Embed Size (px)
Citation preview

Det Informationsvidenskabelige AkademiKøbenhavns Universitet, det Humanistiske Faktultet
Bachelor Projekt
Citationsanalyse&
Automatisk Klassifikation
Af:Heidi S. LarsenAsbjørn Dahl
Vejleder:Toine Bogers
Antal ord: 14.20927. maj 2013

2

Abstract
Introduction This dissertation is a feasibility study of automaticclassification of citations – in theory and practice. It is a critical asses-sment of the potential use of automatic classification in the differentapplication areas of bibliometrics.
Method A experiment was performed in automatic classification of1213 references in 41 articles from the journal Information Research.This serves as a proof of concept, in order to evaluate the practicalfoundation for performing automated classifications of citations usingmachine learning.
Analysis We discuss the theoretical use of results from automaticclassification of citations in the different application areas of bibliome-trics. We discuss the validity of such results from the perspective ofclassification theory.
Results There are non-trivial problems with assigning an unbiasedclassification scheme as the foundation for automatic classification.This is a problem in the area of research evaluation. There is potentialin using automatic classification to improve information retrieval incitation indexes and to study science as a social network in greaterdetail.
Conclusion We conclude that there are several areas of citationanalysis in which automatic classification of citations could prove bene-ficial. But there are still a need for further technical developments inthe processing of text and preliminary studies in classification schemesfor citation types.
3

4

Indhold
1 Introduktion 91.1 Problemformulering & Arbejdsspørgsmal . . . . . . . . . . . . 10
2 Tidligere studier 122.1 Citationsanalysens metoder . . . . . . . . . . . . . . . . . . . 122.2 Citationstyper . . . . . . . . . . . . . . . . . . . . . . . . . . 142.3 Automatiske indholdsanalyser . . . . . . . . . . . . . . . . . . 18
3 Metode & Fremgangsmade 223.1 Eksperiment design . . . . . . . . . . . . . . . . . . . . . . . . 223.2 Udførelsen af eksperimentet . . . . . . . . . . . . . . . . . . . 23
4 Eksperimentets præstationer 254.1 Mal for konsensus . . . . . . . . . . . . . . . . . . . . . . . . . 28
5 Analyse af eksperimentet 285.1 Konsensus i klassifikationen . . . . . . . . . . . . . . . . . . . 305.2 Datagrundlaget . . . . . . . . . . . . . . . . . . . . . . . . . . 32
6 Bibliometriens anvendelsesomrader 346.1 Forskningsevaluering . . . . . . . . . . . . . . . . . . . . . . . 356.2 Videnskabsstudier . . . . . . . . . . . . . . . . . . . . . . . . 386.3 Informationssøgning og –genfinding . . . . . . . . . . . . . . . 39
7 Klassifikationssystemer 417.1 Klassifikationsteori . . . . . . . . . . . . . . . . . . . . . . . . 427.2 Kategoriseringsmuligheder . . . . . . . . . . . . . . . . . . . . 44
8 Behovet for citationsteori 458.1 Et fornyet behov . . . . . . . . . . . . . . . . . . . . . . . . . 46
9 Konklusion 46
10 Fremtidige studier & Perspektivering 47
Appendices 52
Bilag A Oversigt over citationstyper 52
Bilag B Spørgeskemaer 53
5

6

Figurer
1 Venn diagram over de seks studiers kategorisering af citationerefter: A) Referencens anvendelse, B) Holdning til referencenog/eller C) Graden af indflydelse. . . . . . . . . . . . . . . . . 17
2 Et teoretisk fundament for forstaelsen af citationer (Zhangand Milojevic, in press) . . . . . . . . . . . . . . . . . . . . . 20
3 Diagram over eksperimentets struktur. . . . . . . . . . . . . . 244 Eksempel af resultater fra Scikit Learns Support Vector Ma-
chine algoritme . . . . . . . . . . . . . . . . . . . . . . . . . . 275 kNN algoritmens perfomances over positive citationer . . . . 276 kNN algoritmens perfomances over neutrale citationer . . . 297 kNN algoritmens perfomances over negative citationer . . . 298 Forskellige roller i forskningsprocessen (Reuters, 2009). . . . 369 Oversigt over studier i citationstyper, samt typerne benyttet i
disse studier. . . . . . . . . . . . . . . . . . . . . . . . . . . . 5210 Indledende tekst i online spørgeskema. . . . . . . . . . . . . . 5311 Eksempel pa opsætning af online spørgeskema. . . . . . . . . 54
7

8

1 Introduktion
Bibliometrien er et felt der gennem hele sin udvikling har været stærktunderlagt beskaffenheden af sit datagrundlag. Disciplinens tidligste navnstatistisk bibliografi, afspejler det tætte forhold til de første datasæt; de aka-demiske bibliotekers lister over udgivelser (Wittig, 1978). Disse bibliografierover videnskabelige tidsskrifter eller tidsskriftsartikler, skabte grundlag forde tidligste publikationsstudier. Først som et værktøj for bibliotekaren, til atidentificere relevant eller central litteratur til deres samlinger –– siden somen metode til at at opna dybere indsigt i videnskabernes struktur. Her staropdagelsen af den videnskabelige litteraturs eksponentielle vækst af Derek J.De Solla Price (1963), som en af de mindeværdige tidlige publikationsanaly-tiske studier. I de dage var analyser af citationsmønstre en møjsommelig ogtidskrævende affære. De skulle udføres i handen, og samtlige publikationerinvolveret i analysen skulle lokaliseres, hentes hjem og litteraturlisten gem-mengaes. Selv et lille studie kunne være omstændigt at holde rede pa. Derskulle en udvikling i data materialet til for at disciplinen kunne bevægedesig fremad.
Denne udvikling kom i form af Eugene Garfields (1964) Science CitationIndex allerede i 1964. Garfield samlede og indekserede kildelisterne i enstor mængde videnskabeliglitteratur og gjorde det der ved muligt at udførestudier af forskere citationsmønstre langt hurtigere og i et langt større omfangend tidligere. Igen i 1990’erne var udvikling i tilgængelig data instrumenteli dannelse af nye omrader i det bibliometriske landskab. Udbredelsen afinternettet fordrede anvendelsen af den bibliometriske værktøjskasse padette nye medie og derved sa felterne webo- eller cybermetri dagens lys.(Almind and Ingwersen, 1997) Som disse felter har vokset til modne, erder i disse ar en indsats for at inkorporer data fra internettet i kvantitativforskningsanalyse. Dette er bedst illustreret med Altmetrics bevægelsen, dersøger at observere forskeres kommunikation og adfærd pa nettet – formelsom uformel – med det udgangspunkt at dette vil give en dybere indsigt endde klassiske bibliometriske metoder (Priem et al., 2010).
De omvæltninger bibliometrien, sammen med alle andre datadrevne felter,har oplevet med det digitale gennembrud er dog først lige begyndt. Underparoler som Big Data varsler forskere fra datalogien, kognitiv videnskabog andre dataforskere at udviklingen i databehandlingsteknikker vil revolu-tionere nærmest alle fagomrader. Med bibliometriens affinitet for ny dataog nye analyseværktøjer er der god grund til at stille skarpt pa perspek-tiverne og faldgrupperne ved datavidenskabens landvindinger. Her er isærmaskinlæringstekninkker interessante med bibliometriske briller; Bibliometri-ens datagrundlag, videnskabeligt kommunikation, er teksttuelt af natur. Iundersøgelser af den videnskabelige litteratur har bibliometrien matte for-lade sig med at undersøge denne kommunikation per stedfortræder. Manhar optalt forekomster i kildefortegnelser og udgivelseslister, for at drage
9

konklusioner om videnskaben. Indtil nu har bibliometri været begrænset tildisse kommunikative artefakter, og det har været overladt til de kvalitativestudier at bore i selve det teksttuelle indhold.
Det er her maskinlæring og bibliometri syntes som et oplagt match. Ma-skinlæring giver muligheder for statistisk og automatisk at vurdere semantiskesammenhænge i store mængder af tekst. Dette kunne abne dokumenterneop for bibliometriens metoder, ved at muliggøre analyser der kigger dybereend de strukturerne citationer tegner, og abne op for den videnskabeligekommunikations indhold. Men har bibliometrien behov for rigere data, ogvil metoder importeret datavidenskaben nødvendigvis resultere i relevant oggivende indsigt?
Vi arbejder begge med bibliometri til daglig og er bade habefulde ogskeptiske over for eventuelle nyudviklinger. Habefulde fordi bibliometrienhar nogle fundamentale svagheder, vi gerne sa løst, og skeptiske fordi vi haroplevet en tendens til at bruge bibliometrien ukritisk og fx male hvad derkan males frem for hvad der er validt. Vi vil med denne opgave foretageen forundersøgelse af automatisk klassifikation af citationer som metodefor bibliometrien. Vores undersøgelse er designet til at give et overblik overde primære problemstillinger ved automatisk klassifikation af citationer.Formalet er at identificere de problemer, der kan forhindre metoden i at væregangbar inden for bibliometri og finde frem til de tilfælde, hvor det givermening at benytte automatisk klassifikation af citationer.
Vi har indbygget et eksperiment, hvor vi udfører en klassificering af citatio-ner vha. maskinlæring. Dette eksperiment er en gennemførlighedsundersøgelse.Vi bruger eksperimentet som et kvalitativt værktøj til at vurdere metodenstekniske og praktiske forhindringer. Vi vil teste præcisionen af metoden, forat kunne afgøre, hvorvidt metoden fungerede efter hensigten, men ekspe-rimentet er ikke en teknisk analyse af, hvorvidt automatisk klassifikationvirker. Derimod en demonstration af de ikke-trivielle beslutninger, der skaltages for at kunne gennemføre et studie vha. automatisk kategorisering afcitationer.
Dernæst ser vi pa hvilken anvendelse automatisk klassifikation af cita-tioner kan finde i praksis, altsa hvilket videnshul i bibliometriske studierautomatisk klassifikation passer ind i. Vi søger at afklare de teoretiskeproblemstillinger og faldgruber ved at adoptere teknikker til automatiskkategorisering af citationer. Til sidst bruger vi denne viden om disse styrkerog svagheder ved metoden til at vurdere udsigterne til succes med automatiskklassifikation inden for bibliometriens anvendelsesomrader.
1.1 Problemformulering & Arbejdsspørgsmal
Vores undersøgelse vil tage afsæt i følgende arbejdsspørgsmal, et hoved-spørgsmal og to delspørgsmal der hver udspecificerer et relevant element afden overordnede problemstilling:
10

HS I hvilken udstrækning kan automatisk kategorisering anvendes i cita-tionsanalyse?
DS1 Hvad er de teknologiske og praktiske barrierer for brugen af automatiskkategorisering af citationer?
DS2 Hvad er perspektiverne for ny viden/indsigt ved anvendelsen af auto-matisk kategorisering som metode for bibliometrien?
De overordnede arbejdsspørgsmal for denne undersøgelse fordrer denrække delspørgsmal og dispositioner, der ma behandles før det overordnedeproblem kan løses. Nar vi ønsker at besvare i hvilken udstrækning automatisketeknikker kan anvendes i udførelsen af citationsanalyse, forsøger vi at løfteproblemstillingen over en ret teknisk problematik. Undersøgelse er altsa ikkeen øvelse i selv at udføre den bedst mulige automatiske kategorisering afbibliografisk data, men derimod at vurdere, fra bibliometrikerens synspunkt,hvad maskinlæring kan bidrage med til den fremtidige citationsanalytiskeforskning. Der er to linjer i denne problemstilling, der skal vurderes: Dettekniske fundament og det teoretiske fundament.
Bibliometrikere er afhængige af de værktøjer, der udvikles og i biblio-metrien er det traditionelt de metoder, der er lette at udføre, som vinderindpas. For at vurdere i hvilken udstrækning kategorisering kan anvendeser det derfor ogsa vigtigt at tage højde for praktiske anvendelighed. Denform for maskinlæring, vi har afgrænser os til i denne opgave, bygger derforen den mest ligetil tilgang. En række tekniske forudsætninger skal være tilstede, for at kunne udføre et sadant studie vha. automatisk klassifikation.Til det tekniske følger spørgsmal som: Er der data tilradighed, og med hvorstort omfang kan citationsanalytiske studier udføres med denne data?; Ertekst stykkerne omkring en citation umiddelbart tilstrækkelige til at opna højpræcision og recall i klassifikation?; Og, kan mennesker klassificere citationerkonsistent?
Det teoretiske element i undersøgelsen er vigtigt for at kunne vurderegyldigheden og hvilken ny indsigt der kan opnas ved brug de datalogiskemetoder. Med maskinlæring kan man generelt opna gode resultater i klassifi-cering af en række forskelligt tekstmateriale, et væld af forskellige algoritmerog metoder til at finpudse perfomances er til radighed. En sikker automa-tisk kategorisering er ikke alene nok for at opna bibliometiske resultater,altsa kunne bruge resultaterne til at sige noget om videnskab. Tolkning afbibliometrisk data er afhængig af et afsæt i videnskabssociologien.
Fra disciplinens tidligste dage har spørgsmalet om hvorfor og hvordanforskere citater været grundlæggende for gyldigheden af bibliometiske konklu-sioner. Ved at forlige sig med at en citation, udover alle tænkelige bagtankerog dispositioner, i samtlige instanser fortæller at en kilde har ydet indflydelse
11

eller impact, kan man ved akkumulerede citationer deducere en forskersautoritet og topografien af et videnskabeligt felt. Især med ekspert videnom et felt er det muligt af analysere et felt dybere, dog er det hurtigt letat indføre bias nar der afgrænses data og analyseres resultater. Et fremtræ-dende eksempel pa en sadan fejlslutning er White (1998) kortlægning afinformations videnskaben, hvor bibliometrien blev overrepræsenteret somfelt pa grund af problematiske udvælgelseskriterier af den bibliometriskedata. Med deres baggrund i scientometri sa White & McKain ikke nogetproblem i dette forhold, der dog blev kritiseret af informationsvidenskabeligeforskere fra andre felter. Potentialet for fejlslutninger ma antages at værebetydeligt nar man indfører en berigelse af citationsdataene inden udførelseaf citationsanalyse.
Her kan beslutninger taget af praktiske arsager, eller fordi de syntesnon-trivielle, samt andre usikkerheder, influere resultaterne af bibliometriskestudier pa mader der vil være svære at identificere. Med dette i mente ser vifølgende delspørgsmal ma illumineres for at kunne vurdere anvendelighedenaf citationsanalyse beriget med automatisk kategorisering: Hvilke potentialerfor anvendelse er der inde for bibliometriens tre hovedomrader; forsknings-evaluering, videnskabsstudier og informationssøgning og -genfinding?; Erder citationsteoretisk belæg for at udføre citationsanalystiske studier medberiget citationsdata?; Og, i hvilken udstrækning kan kategorier til citationerudvælges uden bias?
2 Tidligere studier
I dette afsnit vil vi behandle tidligere forskning med relevans for vores un-dersøgelse. Afsnittet er delt i tre delafsnit; det første behandler de metoderbibliometrikere traditionelt har benyttet til citationsanalyse, metoder derikke involverer berigelse af den bibliografiske data. Det andet delafsnit afdæk-ker forskning der har beskæftiget sig med at identificere typer og kategorieraf citationer. Tredje og sidste delafsnit vil præsentere studier, der udstik-ker retningslinjer for hvordan automatisk kategorisering kan benyttes enbibliometrisk eller citationsanalytisk sammenhæng.
Formalet med de to første delafsnit er at opstille en kort gennemgang afden metodiske og teoretiske udvikling af den videnskabelige undersøgelse afcitationer, for at give have solidt fundament til senere at analysere hvordanautomatisk kategorisering passer ind i det bibliometriske univers.
2.1 Citationsanalysens metoder
Udviklingen af den citationsanalystiske metode har hidtil hovedsageligt kon-centreret sig om skabe tekniker til at tolke mønstrene i de bibliografiske data.Citationernes betydning, eller mening, er blevet undersøgt i citationsteoreti-ske studier, ofte udført pa et simpel eller erfaringsbaseret empirisk grundlag.
12

Udmiddelbart giver ra citationstal ikke stor indsigt, de varierer i stor gradpa tværs af vidensdomæner, hvilket gør tallene stort set meningsløse udenforderes bibliografiske kontekst, og selv med en naiv tolkning udtømmes dataenehurtigt for interessante konklusioner.
Et af de tidligste værktøjer i den citationsanalytiske værktøjskasse varindikatoreren. Indikatoren er en matematiskformel hvis resultat giver nyemuligheder for tolkning af citationsdata. JIF eller journal impact factorenaf Garfield (1964) til at udvælge tidsskrifter af interesse, er et simpeltoverslag over et tidsskrifts balance mellem modtagne citationer i forhold tilantallet af artikler i tidskriftet, og den maske det mest kendte bade uden- ogindenfor bibliometriske kredse. Indikatoren bliver alment brugt til at betegneet tidsskrifts indflydelse, og formar med en simpel, letforstaelig formel atsupplere citationsdata med større analytisk potentiale.
En stor del af den bibliometiske forskning, helt fra disciplinens begyndelsetil nu, er beskæftiget med at udvikle og forfine made at aggregere citationsda-ta. Et andet populært eksempel pa dette omfattende arbejde med indikatorerer H-indekset (Hirch, 2005) og kohorten af afledte indikatorer, hvis aftryk iden bibliometriske litteratur skal tælles i hundredvis af tidsskrifts artikler, ogsom bruges til at vurdere individuelle forskeres produktivitet og indflydelse.Andet iøjnefaldende arbejde med indikatorer er indførelsen er percentiler(Bornmann and Marx, 2013) eller andre gennemsnitlige mal, der forsøgerat muliggøre sammenligning af citationsdata pa tværs af videnskabeligefagomrader. Desuden adresserer disse mal problemerne ved skæve fordelingeraf citationer, der vanskeliggør statistisk behandling af bibliografisk data.
En anden benyttet tilgang til at udvide tolkningsmulighederne af citations-data er kort- eller netværksbaserede analyser. Med denne slags citatiosanalyselægger tolkningen i de strukturer eller mønstre referencerne danner. Den tid-ligste brug af sadan et værktøj kan ses som udviklingen af co-citationsanalyseaf Henry Small (1973). Kalkulen i co-citationsanalysen er at artikler derciteres i samme tekst ma være emne mæssigt beslægtet. Udviklingen af badehardware og software har siden halvfemserne gjort det muligt at analysereog generere store netværk pa baggrund af citationsdata, og indikatorer franetværkvidenskaben, som centrality, har givet givet bibliometrikerne nyemetoder til at visualisere, præsentere og analysere videnskaben som socialtnetværk (Borner et al., 2003; Newman, 2009, pp.67—70).
Fælles for de citationsanalytiske værktøjer præsenteret her er at de allehar citationsdata som input, og ved forskellige metodiske greb udfolder dennedata sa den kan tolkes og analyseres indenfor forskellige kontekster. Netværks-analyser er excellere i emne- eller sociologiske undersøgelser, indikatorer tilbrede kvantitative vurderinger. Dog finder udfoldelsen af analytisk potentialeaf den bibliografiske data sted som en funktion pa denne data, og datagrund-laget forbliver sa og sige uberørt. Her adskiller automatisk kategorisering afcitationsdata sig fundamentalt fra tidligere metoder i bibliometrien, idet derfinder en berigelse af dataene sted, en berigelse der potentielt kan pavirke
13

resultaterne af alle de bibliometriske værktøjer. Indikatorer kan udvides til attage højde for typen af citationer, klynger i citationsnetværk kan identificerespa grundlag af semantiske sammenhænge mellem forfatterne og ikke ”blot”numerisk signifikans.
2.2 Citationstyper
For at kunne klassificere citationer automatisk er det nødvendigt at forholdesig til hvilke typer af citationer, der forekommer. Bibliometrikere har længediskuteret og søgt indsigt i, hvordan og hvorfor forskere citerer hinanden. Derer uenighed og dermed usikkerhed i, hvad det egentlig er, bibliometrien kanmale ved at tælle citationer (Bornmann and Daniel, 2008). Derfor blev detessentielt af forsta, hvordan forskere praktiserer det at citere. I forskningenfandt man det givende at begynde at skelne forskellige typer af citationer frahinanden.
Under betegnelsen citation context studies eller citation content analysiser der blevet forsket en del i forskeres citationsadfærd, altsa hvordan eller idet hele taget om forskere citerer pa bestemte mader. Det kan selvfølgeligundersøges pa mange mader, de primære værende interviews med forskerne,surveys eller studier af hvordan referencer forekommer i forskeres kommuni-kation – fx hvor mange gange en reference forekommer i en artikel og hvor iartiklen (indledning, konklusion, diskusion), referencen forekommer. Her vilvi fokusere pa de studier, der – ligesom automatisk klassifikation – søger atafgøre spørgsmalet ved at tage fat i teksten omkring referencen. Dette afsnitbeskriver de studier, der har arbejdet med at bestemme typer af citationer.Der bliver foretaget en kort gennemgang, og de lister af citationstyper, derikke er gengivet i teksten, kan findes i bilag A.
Eugene Garfield, grundlæggeren af Institute for Scientific Information(ISI) og moderne bibliometri, var den første, der systematiserede grundenetil at forskere citerer. Det var netop en undersøgelse af om det ville givemening automatisk at klassificere citationer ud fra teksten omkring dem.Ud over mangel pa data for at kunne foretage sadanne studier, papegerGarfield ogsa hvordan citationsadfærd er individuel som en forhindring. Fxgennem et studie, hvor en række af hans studerende bliver bedt om at tilføjereferencer i en artikel, hvor der ikke er referencer tilknyttet. Det resulterer ividt forskellige referencelister – bade i mængden af referencer, de studerendefinder nødvendige og præcis hvor i teksten, de finder det nødvendigt med enreference. Alligevel mener han at kunne opstille en liste af de gængse grundetil at forskere vælger at citere hinanden:
• ”Paying homage to pioneers.”
• ”Giving credit for related work (homage to peers).”
• ”Identifying methodology, equipment, etc.”
14

• ”Providing background reading.”
• ”Correcting one’s own work.”
• ”Corrrecting the work of others.”
• ”Criticizing previous work.”
• ”Substantiating claims.”
• ”Alerting to forthcoming work.”
• ”Providing leads to poorly disseminated, poorly indexed, or uncitedwork.”
• ”Authenciating data and classes of fact (physical constants, etc.)”
• ”Identifying original publications in which an idea or concepts wasdiscussed.”
• ”Identifying original publications or other work describing an eponymicconcept or term (. . . )”
• ”Disclaiming work or ideas of others (negative claims)”
• ”Disputing priority claims of others (negative homage)”
(Garfield, 1965)
Negative arsager til en citation er fremtrædende pa listen, men Garfieldundersøgte aldrig frekvensen af disse grunde eller om nogle af grundenevar mere fremtrædende end andre. Listen er ikke blevet operationaliseretog appliceret i empiriske studier, men blev forløberen for mange empiriskeforsøg pa at kategorisere citationer.
I løbet af 1970’erne ledte en række studier til at bibliometrien empi-risk fik indblik i forekomsten og anvendelsen af citationer. Moravcsic andMurugesan (1975) arbejdede med at afgøre graden af indflydelse, som denrefererede artikel havde pa forskerens arbejde. De opdagede en stor overvægtaf overflødige citationer, hvilket Chubin and Moitra (1975) prøvede at gøreop for ved at ændre i taksonomien af deres kategorisering. For Oppenheimand Renn (1977) er citationstyperne et led i en større analyse af, hvor bredtvidenskabsstudier bliver anvendt. Oppenheim and Renn (1978) undersøgtehvorfor artikler af en vis alder bliver ved med at modtage citationer og omgrundene til at de bliver citeret ændrer sig over tid. Frost (1979) arbejderinden for et humanistisk felt og vil gerne undersøge om forskere inden forhumanisme afhænger mindre af empiri end andre videnskaber.
For alle studiers vedkommende er det ikke en undersøgelse af selvecitationstyperne, der er i centrum. Citationstyperne og kategoriseringen er
15

blot noget, der operationaliseres for at na frem til de slutninger, de søger.Det ses i beskrivelsen af metoden til hvordan fx Oppenheim and Renn (1977)kom frem til kategoriseringen:
”I tried to reduce subjectivity of classification by using simpleand straightforward categories, drawing on the formulations ofthe authors themselves rather than on an abstract, logically tight,a-priori categorization system”
Dette illustrerer problemet ved flere af de kategoriseringer, der er fortagetaf citationstyper, idet at manglen pa systematik uundgaeligt vil føre tilbias, nar der ikke opstilles kriterier for kategorisering. Det lægger op af enantagelse af at kategorierne er naturgivne og ikke et resultat af menneskeligbearbejdning og fortolkning. De fleste studier foregiver at undersøge anven-delsen af citationer, men bygger konklusionerne pa antagelser om, hvordanvidenskab foregar.
Igen fylder forekomsten af negative citationer meget idet de er repræsente-ret i størstedelen af studierne. Moravcsic and Murugesan (1975) identificererdem med kategoriseringen confirmative or negational. Træstrukturen fraChubin and Moitra (1975), hvor det første led er valget mellem affirmativeog negational, gør at systematikken kan ses som en (ujævn) skala over positiveog negative citationer. Oppenheim and Renn (1977) forholder sig ogsa til omholdningen til det citerede er positiv/negativ. Frost (1979) er interessereti om citationen bliver brugt til at støtte op om fakta eller holdning, meninddrager ogsa om forskeren forholder sig positivt eller negativt til det, derciteres. I resultaterne er forekomsten af negative citationer forsvindende lilleog varierende pa tværs af studierne (mellem 1 og 14%).
Som Cronin (1984) noterede er studier af citationstyper – trods man-ge ligheder – ikke del af et samlet forskningsarbejde – men enkeltstaendestudier – der søger at løse problemer inden for alt fra information retrievaltil citationsforskelle mellem videnskaber. De har dog det til fælles at desøger at løse disse forskelligartede problemer ved at undersøge naturen af desammenhænge, der opstar gennem citationer og for at gøre dette benytterde sig alle af at klassificere citationerne ud fra analyse af maden, der bliverciteret pa, som det fremgar af forskningsartiklerne. Resultatet er en langrække af taksonomier og klassifikationer, der varierer alt efter, hvad studietsøger at efterprøve. I figur 1 ses et Venn diagram hvor flere af disse studier ersystematiseret efter, hvad deres kategoriseringer kan bruges til at undersøge.
Der er en del sammenfald i, hvad de vælger at medtage i deres kategori-sering. Næsten alle har som beskrevet forholdt sig til forfatteres forskelligedispositioner: om de anerkender eller misbilliger indholdet, der refereres. Deter dog forskelligt, hvordan de tre aspekter af en citation vægtes i kategori-seringen, alt efter hvor specialiseret kategoriseringen er. Hos Lipetz (1965)er det primært dispositionen, altsa hvordan forfatteren forholder sig til detrefererede, som gerne skulle kunne bestemmes af kategoriseringen, men det
16

Figur 1: Venn diagram over de seks studiers kategorisering af citationer efter:A) Referencens anvendelse, B) Holdning til referencen og/eller C) Graden afindflydelse.
afgøres ved at se pa, hvordan referencen anvendes i teksten (fx applied, notedeller questioned).
Detaljeringsgraden, altsa mængden af underkategorier, fx præcis hvordancitationen anvendes, adskiller sig saledes studierne i mellem. Der er studier,hvor aspekter er meget udspecificeret, men som andre slet ikke forholder sigtil. De mangler klart hierarkiske systematiseringer og beskrivelser, saledes atsystematikkerne kan sammenlignes pa tværs af studier. Disse kategoriseringerer begrænset af deres omfang og deres fokus pa specifikke problemstillinger.Der er et større arbejde i at skulle finde kategoriseringer, der kan gældegenerelt. Alle disse studier vurderer at det er muligt at tildele deres kategorierud fra læsning af teksten, men angiver den arbejdstunge byrde i at klassificerehver citation som grunden til at deres arbejde ikke bliver videreudviklet. Herskulle automatisk klassifikation gerne udvide mulighederne for, hvor megetdata, altsa citationer, det er realistisk at behandle.
17

2.3 Automatiske indholdsanalyser
I det forrige delafsnit gennemgik vi det mangfoldige arbejde med at findeet dækkende kategoriseringssystem over citationstyper. I dette vil vi dettedelafsnit behandle den forskning der gar praktisk til automatisk kategorisering.Først udlægger vi kort hvordan den informationsvidenskabelige tilgang tilhar været, og dernæst identificerer vi nogle studier fra datalogien, der errelevante for denne undersøgelse. Til slut papeger vi nødvendigheden forafklaring i, hvad automatisk klassifikation kan og ikke kan anvendes til atundersøge.
Begrebet citation content analysis har været benyttet af bibliometrikeresiden 1980’erne, og dækker over forskning der behandler og analyserer citatio-ners indhold. Meget af arbejdet i dette felt har dog, som andet arbejde medcitationstyper indenfor bibliometrien og informationsvidenskaben, hovedsag-ligt været teoretisk eller empirisk undersøgende. I bibliometrisk regi har derikke endnu været noget samlet indsats i af udføre automatisk kategoriceringeller indholdsanalyse af citationer i større omfang. White (2004), der erbibliometriker, bemærker at:
”There is more promising line of analysis in informations sciencethan the labour-intesive classification of implicit citation featuresjust described. That is interpretation of explicit words in citationcontext as detected by computer (or very patient human beings).”
White forfølger dog ikke selv denne lovende metode, og forholder sigkun kort til hvordan en sadan analyse skulle udføres. Det er værd at bidemærke i at White ser en forskel mellem indholdsanalyse af citationer udførtmed computer og det han beskriver som labour-intesive classification. Meddenne term mener White de studier der har søgt at kortlægge forkomstenaf citationstyper i litteraturen, altsa identificere hvilke typer af referencerder konkret forekommer og som vi gennemgik i foregaende afsnit. Det eruklart hvordan White mener at computere skal bidrage til at identificerecitationstyper. Maskinlæringsteknikker vil have behov for prækategoriseretdata og kan derfor kun fremskrive klassifikationer til ikke-kategoriseret datapa belæg af menneskers input.
Om White hentyder til andre teknikker der kan udrede statistiske signifi-kante sammenhænge i tekst uden afsæt i menneskers input er uvist. Whitesoverfladiske behandling af de computationelle muligheder i indholdsanalyseaf citationer, kan ses som et symptom pa den generelle tilstand i den biblio-metriske forskning. Her har videnskabssociologisk teori, statistiske metoderog andre værktøjer til at analysere den store mængde bibliografisk datatilradighed været af primær interesse, og kun ganske fa forskere i infor-mationsvidenskaben og i særdeleshed bibliometrien har haft behov for atbeskæftige sig dybere med værktøjer fra datalogien. Man er fra bibliometrienklar over potentialet i datavidenskabens metoder, men incitamentet til rigtigt
18

at engagere sig med udførelsen af automatiske citationsanalytiske studier erøjensynligt ikke stærkt nok endnu.
Den ringe interesse fra bibliometrikere for en datalogisk tilgang til ind-holdsanalyse af citationer falder sammen med en generel mangel pa interessefor indholdsanalyser. Hvor termen bruges især i oversigtsstudier, afslører ensøgning i den videnskabelige litteratur at begrebet kun bruges i title ellerabstract pa ganske fa artikler.1 De studier der giver sig i kast med at anvendedatavidenskabens metoder til citationsanalyse, kommer fra datalogien oghar kun i ringe grad tilknytning til informationsvidenskaben; forskerne ertilknyttet datalogiske institutioner og er kun svagt bibliometrisk koblet tilden informationsvidenskabelige litteratur.
Interdisciplinære tendenser er ikke sjældne i litteraturen om maskinlæring,hvor datalogisk skolede forskere applicerer deres evner og teknikker pa dataenei andre felter, fra biologi til litteraturvidenskab. De studier vi har identificeretder omhandler maskinlæringsteknikker og citationsdata benytter et datalogiskordforrad, med termer som opinion mining og automatic classification ellertermer specifikt relateret til deres bibliometriske emne, der dog ikke er udbredti den brede bibliometriske litteratur som citation function og citing/citationsentences (Teufel et al., 2006a; Piao et al., 2007; Sugiyama et al., 2010;Qazvinian and Radev, 2008; Abu-Jbara and Radev, 2011). Blandt studierneder anvender maskinlæringsteknikker pa citationsdata er det kun fa derkan opfattes som bibliometriske af natur. Studiernes udtrykte formal er istedet ofte orienteret mod en praktisk anvendelse; automatisk opsummeringaf videnskabelige tekster og automatisk vurdering af behovet for referencer itekststykker til at støtte peer review, er nogle af de løsninger studierne søger.
Set med bibliometriske øje er Teufel et al. (2006b) især interessant. Deudfører et studie hvor de vælger et sæt citationstyper og udvikler system tilat udtrække og annotere citationer. Divegensen i menneskers klassifikation afcitationer evalueres og afslutningsvis udfører de en test af IBk algoritmens2
performance til at lære at udføre kategoring af citationskategorierne. Vi vil ianalysen af resultaterne fra vores eget eksperiment vende tilbage til dettestudie.
Et informationsvidenskabeligt studie af Zhang and Milojevic (in press)tager netop fat i at bygge bro mellem datalogi og bibliometri. Studiet læggerop til bibliometriske studier vha. text mining og kodning. Først opstilleset fundament for at forsta citationer og hvilke metoder kan anvendes til atanalysere forskellige aspekter ved citationer.
I figur 2 opstiller Zheng tre karaktertræk ved citationer; det numeriske(mængden af ciationer), det bogstavelige (teksten omkring referencen) og detsocio-kultuelle (forskeres valg af kilder). Det er en udmærket forstaelse at
1Søgestrengen (”context citation analysis”OR”citation context analysis”OR”citationcontent analysis”OR”content citation analysis”) giver 30 resultater i WoS og 29 i Scopusved søgning i hovedregisteret.
2IBk er en variant af den populære k-Nearest Neighbor algoritme.
19
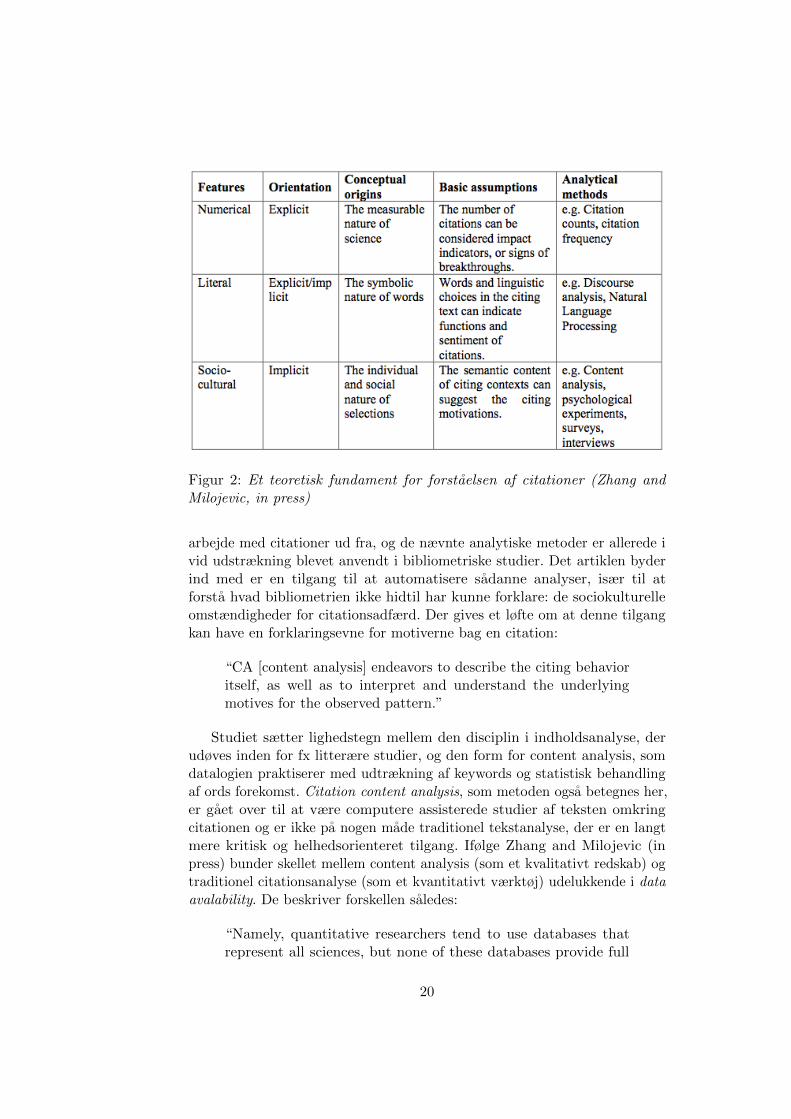
Figur 2: Et teoretisk fundament for forstaelsen af citationer (Zhang andMilojevic, in press)
arbejde med citationer ud fra, og de nævnte analytiske metoder er allerede ivid udstrækning blevet anvendt i bibliometriske studier. Det artiklen byderind med er en tilgang til at automatisere sadanne analyser, især til atforsta hvad bibliometrien ikke hidtil har kunne forklare: de sociokulturelleomstændigheder for citationsadfærd. Der gives et løfte om at denne tilgangkan have en forklaringsevne for motiverne bag en citation:
“CA [content analysis] endeavors to describe the citing behavioritself, as well as to interpret and understand the underlyingmotives for the observed pattern.”
Studiet sætter lighedstegn mellem den disciplin i indholdsanalyse, derudøves inden for fx litterære studier, og den form for content analysis, somdatalogien praktiserer med udtrækning af keywords og statistisk behandlingaf ords forekomst. Citation content analysis, som metoden ogsa betegnes her,er gaet over til at være computere assisterede studier af teksten omkringcitationen og er ikke pa nogen made traditionel tekstanalyse, der er en langtmere kritisk og helhedsorienteret tilgang. Ifølge Zhang and Milojevic (inpress) bunder skellet mellem content analysis (som et kvalitativt redskab) ogtraditionel citationsanalyse (som et kvantitativt værktøj) udelukkende i dataavalability. De beskriver forskellen saledes:
“Namely, quantitative researchers tend to use databases thatrepresent all sciences, but none of these databases provide full
20

text data; while qualitative researchers tend to use relatively smalland homogeneous data, gathering of which is labor-intensive andrequires close reading.”
I studiet præsenteres en code book, der lægger op til studier, der forenerde to grene. Det skal ske ved automatiseret indholdsanalyse, hvor der skaltages højde for en mængde faktorer (fx ved at se pa, hvor i teksten referencenforekommer, for derudfra at kunne sige noget om, hvor væsentlig citationener for forskningens resultater eller hvor mange gange, artiklen bliver refereretsom et mal for graden af kobling/indflydelse).
Studier, der anvender denne tilgang, skal ses som den næste generation afcitations analyse. Med datalogiens redskaber (herunder automatisk klassifice-ring) er der altsa varslet en videreudvikling af bibliometrien, og frameworketlover pa den made et langt mere detaljeret billede af, hvordan forskere citererhinanden. Ved anvendelse af den foreslaede code book i citationsstudier, menerforskerne at kunne give indblik i socio-kulturelle omstændigheder for hvadder i studiet betegnes research behavior.
Cronin (1984, p. 47), der i sit virke har fokus pa hele processen omkringdet at citere, kritiserer de i afsnittet citationstyper beskrevne studiers valgaf klassifikation for at ”ignore the reasons why authors cite some papers inpreference to others”. Han søger – som et led i at kunne koble fx kvalitet ogcitationer – ikke alene indblik i hvordan en forsker bruger andres forskning isine resultater, men de udvælgelseskriterier, det ligger forud for en citation.Der er stor søgning efter svaret pa netop sadanne spørgsmal inden forbibliometrien.
Med beskrivelsen ”the individual and social nature of selections” omudgangspunktet for sociokulturelle omstændigheder for citationer læggerZhang and Milojevic (in press) op til at kunne forklare, det Cronin (og andre)efterspørger. Som det papeges (men ikke tages yderligere forbehold for) iZhang and Milojevic (in press) er det at citere (eller ikke citere) et udtrykfor forfatterens bearbejdning af en andens ideer, hvilket er en psykologiskproces, der fokuserer pa at skabe mening. Den proces er immateriel, hvil-ket vil sige at den ikke er manifesteret i noget fysisk. Saledes er det ikkenoget, der umiddelbart fremgar af teksten, og ikke noget en automatiseretindholdsanalyse vil kunne tolke pa. Saledes misforstar Zang hvad automatiskklassifikation egentlig giver af nye indsigter.
Eksemplet viser at det er vigtigt at stille fokus pa hvad det giver meningat undersøge vha. automatisk klassificering – her menes ikke blot hvad der ermuligt rent teknisk at udføre vha maskin læring eller hvad bibliometrien gernesa besvaret, men om automatisk klassificering egentligt kan give palideligeresultater og reel indsigt i visse aspekter af citationsadfærd.
Det er essentielt at have fokus pa hvad der skal udarbejdes før de tovidenskaber kan opna tværvidenskabelige resultater, og det ville være optimaltmed et fælles begrebsapperat, sa der ikke opstar misforstaelser om, hvad man
21

kan opna med studier vha. automatisk klassifikation. Saledes har vi brugttidligere studier til at identificere et behov for at undersøge, hvad automatiskklassifikation kan tilføre bibliometrien, men i lige sa stor udstrækning enafgrænsning i, hvad den ikke kan besvare af spørgsmal inden for bibliometrien.
3 Metode & Fremgangsmade
For at belyse de to linjer i vores problemstilling bestar denne undersøgelse afto elementer. Igen et praktisk og teoretisk element. De teorier og metodervi sætter i spil er klassifikationteori og maskinlæring. Vi bruger klassifi-kationsteori til at vurdere det teoretiske fundament for at kunne na fremtil valide resultater med automatisk klassifikation inden for bibliometriensanvendelsesomrader. Maskinlæring bruger vi til at efterprøve det praktiskefundament for at kunne foretage sadanne studier.
Det teoretiske element er opbygget først med en analyse af bibliometri-ens anvendelsesomrader, dernæst en diskussion af klassifikationsteoretiskeproblemstillinger inden for hver af disse. Afslutningsvis vil vi perspektiverevores fund og komme med bud pa konkrete tiltag og studier der vil væregivende fremadrettet for bibliometrisken beriget af maskinlæring.
3.1 Eksperiment design
Vi har designet og udfører et simpelt eksperiment med automatisk kate-gorisering af citationer givet af artikler i tidsskriftet Information Research.Formalet med dette eksperiment ikke at opna en resultater med klassifi-kationen, men med afsæt i eksperimentet at diskutere praktiske barriereri udførelsen af sadanne studier for en bibliometriker. Det er et datalogiskstudie at vurdere det tekniske grundlag, vi forsøger med eksperimentet atvurdere den praktiske anvendelighed for bibliometrien.
Begrebet maskinlæring har vi indtil nu benyttet som en primitiv term,med en løs forstaelse af at dette dækker over alle slags teknikker hvor encomputer ud fra en algoritme eller procedure, formulerer en statistikmodelpa baggrund af et kendt data grundlag. Forskningen i disse teknikker eromfattende, og vi vil undlade at ga ind i en diskussion af de mange forskelligeteknikker, algoritmer, teorier osv., da det ville kræve en solid undersøgelsefra det datalogiske synspunkt.
Vi har med vores eksperiment i udgangspunktet bestræbt os pa at fortageden mest ligetil tilgang at udføre maskinlæring af citationsdata pa. Det varvores ræsonnement at ga til den praktiske udførelse sa naivt3 sa muligt. Flereaf beslutningerne der er taget under behandling af dataene er non-trivielle,og ma antages at have stor indflydelses pa forsøgets resultater. I disse tilfælde
3Bemærk at den danske brug af ordet naiv næsten udelukkende bærer negative konno-tationer. Brugen af ordet her skal forsta som uden forudantagelse.
22

har vi valgt den letteste eller mest udmiddelbare løsning, da den simplestetilgang vil være det bedste udgangspunkt til at vurdere gennemførlighed afteknikkerne. I eksperimentet tager vi ikke hensyn til hvem der refererer oghvem der bliver citeret, vi undersøger blot om det er muligt at gennemføreet sadant studie rent praktisk.
Det er her vigtigt at have i mente at eksperimentet i sig selv fungerer somempiri for vores undersøgelse af gennemførlighed. Vi har altsa ikke forsøgt atforbedre vores resultater, ved at massere data og algoritmer i stor grad. Detville ikke tjene til at belyse de overordnede anvendelsesmuligheder nærmere,at ga for dybt ind i finjusteringer. Udførelsen af eksperimentet fungerer altsasom udgangspunkt, eller grund, for vores analyse af anvendeligheden i enbibliometrisk optik, og som afsæt til at vurdere potentialet.
Figur 3 er et diagram over vores arbejdsprocess – fra indhentning afdata, til færdige resultater af maskinlærings forsøget. I følgende delafsnitgennemgar vi denne process.
3.2 Udførelsen af eksperimentet
De videnskabelige tekster brugt i vores forsøg, er hentet fra tidsskriftet In-formation Research. Vi trak alle artikler udgivet fra 2011 til 2013 ud, detskal dog bemærkes at ikke samtlige af disse blev annoteret og benyttet imaskinlæringen. Tidsskriftet er valgt af flere grunde; det er open access,hvilket gør det muligt at udtrække artiklerne i fuld tekst. Desuden er tids-kriftets emneomrade generel informationsvidenskab. Saledes er vi altsa selv istand til at vurdere citationssætningerne. Artiklerne udgives kun som HTMLdokumenter, disse er lette at parse og derved kan relevante tekststykker ud-trækkes. Flere open access tidsskrifter udgiver deres artikler i PDF formatethvilket besværliggør muligehederne for at udtrække og arbejde med teksten.Store tidsskrifter som fx PLoS One4 tilgængeliggør dog deres udgivelseropmærkede formater som XML eller HTML.
Fra de ra HTML dokumenter skar vi først alt opmærkning og tekstfra, der ikke hørte til artiklens hovedtekst. Dette indbefattede abstracts,referencelister, metadata og andre HTML tags. Dernæst udtrak vi hversætning hvor der forekom en reference, samt den forstaende og efterfølgendesætning til citationsætningen. De to omkringstaende sætninger blev tagetmed for at understøtte bedømmelse af citationstypen. Vi benyttede Pythonmodulet Beautiful Soup5 i arbejdet med HTML opmærkningen og moduletNLTK (Bird et al., 2009), til at parse sætningerne fra hinanden.
Citationssætningerne, med de omkringstaende sætninger, blev indskrevet iet spørgeskema for hver artikel, pa online tjenesten Survey Monkey.6 Vi valgteat forsøge at kategorise citationerne som enten positive, neutrale eller negative,
4http://www.plosone.org/static/usageData/, verificeret den 27. maj 2013.5http://www.crummy.com/software/BeautifulSoup/, verificeret den 27. maj 20136http://surveymonkey.com/, verificeret den 27. maj 2013.
23
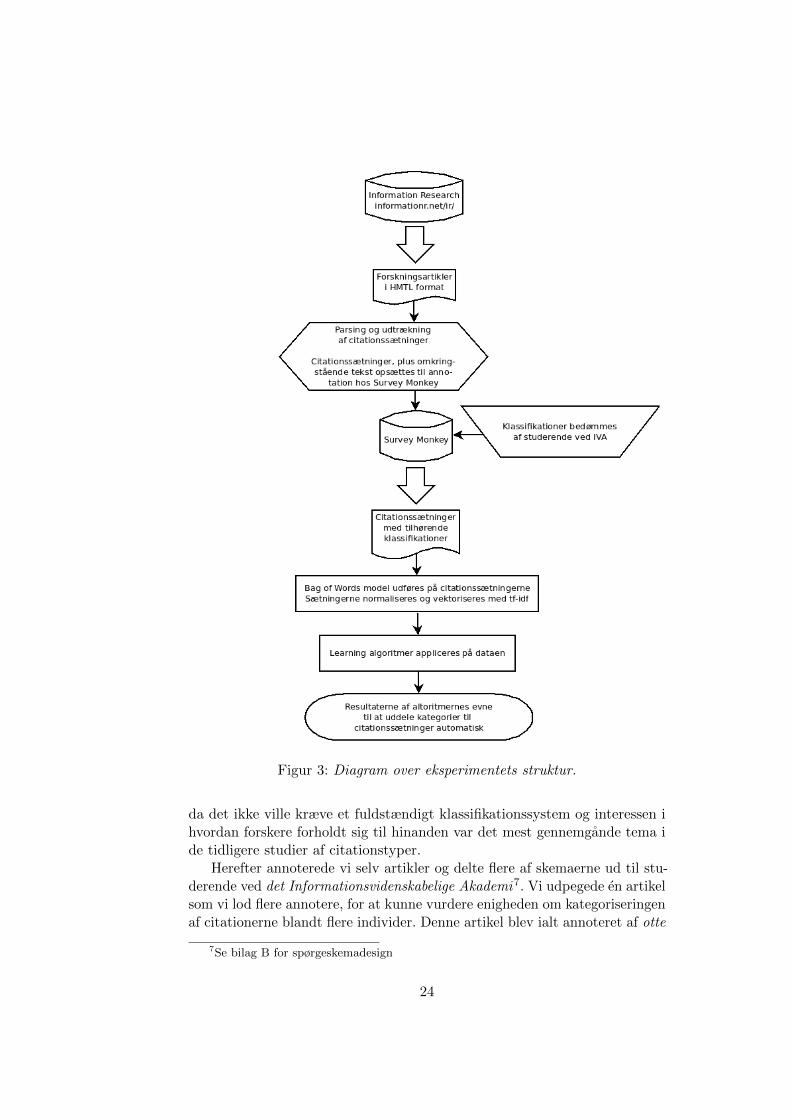
Figur 3: Diagram over eksperimentets struktur.
da det ikke ville kræve et fuldstændigt klassifikationssystem og interessen ihvordan forskere forholdt sig til hinanden var det mest gennemgande tema ide tidligere studier af citationstyper.
Herefter annoterede vi selv artikler og delte flere af skemaerne ud til stu-derende ved det Informationsvidenskabelige Akademi7. Vi udpegede en artikelsom vi lod flere annotere, for at kunne vurdere enigheden om kategoriseringenaf citationerne blandt flere individer. Denne artikel blev ialt annoteret af otte
7Se bilag B for spørgeskemadesign
24

forskellige personer. De resterende artikler blev kun annoteret af en personhver. I alt blev 41 artikler kategoriseret. 59 citationer kunne ikke vurderes,enten fordi parsingen var mislykkedes eller referencen var uforstaelig, og i altblev 1213 citationer kategoriseret.
Efter online annoteringen var afsluttet, blev dataene behandlet endnuengang. De to overskydende sætninger omkring citationssætningen blevfjernet, og hvert ord i citationssætningerne blev stemmet til deres grundformog stopord blev fjernet, begge dele igen ved hjælp af NLTKs standardfunktioner. Saledes far vi de endelige citationssætninger, som er grundlagetfor vores automatiske kategorisering.
Til at udføre maskinlæringen benyttede vi modulet Scikit Learn (Ped-regosa et al., 2011). Dette er et modul der tilbyder en række generellealgoritmer og værktøjer til udførelsen af maskinlæring. Ved hjælp af ScikitLearns vektoriserings funktioner opbyggede vi en bag of words repræsentationaf citationssætningerne. Vi arbejde bade med et vektor rum konstrueret medtf-idf8 og en naiv vektorisring hvor alle ord i det samlede korpus blev benyttetsom features i vores vektor rum, pa lige vilkar. Med afsæt i disse to vektorrum, eksperimenterede vi med flere algoritmer og forskellige størrelser patrænings- og testsæt.
Vi besluttede kun at arbejde med superviseret lærings, og at fokusere paScikits indbyggede repræsentationer af algoritmen K-nearest neighbor]9 ogen Support Vector Machine10 med flere forskellige kerner. De to algoritmervil fremover blive betegnet henholdsvis kNN og SVM.
Kildekoden til vores eksperiment kan findes pa:
https://github.com/DAHLS/BAlearning/
4 Eksperimentets præstationer
I dette afsnit præsenterer vi de bedste resultater fra vores eksperimentteringmed kNN og SVM. Under udførelsen af eksperimentet testede vi mange for-skellige setuper, blandt andet læringsrater (altsa hvordan forskellige størrelserpa test og træningssæt pavirker performans), vektor rummets udformningog indstillinger pa de benyttede algoritmer. Vi vil ikke præsentere data fraalle disse setupper, men vi vil sammenfatte det vi har faet ud af dem.
I vores annoterede citationsdata forekom 25 negative, 169 positive og1019 neutrale citationer. Den sjældne forekomst af negative, og den store
8Term frequency–inverse document frequency, en teknik hvor vægten af et ord i vektorrummet justeres i forhold til antallet af forekomster af ordet i kopusset. (Salton and Buckley,1988)
9http://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.hmtl,verificeret den 27. maj 2013.
10http://scikit-learn.org/dev/modules/generated/sklearn.svm.SVC.html, verificeret den27. maj 2013.
25

overvægt af neutrale citationer, svarer overens med det vores forventningerpa baggrund af de tidligere studier om citationstyper.
Generelt sa vi de bedste resultater ved et træningssæt pa 30% af densamlede data mængde. kNN fungerede bedst med et vektor rum appliceretmed tf-idf, men Support Vektor Maskinen fungerede bedst med alle ter-me repræsenteret lige i vektor rummet. Dette kan maske forklares med atSVMs funger ud fra den antagelse at datapunkterne er normaliseret omkringcenteret af vektor rummet. Vægtning tf-idf indfører, kan muligvis ”skubbe”citationsvektorerne pa en made der harmonerer darligt med SVM algoritmen.
I figur 4 ses de bedste resultater opnaet med Scikits SVM algoritme.Resultaterne for kNN skan ses i figurende 5, 6 og 7. kNN skal indstilles efterhvor mange nabopunkter der influerer algoritmen valg af mærkat. Grafernei figurene viser udviklingen per nabo i algoritmens præcision, genkaldelseog F1 – et overslag mellem præcision og genkaldelse. Det skal bemærkes atantallet af citationssætninger, indenfor de tre kategorier, er forskellige mellemresultaterne præsenteret for de to algoritmer. Dette skyldes at datasættetblandes inden test- og træningssættende deles. Fordelingen for kNN var: 48positive, 310 neutrale og 6 negative.
26
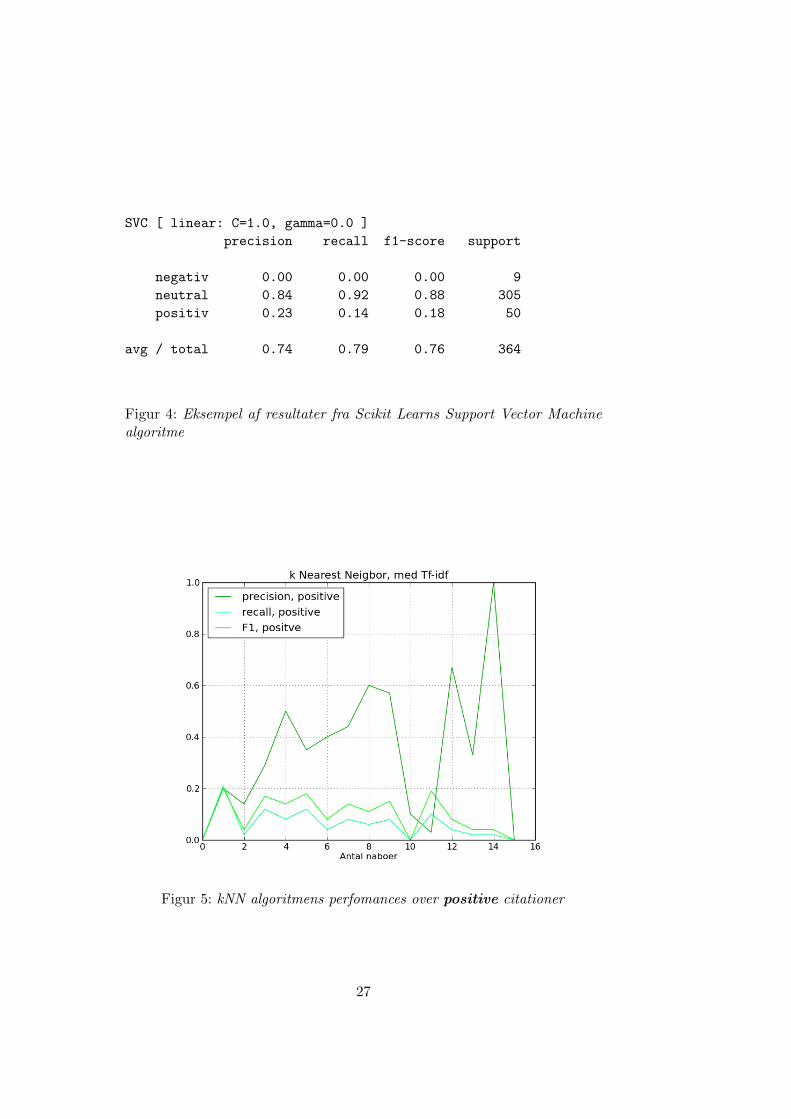
SVC [ linear: C=1.0, gamma=0.0 ]
precision recall f1-score support
negativ 0.00 0.00 0.00 9
neutral 0.84 0.92 0.88 305
positiv 0.23 0.14 0.18 50
avg / total 0.74 0.79 0.76 364
Figur 4: Eksempel af resultater fra Scikit Learns Support Vector Machinealgoritme
Figur 5: kNN algoritmens perfomances over positive citationer
27

4.1 Mal for konsensus
I forbindelse med diskussionen om det er muligt at vurdere citationer, fik viflere til at kategorisere citationer i den samme artikel. Der var 8 respondenter,der kategoriserede 85 referencer i en artikel. I 69 ud af 85 sætninger errespondenterne uenige om kategoriseringen. Dermed kan kun 16 ud af 85sætninger entydigt kategoriseresr.
Hvis man skulle give citationerne en kategori, og lod flertallet bestemme,havde vi 56 neutrale sætninger i forbindelse med en reference, 22 positiveanvendelse af en reference, ingen, der har faet nok negative vurderinger tilat kunne betegnes negative referencer og heller ingen, der ikke vil kunnekategoriseres, fordi enhver citation har faet mindst en kategori tilknyttet. Ide resterende 7 er sa stor uenighed, at de ikke vil kunne kategoriseres ud frasimpelt flertal.
Vi benytter Fleiss’ kappa (Fleiss and Cohen, 1973) til at male internenighed mellem dem, der kategoriserer. Kappa er et statistisk mal, der sigernoget om forholdet mellem den enighed, der er mere sandsynlig end tilfælde,og den grad af overensstemmelse, der er observeret ud over tilfældig fordeling.Formlen skrives som:
k =P − Pe
1 − Pe(1)
En kappa pa 1 svarer til at alle er fuldstændig i enighed; - 1 at der erfuldstændig uenighed. Alt derimellem er en skala over graden af enighed.Dvs. alt over 0 viser en form for enighed, mens alt under 0 viser en form foruenighed. Vi beregnede k til at være 0.05 i vores eksperiment. Der var altsaen meget lav grad af enighed om kategoriseringen.
5 Analyse af eksperimentet
Vi opnaede i vores resultater gode nøgletal for den store neutrale kategori,stort set pa alle made vi kørte eksperimentet. Kategorien inkluderede cita-tionssætninger i alle mulige udformninger, uden nogle specifikke kendetegnudover at de ikke kunne bedømmes som positive eller negative. At algorit-merne derfor med succes kan identificere citationssætninger tilhørende dennekategori er mindre overraskende da stort set alt tekst vil indeholde featuresder forefindes i det neutrale korpus.
SVM algoritmen kunne ikke annotere negative citationer. Ingen af deforskellige kerne indstillinger, linjær, polynomisk, Radial Basis Function ellerSigmoid, formaede at identificere de negative sætninger. Det er muligt at derkan udvikles en kerne der vil performe bedre med de negative, men med voresbegrændsede datagrundlag er SVMs ringe resultat nok nærmere grundet atden naturlige støj i dataene overdøvede nogen statistisk sammenhæng derkan være i de fa negative datapunkter.
28
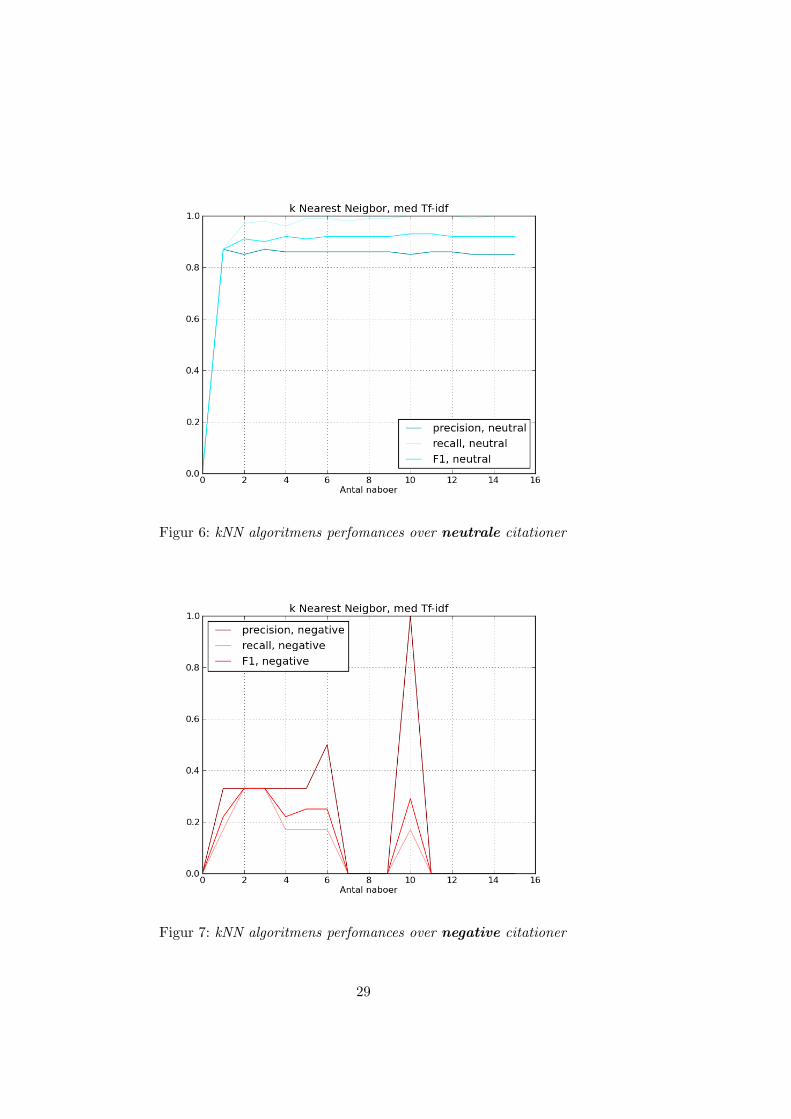
Figur 6: kNN algoritmens perfomances over neutrale citationer
Figur 7: kNN algoritmens perfomances over negative citationer
29

KNN havde bedre held med hensyn til de negative citationer. Med2–6 naboer, opnar algoritmen nogle stabile resultater, der dog uden atvære prægende, potentielt kunne forbedres. Præcisionens høje spring vedde 10 naboer tilskriver vi overfitting. Uden at vage for meget, kunne kNNresultaterne tyde pa at de negative citationssætninger i nogen udstrækningplacerer sig sammen i vektor rummet, og at der altsa nogen grad er etsammenfald mellem features der optræder i citationssætninger, der annoteressom negative af personer med faglig relevant viden.
I forhold til de positive lader det til at kNN algoritmen døjer medoverfitting. Der bliver opnaet relativt høj præcision med de fleste nabo-instillinger. Men den lave genkaldels grad bevidner at den statistiske modelgiver bedømmer et stort antal positive citationer forkert. Denne overfittingser ikke ud til at være et problem for SVM algoritmen, men de meget laveresultater stiller spørgsmalstegn ved om der overhoved er nogen statistisksammenhæng mellem de positive citationssætninger. Hvor en negativ citationformodentlig bliver signifikeret af forholdsord direkte relateret til citationen,skal en positiv attitude til andres forskning udledes af brugen af denneforsknings indhold. Hvis dette er tilfældet vil der ikke være nogle features isætningen omkring citationen der i større grad vil adskille denne fra featuresder forekommer ved ”neutral” brug.
Disse forhold gør at bibliometrikere ma foretage nogle overvejelser iforhold til kategorisering af citationer. Der skal rent praktisk tages hensyn til,hvorvidt kategorierne er for brede eller for smalle til at kunne identificeresvha. maskinlæring.
5.1 Konsensus i klassifikationen
Kategorisering er en kognitiv proces. Det er en udfordring at praktisere kate-gorisering og det er en udfordring at bedømme, hvornar noget er kategoriseretkorrekt. I det følgende vil vi gennemga resultatet fra vores eksperiment medat lade flere kategorisere referencerne i den samme artikel med det formal atdiskutere, hvilke problemstillinger der er i den menneskelig kategorisering afcitationerne.
Respondenterne i vores eksperiment havde svært ved at kategoriserecitationerne ens. Vi udregnede deres enighed til at være 0.05, hvilket vil sige,de var ret tæt pa at være decideret uenige om kategorierne. Andre studier,der har vurderet dette element i teknikken, har opnaet en enighed pa 0.67(Teufel et al., 2006b). Det kan derfor have noget at gøre med den tilgangvi brugte. Respondenterne fik kun meget sma tekststykker at arbejde med.Hvis de havde faet hele artiklen at vurdere ud fra, havde de maske udviststørre sikkerhed i kategoriseringen. Det havde dog ogsa resulteret i en langtstørre arbejdsbyrde i kategoriseringen og dermed potentialerne for metodensudbredelse.
Det kan ogsa være et spørgsmal om, hvem der er i stand til at kategorisere
30

forskeres citationerne. Studier som det nævnte af Teufel et al. (2006b), hvorandre forskere eller forfatterne selv kategoriserer deres citationer, har opnaethøjere enighed. Forskning er i sin natur en meget specialiseret disciplin ogdet kræver maske at man selv praktiserer det, for at kunne gennemskue helekompleksiteten i det at kommunikere forskningsresultater gennem artiklerne.
Det er dog ikke realistisk at ansætte forskere til at kategorisere citationeri vid udstrækning; hvis forskeres vurdering er den eneste, der gælder, er detoplagte at fa forfatteren til selv at angive, hvorfor de citerer. Den opfordringer dog blevet fremført af bibliometrikere før, fx Lipetz (1965), og med godgrund sidenhen ignoreret i videnskaben. Det virker modstridigt at skulleinfluere forskeres praksis, for at kunne fa indblik i deres praksis.
Spørgsmalet er, om det er for stor en forhindring til at kunne foretageautomatisk klassifikation af citationer. Willett (2013) undersøgte forskellenmellem forfatterens grunde til at citere med læserens, for pa den baggrundvurdere om citation context analysis overhovedet er muligt. Han bruger enliste over 18 grunde til at citere, som omfatter de funktioner, en citation kanhave i en tekst, men omtaler disse funktioner som citer motivations, hvilketkunne indikere, at det han er interesseret i er de bagvedliggende grunde forat en forsker i det hele taget vælger at praktisere det at citere.
Resultatet af Willets undersøgelse viser at forfattere og læsere ikke kate-goriserer referencerne ens og Willet konkluderer derfor at citation contextanalysis ikke kan foretages ud fra læseres vurdering af citationer. Men erdet grund nok til ogsa at afvise citation content analysis, altsa vurdering afcitationens indhold, i det hele taget?
I litteraturvidenskab taler man om forfatterens død, som følge af tænkeresom Barthes (1977), der i The Death of the Author, argumenterer for, hvordanlæserens vurdering af værket er lige sa meget værd som skaberens. Det er ikkefordi vi vil tage argumentet til sadanne ekstremer, men pointen er at, hviskritikken ikke fremgar af teksten, sa er det ikke en kritik. Selvom forfatterenkunne havde intentionen om at foretage en kritik og mener det star mellemlinjerne, sa er det kun en kritik, hvis det bliver opfattet som sadant. Deter ikke afgørende i forhold til indholdsanalyse, hvad forfatteren til artiklenmener at have tænkt, men hvad resultatet af denne proces blev. Problemet,der er værd at diskutere i forhold til kategorisering, er saledes kun, hvilkekvalifikationer, man skal have for at kunne aflæse den kritik. Først hvis deneneste, der er i stand til at aflæse kritikken, er den person, den er rettet mod,er det et problem for indholdsanalysen af citationer.
En anden pointe i den forbindelse er, at forfattere maske ikke er bevidsteom, præcis hvorfor de citerer. Som Cronin (1984, p.5) formulerer det: ”authorsmay not be clear in their own minds why it is that they cite the way they do,or how citations relate to the ideology of science.” Det er blevet fremført fleresteder, at citationspraksis er en form for tavs viden, der først bliver italesat,hvis det ikke bliver udført korrekt. Det eneste, vi derfor mener at kunnevurdere en kategorisering ud fra, er ikke en facitliste af forfatterens vurderinger
31

af citationer, men om det er muligt at opna en konsistent klassifikation.
Miller (2004) har undersøgt empirisk, hvad det kræver for en person atforsta forskning og konkluderer at for at kunne bedømme et stykke forskning(i en forskningsartikel) er det nødvendigt at personen besidder en viden om,hvordan et studie er opbygget og en forstaelse af brugen af de specielle termer.Der er her tale om en bedømmelse af selve indholdet af forskningen, og detsamme ma gælde for det metalag i forskning, som en citation er en del af.Det kræver mere end blot forsta, hvad der umiddelbart star. Det kræver entolkning af hele den sammenhæng, en citation indgar i.
I forhold til anvendelsen af metoden ligger den største problemstillingi, hvis man ikke kan stole pa den enkeltes vurdering, og kategoriseringendermed ikke er konsistent. Hvis man er nødt til at fa flere til at behandleden samme data, for at frasortere fejlkategoriseringer og opna en konsistentkategorisering, bliver metoden endnu mere arbejdstung, og ender maske medat kunne afvises med det samme argument, som har afholdt bibliometrikerefra at benytte sig af at inddele citation i typer hidtil: At det er en for storbarriere at fa hver citationerne gennem intellektuel bearbejdning.
Kravet for en god klassifikation er at enhver citation ender i den sammekategori, uanset hvem der bliver sat til at kategorisere. Vores kategorier kanhave influeret det darlige resultat, maske kan man ikke se citationers ladningud fra en ordinal skala, hvis der fx ikke er noget, der adskiller positive franeutrale citationer. Problematikker omkring valg af kategoriseringstyper erdog noget, vi først vil diskutere senere i opgaven. Det vi kan konkludere herer at det er en udfordring at fa en konsistent kategorisering,
Automatisk klassifikation er ikke sa automatiseret at det kan klare siguden menneskelig input. En større forhindring i denne metodes udbredelselader til at hvile i den praktiske barriere i at fa vurderet citationerne ens.Bibliometrikere skal enten arbejde med store datasæt i maskinlæringen for atgøre op for enkelte fejl i kategoriseringen eller sætte mange til at kategoriseredet samme data, for at være sikker pa at citationerne ender i de rigtigekategorier. Begge dele stiller ekstra krav til metoden. Alt indikerer dog atpalideligheden er sa lav, at det maske ikke kan lade sig gøre at opna enighedom, hvilken type en citation er. Deri hviler en stor ricisi for bias.
5.2 Datagrundlaget
Nar vi skal vurdere beskaffenheden af datagrundlaget for automatisk kate-gorisering til citationsanalyse, er der to elementer at tage højde for. Somtidligere bemærket er der et behov for adgang til akademisk litteratur i fuld-tekst, for at udføre studier af den type beskrevet i denne undersøgelse. Detandet element er naturen af de værktøjer der er tilradighed for at behandletekstmaterialet. Lad os først se nærmere pa tekstgrundlaget.
Open Access bevægelsen er det bedste bud pa hvor denne fuldtekst skalkomme fra. Potentiel kunne aftaler med de store udgivere give adgang til
32

store dele af forskningslitteraturen, men omkostningerne ved dette er ikke iproportion med modenheden af metoden. Open Access litteraturen er ikkestor sammenlignet med litteraturen under licens, men der skulle stadig værerigeligt data til yderligere præliminære studier. Directory of Open AccessJournals,11 en katalog over artikler og tidsskrifter udgivet under open access,har i skrivende stund 9315 tidsskrifter indekseret, der indeholder næsten 1,1millioner artikler. Der er altsa rigeligt med tekstuel data at fa fat i.
Der er dog begrænsninger for de bibliometriske studier der kan udføresudelukkende pa open access forskning. Citationskæder kan kun følges, salænge referencerne er til andet open access litteratur. Der er potentieltogsa strukturelle forskelle pa open access forskning og den forskning derudgives i de etablerede tidsskrifter, der kan pavirke slutninger draget udfra et open access datagrundlag. Solomon et al. (2013) har fx vist hvordander i nogen grad er en sammenhæng mellem rater af opnaede citationer ogfinansieringsmodellen for et tidsskrift. Forsigtighed ma udvises hvis fundenei fremtidige studier skal kunne generaliseres.
I behandling af tekstmaterialet inden læringsprocessen syntes der er væremange muligheder for at forbedre datagrundlagets potentiale. Den naive til-gang vi præsenterede her i denne opgave, hvor afgrænsede citationssætningerbenyttes blindt ud fra praktiske betragtninger, lader til at parforme mindretilfredsstillende. I studiet af Teufel et al. (2006b) omtalt tidligere, benyttedede en teknik udviklet af Simone Teufel kaldet Argumentative Zoning. Denneteknik gar ud pa at lokalisere forskellige semantiske dele i en forskningsartikel,sa som indledning, formulering af artiklens formal, præsentation af metodeog sa videre.
Teufel et al. (2006b) brugte denne teknik sammen med frase kendekending,hvor de lokaliserede standard formuleringer, til at identificere de menings-bærende features omkring en citation. Med denne teknik opnar Teufel et al.(2006b) relativt pæne resultater. Der er altsa et stort potentiale i arbejdetmed at udtrække den tekstuelle data korrekt til maskinlæring. Dybere indsigti natural language processing, altsa teknikker til at parse og behandle naturligvil være nødvendigt for at opna interessante resultater i det videre arbejdemed automatisk klassifikation i citationsanalyse.
Det er en stor forhinding for anvendeligheden i bibliometriens øjne atskulle være afhængig af dels avancerede teknikker til forbedring af metodenog dels en udvikling i datagrundlag, saledes at valg af studieomrade ikke erbetinget af datatilgængelighed. Vi forudsætter dog at sadanne forhindingerikke er tilfældet i den videre teoretiske behandling af anvendelsesmulighedernefor automatisk anvendelighed af maskinlæring.
11http://www.doaj.org, verificeret den 27. maj 2013.
33

6 Bibliometriens anvendelsesomrader
I det følgende vil vi undersøge, hvilke omrader af den bibliometriske diciplin,der kunne tage imod maskinlæringsteknikker og hvordan d. Vi vil altsaundersøge, hvad resultaterne fra en undersøgelse, som den vi har gennemførtrent teoretisk kunne bruges til i praksis. I forbindelse med en diskussionom kvantitative metoder argumenterer Morman (1981) for, hvordan bibli-ometriens udvikling er drevet frem af de miljøer, der har en interesse ividenskabskommunikation. Han skriver saledes:
”Citation analysis in the history of science results from the con-vergence of the needs of policy makers of the post-war era, thematuration of the bibliographic citation practice in the scientificliterature during this century, the availability of electronic dataprocessing, and a school of sociology concerned with the internaldynamics of the scientific community.”
Det er derfor essentielt at se pa, hvad de miljøer, anvender bibliometrientil, og hvilke interesser de kunne have i automatisk klassifikation, men ogsahvilke risici der er forbundet med at indføre en klassifikation af citationer.
Først skal det dog defineres, præcis hvilke miljøer, der er tale om. Dekan kun anes i ovenstaende citat af Morman, mens Nicolaisen (2007) i singennemgang af citationsanalyse klart fremhæver bibliometriens tre primæreanvendelsesomrader som:
1. ”Qualitative and quantitative evaluation of scientists, publi-cations, and scientific institutions.”
2. ”Modeling of the historical development of science and tech-nology.”
3. ”Information search and retrieval.”
Zunde (1971)
Det vi vil betegne:
1. Forskningsevaluering
2. Videnskabsstudier
3. Informationssøgning og -genfinding.
I de følgende tre underafsnit gennemgar vi disse anvendelsesomraderog hvordan automatisk klassifikation kunne tænkes at anvendes inden forhver af disse. Først vil vi dog præcisere de underlæggende antagelser, dergøs sig gældende for alle anvendelser af bibliometri. Med antagelser forstasdet grundlæggende udgangspunkt for at kunne anvende de bibliometriskemetoder, som de tager sig ud nu. Nicolaisen (2007) fremfører disse somværende:
34

1. ”Citation of a document implies use of that document bythe citing author.”
2. ”Citations of a document (author, journal, etc.) reflectsthe merit (quality, significance, impact) of that document(author, journal, etc.)”
3. ”Citations are made to the best possible works.”
4. ”A cited document is related in content to the citing docu-ment.”
5. ”All citations are equal.”
Smith (1981)
De forskellige antagelser har større eller mindre betydning inden forhver anvendelsesomrade og automatisk klassifikation kan gøre op med flereaf disse antagelser. Ved at inddele i typer af citationer vil alle citationerfx ikke længere nødvendigvis behandles ens og det ville ogsa være muligtat undersøge om forskningsartikler blev brugt pa samme made. Hvilkenbetydning det kan have for hvert anvendelsesomrade vil vi se pa i de følgendetre afsnit.
6.1 Forskningsevaluering
Formaliseret forskningsevaluering foretages, nar der skal udeles støtte tilforskning, ansættes nye forskere eller universiteter, forskere og forskning paanden vis skal bedømmes og sammenlignes pa baggrund af deres forsknings-resultater. Bibliometri har pa ingen made patent pa forskningsevaluering,men er i Danmark blevet meget udbredt bade i de offentlige finanser medforskningsindikatoren og i private fonde, der støtter forskning. Vi vil i detfølgende beskrive, hvilken rolle bibliometri spiller i forskningsevaluering, oghvordan automatisk klassifikation kan spille ind i den rolle.
I en guide i at benytte sig af bibliometri i forskningsevaluering fremhæverThomson Reuters, udbyderen af Web of Science, at bibliometri anvendes tilat “turn the main tool of science, quantitative analysis, on itself” (Reuters,2009). I den ene sætning underbygger de værdien i et kvantitativt værktøjsom bibliometri. Bibliometri kan ifølge Thompson Reuters udpege ikke dekun den forskning, der er mest produktiv, men med citationsanalyse ogsaden af bedst kvalitet.
Guiden er dog papasselige med ikke at bruge betegnelser som ’de bedste’,og gradbøje effekten af bibliometrisk evaluering ved at sige indikere, fremfor udpege. Bibliometrien inden for forskningsevaluering er meget afhængigaf de tre første antagelser pa Smiths liste, som kan sammendrages til ensamlet forstaelse af citationer inden for forskningsevaluering: En citationer et udtryk for at andre forskere anerkender indholdet i artiklen som detbedste forskning inden for sit omrade.
35

Kvalitetsbegrebet er i den forbindelse centralt for bibliometriske analyse.Bibliometriske værdier bygger pa en antagelse om, at det at blive citeret er etkvalitetsmal i sig selv. At de dygtigste forskere modtager flest citationer, somfølge af at andre forskere bygger videre pa den forskning, de finder anvendelig.Guiden citerer Garfields liste fra 1965 over grunde til at citere, men som vigjorde opmærksom pa i tidligere studier er disse grunde til at citere udtrykfor en opfattelse af videnskab, der kan sættes spørgsmalstegn ved.
Figur 8: Forskellige roller i forskningsprocessen (Reuters, 2009).
Figur 8 er ikke taget med for at vise hvordan det foregar, nar forskning skalfinansieres. Vi har valgt at tage denne illustration med fordi den viser, hvordanThompson Reuters ser deres rolle i forskningsevaluering. I illustrationen bliverder lagt vægt pa at fremhæve hvilke aktører, der er ansvarlig for hvilke led iprocessen. Saledes er udgiveren involveret i udgivelsen af forskningen osv.,men ifølge Thompson Reuters er der under selve evalueringen dog ikketilknyttet nogen aktør. I denne optik er evaluering en opgave, der løser sigselv med bibliometri.
En af de fordele, Thompson fremhæver ved bibliometri – frem for andreformer for evaluering - er netop dets objektivitet, dvs. upartiskhed. “Cita-tion analysis indicates top performers, thus balancing human perceptionsof reputation”. Thompson Reuters søger at distancere sig fra traditionelforskningsevaluering som peer review, men i den argumentation glemmer de
36

at bibliometriske mal ogsa er et udtryk for (en lang række af) vurderingerforetaget af andre forskere og dermed blot er en (anden) form for peer review.Under evaluate outcomes skulle der derfor anføres peers som aktør, uansetom man benytter sig af traditionel peer review eller bibliometri, for at afgøreom forskningen er af den ønskede kvalitet.
Automatisk kategorisering har potentialet til løse nogle af de fundamentalesvagheder ved forskningsevaluering, fx hvordan enhver citation tæller fordet samme i en citationsanalyse – uanset hvor essentiel eller uvæsentligden er for resultatet af forskningen. Det kunne blive lettere at dokumentereværdien i den forskning, der har modtaget støtte, ved at fa et mere præcistbillede af hvem og hvordan, forskningen har influeret. Man kunne ga væk fraden meget endimensionelle opfattelse af forskningsevaluering, hvor malet er’impact’ eller ej, og ga over til en mere kvalitativ vurdering af hvilken form forindflydelse, man gerne sa. Saledes er der potentialer i at benytte bibliometriog automatisk klassifikation af citationer til at evaluere følgevirken af støtte.Det er først nar den samme form for data skal bruges til at forudsige frugtbarforskning, at der kan opsta reelle stridspunkter.
Idet forskningsevalueringens kriterium for udvælgelse er kvalitet af denenkelte aktørs præstation i forhold til andre bliver videnskab ikke set somet kollektivt projekt, men en konkurrence, hvor alle arbejder ud fra egneinteresser. Forskningsevaluering skulle gerne kunne forudsige storhed eller denforskning, der vil vise sig gunstig fremover. Den made forskningsevalueringnu forsøger at udpege og sammenligne kandidater for at kunne forudsigede bedste ’investeringer’ i fremtiden er primært ved hjælp af indikatorer.Hvis en eller anden form for kategorisering af citationerne blev indført, villedet i den forbindelse være muligt at frasortere fx negative citationer, ellercitationer, der ikke bliver anvendt, men blot nævnt, ud fra en opfattelseaf, at sadanne citationer ikke er lige sa meget værd som andre former forcitationer. Negative citationer kunne sagar opfattes som noget, der trækkerned i evalueringen.
Kritiske bidrag til forskningen har maske ikke den samme rolle somempiriske eller teoretiske bidrag, idet de forholder sig til tidligere forsknings-resultater, men det betyder ikke nødvendigvis at de ikke kan spille en rolle iforskningens udvikling. I videnskabsteoretiske udgangspunkter som induktio-nisme og positivisme ses vidensudviklingen som en konstant overbygning patidligere viden. Her er kritik ikke selve grundlaget for videnskabens udvikling,mens det i en videnskabsteoretisk retning som falsifikation spiller en centralrolle. Alt efter hvilke videnskabspraksis, det enkelte fagomrade har traditionfor, vil de være forskelligt, hvilken rolle kritikken spiller i litteraturen.
Risici er ogsa at pavirke praksis, ved fx at give negative citationer en vægt.Hvis det gøres til et mal i sig selv, bliver det et vaben i en positioneringskampmellem forskere. Case and Miller (2011) undersøgte om ”a heightened level ofawareness of their own citation practices” skabter en anden made at citerepa hos bibliometrikere. Det samme spørgsmal kunne være relevant at stille
37

ved at indføre fx negative klassifikationer til forskningsevaluering. Studietfandt at bibliometrikere har andre grunde til at citere end de to dicipliner,der sammenlignes med (psykologi og kommunikation), hvilket kunne indikereat en bevidsthed om konsekvenserne af en citation skaber en ændret adfærd.Udvælgelsen i sammenligningsgrundlag kan dog betvivles, da næsten alledicipliner citerer forskelligt.
Uenighed, kritik og debat er et aspekt af videnskab, der handteres for-skelligt inden for fagomrader. Desuden er der ikke nødvendigvis nogen sam-menhæng mellem kvaliteten af forskerens arbejde og den kritik, forskeren harmodtaget. Det kan være den, der kritiserer, der tager fejl. Det ville saledesikke nødvendigvis være en gavnlig udvikling for videnskaben, hvis evaluerin-gen bygges op om en forstaelse, hvor kontroverser ikke udgør et varierende –og mange tilfælde et givtigt – aspekt af videnskabskommunikation.
6.2 Videnskabsstudier
Nar vi i denne opgave sætter lighedstegn mellem scientometri og bibliometrifølger vi den generelle praksi, hvor de to ord bruges som synonymer. Reelter der fa bibliometriske studier, der ikke omfatter et aspekt af videnskab.Omvendt er videnskabsstudier et vidt begreb og bibliometriske metoderspiller kun ind i et fatal af de studier, der forsøger at forsta videnskab.Bibliometriens rolle i videnskabsstudier er ifølge Zundes definition afgrænsettil studier, som kortlægger videnskaben vha. citationsnetværk, hvilket vi vilfokusere pa at behandle i her.
Vi har allerede i tidligere studier berørt de oplagte muligheder for net-værksanalyse, ved berigelse af data, og en dybere forstaelse af naturen afde links, der fremtræder i et citationsnetværk. Det oplagte spørgsmal, somautomatisk klassifikation har potentialet til at besvare er ikke – som traditio-nel ciationsanalyse – om forskere forholder sig til hinanden, men hvordan deforholder sig til hinanden. Fokus vil her være pa eventuelle videreudviklingerpa konkrete tiltag i bibliometriske studier af videnskab.
Mapping controversies er betegnelsen for et initiativ til at kortlæggevidenskabelige kontroverser i et netværk af aktører. Tankegangen bag er atbruge visualiseringsteknikker til at identificere kontroverser i et netværk. Et afde centrale elementer er herefter bl.a. at forsta de sociale dynamikker ved brugaf sociologiske teoriers forklaringskraft (Whatmore, 2009). Med identificeringaf negative citation kan det udvikle sig fra at undersøge prædefineredeomrader, hvor det pa forhand er klart at en kontrovers har fundet sted, til atudpege de steder i et netværk, hvor kontroverser forløber lige nu. Der er storepotentialer i at undersøge videnskab som socialt system med nye metoder,men at ga fra kortlægning til at undersøge bagvedlæggende mekanismerkræver en bevidsthed om præcis hvad citationsdata afspejler.
Guns (2013) forsøger at danne sig et overblik over hvilke entiteter, info-metrien (og herunder bibliometrien) undersøger. Guns skelner mellem dem
38

der producerer videnskabskommunikation (forskere), de kommunikative arte-fakter (dokumentet) og de koncepter der kommunikeres om (erkendelsen).Han diskuterer, hvorfor forskere citerer, og mener i den forbindelse at ”both”rewarding”(positive) and negative ciations are documentrary reflections ofprocesses in the epistemic dimension.” Han fortsætter: ”Much of informetricssimply assumes epistemic reasons for citations.”
Netværksanalyse og en dybere forstaelse for de links, der opstar mellemaktører, kan give reel indsigt i, hvad en citation er et udtryk for, og dermedgrundlaget for fx forskningsevaluering og de ting, bibliometrien nu kun kanantage. Der er potentialet til at gøre op med opfattelser som denne fra enlærebog i netværksteoriens metoder:
”A non-social network example is the use of citation counts in theevaluation of scientific papers. The number of citations a paperreceives from other papers, which is simply its in-degree in thecitation network, gives a crude measure of whether the paper hasbeen influential or not and is widely used as a metric for judgingthe impact of scientific research.”
(Newman, 2009)
Her indrages kun en entitet – dokumentet, og alle andre aspekter afvidenskabskommunikation ignoreres ved at benævne netværket som værendeikke socialt. I citatet ses en citation som et objekt i sig selv, der ikke er influeretaf faktorer i et socialt netværk. Automatisk klassifikation af citationer alenekan give indblik individers handlemønstre, men ikke de konventioner, derstyrer individet. Hvorfor det især inden for videnskabsstudier er relevant atdiskutere citationsteori, hvor bibliometriske konklusioner bliver bundet op pavidenskabssociologi og en forstaelse for motivationerne for individers ageereni et netværk. Det perspektiv vil vi genoptage og diskutere i afsnittet omcitationsteori.
6.3 Informationssøgning og –genfinding
Garfield skabte Science Citation Index med det formal at give et værktøj tilinformationssøgning de Bellis (2009). Et citationsindex minder om enhveranden en bibliografisk database, men det der adskiller citationsindex fra andrebibliografiske databaser, er at dokumentetet registreres med dets referencelisteog disse referencer bliver gjort til søgeindgange. Citation indeksering hviler paden forudsætning, at en notation i en bibliografi er et udtryk for en relationmellem to dokumenter. Teknikken fortæller intet om naturen af relationen,men udnytter blot forholdet til at indeksere videnskabelig litteratur.
Citationsindeks fordrer en anden form for søgning, idet citationer – somCronin betegner det – bliver anvendt til ”descriptors in their own right”. Det
39

lægger sig især op af den antagelse at dokumenter, der kobles er emnemæssigtbeslægtede. Søgningen kan tage udgangspunkt i et (eller flere) dokument(er)og derudfra finde frem til enten andre, der har forholdt sig til det dokumenteller den litteratur, der fremgar af dokumentets referenceliste.
Ulempen ved at fa alle forbindelser til et dokument er ’the noise factor’,altsa det, der i søgningsregi, betegnes støj, fordi det ikke er relevant i forholdtil brugerens søgekriterier. Brugeren har ingen mulighed for at fa indsigt i,hvordan to dokumenter forholder sig til hinanden og ma sortere i resultaterneved at sætte sig ind i indholdet pa anden vis. For søgningen er det et problemat alle citationer tæller for det samme.
Bibliometrikere har klaget over forskeres tendens til at citere overflødigteller inkonsistent og advokerer pa forskellig vis for at standardisere forskeresindividuelle made at citere pa (Lipetz, 1965). For at forbedre et søgeværktøj,er deres ide at pavirke den made videnskabskommunikation foregar. Som omsøgning i forskningslitteratur vægter højere end skabelsen af forskningslitte-raturen. Cronin (1984) har bedre fat i roden af problematikken:
“Ironically, citation indexing’s greatest advantage is also thecause of its major shortcomings. Citation indexes are based onconnections between documents and authors. There is no needfor the intervention of trained subject indexers.”
I citatet lægges der vægt pa forbindelsens neutralitet som en fordel, idet dennetop ikke som andre former for databaser kræver emnekategorisering, derer en krævende og bekostelig disciplin, hvis den skal udføres manuelt. Nogetautomatisk klassificering ikke vil gøre fuldstændig op med, idet den type vihar undersøgt stadig kræver menneskelig kategorisering, og indekseringenville blive en del mere krævende, som vi allerede har diskuteret ud fra voreseksperiment.
Automatisk klassifikation har et stort potentiale for at komme ud af denneblindgyde ved at efterbehandle naturen af citationer. Det ville være muligtat sortere i søgeresultater ud fra forskellige kriterier, sasom at dokumentetskal være anvendt som metode i de dokumenter, der søges frem. En sadanfunktionalitet sikrer brugeren en langt større kontrol og mulighed i at nafrem til mere specialiserede søgninger og potentielt mere relevante resultater.
Søgefunktionaliteten i citationsindex har traditionel holdt sig fra atrangere søgeresultater efter popularitet, hverken efter antal downloads ellerantal citationer modtaget, al a Googles PageRank algoritme (Page et al.,1999). Søgning i citationsindex fordrer en anden form for søgning. Der er etuudforsket omrade i at arbejde med recommender systemer i citation indexes,hvor automatik klassifikation af citationer kunne spille en rolle i algoritmersanbefaling af relateret litteratur. Der er naturligvis mange scenarier, vi ikkekan beskrive her, men det oplagte ville være at brugeren fx blev anbefaletartikler ud fra forskere, brugeren havde vist interesse i før og de forskere,denne forsker havde forholdt sig positivt til.
40

Automatisk klassifikation inden for informationssøgning og -genfinding harikke de samme problematikker som andre anvendelsesomrader, idet opbygningaf databaser er en heuristisk tilgang, hvor resultatet af implementeringenefterprøves og justeres løbende. Der er stort potentiale og – hvis det gøresordentligt – ikke de samme risici for at pavirke selve den praksis, bibliometrienforsøger at forholde sig til. Det ville være et optimalt sted at starte med atteste metodens anvendelighed ved at lade brugere søge i citationsdatabasermed automatisk kategorisering af citationer. Det kunne fungere som en proxytil større databaser. Der ville dog stadig være problematikker i at opnaen brugbar kategorisering, hvis en sadan database skulle virke pa tværs afvidenskabsfelter, hvilket vil fremga af næste afsnit om klassifikationssystemer.
7 Klassifikationssystemer
Klassifikation er et centralt begreb i informationsvidenskaben. Klassifikations-systemer samler ting, der ligner hinanden i samme kategorier og anbringerbeslægtede kategorier nær hinanden. Det gøres ud fra klassifikationskriterier,der skal systematiseres saledes at der aldrig hersker tvivl om, hvilken kategoriet emne tilhører. Det er en tilgang, der praktiseres i vidensorganisering ogdiskuteres i klassifikationsteorien (Lancaster, 1991).
I vidensorganisering og informationssøgning bliver kategoriseringssyste-mer anvendt til at reducere i og ordne mængden af kategorier, sa antallet erkategorier ikke er sa mange som den samlede mængde af alle individers indi-viduelle opfattelser af det, der skal organiseres. Kategorisering bliver brugt tilat facilitere browsing, altsa nar brugere endnu ikke er helt sikre pa, hvad deleder efter. Paradigmet inden for informationsvidenskab har tidligere væretat dette skal gøres objektivt – altsa uafhængigt af personen, der indekserer.Som det beskrives her er klassifikationens oprindelige indgangsvinkel af findeen systematik, der repræsenterer en objektiv virkelighed:
”Much classification work is built on the notion that what isbeing classified exists independently of humans and that the workof classification and classifiers is to discover the real essencesand represent the kinds and phenomena as they really are” (Mai,2011)
Succeskriteriet er at opna sa naturlig en klassifikation som muligt. I kate-goriseringspraksis menes med naturligt at selv hvis man ændrer pa klas-sifikationskriterierne vil objektet, der undersøges, altid ende i den sammekategori. En god klassifikation sørger for exhausivitet og eksklusivitet. Medudtømmelighed i kategoriseringskontekst menes at ethvert objekt, der skalkategoriseres, tilhører mindst en kategori. Med entydighed menes at ethvertobjekt ikke ma være tilknyttet flere kategorier.
Det kan være et problem at opretholde disse kriterier i forhold til kate-gorisering af citationer, hvis de typer, de forsøges beskrevet med, er vage,
41

upræcise eller overlappende, saledes at det bade for mennesker og maskinerer svært at afgøre, om citationen har den egenskab, der efterspørges eller ej.Som Lipetz gjorde opmærksom pa allerede i 1965:
“Just as there are no absolute and exclusive terms by whicha document may be fully described in subject indexing, thereare no absolute and exclusive categories which fully describethe relationship of a citing publication to the cited publication.”(Lipetz, 1965)
Det er dog udtryk for et praktisk aspekt af en gammeldags vidensorganise-ringen, hvor objektet kun kunne have en fysisk placering. Det behøver ikke isamme udstrækning gøre sig gældende i et digitalt miljø, hvor et dokumentikke skal have placeringer, men godt kan tilknyttes flere emner eller i dettetilfælde typer. Det er muligt at handtere flertydigheden i ciationer (ogsamaskinelt med multilabeling), salænge der skabes en kategoriseringssyste-matik, som kan aflæses ud fra teksten. Lipetz konkluderede at mængden afcitationstyper skulle afgøres ud fra en praktisk afgrænsning:
“Relationship categories, like subject descriptions, may be multi-plied, modified, qualified, or subdivided to infinity. Decisions onhow far to go in relationship coding, as in subject indexing, mustultimately be determined by economic factors which force theconscious or unconscious matching of indexing depth and scopeto the practical value of the results.“ (Lipetz, 1965)
Citationstyper er en form for emnekategorisering og valg af klassificerings-system er netop ikke trivielt, men det skal helst ikke tages ud fra praktiskeog økonomiske overvejelser alene. Det er netop dette ræsonnement for valg ikategoriseringssystem, som automatisk klassifikation af citationer ikke skalafgrænses til. For bibliometriens gyldighed er det vigtigt at forholde sig tilteoretiske implikationer af beslutninger om klassifikationer, hvilket vi vil gørei næste delafsnit.
7.1 Klassifikationsteori
Kategorisering er ogsa et undersøgelsesobjekt for andre videnskaber, fxpsykologien. Her er bruges kategorisering til at forsta, hvordan menneskerbearbejder og handterer en mængde stimuli. Sagt pa en anden made: Kate-gorisering er en made for mennesker at samle ikke identiske stimuli i grupperefter perciperede ligheder. Repræsentation vha. klassifikation er pa den madereduktionistisk og kriterierne for hvad hvilke stimuli, der placeres sammener individuelt og kulturelt betinget (Rosch, 1977). Det illustrer, hvad infor-mationsvidenskaben først er ved at omstille sig til, at klassifikation ikke kanvære objektiv, men er kulturelt betinget. Der er eksempler pa klassifikationer,
42

der har matte ændres, fordi vores opfattelse af verden og begrebet har ændretsig.
Mai (2011) beskriver bevægelsen hen mod en senmoderne forstaelse afkategorisering og skelner mellem classification-as-ontology og classification-as-epistemologi. Klassifikation i det ontologiske paradigme antog at det varmuligt at beskrive ting som de er, uafhængig af menneskelig forstaelse, mensdet epistemologiske tager sit udspring i erkendelsesteori og hvordan dereksisterer forskellige kriterier for sandhed og videns gyldighed pa forskelligetidspunkter og i forskellige traditioner. Mai (2011) kritiserer informationsstu-dier for at have bibeholdt normen om og stadig sigte efter ”decontextualizationand neutral and objective classification”.
Classification-as-epistomology kan ses som et opgør med ideen om in-formation som en ting i sig selv (Buckland, 1997), og flytter fokus over tilaf forsta den kontekst, en kategorisering skabes til. Man opgiver dermedideen om et klassifikationssystem, der vil tjene ethvert formal og idealet omden objektive klassifikation. I forlængelse af der er der opstaet teknikkersom domæneanalyse, som bygger pa den ide at at den bedste made at ka-tegorisere og forsta information pa er at afgrænse sig inden for et domæne(Hjørland and Albrechtsen, 1995). Overført til en praktisk løsning betyderdet at kategorisering ikke længere skal udføres objektivt, men kun efterhensigter og hensyn til konteksten. I domæneanalysen skal disse hensigter oghensyn analyseres, sa kategoriseringen kan finde sted efter den pagældendebrugergruppes strukturer.
Hjørland (2002) mener at et domænes paradigmer eller teoretiske grund-antagelser er centralt for indekseringen og organiseringen af viden. Narinformationsspecialister skal konstruere et vidensorganiserende system, er detvæsentligt at forsta et det domæne, der skal repræsenteres. De grundlæggendekriterier for, hvad der er beslægtet, dvs. de grundlæggende klassifikations-kriterier, fastsættes af de faglige paradigmer i domænet. Pa samme madevil problemet ved at bestemme citationstyper være at de kategorier, dersamles af et videnskabsteoretisk udgangspunkt, ikke nødvendigvis samles afandre. Udvælgelsen af citationstyper bygger pa en række grundantagelser omhvordan videnskab foregar. Det ses tydeligt i de citationstyper vi gennemgiki tidligere studier. Studier i citationstyper er enige om at der er et sæt cita-tionstyper, der kan beskrive citationers rolle i forskningslitteraturen, men deer ingen konsensus om antallet af citationstyper og hvilke citationstyper, dereksisterer. Citationstyperne repræsenterer forskellige opfattelser af, hvordanvidenskab bliver til og hvad der skal til, for at skabe viden.
Det vi nar frem til er at den eneste klassifikation, der er mulig, eren art kollektiv subjektiv kategorisering. Altsa den der stemmer overensmed en afgrænset gruppe brugeres erkendelsesgrundlag. I forlængelse af, atklassifikation af citationer kræver en stillingtagen til videnskabsteoretiskstasted i form af en citationsteori eller anden absolut ide om, hvordan videnbliver til, er det besværligt at opna enighed om de kriterier, en klassifikation
43

skal foretages pa baggrund af. Hvordan eller om det evt. kan løses inden forbibliometriens tre anvendelsesomrader, vil vi diskutere i det følgende.
7.2 Kategoriseringsmuligheder
I forlængelse af at klassifikation er uretfærdig overfor nogle af de dimensioner,der klassificeres, vil en klassifikation pa baggrund af varierende videnskabsop-fattelser aldrig kunne være uden bias. I informationssøgning og –genfindingmener Mai (2010) at man kunne løse dette ved ikke længere at parabe sigobjektiviteten i klassifikationen. Idet “classifications make ontological state-ments that someone, somewhere, at some point will object to” (Mai, 2010), maløsningen – pa klassifikation ikke kan være neutral, uden bias og tilfredsstillealle – være at bekendtgøre pa hvilket grundlag kategoriseringen foretages. Atgøre brugerne bevidste om eventuelle bias, saledes at systemet opretholdertilliden fra brugeren, der selv kan afgøre om det er i overensstemmelse medbrugerens egne kriterier. I informationssøgning og -genfinding ville det altsavære muligt at tilfredsstille nogle, men ikke alle brugergruppers kriterier.
I forhold til forskningsevaluering er det dog en anden problemstilling, daden søger sammenlignelige resultater – ogsa gerne pa tværs af videnskaber.Der er i forvejen (dvs. pa det grundlag som bibliometrien foretages pa nu)netop problemer med at kunne sammenligne videnskaber, pga. videnskabersforskellige praksis og udgangspunkt for erkendelse. Som vi allerede har væretinde pa er negative citationer i nogle vidensdomæner udbredte, men det iandre ikke er tradition for at anerkende tidligere forskning (Frost, 1979).Forskningsevaluering er pa den made ekstra følsom overfor bias. Denne risikofor bias er allerede tilstede i traditionel citationsanalyse – hvis citationer ivirkeligheden ikke er et udtryk for en normativ adfærd – dette bliver holdti ave ved sandsynliggørelsen af de store tals lov og mangel pa statistisksignifikans i afvigere fra normer for god videnskab. Men som Nicolaisen(1997) papeger: ”what if the behavior is not random? What if the behavior isbiased?”
Dette eventuelle bias i forskeres citationsadfærd kan kategoriseringenikke løse. Hvis dertil lægges en usikkerhed i kategoriseringen, der skaberandre bias, bliver bibliometrien en videnskab, hvor der skal tages sa mangeforbehold at fortolkning af data bliver krævende pa grænsen til umulig.Medmindre dictum inden for forskningsevaluering ændrer sig, er det stadigikke muligt at stille et værktøj til radighed, der i sit sammenligningsgrundlagikke forudsætter et videnskabsteoretisk udgangspunkt.
Videnskabsstudier falder ind imellem de to positioner. Den videnskabeligemetode gør det muligt at forholde sig til begrænsningerne i en undersøgelseog eget videnskabsteoretiske stasted. Saledes kan anvendelsen af klassifika-tionssystemer netop afgrænses til et bestemt udgangspunkt og ikke foregiveobjektivitet, men klassifikation med henblik pa nogle former for resultater,lignende de studier af citationstyper, der allerede har fundet sted i lille skala.
44

Ligesom med informationssøgning og -genfinding bibeholder forskningentilliden fra brugeren (i dette tilfælde læseren) ved at transperens i kriteriernefor klassifikation og eget stasted i denne klassifikation.
I det følgende afsnit vil vi behandle citationsteori, et omrade af bibli-ometrien der kan være givende i forhold til at takle problematikken medklassifikation.
8 Behovet for citationsteori
Et helt fundamentalt udgangspunkt i udførelsen af citationsanalyse, er cita-tionsteorien. For at kunne udlede, eller tolke noget, ud fra citationer ma manhave en teori for hvad en citation signifikerer. Som vi var inde pa i delafsnittetvidenskabstudier er citationer ikke naturligt forekommende hændelser, derkan observeres og indsamles, selvom nogle forskere har denne overbevisning.Citationer er kommunikative artefakter fra det sociale system videnskabenbestar af. En citationsteori ma altsa være en socialteori, der evner at forklareaktørernes handlinger indenfor deres sociale system.
Originalt abonnerede mange bibliometrikere pa Robert Mertons idealisti-ske videnskabssociologi som deres citationsteoretiske fundament, dette er ensociologi hvor videnskaben beskrives som et velafbalanceret og selvreguleren-de system. Det mertonianske synspunkt kom i strid modvind med udviklingenaf videnskabs- og teknologistudier i 1970’erne og den socialkonstruktivistiskevidenskabssociologi i det følgende arti. Den videnskab sociologer som BrunoLatour beskriver, hvor forskeres handlinger ikke er styret af en søgen eftersand viden, men derimod hovedsagligt er for at ”vinde” en social kamp,harmonerede darligt med bibliometrien. Kvantitativ analyse af forsknings-kommunikation bliver meningsløs hvis artefakter fra dette ikke signifikererandet end individuelle dispositioner. I dag er diskussionen om citationsteorinæsten forstummet indenfor den bibliometriske forskning. Nicola de Bel-lis (2009) formulerer saledes den gænge holdning til det citationsteortiskespørgsmal:
”[...] citation analysis deals with highly cited papers or withlarge numbers of citations to the oeuvres of research groups;hence, its focus is on the statistical regularities emerging fromthe aggregatio of many individual citing acts.”
Bibliometrikerne forlader sig pa de store tals lov, altsa at de vigtigsteforskere, artikler, tidsskrifter osv., vil rage op blandt det ligegyldige ellermiddelmade ved akkumulerede citationer. Man forliger sig med at citationerantyder pavirkning, forstaet i den bredeste forstand – altsa at lige megethvilke grunde der ellers er for at den enkelte citation blev afgivet, vil encitation altid røbe at modtageren har pavirket afsenderen.
45

Saledes formar bibliometrien at kunne drage brugbare konklusioner fracitationsdata, uden at der forelægger en alment anerkendt og benyttet ci-tationsteori. Men er dette holdbart i tilfælde af automatisk klassifikationanvendes til at berige citationsdataene, og vi ikke længere forlader os pa op-tælle grad pavirkning, men forsøger at optælle forskellige typer af pavirkning?
8.1 Et fornyet behov
I forrige afsnit sa vi pa problemerne med klassifikation, og hvordan disseproblemer forholder sig til kategorisering af citationer. Vores konklusionpa dette var et domæne analytisk inspireret greb, og en anbefaling af atcitationstyper der skal anvendes som grundlag i automatisk klassifikation skaltage udgangspunkt det felt eller omrade der undersøges. I klassifikation afmateriale til genfinding eller søgning, skal dette grundlag findes i brugernesbehov, men nar objektet er videnskabsstudier ma grundlaget findes i densocial praksis de involverede forskere har – altsa et citationsteoretisk grundlag.
Hvis bibliometriske studier baseret pa beriget citationsdata ikke blot skalvære en øvelse i at finde sammenhænge i tilfældig data, ma arbejdet medcitationsteori igen tages op af bibliometrikerne. Hvis en citations muligesignifikans i sit udgangspunkt er styret af hvilke typer der udvægles afbibliometrikeren, vil sikkerheden bibliometrikkerne finder i de store tals lovog akkumulerede citationstal være svære at forsvare som naturlige mønstrei dataene. Sadanne studiers validitet ma sikres gennem et solidt analytiskteoretisk fundament baseret pa videnskabssociologisk empiri.
Potentielt kunne studier med beriget citationsdata, hjælpe bibliometrienud af det citationsteoretiske dødvande den har befundet sig i de sidste artier.Empirien fra studier med forskellige citationstyper, kunne maske belyse hvilkevidenskabssociologiske teorier der besidder den bedste forklaringsevne.
9 Konklusion
Vi har i denne opgave behandlet teoretiske og praktiske problemstillinger vedautomatisk kategorisering af citationstyper inden for bibliometriens forskelligeanvendelsesomrade. Vi vil herudfra konkludere pa i hvor vid udstrækningdenne metode kan appliceres i citationsanalyse.
De praktiske og tekniske barrierer blev vurderet og analyseret ud fravores eksperiment. I forhold til gennemførligheden af metoden var der storeproblemer med at fa personer til at klassificere citationerne ens. Det er derforsvært at konkludere pa, hvad der var fejlkilder i den forbindelse og hvadder skyldes andre faktorer. Det var heller ikke optimalt kun at arbejde medtekststykkerne umiddelbart omkring citationen og i det hele taget at væreafgrænset af datagrundlaget i muligheder for analyse. Alle disse faktorerkan være en hindring i metodens udbredelse og anvendelighed inden forbibliometri.
46

Ud fra vores teoretiske undersøgelse har vi identificeret de anvendelses-omrader, hvor der er potentialer i at benytte automatisk klassificering afcitationer. Automatisk klassificering gør op med centrale dogmer i biblio-metrien, sasom at enhver citation bliver behandlet ens. Der er perspektiveri at inkorporere dette i bade forskningsevaluering, videnskabsstudier og in-formationssøgning og -genfinding, men det er ikke uproblematisk at indføreen klassifikation af citationer i alle disse anvendelsesomrader. Udsigterne tilsucces med automatisk klassifikation er størst inden for videnskabsstudierog informationssøgning og -genfinding. Inden for videnskabsstudier er dermuligheder for indsigt i videnskab som et socialt system.
10 Fremtidige studier & Perspektivering
Hele denne argumentation skal ses som et oplæg og forhabninger til fremtidigestudier inden for bibliometri, sa det vi vil fokusere pa at perspektivere tilher er de studier, der skal til for at forbedre metoden. Til at løse denpraktiske barriere i at afgrænse teksten omkring en citation har vi alleredeomtalt mulige maskinlæringsteknikker, men hvis det skal kunne afgøres, hvadreferencen bliver citeret for i teksten, er der et mere overordnet behov forbrugerstudier af hvordan citationer benyttes i læsningen af forskningsartikler.
I forhold til at kunne klassificere citationer konsistent er der brug for stu-dier i hvordan mennesker konkret forholder sig til citationer. Andre elementeri teksten – fx titel pa det citerede dokument – kunne være meningsbærendeog afgørende for aflæsningen af konteksten. Det kunne gøres med eyetracking,der sporer hvad folks øjne dvæler ved for at aflæse en citation. Den generelleudvikling af natural language processing og digitale teknikker til at læseog uddrage semantiske sammenhænge i tekst, er ogsa interessant i dennesammenhæng. Latent semantisk analyse, den tidligere nævnte argumentativezoning er eksempler pa teknikker til at behandle tekstuel data, der harpotentiale i forbindelse med disse studier.
Udover behovet for dybere praktisk og teknisk viden og kundskab, erder teoretiske problematikker at tage fat pa fremadrettet. Hvad er de over-ordnede spørgsmal der skal stilles og besvares med automatisk understøttetcitationsanalyse? Hvilke huller har vi i vores forstaelse af videnskab og for-skeres adfærd? Er der blinde vinkler i vores viden relateret til emnet? Oger der potentielt destruktive videnskabsteoretiske implikationer ved denneslags analyser? For at citationsanalytiske studier med automatisk berigetcitationsdata kan være succesfulde ser vi et udtalt behov for at kunne arbejdetværdisciplinært, og evne at jonglere de datalogiske, informationsvidenskabeog sociologiske elementer indeholdt i dette brede problemfelt.
47

Litteratur
Abu-Jbara, A. and Radev, D. (2011). Coherent citation-based summarizationof scientific papers. In Proceedings of the 49th Annual Meeting of theAssociation for Computational Linguistics: Human Language Technologies,volume 1, pages 500–509.
Almind, T. C. and Ingwersen, P. (1997). Informetric analyses on the worldwide web: methodological approaches to webometrics. Journal of docu-mentation, 53(4):404–426.
Barthes, R. (1977). The death of the author. Image, music, text, 145.
Bird, S., Klein, E., and Loper, E. (2009). Natural language processing withPython. O’Reilly Media.
Borner, K., Chen, C., and Boyack, K. W. (2003). Visualizing knowledgedomains. Annual review of information science and technology, 37(1):179–255.
Bornmann, L. and Daniel, H.-D. (2008). What do citation counts measure? areview of studies on citing behavior. Journal of Documentation, 64(1):45–80.
Bornmann, L. and Marx, W. (2013). How good is research really? EMBOReports, 14(3):226–230.
Buckland, M. K. (1997). What is a document? Journal of the AmericanSociety for Information, 48(9):804–809.
Case, D. O. and Miller, J. B. (2011). Do bibliometricians cite differently fromother scholars? Journal of the American Society for Information Science,62(3):421–432.
Chubin, D. E. and Moitra, S. D. (1975). Content analysis of references:Adjunct or alternative to citation counting? Social studies of science,5(4):423–441.
Cronin, B. (1984). The citation process: The role and significance of citationsin scientific communication. Taylor Graham: London.
de Bellis, N. (2009). Bibliometrics and Citation Analysis: From the ScienceCitation Index to Cybermetrics. Scarecrow press, Lanham.
Fleiss, J. L. and Cohen, J. (1973). The equivalence of weighted kappa andthe intraclass correlation coefficient as measures of reliability. Educationaland psychological measurement, 33(3):613–619.
48

Frost, C. (1979). The use of citations in literary research: preliminaryclassification of citation functions. Library Quarterly, 49(4):399–414.
Garfield, E. (1964). Science citation index: A new dimension in indexing.Science, 144(3619):649–654.
Garfield, E. (1965). Can citation indexing be automated? In Stevens, M. E.e. a., editor, Statistical association methods for mechanized documentation,pages 189–192. National Bureau of Standards, Washington.
Guns, R. (2013). The three dimensions of informetrics: a conceptual view.Jornal of Documentation, 69(2):295–308.
Hirch, J. E. (2005). An index to quantify an individual’s scientific researchoutput. Proceedings of the National Academy of Sciences of the UnitedStates of America, 102(46):16569–16572.
Hjørland, B. (2002). Domain analysis in information science - eleven ap-proaches - traditional as well as innovative. Journal of Documentation,58(4):422–462.
Hjørland, B. and Albrechtsen, H. (1995). Toward a new horizon in information-science - domain-analysis. Journal of the American Society for InformationScience, 46(6):400–425.
Lancaster, F. W. (1991). Indexing and abstracting in theory and practic.Library Association, London.
Lipetz, B. A. (1965). Improvement of the selectivity of citation indexcesto science literature though inclusion of citation relationship indicators.American Documentation, 16(2):81–90.
Mai, J.-E. (2010). Classification in a social world: bias and trust. Journal ofDocumentation, 66(5):627–612.
Mai, J.-E. (2011). The modernity of classification. Journal of Documentation,67(4):710–730.
Miller, J. D. (2004). Public understanding of, and attitudes toward, scientificresearch: what we know and what we need to know. Public Understandingof Science, 13(1):271–294.
Moravcsic, M. J. and Murugesan, P. (1975). Some results on the function andquality of citations. Annual Review of Information Science and Technology,41(1):609–641.
Morman, E. T. (1981). Citation analysis and the current debate over quan-titative methods in the social studies of science. Society for the SocialStudies of Science Newsletter, 5(3):7–13.
49

Newman, M. (2009). Networks: an introduction. Oxford, UK: OxfordUniversity Press.
Nicolaisen, J. (1997). Bibliometrics and citation analysis: From the sciencecitation index to cybermetrics. Journal of the American Society forInformation Science and Technology, 61(1):205–207.
Nicolaisen, J. (2007). Citation analysis. Annual review of information scienceand technology, 41(3):359–377.
Oppenheim, C. and Renn, S. P. (1977). Science studies: Bibliometric andcontent analysis. Social Studies of Science, 7(1):97–113.
Oppenheim, C. and Renn, S. P. (1978). Highly cited old papers and theseasons why they continue to be cited. Journal of the American Societyfor Information Science, 19(5):225–231.
Page, L., Brin, S., Motwani, R., and Winograd, T. (1999). the pagerankcitation ranking: bringing order to the web.
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel,O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas,J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., and Duchesnay,E. (2011). Scikit-learn: Machine learning in python. Journal of MachineLearning Research, 12:2825–2830.
Piao, S. S., Ananiadou, S., Tsuruoka, Y., Sasaki, Y., and McNaught, J.(2007). Mining opinion polarity relations of citation. In InternationalWorkshop on Computational Semantics (IWCS), pages 366–371.
Price, D. J. D. (1963). Little Science, Big Science. New York, USA: ColumbiaUniversity Press.
Priem, J., Taraborelli, D., Groth, P., and Gameron, N. (2010). Altmetrics:A manifesto. Verificeret den 27. maj 2013, http://altmetrics.org/
manifesto/.
Qazvinian, V. and Radev, D. R. (2008). Scientific paper summarizationusing citation summary networks. In Proceedings of the 22nd InternationalConference on Computational Linguistics-Volume 1, pages 689–696.
Reuters, T. (2009). Using bibliometrics: A guide to evaluating researchperformance with citation data. Verificeret den 27. maj 2013, http:
//www.wrclib.noaa.gov/files/Bibliom_whitepaper.pdf.
Rosch, E. (1977). Human categorization. In Neil, W., editor, Advances incross cultural psychology, pages 1–72. Academic Press, London.
50

Salton, G. and Buckley, C. (1988). Term-weighting approaches in automatictext retrieval. Information processing & management, 24(5):513–523.
Small, H. (1973). Co-citation in the scientific literature: A new measure ofthe relationship between two documents. Journal of the American Societyfor information Science, 24(4):265–269.
Smith, L. C. (1981). Citation analysis. Library Trends, 30:83–106.
Solomon, J. D., Laakso, M., and Bjørk, B.-C. (2013). A longitudinal com-parison of citation rates and growth open access journals. Journal ofInformetrics, 7(3):642–650.
Sugiyama, K., Kumar, T., Kan, M.-Y., and Tripathi, R. C. (2010). Iden-tifying citing sentences in research papers using supervised learning. In2010 International Conference on Information Retrieval & KnowledgeManagement (CAMP), pages 67–72.
Teufel, S., Siddharthan, A., and Tidhar, D. (2006a). An annotation schemefor citation function. In Proceedings of the 7th SIGdial Workshop onDiscourse and Dialogue, pages 80–87.
Teufel, S., Siddharthan, A., and Tidhar, D. (2006b). Automatic classificationof citation function. In Proceedings of the 2006 Conference on EmpiricalMethods in Natural Language Processing (EMNLP), pages 103–110.
Whatmore, S. J. (2009). Mapping knowledgecontroversies: science, demo-cracy and the redistribution of expertise. Progress in Human Geography,33(4):587–598.
White, D. H. (2004). Citation anlysis and discourse analysis revisited. AppliedLinguistics, 25(1):89–116.
White, H D & McCain, K. (1998). Visualizing a discipline: An authorco-citation analysis of information science, 1972-1995. Journal of theAmerican Society for Information Science, 49:327–355.
Willett, P. (2013). Readers’ perceptions of authors’ citation behavior. Journalof Documentation, 69(1):145–156.
Wittig, G. R. (1978). Documentation note: statistical bibliography – ahistorical footnote. Journal of Documentation, 34(3):240–241.
Zhang, G. D. Y. and Milojevic, S. (in press). Citation content analysis(cca): A framework for syntactic and semantic analysis of citation content.Journal of the American Society for Information Science and Technology.
Zunde, P. (1971). Structural models of complex information sources. Infor-mation Storage and Retrieval, 7:1–13.
51

Appendices
Bilag A Oversigt over citationstyper
Figur 9: Oversigt over studier i citationstyper, samt typerne benyttet i dissestudier.
52

Bilag B Spørgeskemaer
Figur 10: Indledende tekst i online spørgeskema.
53

Figur 11: Eksempel pa opsætning af online spørgeskema.
54










![jNewSouthWales KATION PTY LTD v LAMRU PTY … · KATION PTY LTD v LAMRU PTY LTD; LEWIS v NORTEX PTY LTD (In liq) [2009] NSWCA 145 (12 June 2009) Last Updated: 15 June 2009 NEW SOUTH](https://img.pdfslide.us/doc/110x75/5b8894267f8b9aaf728df1c1/jnewsouthwales-kation-pty-ltd-v-lamru-pty-kation-pty-ltd-v-lamru-pty-ltd-lewis.jpg)

















![Liverpool football club presantasjon [lagret automatisk]](https://img.pdfslide.us/doc/110x75/54bc0bb54a795916568b45b5/liverpool-football-club-presantasjon-lagret-automatisk.jpg)
