferrante Eliseo ,Birattari Mauro Dorigo, Marco”Swarm robotics: a review from the swarm engineering perspective, SwarmIntelligence, vol. 7, no. 1, pp. 141, Mar 2013.
[2] Carlo Pinciroli , Vito Trianni, Rehan O’Grady, Giovanni Pini, ArneBrutschy, Manuele Brambilla, Nithin Mathews, Eliseo Ferrante, GianniDi Caro, Frederick Ducatelle, Mauro Birattari, Luca Maria Gambardella,Marco Dorigo ARGoS: a Modular, Parallel, Multi-Engine Simulator forMulti-Robot Systems, Swarm Intelligence, vol. 6, no. 4, pp. 271295, 2012.
[3] Trianni, Vito and De Simone, Daniele and Reina, Andreagiovanni andBaronchelli, Andrea Emergence of Consensus in a Multi-Robot Network:From Abstract Models to Empirical Validation, IEEE Robotics and Au-tomation Letters, vol. 1, pp. 1-1, January 2016.
[4] Reina, Andreagiovanni and Bose, Thomas and Trianni, Vito and Marshall,James : Effects of Spatiality on Value-Sensitive Decisions Made by RobotSwarms, IEEE Robotics and Automation Letters, pp. 461-473, isbn: 978-3-319-73006-6, March 2018.

Contents
List of Figures
List of Tables
1 Introduction 1
2 Decisions and Learning 5
2.1 Collective Decision-making . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.1.1 Speed-accuracy trade off . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.1.2 Speed-value trade off . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.1.3 Examples in nature . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.4 Improving Collective Decision-making through opinion weighting . . . . . 7
2.2 Learning in Collective Systems . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2.1 Necessity of Learning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2.2 Learning and Decision-making . . . . . . . . . . . . . . . . . . . . . . . . 8
2.3 Reinforcement Learning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.3.1 Elements of Reinforcement Learning . . . . . . . . . . . . . . . . . . . . . 9
2.3.2 Exploration vs. Exploitation . . . . . . . . . . . . . . . . . . . . . . . . . 10
3 Collective Learning 11

CONTENTS
3.1 First Approach . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.2 Second approach . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.3 General Experiment setting . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.4 Agent behavior: first approach . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.4.1 Encountering an energy spot . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.4.2 Receiving a query for energy . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.4.3 Choosing a future action upon receiving reward or punishment . . . . . . 19
3.5 Second approach: Learning through approval of others . . . . . . . . . . . . . . . 20
3.5.1 Receiving a query for energy . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.5.2 Receiving a query for energy . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.6 Average reward calculation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
4 Simulation and Results 23
4.1 Simulated Experiment using ARGoS . . . . . . . . . . . . . . . . . . . . . . . . . 23
4.1.1 Why simulation? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
4.1.2 ARGoS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4.1.3 Setting up the experiment . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4.1.4 First approach: Configuration . . . . . . . . . . . . . . . . . . . . . . . . . 27
4.1.5 Second approach: Configuration . . . . . . . . . . . . . . . . . . . . . . . 27
4.1.6 Statistical Evaluation of Results . . . . . . . . . . . . . . . . . . . . . . . 28
4.2 Results from First approach: collective self-learning . . . . . . . . . . . . . . . . . 29
4.2.1 Factors having an impact on the learning process . . . . . . . . . . . . . . 31
4.3 Results from Second approach: learning through approval of others . . . . . . . . 35
4.3.1 Different Swarm Densities . . . . . . . . . . . . . . . . . . . . . . . . . . . 37

CONTENTS
4.3.2 Different Majorities . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
4.3.3 Split Communities . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
5 Conclusion 41
Bibliography 43

List of Figures
3.1 Sampled distribution for starting energy levels . . . . . . . . . . . . . . . . . . . . 13
3.2 Encountering agent behavior . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.3 Listening agent behavior . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.4 Diagram of approval sequence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.5 Calculation of average reward for an action: source [1] . . . . . . . . . . . . . . . 22
4.1 Overview of a foot-bot and its sensing capabilities . . . . . . . . . . . . . . . . . 25
4.2 Picture of real-world Eye-bot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
4.3 ARGoS: Screenshot of simulated experiment at the start . . . . . . . . . . . . . . 26
4.4 Logo of the R programming language . . . . . . . . . . . . . . . . . . . . . . . . . 29
4.5 Energy level distribution after running the experiment . . . . . . . . . . . . . . . 30
4.6 Probabilities shaped over time across the swarm: immediate consumption . . . . 31
4.7 Effect of using communication to share experiences on learning process . . . . . . 32
4.8 Effect of using communication to share experiences on mean and standard devi-ation of energy level . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.9 Experiment with 100 energy spots available . . . . . . . . . . . . . . . . . . . . . 33
4.10 Experiment with low amount of energy spots available from tick 4000 . . . . . . 34
4.11 Evolution of averaged probabilities for consumption after asking having not thelowest amount of energy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36

LIST OF FIGURES
4.12 Histogram of energy levels with added theoretical densities . . . . . . . . . . . . 37
4.13 Comparison between probabilities of experiment with 100 foot-bots to 400 foot-bots 38
4.14 Effect of cooperative community size on energy level distribution . . . . . . . . . 39
4.15 Effect of not well-mixed swarm of opinions . . . . . . . . . . . . . . . . . . . . . . 40

List of Tables
3.1 Summary of decisions and possible actions to take . . . . . . . . . . . . . . . . . 19
4.1 Parameters of Experiment setting: first approach . . . . . . . . . . . . . . . . . . 27
4.2 Parameters of experiment setting: second approach . . . . . . . . . . . . . . . . . 28

1Introduction
A collective robotics system is a system comprised of multiple robots operating in the sameenvironment cooperatively or competitively. A collective of robots has a number of advantagescompared to its individual counterpart but also comes with a number of challenges. One of theseadvantages is that the use of multiple robots means that certain tasks which were previously notfeasible for completion, now become feasible. Another one of the advantages collective systemshave is the aspect of parallelism, where tasks can be finished faster because of the availabilityof multiple robots to do parts of the task simultaneously. One other is increased robustness,because having multiple robots means that the failure of one does not necessarily mean a failureof the system.
These advantages do come at a price however, as collective systems encounter challenges that donot arise in single-robot systems. One of these challenges for example is the aspect of control.In collective systems, one has to figure out how to control and manage the complete system be itwith a centralized, remote or decentralized solution. The control of the system can be complexand also requires increased communication between robots. One other challenge is interference.As the total number of robots goes up, the opportunity of them interfering with each other alsogoes up (robots obstructing each other, inducing noise on sensory equipment,...), negating thebenefits of the multi-robot solution.
1

2 CHAPTER 1. INTRODUCTION
A Swarm robotics system then is a particular case of a collective system with a certain set ofproperties. Swarm robotics is a field of study that has been defined as a new approach towardscoordinating a large amount of robots in a decentralized manner [2], making them completea certain task at hand. Much inspiration in swarm robotics is taken from naturally occurringswarms such as shoals of fish or colonies of ants. [3]. Swarm robotics can also be seen as theapplication of swarm intelligence to robotics, where swarm intelligence is the collective behaviorthat arises from self-organized, decentralized systems that are either natural, such as a colonyof ants, or just purely artificial.
A swarm robotics system has a number of properties attributed to it, the first being the factthat the robots are autonomous, meaning that they operate on themselves. The robots alsohave relatively simple capabilities and in most cases are identical to each other (homogeneousswarm). Another aspect concerns the sensing and communication capabilities of the robots.These capabilities are local, meaning that they are limited to a small range. Furthermore, aswarm system is controlled in a decentralized manner, meaning that there is no central controllerand also no global knowledge available to the system. Lastly, in swarm robotics, robots aregenerally operating cooperatively to complete a certain task.
All these characteristics stimulate certain desirable properties of a swarm robotics. [4] First andforemost, robustness. Robustness in robotic swarms stems from the absence of centralization,meaning that the swarm can easily cope with the loss of an individual without having a bigimpact on the swarm its operation. The flexibility of the swarm is also a property that arisesfrom the robots their characteristics. The swarm is able to deal with unknown environmentsand different tasks. The last emerging property is scalability. Robot swarm systems are easilyscalable, as they can easily deal with a changing swarm size without having a big effect onperformance. All of these traits are naturally exhibited by animals that live in swarms such asshoals of fish and colonies of ants.
The self organization in natural swarms is a very interesting aspect and answers how for ex-ample ants can coordinate their activities without centralized control and have emerging globalbehavior. Self-organization relies on five key ingredients: positive feedback, negative feedback,multiple interactions, communication and randomness [5]. These five ingredients can be clearlyseen in the example of an ant colony foraging for food, a good example illustrating swarm intelli-gence. When ants forage for food, they release a light trail of pheromones, a chemical substancethat can be sensed among ants, along the way. If an ant then encounters a food source, itreturns it to the nest and along the away, it leaves a strong trail of pheromones. Ants are proneto follow trails of pheromones and since this trail will be stronger than others, more ants willbe attracted to it. These ants will then find the food source too and reinforce the strength ofthe pheromone trail. A Positive feedback loop and multiple interactions occur here. What alsois displayed here is indirect communication or stigmergy among ants. Stigmergy happens when

3
one individuals alter the environment with others responding to this changed environment at alater time. This is a form of indirect communication used by ants, but they can also directlycommunicate using sound or touch. A negative feedback loop can also occur when a food re-source has been completely consumed. Ants will then not produce pheromones upon returningfrom the resource letting the pheromone trail decay over time with less and less ants followingthe trail in the future. Finally the element of randomness is embedded into the ants, becausethe likelihood to follow a pheromone trail is not absolute, ants will always have a probabilityto just roam around in a random manner, perhaps finding an even more resourceful source offood [6]. Add all this together and one can see how an ant colony can carefully build a nest orefficiently forage for food.
In the Design of a robotic swarm system, the architecture of the system is developed fromthe starting specifications and requirements. There are two main categories in the designingmethods, behavior-based methods and automatic design methods.[4].In behavior-based design, a swarm system is developed in a trail and error manner until a certaindesired collective behavior is achieved from the swarm. Behavior-based design thus starts withthe development of the microscopic behavior of a swarm robot where the individual goal of anagent must be aligned with the macroscopic goal of the swarm. Behavior-based design oftentakes its inspiration from naturally occurring systems. One option with behavior-based design isthe use of a probabilistic finite state machine, such as in [7]. Another method in behavior-baseddesign, is the use of artificial or virtual physics. In virtual physics , the robots are modeled asparticles and they can exert virtual forces on to each other. An example of this method beingused can be found in [8], where robots are tasked with forming a hexagonal or square lattice.
The second category is called automatic design methods. Here, behavior is automatically gen-erated, thus relieving some of the work on the shoulders of the developer. Two subcategories,Evolutionary robotics and reinforcement learning exist here.Evolutionary robotics or ER is inspired from evolutionary principles such as survival of thefittest and natural selection and is an example of automatic design. ER works by generating astarting population of randomly generated robot behaviors, called individuals or solution. Eachof these solutions is tested and evaluated using a fitness function, a measure for how good theswarm performs at completing a task. Then, a following generation of solutions is generatedbased upon the previous one. Here, the best solutions of the population are reused, modifiedand or combined with others to form the new population. This process of generating a popula-tion, evaluating performance and generating a new population is done until the robots performssufficiently well enough to perform the task at hand.Reinforcement learning (RL) is also a form of an automatic design method. In reinforcementor punishment-reward learning, the behavior of an agent is based on estimating values towardscertain stochastic actions. This estimate is learned through trial and error. The robot learnswhat action is the best through scalar reward signals obtained as a result from its actions and

4 CHAPTER 1. INTRODUCTION
ultimately gains a policy that defines it behavior, mapping states to actions. An example of RLbeing applied can be found in [9]. Here, robots are again tasked with a foraging task, where therobots must try to maximize exploration and food collected while minimizing collisions betweenthemselves.
In this thesis, a swarm of robots is tasked with maximizing its collective lifetime in an unknownenvironment, that is, maximizing the lifetime of the entire population, where no individualdies. The lifetime of a robot is associated with a source of energy, with a dead”individualcorresponding to a robot with no energy left. To achieve this task, two approaches of learningare proposed that are based upon reinforcement learning, each with their own adaptations. Thefirst approach is an adaptation of reinforcement learning where a collective learning is obtainedthrough the local communication of knowledge, accelerating the learning process throughout theswarm. The second novel approach uses a reinforcement learning method that uses the swarmitself, not the environment, to decide about reward and punishment for performed actions. Bothof these methods try to stimulate individuals towards a certain cooperative behavior ultimatelytrying to achieve the goal of maximizing lifetime.The focus here lies on the design and validation of the two approaches for learning used, aswell as researching the effects of certain factors on the learning process such as population size,communication and spatiality.
The rest of the thesis can be summarized as follows:In Chapter 2, collective decision-making is discussed, with a comparison being made betweendecision-making and learning in collective systems. The reinforcement learning technique isalso explained. In Chapter 3, the two proposed learning methods are explained theoretically,with a general experiment scenario being laid out, followed by a more technical explanation ofagent behavior with each approach. Chapter 4 deals with the simulated experiment design andconfiguration that was performed using ARGoS and discusses the obtained results. Finally, inchapter 5 a conclusion is presented.

2Decisions and Learning
2.1 Collective Decision-making
Collective decision-making is a subfield of collective behavior dealing with a choice of a group ofindividuals that is no longer attributable to any individual after being made. It is important forswarm robotics because it is a necessary component in a lot of applications and helps maximizegroup performance [10]. In general for collective decision-making in swarms, there are twocategories, consensus achievement and task allocation. Consensus achievement deals with agroup of individuals reaching common agreement about some subject. Task allocation on theother hand, deals with systems where agents have to allocate themselves to certain differenttasks. The following paragraphs deal with the first category, consensus achievement.
Collective decision-making has some advantages over individual decisions, the first being accu-racy. The traditional argument for better accuracy in group decision is that of ’the wisdomof the crowds’, with the pooling of multiple opinions leading to a more overall informed groupdecision. This is due to the fact that the individual opinion accuracy variation gets canceledout in group decisions, leading to a better decision overall. Another advantage is the fact thata group can simultaneously increase their true positive and decrease false positive rate whenmaking decisions, while individuals can only improve one at the cost of the other [11]. Thisdual improvement effect is also strengthened as the group size increases. A third advantage
5

6 CHAPTER 2. DECISIONS AND LEARNING
here stems from the ability of a larger group to minimize knowledge needed of individuals whilereaching an as informed or better decision than well-informed individuals [12].
A disadvantage that collective decision-making has, in the context of swarm robotics, is that thespatiality and mobility of the robots have a complex effect on consensus dynamics [13]. Becauseof the limited mobility and communication range robots have, it is not a custom that opinions areuniformly distributed across the swarm, making clusters of odd opinions and therefore decisionspossible. A too high density of robots can also negatively effect the mixing of opinions throughoutthe swarm. This in turn makes it difficult to implement theoretical models of collective decision-making into real world systems.
2.1.1 Speed-accuracy trade off
When dealing with decisions that are rewarded only if they are correct or not, one has tomake an important trade off of speed versus accuracy. A trade off that needs to be optimizedfor maximum performance. The ability to make fast decisions is a desirable property in fast-changing environments, because sometimes, taking too long to make a decision will cause theoutcome of a decision to not matter any more. The downside of fast decisions however is thatthere is a bigger chance of making a wrong decision. Accuracy thus also plays an importantrole in the decision-making process, as a qualitative decision leading to the most value for thesystem is obviously preferred. Greater accuracy comes with slower decision-times ,due to moreopinions and information being pooled together, leading to a more informed decision in the end.
2.1.2 Speed-value trade off
A trade off between speed and value occurs when dealing with value-based decisions, meaningdecisions where a collective has to choose the best alternative among a certain set of presentedoptions. Here, the value of the decision is no longer defined by being right or wrong, but rather,by the value of the chosen option. Here a dynamic value-based decision system is desirable,where decisions are taken fast when presented with two high value, equal options and decisionare postponed when presented with two equal, but low value option. The difference between thespeed-accuracy and speed-value trade off can be illustrated using the simple case of choosingbetween two equal value choices. Here, no speed-accuracy trade off is to be made, as bothoptions are correct. A more appropriate trade off to be optimized here is thus the speed-valuetrade off.

2.1. COLLECTIVE DECISION-MAKING 7
2.1.3 Examples in nature
An example of where the speed-value trade off happens is honeybees selecting a new nest. Here,the honeybees dynamically adapt their value-based decision-making process [14]. If the beesfind 2 equal but low quality nests, the decision will be made to postpone the selection. This isdone in favor of finding a better nest, at the cost of time. On the other hand if 2 high qualitynests are found, the only priority here is to select the highest quality one, as quickly as possible.An other example illustrating collective decision-making in nature, is ants choosing a new nestas described in [15]. There, a certain ant species regularly relocates to a new nest, where thenew location has to be collectively decided upon. The mechanism for this decision process startswith multiple scouting ants, scouting for a new nest location and then actively advertising theirlocation to the other ’idle’ ants. These idle ants will adopt the most valuable option the fastestand are prone to then recruit other ants for this options, while ants who support a poor optionwill be prone to go ’idle’ again. This process will go on for a while until a certain majoritythreshold is reached, and the choice will be performed, in this case, the relocation of the nest.
Implementations of collective decision-making often take inspiration from these naturally occur-ring systems such as in [16] and [17], where a binary discrimination problem, a best-of-n problemwith two options, has to be solved. Both of these implementations make use of a positive feed-back loop in order to reach consensus about an option. The positive feedback loop happens dueto the advertising time for a selected option by an agent scaling with the perceived quality ofthe option, meaning high quality options will get advertised for longer than low quality ones,letting the system eventually converge to the highest quality option available and the consensusproblem being solved.
2.1.4 Improving Collective Decision-making through opinion weighting
Collective decision-making can sometimes be improved upon by weighting certain individual’sopinions [18]. This weighting can be done in two ways. Either individuals of the group evaluatethe opinion accuracy of an other individual or the individual himself signals their opinion weightto others, either way, individuals of the collective must be able to evaluate opinion accuracy forthis to be possible. Opinion weighting is most valuable in situations when applied with smallgroups of individuals who are poorly informed, an individual with good opinion accuracy canthen have a greater impact on the decision-making process which is beneficial to the accuracyof the decision.

8 CHAPTER 2. DECISIONS AND LEARNING
2.2 Learning in Collective Systems
2.2.1 Necessity of Learning
When dealing with an unknown environment in which a system has to complete a task withoutprior knowledge of it, it’s clear that the system will have to perform some sort of learningin order to be able to achieve the task. A traditional learning process is comprised of twophases, knowledge collection and knowledge exploitation. Knowledge collection happens throughagents of a system interacting with the environment and each other gaining knowledge throughthese interactions. Using this gained knowledge, the agents of the system can then shape theirbehavior, applying their knowledge to maximize their value in the system. Decision-making isthe exploitation of this gained knowledge, thus knowing which action to perform when presentedwith a certain conditions. A collective learning happens when the learning occurs in a socialcontext, in other words, the group aspect adds a dimension to the learning process or learningresult. This can for example happen when agents of the system share knowledge obtainedwith each other, which is beneficial to the learning process. Another example can be that theindividual learning process leads to the entire collective showing a certain type of behavior.
2.2.2 Learning and Decision-making
It’s clear that learning and decision-making are connected, as when one makes a decision, oftenthis is based upon what one has previously learned. Like learning to put your coat on whenit rains, because you got wet when you previously didn’t. Learning is thus an input for yourdecision, which is based on your past experiences. Decision-making can also be separate fromlearning, in pure reactive decision-making for instance. There, decisions are made based onimmediate observations only, without relying on previous experiences. One more differencebetween the two is the fact that in pure decision-making, your decisions are based on knowledgethat is given to you, not obtained by your own experiences like in learning. This a key factorin why learning is necessary in unknown environments, because assumptions of a model aboutthe environment can’t be made and knowledge is not given to you, pure decision-making can’tbe applied, as assumptions for one environment, don’t hold true for another.
2.3 Reinforcement Learning
To reiterate, reinforcement learning or RL in short is a learning technique where an agent learnsa certain behavior through maximization of a reward signal. The agent does this by interactingwith the environment, collecting knowledge and gaining experience and then in turn, exploiting

2.3. REINFORCEMENT LEARNING 9
this knowledge to learn an optimal policy that maps states to actions and maximizes reward.
Reinforcement learning differs from both supervised and unsupervised learning. Supervisedlearning occurs when an agent is taught from a set of training examples given to them by anexpert, in general in order to solve some sort of classification problem. Reinforcement learningdoes not use these training examples. Supervised learning is not readily applicable in interactiveproblems where RL is used, because finding correct examples of desired behavior in all situationsis very impractical.Unsupervised learning on the other hand is generally is used to find hidden structures in col-lections of unlabeled data, whereas with reinforcement learning , one is trying to maximize areward signal.
A reinforcement learning problem problem is generally framed as a finite Markov decision pro-cess.
2.3.1 Elements of Reinforcement Learning
The first element of a reinforcement learning system, beyond the agent itself is the environment.The environment is that which the agent interacts with over time. Actions are the choices thatare made by the agent in the environment, where states are the basis of these actions.
A next element of the system is the reward signal or function. This signal used in order todefine the goal of the problem. The agents operating in the environment their sole purpose isto maximize this reward signal. By rewarding some actions and punishing others, the behaviorof an agent can get shaped in a desired way.
A value function then, is used by the agents to associate a quality towards a state. This valueis used to estimate the total amount of reward an agent can accumulate starting out from thisstate. A value function thus, does not only contain immediate reward, but also future rewardwhich is important in order for the agent to perform the right sequence of actions which leadto the most reward, rather than greedily choosing the action that leads to the most immediatereward every time.
The element that defines the robot behavior at any given time is called the policy. A policydictates what action should be taken in a certain state, thus defining robot behavior in itself. Apolicy can be stochastic. Finding an optimal policy is often equal to solving the RL problem.
A common method used to solve RL problems is Q-learning. In Q-learning an agent will learnabout the quality or long-term value of its actions through observations. Q-learning starts withan agent setting the Q-value for each possible state-action pair to zero. A state-action pair is anaction performed towards a certain state. After this, the agent starts learning by trying different

10 CHAPTER 2. DECISIONS AND LEARNING
state-action pairs, using a certain update rule that accommodates for the recency of informationand also for future rewards given to the agent. After visiting each state-action pair, the agentknows what to do at each state, leading to optimal behavior.
2.3.2 Exploration vs. Exploitation
The exploration vs. exploitation trade off is one of the main challenges that arises in reinforce-ment learning. On the one hand, to obtain a lot of reward, an agent must perform actions thathave, in the past, obtained reward. But in order to know which actions obtain the most reward,the agent must try explore different suboptimal actions, without prior knowledge about theirreward. If we are dealing with a stochastic task or reward, an action also must be performedseveral times before one gets a reliable estimate about the reward of that action.

3Collective Learning
As the focus of this work lies on the design of a robotic swarm that is able to collectively learnabout the associations between its actions and rewards in order to maximize its collective life-time, two learning methods are proposed which are both based upon reinforcement learning.The main goal of both these approaches is to teach the swarms individuals to collaborate witheach other, which in turn maximizes the collective lifetime of the swarm. This goal stems fromthe fact that the strength of a swarm comes from its numbers. Having a swarm that collectivelylives (with no individual dieing) as long as possible is beneficial to the swarms performance.The first approach allows for a collective self-learning system, using reinforcement learning thatis coupled with a communication of gained knowledge. The second approach, also based onreinforcement learning, places the reward and punishment system in a social context where theswarm itself must decide about the reward of a certain action performed. In both of these tech-niques, the agents use the observed reward to shape their future behavior towards maximizinga reward signal.
3.1 First Approach
In the first approach, a traditional reinforcement learning method is adapted in order for acollective self-learning system to be obtained. Here agents, learn the relationship between their
11

12 CHAPTER 3. COLLECTIVE LEARNING
actions performed and rewards obtained by interacting with the environment. In turn, theyexploit the knowledge they gain to shape their future behavior. Agents keep track of the averagereward received for each action by the environment and they use this knowledge to maximizetheir obtained reward, by picking the actions that have the highest average reward.A collective learning is obtained by adding local communication between agents which is used toshare one’s experiences in the environment, thus sharing obtained knowledge. This acceleratesthe learning process, because one individual can have a positive impact on the learning processof several others. For example, the learning that a certain action leads to punishment, cannow be done by one individual and shared to the others, instead of each individual needing todiscover this punishment themselves.
By rewarding certain actions and punishing others, the environment stimulates a certain indi-vidual behavior of the agent. This is because of the fact that each agent want to maximizetheir obtained reward. The sum of each agent its individual behavior, its interactions with theenvironment and other agents, defines the collective behavior of the swarm. By stimulatingcertain individual collaborative behavior, the desired collective behavior, maximizing collectivelifetime, can be obtained.
3.2 Second approach
The second novel approach, works similarly to the previous method but with one big differencein regards to the reward mechanism. Again, agents will learn the associations between theirrewards and actions performed by interacting in the environment and subsequently observingreceived rewards.The main difference with the first method is the source of the reward. Where previously rewardcame from the environment, it now comes from the swarm itself as every action performed by anagent goes through a local approval process. In this process, the local neighbors of an agent mustdecide on the reward or punishment by approving or disapproving an action. An action whichreceives more approvals than disapprovals is rewarded and vice versa punished. The approvalor disapproval stems from the internal preference of the agent.This process is dependent on having local neighbors that are in range of communication. Aprocess with not a single approval or disapproval will not obtain a reward or punishment, thus,having a dense swarm to avoid these types of situations is beneficial to the learning process.After this approval process, the agents will again shape their future behavior towards actionsthat lead to the highest average reward. Meaning that having a majority of agents of the swarmpreferring certain actions, will lead to these actions obtaining the highest average reward. Inturn, this will shape the individual behavior of each agent of the entire swarm towards theseactions and subsequently will determine the collective swarm behavior.

3.3. GENERAL EXPERIMENT SETTING 13
Having a majority of agents preferring collaborative behavior then, will lead to the entire swarmadopting this behavior.
In order to validate the two proposed techniques, an experiment was to be designed wherea homogeneous robotic swarm is tasked with maximizing its collective lifetime and the twotechniques are applied. The two learning techniques their effectiveness need to be tested, as wellas researching the effects on the learning process of changing certain parameters such as swarmsize and spatiality.
3.3 General Experiment setting
A robotic swarm will be deployed inside of a closed environment that contains energy spotsthat can be consumed when encountered. The agents of the swarm, and these energy spots,are both uniformly distributed across the environment. Each agent of the swarm has an energyvalue inside of it, where each starting value is sampled from a normal distribution with a bigspread. This means that across the swarm, starting energy levels have a wide spread as well.The energy level of each agents decays linearly over time, with the consumption of an energyspot granting the agent additional energy. It is this energy value that is regarded as the lifetimeof an individual, with the collective lifetime of the swarm being the time the swarm surviveswith no agent having an energy value of zero.
The agents have a possible set of actions they can perform in the environment, with each actionbeing dependent on a probability for execution. While exploring the environment, the agentsmust also perform obstacle avoidance, in order to avoid bumping into to each other and thewalls of the environment. The agents can also perform local communication with each other,broadcasting and receiving messages in order to exchange information.
Figure 3.1: Sampled distribution for starting energy levels
The individual goal of each agent is of course to maximize obtained reward. The macroscopic

14 CHAPTER 3. COLLECTIVE LEARNING
goal of the experiment is however, to maximize the swarms collective lifetime through uniformingthe energy levels across the swarm. Agents don’t have any knowledge of this macroscopic goal,but this goal will emerge resulting from reinforcing certain individual collaborative behavior(local interactions between agents and their environment). It is better to have a swarm witha uniform energy level across it then to have one with a big spread, because, in absence ofconsumable energy, a swarm with non-uniform energy levels will have dead individuals morequickly than its uniform counterpart.
3.4 Agent behavior: first approach
There are two scenario’s in which an agent needs to perform one or more actions. What followsis a detailed explanation of each scenario and how the agent behaves itself for the first learningapproach.
3.4.1 Encountering an energy spot
The first scenario in which an agent must take action is when it encounters an energy spot. Anenergy spot is encountered by roaming around in the environment.The behavior of an agent that encounters an energy spot is Illustrated in figure 3.2. The choicesto be made are displayed there. The decisions are purely based on stored probabilities insidethe agent.
The first decision an agent has to make, when it detects an energy spot, is whether or not it willask surrounding agents for their energy level.If the agent decides not to query the neighboring energy levels, the agent will immediatelyconsume the energy spot and gain a certain amount of energy. This action is punished by theenvironment, as a negative reward is given. The collaborative alternative, is to look for theagent that actually needs the energy consumption the most, so if the agent does decide to askneighboring agents for their energy levels, it broadcasts a sharing request message. The action ofasking neighbors for their energy level is rewarded by the environment. The agents that receivethis sharing request message, will also have to make a decision about sharing their energy levelor not, but this will be explained more thoroughly in the next section. After sending out thisrequest, the encountering agent will wait for a certain time window, in which the neighbors canrespond.After the window has passed, the individual will analyze the received replies and can now judgewhich agent actually has the lowest amount of energy of those that responded and itself. Now,the agent which encountered the energy has to make a decision about consuming the energyspot or not.

3.4. AGENT BEHAVIOR: FIRST APPROACH 15
There are two situations possible here. First there is the one where the agent itself does nothave the lowest amount of energy of all locally queried agents. Here, the individual can chooseto either, consume the energy spot or it can give the agent with the lowest amount of energythe chance to consume it, the latter of which is rewarded, with the first choice being punished.If the latter is chosen, the encountering agent broadcasts a selection message, which containssome sort of identification of the agent that has the lowest amount of energy. That agent, afterreceiving this message, then also has to make a decision about obeying this selection commandor not, which will also be more thoroughly explained in the next section.
The other situation naturally occurs when the agent does have the lowest amount of energy.Again, the agent has to make a decision about consuming the energy spot or not. Consumingthe energy spot gains the agent some energy and the environment rewards this action as theagent itself, needs the energy the most. Choosing not to consume the energy spot is the otheroption, which is punished by the environment.
After each received reward, an agent will try to share his gained knowledge to the other agentssurrounding him. The agent does this by broadcasting a message, containing the action itperformed and the reward it received for it. The receiving agents, who are listening for thesesorts of messages, will use this information to shape their own behavior for future decisions, inthe same way it does for rewards received for its own actions.
The results of these punishments and rewards is the fact that the corresponding actions willhave a lesser and greater chance of being executed in the future, shaping the behavior of theagent. For this approach, the benefit of adding communication into the learning process willget researched, as well as trying to introduce a scenario where cooperative agents turn to theirselfish ways again to ensure personal survival and finally a limited energy consumption scenariowill be examined.

16 CHAPTER 3. COLLECTIVE LEARNING
Roa
min
g
Ener
gy s
pot
Enco
unte
red
Not
the
Low
est
Ener
gy
Has
the
low
est
Ener
gy
CO
NSU
ME_
AFTE
R
_ASK
ING
_L
OW
EST
NO
T_C
ON
SUM
E _A
FTER
_ASK
ING
_L
OW
EST
CO
NSU
ME_
AFTE
R
_ASK
ING
N
OT_
LOW
EST
NO
T_C
ON
SUM
E _A
FTER
_ASK
ING
N
OT_
LOW
EST
CO
NSU
ME_
WIT
HO
UT
_ASK
ING
Age
nt e
ncou
nter
ing
a co
nsum
able
ene
rgy
spot
Blue
and
red
arro
ws
indi
cate
act
ions
take
n an
d m
atch
the
colo
r sch
eme
in th
e pr
obab
ility
plot
s of
the
resu
lts c
hapt
er. Y
ello
w in
dica
tes
a st
ate
whe
re a
cho
ice
has
to b
e m
ade.
Gre
en a
nd re
d in
dica
te s
tate
s w
here
rew
ard
or re
spec
tivel
y pu
nish
men
t is
give
n to
the
agen
t.
Consu
me
Query
Ener
gy
levels
Cons
ume
Cons
ume
!Con
sum
e
!Con
sum
e
Broa
dcas
tco
nsum
ptio
nse
lect
ion
mes
sage
Start
INTE
RM
EDIA
TE_
REQ
UES
TIN
G
_EN
ERG
Y_LE
VELS
Text
Figu
re3.
2:En
coun
terin
gag
ent
beha
vior

3.4. AGENT BEHAVIOR: FIRST APPROACH 17
3.4.2 Receiving a query for energy
The previous section dealt with the situation of an agent encountering energy, but now, thebehavior is explained from the ’listening’ side, that is, the agent which receives a request toshare its energy level from another individual.
Upon receiving such a message, the agent has to decide whether it wants to cooperate or not.It can thus respond by broadcasting its energy level or, it can simply not share its energy level,ignoring the request. Not sharing your energy level is punished, while sharing it is rewarded. Ifan agent shares its energy level, it’s possible that the bot will be selected for energy consumptionand thus receive a selection command. After receiving this message, the agent can now decidewhether or not to obey this selection command. Obeying it, will grant the agent energy throughconsumption as well as a reward given by the environment. The individual also has the choiceto ignore the command, an action that is punished by the system.
In figure 3.3 one can see a diagram showing the behavior of a listening agent scenario and in table3.1 one can find a summary of which actions exist in the system and the corresponding rewardor punishment that goes with them. The first three rows correspond with possible decisions foran encountering agent, the bottom two for a listening agent.

18 CHAPTER 3. COLLECTIVE LEARNING
Roa
min
g R
ecei
ved
requ
est f
oren
ergy
leve
l
Star
t
Not
sel
ecte
d fo
r Ene
rgy
Con
sum
ptio
n
NO
T_SH
ARE
INTE
RM
EDIA
TE
_SH
ARIN
G
Rec
eive
dco
nsum
ptio
nse
lect
ion
mes
sage
SHAR
E_AN
D
_OBE
Y
SHAR
E_AN
D_
NO
T_O
BEY
Ignore
requ
est
Share
energ
ylev
elG
etse
lect
ed!C
onsu
me
Cons
ume
Rec
eive
requ
est
Age
nts
that
rece
ive
a re
ques
t to
shar
e th
eir e
nerg
y le
vel
Blue
and
red
arro
ws
indi
cate
act
ions
take
n an
d m
atch
the
colo
r sch
eme
in th
e pr
obab
ility
plot
s. Y
ello
w in
dica
tes
a st
ate
whe
re a
choi
ce h
as to
be
mad
e. G
reen
and
red
indi
cate
sta
tes
whe
re re
war
d or
resp
ectiv
ely
puni
shm
ent i
s gi
ven
to th
e ag
ent.
Figu
re3.
3:Li
sten
ing
agen
tbe
havi
or

3.4. AGENT BEHAVIOR: FIRST APPROACH 19
Table 3.1: Summary of decisions and possible actions to take
Action Rewarded / PunishedCONSUME_WITHOUT_ASKING PunishedINTERMEDIATE_REQUESTING_ENERGY_LEVELS RewardedCONSUME_AFTER_ASKING_LOWEST RewardedNOT_CONSUME_AFTER_ASKING_LOWEST PunishedCONSUME_AFTER_ASKING_NOT_LOWEST PunishedNOT_CONSUME_AFTER_ASKING_NOT_LOWEST RewardedINTERMEDIATE_SHARE RewardedNOT_SHARE PunishedSHARE_AND_OBEY RewardedSHARE_AND_NOT_OBEY Punished
3.4.3 Choosing a future action upon receiving reward or punishment
Upon receiving a reward or punishment by the environment for a performed cation, agents willtry to shape their behavior in such a way that they will maximize their obtained reward forfuture decisions. They do this by keeping track of received rewards and punishments for eachaction they performed and thus, can calculate an average reward or punishment received foreach action. Each decision point in the environment has two possible actions to take, with theagent always picking the actions that obtains the highest average reward. When two actionshave equal average reward, both actions have equal probability of being chosen. The pseudocode for this can be found below (action_p stands for action performed, action_np for actionnot performed at the decision point).
Algorithm 1 Recomputation of probabilities, called when a reward or punishment is received1: procedure RecomputeProbabilities(action_p,action_np)2: if avgReward(action_p) ≥avgReward(action_np) then3: Probability(action_p) ⇐100%4: Probability(action_np) ⇐0%.5: else if avgReward(action_p) ≤avgReward(action_np) then6: Probability(action_p) ⇐0%7: Probability(action_np) ⇐100%.8: else if avgReward(action_p) = avgReward(action_np) then9: Probability(action_p) ⇐50%
10: Probability(action_np) ⇐50%.

20 CHAPTER 3. COLLECTIVE LEARNING
3.5 Second approach: Learning through approval of others
In the previous approach, rewards and punishments came from the environment, rewarding orpunishing the agents based on a set of preset rules. In the second approach, this mechanic ischanged. Now, the punishment or reward comes from the swarm itself. Reward for an actionwill depend on the approval or disapproval of an agent its surrounding neighbors. Agents willagain use the same average reward calculation in order to shape their future behavior as in thefirst approach. The outline for the experiment stays the same, however, there are now 2 types ofagents in the swarm. On the one hand there is the selfish community, which has a preference forselfish, non cooperative actions such as not sharing your energy level, immediate consumption ofencountered energy spots. On the other hand there is the cooperative community, which has apreference for the cooperative actions such as, sharing your energy level and obeying a selectionmessage for consumption.. Each robot is part of either community, decided by an internal value set at the beginning ofthe experiment.The internal agent model also differs, as an agent now has to start a sort of quorum with itsneighbors to approve or disapprove an action. Having a majority of the swarm prefer collabo-rative actions, will, through the social learning mechanism, make the entire swarm eventuallyadopt this collaborative behavior. The goal for this approach is to see the effect of this typeof learning mechanism on the swarm’s behavior and whether or not behavior can be shapedacross the swarm having two communities. What also will be examined is the effect of differentcommunity sizes and absolute population sizes on the learning process, as well as the spatialityof the two communities, being well-mixed or not.
3.5.1 Receiving a query for energy
The behavior model for encountering an energy spot is not much different than from the first ap-proach, the main difference is the approval sequence after each performed action. This sequencestarts with the performing agent first broadcasting a message to neighboring agents, indicatingthat it wants to start an approval sequence for its performed action. Neighboring agents then,upon receiving this request, respond with their approval or disapproval of the action correspond-ing to their own preference (the community they are part of). After the performing agent is donelistening for a certain time window, it will tally up the votes received. According the majorityof the votes, an agent is then either rewarded or punished. The probability of the action is thenupdated according to the average reward received. Figure 3.4 shows a diagram of the approvalsequence.

3.6. AVERAGE REWARD CALCULATION 21
Agent performsAction
Agent broadcastsapproval request toneighbors for this
action
Count approvals anddisapprovals
Action approvedand rewarded
Equal votes or
No votes
Actiondisapproved and
punished
Listen tovotes
Approval Sequence for performed actionsThis diagram shows an approval sequence which happens after each performed action of an agent.
Figure 3.4: Diagram of approval sequence
3.5.2 Receiving a query for energy
The internal model again for listening agents does not differ all that much, only the quorumsequence is now present. This quorum sequence was explained in the previous section.
3.6 Average reward calculation
For calculating the average reward for each action, one can naively just sum up all the receivedrewards and divide them by the number of rewards. This can be done more efficiently though ascan be seen below. Where Q stands for average reward, R stands for reward (amount) receivedand n stands for number of rewards received.

22 CHAPTER 3. COLLECTIVE LEARNING
Figure 3.5: Calculation of average reward for an action: source [1]

4Simulation and Results
4.1 Simulated Experiment using ARGoS
For validation of the two proposed learning techniques, a simulated robot experiment, as ex-plained in the previous chapter, was designed using the ARGoS simulator. What follows isa short explanation about robot simulators and ARGoS in general, followed by the specificexperiment parameters with which both approaches were tested.
4.1.1 Why simulation?
Researchers turn to simulations of robots for multiple reasons. First and foremost, cost. Robots,small or large aren’t cheap and especially in swarm robotics where one can need a large popu-lation of robots, the initial cost of purchase can be very high. A second reason for simulation istime, as running real-world experiments is very time consuming and requires a lot of attention,where as in simulation, multiple experiments can be run in parallel and repeated quickly. An-other reason for simulation to be attractive is the absence of noise on certain sensors for example,this noise can hamper the performance of the robots or certain theoretical applied algorithms.However, this can also be a disadvantage, as algorithms developed for robots using simulationsmight not be fit for real-world functioning, simulators that support simulating noise (Gaussian
23

24 CHAPTER 4. SIMULATION AND RESULTS
noise for example) can help here. Robot simulators come with a certain number of necessities.A first one is accuracy. Simulators need to simulate the robot and environment in a sufficientlyaccurate manner, so that the obtained results are meaningful and can be without too mucheffort, be reproduced in the real world. Performance is next, as simulating large experimentsin the smallest amount of time possible is highly desirable. Scalability, as in supporting a largenumber of robots is necessary for swarm robotics as population size can vary from quite smallto very large.
For swarm robotics, not that many widespread simulators are available that support the simula-tion of many robots simultaneously. Most simulators are based around simulating one complexrobot, instead of many simple ones. Those that do however, like for example Stage, imposedesign and feature limitations on the researchers in terms of supporting different robots andsimplified physics solutions.
4.1.2 ARGoS
ARGoS (Autonomous Robots Go Swarming) is an open source multi-robot simulator that sup-ports large simulations. The three pillars of ARGoS are: high accuracy, high flexibility and highefficiency. High accuracy is an obvious requirement as it is desired that the simulations are anaccurate representation of reality. High flexibility was also important for the creators, as theywanted to make ARGoS compatible with any kind of robot in any use case [19] making it a veryinteresting piece of software for researchers in the swarm robotics field. ARGoS is also one ofthe first simulators that is sufficiently scalable while maintaining flexibility and efficiency whileother simulators can’t combine these three properties at the same time. ARGoS itself is writtenin C++ and runs on Linux and Mac OS X. These advantages make ARGoS a compelling choicefor the use validating and researching the two proposed learning techniques through a simulatedrobot experiment.
Available Robots
There are multiple robots available for simulation in ARGoS. Two of them, the foot-bot andthe eye-bot were developed in the context of the swarmanoid project [20], where the goal wasto design, implement and control a decentralized heterogeneous robot system.The foot-bot is an all terrain robot, that is a particular configuration of the marXBot [21], amodular experimentation robot which was built upon the experience with the earlier S-bot.[22]The foot-bot has an array of sensors to explore its surroundings and has means of communicatingand being aware of other foot-bots around itself using proximity sensors. The foot-bot itselfweighs about 1.8kg and has two cameras, one of which is an omni-directional camera. The

4.1. SIMULATED EXPERIMENT USING ARGOS 25
relative low cost of a single foot-bot, the robustness and large battery make it a great robot touse in swarm robotics experiments. In figure 4.1 one can see an overview of the actual foot-botand its sensing and communication capabilities. Its simulated counterpart replicates most ofthese features.
Figure 4.1: Overview of a foot-bot and its sensing capabilities
The eye-bot then, is a robot helicopter, comprised of 8 rotors that are arranged in an advancedquadrotor configuration. The eye-bot features a light weight carbon-fiber assembly and has abattery life of 10 to 20 minutes. It also features a 360° pan-tilt camera system and a 360° distancescanner which uses infrared. The eye-bot can also attach to the ceiling and stay in one place forlong amounts of time, preserving battery life. It’s specialized in sensing the environment fromabove and providing this information to robots on the ground.
Figure 4.2: Picture of real-world Eye-bot
Next is the e-puck. The e-puck is a small, low-cost mobile robot that was designed for use ineducation. [23]. It uses an open source hardware/software development model and has a widerange of application for educational purposes, even outside of robotics.

26 CHAPTER 4. SIMULATION AND RESULTS
Finally, the spiri, an autonomous quadrotor is also available for simulation. The spiri has awide array of sensor available and runs linux on its embedded hardware. It sports a dual coreprocessor, Wi-Fi and Bluetooth for communication, an HD video camera and more.
For the simulated experiment, the foot-bot is the most compelling choice, as the available sensorsand communication modules are sufficient for applying the two learning approaches. The footbotits proximity sensors are also very handy in order to avoid obstacles in the environment, an abilitywhere the e-puck for example lacks a good obstacle avoidance solution.
4.1.3 Setting up the experiment
In order to actually run an experiment with ARGoS, two things are needed, compiled user code(containing a robot controller) and an XML experiment configuration file (.argos extension).The configuration file is used to configure the actual starting experiment set-up and covers awide array of parameters such as the arena size, the amount of robots, presence of objects, thenumber of to be used physics engines, visualization settings and more. A summary of the mostimportant configured parameters for each approach is given in the next section. The compileduser code consists of a robot controller and optionally some hook functions, with the robotcontroller code being used to operate the robot’s available sensors and actuators. The optionalhook or ”loop” functions are used in order to interact with the running experiment.Two robot controllers were written in C++, mimicking the behavior of the two approachesexplained in the previous chapter.Two different loop functions were also written for each approach, where both are used in orderto log important data and to interact with the running experiment.
Figure 4.3: ARGoS: Screenshot of simulated experiment at the start

4.1. SIMULATED EXPERIMENT USING ARGOS 27
4.1.4 First approach: Configuration
There are number of configurable parameters in the experiment, what follows is a brief summaryof these parameters and their corresponding values with which the experiment was simulated.
Parameter ValueExperiment length 10000 ticks ( 1000 seconds)Arena size 10 m²Number of foot-bots inside the arena 80Foot-bot velocity 20 cm/sFoot-bot communication Range 1.0 mEnergy Decay Rate 0.05 per tick
Sampled normal distribution for starting energy (x)µ=500 ; σ= 250; 0 ≤x ≤1000
Number of energy spots in the arena available simultaneously 60Energy spot respawns after consumption TrueRadius of energy spot 0.02 mSelfish / Cooperative Scenario SelfishNumber of experiment runs 30
Table 4.1: Parameters of Experiment setting: first approach
The foot-bots will start the experiment having a preference for selfish actions in order to showthe switch from selfish behavior to cooperative more clearly. For this approach, the effectivenesswill be tested through comparing the energy level distribution across the swarm before andafter the experiment. Also, the benefit of incorporating collective learning (communication ofexperiences) into the technique will be examined, as well as the effect of having a finite amountof energy spots available for consumption. Finally, a scenario will be introduced where foot-botsare forced back into selfish behavior, because of there not being enough energy spots availableto feed the entire swarm.
4.1.5 Second approach: Configuration
A foot-bot in the swarm is part of the selfish or cooperative community according to an embeddedvalue inside the foot-bot. This value is not changeable so a foot-bot that is part of the selfishcommunity, will always approve of selfish actions, The probabilities stored inside a foot-bot can,on the other hand, be influenced according to approval and disapprovals of surrounding foot-bots. Thus a foot-bot that is part of the selfish community can have cooperative behavior overtime and vice versa.

28 CHAPTER 4. SIMULATION AND RESULTS
Each community, selfish or cooperative, starts the experiment with their probabilities alreadyshaped towards their corresponding behavior, meaning they have increased chances to pick theircorresponding behavior when presented with a decision. Thus at the start of an experiment, theaveraged probabilities of actions across the swarm will be geared towards whatever community(selfish or cooperative) has the biggest size.The foot-bot communication range was upped in this experiment, in order to let more foot-botsparticipate with each vote and to minimize the case of a foot-bot not being surrounded byneighbors and thus not receiving a single vote in the approval process.
Parameter ValueExperiment length 5000 ticks ( 500 seconds)Arena size 10 m²Number of foot-bots inside the arena 100Foot-bot velocity 20 cm/sFoot-bot communication range 1.5 mEnergy decay rate 0.05 per tick
Sampled normal distribution for starting energyµ=500 ; σ= 250; 0 ≤x ≤1000
Number of energy Spots in the arena available simultaneously 100Energy spot respawns after consumption TrueRadius of energy spot 0.02 mPercentage of swarm preferring cooperative actions 70 %
Table 4.2: Parameters of experiment setting: second approach
Again, this approach is validated using the energy level distribution across the swarm at thestart and after the experiment run. The effect of swarm density on the learning process is alsoresearched, as well as the spatiality of the foot-bots at the start of the experiment.
4.1.6 Statistical Evaluation of Results
R is a programming language and software suite that is used for statistical-and data-analysis. Ris open sourced, licensed under the GNU General Public License and is still in active developmenttoday. The main strength of R comes from the easy producing of publication grade plots andthe extensibility of the software through user created libraries or packages.The following plots shown are all produced using the R software. Each plot stems from theaverages taken from 30 different experiment runs, each with a different random seed producingtheir data of the experiment. Using R, the 30 different files are read and loaded into a 3Darray data structure. Averages and standard deviation on the data are then produced using

4.2. RESULTS FROM FIRST APPROACH: COLLECTIVE SELF-LEARNING 29
several libraries like reshape. Each plot shown shows these average values, with the gray ribbonindicating the standard deviation on the values. In plots showing the probabilities of certainactions across the swarm, the name of the variables correspond to the ones shown in the behaviordiagrams of chapter 3. As well as the color blue indicating collaborative behavior, with red beingselfish behavior.
Figure 4.4: Logo of the R programming language
4.2 Results from First approach: collective self-learning
It is clearly observed from figure 4.5 that there is a much tighter spread on energy level dis-tribution after the experiment has been ran. On the plot, the red line indicates the startingsampled distribution with the green one being the resulting normal distribution fitted againstthe end-data using the mean and standard deviation.The foot-bots have definitely learned to cooperate, with the uniformity of the energy level acrossthe swarm as a consequence. The standard deviation on the energy level is now way smaller,down from 250 to 56.88, a great improvement. Furthermore, not a single foot-bot ends uphaving zero energy at the end of the experiment.
This means is that the collective lifetime of the swarm has been optimized. In the event thatthere is no more energy available, this swarm would preserve its population size the longestcompared to a distribution with a similar mean but larger standard deviation.What’s also noticeable from the plot, is that the mean energy value is actually lower than atthe start. This is because there are not enough energy spots to keep the whole swarm fed soover time, energy levels across the swarm would go towards zero.

30 CHAPTER 4. SIMULATION AND RESULTS
Figure 4.5: Energy level distribution after running the experiment
In figure 4.6, one can also see the behavior of foot-bots being shaped over time through thereinforcement mechanism. On the plot, the probabilities of two actions have been displayed atthe decision point, concerning about immediate consumption of an energy spot by an encoun-tering foot-bot. The plot has been capped at 2500 simulation steps or ticks to better displaythe learning process.

4.2. RESULTS FROM FIRST APPROACH: COLLECTIVE SELF-LEARNING 31
Figure 4.6: Probabilities shaped over time across the swarm: immediate consumption
4.2.1 Factors having an impact on the learning process
Speeding up the learning process through collective learning
In the first approach, a form of collective learning happens in the swarm through the com-munication of experiences. In order to see the exact benefit of having this communication ofexperiences, the experiment was ran with and without this communication. In figure 4.7, onecan clearly see the positive effect this factor has on the learning process, as the intersectionbetween the two probabilities happens sooner. Foot-bots learn more quickly that sharing theirenergy level upon request is rewarded when communication is used, having a positive impact onthe individual score of a foot-bot, as well as on the uniforming of the energy level. The standarddeviation on the energy level across the swarm, after introducing communication, is decreasedwith 9%, with the mean energy level increasing with 9.5%. The mean energy level increasing isdue to the fact that less consumptions get lost through the ignoring of consumption selectioncommands or lost consumptions due to a foot-bot simply not consuming an energy spot.

32 CHAPTER 4. SIMULATION AND RESULTS
(a) Without experience sharing (b) With experience sharing
Figure 4.7: Effect of using communication to share experiences on learning process
(a) Without experience sharing (b) With experience sharing
Figure 4.8: Effect of using communication to share experiences on mean and standard deviationof energy level
Finite vs. Infinite amount of energy spots
The experiment is initially configured with an infinite amount of energy spots, which meansthat the energy spots respawn after consumption. Foot-bots thus have an infinite amount

4.2. RESULTS FROM FIRST APPROACH: COLLECTIVE SELF-LEARNING 33
of opportunities to interact with the environment and gather knowledge about rewards andpunishment. Now though, having a limited amount of consumptions available, the foot-bots onlyhave a set amount of times that they can obtain knowledge about the consequences associatedwith their actions, meaning that the learning process will stop after the last energy spot hasbeen consumed. The experiment was ran with thus the same parameters as in table 4.1, withthe only difference being the finite amount of 100 energy spots available.
Figure 4.9: Experiment with 100 energy spots available
From the figure 4.9, one can clearly see that 100 energy spots is not a big enough amount forthe foot-bots to complete the learning process across the swarm, as some foot-bots have not yetobtained knowledge about certain punishments and rewards associated with actions.The aspect of communication in the learning process plays an even bigger role here with a limitedamount of consumptions, as the knowledge gained through these finite amount of consumptions,is multiplied by sharing each experience with several others.
Choosing personal survival over reward
One interesting addition to the experiment was inserting a mechanism for foot-bots to turnselfish again when their personal survival was in danger. This happens when they are left in

34 CHAPTER 4. SIMULATION AND RESULTS
a dire situation, in other words, the foot-bots have a low amount of energy and don’t foreseemany energy consumptions in the future.This scenario is artificially introduced by reducing the amount of energy spots that are simulta-neously available in the environment, while keeping the amount of consumptions unlimited. Thelow density of energy spots in the arena means that the swarm will less often have the opportu-nity to consume an energy spot. With a lesser amount of energy coming in and a constant lineardecay of the energy level, the energy level across the swarm decreases steadily. This in turnmeans that some foot-bots, earlier than others, will approach a low energy level. Pairing thislow energy level with a low predicted energy income results in the foot-bot engaging a personalsurvival mode, where the foot-bot will ignore the learning process and resort to selfish actionsagain.When in this mode, foot-bots will always immediately consume every energy spot they encounterthis in order to maximize their chances of survival. If the foot-bot can consume lots of energy,the survival mode is disengaged and the foot-bot will again turn to its learned behavior.
Figure 4.10: Experiment with low amount of energy spots available from tick 4000

4.3. RESULTS FROM SECOND APPROACH: LEARNING THROUGH APPROVAL OF OTHERS35
The experiment was ran for double the amount of time, to have a clear switch from the learnedcooperative behavior, back to the selfish behavior after introducing the low amount of energyspots. This switch is clearly seen in figure 4.10, with the whole swarm eventually engaging thepersonal survival mode.
4.3 Results from Second approach: learning through approvalof others
For testing the second learning approach, the experiment was performed with 70 % of the foot-bots having a preference for cooperative actions. If the technique has any effect, we should seean increase in the probabilities of these actions and a decrease for the selfish ones over time whenrunning the experiment. As one can see in 4.11, a clear increase in probability for cooperativeactions is seen, where as the other, selfish counterpart, decreases over time. The upper hand theselfish community has, is reflected in the average probabilities at the start of the experiment.This is due to the fact that we have a starting majority of 70%, meaning cooperative actionshave a greater chance of being approved when performed and this over time, shaped the behavioracross the swarm.

36 CHAPTER 4. SIMULATION AND RESULTS
Figure 4.11: Evolution of averaged probabilities for consumption after asking having not thelowest amount of energy
In figure 4.12 a plot is given showing a histogram of the energy levels across the swarm at theend of the experiment. Using the fitdistrplus package from R, several functions are fitted tothis distribution: Weibull, Lognormal, Gamma and Cauchy. The function that best fits thisdistribution here is the Cauchy distribution, as it came with the best goodness-of-fit criteria.

4.3. RESULTS FROM SECOND APPROACH: LEARNING THROUGH APPROVAL OF OTHERS37
Figure 4.12: Histogram of energy levels with added theoretical densities
4.3.1 Different Swarm Densities
The experiment was run with different swarm sizes of 100, 200 and 400 foot-bots.What’s apparent after running these experiments is that increasing swarm size leads to a speedup in the learning process. This is because there are more foot-bots are exploring the envi-ronment simultaneously, leading to more simultaneous interactions happening. Increasing theswarm size also decreases the opportunity for a foot-bot to have no surrounding neighbors tostart the approval sequence with, leading to reward or punishment gained after performing anaction.Increasing the swarm size to speed up the learning process however,can hypothetically also playagainst the swarm. As the increased swarm density leads to more opportunity of interferencewhere robots are performing obstacle avoidance constantly, instead of exploring the actual en-vironment around them. Also, because the communication is vision-based, more footbots doesnot always mean more participation in approval sequences. A population size where the learningprocess starts to decelerate again was not studied due to time limitations.

38 CHAPTER 4. SIMULATION AND RESULTS
Figure 4.13: Comparison between probabilities of experiment with 100 foot-bots to 400 foot-bots
In figure 4.13, the advantage of having a swarm size of 400 compared to 100 foot-bots is displayed.With probabilities for the bigger sized swarm leading to a more cooperative swarm at the endof the experiment.
4.3.2 Different Majorities
In order to see the effect of the size of the cooperative community, the experiment was ranwith different majorities of communities. A minority of 30 % cooperative foot-bots, equal com-munities and a majority of 70 % cooperative foot-bots where used to run the experiment. It’sclearly observed that the preferred behavior of the largest community will dominate the swarm’sbehavior because of the approval mechanic.
In figure 4.14, there is a comparison of the energy distribution between the two extreme cases(minority vs majority of cooperative foot-bots), taken from 30 runs of the experiment.When comparing the experiment with a minority of cooperative bots to a majority of cooperativebots like in figure 4.14, we can see that a majority of selfish foot-bots leads to having a big spreadon the energy level distribution and vice versa a cooperative one leading to a distribution witha clear mean and smaller standard deviation. The selfish majority also leads to more foot-bots

4.3. RESULTS FROM SECOND APPROACH: LEARNING THROUGH APPROVAL OF OTHERS39
with an energy level of zero which is obviously not desired.
One other thing to note is the fact that the mean energy level of the minority (30 % cooperativefoot-bots) experiment is higher than that of the majority (70 % cooperative foot-bots) experi-ment. This is due to the fact that selfish foot-bots prefer the immediate consumption of energyspots, leaving no chance for unused consumptions. Unused consumptions can occur for examplewhen a foot-bot doesn’t obey a consumption selection command.
Running the experiment with equal communities showed that the behavior of the swarm re-mained unchanged, with probabilities of each action staying roughly the same over time. Thisis expected, as a foot-bot has an equal chance to have each action approved or disapproved overtime.
(a) 30 % minority of cooperative foot-bots (b) 70 % majority of cooperative foot-bots
Figure 4.14: Effect of cooperative community size on energy level distribution
4.3.3 Split Communities
The uniform distribution of the foot-bots across the arena, meant that every experiment was runwith a well-mixed swarm, with the two possible opinions being well spread across the swarm.To see the effect of not having a well-mixed swarm at the start, the experiment was ran wherethe two communities were split, each being uniformly distributed over their respective half of thearena. The selfish community started at the left half, the cooperative on the right. This meansthat at the start of the experiment, cooperative foot-bots are mostly surrounded by cooperativeones, and selfish ones by other selfish ones.What was observed from running this experiment was a slower learning process as can be seenin 4.15. It takes a while before the foot-bots start to mix and the cluster of communities getbroken up. In turn, because of this slower learning process, performance is also worse, with a

40 CHAPTER 4. SIMULATION AND RESULTS
bigger standard deviation on the energy levels.
(a) Normal experiment with 70 % majority of coop-erative foot-bots
(b) Same experiment, but with split communities atstart
Figure 4.15: Effect of not well-mixed swarm of opinions

5Conclusion
In this work, two learning techniques based on reinforcement learning, were developed andvalidated using the ARGoS simulator, where a robotic swarm of foot-bots is tasked with theuniforming of an energy level across the swarm, through interacting with the environment andwith each other. The swarm learns the association of reward and actions performed by trial anderror, with each foot-bot trying to individually maximizing its reward signal, in turn collectivelyuniforming the energy level across the swarm.
The first approach is an adaption of reinforcement learning where a communication of knowledgeis added. Here foot-bots are rewarded or punished by the environment for performed actions.When stimulating certain individual cooperative behavior, the swarm collectively uniforms itsenergy level.The aspect of communicating one’s experiences to one another during the learning, has a posi-tive effect on the learning process, spreading knowledge more quickly and resulting in a betterperformance overall in the swarm. Here, the effect of a limited amount of learning opportuni-ties resulted in a halt of the learning process, with the cruciality of the communication aspectbeing highlighted. A scenario where each agent of the swarm resorts to selfish behavior was alsosuccessfully introduced, after adding a survival mechanic to the foot-bot behavior.
The second learning approach, which is quite similar to the first one, also proved effective inshaping the swarm towards cooperative behavior. As running the experiment with a starting
41

42 CHAPTER 5. CONCLUSION
majority of cooperative footbots leads to the entire swarm adapting this behavior. Here, in-creasing the swarm size proved to be beneficial to the learning process, as increased interactionshappens in the environment. Increasing the swarm size beyond a certain point proved inefficienthowever as the density starts to play against the swarm because of increased interference andlesser mixing in the swarm.Because of the approval process of each action, the different majorities of communities plays thekey role in deciding which behavior the swarm adopts. A majority of selfish or cooperative botsleads to a corresponding selfish or cooperative swarm.The complex effect of spatiality was also shown in the experiment run with split communitiesat the start, proving that a not well-mixed swarm has negative effects on the learning process.
Both of these techniques proved effective towards teaching the robot swarm to collaborate andin turn, lead to a swarm that maximizes its collective lifetime, through uniforming the energylevels across the swarm.

Bibliography
[1] A. G. B. Richard S. Sutton, Reinforcement Learning, Second Edition. Bradford, 2018.
[2] Y. Tan and Z. yang Zheng, “Research advance in swarm robotics,” Defence Technology,vol. 9, no. 1, pp. 18 – 39, 2013. [Online]. Available: http://www.sciencedirect.com/science/article/pii/S221491471300024X
[3] D. F., D. C. G.A., P. C., and G. L.M., “Self-organized cooperation between robotic swarms,”Swarm Intelligence, vol. 5, no. 4, pp. 73–96, 2011.
[4] M. Brambilla, E. Ferrante, M. Birattari, and M. Dorigo, “Swarm robotics: a review fromthe swarm engineering perspective,” Swarm Intelligence, vol. 7, no. 1, pp. 1–41, Mar 2013.[Online]. Available: https://doi.org/10.1007/s11721-012-0075-2
[5] “Introduction in swarm intelligence,” accessed: 2018-08-04. [Online]. Avail-able: http://iridia.ulb.ac.be/~mdorigo/INFO-H-414/Overheads/1-Introduction_to_swarm_intelligence.pdf
[6] J.-P. Rennard, “Social insects and self-organization,” https://www.rennard.org/alife/english/antstxt/antstxtgb.htmlf, accessed: 2018-08-04.
[7] O. Soysal and E. Sahin, “Probabilistic aggregation strategies in swarm robotic systems,”pp. 325–332, June 2005.
[8] W. M. Spears, D. F. Spears, J. C. Hamann, and R. Heil, “Distributed, physics-basedcontrol of swarms of vehicles,” Autonomous Robots, vol. 17, no. 2, pp. 137–162, Sep 2004.[Online]. Available: https://doi.org/10.1023/B:AURO.0000033970.96785.f2
[9] M. Yogeswaran, S. G. Ponnambalam, and G. Kanagaraj, “Reinforcement learning in swarm-robotics for multi-agent foraging-task domain,” pp. 15–21, April 2013.
[10] V. Trianni, D. De Simone, A. Reina, and A. Baronchelli, “Emergence of consensus in amulti-robot network: From abstract models to empirical validation,” vol. 1, pp. 1–1, 012016.
43

44 BIBLIOGRAPHY
[11] M. Wolf, R. H. J. M. Kurvers, A. J. W. Ward, S. Krause, and J. Krause,“Accurate decisions in an uncertain world: collective cognition increases true positiveswhile decreasing false positives,” Proceedings of the Royal Society of London B: BiologicalSciences, vol. 280, no. 1756, 2013. [Online]. Available: http://rspb.royalsocietypublishing.org/content/280/1756/20122777
[12] A. J. King and G. Cowlishaw, “When to use social information: the advantage of largegroup size in individual decision making,” Biology Letters, vol. 3, no. 2, pp. 137–139, 2007.[Online]. Available: http://rsbl.royalsocietypublishing.org/content/3/2/137
[13] A. Reina, T. Bose, V. Trianni, and J. Marshall, “Effects of spatiality on value-sensitivedecisions made by robot swarms,” pp. 461–473, 03 2018.
[14] T. Bose, A. Reina, and J. A. Marshall, “Collective decision-making,” Current Opinion inBehavioral Sciences, vol. 16, pp. 30 – 34, 2017, comparative cognition. [Online]. Available:http://www.sciencedirect.com/science/article/pii/S2352154616301930
[15] C. A. C. Parker and H. Zhang, “Biologically inspired decision making for collective roboticsystems,” vol. 1, pp. 375–380 vol.1, Sept 2004.
[16] G. Valentini, E. Ferrante, H. Hamann, and M. Dorigo, “Collective decision with100kilobots: speed versus accuracy in binary discrimination problems,” AutonomousAgents and Multi-Agent Systems, vol. 30, no. 3, pp. 553–580, May 2016. [Online]. Available:https://doi.org/10.1007/s10458-015-9323-3
[17] G. Valentini, H. Hamann, and M. Dorigo, “Self-organized collective decision making: Theweighted voter model,” in Proceedings of the 2014 International Conference on AutonomousAgents and Multi-agent Systems, ser. AAMAS ’14. Richland, SC: International Foundationfor Autonomous Agents and Multiagent Systems, 2014, pp. 45–52. [Online]. Available:http://dl.acm.org/citation.cfm?id=2615731.2615742
[18] J. A. Marshall, G. Brown, and A. N. Radford, “Individual confidence-weighting and groupdecision-making,” Trends in Ecology & Evolution, vol. 32, no. 9, pp. 636 – 645, 2017.[Online]. Available: http://www.sciencedirect.com/science/article/pii/S0169534717301520
[19] C. Pinciroli, V. Trianni, R. O’Grady, G. Pini, A. Brutschy, M. Brambilla, N. Mathews,E. Ferrante, G. Di Caro, F. Ducatelle, M. Birattari, L. M. Gambardella, and M. Dorigo,“ARGoS: a modular, parallel, multi-engine simulator for multi-robot systems,” Swarm In-telligence, vol. 6, no. 4, pp. 271–295, 2012.
[20] D. M. et al., “Swarmanoid: a novel concept for the study of heterogeneous robotic swarms,”IEEE Robotics Automation Magazine, p. Pages In press, 2012.

BIBLIOGRAPHY 45
[21] M. Bonani, V. Longchamp, S. Magnenat, P. Rétornaz, D. Burnier, G. Roulet, F. Vaus-sard, H. Bleuler, and F. Mondada, “The marxbot, a miniature mobile robot opening newperspectives for the collective-robotic research,” pp. 4187–4193, Oct 2010.
[22] F. Mondada, A. Guignard, M. Bonani, D. Bar, M. Lauria, and D. Floreano, “Swarm-bot:from concept to implementation,” in Proceedings 2003 IEEE/RSJ International Conferenceon Intelligent Robots and Systems (IROS 2003) (Cat. No.03CH37453), vol. 2, Oct 2003,pp. 1626–1631 vol.2.
[23] F. Mondada, M. Bonani, X. Raemy, J. Pugh, C. Cianci, A. Klaptocz, S. Magnenat, J.-C. Zufferey, D. Floreano, and A. Martinoli, “The e-puck, a robot designed for educa-tion in engineering,” Proceedingsofthe9thConferenceonAutonomousRobotSystemsandCompe-titions, vol. 1, no. 1, pp. 59–65, 2009.