Embed Size (px)
Citation preview

A Collaboration Model for Community-Based SoftwareDevelopment with Social MachinesDave Murray-Rust1,∗, Ognjen Scekic2, Petros Papapanagiotou1, Hong-Linh Truong2, Dave Roberston1
and Schahram Dustdar2
1Centre for Intelligent Systems and Applications,School of Informatics, University of Edinburgh, UK2Distributed Systems Group, Vienna University of Technology, Austriaf Abstract
Crowdsourcing is generally used for tasks with minimal coordination, providing limited support for dynamic re-configuration. M o dern s y stems, e x emplified by so ci al ma ch ines, ar e su bj ect to co nt inual flu x i n bot h t he cli ent and development communities and their needs. To support crowdsourcing of open-ended development, systems must dynamically integrate human creativity with machine support. While workflows c a n b e u s ed t o h a ndle structured, predictable processes, they are less suitable for social machine development and its attendant uncertainty. We present models and techniques for coordination of human workers in crowdsourced software development environments. We combine the Social Compute Unit—a model of ad-hoc human worker teams—with versatile coordination protocols expressed in the Lightweight Social Calculus. This allows us to combine coordination and quality constraints with dynamic assessments of end-user desires, dynamically discovering and applying development protocols.
Received on 03 February 2015; accepted on 04 July 2015; published on 17 December 2015Keywords: auxiliary information, incremental clustering, data growth, collaborative Filtering, NMFCopyright © 2015 Dave Murray-Rust et al., licensed to EAI. This is an open access article distributed under the terms of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/), which permits unlimiteduse, distribution and reproduction in any medium so long as the original work is properly cited.doi:10.4108/eai.17-12-2015.150812
1. Introduction
Most social computing systems today are based aroundpatterns of work that can be predictably modelled beforeexecution, such as translation, bug discovery, image tagging[1, 2]. However, there are many cases where where atraditional workflow approach is too rigid to address thedynamic an unpredictable nature of the tasks at hand, andmore flexible crowd working systems must be developed[3].
One example of such dynamic systems is the field ofsocial machines—systems where computers carry out thebookkeeping so that humans can concentrate on the creativework[4]. This term covers a diverse class of systems, spanningtask-oriented (Wikipedia) to generic (Twitter); scientific orhumanitarian (GalaxyZoo, Ushahidi) to social (Instagram)[5, 6].
Despite their diversity, a defining feature of socialmachines is that interactions between computational intelli-gence and human creativity are deeply woven into the system,making it difficult to draw a clear line between the human anddigital parts—rather they must be analysed synergistically.
Hence, creating a social machine requires understandingof individual and group human behaviour alongside technicalexpertise, and a view of the system as an interconnectedwhole containing both human and computational elements.
∗Corresponding author. Email: [email protected]
Furthermore, social machines are subject to populationdynamics as the user population changes, and must respondto the exigencies of unfolding situations. In such cases itis important not to over-regulate participating humans, butto let them play an active role in shaping the collaborationduring runtime. On the one hand, this points to leveraginghuman creativity and embracing the uncertainty that comeswith it, in order to respond flexibly. On the other hand, it isoften necessary to impose certain coordination and qualityconstraints for these collaborations in order to manage them.The constraints delimit the decision space within which thehumans are allowed to self-organize.
Recently, a number of human computation frameworkssupporting complex collaboration patterns were proposed(Section 7). They mostly build upon conventional crowd-sourcing platforms offering a process management layercapable of enacting complex workflows. While these systemsrepresent important steps on the road to building complexsocial machines, in cases where unpredictability is inherentto the labour process and we cannot know all of the systemrequirements in advance, a different approach is needed.
In this paper we present models and techniques forcoordination of human workers in crowdsourced softwaredevelopment environments. They support the bootstrappingand adaptation of social machines: using one social machineto generate or alter another one, allowing for flexible,community-driven development, with feedback paths fromuser populations to development choices. This allows both
1
EAEAI Endorsed Transactionson Collaborative Computing Research Article
EAI Endorsed Transactions on Collaborative Computing
11 - 12 2015 | Volume 1 | Issue 5 | e6EAI
European Alliancefor Innovation

human influence on the execution of a computation and theembedding of computational intelligence.
The introduced concept augments the Social Compute Unit(SCU, Section 2.2)—a general framework for managementof ad-hoc human worker teams—with versatile coordinationprotocols encoded in Lightweight Social Coordination Calcu-lus (LSC, Section 2.3). This combination allows us to designand model social machines oriented towards crowdsourc-ing software development. Coordination protocols providehigh level organisation of activities around development—including planning and user assessment/feedback—while aset of coordination and quality constraints guide the assign-ment of workers to tasks. The system as a whole strikes abalance between imposed constraints and creative freedom inthe software development cycle. Concretely, this means thatthe proposed model is able to take into account the feedbackfrom the user population and subsequently alter the process ofthe development of software artefacts. Although we focus oncollaborative software development, the solution we presentis generally applicable to a class of similar problems. Thereare many situations where some form of social machine orcommunity infrastructure is being developed, requiring thedevelopers to react to the changing needs and behaviour ofthe community; increasingly, another social machine is usedto crowdsource the development.
This paper is structured as follows: First we present themotivating scenario of community-influenced, collaborativesoftware development. In Section 2 we analyse how thepresented scenario can be modelled in terms of socialmachines. We then introduce background concepts whichwe use to build our model: Feature Oriented SoftwareDevelopment (FOSD), the Social Compute Unit (SCU)and the Lightweight Social Calculus (LSC). In Section 3we present the coordination model for the social machineemploying the previously introduced background concepts. InSection 4 a proof-of-concept implementation is presented andevaluated through simulation.
1.1. Motivating ScenarioDeveloping software for a large user base with diverginginterests can be challenging. As an illustrative example,let us consider the problem of developing a forum-like scientific platform—a scholarly social machine—tofacilitate multidisciplinary cross-collaboration and sharing ofresults. This includes functionality such as: paper previews,comments, in-place formulae and data rendering, citationpreviews and bookmarking. While these are functionalitiesbeneficial to all scientists, preferences for particular formatsand services will likely differ among different sub-communities. For example, chemists and mathematicianswill have different domain-specific requirements from theplatform. Some examples are:
• Computer scientists need code syntax highlighting,LaTeX rendering, embedding of IEEExplore and ACMDL citations. If any of these features is missing, the
software is not useful to the community. However,they do not particularly care about chemistry-specificfeatures.
• Chemists often use InChi strings to represent chemicalformulae. If the software supports InChi, then chemistswould also want support for compound lookup onPubChem, and visualisation with pyMol. Without thesefeatures, the platform does not help them particularly.On the other hand, syntax highlighting and IEEExploreintegration is not important.
• Individual scientists may be bothered by (lack of)certain features. For example, users may dislike beingforced to use a LinkedIn account to log in, dueto possibility of a third party accessing unpublishedscientific findings.
Some of these features are orthogonal—code syntaxhighlighting and LaTeX rendering are both useful in their ownright—while some are synergistic: a chemist might requireboth parsing InChi strings and PubChem lookup in order tocarry out their particular workflow.
The complexity of developing such software lies incatering to the heterogeneous user needs, requiring numeroustrade-offs when deciding which features to implement.Furthermore, different sub-communities tend to changepreferences regarding required or newly developed featuresduring the development process which need to be takeninto account. Finally, certain members of the scientificcommunity (i.e., targeted users) may decide to take part inthe development process themselves.
2. Modelling Community-Based SoftwareDevelopment
The previously presented scenario is representative of manysocial machines, where a dynamic community forms arounda particular (software) artefact. The population is likelyto change, and feedback between the human participantsand technological infrastructure can lead to changes in thepurpose and direction of technological development.
This means that there are two social machines: i) the targetsocial machine which includes the forum software and itscommunity of users and ii) the development social machine,which is the software developers and their coordinationarchitecture (Figure 1). We use the term utility to denotesome metric for the benefits which a user (in the targetsocial machine) derives from participation. While in principlethis metric could include a multitude of components, withinthis paper we narrow our focus to treat utility as measuringhow well the software’s feature set matches the user’srequirements.
The aim of the development social machine is to increasethe overall utility of the user population, by creating featureswhich match community needs and desires. The developersdo not know ahead of time the true preferences of individuals,
2
EAI Endorsed Transactions on Collaborative Computing
11 - 12 2015 | Volume 1 | Issue 5 | e6EAIEuropean Alliancefor Innovation
Dave Murray-Rust et al.

Development Social Machine Target Social Machine
Forum PlatformCoordination Protocols
deploy
monitor
i ii
Figure 1. Two connected social machines: i) thedevelopment social machine, where crowdsourcedworkers follow coordination protocols to create asoftware artefact; ii) the target social machine, wherea community of practice forms around the softwareartefact created by i).
or the constitution of the community, and hence the effectsof software changes on community behaviour are difficult topredict ahead of time.
Since crowd-labour is increasingly used for the develop-ment of software, we assume it is necessary to use devel-opment methodologies which split work into tasks that areamenable to crowdsourcing. This means that tasks haveto be disassembled into simpler subtasks, and mapped toappropriate developers. The latter is itself a complex problem,as it also includes taking care of inter-task implementationdependencies. Hence, the development social machine mustbe able to i) assess user desires and preferences; ii) identifyand prioritize features for development; iii) coordinate thedevelopment and deployment of these features; iv) organisethese tasks over time with respect to a dynamically changingpopulation and limited resources.
These operations and their relation to the user populationare outlined in Figure 2
2.1. Feature Trees for Artefact DevelopmentA requirement of our model is the representation ofthe current state of the artefact under development—thedevelopment artefact in Figure 2. Since our example isbased on software development, we use the Feature-OrientedSoftware Development (FOSD) paradigm, where softwareartefacts are represented as trees of features: “prominent ordistinctive user-visible aspect, quality, or characteristic[s] ofa software system”[7]. This representation is used so thatdevelopment can be decomposed into small sets of relatedtasks that can be handled relatively independently, to aidcollaborative creation of software artefacts.
Based on the requirements and possibilities in the scenariooutlined in Section 1.1, the feature tree in Figure 4 canbe constructed1. Here, broad classes of functionality, suchas visual embedding of graphical objects are represented as
1The tree was created using FeatureIDE. Details of assumed semantics canbe found at http://www.iti.cs.uni-magdeburg.de/iti_db/research/featureide/
Expansion Prioritisation Development
TargetSocial Machine
DevelopmentSocial Machine
Deploy
ExpandSelect
Implement
Observe
interact
CoordinationProtocols
SoftwareArtefact
DevelopmentArtefact
i
ii
Figure 2. Interaction between the development andtarget social machines, including development steps,developer interaction, user observation and communityinteraction.
Possible PotentialPotentialUtil=4.35
Impl.
Expand Evaluate Implement
Figure 3. States and operations on a single node inthe feature tree. Potential nodes are expanded intoPossible nodes, which can be evaluated against userpreferences, before being implemented.
branches of the tree, with specific instances such as pyMolviewers forming sub-branches and leaves.
Feature trees can be used to represent the current stateof software development; by labelling each node with astate, the team knows whether or not functionality for thatfeature has been implemented, and whether the conditionsfor implementing that functionality have been met. Thisforms a coordination artefact used by the development socialmachine, to organise construction and monitoring of thesoftware artefact used in the target social machine. As shownin Figure 2, once features in the tree are implemented, thesoftware artefact can be deployed to the user population.
Software development can be modelled as modifications tothe feature tree: the re-labelling of nodes as new functionalityis conceived of and implemented (before being deployed to
3
A Collaboration Model for Community-Based Software Development with Social Machines
EAI Endorsed Transactions on Collaborative Computing
11 - 12 2015 | Volume 1 | Issue 5 | e6EAI
European Alliancefor Innovation

Figure 4. An example feature tree for a scientific forum software system.
the target artefact). In this paper, we use a simple state model(Figure 3), where each node is either:
i) Implemented—code has already been created for thisfeature, and it is available to users; ii) Potential—the featurehas been conceptualised and designed, but no code existsyet; iii) Possible—part of the universe of possible features,but one which is not currently under consideration forimplementation2
Based on this representation, development can contain thefollowing steps, or development primitives, which map tooperations of the feature tree:
1. Expansion of the tree converts nodes from possible topotential by finding new features to implement. Thismight be through expert designers, co-creation or directuser solicitation.
2. Evaluation of community needs and their relationto individual features results in labelling nodes withsome indication of how well the community will react.There are many ways to do this, including surveying
2The possible state is largely a convenience for simulation.
the participants; public consultations; focus groups;monitoring of behaviour; and social media analysis.
3. Prioritisation of features to implement, which maybe driven by the result of evaluations, voting by thepopulation, investor demands, expert opinion etc. Thisdecision may depend on which type of costs thecontrollers of the artefact would like to optimise (e.g.,economic, temporal, social).
4. Implementation of the selected features, whether in-house, or crowdsourced, using some particular softwaredesign methodology. When implementing features,the constraints contained in the feature tree mustbe observed (e.g., mandatory features, alternativefeatures).
Within our model, these tasks are carried out by assemblingteams of crowd professionals—SCUs (Section 2.2), capableof executing complex workflows. The formation of SCUsand coordination of their actions are carried out through theCoordination Model (CM), introduced in Section 3, whichallows flexible workflows that adapt to emerging situations.
4
EAI Endorsed Transactions on Collaborative Computing
11 - 12 2015 | Volume 1 | Issue 5 | e6EAIEuropean Alliancefor Innovation
Dave Murray-Rust et al.

2.2. Social Compute Unit (SCU)
An SCU [8] is a loosely-coupled virtual team of socially-connected experts with skills in the relevant domain. TheSCU is created upon request to solve a given task. Ituses the crowdsourcing power of its members and theirprofessional connectedness toward addressing the problemwhich triggered its creation and is dissolved upon problemresolution. The SCU is a programmable entity. Thismeans that its various properties and functionalities (teamassembly, task decomposition, runtime collaboration patterns,coordination, task aggregation) can be ‘programmed’ tosupport different types of human/machine collaborativeefforts. For example, in [9] the authors show how the SCU cansupport well-defined business-processes, such as workflowpatterns for IT incident management. However, SCU can alsobe used to perform looser collaboration patterns leaving spacefor human improvisation and creativity [10].
In this paper we use SCUs within the development socialmachine to execute tasks in the software development cycle,such as implementing a concrete software feature. Concretely,we build upon the particular SCU model presented in[11] and use it in the context of the encompassing socialmachine’s coordination model. Whenever a developmentprimitive (from Section 2.1) needs to be executed, a requestwith input parameters is sent to the SCU provisioningengine to form a team of developers/experts suitable forthat particular primitive (task). The provisioning enginereturns the closest-to-optimal matching subset of availabledevelopers, representing a SCU for that task.
The full list of available input parameters and descriptionsof the team formation algorithms are available in [11]. Inthis paper, however, we vary only the parameter named jobdescription set (J), while assuming default values for theremaining parameters. J contains job descriptions for eachsubtask: J = {j1, j2, · · · , jk}. A job description is a set oftuples ji = {(t1, q1), (t2, q2), · · · , (tm, qm)}, where tl is askill type (e.g., ‘java developer’, ‘test engineer’) and ql ={‘fair′, ‘good′, ‘verygood′} is a fuzzy quality descriptor.The job description (tl, ql) specifies which skills a workerneeds to possess in order to perform the subtask l successfully.
2.3. Lightweight Social Calculus (LSC)
LSC is an extension of LCC [12], which has beenused to represent interaction in many systems [13]. LCCis a declarative, executable specification which can becommunicated between agents at runtime; it is designed togive enough structure to manage fully distributed interactionsby coordinating message passing and the roles whichactors play, while leaving space for the actors to maketheir own decisions. LSC augments LCC with extensionsdesigned to make it more amenable to mixed human-machineinteractions; in practice, this means having language elementswhich cover user input, external computation or databaselookup and storing knowledge and state.
a(invitee(C), A ) :: dinner(Time,Place) <= a(confirmer, C) then confirm(yes) => a(confirmer, C) <-- ok(Time,Place) or confirm(no) => a(confirmer, C) then a(invitee(C), A) .
Role: description and agent idMessage in:content <= sender role
Sequencing
Choice
Resume invitee role Implication: if RHS can besatisfied, substitute and execute LHS
Message out: content =>
receiver role
Body
Figure 5. Example LSC clause from the mealorganisation interaction model (slightly modified forclarity). An agent playing the role of invitee will waitfor a message from a confirmer specifying the timeand place for dinner; the values in the message forTime and Place are substituted in, and the agentthen decides if it will_attend, and sends backthe appropriate message. It then resumes the role ofinvitee in case of alternate suggestions.
An LSC protocol consists of a set of clauses; thehead of each clause is a role specification, and thebody a description of what an agent should do whenplaying that role (see example in Figure 5). The bodycontains message sending (M ⇒ a(role, ID)) and receiving(M ⇐ a(role, ID)), sequencing and choice (then and or),implication (action← condition), the assumption of newroles (a(role, ID)) and any extra computation or conditionsnecessary.
Each agent’s interaction starts with a clause from aprotocol, which is then repeatedly re-written in response toincoming events: incoming messages are matched againstexpected messages, role definitions are replaced with thebody of matching clauses, values are substituted for variablesand so on. As the interaction progresses, this state tree keepsa complete history of the agents actions and communications.This supports the creation of multi-agent institutions [14]where interaction is guided by shared protocols and asubstrate which keeps track of state.
LSC is formal enough that it can be computationallymanipulated, for example to synthesise new protocols[15]. Itshares features with workflow languages—while providingmore flexibility—and can be derived from e.g. BPEL4WSto create completely decentralised business workflows [16].LSC has also been used in the creation of social machinesby binding formal interaction models into natural interactionstreams [17].
Within our model, LSC is used to model the develop-ment social machine, by specifying the interactions amongdevelopers, and between developers and the feature treerepresenting the state of the software artefact. It provides ameans to create a formal representation of software devel-opment processes, allowing for computational coordinationof their enactment, while providing more flexibility thana workflow would allow. LSC provides a bridge between
5
EAI Endorsed Transactions on Collaborative Computing
11 - 12 2015 | Volume 1 | Issue 5 | e6EAIEuropean Alliancefor Innovation
A Collaboration Model for Community-Based Software Development with Social Machines

low level operations—e.g. implementing a particular node—and high level concepts such as “agile methodologies”. Byformalising the coordination protocols and making them firstclass objects, it is possible to share, modify, discover andrate individual protocols; by separating the protocol fromthe domain of application, it is possible to apply the samemethodology to new domains. The flexibility of the languageallows for sub-protocols to be chosen dynamically, so thatdevelopment can be adapted in response to changing needs.Over time the system can build up a view of when eachprotocol is appropriate, and be able to assist with selectionof protocols for novel situations.
3. Coordination ModelThe coordination model represents the artefact regulating theinteractions among social machines. It contains the followingsubmodels, regulating different interaction aspects:
• Data Submodel: A formal data model used to representthe data that is processed and exchanged by socialmachines. It serves both as input and output for thesocial machine. In our example, the data model isrepresented by the feature tree representing the forumsoftware. For the development social machine it servesto indicate the features to develop and dependencies;but also to track the progress of the development cycle.The resulting tree is then subsequently also used as theinput of the target social machine for calculating theoverall population utility, as well as to mark elicitedfeatures for future development cycles.
• Quality-of-Service Submodel: In essence, the devel-opment social machine is providing a software-development service to the target social machine.Therefore, we need a set of metrics to express therequested and measure the obtained quality of thisservice. In this paper, we adopt the metrics alreadyprovided by the SCU [11] to formulate requested QoS.
• Interaction Submodel: The coordination submodelcontains a collection of LSC-encoded protocolsmanaging interactions between social machines andtheir workers. The coordination submodel containsmultiple possible protocols. A metalevel protocol isused to make real-time selection and enactment ofan appropriate subset of concrete protocols, basedon the current state of the coordination model, inputfrom stakeholders or the current behaviour of thecommunity interacting with the artefact. Selectioncould also include discovery of new protocols touse (e.g., as new development methodologies areintroduced) as well as analysis of the historicperformance of existing protocols in similar situations.The use of metaprotocols is crucial in order forthe development social machine to be responsiveto community requirements, and for it to adjustdevelopment trajectories accordingly.
Figure 6 illustrates the usage of the coordination modelartefact for the scenario introduced in Section 1.1. Aniteration in the software development cycle starts by having anactive LSC protocol send a request to the SCU ProvisioningEngine (Figure 6, 1 ). The request contains the necessaryQoS input parameters (described in Section 2.2) for creationof multiple SCUs. Based on these parameters the SCUProvisioning Engine selects appropriate workers from thecrowd of professionals (2 ), assembles and returns the SCUs.The newly created SCUs are passed the feature tree withnodes selected for implementation (3 ), finally constitutinga functional development social machine. The developmentsocial machine starts performing the designated actions on thefeature tree (4 ). The active LSC protocol from the interactionsubmodel takes care that the actions performed by differentSCUs are properly ordered and repeated if necessary (e.g.,due to failure, or insufficient quality). After the SCUs finishexecuting, the resulting feature tree is passed to the targetsocial machine (5 ).
The modified tree is then evaluated by a function assessingthe population utility (6 ). As explained earlier, this isa measure of target community’s satisfaction with theimplemented features. Based on the this value, and the newrequests from the community, the metaprotocol can decidewhether new development iterations are necessary, and if yes,which protocols to use (7 ). Depending on the new priorities,a different protocol can be chosen to control the developmentsocial machine in the new iteration. For example, for theevaluate action, new candidate features may be identifiedby a single SCU of experts, or by having multiple SCUssuggesting new features and then deciding by majority voting.Or, in case of a failure, we may decide to repeat the task withthe same SCU, or escalate to a more reliable (and thus a moreexpensive) one.
In the following sections, we present a proof-of-conceptimplementation of this coordination model. We evaluatethe implemented prototype by simulating a populationand running a number of LSC protocols to showcase itsfunctionality.
4. Implementation and Evaluation
4.1. Prototype Implementation
In order to demonstrate the operation of the coordinationmodel, we have implemented a simulation prototypewhich covers a subset of the conceptual model’s possiblefunctionality. In the simulation, a pool of crowd workersparticipate in improving the scientific forum softwareintroduced in Section 1.1. The (simulated) workers aremanaged by a system running various LSC protocols,representing different approaches to software development.This includes all of the task selection and implementationactivities from Section 2, as well as the team selection workdiscussed in Section 2.2.
6EAI Endorsed Transactions on
Collaborative Computing
11 - 12 2015 | Volume 1 | Issue 5 | e6EAI
European Alliancefor Innovation
Dave Murray-Rust et al.

Feature Tree
SCU QoS Constraints
LSC Protocols
coordination modelfor community-based
software development scenario
F0
F1 F2
Feature trees:
SCU Input parameters:
LSC protocols:
Required Skill Sets
Skill TypesFuzzy
Skill Levels
Jobs(Actions)
‘Good’ ‘Fair’
‘Java’ ‘jQuery’
Job #1
a(agile_process(ExpQ,ImplQ,Count), Ag ) :: a(agile(ExpQ,ImplQ),Ag) then ( null <- Count = 0 or a(agile_process(ExpQ,ImplQ,Cn),Ag) <- Cn is Count - 1 ).
Metaprotocols and inter-SCU protocols, e.g.:
Other optimizable metrics:– connectedness– maximum response time– cost limit
– possible– selected– implemented
SCU Provisioning &Monitoring Engine
F0
F1 F2
SCU
crowd– expand– evaluate– priori tise– implement
1
2
3
4
5
SCUs
Community
futil ()
metaprotocol
monitor
select protocols
development social machine
target social machine
QoS input params
selected feature
tree nodes
modified feature
tree
6
7
Figure 6. Using the Coordination Model to support the community-based, collaborative software developmentscenario.
The implementation uses the scalsc LSC library, withextensions to model feature trees, labour and team selection,and user populations3. Concretely, this comprises:
1. A population of simple software agents representingcommunity members; this is simulated as a hetero-geneous group of individuals, each with their ownpreferences about which features the community soft-ware should contain. The preferences are representedas scores for the presence of conjunctions or disjunc-tions of implemented feature-tree nodes. A typologyapproach is used, where archetypal users are defined fortwo classes (chemists and mathematicians), differingin their preferences for functionality. These users aresampled with multiplicative noise (N (1, 0.1)) added totheir preference scores to provide limited heterogene-ity.
2. A feature tree representing the current state of thesoftware, as defined in Section 3, following the examplein Figure 4;
3Complete source code and installation instructions can be found athttps://bitbucket.org/mo_seph/social-institutions
3. A simplified, idealised SCU model, where teams areformed in response to quality constraints, and performtasks on the feature tree. In this simplified model, weassume that one worker is returned per task, with a skillset that exactly matches the quality constraints [11].Workers have scores for four skills: implementation,evaluation, prioritisation, design, each of which rangesfrom 0..1.
4. A labour model, relating worker qualities to thetime, cost and quality of carrying out primitive treeoperations. This model has been designed to representthe issues at hand in a stylised manner, while having areduced parameter set to help understand the model’sbehaviour. Operations are assigned a basic cost Co,which is then multiplied by the cost of the worker whois carrying it out; worker cost is the sum of the worker’sskill levels (S) raised to an exponent k = 0.5, so thecomplete cost of a worker w operation o is: C(w, o) =Co
∑sk (for s ∈ S). Details of operator cost, time and
implementation specifics are in Table 14.
4We acknowledge that the simulation will be sensitive to the parametervalues chosen (especially k); the results we present are intended only to give
7
A Collaboration Model for Community-Based Software Development with Social Machines
EAI Endorsed Transactions on Collaborative Computing
11 - 12 2015 | Volume 1 | Issue 5 | e6EAIEuropean Alliancefor Innovation

Table 1. Model of primitive tree operations, showing base costs, assumptions made and implementation details.ereal is the true population utility for a feature tree, and sx is the team’s skill in x.
Operation Assumptions Implementation Cost, Time
Expand Only children of potential nodes are considered. A betterdesign process will create nodes which better match thepopulation’s need
Order nodes byerealN (1, (1− sdesign)) andselect the first.
2, 0.5
Evaluate A better evaluation process will be closer to the true valuepopulation’s need
Label nodes with eest =erealN (1, (1− seval)).
0.5, 0.5
Prioritise Better prioritisers order nodes more closely to their trueevaluation order with respect to population’s need
Order nodes byeestN (1, (1− sprioritise))and label with index.
0.01, 0.01
Implement Select highest priority node; better implementers have morechance of success.
Pimpl = simplementation 1, 1
In order to effect changes to the feature tree, a set of LSC-based intra-unit- and meta-protocols are used to constructSCU according to quality metrics, and schedule them tocarry out operations. Listing 1 shows an example high-levelLSC protocol coordinating an agile development process:form_scu triggers the SCU formation, based on a set ofrequired skills and the action to enact, while do_taskcontrols the execution of the selected actions5. Theseprotocols can be written as standard LSC [12], with a smallset of extra predicates for forming teams and manipulatingtrees: form_scu and do_task mentioned above, as wellas current_tree and highest_priority, which aredemonstrated in Listing 1.
4.2. Initial ScenariosIn order to illustrate the operation of the prototype, we runit under two contrasting scenarios, with three different LSC-based workflows imposed through appropriate LSC protocols.In the first scenario—StablePopulation, a population of 1000members of the chemistry community (chemists) is simulatedthroughout the entire simulation runtime. In the secondscenario—DynamicPopulation the initial population of 1000chemists is replaced by 200 chemists and 800 mathematiciansat timestep 20. This is a crude and stylised approach torepresenting a shift in user population, where the platform isadopted by a different user community, but it allows us toillustrate the prototype implementation’s behaviour.
The coordination models we use are loosely based oncurrent or past practice in software development:
• The traditional model starts with a large publicconsultation, where most of the tree is explored and
an indication of capabilities, so no formal sensitivity analysis has been carriedout.5Further details on the prototype implementation, as well as thesource code can be found at https://bitbucket.org/mo_seph/social-institutions
assessed before any implementation takes place. Actualfeature implementation is then carried out by teams(i.e., SCUs) of average-skilled programmers, who havethree attempts to implement any given node.
• The escalation model begins with the same initialpublic consultation, but is followed by a developmentprocess where initially an average (and cheap)developer attempts to implement each node. If thatfails, a high quality, but more expensive, developeris found and brought in to finish the job. This is anexample of a simple metaprotocol, allowing alternativedevelopment pathways to be chosen at runtime.
• The agile model defines a a tight loop of evaluation andimplementation, to allow development to respond to achanging set of user requirements.
4.3. Protocol Assessment and DiscoveryTo illustrate the possibility of evaluating and discoveringprotocols—due to their status as first-class objects [18]—we:i) implement a collection of performance metrics which mightrelate to real-world quatitites of interest; ii) assess differentparameterisations of the agile protocol discussed above. Theagile protocol was picked due to its potential for use inthe dynamic protocol described in Section 4.4. The protocolconsists of a role which two parameters: EvalQ and ImplQ,the skill levels of the evaluating and implementing SCUsrespectively, both in the interval [0, 1]. The values of thesetwo parameters were varied separately so that the effects ofprioritising resources towards the implementation or designstages of the process may be apparent.
Several metrics are used based on a combinationof implementation pragmatics and applicability to thescenario—these are by no means a recommended or completeset—and the most relevant of these are displayed based onthe above factors and an ability to meaningfully distinguishbetween different protocol settings. As well as four basic
8EAI Endorsed Transactions on
Collaborative Computing
11 - 12 2015 | Volume 1 | Issue 5 | e6EAI
European Alliancefor Innovation
Dave Murray-Rust et al.
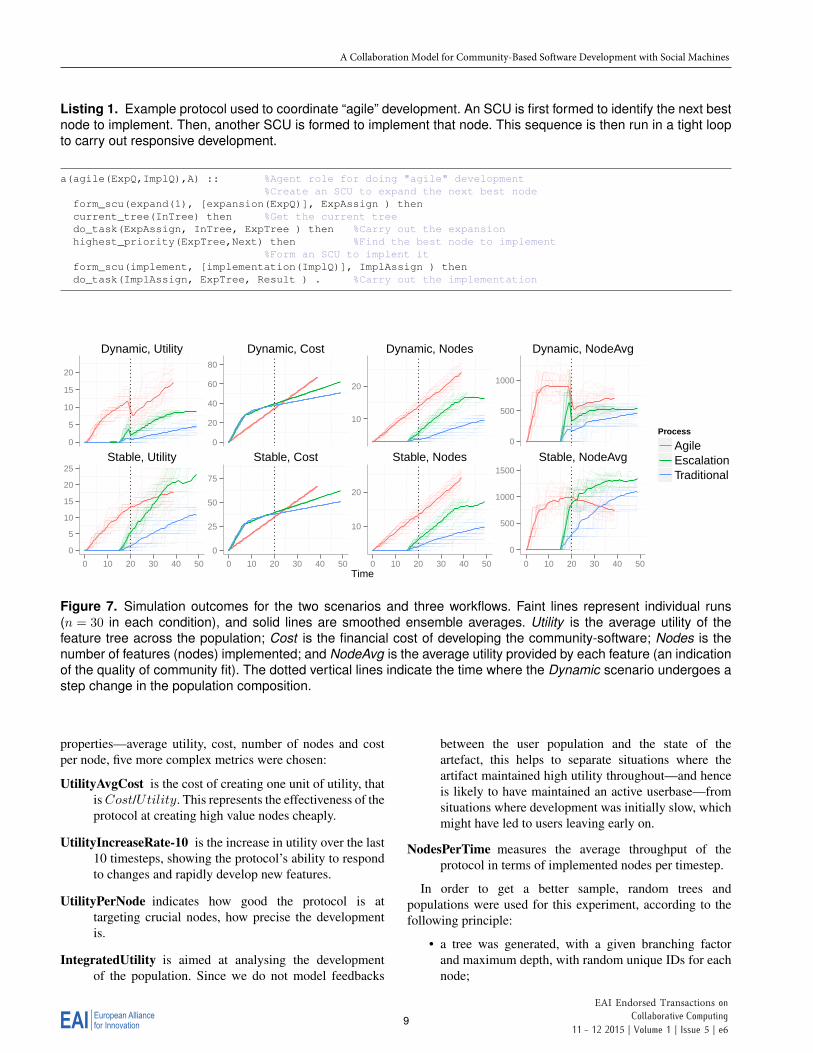
Listing 1. Example protocol used to coordinate “agile” development. An SCU is first formed to identify the next bestnode to implement. Then, another SCU is formed to implement that node. This sequence is then run in a tight loopto carry out responsive development.
a(agile(ExpQ,ImplQ),A) :: %Agent role for doing "agile" development%Create an SCU to expand the next best node
form_scu(expand(1), [expansion(ExpQ)], ExpAssign ) thencurrent_tree(InTree) then %Get the current treedo_task(ExpAssign, InTree, ExpTree ) then %Carry out the expansionhighest_priority(ExpTree,Next) then %Find the best node to implement
%Form an SCU to implent itform_scu(implement, [implementation(ImplQ)], ImplAssign ) thendo_task(ImplAssign, ExpTree, Result ) . %Carry out the implementation
Dynamic, Utility Dynamic, Cost Dynamic, Nodes Dynamic, NodeAvg
Stable, Utility Stable, Cost Stable, Nodes Stable, NodeAvg0
5
10
15
20
0
20
40
60
80
10
20
0
500
1000
0
5
10
15
20
25
0
25
50
75
10
20
0
500
1000
1500
0 10 20 30 40 50 0 10 20 30 40 50 0 10 20 30 40 50 0 10 20 30 40 50Time
Process
AgileEscalationTraditional
Figure 7. Simulation outcomes for the two scenarios and three workflows. Faint lines represent individual runs(n = 30 in each condition), and solid lines are smoothed ensemble averages. Utility is the average utility of thefeature tree across the population; Cost is the financial cost of developing the community-software; Nodes is thenumber of features (nodes) implemented; and NodeAvg is the average utility provided by each feature (an indicationof the quality of community fit). The dotted vertical lines indicate the time where the Dynamic scenario undergoes astep change in the population composition.
properties—average utility, cost, number of nodes and costper node, five more complex metrics were chosen:
UtilityAvgCost is the cost of creating one unit of utility, thatis Cost/Utility. This represents the effectiveness of theprotocol at creating high value nodes cheaply.
UtilityIncreaseRate-10 is the increase in utility over the last10 timesteps, showing the protocol’s ability to respondto changes and rapidly develop new features.
UtilityPerNode indicates how good the protocol is attargeting crucial nodes, how precise the developmentis.
IntegratedUtility is aimed at analysing the developmentof the population. Since we do not model feedbacks
between the user population and the state of theartefact, this helps to separate situations where theartifact maintained high utility throughout—and henceis likely to have maintained an active userbase—fromsituations where development was initially slow, whichmight have led to users leaving early on.
NodesPerTime measures the average throughput of theprotocol in terms of implemented nodes per timestep.
In order to get a better sample, random trees andpopulations were used for this experiment, according to thefollowing principle:
• a tree was generated, with a given branching factorand maximum depth, with random unique IDs for eachnode;
9
A Collaboration Model for Community-Based Software Development with Social Machines
EAI Endorsed Transactions on Collaborative Computing
11 - 12 2015 | Volume 1 | Issue 5 | e6EAIEuropean Alliancefor Innovation

• two archetypes were generated for this tree whichgained utility for the presence of up to 15 of thenodes in the tree, with the level of utility sampled fromN (0, 2).
• these were then used in a population dynamics model,following the template of the dynamic scenario above,with a step change from purely one type to an equalmix of both types at timestep 20.
Based on the availability of metrics, a simulated protocoldiscovery mechanism is implemented. This takes the formof a database of protocols and roles, searchable accordingto individual scores for each metric. These scores weretaken from the average across multiple runs of either i)the maximum value or ii) the final value recorded in thesimulation as appropriate for the metric. The discoverymechanism uses the calculated scores to select the protocoland role that are expected to either increase, decrease,maximize, or minimize particular metrics.
This discovery mechanism is made available to the agentswithin the simulation, by means of a special predicate: sat-isfying i(discover(“CostPerNode′′,min, Proto,Role))would return substitutions such as Proto→ agile, Role→agile(0.5, 0.8), indicating that the way to minimise the costper node is to enact the role agile(0.5, 0.8) in the agileprotocol.
4.4. Dynamic Protocols
Another key benefit of protocols is their flexibility. State canbe brought in, allowing the protocol to adapt to changingsituations. In order to demonstrate this, Listing 2 showsa simple dynamic protocol. Here, the agents are providedwith an extra predicate—metric(M,U)—which retrievesthe current value U of a metric M . For example, the predicatemetric("AvgUtility",U) gives the average utility ofthe population at this moment in time. Protocols can thenbe written which react to this. For example, a protocol canuse this in order to prioritise economic development when thepopulation is happy, but increase utility at any cost when thepopulation is less happy. There are two steps to this: choosingwhich goal to prioritise in terms of a metric to minimise ormaximise, and then using the discovery mechanism to selectthe protocol which best fits that goal.
For simulation purposes, a more complex protocol wasused which would:
• start with the most rapid development strategy(maximise NodesPerT ime);
• monitor the CostPerNode and AvgUtility;
• if CostPerNode is too high, find a role with a lowerexpected cost per node
• if the AvgUtility is too low, find a role with a higherUtilityIncreaseRate− 10
This protocol was run alongside the previous protocolsfrom Section 4.2: traditional,escalation and agile, as wellas the best performing set of agile parameters (Agile1,with EvalQ = 0.9, ImplQ = 1.0) in order to observe theeffects of dynamically selecting protocols and parameters.The output of the search over the agile parameter space wasused, so that all of the roles which were selected were of theform agile(E,I).
5. ResultsFigure 7 shows the simulation outcomes when runningthe described scenarios and workflows. Under the Stablescenario, the agile workflow initially performs best, asdevelopment starts immediately. Over time, however, theescalation workflow achieves higher utility with fewer nodesdue to a greater understanding of the complete featuretree. The traditional workflow is limited by the speedof its average-skilled developers, but utility does increasegradually. Under the Dynamic scenario, the initial behaviouris similar. However, when the population changes at timestep20, the agile workflow adapts more quickly to the change, andcreates nodes which better represent the desires of the newpopulation.
To zoom in on the effects of QoS selection, Figure 8shows the performance of the agile protocol with a rangeof parameterisations for a range of metrics 6. In most cases,the broad shape of the metric curves is similar. It is clearthat the overall system state—few implemented nodes at thebeginning versus many towards the end—and the populationdynamics have a strong effect on the curves. However, theQoS parameters selected can have a large effect on the rangesof the curves. It is also clear that the metrics are able todifferentiate between different parameter settings, with mostgraphs showing a clear ordering. Different metrics producedifferent orderings, for example the Cost graph shows thatfor a value of EvalQ = 0.8, the agile algorithm costs morein total for ImpQ = 0.5 (blue) than for ImpQ = 0.2 (cyan),but the CostPerNode metric shows the average cost perimplemented node is actually less for ImpQ = 0.5 (thusindicating it implements nodes faster).
Figure 9 compares the behaviour of the Dynamic protocol(green) with the previous ones over randomly generated trees.Comparing the two simple agile protocols to the dynamicallyassigned one, it can be seen that the dynamic protocol hasthe lowest cost in total, per node, and per unit of utility, whilemaintaining utility and throughput to levels comparable to the‘optimal’ parameter settings.
6. DiscussionThe initial round of simulations demonstrates the abilityof the coordination model to represent a flexible process.
6As stated previously, these metrics are intended to be plausible, ratherthan comprehensive—the metrics only need to be good enough to drive theprotocol selection described in Section 4.4.
10EAI Endorsed Transactions on
Collaborative Computing
11 - 12 2015 | Volume 1 | Issue 5 | e6EAI
European Alliancefor Innovation
Dave Murray-Rust et al.

Listing 2. Example dynamic protocol, used to choose roles The metric predicate retrieves the current value of aparticular metric. In this particular case, metric(”AvgUtility”, U) reports on user satisfaction, which is then fed intoa choice of which metric to prioritise
a( dynamic_process(Count,T),X ) :: % If the average utility is more than a( i(discover("CostPerNode",min,P,Role)) <- metric("AvgUtility",U) ^ U > T
or % threshold T, minimise cost per nodei(discover("UtilityIncreaseRate",max,Proto,Role)) % Otherwise, maximise utility increase
) then a(Role,X) % recursion for Count nodes elided
CostPerNode Utility Cost Nodes
UtilityAvgCost UtilityIncreaseRate10.0 UtilityPerNode NodesPerTime
0
10
20
30
0
2500
5000
7500
10000
12500
0
50
100
0
10
20
30
40
0.00
0.05
0.10
0.15
−200
0
200
400
0
250
500
750
1000
0.0
0.5
1.0
1.5
2.0
0 20 40 60 80 0 20 40 60 80 0 20 40 60 80 0 20 40 60 80Time
Process
agile−0.5−0.2
agile−0.5−0.5
agile−0.5−0.8
agile−0.8−0.2
agile−0.8−0.5
agile−0.8−0.8
Figure 8. Graph of the performance of the agile protocol on several different metrics over a representative sampleof parameter space. Parameters EvalQ and ImplQ are sampled at 0.5, 0.8 and 0.2, 0.5, 0.8 respectively, giving 6conditions. The metrics shown are: i) CostPerNode, the average cost for each node implemented; ii-iv) Utility,Cost, and number of Nodes; v) UtilityAvgCost, the average cost of each unit of utility; vi) UtilityIncreaseRate10.0,increase rate in utility over a 10 tick window; vii) UtilityPerNode, the total utility divided by the number ofimplemented nodes; viii) NodesPerT ime, the average number of implemented nodes per unit of time. All simulationswere carried out on randomly generated trees with branching factor 4 and max depth 3, with a population of 1000.
When the user community changes, the coordination modelcan respond dynamically, by prioritising different softwarefeatures for implementation. The recovery of the utility curvein the for the agile workflow in the Dynamic scenario postpopulation-change, indicate its ability to responsively re-plan;by not working with a heavyweight process, it can do what theusers need right now.
The difference between the utility curves under thetraditional and escalation workflows demonstrates the effectsof bringing QoS constraints into the development protocol.The traditional workflow tends to be cheaper per unit time,using only low quality developers. However, the escalationworkflow creates more nodes per unit cost, by being able toform SCUs with highly skilled workers when necessary tocarry out difficult jobs. This also results in more nodes createdper unit time, so the population utility rises more rapidly.
In contrast to conventional workflows, the LSC protocolsare dynamic, and can be changed or “plugged in” duringruntime. For example, the dynamic protocol uses the averagepopulation utility to influence the choice of protocols. Thisability to alter the way that work is coordinated allows fora larger human influence on the execution of complex workprocesses.
This demonstrates how a dynamic protocol can beresponsive to population changes and the needs of systemdesigners at once. In this case, there are two componentsof the response. Firstly, the protocol is set up to prioritisedifferent goals at different times. This is an opportunity forthe system designers to elicit and encode their goals, touse their human knowledge of the system and declare theirpriorities. Secondly, the protocol can bring in computationalmachinery to discover protocols which have been previouslyfound to match those goals, and then implement them. This
11
A Collaboration Model for Community-Based Software Development with Social Machines
EAI Endorsed Transactions on Collaborative Computing
11 - 12 2015 | Volume 1 | Issue 5 | e6EAI
European Alliancefor Innovation

CostPerNode Utility Cost Nodes
UtilityAvgCost UtilityIncreaseRate10.0 UtilityPerNode NodesPerTime
0
20
40
60
0
3000
6000
9000
0
50
100
150
0
10
20
30
40
50
0.000
0.025
0.050
0.075
0
100
200
300
400
500
0
100
200
300
400
0.0
0.5
1.0
1.5
2.0
0 20 40 60 80 0 20 40 60 80 0 20 40 60 80 0 20 40 60 80Time
Process
Agile
Agile−0.9−0.1
Dynamic
Escalation
Traditional
Figure 9. Graph of the performance of the Dynamic protocol compared to the more traditional ones. Metrics arethe same as in Figure 8. All simulations were carried out on randomly generated trees with branching factor 4 andmax depth 3, with a population of 1000.
allows the re-use of community knowledge, and a greaterunderstanding the behaviour of different methodologies indifferent situtations. Synergistically, these capabilities allowfor dynamic, flexible protocols which can draw on a poolof cloud workers to create software artefacts in response tocommunity needs.
6.1. Simulation ModellingIn order to explore a range of parameters and modelsquickly and flexibly, we have taken a simulation modellingapproach. Simulation modelling is used in the computationalsocial sciences to explore theoretical ideas in the context ofsynthetic populations, particularly where real studies wouldbe impractical [19, 20]. Recently, this has been applied tocrowdsourcing, in order to generalise results which otherwisewould be tied to a particular situation [21]. However,simulation has the potential to play another role in this area,as developing a computational model of population behaviourcan be used to “close the loop” and aid in the design ofeffective social machines [22].
The simulations presented here represent a highlysimplified version of our conceptual model where intelligentcomputational machinery underpins human creative activityin the development of software artefacts for dynamiccommunities. The use of flexible process languages suchas LSC means that the inter-unit protocols used herecould be augmented to embody more refined developmentmethodologies, with complex patterns of coordination wherenecessary. Similarly, at the metaprotocol level, we have adynamic adjustment of the protocols and parameters chosen,but there is room for additional intelligence to be brought tobear in order to better balance community and stakeholderdemands against time and cost constraints. We have sketched
out a mechanism by which the interactions specified inLSC can be rated and discovered, but there is scope forthem to be exchanged and modified both computationallyor through human intervention. This can help create abetter understanding of which methodologies work in whichsituations. At the intra-unit level, intelligent protocols couldbe used to more flexibly assign workers to sub-tasks, reactingto developing situations and changing requirements.
7. Related Work
Social machines share common ground with other collectiveintelligence applications such as human computation andsocial computing (diagram in [5, p.2]). Many crowdsourcingsystems can be seen as social machines. Of the existingcommercial platforms, of particular relevance here areTopcoder7 and ODesk8, which use different mechanisms toorganise diverse participants around software development.As crowdsourcing platforms are becoming widely used asresearch tools, a number of solutions appeared providingoverlay abstractions offering more advanced workflowmanagement and allowing users to perform more complextasks/computations.
TurKit [23] is a library layered on top of Amazon’sMechanical Turk offering an execution model (crash-and-rerun) which re-offers the same microtasks to thecrowd until they are performed satisfactorily. The entiresynchronisation, task splitting and aggregation is left entirelyto the programmer. The inter-worker synchronisation is out ofprogrammer’s reach. The only constraint that a programmer
7http://www.topcoder.com/8https://www.odesk.com/
12
EAI Endorsed Transactions on Collaborative Computing
11 - 12 2015 | Volume 1 | Issue 5 | e6EAI
European Alliancefor Innovation
Dave Murray-Rust et al.

can specify is to explicitly prohibit certain workers toparticipate in the computations.
Jabberwocky’s [24] ManReduce collaboration modelrequires users to break down the task into appropriate mapand reduce steps which can then be performed by a machineor by a set of humans workers. A number of map steps can beperformed in sequence, followed by possibly multiple reducesteps. Human computations stops the execution until it isperformed. While automating the coordination and executionmanagement, Jabberwocky is limited to the MapReduce-likeclass of problems.
AutoMan [25] integrates the functionality of crowdsourcedmultiple-choice question answering into Scala programminglanguage. The authors focus on automated managementof answering quality. The answering follows a hardcodedworkflow. Synchronisation and aggregation are centrallyhandled by the AutoMan library. The solution is of limitedscope, targeting the designated labour type.
CrowdLang [26] brings in a number of novelties incomparison with the other systems, primarily with respectto the collaboration synthesis and synchronisation. It enablesusers to (visually) specify a hybrid machine-human workflow,by combining a number of generic collaborative patterns(e.g., iterative, contest, collection, divide-and-conquer), andto generate a number of similar workflows by differentlyrecombining the constituent patterns, in order to generate amore efficient workflow. The use of human workflows alsoenables indirect encoding of inter-task dependencies.
To the best of out knowledge, at the moment of writing,CrowdLang and SCU are the only two systems offeringexecution of complex human-machine workflows. However,as explained before, both systems need to know the possible(sub-) workflows in advance. The coordination modelpresented in this paper complements the functionality offeredby systems such as these two, by providing a higher-levelcoordination management layer.
8. Conclusion
In this paper we introduced a novel coordination model forteams of workers performing creative or engineering tasksin complex collaborations. The coordination model augmentsthe existing Social Compute Unit (SCU) concept with coor-dination protocols expressed using the Lightweight SocialCalculus (LSC). The approach allows combining coordina-tion and quality constraints with dynamic assessments ofuser-base requirements. In contrast to existing systems, ourmodel does not impose strict workflows, but rather allowsfor the runtime protocol adaptations, potentially includinghuman interventions. We evaluated our approach by imple-menting a prototype version of the coordination model forthe exemplifying case-study and simulated its behaviour ona heterogeneous population of users, running different sce-narios to demonstrate its effectiveness in delivering end-userutility, and illustrated responses to a dynamically changingpopulation.
In summary, we have given a conceptual model forcombining process models with crowdsourced teams to createsoftware artefacts in support of dynamic communities. Thisformalisation paves the way for increased intelligence to bebrought into crowdsourced software development, creating amore responsive, community-centred process.
AcknowledgementThis work is partially supported by the EU FP7 SmartSocietyproject under grant 600854 and the EPSRC SociaM projectunder grant EP/J017728/1.
References[1] TOKARCHUK, O., CUEL, R. and ZAMARIAN, M. (2012)
Analyzing crowd labor and designing incentives for humansin the loop. IEEE Internet Computing 16(5): 45–51.
[2] DOAN, A., RAMAKRISHNAN, R. and HALEVY, A.Y.(2011) Crowdsourcing systems on the World-Wide Web.Communications of the ACM 54(4): 86.
[3] KITTUR, A., NICKERSON, J.V., BERNSTEIN, M., GERBER,E., SHAW, A., ZIMMERMAN, J., LEASE, M. et al. (2013) Thefuture of crowd work. In Proceedings of the 2013 Conferenceon Computer Supported Cooperative Work, CSCW ’13 (NewYork, NY, USA: ACM): 1301–1318.
[4] BERNERS-LEE, T. and FISCHETTI, M. (2000) Weaving theWeb: The Original Design and Ultimate Destiny of the WorldWide Web by Its Inventor (Harper Information).
[5] SHADBOLT, N.R., SMITH, D.A., SIMPERL, E., KLEEK,M.V., YANG, Y. and HALL, W. (2013) Towards aclassification framework for social machines. In SOCM2013:The Theory and Practice of Social Machines (Association forComputing Machinery).
[6] SMART, P., SIMPERL, E. and SHADBOLT, N. (In Press) ATaxonomic Framework for Social Machines. In MIORANDI,D., MALTESE, V., ROVATSOS, M., NIJHOLT, A. andSTEWART, J. [eds.] Social Collective Intelligence: Combiningthe Powers of Humans and Machines to Build a SmarterSociety (Springer Berlin).
[7] THÜM, T., KÄSTNER, C., BENDUHN, F., MEINICKE, J.,SAAKE, G. and LEICH, T. (2014) FeatureIDE : An ExtensibleFramework for Feature-Oriented Software Development.Science of Computer Programming 79: 70–85.
[8] DUSTDAR, S. and BHATTACHARYA, K. (2011) The SocialCompute Unit. Internet Computing, IEEE 15(3): 64–69.
13
A Collaboration Model for Community-Based Software Development with Social Machines
EAI Endorsed Transactions on Collaborative Computing
11 - 12 2015 | Volume 1 | Issue 5 | e6EAI
European Alliancefor Innovation

[9] SENGUPTA, B., JAIN, A., BHATTACHARYA, K., TRUONG,H.L. and DUSTDAR, S. (2013) Collective Problem SolvingUsing Social Compute Units. Internationl Journal ofCooperative Information Systems 22(4).
[10] RIVENI, M., TRUONG, H.L. and DUSTDAR, S. (2014) On theelasticity of social compute units. In CAiSE: 364–378.
[11] CANDRA, M.Z.C., TRUONG, H.L. and DUSTDAR, S. (2013)Provisioning Quality-aware Social Compute Units in theCloud. In 11th International Conference on Service OrientedComputing (ICSOC 2013) (Berlin, Germany, December 2-5:Springer).
[12] ROBERTSON, D. (2005) A lightweight coordination calculusfor agent systems. In LEITE, J., OMICINI, A., TORRONI,P. and YOLUM, P. [eds.] Declarative Agent Languages andTechnologies II (Springer Berlin Heidelberg), Lecture Notes inComputer Science 3476, 183–197.
[13] ROBERTSON, D. (2012) Lightweight coordination calculus foragent systems: Retrospective and prospective. In SAKAMA, C.,SARDINA, S., VASCONCELOS, W. and WINIKOFF, M. [eds.]Declarative Agent Languages and Technologies IX (SpringerBerlin Heidelberg), Lecture Notes in Computer Science 7169,84–89.
[14] D’INVERNO, M., LUCK, M., NORIEGA, P., RODRIGUEZ-AGUILAR, J.A. and SIERRA, C. (2012) Communicating opensystems. Artificial Intelligence 186: 38–94.
[15] MCGINNIS, J., ROBERTSON, D. and WALTON, C. (2006)Protocol synthesis with dialogue structure theory. In Argumen-tation in Multi-Agent Systems (Springer), 199–216.
[16] GUO, L., ROBERTSON, D. and CHEN-BURGER, Y. (2008)Using multi-agent platform for pure decentralised businessworkflows. Web Intelligence and Agent Systems 6(3): 295–311.
[17] MURRAY-RUST, D. and ROBERTSON, D. (2014) LSCitter:Building social machines by augmenting existing socialnetworks with interaction models. In Proc. World Wide WebCompanion, WWW Companion ’14: 875–880.
[18] MILLER, T. and MCGINNIS, J. (2008) Amongst first-classprotocols. In Engineering Societies in the Agents World VIII,208–223.
[19] GILBERT, N. and TROITZSCH, K. (2005) Simulation for thesocial scientist (McGraw-Hill International).
[20] MACAL, C.M. and NORTH, M.J. (2010) Tutorial on agent-based modelling and simulation. Journal of Simulation 4(3):151–162.
[21] BOZZON, A., FRATERNALI, P., GALLI, L. and KARAM, R.(2013) Modeling crowdsourcing scenarios in socially-enabledhuman computation applications. Journal on Data Semantics :1–20.
[22] KAMAR, E., HACKER, S. and HORVITZ, E. (2012)Combining human and machine intelligence in large-scalecrowdsourcing. In Proceedings of the 11th InternationalConference on Autonomous Agents and Multiagent Systems-Volume 1 (International Foundation for Autonomous Agentsand Multiagent Systems): 467–474.
[23] LITTLE, G. (2009) Turkit: Tools for iterative tasks onmechanical turk. In Visual Languages and Human-CentricComputing, 2009. VL/HCC 2009. IEEE Symposium on: 252–253.
[24] AHMAD, S., BATTLE, A., MALKANI, Z. and KAMVAR,S. (2011) The jabberwocky programming environment forstructured social computing. In ACM Symposium on UserInterface Software and Technology, UIST ’11 (New York, NY,USA: ACM): 53–64.
[25] BAROWY, D.W., CURTSINGER, C., BERGER, E.D. andMCGREGOR, A. (2012) Automan: A platform for integratinghuman-based and digital computation. ACM SIGPLAN Not.47(10): 639–654.
[26] MINDER, P. and BERNSTEIN, A. (2012) Crowdlang: Aprogramming language for the systematic exploration ofhuman computation systems. In Proc. of Social Informatics(SocInfo’12): 124–137.
14
EAI Endorsed Transactions on Collaborative Computing
11 - 12 2015 | Volume 1 | Issue 5 | e6EAI
European Alliancefor Innovation
Dave Murray-Rust et al.





























